This submit was cowritten by Rishi Srivastava and Scott Reynolds from Clarus Care.
Many healthcare practices at this time wrestle with managing excessive volumes of affected person calls effectively. From appointment scheduling and prescription refills to billing inquiries and pressing medical considerations, practices face the problem of offering well timed responses whereas sustaining high quality affected person care. Conventional telephone programs typically result in lengthy maintain occasions, annoyed sufferers, and overwhelmed workers who manually course of and prioritize lots of of calls day by day. These communication bottlenecks not solely affect affected person satisfaction however may also delay essential care coordination.
On this submit, we illustrate how Clarus Care, a healthcare contact middle options supplier, labored with the AWS Generative AI Innovation Heart (GenAIIC) workforce to develop a generative AI-powered contact middle prototype. This answer permits conversational interplay and multi-intent decision by way of an automatic voicebot and chat interface. It additionally incorporates a scalable service mannequin to help progress, human switch capabilities–when requested or for pressing instances–and an analytics pipeline for efficiency insights.
Clarus Care is a healthcare know-how firm that helps medical practices handle affected person communication by way of an AI-powered name administration system. By routinely transcribing, prioritizing, and routing affected person messages, Clarus improves response occasions, reduces workers workload, and minimizes maintain occasions. Clarus is the quickest rising healthcare name administration firm, serving over 16,000 customers throughout 40+ specialties. The corporate handles 15 million affected person calls yearly and maintains a 99% shopper retention fee.
Use case overview
Clarus is embarking on an progressive journey to remodel their affected person communication system from a standard menu-driven Interactive Voice Response (IVR) to a extra pure, conversational expertise. The corporate goals to revolutionize how sufferers work together with healthcare suppliers by making a generative AI-powered contact middle able to understanding and addressing a number of affected person intents in a single interplay. Beforehand, sufferers navigated by way of inflexible menu choices to depart messages, that are then transcribed and processed. This method, whereas practical, limits the system’s means to deal with advanced affected person wants effectively. Recognizing the necessity for a extra intuitive and versatile answer, Clarus collaborated with the GenAIIC to develop an AI-powered contact middle that may comprehend pure language dialog, handle a number of intents, and supply a seamless expertise throughout each voice and internet chat interfaces. Key success standards for the undertaking had been:
- A pure language voice interface able to understanding and processing a number of affected person intents comparable to billing questions, scheduling, and prescription refills in a single name
- <3 second latency for backend processing and response to the person
- The power to transcribe, file, and analyze name data
- Good switch capabilities for pressing calls or when sufferers request to talk instantly with suppliers
- Help for each voice calls and internet chat interfaces to accommodate numerous affected person preferences
- A scalable basis to help Clarus’s rising buyer base and increasing healthcare facility community
- Excessive availability with a 99.99% SLA requirement to facilitate dependable affected person communication
Resolution overview & structure
The GenAIIC workforce collaborated with Clarus to create a generative AI-powered contact middle utilizing Amazon Join and Amazon Lex, built-in with Amazon Nova and Anthropic’s Claude 3.5 Sonnet basis fashions by way of Amazon Bedrock. Join was chosen because the core system as a result of its means to take care of 99.99% availability whereas offering complete contact middle capabilities throughout voice and chat channels.
The mannequin flexibility of Bedrock is central to the system, permitting task-specific mannequin choice based mostly on accuracy and latency. Claude 3.5 Sonnet was used for its high-quality pure language understanding capabilities, and Nova fashions supplied optimization for low latency and comparable pure language understanding and technology capabilities. The next diagram illustrates the answer structure for the primary contact middle answer:
The workflow consists of the next high-level steps:
- A affected person initiates contact by way of both a telephone name or internet chat interface.
- Join processes the preliminary contact and routes it by way of a configured contact circulation.
- Lex handles transcription and maintains dialog state.
- An AWS Lambda achievement perform processes the dialog utilizing Claude 3.5 Sonnet and Nova fashions by way of Bedrock to:
- Classify urgency and intents
- Extract required data
- Generate pure responses
- Handle appointment scheduling when relevant
The fashions used for every particular perform are described in answer element sections.
