In at this time’s fast-paced retail atmosphere, downtime isn’t simply inconvenient, it’s expensive. When a handheld scanner fails throughout peak buying hours or a cell laptop disconnects in the course of a Purchase On-line, Choose Up In-Retailer (BOPIS) transaction, the impression extends to buyer satisfaction, worker productiveness, and in the end, the underside line.
The strategic partnership between Cisco and Zebra Applied sciences, which incorporates Cisco Wi-fi and ThousandEyes integrations with Zebra cell computer systems and scanners, is addressing these challenges head-on, delivering deeper visibility and management for retail organizations.
The Problem: The Visibility Hole
Retail IT groups have lengthy confronted a irritating problem. They’re accountable for sustaining seamless operations throughout shops, warehouses, and distribution facilities, and they’ve operated with restricted visibility into the very gadgets that energy these operations. The 2026 Cisco State of Wi-fi Report shines a light-weight on this, revealing how 86% of retail wi-fi professionals state an absence of visibility impacts their potential to handle operations, with consumer and software visibility gaps inflicting probably the most issues.
When a Zebra cell laptop or scanner experiences connectivity points, troubleshooting turns into an train in educated guesswork. Was it a roaming drawback? Battery depletion? A firmware bug? The solutions too usually stay locked inside the gadgets themselves, forcing IT groups into reactive, time-consuming diagnostic processes.
This visibility hole interprets straight into enterprise impression. In retail, each minute of machine downtime, disrupted connectivity, or software degradation can imply delayed customer support, deserted transactions, incomplete stock counts, or disrupted achievement operations. For organizations working on razor-thin margins, these inefficiencies can accumulate rapidly.
The native integrations between Zebra, Cisco Wi-fi, and Cisco ThousandEyes are constructed to deal with these challenges by real-time intelligence and end-to-end assurance. Let’s take a more in-depth look.
Cisco Wi-fi and Zebra: Most Effectivity By means of Deep Actual-time Visibility
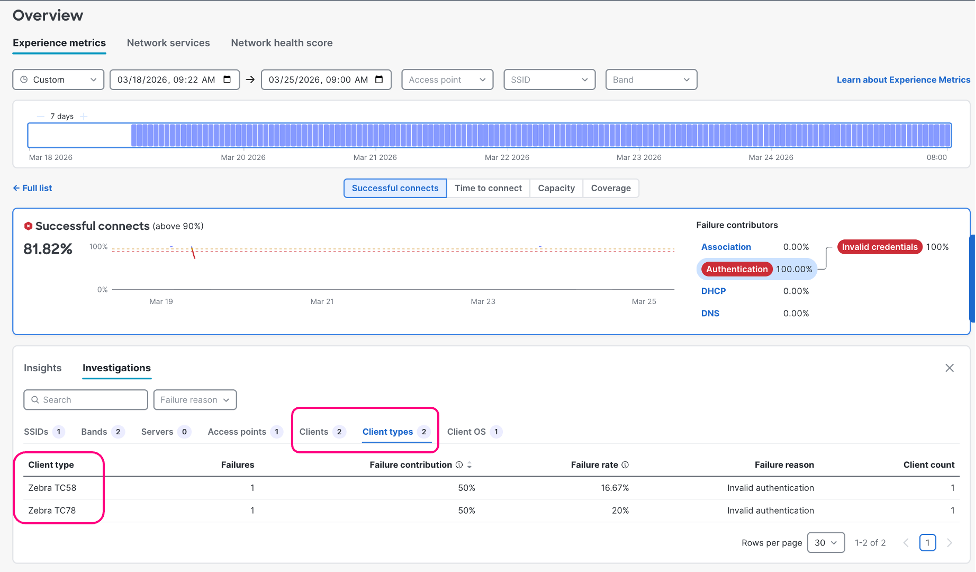
The distinctive integration between Cisco Wi-fi and Zebra Applied sciences essentially adjustments how retailers can decrease the unfavorable enterprise impacts attributable to lack of visibility into the gadgets and environments driving a lot of their operations. By surfacing Zebra-specific telemetry straight inside the Meraki Dashboard, retail IT groups now have fast entry to important machine intelligence together with machine mannequin, OS model, serial numbers, and, maybe most importantly, detailed disassociation motive codes.
This final functionality represents an enormous leap in troubleshooting effectivity. As a substitute of generic “disconnected” notifications, the system now reveals precisely why a tool left the community: deliberate roaming, low-signal dropout, or handbook disconnect. This granular perception transforms troubleshooting from artwork to science, enabling IT groups to determine patterns, proactively handle points, and resolve issues in minutes quite than hours. And all of that is accomplished with out requiring any end-point software program, which means much less to handle for IT groups.
For retail operations, this native integration means associates outfitted with Zebra gadgets can keep steady connectivity throughout important duties, corresponding to processing returns, conducting stock audits, or fulfilling on-line orders. The result’s improved operational effectivity, enhanced buyer experiences, and diminished IT help burden.
Determine 1. Meraki Dashboard natively integrates and shows consumer analytics from Zebra gadgets
Cisco ThousandEyes and Zebra: Finish-to-end Assurance by Proactive Insights
Everybody thinks cell monitoring is nearly whether or not an app is up or down. We imagine it’s about what customers truly expertise—each faucet, each delay, each community hop. Whereas others measure surface-level efficiency, the Cisco + Zebra resolution, powered by ThousandEyes Cellular Endpoint Agent, captures true end-user expertise straight from the machine—throughout networks, purposes, and areas—by proactive testing the place issues truly happen. By repeatedly simulating actual person journeys from Zebra scanners and cell computer systems, IT and helpdesk groups acquire close to real-time visibility throughout the complete digital supply chain, from machine and Wi-Fi or cell connectivity to Web well being and software efficiency.
With out this stage of proactive, device-driven perception, you’re blind to what your customers truly really feel. Points cover within the final mile, throughout unmanaged or unreliable networks, and in real-world situations which might be inconceivable to duplicate in managed environments. That is particularly important in frontline retail, warehouses, and cell supply operations, the place connectivity could also be poor or non-existent and staff depend on a number of cloud-based techniques for stock, transactions, and buyer engagement. With out visibility the place it issues most, groups chase false leads, outages take longer to resolve, and buyer expertise suffers earlier than points are even detected.
With the mixing of ThousandEyes Cellular Endpoint Brokers on Zebra gadgets, as efficiency points unfold, technicians will be alerted and rapidly zero in on well being scores and key metrics to visually decide the supply of the issue, whether or not on the machine, community, or software stage, dramatically accelerating decision instances.
“For a lot of organizations, their most crucial operations occur on the edge—on handheld gadgets utilized in provide chains, manufacturing flooring, buyer onboarding, and parcel supply. If any a part of that digital chain breaks, it straight impacts income and buyer achievement. With ThousandEyes Cellular Endpoint Agent on Zebra gadgets, we offer end-to-end visibility from the machine to the community and cloud providers all the way in which to the applying, serving to companies rapidly determine and resolve points earlier than they disrupt important operations.”
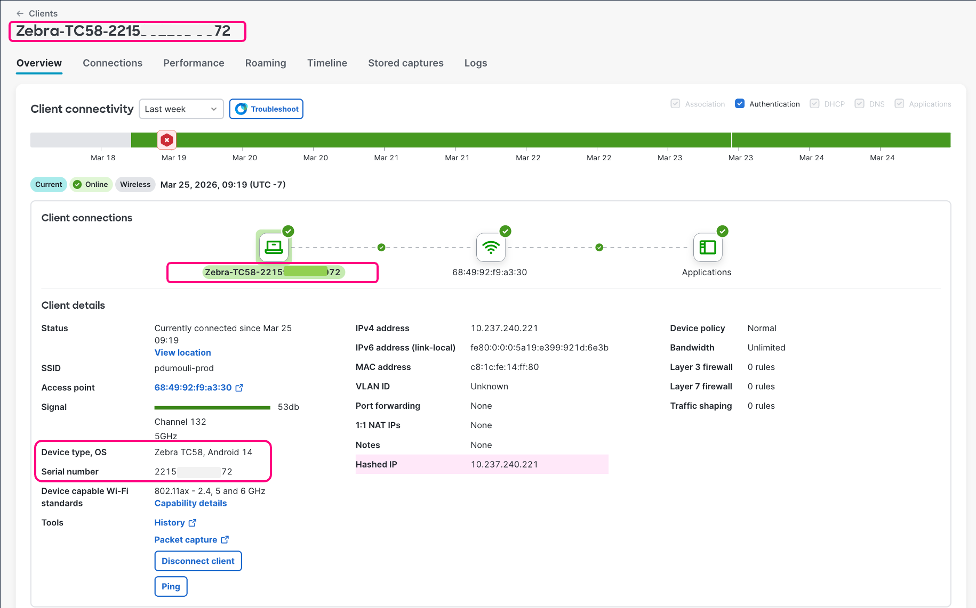
Determine 2. ThousandEyes Cellular Endpoint Expertise shows end-end well being from the Zebra cell machine to the applying.
Enterprise Outcomes That Matter
For retail organizations embracing digital transformation, a complete method such because the one provided by the Cisco and Zebra partnership ensures that know-how enablement interprets into tangible enterprise outcomes quite than operational complications.
