

{kind=link}
Picture by Editor
# Introduction
The rise of giant language fashions (LLMs) like GPT-4, Llama, and Claude has modified the world of synthetic intelligence. These fashions can write code, reply questions, and summarize paperwork with unbelievable competence. For knowledge scientists, this new period is really thrilling, nevertheless it additionally presents a novel problem, which is that the efficiency of those highly effective fashions is basically tied to the standard of the info that powers them.
Whereas a lot of the general public dialogue focuses on the fashions themselves, the unreal neural networks, and the arithmetic of consideration, the missed hero of the LLM age is knowledge engineering. The previous guidelines of knowledge administration are usually not being changed; they’re being upgraded.
On this article, we are going to take a look at how the position of knowledge is shifting, the crucial pipelines required to help each coaching and inference, and the brand new architectures, like RAG, which might be defining how we construct functions. In case you are a newbie knowledge scientist trying to perceive the place your work matches into this new paradigm, this text is for you.
# Shifting From BI To AI-Prepared Information
Historically, knowledge engineering was primarily centered on enterprise intelligence (BI). The objective was to maneuver knowledge from operational databases like transaction information into knowledge warehouses. This knowledge was extremely structured, clear, and arranged into rows and columns to reply questions like, “What had been final quarter’s gross sales?“
The LLM age calls for a deeper view. We now have to help synthetic intelligence (AI). This entails coping with unstructured knowledge just like the textual content in PDFs, the transcripts of buyer calls, and the code in a GitHub repository. The objective is now not simply to collate this knowledge however to rework it so a mannequin can perceive and cause about it.
This shift requires a brand new form of knowledge pipeline, one which handles completely different knowledge sorts and prepares them for 3 completely different levels of an LLM’s lifecycle:
- Pre-training and Positive-tuning: Instructing the mannequin or specializing it for a activity.
- Inference and Reasoning: Serving to the mannequin entry new data on the time it’s requested a query.
- Analysis and Observability: Making certain the mannequin performs precisely, safely, and with out bias.
Let’s break down the info engineering challenges in every of those phases.
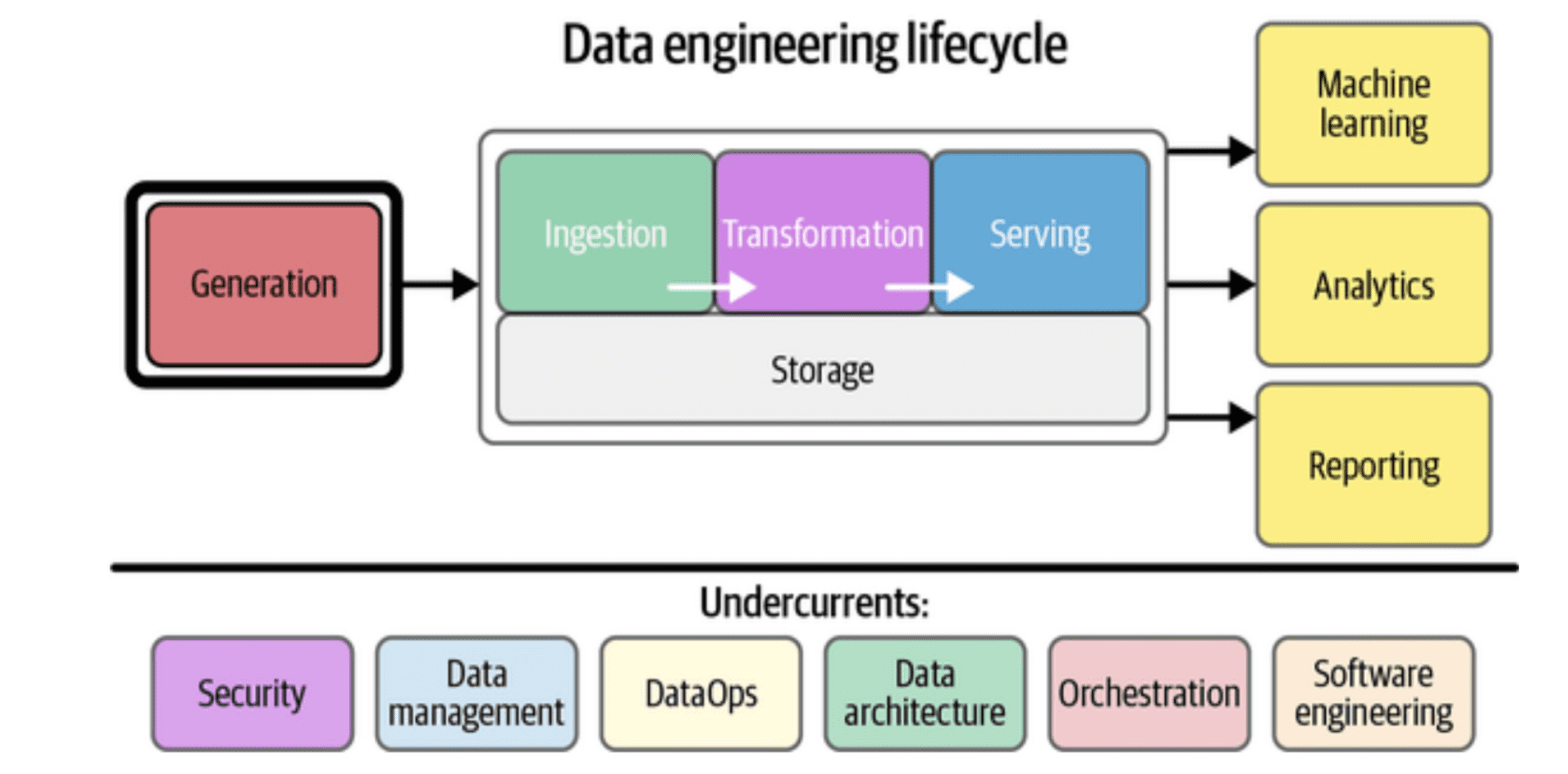
Fig_1: Information Engineering Lifecycle
# Section 1: Engineering Information For Coaching LLMs
Earlier than a mannequin will be useful, it have to be educated. This part is knowledge engineering at a large scale. The objective is to collect a high-quality dataset of textual content that represents a good portion of the world’s information. Let’s take a look at the pillars of coaching knowledge.
