The rising use of generative AI in technical positions has made human smooth abilities and talents a vital requirement for sustaining job safety. Expertise can deal with knowledge processing and code technology, but it surely lacks the power to handle crew operations and develop disaster administration plans.
Employers are actively trying to find candidates who can supervise automated instruments whereas offering the empathy that algorithms lack. Shifting your focus from routine execution to strategic administration is the neatest method to adapt.
The transition from a task-based employee to a high-level important thinker requires deliberate effort. The whole automation of important work capabilities has occurred for professionals who rely completely on specialised knowledge processing. You could basically shift the way you strategy your long-term profession improvement.
Summarize this text with ChatGPT Get key takeaways & ask questions
1. Important Considering and Analytical Judgment
Synthetic intelligence generates data quickly however depends fully on human oversight to confirm details and perceive context. Important considering acts as a mandatory filter to make sure automated outputs align along with your precise enterprise objectives. You should be the gatekeeper who separates helpful knowledge from automated noise.
Professionals should consider algorithmic strategies with wholesome skepticism and analytical rigor. You want the power to ask the best questions and problem flawed assumptions. This requires a degree of contextual consciousness that present machine studying fashions merely don’t possess.
Truth-checking and verification: Making certain all AI-generated claims are correct and backed by dependable sources.
Bias detection: Figuring out and correcting unfair views in algorithmic outputs.
Strategic immediate engineering: Formulating exact inquiries to extract correct data safely.
To see this steadiness of automation and creativity via immediate engineering, take a look at Nice Studying’s YouTube tutorial on Mastering ChatGPT for Productiveness. It supplies a sensible, step-by-step information to automating tedious analysis and summarizing heavy technical paperwork in minutes.
Moreover, to construct the technical instinct wanted for this important oversight, discover Nice Studying’s Grasp Synthetic Intelligence course. Understanding how these fashions truly operate equips you to confidently consider automated outputs, determine biases, and make strategic, data-backed choices.
2. Moral Determination-Making and Threat Administration
AI methods course of knowledge primarily based on programming, missing an inherent understanding of morality or authorized compliance. Human judgment ensures company actions align instantly with strict privateness rules. Leaders should continually consider the moral implications of utilizing rising know-how.
Threat administration includes anticipating the unfavourable penalties of automated enterprise choices. Professionals should set up strict guardrails to guard client knowledge and stop algorithmic discrimination. Because the regulatory atmosphere tightens globally, firms will closely depend on people who perceive technological ethics.
Knowledge privateness advocacy: Defending client data and making certain compliance.
Algorithmic auditing: Reviewing methods for equity and transparency.
Company governance: Establishing moral pointers for know-how use.
To discover ways to implement these moral pointers, discover the 16-week on-line Certificates Program in Utilized Generative AI from Johns Hopkins College. It equips you to mitigate dangers, consider moral implications, and prepare generative fashions utilizing trendy frameworks. You’ll finally study to construct clever AI brokers and deploy accountable Generative AI options that drive enterprise innovation.
3. Emotional Intelligence and Genuine Empathy
Machines can simulate well mannered dialog, however they can’t really feel real empathy or construct precise belief. Excessive-EQ professionals excel at studying the room and understanding unstated crew issues throughout hectic transitions. These people construct genuine interpersonal relationships and foster deep consumer loyalty.
As digital communication saturates the market, the power to construct genuine relationships is a uncommon asset. Algorithms can’t console a annoyed consumer or have a good time a serious crew milestone. Empathy bridges the hole between chilly effectivity and a significant human expertise.
Energetic listening: Totally concentrating on and responding to a speaker’s underlying feelings.
Battle decision: Mediating disputes and discovering mutually useful options.
Relationship constructing: Establishing long-term belief with shoppers and colleagues.
4. Adaptability and Steady Studying
The half-life of technical abilities is shrinking as software program updates and new instruments are launched every day. Professionals who cling to outdated strategies will shortly discover themselves changed by extra environment friendly methods. Adaptability is the straightforward capability to unlearn previous habits and quickly grasp new workflows.
A mindset of steady studying ensures that you simply stay related no matter which software program dominates the market. You could keep curious and examine technological shifts as profession alternatives slightly than threats. Resilience within the face of fast change is a extremely valued trait throughout all main industries.
Agility: Pivoting methods shortly when new data turns into obtainable.
Curiosity: Proactively in search of out new data and experimenting.
Resilience: Bouncing again from failures and sustaining regular productiveness.
Embracing adaptability and steady studying requires constant, hands-on upskilling, and programs just like the Certificates in Generative AI from IIT Bombay provide the most effective worth for learners in search of a protected profession in extremely in-demand domains. You’ll turn out to be a sensible GenAI builder by adapting basis fashions utilizing RAG and creating agentic purposes. In the end, this system empowers you to design, deploy, and function dependable LLM methods utilizing LLMOps practices.
5. Complicated Drawback-Fixing and Inventive Innovation
Whereas AI optimizes current processes, it usually struggles to generate really unique ideas. Algorithms remix current knowledge, making them inherently backward-looking. Human creativity stays the engine of progress, permitting us to design unconventional options to unprecedented issues.
Complicated problem-solving requires pulling insights from unrelated fields and making use of them to distinctive conditions. This lateral considering permits professionals to fully reinvent stagnant enterprise fashions. Creativity depends closely on human instinct, artwork, tradition, and lived expertise.
Lateral considering: Connecting seemingly unrelated ideas to generate revolutionary concepts.
Design considering: Approaching issues with a concentrate on consumer wants.
State of affairs planning: Anticipating future trade shifts and growing methods.
6. Management and Social Affect
AI can’t encourage a workforce or rally a crew via a tough monetary quarter. True management requires character, charisma, and the power to affect others with out relying purely on authority. Organizations desperately want human leaders to information groups via the anxiousness attributable to technological disruption.
Efficient leaders construct psychological security inside their departments. This encourages groups to experiment with new automated instruments with out the worry of quick penalty. Human-to-human mentorship stays important for growing the following technology of high expertise.
Imaginative and prescient casting: Articulating a transparent future that motivates crew members.
Mentorship: Teaching junior staff and guiding their skilled improvement.
Change administration: Main organizations easily via structural shifts.
To efficiently information your group via technological disruption, discover Nice Studying’s Strategic Management for the AI-Pushed Future program. It equips you with the strategic imaginative and prescient and alter administration abilities wanted to construct psychological security and confidently encourage groups adapting to AI.
7. Cross-Practical Collaboration and Communication
The fashionable office requires groups from totally different disciplines to align seamlessly on shared aims. AI can summarize an extended assembly, however human collaboration is required to construct consensus and persuade stakeholders. Efficient communication includes understanding your viewers and delivering a message with whole conviction.
Latest knowledge from LinkedIn’s office reviews spotlight cross-functional coordination and public talking as quickly rising abilities. Leaders should clearly clarify complicated technological modifications to non-technical workers. The power to speak with absolute readability via uncertainty is a defining skilled trait.
Persuasive storytelling: Crafting narratives that encourage motion.
Stakeholder administration: Balancing the competing wants of various companions.
Public talking: Delivering concepts confidently to massive teams.
8. Strategic Enterprise and Income Progress
Whereas AI analyzes market traits and generates lead lists, formulating a complete go-to-market technique requires human instinct. Understanding macroeconomic elements and competitor conduct is important for making high-stakes enterprise choices. People excel at synthesizing this unstructured data to drive precise income.
Driving progress requires superior negotiation abilities and the power to shut offers via relationship constructing. Gross sales professionals use AI for administrative assist, releasing them as much as focus purely on high-value human interactions. The power to determine new income streams stays a uniquely human endeavor.
Go-to-market technique: Planning the launch of latest merchandise.
Excessive-stakes negotiation: Securing favorable phrases in complicated offers.
Market forecasting: Predicting demand primarily based on cultural indicators.
To grasp the human instinct required to drive this progress, discover Nice Studying’s Client Insights and Advertising and marketing Technique program. This course teaches you easy methods to decode client conduct and synthesize complicated market knowledge into high-impact methods that instantly improve income.
Conclusion
Your final profession benefit doesn’t lie in how nicely you code, write, or course of primary knowledge. It lies fully in how nicely you assume, join with others, and lead your crew. Adapting to this evolving office requires a agency dedication to steady, structured apply.
Cease ready in your trade to automate your present position. Taking proactive steps to construct your management and strategic capabilities is the one method to safe your home in an AI-assisted future. If you’re able to formalize these important abilities, exploring the skilled administration and know-how applications is a wonderful place to start out your transition.
Apple is celebrating its fiftieth anniversary this week. So, what do you get for such an event (apart from giving Apple your hard-earned money each time it releases one thing new)? In the event you’ve been a faithful Apple consumer for a lot of of these 50 years–or possibly all of them–why not give your self one thing good for the event?
8BitDo’s Retro 68 Keyboard is designed as a duplicate of the traditional Apple II keyboard that was launched in June 1977 (so not fairly 50 years in the past). However the Apple II was the primary laptop for lots of longtime Apple customers, so that is the proper merchandise to pay tribute to these recollections.
Contained in the retro design are just a few trendy touches. It connects wirelessly through Bluetooth and has a 6,500 mAh battery that provides 300 hours of runtime earlier than it’s good to cost it. It has an RGB backlit and makes use of Kailh Field Ice Cream Professional Max switches for the keys. It weighs in at a hefty 4.85 kilos (2,200 grams), however you most likely received’t be shifting it very far.
It additionally comes with a particular version of 8BitDo’s Wi-fi Tremendous Buttons, which might be programmed to carry out frequent capabilities.
The Retro 68 Keyboard is $500–8BitDo does label it a “Restricted Version” keyboard, however doesn’t say how restricted the stock might be. The corporate does embody a particular anniversary certificates with the keyboard. The keyboard begins transport in June and is accessible for preorder now.
Dying stars can emit a strong jet of radiation, as seen in an artist’s impression
Stocktrek Photos, Inc./Alamy
Astronomers suppose they’ve seen a kind of explosion produced by a dying star referred to as a unclean fireball for the primary time, and it might assist us perceive how large stars die.
When a large star runs out of gas, it may collapse and explode in a number of methods. If a black gap is produced within the collapse, an especially highly effective jet of radiation can burst by way of the star, producing a flash of high-energy gentle referred to as a gamma ray burst.
