
The covariance matrix is central to many statistical strategies. It tells us how variables transfer collectively, and its diagonal entries – variances – are very a lot our go-to measure of uncertainty. However the actual motion lives in its inverse. We name the inverse covariance matrix both the precision matrix or the focus matrix. The place did these phrases come from? I’ll now clarify the origin of those phrases and why the inverse of the covariance is known as that approach. I doubt this has stored you up at evening, however I nonetheless suppose you’ll discover it fascinating.
Why the Inverse Covariance is Known as Precision?
Variance is only a noisy soloist, if you wish to know who actually controls the music – who relies on whom – you take heed to precision . Whereas a variable could look wiggly and wild by itself, you typically can inform the place it lands exactly, conditional on the opposite variables within the system. The inverse of the covariance matrix encodes the conditional dependence any two variables after controlling the remaining. The mathematical particulars seem in an earlier put up and the curious reader ought to seek the advice of that one.
Right here the next code and determine present solely the illustration for the precision terminology. Take into account this little experiment:
![[ X_2, X_3 sim mathcal{N}(0,1) text{, independent and ordinary.} ]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-77932a40aed9b8a19f8cbed462a126fc_l3.svg "Rendered by QuickLaTeX.com")
![[ X_1 = 2X_2 + 3X_3 + text{small noise}.]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-f977845f0df331204b7bb8e60c7d1d32_l3.svg "Rendered by QuickLaTeX.com")
Now, has a big variance (marginal variance), look, it’s far and wide:
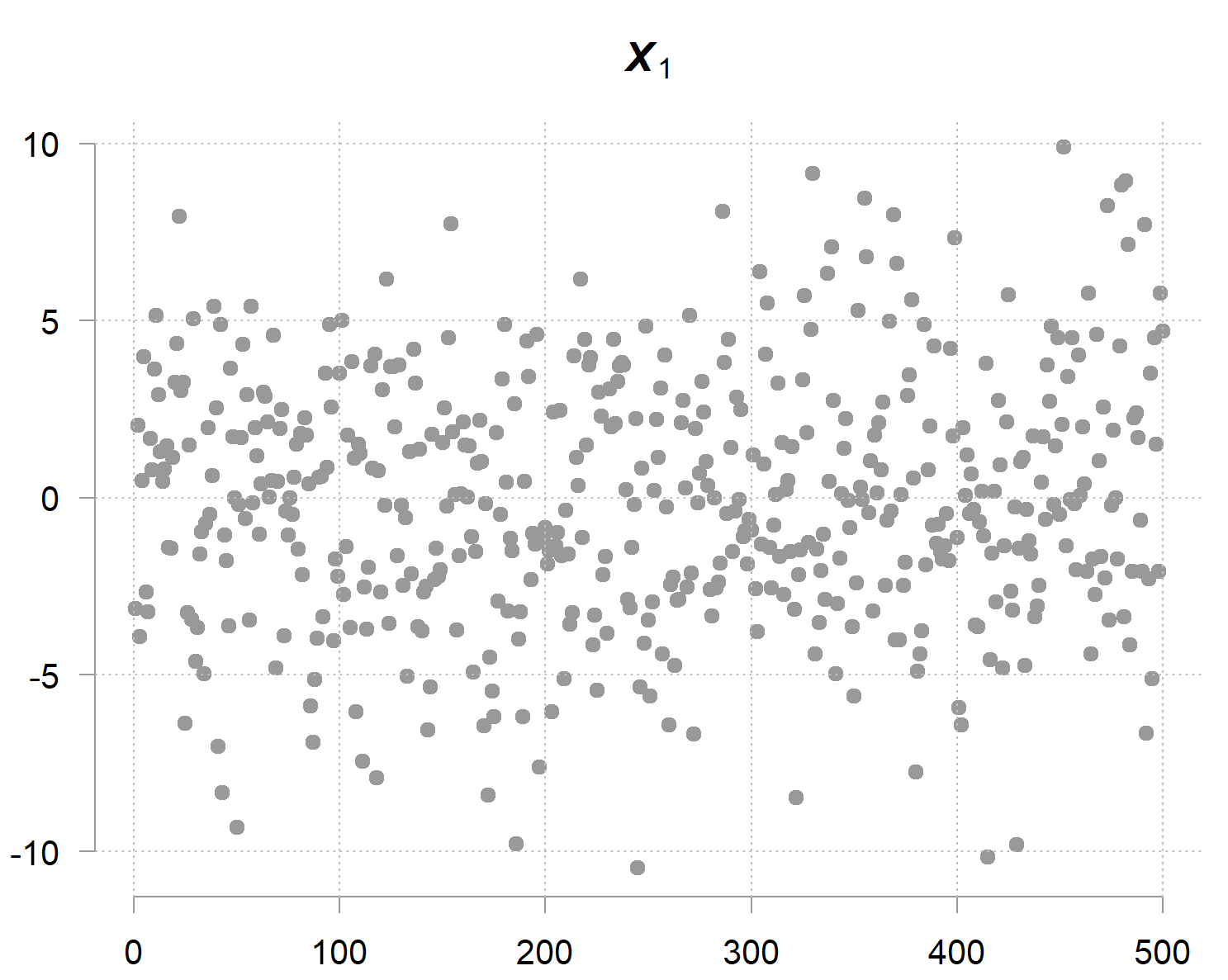
