Astrology has an extended historical past, stretching again 1000’s of years and permeating throughout quite a few historic civilizations. In trendy occasions, astrology is massive enterprise — and it is rising. In 2025, the business was estimated to be value round $3 billion.
On this excerpt from “What Science Says About Astrology” (Columbia College Press, 2026), writer and science journalist Carlos Orsi appears to be like at a research of 20 million those who sought to check whether or not star indicators have a task in romantic compatibility.
Essentially the most strong use of knowledge to check astrology is the research of affection indicators performed by David Voas in 2007, involving information from greater than 20 million folks from the 2001 census from England and Wales. Voas examined the speculation that sure solar indicators had been “extra appropriate” for romantic relationships.
Using the supposed romantic compatibility/incompatibility between indicators or planetary configurations to check astrology’s validity has an extended historical past. This technique was, for instance, employed by Carl Jung (1875–1967) in his work on astrology and synchronicity and within the traditional research by Bernie Silverman.
The concept of astrological compatibility or incompatibility in love has robust common enchantment. The guide “Love Indicators”, by Linda Goodman (1925–1995), an virtually 1,000-page tome, continues to be reprinted and bought 30 years after the writer’s dying (as of this writing, the latest version dates from 2020). Usually, indicators separated on the zodiac wheel by angles of 60° and 120° are thought of favorable for love, whereas these separated by 180° are seen as extraordinarily incompatible. Proper angles additionally are usually interpreted as unhealthy omens.
Voas explains the rationale of his research this manner: Folks born throughout the month-long durations outlined by a specific solar signal are purported to share sure inclinations, for instance, to be beneficiant or delicate or cussed. These tendencies have an effect on private relationships.
We all know from on a regular basis expertise in addition to a mass of social scientific information that people who find themselves comparable in age, schooling, social class, faith, ethnicity and so forth are way more more likely to marry than those that are completely different in these respects. {Couples} are thought to be being properly or poorly matched on the idea of look or persona. If astrological compatibility exists, its results ought to be observable.
Get the world’s most fascinating discoveries delivered straight to your inbox.
This final level — that the results ought to be observable — is essential. Astrologers typically complain that checks primarily based solely on solar indicators are unfair as a result of a solar signal’s affect represents solely a fraction of a whole start chart’s that means. Nevertheless, a pattern of 20 million folks, like Voas’s, neutralizes this objection.
The research did reveal some anomalies — however after digging deeper this impact was defined by errors within the census information.
(Picture credit score: Crispin la valiente/Getty Photographs)
Even when the solar signal accounts for under, say, 0.1% of general romantic compatibility, in a pattern composed of 10 million {couples}, this could end in an extra of 10,000 shaped by folks with appropriate indicators, above and past what could be anticipated if astrology had no impact. Or, because the writer states, “With a sufficiently massive pattern, we must always be capable of detect any tendency for some indicators to draw or repel one another.”
The research’s preliminary aim was to seek out an extra of pairings between indicators deemed appropriate by the consensus of astrological literature. Sadly, Voas writes, such a consensus was arduous to seek out: “There is no such thing as a nice consistency amongst astrologers, and a survey of books and web sites reveals a substantial number of views regarding propitious pairings.” So he opted for the least frequent denominator, looking for any deviation from primary likelihood: “On this analysis I search for proof that any mixture of indicators is discovered roughly typically than could be anticipated to happen by probability.”
The outcomes had been at the least intriguing: The preliminary evaluation indicated an extra of {couples} the place each companions had the identical signal or adjoining indicators — e.g., extra Capricorns with Capricorns or Capricorns with Aquarians than anticipated. There have been about 22,000 additional {couples} with matching indicators past what probability would predict and an extra 5,000 {couples} with adjoining indicators. May this be astrology in motion?
Voas dug deeper into the info and found extra anomalies. For instance, the surplus of {couples} born in the identical month was even larger (23,000) than that of {couples} with the identical signal, and the proportion of {couples} with the identical start date was 41% increased than anticipated by probability. “Now whereas there could also be some people who find themselves drawn to one another as a result of they share a birthday, the surplus in all probability displays response error for essentially the most half,” he wrote. “Census varieties are sometimes accomplished by one member of the family, and that particular person might — by carelessness or forgetfulness — write in his or her birthday when coming into particulars for the partner.”
Different statistical anomalies attributed to errors embrace an extra of start dates recorded as January 1 (in all probability a placeholder when the precise date is unknown), cases of matching days in several months, and matching months with completely different days. Voas’s problem, then, was distinguishing these potential information entry errors from any actual astrological impact — if one existed.
“The partial overlap between astrological indicators and months of start permits an important take a look at,” he wrote, noting that the primary 10 days of the interval lined by any signal falls in a single month whereas the opposite 20 or so fall within the subsequent (for instance, Aries runs from March 21 to April 20). So was an individual born within the final days of March extra more likely to be married to somebody born within the early weeks of March or maybe the early weeks of April? Within the first case, their partner could be from the identical month however a unique signal; within the second, from a unique month however the identical signal.
“The outcomes had been conclusive. The {couples} whose birthdays belonged to the identical signal however fell in several months had been no extra quite a few than probability would dictate. In contrast, there have been extra mixtures of birthdays from completely different components of the identical month than anticipated. This extra in shared months of start might be the results of response error, however in any occasion solar signal shouldn’t be an element.”
The slight extra of {couples} with adjoining indicators was defined by a data-imputation method used within the British census to fill in lacking or illegible information. One companion’s start date was imputed as the primary day of a month and the opposite’s as the primary of the next month. When these imputed information factors had been excluded from the pattern, the “adjoining signal” impact disappeared. The underside line is that an evaluation of 10 million {couples} in England and Wales revealed no astrological impact.
However Voas’s work illustrates how simple it’s to get misplaced in information or be swayed by enthusiasm. Somebody who had stopped at step one — discovering an extra of {couples} with the identical signal — may need mistakenly offered census information as validation for astrology.
This text is excerpted from What Science Says About Astrology by Carlos Orsi. Copyright (c) 2026 Columbia College Press. Utilized by association with the Writer. All rights reserved.
Columbia College Press
What Science Says About Astrology
This guide goals a scientific lens at astrology, from its colourful historical past to experimental checks of its predictions by the social and psychological components that specify its enduring recognition.
