

{kind=link}
Somebody typed “Howdy Claude” and used 13% of their session restrict.
That is an actual Reddit submit from an actual one that opened Claude, despatched a greeting, and watched greater than one-eighth of their utilization disappear earlier than asking a single query.
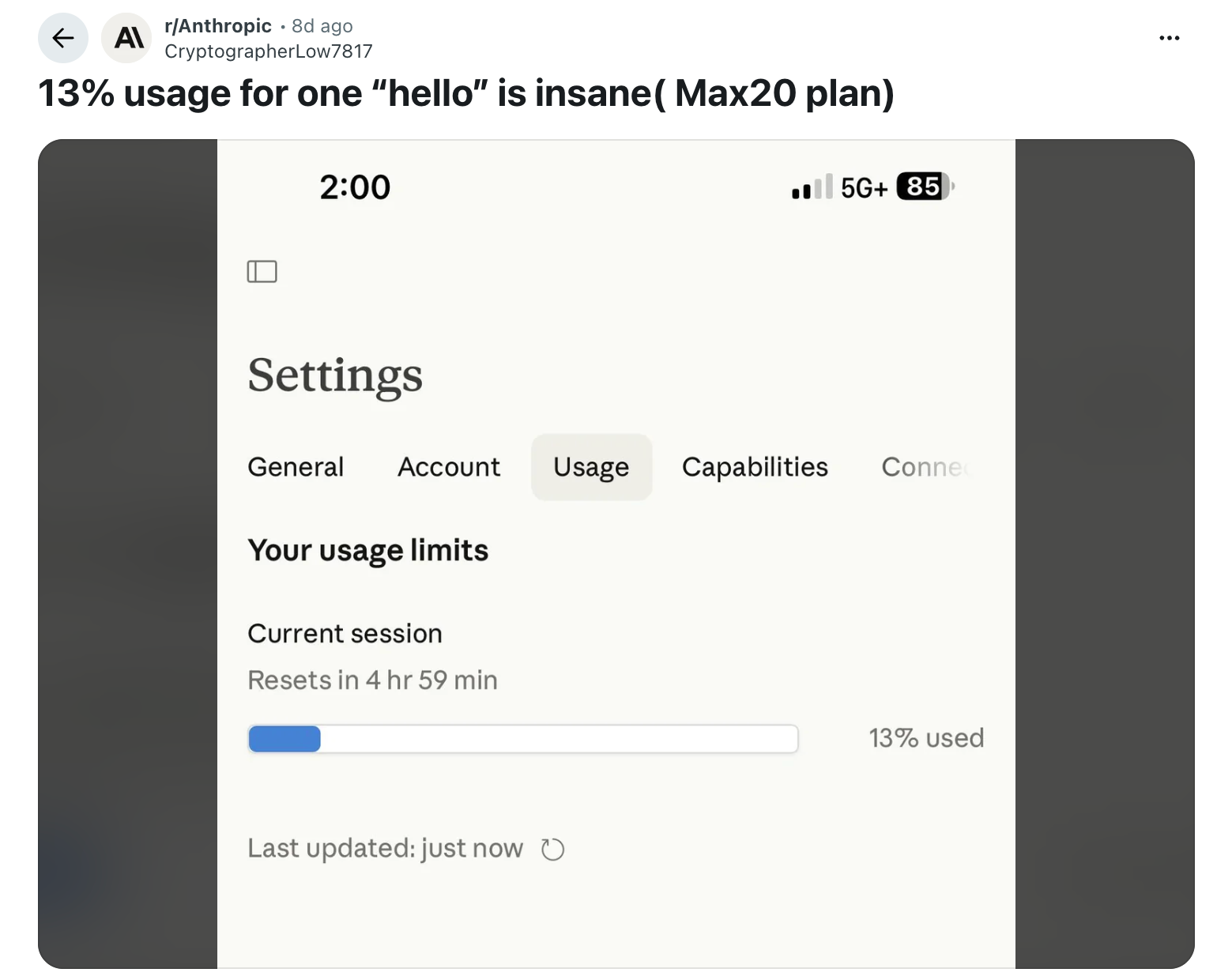
A separate consumer on X reported ending up in a “four-hour cooldown jail” from the identical set off. The factor is, no person had a very good rationalization for why it occurred.
