For the primary time, scientists have noticed a number of complicated constructing blocks of life within the ice round a star outdoors the Milky Manner.
Utilizing the James Webb Area Telescope (JWST), researchers detected 5 massive, carbon-based compounds round a protostar within the Giant Magellanic Cloud, a small galaxy that orbits intently to the Milky Manner. The findings may assist scientists learn the way complicated molecules fashioned within the early universe, in line with a research printed Oct. 20 within theAstrophysical Journal Letters.
The Giant Magellanic Cloud is a dwarf galaxy 160,000 light-years from Earth within the Native Group, a set of gravitationally sure galaxies that features the Milky Manner. The Giant Magellanic Cloud is crammed with scorching, luminous stars that flood it with ultraviolet radiation. It additionally has fewer components heavier than helium than the Milky Manner does. These circumstances make it just like these anticipated in galaxies within the early universe.
“What we be taught within the Giant Magellanic Cloud, we will apply to understanding these extra distant galaxies from when the universe was a lot youthful,” research co-author Marta Sewilo, an astronomer on the College of Maryland and NASA‘s Goddard Area Flight Heart, stated in aassertion. “The tough circumstances inform us extra about how complicated natural chemistry can happen in these primitive environments the place a lot fewer heavy components like carbon, nitrogen and oxygen can be found for chemical reactions.”
In March 2024, the researchers pointed the JWST at a creating star, dubbed ST6, within the Giant Magellanic Cloud. Utilizing devices that measure infrared gentle, they found 5 complicated carbon-based molecules within the ice across the star: methanol, acetaldehyde, ethanol, methyl formate and acetic acid.
Of the 5 molecules, solely methanol has been beforehand detected in protostars outdoors the Milky Manner. Acetic acid, the primary element in vinegar, had by no means even been conclusively present in area ice earlier than.
“Earlier than Webb, methanol had been the one complicated natural molecule conclusively detected in ice round protostars, even in our personal galaxy,” Sewilo stated. “The distinctive high quality of our new observations helped us collect an immense quantity of knowledge from a single spectrum, greater than we have ever had earlier than.”
Get the world’s most fascinating discoveries delivered straight to your inbox.
The researchers additionally discovered indicators that could be brought on by a chemical referred to as glycolaldehyde, though additional research shall be wanted to verify its presence. Glycolaldehyde can react with different molecules to type a sort of sugar referred to as ribose, an essential element of ribonucleic acid (RNA), which is crucial for all times.
Discovering such complicated molecules within the Giant Magellanic Cloud means that chemical reactions on the surfaces of mud grains can produce complicated molecules even underneath harsh circumstances, the researchers stated. In future research, the staff plans to search for these and comparable molecules round different protostars, each within the Milky Manner and in close by galaxies.
“With this discovery, we have made vital developments in understanding how complicated chemistry emerges within the universe and opening new prospects for analysis into how life got here to be,” Sewilo stated within the assertion.
As talked about by David Smith, R 3.4.3 is primarily a bug-fix launch:
It fixes a problem with incorrect time zones on MacOS Excessive Sierra, and a few points with dealing with Unicode characters. (By the way, representing worldwide and particular characters is one thing that R takes nice care in dealing with correctly. It’s not a straightforward activity: a 2003 essay by Joel Spolsky describes the minefield that’s character illustration, and never a lot has modified since then.)
The total checklist of bug fixes and new options is supplied under.
Upgrading to R 3.4.3 on Home windows
In case you are utilizing Home windows you’ll be able to simply improve to the newest model of R utilizing the installr package deal. Merely run the next code in Rgui:
set up.packages("installr") # set up
setInternet2(TRUE) # just for R variations older than 3.3.0
installr::updateR() # updating R.
# If you want it to go sooner, run: installr::updateR(T)
Operating “updateR()” will detect if there’s a new R model out there, and in that case it would obtain+set up it (and many others.). There may be additionally a step-by-step tutorial (with screenshots) on the best way to improve R on Home windows, utilizing the installr package deal. Should you solely see the choice to improve to an older model of R, then change your mirror or attempt once more in just a few hours (it normally take round 24 hours for all CRAN mirrors to get the newest model of R).
I attempt to hold the installr package deal up to date and helpful, so if in case you have any ideas or remarks on the package deal – you might be invited to open a problem within the github web page.
CHANGES IN R 3.4.3
INSTALLATION on a UNIX-ALIKE
A workaround has been added for the modifications in location of time-zone information in macOS 10.13 ‘Excessive Sierra’ and once more in 10.13.1, so the default time zone is deduced accurately from the system setting when R is configured with –with-internal-tzcode (the default on macOS).
R CMD javareconf has been up to date to acknowledge using a Java 9 SDK on macOS.
BUG FIXES
uncooked(0) & uncooked(0) and uncooked(0) | uncooked(0) once more return uncooked(0) (fairly than logical(0)).
intToUtf8() converts integers comparable to surrogate code factors to NA fairly than invalid UTF-8, in addition to values bigger than the present Unicode most of 0x10FFFF. (This aligns with the present RFC3629.)
Repair calling of strategies on S4 generics that dispatch on ... when the decision comprises ....
Following Unicode ‘Corrigendum 9’, the UTF-8 representations of U+FFFE and U+FFFF at the moment are thought to be legitimate by utf8ToInt().
vary(c(TRUE, NA), finite = TRUE) and comparable now not return NA. (Reported by Lukas Stadler.)
The self beginning operate attr(SSlogis, "preliminary") now additionally works when the y values have actual minimal zero and is barely modified generally, behaving symmetrically within the y vary.
The printing of named uncooked vectors is now formatted properly as for different such atomic vectors, due to Lukas Stadler.
Leishmaniasis therapyvaries based mostly on the sort and severity of the illness:
Cutaneous leishmaniasis
Native remedy: Small, uncomplicated pores and skin sores can typically heal on their very own. Therapies for persistent or bigger sores embrace topical treatment, cryotherapy (freezing the lesion), or native injections of antiparasitic medication.
Systemic remedy: For extra in depth or recurrent circumstances, oral or intravenous antiparasitic drugs (like Pentavalent antimonials, Miltefosine) could also be vital.