“Our partnership with Cisco is targeted on serving to prospects unlock better worth from the gadgets they deploy throughout shops, warehouses, and subject operations. By combining Zebra’s machine telemetry with Cisco Wi-fi analytics and ThousandEyes end-to-end visibility, we’re enabling organizations to achieve the operational perception wanted to help staff productiveness and guarantee constant efficiency throughout their complete digital atmosphere.”
— Rowan Fuller, International Partnerships Chief, Zebra Applied sciences
Past technological capabilities, these integrations can ship measurable enterprise worth:
Decreased Downtime: Quicker troubleshooting means much less disruption to back and front of home operations, straight defending income and buyer satisfaction.
Improved Productiveness: Associates spending extra time serving prospects and fewer time coping with malfunctioning gadgets or ready for IT help.
Proactive Administration: Sample recognition enabling IT groups to determine and handle points, corresponding to updating firmware for particular machine batches or addressing protection gaps specifically retailer areas, earlier than they impression operations.
Scalable Operations: As retail organizations develop their footprint or machine deployments, complete visibility ensures constant efficiency throughout all areas with out proportionally growing IT assets.
The Way forward for Retail Expertise
These integrations signify greater than a level resolution; they function a basis for enhanced predictive upkeep and clever automation. As retail continues evolving towards extra linked, data-driven operations, partnerships just like the one between Cisco and Zebra present the infrastructure for sustainable aggressive benefit.
For retail IT leaders evaluating know-how investments, the query isn’t whether or not to embrace this stage of visibility, it’s how rapidly they’ll deploy it to seize the operational and monetary advantages.
“Slurm’s open-source basis presents safeguards akin to clear code, forking capacity, and neighborhood governance, however SchedMD’s management offers Nvidia comfortable energy somewhat than laborious lock-in,” stated Manish Rawat, semiconductor analyst at TechInsights. Rawat stated Nvidia might subtly form the roadmap, prioritising GPU-aware scheduling and topology optimisations that favour its personal {hardware}, and that integration timelines already confirmed sooner help for the CUDA ecosystem in comparison with options akin to AMD’s ROCm or Intel’s oneAPI – creating what he described as a “best-supported path impact.”
What’s Slurm, and why does it matter
Slurm, initially developed at Lawrence Livermore Nationwide Laboratory, runs on roughly 60% of the world’s supercomputers. The software program is in lively use at main AI firms, together with Meta Platforms, French AI startup Mistral, and Anthropic for components of AI mannequin coaching, Reuters reported.
Authorities supercomputers used for climate forecasting and nationwide safety analysis additionally rely upon it. Nvidia acquired Slurm developer SchedMD in December 2025 and described the deal as a push to strengthen its open-source ecosystem and assist customers undertake newer AI methods alongside conventional supercomputing work.
How typically do you end up dealing with small, repetitive duties in your laptop that quietly devour precious time?
Extra typically than we notice, proper? Nonetheless, with instruments like Claude, such duties may be automated by merely describing what you need as a substitute of executing each step manually.
On this weblog, we look at how Claude Code allows process automation, the vary of actions it might probably carry out, and the way it contributes to extra environment friendly and streamlined computing experiences.
Summarize this text with ChatGPT Get key takeaways & ask questions
What’s Claude Code?
Claude Code is a command-line interface (CLI) instrument that acts as an agentic extension of the Claude 3.5 Sonnet mannequin. Not like normal web-based interfaces, Claude Code lives immediately inside your improvement atmosphere.
It’s designed to know the context of your native information, execute terminal instructions, and handle git operations autonomously however below human supervision.
It successfully serves as a “coworker” that may navigate your laptop’s file system to unravel issues, fairly than simply suggesting snippets of code in a browser window.
Key Functionalities: The instrument is constructed round a number of core capabilities that distinguish it from conventional IDE extensions:
System and File Entry: It will possibly learn, write, and create information throughout your listing construction, permitting it to carry out large-scale refactors or complicated knowledge migrations.
Terminal Execution: It has the authority to run shell instructions, which implies it might probably set up dependencies, run construct scripts, and execute take a look at suites to confirm its personal work.
Git Integration: It will possibly examine git standing, stage modifications, and even draft commit messages that precisely mirror the logic of the modifications it has made.
Contextual Consciousness: By indexing your native atmosphere, it understands the relationships between totally different information and modules, making certain that its ideas are technically sound inside your particular undertaking structure.
How Does Claude Code Work?
The operational logic of Claude Code follows a “Agentic Loop.” When a person gives a immediate, the instrument doesn’t merely generate textual content; it initiates a cycle of interpretation, motion, and verification.
Immediate Interpretation: The AI analyzes the person’s pure language request to establish the aim.
Planning: It breaks down the aim right into a sequence of actionable steps, comparable to “Learn file X,” “Establish the bug,” and “Run the take a look at script.”
Motion & Execution: Utilizing its integration with the terminal and APIs, it executes these steps. If a process requires trying to find data, it could use web-search capabilities to search out documentation or libraries.
Self-Correction: If a command fails, for example, if a take a look at returns an error, the agent analyzes the output and adjusts its plan in real-time. This mirrors how Clawdbot makes use of AI brokers to resolve duties by iterating till the target is met.
Security and Permission Dealing with- Automation on a neighborhood machine carries inherent dangers. Claude Code addresses this via a sturdy security layer. It operates on a “human-in-the-loop” mannequin the place important actions, comparable to executing a shell command or writing to a file, require specific person approval. This ensures that the person stays the last word authority, stopping the AI from making unauthorized system modifications.
For those who want a visible introduction to those ideas, watching the Newbie’s Information to Claude AI is extremely beneficial.
For professionals seeking to transfer past merely using instruments like Claude Code to really architecting them, the
JHU Certificates Program in Agentic AI affords a structured pathway. This 16-week on-line program from Johns Hopkins College focuses explicitly on the foundational logic driving fashionable autonomous methods.
Be taught the structure of clever agentic methods. Construct brokers that understand, plan, study, and act utilizing Python-based tasks and cutting-edge agentic architectures.
By participating in hands-on Python tasks to construct a “Sensible Information Processing Agent” and an “Automated Analysis Agent,” contributors develop sensible expertise in multi-agent orchestration and symbolic reasoning.
This complete strategy ensures learners can efficiently design methods that transition from easy conversational fashions to purposeful, safe process executors.
Step-by-Step Information to Automating Duties with Claude Code
Think about having a tireless assistant dwelling proper inside your laptop. It will possibly set up messy scholar obtain folders, write grading scripts, or repair your code autonomously. That’s what Claude Code, an AI coding agent that runs immediately in your command line.
Usually, this requires a paid month-to-month subscription. However as we speak, we’re going to present you 100% free workaround utilizing neighborhood instruments that redirect Claude’s mind to free AI fashions. Let’s get your autonomous assistant arrange!
Earlier than beginning, you may as well discover the Introduction to Claude free course to know the essential interface.
Git for Home windows: Claude Code makes use of this to run instructions. Throughout set up, simply preserve clicking “Subsequent” to just accept all defaults.
OpenRouter Account: To get your free API key (helps Gemini, Llama, and extra).
Command Immediate Home windows: One to run the “Engine” and one to “Speak” to the AI.
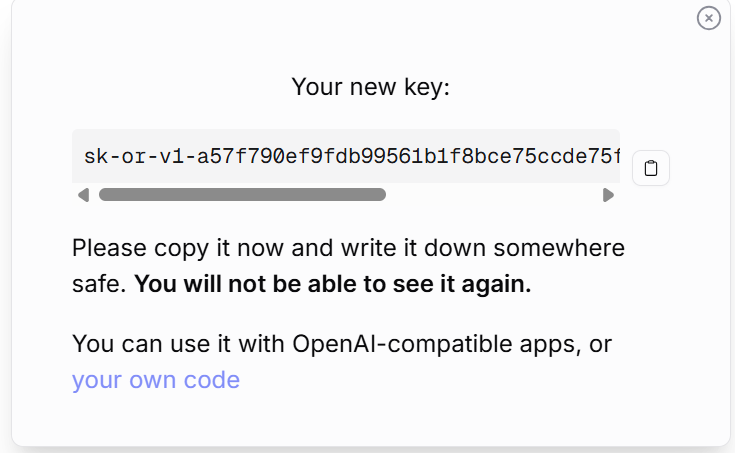
Step 1: Declare Your Free AI API Key
To energy our assistant with out paying Anthropic’s charges, we are going to use OpenRouter, a platform that hosts dozens of free AI fashions.
Go to OpenRouter.ai and click on “Signal Up” (you should use your Google account).
Identify it, like “Claude Code Free”, and click on Create.
Copy the important thing instantly (it can begin with sk-or-v1-…).
Paste it into a short lived notepad doc to avoid wasting this key.
Step 2: Set up Claude Code & The Router
Now we are going to use your laptop’s Terminal (Mac) or PowerShell (Home windows) to put in the official app and the neighborhood “translator” instrument.
