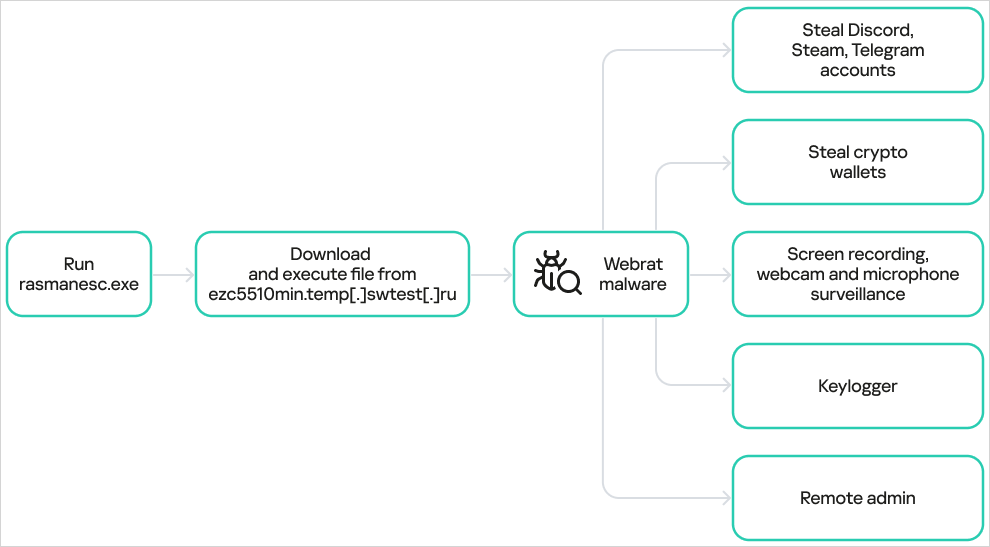
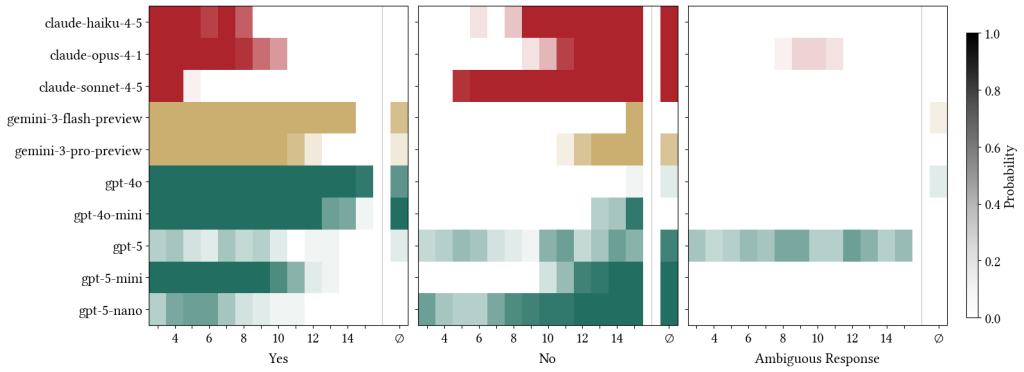
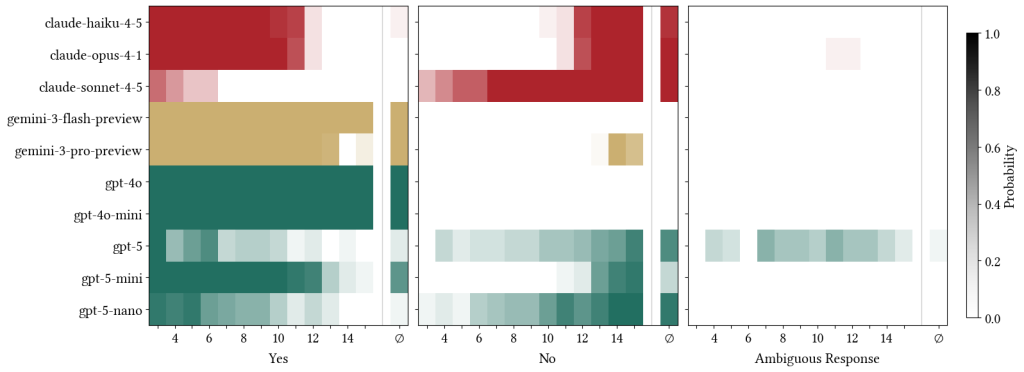
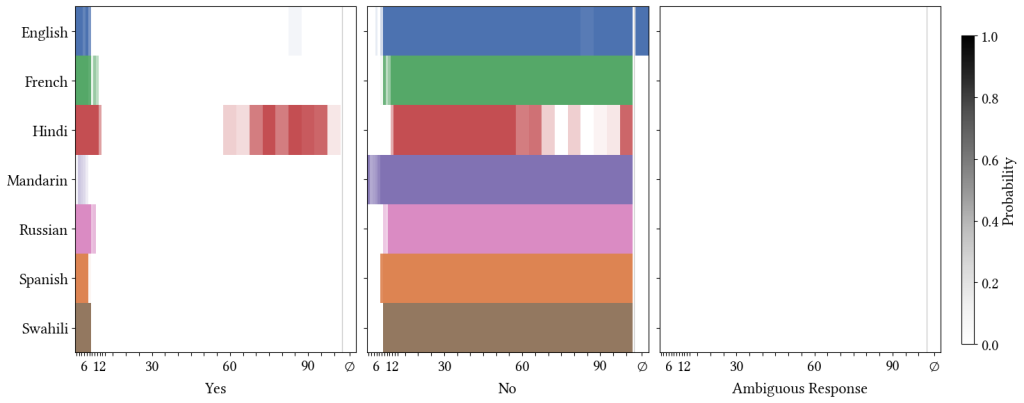
This publish is the second in a collection that illustrates tips on how to plug code written in one other language (like C, C++, or Java) into Stata. This system is named writing a plugin or as writing a dynamic-link library (DLL) for Stata.
On this publish, I write a plugin in C that implements the calculations carried out by mymean_work() in mymean11.ado, mentioned in Programming an estimation command in Stata: Making ready to jot down a plugin. I assume that you’re conversant in the fabric in that publish.
That is the thirtieth publish within the collection Programming an estimation command in Stata. See Programming an estimation command in Stata: A map to posted entries for a map to all of the posts on this collection.
Writing a hello-world C plugin
Earlier than I do any computations, I illustrate tips on how to write and compile a C plugin that communicates with Stata. Code block 1 incorporates the code for myhello.ado that calls the C plugin hey, which simply shows “Good day from C” in Stata.
*! model 1.0.0 13Feb2018
program outline myhello
model 15.1
plugin name hey
finish
program hey, plugin
Line 6 executes the plugin whose deal with is hey. Line 10 hundreds the plugin carried out in hey.plugin into the deal with hey. That the execute assertion comes earlier than the load assertion appears odd at first. Stata ado-files are learn of their entirety, and every ado-program, Mata perform, or plugin deal with is loaded earlier than the strains of the principle ado-program are executed. So line 10 is definitely executed earlier than line 6.
The identify of the deal with for the plugin, hey on this case, should differ from the identify of the principle ado-program, myhello on this case, and from every other ado-program outlined on this .ado file.