These bursts are among the many strongest explosions within the universe and may emit vitality equal to the overall lifetime output of smaller stars, such because the solar, in a single beam. However astronomers nonetheless don’t know precisely how this course of works or how variations between totally different large stars have an effect on the jet.
Physicists have hypothesised that we would see one thing totally different if the jet by some means will get contaminated with heavier matter from the star, resembling protons and neutrons. These particles would act as a sponge, slowing the jet down and inflicting it to emit X-rays, moderately than gamma rays. However till now, this “soiled fireball” state of affairs hadn’t been noticed.
Xiang-Yu Wang at Nanjing College in China and his colleagues have now picked up a flash of X-rays referred to as EP241113a that matches the image of a unclean fireball, utilizing a brand new house telescope referred to as the Einstein Probe.
Wang and his crew detected a flash of sunshine from a galaxy round 9 billion gentle years away, containing as a lot vitality as a gamma ray burst, however in X-ray frequencies as an alternative. The preliminary explosion light to a glow that lasted a number of hours, earlier than dying out regularly, just like a typical gamma ray burst.
“It’s a really thrilling prospect,” says Rhaana Starling on the College of Leicester, UK. “[Dirty fireballs] have been theorised to exist for the reason that 90s, however there hasn’t actually been any compelling proof for them.”
Whereas we all know of hundreds of gamma ray bursts, the occasion producing this blast is prone to be totally different from others, says Starling. It is perhaps a black gap or neutron star that’s interacting with the jet in an attention-grabbing bodily manner, for instance. “If it’s a black gap, then we’re capable of then get a extra full image of black gap formation throughout the universe,” she says.
It additionally reveals us that the gamma ray bursts we sometimes see could possibly be an observational bias, and there could possibly be many extra like this or weaker, says Gavin Lamb at Liverpool John Moores College, UK. “There might nicely be a continuum that goes proper the best way all the way down to no jets.”
Nevertheless, we will’t but make certain that this can be a soiled fireball, says Om Sharan Salafia at Brera Astronomical Observatory in Italy. First, we’ve got to ascertain whether or not the explosion actually did come from a galaxy as distant as Wang and his crew declare. “If all of this holds, then certainly, this transient is a bit puzzling,” he says.
Evaluating single-turn agent interactions follows a sample that almost all groups perceive effectively. You present an enter, gather the output, and choose the outcome. Frameworks like Strands Analysis SDK make this course of systematic by way of evaluators that assess helpfulness, faithfulness, and instrument utilization. In a earlier weblog publish, we coated the way to construct complete analysis suites for AI brokers utilizing these capabilities. Nevertheless, manufacturing conversations hardly ever cease at one flip.
Actual customers have interaction in exchanges that unfold over a number of turns. They ask follow-up questions when solutions are incomplete, change path when new info surfaces, and specific frustration when their wants go unmet. A journey assistant that handles “Ebook me a flight to Paris” effectively in isolation may battle when the identical person follows up with “Really, can we have a look at trains as a substitute?” or “What about accommodations close to the Eiffel Tower?” Testing these dynamic patterns requires greater than static check circumstances with fastened inputs and anticipated outputs.
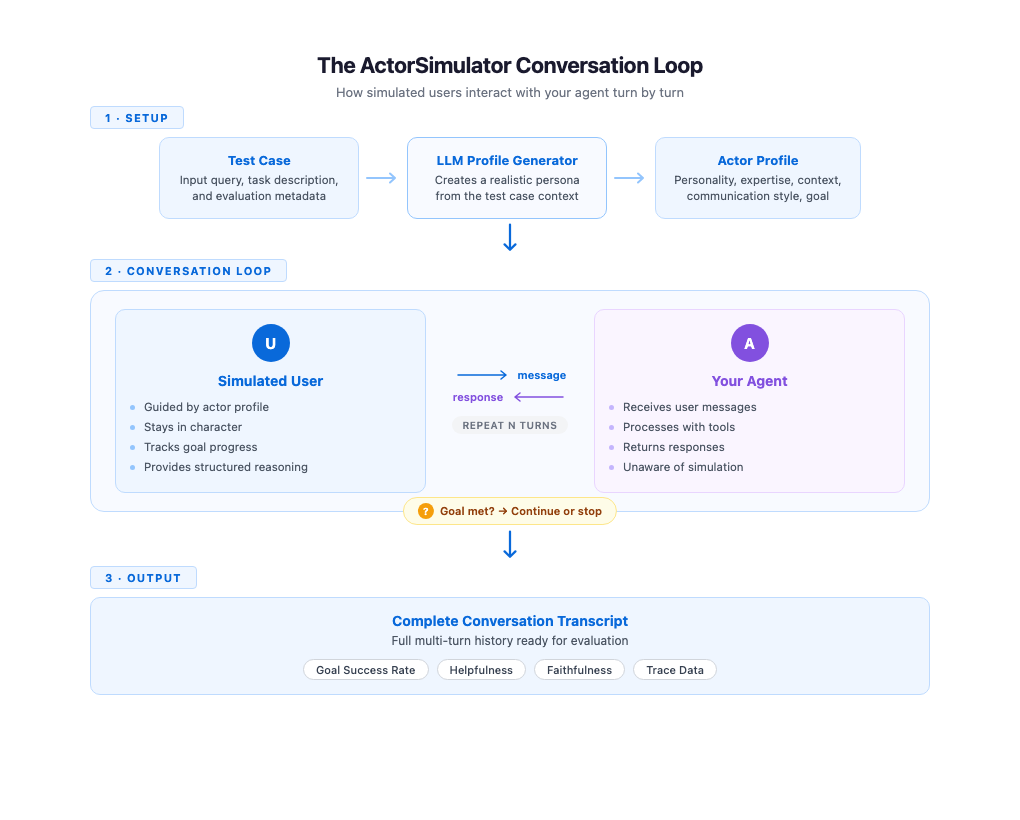
The core problem is scale as a result of you possibly can’t manually conduct a whole lot of multi-turn conversations each time your agent modifications, and writing scripted dialog flows locks you into predetermined paths that miss how actual customers behave. What analysis groups want is a solution to generate lifelike, goal-driven customers programmatically and allow them to converse naturally with an agent throughout a number of turns. On this publish, we discover how ActorSimulator in Strands Evaluations SDK addresses this problem with structured person simulation that integrates into your analysis pipeline.
Why multi-turn analysis is essentially more durable
Single-turn analysis has an easy construction. The enter is understood forward of time, the output is self-contained, and the analysis context is restricted to that single change. Multi-turn conversations break each certainly one of these assumptions.
In a multi-turn interplay, every message depends upon every part that got here earlier than it. The person’s second query is formed by how the agent answered the primary. A partial reply attracts a follow-up about no matter was ignored, a misunderstanding leads the person to restate their unique request, and a stunning suggestion can ship the dialog in a brand new path.
These adaptive behaviors create dialog paths that may’t be predicted at test-design time. A static dataset of I/O pairs, regardless of how massive, can’t seize this dynamic high quality as a result of the “appropriate” subsequent person message depends upon what the agent simply stated.
Handbook testing covers this hole in concept however fails in observe. Testers can conduct lifelike multi-turn conversations, however doing so for each state of affairs, throughout each persona kind, after each agent change isn’t sustainable. Because the agent’s capabilities develop, the variety of dialog paths grows combinatorially, effectively past what groups can discover manually.
Some groups flip to immediate engineering as a shortcut, asking a big language mannequin (LLM) to “act like a person” throughout testing. With out structured persona definitions and express objective monitoring, these approaches produce inconsistent outcomes. The simulated person’s habits drifts between runs, making it tough to check evaluations over time or determine real regressions versus random variation. A structured method to person simulation can bridge this hole by combining the realism of human dialog with the repeatability and scale of automated testing.
What makes a great simulated person
Simulation-based testing is effectively established in different engineering disciplines. Flight simulators check pilot responses to situations that might be harmful or not possible to breed in the true world. Sport engines use AI-driven brokers to discover tens of millions of participant habits paths earlier than launch. The identical precept applies to conversational AI. You create a managed atmosphere the place lifelike actors work together along with your system underneath situations you outline, then measure the outcomes.
For AI agent analysis, a helpful simulated person begins with a constant persona. One which behaves like a technical skilled in a single flip and a confused novice within the subsequent produces unreliable analysis information. Consistency means to keep up the identical communication fashion, experience stage, and character traits by way of each change, simply as an actual particular person would.
Equally necessary is goal-driven habits. Actual customers come to an agent with one thing they wish to accomplish. They persist till they obtain it, alter their method when one thing isn’t working, and acknowledge when their objective has been met. With out express targets, a simulated person tends to both finish conversations too early or proceed asking questions indefinitely, neither of which displays actual utilization.
The simulated person should additionally reply adaptively to what the agent says, not observe a predetermined script. When the agent asks a clarifying query, the actor ought to reply it in character. If the response is incomplete, the actor follows up on no matter was ignored somewhat than transferring on. If the dialog drifts off matter, the actor steers it again towards the unique objective. These adaptive behaviors make simulated conversations useful as analysis information as a result of they train the identical dialog dynamics your agent faces in manufacturing.
Constructing persona consistency, objective monitoring, and adaptive habits right into a simulation framework is what differentiates structured person simulation from ad-hoc prompting. ActorSimulator in Strands Evals is designed round precisely these ideas.
How ActorSimulator works
ActorSimulator implements these simulation qualities by way of a system that wraps a Strands Agent configured to behave as a sensible person persona. The method begins with profile era. Given a check case containing an enter question and an non-compulsory job description, ActorSimulator makes use of an LLM to create an entire actor profile. A check case with enter “I need assistance reserving a flight to Paris” and job description “Full flight reserving underneath price range” may produce a budget-conscious traveler with beginner-level expertise and an off-the-cuff communication fashion. Profile era provides every simulated dialog a definite, constant character.
With the profile established, the simulator manages the dialog flip by flip. It maintains the complete dialog historical past and generates every response in context, retaining the simulated person’s habits aligned with their profile and targets all through. When your agent addresses solely a part of the request, the simulated person naturally follows up on the gaps. A clarifying query out of your agent will get a response that stays in keeping with the persona. The dialog feels natural as a result of each response displays each the actor’s persona and every part stated thus far.
