As a part of the Chinese language spacecraft Shenzhou-15 tumbled again to Earth, its disintegration was tracked by a stunning supply: seismometers.
Seismic networks in southern California picked up floor vibrations induced by shock waves because the spacecraft entered Earth’s ambiance on April 2, 2024. Utilizing that information, scientists have been capable of monitor the trajectory of spacecraft bits extra precisely than counting on current methods to foretell it, the staff stories January 22 in Science. That implies that networks designed to detect earthquakes may also monitor falling area junk — defunct spacecraft or deserted launch {hardware} that may pose dangers to individuals and infrastructure.
As area particles plunges towards Earth, it travels quicker than the velocity of sound, producing shock waves, setting off ripple results under that have been detectable by seismometers. By analyzing the depth of these indicators, in addition to the exact timing once they attain the 127 seismometers within the community, researchers might estimate the particles’ altitude and trajectory. They might even monitor how the spacecraft broke down into a number of items, every one producing their very own cascading shock waves.
House particles is often monitored whereas in orbit utilizing ground-based radar, which may comply with objects as small as about 30 centimeters throughout. However as soon as fragments descend into the higher ambiance, interactions with the air trigger them to interrupt aside, decelerate and alter course in advanced methods. Because of this, predicted reentry paths may be off by a whole lot of kilometers. For Shenzhou-15, seismic information confirmed that it handed about 30 kilometers south of the trajectory predicted by U.S. House Command.
The work was impressed by methods used to trace meteoroids utilizing seismic and acoustic information, each on Earth and Mars. “I labored loads with NASA’s InSight mission, and for us, meteoroids have been truly a really helpful seismic supply,” says Benjamin Fernando, a seismologist and planetary scientist at Johns Hopkins College. InSight put the primary working seismometer on the floor of Mars. “A variety of what we did on this paper is actually taking methods developed for Mars and reapplying them to Earth.”
The precision of the detection is determined by the density of seismometer networks, since sonic booms propagate by way of the ambiance for less than about 100 kilometers. City areas usually have dense protection, however sparsely populated areas in seismically quiet areas don’t. This would possibly restrict the usefulness of the approach at a worldwide scale, says Daniel Stich, a seismologist on the College of Granada in Spain who was not concerned with the research.
Uncontrolled reentries have gotten extra frequent as the variety of spacecraft in orbit grows unchecked. Falling fragments can harm individuals or harm infrastructure, and particles usually incorporates poisonous fuels, flammable supplies or, in uncommon instances, radioactive energy sources. Whereas seismic monitoring is unlikely to supply advance warning, it might assist quickly assess the place particles fell and slender down areas vulnerable to contamination.
The research matches right into a latest pattern often known as environmental seismology, which makes use of seismic information to observe phenomena past earthquakes — from storms and avalanches to explosions, highway visitors throughout COVID or even Taylor Swift live shows, says Jordi Díaz Cusí, a seismologist on the Geosciences Institute of Barcelona who was not concerned with the brand new work. Monitoring the reentry of area particles, he says, “is an effective instance of how seismic information … can be utilized for issues very far faraway from their unique goal.”
I need to estimate, graph, and interpret the results of nonlinear fashions with interactions of steady and discrete variables. The outcomes I’m after will not be trivial, however acquiring what I would like utilizing margins, marginsplot, and factor-variable notation is simple.
Don’t create dummy variables, interplay phrases, or polynomials
Suppose I need to use probit to estimate the parameters of the connection
the place (y) is a binary end result, (d) is a discrete variable that takes on 4 values, (x) is a steady variable, and (P(y|x,d)) is the likelihood of my end result conditional on covariates. To suit this mannequin in Stata, I’d sort
probit y c.x##i.d c.x#c.x
I don’t must create variables for the polynomial or for the interactions between the continual variable (x) and the totally different ranges of (d). Stata understands that c.x#c.x is the sq. of (x) and that c.x##i.d corresponds to the variables (x) and (d) and their interplay. The results of what I typed would appear like this:
I didn’t must create dummy variables, interplay phrases, or polynomials. As we are going to see under, comfort isn’t the one motive to make use of factor-variable notation. Issue-variable notation permits Stata to determine interactions and to differentiate between discrete and steady variables to acquire right marginal results.
This instance used probit, however most of Stata’s estimation instructions permit using issue variables.
Utilizing margins to acquire the results I’m occupied with
I’m occupied with modeling for people the likelihood of being married (married) as a operate of years of education (training), the percentile of revenue distribution to which they belong (percentile), the variety of instances they’ve been divorced (divorce), and whether or not their mother and father are divorced (pdivorce). I estimate the next results:
The typical of the change within the likelihood of being married when every covariate adjustments. In different phrases, the typical marginal impact of every covariate.
The typical of the change within the likelihood of being married when the interplay of divorce and training adjustments. In different phrases, a mean marginal impact of an interplay between a steady and a discrete variable.
The typical of the change within the likelihood of being married when the interplay of divorce and pdivorce adjustments. In different phrases, a mean marginal impact of an interplay between two discrete variables.
The typical of the change within the likelihood of being married when the interplay of percentile and training adjustments. In different phrases, a mean marginal impact of an interplay between two steady variables.
I match the mannequin:
probit married c.training##c.percentile c.training#i.divorce ///
i.pdivorce##i.divorce
The typical of the change within the likelihood of being married when the degrees of the covariates change is given by
. margins, dydx(*)
Common marginal results Variety of obs = 5,000
Mannequin VCE : OIM
Expression : Pr(married), predict()
dy/dx w.r.t. : training percentile 1.divorce 2.divorce 1.pdivorce
----------------------------------------------------------------------------
| Delta-method
| dy/dx Std. Err. z P>|z| [95% Conf. Interval]
-------------+--------------------------------------------------------------
training | .02249 .0023495 9.57 0.000 .017885 .027095
percentile | .9873168 .062047 15.91 0.000 .8657069 1.108927
|
divorce |
1 | -.0434363 .0171552 -2.53 0.011 -.0770598 -.0098128
2 | -.1239932 .054847 -2.26 0.024 -.2314913 -.0164951
|
1.pdivorce | -.0525977 .0131892 -3.99 0.000 -.0784482 -.0267473
----------------------------------------------------------------------------
Observe: dy/dx for issue ranges is the discrete change from the bottom degree.
The primary a part of the margins output states the statistic it will compute, on this case, the typical marginal impact. Subsequent, we see the idea of an Expression. That is normally the default prediction (on this case, the conditional likelihood), however it may be every other prediction out there for the estimator or any operate of the coefficients, as we are going to see shortly.
When margins computes an impact, it distinguishes between steady and discrete variables. That is basic as a result of a marginal impact of a steady variable is a spinoff, whereas a marginal impact of a discrete variable is the change of the Expression evaluated at every worth of the discrete covariate relative to the Expression evaluated on the base or reference degree. This highlights the significance of utilizing factor-variable notation.
I now interpret a few the results. On common, a one-year change in training will increase the likelihood of being married by 0.022. On common, the likelihood of being married is 0.043 smaller within the case the place everybody has been divorced as soon as in contrast with the case the place nobody has ever been divorced, a mean therapy impact of (-)0.043. The typical therapy impact of being divorced two instances is (-)0.124.
Now I estimate the typical marginal impact of an interplay between a steady and a discrete variable. Interactions between steady and discrete variables are adjustments within the steady variable evaluated on the totally different values of the discrete covariate relative to the bottom degree. To acquire these results, I sort
. margins divorce, dydx(training) pwcompare
Pairwise comparisons of common marginal results
Mannequin VCE : OIM
Expression : Pr(married), predict()
dy/dx w.r.t. : training
--------------------------------------------------------------
| Distinction Delta-method Unadjusted
| dy/dx Std. Err. [95% Conf. Interval]
-------------+------------------------------------------------
training |
divorce |
1 vs 0 | .0012968 .0061667 -.0107897 .0133833
2 vs 0 | .0403631 .0195432 .0020591 .0786672
2 vs 1 | .0390664 .0201597 -.0004458 .0785786
--------------------------------------------------------------
The typical marginal impact of training is 0.039 increased when everyone seems to be divorced two instances as an alternative of everybody being divorced one time. The typical marginal impact of training is 0.040 increased when everyone seems to be divorced two instances as an alternative of everybody being divorced zero instances. The typical marginal impact of training is 0 when everyone seems to be divorced one time as an alternative of everybody being divorced zero instances. One other approach of acquiring this result’s by computing a cross or double spinoff. As I discussed earlier than, we use derivatives for steady variables and variations with respect to the bottom degree for the discrete variables. I’ll consult with them loosely as derivatives hereafter. Within the appendix, I present that taking a double spinoff is equal to what I did above.
Analyzing the interplay between two discrete variables is just like analyzing the interplay between a discrete and a steady variable. We need to see the change from the bottom degree of a discrete variable for a change within the base degree of the opposite variable. We use the pwcompare and dydx() choices once more.
. margins pdivorce, dydx(divorce) pwcompare
Pairwise comparisons of common marginal results
Mannequin VCE : OIM
Expression : Pr(married), predict()
dy/dx w.r.t. : 1.divorce 2.divorce
--------------------------------------------------------------
| Distinction Delta-method Unadjusted
| dy/dx Std. Err. [95% Conf. Interval]
-------------+------------------------------------------------
1.divorce |
pdivorce |
1 vs 0 | -.1610815 .0342655 -.2282407 -.0939223
-------------+------------------------------------------------
2.divorce |
pdivorce |
1 vs 0 | -.0201789 .1098784 -.2355367 .1951789
--------------------------------------------------------------
Observe: dy/dx for issue ranges is the discrete change from the
base degree.
