

{kind=link}
Desk of Contents
Introduction to the DeepSeek-V3 Mannequin
The panorama of enormous language fashions has been quickly evolving, with improvements in structure, coaching effectivity, and inference optimization pushing the boundaries of what’s attainable in pure language processing. The DeepSeek-V3 mannequin represents a major milestone on this evolution, introducing a set of cutting-edge strategies that deal with a few of the most urgent challenges in trendy language mannequin improvement:
- reminiscence effectivity throughout inference
- computational value throughout coaching
- efficient seize of long-range dependencies
On this complete lesson, we embark on an formidable journey to construct DeepSeek-V3 from scratch, implementing each element from first rules. This isn’t simply one other theoretical overview. We are going to write precise, working code that you would be able to run, modify, and experiment with. By the tip of this collection, you’ll have a deep understanding of 4 revolutionary architectural improvements and the way they synergistically mix to create a strong language mannequin.
This lesson is the first in a 6-part collection on Constructing DeepSeek-V3 from Scratch:
- DeepSeek-V3 Mannequin: Principle, Config, and Rotary Positional Embeddings (this tutorial)
- Classes 2
- Lesson 3
- Lesson 4
- Lesson 5
- Lesson 6
To study DeepSeek-V3 and construct it from scratch, simply maintain studying.
The 4 Pillars of DeepSeek-V3
Multihead Latent Consideration (MLA): Conventional Transformer fashions face a essential bottleneck throughout inference: the key-value (KV) cache grows linearly with sequence size, consuming huge quantities of reminiscence. For a mannequin with 32 consideration heads and a hidden dimension of 4096, storing keys and values for a single sequence of 2048 tokens requires over 1GB of reminiscence. DeepSeek’s MLA addresses this by introducing a intelligent compression-decompression mechanism impressed by Low-Rank Adaptation (LoRA). As an alternative of storing full key and worth matrices, MLA compresses them right into a low-rank latent house, attaining as much as a 75% discount in KV cache reminiscence whereas sustaining mannequin high quality. This isn’t only a theoretical enchancment; it interprets on to the power to serve extra concurrent customers or course of longer contexts with the identical {hardware} (Determine 1).
Combination of Consultants (MoE): The problem in scaling language fashions is balancing capability with computational value. Merely making fashions wider and deeper turns into prohibitively costly. MoE affords a sublime resolution: as a substitute of each token passing by means of the identical feedforward community, we create a number of “skilled” networks and route every token to solely a subset of them. DeepSeek-V3 implements this with a discovered routing mechanism that dynamically selects probably the most related consultants for every token. With 4 consultants and top-2 routing, we successfully quadruple the mannequin’s capability whereas solely doubling the computation per token. The routing operate learns to specialize completely different consultants for various kinds of patterns — maybe one skilled turns into good at dealing with numerical reasoning, one other at processing dialogue, and so forth.
Multi-Token Prediction (MTP): Conventional language fashions predict one token at a time, receiving a coaching sign just for the rapid subsequent token. That is considerably myopic — people don’t simply take into consideration the very subsequent phrase; we plan forward, contemplating how sentences and paragraphs will unfold. MTP addresses this by coaching the mannequin to foretell a number of future tokens concurrently. If we’re at place  within the sequence, customary coaching predicts token
within the sequence, customary coaching predicts token  . MTP provides auxiliary prediction heads that predict tokens
. MTP provides auxiliary prediction heads that predict tokens  ,
,  , and so forth. This supplies a richer coaching sign, encouraging the mannequin to be taught higher long-range planning and coherence. It’s significantly beneficial for duties requiring forward-looking reasoning.
, and so forth. This supplies a richer coaching sign, encouraging the mannequin to be taught higher long-range planning and coherence. It’s significantly beneficial for duties requiring forward-looking reasoning.
Rotary Positional Embeddings (RoPE): Transformers don’t inherently perceive place — they want specific positional info. Early approaches used absolute place embeddings, however these wrestle with sequences longer than these seen throughout coaching. RoPE takes a geometrical method: it rotates question and key vectors in a high-dimensional house, with the rotation angle proportional to the place. This naturally encodes relative place info and reveals outstanding extrapolation properties. A mannequin educated on 512-token sequences can usually deal with 2048-token sequences at inference time with out degradation.