Objective monitoring runs alongside the dialog. ActorSimulator features a built-in objective completion evaluation instrument that the simulated person can invoke to guage whether or not their unique goal has been met. When the objective is glad or the simulated person determines that the agent can not full their request, the simulator emits a cease sign and the dialog ends. If the utmost flip depend is reached earlier than the objective is met, the dialog additionally stops. This offers you a sign that the agent may not be resolving person wants effectively. This mechanism makes positive conversations have a pure endpoint somewhat than operating indefinitely or slicing off arbitrarily.
Every response from the simulated person additionally contains structured reasoning alongside the message textual content. You may examine why the simulated person selected to say what they stated, whether or not they have been following up on lacking info, expressing confusion, or redirecting the dialog. This transparency is efficacious throughout analysis improvement as a result of you possibly can see the reasoning behind every flip, making it extra simple to hint the place conversations succeed or go off observe.
Getting began with ActorSimulator
To get began, you’ll need to put in the Strands Analysis SDK utilizing: pip set up strands-agents-evals. For a step-by-step setup, you possibly can discuss with our documentation or our earlier weblog for extra particulars. Placing these ideas into observe requires minimal code. You outline a check case with an enter question and a job description that captures the person’s objective. ActorSimulator handles profile era, dialog administration, and objective monitoring mechanically.
The next instance evaluates a journey assistant agent by way of a multi-turn simulated dialog.
from strands import Agent
from strands_evals import ActorSimulator, Case, Experiment
# Outline your check case
case = Case(
enter="I wish to plan a visit to Tokyo with resort and actions",
metadata={"task_description": "Full journey package deal organized"}
)
# Create the agent you wish to consider
agent = Agent(
system_prompt="You're a useful journey assistant.",
callback_handler=None
)
# Create person simulator from check case
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=5
)
# Run the multi-turn dialog
user_message = case.enter
conversation_history = []
whereas user_sim.has_next():
# Agent responds to person
agent_response = agent(user_message)
agent_message = str(agent_response)
conversation_history.append({
"function": "assistant",
"content material": agent_message
})
# Simulator generates subsequent person message
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
conversation_history.append({
"function": "person",
"content material": user_message
})
print(f"Dialog accomplished in {len(conversation_history) // 2} turns")
The dialog loop continues till has_next() returns False, which occurs when the simulated person’s targets are met or simulated person determines that the agent can not full the request or the utmost flip restrict is reached. The ensuing conversation_history incorporates the complete multi-turn transcript, prepared for analysis.
Integration with analysis pipelines
A standalone dialog loop is helpful for fast experiments, however manufacturing analysis requires capturing traces and feeding them into your evaluator pipeline. The following instance combines ActorSimulator with OpenTelemetry telemetry assortment and Strands Evals session mapping. The duty operate runs a simulated dialog and collects spans from every flip, then maps them right into a structured session for analysis.
from opentelemetry.sdk.hint.export import BatchSpanProcessor
from opentelemetry.sdk.hint.export.in_memory_span_exporter import InMemorySpanExporter
from strands import Agent
from strands_evals import ActorSimulator, Case, Experiment
from strands_evals.evaluators import HelpfulnessEvaluator
from strands_evals.telemetry import StrandsEvalsTelemetry
from strands_evals.mappers import StrandsInMemorySessionMapper
# Setup telemetry for capturing agent traces
telemetry = StrandsEvalsTelemetry()
memory_exporter = InMemorySpanExporter()
span_processor = BatchSpanProcessor(memory_exporter)
telemetry.tracer_provider.add_span_processor(span_processor)
def evaluation_task(case: Case) -> dict:
# Create simulator
user_sim = ActorSimulator.from_case_for_user_simulator(
case=case,
max_turns=3
)
# Create agent
agent = Agent(
system_prompt="You're a useful journey assistant.",
callback_handler=None
)
# Accumulate spans throughout dialog
all_target_spans = []
user_message = case.enter
whereas user_sim.has_next():
memory_exporter.clear()
agent_response = agent(user_message)
agent_message = str(agent_response)
# Seize telemetry
turn_spans = listing(memory_exporter.get_finished_spans())
all_target_spans.prolong(turn_spans)
# Generate subsequent person message
user_result = user_sim.act(agent_message)
user_message = str(user_result.structured_output.message)
# Map to session for analysis
mapper = StrandsInMemorySessionMapper()
session = mapper.map_to_session(
all_target_spans,
session_id="test-session"
)
return {"output": agent_message, "trajectory": session}
# Create analysis dataset
test_cases = [
Case(
name="booking-simple",
input="I need to book a flight to Paris next week",
metadata={
"category": "booking",
"task_description": "Flight booking confirmed"
}
)
]
evaluator = HelpfulnessEvaluator()
dataset = Experiment(circumstances=test_cases, evaluator=evaluator)
# Run evaluations
report = Experiment.run_evaluations(evaluation_task)
report.run_display()
This method captures full traces of your agent’s habits throughout dialog turns. The spans embody instrument calls, mannequin invocations, and timing info for each flip within the simulated dialog. By mapping these spans right into a structured session, you make the complete multi-turn interplay obtainable to evaluators like GoalSuccessRateEvaluator and HelpfulnessEvaluator, which may then assess the dialog as a complete, somewhat than remoted turns.
Customized actor profiles for focused testing
Computerized profile era covers most analysis situations effectively, however some testing targets require particular personas. You may wish to confirm that your agent handles an impatient skilled person otherwise from a affected person newbie, or that it responds appropriately to a person with domain-specific wants. For these circumstances, ActorSimulator accepts a totally outlined actor profile that you just management.
from strands_evals.varieties.simulation import ActorProfile
from strands_evals import ActorSimulator
from strands_evals.simulation.prompt_templates.actor_system_prompt import (
DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE
)
# Outline a customized actor profile
actor_profile = ActorProfile(
traits={
"character": "analytical and detail-oriented",
"communication_style": "direct and technical",
"expertise_level": "skilled",
"patience_level": "low"
},
context="Skilled enterprise traveler with elite standing who values effectivity",
actor_goal="Ebook enterprise class flight with particular seat preferences and lounge entry"
)
# Initialize simulator with customized profile
user_sim = ActorSimulator(
actor_profile=actor_profile,
initial_query="I have to e book a enterprise class flight to London subsequent Tuesday",
system_prompt_template=DEFAULT_USER_SIMULATOR_PROMPT_TEMPLATE,
max_turns=10
)
By defining traits like endurance stage, communication fashion, and experience, you possibly can systematically check how your agent performs throughout completely different person segments. An agent that scores effectively with affected person, non-technical customers however poorly with impatient specialists reveals a selected high quality hole that you may deal with. Operating the identical objective throughout a number of persona configurations turns person simulation right into a instrument for understanding your agent’s strengths and weaknesses by person kind.
Finest practices for simulation-based analysis
These greatest practices make it easier to get probably the most out of simulation-based analysis:
Set max_turns based mostly on job complexity, utilizing 3-5 for targeted duties and 8-10 for multi-step workflows. If most conversations attain the restrict with out finishing the objective, enhance it.
Write particular job descriptions that the simulator can consider towards. “Assist the person e book a flight” is just too obscure to guage completion reliably, whereas “flight reserving confirmed with dates, vacation spot, and value” provides a concrete goal.
Use auto-generated profiles for broad protection throughout person varieties and customized profiles to breed particular patterns out of your manufacturing logs, resembling an impatient skilled or a first-time person.
Deal with patterns throughout your check suite somewhat than particular person transcripts. Constant redirects from the simulated person means that the agent is drifting off matter, and declining objective completion charges after an agent change factors to a regression.
Begin with a small set of check circumstances protecting your most typical situations and increase to edge circumstances and extra personas as your analysis observe matures.
Conclusion
We confirmed how ActorSimulator in Strands Evals allows systematic, multi-turn analysis of conversational AI brokers by way of lifelike person simulation. Quite than counting on static check circumstances that seize solely single exchanges, you possibly can outline targets and personas and let simulated customers work together along with your agent throughout pure, adaptive conversations. The ensuing transcripts feed immediately into the identical analysis pipeline that you just use for single-turn testing, supplying you with helpfulness scores, objective success charges, and detailed traces throughout each dialog flip.
To get began, discover the working examples within the Strands Brokers samples repository. For groups evaluating brokers deployed by way of Amazon Bedrock AgentCore, the next AgentCore evaluations pattern show the way to simulate interactions with deployed brokers. Begin with a handful of check circumstances representing your most typical person situations, run them by way of ActorSimulator, and consider the outcomes. As your analysis observe matures, increase to cowl extra personas, edge circumstances, and dialog patterns.
If there have been a set of survival guidelines for knowledge scientists, amongst them must be this: All the time report uncertainty estimates along with your predictions. Nonetheless, right here we’re, working with neural networks, and in contrast to lm, a Keras mannequin doesn’t conveniently output one thing like a normal error for the weights.
We would attempt to think about rolling your individual uncertainty measure – for instance, averaging predictions from networks skilled from completely different random weight initializations, for various numbers of epochs, or on completely different subsets of the info. However we’d nonetheless be apprehensive that our technique is sort of a bit, nicely … advert hoc.
On this publish, we’ll see a each sensible in addition to theoretically grounded strategy to acquiring uncertainty estimates from neural networks. First, nevertheless, let’s shortly discuss why uncertainty is that essential – over and above its potential to avoid wasting an information scientist’s job.
Why uncertainty?
In a society the place automated algorithms are – and might be – entrusted with increasingly more life-critical duties, one reply instantly jumps to thoughts: If the algorithm accurately quantifies its uncertainty, we might have human specialists examine the extra unsure predictions and doubtlessly revise them.
It will solely work if the community’s self-indicated uncertainty actually is indicative of a better likelihood of misclassification. Leibig et al.(Leibig et al. 2017) used a predecessor of the strategy described beneath to evaluate neural community uncertainty in detecting diabetic retinopathy. They discovered that certainly, the distributions of uncertainty have been completely different relying on whether or not the reply was right or not:
Determine from Leibig et al. 2017 (Leibig et al. 2017). Inexperienced: uncertainty estimates for flawed predictions. Blue: uncertainty estimates for proper predictions.
Along with quantifying uncertainty, it may make sense to qualify it. Within the Bayesian deep studying literature, a distinction is usually made between epistemic uncertainty and aleatoric uncertainty(Kendall and Gal 2017).
