
")
{kind=link}
Desk of Contents
- DeepSeek-V3 from Scratch: Combination of Specialists (MoE)
- The Scaling Problem in Neural Networks
- Combination of Specialists (MoE): Mathematical Basis and Routing Mechanism
- SwiGLU Activation in DeepSeek-V3: Bettering MoE Non-Linearity
- Auxiliary-Loss-Free Load Balancing in DeepSeek-V3 MoE
- Sequence-Clever Load Balancing for Combination of Specialists Fashions
- Professional Specialization in MoE: Emergent Habits in DeepSeek-V3
- Implementation: Constructing the DeepSeek-V3 MoE Layer from Scratch
- MoE Computational and Reminiscence Evaluation in DeepSeek-V3
- MoE Professional Specialization in Observe: Actual-World Habits
- Coaching Dynamics of MoE: Load Balancing and Professional Utilization
- Combination of Specialists vs Associated Strategies: Swap Transformers and Sparse Fashions
- Abstract
DeepSeek-V3 from Scratch: Combination of Specialists (MoE)
Within the first two components of this sequence, we established the foundations of DeepSeek-V3 by implementing its core configuration and positional encoding, adopted by a deep dive into Multi-Head Latent Consideration (MLA). Collectively, these parts set the stage for a mannequin that’s each environment friendly and able to dealing with long-range dependencies. With these constructing blocks in place, we now discover one other key innovation in DeepSeek-V3: the Combination of Specialists (MoE).
MoE introduces a dynamic means of scaling mannequin capability with out proportionally rising computational value. As an alternative of activating each parameter for each enter, the mannequin selectively routes tokens via specialised “knowledgeable” networks, permitting it to broaden representational energy whereas maintaining inference environment friendly. On this lesson, we’ll unpack the speculation behind MoE, clarify how knowledgeable routing works, after which implement it step-by-step. This installment continues our broader aim of reconstructing DeepSeek-V3 from scratch — displaying how every innovation, from RoPE to MLA to MoE, suits collectively right into a cohesive structure that balances scale, effectivity, and efficiency.
This lesson is the third in a 6-part sequence on Constructing DeepSeek-V3 from Scratch:
- DeepSeek-V3 Mannequin: Principle, Config, and Rotary Positional Embeddings
- Construct DeepSeek-V3: Multi-Head Latent Consideration (MLA) Structure
- DeepSeek-V3 from Scratch: Combination of Specialists (MoE) (this tutorial)
- Lesson 4
- Lesson 5
- Lesson 6
To find out about DeepSeek-V3 and construct it from scratch, simply maintain studying.
The Scaling Problem in Neural Networks
As we scale neural networks, we face a elementary tradeoff: bigger fashions have larger capability to study advanced patterns, however they’re costlier to coach and deploy. A regular Transformer feedforward layer applies the identical computation to each token:
 = text{GELU}(x W_1 + b_1) W_2 + b_2") ,
,
the place  and
and  are weight matrices, usually with
are weight matrices, usually with  . For our mannequin with
. For our mannequin with  , this implies
, this implies  , giving us roughly 256K parameters per FFN (FeedForward Community) per layer.
, giving us roughly 256K parameters per FFN (FeedForward Community) per layer.
To extend mannequin capability, we may merely make  bigger — say,
bigger — say,  as a substitute of
as a substitute of  . This doubles the FFN parameters and theoretically doubles capability. But it surely additionally doubles the computation for each token, even when most don’t want that further capability.
. This doubles the FFN parameters and theoretically doubles capability. But it surely additionally doubles the computation for each token, even when most don’t want that further capability.
Combination of Specialists (Determine 1) provides a extra environment friendly scaling paradigm: as a substitute of a single massive FFN, we create a number of smaller knowledgeable FFNs and route every token to a subset of those consultants. This provides us the capability of a a lot bigger mannequin whereas sustaining computational effectivity.