The reply is tokens. Most individuals utilizing LLMs at present don’t have any framework for understanding what a token is, why it prices what it prices, or the place their utilization goes earlier than they’ve completed something helpful. Each main LLM – Claude, GPT-5, Gemini, Grok, Llama and many others. runs on the identical underlying economics. Tokens are the forex of this complete business.
When you use any of them often, understanding how tokens work is the distinction between getting actual work completed and hitting your restrict at 11am.
Let’s decode.
What a Token Truly Is
Consider a token as a piece of textual content someplace between a syllable and a phrase in dimension.
Let’s simply say “Unbelievable” is one token. “I’m” is 2 tokens. “Unbelievable” could be three tokens relying on the mannequin, as a result of some fashions break unfamiliar or lengthy phrases into subword items. The OpenAI tokenizer playground (platform.openai.com/tokenizer) helps you to paste any textual content and see precisely the way it will get chopped up in coloured blocks. Value making an attempt as soon as simply to calibrate your instinct.
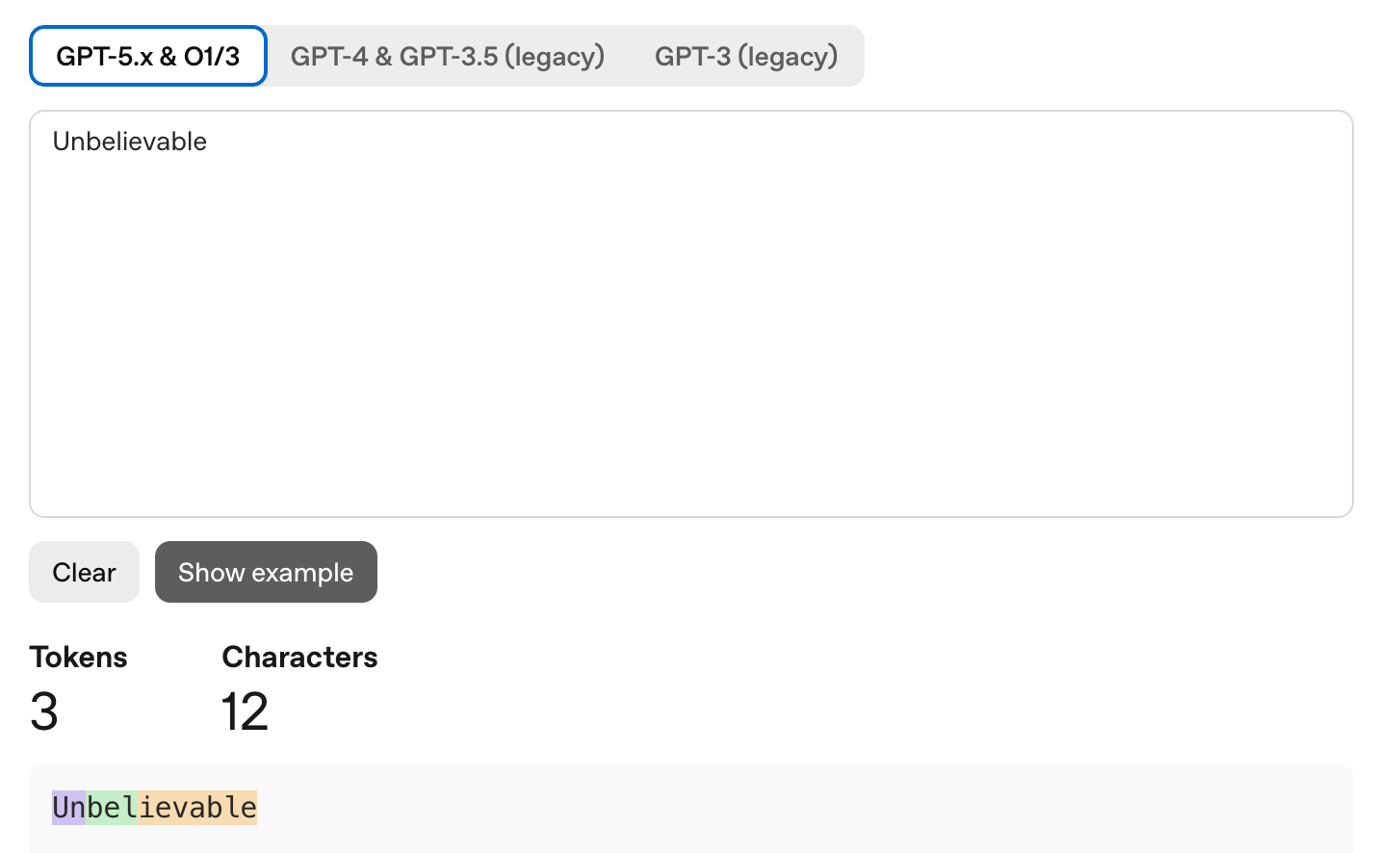
The tough conversion for English: 1,000 tokens ≈ 750 phrases ≈ 2-3 pages of textual content. One token averages about 4 characters or 0.7 phrases. An ordinary 800 phrase weblog submit is roughly 1,000-1,100 tokens.
These numbers solely maintain for English. Code tokenization is worse: 1.5 to 2.0 tokens per phrase, as a result of programming syntax has a number of characters that do not map cleanly onto pure language tokens. Chinese language, Japanese, and Korean are worse nonetheless, consuming 2 to eight occasions extra tokens than English for equal content material. When you write a number of code or work in a non English language, your consumption is meaningfully larger than the back-of-envelope math suggests.
Completely different fashions use completely different tokenizers, so the identical textual content does not value the identical tokens all over the place. 1,000 tokens on GPT-5 (which makes use of the o200k_base tokenizer) could be 1,200 tokens on Claude or 900 tokens on Gemini. Evaluating utilization throughout platforms requires utilizing every mannequin’s particular tokenizer for correct counts.
