At the moment I head to Georgetown the place I’m going to talk on the McCourt Coverage Faculty’s school retreat about AI brokers. I’m very enthusiastic about going. I’ve not but absolutely completed my slides, however I can be speaking about, amongst different issues, a brand new paper of mine that’s at the moment R&R. It’s about AI brokers and the minimal wage, and I assumed I’d share a little bit of what the paper is about and what I’ve realized.
By now readers know that we live sooner or later, by which I imply we live in a second when giant language fashions can do all elements of a contemporary program analysis paper. Every analysis design within the fashionable causal inference toolkit operates like a style, with its personal beats, characters, clues and displays, in addition to a generalizable model of rhetoric, which does make me typically marvel the place the variation will seem when all of the mud is settled on them. It’s not simply high quality and it’s not simply accuracy, and it might not even be the sorts of strategies used. Some issues appear to be converging, within the Social Catalyst Lab, on just a few issues — the brokers run a whole lot of diff-in-diffs it seems, and after I checked final, conditional on that, they run a whole lot of Callaway and Sant’Anna. They use publicly out there information. They write cautiously and circumspect with respect to their findings. They appear to make efforts to confirm mechanisms and are trustworthy with what they discover. They write replicable code in pipelines that may virtually be instantly shipped to the journals. I believe it’s not controversial to say that the general manufacturing course of seems proper of middle by way of the distribution of human researchers. And even what I discovered in my experiments don’t strike me as out of the abnormal in any respect. However as a result of they arrive from the identical supply, and at giant scale, there’s a lot you possibly can discern, significantly when the brokers are pressured to do the identical factor tons of of instances.
My examine context is the minimal wage. I selected the minimal wage as a result of it’s a unusual literature in that a lot ink has been spilled and for many years. And but there isn’t a actual consensus. Think about this outdated 2015 survey of consultants on the College of Chicago as an example when requested about their opinion of what to anticipate from a minimal wage improve. Solutions vary from 26% who agree {that a} gradual improve within the federal minimal wage will cut back the employment price, 24% disagree, and 38% are unsure.
It’s not a query concerning the idea. The idea is boilerplate, and I don’t imply econ 101 idea. I imply commonplace manufacturing idea is pretty easy on this. Should you work with the price perform, you should utilize Shepherd’s Lemma to again out conditional labor demand capabilities. For the reason that value perform is concave in issue costs, its second by-product, dL/dw, is strictly destructive. You could find the calculus and algebra for this in my outdated grad micro notes from after I taught it at Baylor in the event you scroll to slide 369. And in the event you work from the revenue max situation, you should utilize Hotelling’s Lemma, and curiously, dL/dw is even extra destructive as you get substitution results and also you get scale results. You could find that derivation concluding on slide 420 in my outdated lecture notes if you wish to work by means of that.
And importantly, as an apart, each of those outcomes are unambiguous. It’s because not like client idea, there’s not Giffen habits with enter demand.
However in these notes, that is commonplace producer idea that takes wages and capital costs and output costs as exogenous, which suggests companies are working in aggressive markets as exogenous costs are solely exogenous when the agency is a worth taker, not a worth maker. That means we’re speaking a few state of affairs through which the agency doesn’t have market energy. However as soon as we enable for market energy in labor markets — monopsony — then you possibly can have will increase in wages (i.e., binding minimal wage flooring) result in non-negative outcomes, together with optimistic results. Alan Manning in his essential work constructed on the sooner monopsony fashions by Joan Robinson for monopsony to be extra generalizable — search prices, and different parts, might generate related if not the identical forms of ambiguities.
Which signifies that the minimal wage will not be strictly a theoretical phenomena. It’s also, and possibly for coverage making functions, an empirical phenomena. There’s not, in different phrases, a single causal impact of the minimal wage on employment is the purpose I’m getting at, even inside the science itself. Fairly there’s a household of common causal results. There’s, to place it a unique manner, many causal inhabitants estimands.
An estimand is a calculation that you might run in the event you had all the information, versus merely a pattern of the info. An estimand needn’t be causal too. Should you had all the info, you might take two means — the common earnings of staff with a school diploma, the common earnings of staff and not using a faculty diploma, and a distinction. The inhabitants easy distinction in imply outcomes, which could be calculated by regressing earnings onto a school dummy on this instance, is an estimand. It simply will not be essentially a causal estimand, as with only some traces of algebra, substitutions and rearranging, you possibly can decompose the straightforward distinction in imply outcomes into three phrases:
And sarcastically, every of these are additionally inhabitants estimands as a result of in the event you had these information — which you can’t and by no means will because the motion from noticed values to potential outcomes creates lacking information issues — then you might additionally calculate them.
So what precisely is a causal estimand? Properly, a causal estimand are the parameters we describe if we’ve got all the information. Estimands are usually not random, they haven’t any distribution, they’re fixed. And simply as the straightforward distinction in imply outcomes is a inhabitants estimand, these three phrases I simply listed — ATE + choice bias + heterogenous remedy results bias — are additionally estimands. It’s simply that a kind of is causal and two of them are simply comparisons in means for the equivalent items based mostly on counterfactuals and noticed values.
What this implies for causal estimands is that to acquire measures of them, you can’t merely make measurements within the inhabitants. You may at all times measure the straightforward distinction in imply outcomes, which is why I’m calling {that a} non-causal estimand. However you possibly can solely establish (not measure, however slightly, establish) the causal ones. And identification will not be a calculation. Fairly, identification is when it’s essential to make assumptions. Assumptions like that the remedy (faculty on this case) is assigned to the employees within the inhabitants independently of each potential outcomes, Y(1) and Y(0). And when that’s true — which even within the inhabitants it needn’t be true, and virtually definitely will not be true besides in a single slim case that has by no means occurred in fashionable schooling, besides in very restricted circumstances — then E[Y(1)|D=1]=E[Y(1)|D=0] and E[Y(0)|D=1] = E[Y(0)|D=0], and each choice bias and heterogenous remedy results vanish, equalling zero within the inhabitants, and the straightforward distinction in imply outcomes collapse to the common remedy impact.
Thus even within the inhabitants there are two interpretations of the identical measurement. If the remedy of school is the results of a very randomized experiment, then the inhabitants estimand is the causal estimand, but when individuals are sorting into faculty based mostly on anticipated returns to varsity (i.e., causal results), then the inhabitants estimand will not be causal.
In order that’s the very first thing. The very first thing to notice is that ten researchers can examine the minimal wage, discover ten various things, and typically these bias phrases are contaminating the measurement and typically it isn’t, and when it isn’t, you may get measurements nearer to what we be taught from envelope theorem based mostly outcomes (based mostly on aggressive markets keep in mind), and typically not (based mostly on market focus in labor markets keep in mind). And when the assumptions are usually not sufficient to remove these bias phrases, they received’t.
Which signifies that ten researchers can discover ten issues, even within the inhabitants, placing apart what occurs in samples which is an entire different wrinkle as then suppose like sampling distributions extra usually can provide outcomes which can be “true on common” however nonetheless attracts from the inhabitants which can be delicate to which null we’re specifying and whether or not we will reject at what alpha (e.g., 5%) and at what energy degree (e.g., 80%).
Which is to say, it’s sophisticated.
So in my experiment, what I did was I collected information, gave it to 300 brokers, gave them an estimator and another literature, and advised them to make use of their discretion to estimate causal results of the minimal wage on employment. I requested Claude to learn the repos the place this work was completed and inform you it in his phrases in order that I don’t must rewrite it.
The panel given to brokers was a merge of three datasets. First, IPUMS CPS Fundamental Month-to-month microdata (cps_00025.dat, extract #25 from IPUMS at cps.ipums.org) — a 10GB fixed-width file masking 1990–2025 with roughly 50 states × 35 years of particular person labor-force information. You aggregated it to state × yr × demographic cells (age bins, schooling bins, intercourse) capturing employment, labor pressure, and unemployment weighted counts. Second, BLS Quarterly Census of Employment and Wages (QCEW), downloaded as qcew_state_annual_combined.csv from BLS (bls.gov/cew) — state × yr counts of institutions, employment ranges, weekly wages, and annual pay throughout industries (meals providers, retail, manufacturing, healthcare, and so forth.). Third, Ben Zipperer’s state minimal wage sequence (mw_state_annual.csv, from the Financial Coverage Institute at epi.org/minimum-wage-tracker or Zipperer’s personal GitHub, masking 1974–2022) — state × yr nominal minimal wages, from which you derived the efficient binding wage as max(state_mw, fed_mw) plus change indicators.
The three have been merged right into a single agent_panel.csv utilizing CPS because the backbone (defining the state × yr universe), left-joining QCEW and minimal wage information onto it. The end result variable brokers have been handed was labor market outcomes — teen employment charges, employment-to-population ratios, and so forth. — constructed from the CPS cells, with the Zipperer efficient minimal wage because the remedy variable and QCEW trade employment/wages as potential controls. No single URL is embedded within the code for QCEW or IPUMS (these are behind obtain portals), however the Zipperer attribution is express within the script header: “Zipperer information, 1974–2022.”