Visceral leishmaniasis
This kind requires extra aggressive therapy resulting from its severity. Generally used medication embrace Liposomal amphotericin B, Pentavalent antimonials, and Miltefosine. Remedy is normally administered intravenously or orally over a interval of a number of weeks.
Mucocutaneous leishmaniasis
Remedy is just like that of visceral leishmaniasis, usually requiring systemic antiparasitic remedy as a result of severity and potential for disfiguring lesions.
The selection of treatment is dependent upon elements just like the leishmania species, the affected person’s total well being, and the drug availability and resistance patterns within the area.
Monitoring and supportive care are additionally necessary, particularly for visceral leishmaniasis, to handle issues and forestall relapse. In all circumstances, early analysis and applicable therapy are essential for efficient administration of the illness.
The therapy of leishmaniasis faces a spread of great challenges, every complicating the efficient administration of the illness:
Restricted drug choices: There are just a few efficient medication obtainable, and plenty of have critical uncomfortable side effects. This limits the alternatives for therapy, particularly for sufferers with pre-existing well being circumstances or those that expertise extreme uncomfortable side effects.
Drug toxicity: Essentially the most generally used medication, like antimonials and amphotericin B, could be extremely poisonous. They usually trigger hostile results like kidney and liver harm, which require cautious monitoring and administration.
Drug resistance: There’s an growing concern in regards to the parasite growing resistance to current medication. That is significantly problematic for visceral leishmaniasis, the place therapy choices are already restricted. Drug resistance prolongs therapy period and reduces its effectiveness.
Entry and value: Lots of the affected areas are impoverished, and entry to healthcare is restricted. The price of treatment and the necessity for hospitalization (for medication administered intravenously) could be prohibitive for a lot of sufferers.
Administration challenges: Some remedies require intravenous administration, which isn’t all the time possible in distant or resource-limited settings. This limits the power to deal with sufferers successfully in areas the place leishmaniasis is most prevalent.
Geographical variability: The efficacy of remedies can range relying on the geographic area, partly resulting from completely different parasite species and strains. This necessitates region-specific therapy protocols, complicating the standardization of care.
Prolonged therapy regimens: Some types of leishmaniasis require extended therapy programs, which could be difficult for sufferers to finish, resulting in points with compliance and, consequently, therapy effectiveness.
Co-infections and immune standing: In sufferers with compromised immune methods, equivalent to these with HIV/AIDS, leishmaniasis therapy is extra sophisticated and fewer efficient. Moreover, co-infections can complicate therapy selections and outcomes.
Addressing these challenges requires a multifaceted strategy, together with the event of safer, more practical, and simply administered medication, improved diagnostic instruments, and higher entry to healthcare providers in endemic areas.
Analysis into vaccine growth and more practical public well being methods additionally play an important position within the broader effort to manage and ultimately get rid of leishmaniasis.
Ever want you had a crystal ball for the monetary markets? Whereas we won’t fairly do this, regression is a brilliant great tool that helps us discover patterns and relationships hidden in information – it is like being an information detective!
The most typical start line is linear regression, which is mainly about drawing one of the best straight line by information factors to see how issues are related. Easy, proper?
In Half 1 of this collection, we explored methods to make these line-based fashions even higher, tackling issues like curvy relationships (Polynomial Regression) and messy information with too many variables (utilizing Ridge and Lasso Regression). We discovered easy methods to refine these linear predictions.
However what if a line (even a curvy one) simply does not match? Or what if it’s essential to predict one thing completely different, like a “sure” or “no”?
Prepare for Half 2, my good friend!The place we enterprise past the linear world and discover an interesting set of regression methods designed for various sorts of issues:
Logistic Regression: For predicting chances and binary outcomes (Sure/No).
Quantile Regression: For understanding relationships at completely different factors within the information distribution, not simply the typical (nice for danger evaluation!).
Determination Tree Regression: An intuitive flowchart strategy for complicated, non-linear patterns.
Random Forest Regression: Harnessing the “knowledge of the gang” by combining a number of choice timber for accuracy and stability.
Assist Vector Regression (SVR): A strong technique utilizing “margins” to deal with complicated relationships, even in excessive dimensions.
Let’s dive into these highly effective instruments and see how they’ll unlock new insights from monetary information!
Stipulations
Hey there! Earlier than we get into the good things, it helps to be aware of just a few key ideas. You possibly can nonetheless comply with alongside intuitively, however brushing up on these will provide you with a significantly better understanding. Right here’s what to take a look at:
1. Statistics and Chance Know the necessities—imply, variance, correlation, and chance distributions. New to this? Chance Buying and selling is a good intro.
2. Linear Algebra Fundamentals Fundamentals like matrices and vectors are tremendous helpful, particularly for methods like Principal Part Regression.
3. Regression Fundamentals Get comfortable with linear regression and its assumptions. Linear Regression in Finance is a strong start line.
4. Monetary Market Information Phrases like inventory returns, volatility, and market sentiment will come up loads. Statistics for Monetary Markets may also help you sweep up.
5. Discover Half 1 of This Collection Take a look at Half 1 for an outline of Polynomial, Ridge, Lasso, Elastic Web, and LARS. It’s not obligatory, however it supplies glorious context for various regression varieties.
When you’re good with these, you’ll be all set to dive deeper into how regression methods reveal insights in finance. Let’s get began!
What Precisely is Regression Evaluation?
At its core, regression evaluation fashions the connection between a dependent variable (the result we need to predict) and a number of unbiased variables (predictors).
Consider it as determining the connection between various things – for example, how does an organization’s income (the result) relate to how a lot they spend on promoting (the predictor)? Understanding these hyperlinks helps you make educated guesses about future outcomes based mostly on what you recognize.
When that relationship appears like a straight line on a graph, we name it linear regression – good and easy!
What Makes These Fashions ‘Non-Linear’?
Good query! In Half 1, we talked about that ‘linear’ in regression refers to how the mannequin’s coefficients are mixed.
Non-linear fashions, like those we’re exploring right here, break that rule. Their underlying equations or buildings do not simply add up coefficients multiplied by predictors in a easy means. Take into consideration Logistic Regression utilizing that S-shaped curve (sigmoid operate) to squash outputs between 0 and 1, or Determination Bushes making splits based mostly on situations moderately than a easy equation, or SVR utilizing ‘kernels’ to deal with complicated relationships in doubtlessly greater dimensions.