The mixture of those 4 strategies is greater than the sum of its elements. MLA reduces reminiscence strain, permitting us to deal with longer contexts or bigger batch sizes. MoE will increase mannequin capability with out proportional compute will increase, making coaching extra environment friendly. MTP supplies richer gradients, accelerating studying and enhancing mannequin high quality. RoPE permits higher place understanding and size generalization. Collectively, they create a mannequin that’s environment friendly to coach, environment friendly to serve, and able to producing high-quality outputs.
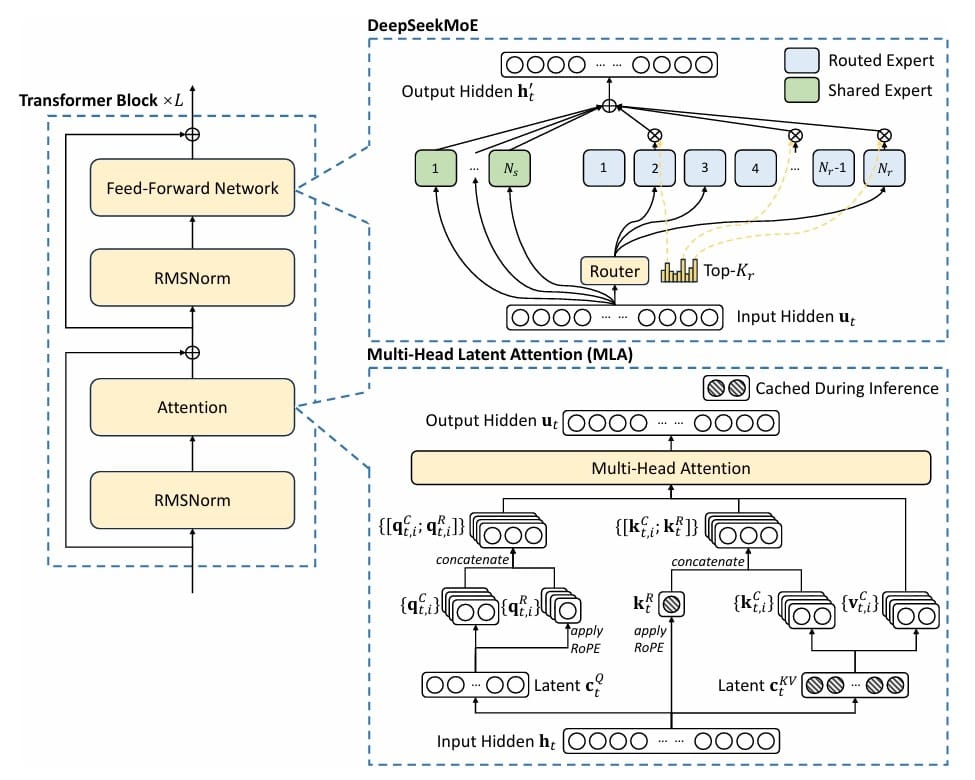
What You Will Construct
By the tip of this collection, you’ll have applied a working DeepSeek-V3 mannequin educated on the TinyStories dataset — a curated assortment of straightforward youngsters’s tales. The dataset is good for demonstrating core language modeling ideas with out requiring huge computational sources. Your mannequin will have the ability to generate coherent, inventive tales within the fashion of kids’s literature. Extra importantly, you’ll perceive each line of code, each architectural resolution, and each mathematical precept behind the mannequin.
The DeepSeek-V3 mannequin we construct makes use of fastidiously chosen hyperparameters for academic functions:
- 6 Transformer layers
- 256-dimensional token embeddings
- 8 consideration heads
- 4 MoE consultants with top-2 routing
- 2-token-ahead prediction coaching goal (MTP)
These decisions steadiness pedagogical readability with sensible efficiency: the mannequin is sufficiently small to coach on a single GPU in an affordable time, but massive sufficient to generate significant outputs and exhibit the important thing architectural improvements.
Stipulations and Setup for Constructing the DeepSeek-V3 Mannequin
Earlier than we dive in, guarantee you may have a working Python atmosphere with PyTorch 2.0+, the transformers library, and customary scientific computing packages (e.g., numpy, datasets). A GPU is extremely really helpful however not required — you possibly can practice on a CPU, although it will likely be slower. The whole code is out there as a Jupyter pocket book, permitting you to experiment interactively.
