

{kind=link}
AI demos typically look spectacular, delivering quick responses, polished communication, and robust efficiency in managed environments. However as soon as actual customers work together with the system, points floor like hallucinations, inconsistent tone, and solutions that ought to by no means be given. What appeared prepared for manufacturing rapidly creates friction and exposes the hole between demo success and real-world reliability.
This hole exists as a result of the problem isn’t just the mannequin, it’s the way you form and floor it. Groups typically default to a single strategy, then spend weeks fixing avoidable errors. The actual query is just not whether or not to make use of immediate engineering, RAG, or fine-tuning, however when and easy methods to use every. On this article, we break down the variations and enable you select the proper path.
The three Errors Most Groups Make First
Earlier than going into element concerning the totally different strategies for utilizing generative AI successfully, let’s begin with a number of the the reason why points persist in a corporation in the case of profitable implementation of generative AI. Many of those errors might be averted.
- Superb Tuning First: Superb-tuning the answer sounds nice (particularly coaching the generative AI mannequin utilizing your information). Nonetheless, fine-tuning your mannequin is commonly the costliest, time-consuming strategy. You could possibly possible have resolved 80% of the issue in as little time as a day by writing a extremely crafted immediate.
- Plug and Play: In case you are treating your Retrieval-Augmented Era (RAG) implementation as merely dropping your paperwork right into a vector database, connecting that database to an occasion of the GPT-4 mannequin, and delivery it. Your implementation is probably going going to fail resulting from poorly designed chunks, poor retrieval high quality, and incorrect mannequin technology primarily based on incorrect paragraphs of textual content.
- Immediate Engineering as an Afterthought: Most groups strategy the constructing of their prompts as if they’re constructing a Google search question. The truth is, growing clear directions, examples, constraints, and output formatting in your system immediate can take a mediocre expertise to a production-quality expertise.
