
: A Novel Reinforcement Studying Algorithm that Trains a weak Meta Agent to Design Agentic Workflows with Stronger LLMs")
{kind=link}
Researchers from Stanford, EPFL, and UNC introduce Weak-for-Robust Harnessing, W4S, a brand new Reinforcement Studying RL framework that trains a small meta-agent to design and refine code workflows that decision a stronger executor mannequin. The meta-agent doesn’t fantastic tune the sturdy mannequin, it learns to orchestrate it. W4S formalizes workflow design as a multi flip Markov resolution course of, and trains the meta-agent with a way known as Reinforcement Studying for Agentic Workflow Optimization, RLAO. The analysis crew stories constant good points throughout 11 benchmarks with a 7B meta-agent educated for about 1 GPU hour.
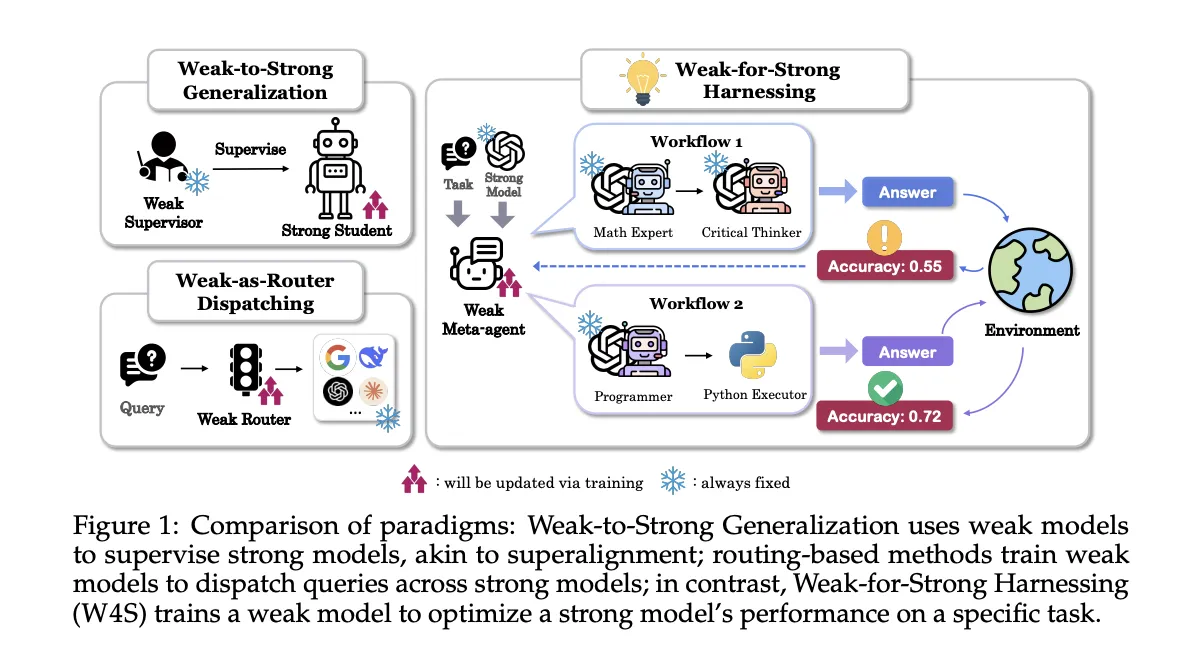
W4S operates in turns. The state accommodates process directions, the present workflow program, and suggestions from prior executions. An motion has 2 parts, an evaluation of what to alter, and new Python workflow code that implements these modifications. The setting executes the code on validation gadgets, returns accuracy and failure instances, and gives a brand new state for the following flip. The meta-agent can run a fast self test on one pattern, if errors come up it makes an attempt as much as 3 repairs, if errors persist the motion is skipped. This loop offers studying sign with out touching the weights of the sturdy executor.
