
")
{kind=link}
Desk of Contents
- Vector Search Utilizing Ollama for Retrieval-Augmented Technology (RAG)
- How Vector Search Powers Retrieval-Augmented Technology (RAG)
- What Is Retrieval-Augmented Technology (RAG)?
- How you can Construct a RAG Pipeline with FAISS and Ollama (Native LLM)
- Configuring Your Improvement Surroundings: Setting Up Ollama and FAISS for a Native RAG Pipeline
- Implementation Walkthrough
-
Integrating Ollama with FAISS Vector Seek for RAG
- Overview and Setup
- Well being Test and Mannequin Discovery
- Making the Ollama Name
- Non-obligatory: Cloud Fallback (OpenAI)
- Deciding on the High-k Related Chunks
- Splitting Solutions into Sentences
- Computing Sentence Assist
- Formatting and Styling
- The Core: generate_rag_response()
- Abstract of the Utilities
-
Operating a Native RAG Pipeline with Ollama and FAISS
- Imports and Module Wiring
- Guarantee Embeddings (load or construct as soon as)
- Guarantee Indexes (Flat should exist; HNSW is optionally available)
- Interactive Q&A Loop — Non-obligatory Mode
- Fairly Printing the Reply and Context (optionally available immediate/assist)
- CLI Entry Level (fundamental) — flags, loading, answering
- Normal Python Entrypoint
- Tiny Gotchas and Suggestions
- How you can Run a Native RAG System with Ollama and FAISS
- Instance Output
- What You Discovered: Constructing a Manufacturing-Prepared Native RAG System with Ollama and FAISS
- Abstract
Vector Search Utilizing Ollama for Retrieval-Augmented Technology (RAG)
Within the earlier classes, you discovered how you can generate textual content embeddings, retailer them effectively, and carry out quick vector search utilizing FAISS. Now, it’s time to place that search energy to make use of — by connecting it with a language mannequin to construct an entire Retrieval-Augmented Technology (RAG) pipeline.
RAG is the bridge between retrieval and reasoning — it lets your LLM (massive language mannequin) entry details it hasn’t memorized. As an alternative of relying solely on pre-training, the mannequin fetches related context from your personal information earlier than answering, making certain responses which are correct, up-to-date, and grounded in proof.
Consider it as asking a well-trained assistant a query: they don’t guess — they rapidly lookup the best pages in your organization wiki, then reply with confidence.
This lesson is the final of a 3-part collection on Retrieval-Augmented Technology (RAG):
- TF-IDF vs. Embeddings: From Key phrases to Semantic Search
- Vector Search with FAISS: Approximate Nearest Neighbor (ANN) Defined
- Vector Search Utilizing Ollama for Retrieval-Augmented Technology (RAG) (this tutorial)
To discover ways to make your LLM do the identical, simply maintain studying.
How Vector Search Powers Retrieval-Augmented Technology (RAG)
Earlier than we begin wiring our first Retrieval-Augmented Technology (RAG) pipeline, let’s pause to grasp how far we’ve come — and why this subsequent step is a pure development.
In Lesson 1, we discovered how you can translate language into geometry.
Every sentence grew to become a vector — a degree in high-dimensional house — the place semantic closeness means directional similarity. As an alternative of matching precise phrases, embeddings seize which means.
In Lesson 2, we tackled the size drawback: when tens of millions of such vectors exist, discovering the closest ones effectively calls for specialised information constructions comparable to FAISS indexes — Flat, HNSW, and IVF.
These indexes permit us to carry out lightning-fast approximate nearest neighbor (ANN) searches with solely a small trade-off in precision.
Now, in Lesson 3, we lastly join this retrieval capacity to an LLM.
Consider the FAISS index as a semantic reminiscence vault — it remembers each sentence you’ve embedded.
RAG acts because the retrieval layer that fetches essentially the most related details once you ask a query, passing these snippets to the mannequin earlier than it generates a solution.
From Search to Context
Conventional vector search stops at retrieval:
You enter a question, it finds semantically comparable passages, and shows them as search outcomes.
RAG goes one step additional — it feeds these retrieved passages into the language mannequin’s enter immediate.
As an alternative of studying uncooked similarity scores, the mannequin sees sentences comparable to:
Context: 1. Vector databases retailer and search embeddings effectively utilizing ANN. 2. FAISS helps a number of indexing methods together with Flat, HNSW, and IVF. Person Query: What’s the benefit of utilizing HNSW over Flat indexes?
Now the mannequin doesn’t should “guess” — it solutions with contextually grounded reasoning.
That’s what transforms search into retrieval-based reasoning (Determine 1).
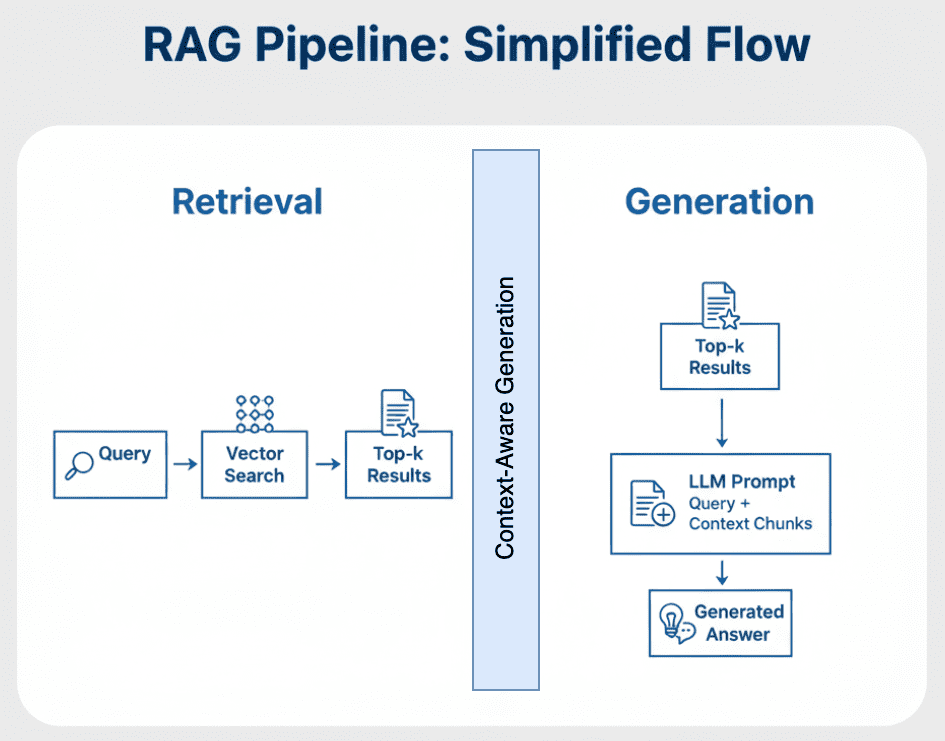
The Circulation of That means
Let’s join all of the elements (Desk 1).

That is the essence of RAG — combining the recall power of retrieval with the reasoning energy of era.
Placing It All Collectively
Think about shopping by a large photograph album of your complete textual content corpus.
Vector search helps you immediately discover photos with comparable colours and patterns — that’s embeddings at work.
However RAG doesn’t cease there. It exhibits these photos to a storyteller (the LLM), who makes use of them to relate a coherent story about what’s occurring throughout them.
Embeddings provide you with semantic lookup.
RAG provides you semantic understanding (Determine 2).
If this stream made sense, you’re prepared for the true motion — understanding how Retrieval Augmented Technology really works beneath the hood.
Subsequent, we’ll break down the structure, elements, and the 2-stage course of that powers fashionable RAG pipelines.
Would you want speedy entry to three,457 photos curated and labeled with hand gestures to coach, discover, and experiment with … totally free? Head over to Roboflow and get a free account to seize these hand gesture photos.
What Is Retrieval-Augmented Technology (RAG)?
