
{kind=link}
Desk of Contents
- Grounded SAM 2: From Open-Set Detection to Segmentation and Monitoring
- Why Segmentation Issues (Past Bounding Packing containers)
- Introducing Grounded SAM 2
- The place SAM Suits within the Pipeline
- Why SAM 2 (and never SAM)
- How Grounded SAM 2 Works Internally
- How Grounded SAM 2 Differs from the Unique Grounded SAM
- Advantages and Use Instances
- Configuring Your Improvement Atmosphere
- Setup and Imports
- Obtain Mannequin Checkpoints
- Detect, Phase, and Observe Perform
- Constructing a Gradio Interface
- Output
- Abstract
Grounded SAM 2: From Open-Set Detection to Segmentation and Monitoring
Within the earlier tutorial, we discovered how Grounding DINO allows open-set object detection utilizing language prompts. By fusing imaginative and prescient and language via multi-stage consideration, the mannequin localizes any object we describe — even ones it has by no means seen throughout coaching. We built-in it right into a video pipeline with Gradio, demonstrating how objects will be tracked body by body utilizing solely pure language.
Nevertheless, as famous in our dialogue on challenges, Grounding DINO outputs solely bounding packing containers. Whereas bounding packing containers determine the place objects are, they lack spatial precision. They seize the encompassing background, battle with overlapping objects, and can’t isolate the precise shapes of objects. For a lot of real-world duties — particularly in robotics, medical imaging, precision modifying, and video analytics — bounding packing containers are inadequate. This limitation naturally results in the subsequent step: segmentation and protracted monitoring, powered by Grounded SAM 2.
Grounded SAM 2 turns into a pure evolution of the Grounding DINO pipeline. It combines language-driven detection with pixel-level segmentation and provides video-aware object monitoring.
In easy phrases, Grounding DINO finds what and the place an object is. SAM 2 exhibits which precise pixels belong to it — and continues monitoring it throughout frames in the video.
This weblog explains how Grounded SAM 2 leverages the strengths of Grounding DINO for detection, then passes the knowledge to the SAM 2 mannequin for high-precision segmentation, enabling a whole vision-language pipeline that may detect, section, and monitor something from a natural-language immediate.
This lesson is the first in a 2-part collection on Imaginative and prescient-Language Fashions — Grounded Imaginative and prescient Fashions (Grounding DINO and SAM):
- Grounding DINO: Open Vocabulary Object Detection on Movies
- Grounded SAM 2: From Open-Set Detection to Segmentation and Monitoring (this tutorial)
To learn to carry out open-vocabulary detection, segmentation, and monitoring with Grounded SAM 2, simply maintain studying.
Why Segmentation Issues (Past Bounding Packing containers)
Bounding field detection works properly for coarse localization. Nevertheless, it captures each foreground and background. For instance, when detecting a “helmet”, the bounding field consists of a part of the rider’s head. When segmenting a leaf on a plant, the bounding field additionally covers branches and background.
Segmentation resolves this by predicting pixel-level object masks. As a substitute of drawing a rectangle, the mannequin outlines the thing’s precise form. This provides far larger spatial precision, which is crucial when:
- Extracting objects for modifying or compositing
- Measuring object measurement or construction
- Performing focused robotic manipulation
- Figuring out visible anomalies (e.g., tumor boundaries in medical scans)
Segmentation fashions historically require massive annotated masks datasets and function on restricted class units. They can’t generalize to new ideas with out retraining.
Grounded SAM 2 addresses this by combining language-driven detection with basis model-based segmentation. This creates a system that understands which object is requested, the place it’s positioned, and which precise pixels belong to it, even when the thing is unseen throughout coaching.
Introducing Grounded SAM 2
In Half 1, Grounding DINO demonstrated {that a} mannequin can:
- Detect arbitrary objects through pure language
- Localize these objects utilizing bounding packing containers
- Generalize to unseen classes
- Course of photographs and movies utilizing the identical language-driven strategy
This established a basis for language-guided visible understanding. However segmentation remained outdoors the pipeline. That hole is now stuffed by Grounded SAM 2.
Grounded SAM 2 is a vision-language pipeline that performs detection, segmentation, and monitoring utilizing pure language prompts.
In easy phrases, Grounding DINO finds what and the place the thing is. SAM 2 determines the precise pixels that belong to the thing. The system then tracks it constantly throughout video frames.
The pipeline extends the philosophy of “detect something we are able to describe” into “detect, isolate, and observe something we are able to describe.”
The place SAM Suits within the Pipeline
First, Grounding DINO detects areas of curiosity utilizing a textual content immediate.
Subsequent, every detected area (bounding field) turns into a immediate for SAM 2.
Then, SAM 2 generates a exact segmentation masks across the detected object.
Lastly, in movies, SAM 2 maintains temporal consistency utilizing memory-based monitoring, permitting seamless object persistence throughout frames.
