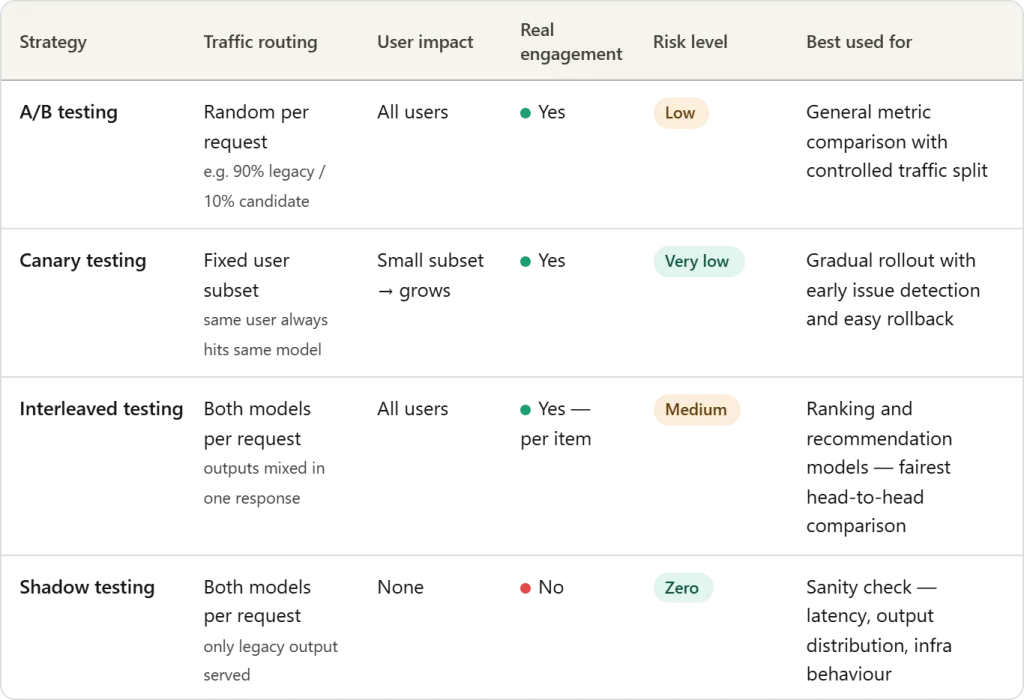
Properly it is a large submit. It began with me simply wanting for example the brand new replace to Claude Code — “Dispatch”. You’ll need to watch me use it within the video. However principally it is a fairly huge replace. Why? As a result of with “Dispatch” you’ll be able to solely run your Claude Code stuff from your cellphone. So it’s essential:
After which comply with the directions by clicking on the Dispatch tab from inside your cellphone. I present you the way it goes down within the video. However actually, it is a fairly large deal. Why? Properly, for vibe coding fashion work within the first place, all you’re doing is chatting anyway. And you realize the place you chat rather a lot anyway? Your textual content message communication which is 80% to 100% of the time out of your cellphone anyway.
So, “Dispatch” goes to completely change your workflow. You’re going to be simply sitting on the sofa, texting every little thing. As long as your laptop computer or desktop is open, I believe it runs. Now we positively need to get a Mac mini or Mac Studio. Set that factor up, get it hooked as much as wifi, let it do all of your work — when you’re operating on a treadmill, from church, throughout your seminars, sitting on the sofa ingesting your morning espresso like I did. No matter. I’m undecided it’s higher per se, but it surely’s 100% going to be the primary manner we work. I’ve little question about that.
So it makes me suppose that it’s solely doable that Claude Code “Dispatch” might have a nontrivial impact on what machine we get. Perhaps I solely want an enormous machine for house, headless like a Mini or Studio, after which I simply have a standard laptop computer the remainder of the time. I imply you may dispatch from the desktop app too. So why not have the blazing quick factor however not essentially two blazing quick issues should you’re on the price range constraint?
However let me stroll you thru it. I’m going to point out you a few movies of me loading up dispatch and revisiting the “milled hashish paper” from the opposite day. That was the one the place I principally simply instructed Claude Code to select a subject for me, do all of the evaluation, and write it up, and it wrote a manuscript in 3.5 hours.