These strategies basically work otherwise from linear fashions, permitting them to seize patterns and deal with issues (like classification or modelling particular information segments) that linear fashions usually cannot.
Logistic (or Logit) regression
You employ Logistic regression when the dependent variable (right here, a dichotomous variable) is binary (consider it as a “sure” or “no” consequence, like a inventory going up or down). It helps predict the binary consequence of an incidence based mostly on the given information.
It’s a non-linear mannequin that offers a logistic curve with values restricted to between 0 and 1. This chance is then in comparison with a threshold worth of 0.5 to categorise the information. So, if the chance for a category is greater than 0.5, we label it as 1; in any other case, it’s 0.
Notice: You cannot use linear regression right here as a result of it might give values outdoors the 0 to 1 vary. Additionally, the dependent variable can take solely two values right here, so the residuals received’t be usually distributed concerning the predicted line.
Wish to be taught extra? Take a look at this weblog for extra on logistic regression and easy methods to use Python code to foretell inventory motion.
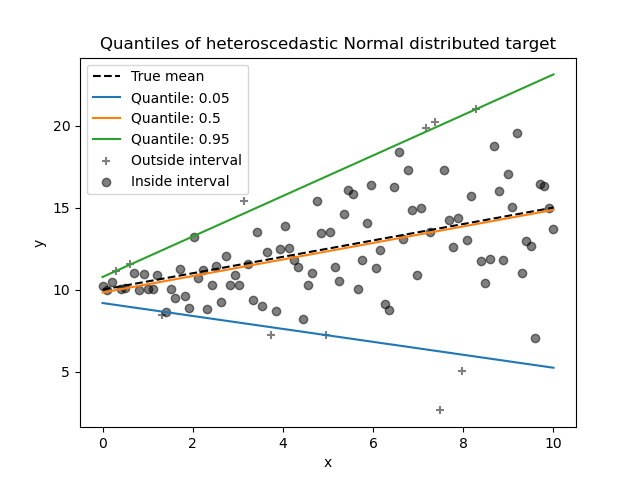
Quantile Regression: Understanding Relationships Past the Common
Conventional linear regression fashions predict the imply of a dependent variable based mostly on unbiased variables. Nevertheless, monetary time collection information usually comprise skewness and outliers, making linear regression unsuitable.
To resolve this drawback, Koenker and Bassett (1978) launched quantile regression. As a substitute of modeling simply the imply, it helps us see the connection between variables at completely different factors (quantiles and percentiles) within the dependent variable’s distribution, equivalent to:
tenth percentile (low good points/losses)
fiftieth percentile (median returns)
99th percentile (excessive good points/losses)
It estimates completely different quantiles (like medians or quartiles) of the dependent variables for the given unbiased variables, as a substitute of simply the imply. We name these conditional quantiles.
Like OLS regression coefficients, which present the adjustments from one-unit adjustments of the predictor variables, quantile regression coefficients present the adjustments within the specified quantile from one-unit adjustments within the predictor variables.
Benefits:
Robustness to Outliers: In line with Lim et al. (2020), common linear regression assumes errors within the information are usually distributed, however this is not dependable when you’ve gotten outliers or excessive values (“fats tails”). Quantile regression handles outliers higher as a result of it focuses on minimizing absolute errors, not the squared ones like common regression. This fashion the affect of utmost values is diminished, offering extra dependable estimates in datasets that aren’t actually “nicely behaved” (with heavy tails or skewed distributions)
Estimating Conditional Median: The conditional median is estimated utilizing the median estimator, which minimizes the sum of absolute errors.
Dealing with Heteroskedasticity: OLS assumes fixed variance of errors (homoskedasticity), however that is usually unrealistic. Quantile regression permits for various error variances, making it efficient when predictor variables affect completely different components of the response variable’s distribution (Koenker & Bassett, 1978).
Let’s take a look at an instance to higher perceive how quantile regression works:
For instance you are attempting to know how the general “temper” of the market (measured by a sentiment index) impacts the each day returns of a selected inventory. Conventional regression would let you know the typical affect of a change in sentiment on the typical inventory return.
However what when you’re notably excited about excessive actions? Quantile regression is used right here:
Wanting on the tenth percentile: You possibly can use quantile regression to see how a adverse shift in market sentiment impacts the worst 10% of potential each day returns (the massive losses). It’d present that adverse sentiment has a a lot stronger adverse affect throughout these excessive downturns than it does on common.
Wanting on the ninetieth percentile: Equally, you would see how optimistic sentiment impacts the greatest 10% of each day returns (the massive good points). It’d reveal that optimistic sentiment has a unique (presumably bigger or smaller) affect on these important upward swings in comparison with the typical.
Wanting on the fiftieth percentile (median): You can even see the affect of sentiment on the standard each day return (the median), which is likely to be completely different from the impact on the typical if the return distribution is skewed.
So, as a substitute of only one common impact, quantile regression offers you a extra full image of how market sentiment influences completely different components of the inventory’s return distribution, particularly the possibly dangerous excessive losses. Isn’t that nice?
Determination Bushes Regression: The Flowchart Method
Think about attempting to foretell a numerical worth – like the value of one thing or an organization’s future income. A Determination Tree provides an intuitive means to do that, working like a flowchart or a sport of ‘sure/no’ questions.
A choice tree is split into smaller and smaller subsets based mostly on sure situations associated to the predictor variables. Consider it like this:
Determination timber begin together with your whole dataset and progressively splits it into smaller and smaller subsets on the nodes, thereby making a tree-like construction. Every of the nodes the place the information is break up based mostly on a situation is known as an inside/break up node, and the ultimate subsets are referred to as the terminal/leaf nodes.
In finance, choice timber could also be used for classification issues like predicting whether or not the costs of a monetary instrument will go up or down.
Determination Tree Regression is after we use a choice tree to foretell steady values (like the value of a home or temperature) as a substitute of classes (like predicting sure/no or up/down).
Right here’s the way it works in regression:
The tree asks a collection of questions based mostly on the enter options (like “Is sq. footage > 1500?”).
Based mostly on the solutions, the information level strikes down the tree till it reaches a leaf.
