Have you ever each wished to make an “simple” calculation–say, after becoming a mannequin–and gotten misplaced since you simply weren’t positive the place to seek out the levels of freedom of the residual or the usual error of the coefficient? Have you ever ever been within the midst of setting up an “simple” calculation and was all of the sudden uncertain simply what e(df_r) actually was? I’ve an answer.
It’s known as Stata’s expression builder. You may get to it from the show dialog (Knowledge->Different Utilities->Hand Calculator)
Within the dialog, click on the Create button to convey up the builder. Actually, it doesn’t seem like a lot:
I wish to present you find out how to use this expression builder; in the event you’ll follow me, it’ll be value your time.
Let’s begin over once more and assume you’re within the midst of an evaluation, say,
. sysuse auto, clear
. regress worth mpg size
Subsequent invoke the expression builder by knocking down the menu Knowledge->Different Utilities->Hand Calculator. Click on Create. It seems like this:
Now click on on the tree node icon (+) in entrance of “Estimation outcomes” after which scroll right down to see what’s beneath. You’ll see
Click on on Scalars:
The center field now incorporates the scalars saved in e(). N occurs to be highlighted, however you would click on on any of the scalars. If you happen to look beneath the 2 packing containers, you see the worth of the e() scalar chosen in addition to its worth and a brief description. e(N) is 74 and is the “variety of observations”.
It really works the identical means for all the opposite classes within the field on the left: Operators, Capabilities, Variables, Coefficients, Estimation outcomes, Returned outcomes, System parameters, Matrices, Macros, Scalars, Notes, and Traits. You merely click on on the tree node icon (+), and the class expands to point out what is on the market.
You’ve now mastered the expression builder!
Let’s attempt it out.
Say you wish to confirm that the p-value of the coefficient on mpg is accurately calculated by regress–which reviews 0.052–or extra possible, you wish to confirm that you understand how it was calculated. You assume the method is
or, as an expression in Stata,
2*ttail(e(df_r), abs(_b[mpg]/_se[mpg]))
However I’m leaping forward. It’s possible you’ll not keep in mind that _b[mpg] is the coefficient on variable mpg, or that _se[mpg] is its corresponding customary error, or that abs() is Stata’s absolute worth perform, or that e(df_r) is the residual levels of freedom from the regression, or that ttail() is Stata’s Pupil’s t distribution perform. We are able to construct the above expression utilizing the builder as a result of all of the parts could be accessed by way of the builder. The ttail() and abs() capabilities are within the Capabilities class, the e(df_r) scalar is within the Estimation outcomes class, and _b[mpg] and _se[mpg] are within the Coefficients class.
What’s good concerning the builder is that not solely are the merchandise names listed but in addition a definition, syntax, and worth are displayed once you click on on an merchandise. Having all this data in a single place makes constructing a posh expression a lot simpler.
One other instance of when the expression builder turns out to be useful is when computing intraclass correlations after xtmixed. Think about a easy two-level mannequin from Instance 1 in [XT] xtmixed, which fashions weight trajectories of 48 pigs from 9 successive weeks:
. use http://www.stata-press.com/information/r12/pig
. xtmixed weight week || id:, variance
The intraclass correlation is a nonlinear perform of variance parts. On this instance, the (residual) intraclass correlation is the ratio of the between-pig variance, var(_cons), to the full variance, between-pig variance plus residual (within-pig) variance, or var(_cons) + var(residual).
The xtmixed command doesn’t retailer the estimates of variance parts instantly. As a substitute, it shops them as log customary deviations in e(b) such that _b[lns1_1_1:_cons] is the estimated log of between-pig customary deviation, and _b[lnsig_e:_cons] is the estimated log of residual (within-pig) customary deviation. So to compute the intraclass correlation, we should first rework log customary deviations to variances:
The issue is that few individuals keep in mind that _b[lns1_1_1:_cons] is the estimated log of between-pig customary deviation. The few who do definitely don’t wish to kind it. So use the expression builder as we do beneath:
On this case, we’re utilizing the expression builder accessed from Stata’s nlcom dialog, which reviews estimated nonlinear mixtures together with their customary errors. As soon as we press OK right here and within the nlcom dialog, we’ll see
The above might simply be prolonged to computing various kinds of intraclass correlations arising in higher-level random-effects fashions. Using the expression builder for that turns into much more useful.
In response to Stack Overflow and Atlassian, builders lose between 6 and 10 hours each week looking for info or clarifying unclear documentation. For a 50-developer staff, that provides as much as $675,000–$1.1 million in wasted productiveness yearly. This isn’t only a tooling subject. It’s a retrieval drawback. Enterprises have loads of knowledge however lack quick, dependable methods to search out the precise info. Conventional search fails as techniques develop advanced, slowing onboarding, selections, and assist. On this article, we discover how fashionable enterprise search solves these gaps.
Why Conventional Enterprise Search Falls Quick
Most enterprise search techniques had been constructed for a special period. They assume comparatively static content material, predictable bugs and queries, and guide tuning to remain related. In fashionable knowledge setting none of these assumptions maintain significance.
Groups work throughout quickly altering datasets. Queries are ambiguous and conversational. Context issues as a lot as Key phrases. But many search instruments nonetheless depend on brittle guidelines and precise matches, forcing customers guess the precise phrasing reasonably than expressing actual intent.
The result’s acquainted. Individuals search repeatedly, refine queries manually or abandon search altogether. In AI-powered purposes, the issue turns into extra severe. Poor retrieval doesn’t simply gradual customers down. It typically feeds incomplete or irrelevant context into language fashions, growing the danger of low-quality or deceptive outputs.
The Change to Hybrid Retrieval
The subsequent technology of enterprise search is constructed on hybrid retrieval. As an alternative of selecting between key phrase search and semantic search, fashionable techniques mix each of them.
Key phrase search excels at precision. Vector search captures which means and intent. Collectively, they allow search experiences which might be quick, versatile and resilient throughout a variety of queries.
Cortex Search is designed orienting this hybrid method from the beginning. It offers low latency, high-quality fuzzy search instantly over Snowflake knowledge, with out requiring groups to handle embeddings and tune relevance parameters or preserve customized infrastructure. The retrieval layer adapts to the info, not the opposite method round.
Fairly than treating search as an add on characteristic, Coretx Search makes it a foundational functionality that scales with enterprise knowledge complexity.
Cortex Search because the Retrieval Layer for AI and Enterprise Search
Cortex Search helps two major use instances which might be more and more central to fashionable knowledge methods.
First isRetrieval Augmented Technology. Cortex Search acts because the retrieval engine that provides massive language fashions with correct, up-to-date enterprise context. This grounding layer is what permits AI chat purposes to ship responses which might be particular, related and aligned with proprietary knowledge reasonably than generic patterns.
Second is Enterprise Search. Cortex Search can energy high-quality search experiences embedded instantly into purposes, instruments and workflows. Customers ask questions in pure language and obtain outcomes ranked by each semantic relevance and key phrase precision.
Below the hood, cortex search indexes textual content knowledge, applies hybrid retrieval and makes use of semantic reranking to floor probably the most related outcomes. Refreshes are automated and incremental, so search outcomes keep aligned with the present state of the info with out guide intervention.
This issues as a result of retrieval high quality instantly shapes consumer belief. When search works persistently, folks depend on it. When it doesn’t, they cease utilizing it and fall again to slower, dearer paths.
How Cortex Search Works in Apply
At a excessive stage, Cortex Search abstracts away the toughest elements of constructing a contemporary retrieval system.
Instance: Powering RAG Functions with Cortex Search
What we’ll Construct: A buyer assist AI assistant that solutions consumer questions by retrieving grounded context from historic assist tickets and transcripts: then passing that context to a Snowflake Cortex LLM to generate correct, particular solutions.
Run the next in a Snowflake Worksheet to create the database, schema
First create a brand new sql file.
CREATE DATABASE IF NOT EXISTS SUPPORT_DB;
CREATE WAREHOUSE IF NOT EXISTS COMPUTE_WH
WAREHOUSE_SIZE = 'X-SMALL'
AUTO_SUSPEND = 60
AUTO_RESUME = TRUE;
USE DATABASE SUPPORT_DB;
USE WAREHOUSE COMPUTE_WH;
Step 2 — Create and Populate the Supply Desk
This desk simulates historic assist tickets. In manufacturing, this might be a stay desk synced out of your CRM, ticketing system, or knowledge pipeline.
CREATE TABLE IF NOT EXISTS SUPPORT_DB.PUBLIC.support_tickets (
ticket_id VARCHAR(20),
issue_category VARCHAR(100),
user_query TEXT,
decision TEXT,
created_at TIMESTAMP_NTZ DEFAULT CURRENT_TIMESTAMP()
);
INSERT INTO SUPPORT_DB.PUBLIC.support_tickets (ticket_id, issue_category, user_query, decision) VALUES
('TKT-001', 'Connectivity',
'My web retains dropping each couple of minutes. The router lights look regular.',
'Agent checked line diagnostics. Discovered intermittent sign degradation on the coax line. Dispatched technician to exchange splitter. Problem resolved after {hardware} swap.'),
('TKT-002', 'Connectivity',
'Web may be very gradual throughout evenings however high quality within the morning.',
'Community congestion detected in buyer section throughout peak hours (6–10 PM). Upgraded buyer to a much less congested node. Speeds normalized inside 24 hours.'),
('TKT-003', 'Billing',
'I used to be charged twice for a similar month. Want a refund.',
'Duplicate billing confirmed because of fee gateway retry error. Refund of $49.99 issued. Buyer notified through e-mail. Root trigger patched in billing system.'),
('TKT-004', 'Machine Setup',
'My new router just isn't exhibiting up within the Wi-Fi listing on my laptop computer.',
'Router was broadcasting on 5GHz solely. Buyer laptop computer had outdated Wi-Fi driver that didn't assist 5GHz. Guided buyer to replace driver. Each 2.4GHz and 5GHz bands now seen.'),
('TKT-005', 'Connectivity',
'Frequent packet loss throughout video calls. Wired connection additionally affected.',
'Packet loss traced to defective ethernet port on modem. Changed modem beneath guarantee. Buyer confirmed secure connection post-replacement.'),
('TKT-006', 'Account',
'Can't log into the client portal. Password reset emails aren't arriving.',
'E-mail supply blocked by SPF report misconfiguration on buyer area. Suggested buyer to offer assist area. Reset e-mail delivered efficiently.'),
('TKT-007', 'Connectivity',
'Web unstable solely when microwave is working within the kitchen.',
'2.4GHz Wi-Fi interference brought on by microwave proximity to router. Beneficial switching router channel from 6 to 11 and enabling 5GHz band. Problem eradicated.'),
('TKT-008', 'Pace',
'Marketed pace is 500Mbps however I solely get round 120Mbps on speedtest.',
'Pace check confirmed 480Mbps at node. Buyer router restricted to 100Mbps because of Quick Ethernet port. Beneficial router improve. Put up-upgrade pace confirmed at 470Mbps.');
Step 3 — Create the Cortex Search Service
This single SQL command handles embedding technology, indexing, and hybrid retrieval setup routinely. The ON clause specifies which column to index for full-text and semantic search. ATTRIBUTES defines filterable metadata columns.
CREATE OR REPLACE CORTEX SEARCH SERVICE SUPPORT_DB.PUBLIC.support_search_svc
ON decision
ATTRIBUTES issue_category, ticket_id
WAREHOUSE = COMPUTE_WH
TARGET_LAG = '1 minute'
AS (
SELECT
ticket_id,
issue_category,
user_query,
decision
FROM SUPPORT_DB.PUBLIC.support_tickets
);
What occurs right here: Snowflake routinely generates vector embeddings for the decision column, builds each a key phrase index and a vector index, and exposes a unified hybrid retrieval endpoint. No embedding mannequin administration, no separate vector database.
You may confirm the service is energetic:
SHOW CORTEX SEARCH SERVICES IN SCHEMA SUPPORT_DB.PUBLIC;
Output:
Step 4 — Question the Search Service from Python
Hook up with Snowflake and use the snowflake-core SDK to question the service:
First Set up required packages:
pip set up snowflake-snowpark-python snowflake-core
Now to search out your account particulars go to your account and click on on “Join a device to Snowflake”
from snowflake.snowpark import Session
from snowflake.core import Root
# --- Connection config ---
connection_params = {
"account": "YOUR_ACCOUNT_IDENTIFIER", # e.g. abc12345.us-east-1
"consumer": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
"function": "SYSADMIN",
"warehouse": "COMPUTE_WH",
"database": "SUPPORT_DB",
"schema": "PUBLIC",
}
# --- Create Snowpark session ---
session = Session.builder.configs(connection_params).create()
root = Root(session)
# --- Reference the Cortex Search service ---
search_svc = (
root.databases["SUPPORT_DB"]
.schemas["PUBLIC"]
.cortex_search_services["SUPPORT_SEARCH_SVC"]
)
def retrieve_context(question: str, category_filter: str = None, top_k: int = 3):
"""Run hybrid search towards the Cortex Search service."""
filter_expr = {"@eq": {"issue_category": category_filter}} if category_filter else None
response = search_svc.search(
question=question,
columns=["ticket_id", "issue_category", "user_query", "resolution"],
filter=filter_expr,
restrict=top_k,
)
return response.outcomes
# --- Take a look at retrieval ---
user_question = "Why is my web unstable?"
outcomes = retrieve_context(user_question, top_k=3)
print(f"n🔍 Question: {user_question}n")
print("=" * 60)
for i, r in enumerate(outcomes, 1):
print(f"n[Result {i}]")
print(f" Ticket ID : {r['ticket_id']}")
print(f" Class : {r['issue_category']}")
print(f" Consumer Question: {r['user_query']}")
print(f" Decision: {r['resolution'][:200]}...")
