

{kind=link}
Evaluating the efficiency of massive language fashions (LLMs) goes past statistical metrics like perplexity or bilingual analysis understudy (BLEU) scores. For many real-world generative AI eventualities, it’s essential to grasp whether or not a mannequin is producing higher outputs than a baseline or an earlier iteration. That is particularly necessary for functions resembling summarization, content material technology, or clever brokers the place subjective judgments and nuanced correctness play a central function.
As organizations deepen their deployment of those fashions in manufacturing, we’re experiencing an rising demand from clients who need to systematically assess mannequin high quality past conventional analysis strategies. Present approaches like accuracy measurements and rule-based evaluations, though useful, can’t totally deal with these nuanced evaluation wants, notably when duties require subjective judgments, contextual understanding, or alignment with particular enterprise necessities. To bridge this hole, LLM-as-a-judge has emerged as a promising method, utilizing the reasoning capabilities of LLMs to guage different fashions extra flexibly and at scale.
At this time, we’re excited to introduce a complete method to mannequin analysis via the Amazon Nova LLM-as-a-Decide functionality on Amazon SageMaker AI, a completely managed Amazon Net Providers (AWS) service to construct, prepare, and deploy machine studying (ML) fashions at scale. Amazon Nova LLM-as-a-Decide is designed to ship sturdy, unbiased assessments of generative AI outputs throughout mannequin households. Nova LLM-as-a-Decide is on the market as optimized workflows on SageMaker AI, and with it, you can begin evaluating mannequin efficiency in opposition to your particular use instances in minutes. Not like many evaluators that exhibit architectural bias, Nova LLM-as-a-Decide has been rigorously validated to stay neutral and has achieved main efficiency on key decide benchmarks whereas intently reflecting human preferences. With its distinctive accuracy and minimal bias, it units a brand new customary for credible, production-grade LLM analysis.
Nova LLM-as-a-Decide functionality offers pairwise comparisons between mannequin iterations, so you can also make data-driven selections about mannequin enhancements with confidence.
How Nova LLM-as-a-Decide was skilled
Nova LLM-as-a-Decide was constructed via a multistep coaching course of comprising supervised coaching and reinforcement studying levels that used public datasets annotated with human preferences. For the proprietary element, a number of annotators independently evaluated 1000’s of examples by evaluating pairs of various LLM responses to the identical immediate. To confirm consistency and equity, all annotations underwent rigorous high quality checks, with ultimate judgments calibrated to mirror broad human consensus relatively than a person viewpoint.
The coaching information was designed to be each various and consultant. Prompts spanned a variety of classes, together with real-world data, creativity, coding, arithmetic, specialised domains, and toxicity, so the mannequin may consider outputs throughout many real-world eventualities. Coaching information included information from over 90 languages and is primarily composed of English, Russian, Chinese language, German, Japanese, and Italian.Importantly, an inside bias examine evaluating over 10,000 human-preference judgments in opposition to 75 third-party fashions confirmed that Amazon Nova LLM-as-a-Decide exhibits solely a 3% mixture bias relative to human annotations. Though it is a important achievement in decreasing systematic bias, we nonetheless advocate occasional spot checks to validate important comparisons.
Within the following determine, you’ll be able to see how the Nova LLM-as-a-Decide bias compares to human preferences when evaluating Amazon Nova outputs in comparison with outputs from different fashions. Right here, bias is measured because the distinction between the decide’s choice and human choice throughout 1000’s of examples. A optimistic worth signifies the decide barely favors Amazon Nova fashions, and a unfavorable worth signifies the alternative. To quantify the reliability of those estimates, 95% confidence intervals had been computed utilizing the usual error for the distinction of proportions, assuming impartial binomial distributions.
Amazon Nova LLM-as-a-Decide achieves superior efficiency amongst analysis fashions, demonstrating sturdy alignment with human judgments throughout a variety of duties. For instance, it scores 45% accuracy on JudgeBench (in comparison with 42% for Meta J1 8B) and 68% on PPE (versus 60% for Meta J1 8B). The information from Meta’s J1 8B was pulled from Incentivizing Pondering in LLM-as-a-Decide through Reinforcement Studying.