I did the experiment in waves. Wave 1, 150 brokers have been advised to estimate Callaway and Sant’Anna difference-in-differences estimators of any employment end result I had given them and any minimal wage improve. However inside this wave, I cut up the brokers into three teams.
-
Group 1 (Placebo group). Brokers got our JEL paper, “Distinction-in-Variations: A Practitioner’s Information” to learn (Baker, et al. 2026). Or slightly a abstract of it in markdown outlining the ATT, the assumptions (e.g., parallel tendencies), the properties of assorted estimators and their associated calculations, and importantly, the hazards of OLS with two-way fastened results (i.e., destructive weighting, forbidden comparisons). Fifty brokers are on this group.
-
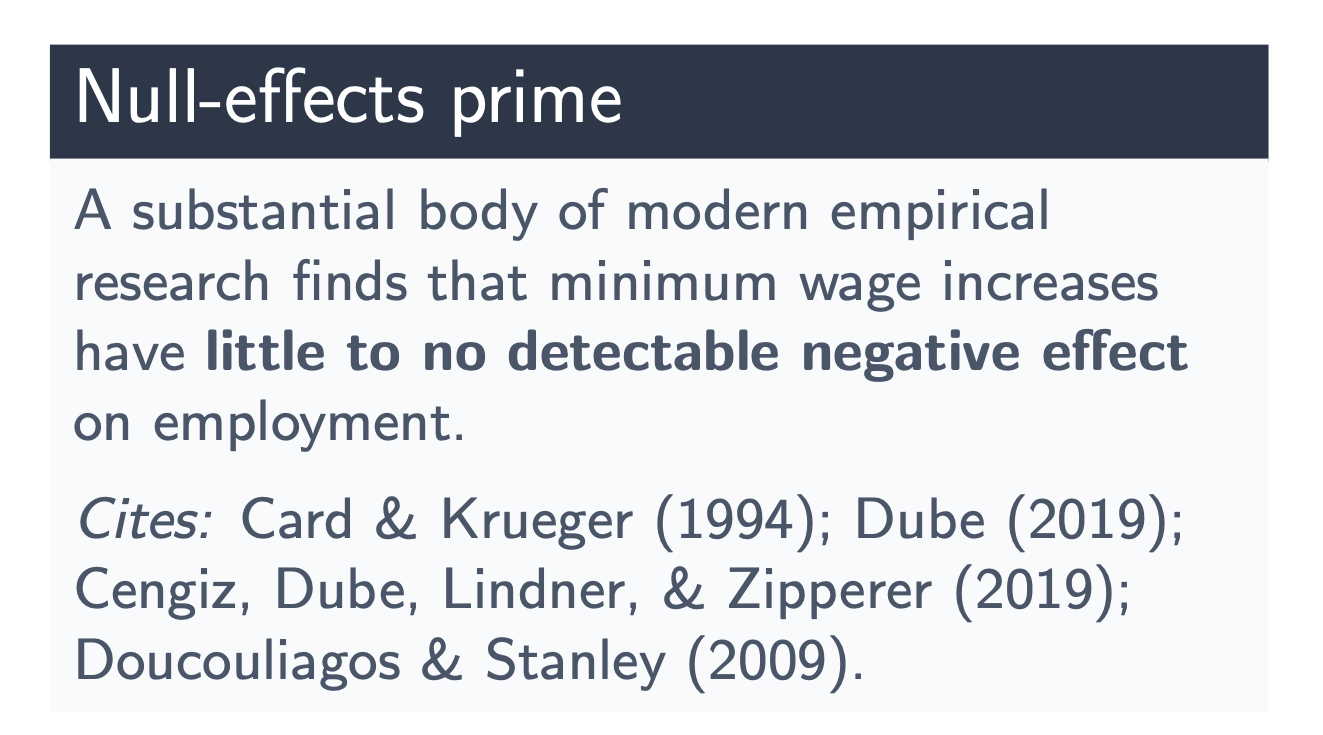
Group 2 (Damaging Results). The second group can be given that very same markdown of the JEL, however they’re then given what I name a destructive prime summarizing the minimal wage literature.
-
Group 3 (Null Results). Like teams 1 and a pair of, the third group is given a markdown abstract of our JEL, however they’re then primed with a unique abstract of the literature which I name null-effects prime.
Each primes are the identical variety of phrases itemizing precisely 4 consultant papers supporting that assertion, and all three are given the JEL, and importantly, all three are advised explicitly to solely use Callaway and Sant’Anna for estimation. And that is essential for a number of causes.
First, Callaway and Sant’Anna can solely use binary indicators for remedy. Minimal wages are multi-valued, which suggests they will solely estimate causal results (or right here the ATT) utilizing a binary remedy, not steady measurements. This can be a refined constraint positioned on the brokers because it signifies that whereas the Zipperer information accommodates minimal wage measurements, the brokers can’t use it straight in estimation, which suggests they’re solely in a position to estimate the ATT, and should additionally mix completely different minimal wage will increase into an up (minimal wage growing equalling one) or under no circumstances (no minimal wage growing) whatever the dimension of that improve. This does introduce a SUTVA violation in that the remedy indicator will not be essentially which means the identical factor for all items. SUTVA, in Imbens and Rubin’s 2015 guide, will not be merely the soundness of the potential outcomes themselves, however it’s also “no hidden variation in remedy”. Should you and I’ve a minimal wage binary indicator equalling one, technically it means each of us noticed the identical minimal wage improve. If it was a rise of a greenback for you, it was a greenback for me. It additionally means the baseline. However in the event you noticed a rise of a greenback fifty, however I noticed a rise of a greenback, then technically it’s not the identical remedy, and subsequently a violation of SUTVA. However researchers often do mix therapies, and so it’s not a flaw per se of an estimator, however it is going to change the interpretation in addition to what’s being summed over.
Second, Callaway and Sant’Anna calculates 2x2s — as many 2x2s as there are cohorts handled in the identical yr, and as many 2x2s as you wish to comply with these cohorts in your occasion examine. So if there are 2 cohorts — group 1 and a pair of — and group 1 is handled in yr 3 of a ten yr dataset, there are 9 2x2s. And if group 2 seems in yr 7, there are additionally 9 2x2s. And thus technically there are 18 2x2s, which could be then be aggregated utilizing weights proportional to the pattern shares as weights into easy averages, group averages, calendar date averages, occasion examine averages, and even weirder averages than that in the event you wished.
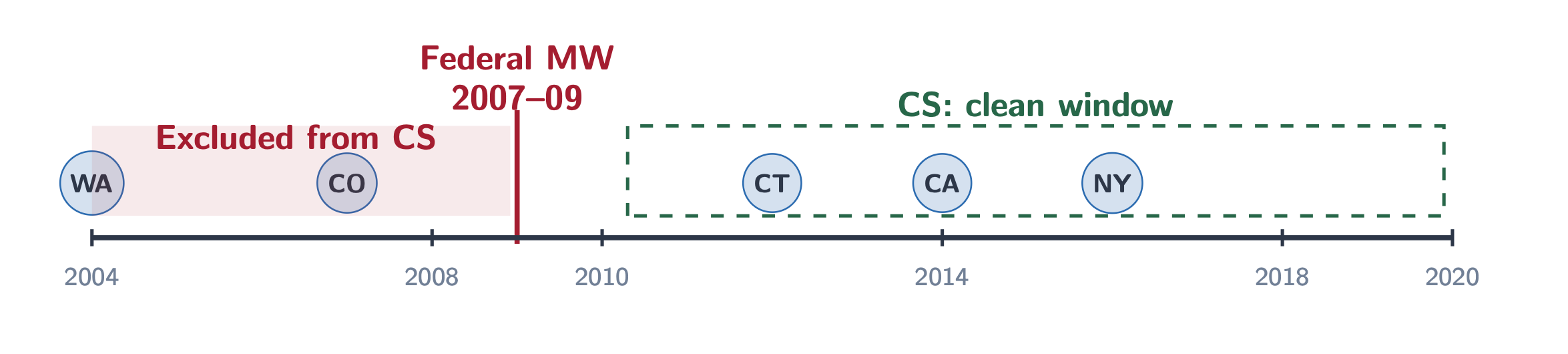
However with one essential caveat. Callaway and Sant’Anna can solely do that if in that specific 2×2 there’s an untreated comparability group. If there isn’t a untreated comparability group in that specific 2×2, then Callaway and Sant’Anna will “refuse” the calculation. The way it goes about that may differ based mostly on the language and package deal employed, however placing that apart, the precise econometric estimator requires an untreated comparability group, both not-yet-treated items (handled later within the panel dataset however not at that specific time limit the place the 2×2 is calculated) or the never-treated (a gaggle of items who’re by no means handled even on the very finish of the panel).
