With a big selection of Nova customization choices, the journey to customization and transitioning between platforms has historically been intricate, necessitating technical experience, infrastructure setup, and appreciable time funding. This disconnect between potential and sensible functions is exactly what we aimed to handle. Nova Forge SDK makes massive language mannequin (LLM) customization accessible, empowering groups to harness the complete potential of language fashions with out the challenges of dependency administration, picture choice, and recipe configuration. We view customization as a continuum throughout the scaling ladder, subsequently, the Nova Forge SDK helps all customization choices, starting from variations based mostly on Amazon SageMaker AI to deep customization utilizing Amazon Nova Forge capabilities.
Within the final publish, we launched the Nova Forge SDK and how you can get began with it together with the conditions and setup directions. On this publish, we stroll you thru the method of utilizing the Nova Forge SDK to coach an Amazon Nova mannequin utilizing Amazon SageMaker AI Coaching Jobs. We consider our mannequin’s baseline efficiency on a StackOverFlow dataset, use Supervised High quality-Tuning (SFT) to refine its efficiency, after which apply Reinforcement High quality Tuning (RFT) on the custom-made mannequin to additional enhance response high quality. After every sort of fine-tuning, we consider the mannequin to point out its enchancment throughout the customization course of. Lastly, we deploy the custom-made mannequin to an Amazon SageMaker AI Inference endpoint.
Subsequent, let’s perceive the advantages of Nova Forge SDK by going by means of a real-world state of affairs of computerized classification of Stack Overflow questions into three well-defined classes (HQ, LQ EDIT, LQ CLOSE).
Case research: classify the given query into the right class
Stack Overflow has 1000’s of questions, various enormously in high quality. Routinely classifying query high quality helps moderators prioritize their efforts and information customers to enhance their posts. This resolution demonstrates how you can use the Amazon Nova Forge SDK to construct an automatic high quality classifier that may distinguish between high-quality posts, low-quality posts requiring edits, and posts that ought to be closed. We use the Stack Overflow Query High quality dataset containing 60,000 questions from 2016-2020, categorized into three classes:
HQ (Excessive High quality): Effectively-written posts with out edits
LQ_EDIT (Low High quality – Edited): Posts with destructive scores and a number of group edits, however stay open
LQ_CLOSE (Low High quality – Closed): Posts closed by the group with out edits
For our experiments, we randomly sampled 4700 questions and cut up them as follows:
Break up
Samples
Share
Objective
Coaching (SFT)
3,500
~75%
Supervised fine-tuning
Analysis
500
~10%
Baseline and post-training analysis
RFT
700 + (3,500 from SFT)
~15%
Reinforcement fine-tuning
For RFT, we augmented the 700 RFT-specific samples with all 3,500 SFT samples (whole: 4,200 samples) to stop catastrophic forgetting of supervised capabilities whereas studying from reinforcement indicators.
The experiment consists of 4 most important phases: baseline analysis to measure out-of-the-box efficiency, supervised fine-tuning (SFT) to show domain-specific patterns, and reinforcement fine-tuning (RFT) on SFT checkpoint to optimize for particular high quality metrics and eventually deployment to Amazon SageMaker AI. For fine-tuning, every stage builds upon the earlier one, with measurable enhancements at each step.
We used a standard system immediate for all of the datasets:
This can be a stack overflow query from 2016-2020 and it may be categorized into three classes:
* HQ: Excessive-quality posts with no single edit.
* LQ_EDIT: Low-quality posts with a destructive rating, and a number of group edits. Nevertheless, they continue to be open after these modifications.
* LQ_CLOSE: Low-quality posts that had been closed by the group with no single edit.
You're a technical assistant who will classify the query from customers into any of above three classes. Reply with solely the class identify: HQ, LQ_EDIT, or LQ_CLOSE.
**Don't add any clarification, simply give the class as output**.
Stage 1: Set up baseline efficiency
Earlier than fine-tuning, we set up a baseline by evaluating the pre-trained Nova 2.0 mannequin on our analysis set. This offers us a concrete baseline for measuring future enhancements. Baseline analysis is vital as a result of it helps you perceive the mannequin’s out-of-the-box capabilities, determine efficiency gaps, set measurable enchancment targets, and validate that fine-tuning is critical.
