

{kind=link}
Giant language fashions (LLMs) carry out effectively on common duties however battle with specialised work that requires understanding proprietary knowledge, inside processes, and industry-specific terminology. Supervised fine-tuning (SFT) adapts LLMs to those organizational contexts. SFT could be applied by two distinct methodologies: Parameter-Environment friendly Wonderful-Tuning (PEFT), which updates solely a subset of mannequin parameters, providing sooner coaching and decrease computational prices whereas sustaining cheap efficiency enhancements; Full-rank SFT, which updates all mannequin parameters moderately than a subset and incorporates extra area information than PEFT.
Full-rank SFT typically faces a problem: catastrophic forgetting. As fashions be taught domain-specific patterns, they lose common capabilities together with instruction-following, reasoning, and broad information. Organizations should select between area experience and common intelligence, which limits mannequin utility throughout enterprise use instances.
Amazon Nova Forge addresses the issue. Nova Forge is a brand new service that you need to use to construct your individual frontier fashions utilizing Nova. Nova Forge clients can begin their improvement from early mannequin checkpoints, mix proprietary knowledge with Amazon Nova-curated coaching knowledge, and host their customized fashions securely on AWS.
On this put up, we share outcomes from the AWS China Utilized Science crew’s complete analysis of Nova Forge utilizing a difficult Voice of Buyer (VOC) classification activity, benchmarked in opposition to open-source fashions. Working with over 16,000 buyer remark samples throughout a posh four-level label hierarchy containing 1,420 leaf classes, we exhibit how Nova Forge’s knowledge mixing strategy supplies two benefits:
- In-domain activity efficiency positive factors: attaining 17% F1 rating enhancements
- Preserved common capabilities: sustaining near-baseline MMLU (Huge Multitask Language Understanding) scores and instruction-following talents post-finetuning
The problem: real-world buyer suggestions classification
Contemplate a typical state of affairs at a big ecommerce firm. The shopper expertise crew receives 1000’s of buyer feedback every day with detailed suggestions spanning product high quality, supply experiences, cost points, web site usability, and customer support interactions. To function effectively, they want an LLM that may mechanically classify every remark into actionable classes with excessive precision. Every classification should be particular sufficient to route the difficulty to the fitting crew: logistics, finance, improvement, or customer support, and set off the suitable workflow. This requires area specialization.
Nevertheless, this similar LLM doesn’t function in isolation. Throughout your group, groups want the mannequin to:
- Generate customer-facing responses that require common communication abilities
- Carry out knowledge evaluation requiring mathematical and logical reasoning
- Draft documentation following particular formatting pointers
This requires broad common capabilities—instruction-following, reasoning, information throughout domains, and conversational fluency.
Analysis methodology
Take a look at overview
To check whether or not Nova Forge can ship each area specialization and common capabilities, we designed a dual-evaluation framework measuring efficiency throughout two dimensions.
