
 I Constructed an AI Assistant")
{kind=link}
# Introduction
It began with a Tuesday that fully obtained away from me. I had three shopper briefs to summarize, a backlog of analysis tabs I stored promising myself I would get to, just a few emails that wanted considerate replies, and a half-written technical doc sitting open in a single tab for the higher a part of 4 days. By the point I appeared up from context-switching between all of it, it was previous 7 PM and I would shipped nearly nothing significant.
That night, as a substitute of closing my laptop computer and calling it a loss, I began serious about the issue otherwise. I wasn’t quick on time. I used to be quick on leverage. Each job I did that day had a model of it I may have delegated to one thing smarter than a browser bookmark. So I began constructing.
This text is an sincere account of that course of: why I constructed a customized AI assistant as a substitute of simply paying for one, what the structure seems to be like, the precise code, what broke, and what it does now that I genuinely depend on.
# The “Why” Comes Earlier than the “How”
Most individuals who resolve to construct an AI assistant begin by Googling “Python LangChain tutorial.” That is backwards. The primary query value sitting with is: why construct it in any respect when Siri, ChatGPT, Copilot, and a dozen different instruments exist already?
The sincere reply for me was management. Not in a paranoid, off-grid means, however within the sensible sense that each off-the-shelf assistant is designed round another person’s assumptions about what you want. They’re general-purpose by design, and general-purpose means compromises. I wished one thing that knew my context, used my tone, related to my particular instruments, and stayed inside a workflow I already trusted.
There’s additionally the info query. Once you use a third-party assistant, your prompts and context undergo their infrastructure. For private productiveness that is arguably positive. For something client-related or commercially delicate, it will get murkier. Constructing your personal means you resolve the place the info lives.
After which there’s the educational curve argument, which I feel will get undersold: you perceive a software much better while you construct it your self. When one thing breaks, the place to look. Once you need it to do one thing new, you do not look ahead to a product replace.
The timing additionally made the choice simpler to justify. Based on MarketsandMarkets, the AI assistant market is projected to develop from $3.35 billion in 2025 to $21.11 billion by 2030 — a 44.5% compound annual development charge. That form of trajectory tells you this expertise is not a pattern. It is infrastructure. Getting fluent in it now, by constructing fairly than simply consuming, places you forward of the place most individuals might be in two years.
That mentioned, constructing is just not at all times the suitable name. In case you want a fast reply engine or a writing help that prices $20/month, purchase it. However if you’d like one thing that integrates along with your precise workflow, learns out of your preferences, and handles duties in a means that is particular to how you’re employed, that is value constructing.
# Selecting the Stack
As soon as I dedicated to constructing, the subsequent choice was what to construct it with. Here is what I really thought-about, not a generic comparability chart.
- The LLM selection got here down to 2 critical choices: OpenAI’s GPT-4o and Anthropic’s Claude. I examined each with the identical prompts throughout analysis, writing, and reasoning duties. GPT-4o is quick and broadly succesful with a mature API. Claude handles lengthy paperwork and nuanced instruction-following notably effectively. I ended up going with GPT-4o as the first mannequin due to its tool-calling reliability and the maturity of its ecosystem, with Claude accessible as a fallback for sure document-heavy duties.
- For orchestration, I selected LangChain. There is a honest quantity of debate in developer circles about whether or not LangChain provides an excessive amount of abstraction, and that criticism is not with out advantage. However for a undertaking like this — one which wants reminiscence, software use, and a reasoning loop — LangChain’s abstractions save actual time. The choice is writing that plumbing your self, which you are able to do, however it’s not the place your consideration is finest spent while you’re attempting to ship one thing practical.
- Reminiscence was a requirement from day one. A stateless chatbot that forgets every thing between classes is helpful for one-off questions. It isn’t helpful for a real assistant. LangChain’s
ConversationBufferMemorylabored positive for in-session context. For persistence throughout classes, I used a easy SQLite-backed strategy, which I will present within the code part. - For instruments, I gave the assistant the flexibility to look the net (through DuckDuckGo’s API — no key required), learn and summarize information I cross it, and name customized Python features I’ve written for particular recurring duties. That is the place the actual worth lives: turning it from a chatbot into one thing that may really do issues.