Why SAM 2 (and never SAM)
Segmentation is essentially totally different from detection. Detection signifies an object’s location utilizing bounding packing containers. Segmentation goes additional — it outlines the precise pixels belonging to an object. This allows exact measurement, clear object isolation, context-aware modifying, and higher downstream inference.
The Phase Something Mannequin (SAM) launched a breakthrough concept: promptable segmentation. As a substitute of coaching a mannequin for fastened classes, SAM learns to generate segmentation masks from easy prompts comparable to factors, bounding packing containers, or coarse areas. The mannequin was educated on 11 million photographs and 1.1 billion masks, leading to distinctive zero-shot generalization. In apply, we offer a picture and a touch, and SAM completes the masks. This makes it splendid for human-in-the-loop annotation, automated masks creation, and visible modifying workflows.
SAM was initially designed for static photographs. It doesn’t preserve temporal consistency, so masks high quality might fluctuate between video frames. That is the place SAM 2 brings a serious enchancment. SAM 2 treats a single picture as a one-frame video and extends segmentation to full video utilizing a streaming-memory transformer. This mechanism maintains compact temporal info throughout frames, permitting the mannequin to refine object masks constantly whereas preserving consistency.
SAM 2 operates reliably even below movement, partial occlusion, or delicate look adjustments. Meta studies larger segmentation accuracy in comparison with the unique SAM, each on photographs and movies. SAM 2 helps box-based or point-based prompting identical to SAM, however provides the flexibility to monitor the identical object throughout time, making it much more appropriate for dynamic duties comparable to video analytics, robotics, and video modifying.
How Grounded SAM 2 Works Internally
Grounded SAM 2 is a pipeline (not a single monolithic mannequin): it composes an open-vocabulary grounding mannequin (Grounding DINO, Florence-2, DINO-X, or comparable) with SAM 2 because the promptable segmenter, then layers on monitoring and heuristics for video. The official repo and neighborhood implementations present this cascade strategy.
Let’s break the pipeline into concrete steps:
- Immediate and Detection: The consumer gives a picture (or video body) and a textual content immediate (e.g., “purple automotive”, “chair on left”). A grounding mannequin (Grounding DINO, Florence-2, or DINO-X) processes the enter and outputs bounding packing containers round all matching objects.
- Segmentation: Every detected field is handed to SAM 2 (or SAM) as a immediate. SAM then generates a exact masks for every object, turning tough packing containers into tight outlines.
- Monitoring (for video): In movies, Grounded SAM 2 hyperlinks these segmented objects throughout frames. It could possibly assign constant IDs to things and observe new objects as they enter the scene. The pipeline may even deal with customized video inputs and “new object” discovery throughout the video.
Thus, the structure is a cascade of fashions: a vision-language detector adopted by a promptable segmenter, with elective monitoring on prime. The Grounded SAM 2 repo calls this a “basis mannequin pipeline” that may floor and monitor something in movies. The strategy is extremely modular (e.g., one can swap in Florence-2 for detection, or use DINO-X for even higher open-world efficiency). Nevertheless, the core concept is similar: language-guided detection plus SAM-based segmentation.
How Grounded SAM 2 Differs from the Unique Grounded SAM
The important change is swapping SAM → SAM 2 and increasing grounding choices. Grounded SAM 2 makes use of SAM 2 (picture+video promptable segmentation), which instantly brings video consistency and improved masks high quality when in comparison with utilizing the unique SAM. This reduces the necessity for ad-hoc temporal smoothing for a lot of use instances.
Grounded SAM 2 generally pairs SAM 2 with stronger or a number of grounding backbones (e.g., Florence-2, DINO-X, or Grounding DINO 1.5). This modularity improves open-world detection efficiency as a result of totally different grounding fashions have totally different strengths in zero-shot semantics and localization.
The monitoring and streaming design is emphasised. The Grounded SAM 2 repository consists of tooling for streaming, real-time demo frameworks, and memory-efficient processing for lengthy movies — sensible considerations that transcend static-image pipelines.
Advantages and Use Instances
Grounded SAM 2 affords a number of benefits over conventional methods:
- Open-Vocabulary Detection and Segmentation: By combining Grounding DINO (or DINO-X, Florence-2) with SAM, Grounded SAM 2 can discover and masks objects of any class described by a immediate. This removes the necessity for a hard and fast class listing and large labeled datasets.
- Excessive-High quality Masks: SAM gives pixel-accurate segmentation masks by default. For instance, in medical imaging or precision agriculture, precise object boundaries are important; Grounded SAM 2 can ship these masks with out further coaching.
- Simplified Knowledge Annotation: The pipeline can robotically label photographs with packing containers and masks. Grounding DINO can enormously pace up annotation duties, changing many hand-designed steps. By chaining it with SAM, one can auto-generate each packing containers and masks for brand spanking new datasets.
- Video Understanding: Grounded SAM 2 naturally extends to video. It could possibly monitor and section objects throughout frames, enabling functions (e.g., video surveillance, sports activities analytics, and robotics), the place figuring out what the thing is and the place it strikes over time is essential.