For domain-specific efficiency, we use a real-world Voice of Buyer (VOC) dataset derived from precise buyer critiques. The dataset accommodates 14,511 coaching samples and 861 check samples, reflecting production-scale enterprise knowledge. The dataset employs a four-level taxonomy the place Degree 4 represents the leaf classes (closing classification targets). Every class features a descriptive clarification of its scope. Instance classes:
| Degree 1 | Degree 2 | Degree 3 | Degree 4 (leaf class) |
| Set up – app configuration | Preliminary setup steerage | Setup course of | Straightforward setup expertise: Set up course of traits and complexity stage |
| Utilization – {hardware} expertise | Night time imaginative and prescient efficiency | Low-light Picture high quality | Night time imaginative and prescient readability: Night time imaginative and prescient mode produces photos in low-light or darkish situations |
| Utilization – {hardware} expertise | Pan-tilt-zoom performance | Rotation functionality | 360-degree rotation: The digicam can rotate a full 360 levels, offering full panoramic protection |
| After-sales coverage and price | Return and alternate coverage | Return course of execution | Product return accomplished: Buyer initiated and accomplished product return as a consequence of performance points |
The dataset reveals excessive class imbalance typical of real-world buyer suggestions environments. The next picture shows the category distribution:
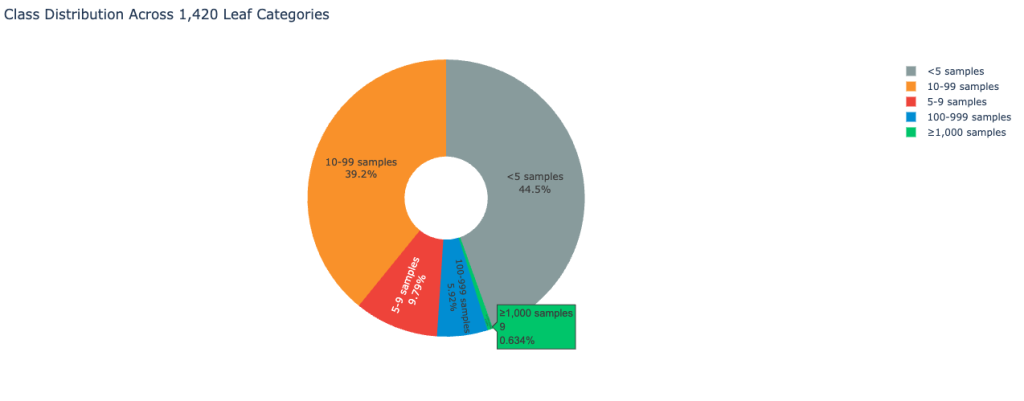
Because of this, the dataset locations a big problem on classification accuracy.
For evaluating general-purpose capabilities, we use the general public check set cut up of the MMLU (Huge Multitask Language Understanding) benchmark (all subsets). The check spans topics within the humanities, social sciences, exhausting sciences, and different areas which can be necessary for some folks to be taught. On this put up, MMLU serves as a proxy for common functionality retention. We use it to measure whether or not supervised fine-tuning improves area efficiency at the price of degrading foundational mannequin behaviors, and to evaluate the effectiveness of Nova knowledge mixing in mitigating catastrophic forgetting.
| Merchandise | Description |
| Whole samples | 15,372 buyer critiques |
| Label hierarchy | 4-level classification, 1,420 classes in whole |
| Coaching set | 14,511 samples |
| Take a look at set | 861 samples |
| MMLU Benchmark all (check cut up) | 14,000 samples |
In-domain activity analysis: voice of buyer classification
To know how Nova Forge performs in actual enterprise eventualities, we first consider mannequin accuracy on the VOC classification activity earlier than and after supervised fine-tuning. With this strategy, we are able to quantify area adaptation positive factors whereas establishing a baseline for subsequent robustness evaluation.
Base mannequin analysis
We start with a base mannequin analysis to evaluate out-of-the-box efficiency on the VOC classification activity with none task-specific fine-tuning. This setup establishes every mannequin’s inherent functionality to deal with extremely granular classification beneath strict output format constraints. The next immediate is used for the VOC classification activity:
# Function Definition
You're a rigorous buyer expertise classification system. Your sole accountability is to map person suggestions to the present label taxonomy at Degree 1 by Degree 4 (L1–L4). It's essential to strictly comply with the predefined taxonomy construction and should not create, modify, or infer any new labels.
## Working Rules
### 1. Strict taxonomy alignment
All classifications should be absolutely grounded within the supplied label taxonomy and strictly adhere to its hierarchical construction.
### 2. Suggestions decomposition utilizing MECE ideas
A single piece of person suggestions could include one or a number of points. It's essential to rigorously analyze all points described and decompose the suggestions into a number of non-overlapping segments, following the MECE (Mutually Unique, Collectively Exhaustive) precept:
- **Semantic singularity**: Every phase describes just one difficulty, perform, service, or touchpoint (for instance, pricing, efficiency, or UI).
- **Independence**: Segments should not overlap in that means.
- **Full protection**: All info within the authentic suggestions should be preserved with out omission.
### 3. No taxonomy growth
It's essential to not invent, infer, or modify any labels or taxonomy ranges.