The typical change within the likelihood of being married when everyone seems to be as soon as divorced and everybody’s mother and father are divorced, in contrast with the case the place nobody’s mother and father are divorced and nobody is divorced, is a lower of 0.161. The typical change within the likelihood of being married when everyone seems to be twice divorced and everybody’s mother and father are divorced, in contrast with the case the place nobody’s mother and father are divorced and nobody is divorced, is 0. We might have obtained the identical consequence by typing margins divorce, dydx(pdivorce) pwcompare, which once more emphasizes the idea of a cross or double spinoff.
Now I have a look at the typical marginal impact of an interplay between two steady variables.
The Expression is the spinoff of the conditional likelihood with respect to percentile. dydx(training) specifies that I need to estimate the spinoff of this Expression with respect to training. The typical marginal impact within the marginal impact of revenue percentile attributable to a change in training is 0.062.
As a result of margins can solely take first derivatives of expressions, I obtained a cross spinoff by making the expression a spinoff. Within the appendix, I present the equivalence between this technique and writing a cross spinoff. Additionally, I illustrate confirm that your expression for the primary spinoff is right.
Graphing
After margins, we are able to plot the leads to the output desk just by typing marginsplot. marginsplot works with the traditional graphics choices and the Graph Editor. For the primary instance above, as an illustration, I might sort
I added the choice xlabel(, angle(vertical)) to acquire vertical labels for the horizontal axis. The result’s as follows:
Conclusion
I illustrated compute, interpret, and graph marginal results for nonlinear fashions with interactions of discrete and steady variables. To interpret interplay results, I used the ideas of a cross or double spinoff and an Expression. I used simulated information and the probit mannequin for my examples. Nevertheless, what I wrote extends to different nonlinear fashions.
Appendix
To confirm that your expression for the primary spinoff is right, you evaluate it with the statistic computed by margins with the choice dydx(variable). For the instance within the textual content:
generate buyer journeys that seem easy and interesting, however evaluating whether or not these journeys are structurally sound stays difficult for present strategies.
This text introduces Continuity, Deepening, and Development (CDP) — three deterministic, content-structure-based metrics for evaluating multi-step journeys utilizing a predefined taxonomy moderately than stylistic judgment.
Historically, optimizing customer-engagement methods has concerned fine-tuning supply mechanics equivalent to timing, channel, and frequency to attain engagement and enterprise outcomes.
In apply, this meant you educated the mannequin to know guidelines and preferences, equivalent to “Don’t contact clients too usually”,“Consumer Alfa responds higher to telephone calls”, and “Consumer Beta opens emails principally within the night.”
To handle this, you constructed a cool-off matrix to stability timing, channel constraints, and enterprise guidelines to control buyer communication.
To this point, so good. The mechanics of supply are optimized.
At this level, the core problem arises when the LLM generates the journey itself. The problem is not only about channel or timing, however whether or not the sequence of messages kinds a coherent, efficient narrative that meets enterprise aims.
And all of a sudden you understand:
There isn’t a normal metric to find out if an AI-generated journey is coherent, significant, or advances enterprise targets.
What We Count on From a Profitable Buyer Journey
From a enterprise perspective, the sequence of contents per journey step can’t be random: it have to be a guided expertise that feels coherent, strikes the client ahead by significant levels, and deepens the connection over time.
Whereas this instinct is frequent, it is usually supported by customer-engagement analysis. Brodie et al. (2011) describe engagement as “a dynamic, iterative course of” that varies in depth and complexity as worth is co-created over time.
In apply, we consider journey high quality alongside three complementary dimensions:
Continuity — whether or not every message suits the context established by prior interactions.
Deepening — whether or not content material turns into extra particular, related, or personalised moderately than remaining generic.
Development — whether or not the journey advances by levels (e.g., from exploration to motion) with out pointless backtracking.
Why Current LLM Analysis Metrics Fall Quick
If we take a look at normal analysis strategies for LLMs, equivalent to accuracy metrics, similarity metrics, human-evaluation standards, and even LLM-as-a-judge, it turns into clear that none present a dependable, unambiguous strategy to consider buyer journeys generated as multi-step sequences.
Let’s look at what normal buyer journey metrics can and may’t present.
Accuracy Metrics (Perplexity, Cross-Entropy Loss)
These metrics measure confidence degree in predicting the subsequent token given the coaching knowledge. They don’t seize whether or not a generated sequence kinds a coherent or significant journey.
These metrics evaluate the generated end result to a reference textual content. Nevertheless, buyer journeys hardly ever have a single appropriate reference, as they adapt to context, personalization, and prior interactions. Structurally legitimate journeys could differ considerably whereas remaining efficient.
Undoubtedly, semantic similarity has its benefits, and we’ll use cosine similarity, however extra on that later.
Human Analysis (Fluency, Relevance, Coherence)
Human judgment usually outperforms automated metrics in assessing language high quality, however it’s poorly suited to steady journey analysis. It’s costly, suffers from cultural bias and ambiguity, and doesn’t perform as a everlasting a part of the workflow however moderately as a one-time effort to bootstrap a fine-tuning stage.
LLM-as-a-Decide (AI suggestions scoring)
Utilizing LLMs to guage outputs from different LLM methods is a formidable course of.
This strategy tends to focus extra on fashion, readability, and tone moderately than structural analysis.
LLM-as-a-Decide might be utilized in multi-stage use instances, however outcomes are sometimes much less exact as a result of elevated danger of context overload. Moreover, fine-grained analysis scores from this technique are sometimes unreliable. Like human evaluators, LAAJ additionally carries biases and ambiguities.
A Structural Method to Evaluating Buyer Journeys
Finally, the first lacking ingredient in evaluating really useful content material sequences throughout the buyer journey is construction.
Probably the most pure strategy to symbolize content material construction is as a taxonomic tree, a hierarchical mannequin consisting of levels, content material themes, and ranges of element.
As soon as buyer journeys are mapped onto this tree, CDP metrics might be outlined as structural variations:
Continuity: easy motion throughout branches
Deepening: transferring into extra particular nodes
Development: transferring ahead by buyer journey levels
The answer is to symbolize a journey as a path by a hierarchical taxonomy derived from the content material house. As soon as this illustration is established, CDP metrics might be computed deterministically from the trail. The diagram under summarizes your entire pipeline.
Picture created by the creator
Developing the Taxonomy Tree
To judge buyer journeys structurally, we first require a structured illustration of content material. We assemble this illustration as a multi-level taxonomy derived straight from customer-journey textual content utilizing semantic embeddings.
The taxonomy is anchored by a small set of high-level levels (e.g., motivation, buy, supply, possession, and loyalty). Each anchors and journey messages are embedded into the identical semantic vector house, permitting content material to be organized by semantic proximity.
Inside every anchor, messages are grouped into progressively extra particular themes, forming deeper ranges of the taxonomy. Every degree refines the earlier one, capturing growing topical specificity with out counting on handbook labeling.
The result’s a hierarchical construction that teams semantically associated journey messages and gives a steady basis for evaluating how journeys move, deepen, and progress over time.
Mapping Buyer Journeys onto the Taxonomy
As soon as the taxonomy is established, particular person buyer journeys are mapped onto it as ordered sequences of messages. Every step is embedded in the identical semantic house and matched to the closest taxonomy node utilizing cosine similarity.
This mapping converts a temporal sequence of messages right into a path by the taxonomy, enabling the structural evaluation of journey evolution moderately than treating the journey as a flat record of texts.
Defining the CDP Metrics
The CDP framework consists of three complementary metrics: Continuity, Deepening, and Development. Every captures a definite side of journey high quality. We describe these metrics conceptually earlier than defining them formally primarily based on the taxonomy-mapped journey.
Desk 1: Every CDP metric captures a distinct side of journey high quality: coherence, specificity, and development.
Setup and Computation
Earlier than analyzing actual journeys, we make clear two elements of the setup. (1) how journey content material is structurally represented, and (2) how CDP metrics are derived from that construction.
Buyer-journey content material is organized right into a hierarchical taxonomy consisting of anchors (L1 journey levels), thematic heads (L2 subjects), and deeper nodes that symbolize growing specificity:
As soon as a journey is mapped onto this hierarchy, Continuity, Deepening, and Development are computed deterministically from the journey’s path by the tree.
Let a buyer journey be an ordered sequence of steps:
J = (x₁, x₂, …, xₙ)
Every step xᵢ is assigned:
aᵢ — anchor (L1 journey stage)
tᵢ — thematic head (L2 subject), the place tᵢ = 0 means “unknown”
Continuity evaluates whether or not consecutive messages stay contextually and thematically coherent.
For every transition (xᵢ →xᵢ₊₁), a step-level continuity rating cᵢ ∈ [0, 1] is assigned primarily based on taxonomy alignment, with greater weights given to transitions that keep throughout the similar subject or intently associated branches.
Transitions are ranked from strongest to weakest (e.g., similar subject, associated subject, ahead stage transfer, backward transfer), and assigned lowering weights:
1 ≥ α₁ > α₂ > α₃ > α₄ > α₅ > α₆ ≥ 0
The general continuity rating is computed as:
C(J) = (1 / (n − 1)) · Σ cᵢ for i = 1 … n−1
Deepening (D)
Deepening measures whether or not a journey accumulates worth by transferring from common content material towards extra particular or detailed interactions. It’s computed utilizing two complementary parts.