In that leaf, the prediction is the common (or generally the median) of the particular values from the coaching information that additionally landed there.
So, the tree splits the information into teams, and every group will get a set quantity because the prediction.
Issues to Watch Out For:
Overfitting: Determination timber can get too detailed and match the coaching information too completely, making them carry out poorly on new, unseen information.
Instability: Small adjustments within the coaching information can generally result in considerably completely different tree buildings. (Strategies like Random Forests and Gradient Boosting usually assist with this).
You could have a full description of the mannequin on this weblog and its use in buying and selling on this weblog.
To be taught extra about choice timber in buying and selling take a look at this Quantra course.
Let’s see a state of affairs the place this is likely to be a great tool:
Think about you are attempting to foretell an organization’s gross sales income for the subsequent quarter. You could have information on its previous efficiency and components like: advertising spend within the present quarter, variety of salespeople, the corporate’s trade sector (e.g., Tech, Retail, Healthcare), and so forth.
The tree would possibly ask:
“Advertising and marketing spend > $500k?” If sure, “Trade = Tech?”. Based mostly on the trail taken, you land on a leaf.
The prediction for a brand new firm following that path could be the typical income of all previous firms that fell into that very same leaf (e.g., the typical income for tech firms with excessive advertising spend).
Random forest regression: Knowledge of the Crowd for Predictions
Keep in mind how particular person Determination Bushes can generally be a bit unstable or would possibly overfit the coaching information? What if we might harness the facility of many choice timber as a substitute of counting on only one?
That is the concept behind Random Forest Regression!
It is an “ensemble” technique, which means it combines a number of fashions (on this case, choice timber) to realize higher efficiency than any single one might alone. You possibly can consider it utilizing the “knowledge of the gang” precept: as a substitute of asking one professional, you ask many, barely completely different specialists and mix their insights. Usually, Random Forests carry out considerably higher than particular person choice timber (Breiman, 2001).
How does the forest get “random”?
The “random” a part of Random Forest comes from two key methods used when constructing the person timber:
Random Information Subsets (Bootstrapping): Every tree within the forest is educated on a barely completely different random pattern of the unique coaching information. This pattern will be chosen “with alternative” (which means some information factors is likely to be chosen a number of instances, and a few is likely to be not noted for that particular tree). This ensures every tree sees a barely completely different perspective of the information.
Random Function Subsets: When deciding easy methods to break up the information at every step inside a tree, the algorithm can solely take into account a random choice of the enter options, not all of them. This stops one or two highly effective options from dominating all of the timber and encourages range.
Making Predictions (Regression = Averaging)
To foretell a price for brand new information, you run it by each tree within the forest. Every tree offers its personal prediction. The Random Forest’s last prediction is solely the common of all these particular person tree predictions. This averaging smooths issues out and makes the mannequin far more secure.
Picture illustration of a Random forest regressor: Supply
Why Use Random Forest Regression?
Excessive Accuracy: Typically supplies very correct predictions.
Robustness: Much less liable to overfitting in comparison with single choice timber and handles outliers moderately nicely. (Breiman, L. , 2001)
Function Significance: Can present estimates of which predictors are most essential.
Issues to Contemplate:
Interpretability: It acts extra like a “black field.” It is more durable to know precisely why it made a particular prediction in comparison with visualizing a single choice tree.
Computation: Coaching many timber will be computationally intensive and require extra reminiscence.
Take a look at this submit if you wish to be taught extra about random forests and the way they can be utilized in buying and selling.
Assume we’d go away you hanging? No means!
Right here’s an instance that will help you higher perceive how random forests work in apply:
You need to predict how a lot a inventory’s value will swing (its volatility) subsequent month, utilizing information like latest volatility, buying and selling quantity, and market concern (VIX index).
A single choice tree would possibly latch onto a particular sample previously information and provides a jumpy prediction. A Random Forest strategy is extra strong:
It builds lots of of timber. Every tree sees barely completely different historic information and considers completely different characteristic combos at every break up. Every tree estimates the volatility. The ultimate prediction is the typical of all these estimates, giving a extra secure and dependable forecast of future volatility than one tree alone might present.
Assist vector regression (SVR): Regression Inside a ‘Margin’ of Error
You is likely to be aware of Assist Vector Machines (SVM) for classification. Assist Vector Regression (SVR) takes the core concepts of SVM and applies them to regression duties – that’s, predicting steady numerical values.
SVR approaches regression a bit otherwise than many different strategies. Whereas strategies like commonplace linear regression attempt to decrease the error between the anticipated and precise values for all information factors, SVR has a unique philosophy.
The Epsilon (ε) Insensitive Tube:
Think about you are attempting to suit a line (or curve) by your information factors. SVR tries to discover a “tube” or “road” round this line with a sure width, outlined by a parameter referred to as epsilon (ε). The purpose is to suit as many information factors as attainable inside this tube.
Picture illustration of Assist vector regression: Supply
Here is the important thing thought: For any information factors that fall inside this ε-tube, SVR considers the prediction “ok” and ignores their error. It solely begins penalizing errors for factors that fall outdoors the tube. This makes SVR much less delicate to small errors in comparison with strategies that attempt to get each level good. The regression line (or hyperplane in greater dimensions) runs down the center of this tube.
Dealing with Curves (Non-Linearity):
What if the connection between your predictors and the goal variable is not straight? SVR makes use of a “kernel trick”. That is like projecting the information right into a higher-dimensional area the place a posh, curvy relationship would possibly appear like an easier straight line (or flat airplane). By discovering one of the best “tube” on this greater dimension, SVR can successfully mannequin non-linear patterns. Frequent kernels embody linear, polynomial, and RBF (Radial Foundation Operate). Your best option depends upon the information.
Execs:
Efficient in high-dimensional areas.
Can mannequin non-linear relationships utilizing kernels.
The ε-margin provides some robustness to small errors/outliers (Muthukrishnan & Jamila, 2020).
Cons:
Could be computationally gradual on massive datasets.
Efficiency is delicate to parameter tuning (selecting ε, a price parameter C, and the proper kernel).
Interpretability will be much less direct than linear regression.
The reason for the entire mannequin will be discovered right here.