Set up the SDK
You’ll be able to set up the SDK with a easy pip command:
The Amazon Nova Forge SDK gives highly effective knowledge loading utilities that deal with validation and transformation routinely. We start by loading our analysis dataset and remodeling it to the format anticipated by Nova fashions:
The CSVDatasetLoader class handles the heavy lifting of information validation and format conversion. The question parameter maps to your enter textual content (the Stack Overflow query), response maps to the bottom reality label, and system accommodates the classification directions that information the mannequin’s habits.
# Normal Configuration
MODEL = Mannequin.NOVA_LITE_2
INSTANCE_TYPE = 'ml.p5.48xlarge'
EXECUTION_ROLE = ''
TRAIN_INSTANCE_COUNT = 4
EVAL_INSTANCE_COUNT = 1
S3_BUCKET = ''
S3_PREFIX = 'stack-overflow'
EVAL_DATA = './eval.csv'
# Load knowledge# Word: 'question' maps to the query, 'response' to the classification label
loader = CSVDatasetLoader(
question='Physique', # Query textual content column
response="Y", # Classification label column (HQ, LQ_EDIT, LQ_CLOSE)
system='system' # System immediate column
)
loader.load(EVAL_DATA)
Subsequent, we use the CSVDatasetLoader to rework your uncooked knowledge into the anticipated format for Nova mannequin analysis:
# Rework to Nova format
loader.rework(methodology=TrainingMethod.EVALUATION, mannequin=MODEL)
loader.present(n=3)
The remodeled knowledge could have the next format:
Earlier than importing to Amazon Easy Storage Service (Amazon S3), validate the remodeled knowledge by operating the loader.validate() methodology. This lets you catch any formatting points early, relatively than ready till they interrupt the precise analysis.
# Validate knowledge format
loader.validate(methodology=TrainingMethod.EVALUATION, mannequin=MODEL)
Lastly, we are able to save the dataset to Amazon S3 utilizing the loader.save_data() methodology, in order that it may be utilized by the analysis job.
# Save to S3
eval_s3_uri = loader.save_data(
f"s3://{S3_BUCKET}/{S3_PREFIX}/knowledge/eval.jsonl"
)
Run baseline analysis
With our knowledge ready, we initialize our SMTJRuntimeManager to configure the runtime infrastructure. We then initialize a NovaModelCustomizer object and name baseline_customizer.consider() to launch the baseline analysis job:
# Configure runtime infrastructure
runtime_manager = SMTJRuntimeManager(
instance_type=INSTANCE_TYPE,
instance_count=EVAL_INSTANCE_COUNT,
execution_role=EXECUTION_ROLE
)
# Create baseline evaluator
baseline_customizer = NovaModelCustomizer(
mannequin=MODEL,
methodology=TrainingMethod.EVALUATION,
infra=runtime_manager,
data_s3_path=eval_s3_uri,
output_s3_path=f"s3://{S3_BUCKET}/{S3_PREFIX}/baseline-eval"
)
# Run analysis# GEN_QA process gives metrics like ROUGE, BLEU, F1, and Precise Match
baseline_result = baseline_customizer.consider(
job_name="blogpost-baseline",
eval_task=EvaluationTask.GEN_QA # Use GEN_QA for classification
)
For classification duties, we use the GEN_QA analysis process, which treats classification as a generative process the place the mannequin generates a category label. The exact_match metric from GEN_QA immediately corresponds to classification accuracy, the share of predictions that precisely match the bottom reality label. The complete listing of benchmark duties may be retrieved from the EvaluationTask enum, or seen within the Amazon Nova Person Information.
Understanding the baseline outcomes
After the job completes, outcomes are saved to Amazon S3 on the specified output path. The archive accommodates per-sample predictions with log possibilities, aggregated metrics throughout the complete analysis set, and uncooked mannequin predictions for detailed evaluation.
Within the following desk, we see the aggregated metrics for all of the analysis samples from the output of the analysis job (word that BLEU is on a scale of 0-100):
Metric
Rating
ROUGE-1
0.1580 (±0.0148)
ROUGE-2
0.0269 (±0.0066)
ROUGE-L
0.1580 (±0.0148)
Precise Match (EM)
0.1300 (±0.0151)
Quasi-EM (QEM)
0.1300 (±0.0151)
F1 Rating
0.1380 (±0.0149)
F1 Rating (Quasi)
0.1455 (±0.0148)
BLEU
0.4504 (±0.0209)
The bottom mannequin achieves solely 13.0% exact-match accuracy on this 3-class classification process, whereas random guessing would yield 33.3%. This clearly demonstrates the necessity for fine-tuning and establishes a quantitative baseline for measuring enchancment.