Output:
Step 5 — Construct the Full RAG Pipeline
Now move the retrieved context into Snowflake Cortex LLM (mistral-large or llama3.1-70b) to generate a grounded reply:
import json
def build_rag_prompt(user_question: str, retrieved_results: listing) -> str:
"""Format retrieved context into an LLM-ready immediate."""
context_blocks = []
for r in retrieved_results:
context_blocks.append(
f"- Ticket {r['ticket_id']} ({r['issue_category']}): "
f"Buyer reported '{r['user_query']}'. "
f"Decision: {r['resolution']}"
)
context_str = "n".be part of(context_blocks)
return f"""You're a useful buyer assist assistant. Use ONLY the context under
to reply the client's query. Be particular and concise.
CONTEXT FROM HISTORICAL TICKETS:
{context_str}
CUSTOMER QUESTION: {user_question}
ANSWER:"""
def ask_rag_assistant(user_question: str, mannequin: str = "mistral-large2"):
"""Full RAG pipeline: retrieve → increase → generate."""
print(f"n📡 Retrieving context for: '{user_question}'")
outcomes = retrieve_context(user_question, top_k=3)
print(f" ✅ Retrieved {len(outcomes)} related tickets")
immediate = build_rag_prompt(user_question, outcomes)
safe_prompt = immediate.exchange("'", "'")
sql = f"""
SELECT SNOWFLAKE.CORTEX.COMPLETE(
'{mannequin}',
'{safe_prompt}'
) AS reply
"""
end result = session.sql(sql).gather()
reply = end result[0]["ANSWER"]
return reply, outcomes
# --- Run the assistant ---
questions = [
"Why is my internet unstable?",
"I'm being charged incorrectly, what should I do?",
"My router is not visible on my devices",
]
for q in questions:
reply, ctx = ask_rag_assistant(q)
print(f"n{'='*60}")
print(f"❓ Buyer: {q}")
print(f"n🤖 AI Assistant:n{reply.strip()}")
print(f"n📎 Grounded in tickets: {[r['ticket_id'] for r in ctx]}")
Output:
Key takeaway: The AI by no means generates generic solutions. Each response is traceable to particular historic tickets, dramatically decreasing hallucination threat and making outputs auditable.
Instance: Constructing Enterprise Search into Functions
What we’ll construct:
A pure language assist ticket search interface — embedded instantly into an software — that lets brokers and clients search historic tickets utilizing plain English. No new infrastructure is required: this instance reuses the very same support_tickets desk and support_search_svc Cortex Search service created within the RAG part above.
This exhibits how the identical Cortex Search service can energy two completely completely different surfaces: an AI assistant on one hand, and a browsable search UI on the opposite.
Step 1 — Verify the Current Service is Lively
Confirm the service created within the earlier part remains to be working:
USE DATABASE SUPPORT_DB;
USE SCHEMA PUBLIC;
SHOW CORTEX SEARCH SERVICES IN SCHEMA RAG_SCHEMA;
Output:
Step 2 — Construct the Enterprise Search Shopper
This module connects to the identical Snowpark session and support_search_svc service, and exposes a search perform with class filtering and ranked end result show — the form of interface you’d embed right into a assist portal, an inner data device, or an agent dashboard.
# enterprise_search.py
from snowflake.snowpark import Session
from snowflake.core import Root
# --- Connection config ---
connection_params = {
"account": "YOUR_ACCOUNT_IDENTIFIER", # e.g. abc12345.us-east-1
"consumer": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
"function": "SYSADMIN",
"warehouse": "COMPUTE_WH",
"database": "SUPPORT_DB",
"schema": "PUBLIC",
}
session = Session.builder.configs(connection_params).create()
root = Root(session)
# --- Identical service because the RAG instance — no new service wanted ---
search_svc = (
root.databases["SUPPORT_DB"]
.schemas["RAG_SCHEMA"]
.cortex_search_services["SUPPORT_SEARCH_SVC"]
)
def search_tickets(question: str, class: str = None, top_k: int = 5) -> listing:
"""Pure language ticket search with non-compulsory class filter."""
filter_expr = {"@eq": {"issue_category": class}} if class else None
response = search_svc.search(
question=question,
columns=["ticket_id", "issue_category", "user_query", "resolution"],
filter=filter_expr,
restrict=top_k,
)
return response.outcomes
def display_tickets(question: str, outcomes: listing, filter_label: str = None):
"""Render search outcomes as a formatted ticket listing."""
label = f" [{filter_label}]" if filter_label else ""
print(f"n🔎 Search{label}: "{question}"")
print(f" {len(outcomes)} ticket(s) foundn")
print("-" * 72)
for i, r in enumerate(outcomes, 1):
print(f" #{i} {r['ticket_id']} | Class: {r['issue_category']}")
print(f" Buyer: {r['user_query']}")
print(f" Decision: {r['resolution'][:160]}...n")
Step 3 — Run Pure Language Ticket Searches
# --- Search 1: Semantic question — no precise match wanted ---
outcomes = search_tickets("machine not connecting to the community")
display_tickets("machine not connecting to the community", outcomes)
# --- Search 3: Account & entry points ---
outcomes = search_tickets("cannot log in or entry my account", class="Account")
display_tickets("cannot log in or entry my account", outcomes, filter_label="Account")
Output:
Step 4 — Expose as a Flask Search API (Optionally available)
Wrap the search perform in a REST endpoint to embed it into any assist portal, inner device, or chatbot backend:
# app.py
from flask import Flask, request, jsonify
from enterprise_search import search_tickets
app = Flask(__name__)
@app.route("/tickets/search", strategies=["GET"])
def ticket_search():
question = request.args.get("q", "")
class = request.args.get("class") # non-compulsory filter
top_k = int(request.args.get("restrict", 5))
if not question:
return jsonify({"error": "Question parameter 'q' is required"}), 400
outcomes = search_tickets(question, class=class, top_k=top_k)
return jsonify({
"question": question,
"class": class,
"rely": len(outcomes),
"outcomes": outcomes,
})
if __name__ == "__main__":
app.run(port=5001, debug=True)
Take a look at with curl:
# Free-text pure language search
curl "http://localhost:5001/tickets/search?q=web+retains+dropping&restrict=3"
Output:
# Filtered by class
curl "http://localhost:5001/tickets/search?q=charged+incorrectly&class=Billing"
Output:
Key takeaway: The identical Cortex Search service that grounds the RAG assistant additionally powers a completely useful enterprise search UI — no duplication of infrastructure, no second index to keep up. One service definition delivers each experiences, and each keep routinely in sync as tickets are added or up to date.
The Enterprise Impression of Higher Retrieval
Poor knowledge search strategies quietly erode enterprise efficiency. Time is misplaced to repeated queries and rework. However, assist groups get entangled in resolving questions that ought to have been self-served within the first place. New hires and clients take longer to succeed in productiveness. AI initiatives stall when outputs can’t be trusted.
In contrast, robust retrieval adjustments how organizations function.
Groups transfer quicker as a result of solutions are simpler to search out. AI purposes carry out higher as a result of they’re grounded in related, present knowledge. Characteristic adoption improves as a result of customers can uncover and perceive capabilities with out friction. Help prices decline as search absorbs routine questions.
Cortex Search turns retrieval from a background utility right into a strategic lever. It helps enterprises unlock the worth already current of their knowledge by making it accessible, searchable and usable at scale.
Steadily Requested Questions
Q1. Why does conventional enterprise search fail in fashionable techniques?
A. It depends on key phrase matching and static indexes, which fail to seize intent and sustain with dynamic, distributed knowledge environments.
Q2. What makes hybrid retrieval simpler than conventional search?
A. It combines key phrase precision with semantic understanding, enabling quicker, extra related outcomes even for ambiguous or conversational queries.
Q3. How does Cortex Search enhance AI and enterprise purposes?
A. It offers correct, real-time retrieval that grounds AI responses and powers search experiences with out advanced infrastructure or guide tuning.
Dentsu’s world functionality heart, Dentsu World Companies (DGS), is shaping the longer term as an innovation engine. DGS has 5,600+ specialists focusing on digital platforms, efficiency advertising and marketing, product engineering, knowledge science, automation and AI, with media transformation on the core. DGS delivers AI-first, scalable options by dentsu’s community seamlessly integrating folks, know-how, and craft. They mix human creativity and superior know-how, constructing a various, future-focused group that adapts shortly to shopper wants whereas guaranteeing reliability, collaboration and excellence in each engagement.
DGS brings collectively world-class expertise, breakthrough know-how and daring concepts to ship impression at scale—for dentsu’s purchasers, its folks and the world. It’s a future-focused, industry-leading office the place expertise meets alternative. At DGS, staff can speed up their profession, collaborate with world groups and contribute to work that shapes the longer term. Discover out extra: Dentsu World Companies
Login to proceed studying and luxuriate in expert-curated content material.
Working highly effective AI in your smartphone isn’t only a {hardware} downside — it’s a mannequin structure downside. Most state-of-the-art imaginative and prescient encoders are huge, and while you trim them down to suit on an edge system, they lose the capabilities that made them helpful within the first place. Worse, specialised fashions are likely to excel at one sort of activity — picture classification, say, or scene segmentation — however collapse while you ask them to do one thing outdoors their lane.
Meta’s AI analysis groups are actually proposing a special path. They launched the Environment friendly Common Notion Encoder (EUPE): a compact imaginative and prescient encoder that handles various imaginative and prescient duties concurrently while not having to be massive.
The Core Downside: Specialists vs. Generalists
To know why EUPE issues, it helps to know how imaginative and prescient encoders work and why specialization is an issue.
A imaginative and prescient encoder is the a part of a pc imaginative and prescient mannequin that converts uncooked picture pixels right into a compact illustration — a set of characteristic vectors — that downstream duties (like classification, segmentation, or answering questions on a picture) can use. Consider it because the ‘eyes’ of an AI pipeline.
Fashionable basis imaginative and prescient encoders are educated with particular targets, which supplies them an edge particularly domains. For instance:
CLIP and SigLIP 2 are educated on text-image pairs. They’re robust at picture understanding and vision-language modeling, however their efficiency on dense prediction duties (which require spatially exact, pixel-level options) typically falls under expectations.
DINOv2 and its successor DINOv3 are self-supervised fashions that be taught distinctive structural and geometric descriptors, making them robust at dense prediction duties like semantic segmentation and depth estimation. However they lack passable vision-language capabilities.
SAM (Phase Something Mannequin) achieves spectacular zero-shot segmentation via coaching on large segmentation datasets, however once more falls quick on vision-language duties.
For an edge system — a smartphone or AR headset — that should deal with all of those activity varieties concurrently, the standard answer is to deploy a number of encoders directly. That shortly turns into compute-prohibitive. The choice is accepting {that a} single encoder will underperform in a number of domains.
Earlier Makes an attempt: Why Agglomerative Strategies Fell Quick on Environment friendly Backbones
Researchers have tried to mix the strengths of a number of specialist encoders via a household of strategies referred to as agglomerative multi-teacher distillation. The fundamental concept: practice a single pupil encoder to concurrently mimic a number of instructor fashions, every of which is a site professional.
AM-RADIO and its follow-up RADIOv2.5 are maybe essentially the most well-known examples of this strategy. They confirmed that agglomerative distillation can work effectively for giant encoders — fashions with greater than 300 million parameters. However the EUPE analysis demonstrates a transparent limitation: while you apply the identical recipe to environment friendly backbones, the outcomes degrade considerably. RADIOv2.5-B, the ViT-B-scale variant, has important gaps in comparison with area specialists on dense prediction and VLM duties.
One other agglomerative methodology, DUNE, merges 2D imaginative and prescient and 3D notion academics via heterogeneous co-distillation, however equally struggles on the environment friendly spine scale.
The foundation trigger, the analysis workforce argue, is capability. Environment friendly encoders merely don’t have sufficient representational capability to straight take up various characteristic representations from a number of specialist academics and unify them right into a common illustration. Making an attempt to take action in a single step produces a mannequin that’s mediocre throughout the board.
https://arxiv.org/pdf/2603.22387
EUPE’s Reply: Scale Up First, Then Scale Down
The important thing perception behind EUPE is a precept named ‘first scaling up after which cutting down.‘
As a substitute of distilling straight from a number of domain-expert academics right into a small pupil, EUPE introduces an intermediate mannequin: a big proxy instructor with sufficient capability to unify the information from all of the area specialists. This proxy instructor then transfers its unified, common information to the environment friendly pupil via distillation.
The complete pipeline has three phases:
Stage 1 — Multi-Instructor Distillation into the Proxy Mannequin. A number of massive basis encoders function academics concurrently, processing label-free photos at their native resolutions. Every instructor outputs a category token and a set of patch tokens. The proxy mannequin — a 1.9B parameter mannequin educated with 4 register tokens — is educated to imitate all academics directly. The chosen academics are:
PEcore-G (1.9B parameters), chosen because the area professional for zero-shot picture classification and retrieval
PElang-G (1.7B parameters), which the analysis workforce discovered is essential for vision-language modeling, significantly OCR efficiency
DINOv3-H+ (840M parameters), chosen because the area professional for dense prediction
To stabilize coaching, instructor outputs are normalized by subtracting the per-coordinate imply and dividing by the usual deviation, computed as soon as over 500 iterations earlier than coaching begins and saved mounted thereafter. That is intentionally less complicated than the complicated PHI-S normalization utilized in RADIOv2.5, and avoids the cross-GPU reminiscence overhead of computing normalization statistics on-the-fly.