Epistemic uncertainty refers to imperfections within the mannequin – within the restrict of infinite knowledge, this sort of uncertainty ought to be reducible to 0. Aleatoric uncertainty is because of knowledge sampling and measurement processes and doesn’t depend upon the scale of the dataset.
Say we practice a mannequin for object detection. With extra knowledge, the mannequin ought to turn into extra positive about what makes a unicycle completely different from a mountainbike. Nonetheless, let’s assume all that’s seen of the mountainbike is the entrance wheel, the fork and the top tube. Then it doesn’t look so completely different from a unicycle any extra!
What could be the implications if we may distinguish each varieties of uncertainty? If epistemic uncertainty is excessive, we are able to attempt to get extra coaching knowledge. The remaining aleatoric uncertainty ought to then preserve us cautioned to consider security margins in our utility.
Most likely no additional justifications are required of why we’d wish to assess mannequin uncertainty – however how can we do that?
Uncertainty estimates by means of Bayesian deep studying
In a Bayesian world, in precept, uncertainty is totally free as we don’t simply get level estimates (the utmost aposteriori) however the full posterior distribution. Strictly talking, in Bayesian deep studying, priors ought to be put over the weights, and the posterior be decided based on Bayes’ rule.
To the deep studying practitioner, this sounds fairly arduous – and the way do you do it utilizing Keras?
In 2016 although, Gal and Ghahramani (Yarin Gal and Ghahramani 2016) confirmed that when viewing a neural community as an approximation to a Gaussian course of, uncertainty estimates may be obtained in a theoretically grounded but very sensible approach: by coaching a community with dropout after which, utilizing dropout at take a look at time too. At take a look at time, dropout lets us extract Monte Carlo samples from the posterior, which might then be used to approximate the true posterior distribution.
That is already excellent news, nevertheless it leaves one query open: How will we select an applicable dropout price? The reply is: let the community be taught it.
Studying dropout and uncertainty
In a number of 2017 papers (Y. Gal, Hron, and Kendall 2017),(Kendall and Gal 2017), Gal and his coworkers demonstrated how a community may be skilled to dynamically adapt the dropout price so it’s satisfactory for the quantity and traits of the info given.
Apart from the predictive imply of the goal variable, it may moreover be made to be taught the variance.
This implies we are able to calculate each varieties of uncertainty, epistemic and aleatoric, independently, which is beneficial within the mild of their completely different implications. We then add them as much as receive the general predictive uncertainty.
Let’s make this concrete and see how we are able to implement and take a look at the supposed conduct on simulated knowledge.
Within the implementation, there are three issues warranting our particular consideration:
The wrapper class used so as to add learnable-dropout conduct to a Keras layer;
The loss operate designed to attenuate aleatoric uncertainty; and
The methods we are able to receive each uncertainties at take a look at time.
Let’s begin with the wrapper.
A wrapper for studying dropout
On this instance, we’ll limit ourselves to studying dropout for dense layers. Technically, we’ll add a weight and a loss to each dense layer we wish to use dropout with. This implies we’ll create a customized wrapper class that has entry to the underlying layer and might modify it.
The logic applied within the wrapper is derived mathematically within the Concrete Dropout paper (Y. Gal, Hron, and Kendall 2017). The beneath code is a port to R of the Python Keras model discovered within the paper’s companion github repo.
So first, right here is the wrapper class – we’ll see methods to use it in only a second:
The wrapper instantiator has default arguments, however two of them ought to be tailored to the info: weight_regularizer and dropout_regularizer. Following the authors’ suggestions, they need to be set as follows.
First, select a price for hyperparameter (l). On this view of a neural community as an approximation to a Gaussian course of, (l) is the prior length-scale, our a priori assumption in regards to the frequency traits of the info. Right here, we comply with Gal’s demo in setting l := 1e-4. Then the preliminary values for weight_regularizer and dropout_regularizer are derived from the length-scale and the pattern dimension.
Now let’s see methods to use the wrapper in a mannequin.
Dropout mannequin
In our demonstration, we’ll have a mannequin with three hidden dense layers, every of which could have its dropout price calculated by a devoted wrapper.
# we use one-dimensional enter knowledge right here, however this is not a necessityinput_dim<-1# this too may very well be > 1 if we wishedoutput_dim<-1hidden_dim<-1024enter<-layer_input(form =input_dim)output<-enter%>%layer_concrete_dropout( layer =layer_dense(items =hidden_dim, activation ="relu"), weight_regularizer =wd, dropout_regularizer =dd)%>%layer_concrete_dropout( layer =layer_dense(items =hidden_dim, activation ="relu"), weight_regularizer =wd, dropout_regularizer =dd)%>%layer_concrete_dropout( layer =layer_dense(items =hidden_dim, activation ="relu"), weight_regularizer =wd, dropout_regularizer =dd)
Now, mannequin output is attention-grabbing: We’ve the mannequin yielding not simply the predictive (conditional) imply, but additionally the predictive variance ((tau^{-1}) in Gaussian course of parlance):
The numerous factor right here is that we be taught completely different variances for various knowledge factors. We thus hope to have the ability to account for heteroscedasticity (completely different levels of variability) within the knowledge.
Heteroscedastic loss
Accordingly, as a substitute of imply squared error we use a price operate that doesn’t deal with all estimates alike(Kendall and Gal 2017):
Along with the compulsory goal vs. prediction verify, this price operate accommodates two regularization phrases:
First, (frac{1}{2 hat{sigma}^2_i}) downweights the high-uncertainty predictions within the loss operate. Put plainly: The mannequin is inspired to point excessive uncertainty when its predictions are false.
Second, (frac{1}{2} log hat{sigma}^2_i) makes positive the community doesn’t merely point out excessive uncertainty all over the place.
This logic maps on to the code (besides that as typical, we’re calculating with the log of the variance, for causes of numerical stability):
With coaching completed, we flip to the validation set to acquire estimates on unseen knowledge – together with these uncertainty measures that is all about!
Receive uncertainty estimates through Monte Carlo sampling
As usually in a Bayesian setup, we assemble the posterior (and thus, the posterior predictive) through Monte Carlo sampling.
In contrast to in conventional use of dropout, there isn’t a change in conduct between coaching and take a look at phases: Dropout stays “on.”
So now we get an ensemble of mannequin predictions on the validation set:
num_MC_samples<-20MC_samples<-array(0, dim =c(num_MC_samples, n_val, 2*output_dim))for(okayin1:num_MC_samples){MC_samples[k, , ]<-(mannequin%>%predict(X_val))}
Bear in mind, our mannequin predicts the imply in addition to the variance. We’ll use the previous for calculating epistemic uncertainty, whereas aleatoric uncertainty is obtained from the latter.
First, we decide the predictive imply as a median of the MC samples’ imply output:
# the means are within the first output columnmeans<-MC_samples[, , 1:output_dim]# common over the MC samplespredictive_mean<-apply(means, 2, imply)
To calculate epistemic uncertainty, we once more use the imply output, however this time we’re within the variance of the MC samples:
Epistemic uncertainty on the validation set, practice dimension = 1000.
That is attention-grabbing. The coaching knowledge (in addition to the validation knowledge) have been generated from a typical regular distribution, so the mannequin has encountered many extra examples near the imply than exterior two, and even three, normal deviations. So it accurately tells us that in these extra unique areas, it feels fairly uncertain about its predictions.
That is precisely the conduct we would like: Danger in mechanically making use of machine studying strategies arises because of unanticipated variations between the coaching and take a look at (actual world) distributions. If the mannequin have been to inform us “ehm, not likely seen something like that earlier than, don’t actually know what to do” that’d be an enormously precious final result.
So whereas epistemic uncertainty has the algorithm reflecting on its mannequin of the world – doubtlessly admitting its shortcomings – aleatoric uncertainty, by definition, is irreducible. After all, that doesn’t make it any much less precious – we’d know we at all times should consider a security margin. So how does it look right here?
Aleatoric uncertainty on the validation set, practice dimension = 1000.
Certainly, the extent of uncertainty doesn’t depend upon the quantity of information seen at coaching time.
Lastly, we add up each varieties to acquire the general uncertainty when making predictions.
Total predictive uncertainty on the validation set, practice dimension = 1000.
Now let’s do this technique on a real-world dataset.
Mixed cycle energy plant electrical power output estimation
This dataset is obtainable from the UCI Machine Studying Repository. We explicitly selected a regression process with steady variables completely, to make for a clean transition from the simulated knowledge.
The dataset accommodates 9568 knowledge factors collected from a Mixed Cycle Energy Plant over 6 years (2006-2011), when the ability plant was set to work with full load. Options encompass hourly common ambient variables Temperature (T), Ambient Stress (AP), Relative Humidity (RH) and Exhaust Vacuum (V) to foretell the web hourly electrical power output (EP) of the plant.
A mixed cycle energy plant (CCPP) consists of fuel generators (GT), steam generators (ST) and warmth restoration steam mills. In a CCPP, the electrical energy is generated by fuel and steam generators, that are mixed in a single cycle, and is transferred from one turbine to a different. Whereas the Vacuum is collected from and has impact on the Steam Turbine, the opposite three of the ambient variables impact the GT efficiency.
We thus have 4 predictors and one goal variable. We’ll practice 5 fashions: 4 single-variable regressions and one making use of all 4 predictors. It most likely goes with out saying that our aim right here is to examine uncertainty info, to not fine-tune the mannequin.
Setup
Let’s shortly examine these 5 variables. Right here PE is power output, the goal variable.
We’ll practice every of the 5 fashions with a hidden_dim of 64.
We then receive 20 Monte Carlo pattern from the posterior predictive distribution and calculate the uncertainties as earlier than.
Right here we present the code for the primary predictor, “AT.” It’s comparable for all different circumstances.
Now let’s see the uncertainty estimates for all 5 fashions!
First, the single-predictor setup. Floor reality values are displayed in cyan, posterior predictive estimates are black, and the gray bands lengthen up resp. down by the sq. root of the calculated uncertainties.
We’re beginning with ambient temperature, a low-variance predictor.
We’re shocked how assured the mannequin is that it’s gotten the method logic right, however excessive aleatoric uncertainty makes up for this (roughly).
Uncertainties on the validation set utilizing ambient temperature as a single predictor.
Now wanting on the different predictors, the place variance is way greater within the floor reality, it does get a bit troublesome to really feel comfy with the mannequin’s confidence. Aleatoric uncertainty is excessive, however not excessive sufficient to seize the true variability within the knowledge. And we certaintly would hope for greater epistemic uncertainty, particularly in locations the place the mannequin introduces arbitrary-looking deviations from linearity.