As we see within the subsequent part, that is largely as a result of mannequin ignoring the formatting necessities of the issue, the place a verbose response together with explanations and analyses is taken into account invalid. We will derive the format-independent classification accuracy by parsing our three labels from the mannequin’s output textual content, utilizing the next classification_accuracy utility perform.
def classification_accuracy(samples):
"""Extract predicted class by way of substring match and compute accuracy."""
right, whole, no_pred = 0, 0, 0
for s in samples:
gold = s["gold"].strip().higher()
pred_raw = s["inference"][0] if isinstance(s["inference"], listing) else s["inference"]
pred_cat = extract_category(pred_raw)
if pred_cat is None:
no_pred += 1
proceed
whole += 1
if pred_cat == gold:
right += 1
acc = right / whole if whole else 0
print(f"Classification Accuracy: {right}/{whole} ({acc*100:.1f}%)")
print(f" No legitimate prediction: {no_pred}/{whole + no_pred}")
return acc
print("???? Baseline Classification Accuracy (extracted class labels):")
baseline_accuracy = classification_accuracy(baseline_samples)
Nevertheless, even with a permissive metric, which ignores verbosity, we get solely a 52.2% classification accuracy. This clearly signifies the necessity for fine-tuning to enhance the efficiency of the bottom mannequin.
Conduct baseline failure evaluation
The next picture exhibits a failure evaluation on the baseline. From the response size distribution, we observe that each one responses included verbose explanations and reasoning regardless of the system immediate requesting solely the class identify. As well as, the baseline confusion matrix compares the true label (y axis) with the generated label (x axis); the LLM has a transparent bias in direction of classifying messages as Excessive High quality no matter their precise classification.
Given these baseline outcomes of each instruction-following failures and classification bias towards HQ, we now apply Supervised High quality-Tuning (SFT) to assist the mannequin perceive the duty construction and output format, adopted by Reinforcement Studying (RL) with a reward perform that penalizes the undesirable behaviors.
Stage 2: Supervised fine-tuning
Now that we’ve got accomplished our baseline and performed the failure area evaluation, we are able to use Supervised High quality Tuning to enhance our efficiency. For this instance, we use a Parameter Environment friendly High quality-Tuning method, as a result of it’s a way that offers us preliminary indicators on fashions studying functionality.
Knowledge preparation for supervised fine-tuning
With the Nova Forge SDK, we are able to convey our datasets and use the SDKs knowledge preparation helper features to curate the SFT datasets with in-build knowledge validations.
As earlier than, we use the SDK’s CSVDatasetLoader to load our coaching CSV knowledge and rework it into the required format:
Now that we’ve got our knowledge well-formed and within the right format, we are able to cut up it into coaching, validation, and take a look at knowledge, and add all three to Amazon S3 for our coaching jobs to reference.
# Save to S3
train_path = loader.save_data(f"s3://{S3_BUCKET}/{S3_PREFIX}/knowledge/prepare.jsonl")
Begin a supervised fine-tuning job
With our knowledge ready and uploaded to Amazon S3, we provoke the Supervised High quality-tuning (SFT) job.
The Nova Forge SDK streamlines the method by serving to us to specify the infrastructure for coaching, whether or not it’s Amazon SageMaker Coaching Jobs or Amazon SageMaker Hyperpod. It additionally provisions the required situations and facilitates the launch of coaching jobs, eradicating the necessity to fear about recipe configurations or API codecs.
For our SFT coaching, we proceed to make use of Amazon SageMaker Coaching Jobs, with 4 ml.p5.48xlarge situations. The SDK validates your surroundings and occasion configuration towards supported values for the chosen mannequin when making an attempt to begin a coaching job, stopping errors from occurring after the job is submitted.
Subsequent, we arrange the configuration for the coaching itself and run the job. You should use the overrides parameter to switch coaching configurations from their default values for higher efficiency. Right here, we set the max_steps to a comparatively small quantity to maintain the length of this take a look at low.