- Good transfers to workers are initiated when pressing instances are detected or when sufferers request to talk with suppliers.
- Dialog information is processed by way of an analytics pipeline for monitoring and reporting (described later on this submit).
Some challenges the workforce tackled in the course of the growth course of included:
- Formatting the contact middle name circulation and repair mannequin in a means that’s interchangeable for various clients, with minimal code and configuration modifications
- Managing latency necessities for a pure dialog expertise
- Transcription and understanding of affected person names
Along with voice calls, the workforce developed an online interface utilizing Amazon CloudFront and Amazon S3 Static Web site Internet hosting that demonstrates the system’s multichannel capabilities. This interface reveals how sufferers can have interaction in AI-powered conversations by way of a chat widget, offering the identical stage of service and performance as voice calls. Whereas the net interface demo makes use of the identical contact circulation because the voice name, it may be additional custom-made for chat-specific language.
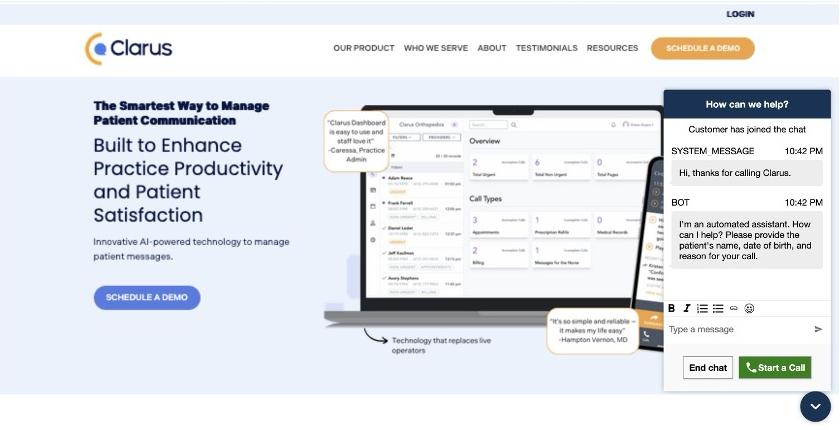
The workforce additionally constructed an analytics pipeline that processes dialog logs to offer priceless insights into system efficiency and affected person interactions. A customizable dashboard affords a user-friendly interface for visualizing this information, permitting each technical and non-technical workers to realize actionable insights from affected person communications. The analytics pipeline and dashboard had been constructed utilizing a beforehand printed reusable GenAI contact middle asset.
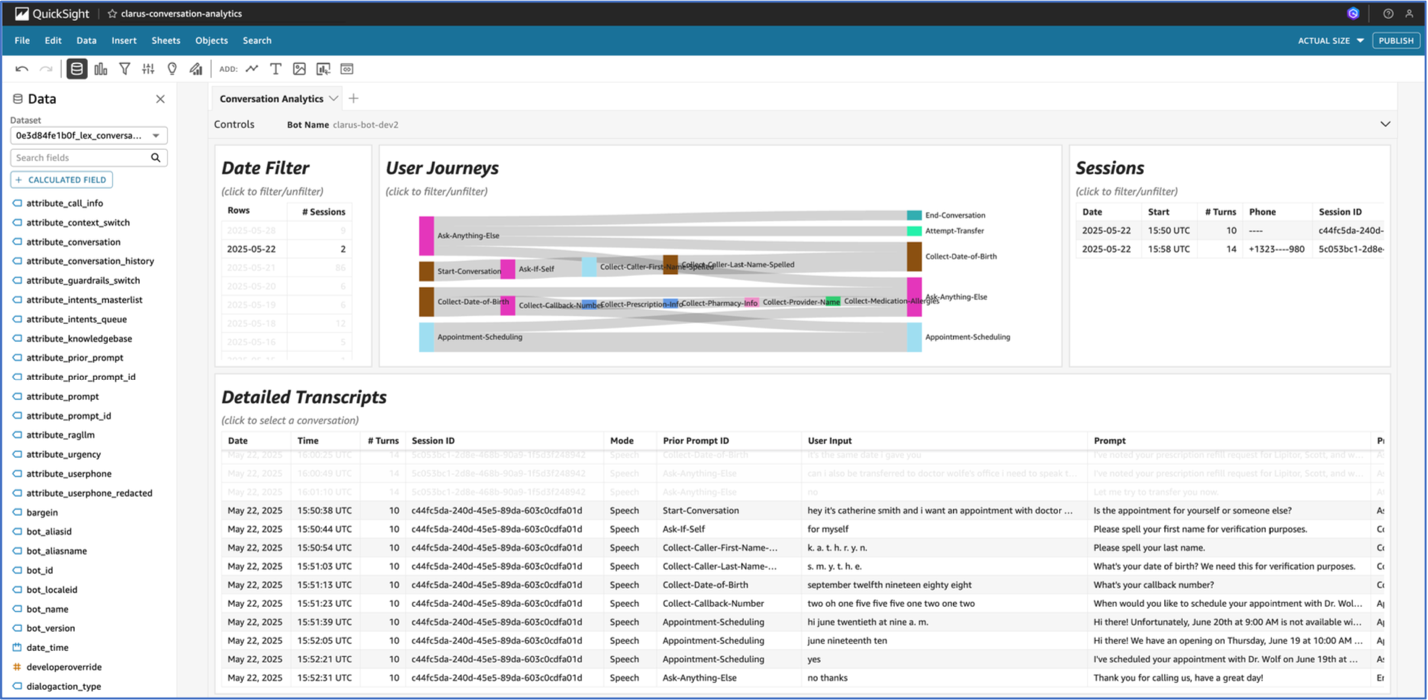
Dialog dealing with particulars