# Set up required packages
!pip set up -q transformers datasets torch speed up tensorboard
# Import core libraries
import os
import math
import torch
import torch.nn as nn
import torch.nn.purposeful as F
from dataclasses import dataclass
from typing import Elective, Tuple, Checklist, Dict
import logging
import json
print(f"PyTorch model: {torch.__version__}")
print(f"CUDA out there: {torch.cuda.is_available()}")
print(f"System: {torch.system('cuda' if torch.cuda.is_available() else 'cpu')}")
Implementing DeepSeek-V3 Mannequin Configuration and RoPE
DeepSeek-V3 Mannequin Parameters and Configuration
Earlier than we are able to construct any neural community, we want a scientific method to handle its hyperparameters — the architectural selections that outline the mannequin. In trendy deep studying, the configuration sample has turn out to be important: we encapsulate all hyperparameters in a single, serializable object that may be saved, loaded, and modified independently of the mannequin code. This isn’t simply good software program engineering — it’s essential for reproducibility, experimentation, and deployment.
DeepSeek-V3’s configuration should seize parameters throughout a number of dimensions. First, there are the usual Transformer parameters:
- vocabulary measurement

- variety of Transformer layers

- hidden dimension

- variety of consideration heads

- most context size

These comply with from the canonical Transformer structure, the place the mannequin transforms enter sequences by means of layers of self-attention and feedforward processing.
Past these fundamentals, we want parameters particular to the DeepSeek-V3 improvements. For MLA, we require the LoRA ranks for key-value compression ( ) and question compression (
) and question compression ( ), in addition to the RoPE dimension (
), in addition to the RoPE dimension ( ). For MoE, we specify the variety of consultants (
). For MoE, we specify the variety of consultants ( ), what number of to activate per token (
), what number of to activate per token ( ), and coefficients for auxiliary losses. For MTP, we outline what number of tokens forward to foretell (
), and coefficients for auxiliary losses. For MTP, we outline what number of tokens forward to foretell ( ).
).
The mathematical relationship between these parameters determines the mannequin’s computational and reminiscence traits. The usual Transformer consideration complexity scales as ") for sequence size
for sequence size  . With MLA’s compression, we cut back the KV cache from
. With MLA’s compression, we cut back the KV cache from  to roughly
to roughly  , the place
, the place  . For our chosen parameters with
. For our chosen parameters with  and
and  , this represents roughly a 50% discount in KV cache measurement.
, this represents roughly a 50% discount in KV cache measurement.
Rotary Positional Embeddings: Geometric Place Encoding
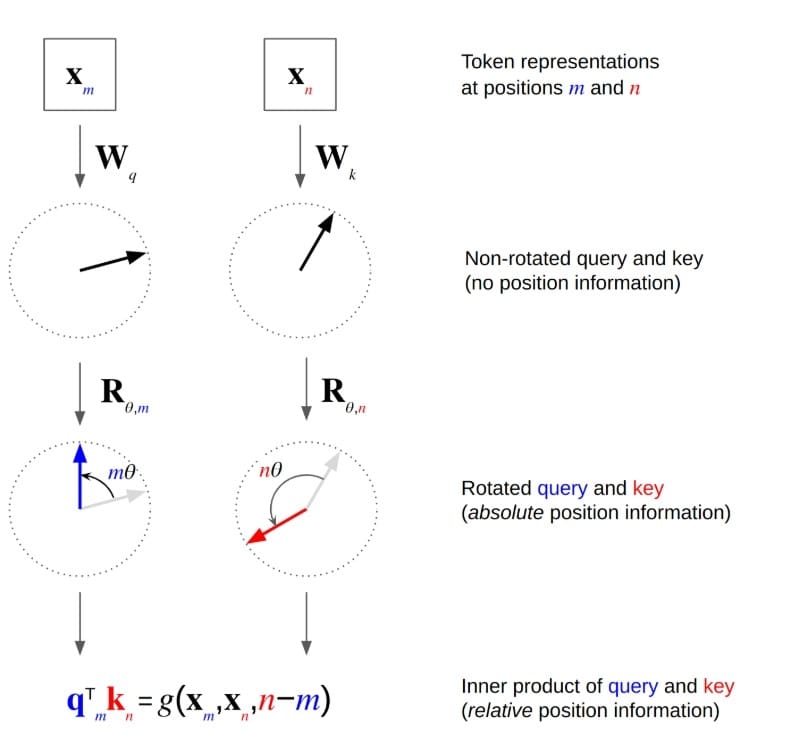
RoPE (Determine 2) represents some of the elegant concepts in trendy Transformer analysis. To know it, we should first study why place issues and the place earlier approaches had limitations.