However however however… given the opposite two variables you possibly can decide fairly precisely (as a result of it doesn’t carry a lot noise by itself); therefore the time period precision. The precision matrix captures precisely this phenomenon. Its diagonal entries aren’t about marginal uncertainty, however conditional uncertainty; how a lot variability stays when the values of the opposite variables are given. The inverse of the precision entry
is the residual variance of
after regression it on the opposite two variables. The mathematics behind it’s present in an earlier put up, for now it’s suffice to jot down:
![[text{For each } i=1,dots,n: quad X_i = sum_{j neq i} beta_{ij} X_j + varepsilon_i, quad text{with } mathrm{Var}(varepsilon_i) = sigma_i^2.]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-b2117260325064797f25890f8fab0508_l3.svg "Rendered by QuickLaTeX.com")
![[quad Omega_{ii} = tfrac{1}{sigma_i^2}, qquad Omega_{ij} = -tfrac{beta_{ij}}{sigma_i^2}.]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-dff21eed569b6f91345eab16be17be60_l3.svg "Rendered by QuickLaTeX.com")
So after accounting for the opposite two variables, you might be left with
![[text{small noise} --> frac{1}{text{small noise}} --> text{high precision}]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-706b578fc06d4f88ca98130a113929b6_l3.svg "Rendered by QuickLaTeX.com")
which on this case appears to be like as follows: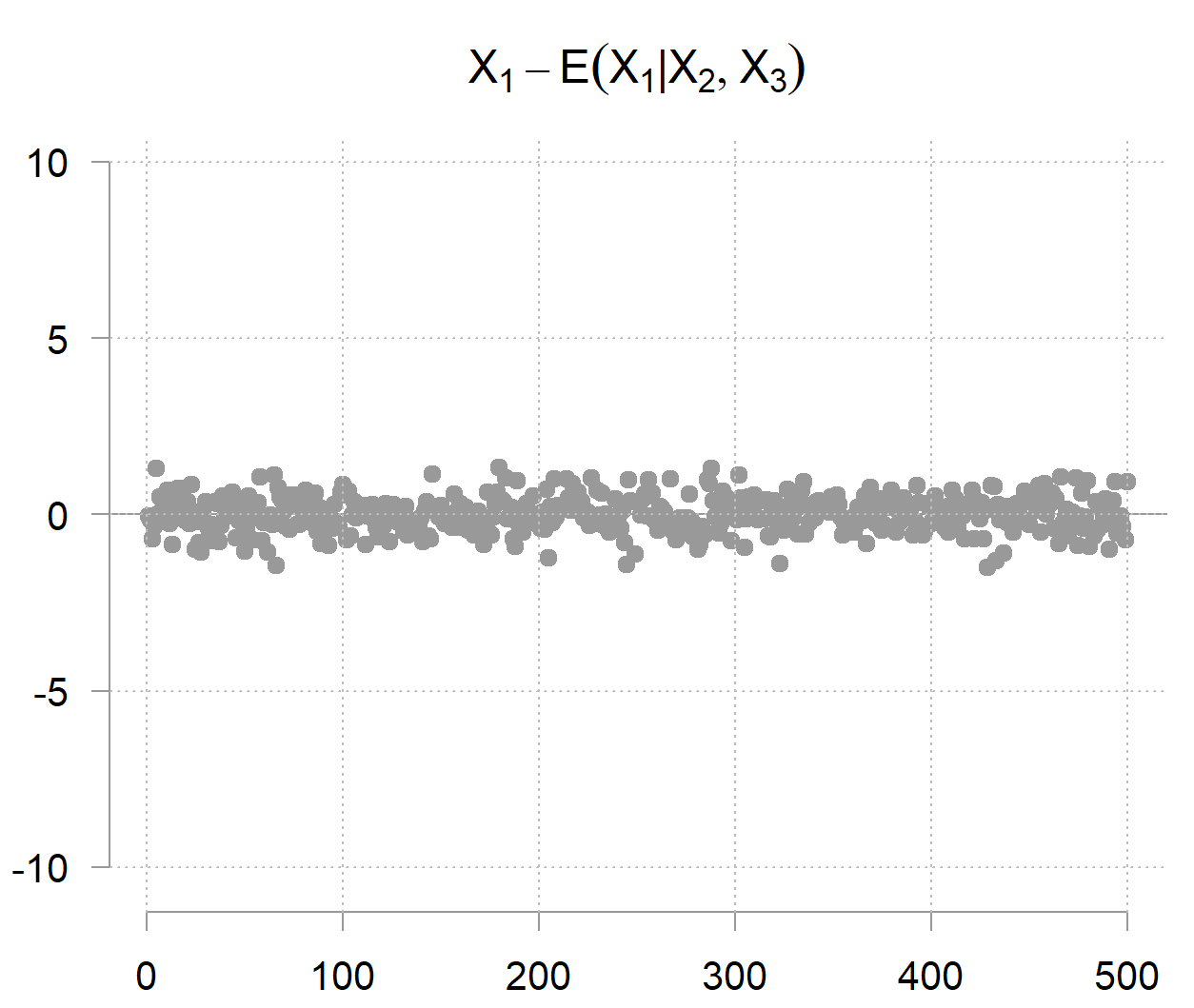
This small illustration additionally reveals a helpful computational perception. As a substitute of immediately inverting the covariance matrix (costly for prime dimensions), you can even run parallel regressions of every variable on all others, which can scale higher on distributed programs.