Stage 2 — Fastened-Decision Distillation into the Environment friendly Scholar. With the proxy mannequin now serving as a single common instructor, the goal environment friendly encoder is educated at a set decision of 256×256. This mounted decision makes coaching computationally environment friendly, permitting an extended studying schedule: 390,000 iterations with a batch measurement of 8,192, cosine studying charge schedule, a base studying charge of 2e-5, and weight decay of 1e-4. Customary information augmentation applies: random resized cropping, horizontal flipping, shade jittering, Gaussian blur, and random solarization. For the distillation loss, the category token loss makes use of cosine similarity, whereas the patch token loss combines cosine similarity (weight α=0.9) and clean L1 loss (weight β=0.1). Adapter head modules — 2-layer MLPs — are appended to the coed to match every instructor’s characteristic dimension. If pupil and instructor patch token spatial dimensions differ, 2D bicubic interpolation is utilized to align them.
Stage 3 — Multi-Decision Finetuning. Ranging from the Stage 2 checkpoint, the coed undergoes a shorter finetuning part utilizing a picture pyramid of three scales: 256, 384, and 512. The scholar and the proxy instructor independently and randomly choose one scale per iteration — so they might course of the identical picture at completely different resolutions. This forces the coed to be taught representations that generalize throughout spatial granularities, accommodating downstream duties that function at numerous resolutions. This stage runs for 100,000 iterations at a batch measurement of 4,096 and base studying charge of 1e-5. It’s deliberately shorter as a result of multi-resolution coaching is computationally expensive — one iteration in Stage 3 takes roughly twice so long as in Stage 2.
Coaching Information. All three phases use the identical DINOv3 dataset, LVD-1689M, which offers balanced protection of visible ideas from the net alongside high-quality public datasets together with ImageNet-1k. The sampling likelihood from ImageNet-1k is 10%, with the remaining 90% from LVD-1689M. In an ablation examine, coaching on LVD-1689M constantly outperformed coaching on MetaCLIP (2.5B photos) on almost all benchmarks — regardless of MetaCLIP being roughly 800M photos bigger — indicating increased information high quality in LVD.
https://arxiv.org/pdf/2603.22387
An Vital Detrimental Outcome: Not All Lecturers Mix Effectively
One of many extra virtually helpful findings issues instructor choice. Intuitively, including extra robust academics ought to assist. However the analysis workforce discovered that together with SigLIP2-G alongside PEcore-G and DINOv3-H+ considerably degrades OCR efficiency. On the proxy mannequin stage, TextVQA drops from 56.2 to 53.2; on the ViT-B pupil stage, it drops from 48.6 to 44.8. The analysis groups’ speculation: having two CLIP-style fashions (PEcore-G and SigLIP2-G) within the instructor set concurrently causes characteristic incompatibility. PElang-G, a language-focused mannequin derived from PEcore-G via alignment with language fashions, proved a much better complement — bettering OCR and common VLM efficiency with out sacrificing picture understanding or dense prediction.
What the Numbers Say
The ablation research validate the three-stage design. Distilling straight from a number of academics to an environment friendly pupil (“Stage 2 solely”) yields poor VLM efficiency, particularly on OCR-type duties, and poor dense prediction. Including Stage 1 (the proxy mannequin) considerably improves VLM duties — TextVQA rises from 46.8 to 48.3, and Realworld from 53.5 to 55.1 — however nonetheless lags on dense duties. Stage 1+3 (skipping Stage 2) offers the strongest dense prediction outcomes (SPair: 53.3, NYUv2: 0.388) however leaves VLM gaps and is dear to run for a full schedule. The complete three-stage pipeline achieves the perfect total steadiness.
On the principle ViT-B benchmark, EUPE-ViT-B constantly stands out:
Picture understanding: EUPE achieves 84.1 on IN1k-KNN, outperforming PEcore-B (79.7), SigLIP2-B (83.2), and DINOv3-ViT-B (83.0). On IN1k-ZS (zero-shot), it scores 79.7, outperforming PEcore-B (78.4) and SigLIP2-B (78.2).
Dense prediction: EUPE achieves 52.4 mIoU on ADE20k, outperforming the dense prediction professional DINOv3-ViT-B (51.8). On SPair-71k semantic correspondence, it scores 51.3, matching DINOv3-ViT-B.
Imaginative and prescient-language modeling: EUPE outperforms each PEcore-B and SigLIP2-B on RealworldQA (55.5 vs. 52.9 and 52.5) and GQA (67.3 vs. 65.6 and 65.2), whereas staying aggressive on TextVQA, SQA, and POPE.
Vs. agglomerative strategies: EUPE outperforms RADIOv2.5-B and DUNE-B on all VLM duties and most dense prediction duties by important margins.
What the Options Really Look Like
The analysis additionally consists of qualitative characteristic visualization utilizing PCA projection of patch tokens into RGB area — a method that reveals the spatial and semantic construction an encoder has realized. The outcomes are telling:
PEcore-B and SigLIP2-B patch tokens include semantic info however are usually not spatially constant, resulting in noisy representations.
DINOv3-ViT-B has extremely sharp, semantically coherent options, however lacks fine-grained discrimination (meals and plates find yourself with comparable representations within the final row instance).
RADIOv2.5-B options are overly delicate, breaking semantic coherence — for instance, black canine fur merges visually with the background.
EUPE-ViT-B combines semantic coherence, positive granularity, complicated spatial construction, and textual content consciousness concurrently — capturing the perfect qualities throughout all area specialists directly.
A Full Household of Edge-Prepared Fashions
EUPE is an entire household spanning two structure varieties:
ViT household: ViT-T (6M parameters), ViT-S (21M), ViT-B (86M)
All fashions are underneath 100M parameters. Inference latency is measured on iPhone 15 Professional CPU through ExecuTorch-exported fashions. At 256×256 decision: ViT-T runs in 6.8ms, ViT-S in 17.1ms, and ViT-B in 55.2ms. The ConvNeXt variants have decrease FLOPs than ViTs of comparable measurement, however don’t essentially obtain decrease latency on CPU — as a result of convolutional operations are sometimes much less environment friendly on CPU structure in comparison with the extremely optimized matrix multiplication (GEMM) operations utilized in ViTs.
For the ConvNeXt household, EUPE constantly outperforms the DINOv3-ConvNeXt household of the identical sizes throughout Tiny, Small, and Base variants on dense prediction, whereas additionally unlocking higher VLM functionality — significantly for OCR and vision-centric duties — that DINOv3-ConvNeXt totally lacks.
Key Takeaways
One encoder to rule all of them. EUPE is a single compact imaginative and prescient encoder (underneath 100M parameters) that matches or outperforms specialised domain-expert fashions throughout picture understanding, dense prediction, and vision-language modeling — duties that beforehand required separate, devoted encoders.
Scale up earlier than you scale down. The core innovation is a three-stage “proxy instructor” distillation pipeline: first combination information from a number of massive professional fashions right into a 1.9B parameter proxy, then distill from that single unified instructor into an environment friendly pupil — fairly than straight distilling from a number of academics directly.
Instructor choice is a design determination, not a given. Including extra academics doesn’t all the time assist. Together with SigLIP2-G alongside PEcore-G degraded OCR efficiency considerably. PElang-G turned out to be the correct VLM complement — a discovering with direct sensible implications for anybody constructing multi-teacher distillation pipelines.
Constructed for actual edge deployment. The complete EUPE household spans six fashions throughout ViT and ConvNeXt architectures. The smallest, ViT-T, runs in 6.8ms on iPhone 15 Professional CPU. All fashions are exported through ExecuTorch and out there on Hugging Face — prepared for on-device integration, not simply benchmarking.
Information high quality beats information amount. In ablation experiments, coaching on LVD-1689M outperformed coaching on MetaCLIP throughout almost all benchmarks — regardless of MetaCLIP containing roughly 800 million extra photos. A helpful reminder that greater datasets don’t routinely imply higher fashions.
A leak suggests Samsung will launch the steady One UI 8.5 replace for the Galaxy S25 sequence on April 30, beginning in South Korea.
Worldwide customers can seemingly count on the rollout to start on Might 4, 2026, based mostly on earlier launch patterns.
The replace follows a prolonged interval of eight beta variations and weeks of exclusivity for the newer Galaxy S26 sequence.
Galaxy S25 homeowners, your look forward to One UI 8.5 may lastly be coming to an finish soon-ish. After releasing eight One UI 8.5 betas, Samsung is now anticipated to lastly launch One UI 8.5 steady for the Galaxy S25 sequence on the finish of this month, in keeping with a brand new leak.
As per Tarun Vats on X, Samsung is predicted to launch One UI 8.5 steady for the Galaxy S25 sequence on April 30, beginning with its house area of South Korea. Presuming the corporate follows final yr’s sample, worldwide rollout might begin from Might 4, 2026, onwards.
Don’t need to miss the very best from Android Authority?
One UI 8.5 has been round in its steady type with the launch of the Galaxy S26 sequence. It’s been many weeks since then, and we frankly anticipated Samsung to maintain software program exclusivity for under a few weeks earlier than gracing its now-older flagship with the most recent Android replace. However late final month, we obtained yet one more One UI 8.5 beta for the Galaxy S25 sequence, bringing the whole to eight.
Whereas we recognize that Samsung is doing its finest to repair bugs, it’s nonetheless a bit disappointing to see the corporate’s ex-flagship nonetheless working an outdated Android model, provided that Android 16 has been out since June 2025 and we’ve nearly reached steady Android 17 too. Even with this leak, we’re nonetheless a couple of month away from a One UI 8.5 steady launch (based mostly on Android 16), and it’s frankly embarrassing given how flagships from different firms have lengthy been up to date to Android 16.
We hope Samsung allocates extra sources, fixes bugs, and rolls out a steady One UI 8.5 replace for the Galaxy S25 sequence quickly.
Thanks for being a part of our group. Learn our Remark Coverage earlier than posting.
Artemis II has as soon as once more made historical past by carrying people farther from Earth than ever earlier than, surpassing the report of 248,655 miles (400,171 kilometers) set by Apollo 13 in 1970.
The earlier report fell immediately (April 6) at 1:57 p.m. EDT (17:57 GMT) because the Orion capsule “Integrity” started its loop across the far facet of the moon. NASA says the mission will attain a most distance of 252,760 miles (406,777 kilometers) from Earth throughout the six-hour lunar flyby, which can break the earlier human-spaceflight report by roughly 4,100 miles (6,600 kilometers).
“On April 15, 1970, throughout the Apollo 13 mission, three explorers set the report for the farthest distance people have ever traveled from our residence planet. At the moment, over 55 years in the past, [Jim] Lovell, [Jack] Swigert and [Fred] Hayes flew 248,655 statute miles away from Earth,” Jenni Gibbons, a Canadian House Company (CSA) astronaut and capsule communicator (Capcom) on the Artemis II mission, stated to the crew as they broke the report. “At present, for all humanity, you are pushing past that frontier.”
Not lengthy after breaking the report, the crew’s journey across the moon turned much more poignant as they noticed a crater between the moon’s close to and much sides. They referred to as all the way down to mission management to request or not it’s named after Artemis II commander Reid Wiseman’s late spouse, Carroll.
Wiseman stated that there was a characteristic on “a very neat place” on the moon “simply on the near-side” of the far-side boundary.
“So at sure occasions of the moon’s transit round Earth, we will see this from Earth,” Wiseman stated, his voice cracking. “We misplaced a cherished one; her title was Carroll. The partner of Reid, the mom of Katie and Ellie.”
“It is a vibrant spot on the moon. We wish to name it Carroll,” he concluded earlier than hugging his crew.
Get the world’s most fascinating discoveries delivered straight to your inbox.
The astronauts additionally noticed one other crater they requested to be named after their capsule, “Integrity.”
“Integrity and Carroll crater. Loud and clear,” mission management responded.
Lunar flyby
The Orion spacecraft will transfer about 3,139 mph (5,052 km/h) because it passes round the moon.
Throughout the lunar flyby, the 4 Artemis II astronauts — Weisman, Christina Koch, Victor Glover and Jeremy Hansen — will {photograph} round 30 science targets on the lunar floor. These embrace the large Orientale basin, a roughly 600-mile-wide (1,000 km) influence crater that straddles the moon’s close to and much sides, and Hertzsprung basin, an older crater on the far facet.
“I want you had been up right here to see the smiling faces,” Artemis II commander and astronaut Reid Weisman stated immediately (April 6) throughout NASA’s livestream of the lunar flyby.
The Artemis II mission could have a better view of the moon than the Apollo missions, giving a unique vantage level of the lunar floor, in accordance with the NASA livestream. These observations are supposed to give scientists contemporary, close-range views of lunar geology from a number of angles throughout the flyby.
“It’s blowing my thoughts what you may see with the bare eye,” Glover stated throughout the NASA livestream.
The flyby is predicted to provide a few of the mission’s most dramatic photos. From the Orion spacecraft, the crewmembers will see “Earthset” as Earth slips behind the moon, adopted later by “Earthrise,” as our planet reappears over the lunar horizon. The primary “Earthrise” picture was famously captured by the Apollo 8 mission in 1968.
Based on the Related Press, the Artemis II astronauts wakened immediately with a recorded message from Apollo 8 astronaut Jim Lovell shortly earlier than he died in August 2025: “Welcome to my outdated neighborhood. It is a historic day and I understand how busy you may be, however do not forget to benefit from the view.”
The mission’s timeline will even permit the astronauts to witness a photo voltaic eclipse because the moon passes in entrance of the solar. Utilizing photo voltaic eclipse glasses and particular digicam lenses, the crewmembers will be capable of see and {photograph} the solar’s outer environment, or corona, because it peaks across the lunar edge.
“We’re able to ship,” Koch stated throughout the NASA livestream.
What are you aware concerning the moon? Take a look at your data with our moon quiz!
Enterprises typically wrestle to onboard new crew members at scale. Human assets (HR) groups spend time on guide duties that delay productiveness, equivalent to processing paperwork to answering repeated questions on advantages and insurance policies. For organizations with many new hires, these steps make it tougher to maintain onboarding constant and compliant. Organizations lose substantial quantities of time per day per new rent throughout onboarding, with new workers sometimes reaching solely a fraction of their potential productiveness within the first month. Amazon Fast is a completely managed agentic service. With it, HR departments can create no-code onboarding brokers that reply new-hire questions, monitor compliance throughout current instruments, and clear tickets mechanically in order that new hires can ramp quicker with much less guide work.
