

{kind=link}
The top is close to on my Gov 50 class. I’ll write an post-mortem report for myself as soon as it’s executed — what I discovered, what labored, what didn’t work, what I must do in another way subsequent time, and so forth. Even what my very own course aims are and whether or not these want a radical overhaul. However till then I believed I’d share a few of the issues I did this semester involving worksheets. I additionally thought I’d share these worksheets for individuals who wish to know extra.
My household is a giant playing cards sport household. The one card sport we performed rising up quite a bit was spades, and as my siblings and me married off, we had sufficient individuals to have two or three tables working and have spherical robin tournaments. However, generally we might have an odd variety of gamers, and due to this fact to get to both 2 or 3 tables taking part in, we’d have to ask somebody over who inevitably didn’t know the sport thus necessitating we educate them spades.
Let me inform you what I discovered from that have. I discovered that every time you might be studying a brand new sport, there are principally two parts to studying. They’re:
-
Studying the foundations of the sport
-
Studying the methods to win the sport
And generally, I believe we might be tempted to try to educate new gamers each of these concurrently as a result of we actually needed them to play at a excessive sufficient degree that they wouldn’t smash the tournaments. That’s as a result of spades has companions, and so should you deliver somebody in who merely performs badly, it may be irritating. So, we might attempt to do each — educate them the foundations of the sport (i.e., dealing playing cards, sequential bidding, passing, factors, trumps, rating holding) and technique (i.e., how a lot to bid).
I believe, although, you actually shouldn’t educate each guidelines and technique on the similar time. What I believe inevitably occurs is that they find yourself not studying both very nicely. As an alternative, you simply have to show individuals solely the foundations at first, fully independently of technique instinct, and simply allow them to play on their very own, focusing solely on guidelines and motion. Technique, I’ve discovered, tends to emerge naturally throughout the thoughts of a participant who is aware of the foundations and performs the sport repeatedly.
You can see this as Kahneman’s “System 1 and System 2” ranges of pondering. Possibly guidelines is the system 1 degree however studying to win is extra the system 2 degree. If that’s the case, then most likely it’s higher to separate them. Or perhaps it’s simply that strategic play is extra of a “returns to expertise” type of human capital that isn’t as simply communicated from one individual to a different. In different phrases, each studying the foundations and studying to win are sorts of human capital, however they aren’t acquired in the identical approach, and due to this fact lecturers ought to separate them out and maybe take a really hands-on method to educating guidelines, however a extra hands-off method to educating technique, permitting the coed to develop their very own methods, and correcting it later as soon as the coed possesses the vocabulary and the conceptual structure to observe what you’re saying.
My Gov 50 class has roughly 200 college students and consists broadly of two dimensions of scholars. These dimensions are:
-
First and second yr college students versus older college students
-
Gov concentrators versus non-Gov concentrators
This creates heterogeneity throughout prior talent, but additionally latent demand for the data.
Principally, Gov 50 is a category that serves two functions at Harvard. First, it’s a requirement for the Gov focus, and that due to this fact shapes each 1 and a couple of. You find yourself with youthful cohorts who’re simply now embarking on their Gov journey. It selects on the concentrators too clearly if it’s a requirement for the most important. So the truth that it’s a prerequisite for the most important itself, you may see then why it selects on each youthful individuals going into the most important. About half the category is undeclared and about half the category are first yr or sophomores.
However the different factor is that Gov 50 is a category that fulfills a broader, university-wide, basic training requirement known as “Quantitative Reasoning with Information”. There are dozens of courses that technically fulfill that requirement — economics has one taught by Chetty, laptop science has one, stats has one.
The factor is as you may most likely discern not each scholar in school has a pure vested curiosity in studying to code, work with information, develop and check social scientific theories and so forth. Some main in classics. Some in faith. Some in literature. Some in philosophy. Some in artwork historical past. Majors that place a better premium on some types of reasoning however not essentially “quant reasoning with information” as a result of finally “quant reasoning with information” at its core might be distilled into one factor:
And I say it that approach as a result of there’s numerous types of information which can be not going to suit right into a spreadsheet and thus can’t be learn into a pc with programming languages — and but they’re “information”. A single dialog with a affected person, for example, will yield information, however not essentially be one thing one would put right into a spreadsheet. Somebody might learn an article, take a look at an image revealed in it, and that image is information — and but it not be one thing you can fairly actually import into a pc utilizing R.