The answer employs a classy dialog administration system that orchestrates pure affected person interactions by way of the multi-model capabilities of Bedrock and punctiliously designed immediate layering. On the coronary heart of this technique is the power of Bedrock to offer entry to a number of basis fashions, enabling the workforce to pick out the optimum mannequin for every particular process based mostly on accuracy, price, and latency necessities. The circulation of the dialog administration system is proven within the following picture; NLU stands for pure language understanding.
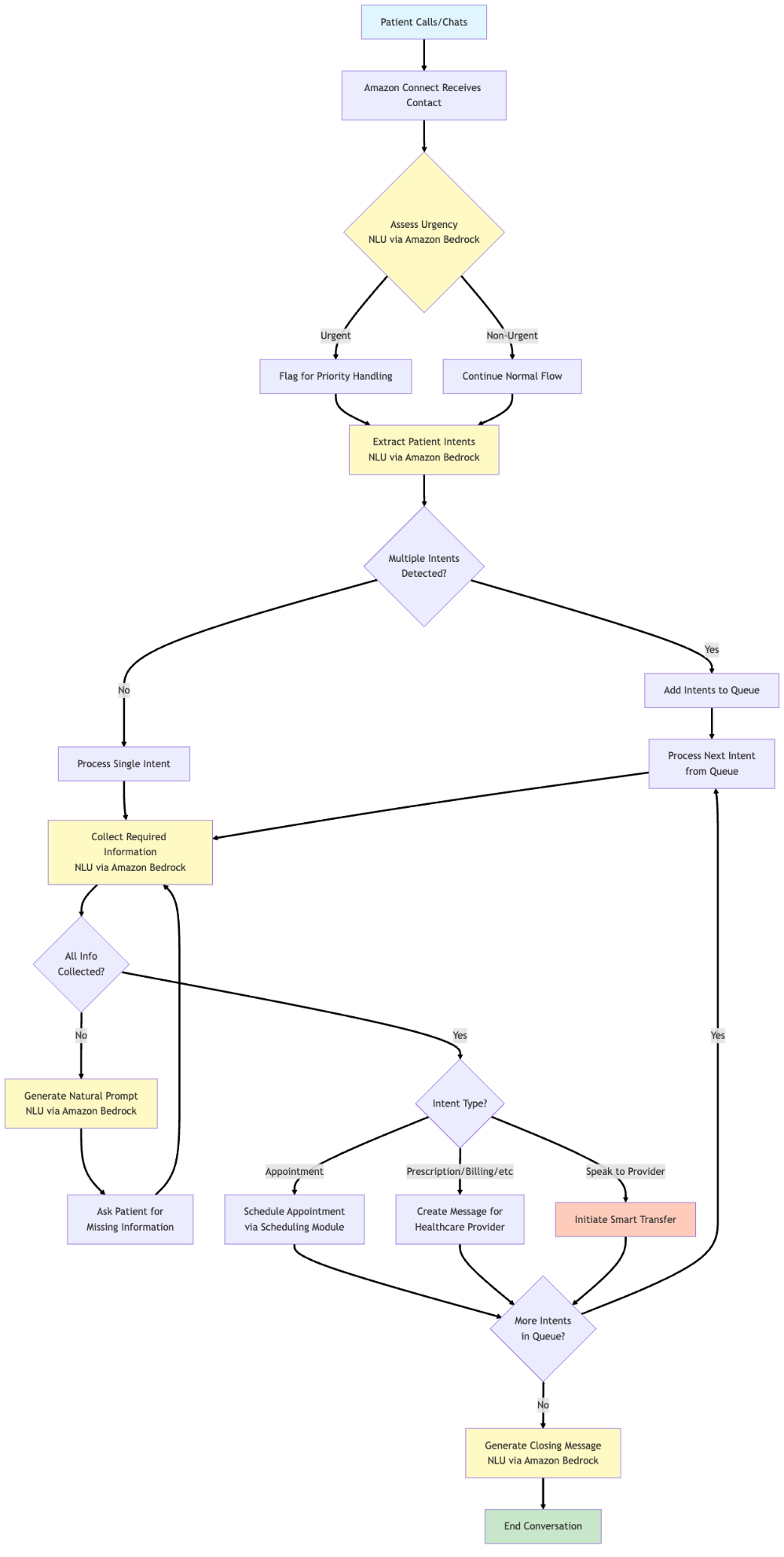
The dialog circulation begins with a greeting and urgency evaluation. When a affected person calls, the system instantly evaluates whether or not the state of affairs requires pressing consideration utilizing Bedrock APIs. This primary step makes positive that emergency instances are shortly recognized and routed appropriately. The system makes use of a centered immediate that analyzes the affected person’s preliminary assertion in opposition to a predefined listing of pressing intent classes, returning both “pressing” or “non_urgent” to information subsequent dealing with.
Following this, the system strikes to intent detection. A key innovation right here is the system’s means to course of a number of intents inside a single interplay. Slightly than forcing sufferers by way of inflexible menu bushes, the system can leverage highly effective language fashions to grasp when a affected person mentions each a prescription refill and a billing query, queuing these intents for sequential processing whereas sustaining pure dialog circulation. Throughout this extraction, we make it possible for the intent and the quote from the person enter are each extracted. This produces two outcomes:
- Built-in mannequin reasoning to make it possible for the proper intent is extracted
- Dialog historical past reference that led to intent extraction, so the identical intent shouldn’t be extracted twice except explicitly requested for