The Place Downside: Self-attention mechanisms are permutation-invariant — if we shuffle the enter tokens, we get the identical output (modulo the shuffling). However language is sequential; “The cat chased the mouse” means one thing very completely different from “The mouse chased the cat.” We have to inject positional info.
Absolute Positional Embeddings: The unique Transformer used sinusoidal positional embeddings: } = sin(text{pos} / 10000^{2i/d_text{model}})") and
and } = cos(text{pos} / 10000^{2i/d_text{model}})") . These are added to enter embeddings. Discovered absolute positional embeddings are an alternative choice. However each wrestle with extrapolation — a mannequin educated on sequences as much as size 512 usually fails when utilized to sequences of size 1024.
. These are added to enter embeddings. Discovered absolute positional embeddings are an alternative choice. However each wrestle with extrapolation — a mannequin educated on sequences as much as size 512 usually fails when utilized to sequences of size 1024.
Relative Place Approaches: Some fashions (e.g., Transformer-XL) use relative positional encodings, explicitly modeling the space between tokens. This helps with extrapolation however provides computational overhead.
RoPE’s Geometric Perception: RoPE takes a special method, encoding place by means of rotation in complicated house. Contemplate the eye rating between question  at place
at place  and key at place
and key at place  :
:

RoPE modifies this by rotating each and by angles proportional to their positions:
^T (R_{theta, n} k) = q^T R_{theta, m}^T R_{theta, n} k = q^T R_{theta, n-m} k")
the place  is the rotation matrix similar to place
is the rotation matrix similar to place  . The important thing perception: rotation matrices fulfill
. The important thing perception: rotation matrices fulfill  , so the eye rating naturally relies on the relative place
, so the eye rating naturally relies on the relative place  slightly than absolute positions.
slightly than absolute positions.
In observe, we implement this in 2D rotation pairs. For a  -dimensional vector, we break up it into
-dimensional vector, we break up it into  pairs and rotate every pair:
pairs and rotate every pair:
 & -sin(mtheta_i) sin(mtheta_i) & cos(mtheta_i) end{bmatrix} begin{bmatrix} q_i q_{i+1} end{bmatrix}")
the place  follows the identical frequency sample as sinusoidal embeddings. This provides us a number of rotation frequencies, permitting the mannequin to seize each fine-grained and coarse-grained positional relationships.
follows the identical frequency sample as sinusoidal embeddings. This provides us a number of rotation frequencies, permitting the mannequin to seize each fine-grained and coarse-grained positional relationships.
Why RoPE Extrapolates Properly: The rotation formulation naturally extends to positions past coaching knowledge. If the mannequin learns {that a} relative place of +5 corresponds to a sure rotation angle, it may possibly apply the identical precept to positions past its coaching vary. The continual nature of trigonometric capabilities means there aren’t any discrete place embeddings that “run out.”
RMSNorm: A Fashionable Normalization Alternative: Earlier than diving into code, we should always point out RMSNorm (Root Imply Sq. Normalization), which DeepSeek makes use of as a substitute of LayerNorm. Whereas LayerNorm computes:
 = gamma dfrac{x - mu}{sqrt{sigma^2 + epsilon}} + beta")
RMSNorm simplifies by eradicating the mean-centering and bias:
 = gamma dfrac{x}{sqrt{dfrac{1}{d}sum_{i=1}^{d} x_i^2 + epsilon}}")
That is computationally cheaper and empirically performs simply as effectively for language fashions. The important thing perception is that the mean-centering time period in LayerNorm might not be mandatory for Transformers, the place the activations are already roughly centered.