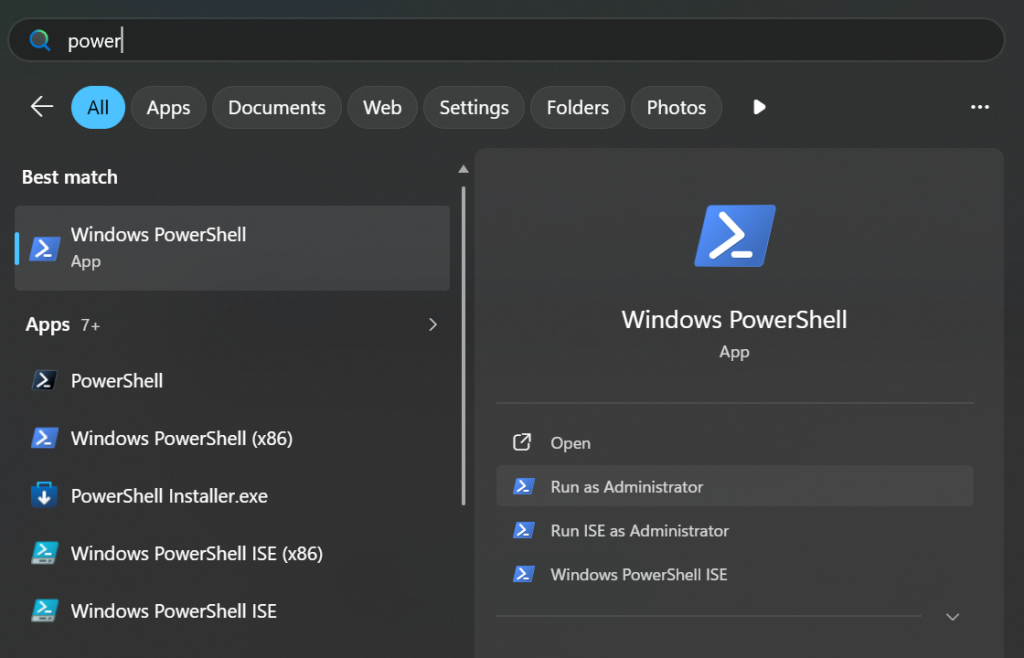
1. Open your command line: -Mac Customers: Press Command + House, sort Terminal, and hit Enter. –Home windows Customers: Press the Home windows Key, sort PowerShell, right-click it, and choose “Run as Administrator”.
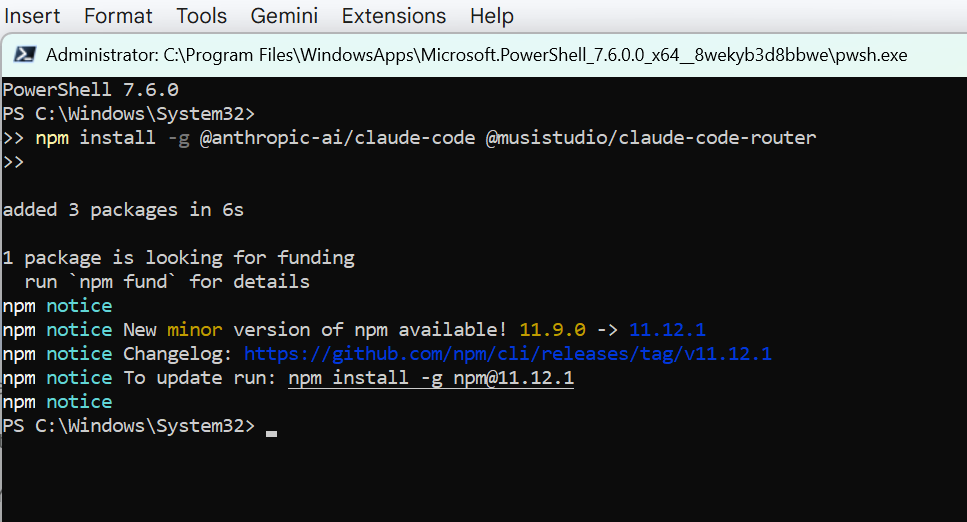
2. Copy and paste the next command precisely as written, then press Enter:
npm set up -g @anthropic-ai/claude-code @musistudio/claude-code-router
3. Anticipate the loading bars to complete. This installs each the official Claude Code app and the claude-code-router bundle.
Step 3: Create Your Configuration Folders
We have to create a hidden folder in your laptop the place the AI router will search for its directions. – For Mac/Linux Customers: Run this command in your Terminal:
mkdir -p ~/.claude-code-router ~/.claude
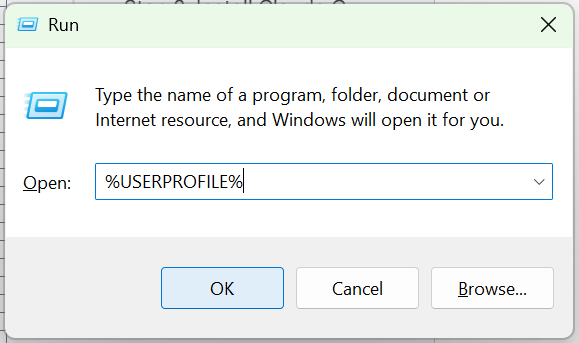
– For Home windows Customers: Let’s create this folder visually!
Press the Home windows Key + R in your keyboard to open the “Run” field.
Sort %USERPROFILE% and press Enter. This opens your foremost person folder (e.g., C:UsersYourName).
Proper-click on any empty white area inside this folder.
Click on New > Folder, title this new folder: .claude-code-router(Be sure you embody the interval on the very starting!) and press Enter.
Step 4: Write the Configuration File
Now we inform the router which free fashions to make use of. We are going to use Google’s lightning-fast Gemini 2.0 Flash mannequin, which OpenRouter gives at no cost.
Open the Notepad app in your Home windows laptop.
Copy the precise code block beneath and paste it into your clean Notepad doc:
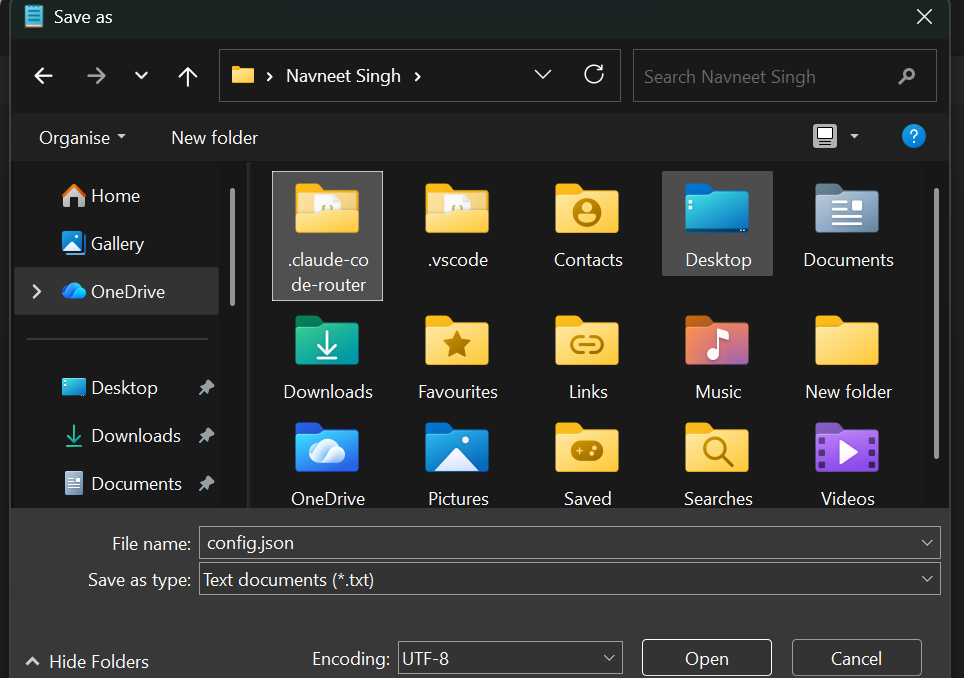
Within the left-hand menu of the save window, discover your foremost Consumer folder, and double-click the .claude-code-router folder you simply created in Step 3 to open it.
Change the “Save as sort” dropdown on the backside from “Textual content Paperwork (.txt)” to “All Information (.*)”.
Identify the file precisely: config.json
Click on Save.
Essential Notice: Go away the textual content “OPENROUTER_API_KEY” precisely as it’s written within the code above. Do not paste your precise OpenRouter key into this Notepad file.
We are going to safe your actual key within the subsequent step!
Step 5: Securely Set Your API Key
Now we have to take that OpenRouter key you saved in Step 1 and inject it securely into your laptop. This enables our router to search out your key with out leaving it uncovered in normal textual content information.
For Mac Customers: -Open your Terminal. -Copy the command beneath, however change YOUR_KEY_HERE along with your precise OpenRouter key (ensure you preserve the quote marks!):
Press Enter. Lastly, run this command to lock within the modifications instantly: supply ~/.zshrc
For Home windows Customers:
Click on your Home windows Begin button, sort cmd, and open the usual Command Immediate app.