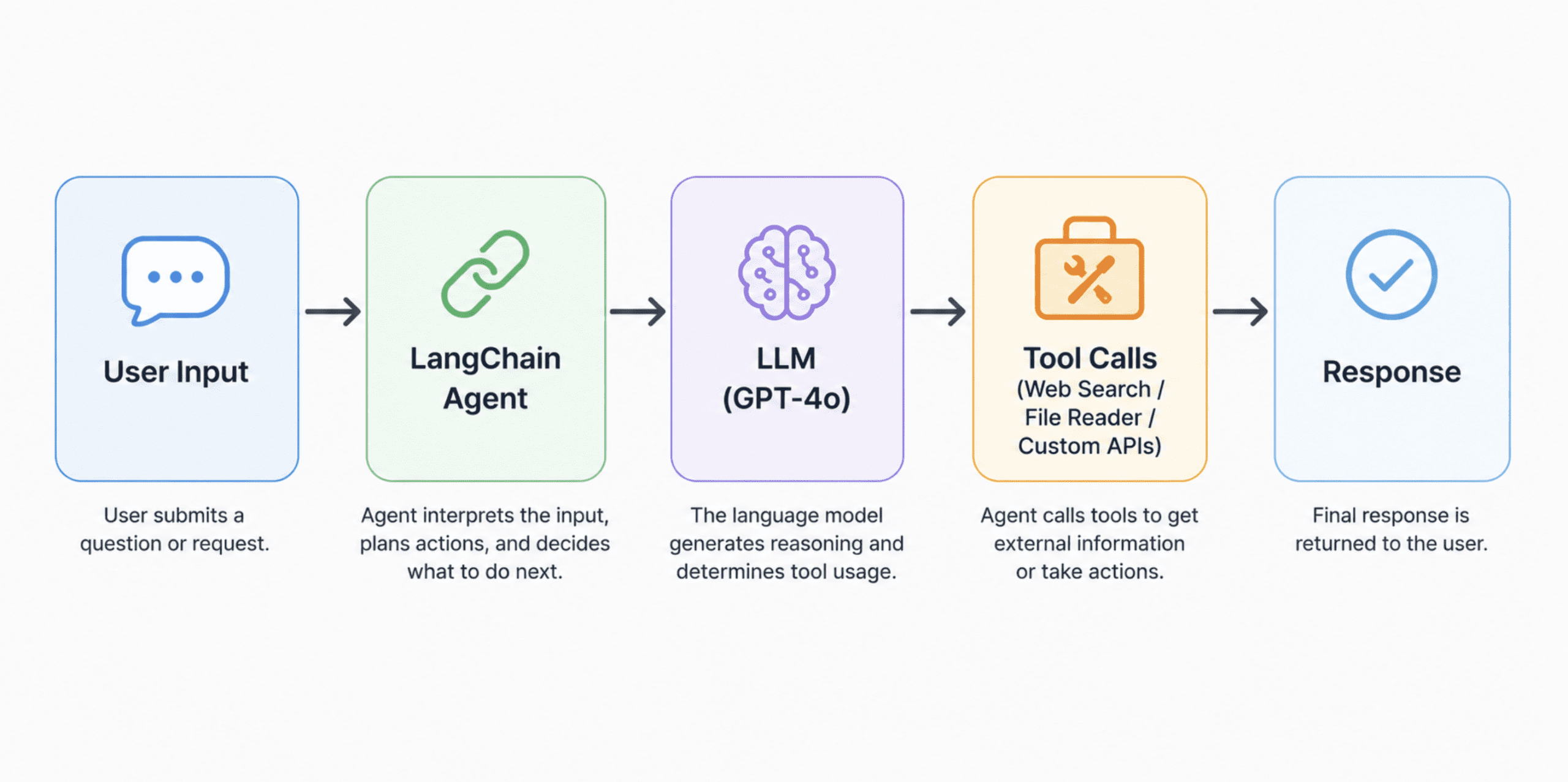
A clear horizontal structure move diagram of the stack
# Setting Up the Atmosphere
Earlier than any code runs, you want three issues so as: Python 3.10 or increased, a digital setting, and your API keys saved safely.
Step 1: Creating and Activating a Digital Atmosphere
# Create a digital setting named 'assistant_env'
python -m venv assistant_env
# Activate it on macOS/Linux
supply assistant_env/bin/activate
# Activate it on Home windows
assistant_envScriptsactivate
A digital setting retains your undertaking’s dependencies remoted from every thing else in your machine. This issues greater than it sounds — dependency conflicts between initiatives are a standard, silent supply of bugs.
