

{kind=link}
In my earlier put up, we discovered the best way to use the Stata Perform Interface (SFI) module to repeat information from Stata to Python. On this put up, I’ll present you the best way to use the SFI module to repeat information from Python to Stata. We can be utilizing the yfinance module to obtain monetary information from the Yahoo! finance web site. You possibly can set up this module in your Python setting by typing pip set up yfinance. Our purpose is to make use of Python to obtain historic information for the Dow Jones Industrial Common (DJIA) and use Stata to create the next graph.
If you’re not aware of Python, it could be useful to learn the primary 4 posts in my Stata/Python Integration sequence earlier than you learn additional.
- Establishing Stata to make use of Python
- 3 ways to make use of Python in Stata
- Easy methods to set up Python packages
- Easy methods to use Python packages
Utilizing the yfinance module to obtain Yahoo! finance information
Let’s start by importing the yfinance module utilizing the alias pd. Then, we’ll use the obtain() technique to obtain information for the DJIA from the Yahoo! finance web site. The obtain() technique accepts three arguments. The primary argument is the inventory image for the DJIA. The second argument is the beginning date for the inventory information, and the third argument is the top date.
python:
import yfinance as yf
dowjones = yf.obtain("^DJI", begin="2010-01-01", finish="2019-12-31")
dowjones
finish
The obtain() technique returns a Pandas information body with 2,515 rows and 6 columns listed by date.
. python:
----------------------------------------------- python (kind finish to exit) ------
>>> import yfinance as yf
>>> dowjones = yf.obtain("^DJI", begin="2010-01-01", finish="2019-12-31")
[*********************100%***********************] 1 of 1 accomplished
>>> dowjones
Open Excessive ... Adj Shut Quantity
Date ...
2010-01-04 10430.690430 10604.969727 ... 10583.959961 179780000
2010-01-05 10584.559570 10584.559570 ... 10572.019531 188540000
2010-01-06 10564.719727 10594.990234 ... 10573.679688 186040000
2010-01-07 10571.110352 10612.370117 ... 10606.860352 217390000
2010-01-08 10606.400391 10619.400391 ... 10618.190430 172710000
... ... ... ... ... ...
2019-12-23 28491.779297 28582.490234 ... 28551.529297 223530000
2019-12-24 28572.570312 28576.800781 ... 28515.449219 86150000
2019-12-26 28539.460938 28624.099609 ... 28621.390625 155970000
2019-12-27 28675.339844 28701.660156 ... 28645.259766 182280000
2019-12-30 28654.759766 28664.689453 ... 28462.140625 181600000
[2515 rows x 6 columns]
>>> finish
--------------------------------------------------------------------------------
We are able to view the main points of the index by typing dowjones.index in Python. The output beneath reveals us that the index column is called ‘Date’, which is saved as the information kind datetime64[ns].
. python: ----------------------------------------------- python (kind finish to exit) ------ >>> dowjones.index DatetimeIndex(['2010-01-04', '2010-01-05', '2010-01-06', '2010-01-07', '2010-01-08', '2010-01-11', '2010-01-12', '2010-01-13', '2010-01-14', '2010-01-15', ... '2019-12-16', '2019-12-17', '2019-12-18', '2019-12-19', '2019-12-20', '2019-12-23', '2019-12-24', '2019-12-26', '2019-12-27', '2019-12-30'], dtype="datetime64[ns]", identify="Date", size=2515, freq=None) >>> finish --------------------------------------------------------------------------------
We should convert the index to a string variable earlier than we copy it to a Stata variable. We are able to use the astype() technique to create a brand new column named dowdate that incorporates the index saved as a string.
. python:
----------------------------------------------- python (kind finish to exit) ------
>>> dowjones['dowdate'] = dowjones.index.astype(str)
>>> dowjones['dowdate']
Date
2010-01-04 2010-01-04
2010-01-05 2010-01-05
2010-01-06 2010-01-06
2010-01-07 2010-01-07
2010-01-08 2010-01-08
...