Uncertainties on the validation set utilizing exhaust vacuum as a single predictor.Uncertainties on the validation set utilizing ambient stress as a single predictor.Uncertainties on the validation set utilizing relative humidity as a single predictor.
Now let’s see uncertainty output once we use all 4 predictors. We see that now, the Monte Carlo estimates fluctuate much more, and accordingly, epistemic uncertainty is rather a lot greater. Aleatoric uncertainty, then again, received rather a lot decrease. Total, predictive uncertainty captures the vary of floor reality values fairly nicely.
Uncertainties on the validation set utilizing all 4 predictors.
Conclusion
We’ve launched a technique to acquire theoretically grounded uncertainty estimates from neural networks.
We discover the strategy intuitively engaging for a number of causes: For one, the separation of various kinds of uncertainty is convincing and virtually related. Second, uncertainty relies on the quantity of information seen within the respective ranges. That is particularly related when pondering of variations between coaching and test-time distributions.
Third, the concept of getting the community “turn into conscious of its personal uncertainty” is seductive.
In apply although, there are open questions as to methods to apply the strategy. From our real-world take a look at above, we instantly ask: Why is the mannequin so assured when the bottom reality knowledge has excessive variance? And, pondering experimentally: How would that adjust with completely different knowledge sizes (rows), dimensionality (columns), and hyperparameter settings (together with neural community hyperparameters like capability, variety of epochs skilled, and activation capabilities, but additionally the Gaussian course of prior length-scale (tau))?
For sensible use, extra experimentation with completely different datasets and hyperparameter settings is definitely warranted.
One other route to comply with up is utility to duties in picture recognition, akin to semantic segmentation.
Right here we’d be enthusiastic about not simply quantifying, but additionally localizing uncertainty, to see which visible elements of a scene (occlusion, illumination, unusual shapes) make objects laborious to determine.
Gal, Yarin, and Zoubin Ghahramani. 2016. “Dropout as a Bayesian Approximation: Representing Mannequin Uncertainty in Deep Studying.” In Proceedings of the 33nd Worldwide Convention on Machine Studying, ICML 2016, New York Metropolis, NY, USA, June 19-24, 2016, 1050–59. http://jmlr.org/proceedings/papers/v48/gal16.html.
Leibig, Christian, Vaneeda Allken, Murat Seckin Ayhan, Philipp Berens, and Siegfried Wahl. 2017. “Leveraging Uncertainty Data from Deep Neural Networks for Illness Detection.”bioRxiv. https://doi.org/10.1101/084210.
The Galaxy S26 FE supposedly appeared in a Geekbench itemizing with Samsung’s Exynos 2500 SoC.
The machine was acknowledged to have achieved 2,426 in its single-core take a look at and eight,004 within the multi-core portion.
Different alleged rumors state it might function the identical 6.7-inch show and 4,900mAh as its S25 FE model.
Now that we have got the S26 flagship sequence out of the best way, rumors are transferring on to Samsung’s subsequent FE.
Sometimes, a couple of steps beneath the entry S-series mannequin, a submit from SamMobile, after recognizing a Geekbench itemizing, alleges its efficiency. First, the publication highlights a couple of rumors, stating the Galaxy S26 FE might function a 6.7-inch OLED show with as much as 120Hz refresh charge. Internally, the Geekbench itemizing suggests the cellphone could possibly be powered by Samsung’s Exynos 2500 chipset, not its newest 2600. That is not too out of the norm, because the S25 FE additionally includes a year-old Exynos chip (2400).
There’s an opportunity this might be okay, as SamMobile states the Galaxy S26 FE’s efficiency is allegedly up by eight p.c within the multi-core take a look at and ~15% for its single-core. The numbers present the S26 FE achieved a rating of two,426 for its single-core and eight,004 for its multi-core. These exams had been performed with the finances mannequin that includes One UI 9 (Android 17) and 8GB of RAM.
Article continues beneath
SamMobile dives into a couple of different rumors that purport a max of 512GB in storage, a 4,900mAh battery, a 50MP foremost lens, a 12MP ultrawide digital camera, and an 8MP telephoto.
On one hand, maybe seeing the Exynos 2500 rumored for the Galaxy S26 FE is an efficient factor. When the S25 FE launched, it featured the Exynos 2400, however so did the S24 FE. This chip relies on Samsung’s 4nm course of. The corporate has since moved on to its 2nm course of for the Exynos 2600 chip. That is nonetheless hypothesis; nevertheless, it might’ve been good to see rumors throw the 2600 on the market for the S26 FE. The chip includes a main 39% improve in CPU capabilities over the 2500, with stronger AI efficiency and double the GPU output.
Humoring these early rumors, the S26 FE is rumored to sport the identical triple digital camera array as its predecessor. The show and the battery additionally carry the identical numbers as final 12 months’s. So, possibly shoppers are in for different enhancements, most likely extra on the software program aspect. The Galaxy S25 FE did not launch till September, so we’re nonetheless practically half a 12 months away from seeing this 12 months’s model.
Android Central’s Take
Samsung tried to weave in flagship-quality options with its Galaxy S25 FE that helped make the budget-oriented cellphone really feel slightly stronger. Seven years of OS and safety updates had been promised, too, which has develop into Samsung’s norm as of late. Contemplating that—in the intervening time—the rumors are suggesting a largely comparable cellphone hardware-wise, possibly extra of that is on the desk. Additionally, I ought to point out that cellphone costs are on the rise as a consequence of RAM, so its value level will probably be one other facet to look at. The S25 FE debuted at $649.
Get the newest information from Android Central, your trusted companion on the planet of Android
After an extended day of educating, Rudy Lerosey-Aubril turned to a well-known job: making ready a Cambrian arthropod fossil for examine. At first look, the specimen regarded typical for its age. However as he rigorously eliminated surrounding materials, one thing uncommon appeared. As an alternative of an antenna, there was a claw.
“Claws are by no means in that location in a Cambrian arthropod,” mentioned Lerosey-Aubril, “It took me a couple of minutes to appreciate the plain, I had simply uncovered the oldest chelicera ever discovered.”
Oldest Recognized Chelicerate Recognized
In a examine printed in Nature, Analysis Scientist Rudy Lerosey-Aubril and Affiliate Professor Javier Ortega-Hernández, Curator of Invertebrate Paleontology within the Museum of Comparative Zoology – each within the Division of Organismic and Evolutionary Biology at Harvard – describe Megachelicerax cousteaui, a 500 million yr previous marine predator found in Utah’s West Desert. It’s now acknowledged because the earliest identified chelicerate, a gaggle that features spiders, scorpions, horseshoe crabs, and sea spiders. This discovering extends the identified historical past of chelicerates by about 20 million years.
“This fossil paperwork the Cambrian origin of chelicerates,” famous Lerosey-Aubril, “and reveals that the anatomical blueprint of spiders and horseshoe crabs was already rising 500 million years in the past.”
Detailed Anatomy of an Historic Predator
Revealing the fossil’s construction required persistence and precision. Lerosey-Aubril spent greater than 50 hours working beneath a microscope with a positive needle to show its options. The animal measured simply over 8 centimeters lengthy and preserved a dorsal exoskeleton made up of a head protect and 9 physique segments.
These two areas had completely different capabilities. The pinnacle protect carried six pairs of appendages used for feeding and sensing. Beneath the physique had been plate-like respiratory buildings that resemble the e book gills seen in trendy horseshoe crabs.
The First Clear Proof of a Chelicera
Essentially the most putting function is the chelicera, a pincer-like appendage that defines chelicerates. This construction separates spiders and their family members from bugs, which as an alternative have antennae on the entrance of their our bodies. Chelicerates depend on greedy appendages, typically related to venom supply.
Regardless of the abundance of Cambrian fossils, no clear instance of a chelicera from that interval had been recognized earlier than. This discovery fills that hole and gives direct proof of when these defining options first appeared.
Bridging a Main Evolutionary Hole
Earlier than this fossil was studied, the oldest identified chelicerates got here from the Early Ordovician Fezouata Biota of Morocco, courting to about 480 million years in the past. The brand new specimen predates them by 20 million years, putting M. cousteaui close to the bottom of the chelicerate lineage.
It represents a transitional kind, linking earlier Cambrian arthropods that appear to lack chelicera with later horseshoe crab-like species generally known as synziphosurines.
“Megachelicerax reveals that chelicera and the division of the physique into two functionally specialised areas developed earlier than the top appendages misplaced their outer branches and have become just like the legs of spiders as we speak,” defined Ortega-Hernández, “it reconciles a number of competing hypotheses; in a manner, everyone was partly proper.”
Early Complexity within the Cambrian Explosion
This fossil captures a key second within the evolution of chelicerates. It reveals that vital parts of their physique plan had been already established shortly after the Cambrian Explosion, a time when life was quickly diversifying.
“This tells us that by the mid-Cambrian, when evolutionary charges had been remarkably excessive, the oceans had been already inhabited by arthropods with anatomical complexity rivaling trendy varieties,” Ortega-Hernández added.
Why Early Success Was Delayed
Even with these superior options, chelicerates didn’t instantly dominate marine ecosystems. For thousands and thousands of years, they remained comparatively unusual and had been overshadowed by teams comparable to trilobites. Solely later did they develop and ultimately transfer onto land.
“An analogous evolutionary sample has been documented in different animal teams,” mentioned Lerosey-Aubril. “This reveals that evolutionary success is just not solely about organic innovation — timing and environmental context matter.”
From Missed Fossil to Main Discovery
The fossil was collected from the center Cambrian Wheeler Formation in Utah’s Home Vary. It was found by avocational fossil collector Lloyd Gunther and donated to the Kansas College Biodiversity Institute and Pure Historical past Museum in 1981. For many years, it remained a part of a group of seemingly bizarre specimens till Lerosey-Aubril selected to look at it as a part of his analysis on early arthropods.
Named After Jacques Cousteau
The species identify Megachelicerax cousteaui honors French explorer Jacques-Yves Cousteau. Lerosey-Aubril – who can be French – and Ortega-Hernández chosen the identify to acknowledge Cousteau’s efforts to spotlight the wonder and vulnerability of marine life.