These outcomes spotlight the energy of Amazon Nova LLM-as-a-Decide in chatbot-related evaluations, as proven within the PPE benchmark. Our benchmarking follows present greatest practices, reporting reconciled outcomes for positionally swapped responses on JudgeBench, CodeUltraFeedback, Eval Bias, and LLMBar, whereas utilizing single-pass outcomes for PPE.
| Mannequin | Eval Bias | Decide Bench | LLM Bar | PPE | CodeUltraFeedback |
| Nova LLM-as-a-Decide | 0.76 | 0.45 | 0.67 | 0.68 | 0.64 |
| Meta J1 8B | – | 0.42 | – | 0.60 | – |
| Nova Micro | 0.56 | 0.37 | 0.55 | 0.6 | – |
On this put up, we current a streamlined method to implementing Amazon Nova LLM-as-a-Decide evaluations utilizing SageMaker AI, deciphering the ensuing metrics, and making use of this course of to enhance your generative AI functions.
Overview of the analysis workflow
The analysis course of begins by making ready a dataset by which every instance features a immediate and two various mannequin outputs. The JSONL format seems to be like this:
After making ready this dataset, you employ the given SageMaker analysis recipe, which configures the analysis technique, specifies which mannequin to make use of because the decide, and defines the inference settings resembling temperature and top_p.
The analysis runs inside a SageMaker coaching job utilizing pre-built Amazon Nova containers. SageMaker AI provisions compute sources, orchestrates the analysis, and writes the output metrics and visualizations to Amazon Easy Storage Service (Amazon S3).
When it’s full, you’ll be able to obtain and analyze the outcomes, which embody choice distributions, win charges, and confidence intervals.
Understanding how Amazon Nova LLM-as-a-Decide works
The Amazon Nova LLM-as-a-Decide makes use of an analysis technique referred to as binary general choice decide. The binary general choice decide is a technique the place a language mannequin compares two outputs facet by facet and picks the higher one or declares a tie. For every instance, it produces a transparent choice. If you mixture these judgments over many samples, you get metrics like win fee and confidence intervals. This method makes use of the mannequin’s personal reasoning to evaluate qualities like relevance and readability in an easy, constant manner.
- This decide mannequin is supposed to offer low-latency common general preferences in conditions the place granular suggestions isn’t needed
- The output of this mannequin is one among [[A>B]] or [[B>A]]
- Use instances for this mannequin are primarily these the place automated, low-latency, common pairwise preferences are required, resembling automated scoring for checkpoint choice in coaching pipelines
Understanding Amazon Nova LLM-as-a-Decide analysis metrics
When utilizing the Amazon Nova LLM-as-a-Decide framework to check outputs from two language fashions, SageMaker AI produces a complete set of quantitative metrics. You need to use these metrics to evaluate which mannequin performs higher and the way dependable the analysis is. The outcomes fall into three predominant classes: core choice metrics, statistical confidence metrics, and customary error metrics.
The core choice metrics report how usually every mannequin’s outputs had been most popular by the decide mannequin. The a_scores metric counts the variety of examples the place Mannequin A was favored, and b_scores counts instances the place Mannequin B was chosen as higher. The ties metric captures situations by which the decide mannequin rated each responses equally or couldn’t determine a transparent choice. The inference_error metric counts instances the place the decide couldn’t generate a sound judgment as a result of malformed information or inside errors.
The statistical confidence metrics quantify how doubtless it’s that the noticed preferences mirror true variations in mannequin high quality relatively than random variation. The winrate studies the proportion of all legitimate comparisons by which Mannequin B was most popular. The lower_rate and upper_rate outline the decrease and higher bounds of the 95% confidence interval for this win fee. For instance, a winrate of 0.75 with a confidence interval between 0.60 and 0.85 means that, even accounting for uncertainty, Mannequin B is constantly favored over Mannequin A. The rating discipline usually matches the rely of Mannequin B wins however may also be custom-made for extra advanced analysis methods.
