
 – Statisfaction")
Say I need to approximate the integral
based mostly on 

![hat{I}(f) = n^{-1}sum_{i=1}^n f(U_i),quad U_isim U([0, 1]^s).](https://s0.wp.com/latex.php?latex=%5Chat%7BI%7D%28f%29+%3D+n%5E%7B-1%7D%5Csum_%7Bi%3D1%7D%5En+f%28U_i%29%2C%5Cquad+U_i%5Csim+U%28%5B0%2C+1%5D%5Es%29.&bg=FFFFFF&fg=181818&s=0&c=20201002)
whose RMSE (root imply sq. error) is 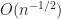
Can I do higher? That’s, can I design an alternate estimator/algorithm, which performs
Surprisingly (to me no less than), the reply to this query has been recognized for a very long time. If I’m able to concentrate on capabilities ![finmathcal{C}^r([0, 1]^s)](https://s0.wp.com/latex.php?latex=f%5Cin%5Cmathcal%7BC%7D%5Er%28%5B0%2C+1%5D%5Es%29&bg=FFFFFF&fg=181818&s=0&c=20201002)

Okay, however how can I really design such an algorithm? The proof of Bakhvalov comprises a easy recipe. Say I’m able to assemble a superb approximation 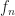

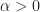
![hat{I}(f) := I(f_n) + n^{-1} sum_{i=1}^n (f-f_n)(U_i),quad U_isim U([0, 1]^s).](https://s0.wp.com/latex.php?latex=%5Chat%7BI%7D%28f%29+%3A%3D+I%28f_n%29+%2B+n%5E%7B-1%7D+%5Csum_%7Bi%3D1%7D%5En+%28f-f_n%29%28U_i%29%2C%5Cquad+U_i%5Csim+U%28%5B0%2C+1%5D%5Es%29.&bg=FFFFFF&fg=181818&s=0&c=20201002)
and it’s simple to test that this new estimator (based mostly on 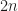
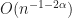
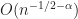
So there’s sturdy connection between stochastic quadrature and performance approximation. In actual fact, the most effective fee you possibly can obtain for the latter is 
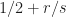
Now you can higher perceive the “with out QMC” within the title. QMC is about utilizing factors which can be “higher” than random factors. However right here I’m utilizing IID factors, and the improved fee comes from the very fact I take advantage of a greater approximation of
Right here is an easy instance of a superb perform approximation. Take 
![f_n(u) = sum_{i=1}^n f(frac{2i-1}{2n}) 1_{[(i-1)/n, i/n]}(u)](https://s0.wp.com/latex.php?latex=f_n%28u%29+%3D+%5Csum_%7Bi%3D1%7D%5En+f%28%5Cfrac%7B2i-1%7D%7B2n%7D%29+1_%7B%5B%28i-1%29%2Fn%2C+i%2Fn%5D%7D%28u%29&bg=FFFFFF&fg=181818&s=0&c=20201002)
that’s, break up ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=FFFFFF&fg=181818&s=0&c=20201002)
![[(i-1)/n, i/n]](https://s0.wp.com/latex.php?latex=%5B%28i-1%29%2Fn%2C+i%2Fn%5D&bg=FFFFFF&fg=181818&s=0&c=20201002)
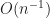
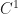
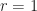
Is it doable to generalise such a development to any 

Additionally, please remind me to not attempt to kind latex in wordpress ever once more, it looks like this: