

{kind=link}
Coaching a contemporary giant language mannequin (LLM) just isn’t a single step however a rigorously orchestrated pipeline that transforms uncooked knowledge right into a dependable, aligned, and deployable clever system. At its core lies pretraining, the foundational section the place fashions be taught basic language patterns, reasoning constructions, and world data from huge textual content corpora. That is adopted by supervised fine-tuning (SFT), the place curated datasets form the mannequin’s conduct towards particular duties and directions. To make adaptation extra environment friendly, methods like LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) allow parameter-efficient fine-tuning with out retraining all the mannequin.
Alignment layers similar to RLHF (Reinforcement Studying from Human Suggestions) additional refine outputs to match human preferences, security expectations, and usefulness requirements. Extra lately, reasoning-focused optimizations like GRPO (Group Relative Coverage Optimization) have emerged to boost structured pondering and multi-step drawback fixing. Lastly, all of this culminates in deployment, the place fashions are optimized, scaled, and built-in into real-world programs. Collectively, these levels kind the trendy LLM coaching pipeline—an evolving, multi-layered course of that determines not simply what a mannequin is aware of, however the way it thinks, behaves, and delivers worth in manufacturing environments.
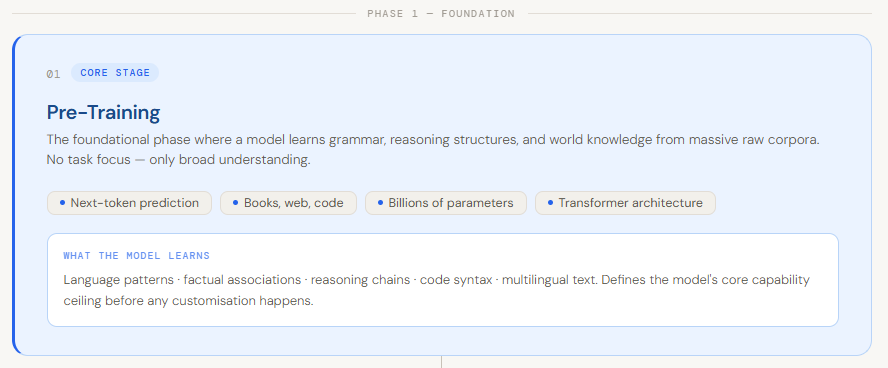
Pre-Coaching
Pretraining is the primary and most foundational stage in constructing a big language mannequin. It’s the place a mannequin learns the fundamentals of language—grammar, context, reasoning patterns, and basic world data—by coaching on huge quantities of uncooked knowledge like books, web sites, and code. As a substitute of specializing in a particular process, the objective right here is broad understanding. The mannequin learns patterns similar to predicting the following phrase in a sentence or filling in lacking phrases, which helps it generate significant and coherent textual content in a while. This stage primarily turns a random neural community into one thing that “understands” language at a basic stage .
What makes pretraining particularly vital is that it defines the mannequin’s core capabilities earlier than any customization occurs. Whereas later levels like fine-tuning adapt the mannequin for particular use circumstances, they construct on high of what was already realized throughout pretraining. Though the precise definition of “pretraining” can fluctuate—typically together with newer methods like instruction-based studying or artificial knowledge—the core thought stays the identical: it’s the section the place the mannequin develops its basic intelligence. With out sturdy pretraining, all the things that follows turns into a lot much less efficient.
Supervised Finetuning
Supervised Tremendous-Tuning (SFT) is the stage the place a pre-trained LLM is customized to carry out particular duties utilizing high-quality, labeled knowledge. As a substitute of studying from uncooked, unstructured textual content like in pretraining, the mannequin is skilled on rigorously curated enter–output pairs which were validated beforehand. This enables the mannequin to regulate its weights based mostly on the distinction between its predictions and the right solutions, serving to it align with particular targets, enterprise guidelines, or communication kinds. In easy phrases, whereas pretraining teaches the mannequin how language works, SFT teaches it the right way to behave in real-world use circumstances.
This course of makes the mannequin extra correct, dependable, and context-aware for a given process. It might probably incorporate domain-specific data, comply with structured directions, and generate responses that match desired tone or format. For instance, a basic pre-trained mannequin may reply to a consumer question like:
“I can’t log into my account. What ought to I do?” with a brief reply like:
“Strive resetting your password.”
After supervised fine-tuning with buyer assist knowledge, the identical mannequin might reply with:
“I’m sorry you’re dealing with this difficulty. You may strive resetting your password utilizing the ‘Forgot Password’ possibility. If the issue persists, please contact our assist crew at [email protected]—we’re right here to assist.”
Right here, the mannequin has realized empathy, construction, and useful steering from labeled examples. That’s the ability of SFT—it transforms a generic language mannequin right into a task-specific assistant that behaves precisely the best way you need.