You should use the Nova Forge SDK to run coaching jobs in dry_run mode. This mode runs all of the validations that the SDK would execute, whereas really operating a job, however doesn’t begin the execution if all validations fail. This lets you know prematurely whether or not a coaching setup is legitimate earlier than making an attempt to make use of it, for example when producing configs routinely or exploring potential settings:
To save lots of the info for a job that you just created, you’ll be able to serialize your outcome object to a JSON file, after which retrieve it later to proceed the place you left off:
# Save to a file
outcome.dump(file_path=".", file_name="training_result.json")
# Load from a file
outcome = TrainingResult.load("training_result.json")
Monitoring the Logs publish SFT launch
After we’ve got launched the SFT job, we are able to now monitor the logs it publishes to Amazon CloudWatch. The logs present per-step metrics together with loss, studying price, and throughput, letting you observe convergence in actual time.
The Nova Forge SDK has built-in utilities for simply extracting and displaying the logs from every platform sort immediately in your pocket book surroundings.
You can too immediately ask a customizer object for the logs, and it’ll intelligently retrieve them for the newest job it created:
customizer.get_logs(restrict=20)
As well as, you’ll be able to observe the job standing in actual time, which is helpful for monitoring when a job succeeds or fails:
outcome.get_job_status() # Returns (JobStatus.IN_PROGRESS, ...) or (JobStatus.COMPLETED, ...)
Evaluating the SFT mannequin
With coaching full, we are able to consider the fine-tuned mannequin on the identical dataset that we used for baseline analysis, to know how a lot we improved in comparison with the baseline. The Nova Forge SDK helps operating evaluations on the fashions generated by a coaching job. The next instance demonstrates this:
Within the following desk, we see the aggregated metrics for a similar analysis dataset after making use of SFT coaching:
Metric
Rating
Delta
ROUGE-1
0.8290 (±0.0157)
0.671
ROUGE-2
0.4860 (±0.0224)
0.4591
ROUGE-L
0.8290 (±0.0157)
0.671
Precise Match (EM)
0.7720 (±0.0188)
0.642
Quasi-EM (QEM)
0.7900 (±0.0182)
0.66
F1 Rating
0.7720 (±0.0188)
0.634
F1 Rating (Quasi)
0.7900 (±0.0182)
0.6445
BLEU
0.0000 (±0.1031)
-0.4504
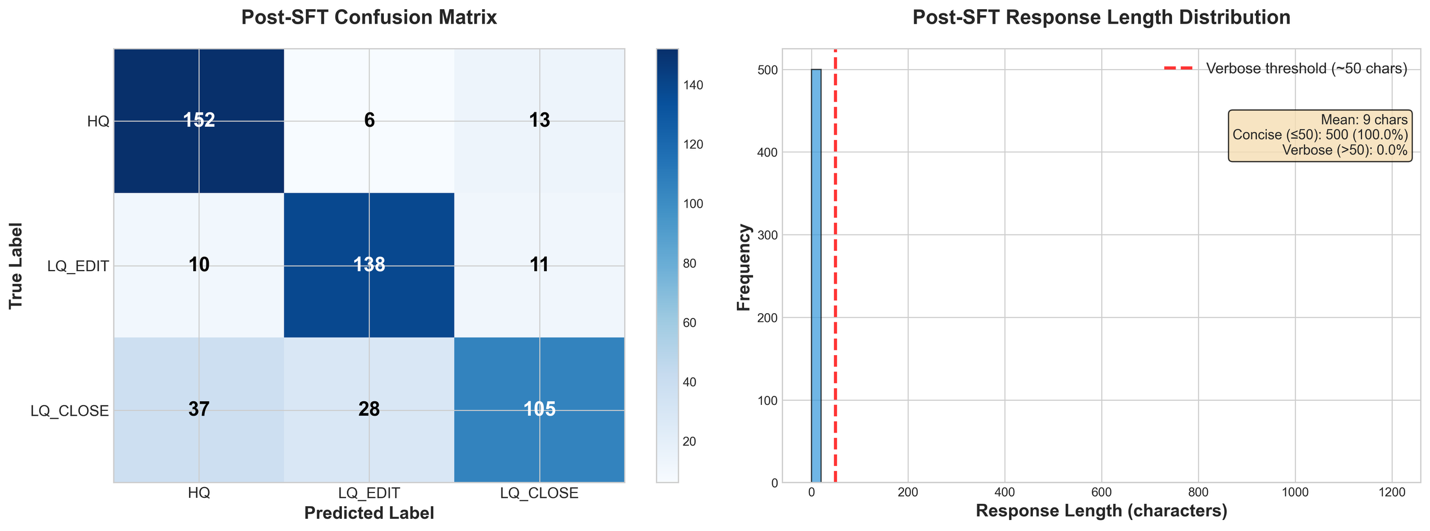
Even with a brief coaching run, we see enhancements in all of our metrics save BLEU (which provides low scores for terribly quick responses), going as much as 77.2% accuracy for actual match metrics.