// Understanding the Three Pillars Of Coaching Information
When constructing a dataset for pre-training or fine-tuning an LLM, knowledge engineers should deal with three essential points:
- LLMs be taught by statistical sample recognition. To grasp a tiny distinction, grammar, and reasoning, they must be uncovered to trillions of tokens (items of phrases). This implies consuming petabytes of knowledge from sources like Widespread Crawl, GitHub, scientific papers, and net archives. The large quantity requires distributed processing frameworks like Apache Spark to deal with the info load.
- A mannequin educated solely on authorized paperwork might be horrible at writing poetry. A distinct dataset is essential for generalisation. Information engineers should construct pipelines that pull from 1000’s of various domains to create a balanced dataset.
- High quality is a very powerful issue to contemplate. That is the place the actual work begins. The web is stuffed with noise, spam, boilerplate textual content (like navigation menus), and false data. A now-famous paper from Databricks, “The Secret Sauce behind 1,000x LLM Coaching Speedups“, highlighted that knowledge high quality is usually extra essential than mannequin structure.
- Pipelines should take away low-quality content material. This consists of deduplication (eradicating near-identical sentences or paragraphs), filtering out textual content not within the goal language, and eradicating unsafe or dangerous content material.
- You need to know the place your knowledge got here from. If a mannequin behaves unexpectedly, you should hint its behaviour again to the supply knowledge. That is the apply of knowledge lineage, and it turns into a crucial compliance and debugging instrument
For an information scientist, understanding {that a} mannequin is just pretty much as good as its coaching knowledge is step one towards constructing dependable techniques.
# Section 2: Adopting RAG Structure
Whereas coaching a basis mannequin is a large endeavor, most firms don’t have to construct one from scratch. As a substitute, they take an current mannequin and join it to their very own non-public knowledge. That is the place Retrieval-Augmented Technology (RAG) has develop into the dominant structure.
RAG solves a core downside of LLMs being frozen in time in the meanwhile of their coaching. For those who ask a mannequin educated in 2022 a few information occasion from 2023, it should fail. RAG provides the mannequin a solution to “search for” data in actual time.
A typical LLM knowledge pipeline for RAG seems like this:
- You’ve gotten inner paperwork (PDFs, Confluence pages, Slack archives). An information engineer builds a pipeline to ingest these paperwork.
