This story appeared in The Logoff, a every day publication that helps you keep knowledgeable concerning the Trump administration with out letting political information take over your life. Subscribe right here.
Welcome to The Logoff: President Donald Trump advised Congress the Iran battle is over. Is it?
What occurred? Friday marks a authorized deadline for Trump, after which he needs to be required to wind down US army operations round Iran. However in response to Trump, he already has: The president wrote in a letter to Congress on Friday that the Iran battle was “terminated” because of the US-Iran ceasefire, which stays in impact with no agency deadline.
“There was no change of fireplace between the US Forces and Iran since April 7, 2026,” Trump wrote within the letter. “The hostilities that started on February 28, 2026, have been terminated.”
Is it true? Probably not, from all proof obtainable. Whereas the US and Iran haven’t been engaged within the form of full-scale hostilities that marked the early weeks of the battle, a US naval blockade of the Strait of Hormuz continues to be in place. (Final month, the US even fired on an Iranian-flagged ship allegedly making an attempt to violate the blockade — in Trump’s phrases, “blowing a gap within the engineroom.”)
US forces additionally stay in place close to Iran, and there’s the ever-present risk that the battle might resume at full power — one thing Trump has continued to threaten as a deal to finish the battle completely eludes him.
What’s the context? Trump’s letter is a reasonably clear try and skate across the Struggle Powers Decision, which requires the US to finish its involvement in army conflicts inside 60 days of notifying Congress of their begin, until Congress votes to authorize the battle. (It hasn’t. There’s additionally the potential of a 30-day extension on that 60-day deadline, which the Trump administration has likewise not but pursued.)
And with that, it’s time to sign off…
Hello readers, completely happy Might Day! Listed below are two mysteries to maintain you entertained over the weekend, from my colleagues at Vox’s Unexplainable podcast. I’ll maintain them mysterious right here — if you wish to be taught extra, the podcast is a superb pay attention. Have an excellent weekend, and we’ll see you again right here on Monday!
2026 has already seen in depth wildfires in Patagonia, Argentina, linked to excessive climate
TOMAS CUESTA / AFP through Getty Pictures
A outstanding scientist has predicted 2026 would be the hottest yr on document, because of each local weather change and a strong El Niño impact that can increase temperatures additional.
The document is held by 2024, when world temperatures exceeded 1.5°C above the pre-industrial common for the primary time.
The second half of this yr will nearly definitely see the beginning of El Niño, a pure local weather section when heat water expands throughout the equatorial Pacific Ocean, heating your entire planet. Some fashions venture it will likely be a “tremendous El Niño”, and maybe the strongest ever. Many consider this may set a brand new world temperature document in 2027, when the total drive of the El Niño is felt.
However James Hansen at Columbia College in New York, who famously instructed the US Congress in 1988 that people have been heating Earth, and his colleagues have now argued in a weblog put up that the document might be damaged already in 2026. “In fact, 2027 might be nonetheless hotter,” they added.
Temperatures are at present being suppressed by La Niña, the planet-cooling counterpart of El Niño. The primary three months of 2026 have been about 0.1°C cooler than the primary three months of 2024, on common. The remainder of the yr must be far hotter for 2026 to surpass 2024.
Based mostly on the common impact of the primary three months on the yearly temperature, Zeke Hausfather at Berkeley Earth in California projected in Carbon Temporary that 2026 can be 1.47°C above the pre-industrial common, making it the second-warmest on document.
However Hansen and his colleagues say that is more likely to be an underestimate. Whereas scientists largely agree that world warming is accelerating, primarily as a result of humanity has lowered air air pollution that was blocking out daylight, Hansen has argued the warming fee is even greater than local weather fashions present.
Of their put up, they notice that sea floor temperatures, that are much less affected by fluctuations within the climate, recommend the world is now 0.17°C hotter than in 2023, when the 2023-24 El Niño developed. This can be a greater distinction than in 2024, when the globe was solely 0.11°C hotter than it was in 2023.
“That margin is broad sufficient that we’re keen to make the prediction that 2026 would be the warmest yr”, they wrote.
Different scientists aren’t so positive. Whereas the annual forecast in December from the Met Workplace, the UK’s climate service, projected the subsequent yr can be 1.46°C above the pre-industrial common, it gave a spread from 1.34°C to 1.58°C. It’s nonetheless untimely to foretell 2026 will beat the 1.55°C recorded in 2024, says Adam Scaife on the Met Workplace.
“There may be uncertainty on these timescales, which implies that the perfect factor you are able to do is to offer a chance,” says Scaife. “No person might be 100 per cent assured.”
Because the equatorial Pacific has continued to heat and El Niño has grow to be extra seemingly, document world temperatures have additionally grow to be extra seemingly, however forecasts nonetheless present a sweep of doable outcomes, based on John Kennedy on the World Meteorological Group. “Hansen’s forecast is extra definitive, however it is only one technique out of a spread which might be on the market,” he says.
In a weblog put up on 30 April, Hausfather calculated 2026 has a 26 per cent likelihood of being the most well liked yr on document and a 56 per cent likelihood of being the second hottest.
However Scaife says Hansen is true to fret that the speed of world warming could also be quicker than projected, as a result of that might recommend the CO2 emitted into the ambiance is warming Earth greater than anticipated. “If local weather sensitivity’s greater than folks assume… that can have an effect on local weather change sooner or later,” he says.
Whatever the precise world temperature, the world is more likely to endure even worse excessive climate as El Niño begins to chew. Locations like Australia and South-East Asia, central and southern Africa, India and the Amazon rainforest will face the danger of heatwaves, drought and wildfires.
“What all of us agree about is that the El Niño goes to be on high of an unprecedented stage of world warming,” says. “These two issues are seemingly to offer us unprecedented occasions later this yr.”
I used to be reviewing some timings from the Stata/MP Efficiency Report this morning. (For many who don’t know, Stata/MP is the model of Stata that has been programmed to benefit from multiprocessor and multicore computer systems. It’s functionally equal to the biggest model of Stata, Stata/SE, and it’s quicker on multicore computer systems.)
What was uncommon this morning is that I used to be working Stata/MP interactively. We often run MP for big batch jobs that run 1000’s of timings on massive datasets — both to tune efficiency or to supply reviews just like the Efficiency Report. That’s the kind of work Stata/MP was designed for — large jobs on large datasets.
I’ll admit proper now that I largely run Stata interactively utilizing the auto dataset, which has 74 observations. I run Stata/MP utilizing all 4 cores of my quad-core pc, however I’m largely losing 3 of them — there is no such thing as a dashing up the computations on 74 observations. This morning I used to be working Stata/MP interactively on a 24-core pc utilizing a considerably bigger dataset.
After some time, I used to be struck by the truth that I wasn’t noticing any annoying delays ready for instructions to run. It felt nearly as if I have been working on the auto dataset. However I wasn’t. I used to be working instructions utilizing 50 covariates on 1 million observations! Regressions, abstract statistics, and so forth.; this was enjoyable. I had by no means performed interactively with a million-observation dataset earlier than.