2019-12-23 2019-12-23
2019-12-24 2019-12-24
2019-12-26 2019-12-26
2019-12-27 2019-12-27
2019-12-30 2019-12-30
Title: dowdate, Size: 2515, dtype: object
>>> finish
--------------------------------------------------------------------------------
Use the SFI module to repeat the Python information to Stata
Now, we’re prepared to make use of the SFI module to repeat the dowjones information body to Stata. We start by importing the Knowledge class from the SFI module. Then, we are able to use the setObsTotal() technique so as to add observations to the present Stata dataset. We should add sufficient observations to the Stata dataset to retailer all of the rows of the dowjones information body. We are able to rely the variety of rows utilizing the
len() technique.
. python: ----------------------------------------------- python (kind finish to exit) ------ ... from sfi import Knowledge >>> Knowledge.setObsTotal(len(dowjones)) >>> finish --------------------------------------------------------------------------------
Subsequent, we’ll add three variables to the Stata dataset. The addVarStr() technique provides a 10-character string variable named “dowdate”. The addVarDouble() technique provides a double-precision variable named “dowclose”. And the addVarInt() technique provides an int variable named “dowvolume”.
. python:
----------------------------------------------- python (kind finish to exit) ------
>>> Knowledge.addVarStr("dowdate",10)
>>> Knowledge.addVarDouble("dowclose")
>>> Knowledge.addVarInt("dowvolume")
>>> finish
--------------------------------------------------------------------------------
Now, we are able to use the retailer() technique to repeat columns from the Pandas information body to variables within the Stata dataset. retailer() accepts 4 arguments. The primary argument is the identify of the Stata variable to which the Pandas column is to be copied. The second argument can be utilized to specify a subset of the information body to be copied. For instance, we may use the vary() operate to specify a spread of rows to repeat. I want to copy all of the observations so I’ve specified “None”. The third argument is the Python information that’s to be copied to Stata. The fourth argument is the identify of an indicator variable that specifies which rows within the Python information body are to be copied to the Stata variable. This argument is non-obligatory. When it’s not specified,
all of the rows within the Python information body are copied.
The primary assertion within the output beneath copies column dowdate from the Python information body dowjones to the Stata variable dowdate. The second assertion copies column Adj Shut from the Python information body dowjones to the Stata variable dowclose. The third assertion within the output beneath copies column Quantity from the Python information body dowjones to the Stata variable dowvolume. Be aware that I’ve specified “None” for the second and fourth arguments as a result of I want to copy all of the rows from the Pandas information body.
. python:
----------------------------------------------- python (kind finish to exit) ------
>>> Knowledge.retailer("dowdate", None, dowjones['dowdate'], None)
>>> Knowledge.retailer("dowclose", None, dowjones['Adj Close'], None)
>>> Knowledge.retailer("dowvolume", None, dowjones['Volume'], None)
>>> finish
--------------------------------------------------------------------------------
Clear the Stata dataset
Let’s checklist the primary 5 observations in our Stata dataset to test our work.
. checklist in 1/5, abbreviate(9)
+-----------------------------------+
| dowdate dowclose dowvolume |
|-----------------------------------|
1. | 2010-01-04 10583.96 1.8e+08 |
2. | 2010-01-05 10572.02 1.9e+08 |
3. | 2010-01-06 10573.68 1.9e+08 |
4. | 2010-01-07 10606.86 2.2e+08 |
5. | 2010-01-08 10618.19 1.7e+08 |
+-----------------------------------+
Our information look fairly good, however we have now a number of information administration duties to finish earlier than we are able to graph the information. First, recall that dowdate is saved as a string. Let’s use Stata’s date() operate to generate a brand new variable named date. The primary argument is the string variable that’s to be transformed to a date. The second argument is the order of the 12 months, month, and day within the first argument. I’ve specified “YMD” as a result of the information in dowdate are saved with the 12 months first, the month second, and the day third.