As soon as the system begins processing intents sequentially, it begins prompting the person for information required to service the intent at hand. This occurs in two interdependent levels:
- Checking for lacking data fields and producing a pure language immediate to ask the person for data
- Parsing person utterances to investigate and extract collected fields and the fields which might be nonetheless lacking
These two steps occur in a loop till the required data is collected. The system additionally considers provider-specific providers at this stage, the place fields required per supplier is collected. The answer routinely matches supplier names talked about by sufferers to the proper supplier within the system. This handles variations like “Dr. Smith” matching to “Dr. Jennifer Smith” or “Jenny Smith,” eradicating the inflexible title matching or extension necessities of conventional IVR programs. The answer additionally contains sensible handoff capabilities. When the system wants to find out if a affected person ought to converse with a selected supplier, it analyses the dialog context to contemplate urgency and routing wants for the expressed intent. This course of preserves the dialog context and picked up data, facilitating a seamless expertise when human intervention is requested. All through the dialog, the system maintains complete state monitoring by way of Lex session attributes whereas the pure language processing happens by way of Bedrock mannequin invocations. These attributes function the dialog’s reminiscence, storing all the things from the person’s collected data and dialog historical past to detected intents and picked up data. This state administration permits the system to take care of context throughout a number of Bedrock API calls, making a extra pure dialogue circulation.