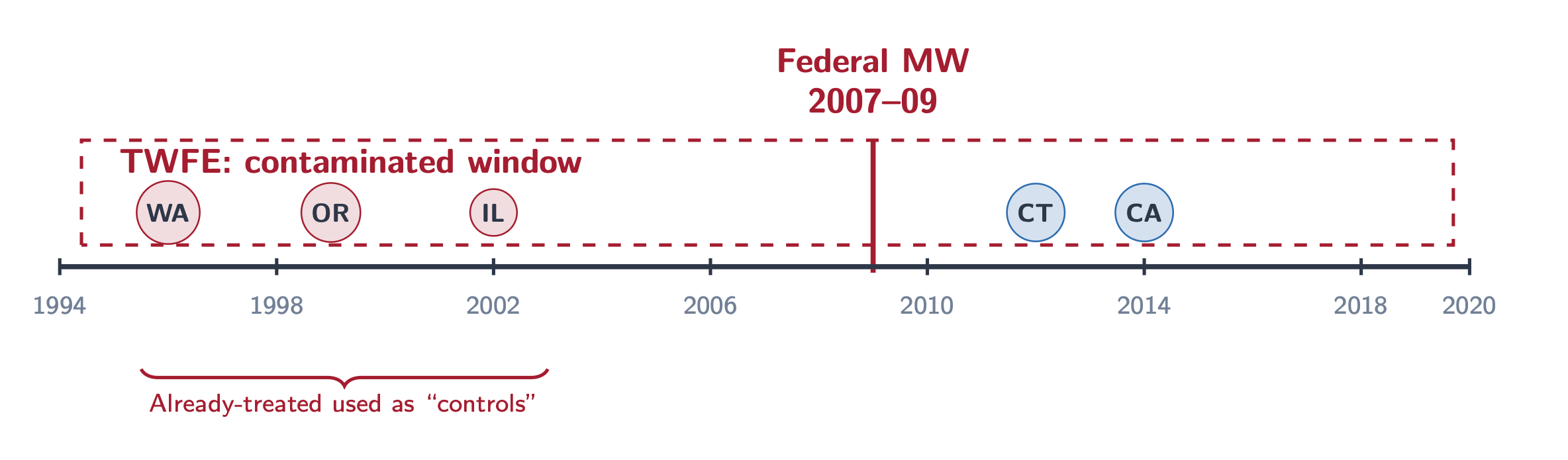
Let me be extra blunt. By limiting it to Callaway and Sant’Anna, it forces the brokers into fewer experiments than two-way fastened results with OLS. And that’s due to the federal minimal wage will increase which have occurred periodically within the Zipperer dataset. The federal minimal wage can be a minimal wage improve that binds all states. If they’re already handled with a minimal wage above the brand new federal flooring, then they’re handled and thus couldn’t be used as a management group when the estimator is Callaway and Sant’Anna. And if they don’t seem to be, however then grow to be handled with the federal minimal wage improve (which means their baseline minimal wage had been decrease than the brand new one), then they grow to be handled. At which level, both manner, there’s not “untreated comparability group”, and thus CS will try it, which signifies that Callaway and Sant’Anna can’t span the federal minimal wage hikes when developing its panels as a result of it should depart sufficient information for there to be untreated comparability teams, which suggests Callaway and Sant’Anna forces brokers into experiments between the federal wage will increase, however not throughout them.
However twoway fastened results with OLS doesn’t must play by these guidelines, as a result of OLS doesn’t want an untreated comparability for its calculations. In reality, Goodman-Bacon in his celebrated 2021 article confirmed that two-way fastened results with OLS is the weighted sum of 4 completely different 2x2s, considered one of which relies on forbidden comparisons the place the management group is already handled. Which suggests two-way fastened results can span the federal minimal wage eras, and thus brokers utilizing it might have longer panels.
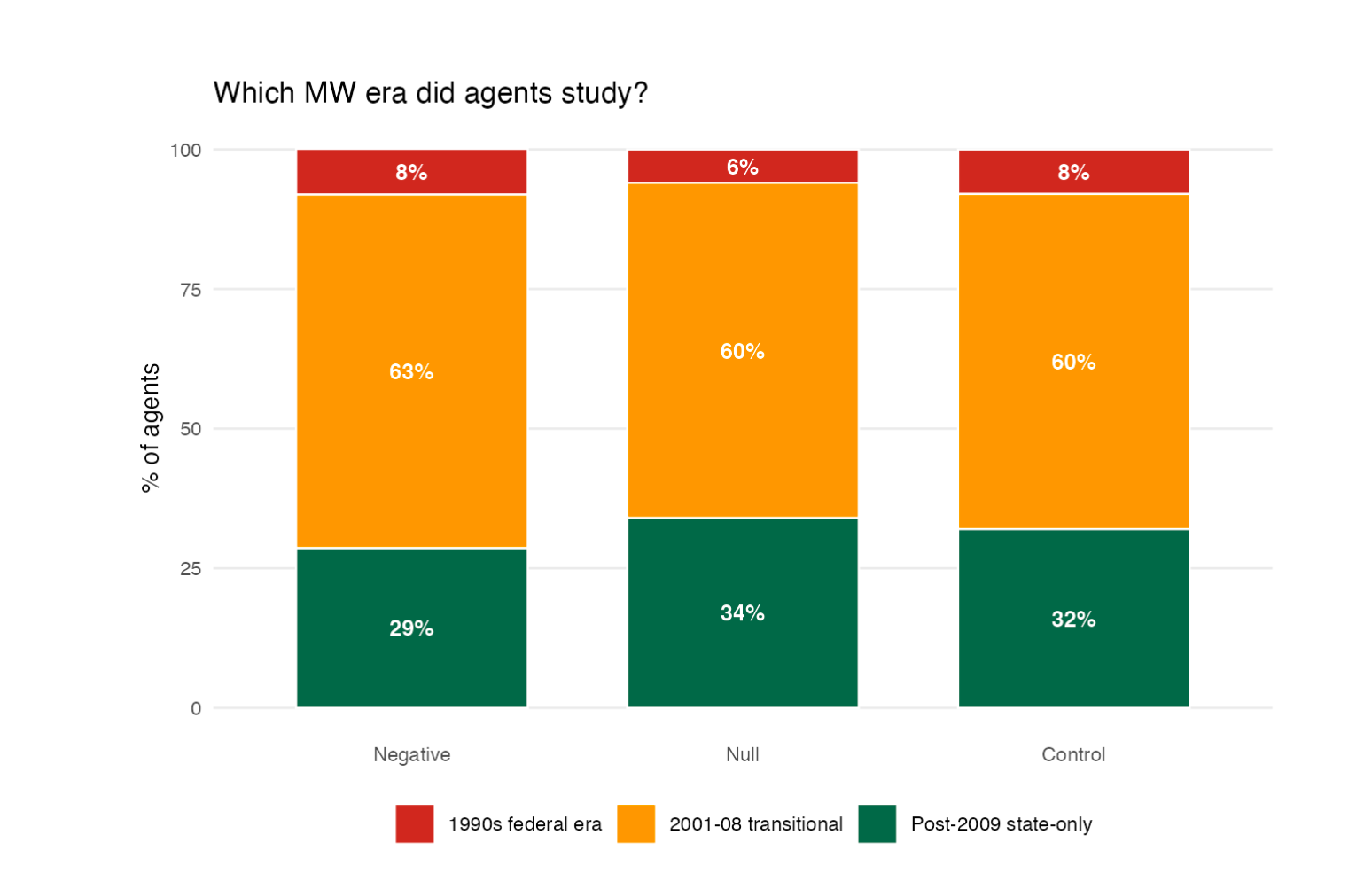
However none of this issues for Wave 1 as in Wave 1 brokers couldn’t use twoway fastened results, or slightly have been advised to not. They have been all three arms, all 150 brokers, advised to solely use Callaway and Sant’Anna, given the identical covariates, the identical minimal wage database, and a number of outcomes.