The code for hey.c is in code block 2.
// model 1.0.0 14Feb2018 #embody "stplugin.h" #embody#embody STDLL stata_call(int argc, char *argv[]) { char msg[81] ; strcpy(msg, "Good day from Cn"); SF_display(msg) ; return((ST_retcode) 0) ; }
Line 2 consists of the Stata plugin header file stplugin.h. Line 6 is the usual declaration for the entry perform for a C plugin for Stata. It’s best to copy it. Inside stata_call(), argc will include the variety of arguments handed to the plugin, and string vector argv will include the arguments themselves.
Line 8 declares and allocates house for the C string msg. Line 10 places “Good day from C” with a brand new line into msg. Line 11 has Stata show what msg incorporates. Line 12 returns zero because the return code. Observe that I casted the literal 0 to be the anticipated sort ST_retcode.
I now talk about tips on how to create the plugin hey.plugin from hey.c. Within the listing that incorporates myhello.ado and hey.c, I even have stplugin.c. stplugin.c defines a perform wanted to make the stata_call() perform obtainable to Stata.
Don’t change the contents of stplugin.h or stplugin.c. In actual fact, you don’t even want to have a look at them.
On my OS X Mac that has the command–line developer instruments put in, I take advantage of gcc to create hey.plugin from stplugin.c and hey.c by typing
gcc -bundle -DSYSTEM=APPLEMAC stplugin.c hey.c -o hey.plugin
The above gcc command compiles the 2 .c information and hyperlinks them to create the DLL hey.plugin, which myhello.ado can name.
In an appendix to this publish, I present directions for creating hey.plugin on different platforms. https://www.stata.com/plugins/ gives full documentation for writing and compiling C plugins.
Having created hey.plugin, I can execute myhello in Stata.