The customary error metrics present an estimate of the statistical uncertainty in every rely. These embody a_scores_stderr, b_scores_stderr, ties_stderr, inference_error_stderr, andscore_stderr. Smaller customary error values point out extra dependable outcomes. Bigger values can level to a necessity for extra analysis information or extra constant immediate engineering.
Decoding these metrics requires consideration to each the noticed preferences and the boldness intervals:
- If the
winrateis considerably above 0.5 and the boldness interval doesn’t embody 0.5, Mannequin B is statistically favored over Mannequin A. - Conversely, if the
winrateis under 0.5 and the boldness interval is totally under 0.5, Mannequin A is most popular. - When the boldness interval overlaps 0.5, the outcomes are inconclusive and additional analysis is really helpful.
- Excessive values in
inference_erroror massive customary errors recommend there might need been points within the analysis course of, resembling inconsistencies in immediate formatting or inadequate pattern dimension.
The next is an instance metrics output from an analysis run:
On this instance, Mannequin A was most popular 16 occasions, Mannequin B was most popular 10 occasions, and there have been no ties or inference errors. The winrate of 0.38 signifies that Mannequin B was most popular in 38% of instances, with a 95% confidence interval starting from 23% to 56%. As a result of the interval consists of 0.5, this final result suggests the analysis was inconclusive, and extra information may be wanted to make clear which mannequin performs higher general.
These metrics, routinely generated as a part of the analysis course of, present a rigorous statistical basis for evaluating fashions and making data-driven selections about which one to deploy.
Resolution overview
This resolution demonstrates the right way to consider generative AI fashions on Amazon SageMaker AI utilizing the Nova LLM-as-a-Decide functionality. The supplied Python code guides you thru your entire workflow.
First, it prepares a dataset by sampling questions from SQuAD and producing candidate responses from Qwen2.5 and Anthropic’s Claude 3.7. These outputs are saved in a JSONL file containing the immediate and each responses.
We accessed Anthropic’s Claude 3.7 Sonnet in Amazon Bedrock utilizing the bedrock-runtime consumer. We accessed Qwen2.5 1.5B utilizing a SageMaker hosted Hugging Face endpoint.
Subsequent, a PyTorch Estimator launches an analysis job utilizing an Amazon Nova LLM-as-a-Decide recipe. The job runs on GPU situations resembling ml.g5.12xlarge and produces analysis metrics, together with win charges, confidence intervals, and choice counts. Outcomes are saved to Amazon S3 for evaluation.
Lastly, a visualization operate renders charts and tables, summarizing which mannequin was most popular, how sturdy the choice was, and the way dependable the estimates are. By way of this end-to-end method, you’ll be able to assess enhancements, monitor regressions, and make data-driven selections about deploying generative fashions—all with out guide annotation.
Stipulations
You’ll want to full the next stipulations earlier than you’ll be able to run the pocket book:
- Make the next quota improve requests for SageMaker AI. For this use case, you should request a minimal of 1 g5.12xlarge occasion. On the Service Quotas console, request the next SageMaker AI quotas, 1 G5 situations (g5.12xlarge) for coaching job utilization
- (Elective) You may create an Amazon SageMaker Studio area (consult with Use fast setup for Amazon SageMaker AI) to entry Jupyter notebooks with the previous function. (You need to use JupyterLab in your native setup, too.)
- Create an AWS Id and Entry Administration (IAM) function with managed insurance policies
AmazonSageMakerFullAccess,AmazonS3FullAccess, andAmazonBedrockFullAccessto provide required entry to SageMaker AI and Amazon Bedrock to run the examples. - Assign as belief relationship to your IAM function the next coverage:
- Create an AWS Id and Entry Administration (IAM) function with managed insurance policies
- Clone the GitHub repository with the belongings for this deployment. This repository consists of a pocket book that references coaching belongings:
Subsequent, run the pocket book Nova Amazon-Nova-LLM-as-a-Decide-Sagemaker-AI.ipynb to start out utilizing the Amazon Nova LLM-as-a-Decide implementation on Amazon SageMaker AI.