On this put up, we stroll via constructing a customized HR onboarding agent with Fast. We present find out how to configure an agent that understands your group’s processes, connects to your HR methods, and automates widespread duties, equivalent to answering new-hire questions and monitoring doc completion. You possibly can adapt this resolution to your onboarding workflow so new hires get constant solutions and HR groups reclaim time beforehand spent on routine inquiries.
Key elements of Amazon Fast
Fast transforms worker onboarding from scattered paperwork and guide processes into an clever, related expertise via the next built-in elements:
Informationbases – Listed content material from exterior sources like SharePoint, OneDrive, and Confluence, in addition to inner content material together with inner web sites, file uploads, and Amazon Easy Storage Service (Amazon S3) buckets. A data base serves as a single searchable repository, so new hires get complete solutions from a number of sources as an alternative of looking via disconnected recordsdata.
Actions (motion connectors) – Safe, permission-aware integrations that allow AI brokers to take actual motion in HR onboarding situations—creating ServiceNow IT tools requests, sending Slack welcome messages to crew channels, or updating onboarding workflows in challenge administration instruments—somewhat than simply offering hyperlinks to types.
Areas – Targeted environments that set up team-centered property together with recordsdata, enterprise intelligence artifacts (equivalent to dashboards and matters), data bases, and actions with sharing controls for crew collaboration.
Fast will help HR groups create specialised onboarding assistants that mix data entry with automated duties. You need to use the built-in system agent (“My assistant”) for speedy assist or create customized chat brokers tailor-made to your group’s particular onboarding wants, equivalent to a devoted HR onboarding assistant that is aware of your organization insurance policies and may mechanically deal with widespread requests like IT setup or advantages enrollment.
Resolution overview
This resolution makes use of a customized chat agent in Fast for worker onboarding. With out an agent, HR would possibly change between wikis, SharePoint, ticketing, chat, and e-mail to coordinate every step. With Fast, the agent presents the newest guidelines from the HR area, solutions with accepted language, opens requests via actions, notifies stakeholders, and factors the worker to the following step. Confirmations and standing stay within the HR instruments, and the agent reads or updates them via actions or flows. The next diagram illustrates the answer structure.
Implementing the answer consists of the next high-level steps:
Create the chat agent in Fast.
Connect the HR area and hyperlink data sources.
Add actions.
Take a look at with actual questions and duties, then share with workers.
Fast supplies two varieties of chat brokers that facilitate this onboarding resolution: the system chat agent (“My assistant”) and customized chat brokers. The system chat agent (“My assistant”) – “My assistant” seems on the Amazon Fast console by default and helps customers ask questions and full duties utilizing assets they’re allowed to entry. Customers can work together with the system agent in a number of methods:
Ask common questions utilizing the agent’s built-in data by selecting Basic data.
Add their very own recordsdata instantly in chat (as much as 20 recordsdata per dialog) for evaluation and questions.
Management the dialog scope by selecting from three modes: All information & apps (searches throughout all accessible assets), Basic data (makes use of solely built-in data), or Particular information & apps (targets specific areas, dashboards, matters, data bases, or actions). For instance, a person would possibly add their worker handbook and ask, “What’s our distant work coverage?” or choose the HR area and ask, “How do I enroll within the medical health insurance plan?” The system agent is offered instantly with no configuration required and adapts its responses primarily based on the chosen scope and out there assets.
Customized brokers provide help to construct specialised assistants for your small business wants. You configure habits (function, tone, response format); connect areas with dashboards, matters, and data bases for grounded solutions; and hyperlink motion connectors so the agent can carry out duties in instruments like Jira, Slack, ServiceNow, Salesforce, Outlook, or Groups. You possibly can share customized brokers with particular customers or teams. Customized brokers supply the next capabilities:
Use case-specific responses – Outline the agent’s persona and response type tailor-made to particular enterprise workflows and necessities.
Steerage via reference paperwork – Add particular paperwork that function response templates for constant messaging and course of guides for following particular steps.
Complete information integration – Hyperlink areas to the agent to offer it entry to various kinds of searchable content material and data sources, together with dashboards for analytics, matters for structured datasets, data bases for exterior, unstructured doc repositories, and native recordsdata uploaded on to the area for added data. This helps the agent reply questions utilizing completely different related information inside the group’s permission construction.
Automated actions – Add motion connectors so customers can create Jira tickets, ship Slack messages, replace Salesforce, or open ServiceNow requests instantly from chat.
Collaboration – Take a look at, refine, and share brokers with teammates. Directors can management who can create and customise brokers via person subscriptions and customized permissions.
You need to use the system chat agent for common help throughout Fast, or create a customized agent tailor-made to a workflow equivalent to HR onboarding. In that case, you outline directions, connect the HR area or data base, and allow actions for requests and notifications.
Within the following sections, we stroll via the steps to implement this resolution utilizing two personas: the HR administrator who units up and shares the agent, and the worker who completes onboarding duties with the agent.
Stipulations
Earlier than you start, ensure you have accomplished the next steps:
At the least one Amazon Fast Enterprise subscription to configure actions and create data bases. Customers who solely use the shared agent might be on the Amazon Fast Skilled subscription
Go to Get began with Atlassian Cloud and create a free website, choosing each Confluence and Jira on the Free plan (as much as 10 customers).
In Confluence, create an “HR Onboarding” area to retailer your HR content material.
In Jira, create a easy HR onboarding challenge that the agent can use for entry or tools requests within the Add actions part.
From the HR paperwork folder within the ZIP file, add the next recordsdata into your HR Onboarding Confluence area:
employee_handbook.pdf
leave_policy.pdf
onboarding_checklist.pdf
performance_review_guidelines.pdf
public_holidays.csv (non-obligatory, used later for reporting or analytics)
In case your group already makes use of a company Confluence website, you may not have permission to create areas or add pattern recordsdata except you request extra entry out of your Confluence administrator. To expertise the worth of Fast with out ready on admin modifications, use a separate Atlassian Cloud website to comply with this put up.
Implementation Steps
This process makes use of two personas: the HR administrator who units up and shares the agent, and the worker who completes onboarding duties with the agent.
HR administrator
The next sequence diagram reveals how the HR administrator creates, configures, and shares the HR onboarding agent in Fast.
Create chat agent
First, you create the chat agent itself, which turns into the only place the place new hires ask questions and get guided via onboarding:
On the Fast console, select Chat brokers within the navigation pane, then select Create.
Enter a easy pure language immediate describing what you need your agent to do (for instance, “Assist new workers with HR onboarding questions and tools requests”).
Fast will mechanically develop your immediate into an in depth persona and response directions and scan your out there assets to hyperlink related areas and motion connectors to the agent.
Overview the generated agent configuration and refine as wanted, updating the preview to save lots of your variations inside the session.
Select Launch chat agent if you end up happy.
Configure habits
Subsequent, you form how the agent ought to reply so its tone, scope, and guardrails match your HR insurance policies and HR model:
Agent metadata – Replace the agent’s identify, description, welcome message, and starter prompts to assist customers uncover and use the chat agent correctly. These components function the primary impression and information customers on find out how to work together successfully along with your HR assistant.
Agent directions – Overview and replace the mechanically generated persona directions, response format, tone, and size settings from the earlier step. The system-generated inputs present a stable basis, however you’ll be able to fine-tune to match your group’s particular HR communication type and necessities.
Reference paperwork – Add particular steering paperwork that present the very best precedence directions for agent habits. These reference paperwork will likely be adopted as prescribed whereas you should utilize the instruction fields to supply high-level steering on habits and objectives.
Join HR data
Now you join your HR data sources so the agent solutions from accepted handbooks and insurance policies as an alternative of inventing its personal language:
Create or select an current HR area that holds handbooks, insurance policies, and checklists. By configuring the agent’s data scope to focus particularly on HR-related content material, you be sure that responses keep inside applicable boundaries and don’t entry unrelated organizational information.
Select Add recordsdata to add recordsdata to the area, together with:
Worker handbooks and coverage paperwork
Advantages data and FAQ paperwork
Coaching supplies and guides
Hyperlink data sources equivalent to SharePoint or a wiki.
Hyperlink the configured area to your agent so it will possibly entry this accepted searchable content material for grounded responses.
Add actions
After the agent can reply questions, you add actions so it will possibly additionally set off work in your HR instruments, equivalent to tickets, requests, and notifications:
Open the Actions card and select Hyperlink actions.
Choose from out there motion connectors that you’ve already configured. For the HR onboarding use case, this might embody instruments equivalent to Jira (to create and replace tickets), ServiceNow (to handle incidents), or Microsoft Outlook (to ship emails).
Solely motion connectors configured with the required OAuth particulars might be linked to the agent, so end-users can authenticate individually throughout their chat. Replace your reference paperwork and persona directions to specify when to invoke particular motion connectors. For instance: “When an worker requests tools, use the ServiceNow connector to create a {hardware} request ticket,” or “For entry requests, create a Jira ticket within the IT-Entry challenge with precedence set to ‘Regular.’”
Customise, check, and share
Lastly, customise the agent with a welcome message and prompt prompts. You possibly can check the agent with practical situations, tune the expertise, and share it with a pilot group so HR can validate the workflow earlier than broad rollout. Take a look at with actual questions and duties utilizing the preview chat.
Once you’re prepared, launch the agent, and will probably be out there in your private library for personal use. To share with others, select Share and add customers and person teams as viewers to make use of the agent. It’s also possible to choose different customers out of your crew to be homeowners to edit and check the agent together with you. HR managers can share the customized agent with new workers through the use of the sharing choices within the navigation pane to grant entry to particular crew members or teams.
Worker
The next sequence diagram reveals how an worker makes use of the onboarding agent to finish required duties and monitor their Day 1 progress in a single place.
Use the onboarding agent
After the agent is revealed and shared with workers as viewers, they will open it from the hyperlink HR supplies (for instance, of their Day 1 e-mail or HR portal) or from the chat brokers record in Fast, after which use it as follows:
The worker opens the shared HR onboarding agent from the hyperlink or from the chat brokers record and begins a brand new Day 1 dialog.
The agent reveals the newest onboarding guidelines from the HR Onboarding area and supplies hyperlinks to required types, coaching, and inner pages so the worker can transfer via the steps so as.
The worker asks coverage or advantages questions in plain language, and the agent solutions utilizing content material from the HR Onboarding area and related HR data sources so responses match HR-approved language.
On this setup, when the worker requests tools or software entry, the agent makes use of a Jira motion connector to create a difficulty within the HR onboarding challenge and returns the problem key and hyperlink so you’ll be able to see the request finish to finish with out touching manufacturing HR methods.
For delicate steps equivalent to I-9 verification, tax types, or direct deposit, the agent directs the worker to the suitable HR system or safe portal as an alternative of gathering paperwork in chat so delicate information stays in the fitting place.
As an worker, the expertise is straightforward: they open a single chat, see their Day 1 guidelines, ask questions in pure language, and let the agent open requests and level them to the fitting methods. As an alternative of juggling emails, portals, and tickets, onboarding appears like a guided dialog the place every subsequent step is obvious.
You’ve gotten now arrange the HR Onboarding Confluence area with pattern HR paperwork, created a customized onboarding agent in Fast, configured its habits, related HR data, and added Jira actions for requests. You need to use this setup as a proof of idea with a small group of latest hires or HR companions, then prolong it by including extra content material, extra actions, or new areas for different HR workflows equivalent to efficiency critiques or coverage updates.
Guardrails and security
Fast contains built-in security and content material controls for chat brokers, so you’ll be able to comply with together with this put up utilizing the default settings in your account. If you wish to experiment with coverage controls as a part of this proof of idea, you may also add a small record of blocked phrases or phrases so the agent avoids particular phrases in HR responses (for instance, casual slang or discouraged wording). Blocked phrases are configured on the Fast console and utilized throughout brokers in your account. For step-by-step directions and extra safety choices equivalent to entry management and encryption, see the Amazon Fast Consumer Information.
Fast tiers
Fast presents two person subscriptions: Skilled and Enterprise. Skilled helps on a regular basis use of chat brokers and areas, operating Amazon Fast Flows and Amazon Fast Analysis, and viewing Amazon Fast Sight dashboards, with the flexibility to create and share customized brokers and areas. Enterprise contains all the pieces in Skilled plus superior authoring options equivalent to configuring actions, creating data bases, constructing automations in Amazon Fast Automate, and authoring dashboards in Fast Sight, with bigger month-to-month utilization allowances. A 30‑day free trial is offered for as much as 25 customers per account. For particulars, seek advice from Amazon Fast pricing.
Conclusion
This put up confirmed find out how to construct an HR onboarding chat agent in Fast, connect HR content material, add actions and non-obligatory flows, and share it with workers. Begin with a pilot that covers your most frequent questions and two or three requests, assessment utilization, and refine the agent’s directions and content material. For subsequent steps, develop the HR area, add extra actions as wanted, and assessment the Fast documentation for superior configuration. Past onboarding, HR groups can discover constructing brokers for worker self-service, efficiency administration, expertise acquisition, studying and growth, analytics, and off-boarding processes to rework their whole HR operations.
Prepared to rework your office productiveness? Get began with Fast, discover pricing choices that suit your wants. Click on right here to start constructing your individual HR agent, discover our official documentation for detailed implementation steering, or contact your AWS account crew to debate how Fast can remodel your group’s strategy to data-driven decision-making.
Requested Monday by reporters on the White Home whether or not this could represent a warfare crime, Trump replied that the Iranian leaders who had killed “45,000 folks within the final month” have been “animals.”
