

{kind=link}
In 2025, generative AI has developed from textual content era to multi-modal use circumstances starting from audio transcription and translation to voice brokers that require real-time information streaming. In the present day’s purposes demand one thing extra: steady, real-time dialogue between customers and fashions—the flexibility for information to circulate each methods, concurrently, over a single persistent connection. Think about a speech to textual content use-case, the place you will want to stream the audio stream as enter and obtain the transcripted textual content as a steady stream. Such use-cases would require bi-directional streaming functionality.
We’re introducing bidirectional streaming for Amazon SageMaker AI Inference, which transforms inference from a transactional alternate right into a steady dialog. Speech works finest with real-time AI when conversations circulate naturally with out interruptions. With bidirectional streaming, speech to textual content turns into quick. The mannequin listens and transcribes on the identical time, so phrases seem the second they’re spoken. Image a caller describing a problem to a assist line. As they communicate, the reside transcript seems in entrance of the decision middle agent, giving the agent immediate context and letting them reply with out ready for the caller to complete. This sort of steady alternate makes voice experiences really feel fluid, responsive and human.
This put up exhibits you the way to construct and deploy a container with bidirectional streaming functionality to a SageMaker AI endpoint. We additionally display how one can carry your personal container or use our accomplice Deepgram’s pre-built fashions and containers on SageMaker AI to allow bi-directional streaming function for real-time inference.
Bidirectional streaming: Deep dive
With bidirectional streaming, information flows each methods without delay via a single, persistent connection.
Within the conventional strategy to inference requests, the consumer sends an entire query and waits, whereas the mannequin processes the request and returns an entire reply earlier than the consumer can ship the subsequent query.
In bidirectional streaming, the consumer’s speech begins flowing whereas the mannequin concurrently begins processing and transcribing the reply instantly.
Customers see outcomes as quickly because the mannequin begins producing them. Sustaining one persistent connection replaces tons of of short-lived connections. This reduces overhead on networking infrastructure, TLS handshakes, and connection administration. Fashions can preserve context throughout a steady stream, enabling multi-turn interactions with out resending dialog historical past every time.
SageMaker AI Inference bidirectional streaming functionality
SageMaker AI Inference combines HTTP/2 and WebSocket protocols for real-time, two-way communication between purchasers and fashions. If you invoke a SageMaker AI Inference endpoint with bidirectional streaming, your request travels via the three-layer infrastructure in SageMaker AI:
- Shopper to SageMaker AI router: Your utility connects to the Amazon SageMaker AI runtime endpoint utilizing HTTP/2, establishing an environment friendly, multiplexed connection that helps bidirectional streaming.
- SageMaker AI router to mannequin container: The router forwards your request to a Sidecar (a light-weight proxy working alongside your mannequin container), which then establishes a WebSocket connection to your mannequin container at
ws://localhost:8080/invocations-bidirectional-stream.
As soon as the connection is established, information flows freely in each instructions:
- Request stream: Your utility sends enter as a sequence of payload chunks over HTTP/2. The SageMaker AI infrastructure converts these into WebSocket information frames—both textual content (for UTF-8 information) or binary—and forwards them to your mannequin container. The mannequin receives these frames in real-time and may start processing instantly, even earlier than the whole enter arrives akin to for transcribing use circumstances.
- Response stream: Your mannequin generates output and sends it again as WebSocket frames. SageMaker AI wraps every body right into a response payload and streams it on to your utility over HTTP/2. Customers see outcomes as quickly because the mannequin produces them—phrase by phrase for textual content, body by body for video, or pattern by pattern for audio.
The WebSocket connection between the Sidecar and mannequin container stays open at some point of your session, with built-in well being monitoring. To take care of connection well being, SageMaker AI sends WebSocket ping frames each 60 seconds to confirm the connection is lively, and your mannequin container responds with pong frames to substantiate it’s wholesome. If 5 consecutive pings go unanswered, the connection is gracefully closed.
Constructing your personal container for implementing bidirectional streaming
If you need to make use of open supply or your personal fashions, you possibly can customise your container to assist bidirectional streaming. Your container should implement the WebSocket protocol to deal with incoming information frames and ship response frames again to SageMaker AI.