Mannequin setup
To conduct an Amazon Nova LLM-as-a-Decide analysis, you should generate outputs from the candidate fashions you need to evaluate. On this undertaking, we used two totally different approaches: deploying a Qwen2.5 1.5B mannequin on Amazon SageMaker and invoking Anthropic’s Claude 3.7 Sonnet mannequin in Amazon Bedrock. First, we deployed Qwen2.5 1.5B, an open-weight multilingual language mannequin, on a devoted SageMaker endpoint. This was achieved by utilizing the HuggingFaceModel deployment interface. To deploy the Qwen2.5 1.5B mannequin, we supplied a handy script so that you can invoke:python3 deploy_sm_model.py
When it’s deployed, inference may be carried out utilizing a helper operate wrapping the SageMaker predictor API:
In parallel, we built-in Anthropic’s Claude 3.7 Sonnet mannequin in Amazon Bedrock. Amazon Bedrock offers a managed API layer for accessing proprietary basis fashions (FMs) with out managing infrastructure. The Claude technology operate used the bedrock-runtime AWS SDK for Python (Boto3) consumer, which accepted a consumer immediate and returned the mannequin’s textual content completion:
When you might have each capabilities generated and examined, you’ll be able to transfer on to creating the analysis information for the Nova LLM-as-a-Decide.
Put together the dataset
To create a sensible analysis dataset for evaluating the Qwen and Claude fashions, we used the Stanford Query Answering Dataset (SQuAD), a extensively adopted benchmark in pure language understanding distributed beneath the CC BY-SA 4.0 license. SQuAD consists of 1000’s of crowd-sourced question-answer pairs protecting a various vary of Wikipedia articles. By sampling from this dataset, we made certain that our analysis prompts mirrored high-quality, factual question-answering duties consultant of real-world functions.
We started by loading a small subset of examples to maintain the workflow quick and reproducible. Particularly, we used the Hugging Face datasets library to obtain and cargo the primary 20 examples from the SQuAD coaching cut up:
This command retrieves a slice of the total dataset, containing 20 entries with structured fields together with context, query, and solutions. To confirm the contents and examine an instance, we printed out a pattern query and its floor fact reply:
For the analysis set, we chosen the primary six questions from this subset:
questions = [squad[i]["question"] for i in vary(6)]
Generate the Amazon Nova LLM-as-a-Decide analysis dataset
After making ready a set of analysis questions from SQuAD, we generated outputs from each fashions and assembled them right into a structured dataset for use by the Amazon Nova LLM-as-a-Decide workflow. This dataset serves because the core enter for SageMaker AI analysis recipes. To do that, we iterated over every query immediate and invoked the 2 technology capabilities outlined earlier:
generate_with_qwen25()for completions from the Qwen2.5 mannequin deployed on SageMakergenerate_with_claude()for completions from Anthropic’s Claude 3.7 Sonnet in Amazon Bedrock
For every immediate, the workflow tried to generate a response from every mannequin. If a technology name failed as a result of an API error, timeout, or different challenge, the system captured the exception and saved a transparent error message indicating the failure. This made certain that the analysis course of may proceed gracefully even within the presence of transient errors:
This workflow produced a JSON Traces file named llm_judge.jsonl. Every line comprises a single analysis document structured as follows:
Then, add this llm_judge.jsonl to an S3 bucket that you simply’ve predefined:
Launching the Nova LLM-as-a-Decide analysis job
After making ready the dataset and creating the analysis recipe, the ultimate step is to launch the SageMaker coaching job that performs the Amazon Nova LLM-as-a-Decide analysis. On this workflow, the coaching job acts as a completely managed, self-contained course of that hundreds the mannequin, processes the dataset, and generates analysis metrics in your designated Amazon S3 location.
We use the PyTorch estimator class from the SageMaker Python SDK to encapsulate the configuration for the analysis run. The estimator defines the compute sources, the container picture, the analysis recipe, and the output paths for storing outcomes:
When the estimator is configured, you provoke the analysis job utilizing the match() technique. This name submits the job to the SageMaker management aircraft, provisions the compute cluster, and begins processing the analysis dataset:
estimator.match(inputs={"prepare": evalInput})
Outcomes from the Amazon Nova LLM-as-a-Decide analysis job
The next graphic illustrates the outcomes of the Amazon Nova LLM-as-a-Decide analysis job.