print("Submit-SFT Classification Accuracy (extracted class labels):")
sft_accuracy = classification_accuracy(sft_samples)
Checking our personal classification accuracy metric, we are able to see 79.0% of analysis datapoints getting the right classification. The small distinction between classification accuracy and actual match scores exhibits us that the mannequin has correctly discovered the required format.
From our detailed efficiency metrics, we are able to see that the response size distribution has been pulled absolutely to non-verbose responses. Within the Confusion Matrix, we additionally see a drastic enhance in classification accuracy for the LQ_EDIT and LQ_CLOSE courses, decreasing the mannequin’s bias in direction of classifying rows as HQ.
Step 3: Reinforcement High quality Tuning
Based mostly on the earlier knowledge, SFT does properly at coaching the mannequin to suit the required format, however there may be nonetheless extra to enhance within the accuracy of the generated labels. Subsequent, we try and iteratively add Reinforcement High quality Tuning on high of our skilled SFT checkpoint. That is usually useful when making an attempt to enhance mannequin accuracy, particularly on advanced use circumstances the place the issue entails extra than simply becoming a required format and the duties may be framed when it comes to a quantifiable reward.
Constructing reward features
For classification, we create an AWS Lambda perform that rewards right predictions with a optimistic rating (+1) and a destructive rating (-1) for unsuitable predictions:
1.0: Appropriate prediction
-1.0: Incorrect prediction
The perform handles three high quality classes (HQ, LQ_EDIT, LQ_CLOSE) and makes use of versatile textual content extraction to deal with minor formatting variations in mannequin outputs (for instance, “HQ”, “HQ.”, “The reply is HQ”). This sturdy extraction makes positive that the mannequin receives correct reward indicators even when producing barely verbose responses. The binary reward construction creates robust, unambiguous gradients that assist the mannequin be taught to tell apart between high-quality and low-quality content material classes.
"""Binary reward perform for classification: +1 right, -1 unsuitable.
Easy and clear sign:
- Appropriate prediction: +1.0
- Incorrect prediction: -1.0
"""
def calculate_reward(prediction: str, ground_truth: str) -> float:
""" Calculates binary reward """
extracted = extract_category(prediction) # Extracts class from prediction and normalize it
truth_norm = normalize_text(ground_truth) # Normalize the groundtruth
# Appropriate prediction
if extracted and extracted == truth_norm: return 1.0
# Incorrect prediction
return -1.0
def lambda_handler(occasion, context):
""" Lambda handler with binary rewards. """
scores: Checklist[RewardOutput] = []
for pattern in occasion:
idx = pattern.get("id", "no_id")
ground_truth = pattern.get("reference_answer", "")
prediction = last_message.get("content material", "")
# Calculate binary reward
reward = calculate_reward(prediction, ground_truth)
scores.append(RewardOutput(id=idx, aggregate_reward_score=reward))
return [asdict(score) for score in scores]
Deploy this Lambda perform to AWS and word the ARN to be used within the RFT coaching configuration.
Subsequent we deploy the lambda perform to AWS account, and get the deployed lambda ARN, so it may be used whereas launching the RFT coaching.
Be sure that so as to add Lambda Invoke Insurance policies to your customization IAM function, in order that Amazon SageMaker AI can invoke the Lambda insurance policies after coaching begins.
Knowledge preparation in direction of RFT
Equally because the SFT experiment setup, we are able to use the Nova Forge SDK to curate the dataset and carry out validations for RFT schema. This helps in bringing the dataset and remodeling them into the OpenAI schema that works for RFT. The next snippet exhibits how you can rework a dataset into RFT dataset.
