

{kind=link}
That is all a piece in progress. I noticed Antonio Mele from LSE publish his adaptation of Boris Cherny’s workflow rules, and I assumed I’d do the identical. If these instruments are helpful to me, possibly they’ll be helpful to others. Take all these with a grain of salt however right here it nonetheless is. Thanks all on your help of the podcast! Please take into account changing into a paying subscriber!
I’ve been utilizing Claude Code intensively because the second week of November, and I’ve developed a workflow that I believe is genuinely completely different from how most individuals use AI assistants. I’ve had folks ask me to clarify it on the whole, in addition to clarify extra particular issues too, so this put up explains that workflow and introduces a public repo the place I’m gathering the instruments, templates, and philosophies I’ve developed alongside the way in which.
The repo is right here: github.com/scunning1975/MixtapeTools
All the pieces I describe under is offered there. Use it, adapt it, ignore it—no matter works for you. I absolutely anticipate anybody who makes use of Claude Code to, like me, develop their very own model, however I believe a few of these rules are most likely all the time going to be there for you it doesn’t matter what.
I believe lots of people use AI coding assistants like it’s a educated seal: inform AI what you need, the AI writes it, achieved. That is form of a barking orders method, and it’s not likely in my view very efficient in lots of non-trivial circumstances. I exploit Claude Code in a different way. I deal with it as a pondering associate in initiatives who occurs to have the ability to write code.
The distinction:
This distinction issues enormously for empirical analysis. The onerous half isn’t writing code—it’s determining what code to put in writing and whether or not the outcomes imply what you suppose they imply. And having somebody or some factor to be in common interplay with as you mirror on what you’re doing, why you’re doing it, and what you’re seeing is, I believe, essential for profitable work.
However, right here’s the basic drawback with Claude Code: Claude Code forgets every little thing between classes. It forgets every little thing in the identical challenge everytime you begin a brand new chat interface with that challenge. It’s straightforward to neglect that due to the continuity of the voice, and since it doesn’t know what it doesn’t know. However it will be important that you simply keep in mind that each time you open the identical challenge from a brand new terminal, otherwise you provoke a brand new challenge from a brand new terminal, you’re ranging from zero context.
Most individuals take care of this by re-explaining every little thing verbally. I take care of it by constructing exterior reminiscence in markdown information. Each challenge has:
-
CLAUDE.md— Issues we’ve encountered and the way we solved them -
README.mdinformation — What every listing incorporates and why -
Session logs — What we did because the final up to date session log, what we found, what’s subsequent, to do objects
Since Claude Code can practically instantaneously sweep by means of the challenge and discover all .md information, eat them, and “perceive”, this course of roughly ensures that functionally talking institutional reminiscence will persist although Claude’s reminiscence itself doesn’t.
So, after I begin a brand new session, I all the time inform Claude to learn the markdown information first. It’s not a nasty behavior to have on the whole too as a result of then you definately and Claude can each get again on the identical web page as that course of can even make it easier to bear in mind the place you left issues off. And as soon as it does that, it now is aware of the context, the earlier selections we’ve made, and the place we left off.
Claude is kind of like a fairly educated Labrador retriever. However it may possibly rush forward, off its leash, and although it is going to come again, it may possibly get into bother within the meantime.
So, to try to reign that in, I continually ask Claude to clarify its understanding again to me:
“Do you see the difficulty with this specification?”
“That’s not it. The issue is the usual errors.”
“Guess at what I’m about to ask you to do.”
This isn’t about testing Claude. It’s about making certain alignment. I don’t like when Claude Code will get forward of me, and begins doing issues earlier than I’m prepared. A part of it’s because it’s nonetheless time consuming to undo what it simply did, and so I simply need to try to management Claude as a lot as I can, and entering into Socratic types of questioning it may possibly assist do this. Plus, I discover that this sort of dialoguing helps me — it’s useful for me to be continually bouncing concepts backwards and forwards.
After I ask it to guess the place I’m going with one thing, I kind of get a really feel for once we are in lock step or if Claude is simply feigning it. If Claude guesses fallacious, that reveals a misunderstanding that wants correcting earlier than we proceed. In analysis, a fallacious flip doesn’t simply waste time—it may possibly result in incorrect conclusions in a broadcast paper. This iteration backwards and forwards I hope can mood that.
I by no means belief numbers alone. I continually ask for figures:
“Make a determine exhibiting this relationship”
“Put it in a slide so I can see it”
A desk that claims “ATT = -0.73” is simple to just accept uncritically. A visualization that exhibits the fallacious sample makes the error seen. Belief photos over numbers. So since making “lovely figures” takes no time anymore with Claude Code, I ask for quite a lot of photos now on a regular basis. Issues that aren’t for publication too — I’m simply attempting to determine computationally what I’m taking a look at, how these numbers are even potential to compute, and recognizing errors instantly.
So, I’ve began gathering my instruments and templates in a public repo: MixtapeTools. And right here’s what’s there and methods to use it:
Begin with workflow.md. This can be a detailed rationalization of every little thing I simply described—the pondering associate philosophy, exterior reminiscence by way of markdown, session startup routines, cross-software validation, and extra.
There’s additionally a 24-slide deck (shows/examples/workflow_deck/) that presents these concepts visually. I attempt to emphasize to Claude Code to make “lovely decks” within the hopes that it’s sufficiently educated about what a gorgeous deck of quantitative stuff is that I don’t have to put in writing some detailed factor about it. The irony is that now that Claude Code can spin up a deck quick, with all of the performance of beamer, Tikz, ggplot and so forth, then I’m making decks for me — not only for others. And so I’m consuming my work by way of decks, nearly like I’d be if I used to be taking notes in a notepad of what I’m doing. Plus, I’m drawn to narrative and visualization, so decks additionally help me in that sense.
The claude/ folder incorporates a template for CLAUDE.md—the file that offers Claude persistent reminiscence inside a challenge. Copy it to your challenge root and fill within the specifics. Claude Code routinely reads information named CLAUDE.md, so each session begins with context.
The shows/ folder incorporates my philosophy of slide design. I’m nonetheless creating this—it’s a little bit of a hodge podge of concepts in the intervening time, and the essay I’ve been writing is overwritten in the intervening time. Plus, I continue learning extra about rhetoric and getting suggestions from Claude utilizing its personal understanding of profitable and unsuccessful decks. So that is nonetheless only a sizzling mess of a bunch of jumbled concepts.
However the thought of the rhetoric of decks is itself fairly primary I believe: slides are sequential visible persuasion. Magnificence coaxes out folks’s consideration and a spotlight is a vital situation for enabled communication between me and them (or me and my coauthors, or me and my future self).
Like each good economist, I imagine in constrained optimization and first order situations, which suggests I believe that each slide in a deck ought to have the identical marginal profit to marginal price ratio (what I name “MB/MC equivalence”). Because of this the marginal worth of the data in that slide is offset by the issue of studying it and that something that’s actually tough to learn should due to this fact be extraordinarily helpful.
This results in looking for methods to cut back the cognitive density in a slide. And it takes critically that you will must usually remind folks of the plot due to the innate distractedness that permeates each speak, irrespective of who’s within the viewers, due to the ubiquity of telephones and social media. And so it’s important to discover a strategy to remind folks of the plot of your speak whereas sustaining that MB/MC equivalence throughout slides. Simple locations to try this are titles. Titles ought to be assertions (”Therapy elevated distance by 61 miles”), not labels (”Outcomes”), since you should assume that the viewers missed what the examine is about and due to this fact doesn’t know what these outcomes are for. And attempt to discover the construction hiding in your record somewhat than merely itemizing with bullets when you can.
There’s a condensed information (rhetoric_of_decks.md), an extended essay exploring the mental historical past (rhetoric_of_decks_full_essay.md), and a deck explaining the rhetoric of decks (examples/rhetoric_of_decks/) (meta!).
I’m engaged on an extended essay about this. For now, that is what I’ve.
That is what I believe researchers will discover most helpful.
The issue: Should you ask Claude to overview its personal code, you’re asking a pupil to grade their very own examination. Claude will rationalize its selections somewhat than problem them. True adversarial overview requires separation.
The answer: The Referee 2 protocol.
-
Do your evaluation in your principal Claude session. You’re the “writer” on this state of affairs I’m going to explain. When you’ve reached a stopping level, then …
-
Open a brand new terminal. That is important—recent context, no prior commitments. Consider this as a separate Claude Code in the identical listing, however bear in mind — Claude has no institutional reminiscence, and so this new one is mainly a clone, nevertheless it’s a clone with the identical talents however with out the reminiscence. Then …
-
Paste the Referee 2 protocol (from
personas/referee2.md) and level it at your challenge. -
Referee 2 performs 5 audits:
-
Referee 2 information a proper referee report in
correspondence/referee2/, full with Main Considerations, Minor Considerations, and Questions for Authors. -
You (i.e., the writer) reply. For every concern: repair your code OR write a justification for not fixing. You report what you’ve achieved, in addition to making the adjustments, after which …
-
Resubmit. Open one other new terminal, paste Referee 2 once more, say “That is Spherical 2.” Iterate till the decision is Settle for.
That is the important thing thought behind why I’m doing it is a perception of mine that hallucination is akin to measurement error and that the DGP for these errors are orthogonal throughout languages.
If Claude writes R code with a refined bug, the Stata model will doubtless have a completely different bug or under no circumstances. The bugs aren’t doubtless correlated as they arrive from completely different syntax, completely different default behaviors, completely different implementation paths and completely different contexts.
However when R, Stata, and Python produce similar outcomes to six+ decimal locations, you will have excessive confidence that at minimal the supposed code is working. It might nonetheless be flawed reasoning, nevertheless it received’t be flawed code. And once they don’t match, you’ve caught a bug that single-language overview would miss.
Referee 2 NEVER modifies writer code.
That is important. Referee 2 creates its personal replication scripts in code/replication/. It by no means touches the writer’s code in code/R/ or code/stata/. The audit should be impartial. If Referee 2 may edit your code, it could not be an exterior examine—it could be the identical Claude that wrote the code within the first place.
Solely the writer modifies the writer’s code.
In follow, the hops is that this technique of revise-and-resubmit with referee 2 catches:
-
Unspoken assumptions: “Did you really confirm X, or simply assume it?”
-
Various explanations: “May the sample come from one thing else?”
-
Documentation gaps: “The place does it explicitly say this?”
-
Logical leaps: “You concluded A, however the proof solely helps B”
-
Lacking verification steps: “Have you ever really checked the uncooked knowledge?”
-
Damaged packages or damaged code: Why are csdid in Stata and did in R producing completely different values for the straightforward ATT when the method for producing these factors estimates has no randomness to it? That query has a solution, and referee 2 will determine the issue and hopefully you’ll be able to then get to a solution.
Referee 2 isn’t about being detrimental. It’s about incomes confidence. A conclusion that survives rigorous problem is stronger than one which was by no means questioned.
Recall the theme of my broader collection on Claude Code — the modal quantitative social scientist might be not the target market of the modal Claude Code explainer, who’s extra doubtless a software program engineer or laptop scientist. So, I need to emphasize how completely different my workflow is from what I would characterize as a extra typical one in software program improvement:
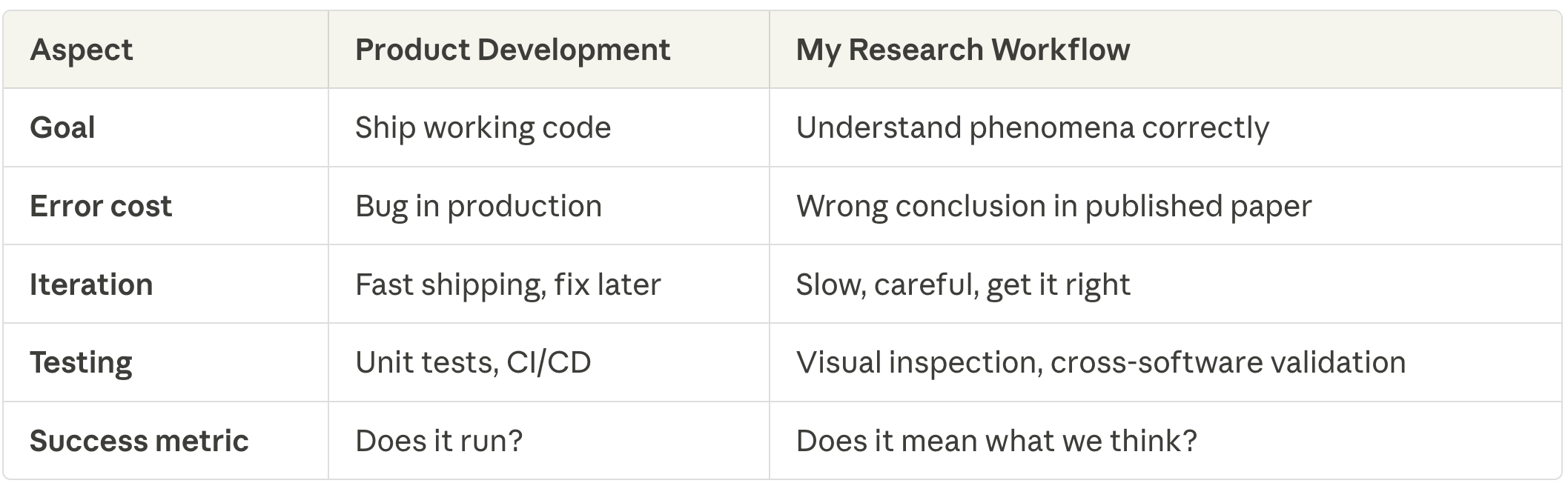
A product developer would possibly see code working and transfer on. But when I see outcomes which are “nearly proper”, I can not proceed in any respect till I determine why it’s not precisely the identical. And that’s as a result of “nearly proper” nearly all the time means a mistake someplace and people must be caught earlier, not later.
The repo will develop as I proceed to formalize extra of my workflow. However proper now it has:
Extra will come as I develop them.
Take every little thing with a grain of salt. These are workflows that work for me. Your mileage might range.