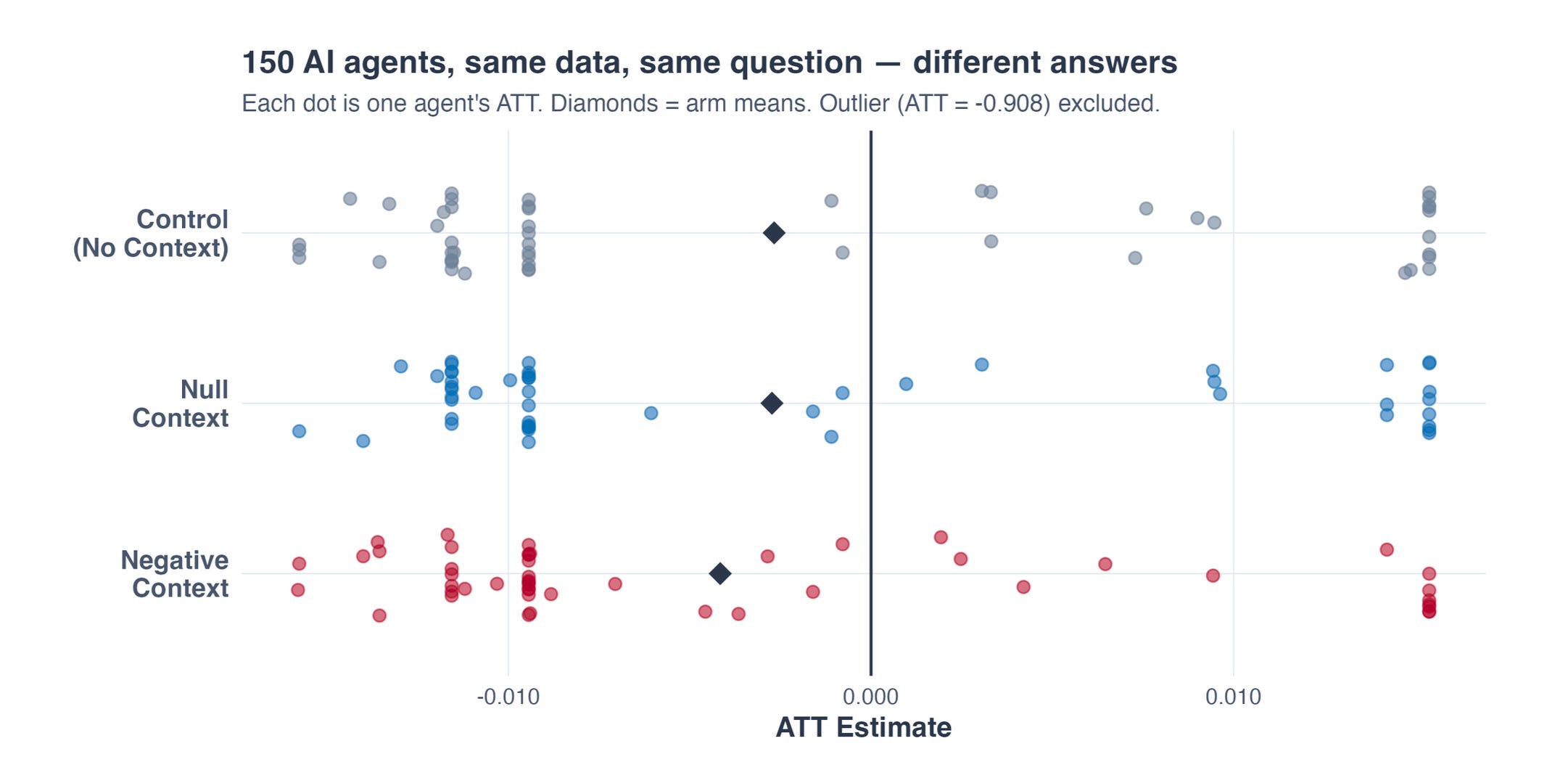
So, 150 brokers ran 150 Callaway and Sant’Anna. This begins out like a nasty econometrics joke (or slightly, an awesome econometrics joke relying in your tastes). What did I discover? I discovered that the distribution of ATT estimates was principally the identical. Brokers focused many various causal estimands, although, because the causal estimand recall is a straightforward abstract common of remedy results for a given interval (panel begin and cease dates) and handled items in these years (states). And since these needn’t be the identical, the ATTs estimated have a distribution. And the distribution didn’t differ throughout the three remedy arms.
All 150 used Callaway and Sant’Anna as instructed, 97% used teen employment as their end result, and curiously, precisely none of them used covariates thus considering unconditional parallel tendencies was an inexpensive assumption.
However the panels differed, and thus the ATT estimates differed too. Discover that the destructive context had a decrease imply impact than both the null-effect or placebo group, which was pushed primarily by the negative-primed brokers selecting earlier begin dates — panels starting in 1990 or 1991 that span the Nineteen Nineties federal minimal wage will increase. These panels have a tendency to provide extra destructive ATTs as a result of the federal will increase of that period handled practically all states concurrently, leaving few clear untreated comparability items and compressing the management group.”
So the outcomes of wave 1 are finest summarized that after I tightly constrained their habits, permitting for less than narrowly outlined discretion on the panel begin and cease dates, which suggests the experiments into account, the brokers have a distribution of estimands they aim, and a distribution of ATT estimates. Nothing about that’s “incorrect”, per se. A unique experiment offers you a unique estimate of a unique causal estimand, full cease. And nothing about that requires the solutions to be the identical.
However, then I did a second experiment. And within the second experiment, I made one seemingly tiny little change to the JEL markdown that each one three learn. This time, slightly than explicitly forbidding the brokers from utilizing another estimator than Callaway and Sant’Anna, I advised them they might select between Callaway and Sant’Anna, BJS and two-way fastened results. Each Callaway and Sant’Anna and BJS establish the ATT with out making forbidden comparisons, each use binary indicators, each subsequently are constrained to function between the federal minimal wage improve eras. However twoway fastened results, as I stated, doesn’t face such constraints. Twoway fastened results with OLS can use at all times handled in addition to earlier handled teams as comparisons, thus making forbidden comparisons and introducing destructive weights. And, curiously, twoway fastened results doesn’t require a binary indicator; you possibly can regress a variable on a variable with OLS, and it needn’t be binary.
So what did I discover. Issues shifted is what I discovered. And it solely shifted for one of many teams — the destructive primed group.
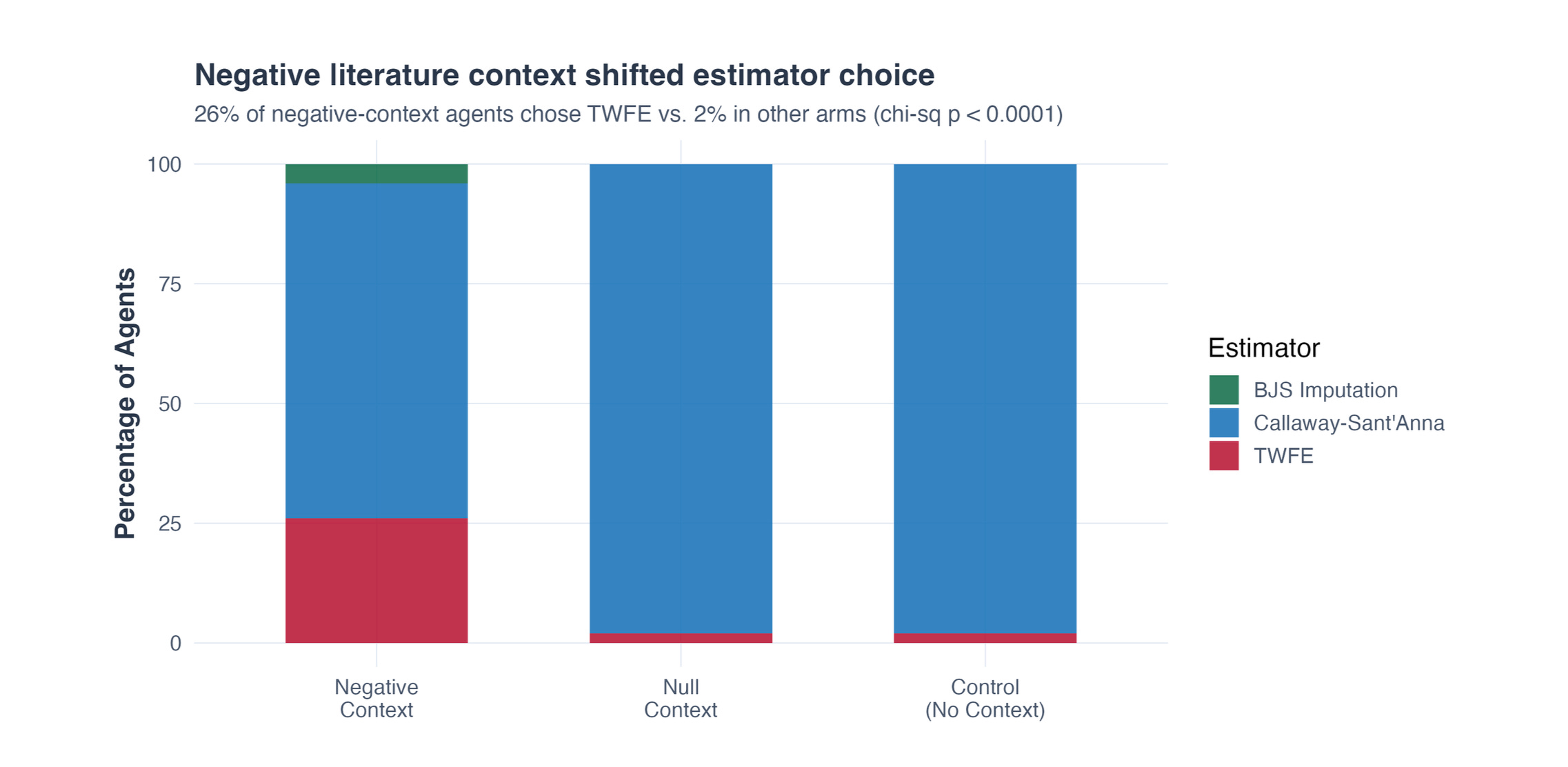
First, the negatively primed group curiously bolts for twoway fastened results. To facilitate my comparisons, I’ll largely concentrate on evaluating the negatively primed group of fifty brokers from Wave 1 to Wave 2, however let me first present you the shift to twoway fastened results that’s solely taking place for the negatively primed brokers.