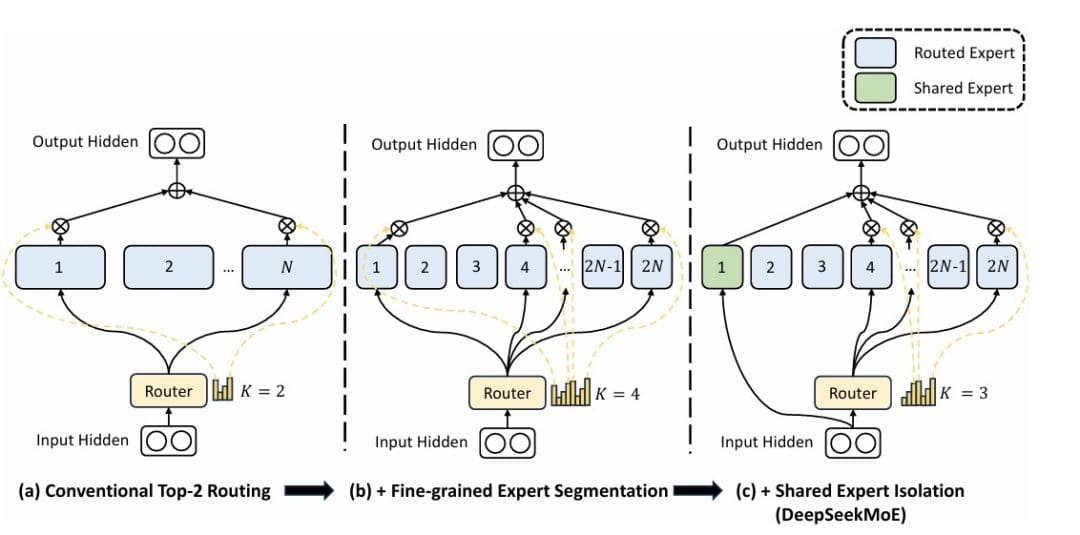
Combination of Specialists (MoE): Mathematical Basis and Routing Mechanism
Contemplate  knowledgeable networks, every with the identical structure as a regular FFN:
knowledgeable networks, every with the identical structure as a regular FFN:
 = text{SwiGLU}(x)")
for  . As an alternative of utilizing all consultants for each token, we choose the top-k consultants. The choice is decided by a discovered routing operate:
. As an alternative of utilizing all consultants for each token, we choose the top-k consultants. The choice is decided by a discovered routing operate:
 = text{softmax}(x W_r + b) in mathbb{R}^N")
the place  is the router weight matrix and
is the router weight matrix and  is a learnable bias vector. This provides us a likelihood distribution over consultants for every token.
is a learnable bias vector. This provides us a likelihood distribution over consultants for every token.
Prime-k Routing: We choose the top-k consultants based mostly on router possibilities:
 = {i mid r_i(x) text{ is in the top-k values of } r(x)}")
The ultimate output combines the chosen consultants, weighted by their normalized routing possibilities:
 = sum_{i in mathcal{T}_k(x)} dfrac{r_i(x)}{sum_{j in mathcal{T}_k(x)} r_j(x)} E_i(x)")
The renormalization }{sum_{j in mathcal{T}_k(x)} r_j(x)}") ensures the chosen consultants’ weights sum to 1.
ensures the chosen consultants’ weights sum to 1.
Capability and Computation: With  consultants and
consultants and  (our configuration), every token prompts 2 out of 4 consultants. If every knowledgeable has the identical measurement as a regular FFN, we’ve
(our configuration), every token prompts 2 out of 4 consultants. If every knowledgeable has the identical measurement as a regular FFN, we’ve  the parameters however solely
the parameters however solely  the computation per token. That is the MoE effectivity benefit: parameter rely scales with , however computation scales with
the computation per token. That is the MoE effectivity benefit: parameter rely scales with , however computation scales with  .
.