Why the Inverse Covariance is Known as Focus?
Now, what motivates the focus terminology? What’s concentrated? Let’s unwrap it. Let’s start by first trying on the density of a single usually distributed random variable:
![[f(x) propto expleft(-frac{1}{2}frac{(x-mu)^2}{sigma^2}right).]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-d12845f6dc510c93daf6e0b6b43110e1_l3.svg "Rendered by QuickLaTeX.com")
So if we now have
, and in any other case we now have
. This unfavorable quantity will then be divided by the variance, or, in our context multiplied by the precision (which is the reciprocal of the variance for a single variable). A better precision worth makes for a negativier (😀) exponent. In flip, it reduces the general density the additional we drift from the imply (suppose sooner mass-drop within the tails), so a sharper, extra peaked density the place the variable’s values are tightly concentrated across the imply. A numeric sanity examine. Beneath are two circumstances with imply zero, one with variance 1 (so precision
), and the opposite with variance 4 (
). We have a look at two values, one on the imply (
), and one farther away (
), and examine the density mass at these values for the 2 circumstances (
,
, and
and
) :
![[ Xsimmathcal N(0,sigma^2),quad tau=frac{1}{sigma^2},quad p_tau(x)=frac{sqrt{tau}}{sqrt{2pi}}exp!left(-tfrac12tau x^{2}right) ]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-aabaea98c484ccef3dea700526e07de1_l3.svg "Rendered by QuickLaTeX.com")
![[ p_{1}(0)=frac{1}{sqrt{2pi}}approx 0.39,qquad p_{4}(0)=frac{2}{sqrt{2pi}}=sqrt{frac{2}{pi}}approx 0.79 ]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-5d4963796d413f0ebb6d04f1fd592853_l3.svg "Rendered by QuickLaTeX.com")
![[ p_{1}(1)=frac{1}{sqrt{2pi}}e^{-1/2}approx 0.24,qquad p_{4}(1)=frac{2}{sqrt{2pi}}e^{-2}approx 0.10 ]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-2d268a7c77b892aeb7da70f4589570b2_l3.svg "Rendered by QuickLaTeX.com")
![[ tauuparrow;Rightarrow;p(0)uparrow,;p(1)downarrow ]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-ff5b9448befd6ebf47c4e8839bcdd878_l3.svg "Rendered by QuickLaTeX.com")
In phrases: larger precision results in decrease density mass away from the imply and, due to this fact, larger density mass across the imply (as a result of the density has to sum as much as one, and the mass should go someplace).
Transferring to the multivariate case. Say that additionally is often distributed, then the joint multivariate Gaussian distribution of our 3 variables is proportional to:
![[f(mathbf{x}) propto exp!left(-tfrac{1}{2}(mathbf{x}-boldsymbol{mu})^top mathbf{Omega} (mathbf{x}-boldsymbol{mu})right)]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-075f7d1e6f5c0d652bf2dd293cdcb212_l3.svg "Rendered by QuickLaTeX.com")
![[mathbf{x} = begin{bmatrix} x_1 x_2 x_3 end{bmatrix}, quad boldsymbol{mu} = begin{bmatrix} mu_1 mu_2 mu_3 end{bmatrix}, quad mathbf{Omega} = begin{bmatrix} Omega_{11} & Omega_{12} & Omega_{13} Omega_{21} & Omega_{22} & Omega_{23} Omega_{31} & Omega_{32} & Omega_{33} end{bmatrix}]](https://eranraviv.com/wp-content/ql-cache/quicklatex.com-804c0cbf11085fc4ddbf1932b3c6bc34_l3.svg "Rendered by QuickLaTeX.com")
In the identical style, immediately units the form and orientation of the contours of the multivariate density. If there is no such thing as a correlation (suppose a diagonal
), what would you count on to see? that we now have a large, subtle, spread-out cloud (indicating little focus). By means of distinction, a full
weights the instructions in a different way; it determines how a lot chance mass will get concentrated in every course by the house.