Massive language fashions (LLMs) now drive probably the most superior conversational brokers, inventive instruments, and decision-support techniques. Nonetheless, their uncooked output usually incorporates inaccuracies, coverage misalignments, or unhelpful phrasing—points that undermine belief and restrict real-world utility. Reinforcement Advantageous‑Tuning (RFT) has emerged as the popular technique to align these fashions effectively, utilizing automated reward alerts to interchange expensive guide labeling.
On the coronary heart of contemporary RFT is reward features. They’re constructed for every area via verifiable reward features that may rating LLM generations via a bit of code (Reinforcement Studying with Verifiable Rewards or RLVR) or with LLM-as-a-judge, the place a separate language mannequin evaluates candidate responses to information alignment (Reinforcement Studying with AI Suggestions or RLAIF). Each these strategies present scores to the RL algorithm to nudge the mannequin to resolve the issue at hand. On this submit, we take a deeper take a look at how RLAIF or RL with LLM-as-a-judge works with Amazon Nova fashions successfully.
Why RFT with LLM‑as‑a-judge in comparison with generic RFT?
Reinforcement Advantageous-Tuning can use any reward sign, easy hand‑crafted guidelines (RLVR), or an LLM that evaluates mannequin outputs (LLM-as-a-judge or RLAIF). RLAIF makes alignment way more versatile and highly effective, particularly when reward alerts are obscure and laborious to craft manually. In contrast to generic RFT rewards that depend on blunt numeric scoring like substring matching, an LLM choose causes throughout a number of dimensions—correctness, tone, security, relevance—offering context-aware suggestions that captures subtleties and domain-specific nuances with out task-specific retraining. Moreover, LLM judges supply built-in explainability via rationales (for instance, “Response A cites peer-reviewed research”), offering diagnostics that speed up iteration, pinpoint failure modes instantly, and scale back hidden misalignments, one thing static reward features can’t do.
Implementing LLM-as-a-judge: Six vital steps
This part covers the important thing steps concerned in designing and deploying LLM-as-a-judge reward features.
Choose the choose structure
The primary vital resolution is choosing your choose structure. LLM-as-a-judge presents two major analysis modes: Rubric-based (point- based mostly) judging and Choice-based judging, every suited to totally different alignment eventualities.
Standards
Rubric-based judging
Choice-based judging
Analysis technique
Assigns a numeric rating to a single response utilizing predefined standards
Compares two candidate responses side-by-side and selects the superior one
Coverage mannequin ought to discover freely with out reference knowledge restrictions
Information necessities
Solely requires cautious immediate engineering to align the mannequin to reward specs
Requires a minimum of one response pattern for choice comparability
Generalizability
Higher for out-of-distribution knowledge, avoids knowledge bias
Is dependent upon high quality of reference responses
Analysis model
Mirrors absolute scoring techniques
Mirrors pure human analysis via comparability
Really useful place to begin
Begin right here if choice knowledge is unavailable and RLVR unsuitable
Use when comparative knowledge is obtainable
Outline your analysis standards
After you’ve chosen your choose kind, articulate the precise dimensions that you just wish to enhance. Clear analysis standards are the muse of efficient RLAIF coaching.
For Choice-based judges:
Write clear prompts explaining what makes one response higher than one other. Be express about high quality preferences with concrete examples. Instance: “Desire responses that cite authoritative sources, use accessible language, and instantly handle the consumer’s query.”
For Rubric-based judges:
We advocate utilizing Boolean (cross/fail) scoring for rubric-based judges. Boolean scoring is extra dependable and reduces choose variability in comparison with fine-grained 1–10 scales. Outline clear cross/fail standards for every analysis dimension with particular, observable traits.
Choose and configure your choose mannequin
Select an LLM with adequate reasoning functionality to guage your goal area, configured via Amazon Bedrock and referred to as utilizing a reward AWS Lambda perform. For frequent domains like math, coding, and conversational capabilities, smaller fashions can work nicely with cautious immediate engineering.
Amazon Nova Professional, Claude Opus, Claude Sonnet
Medium/Light-weight
Common domains like math or coding, balanced cost-performance
Low-Medium
Average-Excessive
Amazon Nova 2 Lite, Claude Haiku
Refine your choose mannequin immediate
Your choose immediate is the muse of alignment high quality. Design it to provide structured, parseable outputs with clear scoring dimensions:
Structured output format – Specify JSON or parseable format for easy extraction
Clear scoring guidelines – Outline precisely how every dimension must be calculated
Edge case dealing with – Handle ambiguous eventualities (for instance, “If response is empty, assign rating 0”)
Desired behaviors – Explicitly state behaviors to encourage or discourage
Align choose standards with manufacturing analysis metrics
Your reward perform ought to mirror the metrics that you’ll use to guage the ultimate mannequin in manufacturing. Align your reward perform with manufacturing success standards to allow fashions designed for the proper aims.
Map every criterion to particular choose scoring dimensions
Validate that choose scores correlate together with your analysis metrics
Check the choose on consultant samples and edge circumstances
Constructing a sturdy reward Lambda perform
Manufacturing RFT techniques course of 1000’s of reward evaluations per coaching step. Construct a resilient reward Lambda perform to assist present coaching stability, environment friendly compute utilization, and dependable mannequin conduct. This part covers methods to construct a reward Lambda perform that’s resilient, environment friendly, and manufacturing prepared.
Composite reward rating structuring
Don’t rely solely on LLM judges. Mix them with quick, deterministic reward parts that catch apparent failures earlier than costly choose evals:
At all times – catches malformed outputs instantly. Low-cost and prompt suggestions.
