
{kind=link}
Information science brokers ought to examine datasets, design workflows, run code, and return verifiable solutions, not simply autocomplete Pandas code. DSGym, launched by researchers from Stanford College, Collectively AI, Duke College, and Harvard College, is a framework that evaluates and trains such brokers throughout greater than 1,000 knowledge science challenges with skilled curated floor reality and a constant submit coaching pipeline.
Why current benchmarks fall brief?
The analysis group first probe current benchmarks that declare to check knowledge conscious brokers. When knowledge recordsdata are hidden, fashions nonetheless retain excessive accuracy. On QRData the typical drop is 40.5 %, on DAEval it’s 86.8 %, and on DiscoveryBench it’s 44.4 %. Many questions are solvable utilizing priors and sample matching on the textual content alone as an alternative of real knowledge evaluation, and so they additionally discover annotation errors and inconsistent numerical tolerances.
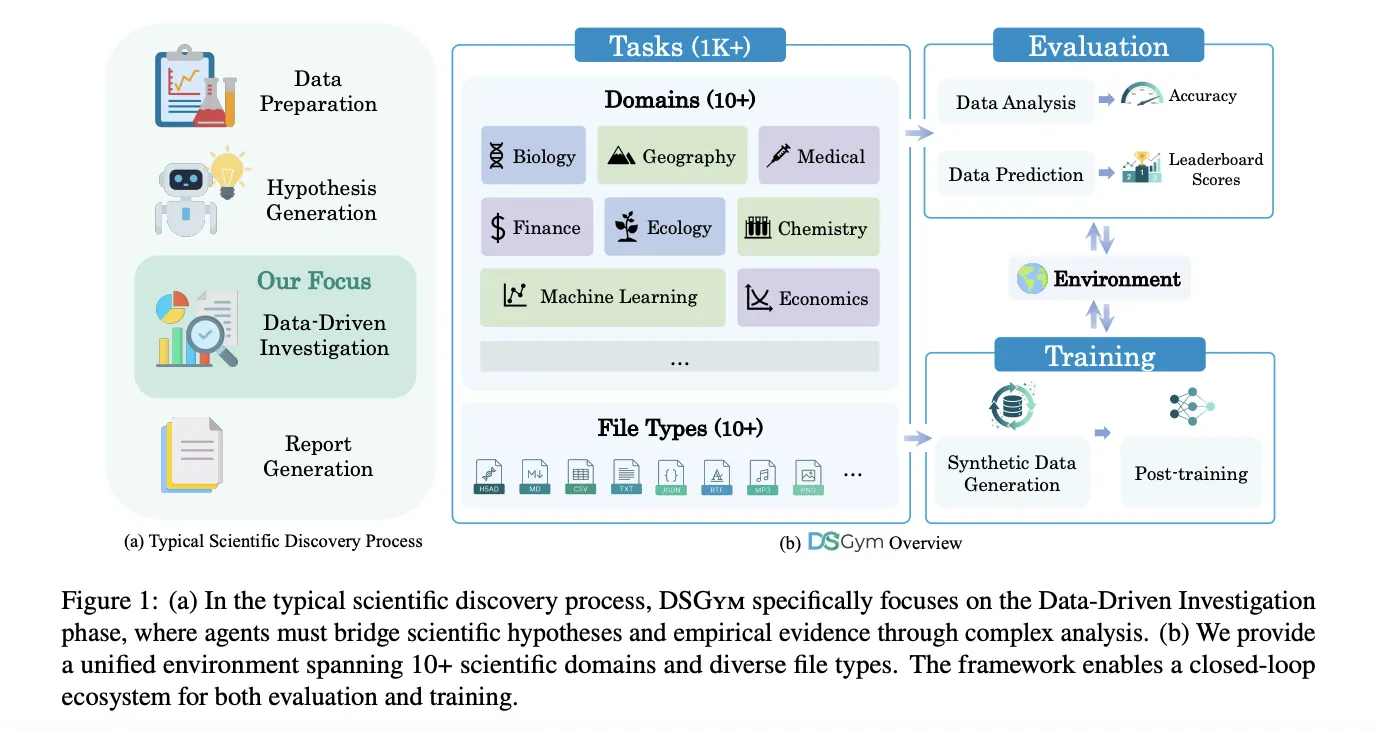
Job, Agent, and Setting
DSGym standardizes analysis into three objects, Job, Agent, and Setting. Duties are both Information Evaluation or Information Prediction. Information Evaluation duties present a number of recordsdata together with a pure language query that should be answered via code. Information Prediction duties present practice and check splits together with an specific metric and require the agent to construct a modeling pipeline and output predictions.
Every process is packed right into a Job Object that holds the info recordsdata, question immediate, scoring operate, and metadata. Brokers work together via a CodeAct model loop. At every flip, the agent writes a reasoning block that describes its plan, a code block that runs contained in the setting, and a solution block when it is able to commit. The Setting is applied as a supervisor and employee cluster of Docker containers, the place every employee mounts knowledge as learn solely volumes, exposes a writable workspace, and ships with area particular Python libraries.