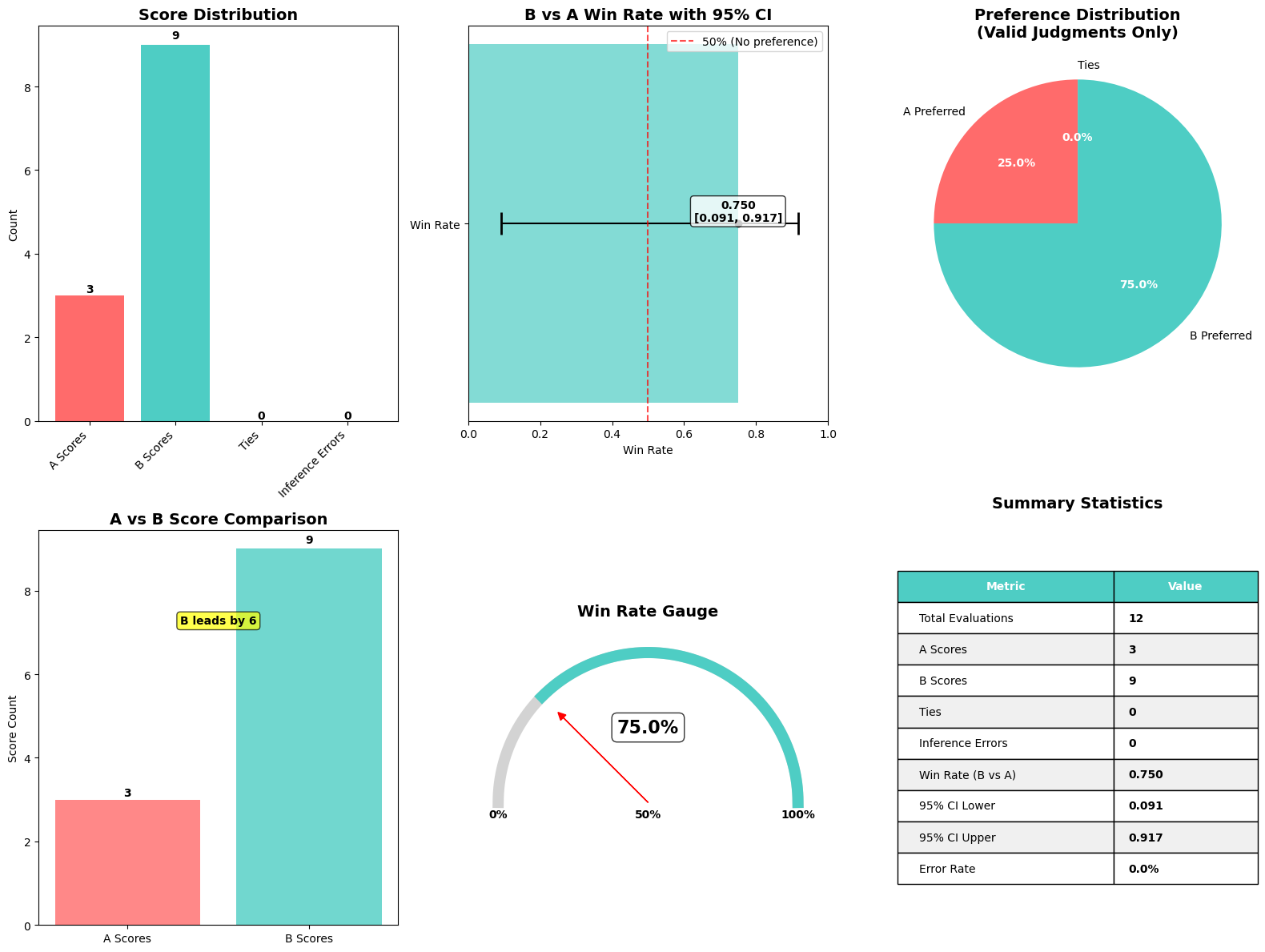
To assist practitioners rapidly interpret the result of a Nova LLM-as-a-Decide analysis, we created a comfort operate that produces a single, complete visualization summarizing key metrics. This operate, plot_nova_judge_results, makes use of Matplotlib and Seaborn to render a picture with six panels, every highlighting a special perspective of the analysis final result.