Massive Language Fashions (LLMs) have modified how we work together with info.
However they arrive with two basic weaknesses: they can’t entry exterior information and they neglect simply.
Even essentially the most highly effective LLMs (e.g., GPT-4 or Mistral) rely solely on patterns discovered throughout coaching.
They don’t know concerning the newest firm stories, your non-public PDFs, or a proprietary codebase until explicitly retrained — which is pricey, sluggish, and sometimes not possible for organizations working with delicate information.
That is precisely the place Retrieval-Augmented Technology (RAG) steps in.
RAG acts as a bridge between frozen LLM information and contemporary, exterior info.
As an alternative of forcing the mannequin to memorize all the things, we give it a retrieval reminiscence system — a searchable information retailer crammed along with your area information.
Think about giving your LLM a library card — and entry to an clever librarian.
Each time a query arrives, the LLM doesn’t depend on its reminiscence alone — it sends the librarian to fetch related paperwork, reads them fastidiously, after which generates a grounded, evidence-based response.
The Retrieve-Learn-Generate Structure Defined
RAG techniques comply with a predictable 3-step pipeline that connects info retrieval with textual content era:
Retrieve
The consumer’s query is first transformed right into a numerical vector (embedding).
This vector represents the semantic which means of the question and is matched towards saved doc vectors in a vector index (e.g., FAISS, Pinecone, or Milvus).
The highest-ok closest matches — which means essentially the most semantically comparable chunks — are returned as potential context.
Learn
These retrieved chunks are merged into a brief context window — successfully a mini-knowledge pack related to the consumer’s question.
This step is important: as an alternative of dumping your complete corpus into the mannequin, we cross solely essentially the most helpful and concise context.
Generate
The LLM (e.g., one working domestically by Ollama or remotely through an API) takes each the question and retrieved context, then composes a solution that blends pure language fluency with factual grounding.
If well-designed, the mannequin avoids hallucinating and gracefully responds “I don’t know” when info is lacking.
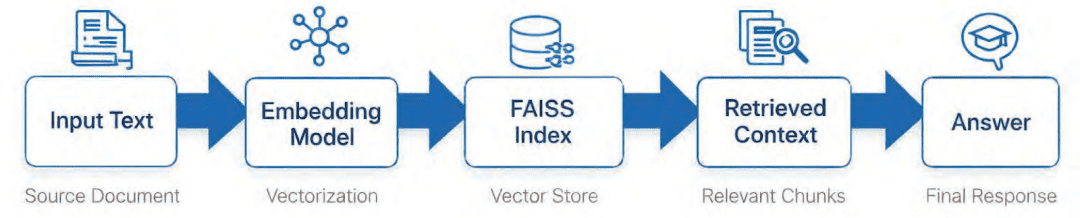
Determine 3 shows a high-level visible abstract of this course of.
Why Retrieval-Augmented Technology (RAG) Improves LLM Accuracy
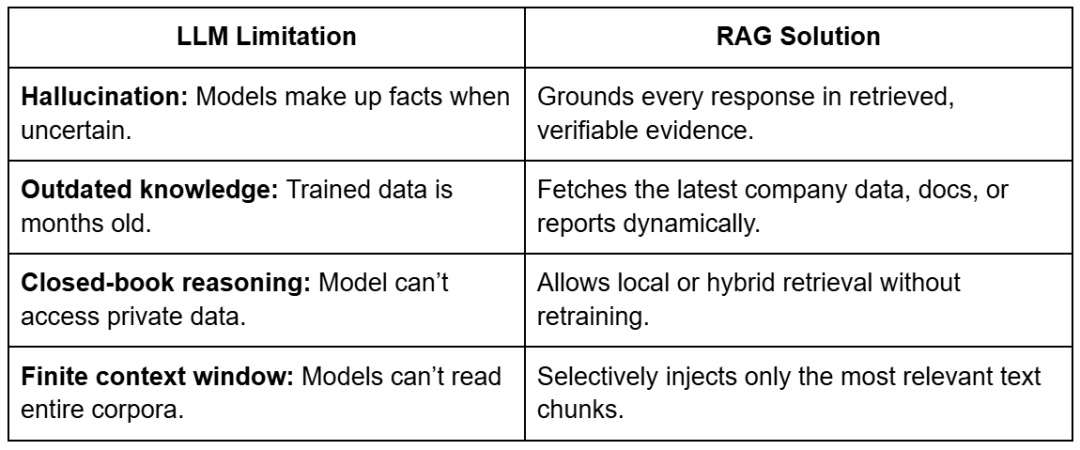
At first look, RAG could look like “simply one other strategy to question a mannequin,” nevertheless it represents a basic shift in how LLMs purpose.
Conventional LLMs retailer information of their parameters — they memorize details.
RAG decouples information from parameters and as an alternative retrieves it on demand.
This implies you possibly can maintain your mannequin small, quick, and environment friendly, whereas nonetheless answering domain-specific queries with accuracy.
Let’s unpack this with just a few concrete benefits, as reported in Desk 2.
The end result?
A modular intelligence system — the place the retriever evolves along with your information, and the generator focuses purely on language reasoning.
The Broader Image: A Hybrid of Search and Technology
You’ll be able to consider RAG as the right fusion of info retrieval and pure language era.
Conventional search engines like google and yahoo cease at retrieval — they return ranked paperwork.
LLMs go additional — they interpret and clarify.
RAG combines each: discover related context, then generate insights from it.
It’s the identical precept behind how people reply questions:
- We first recall or lookup what we all know.
- Then we synthesize a solution in our personal phrases.
RAG provides LLMs the identical ability — combining retrieval precision with generative fluency.
Key Takeaway
RAG doesn’t exchange fine-tuning — it enhances it.
It’s the quickest, least expensive, and most dependable strategy to make LLMs domain-aware with out touching their weights.
When you arrange your retriever (constructed from the FAISS indexes we created in Lesson 2) and join it to a generator (which we’ll later run through Ollama), you’ll have a self-contained clever assistant — one that may purpose over your information and reply advanced questions in pure language.
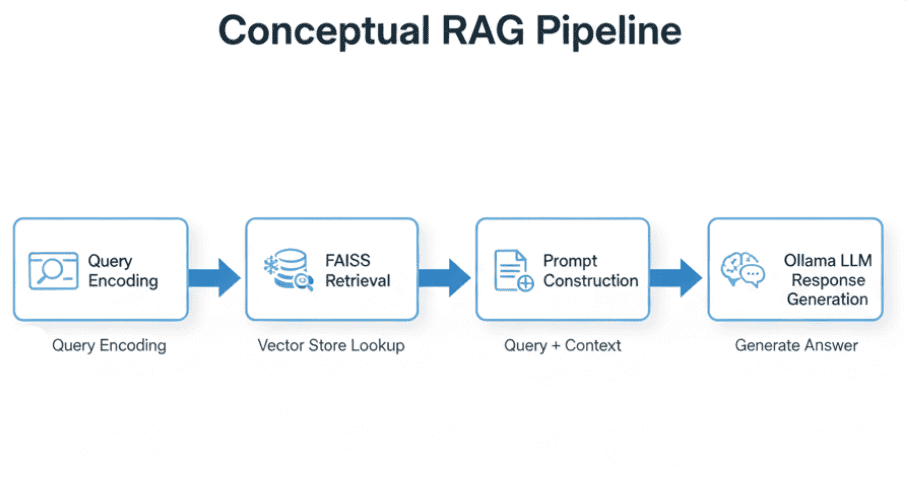
How you can Construct a RAG Pipeline with FAISS and Ollama (Native LLM)
Now that you just perceive what Retrieval Augmented Technology is and why it issues, let’s break down how you can really construct one — conceptually first, earlier than we dive into the code.
A RAG pipeline could sound sophisticated, however in observe it’s a clear, modular system made of three main components: the retriever, the reader, and the generator.