Implementation: Configuration and Rotary Positional Embeddings
Now let’s implement these ideas. We’ll begin with the configuration class:
import json
@dataclass
class DeepSeekConfig:
"""Configuration for DeepSeek mannequin optimized for youngsters's tales"""
vocab_size: int = 50259 # GPT-2 vocabulary measurement + <|story|> + </|story|> tokens
n_layer: int = 6 # Variety of transformer blocks
n_head: int = 8 # Variety of consideration heads
n_embd: int = 256 # Embedding dimension
block_size: int = 1024 # Most context window
dropout: float = 0.1 # Dropout price
bias: bool = True # Use bias in linear layers
# MLA (Multihead Latent Consideration) config
kv_lora_rank: int = 128 # LoRA rank for key-value projection
q_lora_rank: int = 192 # LoRA rank for question projection
rope_dim: int = 64 # RoPE dimension
# MoE (Combination of Consultants) config
n_experts: int = 4 # Variety of consultants
n_experts_per_token: int = 2 # Variety of consultants per token (top-k)
expert_intermediate_size: int = 512 # Knowledgeable hidden measurement
shared_expert_intermediate_size: int = 768 # Shared skilled hidden measurement
use_shared_expert: bool = True # Allow shared skilled
aux_loss_weight: float = 0.0 # Auxiliary loss weight (0.0 for aux-free)
# Multi-token prediction
multi_token_predict: int = 2 # Predict subsequent 2 tokens
Traces 1-5: Configuration Class Construction: We use Python’s @dataclass decorator to outline our DeepSeekConfig class, which mechanically generates initialization and illustration strategies. That is greater than syntactic sugar — it ensures sort hints are revered and supplies built-in equality comparisons. The configuration serves as a single supply of fact for mannequin hyperparameters, making it simple to experiment with completely different architectures by merely modifying this object.
Traces 7-13: Commonplace Transformer Parameters: We outline the core Transformer dimensions. The vocabulary measurement of fifty,259 comes from the GPT-2 tokenizer, with two further customized tokens for story boundaries. We select 6 layers and a 256-dimensional embedding measurement as a steadiness between mannequin capability and computational value — that is sufficiently small to coach on a single shopper GPU however massive sufficient to exhibit the important thing DeepSeek improvements. The block measurement of 1024 determines the mannequin’s most context size, ample for coherent brief tales. The dropout price of 0.1 supplies regularization with out being overly aggressive.
Traces 16-18: MLA Configuration: These parameters management our Multihead Latent Consideration mechanism. The kv_lora_rank of 128 means we compress key-value representations from 256 dimensions right down to 128 — a 50% discount that interprets on to KV cache reminiscence financial savings. The q_lora_rank of 192 supplies barely extra capability for question compression since queries don’t should be cached throughout inference. The rope_dim of 64 specifies what number of dimensions use RoPE — we don’t apply RoPE to all dimensions, solely to a subset, permitting some dimensions to focus purely on content material slightly than place.
Traces 21-29: MoE and MTP Configuration: We configure 4 skilled networks with top-2 routing, that means every token will likely be processed by precisely 2 out of 4 consultants. This provides us 2× extra parameters than a normal feedforward layer whereas sustaining the identical computational value. The aux_loss_weight of 0.01 determines how strongly we penalize uneven skilled utilization — that is essential for stopping all tokens from routing to only one or two consultants. The multi_token_predict parameter determines what number of future tokens the mannequin is educated to foretell at every step.
def __post_init__(self):
"""Initialize particular tokens after dataclass initialization"""
self.special_tokens = >",
"story_end": "</
def to_dict(self):
"""Convert configuration to dictionary"""
return {
'vocab_size': self.vocab_size,
'n_layer': self.n_layer,
'n_head': self.n_head,
'n_embd': self.n_embd,
'block_size': self.block_size,
'dropout': self.dropout,
'bias': self.bias,
'kv_lora_rank': self.kv_lora_rank,
'q_lora_rank': self.q_lora_rank,
'rope_dim': self.rope_dim,
'n_experts': self.n_experts,
'n_experts_per_token': self.n_experts_per_token,
'expert_intermediate_size': self.expert_intermediate_size,
'shared_expert_intermediate_size': self.shared_expert_intermediate_size,
'use_shared_expert': self.use_shared_expert,
'aux_loss_weight': self.aux_loss_weight,
'multi_token_predict': self.multi_token_predict,
'special_tokens': self.special_tokens,
}
def to_json_string(self, indent=2):
"""Convert configuration to JSON string"""
return json.dumps(self.to_dict(), indent=indent)
@classmethod
def from_dict(cls, config_dict):
"""Create configuration from dictionary"""
# Take away special_tokens from dict because it's set in __post_init__
config_dict = {okay: v for okay, v in config_dict.objects() if okay != 'special_tokens'}
return cls(**config_dict)
@classmethod
def from_json_string(cls, json_string):
"""Create configuration from JSON string"""
return cls.from_dict(json.masses(json_string))
Traces 31-75: Particular Strategies for Serialization: We implement __post_init__ so as to add particular tokens after initialization, guaranteeing they’re at all times current however not required within the constructor. The to_dict and to_json_string strategies allow simple serialization for saving configurations alongside educated fashions. The category strategies from_dict and from_json_string present deserialization, creating a whole round-trip for configuration administration. This sample is important for reproducibility — we are able to save a configuration with our educated mannequin and later reconstruct the precise structure.