RFT_DATA = './rft.csv'
rft_loader = CSVDatasetLoader(
question='Physique',
response="Y",
system='system'
)
rft_loader.load(RFT_DATA)
# Rework for RFT
rft_loader.rework(methodology=TrainingMethod.RFT_LORA, mannequin=MODEL)
rft_loader.validate(methodology=TrainingMethod.RFT_LORA, mannequin=MODEL)
# Save to S3
rft_s3_uri = rft_loader.save_data(
f"s3://{S3_BUCKET}/{S3_PREFIX}/knowledge/rft.jsonl"
)
After this transformation you’re going to get knowledge in following OpenAI format:
Launching RFT on SFT checkpoint and Monitoring Logs
Subsequent, we are going to initialize the RFT job itself on high of our SFT checkpoint. For this step, Nova Forge SDK helps you launch your RFT job by bringing the formatted dataset together with the reward perform for use. The next snippet exhibits an instance of how you can run RFT on high of SFT checkpoint, with RFT knowledge and reward perform.
We use the next hyperparameters for the RFT coaching run. To discover the hyperparameters, we purpose for under 40 steps for this RFT job to maintain the coaching time low.
rft_overrides = {
"lr": 0.00001, # Studying price
"number_generation": 4, # N samples per immediate to estimate benefits (variance vs price).
"reasoning_effort": "null", # Permits reasoning mode Excessive / Low / or null for non-reasoning
"max_new_tokens": 50, # This cuts off verbose outputs
"kl_loss_coef": 0.02, # Weight on the KL penalty between the actor (trainable coverage) and a frozen reference mannequin
"temperature": 1, # Softmax temperature
"ent_coeff": 0.01, # A bonus added to the coverage loss that rewards higher-output entropy
"max_steps": 40, # Steps to coach for. One Step = global_batch_size
"save_steps": 30, # Steps after which a checkpoint will probably be saved
"top_k": 5, # Pattern solely from top-Okay logits
"global_batch_size": 64, # Whole samples per optimizer step throughout all replicas (16/32/64/128/256)
}
# Begin RFT coaching
rft_result = rft_customizer.prepare(
job_name="stack-overflow-rft",
rft_lambda_arn=REWARD_LAMBDA_ARN,
overrides = rft_overrides
)
We will monitor the RFT coaching logs utilizing the show_logs() methodology:
Reward statistics exhibiting the typical high quality scores assigned by your Lambda perform to generated responses.
Critic scores indicating how properly the worth mannequin predicts future rewards.
Coverage gradient metrics like loss and KL divergence that measure coaching stability and the way a lot the mannequin is altering from its preliminary state.
Response size statistics to trace output verbosity.
Efficiency metrics together with throughput (tokens/second), reminiscence utilization, and time per coaching step.
Monitoring these logs helps us determine points like reward collapse (declining common rewards), coverage instability (excessive KL divergence), or era issues (response lengths bumping towards the max_token depend). After we determine the problems, we alter our hyperparameters or reward features as wanted.
RFT reward distribution
For the earlier RFT coaching, we used a reward perform of +1.0 for proper responses (responses containing the right label inside them) and -1.0 for incorrect responses.
It’s because our SFT coaching already taught the mannequin the required format. If we don’t over-train and disrupt the patterns from SFT tuning, responses will have already got the right verbosity and the mannequin will attempt to give the correct reply (relatively than giving up or gaming the format).
We assist the prevailing SFT coaching by including kl_loss_coef to decelerate the mannequin’s divergence from the SFT-induced patterns. We additionally restrict the max_tokens, which considerably encourages shorter responses over longer ones (as their classification tokens are assured to be throughout the window). Given the quick coaching length, that is enough to find out that the RFT tuning represents an enchancment within the mannequin’s efficiency.
Evaluating publish SFT+RFT experiment
We use the identical analysis setup as our baseline and post-SFT evaluations to conduct assess our publish SFT+RFT custom-made mannequin. This offers us an understanding of what number of enhancements we are able to understand with iterative coaching. As earlier than, utilizing Nova Forge SDK, we are able to shortly run one other spherical of analysis to search out the mannequin efficiency carry.