LoRA
LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning method designed to adapt giant language fashions with out retraining all the community. As a substitute of updating all of the mannequin’s weights—which is extraordinarily costly for fashions with billions of parameters—LoRA freezes the unique pre-trained weights and introduces small, trainable “low-rank” matrices into particular layers of the mannequin (usually inside the transformer structure). These matrices discover ways to modify the mannequin’s conduct for a particular process, drastically lowering the variety of trainable parameters, GPU reminiscence utilization, and coaching time, whereas nonetheless sustaining sturdy efficiency.
This makes LoRA particularly helpful in real-world situations the place deploying a number of absolutely fine-tuned fashions could be impractical. For instance, think about you need to adapt a big LLM for authorized doc summarization. With conventional fine-tuning, you would wish to retrain billions of parameters. With LoRA, you retain the bottom mannequin unchanged and solely prepare a small set of further matrices that “nudge” the mannequin towards legal-specific understanding. So, when given a immediate like:
“Summarize this contract clause…”
A base mannequin may produce a generic abstract, however a LoRA-adapted mannequin would generate a extra exact, domain-aware response utilizing authorized terminology and construction. In essence, LoRA enables you to specialize highly effective fashions effectively—with out the heavy price of full retraining.

QLoRA
QLoRA (Quantized Low-Rank Adaptation) is an extension of LoRA that makes fine-tuning much more memory-efficient by combining low-rank adaptation with mannequin quantization. As a substitute of maintaining the pre-trained mannequin in normal 16-bit or 32-bit precision, QLoRA compresses the mannequin weights right down to 4-bit precision. The bottom mannequin stays frozen on this compressed kind, and identical to LoRA, small trainable low-rank adapters are added on high. Throughout coaching, gradients movement by way of the quantized mannequin into these adapters, permitting the mannequin to be taught task-specific conduct whereas utilizing a fraction of the reminiscence required by conventional fine-tuning.
This strategy makes it attainable to fine-tune extraordinarily giant fashions—even these with tens of billions of parameters—on a single GPU, which was beforehand impractical. For instance, suppose you need to adapt a 65B parameter mannequin for a chatbot use case. With normal fine-tuning, this may require huge infrastructure. With QLoRA, the mannequin is first compressed to 4-bit, and solely the small adapter layers are skilled. So, when given a immediate like:
“Clarify quantum computing in easy phrases”
A base mannequin may give a generic clarification, however a QLoRA-tuned model can present a extra structured, simplified, and instruction-following response—tailor-made to your dataset—whereas operating effectively on restricted {hardware}. In brief, QLoRA brings large-scale mannequin fine-tuning inside attain by dramatically lowering reminiscence utilization with out sacrificing efficiency.
RLHF
Reinforcement Studying from Human Suggestions (RLHF) is a coaching stage used to align giant language fashions with human expectations of helpfulness, security, and high quality. After pretraining and supervised fine-tuning, a mannequin should produce outputs which can be technically appropriate however unhelpful, unsafe, or not aligned with consumer intent. RLHF addresses this by incorporating human judgment into the coaching loop—people overview and rank a number of mannequin responses, and this suggestions is used to coach a reward mannequin. The LLM is then additional optimized (generally utilizing algorithms like PPO) to generate responses that maximize this realized reward, successfully educating it what people want.
This strategy is particularly helpful for duties the place guidelines are laborious to outline mathematically—like being well mannered, humorous, or non-toxic—however simple for people to judge. For instance, given a immediate like:
“Inform me a joke about work”
A fundamental mannequin may generate one thing awkward and even inappropriate. However after RLHF, the mannequin learns to provide responses which can be extra participating, secure, and aligned with human style. Equally, for a delicate question, as an alternative of giving a blunt or dangerous reply, an RLHF-trained mannequin would reply extra responsibly and helpfully. In brief, RLHF bridges the hole between uncooked intelligence and real-world usability by shaping fashions to behave in methods people really worth.