Now let’s start to discover the potential for every strategy.
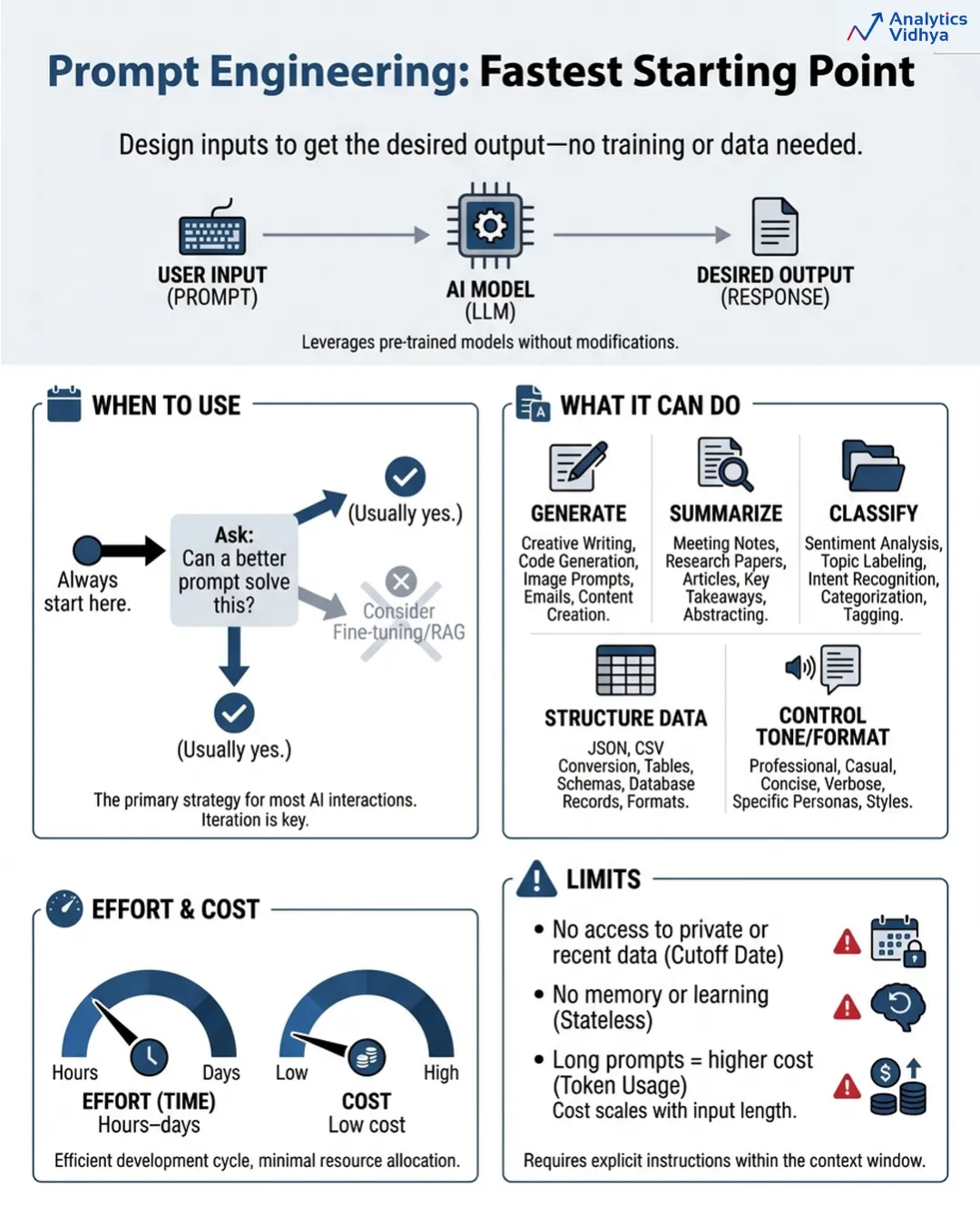
The artwork of immediate engineering requires you to design your mannequin interactions so that you simply obtain your required leads to all conditions. The system operates with none coaching or databases as a result of it requires solely clever consumer enter.
The method appears simple to finish however truly requires extra effort than first obvious. The method of immediate engineering requires all of those duties to be executed appropriately as a result of it wants a exact mannequin to carry out particular actions.
When to make use of it
Your preliminary step ought to be to start out with immediate engineering. Your group ought to comply with this guideline always. Earlier than you spend money on anything, ask: can a greater immediate remedy this? The widespread state of affairs happens the place the response to this query proves to be true greater than you anticipate.
The system can generate content material whereas it generates summaries and classifies info and creates structured information and controls each tone and format and executes particular duties. The system requires higher directions as a result of the mannequin already possesses all crucial data in response to the prevailing requirements.
The precise restrictions
- The system can solely make the most of current info which the mannequin already possesses. Your case wants entry to inner paperwork of your group and up to date product materials and knowledge which exceeds the coaching date of the mannequin design as a result of no immediate can bridge that requirement.
- The system operates by way of prompts as a result of they keep no state info. The system operates by way of prompts which aren’t able to studying. The system begins all operations from a clean state. The system develops excessive bills when it handles prolonged and sophisticated prompts throughout massive operations.
- The required time to finish the duty ranges from a number of hours to a number of days.
- The overall bills for the venture stay at a particularly low stage. The venture ought to proceed till all related questions obtain most factual accuracy.
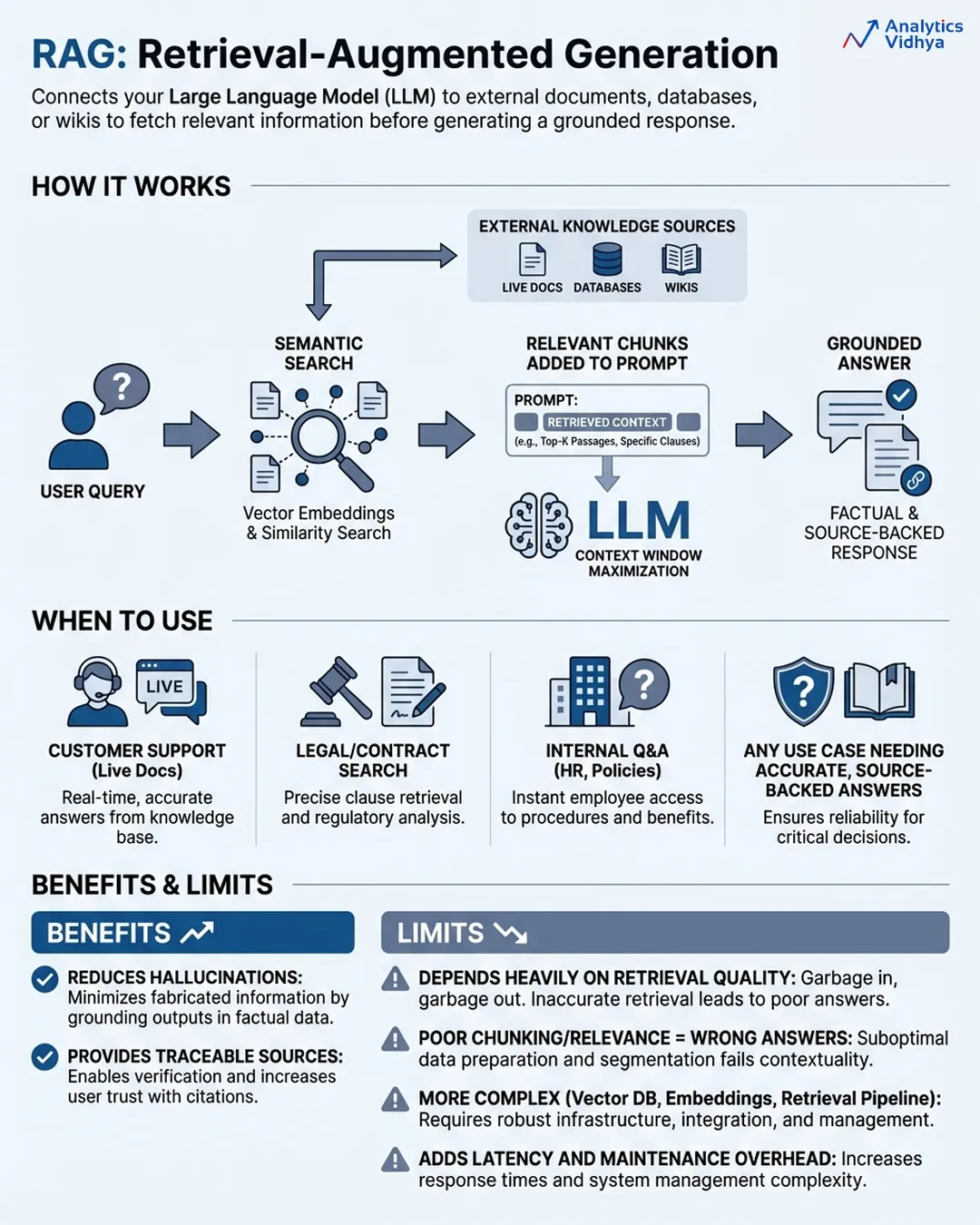