And if you wish to be taught extra about how assist vector machines can be utilized in buying and selling, make sure to take a look at this weblog, my good friend!
By now, you most likely understand how this works, so let’s take a look at a real-life instance that makes use of SVR:
Take into consideration predicting the value of a inventory choice (like a name or put). Choice costs rely upon a number of complicated, non-linear components: the underlying inventory’s value, time left till expiration, anticipated future volatility (implied volatility), rates of interest, and so forth.
SVR (particularly with a non-linear kernel like RBF) is appropriate for this. It may possibly seize these complicated relationships utilizing the kernel trick. The ε-tube focuses on getting the prediction inside a suitable small vary (e.g., predicting the value +/- 5 cents), moderately than stressing about tiny deviations for each single choice.
Abstract
Regression Mannequin
One-Line Abstract
One-Line Use Case
Logistic Regression
Predicts the chance of a binary consequence.
Predicting whether or not a inventory will go up or down.
Quantile Regression
Fashions relationships at completely different quantiles of the dependent variable’s distribution.
Understanding how market sentiment impacts excessive inventory value actions.
Determination Bushes Regression
Predicts steady values by partitioning information into subsets based mostly on predictor variables.
Predicting an organization’s gross sales income based mostly on varied components.
Random Forest Regression
Improves prediction accuracy by averaging predictions from a number of choice timber.
Predicting the volatility of a inventory.
Assist Vector Regression (SVR)
Predicts steady values by discovering a “tube” that most closely fits the information.
Predicting choice costs, which rely upon a number of non-linearly associated components.
Conclusion
And that concludes our tour by the extra numerous landscapes of regression! We have seen how Logistic Regression helps us deal with binary predictions, how Quantile Regression offers us insights past the typical, particularly for danger, and the way Determination Bushes and Random Forests supply intuitive but highly effective methods to mannequin complicated, non-linear relationships. Lastly, Assist Vector Regression supplies a singular, margin-based strategy sensible even in high-dimensional areas.
From the refined linear fashions in Half 1 to the various methods explored right here, you now have a much wider regression toolkit at your disposal. Every mannequin has its strengths and is suited to completely different monetary questions and information challenges.
The important thing takeaway? Regression will not be a one-size-fits-all resolution. Understanding the nuances of various methods permits you to select the proper device for the job, resulting in extra insightful evaluation and highly effective predictive fashions.
And as you proceed studying my good friend, don’t simply cease at idea. Maintain exploring, hold working towards with actual information, and hold refining your abilities. Completely happy modeling!
Maybe you are eager on an entire, holistic understanding of regression utilized on to buying and selling? In that case, take a look at this Quantra course.
In case you’re severe about taking your abilities to the subsequent degree, take into account QuantInsti’s EPAT program—a strong path to mastering monetary algorithmic buying and selling.
With the proper coaching and steerage from trade specialists, it may be attainable so that you can be taught it in addition to Statistics & Econometrics, Monetary Computing & Know-how, and Algorithmic & Quantitative Buying and selling. These and varied points of Algorithmic buying and selling are lined on this algo buying and selling course. EPAT equips you with the required ability units to construct a promising profession in algorithmic buying and selling. Make sure you test it out.
Disclaimer: All investments and buying and selling within the inventory market contain danger. Any choice to position trades within the monetary markets, together with buying and selling in inventory or choices or different monetary devices, is a private choice that ought to solely be made after thorough analysis, together with a private danger and monetary evaluation and the engagement {of professional} help to the extent you consider needed. The buying and selling methods or associated data talked about on this article is for informational functions solely.
Let me begin with a confession: My first API was a catastrophe.
I’d spent weeks coding what I believed was a “masterpiece” for a climate app, solely to comprehend later that nobody — together with my future self — may determine tips on how to use it. The documentation was an afterthought, the error messages have been cryptic, and safety? Let’s simply say it was extra “open home” than “fortress.”
That have taught me that API improvement for net apps and information merchandise isn’t nearly writing code. It’s about empathy — for the builders utilizing your API, the apps counting on it, and the individuals behind the screens.
Whether or not you’re constructing an API to energy a SaaS device, join information pipelines, or allow third-party integrations, let’s stroll by the questions I want I’d requested sooner. Spoiler: You’ll save time, keep away from frustration, and possibly even benefit from the course of.
# What Is API Growth, and Why Ought to I Care?
Consider APIs because the unsung heroes of the apps you employ every day. Once you examine the climate in your cellphone, e book a ride-share, or refresh your social feed, APIs are working behind the scenes to attach providers and share information.
API improvement is the method of constructing these bridges. For net apps, it would imply creating endpoints that allow your frontend discuss to your backend. For information merchandise, it may contain designing methods for customers to securely entry datasets or run analytics.
However right here’s why it issues:
An excellent API makes your product sticky. Builders persist with instruments that save them time.
It’s a progress engine. APIs let companions prolong your product’s performance (suppose Shopify’s app ecosystem).
Unhealthy APIs value you customers. Sophisticated integrations or frequent downtime? Folks will stroll away.
# Designing APIs People Really Wish to Use
Think about strolling right into a library the place each e book is in a random order, with no labels. That’s what a poorly designed API looks like. Right here’s tips on how to keep away from it:
// 1. Begin With The “Why”
Who will use this API? Inside groups? Exterior builders?
What duties do they should accomplish? (e.g. “Fetch real-time gross sales information” or “Submit a assist ticket”).
Professional Tip: Write person tales first. Instance: “As a developer, I wish to filter buyer information by area so I can show location-specific metrics.”
// 2. Maintain It Easy (Significantly)
// 3. Model From Day One
My early mistake: Not versioning. Once I up to date the API, each present integration broke.
Embody the model within the URL: /api/v1/customers
Use semantic versioning (e.g. v1.2.0) to speak modifications
# However How Do I Maintain This Factor Safe?
Safety doesn’t should imply complexity. Let’s steadiness security and value:
Authentication: Begin with API keys for simplicity, then layer in OAuth2 for delicate actions
Charge Limiting: Shield in opposition to abuse. Inform customers their limits in headers:
Encryption: Use HTTPS. At all times. No exceptions
Enter Validation: Sanitize information to stop SQL injection or malicious payloads
# A Actual World Instance
A fintech shopper as soon as used API keys and IP whitelisting for his or her fee gateway. Overkill? Perhaps. However they’ve had zero breaches in 3 years.