Step 2: Putting in the Required Packages
pip set up langchain==0.3.0
langchain-openai
langchain-community
langgraph
duckduckgo-search
python-dotenv
pydantic
requests
Here is what every bundle is doing:
langchainis the core framework that connects your LLM, reminiscence, and instruments.langchain-openaiis the particular connector for OpenAI’s fashions.langchain-communityprovides you entry to community-built instruments and integrations, together with DuckDuckGo search.langgraphhandles extra advanced, stateful agent workflows.duckduckgo-searchlets the assistant search the net while not having an API key.python-dotenvhundreds your API keys from a.envfile as a substitute of hardcoding them.pydantichandles information validation for structured inputs and outputs.
Step 3: Storing Your API Keys Securely
By no means hardcode an API key straight into your script. Create a .env file in your undertaking root:
# .env file -- by no means commit this to model management
OPENAI_API_KEY=your_openai_key_here
Then add .env to your .gitignore file instantly:
# .gitignore
.env
assistant_env/
__pycache__/
# Constructing the Core Assistant
That is the place it comes collectively. I will stroll by means of every element within the order it must be constructed.
- Connecting to the LLM
# assistant.py import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI # Load setting variables from the .env file load_dotenv() # Initialize the language mannequin # temperature controls randomness: 0 = centered and deterministic, 1 = extra artistic # For an assistant that must be correct and constant, maintain this low (0.1 to 0.3) llm = ChatOpenAI( mannequin="gpt-4o", temperature=0.2, api_key=os.getenv("OPENAI_API_KEY") )What this does:
ChatOpenAIcreates a connection to GPT-4o by means of the API. Thetemperatureparameter is value understanding: at 0, the mannequin at all times picks essentially the most possible subsequent token, which produces very constant however typically inflexible output. At 1, it is far more diverse and inventive. For a task-focused assistant, staying between 0.1 and 0.3 provides you reliability with out shedding all of the pure language high quality. - Designing the System Immediate
The system immediate is essentially the most underrated a part of the entire construct. It defines your assistant’s persona, its constraints, and the way it handles ambiguous conditions. Spend extra time right here than you suppose you should.
# The system immediate acts as your assistant's standing directions. # It is despatched firstly of each dialog to anchor its conduct. SYSTEM_PROMPT = """ You're a centered, dependable private assistant. Your job is to assist the consumer analysis subjects, summarize paperwork, draft written content material, and deal with structured duties. You at all times: - Give direct solutions earlier than elaborating - Say while you're uncertain fairly than guessing - Ask for clarification if a job is genuinely ambiguous - Hold responses concise except element is explicitly requested You might have entry to internet search and might learn information the consumer gives. When utilizing these instruments, at all times cite the place you bought your data. Don't make up details, invent citations, or fill gaps with plausible-sounding fiction. """What this does: This immediate is distributed forward of each dialog. Consider it because the job description you’d give a human assistant on their first day. The extra particular it’s, the much less you may must right the mannequin mid-conversation. Obscure directions produce imprecise conduct, each time.
- Including Reminiscence
With out reminiscence, your assistant forgets every thing the second you begin a brand new message. That is the way you repair that.
from langchain.reminiscence import ConversationBufferMemory from langchain_community.chat_message_histories import SQLChatMessageHistory # SQLChatMessageHistory shops dialog historical past in an area SQLite database. # The session_id allows you to preserve separate reminiscence threads (e.g. one per undertaking). message_history = SQLChatMessageHistory( session_id="main_session", connection_string="sqlite:///assistant_memory.db" ) # ConversationBufferMemory wraps the message historical past and feeds it to the LLM # on every flip so the mannequin is aware of what was mentioned earlier than. reminiscence = ConversationBufferMemory( memory_key="chat_history", chat_memory=message_history, return_messages=True )What this does:
SQLChatMessageHistorysaves each alternate to an area SQLite file known asassistant_memory.db. This implies your assistant remembers context between classes. Thesession_idis only a label — you possibly can create a number of classes for various initiatives or subjects, they usually keep fully separate from one another.One caveat: buffer reminiscence shops the complete historical past and can finally hit the mannequin’s context restrict on lengthy conversations. For manufacturing use,
ConversationSummaryMemoryis a better option — it compresses older historical past right into a abstract so that you keep inside token limits. - Giving It Instruments
That is what separates a chatbot from an assistant. Instruments let the mannequin take actual actions.