- Versatility: Segmentation is helpful throughout domains comparable to medical imaging (tumor outlining), picture modifying (isolating objects), and autonomous driving (street scene parsing). Grounded SAM 2 democratizes these duties by open-sourcing the fashions and pipeline.

Would you want speedy entry to three,457 photographs curated and labeled with hand gestures to coach, discover, and experiment with … free of charge? Head over to Roboflow and get a free account to seize these hand gesture photographs.
Configuring Your Improvement Atmosphere
To observe this information, it is advisable have the next libraries put in in your system.
!pip set up -q gradio supervision transformers pillow !pip set up -q sam2
First, we set up all vital Python packages utilizing pip. The -q flag retains the set up logs quiet, making the pocket book output cleaner.
Let’s rapidly perceive the function of every library:
gradio: helps us construct an interactive net interface, as we did earlier for Grounding DINO.supervision: gives annotation utilities to attract masks and packing containers effectively.transformers: permits us to load pretrained vision-language fashions utilizing the Hugging Face API.pillow: helps picture conversion, drawing, and visualization.
We additionally set up sam2, the segmentation basis mannequin utilized in Grounded SAM 2. This bundle provides entry to the SAM 2 implementation, together with prompt-driven masks prediction and video monitoring capabilities.
!git clone -q https://github.com/IDEA-Analysis/Grounded-SAM-2.git %cd Grounded-SAM-2
Then we clone the Grounded SAM 2 official implementation from GitHub. This repository comprises utility scripts, mannequin configuration recordsdata, and instance pipelines utilized by the Grounded SAM 2 authors.
Lastly, we alter the working listing to the cloned folder utilizing the %cd command. This permits us to entry mannequin weights, configuration recordsdata, and inference utilities instantly from the repository.
Setup and Imports
As soon as put in, we import all of the important libraries and helper modules.
import os import cv2 import torch import shutil import numpy as np import gradio as gr import supervision as sv from PIL import Picture from pathlib import Path from huggingface_hub import hf_hub_download from sam2.sam2_image_predictor import SAM2ImagePredictor from sam2.build_sam import build_sam2_video_predictor, build_sam2 from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection from utils.track_utils import sample_points_from_masks from utils.video_utils import create_video_from_images
First, we import os for file path dealing with and listing operations, cv2 (OpenCV) helps learn video frames and deal with picture transformations, torch is used for mannequin inference with GPU acceleration, shutil for file copying and listing cleanup when producing non permanent outcomes, numpy gives environment friendly numerical and array operations, gradio to construct the interactive net interface, and supervision affords utilities to visualise outcomes comparable to drawing masks, monitoring IDs, and overlaying labels.
Then, we import PIL.Picture, which converts frames to PIL photographs that some fashions (e.g., SAM) count on as enter. We additionally import Path (from pathlib), which gives a cleaner solution to handle file system paths, and hf_hub_download, which permits us to obtain mannequin weights instantly from the Hugging Face Hub.
After that, we import the SAM 2 predictor lessons.
SAM2ImagePredictorpermits pixel-level segmentation on static photographs.build_sam2_video_predictorprepares a video segmentation pipeline that maintains reminiscence throughout frames.build_sam2helps load the SAM 2 basis mannequin earlier than initializing its inference mode.
These parts allow us to maneuver past bounding field detection and carry out segmentation and video-based monitoring.
We additionally import AutoProcessor and AutoModelForZeroShotObjectDetection from Hugging Face to load the Grounding DINO processor and mannequin. This provides us language-driven open-set detection — the primary part of the Grounded SAM 2 pipeline.
Lastly, we import utility features from the repository:
sample_points_from_masks: helps extract consultant factors from segmentation masks, which improves monitoring stability throughout time.create_video_from_images: takes a sequence of processed picture frames and stitches them again into an output video.
These utilities assist convert segmentation outcomes into a whole and trackable video pipeline.
Want Assist Configuring Your Improvement Atmosphere?

All that stated, are you:
- Brief on time?
- Studying in your employer’s administratively locked system?
- Eager to skip the trouble of combating with the command line, bundle managers, and digital environments?
- Able to run the code instantly in your Home windows, macOS, or Linux system?
Then be part of PyImageSearch College immediately!
Achieve entry to Jupyter Notebooks for this tutorial and different PyImageSearch guides pre-configured to run on Google Colab’s ecosystem proper in your net browser! No set up required.
And better of all, these Jupyter Notebooks will run on Home windows, macOS, and Linux!