To get began, allow us to construct an instance bi-directional streaming utility with bring-your-own container use case. With this instance we are going to:
- Construct a docker container with bi-directional streaming functionality – a easy echo container that streams the identical bytes as acquired as an enter to the container
- Deploy the container to a SageMaker AI endpoint
- Invoke the SageMaker AI endpoint with the brand new bidirectional streaming API
Conditions
- AWS Account with SageMaker AI permissions
- Docker put in domestically
- Python 3.12+
- Set up aws-sdk-python for SageMaker AI Runtime
InvokeEndpointWithBidirectionalStreamAPI
Construct docker container with bi-directional streaming functionality
First, clone our demo repository and arrange your surroundings as outlined within the README.md. The steps beneath will create a easy demo docker picture and push it Amazon ECR repository in your account.
This creates a container with a Docker label indicating to SageMaker AI that bidirectional streaming functionality is supported on this container.
Deploy the demo bi-directional streaming container to the SageMaker AI endpoint
The next instance script creates the SageMaker AI endpoint with the created container:
Invoke the SageMaker AI endpoint with the brand new bidirectional streaming API
As soon as the SageMaker AI endpoint is InService, we are able to proceed to invoke the endpoint to check the bidirectional streaming performance of the check container.
The next is pattern output displaying the enter and output streams generated by the earlier script. The container echoes incoming information to the output stream, demonstrating bidirectional streaming functionality.
SageMaker AI integration with Deepgram fashions
SageMaker AI and Deepgram have collaborated to construct bidirectional streaming assist for SageMaker AI endpoints. Deepgram, an AWS Superior Tier Associate, delivers enterprise-grade voice AI fashions with industry-leading accuracy and pace. Their fashions energy real-time transcription, text-to-speech and voice brokers for contact facilities, media platforms, and conversational AI purposes.