RAG (Retrieval-Augmented Era): Giving the Intern a Library Card
The RAG system establishes a connection between your LLM and exterior data bases which embody your paperwork and databases and product wikis and assist tickets by way of which the mannequin retrieves related information to create its solutions. The circulate seems to be like this:
- Consumer asks a query
- System searches your data base utilizing semantic search (not simply key phrase matching, it searches by that means)
- Essentially the most related chunks get pulled and inserted into the immediate
- The mannequin generates a solution grounded in that retrieved context
The system distinguishes between two methods your AI can present solutions that are primarily based on its recollections and its entry to authentic factual info. The precise time to make use of RAG happens when your downside requires data which the mannequin must reply appropriately. That is most real-world enterprise use circumstances.
When to make use of it:
- Buyer assist bots that must reference stay product docs.
- Authorized instruments that want to look contracts.
- Inside Q&A methods that pull from HR insurance policies.
- Any state of affairs which requires info from paperwork to attain pinpoint right solutions with out deviation.
RAG helps you doc reply origins as a result of it permits customers to trace which supply offered them right info. The regulated industries discover this stage of transparency an essential worth.
The precise restrictions:
The actual limits of RAG methods depend upon the standard of their retrieval course of as a result of RAG methods exist by way of their retrieval course of. The mannequin generates a whole incorrect response as a result of it receives incorrect fragments in the course of the search course of. Most RAG methods fail as a result of their implementation comprises three hidden issues which embody improper chunking strategies and incorrect mannequin choice with inadequate relevance evaluation strategies.
The system creates further delay as a result of it requires extra advanced constructing parts. It’s worthwhile to deal with three parts which embody a vector database and embedding pipeline and retrieval system. The system requires steady assist as a result of it doesn’t operate as a easy set up.