Journey-based deepening captures how depth adjustments alongside the noticed path:
Δᵢᵈᵉᵖᵗʰ = ℓᵢ₊₁ − ℓᵢ, dᵢ = max(Δᵢᵈᵉᵖᵗʰ, 0)
D_journey(J) = (1 / (n − 1)) · Σ dᵢ
Taxonomy-aware deepening measures how deeply a journey explores the precise taxonomy tree, primarily based on the heads it visits. It evaluates how most of the attainable deeper content material objects (kids, sub-children, and so on.) underneath every visited head are later seen throughout the journey.
D_taxonomy(J) = |D_seen(J)| / |D_exist(J)|
The ultimate deepening rating is a weighted mixture:
Making use of CDP Metrics to an Automotive Buyer Journey
To show how structured analysis works on lifelike journeys, we generated an artificial automotive customer-journey dataset masking the primary levels of the client lifecycle.
Picture created by the creator utilizing Excalidraw
Enter Information: Anchors and Journey Content material
The CDP framework makes use of two important inputs: anchors, which outline journey levels, and customer-journey content material, which gives the messages to guage.
Anchors symbolize significant phases within the lifecycle, equivalent to motivation, buy, supply, possession, and loyalty. Every anchor is augmented with a small set of consultant key phrases to floor it semantically. Anchors serve each as reference factors for taxonomy development and because the anticipated directional move used later within the Development metric.
Buyer-journey content material consists of quick, action-oriented CRM-style messages (emails, calls, chats, in-person interactions) with various ranges of specificity and spanning a number of levels. Though this dataset is synthetically generated, anchor data will not be used throughout taxonomy development or CDP scoring.
CJ messages:
Discover fashions that match your life-style and private targets.
Take a digital tour to find key options and trims.
Evaluate physique types to evaluate house, consolation, and utility.
E book a check drive to expertise dealing with and visibility.
Use the wants evaluation to rank must-have options.
Filter fashions by vary, mpg, or towing to slender decisions.
Taxonomy Development Outcomes
Right here, we utilized the taxonomy development course of to the automotive customer-engagement dataset. The determine under reveals the ensuing customer-journey taxonomy, constructed from message content material and anchor semantics.
Every top-level department corresponds to a journeyanchor (L1), which represents main journey levels equivalent to Motivation, Buy, Supply, Possession, and Loyalty.
Deeper ranges (L2, L3+) group messages by thematic similarity and growing specificity.
Taxonomy of Buyer-Journey Messages
What the Taxonomy Reveals
Even on this compact dataset, the taxonomy highlights a number of purposeful patterns:
Early-stage messages cluster round exploration and comparability, progressively narrowing towards concrete actions equivalent to reserving a check drive.
Buy-related content material separates naturally into monetary planning, doc dealing with, and finalization.
Possession content material reveals a transparent development from upkeep scheduling to diagnostics, price estimation, and guarantee analysis.
Loyalty content material shifts from transactional actions towards suggestions, upgrades, and advocacy.
Whereas these patterns align with how practitioners usually motive about journeys, they come up straight from the information moderately than from predefined guidelines.
Why This Issues for Analysis
This taxonomy now gives a shared structural reference:
Any buyer journey might be mapped as a path by the tree.
Motion throughout branches, depth ranges, and anchors turns into measurable.
Continuity, Deepening, and Development are not summary ideas; they now correspond to concrete structural adjustments.
Within the subsequent part, we use this taxonomy to map actual journey examples and compute CDP scores in steps.
Mapping Buyer Journeys onto the Taxonomy
As soon as the taxonomy is constructed, evaluating a buyer journey turns into a structural drawback.
Every journey is represented as an ordered sequence of customer-facing messages.
As a substitute of judging these messages in isolation, we mission them onto the taxonomy and analyze the ensuing path.
Formally, a journey J = (x₁, x₂, …, xₙ) is mapped to a sequence of taxonomy nodes: (x₁→v₁),(x₂→v₂),…,(xₙ→vₙ) the place every vᵢis the closest taxonomy node primarily based on embedding similarity.
A Step-by-Step Walkthrough: From Journey Textual content to CDP Scores
To make the CDP framework concrete, let’s stroll by a single buyer journey instance and present how it’s evaluated step-by-step.
Step 1 — The Buyer Journey Enter
We start with an ordered sequence of customer-facing messages generated by an LLM. Every message represents a touchpoint in a practical automotive buyer journey:
journey = ['Take a virtual tour to discover key features and trims.';
'We found a time slot for a test drive that fits your schedule.';
'Upload your income verification and ID to finalize the pre-approval decision.';
'Estimate costs for upcoming maintenance items.';
'Track retention offers as your lease end nears.';
'Add plates and registration info before handover.']
Step 2 — Mapping the Journey into the Taxonomy
For structural analysis, every journey step is mapped into the customer-journey taxonomy. Utilizing textual content embeddings, every message is matched to its closest taxonomy node. This produces a journey map (jmap), a structured illustration of how the journey traverses the taxonomy.
Desk 2: Every message is assigned to an anchor (stage), a thematic head, and a depth degree within the taxonomy primarily based on semantic similarity within the shared embedding house. This desk acts as the muse for all future evaluations.
Step 3 — Making use of CDP Metrics to This Journey
As soon as the journey is mapped, we compute Continuity, Deepening, and Development deterministically from step-to-step transitions.
Desk 3: Every row represents a transition between consecutive journey steps, annotated with indicators for continuity, deepening, and development.
Ultimate CDP scores (this journey):
Taken collectively, the CDP indicators point out a journey that’s largely coherent and forward-moving, with one clear second of deepening and one seen structural regression. Importantly, these insights are derived solely from construction, not from stylistic judgments in regards to the textual content.
Conclusion: From Scores to Profitable Journeys
Continuity, Deepening, and Development are decided by construction and might be utilized wherever LLMs generate multi-step content material:
to check different journeys generated by completely different prompts or fashions,
to offer automated suggestions for bettering journey era over time.
On this means, CDP scores provide structural suggestions for LLMs. They complement, moderately than change, stylistic or fluency-based analysis by offering indicators that mirror enterprise logic and buyer expertise.
Though this text focuses on automotive commerce, the idea is broadly relevant. Any system that generates ordered, goal-oriented content material requires sturdy structural foundations.
Massive language fashions are already able to producing fluent, persuasive textual content. The higher problem is making certain that textual content sequencestype coherent narratives that align with enterprise logic and consumer expertise.
CDP gives a strategy to make construction specific, measurable, and actionable.
Thanks for staying with me by this journey. Hopefully, this idea helps you assume in another way about evaluating AI-generated sequences and evokes you to deal with construction as a major sign in your personal methods. All logic introduced on this article is applied within the accompanying Python code on GitHub. You probably have any questions or feedback, please depart them within the feedback part or attain out through LinkedIn.
References
Brodie, R. J., et al. (2011). Buyer engagement: Conceptual area, elementary propositions, and implications for analysis.
The speedy progress of huge language fashions (LLMs), multi‑modal architectures and generative AI has created an insatiable demand for compute. NVIDIA’s Blackwell B200 GPU sits on the coronary heart of this new period. Introduced at GTC 2024, this twin‑die accelerator packs 208 billion transistors, 192 GB of HBM3e reminiscence and a 1 TB/s on‑bundle interconnect. It introduces fifth‑era Tensor Cores supporting FP4, FP6 and FP8 precision with two‑instances the throughput of Hopper for dense matrix operations. Mixed with NVLink 5 offering 1.8 TB/s of inter‑GPU bandwidth, the B200 delivers a step change in efficiency—as much as 4× sooner coaching and 30× sooner inference in contrast with H100 for lengthy‑context fashions. Jensen Huang described Blackwell as “the world’s strongest chip”, and early benchmarks present it affords 42 % higher vitality effectivity than its predecessor.
Fast Digest
Key query
AI overview reply
What’s the NVIDIA B200?
The B200 is NVIDIA’s flagship Blackwell GPU with twin chiplets, 208 billion transistors and 192 GB HBM3e reminiscence. It introduces FP4 tensor cores, second‑era Transformer Engine and NVLink 5 interconnect.
Why does it matter for AI?
It delivers 4× sooner coaching and 30× sooner inference vs H100, enabling LLMs with longer context home windows and combination‑of‑specialists (MoE) architectures. Its FP4 precision reduces vitality consumption and reminiscence footprint.
Who wants it?
Anybody constructing or high quality‑tuning giant language fashions, multi‑modal AI, laptop imaginative and prescient, scientific simulations or demanding inference workloads. It’s preferrred for analysis labs, AI corporations and enterprises adopting generative AI.
Tips on how to entry it?
By way of on‑prem servers, GPU clouds and compute platforms akin to Clarifai’s compute orchestration—which affords pay‑as‑you‑go entry, mannequin inference and native runners for constructing AI workflows.
The sections beneath break down the B200’s structure, actual‑world use instances, mannequin suggestions and procurement methods. Every part consists of professional insights summarizing opinions from GPU architects, researchers and trade leaders, and Clarifai ideas on how you can harness the {hardware} successfully.
B200 Structure & Improvements
How does the Blackwell B200 differ from earlier GPUs?
Reply: The B200 makes use of a twin‑chiplet design the place two reticle‑restricted dies are related by a 10 TB/s chip‑to‑chip interconnect. This successfully doubles the compute density inside the SXM5 socket. Its fifth‑era Tensor Cores add help for FP4, a low‑precision format that cuts reminiscence utilization by as much as 3.5× and improves vitality effectivity 25‑50×. Shared Reminiscence clusters supply 228 KB per streaming multiprocessor (SM) with 64 concurrent warps to extend utilization. A second‑era Transformer Engine introduces tensor reminiscence for quick micro‑scheduling, CTA pairs for environment friendly pipelining and a decompression engine to speed up I/O.