Out of curiousity, I turned off multicore assist. The change was dramatic. Instructions that have been taking lower than a second have been now taking longer, too lengthy. My espresso cup was full, however I contemplated fetching a snack. Working on just one processor was not a lot enjoyable.
On your info, I set rmsg on and ran a number of timings:
Timing (seconds)
Evaluation
24 cores
1 core
generate a brand new variable
.03
.33
summarize 50 variables
.88
19.55
twoway tabulation
.45
.45
linear regression
.65
11.48
logistic regression
7.19
59.27
All timings are on a 1 million commentary dataset. The 2 regressions included 50 covariates.
OK, the timings with 24 cores usually are not fairly the identical as with the auto dataset, however properly inside snug interactive use.
Cautious readers could have seen that the 24-core and 1-core timings for twoway tabulation are the identical. We’ve not rewritten the code for tabulate to assist a number of cores, partly as a result of tabulate is already very quick, and partly as a result of the code for tabulate is remoted, so altering it won’t enhance the efficiency of different instructions. Thus, parallelizing tabulate is on our long-run, not short-run, listing of additives to Stata/MP. We’ve rewritten about 250 sections of Stata’s inside code to assist Symmetric Multi Processing (SMP). Every rewritten part usually improves the efficiency of many instructions.
I switched again to utilizing all 24 cores and returned to my unique work — stress testing adjustments within the variety of covariates and observations. My enjoyable was quelled once I began working some timings of Cox proportional hazards regressions. With my 50 covariates and 1 million observations, a Cox regression took simply over two minutes. Most estimators in Stata are parallelized, together with the estimators for parametric survival fashions. The Cox proportional hazards estimator isn’t. It’s not parallelized as a result of it makes use of a intelligent algorithm that requires sequential computations. After I say sequential I imply that some computations are wholly depending on earlier computations in order that they merely can’t be carried out concurrently, in parallel. There are different algorithms for becoming the Cox mannequin, however they’re orders of magnitude slower. Even parallelized, they might not be quicker than our present sequential algorithm until run on 20 or extra processors. When extra computer systems begin delivery with dozens of cores, we’ll consider including a parallelized algorithm for the Cox estimator.
The pc I used to be working on is a couple of 12 months outdated. There have been a spate of latest and quicker server-grade processors from Intel and AMD previously 12 months. You will get fairly near the efficiency of my 24-core pc utilizing simply 8-cores and the newer chips. That implies that with a more recent 32-core pc, I may enhance my threshold for interactive evaluation to about 4 million observations.
There are 4 pace comparisons above. To see 450 extra, together with graphs and a dialogue of SMP and its implementation in Stata, see the Stata/MP white paper, a.okay.a. the Stata/MP Efficiency Report.
The human mind stays some of the fascinating and perplexing mysteries in medication. Scientists nonetheless battle to match neurological exercise with mind perform and detect issues early, slowing efforts to deal with neurological problems and different illnesses.
Beacon Biosignals is working to make sense of the mind by monitoring its exercise whereas folks sleep. The corporate, which was based by Jake Donoghue PhD ’19 and former MIT researcher Jarrett Revels, developed a light-weight headband that makes use of electroencephalogram (EEG) expertise to measure mind exercise whereas folks take pleasure in their regular sleep routines at residence. These knowledge are processed by machine-learning algorithms to observe the results of novel therapies, discover new indicators of illness development, and create affected person cohorts for medical trials.
“There’s a step-change in what turns into potential whenever you take away the sleep lab and convey clinical-grade EEG into the house,” says Donoghue, who serves as Beacon’s CEO. “It turns sleep from a constrained, facility-based take a look at right into a scalable supply of high-quality knowledge for diagnostics, drug improvement, and longitudinal mind well being.”
Beacon companions with pharmaceutical firms to speed up its path to sufferers. The corporate’s FDA 510(ok)-cleared medical system has already been utilized in over 40 medical trials throughout the globe as a part of research aimed toward treating circumstances together with main depressive dysfunction, schizophrenia, narcolepsy, idiopathic hypersomnia, Alzheimer’s illness, and Parkinson’s illness.
With every deployment, Beacon learns extra about how the mind works — insights it’s utilizing to create a “basis mannequin” of the mind.
“It’s our perception that the dataset that’s going to remodel mind well being doesn’t exist but — however we’re quickly creating it,” Donoghue says. “Our platform can characterize the heterogeneity of illness development, producing dynamic insights which can be unattainable to completely seize via static modalities like sequencing or imaging. The mind is an electrical organ and adjustments via synaptic plasticity, so monitoring mind perform throughout many illnesses at scale will permit us to find novel subgroups of illnesses and map them over time.”
Illuminating the mind
Donoghue educated within the Harvard-MIT Program in Well being Sciences and Know-how, conducting medical coaching for an MD whereas finishing his PhD in neuroscience at MIT below the steering of Earl Miller, MIT’s Picower Professor in Mind and Cognitive Sciences and The Picower Institute for Studying and Reminiscence. Whereas in this system, Donoghue educated at Massachusetts Common Hospital and Boston Youngsters’s Hospital, the place he helped look after sufferers, together with in oncology, through the rise of genomic sequencing to information precision most cancers therapies. He later labored in neurology and psychiatry, the place care usually relied on extra iterative approaches — highlighting a chance to carry equally data-driven precision to mind well being.
“What struck me most was the shortcoming to measure mind perform within the ways in which cardiologists can longitudinally monitor cardiac perform in sufferers from residence,” Donoghue says. “At MIT, I constructed this conviction that processing plenty of mind knowledge and dealing to correlate that with mind perform can be transformative to how these neurological illnesses are recognized and handled.”
Towards the top of his coaching, Donoghue started growing his concepts additional, participating with mentors together with HST and Harvard Medical College professors Sydney Money and Brandon Westover. He had met Revels, who was working as a analysis software program engineer in MIT’s Julia Lab, throughout his PhD, and satisfied him to co-found Beacon with him in 2019.
“We determined constructing a enterprise to know the organ of curiosity — the mind — can be an ideal begin to understanding heterogeneous neuropsychiatric illnesses and constructing higher therapies,” Donoghue recollects.
Beacon started as a computation and analytics firm constructing wearable gadgets to increase medical affect and attain. From its early days, Beacon has been partnering with massive pharmaceutical firms working medical trials, providing a much less invasive approach to watch mind exercise and learn the way their medication are impacting the mind in addition to how sufferers sleep.
“It was clear sleep was the precise window to know the mind,” Donoghue says. “Neural exercise throughout sleep could be an order of magnitude larger and extra structured, virtually like a language. It’s an ideal floor space for understanding mind perform and the way completely different medication have an effect on the mind.”
Donoghue says Beacon’s gadgets can acquire lab-grade knowledge on every affected person for a number of sequential nights, leading to larger high quality evaluation. The corporate makes use of machine studying to extract insights, such because the time sufferers spend in several sleep phases and the variety of small awakenings that happen all through the evening. It could additionally detect delicate sleep structure adjustments that may result in cognitive decline.