Trump’s renewed threats to focus on Iranian infrastructure that provides civilians with primary requirements like energy and water, and his more and more harsh rhetoric — like threatening to ship Iran’s authorities “again to the Stone Ages the place they belong” — have led to accusations that he’s violating home and worldwide legal guidelines of warfare. Senate Minority Chief Chuck Schumer warned Sunday that Trump was “threatening attainable warfare crimes.”
A shift towards the deliberate focusing on of Iran’s civilian infrastructure, nevertheless, might mark a tough flip into deliberate lawbreaking, in addition to a dramatic escalation of a battle the president has been promising is near over. And whereas not each assault on power or bridges is inherently a warfare crime, the size of destruction Trump is threatening, if carried out, would have dire implications — sending a sign that the nation that helped institute and police the trendy guidelines of warfare is now proudly and overtly flouting them.
What makes a bombing unlawful?
Underneath worldwide regulation, additionally codified in US navy laws, a navy goal is authorized if it meets a two-part take a look at: The goal should “make an efficient contribution to navy motion” and its destruction or seize should “supply a particular navy benefit.”
Authorized specialists who spoke with Vox stated that whereas there are undoubtedly circumstances by which an influence station or bridge, and presumably even a desalinization plant, may very well be a reliable navy goal, these determinations would have to be made on a case to case foundation, versus Trump’s menace to destroy them en masse with a purpose to strain Iranian leaders into concessions. On Monday, Trump particularly threatened to destroy each bridge and each energy plant in Iran if his calls for weren’t met.
“The focusing on will not be being pushed by issues of navy benefit, however to politically coerce the opposing social gathering and inflicting ache, issues which might not be reliable goals,” stated Brian Finucane, a former State Division authorized adviser now with the Worldwide Disaster Group.
However “indiscriminate assaults” like those Trump is describing not solely be a violation of the legal guidelines of armed battle by the US however might arguably be thought-about “warfare crimes by those that are concerned within the strikes,” stated Michael Schmitt, a former US Air Pressure decide advocate who now teaches on the College of Studying within the UK. Although the 2 phrases are sometimes used interchangeably, “warfare crimes” are violations severe sufficient that the political leaders and navy commanders concerned might face legal prices.
By the prevailing requirements, a lot of Iran’s personal strikes — from hitting fuel fields, desalination vegetation, and information facilities within the Gulf to utilizing cluster munitions in Israel — are additionally unlawful, clearly meant to impose financial prices or terrorize populations relatively than achieve navy benefit.
Implementing violations is a extra difficult story. Neither Iran nor the US acknowledge the authority of the Worldwide Felony Courtroom — and actually the Trump administration has imposed sanctions on it — however Schmitt notes that warfare crimes are issues of common jurisdiction, that means any nation might theoretically launch a prosecution for them.
For his half, he’s hopeful that regardless of the rhetoric popping out of the White Home, “on the navy stage, cooler heads will prevail, and there will likely be a really surgical by the numbers evaluation of each goal meant to be struck to make sure that it’s a navy goal, that hurt to civilians is justified beneath the rule of proportionality, and that each effort that’s possible has been taken to keep away from civilian hurt.”
Up to now, Trump has typically made a distinction between the Iranian inhabitants and its regime. The escalation towards this warfare started, in any case, when Trump threatened strikes in opposition to the Iranian authorities for its mass killing of protesters in January. And whereas it’s almost unattainable to gauge public opinion in Iran proper now, it’s clear that not less than a big section of the inhabitants is hoping these strikes, regrettable as they is likely to be, might nonetheless carry down the regime.
Trump had made some extent within the first few weeks of the warfare of claiming he was avoiding focusing on Iran’s energy infrastructure. After Israel bombed a serious fuel discipline, spiking international power costs, Trump promised it will by no means occur once more. In his public statements, Trump seemed to be hoping to permit a extra pliant and militarily-weakened new Iranian authorities to rebuild its financial system after the warfare.
Trump seems, in his rhetoric not less than, to be shifting towards a method of collective punishment of Iran as an entire for the actions of its authorities. When he threatened to bomb Iran again to the “Stone Age” in his handle final week, that didn’t sound like only a reference to its nuclear enrichment services.
Deliberately or not, Trump’s description of Iranian leaders as “animals” evokes Israeli Protection Minister Yoav Gallant’s 2023 description of Hamas as “human animals” to justify the “full siege” of Gaza. The constant Israeli authorities justification for the hurt inflicted on civilians was that it was the results of the actions of Hamas.
This isn’t to say that the extent of bodily destruction in Iran will come anyplace near Gaza. However other than questions of legality and morality, the comparability raises troubling strategic questions for the US.
Trump typically seems to be vacillating between a plan to merely pack up and depart Iran as soon as a sure set of navy aims are full, and persevering with the warfare till Iran’s leaders conform to concessions. The most recent threats appear to recommend the latter, however there’s little to point that Iran’s leaders are shut to creating concessions, significantly on the Strait of Hormuz, which has emerged as their essential type of deterrence and leverage on this battle.
A authorities that, as Trump famous, is prepared to kill tens of hundreds of its personal folks to remain in energy, might be not one that’s prone to give up as a result of its persons are struggling with out energy.
Alongside its critical goals, like testing the Orion capsule in deep house and imaging lava flows on the lunar floor, NASA’s Artemis 2 lunar mission has its whimsy, too.
For instance, there’s a beloved moon toy named “Rise” on the mission serving as a zero-gravity indicator and holding a microchip with the names of house followers who signed as much as have their presence enter the lunar enviornment. There are additionally the “wakeup songs,” a convention carried on from earlier crewed missions. These are precisely what you’d anticipate. Every day, on the designated wakeup time for the Artemis 2 crew, Mission Management radios in to Orion and performs a brief snippet of a tune to assist them begin their day with positivity.
The tunes thus far embody a canopy of Ardour Pit’s “Sleepyhead” by the artist Younger & Sick, “In a Daydream” by Freddy Jones Band and Chappell Roan’s “Pink Pony Membership,” which hilariously led to some sass from the crew as a result of Mission Management turned it off earlier than the principle half. “We have been all eagerly awaiting the refrain,” Artemis 2 commander Reid Wiseman mentioned. So, as a way to comply with alongside, we made a Spotify playlist of the Artemis 2 mission soundtrack. We’ll hold updating this text as we get extra wakeup tune reveals.
Listed below are the songs thus far:
Flight Day 1: “Sleepyhead” by Younger & Sick
Flight Day 2: “Inexperienced Mild” by John Legend (feat. André 3000)
Flight Day 3: “In a Daydream” by Freddy Jones Band
Breaking house information, the most recent updates on rocket launches, skywatching occasions and extra!
Flight Day 4: “Pink Pony Membership” by Chappell Roan
Flight Day 5: “Working Class Heroes (Work)” by CeeLo Inexperienced
Flight Day 6: “Good Morning” by Mandisa, TobyMac
Astronaut wakeup calls return to the Apollo years. For example, the Apollo 10 astronauts had the tune “It is Good to Go Trav’ling” by Frank Sinatra as considered one of their wakeup calls, and Apollo 15 had the theme tune from “2001: A House Odyssey.”
The house shuttle program had tons of wakeup calls of their very own. For instance, STS-134 Pilot Greg Johnson’s son selected “Drops of Jupiter” to play for his dad throughout that 2011 mission — to which Johnson mentioned, “I really like that tune, and I really like being in house,” earlier than apologizing for lacking his son’s birthday. That very same mission, the second-to-last of the shuttle program, additionally had “Il Mio Pensiero,” carried out by Ligabue for mission specialist Roberto Vittori.
Through the closing house shuttle mission, STS-135, Pilot Doug Hurley chosen Coldplay’s “Viva la Vida” to be performed (and later picked “Do not Panic” for one more day). R.E.M.’s Michael Stipe additionally personally despatched an a capella model of “Man on the Moon” for the crew.
An in-depth checklist of those wakeup songs will be present in this doc, which additionally options among the cute and, sure, whimsical banter between astronauts and Mission Management. What a stunning custom.
That sounds tremendous. Like so what — huge deal. Bars block folks from coming again once they’re out of line too, so what’s the massive deal?
Till you understand that Hinge’s father or mother firm is owned by Match company, and whenever you get kicked off of Hinge, you get kicked off all their platforms. Bumble, which I as soon as heard somebody from Hinge name it “the one which bought away”, stays impartial, however Tinder, Hinge and lots of others are all owned by one agency.
Given the truth that on-line courting is the modal method that folks date and discover companionship, be it causal or hoping for one thing extra, you begin to understand that getting kicked off hinge actually means getting ejected from the trendy matching market solely. It might be like getting right into a combat on the patriots sport, getting kicked out of the entire patriots video games completely, in addition to all NFL video games, all NBA video games, and most Main League Baseball video games as nicely.
And that’s as a result of on-line courting platforms are like this big vacuum cleaner pulling all contributors there, and as soon as it sticks, it’s an equilibrium and stays one. Barring the electrical energy grid shutting down civilization, I don’t suppose it may be unearthed due to the extraordinarily highly effective community externalities that platforms have.
Which would appear to indicate that perhaps Match is a monopoly. Positive, there’s different apps than simply hinge, however they’re owned by the identical conglomerate, and if penalties on one to all of them, then it makes you surprise what to consider individuals who is perhaps ejected not simply from the positioning, however from all websites, and due to this fact perhaps a lot of the related matching markets solely.
So I informed Claude Code I wished to see extra dependable authentic knowledge concerning the gamers within the on-line courting market, and in addition to see the market’s evolution over time, in addition to earnings. I used to be curious what I may discover out additionally concerning the dept of justices curiosity in corporations and markets like these, if any, and if none, why? So that is what I discovered.
All of those knowledge have been crawled by Claude Code and generated figures have been produced in python.
The figures are constructed from the audited monetary filings of the three publicly traded courting firms: Match Group, Bumble, and Grindr. I truly thought Match owned Grindr earlier than doing this. I knew Bumble was not, although, as a result of I as soon as heard a Hinge worker name it “the one which bought away” as a result of they’d been unsuccessful in buying it.
Match Group was pulled from their 10-Ok and 10-Q filings on EDGAR going again to their 2015 spin-off from IAC, which is once they first began reporting as a standalone entity. Bumble’s numbers begin in 2021, the yr of their IPO, and Grindr’s begin in 2022, once they went public by way of SPAC. So the panel is unbalanced on the early finish, which is unavoidable as a result of these firms merely didn’t exist as public reporting entities earlier than these dates.
For Match Group I’m separating out Tinder and Hinge income from the remainder of the portfolio (which is OkCupid, Loads of Fish, Meetic, , Pairs, Azar, and an extended tail of smaller manufacturers) as a result of the within-portfolio dynamics matter for the story I’ve in my head. Tinder is the money cow, and Hinge is the expansion story.
The acquisition historical past, which isOkCupid in 2011, Meetic in 2011, Loads of Fish in 2015, Hinge phased in 2018-2019, comes from the press releases and 10-Ks on the time of every deal, cross-checked in opposition to contemporaneous reporting.
The HHI numbers I report are computed off income shares of those three corporations, which is the usual DOJ method for a market this concentrated. I need to flag the apparent caveat which is that this treats “courting apps” as a single market, and it ignores personal gamers. I’m not sure of this defensible but it surely’s what I’ve performed.
However even with beneficiant changes for personal opponents, you don’t get out of the “extremely concentrated” vary the DOJ pointers flag for scrutiny. The market sits between roughly 4,600 and 5,600 on the HHI by 2018-2024, and the edge for “extremely concentrated” is 2,500. We’re almost double that.
So right here’s what I’m confused about: how can this market be so concentrated and it haven’t gotten the eye of the division of justice?
The brief reply is that they’ve gotten away with it due to how antitrust legislation treats “zero-price” markets.
The DOJ and FTC have largely not scrutinized mergers in zero-priced industries as a result of customers don’t “pay” for Tinder or Hinge within the conventional sense (the free tier is the product). And since the usual shopper welfare framework appears for worth will increase after mergers, it doesn’t flag it. Match acquired 25+ firms in a decade with basically no merger evaluation.
The FTC has gone after Match, however just for shopper safety stuff. For example, they only settled in March 2026 over OkCupid sharing hundreds of thousands of person images with a facial recognition startup with out consent (no monetary penalty). And there was a $14M settlement in 2025 over misleading subscription practices and making it exhausting to cancel.
However neither of those is about market focus. No one’s asking “ought to one firm personal Tinder, Hinge, OkCupid, , and PlentyOfFish?” Isn’t that attention-grabbing? These are a significant a part of human society, with a particularly excessive HHI, publicly traded corporations, with a product that has large impacts on human welfare and they aren’t scrutinized, maybe as a result of they’re zero priced.
The underside line is that Match has managed to keep away from antitrust scrutiny as a result of courting is considered inconsequential and never severe sufficient to warrant regulation.
However this market is inconsequential provided that you suppose companionship and relationship formation is low-stakes. In the event you take significantly that >50% of {couples} now meet on-line, and one firm controls ~65% of that market, then that is vital social infrastructure being monopolized. The truth that the DOJ hasn’t acted looks like a regulatory failure, however I’m nonetheless fascinated about this.
I might want to confirm these HHI and income calculations in some unspecified time in the future, however earlier than then, let me simply say that it’s so attention-grabbing to have the ability to get a lot knowledge at any level by merely dispatching Claude to go get it. From my telephone! Astonishing.
Multi-column layouts haven’t been used to their full potential, principally as a result of as soon as content material exceeded a restrict, multi-column would pressure a horizontal scroll. It’s unintuitive and a UX no-no, particularly on the trendy internet the place the default scroll is vertical.