The Context Window
Tokens are necessary for 2 distinct causes. The primary is your utilization restrict: how a lot you are able to do earlier than hitting a wall. The second is the context window: how a lot the mannequin can maintain in reminiscence directly.
Each mannequin has a context window measured in tokens. Claude Sonnet 4.6 helps 1 million tokens. GPT-5 has 400K. Gemini 3 Professional has 2 million. Llama 4 Scout has 10 million. These numbers are spectacular however deceptive.
Bigger context home windows do not mechanically imply higher efficiency. Analysis persistently reveals fashions degrade in high quality earlier than reaching their acknowledged limits. A 2024 research from researchers Levy, Jacoby, and Goldberg discovered that LLM reasoning efficiency begins degrading round 3,000 tokens, effectively earlier than any mannequin’s technical most. A 2025 research from Chroma examined 18 fashions together with GPT-4.1, Claude 4, and Gemini 2.5 and documented what they referred to as “context rot”: a progressive decay in accuracy as prompts develop longer, even on easy string-repetition duties. Each mannequin confirmed that extra context will not be all the time higher.
The context window can also be shared by all the things, not simply your message and the mannequin’s reply. System directions, device calls, each earlier flip within the dialog, uploaded recordsdata, and inner reasoning steps all eat from the identical pool.
The Six Silent Token Drains
The bulk assume token utilization appears like: I kind one thing, the mannequin responds, that is one change. However in actuality, it’s not linear and predictable.
1. Dialog Historical past Compounds Quick
Each message you ship in a multi-turn dialog carries your complete prior dialog as context. Flip 1 prices 2 items: you ship 1, the mannequin sends 1 again. Flip 2 prices 4 complete as a result of your second message contains the primary change. Flip 3 prices 6. By flip 10, you may need spent 110 items cumulatively. Those self same ten duties as ten separate one-turn conversations would value 20 items complete. Identical output however 5 and a half occasions inexpensive.