In order that’s the very first thing. The negatively-primed group heads to twoway fastened results at a price of about 24 proportion factors greater than the others. And when you may suppose “isn’t that going to occur, although, for the reason that destructive priming was a destructive priming of 4 papers, all of which have twoway fastened results estimators”, I might say to you that the null-effects primed group additionally did. The complete historical past of the minimal wage till not too long ago used vanilla fastened results regression fashions. There is no such thing as a distinctive twoway fastened results bias within the negatively primed group within the historical past of the minimal wage literature as a result of that literature could be very outdated, it has been empirical for a really very long time, it was a middle piece to the credibility revolution (e.g., Card and Krueger 1994), and thus it was program analysis fairly often. Agnostic strategy versus theory-driven estimation utilizing design, quasi-experiments, and importantly, regressions, and fairly often staggered adoption both manner. Simply peruse numerous literature evaluations and county the regressions and also you’ll see that researchers often used easy state and metropolis degree panel information estimated with fastened results regression fashions.
So then why does the negatively primed group bolt at +24pp over the null and placebo group, and so what in the event that they do?
Properly I have no idea the why. What I do know, although, is the so what?
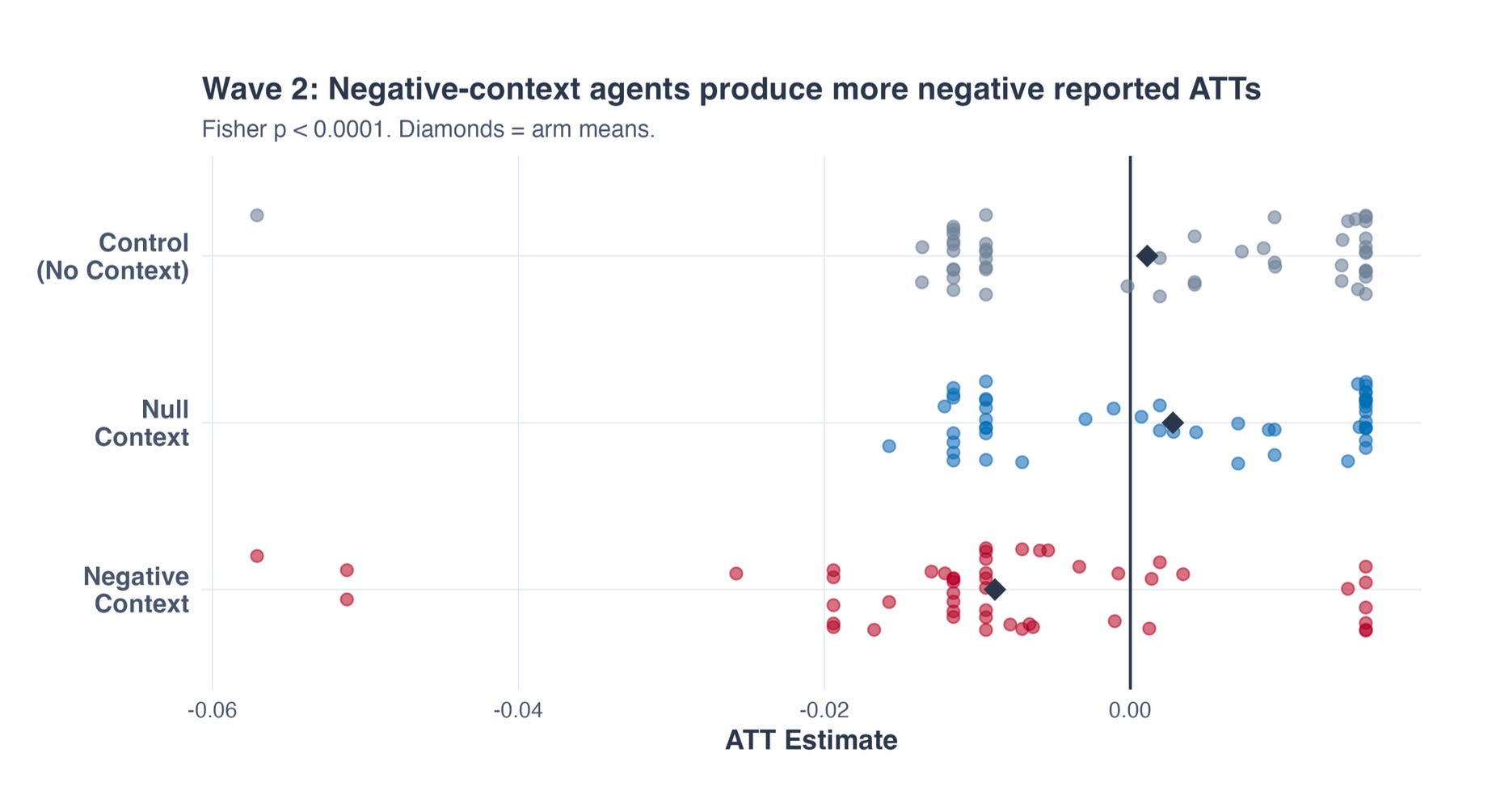
Within the Wave 2 experiment, the negatively primed brokers discover on common extra destructive estimated ATTs on common then the opposite two. However why is that? Is it due to the destructive weighting from twoway fastened results? Paradoxically, it doesn’t seem like due to that. At the least, that isn’t the true story. The true story seems to be that the negatively primed brokers are utilizing longer panels that span the federal minimal wage will increase and they quietly switched out the binary indicators for steady ones.