“Cousteau and his crew impressed generations to look beneath the floor,” mentioned Lerosey-Aubril, “it appeared becoming to call this historic marine animal after somebody who modified the way in which we see ocean life.” Simply as Megachelicerax cousteaui has modified how we view chelicerates.
A Group That Nonetheless Shapes the Fashionable World
Right now, chelicerates embody greater than 120,000 species, from spiders and scorpions to mites, horseshoe crabs, and sea spiders. They occupy a variety of environments on land and in water.
“For 1000’s of years, these animals have quietly existed amongst us, deeply influencing our lives from pop-culture to medical and agricultural contributions,” Ortega-Hernández concluded. “This fossil discovery sheds new gentle on their origins.”
The Lasting Worth of Museum Collections
The researchers additionally emphasised the significance of scientific collections. Establishments such because the College of Kansas Biodiversity Institute and Pure Historical past Museum protect specimens for many years, permitting new insights to emerge as scientific understanding evolves. The authors highlighted the work of curators together with B. Lieberman and J. Kimmig, whose efforts guarantee these collections stay out there for future discoveries.
You don’t have the identical varieties of data with e-book gross sales as you get with tutorial citations the place we will simply have a look at google scholar. Your complete trade is a little bit of a black field from what I’ve learn. Some experiences say the median e-book might promote solely round a dozen books. I as soon as heard that your complete e-book trade is stored afloat by Harry Potter and the Bible.
However I feel it’s price sharing this info as a result of e-book writing is a chance to do inventive work that’s not the identical as what you ordinarily get to do as a tutorial. In economics, we are saying that hardly ever are nook options really optimum. That’s as a result of economists begin by assuming a sure itemizing of preferences that cause them to assume utility features are extra probably quasi-concave, and when they’re quasi-concave, you get indifference curves during which it’s at all times most well-liked to have a little bit of two issues than all of only one.
And I really feel that method about books. It’s not that you need to write books or tutorial articles. Relatively, writing books scratches a distinct itch.
My ambition has at all times been to be the “finest third e-book on the syllabus”. The primary e-book on the syllabus is the textbook the writer makes use of. These are your Jeff Wooldridge’s. The second e-book on the syllabus is perhaps when you had assigned each Wooldridge and Principally Innocent, or perhaps a e-book by Bruce Hansen. Level is, the second e-book is the paired textbook for the category. And the third e-book is a big listing of supplemental readings. They aren’t compulsory for the scholars; they simply are really useful. And there’s often fairly a number of listed.
And my objective has at all times to be everybody’s third e-book, displaying up on so many supplemental readings in order to attempt to dominate, not the textbooks (because the Mixtape actually isn’t a textbook), however relatively to be the e-book that helps college students with the primary and second books. No extra, no much less. Whether or not I’ve been profitable at that may be a completely different query, however that’s at all times been my objective.
The brand new e-book, Causal Inference: the Remix, comes out a while this 12 months. I turned it in final summer season, however I’ve been sluggish getting my proofs again. However yesterday, I obtained the index turned in. I took a knife and slashed via a bunch of stuff, leaving different stuff behind, and simply attempt to trim it down. And with that it’s accomplished.
It’s a weirder e-book in some methods. I discuss so much about rivers in it, amongst different issues. Rivers are the metaphor I take advantage of all through to assist me navigate the completely different threads of causal inference from the Princeton Industrial Relations Part, the Harvard stats division, the pc science neighborhood, the Chicago custom, econometrics itself. The e-book is extra biographical than the earlier one. I’m very keen on making an attempt to pin down individuals in area and time, sociologically, as finest I might.
And naturally, the causal panel stuff is bloated. I get into the weeds on diff-in-diff, and now it’s two chapters lengthy, as a substitute of 1. It’s additionally sadly going to clock in at round 750 pages. I in all probability might’ve made two books out of it, however I didn’t, so now there’s one massive e-book. A Huge Lovely E book. We’ll see what individuals assume.
The 2025 knowledge on the continuing gross sales of the Mixtape itself, although, got here on this week. It continues to promote . Gross sales for the English translation is all I’ve now; it’s tougher to get China. I’m unsure why. I’ll in all probability not have bother getting the Japanese translation 2025 gross sales, however in the meanwhile don’t have it.
So what I’ve accomplished is I’ve requested Claude to do analysis on e-book gross sales, for educational presses and non-academic presses, after which take all the info I’ve on the Mixtape and make no matter graphics he seems like would match with this substack (which I copied and pasted to him so he knew what I used to be writing). However, like I mentioned — I actually wish to counsel to economists and different social scientists that they contemplate e-book writing. It doesn’t require specializing in them in any respect. I simply personally have to diversify my inventive writing throughout completely different domains, together with tutorial writing however not completely, as in any other case I’ll burst.
One of many extra attention-grabbing developments although was that the audio rights have been offered to an organization referred to as Tantor Media. I’m certain that listening to somebody clarify matching estimators and two-way fastened results can be riveting.
However listed here are some information that Claude Code got here up with visually introduced. Right here’s cumulative gross sales thus far throughout all three translations: English, China, Japan.
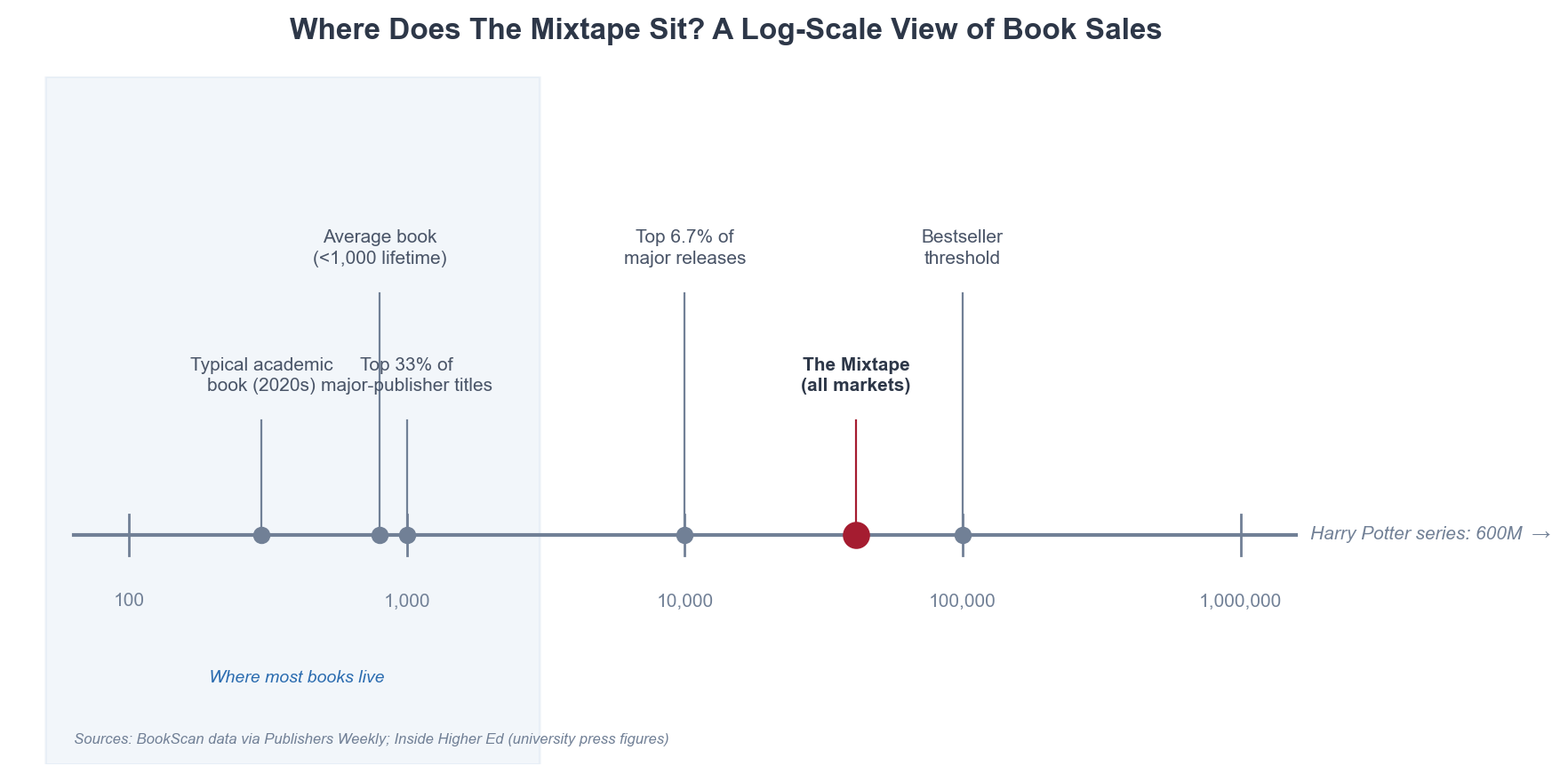
I requested Claude Code to then do analysis on the place it matches within the distribution of books. It appears prefer it’s mainly placing it on log scale. Undecided about these knowledge sources, however I had /referee2 and my new talent /fletcher each do a critique after which get a rewrite. Not fairly a bestseller threshold, however someplace up there.
