2) Helpful instruments to generate faux information units that mimic actual information, and use these faux information units to show. See: Richard Landers‘ and Andrew Luttrell‘s web sites.
I’ve a brand new instance of an unbiased t check for sophistication. Yay! And I train tons of future nurses/PAs, so it’s doubly relevant.
Nevertheless, the authors said that the information wasn’t instantly accessible. Additionally, as soon as it’s accessible, they (very moderately) need to observe their information sharing. Which means that even when I might get their information, I should not be sharing it on this weblog.
I made a decision to create a dataset that mimics the findings. Whereas I’ve different instruments to take action (see above), I made a decision to strive utilizing GenAI this time. I figured that if I had extra descriptive information, I might make a greater pretend dataset. I discovered the CIs (in yellow) for the information factors within the tables:
Armed with means, pattern sizes, and CIs, I wrote this immediate:
“Hello! I would love you to create an information set for me. It ought to include two variables, “ReSeT” and “Normal Care”. The imply for ReSet ought to be 10.5, with a 95% CI of 8.1-12.9, and n = 44. The imply for Normal Care ought to be 14.7 with a 95% CI between 12.2 and 17.2, and n = 42. For the information you generate, each information level ought to be an entire quantity with no decimals.”
After some fanagling (Copilot could not completely generate the information within the parameters I said, however we obtained actually shut), I generated the information units (Right here is the .txt model, and right here is similar information, in JASP format for my fellow JASP customers/instructors)
How I’ll use it at school: Typically, stats instructors construction their class in order that college students clear up a thriller by analyzing information. That is nice. However it’s also good to work backward: Present your college students the visible summary. Have them establish the IV, the DV, and the findings. THEN have them analyze information that, whereas not the true information, does mimic the primary findings. It’s kind of like giving them a street map. They know precisely the place they’re going, however they nonetheless want to investigate the information themselves. Evidently, after I use information units that I create, I ALWAYS inform my college students that they don’t seem to be working with the precise information, however with information that mimics the true findings.
Reminiscence shapes how people assume and the way AI brokers act. With out it, an agent solely responds to the present enter; with it, it will possibly preserve context, recall previous actions, and reuse helpful data.
AI reminiscence spans short-term, episodic, semantic, and long-term reminiscence, every with totally different design trade-offs round storage, retention, retrieval, and management. On this article, we’ll discover agent reminiscence patterns, a sensible bridge between cognitive science and AI engineering.
What Agent Reminiscence Means
Agent reminiscence is the power of an AI agent to retailer info, recollect it later, and use it to enhance future responses or actions. It permits the agent to recollect previous experiences, keep context, acknowledge helpful patterns, and adapt throughout interactions.
That is necessary as a result of an LLM doesn’t mechanically keep in mind all the pieces throughout classes. By default, it primarily works with the enter obtainable within the present context window. Reminiscence have to be added as a separate design layer across the mannequin. This layer decides what ought to be saved, the way it ought to be organized, and when it ought to be retrieved.
In a easy chatbot, reminiscence could solely imply preserving the previous few messages within the dialog. In a extra superior AI agent, reminiscence can embody consumer preferences, previous actions, activity historical past, device outputs, selections, errors, and discovered info. This helps the agent keep away from ranging from zero each time.
For instance, a deployment assistant could keep in mind that a consumer works on the api-gateway service. It could additionally keep in mind that manufacturing deployments want approval on Fridays. When the consumer later asks, “Can I deploy at present?”, the agent can use that saved info to present a extra helpful reply.
So, agent reminiscence isn’t just storage. It’s a full course of:
Every step issues. A great reminiscence system ought to retailer helpful info, retrieve solely what’s related, and preserve the ultimate response grounded in dependable context. This is the reason agent reminiscence have to be handled as a part of system design, not simply as a database characteristic.