Size penalties
Discourage overly verbose or terse responses
When output size issues (for instance, summaries)
Language consistency
Confirm responses match enter language
Essential for multilingual functions
Security filters
Rule-based checks for prohibited content material
At all times – prevents unsafe content material from reaching manufacturing
Infrastructure readiness
Implement exponential backoff: Handles Amazon Bedrock API charge limits and transient failures gracefully
Parallelization technique: Use ThreadPoolExecutor or async patterns to parallelize choose calls throughout rollouts to cut back latency
Keep away from Lambda chilly begin delays: Set an acceptable Lambda timeout (quarter-hour beneficial) and provisioned concurrency (~100 for typical setups)
Error dealing with: Add complete error dealing with that returns impartial/noisy rewards (0.5) fairly than failing your complete coaching step
Check your reward Lambda perform for resilience
Validate choose consistency and calibration:
Consistency: Check choose on the identical samples a number of instances to measure rating variance (must be low for deterministic analysis)
Cross-judge comparability: Examine scores throughout totally different choose fashions to determine analysis blind spots
Human calibration: Periodically pattern rollouts for human overview to catch choose drift or systematic errors
Regression testing: Create a “choose take a look at suite” with recognized good/unhealthy examples to regression take a look at choose conduct
RFT with LLM-as-a-judge – Coaching workflow
The next diagram illustrates the whole end-to-end coaching course of, from baseline analysis via choose validation to manufacturing deployment. Every step builds upon the earlier one, making a resilient pipeline that balances alignment high quality with computational effectivity whereas actively stopping reward hacking and supporting production-ready mannequin conduct.
Actual-world case research: Automating authorized contract overview
On this part, we discuss with a real-world use case with a number one authorized business associate. The duty is to generate feedback on dangers, assessments, and actions on authorized documentation with respect to the insurance policies and former contracts as reference paperwork.
Problem
Accomplice was concerned about fixing the issue of automating the method of reviewing, assessing, and flagging dangers in authorized contract paperwork. Particularly, they wished to guage potential new contracts towards inside tips and laws, previous contracts, and legal guidelines of the nation pertaining to the contract.
Resolution
We formulated this drawback as one the place we’re offering a goal doc (the “contract” that wants analysis), and a reference doc (the grounding doc and context) and count on the LLM to generate a JSON with a number of feedback, remark sorts, and beneficial actions to take based mostly on the evaluation. The unique dataset out there for this use case was comparatively small that included full contracts together with annotations and feedback from authorized specialists. We used LLM as a choose utilizing GPT OSS 120b mannequin because the choose and a customized system immediate throughout RFT.
RFT workflow
Within the following part we cowl particulars of the important thing features within the RFT workflow for this use case.
Reward Lambda perform for LLM-as-a-judge
The next code snippets current the important thing parts of the reward Lambda perform.
Be aware: title of Lambda perform ought to have “SageMaker”, for instance, "arn:aws:lambda:us-east-1:123456789012:perform:MyRewardFunctionSageMaker"
a) Begin with defining a high-level goal
# Contract Evaluation Analysis - Unweighted Scoring
You're an professional contract reviewer evaluating AI-generated feedback. Your PRIMARY goal is to evaluate how nicely every predicted remark identifies points within the TargetDocument contract clauses and whether or not these points are justified by the Reference tips.
b) Outline the analysis strategy
## Analysis Strategy
For every pattern, you obtain:
- **TargetDocument**: The contract textual content being reviewed (the doc underneath analysis)
- **Reference**: Reference tips/requirements used for the overview (the analysis standards)
- **Prediction**: A number of feedback from the AI mannequin
**Essential**: The SystemPrompt reveals what directions the mannequin acquired. Take into account whether or not the mannequin adopted these directions when evaluating the prediction high quality.
**CRITICAL**: Every remark should determine a selected problem, hole, or concern IN THE TARGETDOCUMENT CONTRACT TEXT ITSELF. The remark's text_excerpt subject ought to quote problematic contract language from the TargetDocument, NOT quote textual content from the Reference tips. The Reference justifies WHY the contract clause is problematic, however the problem should exist IN the contract.
Consider EACH predicted remark independently. Feedback ought to flag issues within the contract clauses, not merely cite Reference necessities.
c) Describe the scoring dimensions with clear specs on how a selected rating must be calculated
## Scoring Dimensions (Per Remark)
**EVALUATION ORDER**: Consider on this sequence: (1) TargetDocument_Grounding, (2) Reference_Consistency, (3) Actionability
### 1. TargetDocument_Grounding
**Evaluates**: (a) Whether or not text_excerpt quotes from TargetDocument contract textual content, and (b) Whether or not the remark is related to the quoted text_excerpt
**MANDATORY**: text_excerpt should quote from TargetDocument contract textual content. If text_excerpt quotes from Reference as an alternative, rating MUST be 1.
- **5**: text_excerpt accurately quotes TargetDocument contract textual content AND remark identifies a extremely related, legitimate, and notable problem in that quoted textual content
- **4**: text_excerpt accurately quotes TargetDocument contract textual content AND remark identifies a sound and related problem in that quoted textual content
- **3**: text_excerpt accurately quotes TargetDocument contract textual content AND remark is considerably related to that quoted textual content, however concern has reasonable validity
- **2**: text_excerpt accurately quotes TargetDocument contract textual content BUT remark has weak relevance to that quoted textual content, or concern is questionable
- **1**: text_excerpt does NOT quote TargetDocument contract textual content (quotes Reference as an alternative, or no precise quote), OR remark is irrelevant to the quoted textual content
### 2. Reference_Consistency
...
...
d) Clearly outline the ultimate output format to parse
## Scoring Calculation
**Comment_Score** = Easy common of the three dimensions:
- Comment_Score = (TargetDocument_Grounding + Reference_Consistency + Actionability) / 3
**Aggregate_Score** = Common of all Comment_Score values for the pattern
## Output Format
For every pattern, consider ALL predicted feedback and supply:
```json
{ "feedback": [
{ "comment_id": "...",
"TargetDocument_Grounding": {"score": X, "justification": "...", "supporting_evidence": "Verify text_excerpt quotes actual TargetDocument contract text and comment is relevant to it"},
"Reference_Consistency": {"score": X, "justification": "...", "supporting_reference": "Quote from Reference that justifies the concern OR explain meaningful reasoning"},
"Actionability": {"score": X, "justification": "Assess if action is clear, grounded in TargetDocument and Reference, and relevant to comment"},
"Comment_Score": X.XX
} ],
"Aggregate_Score": {
"rating": X.XX,
"total_comments": N,
"rationale": "..."
