don’t collapse in a single day. They develop slowly, question by question.
“What breaks once I change a desk?”
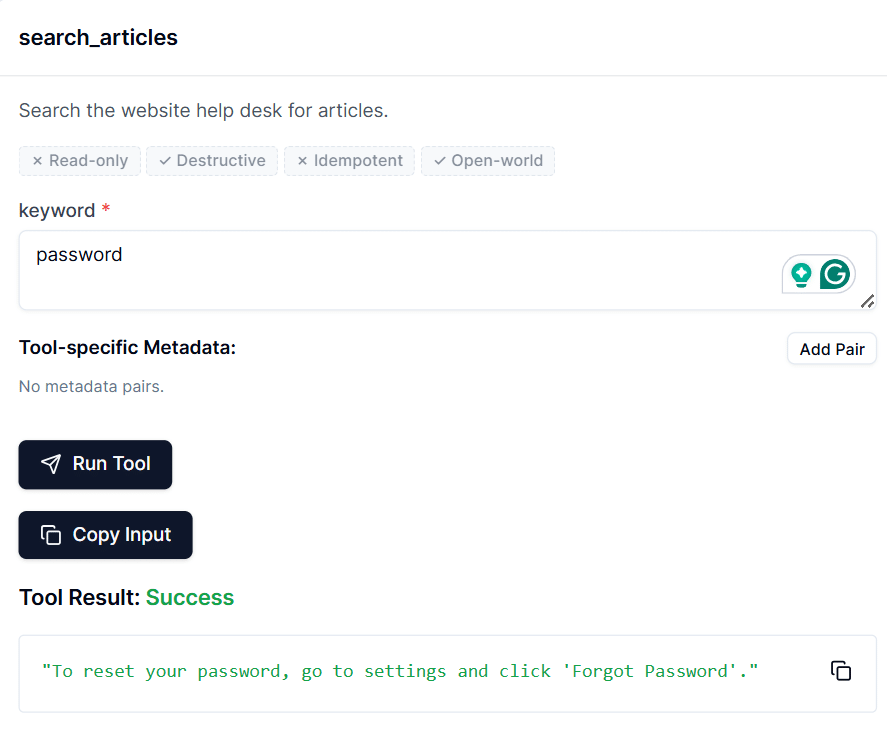
A dashboard wants a brand new metric, so somebody writes a fast SQL question. One other group wants a barely totally different model of the identical dataset, in order that they copy the question and modify it. A scheduled job seems. A saved process is added. Somebody creates a derived desk straight within the warehouse.
Months later, the system appears nothing like the straightforward set of transformations it as soon as was.
Enterprise logic is scattered throughout scripts, dashboards, and scheduled queries. No one is totally positive which datasets rely upon which transformations. Making even a small change feels dangerous. A handful of engineers grow to be the one ones who actually perceive how the system works as a result of there isn’t a documentation.
Many organizations ultimately discover themselves trapped in what can solely be described as a SQL jungle.
On this article we discover how methods find yourself on this state, acknowledge the warning indicators, and convey construction again to analytical transformations. We’ll take a look at the rules behind a well-managed transformation layer, the way it matches into a contemporary knowledge platform, and customary anti-patterns to keep away from:
- How the SQL jungle got here to be
- Necessities of a metamorphosis layer
- The place the transformation layer matches in an information platform
- Widespread anti-patterns
- acknowledge when your group wants a metamorphosis framework
1. How the SQL jungle got here to be
To grasp the “SQL jungle” we first want to take a look at how fashionable knowledge architectures advanced.
1.1 The shift from ETL to ELT
Traditionally knowledge engineers constructed pipelines that adopted an ETL construction:
Extract --> Rework --> Load
Information was extracted from operational methods, reworked utilizing pipeline instruments, after which loaded into an information warehouse. Transformations had been applied in instruments equivalent to SSIS, Spark or Python pipelines.
As a result of these pipelines had been complicated and infrastructure-heavy, analysts depended closely on knowledge engineers to create new datasets or transformations.
Trendy architectures have largely flipped this mannequin
Extract --> Load --> Rework
As a substitute of remodeling knowledge earlier than loading it, organizations now load uncooked knowledge straight into the warehouse, and transformations occur there. This structure dramatically simplifies ingestion and allows analysts to work straight with SQL within the warehouse.
It additionally launched an unintended aspect impact.