Copy the command beneath, however change YOUR_KEY_HERE along with your precise OpenRouter key (ensure you preserve the quote marks round your key!):
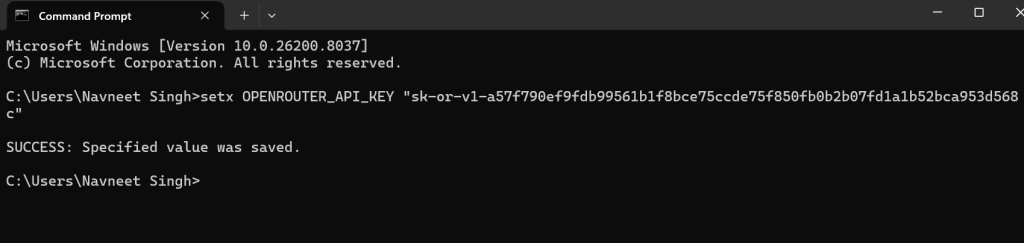
setx OPENROUTER_API_KEY "YOUR_KEY_HERE"
Paste that into your Command Immediate and press Enter.
You need to see a message pop up that claims “SUCCESS: Specified worth was saved.”
CRITICAL STEP: Shut the Command Immediate window utterly. Your laptop is not going to acknowledge the brand new key till you open a contemporary window within the subsequent step!
Step 6: The Every day Workflow (Bringing the AI to Life)
To make use of your free AI assistant, you will need to at all times run two separate command home windows on the identical time.
Half 1: Begin
Open a contemporary Command Immediate (Home windows) or Terminal (Mac).
Sort the next and press Enter:
What to anticipate: You will note a line that claims: Loaded JSON config from: C:Customers…config.json.
Vital: The window will then appear to be it has stopped shifting. That is regular! It means the code is operating silently within the background. Don’t shut this window. Simply reduce it.
Half 2: Begin
1. Open a second, separate Command Immediate or Terminal window.
2. Navigate to the folder the place you need the AI to work (for instance, your Paperwork): Home windows: cd %USERPROFILEpercentDocuments, Mac: cd ~/Paperwork
3. Launch the AI interface by typing:
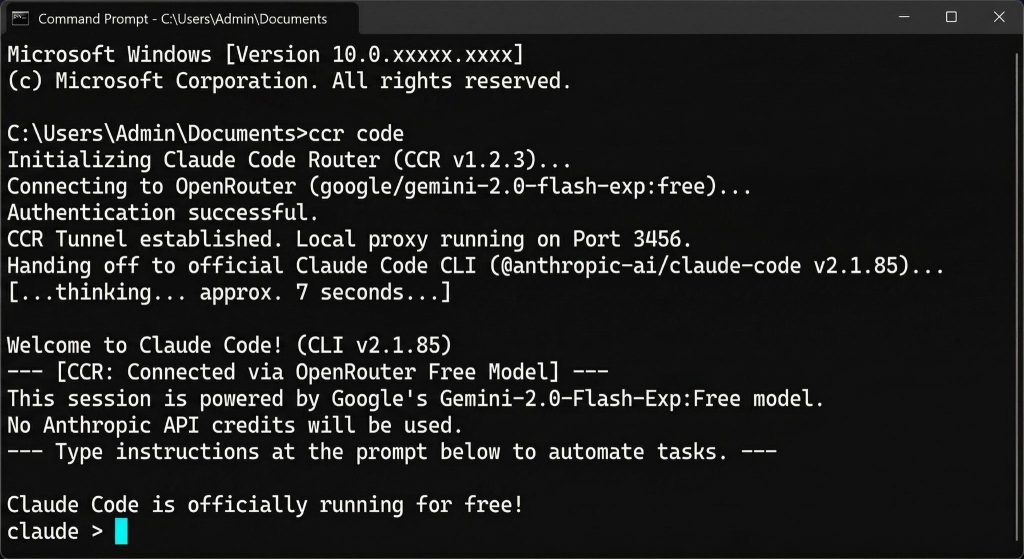
4. Press Enter. Wait about 5–10 seconds. You will note a welcome message and a immediate that appears like claude >. You at the moment are formally utilizing Claude Code at no cost!
Your First Automation Take a look at
As soon as the claude > immediate seems in your second window, let’s give it its first job. Sort this command and hit Enter:
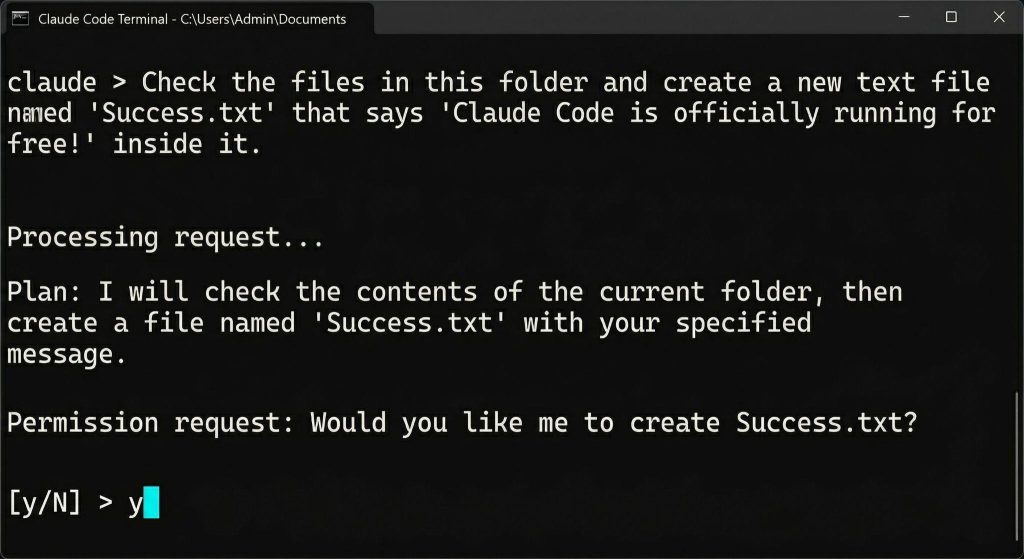
“Examine the information on this folder and create a brand new textual content file named ‘Success.txt’ that claims ‘Claude Code is formally operating at no cost!’ inside it.”
End result:
Execution: Claude will analyze your request and clarify what it’s about.
Permission: It is going to ask, “Would you want me to create Success.txt?” Sort y and hit Enter.
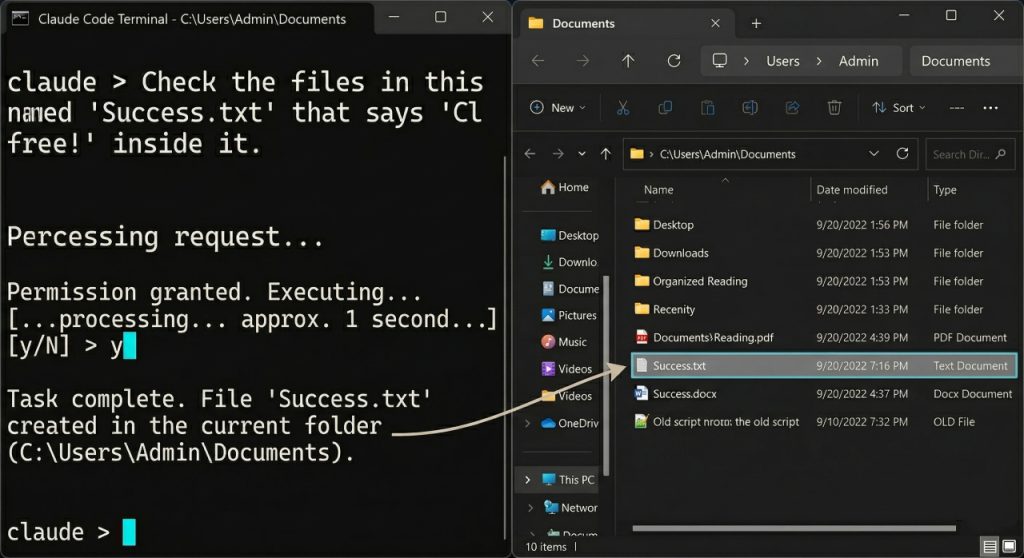
The End result: Claude will verify the file is created. Examine your Paperwork folder, you’ll discover your new file there!
Professional-Suggestions for Home windows Customers
Since Home windows may be tough, embody these three ideas on the backside of your put up to make it really “Final.”
The “Bash Not Discovered” Repair: If Claude says it might probably’t discover Git-Bash, run this command in your terminal as an Administrator:
The “Command Not Acknowledged” Repair: If ccr or claude will not run, shut all terminal home windows and open a model new one. Home windows wants a “refresh” to see newly put in instruments.
Examine Your Key: For those who get an “Unauthorized” error, re-run Step 5 to make sure your OpenRouter API key was saved appropriately.
Different Varieties of Duties Claude Code Can Automate
1. Growth Duties: The system effortlessly handles writing and debugging complicated code, utterly automating testing workflows and producing repetitive setup scripts, which immediately showcase the unimaginable AI purposes in software program improvement.