“We’re beginning to take options of sleep exercise and hyperlink them to outcomes in a method that’s by no means been finished with this degree of precision,” Donoghue says.
To this point, Beacon has taken half in medical trials for sleep and psychiatric problems in addition to neurodegenerative illnesses, the place sleep adjustments can emerge years earlier than the presentation of signs.
“We do plenty of work in areas like Alzheimer’s illness and Parkinson’s, which affected my grandfather,” Donoghue says. “We’re analyzing options of rapid-eye-movement and slow-wave sleep to detect early adjustments that precede medical signs. It’s a chance to maneuver these illnesses from late recognition to a lot earlier, data-driven detection.”
Enhancing mind therapies for thousands and thousands
Final yr, Beacon acquired an at-home sleep apnea testing firm that serves greater than 100,000 sufferers every year throughout the U.S., accelerating entry to high-quality, complete testing within the residence and increasing the attain of its platform. Then in November, the corporate raised $97 million to speed up that enlargement.
“The imaginative and prescient has at all times been to achieve sufferers and assist folks at scale,” Donoghue says. “What’s highly effective is that we’re constructing a longitudinal report of mind perform over time,” Donoghue says. “A affected person would possibly are available in for sleep apnea screening, but when they develop Parkinson’s years later, that earlier knowledge turns into a window into the illness earlier than signs emerged. That turns routine testing right into a basis for fully new prognostic biomarkers — and a path to detecting and intervening in mind illness earlier, probably earlier than signs ever start.”
Within the AI period, it is not sufficient for software program engineers to be whizzes at writing code. On this installment of the IT Leaders Quick-5 — InformationWeek’s column for IT professionals to realize peer insights — Priceline CTO Sejal Amin explains why needs to rent engineers who show strong management expertise and cannot solely leverage AI but in addition command a room.
Amin has held plenty of CTO positions at organizations, together with Shutterstock and Thomson Reuters, and has a background in each economics and pc science. At Priceline, she has prioritized shifting the group from being “oriented round features” to a product working mannequin. As AI permeates Priceline, Amin is concentrated on guaranteeing staff are educated to each use AI successfully and determine the suitable metrics to trace ROI.
This column has been edited for readability and house.
The Determination That Mattered
What choice — technical or organizational — made the most important distinction not too long ago, and why?
Arriving in 2024, I used to be actually taking a look at how product and tech are collaborating, what the organizational mannequin was and the way efficient it was. I made the choice to shift to a product working mannequin to reshape our group with these ideas and ideas in thoughts. It is made a extremely massive impression on our groups, how we function and the velocity at which we’re delivering.
We have been pivoting from a corporation that was actually functionally organized. Useful organizations are actually nice as a result of, over time, individuals construct experience of their craft or operate — however over time, that will get more durable to scale. The product working mannequin is much less oriented round features and way more oriented across the services and products that the product and tech group manages.
“We’re investing closely in technical leaders, not simply technical contributors.” — Sejal Amin, CTO, Priceline
The idea is to create group buildings across the services and products that you simply handle, and also you try this at scale. It is optimized for velocity, supply and stream of labor all through the group. When a group is aware of what services and products they handle, it creates a extremely robust sense of possession and accountability. The suggestions loops between constructing and studying get tighter, and points are addressed quicker. We’re clearly working quicker, and we now have the metrics to indicate for it.
A number of the challenges, like with all issues, was about taking and instructing individuals by means of the change. However all people was prepared for it and prepared to study. There wasn’t very a lot resistance.
What did not go as deliberate not too long ago — and what did it pressure you to rethink?
From a CTO’s perspective, AI is consistently shifting all day, day-after-day, nevertheless it’s additionally increasing who can construct, who can contribute, and that is a extremely good factor. It is a optimistic shift.
We’re seeing enthusiasm from in all places, not simply engineers, however throughout the group, and that creates alternatives. However we additionally have to deal with the best way to use instruments and the best way to channel all of that vitality extra responsibly. When code is generated, it does not imply that it might discover its approach to manufacturing simply with the snap of a finger.
AI accelerates growth considerably, however velocity is not the aim by itself. It must be built-in into our workflow. This is not simply technical shift, it is a cultural shift. We’ve got to create house for innovation, and house for individuals to consider what it means to their work.
We’ve got a governance coverage that was arrange proper on the outset. Initially, we have been utilizing a committee to vet new AI instruments and the appliance of these instruments. However now it isn’t nearly device approval, and we now have arrange an enablement committee round it. Now that folks have the instruments, they want assist in making use of the instruments — like coaching.
We additionally wish to begin prioritizing our most essential use circumstances and baseline metrics. If we’re spending cash on software program, we’re measuring the impression of what that device is. We’re beginning to deal with AI as a portfolio of labor, quite than a bunch of mini little improvements or many little initiatives that run throughout the group.
The Expertise Commerce-Off
The place are you investing in expertise proper now — and what are you consciously not investing in?
A few years in the past, there was a saying known as “the 10x developer,” however we have moved previous that expression. For a very long time, the engineering and the tech trade actually doubled down on engineers who may write actually clear code in isolation, even when they could not maintain a productive dialog with their group or the product supervisor. AI has made that persona or that archetype out of date.
What differentiates an important engineer is their judgment, their product intuition, and their capability to collaborate earlier than the construct begins. I wish to be hiring for versatility, resilience and luxury with ambiguity — all of these softer expertise. We’d like individuals who can thrive when priorities shift, when situations change and when new instruments come alongside.
We’re investing closely in technical leaders, not simply technical contributors. These are individuals who can maintain a room and maintain a roadmap on the identical time. Truthfully, it is simpler stated than executed. Engineers who outline the subsequent decade aren’t those who’re writing probably the most code. They’re those which are collaborating. I am speaking about that within the context of engineering, however that is true throughout all features.
The Exterior Sign
What current exterior growth is most definitely to alter how your group operates, even not directly?
[President and CEO of Nvidia] Jensen Huang was interviewed not too long ago off the again of his Nvidia convention. And he acknowledged that one approach to measure engineering contribution was token consumption. He stated he sees tokens as a really measurable, spendable useful resource. The way in which he is framing that’s having a big effect on what number of corporations suppose.
He stated the price of an engineer isn’t just the wage, nevertheless it’s additionally tokens spent. He had a really draconian view. He stated it is $X in wage, and that engineer will get $X in tokens, and she or he must spend half of that within the first six months on the job. He is basically arguing that the way forward for the engineer is not somebody who writes code, it is somebody who orchestrates AI techniques. It is somebody who consumes tokens as a spendable useful resource, the best way the earlier era consumed compute cycles.
That forces you to utterly rethink the way you consider expertise, the way you construction groups, the way you price range for engineering, and so we’re having all of that dialog right here actively.
What I discover most attention-grabbing is whether or not Jensen is true about that particular metric. Has the dialog shifted from ought to we use AI, to how we measure the people who do use it? I feel it is basically completely different query, and everybody in all places is speaking about the best way to determine that out. As a result of he is on the market making the statements, it may change and shift numerous issues. It is shifting the best way that we’re considering.