1.2 Penalties of ELT
Within the ELT structure, analysts can remodel knowledge themselves. This unlocked a lot sooner iteration but additionally launched a brand new problem. The dependency on knowledge engineers disappeared, however so did the construction that engineering pipelines offered.
Transformations can now be created by anybody (analysts, knowledge scientists, engineer) in anywhere (BI instruments, notebooks, warehouse tables, SQL jobs).
Over time, enterprise logic grew organically contained in the warehouse. Transformations accrued as scripts, saved procedures, triggers and scheduled jobs. Earlier than lengthy, the system become a dense jungle of SQL logic and quite a lot of guide (re-)work.
In abstract:
ETL centralized transformation logic in engineering pipelines.
ELT democratized transformations by transferring them into the warehouse.
With out construction, transformations develop unmanaged, leading to a system that turns into undocumented, fragile and inconsistent. A system through which totally different dashboards could compute the identical metric in numerous methods and enterprise logic turns into duplicated throughout queries, studies, and tables.
1.3 Bringing again construction with a metamorphosis layer
On this article we use a metamorphosis layer to handle transformations contained in the warehouse successfully. This layer combines the engineering self-discipline of ETL pipelines whereas preserving the pace and adaptability of the ELT structure:
The transformation layer brings engineering self-discipline to analytical transformations.
When applied efficiently, the transformation layer turns into the only place the place enterprise logic is outlined and maintained. It acts because the semantic spine of the information platform, bridging the hole between uncooked operational knowledge and business-facing analytical fashions.
With out the transformation layer, organizations typically accumulate giant quantities of knowledge however have problem to show it into dependable data. The reason is that enterprise logic tends to unfold throughout the platform. Metrics get redefined in dashboards, notebooks, queries and so forth.
Over time this results in one of the crucial widespread issues in analytics: a number of conflicting definitions of the identical metric.
2. Necessities of a Transformation Layer
If the core downside is unmanaged transformations, the subsequent logical query is:
What would well-managed transformations seem like?
Analytical transformations ought to comply with the identical engineering rules we anticipate in software program methods, going from ad-hoc scripts scattered throughout databases to “transformations as maintainable software program parts“.
On this chapter, we focus on what necessities a metamorphosis layer should meet with a view to correctly handle transformations and, doing so, tame the SQL jungle.
2.1 From SQL scripts to modular parts
As a substitute of huge SQL scripts or saved procedures, transformations are damaged up into small, composable fashions.
To be clear: a mannequin is simply an SQL question saved as a file. This question defines how one dataset is constructed from one other dataset.
The examples under present how knowledge transformation and modeling software dbt creates fashions. Every software has their very own approach, the precept of turning scripts into parts is extra necessary than the precise implementation.
Examples:
-- fashions/staging/stg_orders.sql
choose
order_id,
customer_id,
quantity,
order_date
from uncooked.orders
When executed, this question materializes as a desk (staging.stg_orders) or view in your warehouse. Fashions can then construct on prime of one another by referencing one another:
-- fashions/intermediate/int_customer_orders.sql
choose
customer_id,
sum(quantity) as total_spent
from {{ ref('stg_orders') }}
group by customer_id
And:
-- fashions/marts/customer_revenue.sql
choose
c.customer_id,
c.identify,
o.total_spent
from {{ ref('int_customer_orders') }} o
be a part of {{ ref('stg_customers') }} c utilizing (customer_id)
This creates a dependency graph:
stg_orders
↓
int_customer_orders
↓
customer_revenue
Every mannequin has a single duty and builds upon different fashions by referencing them (e.g. ref('stg_orders')). This method has has main benefits:
- You’ll be able to see precisely the place knowledge comes from
- You already know what’s going to break if one thing adjustments
- You’ll be able to safely refactor transformations
- You keep away from duplicating logic throughout queries
This structured system of transformations makes transformation system simpler to learn, perceive, keep and evolve.
2.2 Transformations that reside in code
A managed system shops transformations in version-controlled code repositories. Consider this as a mission that comprises SQL recordsdata as an alternative of SQL being saved in a database. It’s just like how a software program mission comprises supply code.
This permits practices which are fairly acquainted in software program engineering however traditionally uncommon in knowledge pipelines:
- pull requests
- code opinions
- model historical past
- reproducible deployments
As a substitute of enhancing SQL straight in manufacturing databases, engineers and analysts work in a managed improvement workflow, even with the ability to experiment in branches.
