

{kind=link}
NVIDIA has launched the Nemotron 3 household of open fashions as a part of a full stack for agentic AI, together with mannequin weights, datasets and reinforcement studying instruments. The household has three sizes, Nano, Tremendous and Extremely, and targets multi agent techniques that want lengthy context reasoning with tight management over inference value. Nano has about 30 billion parameters with about 3 billion lively per token, Tremendous has about 100 billion parameters with as much as 10 billion lively per token, and Extremely has about 500 billion parameters with as much as 50 billion lively per token.
Mannequin household and goal workloads
Nemotron 3 is introduced as an environment friendly open mannequin household for agentic functions. The road consists of Nano, Tremendous and Extremely fashions, every tuned for various workload profiles.
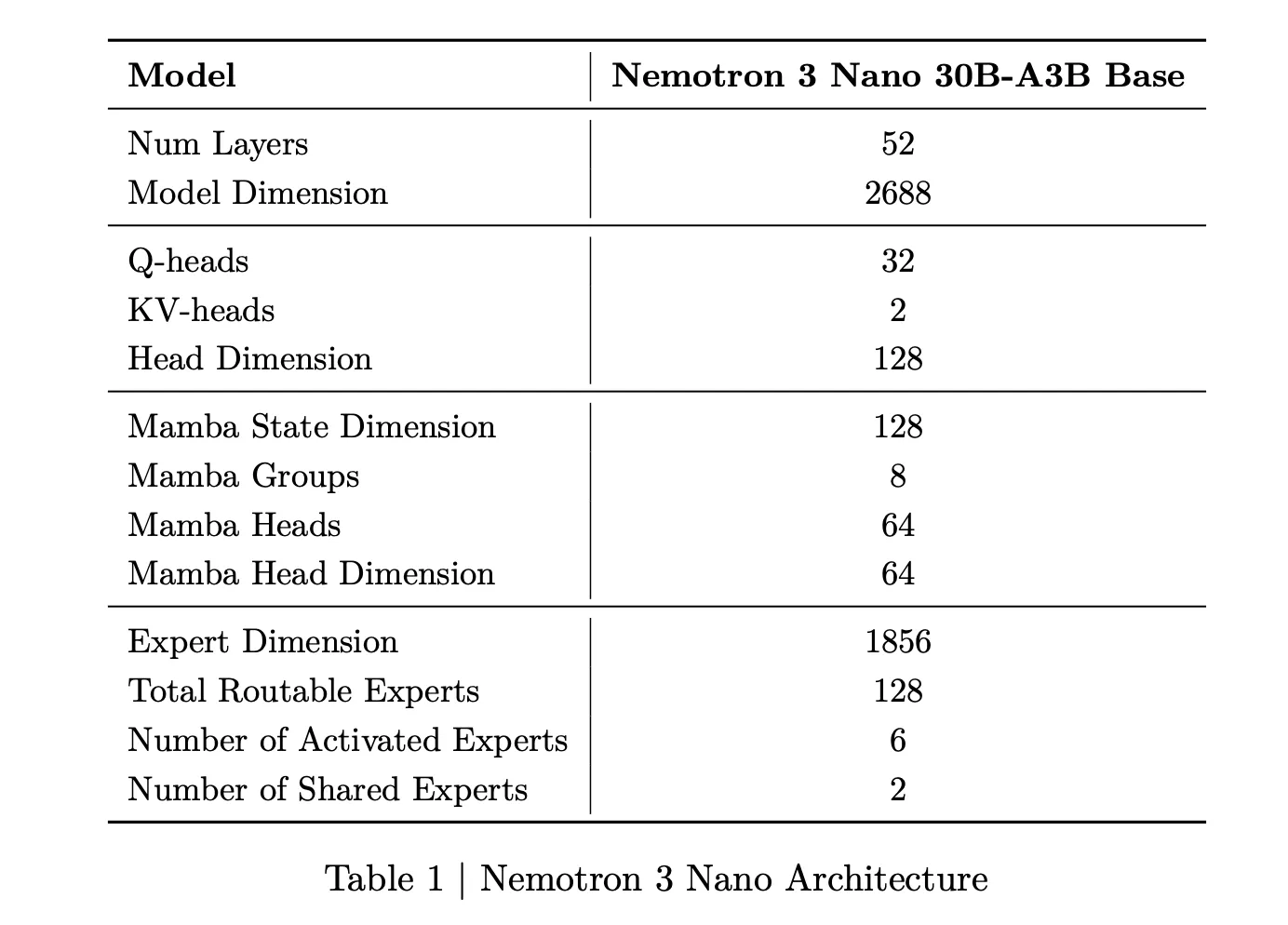
Nemotron 3 Nano is a Combination of Consultants hybrid Mamba Transformer language mannequin with about 31.6 billion parameters. Solely about 3.2 billion parameters are lively per ahead cross, or 3.6 billion together with embeddings. This sparse activation permits the mannequin to maintain excessive representational capability whereas protecting compute low.