2. Information Processing: It excels at parsing huge CSV and JSON information mechanically, executing complicated knowledge cleansing pipelines, and structuring unstructured textual content into organized codecs with out requiring you to make use of heavy spreadsheet purposes.
3. System Monitoring and Upkeep: Claude Code can proactively monitor system efficiency, monitor useful resource utilization, and automate routine upkeep duties comparable to clearing cache, managing logs, and figuring out pointless background processes. This reduces handbook intervention and helps preserve optimum system well being over time.
4. Net and API Automation: It will possibly work together with internet platforms and APIs to automate duties like fetching knowledge from web sites, submitting types, integrating third-party providers, and syncing data throughout purposes. This allows customers to construct highly effective automation workflows with out manually dealing with a number of instruments or interfaces.
If you’re a enterprise chief aiming to leverage these capabilities, the AI Brokers for Enterprise Purposes on-line course by Texas McCombs is an distinctive alternative.
This program helps you learn to establish, design, and implement AI agent options that drive important organizational effectivity. You’ll uncover sensible methods to automate complicated enterprise workflows, improve operational decision-making, and safely and securely lead enterprise-wide technical transformations.
Advantages of Utilizing Claude Code
Saves Time On Repetitive Duties: It drastically cuts down the hours spent manually typing normal instructions, permitting you to immediately generate information, folders, and fundamental code templates in mere seconds.
Reduces Guide Errors: By counting on a extremely exact machine to execute complicated syntax, you utterly eradicate the minor typographical errors that usually crash software program methods and trigger huge frustration.
Makes Automation Accessible: It utterly removes the necessity for deep, expert-level coding information, permitting common professionals to construct customized automations just by typing plain English directions into their laptop terminal:
To grasp the broader financial affect of those productiveness good points, watching the extremely detailed Generative AI Defined: An Overview of LLMs and Their Enterprise Influence video will present invaluable business context.
Greatest Practices for Efficient Automation
Whereas these instruments are extremely highly effective, they have to be used responsibly to forestall unintentional knowledge loss or system errors. Studying how builders adapt to generative AI safely is essential for long-term success.
Write Clear and Particular Prompts: You have to at all times give the system precise, extremely detailed directions, leaving completely zero room for obscure interpretations that would lead the AI to change the improper system information.
Take a look at Automation in Protected Environments: You need to constantly run new, unverified scripts in remoted take a look at folders first, making certain that any sudden errors don’t completely corrupt your necessary, reside working directories.
Overview Generated Code Earlier than Execution: You have to rigorously learn each single line of code the assistant proposes earlier than hitting the verify button, making certain the system strictly follows your supposed technical logic.
If you’re seeking to grasp the creation of those methods your self, taking the Constructing Clever AI Brokers free course provides you with a incredible technical overview. Afterwards, you may discover quite a lot of thrilling undertaking concepts to construct your portfolio.
Conclusion
By organising Claude Code via the free routing strategies detailed above, you may immediately eradicate tedious system chores, streamline complicated file dealing with, and considerably speed up your software program improvement lifecycle. Nonetheless, the true energy of this expertise depends completely on how effectively you information it.
By combining these superior automation instruments with strict human oversight and clear strategic intent, you may remodel your common laptop into an extremely highly effective, hyper-efficient digital workstation.
Google Chrome introduces vertical tabs and an enhanced immersive studying mode as new productiveness options in its newest browser replace.
Macworld stories that vertical tabs permit customers to stack tabs alongside the window’s aspect for higher group and administration.
The improved studying mode creates a distraction-free, full-page interface by eradicating adverts and pictures for targeted content material consumption.
Google introduced on Tuesday two new options for its Chrome browser. Each options have been designed to assist customers be extra productive whereas utilizing the browser.
The primary new characteristic is the flexibility to show tabs vertically within the browser, alongside the aspect of the window. The default is to show tabs alongside the highest, however to change to vertical view, right-click on the Chrome window, and also you’ll discover a new Present Tabs Vertically choice. Choose it, and the tabs transfer to the aspect and stack slightly than occupy a horizontal bar above the primary window.
Safari has the same characteristic within the sidebar, but it surely doesn’t change the highest tab bar.
Tips on how to show tabs vertically in Google Chrome.
Google
The second characteristic is an enhancement to studying mode, which shows a webpage freed from photographs, movies, adverts, and different parts and reveals solely textual content with hyperlinks. Earlier than the replace, the studying mode web page appeared alongside the precise, full webpage. Now, studying mode is offered in a full-page interface. The Immersive Reader mode is much like Safari’s Reader (View > Present Reader), although Safari’s is ready to show photographs.
Google Chrome’s Immersive Studying Mode seems as its personal webpage as an alternative of splitting the view between it and the precise web site.
Google
The brand new options can be found within the newest model of Google Chrome. If you have already got Chrome, you’ll be able to set up the replace by way of Chrome > About Chrome.
Novel approaches are edging us nearer to relieving the agonising ache of migraines for all affected
Sergey Khakimullin/Getty Pictures
One-third of individuals with migraines don’t reply to present remedies, however harnessing the mind’s cleansing system may open up a brand new therapy possibility. A drug that ordinarily treats hypertension helped this method extra successfully take away a chemical substance from the brains of mice that may be a potent driver of migraines. Because of this, the mice confirmed fewer indicators of facial ache, which impacts about 60 per cent of individuals with migraines throughout an episode.
Round 1 in 7 individuals worldwide have migraines. Ache, strain or throbbing within the cheeks, jaw, brow or behind the eyes are frequent signs, and will be exacerbated by even mild contact. “Merely brushing their hair will be painful for [people with migraines],” says Adriana Della Pietra on the College of Iowa, who offered the analysis on the Oxford Glymphatic and Mind Clearance Symposium within the UK on 1 April.
Commonplace migraine remedies embody painkillers similar to triptans, that are thought to cut back irritation and decrease ranges of a neurotransmitter referred to as calcitonin gene-related peptide (CGRP) – a driver of migraines and the goal of our most potent therapies towards the situation. “However numerous individuals don’t reply to the medicine they’re provided, and very often, persons are dwelling by way of hell that may final for days. Very often, they will’t do on a regular basis duties,” says Valentina Mosienko on the College of Bristol, UK, who wasn’t concerned within the analysis.
In an earlier experiment, the researchers discovered that prazosin – a drug that’s accredited to deal with hypertension – relieves facial ache attributable to traumatic mind accidents in mice. Such accidents impair the mind’s waste disposal system, often known as the glymphatic system, whereas prazosin boosts the circulate of waste fluid from mind cells by way of this method. Nevertheless, some migraine-affected mice that the researchers used as a management additionally appeared to profit.
Investigating this additional, the workforce added prazosin to the consuming water of a gaggle of mice for six weeks, whereas a separate group got common water. The researchers then induced migraines in the entire rodents by injecting them with CGRP.
Half an hour later, the workforce prodded the mice’s foreheads with plastic filaments of accelerating thickness. Though none of those is ordinarily painful, the filaments are more and more noticeable as they grow to be thicker. The researchers discovered that the mice within the prazosin group might be touched by considerably thicker filaments with out flinching than the management mice. The previous group acted equally to mice that hadn’t been injected with CGRP, says Della Pietra.
Additional evaluation confirmed that prazosin reversed impairment of the glymphatic system attributable to CGRP, which most likely enhanced its clearance and that of different molecules that transmit ache alerts, says Della Pietra.
The researchers hope to check whether or not the identical results happen in individuals. “If it really works in people, that will be improbable,” says Mosienko. “The drug is already in use, so we all know it’s secure to be used.”
To enhance information middle effectivity, a number of storage units are sometimes pooled collectively over a community so many functions can share them. However even with pooling, important system capability stays underutilized as a result of efficiency variability throughout the units.
MIT researchers have now developed a system that enhances the efficiency of storage units by dealing with three main sources of variability concurrently. Their strategy delivers important pace enhancements over conventional strategies that deal with just one supply of variability at a time.
The system makes use of a two-tier structure, with a central controller that makes big-picture selections about which duties every storage system performs, and native controllers for every machine that quickly reroute information if that system is struggling.
The tactic, which might adapt in real-time to shifting workloads, doesn’t require specialised {hardware}. When the researchers examined this technique on practical duties like AI mannequin coaching and picture compression, it almost doubled the efficiency delivered by conventional approaches. By intelligently balancing the workloads of a number of storage units, the system can improve total information middle effectivity.
“There’s a tendency to need to throw extra sources at an issue to unravel it, however that’s not sustainable in some ways. We would like to have the ability to maximize the longevity of those very costly and carbon-intensive sources,” says Gohar Chaudhry, {an electrical} engineering and pc science (EECS) graduate scholar and lead creator of a paper on this system. “With our adaptive software program answer, you may nonetheless squeeze numerous efficiency out of your current units earlier than it’s good to throw them away and purchase new ones.”
Chaudhry is joined on the paper by Ankit Bhardwaj, an assistant professor at Tufts College; Zhenyuan Ruan PhD ’24; and senior creator Adam Belay, an affiliate professor of EECS and a member of the MIT Laptop Science and Synthetic Intelligence Laboratory. The analysis will probably be introduced on the USENIX Symposium on Networked Methods Design and Implementation.