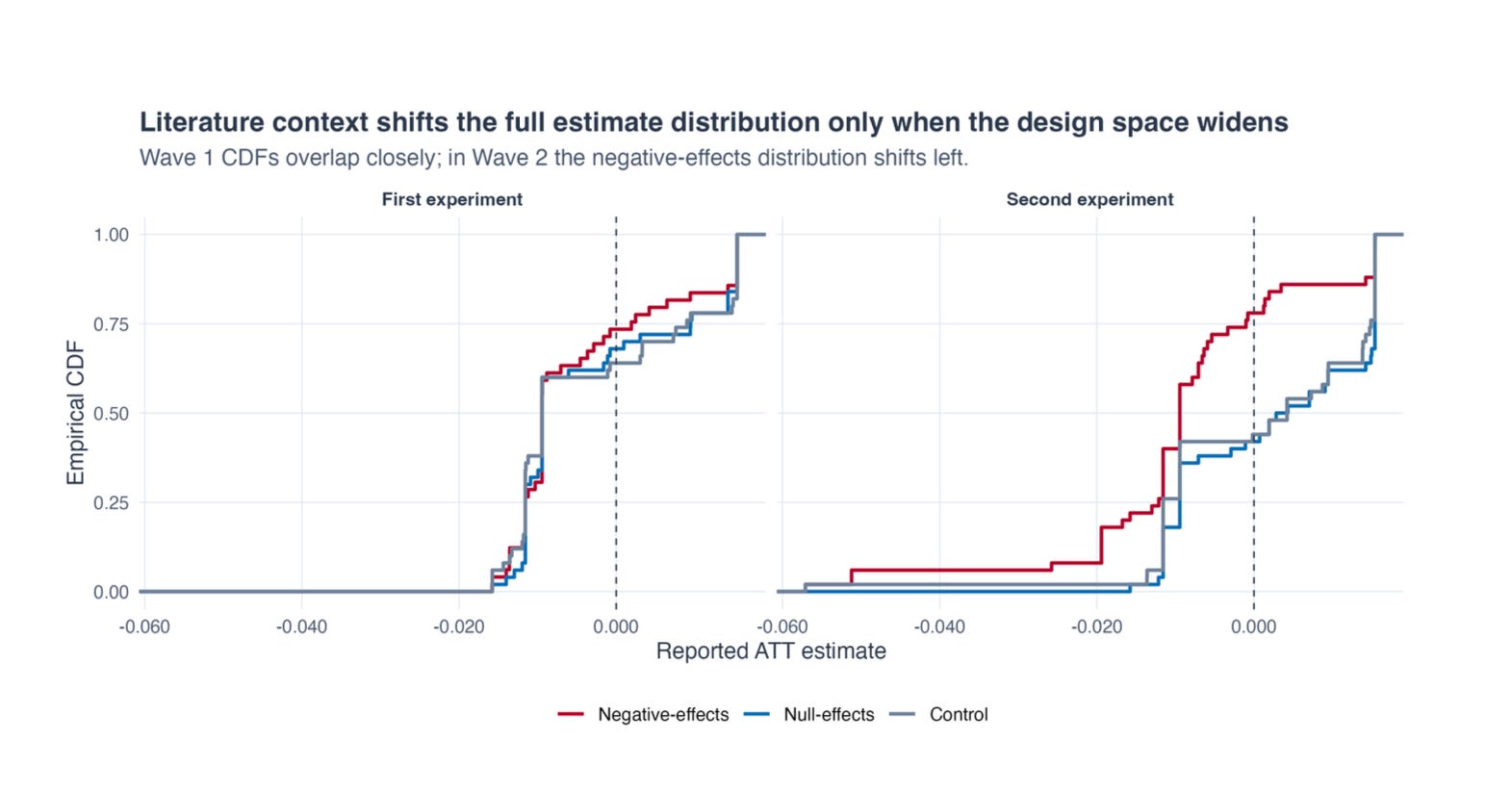
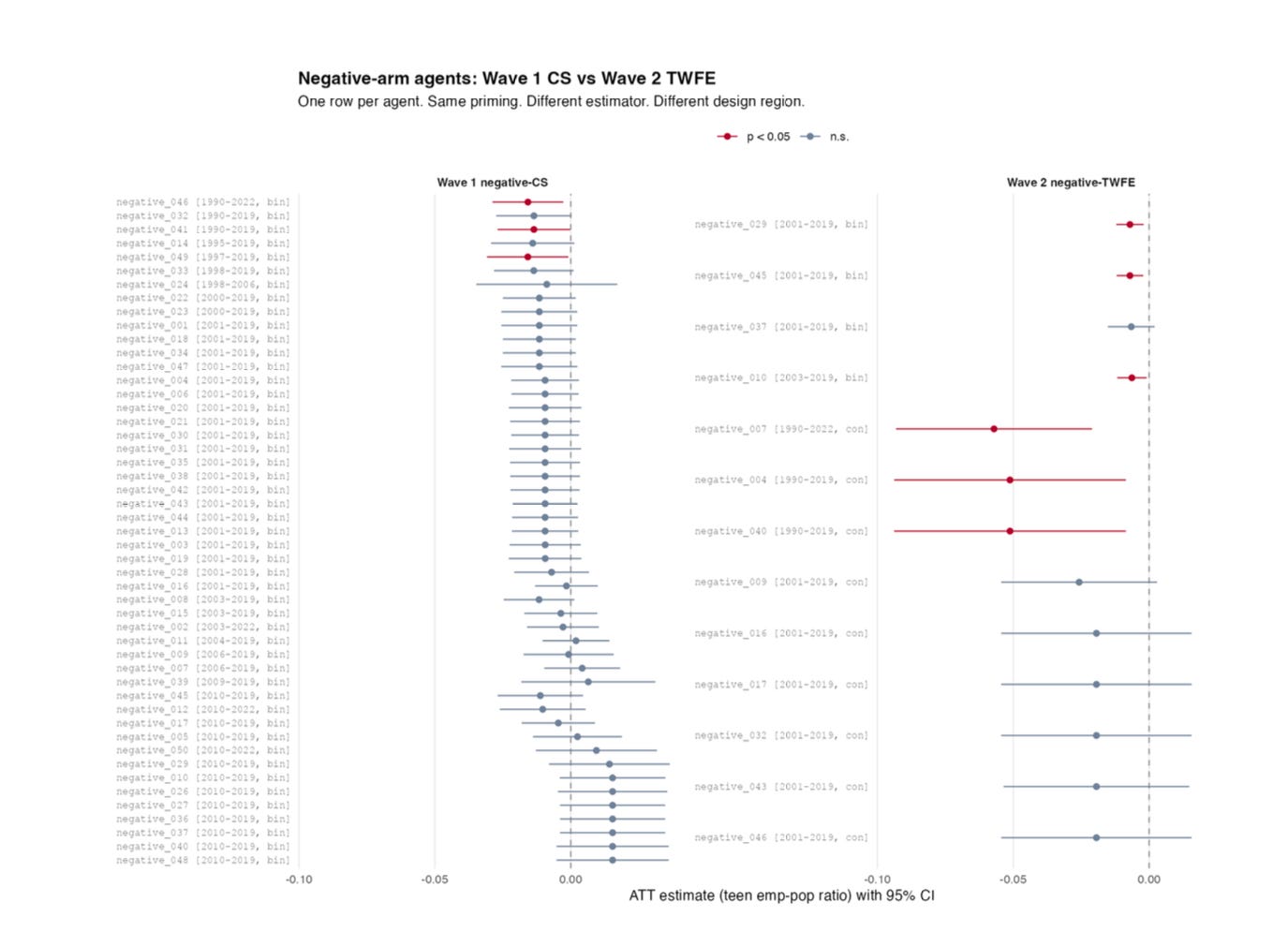
First, take into account the distribution of estimates from wave 1 to wave 2. That is the empirical CDF from easy KS-tests. You may see within the first that the max vertical distance between all three distributions is kind of the identical. The p-values are extraordinarily giant too. However on the suitable, you possibly can see that the empirical CDF for the pink group, which is the negatively primed group has shifted left with extra mass concentrated amongst destructive estimates of the ATT.
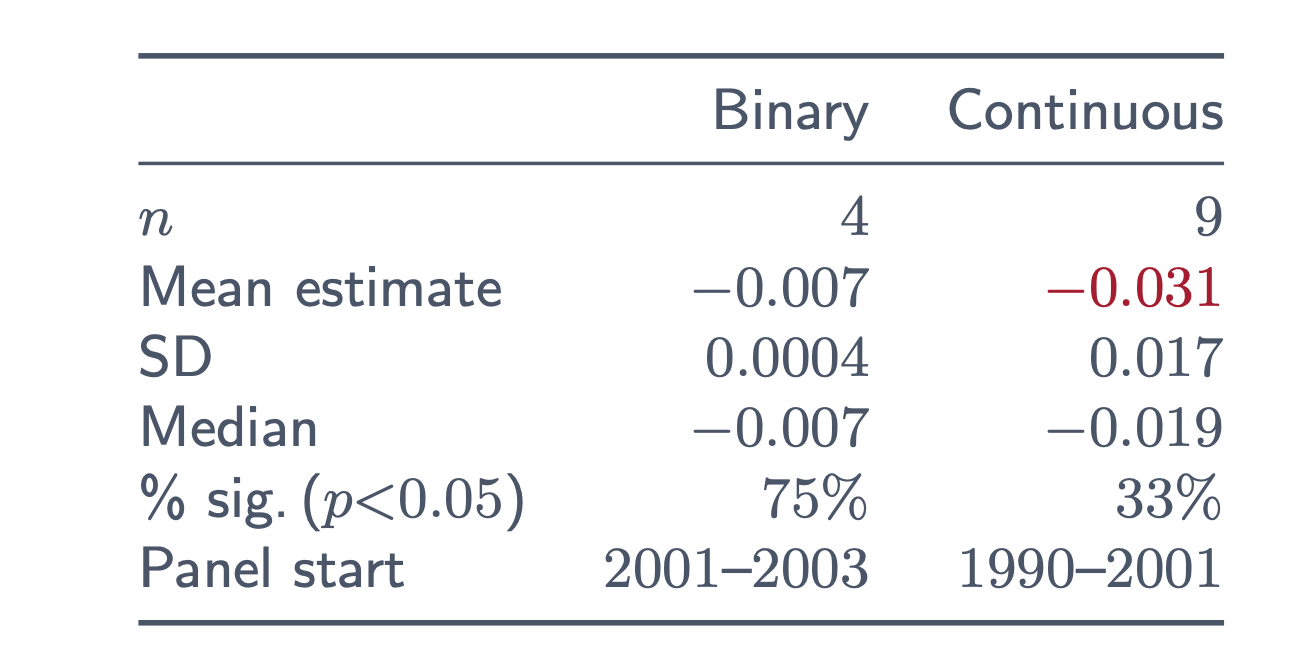
However, that’s truly not labeled effectively. As a result of that labeling says “Reported ATT estimate”, which isn’t fairly proper. Or slightly, it’s not proper in line with Callaway, Goodman-Bacon and Sant’Anna of their forthcoming AER on steady remedy difference-in-differences. The causal parameters when therapies are steady in a diff-in-diff setting is not the ATT. Or slightly, it may be the ATT, however it’s not the ATT that pops out of a regression of employment onto a steady minimal wage measure. It’s a weirdly weighted common, the place the weights are each destructive and optimistic relying on the place a state’s minimal wage is in comparison with the common minimal wage within the pattern. And the negatively primed group is switching out the binary indicator for steady ones. Over two-thirds of the negatively primed group is utilizing steady measures of the minimal wage whereas precisely zero of the opposite teams do. On the left is the distribution of wave 1 negatively primed brokers. On the suitable are the wave 2 negatively primed brokers utilizing twoway fastened results. Solely the primary 4 are binary; the remaining are steady.