Individuals who deal with a dialog like a working doc, including to the identical thread for hours as a result of it feels organized, are doing essentially the most token-expensive factor potential.
A concrete instance: you are utilizing Claude to debug a software program venture. You paste 2,000 tokens of code, ask a query, get a solution, ask a follow-up, and so forth. By the fourth change, the mannequin is processing roughly 12,000 tokens to reply a query that, in isolation, would value 500. The collected historical past is doing many of the spending.
2. Prolonged Considering Generates Tokens You By no means See
Most main LLMs now have a reasoning mode. OpenAI calls it o-series. Google calls it Considering Mode. Anthropic calls it Prolonged Considering. When enabled, the mannequin works by the issue internally earlier than responding.
That inner reasoning generates tokens. Reasoning tokens can quantity to 10 to 30 occasions greater than the seen output. A response that appears like 200 phrases to you may need value 3,000 reasoning tokens behind it.
Claude’s Prolonged Considering is now adaptive, that means the mannequin decides whether or not a activity wants deep reasoning or a fast reply. On the default effort degree, it nearly all the time thinks. So whenever you ask Claude to repair a typo, reformat an inventory, or lookup a primary reality, it is nonetheless burning considering tokens on an issue that does not require them. Toggling Prolonged Considering off for easy duties reduces prices with no high quality tradeoff.
The identical subject applies to OpenAI’s reasoning fashions. GPT-5 routes requests to completely different underlying fashions relying on what your immediate alerts. Phrases like “suppose arduous about this” set off a heavier reasoning mannequin even when you do not want one. OpenAI’s personal documentation warns towards including “suppose step-by-step” to prompts despatched to reasoning fashions, for the reason that mannequin is already doing it internally.
3. System Prompts Run on Each Request
Any AI product constructed on a basis mannequin, together with customized GPTs, Claude Initiatives with customized directions, or enterprise deployments, prepends a system immediate to each message you ship.
A typical system immediate runs 500 to three,500 tokens. Each time you ship something, these tokens run first. An organization working an inner chatbot with a 3,000-token system immediate dealing with 10,000 messages per day spends 30 million tokens on directions alone, earlier than any consumer has requested something significant.
On the particular person degree: a Claude Challenge with intensive customized directions reruns these directions each time you open the venture. Holding venture information tight is straight cheaper, not simply neater.
4. The “Howdy” Drawback
Again to the Reddit submit. How does “hey” devour 13% of a session?
Truly earlier than processing your phrase “hey”, it hundreds the system immediate, venture information, dialog historical past from earlier within the session, and enabled instruments. In Claude Code particularly, it hundreds CLAUDE.md recordsdata, MCP server definitions, and session state from the working listing. All of that’s billed as enter tokens on each change, together with the primary one.

In case your Claude Code surroundings has a fancy CLAUDE.md, a number of MCP servers enabled, and a big venture listing, your baseline token value per message earlier than you’ve got typed something would possibly already be a number of thousand tokens. And “Howdy” in that surroundings prices one phrase plus all of the infrastructure the mannequin must load earlier than it could possibly reply.
5. Uploaded Recordsdata Sit on the Meter Constantly
Importing a 50-page PDF to a Claude Challenge implies that doc is held in context even whenever you’re not actively asking questions on it. It consumes tokens each session as a result of the mannequin wants consciousness of it to reference it when wanted.
Token consumption in any chat comes from uploaded recordsdata, venture information recordsdata, customized directions, message historical past, system prompts, and enabled instruments, on each change. When you add 5 giant paperwork you ended up not referencing, you are still paying for them.
Maintain venture information matched to what you are truly engaged on. Deal with it like RAM, not a submitting cupboard.
6. Agentic Software Calls Explode the Rely
When you use AI brokers, Claude with instruments, ChatGPT with Actions, or any autonomous workflow the place the mannequin calls exterior APIs or searches the net: each device name appends its full consequence to the context. An online search returns roughly 2,000 tokens of outcomes. Run 20 device calls in a single session and you’ve got consumed round 40,000 tokens in device responses alone, earlier than factoring within the rising dialog historical past stacking on high.