The Perspective Shift
What have you ever learn, watched, or listened to not too long ago that modified how you consider management or know-how — even barely?
I am always altering it up. I like to remain within the head of product individuals, so I hearken to Lenny’s Podcast.
After I want to remain on prime of what is going on on within the engineering world, I hearken to The Pragmatic Engineer or Engineering Enablement. Each of these are podcasts that discuss what is going on on in engineering groups, not simply what management thinks is going on. I really like The Atlantic’s Nicholas Thompson’s The Most Fascinating Factor in tech — that is on my each day rotation. He has a expertise for surfacing that one sign that issues that day. And so I wish to learn that each morning. However then there’s just a few others about constructing AI, just like the Dwarkesh Podcast.
Get extra IT management updates and insights 3 times per week direct to your inbox with the InformationWeek e-newsletter.
Paying month-to-month for cloud storage is form of like renting an residence for all of your information. Positive, it really works, but it surely’s a complete lot cheaper to personal your area outright. That is why many new cloud storage platforms are abandoning month-to-month funds for a flat charge mannequin. Internxt is a safe cloud storage supplier that is now providing a 10TB lifetime subscription, and it is even on sale for $349.99 (reg. $2,900).
10TB cloud storage with no month-to-month charge
Make no mistake, 10TB is a ton of room. You should utilize it for images, movies, paperwork, backups, photos of your canine, work folders, college information, photos of your buddy’s canine, and archives you do not need trapped on one pc. Internxt works on Home windows, macOS, Linux, Android, iOS, and internet browsers, so you may get to your information from the gadgets you already use.
Knowledge privateness is an enormous deal, particularly when it issues an enormous library of all of your stuff. That is why Internxt is so intense about safety. Information are end-to-end encrypted, and Internxt makes use of zero-knowledge storage, which implies solely you’ll be able to entry your information. Your information is just not sitting there in a kind the corporate can learn. Information are additionally break up into smaller items earlier than storage, including one other layer between your information and anybody who mustn’t have it.
Internxt is open supply, so its code is public as a substitute of hidden behind a closed system. That provides customers extra transparency about how the service works. It is also GDPR compliant and audited, which is beneficial for those who care about the place your information reside and the way they’re dealt with.
The plan works throughout limitless gadgets, consists of updates, and must be redeemed inside 30 days. Codes are just for new customers and can’t be stacked.
Should you consider getting stronger requires pushing your self to the restrict on the fitness center, new analysis suggests in any other case. Findings from Edith Cowan College (ECU) present that enhancing muscle measurement, power, and efficiency doesn’t rely upon exhausting exercises or feeling sore afterward.
“The concept train have to be exhausting or painful is holding folks again,” ECU’s Director of Train and Sports activities Science, Professor Ken Nosaka, stated.
He factors to a distinct strategy that may be more practical and much simpler to stay with. “As an alternative, we needs to be specializing in eccentric workout routines which may ship stronger outcomes with far much less effort than conventional train — and you do not even want a fitness center!”
What Is Eccentric Train
Eccentric train focuses on the part when muscle groups lengthen reasonably than shorten. This sometimes occurs through the reducing portion of a motion, reminiscent of bringing a dumbbell down, strolling downstairs, or slowly reducing your self right into a chair.
In keeping with the examine, muscle groups can produce larger drive throughout these lengthening actions whereas utilizing much less vitality than they’d throughout lifting, pulling, or climbing actions.
Extra Power With Much less Effort
“You possibly can achieve power with out feeling as exhausted. So, you get extra profit for much less effort. That makes eccentric train interesting for a variety of individuals,” Professor Nosaka stated.
Though these actions can generally result in gentle soreness, particularly for inexperienced persons, discomfort shouldn’t be required to see progress.
Easy Workout routines You Can Do At Residence
Eccentric workout routines are straightforward to include into day by day routines and don’t require particular tools. Examples embrace chair squats, heel drops, and wall push-ups. Analysis exhibits that simply 5 minutes a day of those actions can result in significant enhancements in power and general well being.
Splendid For Older Adults And Learners
As a result of eccentric train places much less pressure on the center and lungs, it’s particularly effectively fitted to older adults and folks with power well being situations. The actions additionally really feel acquainted, which makes them simpler to undertake and keep over time.
“These actions mirror what we already do in day by day life. That makes them sensible, practical and simpler to stay with,” Professor Nosaka stated.
“When train feels achievable, folks hold doing it.”
Builders have been experimenting with HTML-in-Canvas, a hexagonal world map-analytics characteristic, a web-based OS for e-ink units, changing imgsrcs utilizing content material, and extra. That is What’s !vital #10.
HTML-in-Canvas experiments
HTML-in-Canvas, a brand new API that permits us to render actual semantic HTML in a with visible results, is the speak of the city proper now, so let’s lead with that. Amit Sheen confirmed us how the HTML-in-Canvas API works, and likewise created some demos over on the HiC Showroom, like this one (requires Chrome 146 with the chrome://flags/#canvas-draw-element flag enabled):
Constructing a hexagonal world map-analytics characteristic
Ben Schwarz (superior identify, however no relation) talked about constructing a hexagonal world map-analytics characteristic. Whereas it’s extra of a retrospective than a developer walkthrough, it’s a actually attention-grabbing examine analytics, design constraints, inspiration, engineering, and naturally SVG and CSS.
Rekindle is principally a web-based working system for e-ink units like Kindle, Kobo, and Boox, which are sometimes low-powered with few options. Rekindle contains an insane variety of options and apps, and is designed in black-and-white, with no animations, and little doubt with many extra e-ink optimizations.
The takeaway isn’t a tutorial (sadly) and even some commentary (like with the world map retrospective above), it’s that we’ve a complete bunch of media queries that’d be so helpful for e-ink units if it weren’t for the truth that they’re delivery with low-powered, proprietary net browsers that don’t acknowledge them. Media Queries Degree 5 can question hover functionality, the precision of pointers, show replace frequency, colour depth, monochromatic bit-depth, colour index dimension, dynamic vary, and extra, in all probability.
Ideas? Is e-ink optimization more likely to escape within the coming years, or is low demand for these media queries why a devoted service like Rekindle must exist? It’s price noting that the browsers and most of the media queries are in lively growth, so I don’t know. Watch this house, perhaps?
Both method, I’d like to see a dev deep dive on Rekindle!
Changing imgsrcs utilizing content material
Jon found that CSS can be utilized to interchange picture sources, like this:
img {
content material: url(new-image.png) / "New alt textual content";
}
TIL! Who knew you would change the “src” of an #HTML utilizing #CSS:
img { content material: url(no matter.png) }
NO PSEUDOS!
Appears to work in all present browsers too. How did I miss this?
It’s actually attention-grabbing to study this concerning the content material property, which has been Baseline for 11 years now. I experimented a bit extra and found that this trick additionally works with the image-set() perform:
Trendy AI methods battle with reminiscence. They usually neglect previous interactions or depend on Retrieval-Augmented Technology (RAG), which depends upon fixed entry to exterior knowledge. This turns into a limitation when constructing assistants that want each historic context and a deeper understanding of customers.