So, all of that is to say that the category kind of has 4 teams primarily based on these two dimensions: younger Gov, outdated Gov, younger non-Gov, outdated non-Gov. Nevertheless it’s extra concentrated with younger Gov and outdated non-Gov, although there are non-zero values in all 4 too.
What I’ve seen is that this heterogeneity creates — a minimum of in my thoughts — challenges. What sort of prior data are you able to assume? What sort of latent curiosity in statistics and coding are you able to assume? And finally, with 200 college students, does the median scholar actually inform you numerous if the variance is fairly massive?
So what I selected to do — good or unhealthy — is take a reverse method to educating this materials that took plenty of brute power approaches by having college students, generally with required downside units and generally with further credit score assignments, to focus simply on the mechanics of calculations repeatedly. My perception, which is essentially unchallenged after watching it play out, is that there isn’t actually an alternative to merely with pencil and paper fixing calculations by hand a dozen instances, even when that’s tedious, and even when finally in life your laptop will clear up it for you.
For one factor, and I say this provocatively however I actually consider it — I truthfully don’t assume the world wants extra individuals who change into consultants in pushing buttons and have completely no concept what the numbers imply or the place they got here from. The truth is, with generative AI turning into more and more fairly adept at coding for us, the time inputs we are going to spend on doing empirical work goes to fall, and with every new cohort, they won’t even possess the prior human capital about statistics and causal inference that you simply, because the reader, possesses. You possess plenty of human capital about statistics and causal inference since you are already an grownup who was pressured to study that materials in an old-fashioned analog style. You could have human capital now. So while you use generative AI to study, it’s interacting with that human capital. Now, it might be depreciating that human capital if finally your time use and the time inputs on any given calculation virtually actually shrinks to zero. I simply don’t see the way it’s attainable you could spend actually zero items of time on technical work and never depreciate your pre-existing abilities and human capital. However I’ve written about that earlier than, and I’m going to simply desk that for now.
However no matter occurs to consultants who shift in direction of Gen AI to finish analysis duties with code and information, that’s most likely not the identical factor anyway as somebody with out any human capital enterprise empirical duties for the primary time relying solely on Generative AI. For that individual, if I’m proper, then they really find yourself not spending any actual time partaking in actions which will very nicely be the one option to study one thing. As I’ve stated earlier than, earlier than AI, the completion of duties and the time use wanted to study had been principally the very same factor since you couldn’t full the duty with out utilizing time, and thus by finishing the duty you produced two issues: the output from the duty itself (i.e., a desk of coefficients) and human capital (i.e., what these coefficients imply and the way they had been computed). However now, they’re perhaps weakly correlated. They might even be unbiased of each other for the primary time in historical past.
Effectively, in that case, I believe the instructor has to decide — what’s vital? What will not be vital? And that is the place I suppose I’ve drawn a line within the sand. It is very important me that they study issues not simply merely learn to full analysis duties, and if new know-how has made it such that these are actually two separate phenomena, our pedagogies for educating each should change too. I’m unsure in what path they need to change, however they need to change if the outdated pedagogies had been designed to hit each concurrently. And each professor has the ethical proper to determine this out for themselves as I don’t assume we all know almost sufficient about AI’s results on studying within the classroom as we most likely assume we do — in both path. I do know I don’t.
And that is the place I may also simply quip that we’re most likely in the course of one other empirical disaster and if gen AI is inflicting it to be the case that we will produce analysis outputs utilizing zero time inputs, then it means we could have marginally extra researchers (I no concept what this elasticity is however I doubt it’s zero) who’re producing stuff and are completely clueless what they produced. Which I believe means professors should do extra to interact college students in primary data, not simply technical prowess.
So, I’ve three assignemtns I took this semester to serving to college students study the mechanics of issues I discover vital in causal inference and statistics. They had been all further credit score assignments that produced factors for the exams, to begin with. My feeling on this was that if it was further credit score, I might “pay” them to do this. I might have made it required, however I didn’t, so contemplate that to begin with.
The three assignments, although, had been spreadsheet worksheets. And in these worksheets, you needed to manually calculate sure issues I discovered vital repeatedly. They had been this:
-
Present utilizing the decomposition components (from my guide) that any easy comparability in means could be decomposed into the sum of three potential consequence primarily based calculations: the ATE plus choice bias plus a reweighed distinction within the ATT and the ATU.