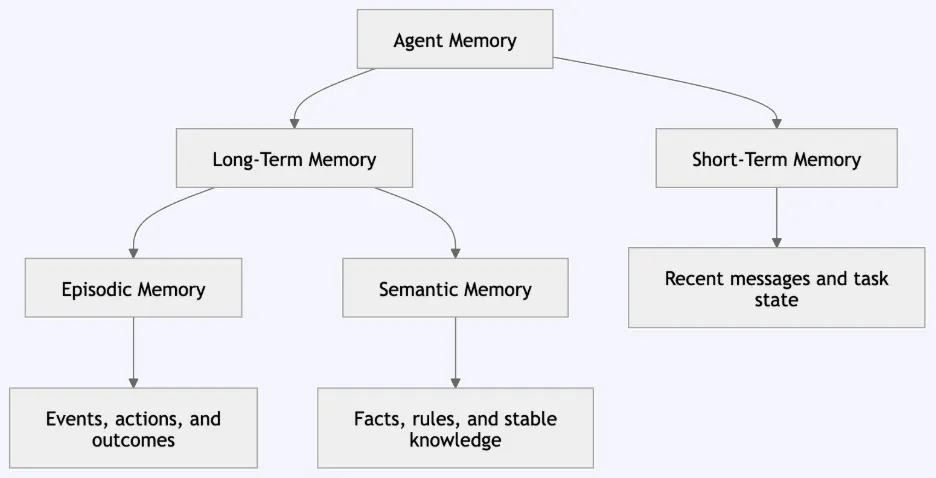
Reminiscence Varieties: From Cognitive Science to AI Brokers
AI agent reminiscence is simpler to grasp after we join it with human reminiscence. In cognitive science, reminiscence is split into totally different techniques as a result of every system has a distinct function. The identical concept applies to AI brokers. A well-designed agent shouldn’t retailer each reminiscence in a single place. It ought to use totally different reminiscence sorts for various duties.
Quick-term reminiscence handles the present activity utilizing latest messages, momentary notes, device outputs, or the present purpose. It’s often applied by a rolling buffer, dialog state, or context window.
Lengthy-term reminiscence shops info throughout classes, equivalent to consumer preferences, previous interactions, insurance policies, paperwork, or discovered info. It’s usually applied utilizing databases, data graphs, vector embeddings, or persistent shops.
Episodic reminiscence information particular previous occasions, together with consumer actions, device calls, selections, and outcomes. It helps with auditability, debugging, and studying from earlier circumstances.
Semantic reminiscence shops reusable data equivalent to info, guidelines, preferences, and ideas. For instance, “Manufacturing deployments on Fridays require approval” is semantic reminiscence as a result of it will possibly information future responses.
A easy method to examine these reminiscence sorts is proven under:
Reminiscence Sort
What It Shops
AI Agent Instance
Most important Use
Quick-term reminiscence
Present context and up to date turns
Previous couple of consumer messages
Keep dialog circulation
Lengthy-term reminiscence
Data saved throughout classes
Consumer profile or undertaking historical past
Personalization and continuity
Episodic reminiscence
Particular occasions and outcomes
“Consumer requested about deployment approval yesterday”
Traceability and studying from historical past
Semantic reminiscence
Information, guidelines, and ideas
“Friday manufacturing deploys want SRE approval”
Reusable data and reasoning
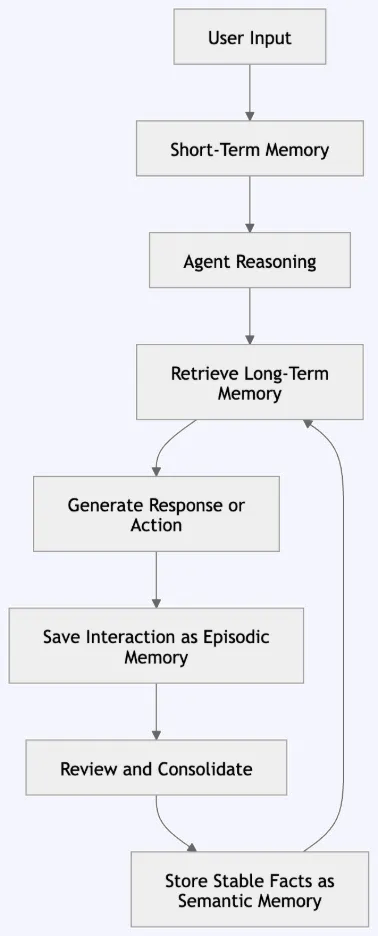
Agent Reminiscence Structure and Information Circulation
After understanding reminiscence sorts, the subsequent step is seeing how they work collectively inside an AI agent. A great reminiscence system doesn’t retailer all the pieces in a single place. It separates reminiscence into layers and strikes info rigorously between them.