For purchasers with strict compliance necessities that require audio processing to by no means go away their AWS VPC, conventional self-hosted choices have required important operational overhead to setup and preserve. Amazon SageMaker bidirectional streaming transforms this expertise so prospects can deploy and scale real-time AI purposes with only a few actions within the AWS Administration Console.
Deepgram Nova-3 speech-to-text mannequin is on the market immediately within the AWS Market for deployment as a SageMaker AI endpoint with extra fashions coming quickly. Capabilities of Deepgram Nova-3 embody multi-lingual transcription, enterprise scale efficiency and area particular recognition. Deepgram is providing a 14 day free trial on Amazon SageMaker AI for builders to prototype purposes with out incurring software program license charges. Infrastructure fees of the chosen machine sort will nonetheless be incurred throughout this time. For extra particulars, see the Amazon SageMaker AI Pricing documentation.
A high-level overview and pattern code is offered within the following part. Seek advice from the detailed fast begin information on the Deepgram documentation web page for extra info and examples. Join with the Deepgram Developer Neighborhood in the event you want extra assist with arrange.
Arrange a Deepgram SageMaker AI real-time inference endpoint
To arrange a Deepgram SageMaker AI endpoint:
- Navigate to the AWS Market Mannequin packages part throughout the Amazon SageMaker AI console and seek for Deepgram.
- Subscribe to the product and proceed to the launch wizard on the product web page.
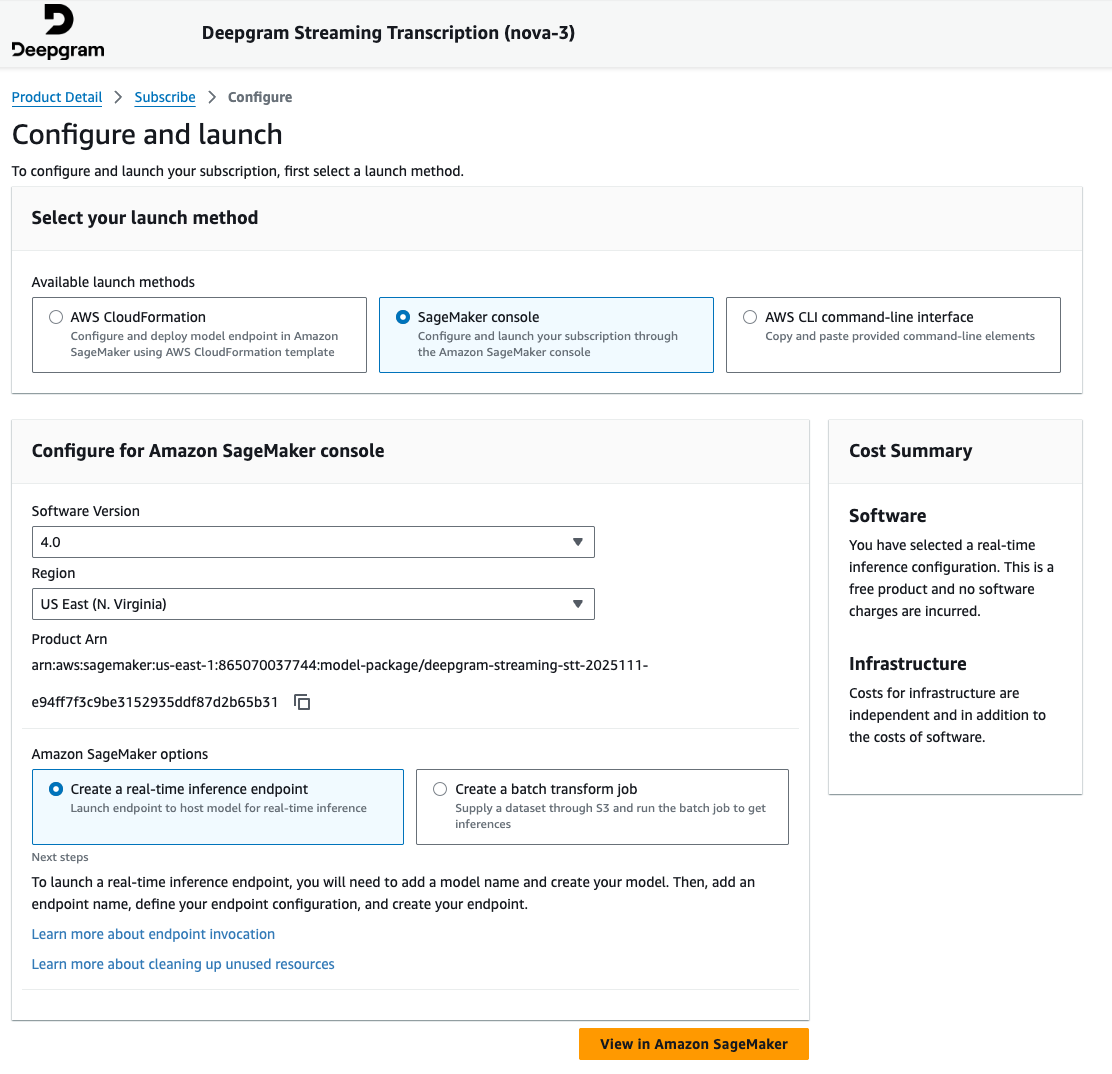
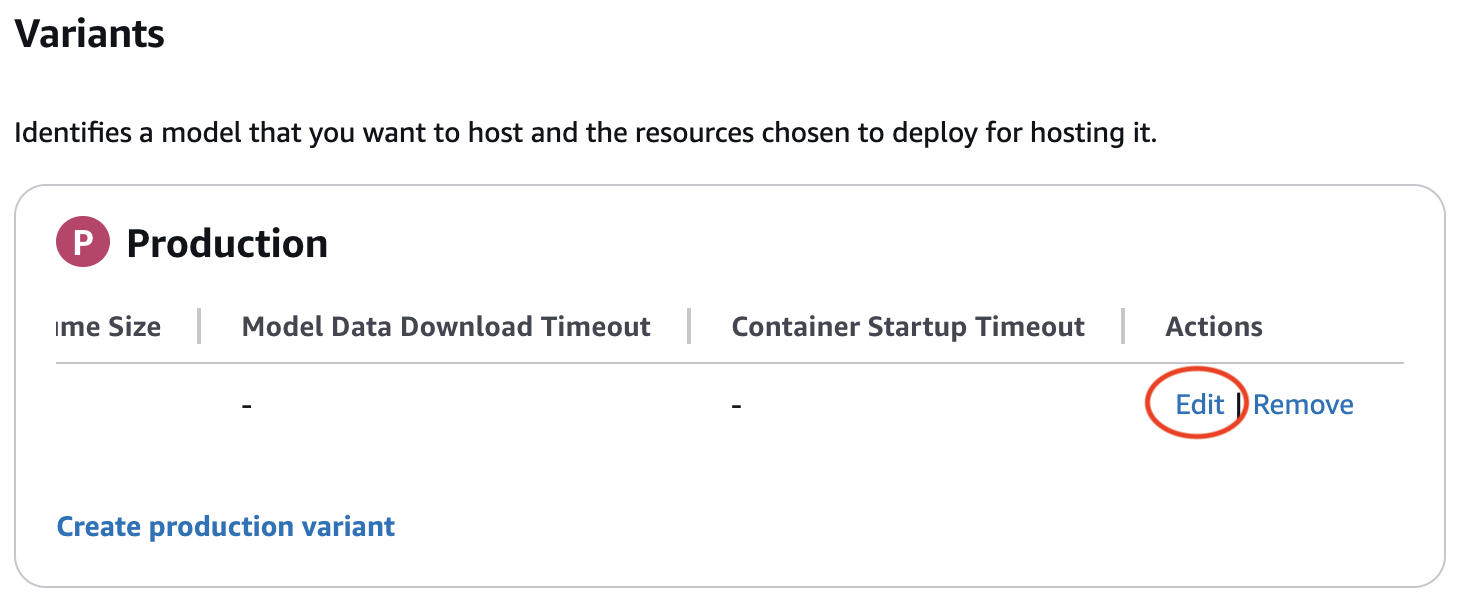
- Proceed by offering particulars within the Amazon SageMaker AI real-time endpoint creation wizard. Confirm that you simply edit the manufacturing variant to incorporate a sound occasion sort when creating your endpoint configuration. The edit button could also be hidden till scrolling proper within the manufacturing variant desk.