Nemotron 3 Tremendous has about 100 billion parameters with as much as 10 billion lively per token. Nemotron 3 Extremely scales this design to about 500 billion parameters with as much as 50 billion lively per token. Tremendous targets excessive accuracy reasoning for big multi agent functions, whereas Extremely is meant for complicated analysis and planning workflows.
Nemotron 3 Nano is on the market now with open weights and recipes, on Hugging Face and as an NVIDIA NIM microservice. Tremendous and Extremely are scheduled for the primary half of 2026.
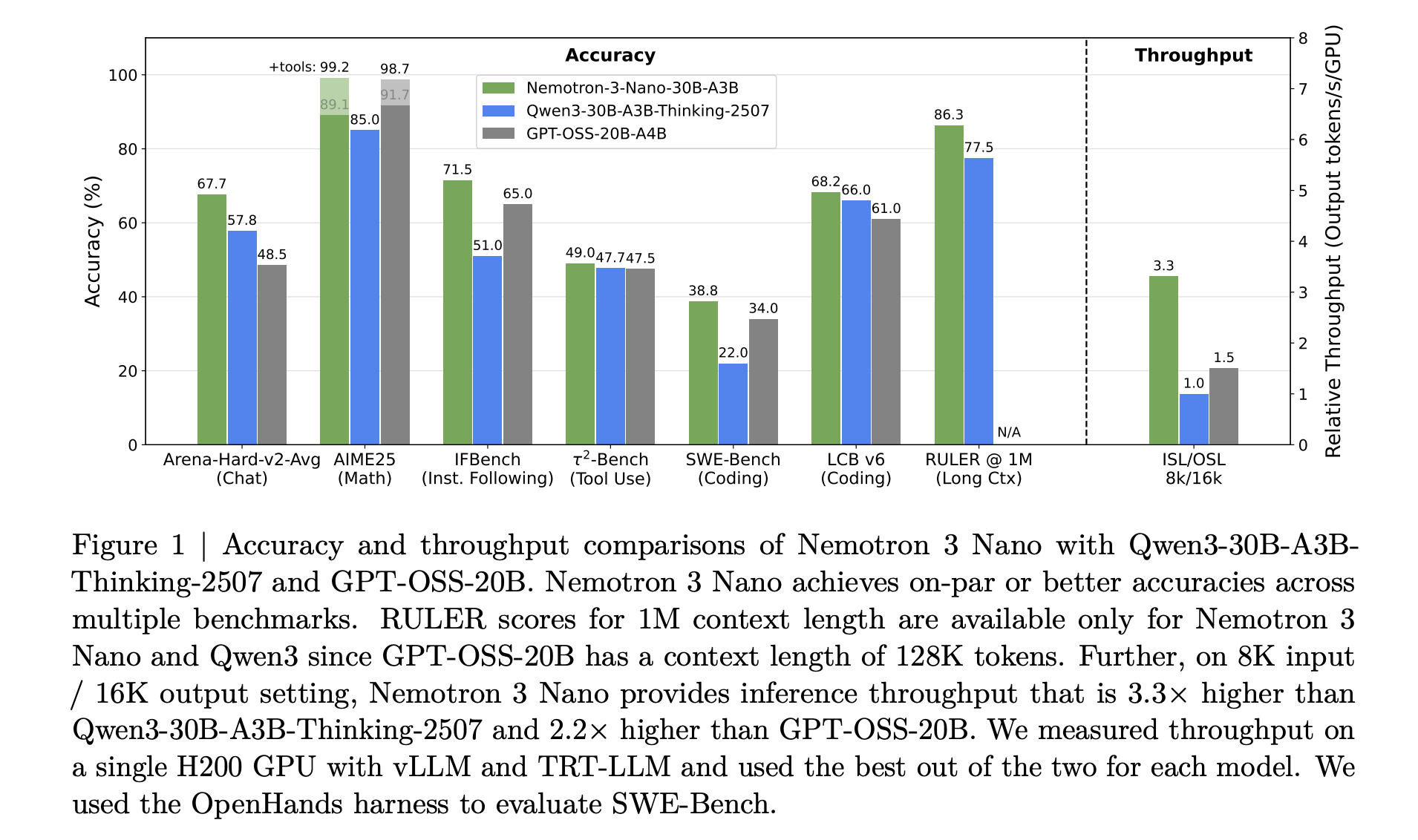