Intent administration
The intent administration system was designed by way of a hierarchical service mannequin construction that displays how sufferers naturally categorical their wants. To traverse this hierarchical service mannequin, the person inputs are parsed utilizing pure language understanding, that are dealt with by way of Bedrock API calls.
The hierarchical service mannequin organizes intents into three major ranges:
- Urgency Stage: Separating pressing from non-urgent providers facilitates acceptable dealing with and routing.
- Service Stage: Grouping associated providers like appointments, prescriptions, and billing creates logical classes.
- Supplier-Particular Stage: Additional granularity accommodates provider-specific necessities and sub-services
This construction permits the system to effectively navigate by way of attainable intents whereas sustaining flexibility for personalisation throughout totally different healthcare amenities. Every intent within the mannequin contains customized directions that may be dynamically injected into Bedrock prompts, permitting for extremely configurable conduct with out code modifications. The intent extraction course of leverages the superior language understanding capabilities of Bedrock by way of a immediate that instructs the mannequin to determine the intents current in a affected person’s pure language enter. The immediate contains complete directions about what constitutes a brand new intent, the entire listing of attainable intents, and formatting necessities for the response. Slightly than forcing classification right into a single intent, we intend to detect a number of wants expressed concurrently. As soon as intents are recognized, they’re added to a processing queue. The system then works by way of every intent sequentially, making extra mannequin calls in a number of layers to gather required data by way of pure dialog. To optimize for each high quality and latency, the answer leverages the mannequin choice flexibility of Bedrock for numerous dialog duties in a similar way:
- Intent extraction makes use of Anthropic’s Claude 3.5 Sonnet by way of Bedrock for detailed evaluation that may determine a number of intents from pure language, ensuring sufferers don’t must repeat data.
- Data assortment employs a sooner mannequin, Amazon Nova Professional, by way of Bedrock for structured information extraction whereas sustaining conversational tone.
- Response technology makes use of a smaller mannequin, Nova Lite, by way of Bedrock to create low-latency, pure, and empathetic responses based mostly on the dialog state.
Doing this helps in ensuring that the answer can:
- Preserve conversational tone and empathy
- Ask for less than the precise lacking data
- Acknowledge data already supplied
- Deal with particular instances like spelling out names
The whole intent administration pipeline advantages from the Bedrock unified Converse API, which offers:
- Constant interface throughout the mannequin calls, simplifying growth and upkeep
- Mannequin model management facilitating secure conduct throughout deployments
- Future-proof structure permitting seamless adoption of recent fashions as they turn into out there
By implementing this hierarchical intent administration system, Clarus can supply sufferers a extra pure and environment friendly communication expertise whereas sustaining the construction wanted for correct routing and knowledge assortment. The flexibleness of mixing the multi-model capabilities of Bedrock with a configurable service mannequin permits for simple customization per healthcare facility whereas retaining the core dialog logic constant and maintainable. As new fashions turn into out there in Bedrock, the system might be up to date to leverage improved capabilities with out main architectural modifications, facilitating long-term scalability and efficiency optimization.