Subsequent, we implement the RoPE module.
class RMSNorm(nn.Module):
"""Root Imply Sq. Layer Normalization"""
def __init__(self, ndim, eps=1e-6):
tremendous().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(ndim))
def ahead(self, x):
norm = x.norm(dim=-1, keepdim=True) * (x.measurement(-1) ** -0.5)
return self.weight * x / (norm + self.eps)
RMSNorm Implementation (Traces 1-10): Our RMSNorm class is remarkably easy. Within the constructor, we create a learnable weight parameter (the  in our equations) initialized to ones. Within the ahead move, we compute the L2 norm of the enter alongside the characteristic dimension, multiply by
in our equations) initialized to ones. Within the ahead move, we compute the L2 norm of the enter alongside the characteristic dimension, multiply by  to get the RMS, after which scale the enter by the inverse of this norm (plus epsilon for numerical stability) and multiply by the discovered weight parameter. This normalization ensures our activations have unit RMS, serving to with coaching stability and gradient circulation.
to get the RMS, after which scale the enter by the inverse of this norm (plus epsilon for numerical stability) and multiply by the discovered weight parameter. This normalization ensures our activations have unit RMS, serving to with coaching stability and gradient circulation.
class RotaryEmbedding(nn.Module):
"""Rotary Positional Embedding (RoPE) for higher place understanding"""
def __init__(self, dim, max_seq_len=2048):
tremendous().__init__()
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim))
self.register_buffer('inv_freq', inv_freq)
self.max_seq_len = max_seq_len
def ahead(self, x, seq_len=None):
if seq_len is None:
seq_len = x.form[-2]
t = torch.arange(seq_len, system=x.system).type_as(self.inv_freq)
freqs = torch.outer(t, self.inv_freq)
cos, sin = freqs.cos(), freqs.sin()
return cos, sin
def apply_rope(x, cos, sin):
"""Apply rotary place embedding"""
x1, x2 = x.chunk(2, dim=-1)
return torch.cat([x1 * cos - x2 * sin, x1 * sin + x2 * cos], dim=-1)
The RotaryEmbedding Class (Traces 12-27): The constructor creates the inverse frequency vector inv_freq following the identical frequency schedule utilized in sinusoidal positional embeddings, the place every pair of dimensions is assigned a frequency following the schedule  . We use
. We use register_buffer slightly than a parameter as a result of these frequencies shouldn’t be discovered — they’re fastened by our positional encoding design. Within the ahead move, we create place indices from 0 to seq_len, compute the outer product with inverse frequencies (giving us a matrix the place entry ") is
is  , and compute the cosine and sine values. These will likely be broadcast and utilized to question and key vectors. The ensuing cosine and sine tensors broadcast throughout the batch, head, and sequence dimensions throughout consideration computation.
, and compute the cosine and sine values. These will likely be broadcast and utilized to question and key vectors. The ensuing cosine and sine tensors broadcast throughout the batch, head, and sequence dimensions throughout consideration computation.
The apply_rope Perform (Traces 29-32): This elegant operate applies the 2D rotation. We chunk the enter into pairs of dimensions (successfully treating every pair of dimensions as the actual and imaginary elements of a posh quantity). We then apply the rotation system:
 = (x_1 cos theta - x_2 sin theta, x_1 sin theta + x_2 cos theta).")