One other method to see that is to do not forget that for the multivariate Gaussian density case, seems within the nominator, so the inverse, the covariance
can be within the denominator. Increased covariance entries means extra unfold, and in consequence a decrease density values at particular person factors and thus a extra subtle multivariate distribution total.
The next two easy situations illustrate the focus precept defined above. Within the code under you possibly can see that whereas I plot solely the primary 2 variables, there are literally 3 variables, however the third one is impartial; so excessive covariance would stay excessive even when we account for the third variable (I say it so that you simply don’t get confused that we now work with the covariance, reasonably then with the inverse). Listed here are the 2 situations:
with correlation
creates spherical contours.
with correlation
creates elliptical contours stretched alongside the correlation course.
Rotate the under interactive plots to get a clearer sense of what we imply by extra/much less focus. Don’t overlook to examine the density scale.
Spherical hill: subtle, much less concentrated
Elongated ridge: steeppeaky, extra concentrated
Hopefully, this rationalization makes the terminology for the inverse covariance clearer.
Code
For Precision
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
# Mix into matrix X <– cbind(X1, X2, X3)
# Compute covariance and precision set.seed(123) n <– 100 # Generate correlated information the place X1 has excessive variance however is predictable from X2, X3 # X1 = 2*X2 + 3*X3 + small noise X2 <– rnorm(n, 0, 1) X3 <– rnorm(n, 0, 1) X1 <– 2*X2 + 3*X3 + rnorm(n, 0, 0.5) # Small conditional variance!
# Mix into matrix X <– cbind(X1, X2, X3)
# Compute covariance and precision Sigma <– cov(X) Omega <– resolve(Sigma)
# Show outcomes cat(“MARGINAL variances (diagonal of Sigma):n”) print(diag(Sigma)) X1 X2 X3 11.3096683 0.8332328 0.9350631
cat(“nPRECISION values (diagonal of Omega):n”) print(diag(Omega)) X1 X2 X3 4.511182 18.066305 41.995608
cat(“nCONDITIONAL variances (1/diagonal of Omega):n”) print(1/diag(Omega)) X1 X2 X3 0.22167138 0.05535166 0.02381201
Verification – Residual variance from regression:
cat(“Var(X1|X2,X3) =”, var(match$residuals), “n”) Var(X1|X2,X3) = 0.2216714 cat(“1/Omega[1,1] =”, 1/Omega[1,1], “n”) 1/Omega[1,1] = 0.2216714
|
For Focus
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
library(MASS) library(rgl) library(htmltools) set.seed(123) n <– 5000 mu <– c(0,0,0)
# Case 1: Low correlation (spherical hill) Sigma1 <– matrix(c(1, 0.1, 0, 0.1, 1, 0, 0, 0, 1), 3, 3) X1 <– mvrnorm(n, mu=mu, Sigma=Sigma1)
# Case 2: Excessive correlation (elongated ridge) Sigma2 <– matrix(c(1, 0.9, 0, 0.9, 1, 0, 0, 0, 1), 3, 3) X2 <– mvrnorm(n, mu=mu, Sigma=Sigma2)
# Density for marginal (X1,X2) kd1 <– kde2d(X1[,1], X1[,2], n=150, lims=c(vary(X1[,1]), vary(X1[,2]))) kd2 <– kde2d(X2[,1], X2[,2], n=150, lims=c(vary(X2[,1]), vary(X2[,2])))
# Plot 1: Low correlation → “spherical mountain” open3d(useNULL=TRUE) persp3d(kd1$x, kd1$y, kd1$z, col = terrain.colours(100)[cut(kd1$z, 100)], side = c(1,1,0.4), xlab=“X1”, ylab=“X2”, zlab=“Density”, clean=TRUE, alpha=0.9) title3d(“Low correlation (spherical, concentrated)”, line=2) widget1 <– rglwidget(width=450, top=450) # Plot 2: Excessive correlation → “ridge mountain” open3d(useNULL=TRUE) persp3d(kd2$x, kd2$y, kd2$z, col = terrain.colours(100)[cut(kd2$z, 100)], side = c(1,1,0.4), xlab=“X1”, ylab=“X2”, zlab=“Density”, clean=TRUE, alpha=0.9) title3d(“Excessive correlation (elongated, much less concentrated)”, line=2) widget2 <– rglwidget(width=450, top=450)
|