Professional Insights:
NVIDIA engineers observe that FP4 triples throughput whereas retaining accuracy for LLM inference; vitality per token drops from 12 J on Hopper to 0.4 J on Blackwell.
Microbenchmark research present the B200 delivers 1.56× greater blended‑precision throughput and 42 % higher vitality effectivity than the H200.
The Subsequent Platform highlights that the B200’s 1.8 TB/s NVLink 5 ports scale practically linearly throughout a number of GPUs, enabling multi‑GPU servers like HGX B200 and GB200 NVL72.
Roadmap commentary notes that future B300 (Blackwell Extremely) GPUs will increase reminiscence to 288 GB HBM3e and ship 50 % extra FP4 efficiency—an necessary signpost for planning deployments.
Structure particulars and new options
The B200’s structure introduces a number of improvements:
Twin‑Chiplet Bundle: Two GPU dies are related by way of a 10 TB/s interconnect, successfully doubling compute density whereas staying inside reticle limits.
208 billion transistors: One of many largest chips ever manufactured.
192 GB HBM3e with 8 TB/s bandwidth: Eight stacks of HBM3e reminiscence ship eight terabytes per second of bandwidth. This bandwidth is crucial for feeding giant matrix multiplications and a focus mechanisms.
fifth‑Technology Tensor Cores: Assist FP4, FP6 and FP8 codecs. FP4 cuts reminiscence utilization by as much as 3.5× and affords 25–50× vitality effectivity enhancements.
NVLink 5: Offers 1.8 TB/s per GPU for peer‑to‑peer communication.
Second‑Technology Transformer Engine: Introduces tensor reminiscence, CTA pairs and decompression engines, enabling dynamic scheduling and decreasing reminiscence entry overhead.
L2 cache and shared reminiscence: Every SM options 228 KB of shared reminiscence and 64 concurrent warps, enhancing thread‑degree parallelism.
Optionally available ray‑tracing cores: Present {hardware} acceleration for 3D rendering when wanted.
Inventive Instance: Think about coaching a 70B‑parameter language mannequin. On Hopper, the mannequin would require a number of GPUs with 80 GB every, saturating reminiscence and incurring heavy recomputation. The B200’s 192 GB HBM3e means the mannequin suits into fewer GPUs. Mixed with FP4 precision, reminiscence footprints drop additional, enabling extra tokens per batch and sooner coaching. This illustrates how structure improvements straight translate to developer productiveness.
Use Instances for NVIDIA B200
What AI workloads profit most from the B200?
Reply: The B200 excels in coaching and high quality‑tuning giant language fashions, reinforcement studying, retrieval‑augmented era (RAG), multi‑modal fashions, and excessive‑efficiency computing (HPC).
Pre‑coaching and high quality‑tuning
Large transformer fashions: The B200 reduces pre‑coaching time by 4× in contrast with H100. Its reminiscence permits lengthy context home windows (e.g., 128k‑tokens) with out offloading.
Positive‑tuning & RLHF: FP4 precision and improved throughput speed up parameter‑environment friendly high quality‑tuning and reinforcement studying from human suggestions. In experiments, B200 delivered 2.2× sooner high quality‑tuning of LLaMA‑70B in contrast with H200.
Inference & RAG
Lengthy‑context inference: The B200’s twin‑die reminiscence allows 30× sooner inference for lengthy context home windows. This hastens chatbots and retrieval‑augmented era duties.
MoE fashions: In combination‑of‑specialists architectures, every professional can run concurrently; NVLink 5 ensures low‑latency routing. A MoE mannequin working on the GB200 NVL72 rack achieved 10× sooner inference and one‑tenth the associated fee per token.
Multi‑modal & laptop imaginative and prescient
Imaginative and prescient transformers (ViT), diffusion fashions and generative video require giant reminiscence and bandwidth. The B200’s 8 TB/s bandwidth retains pipelines saturated.
Ray tracing for 3D generative AI: B200’s optionally available RT cores speed up photorealistic rendering, enabling generative simulation and robotics.
Excessive‑Efficiency Computing (HPC)
Scientific simulation: B200 achieves 90 TFLOPS of FP64 efficiency, making it appropriate for molecular dynamics, local weather modeling and quantum chemistry.
Combined AI/HPC workloads: NVLink and NVSwitch networks create a coherent reminiscence pool throughout GPUs for unified programming.
Professional Insights:
DeepMind & OpenAI researchers have famous that scaling context size requires each reminiscence and bandwidth; the B200’s structure solves reminiscence bottlenecks.
AI cloud suppliers noticed {that a} single B200 can substitute two H100s in lots of inference situations.
Clarifai Perspective
Clarifai’s Reasoning Engine leverages B200 GPUs to run advanced multi‑mannequin pipelines. Prospects can carry out Retrieval‑Augmented Technology by pairing Clarifai’s vector search with B200‑powered LLMs. Clarifai’s compute orchestration robotically assigns B200s for coaching jobs and scales all the way down to price‑environment friendly A100s for inference, maximizing useful resource utilization.
Advisable Fashions & Frameworks for B200
Which fashions greatest exploit B200 capabilities?
Reply: Fashions with giant parameter counts, lengthy context home windows or combination‑of‑specialists architectures achieve probably the most from the B200. Common open‑supply fashions embody LLaMA 3 70B, DeepSeek‑R1, GPT‑OSS 120B, Kimi K2 and Mistral Giant 3. These fashions typically help 128k‑token contexts, require >100 GB of GPU reminiscence and profit from FP4 inference.
DeepSeek‑R1: An MoE language mannequin requiring eight specialists. On B200, DeepSeek‑R1 achieved world‑document inference speeds, delivering 30 ok tokens/s on a DGX system.
Mistral Giant 3 & Kimi K2: MoE fashions that achieved 10× pace‑ups and one‑tenth price per token when run on GB200 NVL72 racks.
LLaMA 3 70B and GPT‑OSS 120B: Dense transformer fashions requiring excessive bandwidth. B200’s FP4 help allows greater batch sizes and throughput.
Imaginative and prescient Transformers: Giant ViT and diffusion fashions (e.g., Secure Diffusion XL) profit from the B200’s reminiscence and ray‑tracing cores.
Which frameworks and libraries ought to I take advantage of?
TensorRT‑LLM & vLLM: These libraries implement speculative decoding, paged consideration and reminiscence optimization. They harness FP4 and FP8 tensor cores to maximise throughput. vLLM runs inference on B200 with low latency, whereas TensorRT‑LLM accelerates excessive‑throughput servers.
SGLang: A declarative language for constructing inference pipelines and performance calling. It integrates with vLLM and B200 for environment friendly RAG workflows.
Open supply libraries: Flash‑Consideration 2, xFormers, and Fused optimizers help B200’s compute patterns.
Clarifai Integration
Clarifai’s Mannequin Zoo consists of pre‑optimized variations of main LLMs that run out‑of‑the‑field on B200. By way of the compute orchestration API, builders can deploy vLLM or SGLang servers backed by B200 or robotically fall again to H100/A100 relying on availability. Clarifai additionally gives serverless containers for customized fashions so you’ll be able to scale inference with out worrying about GPU administration. Native Runners let you high quality‑tune fashions domestically utilizing smaller GPUs after which scale to B200 for full‑scale coaching.
Professional Insights:
Engineers at main AI labs spotlight that libraries like vLLM cut back reminiscence fragmentation and exploit asynchronous streaming, providing as much as 40 % efficiency uplift on B200 in contrast with generic PyTorch pipelines.
Clarifai’s engineers observe that hooking fashions into the Reasoning Engine robotically selects the proper tensor precision, balancing price and accuracy.
Comparability: B200 vs H100, H200 and Opponents
How does B200 evaluate with H100, H200 and competitor GPUs?
The B200 affords probably the most reminiscence, bandwidth and vitality effectivity amongst present Nvidia GPUs, with efficiency benefits even compared with competitor accelerators like AMD MI300X. The desk beneath summarizes the important thing variations.
Metric
H100
H200
B200
AMD MI300X
FP4/FP8 efficiency (dense)
NA / 4.7 PF
4.7 PF
9 PF
~7 PF
Reminiscence
80 GB HBM3
141 GB HBM3e
192 GB HBM3e
192 GB HBM3e
Bandwidth
3.35 TB/s
4.8 TB/s
8 TB/s
5.3 TB/s
NVLink bandwidth per GPU
900 GB/s
1.6 TB/s
1.8 TB/s
N/A
Thermal Design Energy (TDP)
700 W
700 W
1,000 W
700 W
Pricing (cloud price)
~$2.4/hr
~$3.1/hr
~$5.9/hr
~$5.2/hr
Availability (2025)
Widespread
mid‑2024
restricted 2025
out there 2024
Key takeaways:
Reminiscence & bandwidth: The B200’s 192 GB HBM3e and eight TB/s bandwidth dwarfs each H100 and H200. Solely AMD’s MI300X matches reminiscence capability however at decrease bandwidth.
Compute efficiency: FP4 throughput is double the H200 and H100, enabling 4× sooner coaching. Combined precision and FP16/FP8 efficiency additionally scale proportionally.
Power effectivity: FP4 reduces vitality per token by 25–50×; microbenchmark information present 42 % vitality discount vs H200.
Compatibility & software program: H200 is a drop‑in substitute for H100, whereas B200 requires up to date boards and CUDA 12.4+. Clarifai robotically manages these dependencies by means of its orchestration.
