

{kind=link}
- February 25, 2017
- Vasilis Vryniotis
- . 3 Feedback
The ALS algorithm launched by Hu et al., is a extremely popular method utilized in Recommender System issues, particularly when we now have implicit datasets (for instance clicks, likes and so forth). It may possibly deal with massive volumes of information fairly effectively and we are able to discover many good implementations in numerous Machine Studying frameworks. Spark consists of the algorithm within the MLlib part which has just lately been refactored to enhance the readability and the structure of the code.
Spark’s implementation requires the Merchandise and Consumer id to be numbers inside integer vary (both Integer kind or Lengthy inside integer vary), which is cheap as this may help pace up the operations and scale back reminiscence consumption. One factor I seen although whereas studying the code is that these id columns are being casted into Doubles after which into Integers at first of the match/predict strategies. This appears a bit hacky and I’ve seen it put pointless pressure on the rubbish collector. Listed here are the traces on the ALS code that solid the ids into doubles:

To know why that is carried out, one must learn the checkedCast():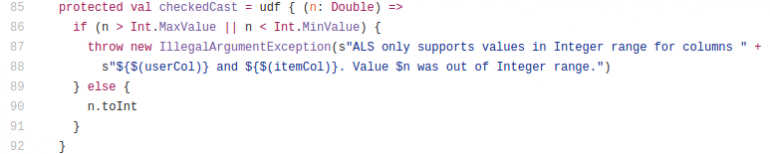
This UDF receives a Double and checks its vary after which casts it to integer. This UDF is used for Schema validation. The query is can we obtain this with out utilizing ugly double castings? I consider sure:
protected val checkedCast = udf { (n: Any) =>
n match {
case v: Int => v // Keep away from pointless casting
case v: Quantity =>
val intV = v.intValue()
// True for Byte/Brief, Lengthy inside the Int vary and Double/Float with no fractional half.
if (v.doubleValue == intV) {
intV
}
else {
throw new IllegalArgumentException(s"ALS solely helps values in Integer vary " +
s"for columns ${$(userCol)} and ${$(itemCol)}. Worth $n was out of Integer vary.")
}
case _ => throw new IllegalArgumentException(s"ALS solely helps values in Integer vary " +
s"for columns ${$(userCol)} and ${$(itemCol)}. Worth $n will not be numeric.")
}
}
The code above reveals a modified checkedCast() which receives the enter, checks asserts that the worth is numeric and raises exceptions in any other case. For the reason that enter is Any, we are able to safely take away all of the solid to Double statements from the remainder of the code. Furthermore it’s affordable to count on that because the ALS requires ids inside integer vary, nearly all of individuals really use integer varieties. Consequently on line 3 this technique handles Integers explicitly to keep away from doing any casting. For all different numeric values it checks whether or not the enter is inside integer vary. This test occurs on line 7.
One might write this in another way and explicitly deal with all of the permitted varieties. Sadly this may result in duplicate code. As a substitute what I do right here is convert the quantity into Integer and evaluate it with the unique Quantity. If the values are equivalent one of many following is true:
- The worth is Byte or Brief.
- The worth is Lengthy however inside the Integer vary.
- The worth is Double or Float however with none fractional half.
To make sure that the code runs effectively I examined it with the usual unit-tests of Spark and manually by checking the conduct of the strategy for numerous authorized and unlawful values. To make sure that the answer is no less than as quick as the unique, I examined quite a few instances utilizing the snippet beneath. This may be positioned within the ALSSuite class in Spark:
take a look at("Velocity distinction") {
val (coaching, take a look at) =
genExplicitTestData(numUsers = 200, numItems = 400, rank = 2, noiseStd = 0.01)
val runs = 100
var totalTime = 0.0
println("Performing "+runs+" runs")
for(i <- 0 till runs) {
val t0 = System.currentTimeMillis
testALS(coaching, take a look at, maxIter = 1, rank = 2, regParam = 0.01, targetRMSE = 0.1)
val secs = (System.currentTimeMillis - t0)/1000.0
println("Run "+i+" executed in "+secs+"s")
totalTime += secs
}
println("AVG Execution Time: "+(totalTime/runs)+"s")
}
After a number of exams we are able to see that the brand new repair is barely quicker than the unique:
|
Code |
Variety of Runs |
Whole Execution Time |
Common Execution Time per Run |
| Authentic | 100 | 588.458s | 5.88458s |
| Mounted | 100 | 566.722s | 5.66722s |
I repeated the experiments a number of instances to verify and the outcomes are constant. Right here yow will discover the detailed output of 1 experiment for the authentic code and the repair. The distinction is small for a tiny dataset however previously I’ve managed to realize a noticeable discount in GC overhead utilizing this repair. We will affirm this by working Spark regionally and attaching a Java profiler on the Spark occasion. I opened a ticket and a Pull-Request on the official Spark repo however as a result of it’s unsure if will probably be merged, I believed to share it right here with you and it’s now a part of Spark 2.2.
Any ideas, feedback or critisism are welcome! 🙂