Every half does one job properly, and collectively they kind the spine of each production-grade RAG system — whether or not you’re querying just a few PDFs or a whole information base.
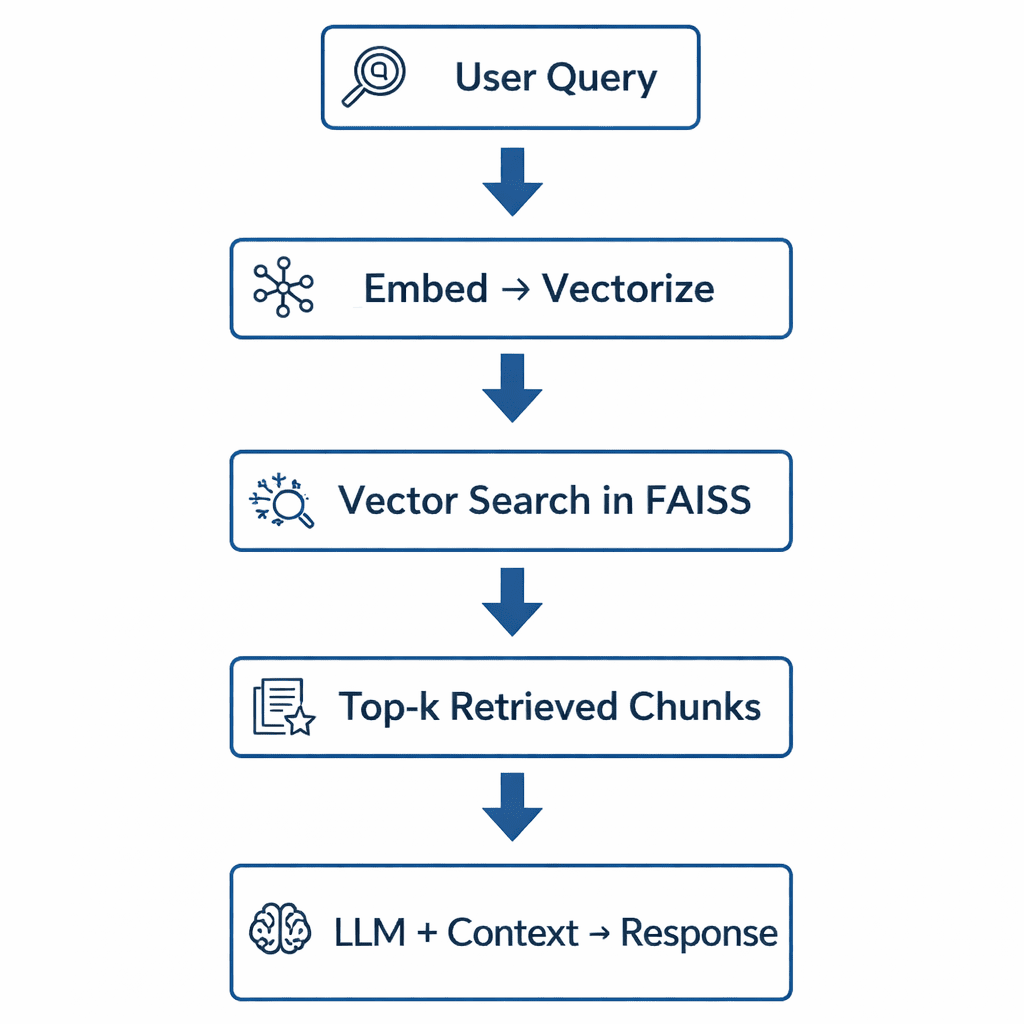
Step 1: Implementing HNSW Vector Search with FAISS for RAG
The retriever’s job is to go looking your doc corpus and return the chunks most related to a consumer question.
It’s powered by the vector indexes you inbuilt Lesson 2, which allow environment friendly approximate nearest-neighbor (ANN) search.
When a consumer asks a query, right here’s what occurs:
- The question textual content is embedded utilizing the identical Sentence Transformer mannequin used throughout indexing.
- That question embedding is in contrast along with your saved doc embeddings through a FAISS index.
- The retriever returns the top-k outcomes (sometimes 3-5 chunks) ranked by cosine similarity.
Consider it as Google Seek for your non-public information — besides as an alternative of matching key phrases, it matches which means (Determine 4).

Step 2: Immediate Engineering for Retrieval-Augmented Technology (RAG)
As soon as the related chunks are retrieved, we are able to’t simply throw them on the LLM.
They have to be assembled and formatted right into a coherent, bounded immediate.
That is the job of the reader — a light-weight logic layer that:
- Ranks and filters retrieved chunks by similarity rating or metadata (e.g., doc identify or part).
- Merges them right into a context block that stays inside the LLM’s context-window restrict (say, 4K-8K tokens).
- Wraps them inside a constant immediate template.
In our code, this can be dealt with utilizing utilities from config.py — notably build_prompt(), which mixes system prompts, retrieved textual content, and consumer queries right into a closing message prepared for the mannequin (Determine 5).
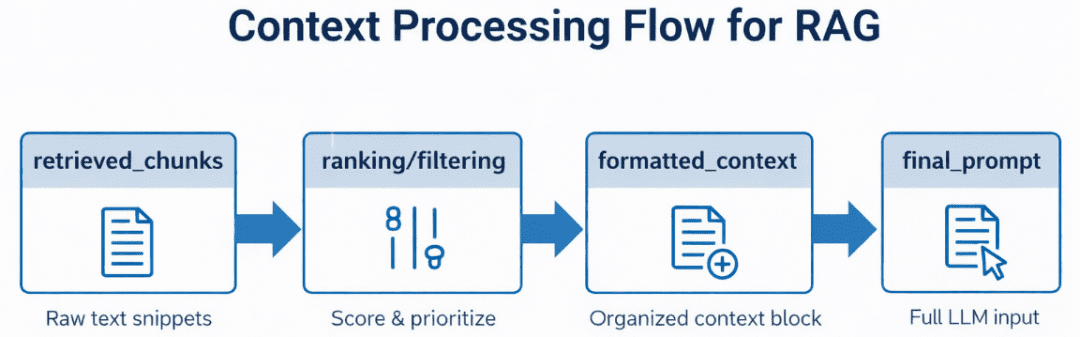
Step 3: Producing Grounded Solutions with Ollama Native LLM
Lastly, the generator — your LLM — reads the composed immediate and generates a response grounded within the retrieved information.
In our implementation, this would be the stage the place we combine with Ollama, a neighborhood LLM runtime able to working fashions (e.g., Llama 3, Mistral, or Gemma 2) in your machine.
However the design will keep framework-agnostic, so you possibly can later swap Ollama for an API name to OpenAI, Claude, or an enterprise mannequin working in-house.
What makes this step highly effective is the synergy between retrieval and era: the LLM isn’t hallucinating — it’s reasoning with proof. If the context doesn’t comprise the reply, it ought to politely say so, because of the strict vs. synthesis immediate patterns outlined in config.py (Determine 6).
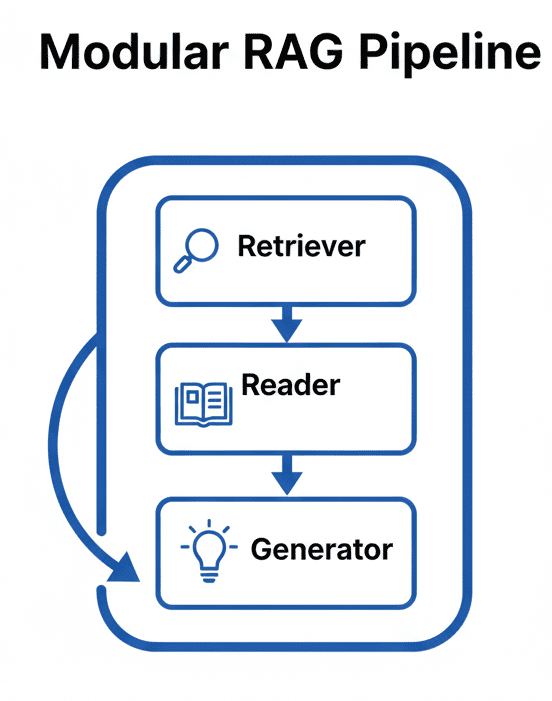
Including Suggestions Loops to Enhance Retrieval Accuracy
In additional superior techniques, RAG doesn’t finish at era. You’ll be able to seize consumer suggestions (e.g., thumbs-up/down or re-query actions) to fine-tune retrieval parameters, re-rank paperwork, and even re-embed sections of your corpus. This transforms a static RAG setup right into a frequently studying information engine.