-
Calculating of regression coefficients from a bivariate regression manually utilizing a small dataset of 5 observations
-
Calculating regression coefficients from a multivariate regression (two covariates) manually utilizing a small dataset of 4 observations.
I needed to now share the image of those so you may see what it entailed.
Decomposition worksheet
The spreadsheet for the decomposition worksheet is right here at dropbox if you wish to see it. The options are all crammed out with excel formulation so if you wish to see how this was executed, you are able to do so by clicking on every cell. It’s plenty of averaging and differencing, and I discover that actually insightful for college students. The reason being as a result of each school scholar can add, subtract and divide. So in the event that they discover one thing complicated, it’s unlikely to be that it’s complicated as a result of they “will not be good at math” when there may be virtually no math in any respect. Their confusion have to be coming from not understanding “the foundations” — that’s, the order of these additions, subtractions and divisions, not the precise addition, subtraction and division itself. And by separating it out, and making them observe the algorithm by hand, paying them alongside the best way, my principle is that they’ll develop over time to grasp what that is about with out me having to inform them. Or reasonably, it brings them to an eventual place the place they possess the vocabulary — even over one thing as primary as potential outcomes themselves — that they will ask questions in any respect.
I gained’t clarify the decomposition right here; I’ll simply level you to my guide that does. And I’ll present a hyperlink beneath to the spreadsheet for individuals who need it in addition to entrance web page so you may see it right here in a screenshot. Nevertheless it’s my sturdy opinion that this decomposition is essential for understanding causal inference, and so I wish to discover a approach to assist them study it too, and muscle reminiscence by means of repetition is how I selected to do it.
Bivariate Regression worksheets
The second and third purpose was to assist them perceive what regression coefficients are and the way they’re calculated with out utilizing matrix algebra. That is purely pushed by the character of the course, thoughts you, although I believe more and more it most likely is beneficial for others as nicely in the event that they don’t have a stats background and but are anticipated to run regressions regularly.
First I needed them to study the components for calculating a regression coefficient while you solely have on covariate and I gave it to them because the covariance between the result and the covariate divided by the variance of the covariate, or what I repeatedly simply known as a “scaled covariance”. The screenshot for that is right here.
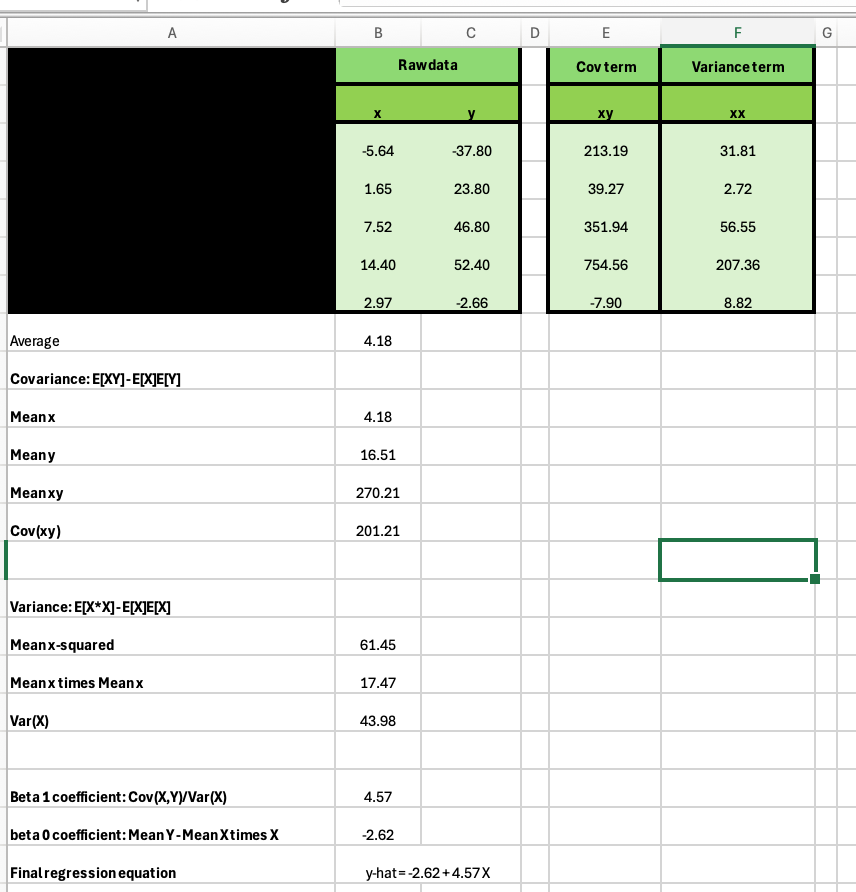
What I like about this one is that I gave them a dataset of 5 observations labeled “uncooked information”. The components for calculating a regression coefficient, like I stated, has two elements: the numerator (covariance) and the denominator (variance). And inside every, there’s some issues that I believe college students actually don’t all the time perceive and that’s that generally they’re taking a mean first after which multiplying two issues (“the product of the averages”) however generally they do the identical factor in reverse order (“the typical of the product”). So utilizing the “small dataset” they use the excel formulation and calculate merchandise and averages themselves, after which mix them to get covariance and variance, after which use these to get the regression coefficients on the intercept (beta_0) and the slope coefficient (beta 1) itself.