SwiGLU Activation in DeepSeek-V3: Bettering MoE Non-Linearity
DeepSeek makes use of SwiGLU (Swish-Gated Linear Unit) as a substitute of the normal GELU (Gaussian Error Linear Models) activation. SwiGLU is a gated activation operate that has proven superior efficiency in language fashions:
 = text{SiLU}(text{gate}(x)) odot text{up}(x)")
the place:
 = x W_text{gate}") : tasks enter to hidden dimension
: tasks enter to hidden dimension = x W_text{up}") : is one other projection to hidden dimension
: is one other projection to hidden dimension = x cdot sigma(x)") : is the Swish activation (easy model of ReLU)
: is the Swish activation (easy model of ReLU) : denotes element-wise multiplication
: denotes element-wise multiplication- The result’s then projected again:
)")
The gating mechanism permits the community to regulate info movement extra exactly than easy activation capabilities. The  activation offers easy gradients all over the place, enhancing coaching dynamics in comparison with ReLU’s laborious threshold.
activation offers easy gradients all over the place, enhancing coaching dynamics in comparison with ReLU’s laborious threshold.
Shared Professional in DeepSeek-V3: Common Processing in MoE Layers
DeepSeek introduces a shared knowledgeable that processes all tokens along with the routed consultants. This design addresses a key limitation of pure MoE: some computations are helpful for all tokens no matter their content material.
 = text{SharedExpert}(x) + sum_{i in mathcal{T}_k(x)} w_i E_i(x)")
The shared knowledgeable has a bigger hidden dimension (768 in our configuration vs 512 for particular person consultants) and processes each token. This ensures that:
- Widespread patterns are effectively dealt with by devoted capability
- Specialised consultants can deal with token-specific options
- Coaching is extra secure with assured gradient movement
The shared knowledgeable serves as a “base” computation that’s at all times current, whereas routed consultants add specialised processing on high of it.
Auxiliary-Loss-Free Load Balancing in DeepSeek-V3 MoE
A important problem in MoE is load balancing. If the router learns to at all times ship tokens to the identical one or two consultants, we lose the advantages of getting a number of consultants — the unused consultants contribute nothing, and the overused ones develop into bottlenecks.
Conventional MoE fashions use an auxiliary loss that penalizes uneven knowledgeable utilization:
^2")
the place  is the variety of tokens routed to knowledgeable
is the variety of tokens routed to knowledgeable  ,
,  is batch measurement, and
is batch measurement, and  is a coefficient. Nevertheless, auxiliary losses add complexity and require cautious tuning.
is a coefficient. Nevertheless, auxiliary losses add complexity and require cautious tuning.
DeepSeek’s Innovation: Auxiliary-loss-free load balancing via dynamic bias updates. As an alternative of penalizing imbalance throughout coaching, we modify the router biases to encourage balanced utilization:
Throughout coaching, we monitor what number of tokens are routed to every knowledgeable. This provides us an expert_usage vector, the place every entry counts the variety of tokens assigned to a specific knowledgeable. We then compute the common utilization throughout all consultants.
To take care of a balanced load, we modify the router biases: if an knowledgeable is used greater than the common, its bias is decreased to make it much less more likely to be chosen sooner or later; whether it is used lower than the common, its bias is elevated to make it extra more likely to be chosen. This dynamic bias replace encourages truthful distribution of tokens throughout consultants with out requiring an specific auxiliary loss.
Let  denote the utilization (variety of tokens) of knowledgeable , and let
denote the utilization (variety of tokens) of knowledgeable , and let

be the common utilization throughout all consultants. The router bias for knowledgeable , denoted  , is up to date as:
, is up to date as:
 ,
,
the place  is the educational charge controlling the magnitude of the bias adjustment.
is the educational charge controlling the magnitude of the bias adjustment.
This method:
- Eliminates the necessity for auxiliary loss hyperparameter tuning
- Supplies smoother load balancing over time
- Doesn’t intrude with the first process loss
- Routinely adapts to knowledge distribution adjustments
The bias updates are carried out with a small studying charge (0.001 in our implementation) to make sure gradual adjustment with out disrupting coaching.
Sequence-Clever Load Balancing for Combination of Specialists Fashions
For even higher load balancing, DeepSeek can use a complementary sequence-wise auxiliary loss. This encourages totally different sequences in a batch to make use of totally different consultants:
") ,
,
the place is the knowledgeable utilization vector for sequence (i.e., which consultants had been used), and  measures similarity. By minimizing this loss, we encourage sequences to be complementary — if sequence A makes use of consultants 1 and a pair of closely, sequence B ought to use consultants 3 and 4.
measures similarity. By minimizing this loss, we encourage sequences to be complementary — if sequence A makes use of consultants 1 and a pair of closely, sequence B ought to use consultants 3 and 4.