. generate date = date(dowdate,"YMD")
. checklist in 1/5, abbreviate(9)
+-------------------------------------------+
| dowdate dowclose dowvolume date |
|-------------------------------------------|
1. | 2010-01-04 10583.96 1.798e+08 18266 |
2. | 2010-01-05 10572.02 1.885e+08 18267 |
3. | 2010-01-06 10573.68 1.860e+08 18268 |
4. | 2010-01-07 10606.86 2.174e+08 18269 |
5. | 2010-01-08 10618.19 1.727e+08 18270 |
+-------------------------------------------+
The information in date don’t seem like dates to you and me. The date() operate returns the variety of days since January 1, 1960. We are able to use format to show the information in a well-known date format.
. format %tdCCYY-NN-DD date
. checklist in 1/5, abbreviate(9)
+------------------------------------------------+
| dowdate dowclose dowvolume date |
|------------------------------------------------|
1. | 2010-01-04 10583.96 1.798e+08 2010-01-04 |
2. | 2010-01-05 10572.02 1.885e+08 2010-01-05 |
3. | 2010-01-06 10573.68 1.860e+08 2010-01-06 |
4. | 2010-01-07 10606.86 2.174e+08 2010-01-07 |
5. | 2010-01-08 10618.19 1.727e+08 2010-01-08 |
+------------------------------------------------+
Subsequent, dowvolume is displayed in scientific notation. We are able to once more use format to show the numbers with commas within the hundreds place.
. format %16.0fc dowvolume
. checklist in 1/5, abbreviate(9)
+--------------------------------------------------+
| dowdate dowclose dowvolume date |
|--------------------------------------------------|
1. | 2010-01-04 10583.96 179,780,000 2010-01-04 |
2. | 2010-01-05 10572.02 188,540,000 2010-01-05 |
3. | 2010-01-06 10573.68 186,040,000 2010-01-06 |
4. | 2010-01-07 10606.86 217,390,000 2010-01-07 |
5. | 2010-01-08 10618.19 172,710,000 2010-01-08 |
+--------------------------------------------------+
It appears like dowvolume is rounded to the closest 10,000. So let’s divide dowvolume by 1,000,000 and use format to show the information with two decimal locations. Let’s additionally label dowvolume in order that we don’t overlook that the information are saved as “tens of millions of shares”.
. exchange dowvolume = dowvolume/1000000
(2,515 actual modifications made)
. format %10.2fc dowvolume
. label variable dowvolume "DJIA Quantity (Tens of millions of Shares)"
. checklist in 1/5, abbreviate(9)
+------------------------------------------------+
| dowdate dowclose dowvolume date |
|------------------------------------------------|
1. | 2010-01-04 10583.96 179.78 2010-01-04 |
2. | 2010-01-05 10572.02 188.54 2010-01-05 |
3. | 2010-01-06 10573.68 186.04 2010-01-06 |
4. | 2010-01-07 10606.86 217.39 2010-01-07 |
5. | 2010-01-08 10618.19 172.71 2010-01-08 |
+------------------------------------------------+
Our information are formatted and able to graph.
Graph the information
I’d wish to create a graph that features a line graph for dowclose and a bar chart for dowvolume. That is straightforward with graph twoway. We are able to use graph twoway line to create a line plot for dowclose and graph twoway bar for dowvolume. Chances are you’ll be aware of most of the graphics choices within the code block beneath. I’ve used title() so as to add a title and used xtitle(“”) and ytitle(“”) to take away the titles from the x and y axes, respectively. I’ve used xlabel and ylabel() to label the axes. And I’ve used legend() to format the legend.