}
}
```
e) Create a high-level Lambda handler, offering adequate multithreading for sooner inference
def lambda_handler(occasion, context):
scores: Record[RewardOutput] = []
samples = occasion
max_workers = len(samples)
print(f"Evaluating {len(samples)} objects with {max_workers} threads...")
with ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [executor.submit(judge_answer, sample) for sample in samples]
scores = [future.result() for future in futures]
print(f"Accomplished {len(scores)} evaluations")
return [asdict(score) for score in scores]
Deployment of the Lambda perform
We used the next AWS Identification and Entry Administration (IAM) permissions and settings within the Lambda perform. The next configurations are required for reward Lambda features. RFT coaching can fail if any of them are lacking.
a) Permissions for Amazon SageMaker AI execution function
Your Amazon SageMaker AI execution function will need to have permission to invoke your Lambda perform. Add this coverage to your Amazon SageMaker AI execution function:
b) Permissions for Lambda perform execution function
Your Lambda perform’s execution function wants fundamental Lambda execution permissions and the permissions to Invoke the choose Amazon Bedrock mannequin.
Be aware: This resolution follows the AWS shared duty mannequin. AWS is chargeable for securing the infrastructure that runs AWS companies within the cloud. You’re chargeable for securing your Lambda perform code, configuring IAM permissions, implementing encryption and entry controls, managing knowledge safety and privateness, configuring monitoring and logging, and verifying compliance with relevant laws. Observe the precept of least privilege by scoping permissions to particular useful resource ARNs. For extra data, see Safety in AWS Lambda and Amazon SageMaker AI Safety within the AWS documentation.
c) Add provisioned concurrency
Publish a model of the Lambda and to allow the perform to scale with out fluctuations in latency, we added some provisioned concurrency. 100 was adequate on this case, nevertheless, there’s extra room for value enhancements right here.
d) Set Lambda timeout to fifteen minutes
Customizing the coaching configuration
We launched Nova Forge SDK that can be utilized for your complete mannequin customization lifecycle—from knowledge preparation to deployment and monitoring. Nova Forge SDK removes the necessity to seek for the suitable recipes or container URI for particular strategies.
You should use the Nova Forge SDK to customise coaching parameters in two methods: present a full recipe YAML utilizing recipe_path or cross particular fields utilizing overrides for selective modifications. For this use case, we use overrides to tune the rollout and coach settings as proven within the following part.
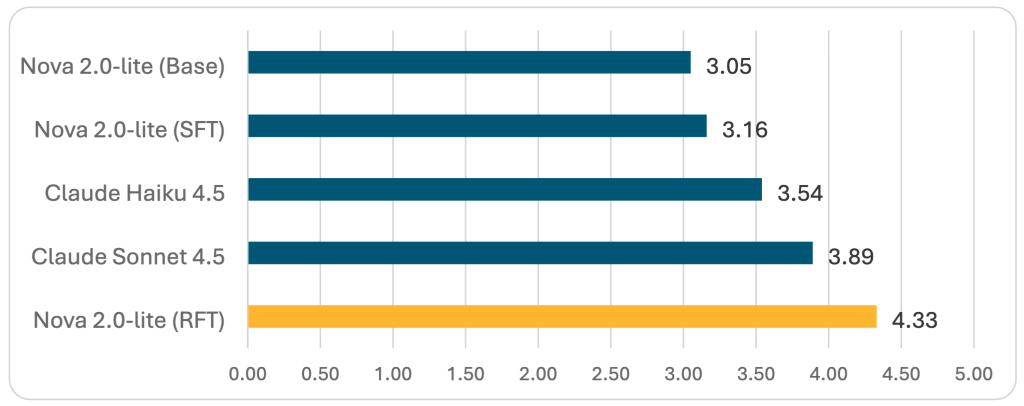
RFT with Amazon Nova 2 Lite achieved a 4.33 mixture rating—the best efficiency throughout all evaluated fashions—whereas sustaining excellent JSON schema validation. This represents a big enchancment, demonstrating that RFT can produce production-ready, specialised fashions that outperform bigger general-purpose options.
We evaluated fashions utilizing a “better of okay” single-comment setting, the place every mannequin generated a number of feedback per pattern and we scored the highest-quality output. This strategy establishes an higher sure on efficiency and allows a good comparability between fashions that produce single versus a number of outputs.
RFT achieved the best efficiency amongst evaluated fashions on this research.
Amazon Nova 2 Lite with RFT achieved a 4.33 mixture rating, outperforming each Claude Sonnet 4.5 and Claude Haiku 4.5, whereas additionally attaining excellent JSON schema validation.
Removes pointless coaching artifacts
Throughout SFT iterations, we noticed problematic behaviors together with repetitive remark technology and unnatural Unicode character predictions. These points, probably attributable to overfitting or dataset imbalances, didn’t seem in RFT checkpoints. RFT’s reward-based enhancements naturally discourages such artifacts, producing extra strong and dependable outputs.
Robust generalization to new choose standards
After we evaluated RFT fashions utilizing a modified choose immediate (aligned however not an identical to the coaching reward perform), efficiency remained sturdy. This demonstrates that RFT learns generalizable high quality patterns fairly than overfitting particular analysis standards. This can be a vital benefit for real-world deployment the place necessities evolve.
Compute concerns
RFT required 4–8 rollouts per coaching pattern, rising compute prices in comparison with SFT. This overhead is amplified when utilizing non-zero reasoning effort settings. Nonetheless, for mission-critical functions the place alignment high quality instantly impacts enterprise outcomes—similar to authorized contract overview, monetary compliance, or healthcare documentation, the efficiency good points justify the extra compute prices.
Conclusion
Reinforcement Advantageous-Tuning (RFT) with LLM-as-a-judge represents a strong strategy to aligning LLMs for domain-specific functions. As demonstrated in our authorized contract overview case research, this system delivers important enhancements over each base fashions and conventional supervised fine-tuning (SFT) approaches, with RFT attaining the best mixture scores throughout all analysis dimensions. For groups constructing mission-critical AI techniques the place alignment high quality instantly impacts enterprise outcomes, RFT with LLM-as-a-judge presents a compelling path ahead. The methodology’s explainability, flexibility, and superior efficiency make it significantly priceless for advanced domains like authorized overview (or Monetary Companies or Healthcare) the place refined nuances matter.