Professional Specialization in MoE: Emergent Habits in DeepSeek-V3
An enchanting property of MoE is knowledgeable specialization. Regardless that we don’t explicitly inform consultants what to concentrate on, they usually study to deal with several types of patterns. In language fashions, researchers have noticed:
- Syntactic consultants: Deal with grammatical buildings, verb conjugations
- Semantic consultants: Course of which means, synonyms, and conceptual relationships
- Area consultants: Specialise in particular subjects (e.g., scientific textual content, dialogue)
- Numerical consultants: Deal with arithmetic, dates, portions
This specialization emerges naturally because the routing operate learns which consultants are simplest for various inputs. Gradient movement throughout coaching reinforces this — when an knowledgeable performs properly on sure patterns, the router learns to ship comparable patterns to that knowledgeable.
Mathematically, we are able to consider every knowledgeable as studying a neighborhood mannequin ") that’s significantly good in some area of the enter area. The router operate
that’s significantly good in some area of the enter area. The router operate ") implicitly partitions the enter area, assigning totally different areas to totally different consultants. That is just like a combination of consultants in classical machine studying, however discovered end-to-end via backpropagation.
implicitly partitions the enter area, assigning totally different areas to totally different consultants. That is just like a combination of consultants in classical machine studying, however discovered end-to-end via backpropagation.
Implementation: Constructing the DeepSeek-V3 MoE Layer from Scratch
Let’s implement the whole MoE layer with knowledgeable networks, routing, and cargo balancing:
class SwiGLU(nn.Module):
"""SwiGLU activation operate utilized in DeepSeek consultants"""
def __init__(self, input_dim: int, hidden_dim: int, output_dim: int, bias: bool = True):
tremendous().__init__()
self.gate_proj = nn.Linear(input_dim, hidden_dim, bias=bias)
self.up_proj = nn.Linear(input_dim, hidden_dim, bias=bias)
self.down_proj = nn.Linear(hidden_dim, output_dim, bias=bias)
def ahead(self, x: torch.Tensor):
gate = F.silu(self.gate_proj(x)) # SiLU activation
up = self.up_proj(x)
return self.down_proj(gate * up)
Strains 1-13: SwiGLU Activation: The SwiGLU class implements a gated activation mechanism. We have now 3 linear projections:
gate_proj: for the gating signup_proj: for the worth departmentdown_proj: for the output projection
The ahead move applies SiLU (Sigmoid Linear Unit) to the gate projection, multiplies it element-wise with the up-projection, and tasks again down. This creates a extra expressive activation than easy GELU, with the gating mechanism permitting fine-grained management over info movement.
class MoEExpert(nn.Module):
"""Professional community for Combination of Specialists utilizing SwiGLU"""
def __init__(self, config: DeepSeekConfig):
tremendous().__init__()
self.expert_mlp = SwiGLU(
config.n_embd,
config.expert_intermediate_size,
config.n_embd,
config.bias
)
def ahead(self, x: torch.Tensor):
return self.expert_mlp(x)
Strains 14-27: Professional with SwiGLU: Every MoEExpert is now a SwiGLU community as a substitute of a easy FFN. The intermediate measurement (expert_intermediate_size) controls capability — we use 512 in our configuration, which is smaller than the shared knowledgeable’s 768. This asymmetry displays the truth that routed consultants deal with specialised patterns, whereas the shared knowledgeable handles widespread operations.