Thanks once more everybody for all of your help on this substack! I actually recognize all of the help, as I mentioned yesterday, each for these Claude Code posts, but additionally for your entire historical past of the substack. All of the emails, all of the feedback — it’s very cool. I like doing this, so I recognize it. It’s a true labor of affection. For those who actually get worth from it such that the marginal advantage of the substack every month exceeds $5, then think about turning into a paying subscriber! It’s solely $5/month! 🙂
Establishing “Dispatch” in your cellphone and desktop app.
First, let me present you the place you need to look. Dispatch just isn’t within the “Code” a part of the desktop app. Reasonably it’s within “Cowork”. And spot, it’s essential pull down “Claude” menu prime left (on the Mac desktop app anyway), and replace it. I’m already having to replace once more apparently.
When you do this, you then must go to the App Retailer, and replace your Claude cellphone app. Then return to the desktop app, to “Dispatch” and I believe you’ll must do some steps that I’ve already forgotten. However it’s possible you’ll both must scan a QR code, or you might have to simply reinitiate your Claude connection on the web site. However the level is, there’s a bit of setup, and when you do the setup, you’re able to go. So do this first.
Now let me present you the video stroll throughs. They’re, as soon as once more, round >1 hours however I believe it’s possible you’ll discover it attention-grabbing. First, you may watch me navigate the Dispatch stuff. However secondly, it’s within the context of “doing sensible empirical analysis”, which as you realize is form of the best way I write all these Claude Code posts. It’s much less abstractly about “right here is that this Claude Code idea known as /hooks!” However fairly it’s extra like “right here I’m utilizing a /hook for this mission I’m engaged on” sort of deal. Which I believe for the individuals who subscribe actually is the best way to do it. I do know it’s how I need to do it anyway.
However the second factor is me actually operating all of the coding from the cellphone. Working R, merging, even having Claude Code freaking internet crawl to get extra knowledge! Insane stuff. I’m actually not even certain if I even will primarily use the cellphone or the pc. I’m such a compulsive texter within the first place that for all I do know, I received’t even use my laptop computer once more. However right here, you watch and see what you suppose.
Video 1
Video 2
When Your Estimator Returns a Quantity That Isn’t an Estimate
That is frankly an enormous submit. It’s about Dispatch, it’s about logit, it’s about difference-in-differences, it’s about Callaway and Sant’Anna, it’s about conditional parallel tendencies. And whereas I want I might’ve made this shorter, I’m not going to. So frankly, possibly simply copy and paste it into Claude and interrogate the substack submit that manner should you don’t need to learn it. I’ll attempt to be fast although.
So earlier this week, I dug into that hashish reform paper that Claude “milled” up for me the opposite day. I couldn’t actually fake I didn’t see these occasion research (you may see it within the above substack if you wish to se it because it’s the picture on the quilt of the substack). The pre-trends appeared flat and the post-treatment estimates had been optimistic. It was round a 2% improve in wages as a consequence of leisure hashish reform and I simply couldn’t cease seeing it in my head.
So what I did was learn the paper. I learn it just a few occasions. And recall — I didn’t write this. Claude got here up with the concept (I didn’t even give the hashish thought to him), collected the information utilizing his “internet crawl” bash command, selected the estimator (Callaway and Sant’Anna for staggered therapy difference-in-differences), after which chosen did all of the evaluation together with the occasion research. After which he wrote it up “within the voice of Martin Weitzman”, who as many very long time readers know is my favourite author within the historical past of economics. That’s for an additional day although. Level is, he did it and that is the paper. The entire thing took 3.5 hours, and by now, most individuals studying this have already seen any such “paper mill on the supply” experiment just a few occasions, or accomplished it themselves, and due to this fact perceive why I wrote this submit saying I predict a smashing of milled papers colliding with our subject journals, editor desk, and loading up requests for referees by multiples of possibly 5-10x fold.