Organizations contemplating this strategy ought to begin small—validate their choose design on curated benchmarks, confirm infrastructure resilience, and scale regularly whereas monitoring for reward hacking. With correct implementation, RFT can rework succesful base fashions into extremely specialised, production-ready techniques that constantly ship aligned, reliable outputs.
The authorized contract overview use case described on this submit is for technical demonstration functions solely. AI-generated contract evaluation shouldn’t be an alternative choice to skilled authorized recommendation. Seek the advice of certified authorized counsel for authorized issues.
Python decorators could be extremely helpful in initiatives involving AI and machine studying system growth. They excel at separating key logic like modeling and information pipelines from different boilerplate duties, like testing and validation, timing, logging, and so forth.
This text outlines 5 significantly helpful Python decorators that, primarily based on builders’ expertise, have confirmed themselves efficient at making AI code cleaner.
The code examples beneath embody easy, underlying logic primarily based on Python commonplace libraries and greatest practices, e.g. functools.wraps. Their main purpose is for example the usage of every particular decorator, so that you simply solely want to fret about adapting the decorator’s logic to your AI coding challenge.
# 1. Concurrency Limiter
A really helpful decorator when coping with (usually annoying) free-tier limits in the usage of third-party massive language fashions (LLMs). When hitting such limits because of sending too many asynchronous requests, this sample introduces a throttling mechanism to make these calls safer. By semaphores, the variety of instances an asynchronous operate executes is proscribed:
It’s no shock that in complicated software program like that governing machine studying techniques, commonplace print() statements get simply misplaced, particularly as soon as deployed in manufacturing.
By the next logging decorator, it’s doable to “catch” executions and errors and format them into structured JSON logs which can be simply searchable for fast debugging. The code instance beneath can be utilized as a template to brighten, as an illustration, a operate that defines a coaching epoch in a neural network-based mannequin:
import logging, json, time
from functools import wraps
def json_log(func):
@wraps(func)
def wrapper(*args, **kwargs):
begin = time.time()
strive:
res = func(*args, **kwargs)
logging.information(json.dumps({"step": func.__name__, "standing": "success", "time": time.time() - begin}))
return res
besides Exception as e:
logging.error(json.dumps({"step": func.__name__, "error": str(e)}))
elevate
return wrapper
# Utility
@json_log
def train_epoch(mannequin, training_data):
return mannequin.match(training_data)
# 3. Characteristic Injector
Enter a very helpful decorator through the mannequin deployment and inference levels! Say you’re shifting your machine studying mannequin from a pocket book into a light-weight manufacturing atmosphere, e.g. utilizing a FastAPI endpoint. Manually making certain that uncooked incoming information from finish customers undergoes the identical transformations as the unique coaching information can typically turn out to be a little bit of a ache. The characteristic injector helps guarantee consistency in the best way options are generated from uncooked information, all beneath the hood.
That is extremely helpful through the deployment and inference section. When shifting a mannequin from a Jupyter pocket book right into a manufacturing atmosphere, a significant headache is making certain the uncooked incoming person information will get the identical transformations as your coaching information. This decorator ensures these options are generated constantly beneath the hood earlier than the information ever reaches your mannequin.
The instance beneath simplifies the method of including a characteristic referred to as 'is_weekend', primarily based on whether or not a date column in an present dataframe incorporates a date related to a Saturday or Sunday:
from functools import wraps
def add_weekend_feature(func):
@wraps(func)
def wrapper(df, *args, **kwargs):
df = df.copy() # Prevents Pandas mutation warnings
df['is_weekend'] = df['date'].dt.dayofweek.isin([5, 6]).astype(int)
return func(df, *args, **kwargs)
return wrapper
# Utility
@add_weekend_feature
def process_data(df):
# 'is_weekend' is assured to exist right here
return df.dropna()
# 4. Deterministic Seed Setter
This one stands out for 2 particular levels of the AI/machine studying lifecycle: experimentation and hyperparameter tuning. These processes sometimes entail the usage of a random seed as a part of adjusting key hyperparameters like a mannequin’s studying charge. Say you simply adjusted its worth, and out of the blue, the mannequin accuracy drops. In a scenario like this, you could have to know whether or not the trigger behind this efficiency drop is the brand new hyperparameter setting or just a foul random initialization of weights. By locking the seed, we isolate variables, thereby making the outcomes of exams like A/B extra dependable.
A lifesaving decorator, significantly in native growth environments and CI/CD testing. Say you’re constructing an utility layer on high of an LLM — as an illustration, a retrieval-augmented era (RAG) system. If a adorned operate fails as a result of exterior components, like connection timeouts or API utilization limits, as an alternative of throwing an exception, the error is intercepted by this decorator and a predefined set of “mock check information” is returned.
Why a lifesaver? As a result of this mechanism can guarantee your utility doesn’t fully cease if an exterior service quickly fails.
This text examined 5 efficient Python decorators that can assist make your AI and machine studying code cleaner throughout quite a lot of particular conditions: from structured, easy-to-search logging to managed random seeding for features like information sampling, testing, and extra.
Iván Palomares Carrascosa is a pacesetter, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.
TL;DR: The MagTag Extremely Slim Tracker Card, which works with the Apple Discover My app, is on sale for $23.99 (MSRP $59.99), making it a simple solution to monitor your pockets or bag in actual time with out including any bulk.
Dropping your pockets isn’t simply inconvenient — it’s a full-day derailment. Playing cards to cancel, IDs to exchange, and that nagging feeling you left it someplace apparent. Most trackers assist, however they’re cumbersome sufficient that you just don’t all the time need them crammed into one thing slim like a pockets. The MagTag Extremely Slim Tracker Card connects to the Apple Discover My app to be sure you by no means lose it once more, and proper now it’s down 60% from $59.99 to $23.99.
It’s constructed to be virtually invisible (about as skinny as a bank card), so it slides into your pockets, passport holder, or bag with out altering the way you carry issues. As soon as it’s in place, it faucets into Apple’s Discover My community for real-time monitoring. For those who depart one thing behind, you’ll get a heads-up, and if it’s close by, you may set off a sound to trace it down shortly.
Why the MagTag Extremely Slim Tracker Card stands out:
Extremely-slim 1.5mm design that matches in wallets and tight areas
Works with Apple Discover My for international monitoring
Loud beeping that makes close by objects simple to find
Rechargeable battery that lasts as much as 5 months with wi-fi charging
Waterproof and dustproof for on a regular basis use and journey
It’s a kind of small upgrades that quietly removes a recurring headache.