DSGym Duties, DSBio, and DSPredict
On high of this runtime, DSGym Duties aggregates and refines current datasets and provides new ones. The analysis group clear QRData, DAEval, DABStep, MLEBench Lite, and others by dropping unscorable gadgets and making use of a shortcut filter that removes questions solved simply by a number of fashions with out knowledge entry.
To cowl scientific discovery, they introduce DSBio, a collection of 90 bioinformatics duties derived from peer reviewed papers and open supply datasets. Duties cowl single cell evaluation, spatial and multi-omics, and human genetics, with deterministic numerical or categorical solutions supported by skilled reference notebooks.
DSPredict targets modeling on actual Kaggle competitions. A crawler collects current competitions that settle for CSV submissions and fulfill dimension and readability guidelines. After preprocessing, the suite is cut up into DSPredict Straightforward with 38 playground model and introductory competitions, and DSPredict Arduous with 54 excessive complexity challenges. In complete, DSGym Duties consists of 972 knowledge evaluation duties and 114 prediction duties.
What present brokers can and can’t do
The analysis covers closed supply fashions corresponding to GPT-5.1, GPT-5, and GPT-4o, open weights fashions corresponding to Qwen3-Coder-480B, Qwen3-235B-Instruct, and GPT-OSS-120B, and smaller fashions corresponding to Qwen2.5-7B-Instruct and Qwen3-4B-Instruct. All are run with the identical CodeAct agent, temperature 0, and instruments disabled.
On cleaned common evaluation benchmarks, corresponding to QRData Verified, DAEval Verified, and the simpler cut up of DABStep, high fashions attain between 60 % and 90 % precise match accuracy. On DABStep Arduous, accuracy drops for each mannequin, which exhibits that multi step quantitative reasoning over monetary tables continues to be brittle.
DSBio exposes a extra extreme weak point. Kimi-K2-Instruct achieves the most effective general accuracy of 43.33 %. For all fashions, between 85 and 96 % of inspected failures on DSBio are area grounding errors, together with misuse of specialised libraries and incorrect organic interpretations, reasonably than fundamental coding errors.
On MLEBench Lite and DSPredict Straightforward, most frontier fashions obtain close to good Legitimate Submission Fee above 80 %. On DSPredict Arduous, legitimate submissions not often exceed 70 % and medal charges on Kaggle leaderboards are close to 0 %. This sample helps the analysis group’s commentary of a simplicity bias the place brokers cease after a baseline answer as an alternative of exploring extra aggressive fashions and hyperparameters.
DSGym as a knowledge manufacturing facility and coaching floor
The identical setting can even synthesize coaching knowledge. Ranging from a subset of QRData and DABStep, the analysis group ask brokers to discover datasets, suggest questions, clear up them with code, and file trajectories, which yields 3,700 artificial queries. A choose mannequin filters these to a set of two,000 top quality question plus trajectory pairs known as DSGym-SFT, and fine-tuning a 4B Qwen3 based mostly mannequin on DSGym-SFT produces an agent that reaches aggressive efficiency with GPT-4o on standardized evaluation benchmarks regardless of having far fewer parameters.

Key Takeaways
- DSGym supplies a unified Job, Agent, and Setting framework, with containerized execution and a CodeAct model loop, to guage knowledge science brokers on actual code based mostly workflows as an alternative of static prompts.
- The benchmark suite, DSGym-Duties, consolidates and cleans prior datasets and provides DSBio and DSPredict, reaching 972 knowledge evaluation duties and 114 prediction duties throughout domains corresponding to finance, bioinformatics, and earth science.
- Shortcut evaluation on current benchmarks exhibits that eradicating knowledge entry solely reasonably reduces accuracy in lots of circumstances, which confirms that prior evaluations typically measure sample matching on textual content reasonably than real knowledge evaluation.
- Frontier fashions obtain sturdy efficiency on cleaned common evaluation duties and on simpler prediction duties, however they carry out poorly on DSBio and DSPredict-Arduous, the place most errors come from area grounding points and conservative, underneath tuned modeling pipelines.
- The DSGym-SFT dataset, constructed from 2,000 filtered artificial trajectories, permits a 4B Qwen3 based mostly agent to strategy GPT-4o stage accuracy on a number of evaluation benchmarks, which exhibits that execution grounded supervision on structured duties is an efficient method to enhance knowledge science brokers.
Try the Paper, and Repo. Additionally, be at liberty to observe us on Twitter and don’t overlook to affix our 100k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you’ll be able to be part of us on telegram as effectively.

Michal Sutter is a knowledge science skilled with a Grasp of Science in Information Science from the College of Padova. With a strong basis in statistical evaluation, machine studying, and knowledge engineering, Michal excels at remodeling advanced datasets into actionable insights.