Instance 1: myhello
. myhello Good day from C
For simplicity, I’ve stplugin.h, stplugin.c, hey.c, myhello.ado, and hey.plugin in the identical listing. For bigger initiatives, I might put the .ado and .plugin information in directories on Stata’s ADOPATH and use my compiler’s setting to handle the place I put my header and C supply information. For the examples on this publish, I put all my .ado information, header information, C supply information, and created .plugin information right into a single listing.
Gaining access to the Stata information in your plugin
hey.plugin makes Stata show one thing created contained in the plugin. The following step is giving the plugin entry to the info in Stata. As an instance this course of, I talk about mylistc.ado, which makes use of a plugin to checklist out observations of the desired variables.
Let’s have a look at the ado-code first.
*! model 1.0.0 13Feb2018
program outline mylistc, eclass
model 15.1
syntax varlist(numeric max=3) [if] [in]
marksample touse
show "Variables listed: `varlist'"
plugin name mylistw `varlist' if `touse' `in'
finish
program mylistw, plugin
In line 6, syntax creates three native macros. It places the variables specified by the consumer into the native macro varlist. It places any if situation specified by the consumer into the native macro if. It places any in situation specified by the consumer into the native macro in. I specified max=3 to syntax to restrict the variety of variables to three. This limitation is foolish, and I might not want it for an instance Stata/Mata program, nevertheless it simplifies the instance C plugin.
In line 7, marksample creates a sample-inclusion variable and places its identify within the native macro touse. The sample-inclusion variable is zero for every excluded remark and one for every included remark. marksample makes use of the variables within the native macro varlist, the situation within the native macro if, and the vary within the native macro in to create the sample-inclusion variable. (All three native macros had been created by syntax.) An remark is excluded if any of the variables within the native macro varlist include a lacking worth, if it was excluded by the situation within the native macro if, or if it was excluded by the vary within the native macro in. The sample-inclusion variable is one for observations that weren’t excluded.
In line 9, I additional simplified the C plugin by displaying the names of the variables whose values are listed out by the plugin.
In line 10, plugin calls mylistw.plugin. As a result of `varlist’ is specified, the Stata plugin interface (SPI) perform SF_vdata() will have the ability to entry the variables contained within the native macro varlist. As a result of if `touse’ is specified, the SPI perform SF_ifobs() will return zero if the sample-inclusion variable in `touse’ is zero, and the perform will return one if the sample-inclusion variable is one. As a result of `in’ is specified, the SPI features SF_in1() and SF_in2() respectively return the primary and final observations in any user-specified in vary.
Specifying `in’ will not be essential to determine the pattern specified by the consumer, as a result of if `touse’ already specifies this sample-inclusion info. Nevertheless, specifying `in’ can dramatically scale back the vary of observations within the loop over the info, thereby rushing up the code.
In a listing that incorporates stplugin.h, stplugin.c, and mylistw.c, I created mylistw.plugin on my Mac by typing
gcc -bundle -DSYSTEM=APPLEMAC stplugin.c mylistw.c -o mylistw.plugin
// model 1.0.0 14Feb2018 #embody "stplugin.h" #embody#embody #embody STDLL stata_call(int argc, char *argv[]) { ST_int i, j, nObs, nVars ; ST_int first, final ; ST_double worth ; ST_retcode rc ; int nchar ; char line[82], strval[27], msg[81] ; rc = (ST_retcode) 0 ; // Put the primary remark in pattern into first first = SF_in1(); // Put the final remark in pattern into final final = SF_in2(); // Put variety of variables in varlist handed in to plugin into nVars nVars = SF_nvars() ; // Provoke variety of observations counter to 0 nObs = 0 ; // Loop over observations for(i=first; i<=final; i++) { line[0] = '�' ; // Solely show observations for which if restriction is true if (!SF_ifobs(i)) { proceed ; } // Increment variety of observations counter ++nObs ; // Loop over variables for(j=1; j<=nVars; j++) { // Put worth of remark i on variable j into worth rc = SF_vdata(j, i, &worth); // Return with error if downside getting worth if(rc>0) { sprintf(msg, "Downside accessing Stata datan") ; SF_error(msg) ; return(rc) ; } // Return with error if lacking worth if (SF_is_missing(worth)) { sprintf(msg, "lacking values encounteredn") ; SF_error(msg) ; return( (ST_retcode) 416 ) ; } nchar = snprintf(strval,25,"%f ",worth) ; // Return with error if quantity is simply too massive or can't be // formated into string as float if (nchar<=0 || nchar>25) { sprintf(msg, "quantity is simply too massive or badly formatedn") ; SF_error(msg) ; return( (ST_retcode) 498 ) ; } // If new model of line will not be too massive, concatenate string worth onto line if ( (strlen(strval) + strlen(line))<=80) { strcat(line,strval) ; } else { sprintf(msg, "Greater than 80 bytes in linen") ; SF_error(msg) ; return( (ST_retcode) 498 ) ; } } // We all know that line has 80 bytes or much less, so subsequent line is protected strcat(line,"n") ; // Show line in Stata SF_display(line) ; } sprintf(line, "First remark was %dn", first) ; SF_display(line) ; sprintf(line, "Final remark was %dn", final) ; SF_display(line) ; sprintf(line, "Variety of observations listed was %dn", nObs) ; SF_display(line) ; return(rc) ; }
If you’re studying this publish, you possibly can learn customary C. I talk about how mylistw.c illustrates the construction of a C plugin for Stata, and I clarify the kinds and the features outlined by the SPI used within the code. Full particulars concerning the SPI can be found at https://www.stata.com/plugins/.