Obtain Mannequin Checkpoints
To run Grounded SAM 2, we first obtain the official mannequin weights and configuration recordsdata.
sam2_ckpt_path = hf_hub_download(
repo_id="fb/sam2-hiera-large",
filename="sam2_hiera_large.pt"
)
sam2_config_path = hf_hub_download(
repo_id="fb/sam2-hiera-large",
filename="sam2_hiera_l.yaml"
)
print("✅ SAM2 checkpoint downloaded:", sam2_ckpt_path)
print("✅ SAM2 config path:", sam2_config_path)
shutil.copy(sam2_ckpt_path, "/content material/sam2_hiera_large.pt")
shutil.copy(sam2_config_path, "/content material/sam2_hiera_l.yaml")
print("✅ Copied to /content material")
First, we use hf_hub_download() to obtain the SAM 2 mannequin checkpoint from the Hugging Face Hub. The repo_id factors to the official mannequin repository, and filename specifies the precise checkpoint file. This .pt file comprises the pre-trained weights utilized by SAM 2 when predicting segmentation masks.
Subsequent, we obtain the mannequin configuration file. This .yaml file defines mannequin settings comparable to structure parameters, scaling methods, and immediate dealing with. SAM 2 makes use of it throughout initialization to make sure the weights are loaded accurately.
Then, we show the obtain paths to substantiate that each recordsdata had been retrieved efficiently. This ensures appropriate mannequin retrieval earlier than shifting ahead.
After that, we copy the downloaded recordsdata to the /content material/ listing. This step centralizes the checkpoint and configuration file, making them simpler to entry when constructing the mannequin. It’s notably helpful in environments like Google Colab, the place code execution usually expects assets within the root working listing.
Lastly, we verify the copy operation. At this level, each the SAM 2 checkpoint and its configuration file can be found on the root listing and able to be loaded.
Detect, Phase, and Observe Perform
Now, we outline the principle perform, which takes a video and a textual content immediate, then:
- Makes use of Grounding DINO to detect the thing from language,
- Makes use of SAM 2 to section it,
- Makes use of the video predictor to trace masks throughout frames,
- Renders an annotated output video.
def run_tracking(video_file, text_prompt, prompt_type, progress=gr.Progress()):
if video_file is None:
increase gr.Error("Please add a video file.")
We outline a perform run_tracking that Gradio will name (Line 1). It accepts:
video_file: the uploaded videotext_prompt: the language question (e.g., “purple automotive”)prompt_type: how we seed SAM 2 (“level”, “field”, or “masks”)progress: a Gradio helper to report standing updates within the UI
First, we examine if a video was supplied. If not, we increase a Gradio error (Please add a video file.). This seems as a helpful message within the net UI as an alternative of a uncooked Python traceback (Strains 2 and three).
progress(0, "Initializing fashions...")
machine = "cuda" if torch.cuda.is_available() else "cpu"
MODEL_ID = "IDEA-Analysis/grounding-dino-base"
SAVE_TRACKING_RESULTS_DIR = "./tracking_results"
SOURCE_VIDEO_FRAME_DIR = "./custom_video_frames"
OUTPUT_VIDEO_PATH = "./output_tracking.mp4"
torch.autocast(device_type=machine, dtype=torch.bfloat16).__enter__()
if machine == "cuda" and torch.cuda.get_device_properties(0).main >= 8:
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
video_predictor = build_sam2_video_predictor(
"sam2_hiera_l.yaml",
ckpt_path=sam2_ckpt_path,
machine=machine
)
sam2_image_model = build_sam2("sam2_hiera_l.yaml", ckpt_path=sam2_ckpt_path)
image_predictor = SAM2ImagePredictor(sam2_image_model)
processor = AutoProcessor.from_pretrained(MODEL_ID)
grounding_model = AutoModelForZeroShotObjectDetection.from_pretrained(MODEL_ID).to(machine)
Subsequent, we initialize the progress bar at 0% with a standing message (Initializing Fashions…). This provides speedy suggestions that one thing has began (Line 5). We detect whether or not a GPU is on the market. If sure, we use "cuda"; in any other case, we fall again to "cpu". This decides the place fashions and tensors will stay (Line 7).
We outline a couple of constants (Strains 9-12):
MODEL_ID: which Grounding DINO checkpoint to load (right here we usegrounding-dino-basemannequin launched byIDEA-Analysis)SAVE_TRACKING_RESULTS_DIR: the place we’ll save annotated framesSOURCE_VIDEO_FRAME_DIR: the place uncooked frames extracted from the enter video will likely be savedOUTPUT_VIDEO_PATH: remaining video file path
We allow computerized blended precision with bfloat16. This reduces reminiscence utilization and quickens inference, particularly on trendy GPUs (Line 14). If we’re on a current NVIDIA GPU (compute functionality ≥ 8), we additionally allow TF32 for matmul operations and cuDNN. This provides an additional efficiency enhance with minimal high quality trade-off (Strains 15-17).
We load two variants of the SAM 2 mannequin:
video_predictor: specialised for video monitoring. It maintains reminiscence and propagates masks throughout frames (Strains 19-23).sam2_image_modelandSAM2ImagePredictor: used for single-image segmentation on the preliminary annotated body (Strains 24 and 25).