// Scaling With out Shedding Sleep
APIs are like eating places. When you’re profitable, you’ll get extra prospects than you deliberate for. Right here’s tips on how to scale gracefully:
Cache Continuously Used Knowledge: Use Redis or CDNs to retailer responses like product catalogs or static datasets
Monitor Efficiency: Instruments like New Relic or Prometheus can provide you with a warning to sluggish endpoints or spikes in error charges
Go Stateless: Keep away from storing session information on the server. This allows you to spin up new API cases throughout visitors surges
Examine this: A meals supply app’s API crashed each Friday at 6 PM. It turned out that their restaurant menu endpoints couldn’t deal with the dinner rush. Including caching and cargo balancing made their “crash o’clock” a non-issue.
// Documentation: The Love Letter Your API Deserves
Nice documentation is sort of a pleasant tour information. It says, “I’ve acquired your again.” Right here’s tips on how to write it:
Begin with a “Howdy World” Instance
Present a easy API name and response.
Clarify Error Codes Clearly
Don’t simply say 400: Unhealthy Request. Add: “This normally means a required area is lacking, like e mail.”
Use Interactive Instruments
Swagger UI or Postman Collections lets customers check endpoints with out writing code.
Professional Transfer: Embody a “Troubleshooting” part with frequent points (e.g. “Getting a 403? Examine your API key permissions.”).
# The Artwork of Versioning With out Annoying Everybody
Change is inevitable. Right here’s tips on how to roll out API updates with out burning bridges:
Sundown Previous Variations Progressively: Give customers 6+ months emigrate, with clear warnings
Use Function Flags: Let customers choose into beta options (e.g. ?beta=true)
# Pace Issues: Optimizing API Efficiency
Gradual APIs frustrate customers and drain assets. Fast fixes:
Paginate Giant Responses: Return information in chunks: /merchandise?web page=2&restrict=50
Compress Payloads: Allow GZIP compression
Lazy-Load Nested Knowledge: Return fundamental person data first, and let builders fetch profiles through /customers/{id}/profile if wanted
# Wrapping Up
API improvement isn’t about perfection — it’s about iteration. Begin small, take heed to suggestions, and refine.
By following this step-by-step information, you’ve discovered tips on how to construct a strong API for net apps and information merchandise. Whether or not you’re constructing any kind of software, the rules stay the identical. Joyful coding!
Shittu Olumide is a software program engineer and technical author enthusiastic about leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying complicated ideas. It’s also possible to discover Shittu on Twitter.
Knowledge engineering companies have advanced right into a essential pillar of enterprise technique. They empower companies to handle large datasets, optimize choices, and uncover hidden insights. In 2025, firms that leverage large knowledge engineering companies are reaching quicker innovation, stronger operational effectivity, and a data-driven edge over their rivals.
Introduction
The world runs on knowledge — each click on, transaction, and interplay creates a digital footprint. But, uncooked knowledge by itself holds no worth except it’s structured, processed, and interpreted accurately. That is the place knowledge engineering companies play a transformative function.
These companies create the pipelines, frameworks, and methods that transfer knowledge from scattered sources to a centralized, dependable basis prepared for analytics and AI. From international firms to rising startups, companies are realizing that strategic knowledge engineering just isn’t a back-end activity anymore — it’s a driver of progress and innovation.
The Position of Knowledge Engineering within the Fashionable Enterprise
Each main group in the present day will depend on seamless knowledge stream — throughout departments, geographies, and digital methods. Knowledge engineering companies be certain that this stream is clear, structured, and safe.
They allow enterprises to:
Consolidate a number of knowledge sources right into a single view
Allow real-time analytics for quicker decision-making
Construct scalable architectures that develop with enterprise wants
Assist AI and machine studying fashions with constant, high-quality knowledge
Improve knowledge governance and compliance in regulated sectors
In the meantime, large knowledge engineering companies prolong these capabilities to deal with large volumes of structured and unstructured knowledge. They depend on distributed methods, cloud platforms, and automation instruments to handle billions of knowledge factors throughout enterprise items and time zones.
Why Knowledge Engineering Providers Matter for International Enterprise Technique
In 2025, companies are not competing on product or value alone — they’re competing on knowledge intelligence.
Executives can’t afford to depend on instinct. Actual-time analytics powered by knowledge engineering lets organizations make quick, evidence-based choices — from demand forecasting to buyer expertise optimization.
2. Powering Predictive and Generative Analytics
Fashionable knowledge engineering pipelines allow predictive modeling, anomaly detection, and even generative AI use instances — permitting companies to forecast outcomes and simulate future eventualities.
3. Lowering Prices and Technical Debt
Automated knowledge pipelines reduce redundant duties, cut back infrastructure waste, and guarantee sustainable scaling with out skyrocketing prices.
4. Enabling Personalization at Scale
Retail, healthcare, and finance sectors are leveraging knowledge engineering to personalize buyer interactions in actual time — enhancing retention and engagement metrics.
5. Strengthening Danger and Compliance Administration
Nicely-engineered knowledge frameworks guarantee knowledge lineage, entry management, and traceability — important for assembly compliance and governance necessities globally.
Structure That Drives Transformation
Fashionable knowledge engineering architectures mix a number of parts:
Knowledge Ingestion Layer: Captures knowledge from APIs, databases, sensors, and functions.
Transformation Layer: Cleans, standardizes, and enriches knowledge for analytics.
Storage Layer: Combines knowledge lakes for flexibility and knowledge warehouses for construction.
Processing Layer: Makes use of distributed methods to investigate large-scale knowledge.
Entry Layer: Supplies safe, self-service entry for analysts, AI methods, and enterprise instruments.
Enterprises adopting modular, cloud-native architectures can broaden or modify these layers seamlessly — making certain long-term scalability and innovation.
Huge Knowledge Engineering Providers: Constructing for the Subsequent Decade
As international knowledge volumes proceed to double each two years, conventional methods merely can’t sustain. Huge knowledge engineering companies supply the resilience and velocity wanted for this new actuality.