MemPalace gives a special strategy, enabling structured, persistent reminiscence with greater precision and consistency. On this article, we discover the way it improves AI reminiscence methods and how one can implement it successfully.
What’s MemPalace?
MemPalace is an open-source, local-first reminiscence system that shops conversations and venture knowledge of their unique type. Every message is handled as a definite reminiscence unit, enabling persistent, structured recall.
Its design follows a hierarchical “palace” mannequin: Wings for folks or initiatives, Rooms for subjects, Halls for reminiscence varieties, and Drawers for transcripts, with Closets for summaries.
How It Differs from Conventional Reminiscence Methods
Conventional methods like RAG pipelines or vector databases concentrate on retrieval effectivity, which leads to decreased context richness. They divide knowledge into segments, create embeddings, and acquire related segments through the inference course of.
MemPalace makes use of a definite technique to retailer info:
The system retains full info in its unique type as an alternative of utilizing solely its embedding.
The system establishes a hierarchical construction, which reinforces its means to know context.
The system makes use of a mix of symbolic construction and vector search to attach two totally different methods of information.
The system achieves superior reasoning capabilities and higher traceability options by way of its hybrid framework when in comparison with standard reminiscence methods.
The Core Concept: Verbatim Reminiscence vs Summarization
Most agent reminiscence instruments use an LLM to summarize or extract key info from conversations. The instruments Mem0 and Zep analyze chat content material to create transient reviews which embrace important info and consumer preferences. The answer leads to the lack of each contextual info and delicate particulars. As an LLM should determine what’s “vital” and discard the remaining.
MemPalace takes the other strategy: “retailer the whole lot”. The system retains a whole file of all messages between customers and assistants. The system retains all knowledge intact with none type of summarization or deletion. The tactic of unprocessed knowledge storage offers vital benefits which embrace:
Full context: The system maintains full entry to all dialog particulars which permits the AI to reconstruct the whole dialogue.
Larger recall: The entire phrase database of MemPalace permits the system to attain excellent accuracy in retrieving info. Its uncooked mode achieves 96.6% recall@5 outcomes on LongMemEval which accommodates 500 questions.
Traceability: The system maintains the whole lot so customers can examine solutions towards unique chat logs.
Deep Dive Into: MemPalace Structure
The design of MemPalace makes use of the traditional mnemonic technique of loci as its basis. The system creates a multi-tiered framework which permits customers to simply find and entry saved recollections. The reminiscence palace system establishes its hierarchical construction and knowledge processing system by way of the next overview.
The “Palace” Hierarchical Reminiscence Design
Wings (Venture-Degree Segmentation): Wings outline major divisions which embody whole domains or initiatives. This allows you to separate your recollections into two classes which embrace private recollections and team-based recollections. Matters inside a wing turn into organized into particular Rooms after the definition of wings.
Rooms (Matter-Degree Group): Rooms operate as areas that join all topics which exist inside a wing. The “Work” wing accommodates three separate rooms that are named “Conferences” and “Tasks” and “Emails”. Every doc or dialog will get assigned to a particular wing and room mixture.
Halls (Reminiscence Sorts: Info, Occasions, Preferences): Throughout all wings, there are frequent Halls which classify reminiscence varieties. MemPalace defines halls like hall_facts, hall_events, hall_discoveries, hall_preferences, and hall_advice. For example, a venture determination (“swap to GraphQL”) goes into the hall_facts of its room; a gathering abstract goes into hall_events. Halls allow you to retrieve all “info” from any wing or limit to a wing-specific corridor.
Drawers (Uncooked Verbatim Storage): Each reminiscence chunk exists inside a particular Drawer. A drawer accommodates a textual content file which accommodates the whole transcript of a chat or electronic mail or code file which exists precisely because it was recorded. Drawers operate as unaltered archives which save their contents of their unique type. MemPalace establishes further Closets which accompany every drawer while you select to activate compression.
Closets (Compressed Representations): A closet accommodates the AAAK-compressed abstract (or “abstract”) which represents that drawer. Closets direct customers to their unique drawer content material which features as a compact index. MemPalace makes use of the drawers themselves for retrieval functions, however this operate exists as its default function.
Storage and Retrieval Pipeline
MemPalace’s pipeline consists of two essential elements which function as writing reminiscence for ingestion and as studying reminiscence for query-time retrieval.
Verbatim Storage (Ingestion): At any time when a dialog or file is mined, MemPalace writes every message as a brand new Drawer entry in its database. The textual content goes straight right into a vector retailer (default: ChromaDB) with out LLM filtering. In distinction to extractive methods like Mem0, MemPalace merely saves the uncooked content material. Metadata like wing, room, and corridor tags are hooked up so later queries can filter by context.
Vector Search with ChromaDB: For retrieval, MemPalace leverages semantic vector search. Every drawer is embedded (utilizing the default mannequin) and saved in ChromaDB. While you question MemPalace, the system vectorizes your question and finds probably the most related drawers by cosine similarity. This normally returns matches in milliseconds.
Metadata Layer (Information Graph): Past uncooked textual content, MemPalace builds a temporal information graph in native SQLite. Every truth (topic–predicate–object) is saved with validity home windows (begin/finish dates). This consists of:
Temporal relationships
Entity linking
Context dependencies
Compression Mechanism (AAAK)
MemPalace offers an elective compression operate which it designates as AAAK. AAAK features as a particular shorthand system which permits customers to retailer in depth info by way of minimal token utilization. The system performs lossy compression as a result of its major mechanism makes use of common expressions to rework phrases into abbreviations whereas choosing key sentences for extraction, which leads to roughly 30 occasions discount of tokens.
Lossless Compression Technique: The long-term objective of AAAK is to be “lossless” in content material. The perfect encoding ought to allow you to reconstruct each factual assertion. AAAK ought to present full proof of who carried out which actions at which occasions for which causes. The design constraints forbid proprietary tokenizers or embeddings AAAK should work throughout any mannequin.
Token Effectivity and Context Injection: The long-term objective of AAAK is to be “lossless” in content material. The perfect encoding ought to allow you to reconstruct each factual assertion. AAAK ought to present full proof of who carried out which actions at which occasions for which causes. The design constraints forbid proprietary tokenizers or embeddings AAAK should work throughout any mannequin.
How MemPalace Works (Finish-to-Finish Circulation)
The system permits AI brokers to keep up everlasting reminiscence parts which customers can search at any time. The system transforms spoken dialogue into vector representations which it saves in ChromaDB. The agent accesses its important recollections when it requires particular info as an alternative of utilizing its full reminiscence database.
Information Ingestion (Dialog Mining)
Information ingestion is step one. MemPalace listens to each flip of a dialog and captures consumer messages, AI responses, and metadata. It then prepares this uncooked textual content for storage.
Chunking: MemPalace splits lengthy messages into 512-token chunks with 64-token overlaps. This prevents context loss at chunk boundaries.