from langchain.brokers import AgentExecutor, create_openai_tools_agent from langchain_community.instruments import DuckDuckGoSearchRun from langchain.instruments import software from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder # Instrument 1: Net search through DuckDuckGo -- no API key required search_tool = DuckDuckGoSearchRun() # Instrument 2: A customized file reader you outline your self # The @software decorator registers this operate as one thing the agent can name @software def read_file(file_path: str) -> str: """ Reads a textual content file from the given path and returns its contents. Use this when the consumer asks you to learn, analyze, or summarize a file. """ attempt: with open(file_path, "r", encoding="utf-8") as f: return f.learn() besides FileNotFoundError: return f"File not discovered: {file_path}" besides Exception as e: return f"Error studying file: {str(e)}" # Register the instruments the agent can use instruments = [search_tool, read_file] # Construct the immediate template # MessagesPlaceholder slots within the reminiscence (chat historical past) and the agent's scratchpad immediate = ChatPromptTemplate.from_messages([ ("system", SYSTEM_PROMPT), MessagesPlaceholder(variable_name="chat_history"), ("human", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad") ]) # Create the agent -- this combines the LLM, the instruments, and the immediate agent = create_openai_tools_agent(llm, instruments, immediate) # AgentExecutor is the runtime loop: it calls the agent, runs any instruments it selects, # feeds the outcomes again, and repeats till it has a last reply agent_executor = AgentExecutor( agent=agent, instruments=instruments, reminiscence=reminiscence, verbose=True, # Set to False in manufacturing; True allows you to see the reasoning steps max_iterations=5 # Prevents the agent from working in circles on exhausting issues )What this does: The
AgentExecutoris the engine. Once you ship it a message, it does not simply cross it to the LLM and return no matter comes again. It runs a loop: the mannequin decides whether or not it wants to make use of a software, calls the software if that’s the case, will get the outcome, thinks about what to do subsequent, and solely returns a last reply when it is glad. That is the ReAct (Reasoning + Appearing) sample in follow.
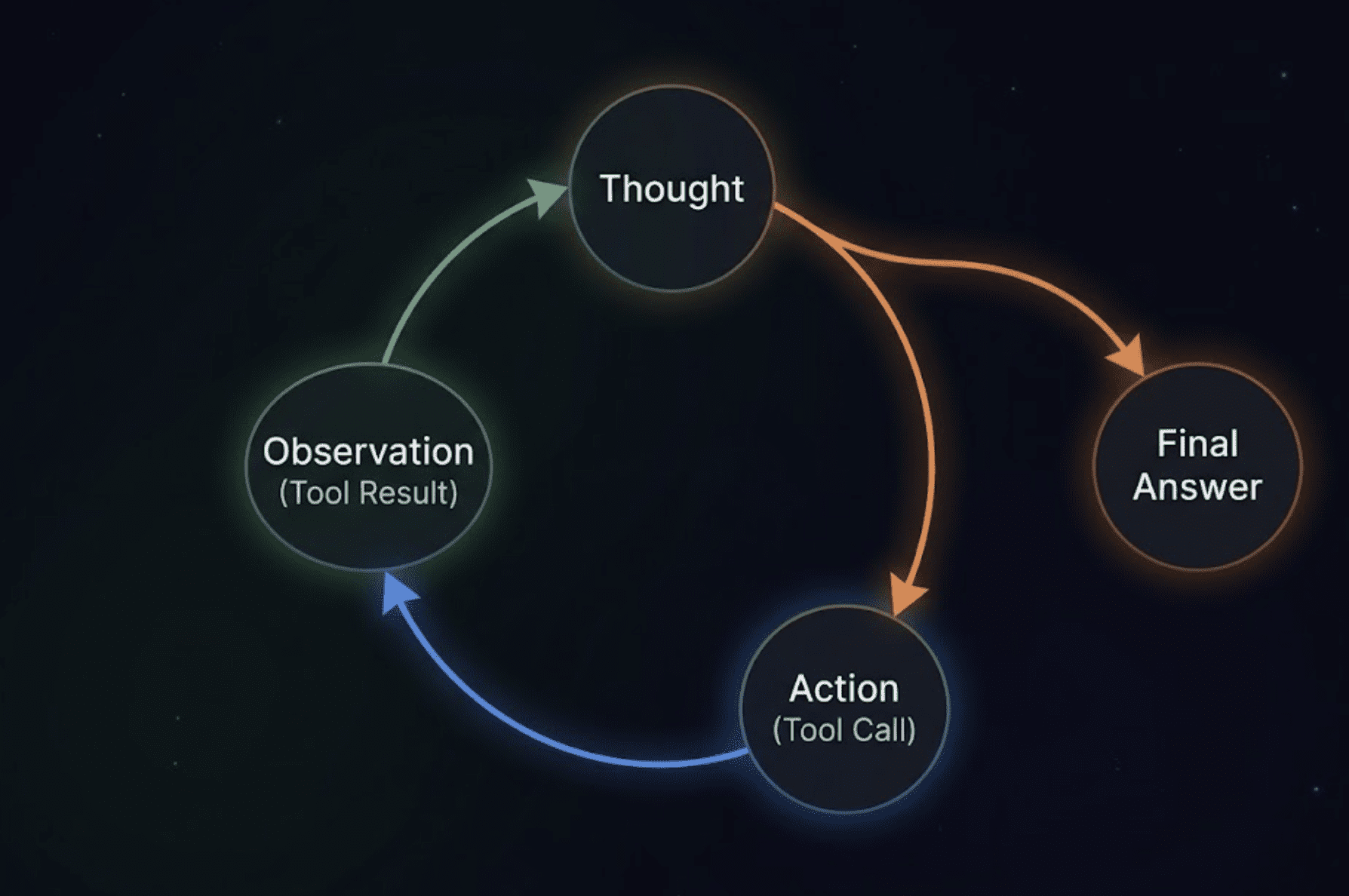
A round loop diagram displaying 4 labeled levels related by arrows
Placing all of it collectively, the primary run loop:
def chat(user_input: str) -> str:
"""
Ship a message to the assistant and get a response.
Reminiscence is dealt with routinely by the agent_executor.
"""
attempt:
response = agent_executor.invoke({"enter": user_input})
return response["output"]
besides Exception as e:
# Sleek error dealing with -- tells you what broke with out crashing the session
return f"One thing went incorrect: {str(e)}. Please attempt once more or rephrase your request."
# Easy command-line interface to run the assistant
if __name__ == "__main__":