class MixtureOfExperts(nn.Module):
"""
DeepSeek MoE layer with shared knowledgeable and auxiliary-loss-free load balancing
Key options:
- Shared knowledgeable that processes all tokens
- Auxiliary-loss-free load balancing through bias updates
- Prime-k routing to chose consultants
"""
def __init__(self, config: DeepSeekConfig):
tremendous().__init__()
self.config = config
self.n_experts = config.n_experts
self.top_k = config.n_experts_per_token
self.n_embd = config.n_embd
# Router: learns which consultants to make use of for every token
self.router = nn.Linear(config.n_embd, config.n_experts, bias=False)
# Professional networks
self.consultants = nn.ModuleList([
MoEExpert(config) for _ in range(config.n_experts)
])
# Shared knowledgeable (processes all tokens)
if config.use_shared_expert:
self.shared_expert = SwiGLU(
config.n_embd,
config.shared_expert_intermediate_size,
config.n_embd,
config.bias
)
else:
self.shared_expert = None
# Auxiliary-loss-free load balancing
self.register_buffer('expert_bias', torch.zeros(config.n_experts))
self.bias_update_rate = 0.001
self.dropout = nn.Dropout(config.dropout)
Strains 28-68: MoE Layer Construction: The MixtureOfExperts class orchestrates routing and knowledgeable execution. The three key additions:
shared_expert: full-capacity knowledgeable that processes all tokensexpert_bias: buffer for auxiliary-loss-free balancingbias_update_rate: controls how shortly biases adapt
The dropout offers regularization throughout the whole MoE output.
def ahead(self, x: torch.Tensor):
batch_size, seq_len, hidden_dim = x.form
x_flat = x.view(-1, hidden_dim)
# Routing section with bias for load balancing
router_logits = self.router(x_flat) + self.expert_bias
# Prime-k routing
top_k_logits, top_k_indices = torch.topk(router_logits, self.top_k, dim=-1)
routing_weights = torch.zeros_like(router_logits)
routing_weights.scatter_(-1, top_k_indices, F.softmax(top_k_logits, dim=-1))
# Professional computation
output = torch.zeros_like(x_flat)
expert_usage = torch.zeros(self.n_experts, gadget=x.gadget)
Strains 70-84: Routing with Learnable Bias. The ahead move begins by flattening the enter for environment friendly processing. We compute router logits and add the knowledgeable bias — that is the important thing to auxiliary-loss-free balancing. Overused consultants have adverse bias (making them much less more likely to be chosen), whereas underused consultants have optimistic bias (encouraging them to be chosen). We then carry out top-k choice and softmax normalization throughout the chosen consultants.
# Course of via chosen consultants
for expert_idx in vary(self.n_experts):
expert_mask = (top_k_indices == expert_idx).any(dim=-1)
expert_usage[expert_idx] = expert_mask.sum().float()
if expert_mask.any():
expert_input = x_flat[expert_mask]
expert_output = self.consultants[expert_idx](expert_input)
# Weight by routing likelihood
weights = routing_weights[expert_mask, expert_idx].unsqueeze(-1)
output[expert_mask] += expert_output * weights
# Add shared knowledgeable output (processes all tokens)
if self.shared_expert will not be None:
shared_output = self.shared_expert(x_flat)
output += shared_output
# Auxiliary-loss-free load balancing (replace biases throughout coaching)
if self.coaching:
with torch.no_grad():
avg_usage = expert_usage.imply()
for i in vary(self.n_experts):
if expert_usage[i] > avg_usage:
self.expert_bias[i] -= self.bias_update_rate
else:
self.expert_bias[i] += self.bias_update_rate
output = self.dropout(output)
return output.view(batch_size, seq_len, hidden_dim), router_logits.view(batch_size, seq_len, -1)
Strains 86-97: Professional Processing. We iterate over all consultants, figuring out which tokens route to every one through the expert_mask. For every knowledgeable with assigned tokens, we extract these tokens, course of them via the knowledgeable community, weight them by routing likelihood, and accumulate them into the output. This selective execution is what makes MoE environment friendly — we don’t compute all consultants for all tokens.
Strains 100-102: Shared Professional. The shared knowledgeable processes all tokens unconditionally and provides its output to the routed consultants’ output. This ensures each token receives some baseline processing, enhancing coaching stability and offering capability for common patterns. The shared knowledgeable’s bigger hidden dimension (768 vs 512) displays its broader accountability.
Strains 105-112: Auxiliary-Loss-Free Balancing. Throughout coaching, we replace knowledgeable biases based mostly on utilization. We compute common utilization throughout consultants, then modify biases: overused consultants obtain adverse changes (discouraging future choice), whereas underused consultants obtain optimistic changes (encouraging future choice). Utilizing the torch.no_grad() context ensures these bias updates don’t intrude with gradient computation. The small replace charge (0.001) offers easy, secure balancing over time.