Claude Code brokers performing 10 reasoning steps throughout a big codebase can course of 50,000 to 100,000 tokens per activity. For a group of engineers every working a number of agent classes per day, this turns into the first value driver.
Protect Your Token Price range
Begin a New Dialog for Each New Process
Given the compounding math above, conserving one lengthy dialog open throughout a number of unrelated duties is the most costly approach to make use of an LLM. A ten-turn dialog spanning 5 matters prices greater than 5 2-turn conversations masking the identical floor.
The intuition to maintain all the things in a single thread feels organized. However resist it. So observe: new activity, new dialog.
Match the Mannequin to the Work
Frontier fashions, Claude Opus, GPT-5, and Gemini 3 Professional, are costlier than their smaller siblings, and for many duties the standard distinction is negligible. Claude Sonnet handles advanced coding, detailed evaluation, long-form writing, and analysis synthesis with out significant high quality loss versus Opus. The distinction reveals up solely on significantly advanced multi-step reasoning, which represents a fraction of precise every day utilization.
Default to the mid-tier mannequin (Sonnet, GPT-4o, Gemini Flash Professional). Use the flagship when the duty genuinely calls for it. Keep away from this:
Flip Off Prolonged Considering for Easy Duties
For Claude: toggle Prolonged Considering off beneath “Search and instruments” when doing fast edits, brainstorming, factual lookups, or reformatting. Response high quality on these duties will not change. Token value drops considerably.
For GPT: use customary GPT-4o somewhat than o-series fashions for something that does not require deep multi-step reasoning. The o-series is purpose-built for arduous reasoning issues and wasteful for all the things else.
Write Shorter Prompts
The analysis says quick prompts typically work higher than lengthy ones, they usually’re cheaper. The sensible candy spot for many duties is 150-300 phrases. That is particular sufficient to provide the mannequin actual course with out stuffing it with context it does not want.
Write the shortest model of your immediate that describes your intent. Take a look at it. Add solely what’s truly lacking within the output.
For instance, as an alternative of: “I am engaged on a advertising and marketing marketing campaign for a B2B SaaS product that helps finance groups automate their accounts payable workflows. I might such as you to assist me write a topic line for an electronic mail going to CFOs at mid-market corporations. The tone ought to be skilled however not overly formal. It ought to convey urgency with out being pushy. The e-mail is a part of a drip sequence and that is the third electronic mail within the sequence, which suggests the recipient has already heard from us twice and hasn’t responded but…”
Attempt: “Write 5 topic strains for electronic mail #3 in a B2B drip to CFO prospects. Product: AP automation SaaS. Tone: skilled, slight urgency.”
The output is identical high quality. The token value is a fraction.
Skip Pleasantries Inside Classes
Each “thanks, that is useful!” or “nice, now are you able to additionally…” extends the dialog and inflates the working context. In a token-constrained surroundings, social filler prices actual utilization for no informational profit.
That is additionally the mechanical rationalization for the “hey” downside. In a loaded surroundings, a greeting is a full flip that hundreds all of the infrastructure and generates a full response for zero informational worth. Mixed with a fancy system surroundings, that provides as much as 5-10% of a session earlier than any actual work begins. And that is cap:

Request Structured Outputs
Asking for structured outputs, reminiscent of JSON, numbered lists, or tables, usually requires fewer output tokens than narrative explanations whereas producing extra usable outcomes. Specifying “Record 3 product options as JSON with keys: characteristic, profit, precedence” generates a parseable response in fewer tokens than “describe the three most necessary product options intimately.”
Analysis on this sample reveals output token reductions of 30-50% for equal informational content material.
Maintain Challenge Data Matched to the Present Process
Solely embody paperwork straight related to what you are engaged on now. Archive previous recordsdata when a venture part ends. Each file in a Claude Challenge runs on each session whether or not you reference it or not.