I might’ve gone additional with this and virtually did, however finally selected to not as I used to be doing an excessive amount of on the fly. However after getting the intercept and the slope, you get fitted values or predicted outcomes. And after getting these, you will get residuals, and begin doing much more issues like calculate commonplace errors, sum of squared residuals, R-squared and so forth.
It’s fairly simple, and has sufficient shifting elements that college students need to watch out. However how do they know they acquired it proper? As a result of the project additionally required that they run regressions in R and ensure that their handbook calculations had been numerically equivalent to what was produced by R utilizing lm(y~x).
Multivariate Regression worksheets
This was the one I wasn’t certain about and almost didn’t do it, however I did do it ultimately. I required that college students calculate by hand the regression coefficients when you might have two covariates and ensure it was equivalent to what was producing utilizing lm(y~x) in R.
Now why would you ever do that if in actuality you by no means use this components to calculate it? I believe it’s because over time, the extra I’ve taught causal inference, the extra I’ve come to see many issues if not most issues in causal inference as “easy comparisons”. And easy comparisons to me can all the time be calculated by hand with a sufficiently small dataset. You’ll be able to calculate the LATE by hand utilizing IV since IV collapses into the Wald estimator which is a ratio fo two covariances., for example. You’ll be able to calculate diff-in-diff as easy “2x2s” and combination utilizing easy weights. Some unconfoundedness strategies are very simple — so simple that while you see them, you marvel the way it’s remotely attainable this might even be a scientific discipline. However a lot of that is simpler than it seems.
However the components for multivariate regression with two covariates and no matrix algebra is daunting, little doubt. It’s this:
In order that’s plenty of work. And I don’t make them do each; I simply make them do considered one of them. I simply pay them with further credit score to do it as a result of labor provide curves slope upward.
It sounds foolish to say this out loud, however I really spend an inordinate period of time tinkering with the format of the spreadsheet, making an attempt completely different colours, making an attempt to determine the place I would like the merchandise and expectations to go, and so forth. The factor is I’ve completely no talent in any respect aesthetically with design, so finally what I find yourself creating is one thing that works for my mind, and I’m virtually optimistic doesn’t work on some summary, basic sense. I’m certain Tufte would hate that is my level.
However anyway, I’ve three examples within the tabs on this spreadsheet already accomplished to calculate the slope coefficient on the primary covariate, after which I’ve 6 further credit the place they do it themselves on the different covariate and the max further credit score you get should you do all of that is 3 factors on the check. They usually had to do that in Part this week, together with Frisch-Waugh-Lovell stuff (which once more, perhaps finish of semester I’ll look again and assume that was insane to do).
I don’t know ultimately if that is the simplest pedagogy. What I do know, although, is that pedagogy is endogenous to at least one’s course targets. And if my purpose is that college students study these items, not simply know the right way to run lm(y~x) or equal in R, then given the choice of college students, I’ve to seek out methods to get this human capital funding to a minimum of exist as a possible platform. And my course goal will not be merely that they learn to work with information; it’s additionally that they study to “cause quantitatively with information”, and reasoning to me consists of data of the underlying principle. Possibly not exhaustively, however I believe should you went by means of these worksheets and acquired full credit score on the additional credit score, it’s borderline unattainable that you simply didn’t degree up your data. And that has been reported to me by many college students — they did study one thing that had been in any other case elusive from these tedious and repetitive calculations in these worksheets.
So we’ll see. If nothing else, I’ve been producing plenty of information by having to design and educate this class at Harvard and at this scale. And I hope to develop from this expertise, hope college students could have too, and I belief each will occur.