For those who’re bored with second-guessing the place you left issues, grabbing the MagTag Extremely Slim Tracker Card is a simple solution to keep a step forward — on sale for simply $23.99 (MSRP $59.99).
MagTag Extremely Slim Tracker Card – Works with Apple Discover My AppSee Deal
Russia’s new Soyuz 5 rocket has taken to the skies in the end.
The Soyuz 5 lifted off for the primary time ever on Thursday (April 30), rising off a pad on the Russia-run Baikonur Cosmodrome in Kazakhstan at 2:00 p.m. EDT (1800 GMT; 11:00 p.m. native time in Baikonur).
Issues apparently went properly on the flight, which was a quick suborbital shakeout cruise.
“The primary take a look at launch of the brand new Soyuz 5 rocket was successful!” officers with Russia’s federal area company, generally known as Roscosmos, stated through the Telegram app on Thursday.
“The primary and second levels of Soyuz 5 carried out as deliberate, and a mockup was launched onto the calculated suborbital trajectory, adopted by a reentry into an space within the Pacific Ocean beforehand closed to transport and aviation,” they added in one other Telegram submit.
Thursday’s launch was a very long time coming for the Soyuz 5, which has been in improvement since 2017. It “was designed to interchange the medium-class Zenit autos in-built Ukraine and supply Russia with a first-stage booster for [a] future super-heavy rocket,” in accordance with RussianSpaceWeb.com.
Roscosmos initially hoped “that the low-cost automobile would complement the Angara household of rockets for home wants and would make Russia aggressive once more on the worldwide launch market,” the outlet added.
The Soyuz 5’s homegrown nature took on added significance for Russia in February 2022, when the nation invaded Ukraine, which has lengthy been a powerhouse of rocket design and manufacturing. That invasion is ongoing, so Ukraine can be placing its rocketry experience to make use of towards Russia nowadays.
It is unclear, nonetheless, if the brand new rocket will entice worldwide clients. Russia has misplaced most of its area partnerships as a result of Ukraine invasion, and the Soyuz 5 does not look like sufficient of a breakthrough to revive any.
The rocket is comparable in dimension and lifting energy to SpaceX‘s workhorse Falcon 9; the Soyuz 5 can haul about 20 tons (18 metric tons) to low Earth orbit, in comparison with 25.1 tons (22.8 metric tons) for the SpaceX launcher. However the Falcon 9’s first stage is reusable, whereas the Soyuz 5 is a totally expendable automobile.
Not too long ago, I revealed a story concerning the new random features which have landed in CSS and the way they work. On this article, we’ll discover the challenges of randomness in CSS, how the idea has developed over time, and why this native function is a giant deal.
One of many first issues I needed to do once I began growing web sites was create distinctive experiences that modified from individual to individual. Simply little issues: a random background right here, random colours there… Even small micro-interactions, like confetti or falling snow, wanted some degree of randomness to really feel pure.
And I used to be not alone! I quickly found that many net builders (“site owners,” on the time) needed to do issues like that: including wow elements and a way of uniqueness to their websites. However we had an issue: CSS.
CSS is a declarative and deterministic language. Two traits that conflict with the concept of pure variation:
Declarative signifies that it focuses on the what, not the how. In distinction to crucial languages, builders utilizing CSS inform the browser what the anticipated result’s, however not tips on how to obtain it.
Deterministic signifies that for a given enter we’ll get the identical output. At all times the identical. If you happen to specify {that a} shade can be purple, that shade can be purple, not blue or yellow.
That is by design, and it’s one of many issues that makes CSS predictable and dependable. If you happen to perceive how the structure engine works, you possibly can inform which kinds can be utilized at any given time. Which is nice… however not so nice if you wish to generate random content material.
And so started a difficult (and typically tortuous) journey for designers and builders to realize pure variation from a deterministic system.
The Lengthy and Winding Highway to Random Kinds
The trail to random kinds in CSS is paved with a number of makes an attempt and shortcomings. However at each step alongside the best way, builders discovered new options that improved on the earlier ones. Even when solely a little bit.
Be aware: This timeline displays logical progress greater than a strict historic or chronological order.
CSS Pseudo-Randomness and Patterns
We will simulate randomness in CSS by creating patterns. However this isn’t really random. The outcomes will all the time be the identical, and in the end individuals will discover the sample.
One solution to create this simulation is through the use of :nth-child() selectors or by enjoying with animations. The primary technique is straightforward however yields subpar outcomes; the second could trick and impress some individuals.
For sure, these strategies are hacks that don’t present randomization at any degree. A human could not be capable of exactly predict which worth comes subsequent — at the very least not with out some effort — however a machine definitely can.
Pre-Processors to the Rescue
We turned to the following neatest thing: tooling. Particularly, CSS preprocessors reminiscent of Sass, SCSS, Much less, and the like. These instruments embody math modules that present random features we are able to use at compilation time.
The important thing phrase within the earlier paragraph is “at compilation time.” Sure, we’re producing random values for our CSS properties. However as soon as these values are produced throughout compilation, they’re frozen eternally (or till the following compilation, to be extra exact). Identical to a mosquito caught in amber.
The values can be random when the CSS is generated, however each time guests go to or refresh the web page, they may get the identical ones. To provide new values, we would wish to recompile the stylesheets.
This was a child step towards styling randomization, however there was nonetheless a protracted solution to go.
Server-Aspect Randomness
We moved to the following neatest thing: utilizing different languages to generate random values and passing them to CSS by means of HTML. Server-side languages like PHP, Java, ASP, and others had been good for this job whereas producing the HTML (and even the CSS itself).
This method works effectively: we get new random values each time the web page is generated, which normally means each time it’s visited or refreshed. We even have full management over the randomization, since we are able to implement our personal features.
It has shortcomings, too. If new content material is added dynamically to the web page, it will get caught with the “frozen” values generated in the course of the preliminary web page load. Higher than patterns, higher than preprocessors… however nonetheless not good.
This limitation grew to become a fair greater downside with the rise and widespread adoption of single-page functions and client-side JavaScript architectures.