print("Assistant prepared. Sort 'stop' to exit.n")
whereas True:
user_input = enter("You: ").strip()
if user_input.decrease() in ["quit", "exit", "q"]:
print("Goodbye.")
break
if not user_input:
proceed
response = chat(user_input)
print(f"nAssistant: {response}n")
What this does: The chat() operate is the one entry level for the entire system. You cross it a string, it handles every thing — reminiscence retrieval, software calls, LLM reasoning, error dealing with — and returns a string. The if __name__ == "__main__" block turns the entire script right into a working command-line assistant you possibly can run instantly with python assistant.py.
# Testing and Fixing What Breaks
The primary time I ran this, the assistant gave a assured reply that was factually incorrect, ignored a software it ought to have used, and formatted a response in a means I hated. None of that’s uncommon. It isn’t an indication the construct is damaged — it is the beginning of the actual work.
Crucial factor to check early is whether or not the agent really makes use of its instruments when it ought to. A standard failure mode is the mannequin attempting to reply from reminiscence when it must be looking, as a result of the system immediate did not make the expectation express sufficient. I mounted this by including to the system immediate:
When answering questions on latest occasions, present information, or something
time-sensitive, at all times use the net search software. Don't depend on your
coaching data for details which will have modified.
On error dealing with: this issues greater than most tutorials let on. Based on analysis from Mordor Intelligence, almost half of AI-generated code fails its first safety assessment. The identical precept applies to AI-generated responses — output must be handled as a draft, not a last reply, till you’ve got established belief in a specific kind of job. The attempt/besides block within the chat() operate above is a begin, however you may wish to develop it as you uncover the particular methods your assistant fails.
For extra structured testing, write check circumstances like this:
# test_assistant.py
# Run these to confirm the assistant behaves as anticipated earlier than deploying
test_cases = [
{
"input": "What is the current price of Bitcoin?",
"expected_behavior": "Should use web search, not answer from memory"
},
{
"input": "Summarize the file at /tmp/test_document.txt",
"expected_behavior": "Should call the read_file tool"
},
{
"input": "What did I ask you five messages ago?",
"expected_behavior": "Should reference conversation memory correctly"
}
]
for case in test_cases:
print(f"Testing: {case['input']}")
print(f"Anticipated: {case['expected_behavior']}")
outcome = chat(case["input"])
print(f"Bought: {outcome[:200]}...") # Print first 200 characters of response
print("---")
Run these after any change to the system immediate or software configuration. Small immediate adjustments usually have shocking downstream results.