The agent receives consumer enter, makes use of short-term reminiscence for the present dialog, and retrieves related long-term reminiscence when wanted. After responding or appearing, it will possibly save the interplay as episodic reminiscence. Over time, necessary or repeated info can grow to be semantic reminiscence.
This circulation retains the agent helpful with out overloading the context window. Since LLMs don’t keep in mind all the pieces throughout classes by default, reminiscence have to be added across the mannequin. A great system shops solely helpful info and retrieves solely what’s related.
On this structure, short-term reminiscence helps the present activity. Episodic reminiscence information what occurred. Semantic reminiscence shops steady info, guidelines, and preferences. Lengthy-term reminiscence connects these layers and makes helpful info obtainable in future classes.
A sensible agent reminiscence pipeline often follows these steps:
Step
What Occurs
Instance
Enter
The consumer sends a question
“Can I deploy at present?”
Quick-term reminiscence
The agent checks latest context
Consumer is engaged on api-gateway
Retrieval
The agent searches saved reminiscence
Friday deployments want approval
Reasoning
The agent combines question and reminiscence
At the moment is Friday, approval is required
Response
The agent provides a solution
“You may deploy solely after SRE approval.”
Episodic write
The interplay is logged
Consumer requested about Friday deployment
Semantic replace
Secure info could also be saved
Manufacturing Friday deploys require approval
This design retains the system clear. Uncooked occasions are saved first. Secure data is created later. The agent retrieves solely essentially the most related recollections as an alternative of inserting all previous knowledge into the immediate. This makes the system quicker, simpler to judge, and safer to handle.
Palms-on: Constructing Agent Reminiscence with LangGraph in Google Colab
On this hands-on part, we are going to construct one LangGraph agent that makes use of three reminiscence patterns:
Reminiscence Sort
Objective
Quick-term reminiscence
Retains the present dialog thread energetic
Episodic reminiscence
Shops what occurred in previous interactions
Semantic reminiscence
Shops reusable info, guidelines, and preferences
We need to construct an agent that may:
1. Bear in mind the present dialog. 2. Save previous interactions as episodic reminiscence. 3. Retailer reusable info as semantic reminiscence. 4. Retrieve helpful reminiscence earlier than answering.
Instance circulation:
Step 1: Set up Required Packages
!pip -q set up -U langgraph langchain-openai
Step 2: Set the API Key
In Colab, use getpass so the secret’s hidden.
import os
from getpass import getpass
if "OPENAI_API_KEY" not in os.environ:
os.environ["OPENAI_API_KEY"] = getpass("Enter your OpenAI API key: ")
Step 3: Import Libraries
from dataclasses import dataclass
from datetime import datetime, timezone
import uuid
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.reminiscence import InMemorySaver
from langgraph.retailer.reminiscence import InMemoryStore
from langgraph.runtime import Runtime
We use user_id to maintain reminiscence separated by consumer.
@dataclass
class AgentContext:
user_id: str
That is necessary as a result of one consumer’s reminiscence shouldn’t seem in one other consumer’s dialog.
Step 7: Add Helper Capabilities
This helper extracts a semantic reminiscence when the consumer says “keep in mind that”.
def extract_semantic_memory(message: str):
lower_message = message.decrease()
if lower_message.startswith("keep in mind that"):
return message.exchange("Do not forget that", "").exchange("keep in mind that", "").strip()
return None
This helper codecs saved recollections earlier than passing them to the mannequin.
def format_memories(objects, key):
if not objects:
return "No related recollections discovered."
return "n".be part of(
f"- {merchandise.worth[key]}"
for merchandise in objects
)
Step 8: Outline the Agent Node
That is the primary a part of the demo. The agent does 4 issues:
1. Reads the newest consumer message. 2. Retrieves semantic recollections. 3. Generates a response. 4. Saves episodic and semantic reminiscence.