Strains 114-115: Output and Return. We apply dropout to the mixed output (routed + shared consultants) and reshape again to the unique dimensions. We return each the output and router logits — the latter can be utilized for non-obligatory auxiliary loss computation.
def _complementary_sequence_aux_loss(self, router_logits, seq_mask=None):
"""
router_logits: [batch_size, seq_len, num_experts]
Uncooked logits from the router earlier than softmax.
seq_mask: non-obligatory masks for padding tokens.
"""
# Convert to possibilities
probs = F.softmax(router_logits, dim=-1) # [B, T, E]
# Combination per-sequence knowledgeable utilization
if seq_mask will not be None:
probs = probs * seq_mask.unsqueeze(-1) # masks padding
seq_usage = probs.sum(dim=1) # [B, E]
# Normalize per sequence
seq_usage = seq_usage / seq_usage.sum(dim=-1, keepdim=True)
# Compute pairwise similarity between sequences
sim_matrix = torch.matmul(seq_usage, seq_usage.transpose(0, 1)) # [B, B]
# Encourage complementarity: decrease similarity off-diagonal
batch_size = seq_usage.measurement(0)
off_diag = sim_matrix - torch.eye(batch_size, gadget=sim_matrix.gadget)
loss = off_diag.imply()
return loss
Strains 117-143: Complementary Sequence-Clever Loss. This methodology implements another load-balancing method. It converts router logits to possibilities, aggregates knowledgeable utilization for every sequence, and computes pairwise similarity between sequences’ knowledgeable utilization patterns. By minimizing off-diagonal similarity, we encourage totally different sequences to make use of totally different consultants, selling variety in knowledgeable utilization. This may be added to the coaching loss with a small weight (e.g., 0.01).
MoE Design Selections in DeepSeek-V3: SwiGLU, Shared Specialists, and Routing
A number of implementation decisions benefit dialogue:
SwiGLU vs GELU: We use SwiGLU as a substitute of conventional GELU as a result of empirical analysis reveals it constantly outperforms GELU in language fashions. The gating mechanism offers extra expressive energy, and SiLU’s smoothness improves gradient movement. The computational value is barely greater (three projections as a substitute of two), however the high quality enchancment justifies it.
Shared Professional Design: The shared knowledgeable is a DeepSeek innovation that addresses a key limitation of pure MoE: some computations profit all tokens. By offering devoted capability for common processing, we free routed consultants to specialize extra aggressively. The bigger hidden dimension (768 vs 512) for the shared knowledgeable displays empirical findings that shared capability requires extra parameters than particular person consultants.
Auxiliary-Loss-Free Balancing: Conventional MoE makes use of auxiliary losses, akin to:

the place  is the fraction of tokens routed to knowledgeable and
is the fraction of tokens routed to knowledgeable and  is the common routing likelihood. This requires tuning (usually 0.01-0.1). Our bias-based method eliminates the necessity for this hyperparameter, simplifying coaching. The tradeoff is that bias updates are much less direct than gradient-based studying, however in follow, the smoother adaptation works properly.
is the common routing likelihood. This requires tuning (usually 0.01-0.1). Our bias-based method eliminates the necessity for this hyperparameter, simplifying coaching. The tradeoff is that bias updates are much less direct than gradient-based studying, however in follow, the smoother adaptation works properly.
Complementary Sequence-Clever Loss: This various balancing method is beneficial when batch variety is excessive. By encouraging totally different sequences to make use of totally different consultants, we naturally obtain stability. Nevertheless, if the batch comprises very comparable sequences (e.g., all from the identical area), this loss is probably not efficient. It’s finest utilized in mixture with bias-based balancing or as an non-obligatory auxiliary goal.
Professional Capability: Manufacturing MoE programs usually implement knowledgeable capability constraints — if too many tokens route to at least one knowledgeable, extra tokens are dropped or routed to a second alternative. We don’t implement this in our academic mannequin, however the formulation can be:

the place issue is often 1.25-1.5. Tokens past this capability are dealt with through overflow methods.