2.3 Information High quality as a part of improvement
One other key functionality a managed transformation system ought to present is the flexibility to outline and run knowledge checks.
Typical examples embody:
- guaranteeing columns aren’t null
- verifying uniqueness of major keys
- validating relationships between tables
- implementing accepted worth ranges
These checks validate assumptions in regards to the knowledge and assist catch points early. With out them, pipelines typically fail silently the place incorrect outcomes propagate downstream till somebody notices a damaged dashboard
2.4 Clear lineage and documentation
A managed transformation framework additionally offers visibility into the information system itself.
This usually consists of:
- computerized lineage graphs (the place does the information come from?)
- dataset documentation
- descriptions of fashions and columns
- dependency monitoring between transformations
This dramatically reduces reliance on tribal information. New group members can discover the system reasonably than counting on a single one who “is aware of how the whole lot works.”
2.5 Structured modeling layers
One other widespread sample launched by managed transformation frameworks is the flexibility to separate transformation layers.
For instance, you would possibly make the most of the next layers:
uncooked
staging
intermediate
marts
These layers are sometimes applied as separate schemas within the warehouse.
Every layer has a particular function:
- uncooked: ingested knowledge from supply methods
- staging: cleaned and standardized tables
- intermediate: reusable transformation logic
- marts: business-facing datasets
This layered method prevents analytical logic from turning into tightly coupled to uncooked ingestion tables.
3. The place the Transformation Layer Suits in a Information Platform
With the earlier chapters, it turns into clear to see the place a managed transformation framework matches inside a broader knowledge structure.
A simplified fashionable knowledge platform typically appears like this:
Operational methods / APIs
↓
1. Information ingestion
↓
2. Uncooked knowledge
↓
3. Transformation layer
↓
4. Analytics layer
Every layer has a definite duty.
3.1 Ingestion layer
Accountability: transferring knowledge into the warehouse with minimal transformation. Instruments usually embody customized ingestion scripts, Kafka or Airbyte.
3.2 Uncooked knowledge layer
Accountable for storing knowledge as shut as potential to the supply system. Prioritizes completeness, reproducibility and traceability of knowledge. Little or no transformation ought to occur right here.
3.3 Transformation layer
That is the place the principal modelling work occurs.
This layer converts uncooked datasets into structured, reusable analytical fashions. Typical duties encompass cleansing and standardizing knowledge, becoming a member of datasets, defining enterprise logic, creating aggregated tables and defining metrics.
That is the layer the place frameworks like dbt or SQLMesh function. Their position is to make sure these transformations are
- structured
- model managed
- testable
- documented
With out this layer, transformation logic tends to fragment throughout queries dashboards and scripts.
3.4 Analytics layer
This layer consumes the modeled datasets. Typical customers embody BI instruments like Tableau or PowerBI, knowledge science workflows, machine studying pipelines and inner knowledge purposes.
These instruments can depend on constant definitions of enterprise metrics since transformations are centralized within the modelling layer.
3.5 Transformation instruments
A number of instruments try to deal with the problem of the transformation layer. Two well-known examples are dbt and SQLMesh. These instruments make it very accessible to simply get began making use of construction to your transformations.
Simply do not forget that these instruments aren’t the structure itself, they’re merely frameworks that assist implement the architectural layer that we want.
4. Widespread Anti-Patterns
Even when organizations undertake fashionable knowledge warehouses, the identical issues typically reappear if transformations stay unmanaged.
Beneath are widespread anti-patterns that, individually, could seem innocent, however collectively they create the circumstances for the SQL jungle. When enterprise logic is fragmented, pipelines are fragile and dependencies are undocumented, onboarding new engineers is gradual and methods grow to be troublesome to take care of and evolve.
4.1 Enterprise logic applied in BI instruments
One of the vital widespread issues is enterprise logic transferring into the BI layer. Take into consideration “calculating income in a Tableau dashboard”.
At first this appears handy since analysts can rapidly construct calculations with out ready for engineering help. In the long term, nonetheless, this results in a number of points:
- metrics grow to be duplicated throughout dashboards
- definitions diverge over time
- problem debugging
As a substitute of being centralized, enterprise logic turns into fragmented throughout visualization instruments. A wholesome structure retains enterprise logic within the transformation layer, not in dashboards.