Placing It All Collectively
Determine 7 shows a conceptual stream that ties the three elements collectively.
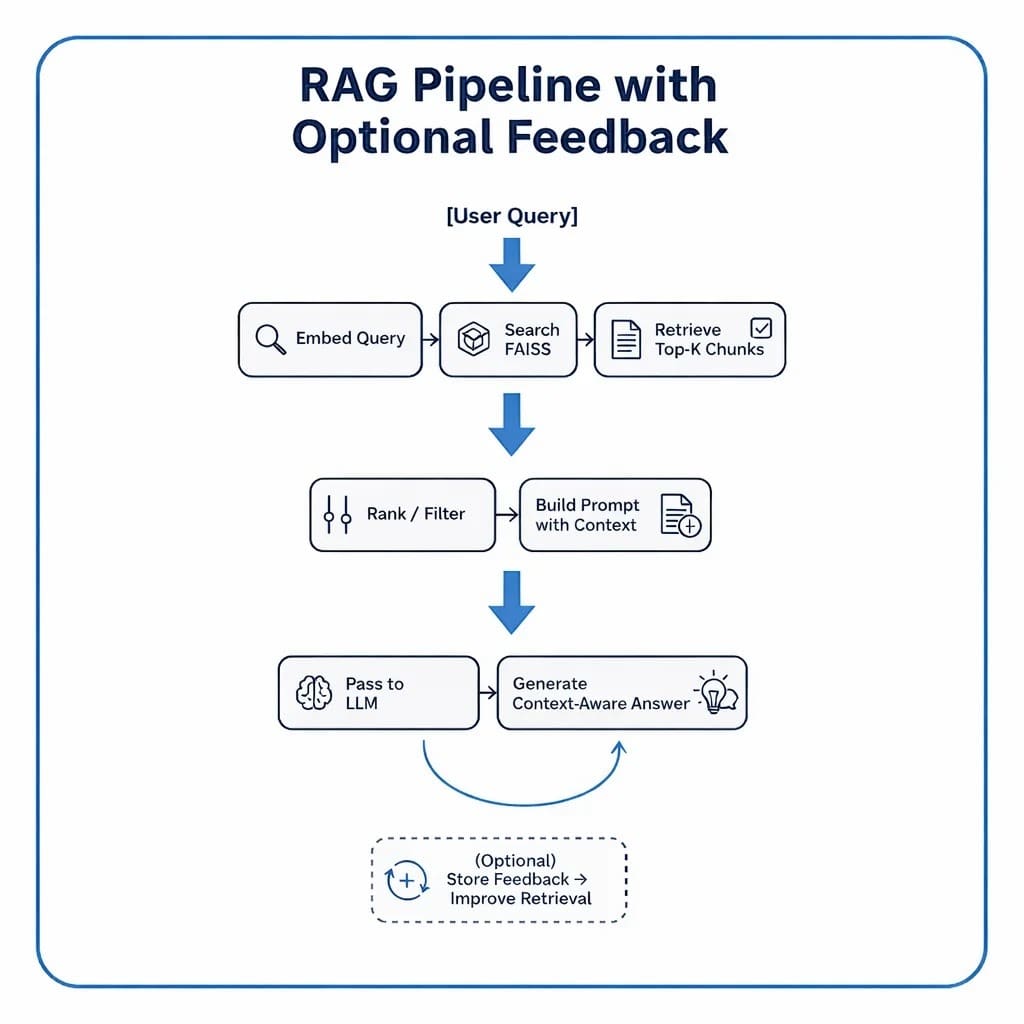
Every field on this pipeline maps on to a bit of your upcoming implementation.
In code, these steps will unfold by modular utilities and clear interfaces so you possibly can swap retrievers, tweak immediate templates, or change fashions with out rewriting your complete system.
Configuring Your Improvement Surroundings: Setting Up Ollama and FAISS for a Native RAG Pipeline
To comply with this RAG pipeline information, you’ll want a number of Python packages put in in your system. The tutorial builds upon semantic embeddings and vector search, requiring machine studying libraries, HTTP purchasers, and visualization instruments.
$ pip set up sentence-transformers==2.7.0 $ pip set up faiss-cpu==1.8.0.post1 $ pip set up numpy==1.26.4 $ pip set up requests==2.32.3 $ pip set up wealthy==13.8.1
Non-obligatory Dependencies
For visualization and enhanced performance:
$ pip set up scikit-learn==1.5.1 $ pip set up matplotlib==3.9.2 $ pip set up ollama>=0.1.0
This installs the Python shopper solely. The Ollama runtime have to be put in individually.
Native LLM Setup (Ollama)
The RAG pipeline makes use of Ollama for native language mannequin inference. Set up Ollama individually:
- Set up Ollama: Go to ollama.ai and comply with the set up directions on your platform.
- Pull a mannequin: As soon as Ollama is put in, obtain a mannequin:
$ ollama pull llama3
- Confirm set up:
$ ollama checklist
Want Assist Configuring Your Improvement Surroundings?

All that stated, are you:
- Brief on time?
- Studying in your employer’s administratively locked system?
- Desirous to skip the trouble of preventing with the command line, package deal managers, and digital environments?
- Able to run the code instantly in your Home windows, macOS, or Linux system?
Then be a part of PyImageSearch College right this moment!
Acquire entry to Jupyter Notebooks for this tutorial and different PyImageSearch guides pre-configured to run on Google Colab’s ecosystem proper in your internet browser! No set up required.
And better of all, these Jupyter Notebooks will run on Home windows, macOS, and Linux!
Implementation Walkthrough
We’ll cowl this in 3 components:
config.py: central configuration and immediate templatesrag_utils.py: retrieval + LLM integration logic03_rag_pipeline.py: driver script that ties all the things collectively
Configuration (config.py)
The config.py module defines paths, constants, and templates which are used all through the RAG pipeline. Consider it because the “management room” on your complete setup.
Listing and Path Setup
BASE_DIR = Path(__file__).resolve().mum or dad.mum or dad DATA_DIR = BASE_DIR / "information" INPUT_DIR = DATA_DIR / "enter" OUTPUT_DIR = DATA_DIR / "output" INDEX_DIR = DATA_DIR / "indexes" FIGURES_DIR = DATA_DIR / "figures"
Right here, we outline a constant listing construction so that each script can discover information, indexes, and output recordsdata, no matter the place it runs from.
This ensures reproducibility — a key trait for multi-script tasks like this one.
Tip: Utilizing Path(__file__).resolve().mum or dad.mum or dad routinely factors to your venture’s root listing, protecting all paths moveable.
Corpus and Embedding Artifacts
CORPUS_PATH = INPUT_DIR / "corpus.txt" CORPUS_META_PATH = INPUT_DIR / "corpus_metadata.json" EMBEDDINGS_PATH = OUTPUT_DIR / "embeddings.npy" METADATA_ALIGNED_PATH = OUTPUT_DIR / "metadata_aligned.json" DIM_REDUCED_PATH = OUTPUT_DIR / "pca_2d.npy"
These paths characterize:
- Corpus recordsdata: your enter textual content and metadata
- Embedding artifacts: precomputed vectors and PCA-reduced coordinates for visualization
We additionally embody atmosphere variable overrides (i.e., CORPUS_PATH, CORPUS_META_PATH) to make it straightforward to level to new datasets with out modifying code.