MoE Computational and Reminiscence Evaluation in DeepSeek-V3
Let’s analyze the computational value. For the standard FFN with hidden dimension  :
:

For our MoE with routed consultants (every with  ), chosen, and shared knowledgeable (
), chosen, and shared knowledgeable ( ):
):

The SwiGLU computation includes three projections:

For our configuration:
- Routing:
 (negligible)
(negligible) - Routed consultants:

- Shared knowledgeable:

- Whole:
 2.75M FLOPs per token
2.75M FLOPs per token
Examine to a regular FFN with :  FLOPs. Our MoE makes use of 2.6× extra computation however has a lot greater capability (4 consultants × 512 + 1 shared × 768 = 2,816 vs 1,024). We get 2.7× capability for 2.6× computation — roughly linear scaling, which is the aim.
FLOPs. Our MoE makes use of 2.6× extra computation however has a lot greater capability (4 consultants × 512 + 1 shared × 768 = 2,816 vs 1,024). We get 2.7× capability for 2.6× computation — roughly linear scaling, which is the aim.
Reminiscence utilization in the course of the ahead move shops activations for energetic consultants solely. Throughout backpropagation, we’d like gradients for all consultants (since routing is differentiable), but the reminiscence stays manageable. The bias vector is tiny (4 floats for 4 consultants).
MoE Professional Specialization in Observe: Actual-World Habits
Whereas we are able to’t show this in our small toy mannequin, in larger-scale MoE fashions, knowledgeable specialization is observable via evaluation of routing patterns. Researchers have visualized which consultants activate for several types of inputs, revealing clear specialization. For instance:
- Multilingual fashions: Completely different consultants deal with totally different languages
- Code fashions: Some consultants deal with syntax, others semantics, others API patterns
- Reasoning fashions: Numerical consultants for math, logical consultants for inference, retrieval consultants for factual recall
This specialization isn’t programmed — it emerges from optimization. The routing operate learns to partition the enter area, and consultants study to excel of their assigned partitions. It’s a ravishing instance of how end-to-end studying can uncover structured options.
Coaching Dynamics of MoE: Load Balancing and Professional Utilization
In follow, MoE coaching displays attention-grabbing dynamics:
Early Coaching: Routing is initially random or near-uniform. All consultants obtain an analogous load. The shared knowledgeable learns fundamental patterns that profit all tokens.
Mid Coaching: Routing begins specializing. Some consultants develop into most well-liked for sure patterns. Load imbalance can emerge with out cautious administration. Bias-based balancing begins correcting the imbalance.
Late Coaching: Specialists are clearly specialised. Routing is assured (excessive softmax possibilities for chosen consultants). Load is balanced via steady bias adjustment. The shared knowledgeable handles common operations whereas routed consultants deal with specialised patterns.
Monitoring knowledgeable utilization throughout coaching is efficacious. We will log:
- Per-expert choice frequency
- Routing entropy (greater means extra uniform)
- Professional bias magnitudes (massive values point out sturdy correction wanted)
Combination of Specialists vs Associated Strategies: Swap Transformers and Sparse Fashions
MoE shares concepts with a number of different architectural patterns:
Swap Transformers: Use top-1 routing (just one knowledgeable per token) for max effectivity. Easier however much less expressive than top-k.
Professional Selection: As an alternative of tokens selecting consultants, consultants select tokens. Helps with load balancing however adjustments the computational sample.
Sparse Consideration: Like MoE, selectively prompts components of the community. Could be mixed with MoE for excessive effectivity.
Dynamic Networks: Adapt community construction based mostly on enter. MoE is a particular type of dynamic computation.
With our MoE implementation full, we’ve added environment friendly scaling to our mannequin — the capability grows superlinearly with computation value. Mixed with MLA’s reminiscence effectivity and the upcoming MTP’s improved coaching sign, we’re constructing a mannequin that’s environment friendly in coaching, environment friendly in inference, and able to sturdy efficiency. Subsequent, we’ll sort out Multi-Token Prediction, which improves the coaching sign itself by having the mannequin look additional forward.