Metadata tagging: Every chunk will get a job (consumer or assistant), a flip quantity, a session ID, and a timestamp.
Deduplication: MemPalace makes use of deterministic IDs like session-turn-N. Re-saving the identical flip merely overwrites the prevailing file.
Reminiscence Indexing and Structuring
The system processes knowledge by way of its ingest course of which produces vector embeddings for every knowledge phase. The system makes use of a sentence-transformer mannequin which converts textual content right into a high-dimensional numerical vector. ChromaDB shops this vector along with the unique textual content and its accompanying info.
The indexing course of has two key elements:
The Vector Retailer: ChromaDB organizes its embeddings by way of an HNSW (Hierarchical Navigable Small World) index system. The construction permits customers to carry out quick approximate nearest-neighbor looking out. The system locates semantically matching recollections inside a number of milliseconds by looking out by way of its database of saved reminiscence chunks.
The Metadata Layer: The index shops vector knowledge along with its related metadata dictionary. The consumer can select to filter outcomes based mostly on any database subject throughout question execution. The consumer can select to filter outcomes between summary-type chunks and particular session turns from a specific session. The system makes use of structured filtering strategies to attain each fast and actual knowledge retrieval.
Question-Time Retrieval and Rating
The system transforms consumer messages into question vectors which MemPalace makes use of to seek out probably the most related database entries by way of its search of ChromaDB. The system solely shows outcomes for chunks that exceed the minimal rating threshold of 0.70.
The retrieval pipeline applies three filters so as:
Session filter: The system limits outcomes to the current session as a result of it makes use of the present session_id. Cross-session bleed doesn’t happen.
Kind filter: The system permits customers to decide on whether or not they need abstract chunks or uncooked flip chunks for acquiring high-level context.
Rating threshold: The system removes outcomes which don’t meet the established minimal similarity requirement. This prevents irrelevant recollections from polluting the context.
Context Injection into LLMs
MemPalace doesn’t stuff the whole dialog historical past into the immediate. The system creates a structured block which accommodates the top-Ok retrieved chunks and provides it earlier than the system immediate. The LLM sees solely related previous context not each flip.
The injected context block appears to be like like this:
Every reminiscence block features a similarity rating and switch quantity. The LLM receives provenance info by way of this mechanism. The consumer can choose between two reminiscence choices which include rating values of 0.94 and 0.71 respectively. The injection provides zero overhead to ChromaDB as a result of it makes use of outcomes which the system retrieved through the search course of.
Easy methods to Use MemPalace with in Agentic Frameworks (LangGraph)
LangGraph allows you to assemble brokers by way of state machines which function with nodes that execute single duties and edges which decide motion between nodes. MemPalace operates by way of two specialised nodes which embrace a retrieval node that connects to the chat node and a saving node that connects to the chat node. The system offers LangGraph brokers with everlasting reminiscence storage which customers can search by way of.
The part offers a information which explains the best way to full every integration step. The part offers full Python code along with the terminal output that ought to seem at every growth stage.
Step 1: Set up packages
MemPalace, LangGraph, ChromaDB, and the sentence-transformer library ought to be put in in a Python digital setting.
Create a .env file on the root of your venture. The variables decide each the placement the place ChromaDB shops its knowledge and the precise embedding mannequin which MemPalace will make the most of.
OPENAI_API_KEY=sk-...
MEMPALACE_DB_PATH="./chroma_palace"
MEMPALACE_COLLECTION="agent_memory"
MEMPALACE_EMBED_MODEL="all-MiniLM-L6-v2"
Step 3: Initialize the MemPalace
This can create the ChromaDB consumer connection and prepares the embedding operate and creates a MemPalace occasion. The gathering is created by executing this system as soon as. This system routinely masses the prevailing assortment throughout all following executions. Put the under piece of code in palace_init.py.
import os
from dotenv import load_dotenv
import chromadb
from chromadb.utils import embedding_functions
from mempalace import MemPalace, PalaceConfig
load_dotenv()
# 1. Persistent ChromaDB consumer
chroma_client = chromadb.PersistentClient(
path=os.getenv('MEMPALACE_DB_PATH', './chroma_palace')
)
# 2. Sentence-transformer embedding operate
embed_fn = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name=os.getenv('MEMPALACE_EMBED_MODEL', 'all-MiniLM-L6-v2'),
system="cpu" # swap to 'cuda' if a GPU is accessible
)
# 3. Get or create a named assortment
assortment = chroma_client.get_or_create_collection(
identify=os.getenv('MEMPALACE_COLLECTION', 'agent_memory'),
embedding_function=embed_fn,
metadata={'hnsw:house': 'cosine'}
)
# 4. Configure MemPalace
config = PalaceConfig(
max_memories=5000,
similarity_threshold=0.75,
chunk_size=512,
chunk_overlap=64,
top_k=5,
)
Output:
# First run (empty palace): Palace prepared. Recollections saved: 0
LangGraph transfers a state dictionary by way of its node connections. The AgentStateTypedDict requires 4 particular fields which embrace the message checklist, the injected reminiscence context, a flip counter, and the session ID. The chat node reads from this state and writes again to it. Put this in agent.py
from __future__ import annotations
from typing import Annotated, TypedDict, Checklist
from langgraph.graph import StateGraph, END
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage
from langchain_openai import ChatOpenAI
class AgentState(TypedDict):
messages: Checklist[BaseMessage]
memory_context: str # retrieved recollections, injected into system immediate
turn_count: int # tracks turns for auto-save set off
session_id: str
llm = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0.7)
def build_system_prompt(memory_ctx: str) -> str:
base="You're a useful assistant with persistent reminiscence.n"
if memory_ctx:
return base + f'n## Related recollections:n{memory_ctx}n'
return base
def chat_node(state: AgentState) -> AgentState:
system = build_system_prompt(state['memory_context'])
response = llm.invoke([
{'role': 'system', 'content': system},
*state['messages']
])
return {
**state,
'messages': state['messages'] + [AIMessage(content=response.content)],
'turn_count': state['turn_count'] + 1,
}
Step 5: Add the retrieval search hook
The retrieve node runs earlier than each chat flip. The system takes the newest human message and makes use of it to look ChromaDB by way of MemPalace. The output outcomes from this course of are saved in memory_context. The chat node then sees that context in its system immediate. Put this in search_hooks.py
from langchain_core.messages import HumanMessage
from palace_init import palace
from agent import AgentState
def retrieve_memories_node(state: AgentState) -> AgentState:
messages = state['messages']
if not messages:
return {**state, 'memory_context': ''}
# Use the final human message because the search question
question = ''
for msg in reversed(messages):
if isinstance(msg, HumanMessage):
question = msg.content material
break
if not question:
return {**state, 'memory_context': ''}
# Search ChromaDB through MemPalace
outcomes = palace.search(
question=question,
top_k=5,
filters={'session_id': state['session_id']},
min_score=0.70
)
if not outcomes:
return {**state, 'memory_context': ''}
# Format outcomes for the system immediate
ctx_lines = []
The save node runs after the chat node based on a conditional edge. When turn_count reaches a a number of of 15, it writes the final 15 messages to ChromaDB with function, flip, and timestamp metadata. The system then resets turn_count to zero. Put this in autosave.py
The increasing palace building wants more room as a result of unprocessed supplies take up space and constructing supplies turn into more durable to retrieve. The summarize node fires after each save, as soon as the overall doc rely exceeds a threshold. The method combines 15 earlier dialogue segments right into a single abstract which it creates by way of LLM expertise whereas it removes all unprocessed materials. Put this in summarizer.py
from datetime import datetime
from typing import Checklist
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai import ChatOpenAI
from palace_init import palace
SUMMARIZE_EVERY = 15 # batch window measurement
COMPRESS_THRESHOLD = 50 # solely compress as soon as palace exceeds this
summarizer_llm = ChatOpenAI(mannequin="gpt-4o-mini", temperature=0)
SUMMARY_PROMPT = '''You're a reminiscence compressor for an AI assistant.