This operate takes the analysis metrics dictionary—produced when the analysis job is full—and generates the next visible parts:
- Rating distribution bar chart – Reveals what number of occasions Mannequin A was most popular, what number of occasions Mannequin B was most popular, what number of ties occurred, and the way usually the decide failed to provide a choice (inference errors). This offers a right away sense of how decisive the analysis was and whether or not both mannequin is dominating.
- Win fee with 95% confidence interval – Plots Mannequin B’s general win fee in opposition to Mannequin A, together with an error bar reflecting the decrease and higher bounds of the 95% confidence interval. A vertical reference line at 50% marks the purpose of no choice. If the boldness interval doesn’t cross this line, you’ll be able to conclude the result’s statistically important.
- Choice pie chart – Visually shows the proportion of occasions Mannequin A, Mannequin B, or neither was most popular. This helps rapidly perceive choice distribution among the many legitimate judgments.
- A vs. B rating comparability bar chart – Compares the uncooked counts of preferences for every mannequin facet by facet. A transparent label annotates the margin of distinction to emphasise which mannequin had extra wins.
- Win fee gauge – Depicts the win fee as a semicircular gauge with a needle pointing to Mannequin B’s efficiency relative to the theoretical 0–100% vary. This intuitive visualization helps nontechnical stakeholders perceive the win fee at a look.
- Abstract statistics desk – Compiles numerical metrics—together with complete evaluations, error counts, win fee, and confidence intervals—right into a compact, clear desk. This makes it simple to reference the precise numeric values behind the plots.
As a result of the operate outputs an ordinary Matplotlib determine, you’ll be able to rapidly save the picture, show it in Jupyter notebooks, or embed it in different documentation.
Clear up
Full the next steps to scrub up your sources:
- Delete your Qwen 2.5 1.5B Endpoint
- In case you’re utilizing a SageMaker Studio JupyterLab pocket book, shut down the JupyterLab pocket book occasion.
How you should use this analysis framework
The Amazon Nova LLM-as-a-Decide workflow provides a dependable, repeatable manner to check two language fashions by yourself information. You may combine this into mannequin choice pipelines to determine which model performs greatest, or you’ll be able to schedule it as a part of steady analysis to catch regressions over time.
For groups constructing agentic or domain-specific programs, this method offers richer perception than automated metrics alone. As a result of your entire course of runs on SageMaker coaching jobs, it scales rapidly and produces clear visible studies that may be shared with stakeholders.
Conclusion
This put up demonstrates how Nova LLM-as-a-Decide—a specialised analysis mannequin out there via Amazon SageMaker AI—can be utilized to systematically measure the relative efficiency of generative AI programs. The walkthrough exhibits the right way to put together analysis datasets, launch SageMaker AI coaching jobs with Nova LLM-as-a-Decide recipes, and interpret the ensuing metrics, together with win charges and choice distributions. The totally managed SageMaker AI resolution simplifies this course of, so you’ll be able to run scalable, repeatable mannequin evaluations that align with human preferences.
We advocate beginning your LLM analysis journey by exploring the official Amazon Nova documentation and examples. The AWS AI/ML neighborhood provides intensive sources, together with workshops and technical steerage, to help your implementation journey.
To be taught extra, go to:
In regards to the authors
 Surya Kari is a Senior Generative AI Knowledge Scientist at AWS, specializing in growing options leveraging state-of-the-art basis fashions. He has intensive expertise working with superior language fashions together with DeepSeek-R1, the Llama household, and Qwen, specializing in their fine-tuning and optimization. His experience extends to implementing environment friendly coaching pipelines and deployment methods utilizing AWS SageMaker. He collaborates with clients to design and implement generative AI options, serving to them navigate mannequin choice, fine-tuning approaches, and deployment methods to attain optimum efficiency for his or her particular use instances.