Anyway, I learn the paper and I seen that the CS estimator was utilizing “log state inhabitants” as a covariate. So I wished to consider that extra rigorously. So what I did was I requested Claude Code to gather “a ton of covariates” from the net that in his opinion had been applicable for a conditional parallel tendencies assumption. What’s that? Properly to me, the conditional parallel tendencies assumption is framed finest within the Heckman, Ichimura and Todd (1997, Restud) arrange the place you kind of regress the primary totally different (development) final result onto a bunch of baseline covariates for the management group solely, then use these fitted values to impute the primary totally different predicted final result for the therapy group. Which implies that I kind of consider the variables which are extremely predictive of the primary distinction final result as candidates to fulfill parallel tendencies since that’s what HIT97 does of their two step imputation process.
Anyway, Claude Code got here up with a candidate checklist of covariates and internet crawled till he discovered them, then pulled them in. After which what he did was put them in one by one, which I’ll present you now.
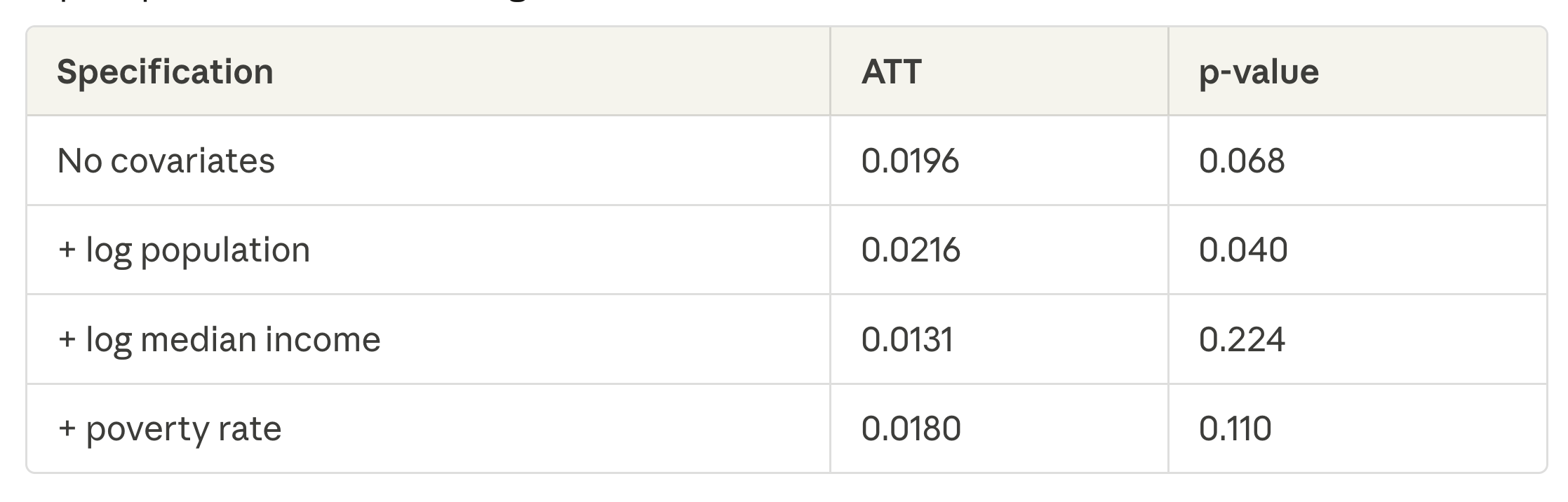
You’ll be able to see that none of those easy ATTs are statistically important although — the usual error is twice as massive because the ATT once I embody inhabitants, however had been even bigger with out something. So meaning the occasion research, in the event that they had been accomplished appropriately, had been most likely issues I actually need to dig into, and can.
One of many issues he present in doing this was that the state unemployment price he pulled by way of the BLS API.
BTW, can we simply paused for a second. We now apparently dwell in a world the place “synthetic intelligence” doesn’t simply exist, however that Claude Code will autonomously pull knowledge into my native folder on my precise laptop utilizing the API, then simply begin merging information and operating evaluation? I nonetheless can’t. I’m undecided when I’ll cease being amazed by that one reality.