Scheduling
The scheduling part of the answer is dealt with in a separate, purpose-built module. If an ‘appointment’ intent is detected in the primary handler, processing is handed to the scheduling module. The module operates as a state machine consisting of dialog states and subsequent steps. The general circulation of the scheduling system is proven under:
Scheduling System Circulation
1. Preliminary State
- Point out workplace hours
- Ask for scheduling preferences
- Transfer to GATHERING_PREFERENCES
2. GATHERING_PREFERENCES State
- Extract and course of time preferences utilizing LLM
- Verify time preferences in opposition to present scheduling database
- Three attainable outcomes:
a. Particular time out there
- Current time for affirmation
- Transfer to CONFIRMATION
b. Vary choice
- Discover earliest out there time in vary
- Current this time for affirmation
- Transfer to CONFIRMATION
c. No availability (particular or vary)
- Discover various occasions (±1 days from requested time)
- Current out there time blocks
- Ask for choice
- Keep in GATHERING_PREFERENCES
- Increment try counter
3. CONFIRMATION State
- Two attainable outcomes:
a. Consumer confirms (Sure)
- Guide appointment
- Ship affirmation message
- Transfer to END
b. Consumer declines (No)
- Ask for brand new preferences
- Transfer to GATHERING_PREFERENCES
- Increment try counter
4. Further Options
- Most makes an attempt monitoring (default MAX_ATTEMPTS = 3)
- When max makes an attempt reached:
- Apologize and escalate to workplace workers
- Transfer to END
5. END State
- Dialog accomplished
- Both with profitable reserving or escalation to workers
There are three fundamental LLM prompts used within the scheduling circulation:
- Extract time preferences (Nova Lite is used for low latency and use choice understanding)
Extract present scheduling preferences from the dialog. The response have to be on this format:
Clarify:
- What kind of preferences had been expressed (particular or vary)
- The way you interpreted any relative dates or occasions
- Why you structured and prioritized the preferences as you probably did
- Any assumptions you made
[
{{
"type": "specific",
"priority": n,
"specificSlots": [
{{
"date": "YYYY-MM-DD",
"startTime": "HH:mm",
"endTime": "HH:mm"
}}
]
}},
{{
"kind": "vary",
"precedence": n,
"dateRange": {{
"startDate": "YYYY-MM-DD",
"endDate": "YYYY-MM-DD",
"daysOfWeek": [], // "m", "t", "w", "th", "f"
"timeRanges": [
{{
"startTime": "HH:mm",
"endTime": "HH:mm"
}}
]
}}
}}
]
Tips:
- If time preferences have modified all through the dialog, solely extract present preferences
- You will have a number of of the identical kind of choice if wanted
- Guarantee correct JSON formatting, the JSON portion of the output ought to work appropriately with json.masses(). Don't embody feedback in JSON.
- Convert relative dates (tomorrow, subsequent Tuesday) to particular dates
- Key phrases:
* morning: 09:00-12:00
* afternoon: 12:00-17:00
- Convert time descriptions to particular ranges (e.g. "morning earlier than 11": 09:00-11:00, "2-4 pm": 14:00-16:00)
- Appointments are solely out there on weekdays from 9:00-17:00
- If no finish time is specified for a slot, assume a 30-minute length
Instance:
(Instance part eliminated for brevity)
Now, extract the scheduling preferences from the given dialog.
Present time: {current_time}
In the present day is {current_day}
Dialog:
{conversation_history}
- Decide if person is confirming or denying time (Nova Micro is used for low latency on a easy process)
Decide if the person is confirming or declining the prompt appointment time. Return "true" if they're clearly confirming, "false" in any other case.
true|false
Consumer message: {user_message}
- Generate a pure response based mostly on a subsequent step (Nova Lite is used for low latency and response technology)
Given the dialog historical past and the following step, generate a pure and contextually acceptable response to the person.
Output your response in tags:
Your response right here
Dialog historical past:
{conversation_history}
Subsequent step:
{next_step_prompt}
The attainable steps are:
Ask the person once they wish to schedule their appointment with {supplier}. Don't say Hello or Hey, that is mid-conversation.
Point out that our workplace hours are {office_hours}.
The time {time} is offered with {supplier}.
Ask the person to substantiate sure or no if this time works for them earlier than continuing with the reserving.
Don't say the appointment is already confirmed.
Inform the person that their requested time {requested_time} shouldn't be out there.