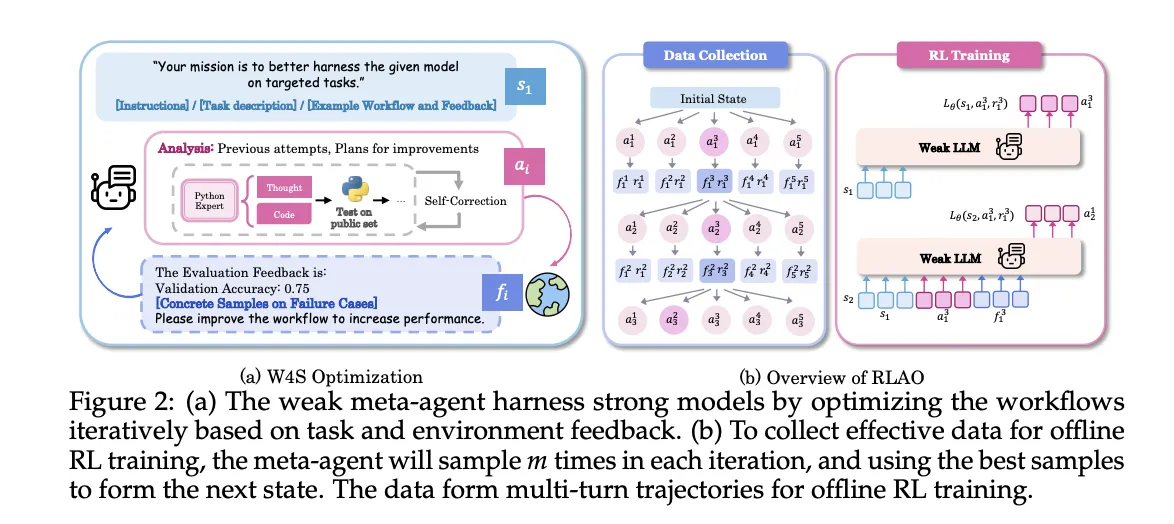
W4S runs as an iterative loop
- Workflow technology: The weak meta agent writes a brand new workflow that leverages the sturdy mannequin, expressed as executable Python code.
- Execution and suggestions: The sturdy mannequin executes the workflow on validation samples, then returns accuracy and error instances as suggestions.
- Refinement: The meta agent makes use of the suggestions to replace the evaluation and the workflow, then repeats the loop.
Reinforcement Studying for Agentic Workflow Optimization (RLAO)
RLAO is an offline reinforcement studying process over multi flip trajectories. At every iteration, the system samples a number of candidate actions, retains the very best performing motion to advance the state, and shops the others for coaching. The coverage is optimized with reward weighted regression. The reward is sparse and compares present validation accuracy to historical past, a better weight is given when the brand new consequence beats the earlier finest, a smaller weight is given when it beats the final iteration. This goal favors regular progress whereas controlling exploration price.
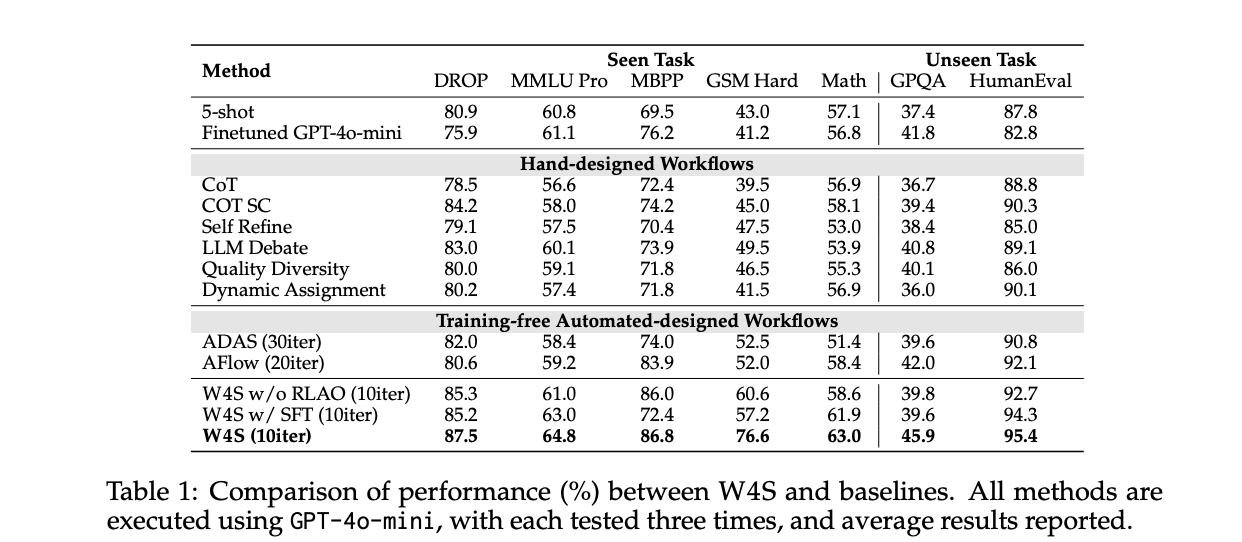
Understanding the Outcomes
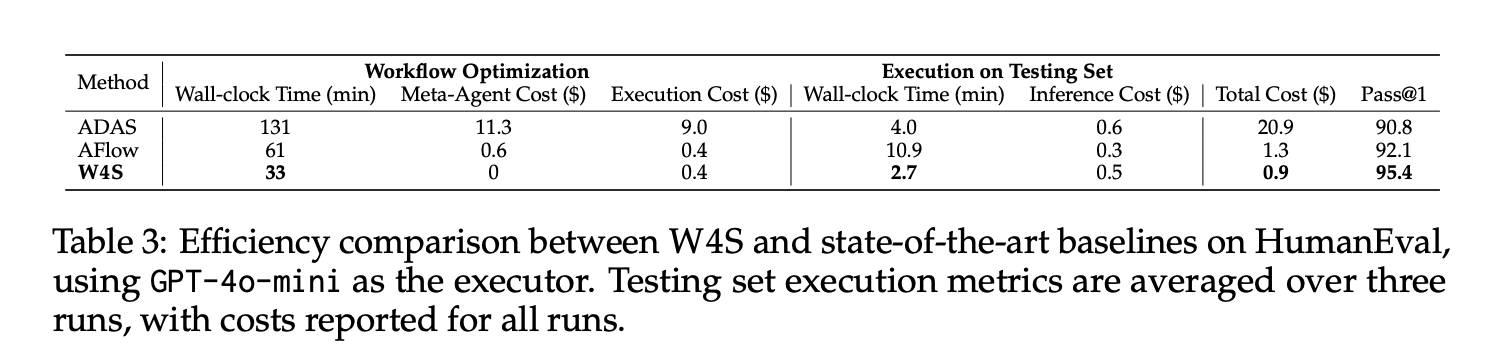
On HumanEval with GPT-4o-mini as executor, W4S achieves Move@1 of 95.4, with about 33 minutes of workflow optimization, zero meta-agent API price, an optimization execution price of about 0.4 {dollars}, and about 2.7 minutes to execute the take a look at set at about 0.5 {dollars}, for a complete of about 0.9 {dollars}. Beneath the identical executor, AFlow and ADAS path this quantity. The reported common good points towards the strongest automated baseline vary from 2.9% to 24.6% throughout 11 benchmarks.
On math switch, the meta-agent is educated on GSM Plus and MGSM with GPT-3.5-Turbo as executor, then evaluated on GSM8K, GSM Onerous, and SVAMP. The paper stories 86.5 on GSM8K and 61.8 on GSM Onerous, each above automated baselines. This means that the discovered orchestration transfers to associated duties with out re coaching the executor.