Okay however again to the work. We discovered collectively that the unemployment price had tons of NAs as a result of it was month-to-month knowledge not annual knowledge. I had him determine that out by calculating NxT (N=50 states; T was 2003 to 2024) after which counting all covariates and outcomes that weren’t that quantity. By the best way, strongly encourage you add this into your workflow as an early step. Why? As a result of a lot is now occurring behind the scenes, and we’re very doubtless to be working with imbalance panels unknowingly if we actually are ten steps faraway from even seeing the output.
Anyway, he did all that, and we grew to become all in favour of covariates, which led to this.
Propensity scores, CS and “small handled models”
So it’s possible you’ll recall the opposite day that I did that many analyst design the place I estimated the variation in ATT estimates throughout three programming languages (python, R and Stata) every of which had two packages, giving me six packages per CS specification. The outcomes had been miserable.
Mainly loads of what I discovered needed to do with how the totally different packages dealt with “large numbers” from that early, largely hidden first stage, in CS of estimating a logit, cohort by cohort, modeling the therapy project (a dummy variable therapy indicator) in opposition to baseline covariates. And should you recall the best way that every bundle was rounding and utilizing floating numbers was creating all these issues, however the packages dealt with the issue in a different way which precipitated the ATT estimates to swing round, however just for circumstances the place you had covariates in any respect, and had been utilizing double strong and the IPW.
So logits have ever since been in my head, however actually, they’ve been in my head for years with CS. However right here’s the gist of it — there’s an early paper from the Nineties by Peduzzi, et al. (1996) that kind of discovered that you just want round “10 occasions” per covariate to keep away from good separation with one thing like logit. Yow will discover the paper right here. They use the phrase “occasions per variable” or EPV. And principally, with logistic regressions, they did a Monte Carlo and located that when the EPV values had been 10+, you had been superb. Which means “10 handled states” for every covariate in our context. however while you had lower than 10, the regression coefficients get wonky and are biased in each optimistic and detrimental path. You’ll be able to see the summary right here, however I extremely encourage you to learn this paper in case you are operating CS with the double strong or IPW specification.
Within the case of diff-in-diff, an “occasion” is the variety of handled models on the cohort stage. It’s a left hand aspect variable idea — it’s the variety of handled models. And when you might imagine “properly I’m superb. I’ve 20 handled states”. Sure, you do have 20 handled states. However bear in mind — CS estimates every propensity rating, and every 2×2, per cohort-year. So, don’t ask what number of handled states you could have. Ask what number of handled states do I’ve in a given 12 months? Do you could have 10? Do you could have 5? Do you could have 1? The reply is “Sure”. You almost certainly have state of affairs the place 10 states get handled, the place 5 get handled, and actually, you most likely just a few singletons in several years.
This can be a large deal, I believe. If you’re actually solely having a single handled state in your CS state of affairs, and are estimating a logit below the hood since you did double strong, or IPW, then you definately actually shouldn’t even doing it within the first place. You will get the unsuitable propensity scores if it even does it. It’s all below the hood bear in mind. CS did, csdid, diff-diff, variations, all of them — they don’t report the coefficients from the logit. Typically they don’t even maintain the coefficients. They will not even retailer the propensity scores so you may test this out. So I believe this isn’t a trivial deal.
Why? Why is that this not trivial. As a result of in the US, we regularly are working with state stage knowledge. And we’re working with staggered adoption. And we regularly covariates. And an increasing number of we’re estimating Callaway and Sant’Anna. Which implies we’re working with conditions which typically have fewer than 10 occasions per variable. Which implies the logit is biased. Ugh.
You’ll be able to watch me and Claude Code in “Dispatch” speak about all this, however I extremely encourage you interrogate Claude Code by yourself. He is aware of that Peduzzi, et al. (1996) paper too, however go forward and provides him this hyperlink when you’re at it, after which have him examine conditions the place you could have fewer than 10 occasions per covariate utilizing a logit on your state-level dataset and inform me what you discover.