Index Artifacts
FLAT_INDEX_PATH = INDEX_DIR / "faiss_flat.index" HNSW_INDEX_PATH = INDEX_DIR / "faiss_hnsw.index"
These outline storage on your Flat (precise) and HNSW (approximate) FAISS indexes.
They’re generated in Lesson 2 and reused right here for retrieval.
Mannequin and Common Settings
EMBED_MODEL_NAME = "sentence-transformers/all-MiniLM-L6-v2" SEED = 42 DEFAULT_TOP_K = 5 SIM_THRESHOLD = 0.35
- Sentence Transformer mannequin: the identical compact mannequin used for embedding queries and paperwork
SEED: ensures deterministic samplingDEFAULT_TOP_K: variety of chunks retrieved per querySIM_THRESHOLD: a similarity cut-off to filter weak matches
Immediate Templates for RAG
STRICT_SYSTEM_PROMPT = (
"You're a concise assistant. Use ONLY the offered context."
" If the reply will not be contained verbatim or explicitly, say you have no idea."
)
SYNTHESIZING_SYSTEM_PROMPT = (
"You're a concise assistant. Rely ONLY on the offered context, however you MAY synthesize"
" a solution by combining or paraphrasing the details current. If the context really lacks"
" adequate proof, say you have no idea as an alternative of guessing."
)
The next 2 templates management LLM conduct:
- Strict mode: purely extractive, no paraphrasing
- Synthesizing mode: permits combining retrieved snippets to kind explanatory solutions
This distinction is essential when testing retrieval high quality versus era high quality.
Clever Immediate Builder
def build_prompt(context_chunks, query: str, allow_synthesis: bool = False) -> str:
system_prompt = SYNTHESIZING_SYSTEM_PROMPT if allow_synthesis else STRICT_SYSTEM_PROMPT
context_str = "nn".be a part of(context_chunks)
return f"System: {system_prompt}n{CONTEXT_HEADER}n{context_str}nn" + USER_QUESTION_TEMPLATE.format(query=query)
This perform assembles the ultimate immediate fed into the LLM.
It concatenates retrieved context snippets, appends the system directions, and ends with the consumer question.
Tip: The important thing right here is flexibility — by toggling allow_synthesis, you possibly can dynamically change between closed-book and open-book answering kinds.
Listing Bootstrap
for d in (OUTPUT_DIR, INDEX_DIR, FIGURES_DIR):
d.mkdir(mother and father=True, exist_ok=True)
Ensures that each one essential folders exist earlier than any writing happens — a small however important safeguard for manufacturing stability (Determine 8).
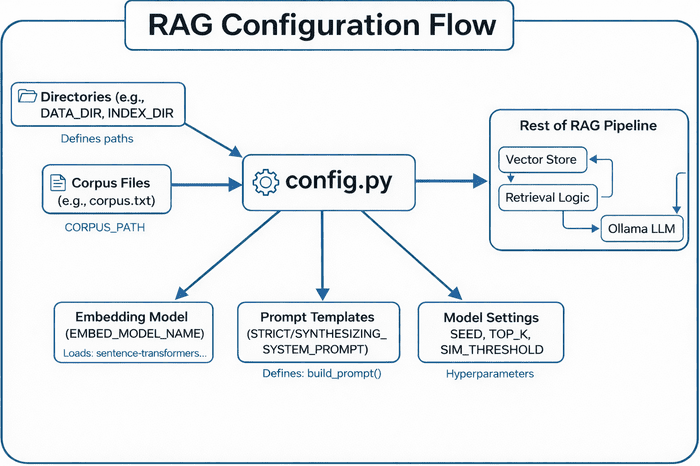
config.py centralizes paths, corpus recordsdata, embedding fashions, immediate templates, and mannequin settings — feeding these configurations into the remainder of the RAG pipeline (i.e., vector retailer, retrieval logic, and Ollama LLM) (supply: picture by the writer).At this level, the configuration module gives the inspiration for the subsequent step: really retrieving and producing solutions.
Integrating Ollama with FAISS Vector Seek for RAG
Now that our FAISS index is able to serve embeddings, the subsequent step is to join it with an LLM — the ultimate reasoning layer that generates natural-language solutions based mostly on retrieved context.
The rag_utils.py file is the place retrieval meets era.
It ties collectively the embedding search outcomes, builds prompts, calls the LLM (Ollama by default), and even provides explainability by citations and per-sentence assist scoring.
Overview and Setup
Let’s begin by wanting on the high of the file:
import os, json, re, requests
import numpy as np
from typing import Record, Dict, Tuple, Any
attempt:
import ollama # sort: ignore
besides ImportError:
ollama = None
On the core, this script:
- Makes use of Ollama for native LLM inference, however gracefully falls again to HTTP if the Python shopper isn’t put in.
- Imports NumPy for quick vector math, requests for API calls, and typing hints for readability.
Then, it configures Ollama’s endpoints:
OLLAMA_BASE_URL = os.getenv("OLLAMA_BASE_URL", "http://localhost:11434")
OLLAMA_API_URL = f"{OLLAMA_BASE_URL}/api/generate"
OLLAMA_TAGS_URL = f"{OLLAMA_BASE_URL}/api/tags"
Tip: You’ll be able to override OLLAMA_BASE_URL with an atmosphere variable — useful when deploying on distant servers or Docker containers (Determine 9).
Well being Test and Mannequin Discovery
Earlier than we make any era calls, it’s good observe to verify that Ollama is definitely reachable.
def ollama_available() -> bool:
attempt:
r = requests.get(OLLAMA_TAGS_URL, timeout=2)
return r.status_code == 200
besides requests.RequestException:
return False
If this returns False, your RAG pipeline will nonetheless work — it is going to merely skip era or return a warning message.
Equally, you possibly can checklist all domestically obtainable fashions:
def list_ollama_models() -> Record[str]:
"""Return a listing of accessible native Ollama mannequin names (empty if unreachable)."""
resp = requests.get(OLLAMA_TAGS_URL, timeout=2)
resp.raise_for_status()
information = resp.json()
fashions = []
for m in information.get("fashions", []):
identify = m.get("identify", "")
if identify.endswith(":newest"):
identify = identify.rsplit(":", 1)[0]
if identify:
fashions.append(identify)
return sorted(set(fashions))
This allows you to dynamically question what’s put in (e.g., llama3, mistral, or gemma2).
In the event you’re working an interactive RAG app, this checklist can populate a dropdown for consumer choice.
Making the Ollama Name
Right here’s the center of your LLM connector:
def call_ollama(mannequin: str, immediate: str, stream: bool = False) -> str:
"""Name Ollama utilizing python shopper if obtainable else uncooked HTTP."""
if ollama will not be None:
attempt:
if stream:
out = []
for chunk in ollama.generate(mannequin=mannequin, immediate=immediate, stream=True):
out.append(chunk.get("response", ""))
return "".be a part of(out)
else:
resp = ollama.generate(mannequin=mannequin, immediate=immediate)
return resp.get("response", "")
besides Exception:
cross
- If the
ollamalibrary is put in, the perform makes use of its official Python shopper for higher effectivity and streaming assist. - If not, it falls again to a handbook HTTP request:
payload = {"mannequin": mannequin, "immediate": immediate, "stream": stream}
resp = requests.publish(OLLAMA_API_URL, json=payload, timeout=120, stream=stream)
It even helps streaming tokens one after the other — helpful for constructing chat UIs or dashboards that show the reply because it’s generated.
Why this twin strategy?
Not all environments (e.g., Docker containers or light-weight cloud runners) have the ollama Python package deal put in, however they will nonetheless entry the REST (Representational State Switch) API.