Supply these various time or time ranges with {supplier}: {blocks}
Ask which period would work finest for them.
Acknowledge that the prompt time does not work for them.
Ask what different day or time they would favor for his or her appointment with {supplier}.
Remind them that our workplace hours are {office_hours}.
- Let the person know you’ll escalate to the workplace
Apologize that you have not been capable of finding an appropriate time.
Inform the person that you will have our workplace workers attain out to assist discover an appointment time that works for them.
Thank them for his or her persistence.
- Finish a dialog with reserving affirmation
VERY BRIEFLY affirm that their appointment is confirmed with {supplier} for {time}.
Don't say anything.
Instance: Appointment confirmed for June fifth with Dr. Wolf
System Extensions
Sooner or later, Clarus can combine the contact middle’s voicebot with Amazon Nova Sonic. Nova Sonic is a speech-to-speech LLM that delivers real-time, human-like voice conversations with main worth efficiency and low latency. Nova Sonic is now instantly built-in with Join.
Bedrock has a number of extra providers which assist with scaling the answer and deploying it to manufacturing, together with:
Conclusion
On this submit, we demonstrated how the GenAIIC workforce collaborated with Clarus Care to develop a generative AI-powered healthcare contact middle utilizing Amazon Join, Amazon Lex, and Amazon Bedrock. The answer showcases a conversational voice interface able to dealing with a number of affected person intents, managing appointment scheduling, and offering sensible switch capabilities. By leveraging Amazon Nova and Anthropic’s Claude 3.5 Sonnet language fashions and AWS providers, the system achieves excessive availability whereas providing a extra intuitive and environment friendly affected person communication expertise.The answer additionally incorporates an analytics pipeline for monitoring name high quality and metrics, in addition to an online interface demonstrating multichannel help. The answer’s structure offers a scalable basis that may adapt to Clarus Care’s rising buyer base and future service choices.The transition from a standard menu-driven IVR to an AI-powered conversational interface permits Clarus to assist improve affected person expertise, improve automation capabilities, and streamline healthcare communications. As they transfer in the direction of implementation, this answer will empower Clarus Care to fulfill the evolving wants of each sufferers and healthcare suppliers in an more and more digital healthcare panorama.
If you wish to implement an analogous answer in your use case, take into account the weblog Deploy generative AI brokers in your contact middle for voice and chat utilizing Amazon Join, Amazon Lex, and Amazon Bedrock Information Bases for the infrastructure setup.
In regards to the authors
 Rishi Srivastava is the VP of Engineering at Clarus Care. He’s a seasoned business chief with over 20 years in enterprise software program engineering, specializing in design of multi-tenant Cloud based mostly SaaS structure and, conversational AI agentic options associated to affected person engagement. Beforehand, he labored in monetary providers and quantitative finance, constructing latent issue fashions for classy portfolio analytics to drive data-informed funding methods.
Rishi Srivastava is the VP of Engineering at Clarus Care. He’s a seasoned business chief with over 20 years in enterprise software program engineering, specializing in design of multi-tenant Cloud based mostly SaaS structure and, conversational AI agentic options associated to affected person engagement. Beforehand, he labored in monetary providers and quantitative finance, constructing latent issue fashions for classy portfolio analytics to drive data-informed funding methods.
 Scott Reynolds is the VP of Product at Clarus Care, a healthcare SaaS communications and AI-powered affected person engagement platform. He’s spent over 25 years within the know-how and software program market creating safe, interoperable platforms that streamline medical and operational workflows. He has based a number of startups and holds a U.S. patent for patient-centric communication know-how.
Scott Reynolds is the VP of Product at Clarus Care, a healthcare SaaS communications and AI-powered affected person engagement platform. He’s spent over 25 years within the know-how and software program market creating safe, interoperable platforms that streamline medical and operational workflows. He has based a number of startups and holds a U.S. patent for patient-centric communication know-how.