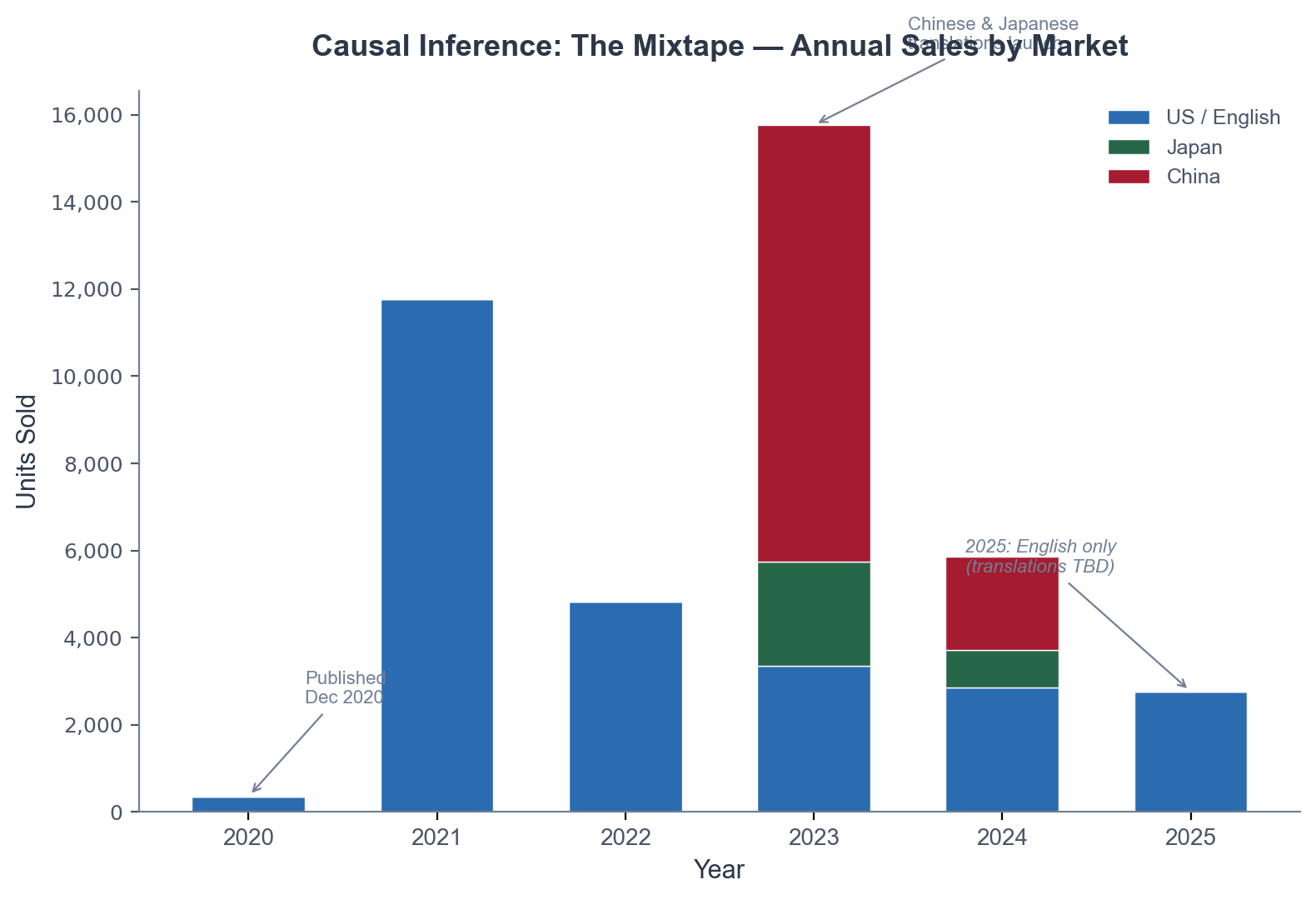
Right here it’s 12 months by 12 months. Apologies that the labels suck. I often work tougher to get these straightened out. However you’ll be able to see 2023 was massive due to China translation. However the English has stabilized. The 2025 numbers have been only a hundred lower than the 2024 numbers for US / English talking.
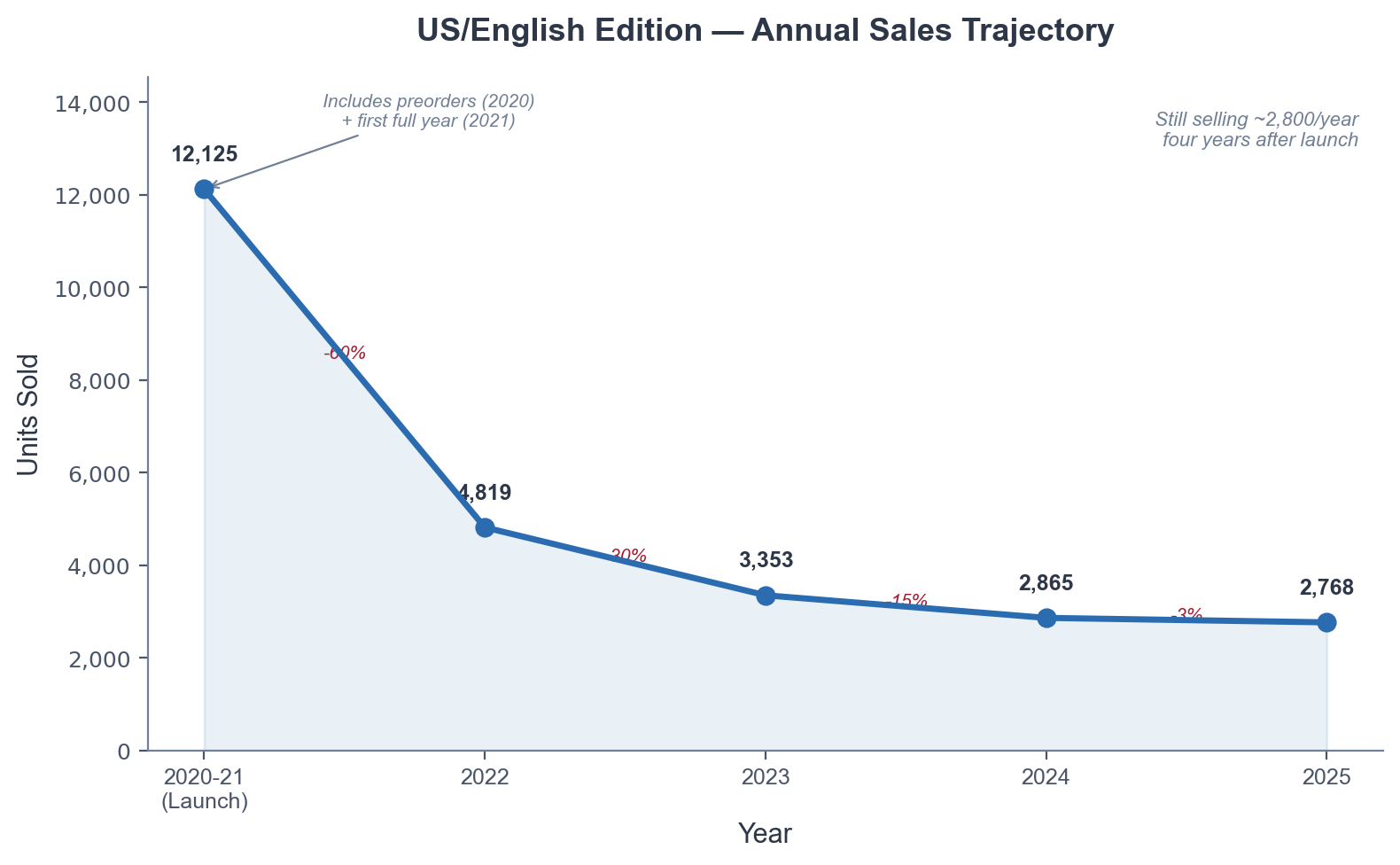
After which right here is that similar factor over time. You possibly can see the English talking trajectory individually.
In order that’s been fairly a enjoyable expertise to be sincere. And thanks everybody in your encouragement and assist for me personally and professionally all these years. It’s buoyed my spirits.
So, on the e-book, entrance, what comes subsequent after the Remix? Undecided. I’ve been toying through the years with completely different initiatives. At completely different occasions, these have been the concepts I’ve toyed with, some I went additional on than others.
A biography of the Nobel Laureates — David Card, Guido Imbens, Josh Angrist
A biographical historical past of the Princeton Industrial Relations Part that may embody the Nobel Laureate tales.
A biography of particular labor economists — particularly Josh Angrist, David Card, Francine Blau have all been individuals I’ve thought of.
A e-book on “AI Brokers for Analysis Staff”. This one I’ve accomplished essentially the most work on, as it could be largely impressed by the 38 or so substack posts right here, in addition to the completely different public talks I’ve given about generative AI through the years, in addition to the category I developed at Baylor, “The Economics of AI”. It could combine my private type with an effort to serving to individuals ramp up whereas eager about the bigger implications of AI on work.
And maybe my weirdest thought — a collection of books geared toward highschool and early school age children involving a personal eye named Jack Stone who solves often murders that occur at universities. They sadly require he learns what diff-in-diff and instrumental variables is in order that he can work out clues. It sounds nice on paper — or perhaps it sounds unhealthy on paper — however I did tons of analysis on it two years in the past one summer season after I was presupposed to be engaged on The Remix. I’ve a really vivid dream sequence in a single chapter of Jack Stone assembly with Alberto Abadie floating collectively over the Charles River and Alberto explaining kappa weighting and instrumental variables to the Jack. That was a wild thought I had. I used to be basing it on numerous style tropes, notably Raymond Chandler formulation, and so in Europe was studying as lots of these books as I might to attempt to work out simply what made a Chandler plot a Chandler plot. Guess what doesn’t make a Chandler plot a Chandler plot — characters explaining IV to the non-public eye.
So who is aware of. I’m going to Europe for 9 weeks beginning early Might. I’ll do that:
Zurich
Glasgow
Third Annual CodeChella Madrid
European Fee in Milan
Convention talks in Pisa
Berlin
Quick break
Maastricht
San Sebastián for a trip
After which I come again to Boston. My lease right here runs out the tip of August. I’m presently debating whether or not to maintain it for a 12 months and commuting forwards and backwards or whether or not to simply let it go. There’s private causes for it, and I preserve weighing professionals and cons. I’ve one other month to determine, so want me luck in deciding it.
The rise of frameworks like LangChain and CrewAI has made constructing AI brokers simpler than ever. Nonetheless, growing these brokers usually entails hitting API price limits, managing high-dimensional knowledge, or exposing native servers to the web.
As a substitute of paying for cloud companies through the prototyping part or polluting your host machine with dependencies, you’ll be able to leverage Docker. With a single command, you’ll be able to spin up the infrastructure that makes your brokers smarter.
Listed below are 5 important Docker containers that each AI agent developer ought to have of their toolkit.
# 1. Ollama: Run Native Language Fashions
Ollama dashboard
When constructing brokers, sending each immediate to a cloud supplier like OpenAI can get costly and gradual. Generally, you want a quick, non-public mannequin for particular duties — resembling grammar correction or classification duties.
Ollama lets you run open-source massive language fashions (LLMs) — like Llama 3, Mistral, or Phi — straight in your native machine. By operating it in a container, you retain your system clear and may simply swap between completely different fashions with out a complicated Python surroundings setup.