From the output we are able to see that the agent remembers that the service is api-gateway and that manufacturing has a freeze on Fridays.
This reveals short-term reminiscence as a result of the agent makes use of earlier messages from the identical thread.
Demo 2: Episodic Reminiscence
Episodic reminiscence shops what occurred throughout interactions. In our agent, each consumer message and agent response is saved as an episode.
Run this cell to examine saved episodic recollections:
episodic_namespace = (
"episodic_memory",
"user-123"
)
episodes = retailer.search(
episodic_namespace,
restrict=10
)
for episode in episodes:
print(episode.worth["event"])
print()
Output:
That is episodic reminiscence as a result of it shops particular occasions. It information what occurred, when it occurred, and the way the agent responded.
Demo 3: Semantic Reminiscence
Semantic reminiscence shops reusable info. On this demo, the agent saves a semantic reminiscence when the consumer begins a message with “Do not forget that”.
Run this cell:
response_4 = graph.invoke(
{
"messages": [
{
"role": "user",
"content": "Remember that production deployments on Fridays require SRE approval."
}
]
},
config=config,
context=context
)
print(response_4["messages"][-1].content material)
Now ask a query that ought to use this saved reality:
We will see that the agent answered that Friday manufacturing deployments require SRE approval.
This reveals semantic reminiscence as a result of the saved reality is reusable. It’s not only a file of 1 occasion. It’s data the agent can use once more later.
Examine Semantic Reminiscence
Run this cell to see the saved semantic info:
semantic_namespace = (
"semantic_memory",
"user-123"
)
semantic_memories = retailer.search(
semantic_namespace,
question="Friday deployment approval",
restrict=5
)
for reminiscence in semantic_memories:
print(reminiscence.worth["fact"])
Output:
Reminiscence Sort
The place It Seems within the Demo
What It Does
Quick-term reminiscence
Similar thread_id
Retains the dialog related
Episodic reminiscence
episodic_memory namespace
Shops interplay historical past
Semantic reminiscence
semantic_memory namespace
Shops reusable info
Consumer separation
user_id in namespace
Prevents reminiscence mixing throughout customers
This hands-on demo reveals how totally different reminiscence sorts can work collectively in a single LangGraph agent. Quick-term reminiscence retains the present dialog energetic. Episodic reminiscence shops what occurred. Semantic reminiscence shops reusable data. In Google Colab, in-memory storage is easy and helpful for studying. For manufacturing techniques, these reminiscence layers ought to be moved to persistent storage so the agent can protect reminiscence after restarts.
Selecting the Proper Storage Backend
After constructing reminiscence into an agent, the subsequent query is the place to retailer it. The perfect storage backend depends upon how the reminiscence will probably be used.
Quick-term reminiscence wants quick entry through the present dialog. Episodic reminiscence must retailer occasions and historical past. Semantic reminiscence wants search over info, guidelines, and preferences. Lengthy-term reminiscence wants to remain obtainable throughout classes.
Vector retailer, Chroma, FAISS, PostgreSQL with vector assist
Helps search over which means
Lengthy-term reminiscence
PostgreSQL, MongoDB, sturdy key-value retailer
Retains reminiscence throughout classes
A great reminiscence backend must also assist separation by consumer, thread, and reminiscence kind. This prevents reminiscence from mixing throughout customers and makes retrieval simpler to regulate.
Select the backend based mostly on the reminiscence’s job. Quick-term reminiscence wants pace. Episodic reminiscence wants historical past. Semantic reminiscence wants search. Lengthy-term reminiscence wants sturdiness. A well-designed agent separates these reminiscence layers so the system stays quick, searchable, and simpler to handle.
Safety, Privateness, and Governance
Reminiscence makes an agent extra helpful, nevertheless it additionally will increase threat. When info is saved throughout classes, incorrect or delicate recollections can have an effect on future responses. A reminiscence system should due to this fact management what’s saved, who can entry it, how lengthy it stays, and the way it may be deleted.