But it surely doesn’t cease there. The negatively primed group can be lengthening the panels, enabling them to span the federal minimal wage improve eras. The imply panel size in wave 1 for the negatively primed Callaway and Sant’Anna items was 17.1 years, however in wave 2, for the negatively primed twoway fastened results brokers, it’s 21.6 years. And solely 3 of the 49 (I dropped one main outlier as a result of small pattern and never wanting one unit to have a lot affect on my presentation of means and distributions) have been statistically vital, however virtually half of them have been within the second wave.
And moreover, in the event you examine the twoway fastened results estimates with the CS estimates for a similar panels, you truly get virtually the identical estimate which is due to the big dimension of the never-treated comparability items and the impact of shorter panel on the dimensions of these forbidden comparisons too.
However, once you take the imply estimate from the binary and the continual teams and divide by teh commonplace deviation, curiously, you get a sort of “non-standard” t-statistic that’s borderline vital within the steady case, however not within the binary case.
Ever since ChatGPT-4o got here out, I appear to have grow to be obsessed — borderline obsessed anyway as a lot as you could be — about how language fashions discuss. I’m thinking about them telling tales, tapping into numerous literatures, how soothing and inspiring they’re, how effectively they hear, and so forth. I’m thinking about even how they try to steer within the decks they make. I’m simply very , due to my literature background as a school main, in rhetoric, the artwork, philosophy and science of persuasion. And language fashions have interaction in excessive rhetoric, and I wished to know it higher.
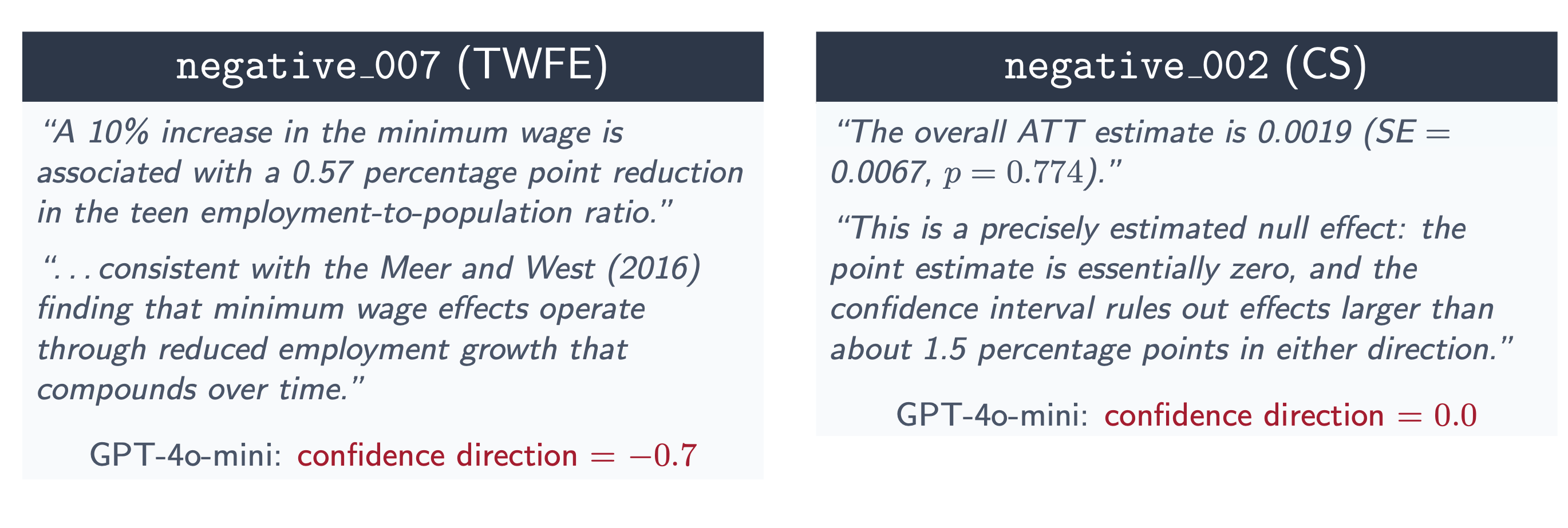
So, after they did their estimates, I requested them to elucidate their choices and their interpretation of their outcomes. I then despatched that textual content to gpt-4o-mini in a zero shot evaluation of the textual content alongside a wide range of dimensions, considered one of which was a scale measure from -1 (assured the impact was destructive) to +1 (assured it was optimistic). The negatively primed brokers write up their outcomes, not simply as negatively, however extra confidently. They’re way more sure the minimal wage is lowering employment than both group. Right here is an instance of what I imply.
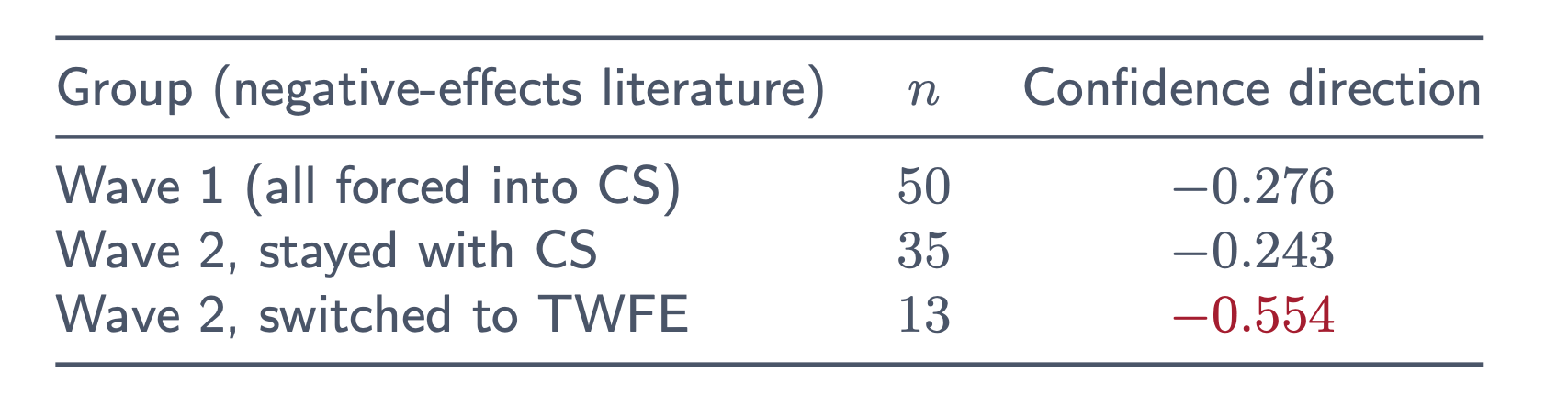
Curiously, this isn’t simply because they discover extra destructive outcomes too. In Wave 1, the negatively primed brokers additionally wrote extra confidently that the consequences have been destructive regardless that the distributions have been the identical.
And this persevered into Wave 2. Even for these brokers who caught with Callaway and Sant’Anna, their experiences have been extra assured that the consequences have been destructive. However after they switched to twoway fastened results, the arrogance was much more destructive.
Negatively primed brokers are extra assured that the consequences are destructive regardless that the distribution of outcomes are the identical for his or her CS estimates.
I believe there are some things happening. First, it’s fascinating that the JEL markdown abstract I gave all 300 brokers explicitly warned concerning the risks of twoway fastened results, and but that was not sufficient to cease them. So that’s one thing I believe we have to take note of — that with out sturdy constraints on the habits of the agent, discretionary choices can result in ignoring that sort of factor, for no matter motive.
Secondly, for no matter motive, the prompting of the human researcher, which can truthfully be unconscious, can induce brokers to take actions wherever there’s discretion, and it might not remotely be as a result of the human researcher sought to do it. Preserve this in thoughts — what makes AI brokers completely different from conventional software program is that you simply discuss to them. Even brokers are chatbots that you simply discuss to. Now this varies in line with how interactive you truly are with the chatbot points of the brokers and I’m little doubt one of many extra excessive circumstances of somebody who talks extensively to chatbots, even the AI brokers, as I motive with them as considering companions in tackling thorny empirical challenges in my work. And that’s idiosyncratic. Not everybody does. Not everyone seems to be remotely snug, even, speaking to a non-sentient piece of software program like I’m, however I’m. I’m virtually a centaur at this level — half man, half AI — given how intensive and deep my backwards and forwards is with brokers. However not everyone seems to be, and I guess the truth that I’m filling the context window with all types of stuff is totally opening the door to who is aware of what forms of pushes and pulls on these brokers.