Surya Kari is a Senior Generative AI Knowledge Scientist at AWS, specializing in growing options leveraging state-of-the-art basis fashions. He has intensive expertise working with superior language fashions together with DeepSeek-R1, the Llama household, and Qwen, specializing in their fine-tuning and optimization. His experience extends to implementing environment friendly coaching pipelines and deployment methods utilizing AWS SageMaker. He collaborates with clients to design and implement generative AI options, serving to them navigate mannequin choice, fine-tuning approaches, and deployment methods to attain optimum efficiency for his or her particular use instances.
 Joel Carlson is a Senior Utilized Scientist on the Amazon AGI basis modeling crew. He primarily works on growing novel approaches for enhancing the LLM-as-a-Decide functionality of the Nova household of fashions.
Joel Carlson is a Senior Utilized Scientist on the Amazon AGI basis modeling crew. He primarily works on growing novel approaches for enhancing the LLM-as-a-Decide functionality of the Nova household of fashions.
 Saurabh Sahu is an utilized scientist within the Amazon AGI Basis modeling crew. He obtained his PhD in Electrical Engineering from College of Maryland Faculty Park in 2019. He has a background in multi-modal machine studying engaged on speech recognition, sentiment evaluation and audio/video understanding. Presently, his work focuses on growing recipes to enhance the efficiency of LLM-as-a-judge fashions for varied duties.
Saurabh Sahu is an utilized scientist within the Amazon AGI Basis modeling crew. He obtained his PhD in Electrical Engineering from College of Maryland Faculty Park in 2019. He has a background in multi-modal machine studying engaged on speech recognition, sentiment evaluation and audio/video understanding. Presently, his work focuses on growing recipes to enhance the efficiency of LLM-as-a-judge fashions for varied duties.
 Morteza Ziyadi is an Utilized Science Supervisor at Amazon AGI, the place he leads a number of initiatives on post-training recipes and (Multimodal) massive language fashions within the Amazon AGI Basis modeling crew. Earlier than becoming a member of Amazon AGI, he spent 4 years at Microsoft Cloud and AI, the place he led initiatives targeted on growing pure language-to-code technology fashions for varied merchandise. He has additionally served as an adjunct school at Northeastern College. He earned his PhD from the College of Southern California (USC) in 2017 and has since been actively concerned as a workshop organizer, and reviewer for quite a few NLP, Laptop Imaginative and prescient and machine studying conferences.
Morteza Ziyadi is an Utilized Science Supervisor at Amazon AGI, the place he leads a number of initiatives on post-training recipes and (Multimodal) massive language fashions within the Amazon AGI Basis modeling crew. Earlier than becoming a member of Amazon AGI, he spent 4 years at Microsoft Cloud and AI, the place he led initiatives targeted on growing pure language-to-code technology fashions for varied merchandise. He has additionally served as an adjunct school at Northeastern College. He earned his PhD from the College of Southern California (USC) in 2017 and has since been actively concerned as a workshop organizer, and reviewer for quite a few NLP, Laptop Imaginative and prescient and machine studying conferences.
 Pradeep Natarajan is a Senior Principal Scientist in Amazon AGI Basis modeling crew engaged on post-training recipes and Multimodal massive language fashions. He has 20+ years of expertise in growing and launching a number of large-scale machine studying programs. He has a PhD in Laptop Science from College of Southern California.
Pradeep Natarajan is a Senior Principal Scientist in Amazon AGI Basis modeling crew engaged on post-training recipes and Multimodal massive language fashions. He has 20+ years of expertise in growing and launching a number of large-scale machine studying programs. He has a PhD in Laptop Science from College of Southern California.
 Michael Cai is a Software program Engineer on the Amazon AGI Customization Group supporting the event of analysis options. He obtained his MS in Laptop Science from New York College in 2024. In his spare time he enjoys 3d printing and exploring modern tech.
Michael Cai is a Software program Engineer on the Amazon AGI Customization Group supporting the event of analysis options. He obtained his MS in Laptop Science from New York College in 2024. In his spare time he enjoys 3d printing and exploring modern tech.