Reasoning (GRPO)
Group Relative Coverage Optimization (GRPO) is a more recent reinforcement studying method designed particularly to enhance reasoning and multi-step problem-solving in giant language fashions. In contrast to conventional strategies like PPO that consider responses individually, GRPO works by producing a number of candidate responses for a similar immediate and evaluating them inside a gaggle. Every response is assigned a reward, and as an alternative of optimizing based mostly on absolute scores, the mannequin learns by understanding which responses are higher relative to others. This makes coaching extra environment friendly and higher suited to duties the place high quality is subjective—like reasoning, explanations, or step-by-step drawback fixing.
In apply, GRPO begins with a immediate (typically enhanced with directions like “assume step-by-step”), and the mannequin generates a number of attainable solutions. These solutions are then scored, and the mannequin updates itself based mostly on which of them carried out finest inside the group. For instance, given a immediate like:
“Remedy: If a prepare travels 60 km in 1 hour, how lengthy will it take to journey 180 km?”
A fundamental mannequin may soar to a solution straight, typically incorrectly. However a GRPO-trained mannequin is extra prone to produce structured reasoning like:
“Pace = 60 km/h. Time = Distance / Pace = 180 / 60 = 3 hours.”
By repeatedly studying from higher reasoning paths inside teams, GRPO helps fashions turn out to be extra constant, logical, and dependable in advanced duties—particularly the place step-by-step pondering issues.

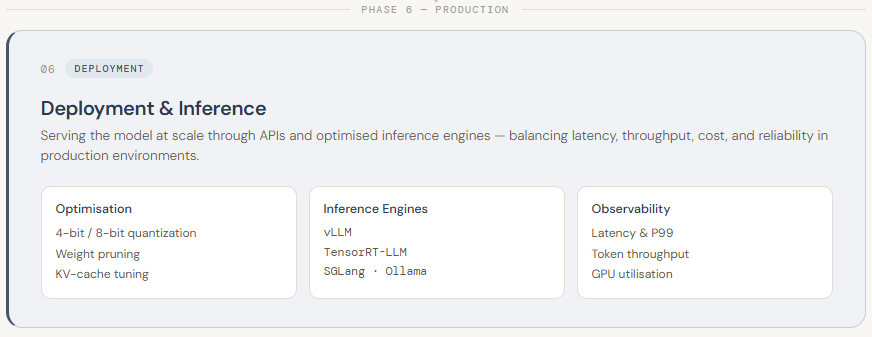
Deployment
LLM deployment is the ultimate stage of the pipeline, the place a skilled mannequin is built-in right into a real-world setting and made accessible for sensible use. This usually entails exposing the mannequin by way of APIs so purposes can work together with it in actual time. In contrast to earlier levels, deployment is much less about coaching and extra about efficiency, scalability, and reliability. Since LLMs are giant and resource-intensive, deploying them requires cautious infrastructure planning—similar to utilizing high-performance GPUs, managing reminiscence effectively, and guaranteeing low-latency responses for customers.
To make deployment environment friendly, a number of optimization and serving methods are used. Fashions are sometimes quantized (e.g., diminished from 16-bit to 4-bit precision) to decrease reminiscence utilization and pace up inference. Specialised inference engines like vLLM, TensorRT-LLM, and SGLang assist maximize throughput and scale back latency. Deployment could be carried out by way of cloud-based APIs (like managed companies on AWS/GCP) or self-hosted setups utilizing instruments similar to Ollama or BentoML for extra management over privateness and price. On high of this, programs are constructed to observe efficiency (latency, GPU utilization, token throughput) and routinely scale sources based mostly on demand. In essence, deployment is about turning a skilled LLM into a quick, dependable, and production-ready system that may serve customers at scale.

I’m a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I’ve a eager curiosity in Information Science, particularly Neural Networks and their utility in varied areas.