Superb-Tuning: Sending the Intern Again to College
Superb-tuning lets you prepare your personal mannequin by way of the method of coaching a pre-existing base mannequin together with your particular labeled dataset which comprises all of the enter and output examples that you simply want. The mannequin’s weights are up to date. The system implements modifications in response to its current construction with out requiring further directions to operate. The mannequin undergoes transformation as a result of the system implements its personal modifications.
The result’s a specialised model of the bottom mannequin which has discovered to make use of the vocabulary out of your area whereas producing outputs in response to your specified model and following your outlined behaviour guidelines and your particular activity necessities.
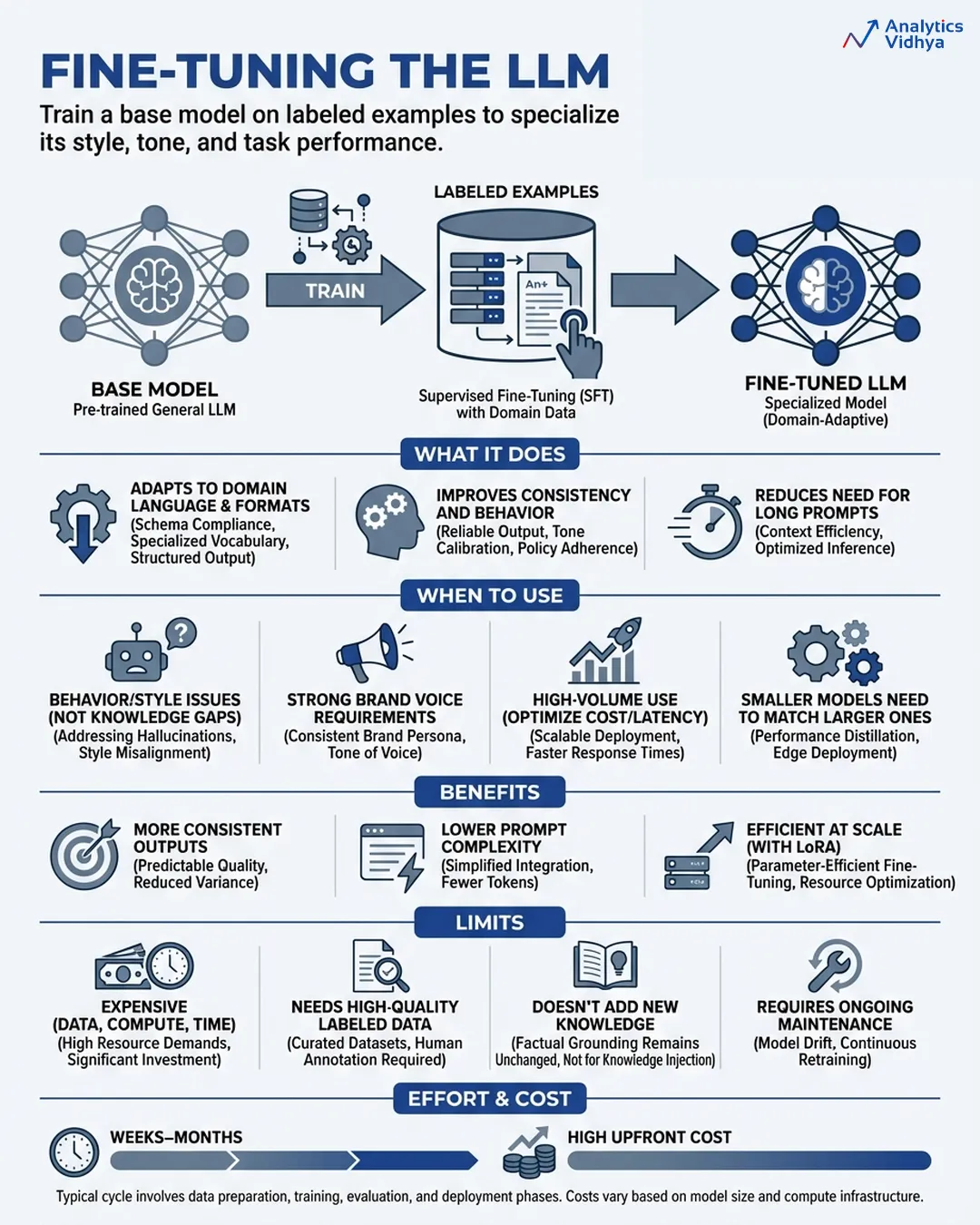
The trendy methodology of LoRA (Low-Rank Adaptation) achieves higher accessibility by way of its system which wants only some parameter updates to function as a result of this methodology decreases computing bills whereas sustaining most efficiency advantages.