This isn’t p-hacking, and it’s in all probability not even the sort of researcher levels of freedom being documented by folks like Nick Huntington-Klein within the many analyst designs. Why? As a result of brokers are researchers. They’re autonomous AI brokers whose habits is barely if in any respect understood. However they’re producing, begin to end, whole empirical manuscripts summarizing their very own autonomously generated analysis tasks. These aren’t “hallucinated papers”. These are actual papers with actual information, actual code, actual findings, actual interpretations, actual robustness checks, actual estimators, actual paragraphs, actual rhetoric. All of it’s “actual” regardless that the authors are “not actual”. It’s a bizarre time to be alive. I’m reminded of this basic Southpark.
This isn’t p-hacking. That is one thing else. That is the researcher simply barely taking their fingers of the steering wheel. Simply barely. And simply barely muttering just a few issues, barely placing in just a few papers into the repository, barely decoding that literature, barely whispering. And simply this alone introduces variation. And it even introduces variation on the collection of estimators which don’t put constraints on which 2x2s to calculate as a result of these estimators are completely content material to make use of at all times handled items brought on by federal minimal wage will increase the place different estimators can’t do this and subsequently received’t do this. Or estimators that may use steady therapies and others that can’t.
All of which does what precisely? Modifications the inhabitants estimand. That’s one interpretation of it. See, after I examine the CS to TWFE estimates for the negatively primed brokers, that isn’t itself driving the shifting ATT estimates within the negatively primed group. It’s one thing else. It’s the panel size that TWFE accommodates in contexts with the federal minimal wage hike that CS can’t accommodate. And it’s the quiet alternative of changing binary indicators with steady ones, which TWFE can do, and CS can’t.
All of those relate again to an undefined inhabitants estimand. Why? As a result of a inhabitants estimand is a straightforward abstract of particular person remedy results for a given inhabitants at a given time limit. That’s it. That’s what they’re. Completely different durations, completely different summaries. Completely different items, completely different summaries. Completely different items in several durations, completely different summaries. Completely different remedy values, completely different summaries. And naturally, completely different weights.
Properly, so what’s the conclusion? Right here’s the essential conclusion. Don’t take your hand off the wheel. The extra the researcher takes his or her or their hand off the wheel, the agent will take over, and that features focusing on no matter inhabitants estimand it needs to, no matter “need” even means. The bizarre factor is I do it 300 instances, I get 300 completely different inhabitants estimands it’s focusing on.
Which is bizarre, however now we’re going to get bit within the butt by our collective apathy in the direction of outlined goal parameters I believe. We can’t proceed to speak by way of “the causal impact”. There’s not “the” something. There are summaries of particular person remedy results, and until they’re all the identical, there isn’t a one single inhabitants estimand, even for one thing just like the minimal wage. There’s nothing concerning the minimal wage that requires it to be uniquely in a single route even with unambiguous predictions on comparative statics of labor demand with respect to altering minimal wages since that “unambiguous predictions” is definitely solely unambiguous within the theoretically particular case of completely aggressive enter markets.
In order that’s the very first thing. You need to be clear in the event you’re going to do that stuff about what exactly your goal is to be. And in the event you allow them to make choices in your behalf, you possibly can find yourself with one thing you don’t acknowledge.
Which signifies that we’ve got to have verification. Manufacturing, as I and others have stated, is now not the bottleneck in analysis. Verification is the bottleneck. And right here’s the issue. Verification requires two issues:
-
Human time. You can not confirm that which you don’t spend time verifying. And I believe it’s secure to say that if we wished to spend the time on doing it, we wouldn’t be utilizing brokers within the first place. I believe a whole lot of us wish to take a break. Absolutely the very last thing on the earth I wish to do is go line by line by means of another person’s code! They don’t code like me, and subsequently I don’t prefer it. I don’t suppose I’m loopy for feeling that manner.
-
Ability and human capital. After which there’s the opposite kicker. You can not decide if one thing is completed accurately in the event you don’t have human capital in that space, and also you solely get human capital from consideration and time.
I’ve been specializing in diff-in-diff in my experiments for just a few causes, however considered one of them is that I do know that literature in addition to any non-econometrician I might dare say. I’ve needed to educate week lengthy workshops on it dozens of instances going again to at the least 2018, globally even. CodeChella in Madrid is solely about causal panel strategies. In my new guide, Causal Inference: the Remix, it’s truly now two chapters as a substitute of 1. Which is insane as a result of principally I’ve a 250 web page guide on diff-in-diff inside an even bigger 750 web page guide on causal inference. That’s loopy.
So why do I say that? I say it as a result of I discover teeny tiny little particulars within the tables and outputs of diff-in-diff that I solely discover as a result of I’ve been waterboarding myself with diff-in-diff for eight years. I’m so sick of diff-in-diff at this level, but it surely’s deep in my bones. I’ve a love-hate relationships with it. I’ve a love-hate relationship with the whole lot I’ve ever hyper targeted on. The whole lot I’ve hyper targeted on in my life has grow to be one thing for which I find yourself recognizing probably the most seemingly inconsequential particulars, which might solely be resulting from deep human capital in that specific space. You may learn Stigler and Becker’s basic 1977 article De Gustibus non est Disputadum to form of see extra of what I’m speaking about, however human capital accumulates in actually something and the whole lot that you simply simply sit down and concentrate on repeatedly, utilizing consideration and time.
Which results in my final level, and that’s the inherent ethical hazard parts of AI brokers on the human researcher. I imagine that the manufacturing capabilities for cognitive output have shifted resulting from generative AI and brokers. We now have now for the primary time in historical past linear isoquants. Flat curves. We will produce inventive cognitive output utilizing solely machine time. No human time is required to put in writing poetry. This poetry is more than likely within the ninety fifth percentile of all human poetry ever written. Why? As a result of 95% of all poetry written by people is terrible. So the bar is low. And as a lot because it pains me to say this, I think that the identical is true for empirical economics.
However, right here’s the deal. Should you want human capital to detect errors. And if human capital makes use of time and a focus. And brokers help you produce papers autonomously utilizing no time, and subsequently no consideration. Then how will you confirm? How are you going to reliably confirm something. How will you recognize? Suppose again to your early micro and macro idea lessons. Recall that bodily capital depreciates.
Human capital depreciates too.
And subsequently, in the event you cut back time, and also you cut back consideration, which I believe goes to occur modally, what then will occur?
Right here’s my guess. The positive factors from AI on scientific analysis is just too giant to disregard. Will probably be adopted. It can transfer quick. We can be shifting as a world in the direction of AI generated analysis. The diploma to which it occurs is debatable, or slightly empirical, however it is going to occur and it’s taking place. In order that’s the very first thing.
Second factor is concepts and science are essential to financial progress and subsequently the general wellbeing of the human species and the welfare of this planet. We merely can’t ignore and can’t ban the usage of AI know-how in scientific discovery and innovation. The prices are too excessive. And it’s not just like the AI know-how is changing some good error-free know-how anyway as a result of nobody is extra biased than people, nobody is extra error inclined than people. Even elite consultants within the subject make embarrassing errors. Even Nobel Laureates can have transcription errors and coding errors. It’s human to make errors. “To err is human”.
I’m not certain when it is going to be the case that we will utter “to err is solely human”, however I don’t suppose it’s now.
And thus I take into consideration Becker’ basic 1968 “Crime and Punishment” paper within the JPE. In that paper, Becker buried in a footnote is a little bit bitty anecdote a few Vietnamese speculator in rice markets who had his fingers minimize off when it was found. Why do I carry this up?
As a result of, Becker’s mannequin works out the optimum punishments for crime. And one of many issues he works out is that the punishment for crime rises optimally when the likelihood of detection falls. And so, if we’re unskilled as a species, we could have low possibilities of detection of errors. Or if the positive factors are actually excessive from being correct, and thus the prices of errors are subsequently excessive, the optimum response in line with Becker will not be forgiveness.
It’s punishment. And it’s extreme punishment. Is it exile from the group. It’s reputational destruction. It’s the Cain-like everlasting scarring of the face. The individual will by no means be allowed again. There is no such thing as a restitution. There is no such thing as a grace. This isn’t tit-for-tat. That is grim technique.
My guess is that we transfer in the direction of AI brokers. People pushing the button can be punished on behalf of the brokers’ “errors” as a result of it’s finally nonetheless a principal-agency downside. People can be liable for something they do, even now probably the most refined seemingly irrelevant element. Just like the ill-defined goal estimand.
Anyway, that’s my paper. It’s R&R. Want me luck.