Outcomes
Metric
Rating
Delta
ROUGE-1
0.8400 (±0.0153)
0.011
ROUGE-2
0.4980 (±0.0224)
0.012
ROUGE-L
0.8400 (±0.0153)
0.011
Precise Match (EM)
0.7880 (±0.0183)
0.016
Quasi-EM (QEM)
0.8060 (±0.0177)
0.016
F1 Rating
0.7880 (±0.0183)
0.016
F1 Rating (Quasi)
0.8060 (±0.0177)
0.016
BLEU
0.0000 (±0.0984)
0
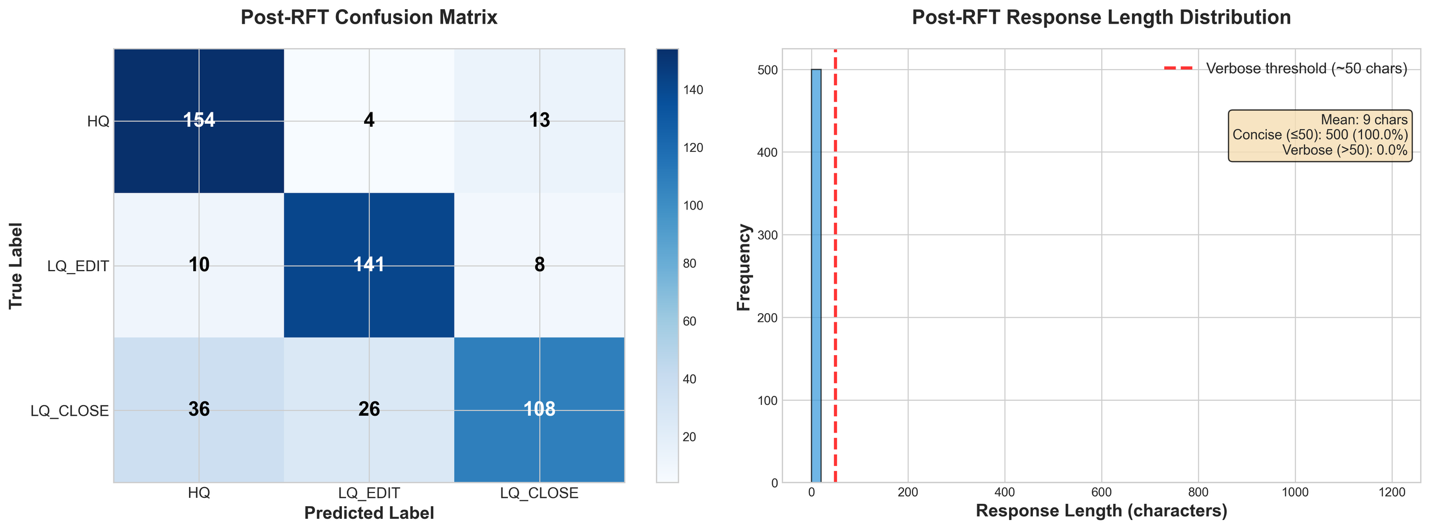
Upon incorporating Reinforcement High quality-Tuning (RFT) into our present mannequin, we see improved efficiency in comparison with the baseline and the standalone Supervised High quality-Tuning (SFT) mannequin. All our metrics persistently improved by round 1 %.
Evaluating the metrics, we see that the order of improvement-deltas is completely different from that of the SFT fine-tuning, indicating that RFT is calibrating completely different patterns within the mannequin relatively than reinforcing the teachings from the SFT run.
The detailed efficiency metrics present that our mannequin continues to comply with to the requested output format, remembering the teachings of the SFT run. As well as, the classifications themselves are extra focused on the right diagonal, with every of the wrong squares of the confusion matrix exhibiting a lower in inhabitants.
These preliminary indications present that iterative coaching can assist push efficiency additional than only a single coaching session. With tuned hyperparameters on longer coaching runs, we may convey these enhancements even additional.
Ultimate outcome evaluation
Metric
Baseline
Submit-SFT
Submit-RFT
Delta (RFT-Base)
ROUGE-1
0.158
0.829
0.84
0.682
ROUGE-2
0.0269
0.486
0.498
0.4711
ROUGE-L
0.158
0.829
0.84
0.682
Precise Match (EM)
0.13
0.772
0.788
0.658
Quasi-EM (QEM)
0.13
0.79
0.806
0.676
F1 Rating
0.138
0.772
0.788
0.65
F1 Rating (Quasi)
0.1455
0.79
0.806
0.6605
BLEU
0.4504
0
0
-0.4504
Throughout all analysis metrics, we see:
General Enchancment: The 2-stage customization method (SFT + RFT) achieved constant enhancements throughout all metrics, with ROUGE-1 enhancing by +0.682, EM by +0.658, and F1 by +0.650 over baseline.