The choices yaxis(2) and axis(2) could also be unfamiliar to you. The yaxis(2) possibility creates a second y axis on the appropriate facet of the graph for the bar chart. The axis(2) possibility within the ytitle() and ylabel() specify that these choices apply to the second y axis. Be aware that I’ve plotted dowclose with a inexperienced line and labeled the left y axis with a inexperienced font to emphasise that the left axis describes the road graph. Equally, I’ve I’ve plotted dowvolume with blue bars and labeled the appropriate y axis with a blue font to emphasise that the appropriate axis describes the bar graph.
twoway (line dowclose date, lcolor(inexperienced) lwidth(medium)) ///
(bar dowvolume date, fcolor(blue) lcolor(blue) yaxis(2)), ///
title("Dow Jones Industrial Common (2010 - 2019)") ///
xtitle("") ytitle("") ytitle("", axis(2)) ///
xlabel(, labsize(small) angle(horizontal)) ///
ylabel(5000(5000)30000, ///
labsize(small) labcolor(inexperienced) ///
angle(horizontal) format(%9.0fc)) ///
ylabel(0(500)3000, ///
labsize(small) labcolor(blue) ///
angle(horizontal) axis(2)) ///
legend(order(1 "Closing Worth" 2 "Quantity (tens of millions)") ///
cols(1) place(10) ring(0))
The code block above creates the next graph.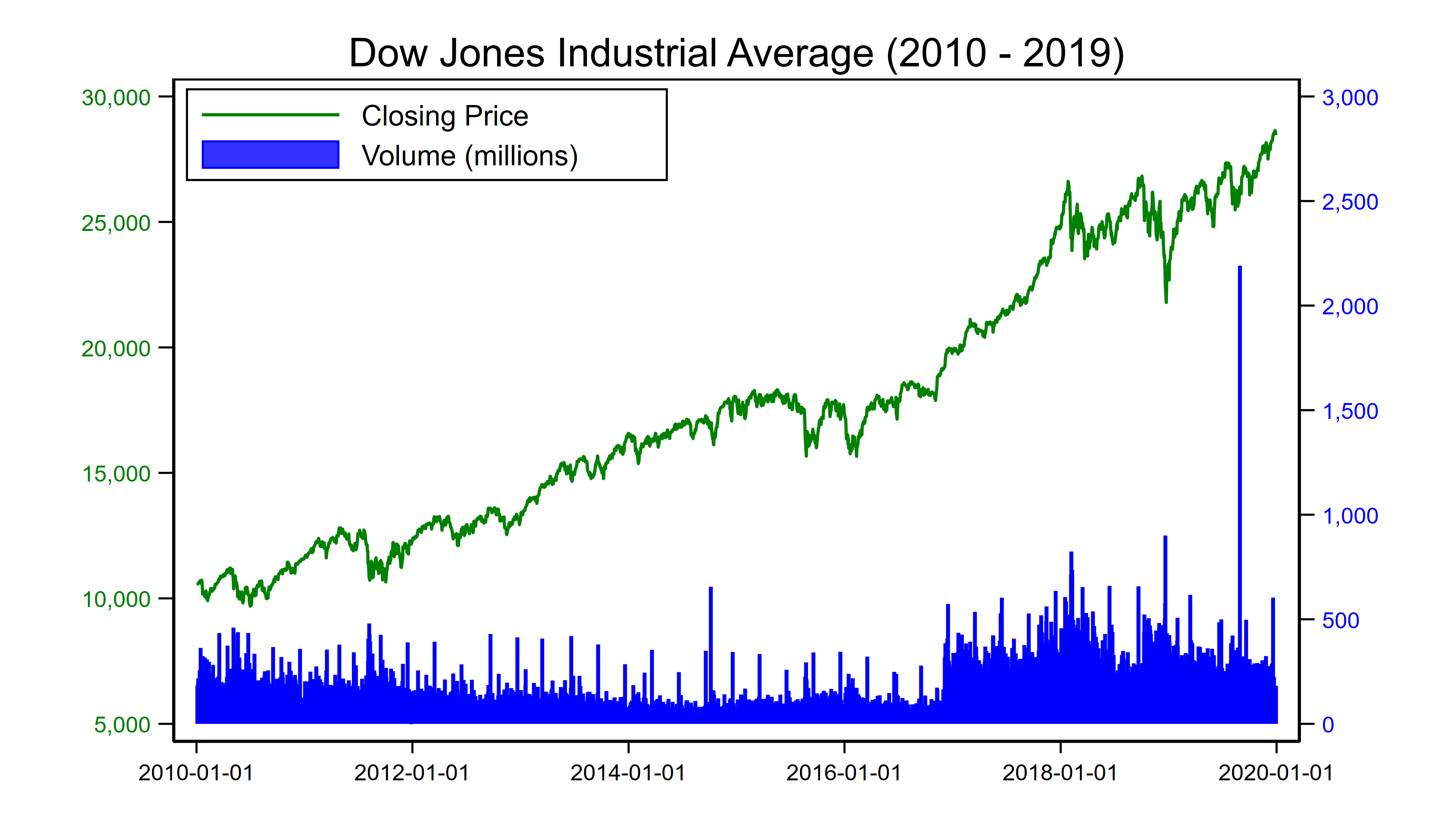
Conclusion
We did it! We used the Yahoo! finance module in Python to obtain information for the Dow Jones Industrial Common and import it to a Pandas information body. We used the Stata Perform Interface (SFI) module to create new variables in Stata and duplicate particular columns from the Pandas information body to Stata variables. And we used graph twoway to create a graph with Stata. I’ve collected the examples beneath.
Subsequent time, I’ll present you the best way to use the Stata Perform Interface (SFI) module to repeat scalars, macros, and matrices backwards and forwards between Stata and Python.
instance.do