Key focus areas embrace:
Actual-time knowledge processing with stream analytics and event-driven methods
Cloud migration and hybrid architectures for agility and price management
AI-assisted knowledge high quality checks for reliability at scale
Knowledge automation frameworks that cut back handbook oversight
Edge knowledge engineering for IoT and distant operations
These methods are shaping the inspiration for data-driven economies, particularly as enterprises undertake multi-cloud ecosystems and federated knowledge fashions.
Tendencies Defining Knowledge Engineering in 2025
AI-Augmented Pipelines:Machine studying is now optimizing pipeline efficiency, detecting anomalies, and automating knowledge transformations.
Knowledge Mesh Adoption: Decentralized architectures enable groups to personal their knowledge domains whereas sustaining international consistency.
Actual-Time Analytics Turns into the Norm: Batch processing is being changed by streaming-first designs for fast insights.
Knowledge Observability Platforms: Enterprises are investing in instruments to watch knowledge well being, lineage, and reliability repeatedly.
Privateness-Pushed Engineering: Constructed-in encryption, anonymization, and compliance mechanisms have gotten default parts of structure.
Sustainability and Inexperienced Knowledge: Optimizing compute assets and decreasing knowledge storage waste at the moment are key CSR initiatives for big enterprises.
Strategic Implementation Roadmap
Constructing a contemporary knowledge engineering technique entails:
Auditing Present Infrastructure: Determine silos, redundancies, and bottlenecks.
Defining Enterprise Aims: Tie knowledge initiatives on to income, price, and buyer KPIs.
Deciding on the Proper Stack: Select scalable applied sciences aligned with cloud or on-prem ecosystems.
Automation First: Automate ingestion, transformation, and monitoring to make sure reliability.
Investing in Expertise: Expert engineers and knowledge architects stay probably the most essential property.
Steady Optimization: Often consider pipeline effectivity, storage utilization, and knowledge high quality.
Challenges and How Main Enterprises Overcome Them
Even with all of the technological progress, implementing knowledge engineering companies at scale comes with its personal set of challenges. Nonetheless, what separates main enterprises from the remaining is how strategically they reply to those hurdles.
Probably the most persistent points organizations face is knowledge silos and duplication. When info stays scattered throughout departments, it creates fragmented insights and inconsistent reporting. High-performing firms deal with this by establishing centralized knowledge cataloging methods and strong governance frameworks that guarantee knowledge stays accessible, standardized, and reliable throughout the group.
One other rising concern is excessive infrastructure prices, particularly as companies scale their knowledge pipelines and real-time analytics workloads. These prices can simply decelerate innovation if not managed successfully. Ahead-thinking enterprises fight this by implementing cloud price optimization methods and leveraging tiered storage methods that steadiness efficiency with affordability.
Then comes the ever-present problem of knowledge high quality. Inaccurate or incomplete knowledge instantly impacts decision-making, eroding confidence in analytics. To mitigate this, firms are turning to automated knowledge validation, anomaly detection algorithms, and machine learning-powered cleaning strategies to keep up a gentle stream of high-quality, dependable info.
Safety and compliance have additionally develop into main areas of focus, particularly with rising international knowledge privateness rules. Breaches or non-compliance not solely carry monetary penalties however can significantly hurt model popularity. Main organizations are countering this via zero-trust safety architectures, end-to-end encryption, and role-based entry management, making certain delicate knowledge stays protected at each step of its journey.
Lastly, the expertise hole continues to problem many enterprises. The demand for expert knowledge engineers far exceeds provide, making it tougher to keep up momentum on key tasks. Modern companies are addressing this subject via steady upskilling applications, the adoption of AI-assisted engineering instruments, and partnerships with specialised service suppliers to bridge useful resource gaps effectively.
By recognizing and proactively addressing these challenges, enterprises should not solely enhancing their knowledge ecosystems but in addition gaining a aggressive edge within the period of large knowledge engineering companies.
The Enterprise Impression: Turning Knowledge into Technique
Firms investing in knowledge engineering companies report measurable outcomes:
30–40% quicker decision-making cycles
25% discount in operational inefficiencies
Vital improve in data-driven product launches
Enhanced resilience via predictive analytics
In essence, the smarter the info infrastructure, the quicker a enterprise adapts to vary.
Trending FAQs on Knowledge Engineering in 2025
Q1. How is AI altering the function of knowledge engineers? AI is automating repetitive duties like pipeline optimization and error detection, permitting knowledge engineers to concentrate on higher-value structure and enterprise technique design.
Q2. What’s the distinction between knowledge engineering and knowledge science? Knowledge engineering builds and maintains the infrastructure that permits knowledge science. With out well-engineered knowledge pipelines, even the very best fashions fail to ship correct insights.
Q3. Why are large knowledge engineering companies essential for international enterprises? They permit firms to deal with high-volume, high-velocity knowledge — powering real-time analytics and innovation throughout distributed methods and worldwide operations.
This fall. How can organizations guarantee sustainable knowledge progress? By automated archiving, compression, and sustainable compute practices that cut back pointless knowledge duplication and power consumption.
Q5. What future developments will outline knowledge engineering within the subsequent 5 years? Count on stronger integration between AI and knowledge pipelines, federated knowledge governance, privacy-preserving computation, and sustainability-focused engineering.
Q6. Is cloud migration needed for contemporary knowledge engineering? Whereas not obligatory, cloud and hybrid fashions present flexibility, scalability, and price effectivity that on-prem methods typically can’t match.
Q7. What’s the most important problem firms face in the present day? Aligning knowledge engineering investments with precise enterprise outcomes. Many organizations concentrate on instruments earlier than technique — the reverse method yields higher ROI.
Conclusion
The evolution of knowledge engineering companies marks a turning level for enterprises worldwide. In a panorama the place knowledge doubles each few years, strategic engineering defines who leads and who lags.
Firms that undertake large knowledge engineering companies with automation, AI integration, and powerful governance won’t solely thrive in 2025 — they are going to form the way forward for digital enterprise itself.
The message is evident: Knowledge isn’t simply an asset anymore; it’s the structure of technique.