When to make use of it
Superb-tuning earns its place when you might have a behaviour downside, not a data downside.
- Your model voice is very particular and prompting alone can’t maintain it persistently at scale.
- Your particular activity requires you to make use of a smaller mannequin that prices much less whereas performing on the identical stage as a bigger common mannequin.
- The mannequin requires full understanding of all domain-specific phrases and specific reasoning strategies and their related codecs.
- It’s worthwhile to take away all pricey immediate directions as a result of your system handles a big quantity of inference requests.
- It’s worthwhile to scale back undesirable behaviors which embody particular kinds of hallucinations and inappropriate refusals and incorrect output patterns.
The device turns into appropriate in your wants once you intend to develop a extra compact mannequin. A fine-tuned GPT-3.5 or Sonnet system can carry out at an identical stage as GPT-4o when used for particular duties whereas needing much less processing energy throughout inference.
The actual limits
- Superb-tuning requires substantial money assets and time assets and information assets for its execution. The method calls for lots of to 1000’s of top-notches labeled samples along with in depth computational assets in the course of the studying section and steady maintenance at any time when the elemental mannequin receives enhancements. Unhealthy coaching information doesn’t simply fail to assist, it actively hurts.
- Superb-tuning doesn’t give the mannequin new data. The method modifies mannequin operations. The mannequin is not going to purchase product data by way of inner paperwork as a result of they’ve turn into outdated. The system exists to perform that purpose.
- Coaching runs would require weeks to finish whereas information high quality will want months to finish its iteration cycles and the general bills can be a lot increased than typical crew budgets.
- The time wanted for work completion ranges from weeks to months. The preliminary funding can be substantial whereas the inference bills will exceed base mannequin prices by six occasions. The answer ought to be used when organizations want to ascertain constant efficiency throughout their operations after finishing each immediate engineering and RAG implementation.
The Choice Framework
There are few issues to bear in mind whereas deciding which optimization methodology to go for first:
- Is it a communication concern? → Begin by doing immediate engineering first, together with examples and specific formatting. Ship in days or much less.
- Is it a difficulty of data? → Incorporate RAG. Overlay a clear retrieval on prime of current paperwork. Ensure that the reply from the mannequin contains proof from exterior sources.