Leveraging untapped efficiency
Stable-state drives (SSDs) are high-performance digital storage units that enable functions to learn and write information. As an example, an SSD can retailer huge datasets and quickly ship information to a processor for machine-learning mannequin coaching.
Pooling a number of SSDs collectively so many functions can share them improves effectivity, since not each software wants to make use of your entire capability of an SSD at a given time. However not all SSDs carry out equally, and the slowest system can restrict the general efficiency of the pool.
These inefficiencies come up from variability in SSD {hardware} and the duties they carry out.
To make the most of this untapped SSD efficiency, the researchers developed Sandook, a software-based system that tackles three main types of performance-hampering variability concurrently. “Sandook” is an Urdu phrase meaning “field,” to indicate “storage.”
One kind of variability is attributable to variations within the age, quantity of damage, and capability of SSDs that will have been bought at completely different instances from a number of distributors.
The second kind of variability is as a result of mismatch between learn and write operations occurring on the identical SSD. To put in writing new information to the system, the SSD should erase some current information. This course of can decelerate information reads, or retrievals, occurring on the similar time.
The third supply of variability is rubbish assortment, a means of gathering and eradicating outdated information to unlock area. This course of, which slows SSD operations, is triggered at random intervals {that a} information middle operator can’t management.
“I can’t assume all SSDs will behave identically via my complete deployment cycle. Even when I give all of them the identical workload, a few of them will probably be stragglers, which hurts the web throughput I can obtain,” Chaudhry explains.
Plan globally, react domestically
To deal with all three sources of variability, Sandook makes use of a two-tier construction. A worldwide schedular optimizes the distribution of duties for the general pool, whereas quicker schedulers on every SSD react to pressing occasions and shift operations away from congested units.
The system overcomes delays from read-write interference by rotating which SSDs an software can use for reads and writes. This reduces the possibility reads and writes occur concurrently on the identical machine.
Sandook additionally profiles the everyday efficiency of every SSD. It makes use of this info to detect when rubbish assortment is probably going slowing operations down. As soon as detected, Sandook reduces the workload on that SSD by diverting some duties till rubbish assortment is completed.
“If that SSD is doing rubbish assortment and might’t deal with the identical workload anymore, I need to give it a smaller workload and slowly ramp issues again up. We need to discover the candy spot the place it’s nonetheless performing some work, and faucet into that efficiency,” Chaudhry says.
The SSD profiles additionally enable Sandook’s international controller to assign workloads in a weighted style that considers the traits and capability of every system.
As a result of the worldwide controller sees the general image and the native controllers react on the fly, Sandook can concurrently handle types of variability that occur over completely different time scales. As an example, delays from rubbish assortment happen instantly, whereas latency attributable to put on and tear builds up over many months.
The researchers examined Sandook on a pool of 10 SSDs and evaluated the system on 4 duties: working a database, coaching a machine-learning mannequin, compressing photos, and storing person information. Sandook boosted the throughput of every software between 12 and 94 % when in comparison with static strategies, and improved the general utilization of SSD capability by 23 %.
The system enabled SSDs to realize 95 % of their theoretical most efficiency, with out the necessity for specialised {hardware} or application-specific updates.
“Our dynamic answer can unlock extra efficiency for all of the SSDs and actually push them to the restrict. Each little bit of capability it can save you actually counts at this scale,” Chaudhry says.
Sooner or later, the researchers need to incorporate new protocols obtainable on the newest SSDs that give operators extra management over information placement. In addition they need to leverage the predictability in AI workloads to extend the effectivity of SSD operations.
“Flash storage is a robust expertise that underpins trendy datacenter functions, however sharing this useful resource throughout workloads with extensively various efficiency calls for stays an excellent problem. This work strikes the needle meaningfully ahead with a chic and sensible answer prepared for deployment, bringing flash storage nearer to its full potential in manufacturing clouds,” says Josh Fried, a software program engineer at Google and incoming assistant professor on the College of Pennsylvania, who was not concerned with this work.
This analysis was funded, partially, by the Nationwide Science Basis, the U.S. Protection Superior Analysis Initiatives Company, and the Semiconductor Analysis Company.
I’ve had this dialog many instances: A expertise chief pulls me apart and says some model of: “We preserve faltering. Handoffs disintegrate. No one owns the result. How can we repair it?”
My reply? It is in all probability not your course of or your tech stack. It is your organizational mannequin.
Challenge-based buildings have been a dependable administration method in tech-first organizations, and for good purpose. It is what scaled advanced programs, delivered large infrastructure and introduced extremely coordinated engineering efforts to life. It is sensible: outline the deliverable, set the timeline, employees a staff, ship it, exit. Repeat. However the tempo of expertise has outrun it.
What challenge fashions really price you
At the moment’s merchandise should not static deliverables — they’re programs that evolve constantly. They require fixed iteration, ongoing funding and tight alignment with buyer conduct.
A mannequin constructed round outlined endpoints creates friction in that type of atmosphere.
Work will get handed off throughout groups. The staff that builds one thing is commonly not the one chargeable for operating or bettering it. Finish-to-end possession will get diluted. Context fades at every transition. Accountability begins to interrupt down.
I’ve seen organizations with distinctive expertise gradual to a crawl as a result of the mannequin surrounding it created friction at each handoff.
Planview’s 2023 Challenge to Product State of the Trade Report discovered that even with Agile groups, solely 8% of deliberate work finally delivered its supposed worth for the 326 IT leaders surveyed at 253 distinctive corporations.The precise quantity is much less vital than what it displays. Delivery one thing and making it work should not the identical factor.
As a result of on this mannequin, when one thing breaks or a buyer expertise degrades, the response is commonly to spin up one other challenge. A brand new workstream and new constitution. In the meantime, months cross and rivals transfer forward.
The result’s a niche between supply and consequence. And the construction is guilty.
The shift most organizations keep away from
Shifting to a product-led group does not require a brand new methodology or new instruments — only a completely different philosophy.
In a challenge mannequin, groups are accountable for delivering an outlined scope inside a set timeframe. As soon as that work is full, possession strikes on.
In a product mannequin, a cross-functional staff owns a product or buyer consequence. They do not hand it off when the challenge closes. They construct it, function it, and enhance it. They’re accountable for not simply whether or not one thing shipped, but in addition for the way it performs, the way it evolves and what it delivers to the enterprise and the shopper.
Microsoft, Adobe and Spotify are the examples everybody cites as a result of the outcomes are arduous to argue with. When Satya Nadella reshaped Microsoft round merchandise and platforms moderately than challenge deliverables, it modified how briskly the corporate might transfer and the way cleanly it might coordinate throughout a really giant group.
That shift sounds easy. In apply, it is arduous however price it.
What a product mannequin really modifications
When possession is steady, the way in which groups function modifications with it.
Selections are made with an extended view. Tradeoffs are clearer as a result of the identical staff lives with the results. Work is prioritized based mostly on influence, not simply timelines.
The suggestions loop between constructing and studying tightens. Points are addressed sooner as a result of context stays with the staff. Enhancements construct on one another as an alternative of beginning over.
Velocity appears to be like completely different on this mannequin: It isn’t about shifting sooner from challenge to challenge. It’s about lowering the friction between steps so progress carries ahead.
The way to make the change with out breaking all the pieces
This transition doesn’t require a full reset, nevertheless it does require readability. Earlier than you embark on a migration, deal with three areas. Getting these proper is commonly the distinction between a transition that stalls and one which positive factors momentum.
Be trustworthy about the place possession actually lives and the place it breaks down. The place does the buck cease on a roadmap resolution? Who will get the two a.m. name when one thing breaks? Undecided? That is your baseline for change.
Second, resist the urge to alter all the pieces directly. Begin with one or two areas the place a persistent product staff would have a transparent, measurable influence. Early progress ought to construct momentum, not create chaos.
Third, have a look at how groups are evaluated. If success is outlined by supply milestones, groups will optimize for supply. If success is outlined by outcomes, conduct modifications. Ask: Did buyer satisfaction go up? Did our retention charges enhance? What’s the bottom-line influence? Did merchandise or programs get extra dependable? When you may ask these sorts of questions as an alternative of “Did it ship?” the tradition will observe.
The payoff
This type of transition requires wholesale rethinking round profession paths, reporting strains, planning and budgeting. Nevertheless, the payoff is there.
Organizations that make this transfer expertise sooner iteration, clearer accountability and stronger alignment between groups and enterprise outcomes.
Although the work usually does not really feel completed in the identical method as a result of there isn’t a clear endpoint, the progress turns into steady. As well as, groups can see the correlation between their work and the end result.
The challenge mannequin was proper for a unique period. It rewarded precision, sequencing and management. However at present calls for pace, adaptability and possession. These reside in product groups, not challenge charters.
Why it issues now
AI is accelerating how merchandise are constructed and the way rapidly they’ll evolve. Buyer expectations are rising on the similar time. On this atmosphere, organizations that may study and adapt rapidly get the benefit. Success at present nonetheless requires the correct instruments and expertise, nevertheless it’s now essential to have groups structured with a product focus that emphasizes continuity and possession.