The chunking operation splits alongside the final dimension. We compute every rotated element after which concatenate them again collectively. This vectorized implementation is way extra environment friendly than iterating over dimension pairs in Python.
Design Decisions and Tradeoffs: A number of selections advantage dialogue. We selected partial RoPE (rope_dim=64 slightly than full n_embd=256) as a result of empirical analysis exhibits that making use of RoPE to all dimensions can generally harm efficiency — some dimensions profit from remaining content-focused slightly than encoding place. Our LoRA ranks are pretty excessive (128 and 192) relative to the 256-dimensional embeddings; in bigger fashions, the compression ratio could be extra aggressive. The particular tokens sample (story_start and story_end) supplies specific boundaries that assist the mannequin be taught story construction — it is aware of when a technology ought to terminate.
What’s subsequent? We suggest PyImageSearch College.
86+ complete lessons • 115+ hours hours of on-demand code walkthrough movies • Final up to date: March 2026
★★★★★ 4.84 (128 Rankings) • 16,000+ College students Enrolled
I strongly imagine that for those who had the correct trainer you could possibly grasp laptop imaginative and prescient and deep studying.
Do you assume studying laptop imaginative and prescient and deep studying must be time-consuming, overwhelming, and sophisticated? Or has to contain complicated arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All you’ll want to grasp laptop imaginative and prescient and deep studying is for somebody to clarify issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter schooling and the way complicated Synthetic Intelligence subjects are taught.
If you happen to’re severe about studying laptop imaginative and prescient, your subsequent cease must be PyImageSearch College, probably the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line right this moment. Right here you’ll discover ways to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and tasks. Be part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you may discover:
- &test; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV subjects
- &test; 86 Certificates of Completion
- &test; 115+ hours hours of on-demand video
- &test; Model new programs launched often, guaranteeing you possibly can sustain with state-of-the-art strategies
- &test; Pre-configured Jupyter Notebooks in Google Colab
- &test; Run all code examples in your internet browser — works on Home windows, macOS, and Linux (no dev atmosphere configuration required!)
- &test; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &test; Straightforward one-click downloads for code, datasets, pre-trained fashions, and so on.
- &test; Entry on cellular, laptop computer, desktop, and so on.
Abstract
On this weblog, we stroll by means of the foundations of DeepSeek-V3, beginning with its theoretical underpinnings and the 4 pillars that form its structure. We discover why these pillars matter, how they information the design of the mannequin, and what we intention to construct by the tip of the lesson. By laying out the stipulations and setup, we be sure that we’re outfitted with the correct instruments and mindset earlier than diving into the implementation particulars.
Subsequent, we concentrate on the mannequin configuration, the place we break down the important parameters that outline DeepSeek-V3’s conduct. We talk about how these configurations affect efficiency, scalability, and flexibility, and why they’re essential for constructing a sturdy mannequin. Alongside this, we introduce Rotary Positional Embeddings (RoPE), a geometrical method to positional encoding that enhances the mannequin’s means to seize sequential info with precision.
Lastly, we deliver concept into observe by implementing each the configuration and RoPE step-by-step. We spotlight how these elements combine seamlessly, forming the spine of DeepSeek-V3. By the tip, we not solely perceive the theoretical points but additionally achieve hands-on expertise in constructing and customizing the mannequin. Collectively, these steps demystify the method and set the stage for deeper experimentation with superior Transformer architectures.
Quotation Info
Mangla, P. “DeepSeek-V3 Mannequin: Principle, Config, and Rotary Positional Embeddings,” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/1atre
@incollection{Mangla_2026_deepseek-v3-model-theory-config-and-rotary-positional-embeddings,
creator = {Puneet Mangla},
title = {{DeepSeek-V3 Mannequin: Principle, Config, and Rotary Positional Embeddings}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
yr = {2026},
url = {https://pyimg.co/1atre},
}
To obtain the supply code to this put up (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your e mail deal with within the type under!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your e mail deal with under to get a .zip of the code and a FREE 17-page Useful resource Information on Pc Imaginative and prescient, OpenCV, and Deep Studying. Inside you may discover my hand-picked tutorials, books, programs, and libraries that will help you grasp CV and DL!
The put up DeepSeek-V3 Mannequin: Principle, Config, and Rotary Positional Embeddings appeared first on PyImageSearch.