Non-obligatory: Cloud Fallback (OpenAI)
There’s a commented-out part offering an optionally available fallback to OpenAI’s API.
If uncommented, you possibly can rapidly change between native and cloud fashions (e.g., gpt-4o-mini).
# OPENAI_MODEL = os.getenv("OPENAI_MODEL", "gpt-4o-mini")
# openai.api_key = os.getenv("OPENAI_API_KEY")
# def call_openai(immediate: str, mannequin: str = OPENAI_MODEL) -> str:
# ...
This flexibility enables you to deploy the identical RAG logic on-premises (Ollama) or within the cloud (OpenAI).
Deciding on the High-k Related Chunks
As soon as a consumer asks a query, we compute its embedding and retrieve comparable textual content chunks:
def select_top_k(question_emb, embeddings, texts, metadata, ok=5, sim_threshold=0.35):
sims = embeddings @ question_emb # cosine if normalized
ranked = np.argsort(-sims)
outcomes = []
for idx in ranked[:k * 2]:
rating = float(sims[idx])
if rating < sim_threshold and len(outcomes) >= ok:
break
outcomes.append({
"id": metadata[idx]["id"],
"textual content": texts[idx],
"rating": rating,
"subject": metadata[idx].get("subject", "unknown")
})
if len(outcomes) >= ok:
break
return outcomes
This perform:
- Computes cosine similarities between the question and all embeddings.
- Ranks them, filters by a similarity threshold, and returns the top-ok chunks with metadata.
This light-weight retrieval replaces the necessity to re-query FAISS each time — excellent for fast experiments or small datasets.
Splitting Solutions into Sentences
As soon as the LLM produces a solution, we could wish to analyze it sentence-by-sentence.
def _sentence_split(textual content: str) -> Record[str]:
uncooked = re.break up(r'(?<=[.!?])s+|n+', textual content.strip())
return [s.strip() for s in raw if s and not s.isspace()]
This regex-based strategy avoids heavy NLP libraries and nonetheless performs properly for many English prose.
Computing Sentence Assist
A novel function of this pipeline is its capacity to attain every sentence within the LLM’s reply by how properly it aligns with the retrieved context chunks.
This helps decide which components of the generated reply are literally supported by the retrieved proof — forming the premise for citations comparable to [1], [2].
def _compute_support(sentences, retrieved, metadata, embeddings, mannequin):
id_to_idx = {m["id"]: i for i, m in enumerate(metadata)}
chunk_vecs, ranks = [], []
for rank, r in enumerate(retrieved, begin=1):
idx = id_to_idx.get(r["id"])
if idx is None:
proceed
chunk_vecs.append(embeddings[idx])
ranks.append(rank)
if not chunk_vecs:
return [], sentences
chunk_matrix = np.vstack(chunk_vecs)
sent_embs = mannequin.encode(sentences, normalize_embeddings=True, convert_to_numpy=True)
Every sentence is embedded and in comparison with the embeddings of the top-ok retrieved chunks.
This yields 2 helpful artifacts:
support_rows: structured desk of assist scorescited_sentences: reply textual content annotated with citations comparable to [1], [2]
Instance: Sentence-to-Context Alignment
For instance, suppose the consumer requested:
“What’s Streamlit used for?”
The retriever would return the top-ok most related chunks for that question.
Every sentence within the mannequin’s generated reply is then in comparison with the retrieved chunks to find out how properly it’s supported (Desk 3).
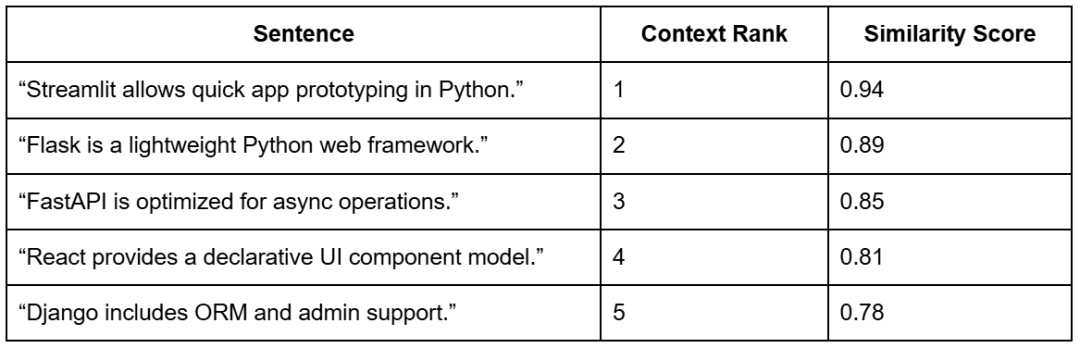
Notice: The context ranks come from the retrieval step based mostly on the question “What’s Streamlit used for?”. The similarity scores present how strongly every sentence aligns with these retrieved chunks — indicating how properly every a part of the generated reply is supported by proof.
Formatting and Styling
To show outcomes properly, the _apply_style() helper helps totally different output kinds:
def _apply_style(reply, fashion, cited_sentences):
if fashion == "bullets" and cited_sentences:
return "n" + "n".be a part of(f"- {s}" for s in cited_sentences)
return reply
This permits each paragraph and bullet-point summaries with inline citations — excellent for user-facing dashboards.
The Core: generate_rag_response()
Lastly, the star of this file — the principle RAG era perform:
def generate_rag_response(query, mannequin, embeddings, texts, metadata,
llm_model_name="llama3", top_k=5,
allow_synthesis=False, force_strict=False,
add_citations=False, compute_support=False,
fashion="paragraph") -> Dict:
This perform orchestrates the total retrieval-generation pipeline:
Step 1: Detect intent and embeddings
It embeds the query and routinely decides whether or not to permit synthesis:
if any(pat in q_lower for pat in config.AUTO_SYNTHESIS_PATTERNS):
allow_synthesis = True
heuristic_triggered = True
So if a question incorporates phrases like “why” or “advantages”, the mannequin routinely switches to a paraphrasing mode as an alternative of strict extraction.
Step 2: Retrieve top-ok chunks
high = select_top_k(q_emb, embeddings, texts, metadata, ok=top_k) immediate = build_prompt([r["text"] for r in high], query, allow_synthesis=allow_synthesis)
Step 3: Generate through LLM
if not ollama_available():
reply = "[Ollama not available at base URL.]"
else:
reply = call_ollama(llm_model_name, immediate)
Step 4: Non-obligatory post-processing
If citations or assist scoring are enabled:
sentences = _sentence_split(reply) support_rows, cited_sentences = _compute_support(sentences, high, metadata, embeddings, mannequin) reply = _apply_style(reply, fashion, cited_sentences)
Lastly, it returns a structured dictionary — containing all the things from the retrieved context to the generated reply and assist metrics.