- LLMs have a restricted “context window” (the quantity of textual content they’ll course of without delay). You can’t throw a 500-page guide on the mannequin. Subsequently, the pipeline should intelligently chunk the paperwork into smaller, digestible items (e.g., a number of paragraphs every).
- Every chunk is handed via one other mannequin (an embedding mannequin) that converts the textual content right into a numerical vector, a protracted listing of numbers that represents the that means of the textual content.
- These vectors are then saved in a specialised database designed for velocity: a vector database.
When a person asks a query, the method reverses:
- The person’s question is transformed right into a vector utilizing the identical embedding mannequin.
- The vector database performs a similarity search, discovering the chunks of textual content which might be most semantically just like the person’s query.
- These related chunks are handed to the LLM together with the unique query, with a immediate like, “Reply the query primarily based solely on the next context.”
// Tackling the Information Engineering Problem
The success of RAG relies upon fully on the standard of the ingestion pipeline. If the breakdown technique is poor, the context might be damaged. If the embedding mannequin is mismatched to your knowledge, the retrieval will fetch irrelevant data. Information engineers are chargeable for controlling these parameters and constructing the dependable pipelines that make RAG functions work.
# Section 3: Constructing The Fashionable Information Stack For LLMs
To construct these pipelines, the process is altering. As an information scientist, you’ll encounter a brand new “stack” of applied sciences designed to deal with vector search and LLM orchestration.
- Vector Databases: These are the core of the RAG stack. Not like conventional databases that seek for precise key phrase matches, vector databases search by that means.
- Orchestration Frameworks: These instruments provide help to chain collectively prompts, LLM calls, and knowledge retrieval right into a coherent utility.
- Examples: LangChain and LlamaIndex. They supply pre-built connectors for vector shops and templates for widespread RAG patterns.
- Information Processing: Good old school ETL (Extract, Remodel, Load) remains to be important. Instruments like Spark are used to scrub and put together the huge datasets wanted for fine-tuning.
The important thing takeaway is that the fashionable knowledge stack will not be a substitute for the previous one; it’s an extension. You continue to want your knowledge warehouse (like Snowflake or BigQuery) for structured analytics, however now you want a vector retailer alongside it to energy AI options.

Fig_2: The Fashionable Information Stack for LLMs
# Section 4: Evaluating And Observing
The ultimate piece of the puzzle is analysis. In conventional machine studying, you may measure mannequin efficiency with a easy metric like accuracy (was this picture a cat or a canine?). With generative AI, analysis is extra nuanced. If the mannequin writes a paragraph, is it correct? Is it clear? Is it secure?
Information engineering performs a task right here via LLM observability. We have to observe the info flowing via our techniques to debug failures.
Take into account a RAG utility that provides a nasty reply. Why did it fail?
- Was the related doc lacking from the vector database? (Information Ingestion Failure)
- Was the doc within the database, however the search didn’t retrieve it? (Retrieval Failure)
- Was the doc retrieved, however the LLM ignored it and made up a solution? (Technology Failure)
To reply these questions, knowledge engineers construct pipelines that log the whole interplay. They retailer the person question, the retrieved context, and the ultimate LLM response. By analyzing this knowledge, groups can establish bottlenecks, filter out unhealthy retrievals, and create datasets to fine-tune the mannequin for higher efficiency sooner or later. This closes the loop, turning your utility right into a steady studying system.
# Concluding Remarks
We’re coming into a part the place AI is turning into the first interface via which we work together with knowledge. For knowledge scientists, this represents a large alternative. The abilities required to scrub, construction, and handle knowledge are extra worthwhile than ever.
Nonetheless, the context has modified. You need to now take into consideration unstructured knowledge with the identical warning you as soon as utilized to structured tables. You need to perceive how coaching knowledge shapes mannequin habits. You need to be taught to design LLM knowledge pipelines that help retrieval-augmented technology.
Information engineering is the muse upon which dependable, correct, and secure AI techniques are constructed. By mastering these ideas, you aren’t simply maintaining with the pattern; you might be constructing the infrastructure for the longer term.
Shittu Olumide is a software program engineer and technical author obsessed with leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying advanced ideas. You can too discover Shittu on Twitter.