4.2 Large SQL queries
One other widespread anti-pattern is writing extraordinarily giant SQL queries that carry out many transformations directly. Take into consideration queries that:
- be a part of dozens of tables
- comprise deeply nested subqueries
- implement a number of phases of transformation in a single file
These queries rapidly grow to be troublesome to learn, debug, reuse and keep. Every mannequin ought to ideally have a single duty. Break transformations into small, composable fashions to extend maintainability.
4.3 Mixing transformation layers
Keep away from mixing transformation duties throughout the identical fashions, like:
- becoming a member of uncooked ingestion tables straight with enterprise logic
- mixing knowledge cleansing with metric definitions
- creating aggregated datasets straight from uncooked knowledge
With out separation between layers, pipelines grow to be tightly coupled to uncooked supply constructions. To treatment this, introduce clear layers equivalent to the sooner mentioned uncooked, staging, intermediate or marts.
This helps isolate duties and retains transformations simpler to evolve.
4.4 Lack of testing
In lots of methods, knowledge transformations run with none type of validation. Pipelines execute efficiently even when the ensuing knowledge is inaccurate.
Introducing automated knowledge checks helps detect points like duplicate major keys, sudden null values and damaged relationships between tables earlier than they propagate into studies and dashboards.
4.5 Enhancing transformations straight in manufacturing
One of the vital fragile patterns is modifying SQL straight contained in the manufacturing warehouse. This causes many issues the place:
- adjustments are undocumented
- errors instantly have an effect on downstream methods
- rollbacks are troublesome
In a very good transformation layer, transformations are handled as version-controlled code, permitting adjustments to be reviewed and examined earlier than deployment.
5. Acknowledge When Your Group Wants a Transformation Framework
Not each knowledge platform wants a completely structured transformation framework from day one. In small methods, a handful of SQL queries could also be completely manageable.
Nevertheless, because the variety of datasets and transformations grows, unmanaged SQL logic tends to build up. Sooner or later the system turns into obscure, keep, and evolve.
There are a number of indicators that your group could also be reaching this level.
- The variety of transformation queries retains rising
Consider dozens or a whole lot of derived tables
- Enterprise metrics are outlined in a number of locations
Instance: totally different definition of “lively customers” throughout groups
- Issue understanding the system
Onboarding new engineers takes weeks or months. Tribal information required for questions on knowledge origins, dependencies and lineage
- Small adjustments have unpredictable penalties
Renaming a column could break a number of downstream datasets or dashboards
- Information points are found too late
High quality points floor after a clients discovers incorrect numbers on a dashboard; the results of incorrect knowledge propagating unchecked by means of a number of layers of transformations.
When these signs start to seem, it’s often time to introduce a structured transformation layer. Frameworks like dbt or SQLMesh are designed to assist groups introduce this construction whereas preserving the flexibleness that fashionable knowledge warehouses present.
Conclusion
Trendy knowledge warehouses have made working with knowledge sooner and extra accessible by shifting from ETL to ELT. Analysts can now remodel knowledge straight within the warehouse utilizing SQL, which drastically improves iteration pace and reduces dependence on complicated engineering pipelines.
However this flexibility comes with a danger. With out construction, transformations rapidly grow to be fragmented throughout scripts, dashboards, notebooks, and scheduled queries. Over time this results in duplicated enterprise logic, unclear dependencies, and methods which are troublesome to take care of: the SQL jungle.
The answer is to introduce engineering self-discipline into the transformation layer. By treating SQL transformations as maintainable software program parts — model managed, modular, examined, and documented — organizations can construct knowledge platforms that stay comprehensible as they develop.
Frameworks like dbt or SQLMesh may help implement this construction, however an important change is adopting the underlying precept: managing analytical transformations with the identical self-discipline we apply to software program methods.
With this we will create an information platform the place enterprise logic is clear, metrics are constant, and the system stays comprehensible even because it grows. When that occurs, the SQL jungle turns into one thing way more beneficial: a structured basis that the whole group can belief.
I hope this text was as clear as I supposed it to be but when this isn’t the case please let me know what I can do to make clear additional. Within the meantime, take a look at my different articles on every kind of programming-related subjects.
Blissful coding!
— Mike


.webp)

: Base Layers, Hoodies, Jackets & Extra")

-SOURCE-Unbound.jpg)

-Offwhite-Background-SOURCE-Ibex.jpg)