Test What You Have Left
Most AI merchandise do not present a token meter. This is discover your utilization anyway, by platform.
Claude (claude.ai)
Go to Settings → Utilization, or navigate on to claude.ai/settings/utilization. This reveals cumulative utilization towards your plan’s restrict. It is a lagging indicator and does not present real-time token rely inside a dialog.
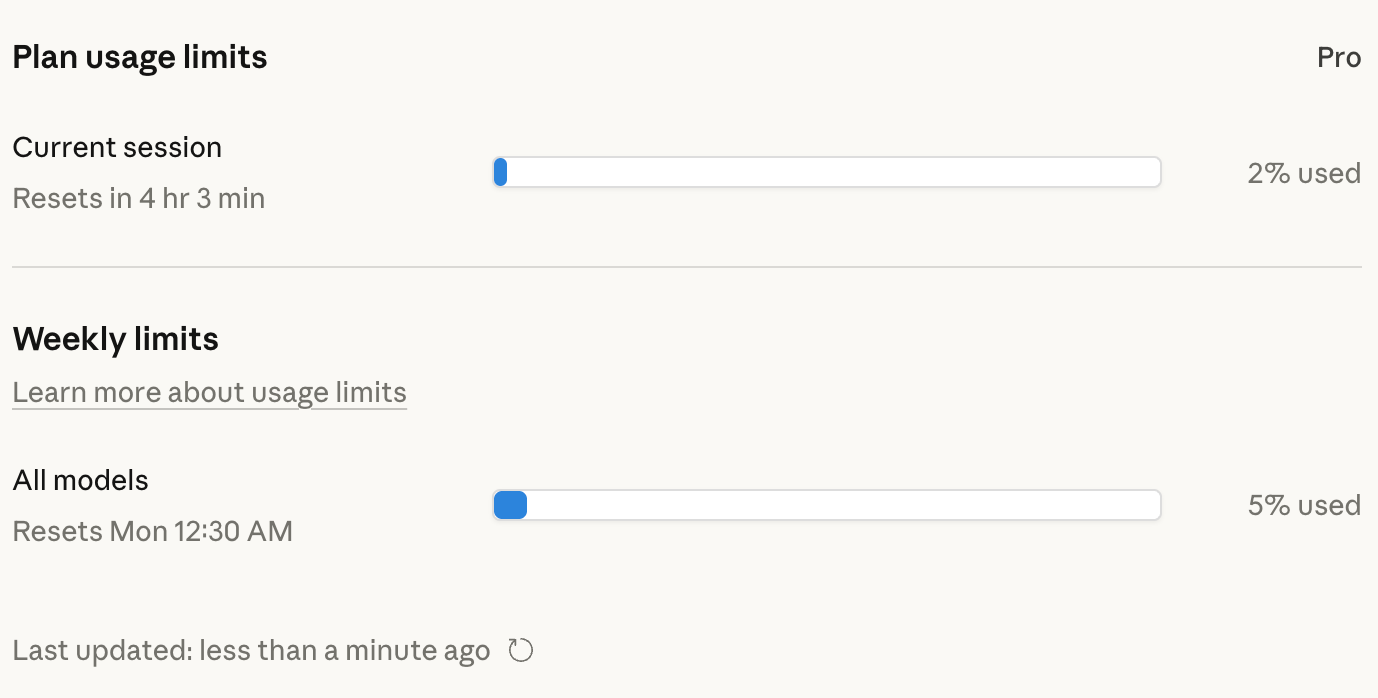
For Claude Code particularly: /value reveals API-level customers their token spend for the present session damaged down by class. /stats reveals subscribers their utilization patterns over time.