mylistw.c returns zero to Stata if all went nicely, and it returns a nonzero error code if one thing went flawed. Each time I name a perform in mylistw.c that would fail, I test its return code. If that perform failed, I make Stata show an error message, and I return a nonzero error code to Stata. This logic gives the general construction to mylisw.c. Many of the code offers with error circumstances or takes care to not put extra characters right into a string buffer than it will probably maintain.
C plugins learn from or write to Stata objects utilizing features outlined within the SPI. mylistw.c doesn’t return any outcomes, so it has a easy construction.
- It makes use of SPI features to learn from the desired pattern of the info in Stata.
- It makes use of customary C and SPI features to checklist observations for the desired pattern, and it retains a counter of what number of observations are within the specified pattern.
- It makes use of customary C and SPI features to show which was the primary remark within the pattern, which was the final remark within the pattern, and what number of observations had been within the specified pattern.
Now, I talk about particular components of mylistw.c.
In strains 9–12, I take advantage of the SPI outlined varieties ST_int, ST_double, and ST_retcode for variables that the SPI features return or which can be arguments to the SPI features. Utilizing these outlined varieties is important, as a result of their mappings to primitive C varieties fluctuate over time.
rc holds the return code that the plugin will return to Stata. In line 16, I initialize rc to zero. If an SPI perform that may fail does what was requested, it returns a return code of zero. If an SPI perform can’t do what was requested, it returns a nonzero return code. Every time I name an SPI perform that would fail, I retailer the code it returns in rc. If rc will not be zero, I make Stata show an error message and make the plugin return the nonzero worth saved in rc.
Strains 18, 20, and 22 use SPI features. SF_in1() places the primary remark specified by an in vary into first. SF_in2() places the final remark specified by an in vary into final. If an in vary was not specified to plugin, first will include one, and final will include the variety of observations within the dataset. SF_nvars() places the variety of variables specified within the varlist in to nVars.
Strains 30–32 be certain that we skip over observations that had been excluded by the if restriction specified to plugin in line 10 of mylistc.ado. As an instance some particulars, think about instance 2.
Instance 2: mylistc
. sysuse auto, clear (1978 Vehicle Knowledge) . mylistc mpg trunk rep78 if trunk < 21 in 2/10 Variables listed: mpg trunk rep78 17.000000 11.000000 3.000000 20.000000 16.000000 3.000000 15.000000 20.000000 4.000000 20.000000 16.000000 3.000000 16.000000 17.000000 3.000000 19.000000 13.000000 3.000000 First remark was 2 Final remark was 10 Variety of observations listed was 6
In line 30, SF_ifobs(i) returns one when the if restriction specified to plugin is one for remark i and 0 in any other case. In line 10 of mylist.ado, we see that the if restriction handed into plugin is if `touse’. As mentioned above, the sample-inclusion variable within the native macro touse is zero for excluded observations and one for the included observations.
The in vary on line 10 of mylistc.ado was included in order that the loop over the observations in line 27 of mylistw.c would solely go from the start to the tip of any specified in vary. In instance 2, as a substitute of looping over all 74 observations within the auto dataset, the loop on line 27 of mylistw.c solely goes from 2 to 10.
In instance 2, the sample-inclusion variable is 1 for six observations and 0 for the opposite 68 observations. The in 2/10 vary excludes remark one and the observations from 11–74. Of the primary 10 observations, 2 are excluded as a result of rep78 is lacking. One remark is excluded as a result of trunk is 21.
For comparability, all 9 observations between 2 and 10 are listed in instance 3.