Abstract of the Utilities
The rag_utils.py file gives a strong and extensible RAG spine:
- Native-first design: works seamlessly with Ollama or over HTTP
- Hybrid retrieval: embedding search + FAISS indexes
- Explainable outputs: sentence-level assist and citations
- Immediate management: configurable synthesis vs. strict modes
- Output flexibility: paragraph or bullet kinds, JSON export
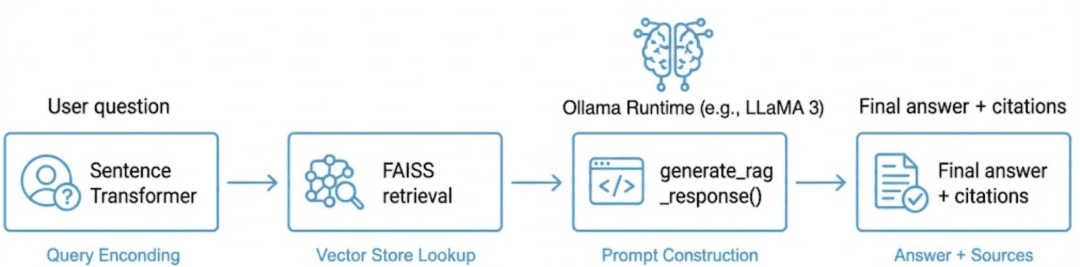
Operating a Native RAG Pipeline with Ollama and FAISS
Imports and Module Wiring
""" Steps: 1. Load embeddings & indexes (or construct fallbacks) 2. Settle for consumer query(s) 3. Retrieve top-k related chunks 4. Assemble immediate & name Ollama (fallback to placeholder if unavailable) 5. Show reply with retrieved context & scores """ from __future__ import annotations import argparse import json from pathlib import Path import numpy as np from wealthy import print from wealthy.desk import Desk from pyimagesearch import config from pyimagesearch.embeddings_utils import load_embeddings, load_corpus, get_model, generate_embeddings from pyimagesearch.vector_search_utils import build_flat_index, load_index, build_hnsw_index from pyimagesearch.rag_utils import generate_rag_response, list_ollama_models, ollama_available
What this units up:
- CLI (command line interface) flags (
argparse), fairly terminal output (wealthy), NumPy for arrays. - Pulls in config paths, embedding helpers, FAISS index builders and loaders, the RAG core (
generate_rag_response), and Ollama helpers.
Guarantee Embeddings (load or construct as soon as)
def ensure_embeddings(corpus_path=None, meta_path=None):
if config.EMBEDDINGS_PATH.exists():
emb, meta = load_embeddings()
texts, _ = load_corpus(corpus_path or config.CORPUS_PATH, meta_path or config.CORPUS_META_PATH)
return emb, meta, texts
texts, meta = load_corpus(corpus_path or config.CORPUS_PATH, meta_path or config.CORPUS_META_PATH)
mannequin = get_model()
emb = generate_embeddings(texts, mannequin=mannequin)
from pyimagesearch.embeddings_utils import save_embeddings
save_embeddings(emb, meta)
return emb, meta, texts
What it does (and why):
- If
information/output/embeddings.npyis current, it hundreds the embeddings and aligned metadata, then reads the present corpus to make sure your textual content checklist is updated. - If not current, it embeds the corpus with SentenceTransformer and caches each artifacts to disk for velocity on re-runs.
Guarantee Indexes (Flat should exist; HNSW is optionally available)
def ensure_indexes(embeddings):
# Strive load flat
idx = None
if config.FLAT_INDEX_PATH.exists():
attempt:
from pyimagesearch.vector_search_utils import load_index
idx = load_index(config.FLAT_INDEX_PATH)
besides Exception:
idx = None
if idx is None:
idx = build_flat_index(embeddings)
# Non-obligatory: try HNSW
hnsw = None
if config.HNSW_INDEX_PATH.exists():
attempt:
hnsw = load_index(config.HNSW_INDEX_PATH)
besides Exception:
hnsw = None
else:
attempt:
hnsw = build_hnsw_index(embeddings)
besides Exception:
hnsw = None
return idx, hnsw
What it does (and why):
- Flat index (precise, internal product): Makes an attempt to load from disk; if lacking, builds from the embedding matrix. This ensures you all the time have an accurate baseline.
- HNSW (approximate, quick): Hundreds if obtainable; in any other case builds the index. If FAISS isn’t put in with HNSW assist, it fails gracefully and returns
None. - Returns: A tuple (
flat,hnsw) for downstream use.
Interactive Q&A Loop — Non-obligatory Mode
def interactive_loop(mannequin, embeddings, texts, metadata, llm_model: str, top_k: int, allow_synth: bool):
print("[bold cyan]Enter questions (sort 'exit' to stop).[/bold cyan]")
whereas True:
attempt:
q = enter("Query> ").strip()
besides (EOFError, KeyboardInterrupt):
print("n[red]Exiting.[/red]")
break
if not q:
proceed
if q.decrease() in {"exit", "stop"}:
break
end result = generate_rag_response(q, mannequin, embeddings, texts, metadata, llm_model_name=llm_model, top_k=top_k, allow_synthesis=allow_synth)
show_result(end result)
What it does (and why):
- Enables you to chat along with your native RAG system.
- For every typed query, calls
generate_rag_response(...)— retrieves context → builds the immediate → calls Ollama → codecs the reply — and prints a wealthy desk of the outcomes.
Fairly Printing the Reply and Context (optionally available immediate/assist)
def show_result(end result, show_prompt: bool = False, show_support: bool = False):
print("n[bold green]Reply[/bold green]:")
print(end result["answer"].strip())
synth_flag = "sure" if end result.get("synthesis_used") else "no"
if end result.get("synthesis_used") and end result.get("synthesis_heuristic"):
print(f"[dim]Synthesis: {synth_flag} (auto-enabled by heuristic)n[/dim]")
else:
print(f"[dim]Synthesis: {synth_flag}n[/dim]")
desk = Desk(title="Retrieved Context")
desk.add_column("Rank")
desk.add_column("ID")
desk.add_column("Rating", justify="proper")
desk.add_column("Snippet")
for i, r in enumerate(end result["retrieved"], begin=1):
snippet = r["text"][:80] + ("..." if len(r["text"]) > 80 else "")
desk.add_row(str(i), r["id"], f"{r['score']:.3f}", snippet)
print(desk)
if show_prompt:
print("[bold yellow]n--- Immediate Despatched to LLM ---[/bold yellow]")
print(end result.get("immediate", "[prompt missing]"))
if show_support and end result.get("assist"):
support_table = Desk(title="Sentence Assist Scores")
support_table.add_column("Sentence")
support_table.add_column("Rank")
support_table.add_column("Rating", justify="proper")
for row in end result["support"]:
support_table.add_row(row["sentence"], str(row["citation_rank"]), f"{row['support_score']:.3f}")
print(support_table)
What it does (and why):
- Prints the closing reply and signifies whether or not synthesis was used (together with whether or not it was auto-enabled by the heuristic).
- Renders a Retrieved Context desk displaying rank, ID, similarity rating, and a clear snippet.
- If
--show-promptis used, prints the total immediate for transparency. - If
--support-scoresis enabled, exhibits per-sentence assist power towards the retrieved chunks — helpful for debugging groundedness.
CLI Entry Level (fundamental) — flags, loading, answering
def fundamental():
parser = argparse.ArgumentParser(description="Minimal RAG pipeline demo")
parser.add_argument("--llm-model", default="llama3", assist="Ollama mannequin identify (have to be pulled beforehand, e.g. 'ollama pull llama3')")
parser.add_argument("--top-k", sort=int, default=config.DEFAULT_TOP_K)
parser.add_argument("--corpus-path", sort=str, assist="Override corpus file path")
parser.add_argument("--corpus-meta-path", sort=str, assist="Override corpus metadata path")
parser.add_argument("--question", sort=str, assist="Single query to reply (skip interactive mode)")
parser.add_argument("--allow-synthesis", motion="store_true", assist="Allow mannequin to synthesize reply by combining offered context details")
parser.add_argument("--list-models", motion="store_true", assist="Record obtainable native Ollama fashions and exit")
parser.add_argument("--show-prompt", motion="store_true", assist="Show the total constructed immediate for debugging/educating")
parser.add_argument("--strict", motion="store_true", assist="Drive strict extractive mode (disable synthesis even when heuristic matches)")
parser.add_argument("--citations", motion="store_true", assist="Annotate sentences with quotation indices")
parser.add_argument("--style", selections=["paragraph", "bullets"], default="paragraph", assist="Reply formatting fashion")
parser.add_argument("--support-scores", motion="store_true", assist="Compute and show per-sentence assist scores")
parser.add_argument("--json", motion="store_true", assist="Output full end result JSON to stdout (suppresses fairly tables besides retrieved context)")
args = parser.parse_args()
if args.list_models:
if not ollama_available():
print("[red]Ollama not reachable at default base URL. Begin Ollama to checklist fashions.[/red]")
return
fashions = list_ollama_models()
if not fashions:
print("[yellow]No fashions returned. Pull some with: ollama pull llama3[/yellow]")
else:
print("[bold cyan]Obtainable Ollama fashions:[/bold cyan]")
for m in fashions:
print(f" - {m}")
return
print(f"[bold magenta]Utilizing LLM mannequin:[/bold magenta] {args.llm_model}")
print("[bold magenta]Loading embeddings...[/bold magenta]")
embeddings, metadata, texts = ensure_embeddings(corpus_path=args.corpus_path, meta_path=args.corpus_meta_path)
mannequin = get_model()
print("[bold magenta]Getting ready indexes (flat + optionally available hnsw)...[/bold magenta]")
flat, hnsw = ensure_indexes(embeddings)