What’s subsequent? We advocate PyImageSearch College.
86+ whole lessons • 115+ hours hours of on-demand code walkthrough movies • Final up to date: March 2026
★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly imagine that for those who had the fitting trainer you may grasp laptop imaginative and prescient and deep studying.
Do you assume studying laptop imaginative and prescient and deep studying needs to be time-consuming, overwhelming, and complex? Or has to contain advanced arithmetic and equations? Or requires a level in laptop science?
That’s not the case.
All you have to grasp laptop imaginative and prescient and deep studying is for somebody to elucidate issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to vary schooling and the way advanced Synthetic Intelligence subjects are taught.
Should you’re severe about studying laptop imaginative and prescient, your subsequent cease ought to be PyImageSearch College, essentially the most complete laptop imaginative and prescient, deep studying, and OpenCV course on-line right now. Right here you’ll learn to efficiently and confidently apply laptop imaginative and prescient to your work, analysis, and tasks. Be part of me in laptop imaginative and prescient mastery.
Inside PyImageSearch College you will discover:
- &verify; 86+ programs on important laptop imaginative and prescient, deep studying, and OpenCV subjects
- &verify; 86 Certificates of Completion
- &verify; 115+ hours hours of on-demand video
- &verify; Model new programs launched frequently, guaranteeing you may sustain with state-of-the-art methods
- &verify; Pre-configured Jupyter Notebooks in Google Colab
- &verify; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev setting configuration required!)
- &verify; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
- &verify; Straightforward one-click downloads for code, datasets, pre-trained fashions, and so forth.
- &verify; Entry on cellular, laptop computer, desktop, and so forth.
Abstract
Within the third installment of our DeepSeek-V3 from Scratch sequence, we flip our consideration to the Combination of Specialists (MoE) framework, a strong method to scaling neural networks effectively. We start by unpacking the scaling problem in fashionable architectures and the way MoE addresses it via selective knowledgeable activation. From its mathematical basis to the introduction of SwiGLU activation, we discover how enhanced non-linearity and common shared consultants contribute to extra versatile and expressive fashions.
We then look at the mechanics of load balancing, highlighting improvements (e.g., auxiliary-loss-free balancing and complementary sequence-wise methods). These methods be sure that consultants are used successfully with out introducing pointless complexity. We additionally discover how knowledgeable specialization emerges naturally throughout coaching, resulting in various behaviors throughout consultants that enhance general efficiency. This emergent specialization is not only theoretical — it turns into seen in follow, shaping how the mannequin processes several types of enter.
Lastly, we stroll via the implementation of MoE, discussing design selections, computational trade-offs, and reminiscence evaluation. We join these insights to associated methods, displaying how MoE integrates into the broader panorama of environment friendly deep studying. By the top, we not solely perceive the speculation but additionally acquire sensible data of implement and optimize MoE inside DeepSeek-V3. This a part of the sequence equips us with the instruments to harness knowledgeable specialization whereas maintaining coaching dynamics balanced and environment friendly.
Quotation Data
Mangla, P. “DeepSeek-V3 from Scratch: Combination of Specialists (MoE),” PyImageSearch, S. Huot, A. Sharma, and P. Thakur, eds., 2026, https://pyimg.co/a1w0g
@incollection{Mangla_2026_deepseek-v3-from-scratch-moe,
writer = {Puneet Mangla},
title = {{DeepSeek-V3 from Scratch: Combination of Specialists (MoE)}},
booktitle = {PyImageSearch},
editor = {Susan Huot and Aditya Sharma and Piyush Thakur},
12 months = {2026},
url = {https://pyimg.co/a1w0g},
}
To obtain the supply code to this publish (and be notified when future tutorials are revealed right here on PyImageSearch), merely enter your e-mail deal with within the kind under!

Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your e-mail deal with under to get a .zip of the code and a FREE 17-page Useful resource Information on Pc Imaginative and prescient, OpenCV, and Deep Studying. Inside you will discover my hand-picked tutorials, books, programs, and libraries that can assist you grasp CV and DL!
The publish DeepSeek-V3 from Scratch: Combination of Specialists (MoE) appeared first on PyImageSearch.