Instance 3: checklist
. checklist mpg trunk rep78 in 2/10
+---------------------+
| mpg trunk rep78 |
|---------------------|
2. | 17 11 3 |
3. | 22 12 . |
4. | 20 16 3 |
5. | 15 20 4 |
6. | 18 21 3 |
|---------------------|
7. | 26 10 . |
8. | 20 16 3 |
9. | 16 17 3 |
10. | 19 13 3 |
+---------------------+
Returning to line 38 of mylistw.c, rc = SF_vdata(j, i, &worth) places the worth of remark i on variable j into worth, and it places the code returned by SF_vdata() into rc. If all goes nicely, rc incorporates 0, and the error block in strains 41–43 will not be entered. If SF_vdata() can’t retailer the info into worth, the error block in strains 41–43 is entered, and it makes Stata show an error message and causes mylistw.plugin to exit with the error code that rc incorporates. Within the error block, SF_error() makes Stata show the contents of a C string in crimson.
SF_vdata() can solely entry variables of 1 the numerical Stata information varieties (byte, int, lengthy, float, or double). (Use SF_sdata() for string information.) No matter which Stata numerical sort the variable is, SF_vdata() shops the consequence as an ST_double. In instance 2, mpg, trunk, rep78 are all of sort int in Stata, however every was saved into worth as an ST_double.
In line 46, SF_is_missing(worth) returns 1 if worth is a lacking worth and 0 in any other case. Strains 46–50 trigger mlistw.plugin to exit with error 416 if any remark in one of many variables incorporates a lacking worth. These strains are redundant, as a result of the sample-inclusion variable handed into mylistw.plugin excluded observations containing lacking values. I included these strains for instance how I might safely exclude lacking values from contained in the plugin and to reiterate that C code should rigorously cope with lacking values. Stata lacking values are legitimate double precision numbers in C. You’re going to get flawed outcomes when you embody Stata lacking values in calculations.
The remaining strains assemble the C string line that’s handed to Stata to show for every remark and at last show the abstract details about the pattern.
Estimating the imply in a C plugin
I now talk about the ado-command mymeanc, which makes use of mycalcs.plugin to implement the calculations carried out by mymean_work(), in mymean11.ado mentioned in Programming an estimation command in Stata: Making ready to jot down a plugin.
The code for mymeanc is in mymeanc.ado, which is in code block 5.
*! model 1.0.0 13Feb2018
program outline mymeanc, eclass
model 15.1
syntax varlist(numeric) [if] [in]
marksample touse
tempname b V N
native okay : phrase depend `varlist'
matrix `b' = J(1, `okay', .)
matrix `V' = J(`okay', `okay', .)
plugin name mycalcs `varlist' if `touse' `in', `b' `V' `N'
matrix colnames `b' = `varlist'
matrix colnames `V' = `varlist'
matrix rownames `V' = `varlist'
ereturn publish `b' `V', esample(`touse')
ereturn scalar N = `N'
ereturn scalar df_r = `N'-1
ereturn show
finish
program mycalcs, plugin
The final construction of this program is identical as mymean10.ado and mymean11, mentioned in Programming an estimation command in Stata: Making ready to jot down a plugin. From a fowl’s-eye view, mymeanc.ado,
- parses the consumer enter;
- creates some names and objects to carry the outcomes;
- calls a piece program to do the calculations;
- shops the outcomes returned by the work program in e(); and
- shows the outcomes.
The primary distinction between mymeanc.ado and mymean11.ado is that the work program is a C plugin as a substitute of a Mata perform.
Strains 6 and seven are equivalent to these in mylistc.ado. For an outline of how these strains create the native macro varlist, the sample-inclusion variable contained within the native macro touse, and the native macro in that incorporates any user-specified in vary, see the dialogue of mylistc.ado in Gaining access to the Stata information in your plugin.
Line 8 places non permanent names into the native macros b, V, and N. We use these names for outcomes computed by the C plugin and know that we’ll not overwrite any outcomes {that a} consumer has saved in international Stata reminiscence. (Recall that Stata matrices and scalars are international objects in Stata; see Utilizing non permanent names for international objects in Programming an estimation command in Stata: A primary ado-command for a dialogue of this subject.) As well as, Stata will drop the objects within the non permanent names created by tempname, when mymeanc
terminates.
Strains 10–12 create Stata matrices to carry the outcomes. We use the non permanent names created by tempname for these matrices.