The principle dangers embody reminiscence poisoning, immediate injection by saved content material, delicate knowledge leakage, cross-user reminiscence leakage, and off reminiscence. For instance, an agent shouldn’t save API keys, passwords, tokens, or non-public consumer knowledge as reminiscence.
A protected reminiscence system ought to observe just a few clear guidelines:
Rule
Why It Issues
Retailer solely helpful info
Reduces noise and pointless threat
Keep away from secrets and techniques and delicate knowledge
Prevents unintended publicity
Separate reminiscence by consumer and undertaking
Avoids cross-user leakage
Validate necessary recollections
Prevents false or dangerous recollections
Help deletion
Permits unsafe or outdated reminiscence to be eliminated
Hold reminiscence under system guidelines
Prevents saved content material from overriding core directions
Reminiscence must also embody provenance when doable. The system ought to know the place a reminiscence got here from, when it was created, and whether or not it’s nonetheless legitimate.
Agent reminiscence ought to be helpful, nevertheless it should even be managed. A great reminiscence system shops solely protected and invaluable info, separates customers clearly, helps deletion, and prevents saved recollections from overriding mounted system guidelines. This makes agent reminiscence safer, extra dependable, and simpler to handle
Conclusion
Agent reminiscence helps AI brokers keep context, recall previous interactions, and reuse helpful data. By separating reminiscence into short-term, episodic, semantic, and long-term layers, builders can construct brokers which can be extra organized and dependable. Quick-term reminiscence helps the present dialog. Episodic reminiscence information occasions. Semantic reminiscence shops reusable info. Lengthy-term reminiscence retains necessary info throughout classes. The LangGraph demo reveals how these concepts will be applied in follow. Nonetheless, reminiscence have to be managed rigorously. A great system ought to retailer solely helpful info, shield delicate knowledge, assist deletion, and forestall reminiscence leakage. Properly-designed reminiscence makes brokers extra constant, personalised, and reliable.
Steadily Requested Questions
Q1. What’s agent reminiscence?
A. Agent reminiscence lets AI brokers retailer, recall, and reuse info to enhance future responses.
Q2. Why do AI brokers want totally different reminiscence sorts?
A. Totally different reminiscence sorts deal with present context, previous occasions, reusable info, and long-term continuity.
Q3. What makes agent reminiscence protected?
A. Protected reminiscence shops solely helpful info, protects delicate knowledge, separates customers, helps deletion, and prevents leakage.
Hello, I’m Janvi, a passionate knowledge science fanatic at the moment working at Analytics Vidhya. My journey into the world of information started with a deep curiosity about how we are able to extract significant insights from complicated datasets.
Login to proceed studying and luxuriate in expert-curated content material.
Some 14,000 folks have just lately opted in to a case that’s successfully placing AI hiring methods on trial. The contributors are all a minimum of 40 years previous and declare they had been unfairly denied jobs after being screened by Workday’s recruiting methods that rating, kind and rank candidates.
The sweep of the case, Mobley v. Workday Inc., is giant. It considers how antidiscrimination legal guidelines apply to AI methods and who’s liable, the seller or the client. Clients aren’t being sued; Workday is. Its protection is that employers — not Workday — management the hiring choices and outcomes.
If that wasn’t sufficient for CIOs to think about, the case can also be changing into a battle over the arithmetic used to detect bias, with either side arguing that the identical knowledge proves their case. And that raises questions on whether or not bias audits will be trusted.
The significance of the case was famous by the Equal Employment Alternative Fee. In 2024, it filed an amicus transient in help of Mobley, although it didn’t tackle the deserves of the case. The company — then below the Biden administration — warned that “if Workday’s algorithmic instruments in truth make hiring choices (and on the dimensions Mobley suggests), it could be all of the extra vital to make sure that Workday complies with federal anti-discrimination legislation.”
To be clear, Workday claims its methods will not be biased. It argues that people have full management and make all of the essential choices. The plaintiffs argue in any other case. The case is a great distance from being determined.