# The Full Code
The whole lot above has been defined in items. Right here it’s as one full, copy-paste-ready file. Put it aside as assistant.py, ensure your .env file is in the identical listing, and run it with python assistant.py.
# assistant.py
# Full AI Assistant -- constructed with LangChain, GPT-4o, DuckDuckGo Search, and SQLite reminiscence
# Necessities: Python 3.10+ | Run: pip set up langchain==0.3.0 langchain-openai
# langchain-community langgraph duckduckgo-search python-dotenv pydantic requests
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.reminiscence import ConversationBufferMemory
from langchain_community.chat_message_histories import SQLChatMessageHistory
from langchain.brokers import AgentExecutor, create_openai_tools_agent
from langchain_community.instruments import DuckDuckGoSearchRun
from langchain.instruments import software
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# ──────────────────────────────────────────────
# 1. LOAD ENVIRONMENT VARIABLES
# ──────────────────────────────────────────────
# Reads OPENAI_API_KEY out of your .env file.
# By no means hardcode API keys straight in your supply code.
load_dotenv()
# ──────────────────────────────────────────────
# 2. INITIALIZE THE LANGUAGE MODEL
# ──────────────────────────────────────────────
# temperature=0.2 retains responses centered and constant.
# Increase it towards 1.0 if you'd like extra artistic, diverse output.
llm = ChatOpenAI(
mannequin="gpt-4o",
temperature=0.2,
api_key=os.getenv("OPENAI_API_KEY")
)
# ──────────────────────────────────────────────
# 3. DEFINE THE SYSTEM PROMPT
# ──────────────────────────────────────────────
# That is the assistant's standing instruction set.
# It shapes conduct on each single flip -- deal with it rigorously.
SYSTEM_PROMPT = """
You're a centered, dependable private assistant.
Your job is to assist the consumer analysis subjects, summarize paperwork,
draft written content material, and deal with structured duties. You at all times:
- Give direct solutions earlier than elaborating
- Say while you're uncertain fairly than guessing
- Ask for clarification if a job is genuinely ambiguous
- Hold responses concise except element is explicitly requested
You might have entry to internet search and might learn information the consumer gives.
When utilizing these instruments, at all times cite the place you bought your data.
When answering questions on latest occasions, present information, or something
time-sensitive, at all times use the net search software. Don't depend on your
coaching data for details which will have modified.
Don't make up details, invent citations, or fill gaps with plausible-sounding fiction.
"""
# ──────────────────────────────────────────────
# 4. SET UP PERSISTENT MEMORY
# ──────────────────────────────────────────────
# SQLChatMessageHistory saves dialog historical past to an area SQLite database.
# This implies the assistant remembers context throughout classes, not simply inside one.
# Change session_id to maintain separate reminiscence threads (e.g. one per undertaking).
message_history = SQLChatMessageHistory(
session_id="main_session",
connection_string="sqlite:///assistant_memory.db"
)
# ConversationBufferMemory wraps the message historical past and injects it
# into every immediate so the mannequin at all times has the complete dialog context.
# Observe: for very lengthy conversations, swap this for ConversationSummaryMemory
# to keep away from hitting the mannequin's token restrict.
reminiscence = ConversationBufferMemory(
memory_key="chat_history",
chat_memory=message_history,
return_messages=True
)
# ──────────────────────────────────────────────
# 5. DEFINE TOOLS
# ──────────────────────────────────────────────
# Instrument 1: Net search through DuckDuckGo -- no API key required
search_tool = DuckDuckGoSearchRun()
# Instrument 2: Customized file reader
# The @software decorator registers this Python operate as a callable software
# that the agent can invoke when the consumer asks it to learn a file.
@software
def read_file(file_path: str) -> str:
"""
Reads a textual content file from the given path and returns its contents.
Use this when the consumer asks you to learn, analyze, or summarize a file.