What I’m Pondering
So I’m going to be excited about this for some time. This “occasions per variable” deal just isn’t trivial. See, in our JEL paper, we studied Medicaid reform on mortality utilizing county-level knowledge. Not state-level knowledge. Why does that matter?
Properly, that issues as a result of you could have loads of occasions per variable should you drop all the way down to the county stage. A single state like Texas has 254 counties. So if Texas will get handled, then you definately don’t get one handled unit — you get 254 handled models.
It would really feel prefer it’s dishonest, but it surely isn’t. Verify the JEL paper the place we talk about weighting by county inhabitants and the way that modifications the goal parameter from the “common county” to the “common particular person”. I believe really that should you inhabitants weighted in state stage knowledge, and inhabitants weighted in county stage knowledge, the goal ATT parameter is similar both manner and so is the parallel tendencies assumption. Each the ATT and the parallel tendencies assumption will probably be expressed as weighted means. So I believe it’s going to be similar.
Besides in a single state of affairs. And that’s covariates and the logit estimation. You probably have just one handled state versus 254 handled counties, and also you estimate a logit with 1 or 2 covariates, I believe that can mess up stuff within the former, however not a lot within the latter. So in case your aim is the inhabitants stage ATT within the first place, I believe it’s essential transfer all the way down to the county stage simply to outlive this complete factor! I’m going to dig into it extra with a simulation myself, however frankly, I believe you must too. Begin excited about it — you don’t want my substack for that.
However I don’t suppose it’s trivial in any respect, and I don’t suppose it’s one thing extensively appreciated with CS. We spend a lot time targeted on staggering and so little time excited about covariates as of late. And there may be an informality we how we speak in regards to the parallel tendencies assumption, focusing solely on the occasion research, and due to this fact the inclusion of covariates is form of one in every of these “ehhh” sort issues. However I’ve seen the signal flip in an occasion research from one covariate. I’ll write one other submit about it one other time, although. For now, study these occasions per variable, however I don’t suppose we’re speaking about this sufficient, in any respect. So I could go on a little bit of a rabbit gap on this. So buckle up.
Think about regression adjustment over the propensity rating
However there may be a simple repair should you can’t get your arms on county stage knowledge — don’t specify double strong and don’t specify IPW. Use regression adjustment as a substitute. Why?
As a result of, initially, regression adjustment just isn’t logistic regression, which is what that Peduzzi, et al. (1996) article is about. In order that’s one factor.
Two, there are not any “occasions per variable” while you use regression adjustment. Why? As a result of in regression adjustment, you might be regressing the primary distinction within the final result in opposition to the baseline covariates utilizing OLS. There aren’t any occasions. There’s no dummy. You aren’t modeling the therapy with regression adjustment — you might be modeling the primary distinction final result. I believe it’s possible you’ll can get away with it there, and actually you aren’t sacrificing a ton. You’re nonetheless interesting to conditional parallel tendencies. And also you additionally don’t want widespread help with OLS. The unique HIT 1997 I believe did want that because it was nonparametric, however I believe below the hood in CS it’s vanilla OLS, so it’ll simply extrapolate with funky traces.
In order that may even be one thing I’m going to be attending to the underside of, which suggests Claude Code will come to the mountain prime with me to be taught extra about logits within the context of difference-in-differences and CS.
Dispatch and Conclusion
There’s extra however I’m going to cease there, however within the movies you’ll discover much more issues we talked about. However right here’s the factor I need to let you know.
I actually dug this Dispatch. Large time. I believe I’m going to get a Mini or a Studio too. I believe it’s time. This iMac desktop I’ve sucks within the age of Claude Code. My MacBook Professional is okay. I don’t plan on updating it for most likely a 12 months or two as I actually maxed it out again in 2022. And to this point it’s not giving me bother.
However that iMac I bought may as properly be a calculator at this level within the age of Claude Code. A headless mini or simply linked to my exterior monitor might be superb. I solely get round $250 for the commerce in on this factor, however no matter. I believe having a house workplace arrange is value it given the form of work I now do. So, that’s the place I’m heading. Hope this was useful. Try Dispatch. I believe it’s going to blow you away.














")