This mirrors our conceptual pipeline:
- Use image-level SAM 2 to acquire a clear beginning masks
- Use video-level SAM 2 to propagate it all through the whole video
We then load (Strains 27 and 28):
processor: handles all preprocessing (picture + textual content → tensors),grounding_model: the Grounding DINO mannequin checkpoint for zero-shot object detection. We additionally transfer the mannequin to the chosen machine for environment friendly inference.
progress(0.2, "Extracting video frames...")
video_path = video_file
frame_generator = sv.get_video_frames_generator(video_path, stride=1)
source_frames = Path(SOURCE_VIDEO_FRAME_DIR)
source_frames.mkdir(dad and mom=True, exist_ok=True)
with sv.ImageSink(target_dir_path=source_frames, overwrite=True, image_name_pattern="{:05d}.jpg") as sink:
for body in frame_generator:
sink.save_image(body)
frame_names = [p for p in os.listdir(SOURCE_VIDEO_FRAME_DIR) if p.lower().endswith((".jpg", ".jpeg"))]
frame_names.type(key=lambda p: int(os.path.splitext(p)[0]))
We replace progress to 20%, indicating that video body extraction has began (Line 30). We deal with the uploaded video file path as video_path (Line 32). Then, we ask supervision to create a body generator, yielding each body (stride=1) (Line 33). We create the SOURCE_VIDEO_FRAME_DIR if it doesn’t exist which can retailer all extracted frames as photographs (Strains 35 and 36).
Inside this context (Strains 38-40), we:
- Use
ImageSinkto put in writing every body to disk, - Title frames as
00000.jpg,00001.jpg, and so forth. (zero-padded 5-digit indices). This provides a clear listing of ordered frames.
We listing all JPEG frames within the listing and kind them numerically based mostly on their file identify index. This ensures body 0, 1, 2, … order is preserved for later steps (Strains 42 and 43).
progress(0.35, "Working object grounding...")
inference_state = video_predictor.init_state(video_path=SOURCE_VIDEO_FRAME_DIR)
ann_frame_idx = 0
img_path = os.path.be part of(SOURCE_VIDEO_FRAME_DIR, frame_names[ann_frame_idx])
picture = Picture.open(img_path)
inputs = processor(photographs=picture, textual content=text_prompt, return_tensors="pt").to(machine)
with torch.no_grad():
outputs = grounding_model(**inputs)
outcomes = processor.post_process_grounded_object_detection(outputs, inputs.input_ids, threshold=0.3, text_threshold=0.3, target_sizes=[image.size[::-1]])
input_boxes = outcomes[0]["boxes"].cpu().numpy()
class_names = outcomes[0]["labels"]
image_predictor.set_image(np.array(picture.convert("RGB")))
# deal with a number of detections safely
if len(input_boxes) == 0:
increase gr.Error("No objects detected. Strive rising threshold or altering immediate.")
first_box = input_boxes[0].tolist()
masks, _, _ = image_predictor.predict(
point_coords=None,
point_labels=None,
field=first_box,
multimask_output=False,
)
if masks.ndim == 4:
masks = masks.squeeze(1)
OBJECTS = class_names
We bump progress to 35% and sign that object grounding (detection) is about to begin (Line 45). We initialize the SAM 2 video inference state utilizing the listing of frames (Line 47). This prepares inside reminiscence and indexing. We additionally resolve that body 0 is the annotation body (ann_frame_idx = 0), the place we’ll give SAM 2 our prompts (factors/field/masks) (Line 48).
We load the primary body as a PIL picture. This will likely be fed to Grounding DINO and SAM 2 for preliminary grounding and masks era. We preprocess each the picture and the text_prompt utilizing the processor. We convert all the pieces into PyTorch tensors and transfer them to the machine (Strains 50-53).
Then, we run the Grounding DINO mannequin inside torch.no_grad() (no gradient monitoring wanted for inference). The mannequin predicts uncooked detection outputs (logits, field coordinates, and so forth.) (Strains 54 and 55).
Subsequent, we post-process detections (Line 57):
- Map predictions again to the unique picture measurement (
target_sizes), - Apply field and textual content thresholds (
0.3right here), - Extract
packing containersandlabels. We convert packing containers to a NumPy array, and maintain the textual content labels asclass_names.
We offer the primary body to the SAM 2 picture predictor in RGB format. This lets the predictor run segmentation on this body. We deal with the case the place Grounding DINO finds no objects. In that state of affairs, we increase a user-friendly error suggesting a unique threshold or immediate. We select the first detected field because the area of curiosity. In a extra superior model, we may loop over all packing containers; right here we maintain it easy for the demo (Strains 58-66).
We name SAM 2 picture predictor with (Strains 68-73):
- No level prompts (
point_coords=None) - A field immediate (
field=first_box) multimask_output=Falseto get a single greatest masks
SAM 2 returns masks equivalent to the thing contained in the bounding field.