"""
attempt:
with open(file_path, "r", encoding="utf-8") as f:
return f.learn()
besides FileNotFoundError:
return f"File not discovered: {file_path}"
besides Exception as e:
return f"Error studying file: {str(e)}"
# Accumulate all instruments into a listing -- add extra customized instruments right here as you construct them
instruments = [search_tool, read_file]
# ──────────────────────────────────────────────
# 6. BUILD THE AGENT
# ──────────────────────────────────────────────
# The immediate template constructions each message despatched to the mannequin.
# MessagesPlaceholder slots within the reminiscence (chat_history) and the agent's
# inside reasoning scratchpad on every flip.
immediate = ChatPromptTemplate.from_messages([
("system", SYSTEM_PROMPT),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# create_openai_tools_agent wires collectively the LLM, the instruments, and the immediate
# right into a single agent that is aware of methods to resolve when and which instruments to name.
agent = create_openai_tools_agent(llm, instruments, immediate)
# AgentExecutor is the runtime loop.
# It calls the agent, runs any instruments it selects, feeds these outcomes again,
# and repeats till it reaches a last reply (or hits max_iterations).
agent_executor = AgentExecutor(
agent=agent,
instruments=instruments,
reminiscence=reminiscence,
verbose=True, # Set to False in manufacturing; True reveals the reasoning steps
max_iterations=5 # Prevents the agent from looping indefinitely on exhausting issues
)
# ──────────────────────────────────────────────
# 7. THE CHAT FUNCTION
# ──────────────────────────────────────────────
def chat(user_input: str) -> str:
"""
Ship a message to the assistant and get a response.
Reminiscence, software use, and error dealing with are all managed right here.
"""
attempt:
response = agent_executor.invoke({"enter": user_input})
return response["output"]
besides Exception as e:
# Returns a readable error message as a substitute of crashing the session.
# In manufacturing, log the complete exception right here for debugging.
return f"One thing went incorrect: {str(e)}. Please attempt once more or rephrase your request."
# ──────────────────────────────────────────────
# 8. COMMAND-LINE INTERFACE
# ──────────────────────────────────────────────
# Run this file straight to start out a command-line session: python assistant.py
# To wrap it in a browser UI as a substitute, see Gradio or Streamlit in Half 7.
if __name__ == "__main__":
print("Assistant prepared. Sort 'stop' to exit.n")
whereas True:
user_input = enter("You: ").strip()
if user_input.decrease() in ["quit", "exit", "q"]:
print("Goodbye.")
break
if not user_input:
proceed
response = chat(user_input)
print(f"nAssistant: {response}n")
// Outcomes
After about two weeks of standard use, this is what the assistant really handles for me now:
- Analysis synthesis: I give it a subject and three to 5 URLs, and it pulls the important thing factors right into a structured abstract. What used to take 45 minutes takes about 4 minutes, with the remaining time spent alone verification and judgment.
- Draft technology: First drafts of emails, summaries, and structured paperwork. The output is not last and I do not count on it to be, however having one thing to edit is quicker than ranging from a clean web page each time.
- File digestion: I drop assembly notes, PDFs, and log information right into a folder and ask it to drag out particular data. It handles this reliably so long as the information are text-based and beneath about 50,000 phrases.
The time financial savings are actual. Knowledge from DX’s evaluation of 135,000+ builders discovered a median of three.6 hours saved per week when utilizing AI instruments, and every day customers confirmed even bigger positive factors. My expertise is in that vary for task-heavy days, although it varies quite a bit by the kind of work.
# Wrapping Up
That Tuesday I described firstly — the one the place I labored all day and shipped nearly nothing — nonetheless occurs. However it occurs much less, and when it does, it is hardly ever as a result of I used to be caught within the incorrect form of work. The assistant handles the elements of the job that do not require me particularly, which frees me to spend extra time on the elements that do.
What I did not count on is that constructing it modified how I take into consideration the work itself. Once you’re chargeable for a software, you begin noticing friction otherwise. You begin asking “may this be delegated?” extra constantly, which is a helpful psychological behavior no matter whether or not you will have AI concerned.
The barrier to constructing one thing like that is decrease than it seems. The total working assistant above is beneath 150 traces of Python, makes use of freely accessible frameworks, and runs on any machine with Python put in. The toughest half is deciding what you really need it to do — and that query is value answering rigorously, as a result of a centered assistant beats a common one each time.
Begin small. Give it one job. Add complexity solely while you run out of worth on the less complicated degree. That strategy works for instruments, and it really works for constructing habits round them.
Shittu Olumide is a software program engineer and technical author keen about leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying advanced ideas. It’s also possible to discover Shittu on Twitter.