Line 14 in mymeanc.ado is just like its counterpart of line 10 in mylistc.ado. On this case, plugin calls mycalcs.plugin to do the work. The small print of varlist, if `touse’ and `in’ had been mentioned above. What’s new is that we move the argument `b’ `V’ `N’ to move the non permanent names to mycalcs.plugin.
mycalcs.plugin
- does the calculations;
- places the estimated means into the Stata matrix whose identify is within the native macro b;
- places the estimated variance of the estimator (VCE) into the Stata matrix whose identify is within the native macro V; and
- places the variety of observations within the pattern into the Stata scalar whose identify is within the native macro N.
Strains 16–18 put the variable names on the column stripe of the vector of estimated means and on the row and column stripes of the VCE matrix. Strains 19–21 retailer the ends in e(). Line 22 shows the outcomes.
I now talk about the code that creates mycalcs.plugin. Earlier than discussing particulars, let’s create the plugin and run an instance.
In a listing that incorporates mycalcs.c, mycalcsw.h, mycalcsw.c, stplugin.c, and stplugin.h, I created mycalcs.plugin on my Mac by typing
gcc -bundle -DSYSTEM=APPLEMAC stplugin.c mycalcsw.c mycalcs.c -o mycalcs.plugin
Having created mycalcs.plugin, I ran instance 3.
Instance 3: mymeanc
. mymeanc mpg trunk rep78 in 1/60
------------------------------------------------------------------------------
| Coef. Std. Err. t P>|t| [95% Conf. Interval]
-------------+----------------------------------------------------------------
mpg | 20.125 .6659933 30.22 0.000 18.79032 21.45968
trunk | 14.42857 .5969931 24.17 0.000 13.23217 15.62497
rep78 | 3.160714 .118915 26.58 0.000 2.922403 3.399025
------------------------------------------------------------------------------
I now talk about some facets of the C code used to create mycalcs.plugin. I start with mycalcs.c in code block 6, which incorporates the code for the entry perform stata_call().
// model 1.0.0 14Feb2018 #embody "stplugin.h" #embody#embody #embody #embody "mycalcsw.h" //Unicode characters could make Stata names as much as 32*4+1 bytes STDLL stata_call(int argc, char *argv[]) { ST_int first, final, nVars, nObs ; ST_int i ; ST_retcode rc ; char bname[130], vname[130], nname[130], msg[81] ; ST_double *bmat, *vmat ; bmat = NULL ; vmat = NULL ; // Put variety of variables in varlist in to nVars nVars = SF_nvars() ; // Put the primary remark in pattern into first first = SF_in1(); // Put the final remark in pattern into final final = SF_in2(); // Test that arguments should not too lengthy for buffers for(i=0; i<3; i++) { if (strlen(argv[i])>129) { sprintf(msg, "Argument %d is greater than 129 bytes longn",i+1); SF_error(msg) ; return((ST_retcode) 198) ; } } // Retailer arguments into strings // NB: No extra checking required // SPI features will return nonzero codes if arguments specify dangerous names strcpy(bname,argv[0]) ; strcpy(vname,argv[1]) ; strcpy(nname,argv[2]) ; // Allocate house for bmat and initialize to 1 x c matrix of zeros rc = InitCmat(&bmat, (ST_int) 1, nVars ) ; if (rc>0) { return( rc ) ; } // Allocate house for vmat and initialize to nVars x nVars matrix of zeros rc = InitCmat(&vmat, nVars, nVars ) ; if (rc>0) { free(bmat) ; return( rc ) ; } // Put pattern averages in bmat and variety of obs in n rc = MyAve(bmat, first, final, nVars, &nObs) ; if(rc>0) { free(bmat) ; free(vmat) ; return(rc) ; } // Put VCE in vmat rc = MyV(bmat, vmat, first, final, nVars, nObs) ; if(rc>0) { free(bmat) ; free(vmat) ; return(rc) ; } // Copy pattern averages from bmat to Stata matrix bname rc = CopyCtoStataMatrix(bmat, bname, (ST_int) 1, nVars) ; if(rc>0) { free(bmat) ; free(vmat) ; return(rc) ; } // Copy VCE from vmat to Stat matrix vname rc = CopyCtoStataMatrix(vmat, vname, nVars, nVars) ; if(rc>0) { free(bmat) ; free(vmat) ; return(rc) ; } // Copy variety of obs from nObs to nname rc = SF_scal_save(nname, (ST_double) nObs); if(rc>0) { free(bmat) ; free(vmat) ; return(rc) ; } free(bmat) ; free(vmat) ; return(rc) ; }
In abstract, the code in mycalcs.c performs the next duties.
- It places the names of Stata objects handed in as arguments into C strings that may be handed to work features.
- It makes use of the work perform InitCmat() to allocate house for the C arrays bmat and vmat that can maintain matrix outcomes.