Competitor comparability: AMD’s MI300X has comparable reminiscence however decrease FP4 throughput and restricted software program help. Upcoming MI350/MI400 chips could slim the hole, however NVLink and software program ecosystem maintain B200 forward.
Professional Insights:
Analysts observe that B200 pricing is roughly 25 % greater than H200. For price‑constrained duties, H200 could suffice, particularly the place reminiscence moderately than compute is bottlenecked.
Benchmarkers spotlight that B200’s efficiency scales linearly throughout multi‑GPU clusters resulting from NVLink 5 and NVSwitch.
Inventive instance evaluating H200 and B200
Suppose you’re working a chatbot utilizing a 70 B‑parameter mannequin with a 64k‑token context. On an H200, the mannequin barely suits into 141 GB of reminiscence, requiring off‑chip reminiscence paging and leading to 2 tokens per second. On a single B200 with 192 GB reminiscence and FP4 quantization, you course of 60 ok tokens per second. With Clarifai’s compute orchestration, you’ll be able to launch a number of B200 cases and obtain interactive, low‑latency conversations.
Getting Entry to the B200
How will you procure B200 GPUs?
Reply: There are a number of methods to entry B200 {hardware}:
On‑premises servers: Firms can buy HGX B200 or DGX GB200 NVL72 methods. The GB200 NVL72 integrates 72 B200 GPUs with 36 Grace CPUs and affords rack‑scale liquid cooling. Nonetheless, these methods devour 70–80 kW and require specialised cooling infrastructure.
GPU Cloud suppliers: Many GPU cloud platforms supply B200 cases on a pay‑as‑you‑go foundation. Early pricing is round $5.9/hr, although provide is restricted. Anticipate waitlists and quotas resulting from excessive demand.
Compute marketplaces: GPU marketplaces enable brief‑time period leases and per‑minute billing. Think about reserved cases for lengthy coaching runs to safe capability.
Clarifai’s compute orchestration: Clarifai gives B200 entry by means of its platform. Customers join, select a mannequin or add their very own container, and Clarifai orchestrates B200 sources behind the scenes. The platform affords computerized scaling and value optimization—e.g., falling again to H100 or A100 for much less‑demanding inference. Clarifai additionally helps native runners for on‑prem inference so you’ll be able to check fashions domestically earlier than scaling up.
Professional Insights:
Knowledge middle engineers warning that B200’s 1 kW TDP calls for liquid cooling; thus colocation amenities could cost greater charges【640427914440666†L120-L134】.
Cloud suppliers emphasize the significance of GPU quotas; reserving forward and utilizing reserved capability ensures continuity for lengthy coaching jobs.
Clarifai onboarding tip
Signing up with Clarifai is easy:
Create an account and confirm your e mail.
Select Compute Orchestration > Create Job, choose B200 because the GPU kind, and add your coaching script or select a mannequin from Clarifai’s Mannequin Zoo.
Clarifai robotically units acceptable CUDA and cuDNN variations and allocates B200 nodes.
Monitor metrics within the dashboard; you’ll be able to schedule auto‑scale guidelines, e.g., downscale to H100 throughout idle durations.
GPU Choice Information
How must you resolve between B200, H200 and B100?
Reply: Use the next determination framework:
Mannequin dimension & context size: For fashions >70 B parameters or contexts >128k tokens, the B200 is important. In case your fashions slot in <141 GB and context <64k, H200 could suffice. H100 handles fashions <40 B or high quality‑tuning duties.
Latency necessities: When you want sub‑second latency or tokens/sec past 50 ok, select B200. For average latency (10–20 ok tokens/s), H200 gives a great commerce‑off.
Finances issues: Consider price per FLOP. B200 is about 25 % dearer than H200; due to this fact, price‑delicate groups could use H200 for coaching and B200 for inference time‑crucial duties.
Software program & compatibility: B200 requires CUDA 12.4+, whereas H200 runs on CUDA 12.2+. Guarantee your software program stack helps the mandatory kernels. Clarifai’s orchestration abstracts these particulars.
Energy & cooling: B200’s 1 kW TDP calls for correct cooling infrastructure. In case your facility can’t help this, take into account H200 or A100.
Future proofing: In case your roadmap consists of combination‑of‑specialists or generative simulation, B200’s NVLink 5 will ship higher scaling. For smaller workloads, H100/A100 stay price‑efficient.
Professional Insights:
AI researchers typically prototype on A100 or H100 resulting from availability, then migrate to B200 for remaining coaching. Instruments like Clarifai’s simulation let you check reminiscence utilization throughout GPU varieties earlier than committing.
Knowledge middle planners advocate measuring energy draw and including 20 % headroom for cooling when deploying B200 clusters.
Case Research & Actual‑World Examples
How have organizations used the B200 to speed up AI?
DeepSeek‑R1 world‑document inference
DeepSeek‑R1 is a mix‑of‑specialists mannequin with eight specialists. Operating on a DGX with eight B200 GPUs, it achieved 30 ok tokens per second and enabled coaching in half the time of H100. The mannequin leveraged FP4 and NVLink 5 for professional routing, decreasing price per token by 90 %. This efficiency would have been not possible on earlier architectures.
Mistral Giant 3 & Kimi K2
These fashions use dynamic sparsity and lengthy context home windows. Operating on GB200 NVL72 racks, they delivered 10× sooner inference and one‑tenth price per token in contrast with H100 clusters. The combination‑of‑specialists design allowed scaling to fifteen or extra specialists, every mapped to a GPU. The B200’s reminiscence ensured that every professional’s parameters remained native, avoiding cross‑gadget communication.
Scientific simulation
Researchers in local weather modeling used B200 GPUs to run 1 km‑decision world local weather simulations beforehand restricted by reminiscence. The 8 TB/s reminiscence bandwidth allowed them to compute 1,024 time steps per hour, greater than doubling throughput relative to H100. Equally, computational chemists reported a 1.5× discount in time‑to‑resolution for ab‑initio molecular dynamics resulting from elevated FP64 efficiency.
Clarifai buyer success
An e‑commerce firm used Clarifai’s Reasoning Engine to construct a product advice chatbot. By migrating from H100 to B200, the corporate minimize response instances from 2 seconds to 80 milliseconds and diminished GPU hours by 55 % by means of FP4 quantization. Clarifai’s compute orchestration robotically scaled B200 cases throughout visitors spikes and shifted to cheaper A100 nodes throughout off‑peak hours, saving price with out sacrificing high quality.
Inventive instance illustrating energy & cooling
Consider the B200 cluster as an AI furnace. Every GPU attracts 1 kW, equal to a toaster oven. A 72‑GPU rack due to this fact emits roughly 72 kW—like working dozens of ovens in a single room. With out liquid cooling, parts overheat shortly. Clarifai’s hosted options disguise this complexity from builders; they keep liquid‑cooled information facilities, letting you harness B200 energy with out constructing your individual furnace.
Rising Tendencies & Future Outlook
What’s subsequent after the B200?
Reply: The B200 is the primary of the Blackwell household, and NVIDIA’s roadmap consists of B300 (Blackwell Extremely) and future Vera/Rubin GPUs, promising much more reminiscence, bandwidth and compute.
B300 (Blackwell Extremely)
The upcoming B300 boosts per‑GPU reminiscence to 288 GB HBM3e—a 50 % enhance over B200—through the use of twelve‑excessive stacks of DRAM. It additionally gives 50 % extra FP4 efficiency (~15 PFLOPS). Though NVLink bandwidth stays 1.8 TB/s, the additional reminiscence and clock pace enhancements make B300 preferrred for planetary‑scale fashions. Nonetheless, it raises TDP to 1,100 W, demanding much more sturdy cooling.
Future Vera & Rubin GPUs
NVIDIA’s roadmap extends past Blackwell. The “Vera” CPU will double NVLink C2C bandwidth to 1.8 TB/s, and Rubin GPUs (possible 2026–27) will characteristic 288 GB of HBM4 with 13 TB/s bandwidth. The Rubin Extremely GPU could combine 4 chiplets in an SXM8 socket with 100 PFLOPS FP4 efficiency and 1 TB of HBM4E. Rack‑scale VR300 NVL576 methods may ship 3.6 exaflops of FP4 inference and 1.2 exaflops of FP8 coaching. These methods would require 3.6 TB/s NVLink 7 interconnects.
Software program advances
Speculative decoding & cascaded era: New decoding methods like speculative decoding and multi‑stage cascaded fashions minimize inference latency. Libraries like vLLM implement these methods for Blackwell GPUs.
Combination‑of‑Consultants scaling: MoE fashions have gotten mainstream. B200 and future GPUs will help a whole lot of specialists per rack, enabling trillion‑parameter fashions at acceptable price.
Sustainability & Inexperienced AI: Power use stays a priority. FP4 and future FP3/FP2 codecs will cut back energy consumption additional; information facilities are investing in liquid immersion cooling and renewable vitality.
Professional Insights:
The Subsequent Platform emphasizes that B300 and Rubin usually are not simply reminiscence upgrades; they ship proportional will increase in FP4 efficiency and spotlight the necessity for NVLink 6/7 to scale to exascale.
Trade analysts predict that AI chips will drive greater than half of all semiconductor income by the tip of the last decade, underscoring the significance of planning for future architectures.
Clarifai’s roadmap
Clarifai is constructing help for B300 and future GPUs. Their platform robotically adapts to new architectures; when B300 turns into out there, Clarifai customers will take pleasure in bigger context home windows and sooner coaching with out code modifications. The Reasoning Engine may even combine Vera/Rubin chips to speed up multi‑mannequin pipelines.
FAQs
Q1: Can I run my current H100/H200 workflows on a B200?