And JavaScript… Lastly!
With the proliferation of net functions, it made sense to maneuver randomness to JavaScript. The language is already closely used, and including just a few random features to the combination doesn’t appear to be a giant stretch.
And JavaScript lastly solved it! For the primary time, kinds may truly behave with pure variation: random on creation, on refresh, and even on mutation.
It may be completed in some ways, too: utilizing frameworks, CSS-in-JS libraries, or plain vanilla JavaScript. The strategies to include styling by means of this language are huge and effectively supported. There are some efficiency and complexity issues, however JavaScript will get the job completed.
We lastly had true randomization in net kinds… simply not in CSS itself.
A Internet Downside, and a Internet Resolution
That final half is essential. We now have randomization on the net (JavaScript will get the job completed) however one thing feels off. One thing doesn’t fairly really feel proper. At its core, that discomfort comes from two issues:
We’re making use of an crucial answer to a declarative downside.
We’re shifting structure selections from CSS to JavaScript.
An Crucial Resolution to a Declarative Downside
We talked about earlier that CSS is a declarative language that focuses on the what, whereas JavaScript is an crucial language that focuses on the how.
By shifting randomization to JavaScript, we are attempting to reply a what query with a how reply. It really works, but it surely’s not ultimate.
Utilizing JavaScript, we lastly achieved type randomness in any respect ranges: when the web page is created, when it’s refreshed, and when parts are added or modified (mutation). However in doing so, we’re breaking the mannequin.
CSS handles structure, and JavaScript handles logic. We solved a CSS limitation by shifting structure selections into JavaScript, making a mismatch that produces that delicate “this isn’t fairly proper” feeling — even when all the things technically works.
The CSS Resolution
The answer to this mannequin mismatch is easy: transfer randomization to CSS. Resolve a structure downside immediately within the structure layer as an alternative of delegating it to a distinct instrument or language. And this occurred with the introduction of two new random features as a part of the CSS Values and Items Module Degree 5:
random(): generates a random worth between a minimal and a most.
random-item(): selects a random worth from a given listing.
This method additionally aligns with the Rule of Least Energy, which suggests selecting the least highly effective language appropriate for a given goal. In follow, this implies fixing an issue utilizing the least highly effective language able to expressing and fixing it.
Often, that language can be higher suited to the duty. Its options can be tailored to the extent at which they’re utilized, making them less complicated, extra environment friendly, and higher performing. Whereas a extra highly effective language can definitely do the job, it usually introduces an pointless layer of complexity and abstraction.
On the internet platform, we’ve got HTML for construction (least highly effective), CSS for styling and structure (extra highly effective), and JavaScript (considerably extra highly effective). By implementing randomization in CSS, we transfer the answer to the suitable layer whereas additionally following the Rule of Least Energy.
And that’s one of many causes the brand new random CSS options are such a giant deal… and why they signify one thing a lot greater than simply one other function.
The Huge Deal
CSS has all the time been deterministic by design, and native randomness breaks with that custom. It isn’t simply one other function, it represents a shift in how we take into consideration CSS as a language and concerning the net platform itself.
For the primary time, CSS can mannequin pure methods with variation immediately: no hacks, no instruments, no outsourcing structure selections to different languages. Randomization takes an honored place within the styling layer, the place it all the time belonged.
This unlocks artistic potentialities: generative layouts, natural patterns, playful micro-interactions, and design methods that really feel alive and distinctive. However it additionally restores architectural readability: every layer of the net as soon as once more does the job it was designed for.
With this alteration, CSS strikes from being purely a styling language towards changing into a generative structure system. It’s not only a passive actor in net growth; it turns into an energetic participant within the rendering course of, defining an area of potential outcomes that the browser resolves right into a concrete web page.
And that’s the actual massive deal. Native randomness isn’t nearly making issues look completely different; it’s about making the platform extra coherent and expressive.
It’s additionally a reminder that CSS remains to be evolving, and that typically the options individuals overlook can reshape how we take into consideration a language, and what we think about is feasible on the net.
Should you haven’t heard, Zero To Mastery (ZTM) simply opened up their ENTIRE coaching platform for free for 10 days. That’s 167 programs with 1,700+ hours of video classes and 29 profession paths.
Be taught Python, Immediate Engineering, AI Engineering, Vibe Coding, Information Engineering, SQL, Machine Studying, Moral Hacking, Cloud, DevOps, and extra, for $0.
No bank card required. Simply limitless free studying for 10 days. April 30 – Might 10.
There are a ton of causes, however I’ll simply provide you with three shortly since it’s best to actually simply go enroll and take a look at it for your self.
1. These guys have helped 1,000s of individuals go from no prior tech coaching to altering careers and being employed at locations like Tesla, NVIDIA, Apple, Amazon, IBM, Microsoft, Google, Uber, Shopify, Meta, and extra!
2. Tech strikes quick, and the very last thing you need is to spend months studying from outdated data. That is why ZTM’s programs are always up to date, extremely rated (4.8 on TrustPilot), and utilized by high corporations to coach their very own staff. Go learn the opinions for your self.
3. They’ve an energetic neighborhood of 1,000s of scholars, mentors, and instructors on Discord to assist and help you each step of your journey. Once we say energetic, we imply it. Individuals are chatting and serving to one another out, and instructors are serving to college students in there each single day.
What Ought to You Be taught?
Should you’re undecided the place to start out, ZTM has a tech profession path quiz that you would be able to take first. Merely reply a couple of questions and it’ll assist provide you with a customized roadmap of programs and steps to comply with.
Listed below are a couple of of the most well-liked choices:
Turn out to be an AI Engineer. That is the position everyone seems to be scrambling to rent for proper now, and there aren’t almost sufficient individuals who can really do it.
Turn out to be a Machine Studying Engineer. These are the individuals who make AI really work beneath the hood. If everybody else is utilizing AI, these are those constructing it.
Turn out to be a Full-Stack Net Developer. That is the most effective first step for those who simply need to get employed quick, and nonetheless has the very best quantity of open jobs in tech.
Turn out to be an AI Developer. Consider it just like the 80/20 of a full-stack developer. You continue to be taught the important thing fundamentals, however leverage the newest AI instruments to 10x your effectivity and get constructing actual tasks sooner.