- It makes use of the work features MyAve() and MyV() to compute the outcomes which can be saved in bmat, vmat, and nObs.
- It makes use of the work perform CopyCtoStataMatrix() and the SPI perform SF_scal_save() to repeat the outcomes from bmat, vmat, and nObs to the Stata objects whose names had been parsed in step 1.
- It frees the allotted C arrays and returns a return code.
mycalcs.c is simple to learn, as a result of I put all the small print into the work features. These features are outlined in mycalcsw.c, and I talk about them under.
Like mylistw.c, mycalcs.c makes use of the return code rc to deal with error circumstances. Every work perform returns zero if all went nicely, and it returns a nonzero error code if it couldn’t carry out the requested job. If the return code will not be zero, mycalcs.c enters right into a block of code to deal with the error. Every error block makes Stata show an error message, it frees any allotted C arrays, and at last, it causes stata_call() to return the nonzero code.
I now talk about the work features in mycalcsw.c in code block 7.
// model 1.0.0 14Feb2018 #embody#embody #embody "stplugin.h" #embody "mycalcsw.h" // Observe: Matrices are lengthy vectors with row-major storage // The i,j ingredient of an r x c matrix is // the (i-1)*r + (j-1) ingredient of the of the vector // beneath C-style zero-base indexing // // Outline preprocesor macros to facilitate readability #outline M(i, j) *(*mat + (i)*c + j) #outline B(j) *(bmat+j) #outline E(j) *(emat+j) #outline V(i, j) *(vmat + (i)*c + j) #outline C(i, j) *(cmat + (i)*c + j) ST_retcode InitCmat(ST_double **mat, ST_int r, ST_int c) { ST_int i, j ; char msg[80] ; *mat = (ST_double *) malloc((size_t) r*c*sizeof(ST_double)) ; if (*mat == NULL ) { sprintf(msg, "Inadequate memoryn") ; SF_error(msg) ; return( (ST_retcode) 909) ; } for(i=0; i 0) { sprintf(msg, "Downside accessing Stata datan") ; SF_error(msg) ; return(rc) ; } if (SF_is_missing(worth)) { sprintf(msg, "lacking values encounteredn") ; SF_error(msg) ; return( (ST_retcode) 416 ) ; } B(j) += worth ; } } } DivideByScalar(bmat, (ST_int) 1, nVars, (ST_double) *nObs) ; return(rc) ; } ST_retcode MyV(ST_double *bmat, ST_double *vmat, ST_int first, ST_int final, ST_int nVars, ST_int nObs) { ST_int i, j, j2, c ; ST_double *emat, worth ; char msg[80] ; ST_retcode rc ; // utilized in macros for matrices c = nVars ; emat = NULL; rc = InitCmat(&emat, 1, nVars ) ; if (rc>0) { return( rc ) ; } for(i=first-1; i 0) { free(emat) ; sprintf(msg, "Downside accessing Stata datan") ; SF_error(msg) ; return(rc) ; } if (SF_is_missing(worth)) { free(emat) ; sprintf(msg, "lacking values encounteredn") ; SF_error(msg) ; return( (ST_retcode) 416 ) ; } E(j) = worth - B(j) ; } for(j=0; j 0) { sprintf(msg, "can't entry Stata matrix %sn", smat) ; SF_error(msg) ; return(rc) ; } } } return(rc) ; } // Substitute every ingredient in r x c matrix mat with that ingredient // divided by val void DivideByScalar(ST_double *vmat, ST_int r, ST_int c, ST_double val) { ST_int i, j ; for(i=0; i Two facets of how I carried out matrices in C arrays deserve some remark. First, I saved the matrices as vectors with row-major storage, as I discussed within the feedback on strains 7–10. Second, I used the preprocessor macros outlined on strains 14–18 to make the code simpler to learn. Observe that I undefined these macros on strains 166–169.
Other than its use of SF_error() to make Stata show an error message if malloc() can't allocate reminiscence, the work perform InitCmat() makes use of customary C to implement a matrix allocation and initialization perform.
The work perform MyAve() is a C implementation of the MyAve() carried out in Mata in Programming an estimation command in Stata: Making ready to jot down a plugin. MyAve() handles Stata information and lacking values as I described above, after I mentioned mylistw.c. The work perform DivideByScalar(), referred to as on line 71, divides every ingredient in bmat by the variety of pattern observations saved in n. (Casts be certain that floating level as a substitute of integer division is carried out.)
The work perform MyV() is a C implementation of the MyV() carried out in Mata in Programming an estimation command in Stata: Making ready to jot down a plugin. MyV() makes use of many of the coding strategies and features mentioned to date. This perform is longer than the others, however the whole lot in it's both customary C or one thing that I've already mentioned.