A: Sure—offered your code makes use of CUDA‑normal APIs. Nonetheless, you will need to improve to CUDA 12.4+ and cuDNN 9. Libraries like PyTorch and TensorFlow already help B200. Clarifai abstracts these necessities by means of its orchestration.
Q2: Does B200 help single‑GPU multi‑occasion GPU (MIG)?
A: No. In contrast to A100, the B200 doesn’t implement MIG partitioning resulting from its twin‑die design. Multi‑tenancy is as an alternative achieved on the rack degree by way of NVSwitch and virtualization.
Q3: What about energy consumption?
A: Every B200 has a 1 kW TDP. You will need to present liquid cooling to keep up secure working temperatures. Clarifai handles this on the information middle degree.
This autumn: The place can I hire B200 GPUs?
A: Specialised GPU clouds, compute marketplaces and Clarifai all supply B200 entry. As a consequence of demand, provide could also be restricted; Clarifai’s reserved tier ensures capability for lengthy‑time period initiatives.
Q5: How does Clarifai’s Reasoning Engine improve B200 utilization?
A: The Reasoning Engine connects LLMs, imaginative and prescient fashions and information sources. It makes use of B200 GPUs to run inference and coaching pipelines, orchestrating compute, reminiscence and duties robotically. This eliminates guide provisioning and ensures fashions run on the optimum GPU kind. It additionally integrates vector search, workflow orchestration and immediate engineering instruments.
Q6: Ought to I look ahead to the B300 earlier than deploying?
A: In case your workloads demand >192 GB of reminiscence or most FP4 efficiency, ready for B300 could also be worthwhile. Nonetheless, the B300’s elevated energy consumption and restricted early provide imply many customers will undertake B200 now and improve later. Clarifai’s platform permits you to transition seamlessly as new GPUs turn out to be out there.
Conclusion
The NVIDIA B200 marks a pivotal step within the evolution of AI {hardware}. Its twin‑chiplet structure, FP4 Tensor Cores and large reminiscence bandwidth ship unprecedented efficiency, enabling 4× sooner coaching and 30× sooner inference in contrast with prior generations. Actual‑world deployments—from DeepSeek‑R1 to Mistral Giant 3 and scientific simulations—showcase tangible productiveness beneficial properties.
Trying forward, the B300 and future Rubin GPUs promise even bigger reminiscence swimming pools and exascale efficiency. Staying present with this {hardware} requires cautious planning round energy, cooling and software program compatibility, however compute orchestration platforms like Clarifai summary a lot of this complexity. By leveraging Clarifai’s Reasoning Engine, builders can concentrate on innovating with fashions moderately than managing infrastructure. With the B200 and its successors, the horizon for generative AI and reasoning engines is increasing sooner than ever.
Google launched Private Intelligence for AI Mode in Search, stating customers can choose in and grant it entry to their Gmail and Pictures.
AI Mode is claimed to assist customers plan journeys and store by diving into their earlier purchases in Gmail or Pictures to floor related content material they could have interaction with.
Google says this characteristic is rolling out in Labs for AI Professional and AI Extremely subscribers within the U.S. over the following few days.
Gemini obtained an identical replace roughly per week in the past; nonetheless, it does a little bit extra, connecting to YouTube, Pictures, Gmail, and extra to assist customers.
Gemini‘s not the one characteristic getting private this 12 months. Google publicizes what’s subsequent for its in-depth AI Mode in Search.
Google launched Private Intelligence for AI Mode in Search earlier this morning (Jan 22) in a Key phrase publish. In the event you’re conversant in what Google did with Gemini’s model, you would possibly know the place this replace’s headed. The corporate teases that Private Intelligence in AI Mode will enable you “faucet into your personal private context and insights to unlock much more useful Search responses which might be tailor-made to you.”
This replace considerations Google AI Professional and AI Extremely subscribers as an “opt-in” characteristic, which is able to linking AI Mode to your Google Pictures and Gmail accounts. The publish alludes to AI Mode’s enhanced capabilities, because it will not merely “suggest” gadgets based mostly on pursuits alone. The corporate offers the instance of looking for new sneakers. For the reason that consumer (on this instance) had not too long ago bought a pair, AI Mode used that as gasoline to search out another type.
Google supplied one other buying instance, stating Private Intelligence in AI Mode will leverage your flight info (Gmail), in addition to your vacation spot, to search out clothes concepts for you.
Touring is one other key spotlight, with Google stating AI Mode will sift via your Cloud-stored Pictures for captured recollections from earlier journeys. In the event you’ve requested it that can assist you plan an gratifying weekend away, it will use that to recommend locations you have not been to but or actions you in all probability did not consider.
AI Mode’s desires to know extra to assist extra
Picture 1 of 2
(Picture credit score: Google)
(Picture credit score: Google)
AI Mode is an extension of its Gemini 3 software program; nonetheless, Google says the characteristic is not going to use what it is used from Gmail and Pictures for coaching.
This echoes what was mentioned about Private Intelligence in Gemini per week in the past. The publish provides that customers “stay in management” with this characteristic in AI Mode. As beforehand said, Private Intelligence is an opt-in characteristic. If you don’t need AI Mode digging round, you do not have to let it. If you need to allow it, Google informs that the one knowledge AI Mode takes for coaching is “particular prompts” and “the mannequin’s response.”
Get the most recent information from Android Central, your trusted companion on the earth of Android
Proper now, the power to let AI Mode look into Pictures and Gmail is arriving by way of a Labs experimental operate for AI Professional and AI Extremely subscribers within the U.S. It’d take a number of days earlier than these subscribers see an invite obtainable, so examine on it periodically. If you don’t, Google says you possibly can hop into Search > Profile icon > Search personalization > Related Content material apps > Join Workspace and Google Pictures.
Gemini received private roughly per week in the past, when Google first launched Private Intelligence. Gemini can do some extra, as customers can grant it entry to Pictures, Gmail, YouTube, and extra for help. The characteristic was equally made obtainable for Google AI Professional and AI Extremely subscribers within the U.S.
Microplastics journey by air and sea, turning up even in distant areas.
Ben Stansall/Getty Pictures
Microplastics are pervasive, discovered all over the place on Earth, from the Sahara Desert to patches of Arctic sea ice. But regardless of these plastic particles’ ubiquity, scientists have struggled to find out precisely what number of of them are in our environment.
The median focus of microplastics is 0.08 particle per cubic meter (m3) over land and 0.003 particle per m3 over sea, the research discovered.
On supporting science journalism
In case you’re having fun with this text, take into account supporting our award-winning journalism by subscribing. By buying a subscription you might be serving to to make sure the way forward for impactful tales in regards to the discoveries and concepts shaping our world at present.
These estimates are between 100 and 10,000 occasions decrease than earlier accountings of atmospheric microplastics—a discrepancy that the researchers behind the brand new research say underscores the necessity for higher international measures of those pollution.
“We knew that uncertainties of current emission estimates have been very massive,” says Andreas Stohl, senior creator of the research and an atmospheric scientist on the College of Vienna. “They’re even nonetheless massive after our research, however we may not less than slim down the uncertainty vary, particularly in terms of the significance of land-based versus ocean-based emissions.”
A microplastic is any plastic particle sized between one micron and 5 millimeters. Simply swept up by wind and carried lengthy distances by water, these tiny motes are additionally exceedingly troublesome to detect and nearly inconceivable to take away from the surroundings.
Previous estimates have centered on accounting for microplastics generated by human exercise or immediately measuring their focus within the air in any given space. However these measures are extremely variable: alongside the southeastern coast of China, for instance, atmospheric microplastic estimates have ranged from 0.004 to 190 particles per m3. To attempt to get at a extra international estimate, Stohl and his crew compiled 2,782 measurements collected at 283 places worldwide.
The researchers hope the findings will act as a baseline for future research of world microplastic ranges, together with new measures that can be capable of account for even smaller particles than they did.
It’s Time to Stand Up for Science
In case you loved this text, I’d prefer to ask in your help. Scientific American has served as an advocate for science and trade for 180 years, and proper now will be the most crucial second in that two-century historical past.
I’ve been a Scientific American subscriber since I used to be 12 years previous, and it helped form the best way I have a look at the world. SciAm at all times educates and delights me, and conjures up a way of awe for our huge, stunning universe. I hope it does that for you, too.
In case you subscribe to Scientific American, you assist be certain that our protection is centered on significant analysis and discovery; that we have now the assets to report on the choices that threaten labs throughout the U.S.; and that we help each budding and dealing scientists at a time when the worth of science itself too usually goes unrecognized.
Your organization spent two million {dollars} on an AI venture. The pilot regarded robust. The demo labored. Then the outcomes flatlined. You aren’t alone!
Most corporations face AI adoption challenges. They see little or no or nearly no measurable return from their AI adoptions. Failure to achieve scale results in cash down the drain.
The issue isn’t the mannequin. The issue is folks, course of, and technique. Though these points are fixable. Let’s see how!
Why AI Adoption Is Important
AI drives velocity, accuracy, and higher choices. It removes repetitive work and frees your groups to give attention to high-value duties. Most corporations adopting AI see a major change in operational effectivity.
Nevertheless, when corporations make giant shifts quickly, they face AI adoption challenges. Pilot tasks work, however scaling fails. Groups push again, and the methods block progress. Expertise fall brief. Knowledge is unreliable to say the least. These and lots of such causes are why corporations wrestle with AI adoption. Right here’s extra on the frequent challenges in AI adoption for companies.