NVIDIA Nemotron 3 Nano delivers about 4 occasions increased token throughput than Nemotron 2 Nano and reduces reasoning token utilization considerably, whereas supporting a local context size of as much as 1 million tokens. This mix is meant for multi agent techniques that function on massive workspaces similar to lengthy paperwork and enormous code bases.
Hybrid Mamba Transformer MoE structure
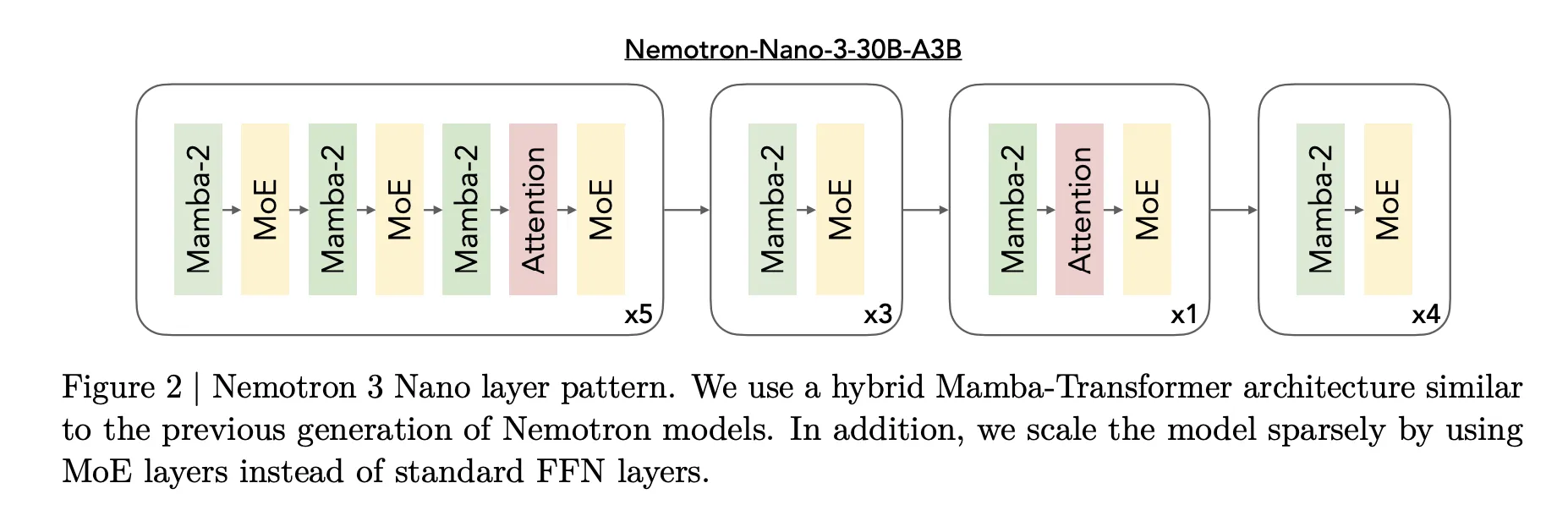
The core design of Nemotron 3 is a Combination of Consultants hybrid Mamba Transformer structure. The fashions combine Mamba sequence blocks, consideration blocks and sparse professional blocks inside a single stack.