## Label Taxonomy
The next part supplies the label taxonomy: {tag class}. Use this taxonomy to carry out L1–L4 classification for the unique VOC suggestions. No taxonomy growth is allowed.
## Process Directions
You may be given a bit of person suggestions: {person remark}. Customers could come from completely different areas and use completely different languages. It's essential to precisely perceive the person's language and intent earlier than assigning labels.
Confer with the supplied examples for the anticipated labeling format.
## Output Format
Return the classification leads to JSON format solely. For every suggestions phase, output the unique textual content together with the corresponding L1–L4 labels and sentiment. Don't generate or rewrite content material.
```json
[
{
"content": "
"L1": "
"L2": "
"L3": "
"L4": "
"emotion": "
}
]
```
For base mannequin analysis, we chosen:
| Mannequin | Precision | Recall | F1-Rating |
| Nova 2 Lite | 0.4596 | 0.3627 | 0.387 |
| Qwen3-30B-A3B | 0.4567 | 0.3864 | 0.394 |
The F1-scores reveal that Nova 2 Lite and Qwen3-30B-A3B exhibit comparable efficiency on this domain-specific activity, with each fashions attaining F1-scores close to 0.39. These outcomes additionally spotlight the inherent problem of the duty: even robust basis fashions battle with fine-grained label classification when no domain-specific knowledge is supplied.
Supervised fine-tuning
We then apply full-parameter supervised fine-tuning (SFT) utilizing buyer VOC knowledge. All fashions are fine-tuned utilizing the identical dataset and comparable coaching configurations for a good comparability.
Coaching infrastructure:
In area activity efficiency comparability
| Mannequin | Coaching Information | Precision | Recall | F1-Rating |
| Nova 2 Lite | None (baseline) | 0.4596 | 0.3627 | 0.387 |
| Nova 2 Lite | Buyer knowledge solely | 0.6048 | 0.5266 | 0.5537 |
| Qwen3-30B | Buyer knowledge solely | 0.5933 | 0.5333 | 0.5552 |
After fine-tuning on buyer knowledge alone, Nova 2 Lite achieves a considerable efficiency enchancment, with F1 rising from 0.387 to 0.5537—an absolute achieve of 17 factors. This end result locations the Nova mannequin within the prime tier for this activity and makes its efficiency akin to that of the fine-tuned Qwen3-30B open-source mannequin. These outcomes affirm the effectiveness of Nova full-parameter SFT for advanced enterprise classification workloads.
Common capabilities analysis: MMLU benchmark
Fashions fine-tuned for VOC classification are sometimes deployed past a single activity and built-in into broader enterprise workflows. Preserving general-purpose capabilities is necessary. Business-standard benchmarks reminiscent of MMLU present an efficient mechanism for evaluating general-purpose capabilities and detecting catastrophic forgetting in fine-tuned fashions.
For the fine-tuned Nova mannequin, Amazon SageMaker HyperPod presents out-of-the-box analysis recipes that streamline MMLU analysis with minimal configuration.
| Mannequin | Coaching knowledge | VOC F1-Rating | MMLU accuracy |
| Nova 2 Lite | None (baseline) | 0.38 | 0.75 |
| Nova 2 Lite | Buyer knowledge solely | 0.55 | 0.47 |
| Nova 2 Lite | 75% buyer + 25% Nova knowledge | 0.5 | 0.74 |
| Qwen3-30B | Buyer knowledge solely | 0.55 | 0.0038 |
When Nova 2 Lite is fine-tuned utilizing buyer knowledge solely, we observe a important drop in MMLU accuracy from 0.75 to 0.47, indicating the lack of general-purpose capabilities. The degradation is much more pronounced for the Qwen mannequin, which largely loses instruction-following capacity after fine-tuning. An instance of Qwen mannequin degraded output:
{
"prediction": "[n {n "content": "x^5 + 3x^3 + x^2 + 2x in Z_5",n "A": "0",n "B": "1",n "C": "0,1",n "D": "0,4",n "emotion": "neutral"n }n]"
}This habits can also be associated to the VOC immediate design, the place class information is internalized by supervised fine-tuning—a standard strategy in large-scale classification techniques.