SFT vs RFT Roles: SFT gives the muse for area adaptation with the most important efficiency good points, whereas RFT fine-tunes decision-making by means of reward-based studying.
BLEU scores should not significant for this classification process, as BLEU measures n-gram overlap for era duties. Since our mannequin outputs single-token classifications (HQ, LQ_EDIT, LQ_CLOSE), BLEU can’t seize the standard of those categorical predictions and ought to be disregarded in favor of actual match (EM) and F1 metrics.
Step 4: Deployment to an Amazon SageMaker AI Inference
Now that we’ve got our closing mannequin prepared, we are able to deploy it the place it might serve actual predictions. The Nova Forge SDK makes deployments easy, whether or not you select Amazon Bedrock for absolutely managed inference or Amazon SageMaker AI for extra management over your infrastructure.
The SDK helps two deployment targets, every with distinct benefits:
Amazon Bedrock gives a totally managed expertise with two choices:
On-Demand: Serverless inference with computerized scaling and pay-per-use pricing which is ideal for variable workloads and growth
Provisioned Throughput: Devoted capability with predictable efficiency for manufacturing workloads with constant site visitors
Amazon SageMaker AI Inference gives flexibility if you want customized occasion varieties or particular surroundings configurations. You’ll be able to specify the occasion sort, preliminary occasion depend, and configure mannequin habits by means of surroundings variables whereas the SDK handles the deployment complexity.
We deploy to Amazon SageMaker AI Inference for this demonstration.
This may create the execution function blogpost-sagemaker if it doesn’t exist and use it throughout deployment. If you have already got a job that you just wish to use, you’ll be able to move the identify of that function immediately.
Invoke endpoint
After the endpoint is deployed, we are able to invoke it utilizing the SDK. The invoke_inference methodology gives streaming output for SageMaker endpoints and non-streaming for Amazon Bedrock endpoints. We will use the next code to invoke it:
streaming_chat_request = {
"messages": [{"role": "user", "content": "Tell me a short story"}],
"max_tokens": 200,
"stream": True,}
ENDPOINT_NAME = f"arn:aws:sagemaker:REGION:ACCOUNT_ID:endpoint/{ENDPOINT_NAME}"
inference_result = rft_customizer.invoke_inference(
request_body=streaming_chat_request,
endpoint_arn=ENDPOINT_NAME
)
inference_result.present()
Step 5: Cleanup
After you’ve completed testing your deployment, clear up these assets to keep away from ongoing AWS costs.
import boto3
iam_client = boto3.consumer('iam')
role_name="your-role-name"
# Detach managed insurance policies
attached_policies = iam_client.list_attached_role_policies(RoleName=role_name)
for coverage in attached_policies['AttachedPolicies']:
iam_client.detach_role_policy(
RoleName=role_name,
PolicyArn=coverage['PolicyArn']
)
# Delete inline insurance policies
inline_policies = iam_client.list_role_policies(RoleName=role_name)
for policy_name in inline_policies['PolicyNames']:
iam_client.delete_role_policy(
RoleName=role_name,
PolicyName=policy_name
)
# Take away from occasion profiles
instance_profiles = iam_client.list_instance_profiles_for_role(RoleName=role_name)
for profile in instance_profiles['InstanceProfiles']:
iam_client.remove_role_from_instance_profile(
InstanceProfileName=profile['InstanceProfileName'],
RoleName=role_name
)
# Delete the function
iam_client.delete_role(RoleName=role_name)
Conclusion
The Nova Forge SDK transforms mannequin customization from a posh, infrastructure-heavy course of into an accessible, developer-friendly workflow. By our Stack Overflow classification case research, we demonstrated how groups can use the SDK to realize measurable enhancements by means of iterative coaching, shifting from 13% baseline accuracy to 79% after SFT, and reaching 80.6% with extra RFT.
By eradicating the normal limitations to LLM customization, technical experience necessities, and time funding, the Nova Forge SDK empowers organizations to construct fashions that perceive their distinctive context with out sacrificing the final capabilities that make basis fashions useful. The SDK handles configuring compute assets, orchestrating the complete customization pipeline, monitoring coaching jobs, and deploying endpoints. The result’s enterprise AI that’s each specialised and clever, domain-expert and broadly succesful.
Able to customise your individual Nova fashions? Get began with the Nova Forge SDK on GitHub and discover the full documentation to start constructing fashions tailor-made to your enterprise wants.


{kind=link}