Derek Mobley, a Black man over 40 and a Morehouse Faculty graduate, filed the case in February 2023 after he was rejected from greater than 100 jobs he utilized to by way of Workday’s platform.
Disparate affect and AI hiring legal responsibility
On the middle of the case is a key query: whether or not a protected group — folks over 40, girls and racial minorities — was harmed, even when there was no intentional discrimination. That is referred to as disparate affect evaluation.
U.S. District Choose Rita Lin of the Northern District of California, who’s listening to the case, wrote in a courtroom order that the “essential concern on the coronary heart of Mobley’s declare is whether or not that system has a disparate affect on candidates over forty.” She allowed the opt-ins, or the candidates claiming they had been harmed, after Mobley confirmed sufficient to counsel the hurt is perhaps systemic.
Workday bias audit: 4-fifths rule vs. normal deviation evaluation
The methodological dispute in Mobley activates a mathematical downside: either side have analyzed largely the identical numbers and reached reverse conclusions.
In late 2024, Workday revealed the outcomes of an exterior bias audit overlaying 10 of its largest enterprise clients, performed utilizing the methodology of New York Metropolis’s Native Legislation 144. The NYC legislation requires unbiased bias audits of automated hiring instruments. The conclusion: “no proof of disparate affect” on race or gender.
Mobley’s legal professionals ran their very own evaluation on the identical revealed numbers. Of their second amended criticism filed in January, they concluded the info confirmed statistically important disparities towards each African American candidates and girls — disparities, plaintiffs alleged, with odds larger than one in a quadrillion that the system was race-neutral.
Workday used the “four-fifths rule” — a take a look at really helpful by the U.S. Equal Employment Alternative Fee that flags a system as probably biased solely when one group’s choice fee falls beneath 80% of the highest-selected group’s fee.
Mobley’s legal professionals used standard-deviation evaluation. It alerts potential bias when hiring-rate variations throughout teams exceed what likelihood alone would predict.
However Mobley’s attorneys eliminated that statistical argument from the third amended criticism, filed in March.
In an electronic mail, Mobley’s legal professional, Lee Winston, confirmed that “the statistic from the sooner criticism is now not within the operative criticism.” However he did add that “discovery stays ongoing.”
A brand new submitting means that the plaintiffs need extra knowledge from Workday, which can allow them to run a brand new evaluation.
In April, the plaintiffs requested the courtroom to compel Workday to show over its bias-testing knowledge, the supply code for the testing, and the testing outcomes. In earlier filings, Workday has opposed this, claiming attributes similar to algorithmic logic, if uncovered, may very well be utilized by opponents, in accordance with courtroom papers.
Why AI bias audits can produce conflicting outcomes
The plaintiffs’ movement underscores a broader problem with AI methods. Outputs can shift or “drift” from their authentic habits because the system gathers new knowledge.
Bias testing is “an ongoing analysis problem,” stated Jason Hong, professor emeritus at Carnegie Mellon College, whose analysis has targeted on AI bias and auditing. “Proper now, it’s totally chaotic,” he stated. He wasn’t commenting on Workday’s lawsuit.
Hong stated the difficulty begins with the phrase equity, which has a couple of definition in the case of assessing bias. One technique minimizes errors throughout the entire knowledge set. A special one focuses on error charges, attempting to make sure that the system’s errors — wrongly rejecting a certified particular person, wrongly advancing an unqualified one — occur on the similar fee throughout teams. A 3rd tries to make sure the system makes right choices on the similar fee throughout teams.
However these definitions of equity are mathematically incompatible.
Hong pointed to a 2016 paper by Alexandra Chouldechova, then a professor of statistics and public coverage at Carnegie Mellon, “Honest Prediction with Disparate Influence: A Research of Bias in Recidivism Prediction Devices,” which underscores the bounds of statistical definitions of bias: “You will need to keep in mind that equity itself — together with the notion of disparate affect — is a social and moral idea, not a statistical one,” the paper notes. The paper reveals that completely different statistical checks can measure completely different elements of outcomes, and attain conflicting conclusions on the identical knowledge.