Throughout seen duties with GPT-4o-mini as executor, W4S surpasses coaching free automated strategies that don’t be taught a planner. The examine additionally runs ablations the place the meta-agent is educated by supervised fantastic tuning quite than RLAO, the RLAO agent yields higher accuracy below the identical compute funds. The analysis crew embrace a GRPO baseline on a 7B weak mannequin for GSM Onerous, W4S outperforms it below restricted compute.
Iteration budgets matter. The analysis crew units W4S to about 10 optimization activates principal tables, whereas AFlow runs about 20 turns and ADAS runs about 30 turns. Regardless of fewer turns, W4S achieves greater accuracy. This means that discovered planning over code, mixed with validation suggestions, makes the search extra pattern environment friendly.
Key Takeaways
- W4S trains a 7B weak meta agent with RLAO to put in writing Python workflows that harness stronger executors, modeled as a multi flip MDP.
- On HumanEval with GPT 4o mini as executor, W4S reaches Move@1 of 95.4, with about 33 minutes optimization and about 0.9 {dollars} complete price, beating automated baselines below the identical executor.
- Throughout 11 benchmarks, W4S improves over the strongest baseline by 2.9% to 24.6%, whereas avoiding fantastic tuning of the sturdy mannequin.
- The tactic runs an iterative loop, it generates a workflow, executes it on validation knowledge, then refines it utilizing suggestions.
- ADAS and AFlow additionally program or search over code workflows, W4S differs by coaching a planner with offline reinforcement studying.
W4S targets orchestration, not mannequin weights, and trains a 7B meta agent to program workflows that decision stronger executors. W4S formalizes workflow design as a multi flip MDP and optimizes the planner with RLAO utilizing offline trajectories and reward weighted regression. Reported outcomes present Move@1 of 95.4 on HumanEval with GPT 4o mini, common good points of two.9% to 24.6% throughout 11 benchmarks, and about 1 GPU hour of coaching for the meta agent. The framing compares cleanly with ADAS and AFlow, which search agent designs or code graphs, whereas W4S fixes the executor and learns the planner.
Take a look at the Technical Paper and GitHub Repo. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t overlook to hitch our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you possibly can be a part of us on telegram as properly.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at reworking complicated datasets into actionable insights.