Take the next case for instance:
The CSS code for which may look one thing like this:
When the content material dimension exceeds the physique container, multi-column creates extra columns and a horizontal scroll. Nonetheless, we lastly have the instruments which have just lately landed in Chrome that “repair” this with out having to resort to trickier options.
Chrome 145 introduces the column-height and column-wrap properties, enabling us to wrap the extra content material into a brand new row beneath, making a vertical scroll as an alternative of a horizontal scroll.
So, now we are able to do one thing like this in Chrome 145+:
And we get this good multi-column format that maintains the column-count:
This successfully transforms Multi-Column layouts into 2D Flows, serving to us create a extra web-appropriate scroll.
⚠️ Browser Help: As of April 2026, column-wrap and column-height can be found in Chrome 145+. Firefox, Safari, and Edge don’t but assist these properties.
What this truly solves
The brand new properties will be genuinely helpful in a number of instances:
Mounted-height content material blocks
That is most likely one of the vital helpful use instances for these properties. In the event you’re working with content material that has predictable or capped heights, like card grids the place every card has a max-height, then this works fantastically.
Toggle between column-wrap: wrap and column-wrap: nowrap within the following demo (Chrome 145+ wanted) to examine the distinction.
In case you’re checking this in an unsupported browser, that is the nowrap format:
And that is the wrap format:
Wrapping creates a way more seamless circulate.
Nonetheless, in case the content-per-card is unbalanced, then even with wrapping, it might result in unbalanced layouts:
Newspaper-style and Journal-style layouts
One other actual life use case is when designing newspaper-style layouts or sections the place you’re keen to set express container and column heights. As will be seen within the earlier instance, the mix of column-height and column-wrap helps make the format responsive for various display sizes, whereas retaining a extra intuitive circulate of data.
Block-direction carousels
That is my private favourite use case of the column-wrap function! By setting the column peak to match the viewport (e.g., 100dvh), you may primarily deal with the multi-column circulate as a pagination system, the place your content material fills the peak of the display after which “wraps” vertically. When mixed with scroll-snap-type: y obligatory, you get a fluid, vertical page-flipping expertise that handles content material fragmentation with none handbook clipping or JavaScript calculation.