Typically masks include an additional singleton dimension; we take away it to simplify the form. We additionally retailer OBJECTS because the listing of detected class labels from Grounding DINO (Strains 74-76).
progress(0.5, "Registering prompts...")
if prompt_type == "level":
all_sample_points = sample_points_from_masks(masks=masks, num_points=10)
for object_id, (label, factors) in enumerate(zip(OBJECTS, all_sample_points), begin=1):
labels = np.ones(factors.form[0], dtype=np.int32)
video_predictor.add_new_points_or_box(inference_state, ann_frame_idx, object_id, factors=factors, labels=labels)
elif prompt_type == "field":
for object_id, (label, field) in enumerate(zip(OBJECTS, input_boxes), begin=1):
video_predictor.add_new_points_or_box(inference_state, ann_frame_idx, object_id, field=field)
else: # masks
for object_id, (label, masks) in enumerate(zip(OBJECTS, masks), begin=1):
video_predictor.add_new_mask(inference_state, ann_frame_idx, object_id, masks=masks)
We transfer the progress to 50%. Now we ship our prompts (factors/packing containers/masks) to the video predictor (Line 78).
First, if prompt_type is "level" (Strains 80-84):
- We pattern 10 factors from every masks utilizing
sample_points_from_masks. - For every object, we deal with all sampled factors as foreground (
labels = 1). - We name
add_new_points_or_boxto register these factors as prompts at bodyann_frame_idx.
This mimics a consumer clicking on the thing area.
If prompt_type is "field" (Strains 86-88):
- We loop over all detected packing containers and labels,
- We register every bounding field instantly as a field immediate.
SAM 2 makes use of these packing containers to initialize segmentation and monitoring.
In any other case (default case, "masks") (Strains 90-92):
- We register full binary masks as prompts with
add_new_mask, - That is the strongest type of supervision, giving SAM 2 a full understanding of the thing form on the primary body.
progress(0.65, "Propagating masks via the video...")
video_segments = {}
for out_frame_idx, out_obj_ids, out_mask_logits in video_predictor.propagate_in_video(inference_state):
video_segments[out_frame_idx] = {out_obj_id: (out_mask_logits[i] > 0).cpu().numpy() for i, out_obj_id in enumerate(out_obj_ids)}
We transfer progress to 65%. Now SAM 2’s video predictor will take over and carry out monitoring (Line 94).
We create an empty dictionary video_segments (Line 96).
Then, for every body produced by propagate_in_video (Line 97):
out_frame_idx: index of the body,out_obj_ids: IDs of objects current in that body,out_mask_logits: uncooked masks logits for these objects.
We convert logits to binary masks (logits > 0) and retailer them in video_segments[out_frame_idx]. This provides a whole mapping from body → object → masks (Line 98).
progress(0.8, "Rendering annotated frames...")
if not os.path.exists(SAVE_TRACKING_RESULTS_DIR): os.makedirs(SAVE_TRACKING_RESULTS_DIR)
ID_TO_OBJECTS = {i: obj for i, obj in enumerate(OBJECTS, begin=1)}
for frame_idx, segments in video_segments.gadgets():
img = cv2.imread(os.path.be part of(SOURCE_VIDEO_FRAME_DIR, frame_names[frame_idx]))
object_ids = listing(segments.keys())
masks = np.concatenate(listing(segments.values()), axis=0)
detections = sv.Detections(xyxy=sv.mask_to_xyxy(masks), masks=masks, class_id=np.array(object_ids))
box_annotator = sv.BoxAnnotator()
label_annotator = sv.LabelAnnotator()
mask_annotator = sv.MaskAnnotator()
annotated = box_annotator.annotate(img.copy(), detections)
annotated = label_annotator.annotate(annotated, detections, labels=[ID_TO_OBJECTS[i] for i in object_ids])
annotated = mask_annotator.annotate(annotated, detections)
cv2.imwrite(os.path.be part of(SAVE_TRACKING_RESULTS_DIR, f"annotated_{frame_idx:05d}.jpg"), annotated)
We improve progress to 80%. We make sure the output listing for annotated frames exists. We additionally construct a mapping from object ID → class label string (Strains 100-103).
For every body (Strains 105-108):
- We learn the unique body utilizing OpenCV.
- We acquire all object IDs current on this body.
- We concatenate their masks right into a single array (one masks per object).
Subsequent, we construct a Detections object for supervision (Line 110):
xyxy: bounding packing containers derived from masks throughmask_to_xyxymasks: the segmentation masksclass_id: integer object IDs
We additionally create annotators for: Packing containers, Labels, and Masks (Strains 111-113).
We then (Strains 115-117):
- Draw bounding packing containers on the body
- Draw textual content labels utilizing
ID_TO_OBJECTS - Overlay coloured masks for every object
This produces a properly visualized body with field + label + masks all collectively.
Lastly, we save every annotated body as a picture in TRACKING_RESULTS, once more with zero-padded index within the filename (Line 119).
progress(0.95, "Creating output video...") create_video_from_images(SAVE_TRACKING_RESULTS_DIR, OUTPUT_VIDEO_PATH) progress(1, "Completed.") return OUTPUT_VIDEO_PATH
We transfer progress to 95%, signalling the final step (Line 121).