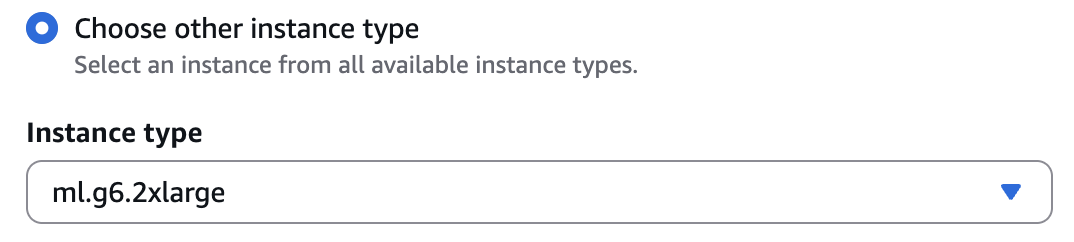
ml.g6.2xlargeis a most popular occasion sort for preliminary testing. Seek advice from the Deepgram documentation for particular {hardware} necessities and choice steerage.
- Within the endpoint abstract web page, be aware of the endpoint identify you offered as this can be wanted within the following part.
Utilizing the Deepgram SageMaker AI real-time inference endpoint
We’ll now stroll via a pattern typescript utility that streams an audio file to the Deepgram mannequin hosted on a SageMaker AI real-time inference endpoint and prints a transcription streamed again in real-time.
- Create a easy perform to stream the WAV file
- This perform opens an area audio file and sends it to Amazon SageMaker AI Inference in small binary chunks.
- Configure the Amazon SageMaker AI runtime consumer
- This part configures the AWS Area, the SageMaker AI endpoint identify, and the Deepgram mannequin route contained in the container. Replace the next values as essential:
areaif not utilizing us-east-1endpointNamefamous from the endpoint setup abovecheck.wavif utilizing a distinct identify for the domestically saved audio file
- This part configures the AWS Area, the SageMaker AI endpoint identify, and the Deepgram mannequin route contained in the container. Replace the next values as essential:
- Invoke the endpoint and print the streaming transcription
- This last snippet sends the audio stream to the SageMaker AI endpoint and prints Deepgram’s streaming JSON occasions as they arrive. The appliance will present reside speech-to-text output being generated.
Conclusion
On this put up, we offered an summary of constructing actual time brokers with generative AI, the challenges, and the way SageMaker AI bidirectional streaming helps you handle these challenges. We additionally offered particulars on the way to construct your personal container to leverage bidirectional streaming function. We then walked you thru the steps to construct a pattern chatbot container and the real-time speech-to-text mannequin supplied by our accomplice Deepgram which is a core element in a real-time voice AI agent utility.
Begin constructing bidirectional streaming purposes with LLMs and SageMaker AI immediately.
In regards to the authors
 Lingran Xia is a software program improvement engineer at AWS. He at the moment focuses on enhancing inference efficiency of machine studying fashions. In his free time, he enjoys touring and snowboarding.
Lingran Xia is a software program improvement engineer at AWS. He at the moment focuses on enhancing inference efficiency of machine studying fashions. In his free time, he enjoys touring and snowboarding.
 Vivek Gangasani is a Worldwide Lead GenAI Specialist Options Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy, handle, and scale their GenAI fashions with SageMaker and GPUs. At present, he’s centered on growing methods and options for optimizing inference efficiency and GPU effectivity for internet hosting Massive Language Fashions. In his free time, Vivek enjoys mountaineering, watching films, and making an attempt completely different cuisines.