Limitations To Enterprise AI Implementation
1.Workforce Readiness
What’s the function of workforce preparedness in AI adoption? Most groups shouldn’t have the talents to run AI at scale. Half of all companies cite a scarcity of expert expertise as their prime blocker. In keeping with Statista, in 2025, the most important limitations to AI adoption have been the dearth of expert professionals, cited by 50% of companies, a scarcity of imaginative and prescient amongst managers and leaders, cited by 43%, adopted by the excessive prices of AI services and products at 29%.
Expertise shortages present up in 3 ways:
You attempt to rent: The expertise pool is small and costly.
You attempt to upskill: Coaching takes time.
You depend on just a few consultants: In the event that they depart, your venture fails.
The repair is straightforward. Construct a blended mannequin. Rent the place wanted. When coaching your groups, create a tradition of studying. Unfold data throughout groups.
2. ROI Uncertainty
Management needs clear returns. Few corporations outline them properly. Many groups observe with no clear final result. They guess at targets, they usually use imprecise metrics. Some AI tasks take time to indicate impression. Early advantages are small and oblique. Many leaders anticipate quick outcomes and lose curiosity earlier than the venture matures.
To enhance outcomes, corporations should outline one major final result, set clear timelines, and observe progress with easy metrics.
3. AI Adoption Points in Legacy Methods
How do legacy methods impression AI implementation? Many corporations face integration points. Previous methods retailer knowledge in incompatible codecs. Since knowledge lives in silos, infrastructure is gradual. APIs fail to assist real-time knowledge. Integration turns into costly. Your crew struggles to attach fashionable instruments with outdated methods.
The repair is a staged strategy —modernize in small steps, consolidate knowledge, and clear your core methods earlier than scaling AI.
4.Lack of Clear Targets
Many leaders approve AI tasks with out a clear purpose. Groups decide use circumstances that sound attention-grabbing however remedy no actual enterprise drawback. With out clear aims, the venture drifts. Nobody is aware of what success means. Outcomes are onerous to measure.
The higher means—begin with one enterprise drawback, gradual response instances. Set a particular purpose and develop round it.
5. Issues Round Knowledge Safety
Executives fear about knowledge publicity. These issues are legitimate. Poor knowledge governance creates threat. Corporations typically have no idea the place knowledge lives or who makes use of it. Knowledge high quality points value the US economic system over three trillion {dollars} a yr. Regulated industries face increased requirements. One mistake creates authorized and monetary threat.
The repair— handle safety early. Set guidelines. Clear your knowledge. Guarantee to safeguard confidential knowledge.
6. Absence of Reliable Companions
Many corporations attempt to construct AI alone. Others rent companions with no actual expertise. Each paths fail. AI requires ability, time, and construction. Most groups lack the bandwidth. Distributors with weak business data add extra threat. The result’s predictable. Unsuitable use circumstances. Unsuitable tech stack. Poor rollout. Initiatives that by no means scale.
Work with companions who know your business and have delivered actual outcomes. Ask for proof. Search for groups that concentrate on folks and course of, not solely instruments.
Break The Limitations to AI Adoption Harness AI With Knowledgeable Steering & Clear Roadmaps
How Leaders Transfer Ahead: Your AI Adoption Playbook
What’s the finest technique for profitable AI adoption? Most leaders ask this query after stalled pilots and unclear outcomes. An MIT report exhibits that 95% of generative AI pilots fail. Solely 5 % ship quick income progress. The issues are recognized. The blockers are clear. What issues now’s a plan you’ll be able to act on. The following steps offer you a easy path to secure adoption, clear worth, and long-term progress. Every technique focuses on one purpose. Cut back friction and enhance accuracy. Strengthen belief. Create a system your groups belief and use with confidence.
Technique 1: Use the 30 P.c Rule and Hold Management
AI ought to take the repetitive work, however your folks ought to make the choices that matter. A easy cut up works. AI handles most repetitive actions. People deal with the strategic elements that drive worth. Examples embody assist, finance, and authorized evaluate. AI processes the majority of the work. People personal edge circumstances, choices, and context. This mannequin improves belief. Corporations obtain higher client belief percentages after they implement accountable AI together with human supervision.
What the 30 P.c Rule Tells You
AI handles repetitive work properly. People deal with judgment and technique. In authorized work, AI opinions most clauses. Attorneys give attention to the few that matter. In finance, AI handles routine evaluation. People deal with portfolio choices and shopper technique. Automating the improper duties destroys worth. Defend the human layer. It creates the essential perception your corporation wants.
Technique 2: All the time Hold a Human within the Loop
AI wants steady human steering. Throughout coaching, people label knowledge and regulate outputs. Earlier than launch, consultants check the system and repair errors. After launch, groups monitor choices and report points. This reduces bias and errors. It additionally builds inside confidence.
Technique 3: Construct a Clear Roadmap
Don’t begin with superior use circumstances. Begin small. Section 1. Reduce operational limitations and streamline routine actions. Make the most of RPA, chatbots, and doc dealing with. These fast wins construct momentum. Section 2. Predict future outcomes. Use forecasting, segmentation, and advice fashions. These tasks supply long run worth. Section 3. Scale what works. Combine with core methods. Construct new enterprise fashions. Every section helps the following. Set clear metrics for every section and observe them with out excuses.
Technique 4: Usher in AI consultants who know what they’re doing
Sturdy companions shorten your studying curve. Select companions who know your business. Ask for actual case research. Affirm they perceive organizational change. Verify their capacity to work along with your present methods. A great accomplice brings a transparent methodology. They information you from evaluation to deployment and assist scaling.
Fingent guides corporations from confusion to readability. Their mannequin is straightforward and confirmed.
Stage 1. Cut back Friction Fingent identifies repetitive processes. We deploy RPA, doc processing, and chatbots. This frees your crew to give attention to excessive worth duties.
Stage 2. Predict Outcomes Fingent builds predictive analytics, advice engines, and segmentation fashions. Our consultants allow you to enhance forecasting and buyer insights. We strengthen your governance and knowledge self-discipline.
Stage 3. Scale and Advance Fingent expands profitable use circumstances. We combine with core methods. Moreover, we assist long-term transformation and new enterprise worth.
AI augmenting human experience (not changing legal professionals)
Human-in-the-loop strategy for strategic choices
Lower in common whole declare prices and declare cycle time
What Units Fingent Aside?
We offer human oversight as an ordinary. We run validation loops and observe robust governance. We repair knowledge points with clear mapping, cleanup, and safety.
We begin small, however guarantee massive outcomes. We give attention to modernizing legacy methods and integrating AI with out disrupting operations. And that’s not the place we cease. Fingent helps cultural change and upskilling to assist companies construct confidence in leveraging new-age applied sciences to their most profit.
Talk about your concepts with us and listen to our skilled options tailor-made to your distinctive wants.
Samsung says that customers can expertise the Galaxy Z TriFold from tomorrow.
The system will likely be on show at choose Samsung Expertise Shops, largely situated in California, New York, and Texas.
The US launch date is but to be formally introduced.
No matter your opinion of a triple-panel telephone, you may nonetheless be curious to examine one out for your self. Within the case of the Samsung Galaxy Z TriFold, that doesn’t imply you must watch for the as-yet-unannounced US launch date or spend a small fortune to order one when that date comes. Samsung says the Galaxy Z TriFold will likely be out there to expertise in individual throughout the US beginning tomorrow, forward of its official US launch.
Do you propose on shopping for the Galaxy Z TriFold?
1253 votes
The announcement comes through Samsung’s US Newsroom, which says the system will likely be on show at a restricted variety of Expertise Retailer areas. It’s not the launch, nevertheless it does mark the primary time most US clients will have the ability to get hands-on with Samsung’s most experimental foldable with out touring abroad or attending an trade occasion.
Don’t wish to miss the perfect from Android Authority?
We’ve already hung out with the system on the Dubai Mall and at CES 2026. Whereas reactions have been blended, it’s undoubtedly a really completely different form of foldable, and it makes a minimum of a bit extra sense when you maintain it. Primarily based on Korean pricing, the Galaxy Z TriFold is predicted to price round $2,500 when it launches within the US, though Samsung has but to substantiate official US pricing or a precise launch date past a Q1 2026 window.
Samsung hasn’t precisely made this a nationwide rollout. The Galaxy Z TriFold will solely be out there to strive at one of many seven Samsung Expertise Shops throughout the nation, situated in a handful of main buying facilities in California, New York, Texas, and Minnesota. You may take a look at the areas right here.
Thanks for being a part of our neighborhood. Learn our Remark Coverage earlier than posting.
Extreme sitting is not good for an individual’s bodily or psychological well being, however there is a sort of sedentary exercise that won’t shrink our brains or price our cognition to the identical extent.
A scientific evaluation of 85 research has now discovered good motive to distinguish between ‘lively’ sitting, like enjoying playing cards or studying, and ‘passive’ sitting, like watching TV.
The previous may very well increase mind well being.
That is most likely as a result of lively sitting engages the mind, whereas passive sitting lets an individual take a again seat each bodily and cognitively.
“Complete sitting time has been proven to be associated to mind well being; nevertheless, sitting is commonly handled as a single entity, with out contemplating the particular sort of exercise,” explains public well being researcher Paul Gardiner from the College of Queensland in Australia.
“Most individuals spend many hours sitting every day, so the kind of sitting actually issues … These findings present that small on a regular basis decisions – like studying as an alternative of watching tv – might assist preserve your mind more healthy as you age.”
Clearly, train stays extremely necessary for cognitive well being, however giving your mind a exercise can be necessary, and that does not essentially imply it’s a must to be in your ft.