We name create_video_from_images to sew the annotated frames right into a single video file.
The perform makes use of body order and FPS (Frames Per Second) configuration to match the unique video playback (Line 123).
Lastly, we set the progress to 100% and return the trail to the output video. Gradio will show this video within the UI (Strains 125 and 126).
This single perform:
- Makes use of Grounding DINO to search out objects from a textual content immediate
- Makes use of SAM 2 to acquire an preliminary high-quality masks on the primary body
- Registers prompts (factors/field/masks) into the SAM 2 video predictor
- Propagates masks throughout all frames, creating temporally constant segmentation
- Renders and exports a totally annotated video
Constructing a Gradio Interface
We now create a easy Gradio net interface that enables customers to add a video, write a textual content immediate, select the immediate sort, and visualize the segmentation monitoring consequence instantly.
with gr.Blocks() as demo:
gr.Markdown("# Grounded SAM 2 Demo")
video_input = gr.Video(label="Add Video")
text_prompt = gr.Textbox(label="Textual content Immediate", worth="hippopotamus.")
prompt_type = gr.Radio(["point", "box", "mask"], worth="field", label="Immediate Sort")
run_btn = gr.Button("Run Monitoring")
output_video = gr.Video(label="Tracked Output")
download_btn = gr.File(label="Obtain Output Video")
def wrap(video_file, textual content, ptype):
out = run_tracking(video_file, textual content, ptype)
return out, out
run_btn.click on(fn=wrap, inputs=[video_input, text_prompt, prompt_type], outputs=[output_video, download_btn])
demo.launch(debug=True)
First, we open a Gradio Blocks container, which provides us full management over structure. Then, we show a Markdown title. This helps point out that the interface helps monitoring utilizing Grounding DINO and SAM 2, optimized for Colab execution (Strains 1 and a couple of).
Subsequent, we outline all enter parts (Strains 4-6):
video_input: accepts the enter videotext_prompt: takes the language question. Right here we initialize it with"hippopotamus."as a default instanceprompt_type: permits choosing how we provide the preliminary steering to SAM 2 (both through level, field, or mask-based prompting). We setfieldbecause the default since it really works reliably most often.
Then, we create (Strains 8-10):
- A button to begin monitoring
- A video widget to show the ultimate segmented and tracked output
- A file part to permit downloading the identical output video
This retains the interplay easy: add → run → view → obtain.
After that, we outline a wrapper perform. It calls run_tracking() utilizing the inputs from the interface, then returns the identical output path twice — one for preview and one for obtain (Strains 12-14).
Right here, we hyperlink the button click on to the monitoring execution. When the consumer presses Run Monitoring, Gradio passes the uploaded video, the textual content immediate, and the chosen immediate sort to our perform, then shows the consequence (Line 16).
Lastly, we launch the interface (Determine 1). Setting debug=True allows higher error reporting, particularly helpful throughout improvement in Colab (Line 19).
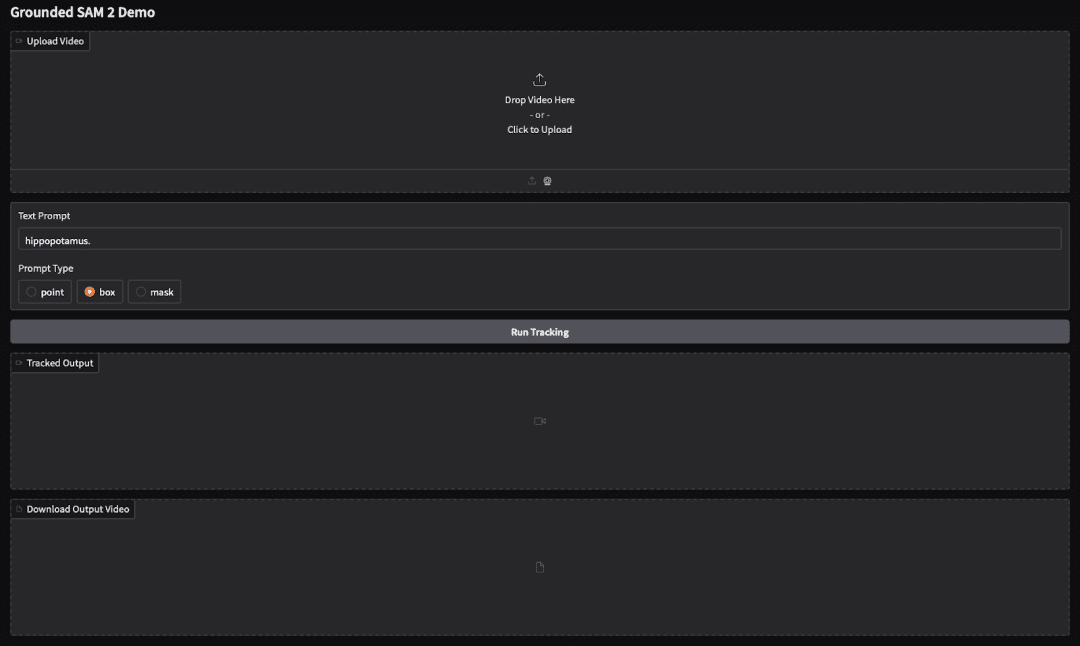
Output
Within the Gradio interface, we uploaded a brief animated clip and entered the textual content immediate “a cartoon bunny.” After clicking Run Monitoring, the pipeline started processing the video body by body.