# NOTE: We use embedding matrix straight for retrieval choice in rag_utils (cosine) for transparency.
if args.query:
end result = generate_rag_response(
args.query,
mannequin,
embeddings,
texts,
metadata,
llm_model_name=args.llm_model,
top_k=args.top_k,
allow_synthesis=args.allow_synthesis,
force_strict=args.strict,
add_citations=args.citations,
compute_support=args.support_scores,
fashion=args.fashion,
)
if args.json:
import json as _json
print(_json.dumps(end result, indent=2))
show_result(end result, show_prompt=args.show_prompt, show_support=args.support_scores)
else:
# For interactive mode we maintain earlier conduct (may prolong flags equally if desired)
interactive_loop(mannequin, embeddings, texts, metadata, args.llm_model, args.top_k, args.allow_synthesis)
print("[green]nFinished RAG demo.n[/green]")
What it does (and why):
- Defines a wealthy set of flags to manage the mannequin, retrieval depth, strictness vs. synthesis, immediate visibility, citations, fashion, and JSON output.
--list-modelsenables you to sanity-check your native Ollama setup with out working the total pipeline.- Hundreds or creates embeddings, prepares indexes, then both:
- solutions a single query (
--question ...), or - launches the interactive loop.
- solutions a single query (
- Non-obligatory JSON output is beneficial for scripting or automated assessments.
Normal Python Entrypoint
if __name__ == "__main__":
fundamental()
What it does:
- Runs the CLI once you execute
python 03_rag_pipeline.py.
Tiny Gotchas and Suggestions
- If FAISS was put in with out HNSW assist,
ensure_indexeswill nonetheless work — it simply won’t present an HNSW index. The Flat index is all the time obtainable. - Ensure that the Ollama mannequin you request (e.g.,
llama3) is pulled first:
ollama pull llama3
- You’ll be able to view precisely what the mannequin noticed with:
python 03_rag_pipeline.py --question "What's IVF indexing?" --show-prompt
- For educating and debugging groundedness:
python 03_rag_pipeline.py --question "Why normalize embeddings?" --citations --support-scores
How you can Run a Native RAG System with Ollama and FAISS
Now that all the things’s wired up — embeddings, FAISS indexes, and the RAG utilities — it’s time to see the total pipeline in motion.
You can begin by verifying your native Ollama setup and making certain the mannequin (e.g., Llama 3) is pulled:
ollama pull llama3
Then, out of your venture root, launch the RAG pipeline:
python 03_rag_pipeline.py --question "What's FAISS?" --show-prompt --support-scores
In the event you’d reasonably chat interactively:
python 03_rag_pipeline.py
You’ll be greeted with a immediate like:
Query> Why can we normalize embeddings?
and may exit at any time with exit or Ctrl+C.
Instance Output
Right here’s what a typical run appears like inside your terminal (Determine 11).

What You Discovered: Constructing a Manufacturing-Prepared Native RAG System with Ollama and FAISS
By the tip of this tutorial, you’ll have constructed and examined an entire, native Retrieval-Augmented Technology (RAG) system:
- Related the FAISS vector retailer inbuilt Lesson 2 to a neighborhood LLM served by Ollama.
- Used embeddings to retrieve semantically related chunks out of your corpus.
- Constructed prompts dynamically and generated grounded solutions, optionally together with citations and synthesis.
This closes the loop of your vector → retrieval → era workflow — forming the inspiration for extra superior, production-ready RAG pipelines.
What’s subsequent? We suggest PyImageSearch College.
86+ complete courses • 115+ hours hours of on-demand code walkthrough movies • Final up to date: February 2026
★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly consider that in case you had the best trainer you may grasp laptop imaginative and prescient and deep studying.
Do you suppose studying laptop imaginative and prescient and deep studying needs to be time-consuming, overwhelming, and complex? Or has to contain advanced arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All you have to grasp laptop imaginative and prescient and deep studying is for somebody to clarify issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to vary schooling and the way advanced Synthetic Intelligence matters are taught.
In the event you’re critical about studying laptop imaginative and prescient, your subsequent cease ought to be PyImageSearch College, essentially the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line right this moment. Right here you’ll discover ways to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and tasks. Be part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
- &examine; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV matters
- &examine; 86 Certificates of Completion
- &examine; 115+ hours hours of on-demand video
- &examine; Model new programs launched frequently, making certain you possibly can sustain with state-of-the-art methods
- &examine; Pre-configured Jupyter Notebooks in Google Colab
- &examine; Run all code examples in your internet browser — works on Home windows, macOS, and Linux (no dev atmosphere configuration required!)
- &examine; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &examine; Simple one-click downloads for code, datasets, pre-trained fashions, and many others.
- &examine; Entry on cell, laptop computer, desktop, and many others.
Abstract
On this closing lesson, you introduced all the things collectively (i.e., embeddings, vector search, and era) to construct an entire Retrieval-Augmented Technology (RAG) pipeline from scratch. You started by understanding how retrieval connects to language fashions, bridging the hole between semantic search and contextual reasoning.
Subsequent, you explored how the system makes use of SentenceTransformer embeddings and FAISS indexes to fetch related context from a corpus earlier than producing a solution. You then examined the RAG utilities intimately — from ollama_available() and call_ollama(), which deal with mannequin calls and fallbacks, to select_top_k(), which performs the essential retrieval step by rating and filtering outcomes based mostly on cosine similarity. You additionally noticed how automated synthesis heuristics decide when to permit the LLM to mix info creatively, including flexibility to the pipeline.
Then got here the driver script, the place the theoretical items remodeled right into a working software. You walked by the total stream — loading embeddings, making ready indexes, retrieving the top-ok most related chunks, and producing context-aware solutions through Ollama. You additionally discovered how you can add citations, measure assist scores, and change between strict and synthesis modes for clear reasoning.
Lastly, you ran the pipeline domestically, queried your personal information, and noticed significant, grounded responses generated by a neighborhood LLM. With this, you accomplished a real end-to-end workflow — from encoding and indexing information to retrieving and producing solutions — working totally offline and powered by FAISS and Ollama.
In brief, you didn’t simply study RAG — you constructed it.
Quotation Data
Singh, V. “Vector Search Utilizing Ollama for Retrieval-Augmented Technology (RAG),” PyImageSearch, P. Chugh, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/q68nv
@incollection{Singh_2026_vector-search-using-ollama-for-rag,
writer = {Vikram Singh},
title = {{Vector Search Utilizing Ollama for Retrieval-Augmented Technology (RAG)}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Aditya Sharma and Piyush Thakur},
12 months = {2026},
url = {https://pyimg.co/q68nv},
}
To obtain the supply code to this publish (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your electronic mail handle within the kind under!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your electronic mail handle under to get a .zip of the code and a FREE 17-page Useful resource Information on Laptop Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that can assist you grasp CV and DL!
The publish Vector Search Utilizing Ollama for Retrieval-Augmented Technology (RAG) appeared first on PyImageSearch.