If execution feels slower than it ought to, it’s price trying past your stack. The constraint is commonly not technical. It’s structural.
Not too long ago, we confirmed the best way to generate pictures utilizing generative adversarial networks (GANs). GANs could yield wonderful outcomes, however the contract there mainly is: what you see is what you get.
Generally this can be all we wish. In different instances, we could also be extra concerned with really modelling a website. We don’t simply wish to generate realistic-looking samples – we wish our samples to be situated at particular coordinates in area house.
For instance, think about our area to be the house of facial expressions. Then our latent house is perhaps conceived as two-dimensional: In accordance with underlying emotional states, expressions differ on a positive-negative scale. On the similar time, they differ in depth. Now if we skilled a VAE on a set of facial expressions adequately masking the ranges, and it did actually “uncover” our hypothesized dimensions, we may then use it to generate previously-nonexisting incarnations of factors (faces, that’s) in latent house.
Variational autoencoders are just like probabilistic graphical fashions in that they assume a latent house that’s accountable for the observations, however unobservable. They’re just like plain autoencoders in that they compress, after which decompress once more, the enter area. In distinction to plain autoencoders although, the essential level right here is to plan a loss perform that enables to acquire informative representations in latent house.
In a nutshell
In commonplace VAEs (Kingma and Welling 2013), the target is to maximise the proof decrease sure (ELBO):
[ELBO = E[log p(x|z)] – KL(q(z)||p(z))]
In plain phrases and expressed when it comes to how we use it in observe, the primary element is the reconstruction loss we additionally see in plain (non-variational) autoencoders. The second is the Kullback-Leibler divergence between a previous imposed on the latent house (usually, an ordinary regular distribution) and the illustration of latent house as realized from the info.
A significant criticism concerning the normal VAE loss is that it leads to uninformative latent house. Options embody (beta)-VAE(Burgess et al. 2018), Information-VAE (Zhao, Music, and Ermon 2017), and extra. The MMD-VAE(Zhao, Music, and Ermon 2017) applied beneath is a subtype of Information-VAE that as an alternative of constructing every illustration in latent house as related as attainable to the prior, coerces the respective distributions to be as shut as attainable. Right here MMD stands for most imply discrepancy, a similarity measure for distributions primarily based on matching their respective moments. We clarify this in additional element beneath.
Our goal at this time
On this publish, we’re first going to implement an ordinary VAE that strives to maximise the ELBO. Then, we evaluate its efficiency to that of an Information-VAE utilizing the MMD loss.
Our focus will likely be on inspecting the latent areas and see if, and the way, they differ as a consequence of the optimization standards used.
The area we’re going to mannequin will likely be glamorous (trend!), however for the sake of manageability, confined to measurement 28 x 28: We’ll compress and reconstruct pictures from the Style MNIST dataset that has been developed as a drop-in to MNIST.
An ordinary variational autoencoder
Seeing we haven’t used TensorFlow keen execution for some weeks, we’ll do the mannequin in an keen approach.
If you happen to’re new to keen execution, don’t fear: As each new approach, it wants some getting accustomed to, however you’ll rapidly discover that many duties are made simpler when you use it. A easy but full, template-like instance is obtainable as a part of the Keras documentation.
Setup and knowledge preparation
As regular, we begin by ensuring we’re utilizing the TensorFlow implementation of Keras and enabling keen execution. Moreover tensorflow and keras, we additionally load tfdatasets to be used in knowledge streaming.
By the way in which: No must copy-paste any of the beneath code snippets. The 2 approaches can be found amongst our Keras examples, specifically, as eager_cvae.R and mmd_cvae.R.
The info comes conveniently with keras, all we have to do is the same old normalization and reshaping.
What do we’d like the check set for, given we’re going to practice an unsupervised (a greater time period being: semi-supervised) mannequin? We’ll use it to see how (beforehand unknown) knowledge factors cluster collectively in latent house.
The mannequin actually is 2 fashions: the encoder and the decoder. As we’ll see shortly, in the usual model of the VAE there’s a third element in between, performing the so-called reparameterization trick.
The encoder is a customized mannequin, comprised of two convolutional layers and a dense layer. It returns the output of the dense layer cut up into two elements, one storing the imply of the latent variables, the opposite their variance.
We select the latent house to be of dimension 2 – simply because that makes visualization straightforward.
With extra advanced knowledge, you’ll in all probability profit from selecting the next dimensionality right here.
So the encoder compresses actual knowledge into estimates of imply and variance of the latent house.
We then “not directly” pattern from this distribution (the so-called reparameterization trick):
The sampled values will function enter to the decoder, who will try and map them again to the unique house.
The decoder is mainly a sequence of transposed convolutions, upsampling till we attain a decision of 28×28.
Word how the ultimate deconvolution doesn’t have the sigmoid activation you might need anticipated. It is because we will likely be utilizing tf$nn$sigmoid_cross_entropy_with_logits when calculating the loss.
Talking of losses, let’s examine them now.
Loss calculations
One solution to implement the VAE loss is combining reconstruction loss (cross entropy, within the current case) and Kullback-Leibler divergence. In Keras, the latter is obtainable immediately as loss_kullback_leibler_divergence.
Right here, we observe a current Google Colaboratory pocket book in batch-estimating the whole ELBO as an alternative (as an alternative of simply estimating reconstruction loss and computing the KL-divergence analytically):
From the coaching loop, we are going to, in sure intervals, additionally name three capabilities not reproduced right here (however accessible within the code instance): generate_random_clothes, used to generate garments from random samples from the latent house; show_latent_space, that shows the whole check set in latent (2-dimensional, thus simply visualizable) house; and show_grid, that generates garments in keeping with enter values systematically spaced out in a grid.
Let’s begin coaching! Really, earlier than we try this, let’s take a look at what these capabilities show earlier than any coaching: As a substitute of garments, we see random pixels. Latent house has no construction. And several types of garments don’t cluster collectively in latent house.
Coaching loop
We’re coaching for 50 epochs right here. For every epoch, we loop over the coaching set in batches. For every batch, we observe the same old keen execution stream: Contained in the context of a GradientTape, apply the mannequin and calculate the present loss; then outdoors this context calculate the gradients and let the optimizer carry out backprop.
What’s particular right here is that we now have two fashions that each want their gradients calculated and weights adjusted. This may be taken care of by a single gradient tape, supplied we create it persistent.
After every epoch, we save present weights and each ten epochs, we additionally save plots for later inspection.
How effectively did that work? Let’s see the sorts of garments generated after 50 epochs.
Additionally, how disentangled (or not) are the totally different courses in latent house?
And now watch totally different garments morph into each other.
How good are these representations? That is laborious to say when there may be nothing to match with.
So let’s dive into MMD-VAE and see the way it does on the identical dataset.
MMD-VAE
MMD-VAE guarantees to generate extra informative latent options, so we might hope to see totally different conduct particularly within the clustering and morphing plots.
Knowledge setup is identical, and there are solely very slight variations within the mannequin. Please try the whole code for this instance, mmd_vae.R, as right here we’ll simply spotlight the variations.
Variations within the mannequin(s)
There are three variations as regards mannequin structure.
One, the encoder doesn’t must return the variance, so there isn’t a want for tf$cut up. The encoder’s name technique now simply is
Between the encoder and the decoder, we don’t want the sampling step anymore, so there isn’t a reparameterization.
And since we received’t use tf$nn$sigmoid_cross_entropy_with_logits to compute the loss, we let the decoder apply the sigmoid within the final deconvolution layer:
Now, as anticipated, the massive novelty is within the loss perform.
The loss, most imply discrepancy (MMD), relies on the concept that two distributions are an identical if and provided that all moments are an identical.
Concretely, MMD is estimated utilizing a kernel, such because the Gaussian kernel
[k(z,z’)=frac{e^z-z’}{2sigma^2}]
to evaluate similarity between distributions.
The concept then is that if two distributions are an identical, the common similarity between samples from every distribution must be an identical to the common similarity between combined samples from each distributions:
[MMD(p(z)||q(z))=E_{p(z),p(z’)}[k(z,z’)]+E_{q(z),q(z’)}[k(z,z’)]−2E_{p(z),q(z’)}[k(z,z’)]]
The next code is a direct port of the creator’s authentic TensorFlow code:
The coaching loop differs from the usual VAE instance solely within the loss calculations.
Listed below are the respective strains:
with(tf$GradientTape(persistent =TRUE)%as%tape, {imply<-encoder(x)preds<-decoder(imply)true_samples<-k_random_normal( form =c(batch_size, latent_dim), dtype =tf$float64)loss_mmd<-compute_mmd(true_samples, imply)loss_nll<-k_mean(k_square(x-preds))loss<-loss_nll+loss_mmd})
So we merely compute MMD loss in addition to reconstruction loss, and add them up. No sampling is concerned on this model.
After all, we’re curious to see how effectively that labored!
Outcomes
Once more, let’s take a look at some generated garments first. It looks as if edges are a lot sharper right here.
The clusters too look extra properly unfold out within the two dimensions. And, they’re centered at (0,0), as we might have hoped for.
Lastly, let’s see garments morph into each other. Right here, the graceful, steady evolutions are spectacular!