Privateness and price are main issues when constructing brokers. The Ollama Docker picture makes it simple to serve fashions like Llama 3 or Mistral by way of a REST API.
// Explaining Why It Issues for Agentic Builders
As a substitute of sending delicate knowledge to exterior APIs like OpenAI, you can provide your agent a “mind” that lives inside your personal infrastructure. That is necessary for enterprise brokers who deal with proprietary knowledge. By operating docker run ollama/ollama, you instantly have a neighborhood endpoint that your agent code can name to generate textual content or cause about duties.
// Initiating a Fast Begin
To drag and run the Mistral mannequin by way of the Ollama container, use the next command. This maps the port and retains the fashions continued in your native drive.
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
As soon as the container is operating, it’s essential to pull a mannequin by executing a command contained in the container:
docker exec -it ollama ollama run mistral
// Explaining Why It is Helpful for Agentic Builders
Now you can level your agent’s LLM shopper to http://localhost:11434. This offers you a neighborhood, API-compatible endpoint for quick prototyping and ensures your knowledge by no means leaves your machine.
// Reviewing Key Advantages
Knowledge Privateness: Hold your prompts and knowledge safe
Price Effectivity: No API charges for inference
Latency: Sooner responses when operating on native GPUs
Brokers require reminiscence to recall previous conversations and area data. To offer an agent long-term reminiscence, you want a vector database. These databases retailer numerical representations (embeddings) of textual content, permitting your agent to seek for semantically related info later.
Qdrant is a high-performance, open-source vector database inbuilt Rust. It’s quick, dependable, and affords each a gRPC and a REST API. Working it in Docker offers you a production-grade reminiscence system on your brokers immediately.
// Explaining Why It Issues for Agentic Builders
To construct a retrieval-augmented era (RAG) agent, it’s essential to retailer doc embeddings and retrieve them rapidly. Qdrant acts because the agent’s long-term reminiscence. When a person asks a query, the agent converts it right into a vector, searches Qdrant for related vectors — representing related data — and makes use of that context to formulate a solution. Working it in Docker retains this reminiscence layer decoupled out of your utility code, making it extra strong.
// Initiating a Fast Begin
You can begin Qdrant with a single command. This exposes the API and dashboard on port 6333 and the gRPC interface on port 6334.
docker run -d -p 6333:6333 -p 6334:6334 qdrant/qdrant
After operating this, you’ll be able to join your agent to localhost:6333. When the agent learns one thing new, retailer the embedding in Qdrant. The following time the person asks a query, the agent can search this database for related “reminiscences” to incorporate within the immediate, making it really conversational.
# 3. n8n: Glue Workflows Collectively
n8n dashboard
Agentic workflows hardly ever exist in a vacuum. You typically want your agent to verify your electronic mail, replace a row in a Google Sheet, or ship a Slack message. When you might write the API calls manually, the method is commonly tedious.
n8n is a fair-code workflow automation software. It lets you join completely different companies utilizing a visible UI. By operating it regionally, you’ll be able to create complicated workflows — resembling “If an agent detects a gross sales lead, add it to HubSpot and ship a Slack alert” — with out writing a single line of integration code.
// Initiating a Fast Begin
To persist your workflows, you must mount a quantity. The next command units up n8n with SQLite as its database.
docker run -d --name n8n -p 5678:5678 -v n8n_data:/house/node/.n8n n8nio/n8n
// Explaining Why It is Helpful for Agentic Builders
You’ll be able to design your agent to name an n8n webhook URL. The agent merely sends the information, and n8n handles the messy logic of speaking to third-party APIs. This separates the “mind” (the LLM) from the “arms” (the integrations).
Entry the editor at http://localhost:5678 and begin automating.
# 4. Firecrawl: Rework Web sites into Giant Language Mannequin-Prepared Knowledge
Firecrawl dashboard
One of the crucial widespread duties for brokers is analysis. Nonetheless, brokers battle to learn uncooked HTML or JavaScript-rendered web sites. They want clear, markdown-formatted textual content.
Firecrawl is an API service that takes a URL, crawls the web site, and converts the content material into clear markdown or structured knowledge. It handles JavaScript rendering and removes boilerplate — resembling adverts and navigation bars — robotically. Working it regionally bypasses the utilization limits of the cloud model.
// Initiating a Fast Begin
Firecrawl makes use of a docker-compose.yml file as a result of it consists of a number of companies, together with the app, Redis, and Playwright. Clone the repository and run it.
git clone https://github.com/mendableai/firecrawl.git
cd firecrawl
docker compose up
// Explaining Why It is Helpful for Agentic Builders
Give your agent the flexibility to ingest reside internet knowledge. In case you are constructing a analysis agent, you’ll be able to have it name your native Firecrawl occasion to fetch a webpage, convert it to wash textual content, chunk it, and retailer it in your Qdrant occasion autonomously.
# 5. PostgreSQL and pgvector: Implement Relational Reminiscence
PostgreSQL dashboard
Generally, vector search alone is just not sufficient. You might want a database that may deal with structured knowledge — like person profiles or transaction logs — and vector embeddings concurrently. PostgreSQL, with the pgvector extension, lets you just do that.
As a substitute of operating a separate vector database and a separate SQL database, you get the most effective of each worlds. You’ll be able to retailer a person’s identify and age in a desk column and retailer their dialog embeddings in one other column, then carry out hybrid searches (e.g. “Discover me conversations from customers in New York about refunds”).
// Initiating a Fast Begin
The official PostgreSQL picture doesn’t embrace pgvector by default. It’s good to use a particular picture, such because the one from the pgvector group.
docker run -d --name postgres-pgvector -p 5432:5432 -e POSTGRES_PASSWORD=mysecretpassword pgvector/pgvector:pg16
// Explaining Why It is Helpful for Agentic Builders
That is the final word backend for stateful brokers. Your agent can write its reminiscences and its inside state into the identical database the place your utility knowledge lives, making certain consistency and simplifying your structure.
# Wrapping Up
You don’t want an enormous cloud finances to construct refined AI brokers. The Docker ecosystem offers production-grade alternate options that run completely on a developer laptop computer.
By including these 5 containers to your workflow, you equip your self with:
Brains: Ollama for native inference
Reminiscence: Qdrant for vector search
Arms: n8n for workflow automation
Eyes: Firecrawl for internet ingestion
Storage: PostgreSQL with pgvector for structured knowledge
Begin your containers, level your LangChain or CrewAI code to localhost, and watch your brokers come to life.
// Additional Studying
Shittu Olumide is a software program engineer and technical author obsessed with leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying complicated ideas. You can too discover Shittu on Twitter.
Google has added two new service tiers to the Gemini API that allow enterprise builders to regulate the price and reliability of AI inference relying on how time-sensitive a given workload is.
Whereas the price of coaching massive language fashions for synthetic intelligence has been a priority prior to now, the main focus of consideration is more and more transferring to inferencing, or the value of utilizing these fashions.
The brand new tiers, referred to as Flex Inference and Precedence Inference, handle an issue that has grown extra acute as enterprises transfer past easy AI chatbots into advanced, multi-step agentic workflows, the corporate mentioned in a weblog put up printed Thursday.
In a separate announcement on the identical day, Google additionally launched Gemma 4, the most recent era of its open mannequin household for builders preferring to run fashions domestically fairly than through a paid API, describing it as its most succesful open launch so far.
The brand new API service tiers are meant to simplify life for builders of agentic methods involving background duties that don’t require immediate responses and interactive, user-facing options the place reliability is vital. Till now, supporting each workload varieties meant sustaining separate architectures: normal synchronous serving for real-time requests and the asynchronous Batch API for much less time-sensitive jobs.
“Flex and Precedence assist to bridge this hole,” the put up mentioned. “Now you can route background jobs to Flex and interactive jobs to Precedence, each utilizing normal synchronous endpoints.”
The 2 tiers function by means of a single synchronous interface, with precedence set through a service_tier parameter within the API request.
Decrease value vs larger availability
Flex Inference is priced at 50% of the usual Gemini API price, however affords lowered reliability and better latency. I is suited to background CRM updates, large-scale analysis simulations, and agentic workflows “the place the mannequin ‘browses’ or ‘thinks’ within the background,” Google mentioned. It’s out there to all paid-tier customers for GenerateContent and Interactions API requests.
For enterprise platform groups, the sensible worth is that background AI workloads corresponding to information enrichment, doc processing, and automatic reporting could be run at materially decrease value with no separate asynchronous structure, and with out the necessity to handle enter/output information or ballot for job completion.
Precedence Inference provides requests the very best processing precedence on Google’s infrastructure, “even throughout peak load,” the put up said.
Nonetheless, as soon as a buyer’s site visitors exceeds their Precedence allocation, overflow requests whereas not outright rejected are routinely routed to the Normal tier as an alternative.
“This retains your utility on-line and helps to make sure enterprise continuity,” Google mentioned, including that the API response will point out which tier dealt with every request, giving builders visibility into each efficiency and billing. Precedence Inference is offered to Tier 2 and Tier 3 paid tasks.
However the downgrade mechanism raises issues for regulated industries, in accordance ot Greyhound Analysis Chief Analyst Sanchit Vir Gogia.
“Two an identical requests, submitted underneath completely different system circumstances, can expertise completely different latency, completely different prioritisation, and probably completely different outcomes,” he mentioned. “In isolation, this appears like a efficiency problem. In follow, it turns into an consequence integrity problem.”
For banking, insurance coverage, and healthcare, he mentioned, that variability raises direct questions round equity, explainability, and auditability. “Sleek degradation, with out full transparency and governance, isn’t resilience,” Gogia mentioned. “It’s ambiguity launched into the system at scale.”
What it means for enterprise AI technique
The brand new tiers are a part of a broader business shift towards tiered inference pricing that Gogia mentioned displays constrained AI infrastructure fairly than purely business innovation.
“Tiered inference pricing is the clearest sign but that AI compute is transitioning right into a utility mannequin,” he mentioned, “however with out the maturity, transparency, or standardisation that enterprises usually affiliate with utilities.” The underlying driver, he mentioned, is structural shortage — energy availability, specialised {hardware}, and information centre capability — and tiering is how suppliers are managing allocation underneath these constraints.
For CIOs and procurement groups, vendor contracts can now not stay generic, Gogia mentioned. “They need to explicitly outline service tiers, define downgrade circumstances, implement efficiency ensures, and set up mechanisms for value management and auditability.”