- Is it a behaviour concern? → Take into consideration fine-tuning the mannequin. The mannequin continues to misbehave resulting from prompting or information alone being inadequate.
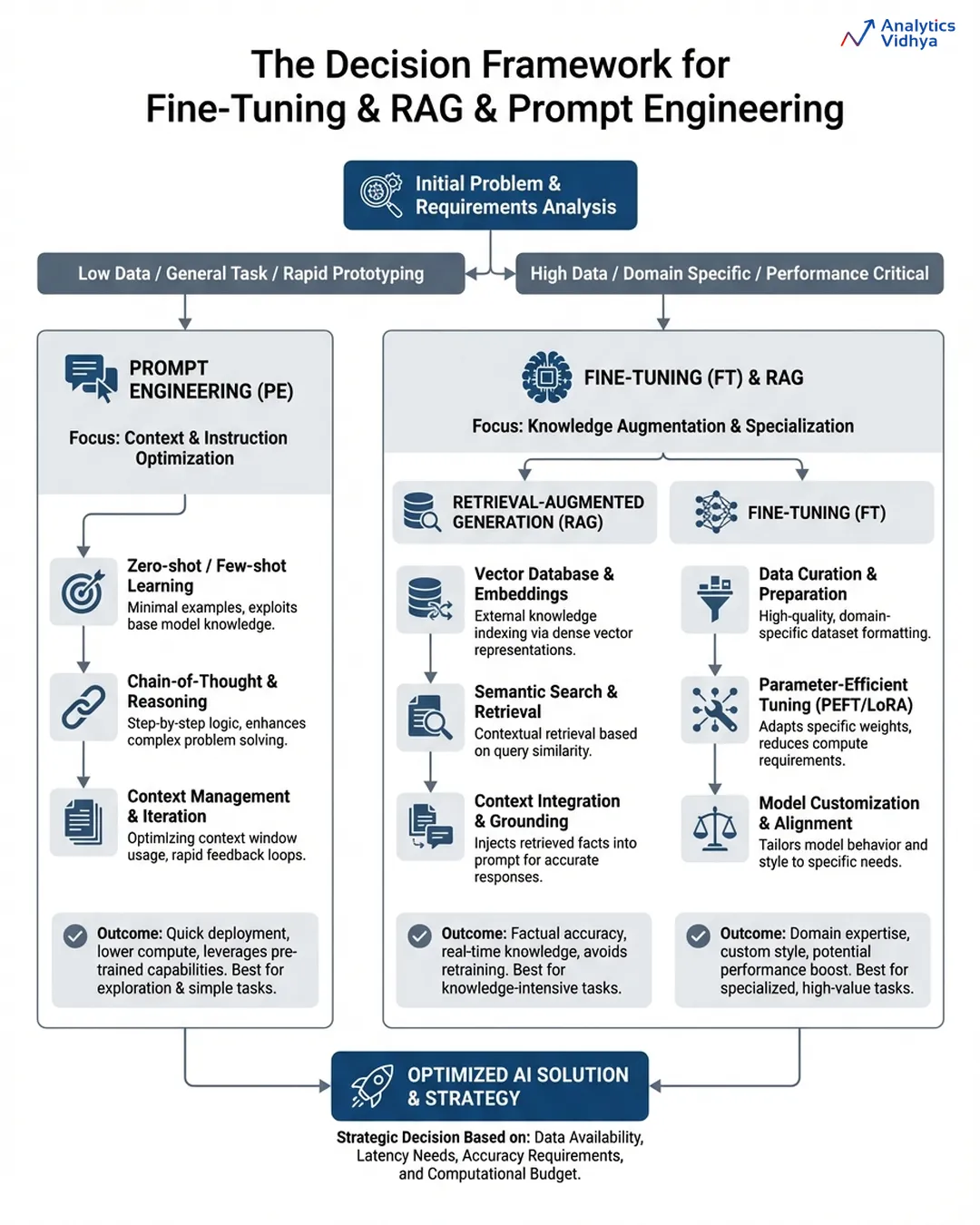
You’ll discover that almost all manufacturing methods will incorporate all three kinds of options layered collectively, and the sequence wherein they had been used is essential: immediate engineering is finished first, RAG is applied as soon as data is the limiting issue, and fine-tuning is utilized when there are nonetheless points with constant behaviour throughout massive scale.
Abstract Comparability
Let’s attempt to perceive a differentiation between all three primarily based on some essential parameters:
| Immediate Engineering | RAG | Superb-Tuning | |
| Solves | Communication | Information gaps | Habits at scale |
| Pace | Hours | Days–Weeks | Months |
| Value | Low | Medium | Excessive |
| Updates simply? | Sure | Sure | No — retrain wanted |
| Provides new data? | No | Sure | No |
| Adjustments mannequin habits? | Briefly | No | Completely |
Now, let’s see an in depth comparability through an infographic:

You should use this infographic for future reference.
Conclusion
The largest mistake in AI product growth is selecting instruments earlier than understanding the issue. Begin with immediate engineering, as most groups underinvest right here regardless of its velocity, low value, and shocking effectiveness when achieved properly. Transfer to RAG solely once you hit limits with data entry or want to include proprietary information.
Superb-tuning ought to come final, solely after different approaches fail and habits breaks at scale. The very best groups usually are not chasing advanced architectures, they’re those who clearly outline the issue first and construct accordingly.
Incessantly Requested Questions
A. Begin with immediate engineering to unravel communication and formatting points rapidly and cheaply earlier than including complexity.
A. Use RAG when your system wants correct, up-to-date, or proprietary data past what the bottom mannequin already is aware of.
A. Select fine-tuning solely when habits stays inconsistent at scale after prompts and RAG fail to repair the issue.
Knowledge Science Trainee at Analytics Vidhya
I’m presently working as a Knowledge Science Trainee at Analytics Vidhya, the place I concentrate on constructing data-driven options and making use of AI/ML methods to unravel real-world enterprise issues. My work permits me to discover superior analytics, machine studying, and AI functions that empower organizations to make smarter, evidence-based selections.
With a powerful basis in laptop science, software program growth, and information analytics, I’m obsessed with leveraging AI to create impactful, scalable options that bridge the hole between expertise and enterprise.
📩 You too can attain out to me at [email protected]
Login to proceed studying and luxuriate in expert-curated content material.