Additionally, almost all house is stuffed with significant objects, which hasn’t been the case above.
MNIST
For curiosity’s sake, we generated the identical sorts of plots after coaching on authentic MNIST.
Right here, there are hardly any variations seen in generated random digits after 50 epochs of coaching.
Left: random digits as generated after coaching with ELBO loss. Proper: MMD loss.
Additionally the variations in clustering are usually not that massive.
Left: latent house as noticed after coaching with ELBO loss. Proper: MMD loss.
However right here too, the morphing seems way more natural with MMD-VAE.
Left: Morphing as noticed after coaching with ELBO loss. Proper: MMD loss.
Conclusion
To us, this demonstrates impressively what massive a distinction the fee perform could make when working with VAEs.
One other element open to experimentation stands out as the prior used for the latent house – see this speak for an summary of different priors and the “Variational Combination of Posteriors” paper (Tomczak and Welling 2017) for a preferred current method.
For each price capabilities and priors, we anticipate efficient variations to turn out to be approach larger nonetheless after we go away the managed setting of (Style) MNIST and work with real-world datasets.
Burgess, C. P., I. Higgins, A. Pal, L. Matthey, N. Watters, G. Desjardins, and A. Lerchner. 2018. “Understanding Disentangling in Beta-VAE.”ArXiv e-Prints, April. https://arxiv.org/abs/1804.03599.
Google Pictures lastly provides video playback pace management.
Now you can watch movies from 0.5x to 2x straight contained in the app.
It is rolling out now on Android, however availability is gradual and iOS continues to be ready.
Google Pictures has been the primary gallery app for many individuals for years, however it at all times missed one easy characteristic: you couldn’t change video playback pace. In the event you needed to rapidly get by way of an extended recital or decelerate a sports activities spotlight, you had been caught at regular pace. That’s lastly altering.
Android Central’s Take
It is a customary characteristic in most media apps, so it’s shocking it took this lengthy to reach in Google Pictures.
Google is including a video playback pace management to Google Pictures on Android. Now you may pace up or decelerate movies proper within the app.
There are a number of pace choices, often from 0.5x for slower playback as much as 2x for quicker viewing, in accordance with Google Pictures’ help web page.
Article continues under
The brand new pace management seems once you play a video, so you should utilize it rapidly with out looking out by way of menus.
Picture 1 of 2
(Picture credit score: Android Central)
(Picture credit score: Android Central)
Why this took so lengthy
Google Pictures has grown past simply being a gallery app. Over time, it’s turn into a full media hub with modifying instruments, AI options, and cloud syncing.
Android Central’s Take
That is a type of updates that makes life simpler, and I’ll use it day-after-day. Skimming lengthy clips at 2x pace or slowing all the way down to catch particulars simply is sensible now. Nonetheless, it’s shocking Google took so lengthy so as to add such a primary characteristic that’s been in different media gamers for years. Higher late than by no means.
Nonetheless, video playback options have at all times lagged behind. Apps like YouTube, which can also be owned by Google, have supplied playback pace controls for years, however Google Pictures targeted extra on storage and easy modifying.
As extra individuals use Google Pictures to retailer lengthy movies like occasions, vlogs, or lectures, not having pace management began to really feel outdated.
Get the most recent information from Android Central, your trusted companion on this planet of Android
This characteristic is very useful you probably have a big video library, which is frequent for Google Pictures customers.
The characteristic is rolling out to Android customers now, however like most Google updates, it’s arriving progressively. In the event you don’t see it but, you’re not the one one.
Proper now, this replace is just for Android. There’s no set timeline for iOS but, however it’ll in all probability present up there finally.
Researchers on the College of California San Diego report {that a} weeklong program combining meditation and different mind-body strategies can rapidly produce measurable modifications in each mind exercise and blood biology. The research discovered that these practices activated pure pathways concerned in mind flexibility, metabolism, immune operate, and ache aid. Printed in Communications Biology, the findings provide new proof that psychological practices can affect bodily well being in vital methods.
Meditation and comparable approaches have been used for hundreds of years to assist well-being, however scientists have struggled to elucidate precisely how they have an effect on the physique. This new analysis, half of a big initiative funded by the InnerScience Analysis Fund, is the primary to systematically measure the mixed organic results of a number of mind-body strategies delivered over a short while.
“We have identified for years that practices like meditation can affect well being, however what’s placing is that combining a number of mind-body practices right into a single retreat produced modifications throughout so many organic methods that we may measure immediately within the mind and blood,” stated senior research creator Hemal H. Patel, Ph.D., professor of anesthesiology at UC San Diego College of Medication and analysis profession scientist on the Veterans Affairs San Diego Healthcare System. “This is not about simply stress aid or leisure; that is about essentially altering how the mind engages with actuality and quantifying these modifications biologically.”
Contained in the 7-Day Meditation Program
The research adopted 20 wholesome adults who took half in a 7-day residential retreat led by neuroscience educator and creator Joe Dispenza, D.C. Members attended lectures and accomplished about 33 hours of guided meditation together with group-based therapeutic actions.
These periods used an “open-label placebo” method, that means members had been conscious that some practices had been offered as placebos. Even so, such interventions can nonetheless produce actual results by way of expectation, shared expertise, and social connection.
Earlier than and after the retreat, researchers used useful magnetic resonance imaging (fMRI) to observe mind exercise. Blood samples had been additionally analyzed to trace modifications in metabolism, immune operate, and different organic markers.
Mind, Immune, and Metabolic Adjustments Noticed
After the retreat, a number of notable modifications had been detected:
Mind community modifications: Exercise decreased in areas linked to inside psychological chatter, suggesting extra environment friendly mind operate.
Enhanced neuroplasticity: Blood plasma collected after the retreat inspired lab-grown neurons to increase and type new connections.
Pure ache aid: Ranges of endogenous opioids, the physique’s pure painkillers, rose following the retreat.
Immune activation: Each inflammatory and anti inflammatory alerts elevated, pointing to a balanced and adaptive immune response.
Gene and molecular signaling modifications: Small RNA and gene exercise shifted in methods linked to brain-related organic pathways.
Mystical Experiences Linked to Mind Connectivity
Members additionally accomplished the Mystical Expertise Questionnaire (MEQ-30), which measures emotions akin to unity, transcendence, and altered consciousness throughout meditation. Scores elevated from a median of two.37 earlier than the retreat to three.02 afterward.
Those that reported stronger mystical experiences additionally confirmed extra pronounced organic modifications, together with better coordination between totally different mind areas. This means that deeper subjective experiences could also be tied to measurable modifications in mind operate.
Meditation and Psychedelic-Like Mind States
The researchers discovered that the mind exercise patterns noticed after the retreat carefully resembled these beforehand linked to psychedelic substances.
“We’re seeing the identical mystical experiences and neural connectivity patterns that sometimes require psilocybin, now achieved by way of meditation apply alone,” added Patel. “Seeing each central nervous system modifications in mind scans and systemic modifications in blood chemistry underscores that these mind-body practices are performing on a whole-body scale.”
The findings assist clarify how non-drug approaches like meditation might assist total well being. By boosting neuroplasticity and influencing immune exercise, these practices may enhance emotional regulation, stress resilience, and psychological well-being. The rise in pure pain-relief chemical substances additionally factors to potential functions for managing persistent ache.
What Comes Subsequent for Thoughts-Physique Analysis
Though the research targeted on wholesome people, the researchers word that extra work is required to find out how these results translate to medical populations. Future research will discover whether or not comparable packages may assist individuals with persistent ache, temper issues, or immune-related circumstances.
The staff additionally plans to look at how totally different components of the retreat, together with meditation, reconceptualization, and open-label placebo therapeutic, contribute individually and collectively. One other key query is how lengthy these organic modifications final and whether or not repeated apply can strengthen or preserve them.
“This research reveals that our minds and our bodies are deeply interconnected — what we consider, how we focus our consideration, and the practices we take part in can depart measurable fingerprints on our biology,” stated first creator Alex Jinich-Diamant, a doctoral pupil within the Departments of Cognitive Science and Anesthesiology at UC San Diego. “It is an thrilling step towards understanding how aware expertise and bodily well being are intertwined, and the way we’d harness that connection to advertise well-being in new methods.”
Extra coauthors of the research embrace Sierra Simpson, Juan P. Zuniga-Hertz, Ramamurthy Chitteti, Jan M. Schilling, Jacqueline A. Bonds, Laura Case, Andrei V. Chernov, Natalia Esther Amkie Stahl, Michael Licamele, Narin Fazlalipour and, Swetha Devulapalli, at UC San Diego; Joe Dispenza and Michelle A. Poirier at Metamorphosis LLC; Jacqueline Maree and Tobias Moeller-Bertram at VitaMed Analysis; and Leonardo Christov-Moore and Nicco Reggente on the Institute for Superior Consciousness Research.
This work was supported by the InnerScience Analysis Fund and a Veterans Administration Analysis Profession Scientist Award (BX005229).
Disclosure: One co-author (Joe Dispenza) is employed by Encephalon, Inc., the corporate providing the retreat; all different authors declare no competing pursuits.