Vivek Gangasani is a Worldwide Lead GenAI Specialist Options Architect for SageMaker Inference. He drives Go-to-Market (GTM) and Outbound Product technique for SageMaker Inference. He additionally helps enterprises and startups deploy, handle, and scale their GenAI fashions with SageMaker and GPUs. At present, he’s centered on growing methods and options for optimizing inference efficiency and GPU effectivity for internet hosting Massive Language Fashions. In his free time, Vivek enjoys mountaineering, watching films, and making an attempt completely different cuisines.
 Victor Wang is a Sr. Options Architect at Amazon Net Providers, primarily based in San Francisco, CA, supporting GenAI Startups together with Deepgram. Victor has spent 7 years at Amazon; earlier roles embody software program developer for AWS Web site-to-Web site VPN, AWS ProServe Advisor for Public Sector Companions, and Technical Program Supervisor for Amazon Aurora MySQL. His ardour is studying new applied sciences and touring the world. Victor has flown over two million miles and plans to proceed his everlasting journey of exploration.
Victor Wang is a Sr. Options Architect at Amazon Net Providers, primarily based in San Francisco, CA, supporting GenAI Startups together with Deepgram. Victor has spent 7 years at Amazon; earlier roles embody software program developer for AWS Web site-to-Web site VPN, AWS ProServe Advisor for Public Sector Companions, and Technical Program Supervisor for Amazon Aurora MySQL. His ardour is studying new applied sciences and touring the world. Victor has flown over two million miles and plans to proceed his everlasting journey of exploration.
 Chinmay Bapat is an Engineering Supervisor within the Amazon SageMaker AI Inference crew at AWS, the place he leads engineering efforts centered on constructing scalable infrastructure for generative AI inference. His work allows prospects to deploy and serve massive language fashions and different AI fashions effectively at scale. Exterior of labor, he enjoys taking part in board video games and is studying to ski.
Chinmay Bapat is an Engineering Supervisor within the Amazon SageMaker AI Inference crew at AWS, the place he leads engineering efforts centered on constructing scalable infrastructure for generative AI inference. His work allows prospects to deploy and serve massive language fashions and different AI fashions effectively at scale. Exterior of labor, he enjoys taking part in board video games and is studying to ski.
 Deepti Ragha is a Senior Software program Improvement Engineer on the Amazon SageMaker AI crew, specializing in ML inference infrastructure and mannequin internet hosting optimization. She builds options that enhance deployment efficiency, cut back inference prices, and make ML accessible to organizations of all sizes. Exterior of labor, she enjoys touring, mountaineering, and gardening.
Deepti Ragha is a Senior Software program Improvement Engineer on the Amazon SageMaker AI crew, specializing in ML inference infrastructure and mannequin internet hosting optimization. She builds options that enhance deployment efficiency, cut back inference prices, and make ML accessible to organizations of all sizes. Exterior of labor, she enjoys touring, mountaineering, and gardening.
 Kareem Syed-Mohammed is a Product Supervisor at AWS. He’s focuses on enabling Gen AI mannequin improvement and governance on SageMaker HyperPod. Previous to this, at Amazon QuickSight, he led embedded analytics, and developer expertise. Along with QuickSight, he has been with AWS Market and Amazon retail as a Product Supervisor. Kareem began his profession as a developer for name middle applied sciences, Native Knowledgeable and Adverts for Expedia, and administration guide at McKinsey.
Kareem Syed-Mohammed is a Product Supervisor at AWS. He’s focuses on enabling Gen AI mannequin improvement and governance on SageMaker HyperPod. Previous to this, at Amazon QuickSight, he led embedded analytics, and developer expertise. Along with QuickSight, he has been with AWS Market and Amazon retail as a Product Supervisor. Kareem began his profession as a developer for name middle applied sciences, Native Knowledgeable and Adverts for Expedia, and administration guide at McKinsey.
 Xu Deng is a Software program Engineer Supervisor with the SageMaker crew. He focuses on serving to prospects construct and optimize their AI/ML inference expertise on Amazon SageMaker. In his spare time, he loves touring and snowboarding.
Xu Deng is a Software program Engineer Supervisor with the SageMaker crew. He focuses on serving to prospects construct and optimize their AI/ML inference expertise on Amazon SageMaker. In his spare time, he loves touring and snowboarding.