A haunting grin appeared on the solar as vibrant energetic areas and darkish coronal holes mixed to create a jack-o’-lantern face simply in time for Halloween. The picture was captured by NASA’s Photo voltaic Dynamics Observatory on Oct. 28 on the 193-angstrom wavelength. (Picture credit score: NASA/SDO)
The solar is entering into the Halloween spirit as soon as once more. NASA’s Photo voltaic Dynamics Observatory (SDO) captured a hauntingly festive view of our star on Oct. 28, wanting like a cosmic jack-o’-lantern grinning down at Earth.
Within the picture, captured by SDO’s Atmospheric Imaging Meeting (AIA), darkish coronal holes and vibrant energetic areas mix to type what seems to be glowing eyes, a nostril and a mischievous smile carved throughout the photo voltaic floor.
That “mouth” nonetheless, is greater than only a ornament. It is truly an unlimited coronal gap, an space on the solar‘s floor the place the magnetic subject opens up, permitting charged particles (photo voltaic wind) to stream freely into area. This explicit gap is at present spewing a high-speed photo voltaic wind stream towards Earth, which may spark minor (G1) to average (G2) geomagnetic storm situations from Oct. 28 by means of Oct. 29, in accordance with area climate forecasters.
If geomagnetic storm situations intensify, auroras can unfold past their normal polar areas, into mid-latitudes. 22 years in the past this week, the notorious Halloween storms of 2003 noticed a barrage of highly effective photo voltaic eruptions set off spectacular auroras and disrupt satellites and energy programs worldwide.
SDO has been watching the solar since 2010, offering steady, high-resolution views that assist scientists perceive how the solar’s magnetic power drives area climate, which in flip impacts our lives right here on Earth.
This is not the primary time the observatory has noticed a spooky face on the solar. Again in 2014, it captured this eerie jack-o’-lantern-like grin.
Photo voltaic jack-o’-lantern captured by NASA’s Photo voltaic Dynamics Observatory on Oct. 8, 2014. (Picture credit score: NASA/SDO)
Breaking area information, the most recent updates on rocket launches, skywatching occasions and extra!
A standard downside in machine studying is the “uncommon case” state of affairs. In lots of classification issues, the category of curiosity (fraud, buy by an internet customer, loss of life of a affected person) is uncommon sufficient {that a} knowledge pattern might not have sufficient cases to generate helpful predictions. One approach to take care of this downside is, in essence, knowledge fabrication: attaching artificial class labels to instances the place we don’t know the precise label.
That is referred to as label propagation or label spreading and sounds bogus. Nevertheless, it has labored in check instances. The thought is as follows:
1. Begin with a small variety of instances the place the label (class) is understood. (Now we have solely a small variety of 1’s, the category of curiosity, as the category happens solely not often). 2.Establish extra instances the place the label is unknown however the case is similar to the recognized 1’s in different respects. 3.Label these instances as 1’s. 4.Mix the actual 1’s with the bogus 1’s and use it because the coaching knowledge for a mannequin.
Granted, a supply of error is launched: we’re solely guessing on the artificial labels. Simulations, although, have proven that this may be greater than offset by the discount in one other sort of error: small pattern error. Label spreading takes benefit of the data contained within the predictor values for the same instances. It’s analogous to imputing lacking knowledge, which additionally permits us to make use of extra of the info in becoming a mannequin.
Label spreading is usually utilized to graph knowledge; i.e., knowledge that describe the hyperlinks (edges) between instances (nodes) in a community. Nodes with unknown labels can take the label that predominates within the close by community neighborhood.
Simply launched from Stata Press: A Light Introduction to Stata, Revised Sixth Version
Stata Press is happy to announce the discharge of A Light Introduction to Stata, Revised Sixth Version by Alan C. Acock. Should you, or somebody you understand, are new to Stata, it would be best to try the revised version of Stata Press’s longtime greatest vendor, which is now accessible and absolutely up to date for Stata 17.
A Light Introduction to Stata, Revised Sixth Version begins from the very starting with the idea that the reader might not have prior expertise with any statistical software program. This assumption of a clean slate is central to the construction and contents of the ebook. Acock begins with the fundamentals; for instance, the a part of the ebook that offers with information administration begins with a cautious and detailed instance of turning survey information on paper right into a Stata-ready dataset. When explaining how one can go about fundamental exploratory statistical procedures, Acock consists of notes that can assist the reader develop good work habits. This combination of explaining good Stata habits and explaining good statistical habits continues all through the ebook.
The revised sixth version is absolutely updated for Stata 17. All command syntax, output, menus, dialog packing containers, and directions for utilizing the point-and-click interface have been up to date. Examples now embrace new Stata options such because the redesigned desk command and accumulate suite for creating and exporting custom-made tables in addition to the choice for creating graphs with transparency.
This ebook is good for these simply starting to be taught Stata and makes a fantastic companion for an introductory statistics course. The creator introduces each the statistical ideas and their implementation in Stata.
There are lots of upcoming releases of Stata Press books. To see the total checklist of forthcoming books, please go to our forthcoming web page. While you’re there, join alerts, and be the primary to know when a brand new ebook is launched. Go to Stata Press to see our full checklist of books.
People excel at processing huge arrays of visible data, a ability that’s essential for reaching synthetic normal intelligence (AGI). Over the many years, AI researchers have developed Visible Query Answering (VQA) techniques to interpret scenes inside single photographs and reply associated questions. Whereas latest developments in basis fashions have considerably closed the hole between human and machine visible processing, typical VQA has been restricted to cause about solely single photographs at a time relatively than entire collections of visible knowledge.
This limitation poses challenges in additional advanced eventualities. Take, for instance, the challenges of discerning patterns in collections of medical photographs, monitoring deforestation by way of satellite tv for pc imagery, mapping city adjustments utilizing autonomous navigation knowledge, analyzing thematic parts throughout giant artwork collections, or understanding shopper habits from retail surveillance footage. Every of those eventualities entails not solely visible processing throughout a whole lot or hundreds of photographs but additionally necessitates cross-image processing of those findings. To deal with this hole, this challenge focuses on the “Multi-Picture Query Answering” (MIQA) process, which exceeds the attain of conventional VQA techniques.
Visible Haystacks: the primary “visual-centric” Needle-In-A-Haystack (NIAH) benchmark designed to scrupulously consider Giant Multimodal Fashions (LMMs) in processing long-context visible data.









")