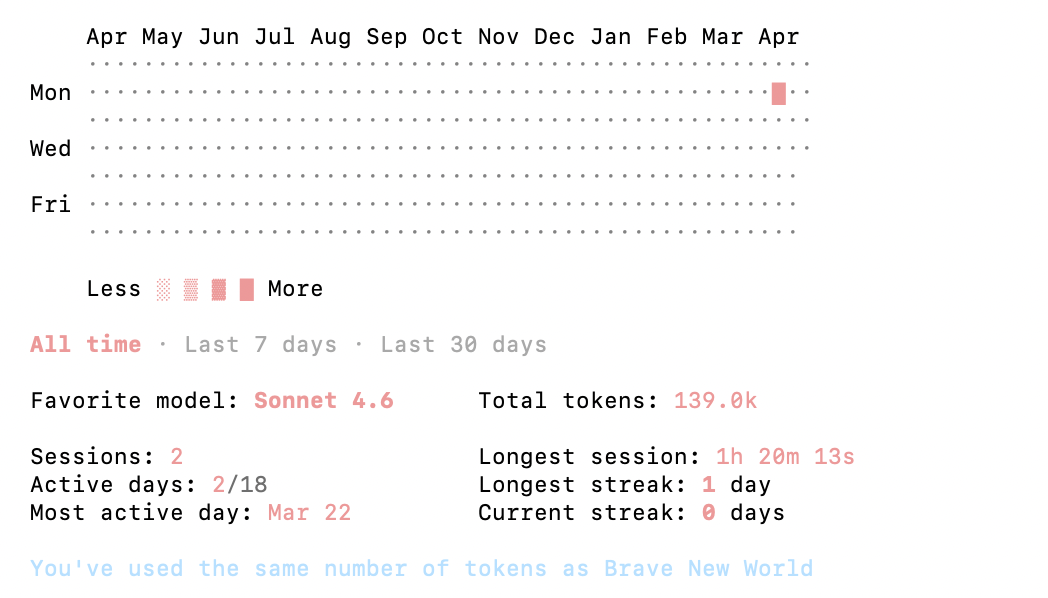
Third-party instruments for Claude Code
ccusage is a CLI device that reads Claude’s native JSONL log recordsdata and reveals utilization damaged down by date, session, or venture. It runs as a one-line npx command with no full set up. For Professional and Max subscribers who cannot see consumption within the Anthropic Console (as a result of they pay a flat subscription somewhat than per-token), that is the first option to observe the place utilization goes.
Claude-Code-Utilization-Monitor supplies a real-time terminal UI with progress bars, burn price analytics, and predictions for when your present session will run out. It auto-detects your plan and applies the proper limits: Professional is round 44,000 tokens per 5-hour window, Max5 round 88,000, and Max20 round 220,000. Run it in a separate terminal window and you will see consumption replace dwell.
Claude Utilization Tracker is a Chrome extension that estimates token consumption straight within the claude.ai interface, monitoring recordsdata, venture information, historical past, and instruments, with a notification when your restrict resets.
ChatGPT
OpenAI does not expose token utilization to shopper customers straight. Developer accounts with API entry can see per-request token counts at platform.openai.com/utilization. Shopper subscribers don’t have any native meter. Third-party extensions exist within the Chrome retailer however aren’t formally supported.
API customers (any platform)
Each API response contains token counts within the metadata. For Claude, input_tokens and output_tokens seem in each response object. For OpenAI, the equal fields are utilization.prompt_tokens and utilization.completion_tokens. Construct logging round these fields from the beginning, it is the one dependable option to observe consumption at scale.
Earlier than you ship: token counters
Instruments like runcell.dev/device/token-counter and langcopilot.com/instruments/token-calculator allow you to paste textual content and get an prompt rely earlier than sending, utilizing every mannequin’s official tokenizer. No signup are required and it runs within the browser. Helpful earlier than submitting giant paperwork or advanced prompts.
The Talent Value Having
Token literacy was once a developer concern however not at present.
The identical shift occurred with knowledge. Ten years in the past, knowledge literacy meant SQL and spreadsheets, practitioner territory. Now each enterprise decision-maker is predicted to learn a dashboard, interpret a funnel, and query a metric. Tokens are on the identical trajectory.
LLMs are embedded in actual work now: drafting, evaluation, coding, analysis. The individuals who perceive the underlying economics will use them extra successfully, hit limits much less usually, and get extra from the identical subscription.
Cheers.