Brian Halperin joined AWS in 2024 as a GenAI Strategist within the Generative AI Innovation Heart, the place he helps enterprise clients unlock transformative enterprise worth by way of synthetic intelligence. With over 9 years of expertise spanning enterprise AI implementation and digital know-how transformation, he brings a confirmed observe file of translating advanced AI capabilities into measurable enterprise outcomes. Brian beforehand served as Vice President on an working workforce at a world various funding agency, main AI initiatives throughout portfolio corporations.
joined AWS in 2024 as a GenAI Strategist within the Generative AI Innovation Heart, the place he helps enterprise clients unlock transformative enterprise worth by way of synthetic intelligence. With over 9 years of expertise spanning enterprise AI implementation and digital know-how transformation, he brings a confirmed observe file of translating advanced AI capabilities into measurable enterprise outcomes. Brian beforehand served as Vice President on an working workforce at a world various funding agency, main AI initiatives throughout portfolio corporations.
 Brian Yost is a Principal Deep Studying Architect within the AWS Generative AI Innovation Heart. He focuses on making use of agentic AI capabilities in buyer help eventualities, together with contact middle options.
Brian Yost is a Principal Deep Studying Architect within the AWS Generative AI Innovation Heart. He focuses on making use of agentic AI capabilities in buyer help eventualities, together with contact middle options.
 Parth Patwa is a Information Scientist within the Generative AI Innovation Heart at Amazon Net Companies. He has co-authored analysis papers at prime AI/ML venues and has 1500+ citations.
Parth Patwa is a Information Scientist within the Generative AI Innovation Heart at Amazon Net Companies. He has co-authored analysis papers at prime AI/ML venues and has 1500+ citations.
 Smita Bailur is a Senior Utilized Scientist on the AWS Generative AI Innovation Heart, the place she brings over 10 years of experience in conventional AI/ML, deep studying, and generative AI to assist clients unlock transformative options. She holds a masters diploma in Electrical Engineering from the College of Pennsylvania.
Smita Bailur is a Senior Utilized Scientist on the AWS Generative AI Innovation Heart, the place she brings over 10 years of experience in conventional AI/ML, deep studying, and generative AI to assist clients unlock transformative options. She holds a masters diploma in Electrical Engineering from the College of Pennsylvania.
 Shreya Mohanty Shreya Mohanty is a Strategist within the AWS Generative AI Innovation Heart the place she focuses on mannequin customization and optimization. Beforehand she was a Deep Studying Architect, centered on constructing GenAI options for purchasers. She makes use of her cross-functional background to translate buyer targets into tangible outcomes and measurable affect.
Shreya Mohanty Shreya Mohanty is a Strategist within the AWS Generative AI Innovation Heart the place she focuses on mannequin customization and optimization. Beforehand she was a Deep Studying Architect, centered on constructing GenAI options for purchasers. She makes use of her cross-functional background to translate buyer targets into tangible outcomes and measurable affect.
 Yingwei Yu Yingwei Yu is an Utilized Science Supervisor on the Generative AI Innovation Heart (GenAIIC) at Amazon Net Companies (AWS), based mostly in Houston, Texas. With expertise in utilized machine studying and generative AI, Yu leads the event of progressive options throughout numerous industries. He has a number of patents and peer-reviewed publications in skilled conferences. Yingwei earned his Ph.D. in Pc Science from Texas A&M College – Faculty Station.
Yingwei Yu Yingwei Yu is an Utilized Science Supervisor on the Generative AI Innovation Heart (GenAIIC) at Amazon Net Companies (AWS), based mostly in Houston, Texas. With expertise in utilized machine studying and generative AI, Yu leads the event of progressive options throughout numerous industries. He has a number of patents and peer-reviewed publications in skilled conferences. Yingwei earned his Ph.D. in Pc Science from Texas A&M College – Faculty Station.

![6 New Options of Grok Think about 1.0 [MUST TRY]](https://cdn.analyticsvidhya.com/wp-content/uploads/2026/02/Grok-Imagine-1.0-is-Here-Make-10-seconds-720p-videos-with-Super-Fine-Audio-1.png "6 New Options of Grok Think about 1.0 [MUST TRY]")








")