For Nemotron 3 Nano, the analysis crew describes a sample that interleaves Mamba 2 blocks, consideration blocks and MoE blocks. Normal feedforward layers from earlier Nemotron generations are changed by MoE layers. A realized router selects a small subset of consultants per token, for instance 6 out of 128 routable consultants for Nano, which retains the lively parameter depend shut to three.2 billion whereas the total mannequin holds 31.6 billion parameters.
Mamba 2 handles lengthy vary sequence modeling with state house type updates, consideration layers present direct token to token interactions for construction delicate duties, and MoE supplies parameter scaling with out proportional compute scaling. The necessary level is that almost all layers are both quick sequence or sparse professional computations, and full consideration is used solely the place it issues most for reasoning.
For Nemotron 3 Tremendous and Extremely, NVIDIA provides LatentMoE. Tokens are projected right into a decrease dimensional latent house, consultants function in that latent house, then outputs are projected again. This design permits a number of occasions extra consultants at comparable communication and compute value, which helps extra specialization throughout duties and languages.
Tremendous and Extremely additionally embrace multi token prediction. A number of output heads share a typical trunk and predict a number of future tokens in a single cross. Throughout coaching this improves optimization, and at inference it permits speculative decoding like execution with fewer full ahead passes.
Coaching knowledge, precision format and context window
Nemotron 3 is educated on massive scale textual content and code knowledge. The analysis crew experiences pretraining on about 25 trillion tokens, with greater than 3 trillion new distinctive tokens over the Nemotron 2 era. Nemotron 3 Nano makes use of Nemotron Widespread Crawl v2 level 1, Nemotron CC Code and Nemotron Pretraining Code v2, plus specialised datasets for scientific and reasoning content material.
Tremendous and Extremely are educated largely in NVFP4, a 4 bit floating level format optimized for NVIDIA accelerators. Matrix multiply operations run in NVFP4 whereas accumulations use increased precision. This reduces reminiscence strain and improves throughput whereas protecting accuracy shut to straightforward codecs.
All Nemotron 3 fashions help context home windows as much as 1 million tokens. The structure and coaching pipeline are tuned for lengthy horizon reasoning throughout this size, which is important for multi agent environments that cross massive traces and shared working reminiscence between brokers.
Key Takeaways
- Nemotron 3 is a 3 tier open mannequin household for agentic AI: Nemotron 3 is available in Nano, Tremendous and Extremely variants. Nano has about 30 billion parameters with about 3 billion lively per token, Tremendous has about 100 billion parameters with as much as 10 billion lively per token, and Extremely has about 500 billion parameters with as much as 50 billion lively per token. The household targets multi agent functions that want environment friendly lengthy context reasoning.
- Hybrid Mamba Transformer MoE with 1 million token context: Nemotron 3 fashions use a hybrid Mamba 2 plus Transformer structure with sparse Combination of Consultants and help a 1 million token context window. This design provides lengthy context dealing with with excessive throughput, the place solely a small subset of consultants is lively per token and a spotlight is used the place it’s most helpful for reasoning.
- Latent MoE and multi token prediction in Tremendous and Extremely: The Tremendous and Extremely variants add latent MoE the place professional computation occurs in a decreased latent house, which lowers communication value and permits extra consultants, and multi token prediction heads that generate a number of future tokens per ahead cross. These modifications enhance high quality and allow speculative type speedups for lengthy textual content and chain of thought workloads.
- Giant scale coaching knowledge and NVFP4 precision for effectivity: Nemotron 3 is pretrained on about 25 trillion tokens, with greater than 3 trillion new tokens over the earlier era, and Tremendous and Extremely are educated primarily in NVFP4, a 4 bit floating level format for NVIDIA GPUs. This mix improves throughput and reduces reminiscence use whereas protecting accuracy shut to straightforward precision.
Try the Paper, Technical weblog and Mannequin Weights on HF. Be happy to take a look at our GitHub Web page for Tutorials, Codes and Notebooks. Additionally, be at liberty to observe us on Twitter and don’t neglect to hitch our 100k+ ML SubReddit and Subscribe to our Publication.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.