Mess around with the next demo and test it out for your self. Except you’re on Chrome 145+ you’ll get a horizontal scroll as an alternative of the meant vertical.
There’s a little bit of a disadvantage to this although: If the content material on a slide is just too lengthy, column-wrap will make it circulate vertically, however the circulate feels interrupted by that imbalance.
What they don’t resolve
Whereas these properties are genuinely useful, they aren’t one-stop options for all multi-column designs. Listed below are a couple of conditions the place they won’t be the “proper” strategy.
Really dynamic content material
If the content material peak is unknown or unpredictable upfront (e.g., user-generated content material, CMS-driven pages), then these properties are of little use. The design can nonetheless be wrapped vertically with the column-wrap property, nonetheless, the format would stay unpredictable and not using a fastened column peak.
It could actually result in over-estimating the column peak, leaving awkward gaps within the format. Equally, it might lead you to under-estimate the peak, leading to unbalanced columns. The repair right here is then to make use of JS to calculate heights, which defeats the concept of a CSS-native answer.
Media-query-free responsiveness
For a very “responsive” format, we nonetheless want to make use of media queries to regulate column-count and column-height for various viewport sizes. Whereas the wrapping helps and creates incremental advantages for a CSS-native answer, it might solely assist regulate the overflow habits. Therefore, the dependency on media question persists when supporting various display sizes.
Complicated alignment wants
In the event you want exact management over the place objects sit in relation to one another, CSS Grid continues to be a greater choice. Whereas multi-column with wrapping provides you circulate, it nonetheless lacks positioning management.
Evaluating alternate options
Let’s see how the multi-column strategy compares with current alternate options like CSS Grid, CSS Flexbox, and the evolving CSS Masonry, that provide comparable layouts.
One key distinction is that whereas grid and flexbox handle distinct containers, multi-column is the one system that may fragment a single steady stream of content material throughout a number of columns and rows. This makes it the most effective match for presenting long-form content material, like we noticed within the newspaper format instance.
