

{kind=link}
There’s a set of ideas crossing my thoughts that I’d wish to share right now. Hopefully that is helpful for everybody. Per my ordinary, since this isn’t a direct Claude Code publish, I flip cash as as to if to right away paywall it. And it’s once more two heads vs one tails, and subsequently it’s paywalled, about 30-40% of the best way down.
So thanks once more in your help of me and this substack. It’s enormously appreciated.
Probably the most poplar new diff-in-diff estimators is Callaway and Sant’anna. It has over 11,000 cites and within the APE knowledge from the Social Catalyst Lab, it’s the commonest estimator selected by AI Brokers. It’s used when there are a number of therapy intervals or “staggered adoption”.
It’s a simple estimator in some ways. In contrast to two-way fastened results, the place the entire knowledge is processed as soon as utilizing matrix calculations to resolve for a single coefficient, CS as its typically known as estimates smaller constructing block coefficients, one after the other, after which takes weighted averages of them when you’ve accomplished doing them. These coefficients are known as 2x2s and when assumptions maintain they map onto one thing known as the group-time ATT, or ATT(g,t). The ATT(g,t) is a inhabitants estimand, as they are saying, which in a sampling framework means for those who had all the info, you’d calculate it like this:
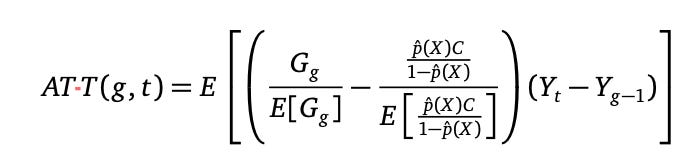
The capital G is a dummy variable indicating whether or not you might be in a gaggle, g. The “p-hat” is the propensity rating (on this case estimated with logit), the C is a dummy indicating you might be not handled. And Y is the result.