python: import yfinance as yf from sfi import Knowledge, Macro # Use the yfinance module to obtain the DJIA information dowjones = yf.obtain("^DJI", begin="2010-01-01", finish="2019-12-31") # Show the column names dowjones.columns # Show the identify of the index dowjones.index.identify # Show the index information dowjones.index # Copy the index to a string column dowjones['dowdate'] = dowjones.index.astype(str) dowjones[['dowdate','Adj Close', 'Volume']] # Set the variety of observations within the Stata dataset Knowledge.setObsTotal(len(dowjones)) # Add observations to the present dataset # Create the variables within the Stata dataset Knowledge.addVarStr("dowdate",10) Knowledge.addVarDouble("dowclose") Knowledge.addVarInt("dowvolume") # Write the information from the Pandas information body to the Stata variables Knowledge.retailer("dowdate", None, dowjones['dowdate'], None) # This works too #Knowledge.retailer("dowdate", None, dowjones.index.astype(str), None) Knowledge.retailer("dowclose", None, dowjones['Adj Close'], None) Knowledge.retailer("dowvolume", None, dowjones['Volume'], None) finish // Use the date() operate to create the variable date generate date = date(dowdate,"YMD") format %tdCCYY-NN-DD date label var date "Date" // Format the variable dowclose format %10.2f dowclose label var dowclose "DJIA Closing Worth" // Format the variable dowvolume exchange dowvolume = dowvolume/1000000 format %10.2fc dowvolume label var dowvolume "DJIA Quantity (Tens of millions of Shares)" checklist in 1/5, abbrev(9) // Create the graph twoway (line dowclose date, lcolor(inexperienced) lwidth(medium)) /// (bar dowvolume date, fcolor(blue) lcolor(blue) yaxis(2)), /// title("Dow Jones Industrial Common (2010 - 2019)") /// xtitle("") ytitle("") ytitle("", axis(2)) /// xlabel(, labsize(small) angle(horizontal)) /// ylabel(5000(5000)30000, /// labsize(small) labcolor(inexperienced) /// angle(horizontal) format(%9.0fc)) /// ylabel(0(500)3000, /// labsize(small) labcolor(blue) /// angle(horizontal) axis(2)) /// legend(order(1 "Closing Worth" 2 "Quantity (tens of millions)") /// cols(1) place(10) ring(0))