CSS Grid lets us management placement by way of the grid construction, making it nice for advanced layouts requiring exact positioning or following uneven designs, like dashboards or responsive picture galleries that must auto-fit in response to the display dimension.
Flexbox with wrapping is nice for creating customary UI elements like navigation bars and tag clouds that ought to wrap round on smaller display sizes.
Be aware: Chrome can be experimenting with a brand new flex-wrap: steadiness key phrase that might present extra wrapping management as nicely.
CSS Grid and Flexbox with wrapping are each good matches for layouts the place every merchandise is impartial. They work nicely with content material of dynamic heights and supply higher alignment management in comparison with a multi-column strategy. Nonetheless, multi-column with the up to date properties has an edge in the case of fragmentation-aware layouts as we’ve seen.
CSS Masonry, alternatively, will likely be helpful for interlocking objects with various heights. This makes it good for creating type boards (like Pinterest) that pack objects with various heights in an environment friendly and aesthetic method. One other good use case is e-commerce web sites that use a masonry grid for product shows as a result of descriptions and pictures can result in differing card heights.
Conclusion
The brand new column-wrap and column-height properties supported in Chrome 145 might considerably enhance the usability of multi-column layouts. By enabling 2D flows, we have now a approach to fragment content material with out dropping the vertical scrolling expertise.
That stated, these options is not going to be a substitute for the structural precision of CSS Grid or the item-based flexibility of Flexbox. However they’ll fill a singular area of interest. As browser assist continues to broaden, one of the best ways to strategy multi-column format is with an understanding of each its benefits and limitations. They received’t resolve dynamic peak points or remove the necessity for media queries, however will enable flowing steady content material in a 2D area.










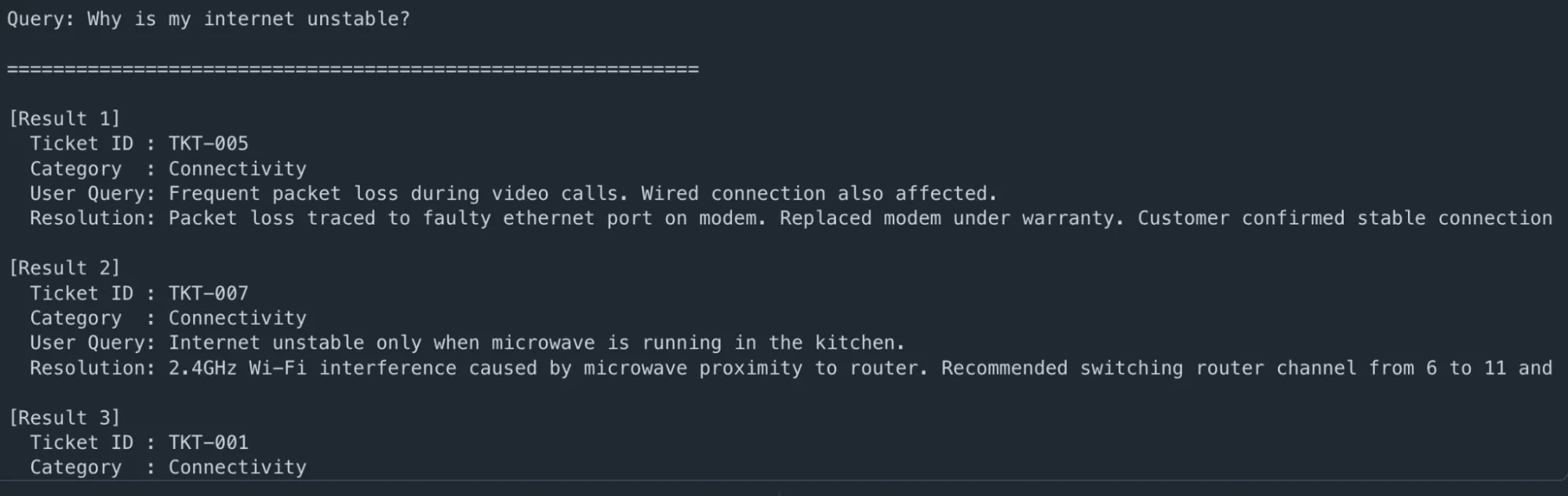
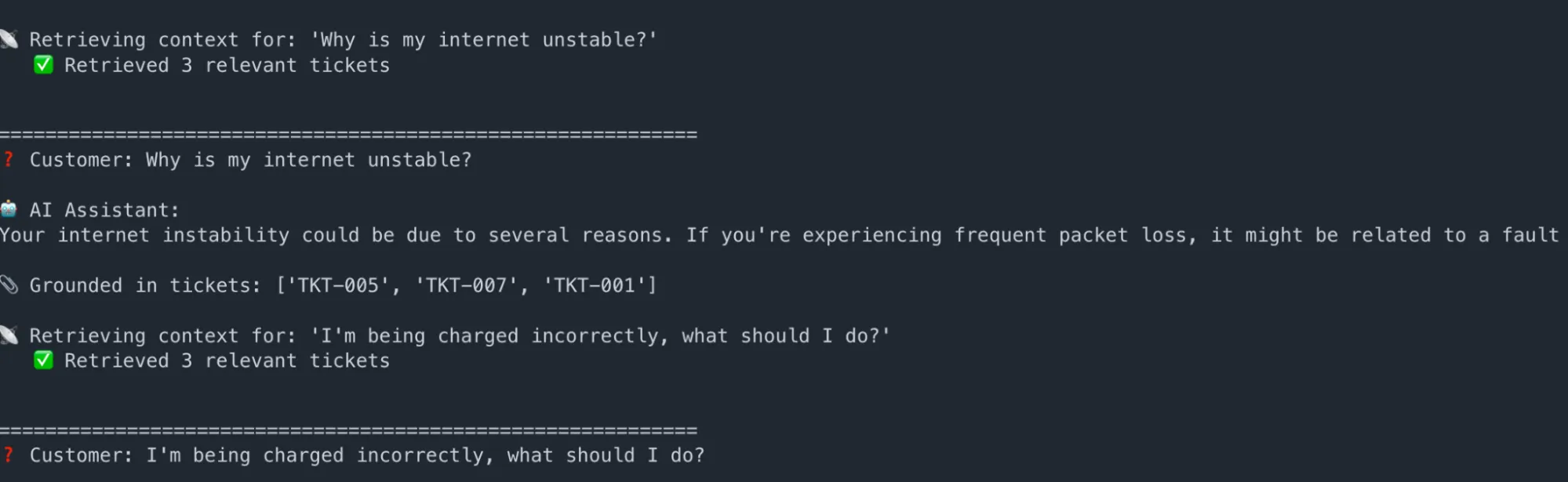
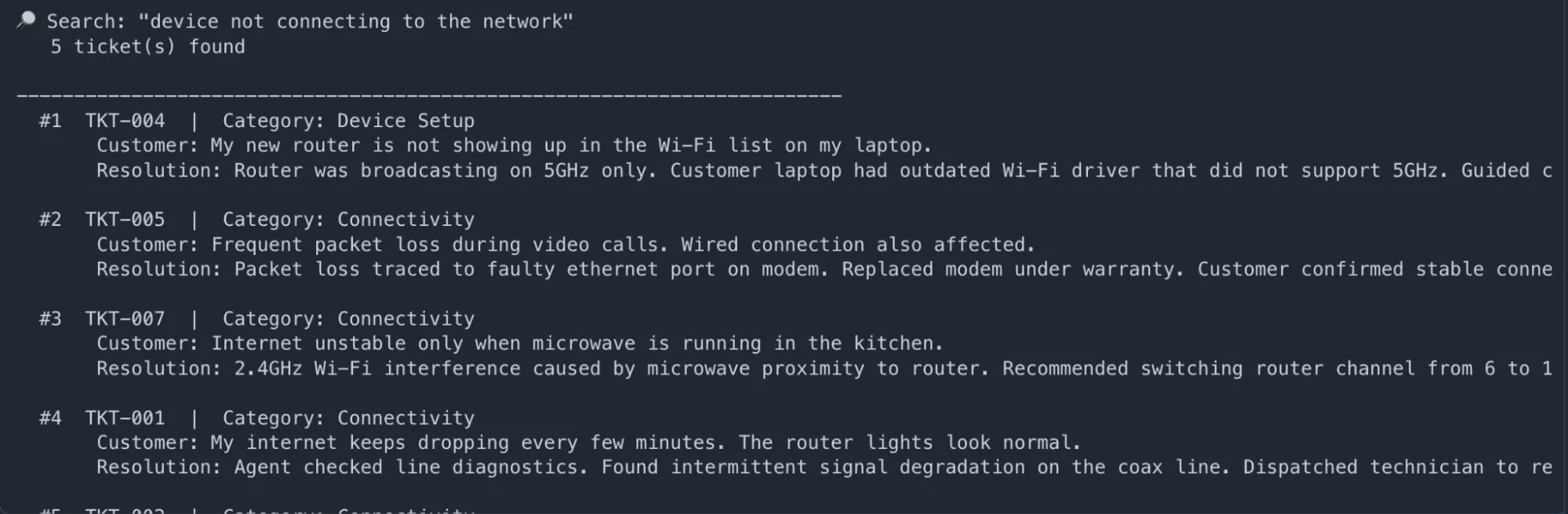


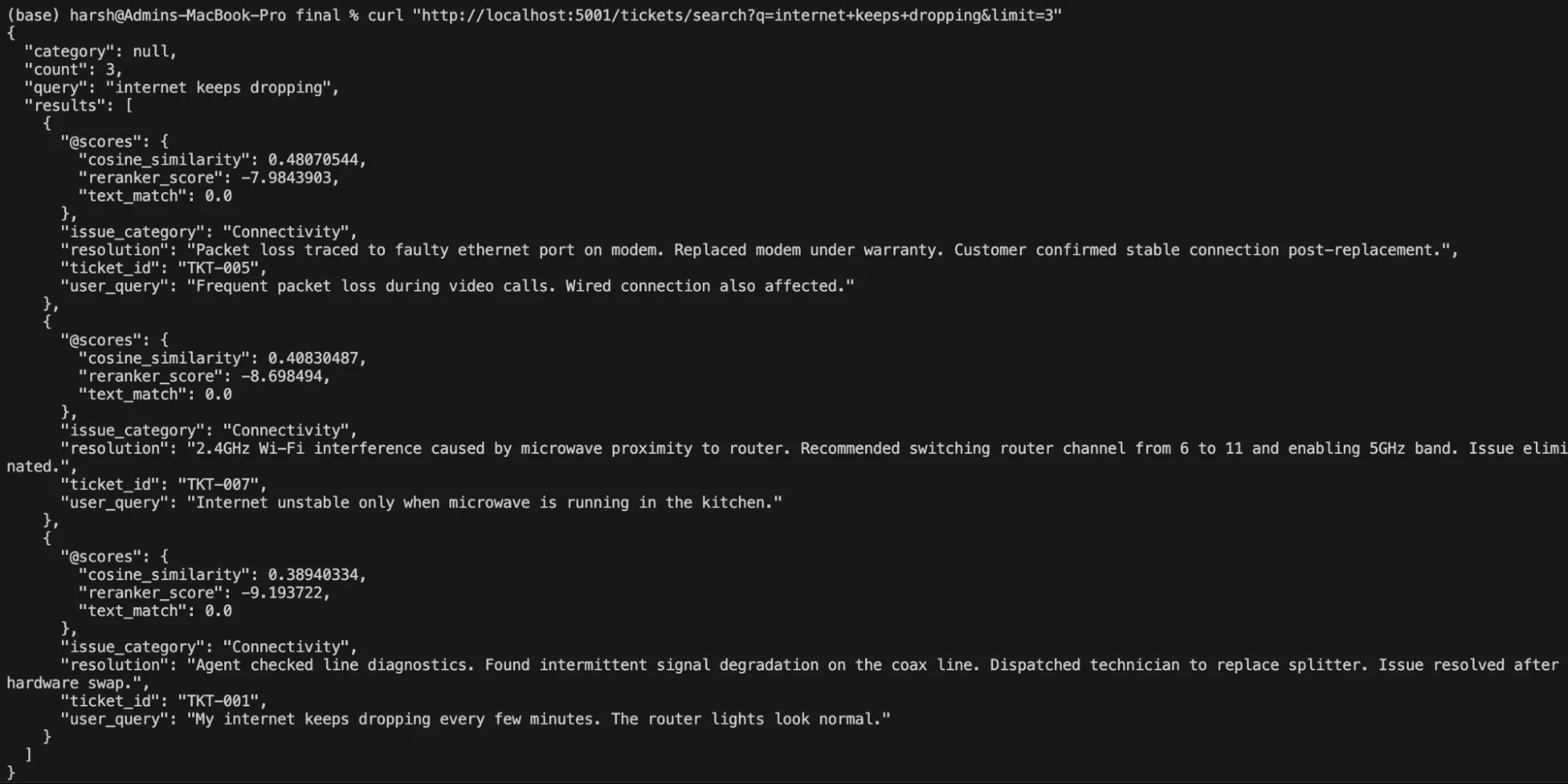
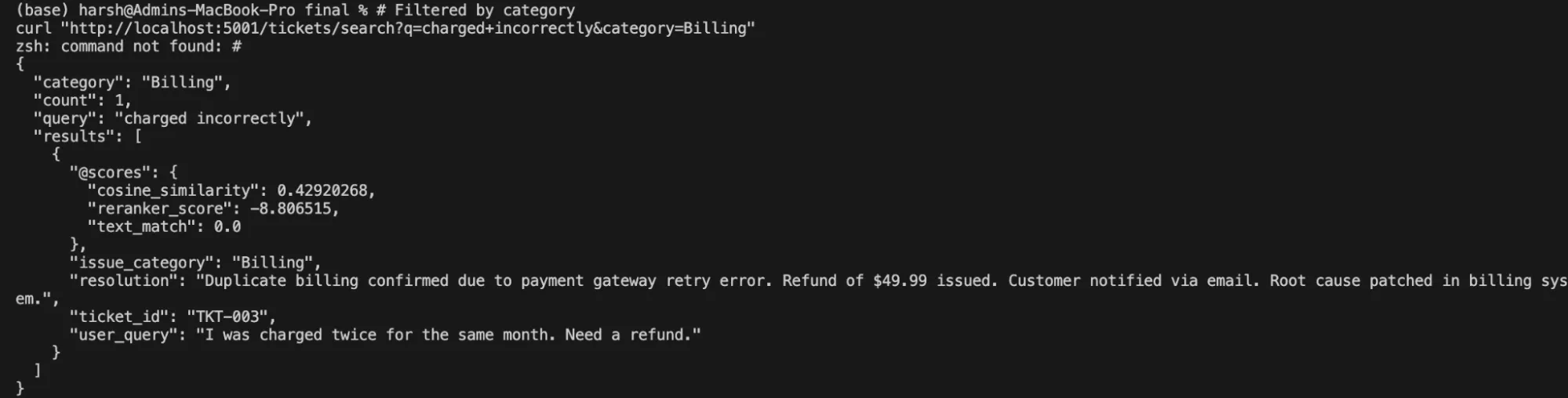

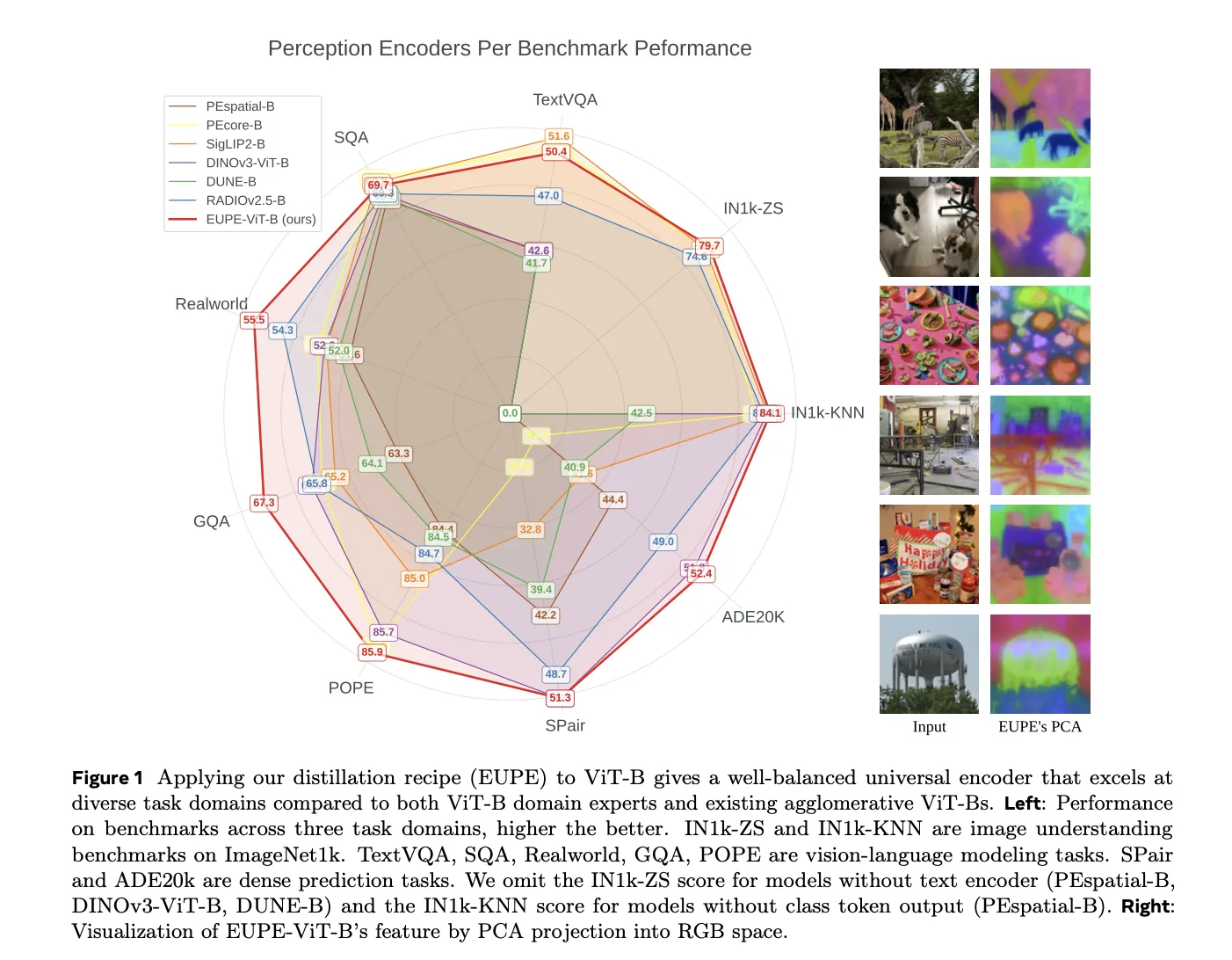
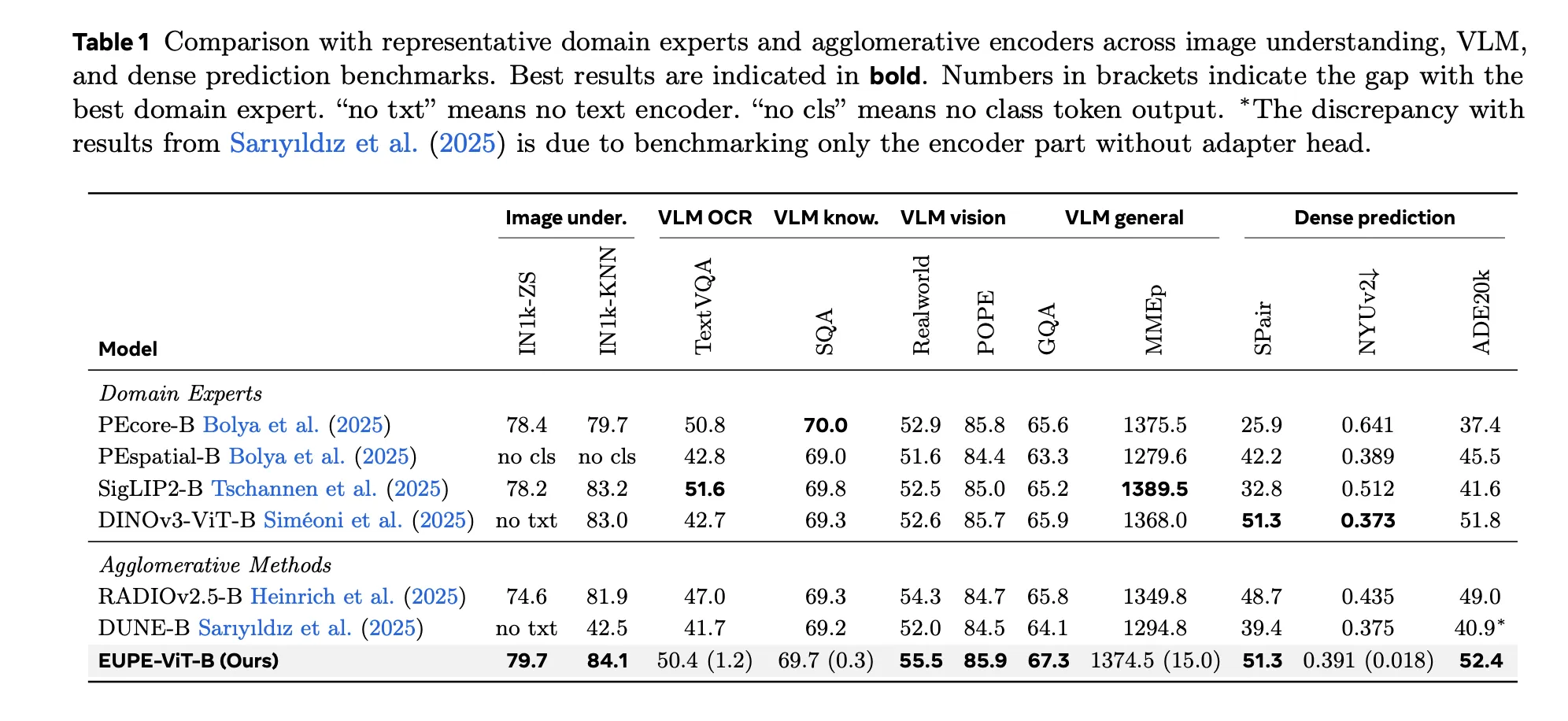




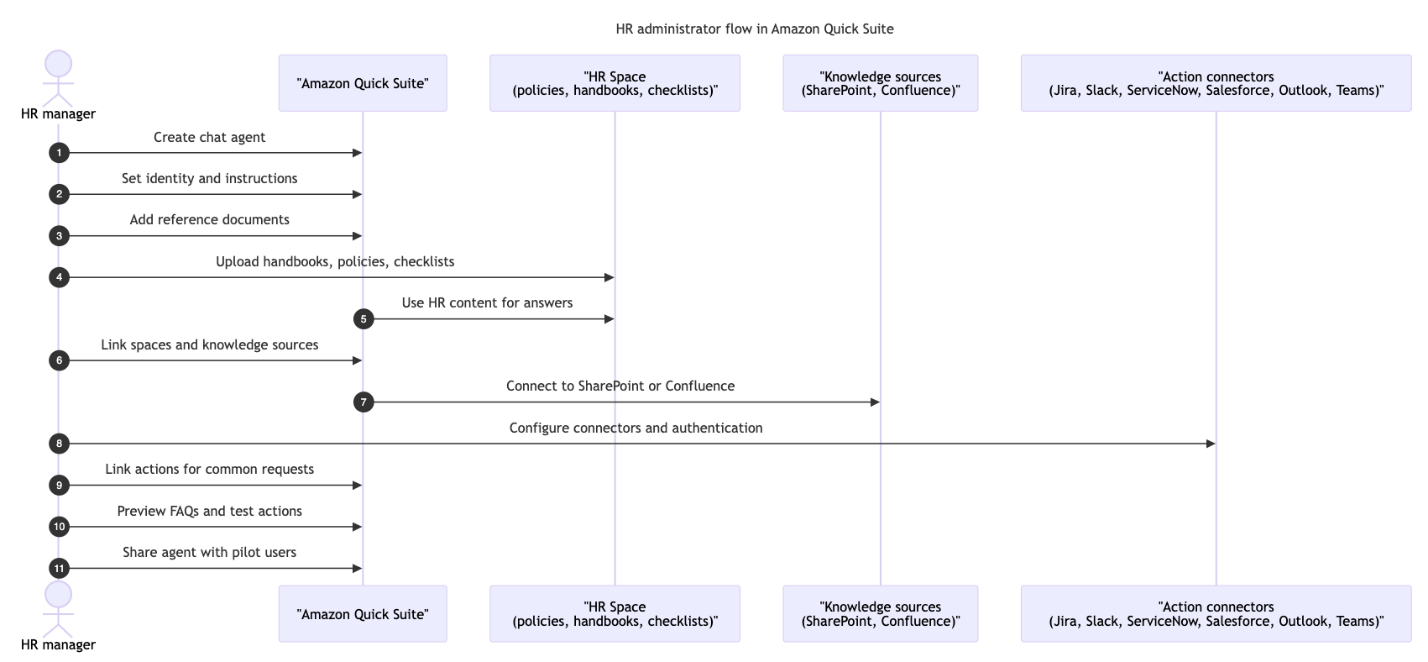

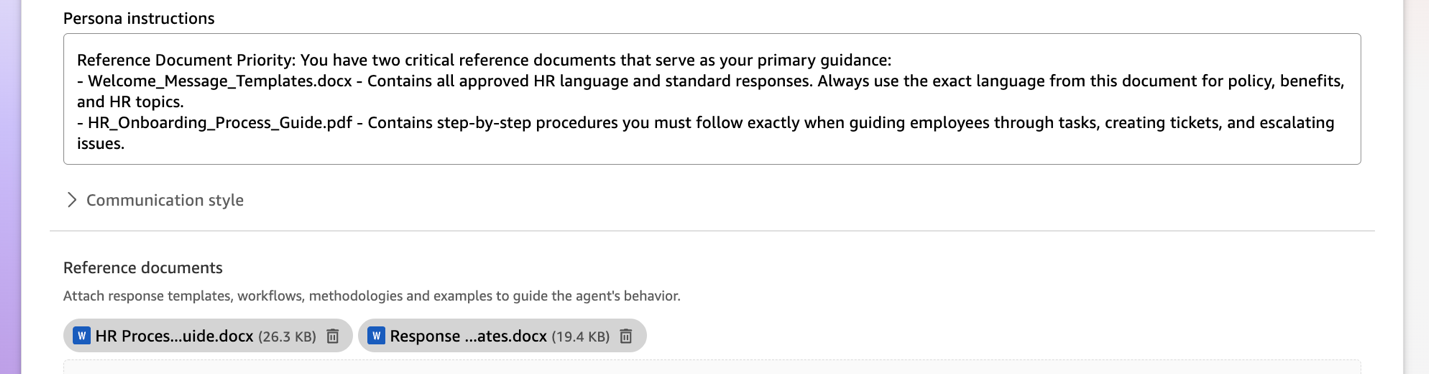
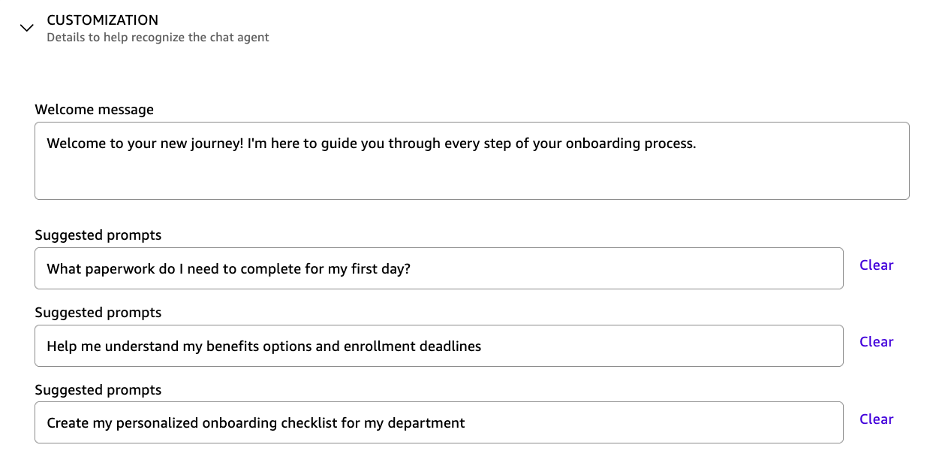
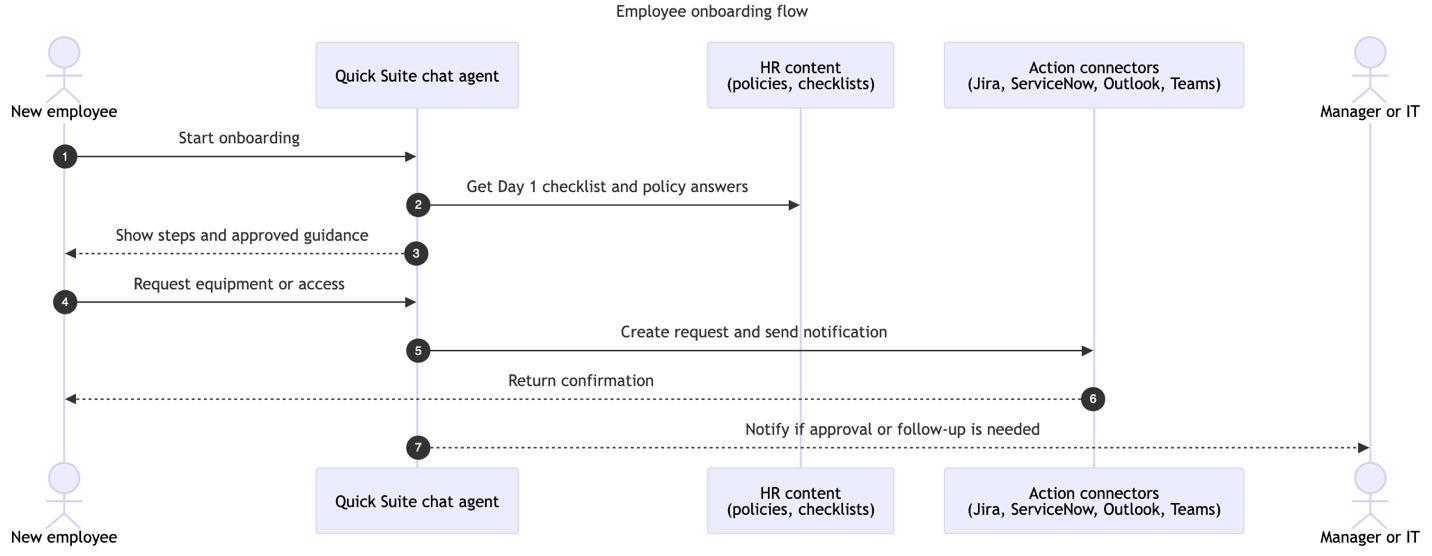




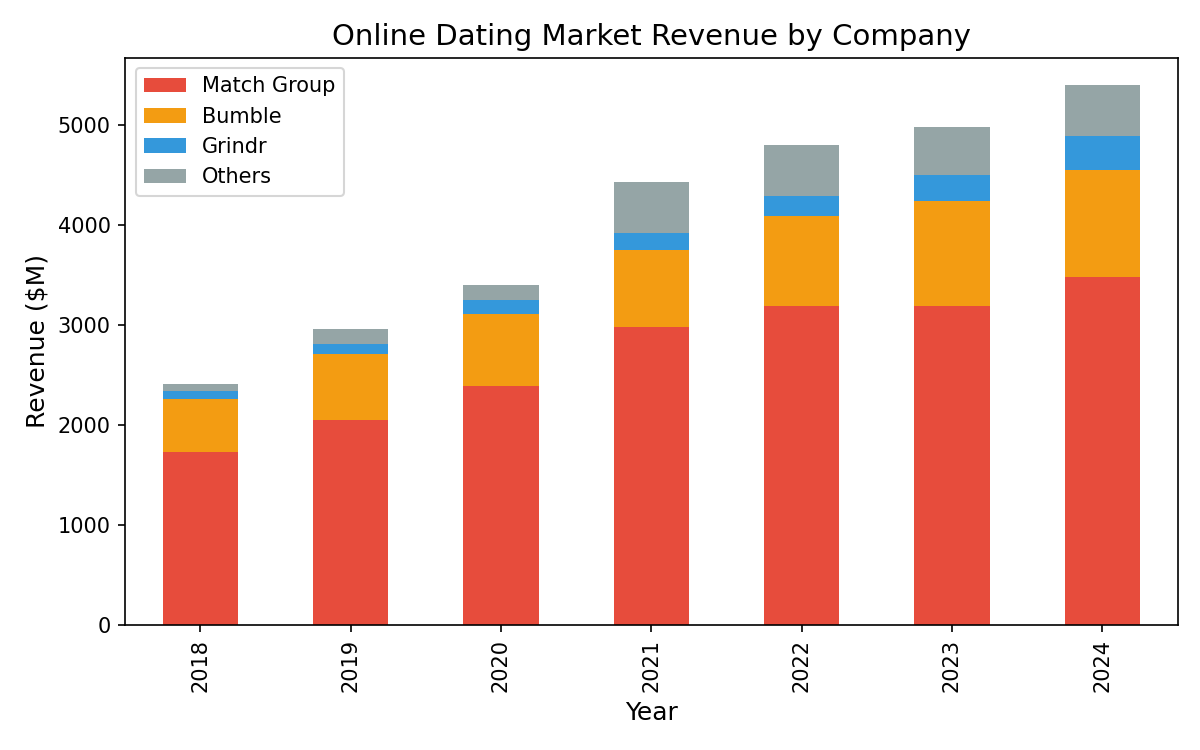
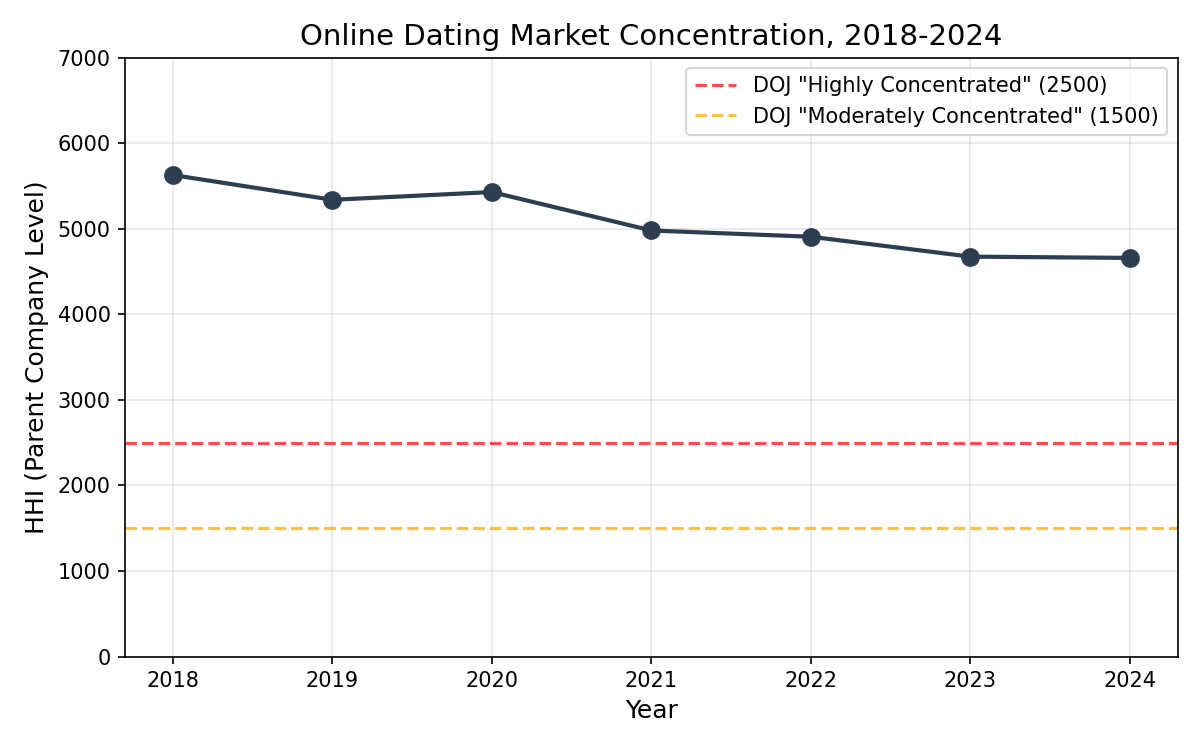




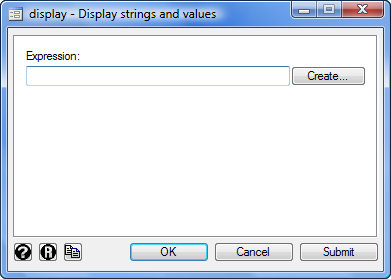{kind=link}