First, Grounding DINO analyzed every body and detected areas matching the textual content description. Subsequent, SAM 2 generated exact segmentation masks across the detected object. The system then propagated these masks throughout all frames utilizing video memory-based monitoring.
Because the video was processed, the interface displayed the annotated leads to the Tracked Output part. Every body confirmed the thing with bounding packing containers, segmentation masks, and textual content labels overlaid. In our instance, the bunny remained constantly tracked throughout the clip.
This visible output confirms each spatial accuracy (through segmentation) and temporal consistency (through monitoring), demonstrating the place and when the described object seems all through the video.
What’s subsequent? We advocate PyImageSearch College.
86+ complete lessons • 115+ hours hours of on-demand code walkthrough movies • Final up to date: January 2026
★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly consider that in case you had the fitting instructor you possibly can grasp pc imaginative and prescient and deep studying.
Do you suppose studying pc imaginative and prescient and deep studying needs to be time-consuming, overwhelming, and complex? Or has to contain complicated arithmetic and equations? Or requires a level in pc science?
That’s not the case.
All it is advisable grasp pc imaginative and prescient and deep studying is for somebody to elucidate issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter training and the way complicated Synthetic Intelligence matters are taught.
In the event you’re critical about studying pc imaginative and prescient, your subsequent cease must be PyImageSearch College, essentially the most complete pc imaginative and prescient, deep studying, and OpenCV course on-line immediately. Right here you’ll learn to efficiently and confidently apply pc imaginative and prescient to your work, analysis, and initiatives. Be a part of me in pc imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
- &examine; 86+ programs on important pc imaginative and prescient, deep studying, and OpenCV matters
- &examine; 86 Certificates of Completion
- &examine; 115+ hours hours of on-demand video
- &examine; Model new programs launched recurrently, making certain you may sustain with state-of-the-art methods
- &examine; Pre-configured Jupyter Notebooks in Google Colab
- &examine; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev surroundings configuration required!)
- &examine; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &examine; Simple one-click downloads for code, datasets, pre-trained fashions, and so forth.
- &examine; Entry on cellular, laptop computer, desktop, and so forth.
Abstract
On this tutorial, we explored how Grounded SAM 2 extends the capabilities of Grounding DINO by shifting from bounding field detection to full segmentation and video monitoring. Within the earlier weblog, we noticed how Grounding DINO performs open-set object detection utilizing pure language prompts. It understands what to search for and localizes objects utilizing bounding packing containers, however lacks pixel-level precision.
Right here, we addressed that limitation utilizing SAM 2. First, we launched segmentation as a extra correct manner of figuring out object boundaries. We then mentioned how SAM and SAM 2 carry out promptable segmentation, wherein easy hints (e.g., packing containers or factors) are enough to generate high-quality masks. SAM 2 improves this additional with a streaming-memory transformer that maintains masks consistency throughout video frames.
Subsequent, we constructed a whole pipeline that mixes Grounding DINO for detection and SAM 2 for segmentation and monitoring. We applied a step-by-step workflow to detect objects from language, generate masks within the first body, and propagate them all through the video. Lastly, we wrapped the whole pipeline inside an interactive Gradio interface, enabling video add, textual content prompting, and real-time visualization with an choice to obtain outcomes.
This transforms the system from “detect objects by description” to “detect, section, and monitor something described in phrases”. Grounded SAM 2 allows exact visible understanding utilizing language, making it splendid for robotics, video evaluation, medical imaging, modifying, and automatic annotation.
Quotation Info
Thakur, P. “Grounded SAM 2: From Open-Set Detection to Segmentation and Monitoring,” PyImageSearch, P. Chugh, S. Huot, G. Kudriavtsev, and Aditya Sharma, eds., 2026, https://pyimg.co/flutd
@incollection{Thakur_2026_grounded-sam-2-open-set-segmentation-and-tracking,
writer = {Piyush Thakur},
title = {{Grounded SAM 2: From Open-Set Detection to Segmentation and Monitoring}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Georgii Kudriavtsev and Aditya Sharma},
12 months = {2026},
url = {https://pyimg.co/flutd},
}
To obtain the supply code to this submit (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your e mail deal with within the kind beneath!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your e mail deal with beneath to get a .zip of the code and a FREE 17-page Useful resource Information on Laptop Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that can assist you grasp CV and DL!
The submit Grounded SAM 2: From Open-Set Detection to Segmentation and Monitoring appeared first on PyImageSearch.