Given the dialog excerpt under, produce a dense factual abstract.
Protect all consumer preferences, selections, and context.
Write in third particular person. Purpose for 3-6 sentences.
Dialog:
{transcript}
Abstract:'''
def _format_transcript(messages: Checklist[BaseMessage]) -> str:
traces = []
for msg in messages:
function="Consumer" if isinstance(msg, HumanMessage) else 'Assistant'
traces.append(f'{function}: {msg.content material}')
return 'n'.be part of(traces)
def summarize_and_compress(messages, session_id, batch_start) -> str:
transcript = _format_transcript(messages)
immediate = SUMMARY_PROMPT.format(transcript=transcript)
response = summarizer_llm.invoke([HumanMessage(content=prompt)])
summary_text = response.content material.strip()
summary_id = f'{session_id}-summary-turns-{batch_start}-{batch_start + len(messages)}'
palace.add_batch(
paperwork=[summary_text],
metadatas=[{
'session_id': session_id,
'type': 'summary',
'turn_start': batch_start,
'turn_end': batch_start + len(messages),
'saved_at': datetime.utcnow().isoformat(),
'raw_turns': len(messages),
}],
ids=[summary_id],
)
The method begins with 15 uncooked chunks which the LLM transforms into 3-6 sentence summaries. The method leads to a single abstract chunk. ChromaDB deletes the 15 originals. The method leads to a storage discount of roughly 93 % whereas sustaining the unique that means of the content material. Now we’ll create a summarizer node which can determine when the agent will present abstract.
from agent import AgentState
from palace_init import palace
from summarizer import (
summarize_and_compress,
delete_raw_batch,
SUMMARIZE_EVERY,
COMPRESS_THRESHOLD
)
def summarize_node(state: AgentState) -> AgentState:
if palace.rely() < COMPRESS_THRESHOLD:
print(f' [Summarizer] Skipped — {palace.rely()} docs in palace.')
return state
messages = state['messages']
session_id = state['session_id']
total_turns = len(messages)
batch_start = max(0, total_turns - SUMMARIZE_EVERY * 2)
batch_end = batch_start + SUMMARIZE_EVERY
batch = messages[batch_start:batch_end]
if not batch:
return state
summarize_and_compress(batch, session_id, batch_start)
delete_raw_batch(session_id, batch_start, batch_end)
print(f' [Summarizer] Palace measurement after compression: {palace.rely()}')
return state
def should_summarize(state: AgentState) -> str:
return 'summarize' if state['turn_count'] == 0 else 'finish'
Step 8: Assemble the complete LangGraph pipeline
The method requires you to merge all nodes into one StateGraph construction The graph flows: retrieve -> chat -> (save | finish) -> (summarize | finish). The graph maintains operational effectivity as a result of its conditional edges permit nodes to activate solely when their respective triggering circumstances are met. Now we’ll lastly mix all of the above nodes right into a full_graph.py
from langgraph.graph import StateGraph, END
from agent import AgentState, chat_node
from search_hooks import retrieve_memories_node
from autosave import save_memories_node, should_save
from summarize_node import summarize_node, should_summarize
graph = StateGraph(AgentState)
graph.add_node('retrieve', retrieve_memories_node)
graph.add_node('chat', chat_node)
graph.add_node('save', save_memories_node)
graph.add_node('summarize', summarize_node)
graph.set_entry_point('retrieve')
graph.add_edge('retrieve', 'chat')
# After chat: save if turn_count hit the edge
graph.add_conditional_edges(
'chat',
should_save,
{
'save': 'save',
'finish': END
}
)
# After save: compress if palace is giant sufficient
graph.add_conditional_edges(
'save',
should_summarize,
{
'summarize': 'summarize',
'finish': END
}
)
graph.add_edge('summarize', END)
agent = graph.compile()
Step 9: Check with a pattern dialog
For this we are going to conduct a 20-turn check dialog to check three features which embrace auto-save timing at flip 15 and reminiscence retrieval from flip 10 and subsequent occasions and the accuracy of cross-session recall outcomes which present similarity scores.
import uuid
from langchain_core.messages import HumanMessage
from full_graph import agent
from palace_init import palace
SAMPLE_TURNS = [
'Hi! I am building a FastAPI backend for a SaaS app.',
'I prefer async endpoints. PostgreSQL is my database.',
'Can you suggest a folder structure for the project?',
'I want to add JWT authentication.',
'Pydantic v2 for validation, SQLAlchemy 2 async ORM.',
'Keep code examples concise — no verbose explanations.',
'What is the best way to handle database migrations?',
'Show me an async endpoint with a DB session dependency.',
'Add rate limiting to the auth routes.',
'How should I structure Pydantic schemas?',
'I also need background tasks for email sending.',
'Use Redis for caching user sessions.',
'What testing framework do you recommend?',
'Help me write a pytest fixture for the DB.',
'Run a final check — is the project structure solid?', # turn 15 -> save
'Now add a websocket for real-time notifications.',
'How do I deploy this to AWS ECS?',
'Add a Dockerfile and docker-compose.yml.',
'Configure CORS for the frontend at localhost:3000.',
'Final review — anything I missed?', # turn 20
]
def run_test():
session_id = str(uuid.uuid4())
state = {
'messages': [],
'memory_context': '',
}
--- Cross-session recall --- [0.94] Flip 4: Pydantic v2 for validation, SQLAlchemy 2 async ORM... [0.91] Flip 1: I choose async endpoints. PostgreSQL is my database... [0.77] Flip 11: Use Redis for caching consumer classes...
The output reveals how the system builds and makes use of reminiscence step-by-step. The system begins with out reminiscence as a result of it must entry earlier info. The system begins to retrieve useful knowledge after the dialogue progresses. At flip 15, it saves 15 messages into long-term reminiscence. The system makes use of its reminiscence after flip 20 to enhance its solutions. The system demonstrates reminiscence retention by precisely recollecting important particulars from earlier talks.