The work perform CopyCtoStataMatrix() copies outcomes from a C array to a Stata matrix. It makes use of SF_mat_store( smat, (i+1) , (j+1), C(i,j) ) to repeat the ingredient from row i and column j of a C array to to the corresponding ingredient within the Stata matrix. The Stata matrix components are specified as (i+1) and (j+1) as a result of the C matrices in my code use zero-based indexing whereas SF_mat_store() makes use of one-based indexing for the Stata matrix components.
The work perform DivideByScalar() divides every ingredient in a C array by a scalar.
For completeness, I now talk about mycalcsw.h. mycalcsw.h, given in code block 8, incorporates perform prototypes of the work features outlined in mycalcsw.c.
Code block 8: mycalcsw.h // model 1.0.0 14Feb2018 // header file for mycalcs.c and mycalcw.c ST_retcode InitCmat(ST_double **mat, ST_int r, ST_int c) ; ST_retcode MyAve(ST_double *bmat, ST_int first, ST_int final, ST_int nVars, ST_int *nObs) ; ST_retcode MyV(ST_double *bmat, ST_double *vmat, ST_int first, ST_int final, ST_int nVars, ST_int nObs) ; ST_retcode CopyCtoStataMatrix(ST_double *cmat, char *smat, ST_int r, ST_int c) ; void DivideByScalar(ST_double *mat, ST_int r, ST_int c, ST_double val) ;Achieved and undone
I confirmed tips on how to implement a C plugin that does the calculations carried out by Mata work features in mymean10.ado and mymean11.ado, as mentioned in program 29 publish.
Within the subsequent publish, I present tips on how to implement these calculations in a C++ plugin.
Appendix
Within the textual content, I confirmed tips on how to compile and hyperlink a plugin on an OS 10 Mac utilizing the
command-line developer instruments. Right here I give the instructions for the gcc compiler on Home windows 10 and on RedHat Linux.Home windows 10
This subsection gives the instructions to compile and hyperlink the plugins in a Cygwin setting on a 64-bit Home windows 10 system. In contrast to the opposite platforms, we can't simply use gcc. In Cygwin, gcc compiles functions to run within the Cygwin POSIX/Unix setting. We need to use Cygwin to compile a library that can hyperlink to, and run in, a local Home windows utility. Cygwin has minimalist GNU compilers for Home windows (MinGW) that can do what we would like. The identify of the suitable compiler is platform dependent. On my 64-bit, x86-Intel machine, I used the x86_64-w64-mingw32-gcc compiler.
hey.plugin
In a listing containing stplugin.h, stplugin.c, and hey.c, create hey.plugin by typing
x86_64-w64-mingw32-gcc -shared -mno-clwb stplugin.c hey.c -o hey.plugin
mylistw.plugin
In a listing that incorporates stplugin.h, stplugin.c, and mylistw.c, create mylistw.plugin by typing
x86_64-w64-mingw32-gcc -shared -mno-clwb stplugin.c mylistw.c -o mylistw.plugin
mycalcs.plugin
In a listing that incorporates stplugin.c, stplugin.h, mycalcs.c, mycalcsw.h, and mycalcsw.c, create mycalcs.plugin by typing
x86_64-w64-mingw32-gcc -shared -mno-clwb stplugin.c mycalcsw.c mycalcs.c -o mycalcs.plugin
RedHat Linux
This subsection gives the gcc instructions to compile and hyperlink plugins on RedHat Linux.
hey.plugin
In a listing containing stplugin.h, stplugin.c, and hey.c, create hey.plugin by typing
gcc -shared -fPIC -DSYSTEM=OPUNIX stplugin.c hey.c -o hey.plugin
mylistw.plugin
In a listing that incorporates stplugin.h, stplugin.c, and mylistw.c, create mylistw.plugin by typing
gcc -shared -fPIC -DSYSTEM=OPUNIX stplugin.c mylistw.c -o mylistw.plugin
mycalcs.plugin
In a listing that incorporates stplugin.c, stplugin.h, mycalcs.c, mycalcsw.h, and mycalcsw.c, create mycalcs.plugin by typing
gcc -shared -fPIC -DSYSTEM=OPUNIX stplugin.c mycalcsw.c mycalcs.c -o mycalcs.plugin








 Anthony Liguori is an AWS VP and Distinguished Engineer for Amazon Bedrock, and the lead engineer for Mantle.
Anthony Liguori is an AWS VP and Distinguished Engineer for Amazon Bedrock, and the lead engineer for Mantle.