Notably, when Nova knowledge mixing is utilized throughout fine-tuning, Nova 2 Lite retains near-baseline common efficiency. MMLU accuracy stays at 0.74, solely 0.01 beneath the unique baseline, whereas VOC F1 nonetheless improves by 12 factors (0.38 → 0.50). This validates that Nova knowledge mixing is a sensible and efficient mechanism for mitigating catastrophic forgetting whereas preserving area efficiency.
Key findings and sensible suggestions
This analysis reveals that when the bottom mannequin supplies a robust basis, full-parameter supervised fine-tuning on Amazon Nova Forge can ship substantial positive factors for advanced enterprise classification duties. On the similar time, the outcomes affirm that catastrophic forgetting is an actual concern in manufacturing fine-tuning workflows. Wonderful-tuning on buyer knowledge alone can degrade general-purpose capabilities reminiscent of instruction following and reasoning, limiting a mannequin’s usability throughout broader enterprise eventualities.
The knowledge mixing functionality of Nova Forge supplies an efficient mitigation technique. By mixing buyer knowledge with Nova-curated datasets throughout fine-tuning, groups can protect near-baseline common capabilities whereas persevering with to realize robust domain-specific efficiency.
Primarily based on these findings, we advocate the next practices when utilizing Nova Forge:
- Use supervised fine-tuning to maximise in-domain efficiency for advanced or extremely custom-made duties.
- Apply Nova knowledge mixing when fashions are anticipated to help a number of general-purpose workflows in manufacturing, to cut back the danger of catastrophic forgetting.
Collectively, these practices assist stability mannequin customization with manufacturing robustness, enabling extra dependable deployment of fine-tuned fashions in enterprise environments.

Conclusion
On this put up, we demonstrated how organizations can construct specialised AI fashions with out sacrificing common intelligence with Nova Forge knowledge mixing capabilities. Relying in your use instances and enterprise aims, Nova Forge can ship different advantages, together with entry checkpoints throughout all phases of mannequin improvement and performing reinforcement studying with reward features in your atmosphere. To get began along with your experiments, see the Nova Forge Developer Information for detailed documentation.
In regards to the authors
 Yuan Wei is an Utilized Scientist at Amazon Internet Providers, working with enterprise clients on proof-of-concepts and technical advisory. She focuses on giant language fashions and vision-language fashions, with a concentrate on evaluating rising strategies beneath real-world knowledge, value, and system constraints.
Yuan Wei is an Utilized Scientist at Amazon Internet Providers, working with enterprise clients on proof-of-concepts and technical advisory. She focuses on giant language fashions and vision-language fashions, with a concentrate on evaluating rising strategies beneath real-world knowledge, value, and system constraints.
 Xin Hao is a Senior AI/ML Go-to-Market Specialist at AWS, serving to clients obtain success with Amazon Nova fashions and associated Generative AI options. He has in depth hands-on expertise in cloud computing, AI/ML, and Generative AI. Previous to becoming a member of AWS, Xin spent over 10 years within the industrial manufacturing sector, together with industrial automation and CNC machining.
Xin Hao is a Senior AI/ML Go-to-Market Specialist at AWS, serving to clients obtain success with Amazon Nova fashions and associated Generative AI options. He has in depth hands-on expertise in cloud computing, AI/ML, and Generative AI. Previous to becoming a member of AWS, Xin spent over 10 years within the industrial manufacturing sector, together with industrial automation and CNC machining.
 Sharon Li is an AI/ML Specialist Options Architect at Amazon Internet Providers (AWS) based mostly in Boston, Massachusetts. With a ardour for leveraging cutting-edge know-how, Sharon is on the forefront of creating and deploying progressive generative AI options on the AWS cloud platform.
Sharon Li is an AI/ML Specialist Options Architect at Amazon Internet Providers (AWS) based mostly in Boston, Massachusetts. With a ardour for leveraging cutting-edge know-how, Sharon is on the forefront of creating and deploying progressive generative AI options on the AWS cloud platform.