MemPalace vs Conventional Reminiscence Methods
Side
MemPalace vs RAG Pipelines
MemPalace vs Vector Databases
MemPalace vs Agent Reminiscence Frameworks
Core Perform
RAG retrieves static paperwork equivalent to PDFs and information bases at question time.
Vector databases retailer embeddings for similarity search.
Agent reminiscence frameworks retailer short-term chat reminiscence or key-value knowledge.
Reminiscence Kind
RAG doesn’t retailer earlier dialogue classes or monitor consumer habits.
Vector databases present flat embedding storage with out reminiscence construction.
These frameworks normally preserve transient information or important info.
MemPalace Distinction
MemPalace acts as a persistent reminiscence retailer past a single immediate.
MemPalace provides organized spatial parts equivalent to wings, rooms, and halls.
MemPalace can substitute business reminiscence instruments whereas giving customers full management.
Key Benefit
RAG might be layered on prime of MemPalace as doc reminiscence.
Its hierarchy helps customers slim down search outcomes extra successfully.
It gives privateness, management, and a local-first various to paid providers like Letta.
Way forward for AI Reminiscence Methods
The demonstration of MemPalace reveals how synthetic intelligence methods now function with everlasting structured reminiscence as a result of their brokers operate as ongoing studying methods as an alternative of working as non-dependent devices. The architectural growth progresses from RAG to new methods which rely upon reminiscence as their core aspect for executing reasoning duties and managing consumer interactions.
Towards Persistent AI Brokers: The event of persistent AI brokers now permits methods to keep up operational reminiscence which permits them to trace their present duties and actions repeatedly whereas waking up with full job information.
Reminiscence-Centric AI Architectures: The analysis focuses on creating hybrid methods which mix LLMs for reasoning duties with reminiscence methods that deal with info storage and retrieval and organizational buildings.
Analysis Instructions in Lengthy-Time period Reminiscence: The researchers work on creating extra environment friendly compression strategies and improved temporal reasoning retrieval methods and scalable information graphs which might be assessed utilizing enhanced analysis requirements.
Conclusion
The group of MemPalace units a brand new customary for AI reminiscence methods by prioritizing constancy, construction, and long-term retention. Its hierarchical design and actual knowledge preservation overcome limitations of conventional methods like RAG and summarization-based approaches.
Its energy comes from combining AAAK compression, a temporal information graph, and MCP integration. The following step for context-aware brokers is constructing reminiscence methods that protect full consumer experiences, not simply outputs. MemPalace displays this shift by enabling prolonged reminiscence capabilities and marking a major step towards true AI reminiscence.
Regularly Requested Questions
Q1. What’s MemPalace?
A. MemPalace is a local-first reminiscence system that shops full conversations as structured, persistent reminiscence items for correct recall and context.
Q2. How is MemPalace totally different from RAG?
A. In contrast to RAG, MemPalace shops full knowledge verbatim and makes use of hierarchical construction for richer context, higher reasoning, and improved traceability.
Q3. Why does MemPalace keep away from summarization?
A. It preserves all particulars by storing uncooked conversations, guaranteeing greater recall, full context, and verifiable reminiscence with out dropping delicate info.
Hiya! I am Vipin, a passionate knowledge science and machine studying fanatic with a powerful basis in knowledge evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy knowledge, and fixing real-world issues. My objective is to use data-driven insights to create sensible options that drive outcomes. I am desirous to contribute my expertise in a collaborative setting whereas persevering with to be taught and develop within the fields of Information Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.
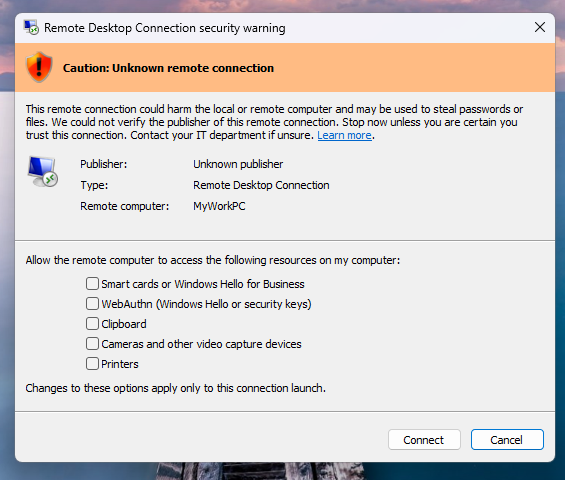
Microsoft has mounted a recognized concern inflicting newly launched Home windows safety warnings to show incorrectly when opening Distant Desktop (.rdp) information.
This recognized concern impacts all supported Home windows variations, together with Home windows 11 (KB5083768 & KB5083769), Home windows 10 (KB5082200), and Home windows Server (KB5082063), on gadgets with a number of screens and completely different show scaling settings.
Microsoft addressed the bug within the non-compulsory KB5083631 preview cumulative replace for Home windows 11, launched on Thursday, together with 34 different modifications.
“This replace addresses a problem that impacts the Distant Desktop Connection safety warning dialog. The dialog might render incorrectly in multi-monitor state of affairs when the screens had completely different scaling set,” Microsoft mentioned. “This may happen after putting in the April 2026 (KB5083769) safety replace.”
As Microsoft defined when it acknowledged the bug on Wednesday, the safety warnings showing when opening RDP information could not show accurately. On affected Home windows programs, the buttons within the alert home windows are misaligned or partially hidden, and the textual content is tough to learn, making it tough, and in some instances not possible, to work together with the safety dialog.
These warnings had been launched on Home windows programs with the April 2026 cumulative updates to disable dangerous shared sources by default as a protection towards phishing assaults that abuse Distant Desktop connection (.rdp) information.
RDP information are generally used to hook up with distant programs in enterprise environments as a result of they are often preconfigured to robotically redirect native sources to a distant host. Nevertheless, risk actors have additionally more and more abused them in phishing campaigns, together with the Russian APT29 cyber-espionage group, which has used them to steal paperwork and credentials from victims’ gadgets remotely.
After putting in the April safety updates, a one-time instructional immediate will seem when opening an RDP file for the primary time, warning in regards to the related dangers.
Afterward, a safety dialog is displayed earlier than any connection is made when opening RDP information, exhibiting whether or not the file is signed by a verified writer, the distant system’s tackle, and all native useful resource redirections (together with drives, clipboard, or gadgets), with each choice disabled by default.
If RDP information are usually not digitally signed, Home windows shows a “Warning: Unknown distant connection” warning, with the writer labeled as unknown. Nevertheless, if they’re digitally signed, Home windows will warn customers to confirm their legitimacy earlier than connecting.
In accordance with consumer studies, the KB5083769 safety replace additionally breaks third-party backup apps from a number of distributors on Home windows 11 24H2 / 25H2 programs resulting from a VSS (Quantity Shadow Copy Service) timeout.
AI chained 4 zero-days into one exploit that bypassed each renderer and OS sandboxes. A wave of recent exploits is coming.
On the Autonomous Validation Summit (Might 12 & 14), see how autonomous, context-rich validation finds what’s exploitable, proves controls maintain, and closes the remediation loop.