Throughout quite a few research, Gardiner and colleagues discovered that lively sitting actions, like studying, enjoying card video games, and utilizing a pc, confirmed “overwhelmingly optimistic associations with cognitive well being, enhancing cognitive features similar to government perform, situational reminiscence, and dealing reminiscence.”
In the meantime, passive sitting was most constantly related to destructive cognitive outcomes, together with elevated danger of dementia.
The impact sizes have been small however important. The research authors hope their outcomes will assist inform future well being analysis and extra nuanced well being steering.
For instance, the researchers counsel tips ought to acknowledge the distinction between passively watching TV and actively utilizing a pc, and encourage individuals to take brief breaks to stimulate their brains and transfer.
Their evaluation centered on research of typical sedentary actions in pure settings, slightly than structured applications designed to spice up mind perform, making it related to individuals’s on a regular basis lives.
“Well being recommendation may shift from merely saying ‘sit much less’ to encouraging extra mentally participating actions whereas sitting,” argues Gardiner.
“This might assist individuals make straightforward, lifelike adjustments that help lengthy‑time period mind well being and doubtlessly cut back dementia danger.”
There are some exceptions (notably from Dennis O’Neil), on the entire although…
The Courageous and the Daring #94 February-March 1971
The trope of the youth motion rising as much as suppress, imprison, or straight out bloodbath everybody over thirty-five was extraordinarily frequent within the late sixties and early seventies and even made it to the covers of mainstream comics. The subgenre is essentially forgotten now, however the nervousness it mirrored had an incredible deal to do with the rise of Reagan just a few years later.
The title of this comedian was an apparent on the time reference to arguably the definitive youth paranoia film.
“You say you desire a revolution”
This was going to be a part of an upcoming put up however I made a decision it labored higher freestanding.
Again
within the late sixties there was a stunning well-liked style of apocalyptic
dystopias impressed by fears of the youth motion. Numerous examples
in episodic tv (three or 4 from Star Trek alone). The 1967 novel Logan’s Run (however not the 1976 film which dropped the political facets of the story). Arguably movies If and Clockwork Orange (although on this case, not the e book, which is extra part of the post-war panic over juvenile delinquency). Corman’s Gasoline-s-s-s. Actually others I’m forgetting.
Although not the very best within the bunch, essentially the most consultant was Wild within the Streets.
Wild within the Streets figures prominently in Pauline Kael’s essay “Trash, Artwork, and the Films“: [emphasis added]
There
is a lot discuss now concerning the artwork of the movie that we could also be at risk
of forgetting that a lot of the films we take pleasure in will not be artistic endeavors. The Scalphunters, for instance, was one of many few entertaining
American films this previous yr, however skillful although it was, one may
hardly name it a murals — if such phrases are to have any helpful
that means. Or, to take a extremely gross instance, a film that’s as crudely
made as Wild within the Streets — slammed along with spit and
hysteria and opportunism — can however be pleasurable, although it’s
nearly a basic instance of an unartistic film. What makes these films
— that aren’t artistic endeavors — pleasurable? The Scalphunters was
extra entertaining than most Westerns largely as a result of Burt Lancaster and
Ossie Davis had been peculiarly humorous collectively; a part of the pleasure of the
film was attempting to determine what made them so humorous. Burt Lancaster
is an odd sort of comic: what’s distinctive about him is that his
comedy appears to come back out of his physicality. In critical roles an
undistinguished and too clearly hard-working actor, he has an
apparently easy aptitude for comedy and nothing is extra infectious
than an actor who can chill out in entrance of the digital camera as if he had been having a
good time. (George Segal generally appears to have this present of a
great amiability, and Brigitte Bardot was radiant with it in Viva Maria!)
By some means the alchemy of character within the pairing of Lancaster and
Ossie Davis — one other powerfully humorous actor of super bodily
presence — labored, and the director Sydney Pollack stored tight management so
that it wasn’t overdone.
And Wild within the Streets? It’s a
blatantly crummy-looking image, however that in some way works for it as an alternative
of in opposition to it as a result of it’s sensible in a variety of ways in which better-made
photos aren’t. It appears like different latest merchandise from American
Worldwide Photos however it’s as if one had been studying a comic book strip
that seemed similar to the strip of the day earlier than, and but on this new
one there are stunning expressions on the faces and a few of the
balloons are actually witty. There’s not a hint of sensitivity within the
drawing or within the concepts, and there’s one thing quite specifically humorous
about wit with none grace in any respect; it may be loved in a very
crude method — as Pop wit. The fundamental thought is corny — It Can’t Occur Right here with the freaked-out younger as a brand new breed of fascists — however it’s handled within the paranoid fashion of editorials about youth (it even begins by blaming every thing on the dad and mom). And an inexpensive thought that’s thispresent andwidespread has an nearly lunatic allure, a nightmare gaiety. There’s a relish that individuals have for the concept of drug-taking children as monsters threatening them
— the every day papers merging into Village of the Damned. Tapping and
exploiting this type of hysteria for a satirical fantasy, the author
Robert Thom has used what is offered and apparent however he’s completed it with
simply sufficient mockery and elegance to make it humorous. He throws in touches of
characterization and occasional traces that aren’t there simply to
additional the plot, and these throwaways make odd connections in order that the
film turns into nearly frolicsome in its paranoia (and in its enjoyment of
its personal cleverness).
It is easy to be
dismissive of those fears fifty plus years later, however the revolutionary
rhetoric of the motion was typically excessive and was punctuated by the
occasional bombing, financial institution theft, and many others.
However in all probability the largest
mistake individuals made when predicting the influence of the sixties youth
motion was taking them at their phrase, believing that their dedication
to radicalism (and even liberalism) would outlast the top of the Vietnam
Battle. The post-war era would change the nation, however I doubt
anybody in 1969 would have guessed how.

















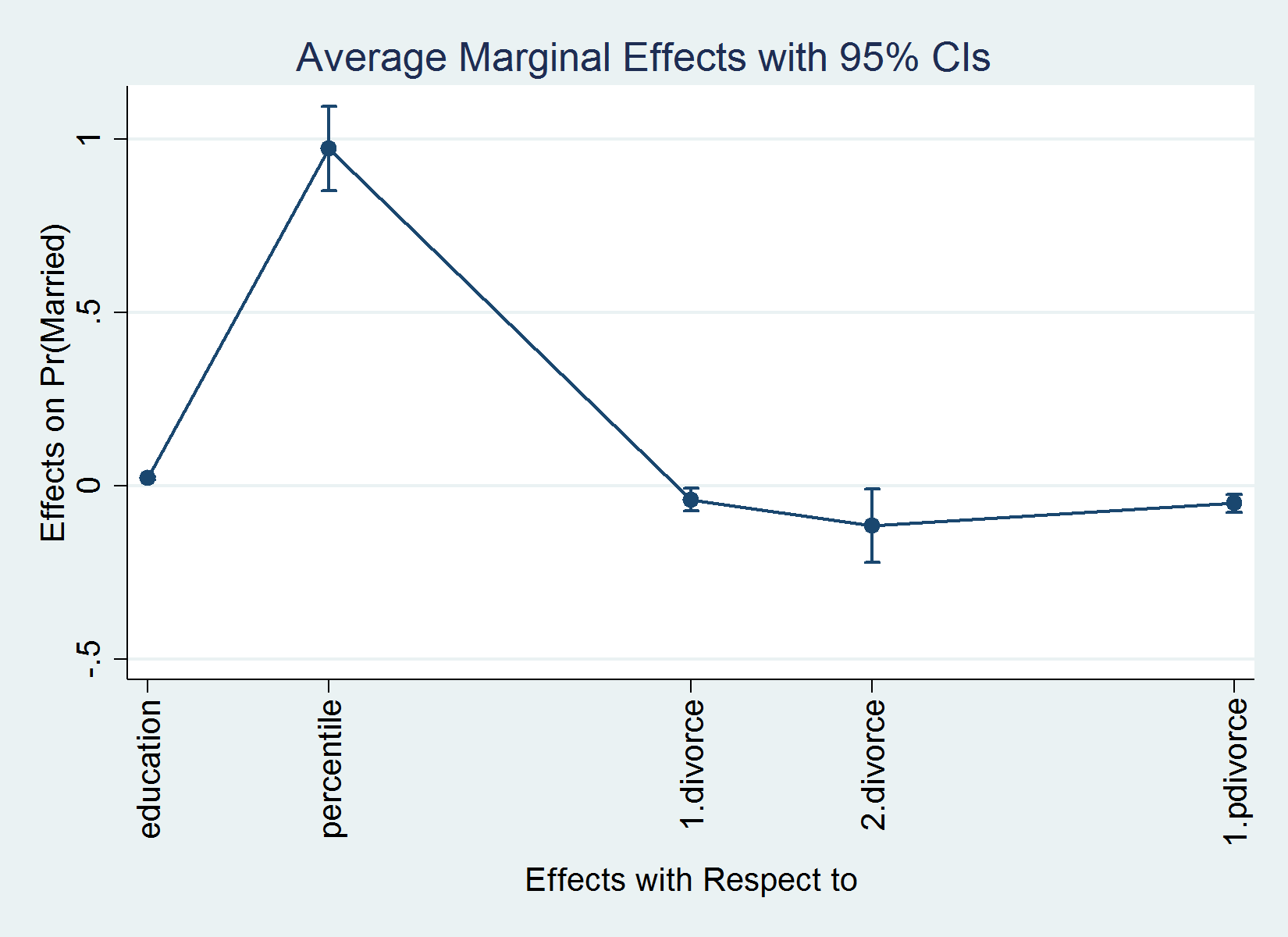{kind=link}
{kind=link}