Turn out to be a Information Engineer. Each firm wants information. You’re the particular person answerable for constructing the pipes that every one the machine studying folks rely on. They’ll’t work with out your abilities.
If there’s a particular ability you’re interested by, quite than a full profession path, your choices are just about limitless. You may take a look at their full checklist of programs right here.
Don’t miss out!
Zero To Mastery Free Weekruns from April thirtieth to Might tenth, supplying you with entry to their total course library (that’s all 167 programs) and entry to their non-public Discord!
That is an unimaginable alternative to be taught actual in-demand abilities that may assist set you aside in your profession or the job market.
No bank card. No threat. Simply job-ready abilities, utterly free for over every week.
I used Squad from the Copilot CLI, constructing a primary Node Categorical software, with an online entrance finish. What was maybe most attention-grabbing concerning the course of was that the Squad harness allowed its role-based brokers to work in parallel: an agent constructing back-end code to help service APIs might run concurrently an agent that was constructing a React-based person interface. The preliminary squad of brokers that Squad generated included an architect in addition to front-end and back-end builders.
Squad’s output was, no less than in my take a look at purposes, clear and simple to know, prepared for use as the idea for a extra advanced software. It was delivered shortly, utilizing a test-driven method to make sure that code carried out as supposed, with no apparent bugs. By taking a proper method to software program improvement, Squad can cut back dangers and clarify its actions to a human person. It may also be used to doc the code it delivers, utilizing one other specialised agent to ship documentation.
There’s loads of human supervision within the course of, although there’s additionally the choice of handing over management of repetitive duties to Squad. After a while, you possibly can construct up sufficient belief that you simply don’t must approve each new file or listing. A squad works within the context of your Git repository, however if you’d like extra safety you possibly can select to run your squad inside a dev container, conserving it in an remoted atmosphere.
The corporate says its mission is to make constructing AI fashions much less like alchemy and extra like a science. Certain, LLMs like ChatGPT and Gemini can do superb issues. However no one is aware of precisely how or why they work, and that may make it laborious to repair their flaws or block undesirable behaviors.
“We noticed this widening hole between how nicely fashions have been understood and simply how broadly they have been being deployed,” Goodfire’s CEO, Eric Ho, tells MIT Know-how Overview in an unique chat forward of Silico’s launch. “I feel the dominant feeling in each single main frontier lab immediately is that you simply simply want extra scale, extra compute, extra knowledge, and you then get AGI [artificial general intelligence] and nothing else issues. And we’re saying no, there’s a greater method.”
Goodfire is one in all a small handful of corporations, together with business leaders Anthropic, OpenAI, and Google DeepMind, pioneering a method generally known as mechanistic interpretability, which goals to perceive what goes on inside an AI mannequin when it carries out a activity by mapping its neurons and the pathways between them. (MIT Know-how Overview picked mechanistic interpretability as one in all its 10 Breakthrough Applied sciences of 2026.)
Goodfire needs to make use of this strategy not solely to audit fashions—that’s, finding out those who have already been educated—however to assist design them within the first place.
“We need to take away the trial and error and switch coaching fashions into precision engineering,” says Ho. “And meaning exposing the knobs and dials so that you could truly use them throughout the coaching course of.”
Goodfire has already used its strategies and instruments to tweak the behaviors of LLMs—for instance, lowering the variety of hallucinations they produce. With Silico, the corporate is now packaging up lots of these in-house strategies and transport them as a product.
The device makes use of brokers to automate a lot of the advanced work. “Brokers are actually sturdy sufficient to do lots of the interpretability work that we have been doing utilizing people,” says Ho. “That was form of the hole that wanted to be bridged earlier than this was truly a viable platform that clients might use themselves.”
Leonard Bereska, a researcher on the College of Amsterdam who has labored on mechanistic interpretability, thinks Silico seems to be like a useful gizmo. However he pushes again on Goodfire’s loftier aspirations. “In actuality, they’re including precision to the alchemy,” he says. “Calling it engineering makes it sound extra principled than it’s.”
Verizon offers that get you a free smartphone aren’t precisely unprecedented, however a proposal that will get you a free Samsung Galaxy S26 AND a $100 reward card? That feels like a trick, but it surely’s precisely what’s occurring on the provider’s web site right now.
It really works like this: buy the Samsung Galaxy S26 and add a line with Verizon’s Limitless Welcome, Limitless Plus, or Limitless Final plan and the provider will hook you up with $900 in promo credit score. That is sufficient to make the flagship cellphone utterly free, and if that wasn’t sufficient, Verizon may also throw in a free $100 reward card, only for kicks.
Get a free Galaxy S26 and 100 bucks to spend on equipment at Verizon
✅Really useful if: you are on the lookout for a brand new cellphone plan that comes with a free machine; you need an Android cellphone with lightning-fast efficiency, AI options, and years of assured software program assist.
❌Skip this deal if: you’ll be able to afford the more-powerful Samsung Galaxy S26 Extremely; you are joyful along with your present cellphone plan; you favor to purchase units unlocked.
One of many greatest Samsung telephones in the marketplace right now, the Galaxy S26 is powered by the superb Snapdragon 8 Gen 5 Elite chipset and comes with 12GB of RAM, 256GB of base storage, and 7 years of OS and safety upgrades assured. The cellphone additionally sports activities an even bigger battery and AMOLED show than its predecessor, the Galaxy S25, plus you get the entire newest AI-boosted software program options from Galaxy AI.
All three Verizon plans included within the deal get you limitless discuss, textual content, and knowledge on the provider’s huge 5G / 4G LTE community, however going with the costlier Limitless Plus and Limitless Final plans will get you premium perks like 5G Extremely Wideband and cellular hotspot knowledge.
Due to Verizon’s myPlan system, nevertheless, you too can combine and match extra perks on any plan for a small month-to-month price. These piecemeal advantages embody stuff like streaming subscriptions, worldwide advantages, and cloud storage, and most of the perks price as little as $10 apiece.
The dear Samsung Galaxy S26 Extremely could be the higher cellphone total, however in the event you worth bang for the buck in a extra compact body, this Verizon deal affords a good way to get the complete Samsung expertise with out paying a cent for the machine. Throw on a $100 reward card and also you’re taking a look at an Android reward that simply retains on giving.