A Workday spokesperson, in an electronic mail, dismissed the plaintiffs’ method: “Plaintiff is taking the identical knowledge and operating completely different evaluation that merely isn’t scientific on this utility.”
Workday’s personal filings have raised considerations in regards to the state of AI bias auditing. In a January 2023 public remark to New York Metropolis regulators on Native Legislation 144, the corporate urged regulators to “acknowledge the immature state of the AI auditing discipline” and argued that third-party AI auditors lack “a revered unbiased skilled physique to determine baseline auditing standards or police unethical practices.” Workday argued as an alternative for permitting inside auditors, saying employers had robust incentives to make sure their instruments weren’t used discriminatorily, since misuse would carry authorized, monetary and reputational penalties.
“The claims within the go well with are false,” Workday stated in a press release. “Workday’s AI recruiting instruments do not make hiring choices and are designed with human oversight at their core. Our expertise seems to be solely at job {qualifications}, not protected traits like race, age, or incapacity. We rigorously take a look at our merchandise as a part of our Accountable AI program to substantiate our instruments don’t hurt protected teams.”
Mobley alleges within the criticism that “the rejections — usually inside hours or minutes of submission — are in keeping with the operation of those automated screening instruments figuring out and performing upon such proxy indicators of incapacity and well being standing, moderately than any individualized evaluation of his {qualifications}.
The political surroundings hasn’t decreased the authorized threat. President Donald Trump rejects the disparate-impact concept; in an government order final 12 months, he barred federal businesses from utilizing it, arguing it forces hiring on the idea of race as an alternative of benefit. However the order would not tackle AI in hiring, bias or the necessity for audits. And it would not have an effect on personal litigation like Mobley.
CIOs mustn’t rely solely on vendor AI audits
The Mobley v. Workday case could go on for years, however CIOS want a technique now for independently auditing and overseeing AI hiring methods. The recommendation from the consultants interviewed for this story is constant: do not depend on the seller’s audit. Construct inside oversight with technical, authorized and ethics workers members who can query what the AI is doing and may override it.
Andrew Pery, an AI ethics evangelist at Abbyy, an clever automation firm, stated there’s a false impression {that a} vendor’s attestations and certifications are adequate to handle the chance. “Nothing may very well be farther from the reality,” he stated. Pery was talking usually, not in regards to the Workday case.
Efficient oversight wants knowledge scientists, technical workers, ethics specialists and human reviewers with the authority to override an AI resolution, Pery stated. Oversight of AI can also be a board-level concern, he stated. AI bias in hiring carries actual penalties. “It impacts model fairness. It impacts buyer loyalty. It impacts valuation, so governance is changing into a part of guaranteeing that there is correct board-level controls applied.”
Sturdy governance solely works if it could actually see the technical issues.
How AI hiring methods can use proxy knowledge to deduce protected traits
AI methods, even when they’re barred from utilizing protected attributes similar to gender, race or age, could depend on proxies like commencement 12 months or full tackle to deduce them, stated Rodica Neamtu, a pc science professor at Worcester Polytechnic Institute. The system makes use of these proxies to make inferences a human by no means explicitly requested it to make.
“That is how bias begins creeping in,” she stated.
“Firms don’t disclose sufficient in regards to the instruments that they promote, which implies that it’s quintessential to maintain the people within the loop,” Neamtu stated. People carry their very own cognitive biases, however well-trained individuals who perceive bias and the way it develops would enhance the method, she stated.
“AI is a threat like some other mission-critical threat,” stated Carl Hahn, a companion at Steptoe LLP and former chief ethics and compliance officer at Northrop Grumman.
“Administration wants to determine efficient controls and practices that govern AI methods after which audit whether or not these controls function as designed.”
The corporate that makes use of the AI is “in the end liable for the output of the audit and for demonstrating efficient, strong and disciplined compliance,” Hahn stated.
“The seller is solely contributing to the method.”
On this publish we are going to use Keras to categorise duplicated questions from Quora.
The dataset first appeared within the Kaggle competitors Quora Query Pairs and consists of roughly 400,000 pairs of questions together with a column indicating if the query pair is taken into account a reproduction.
Our implementation is impressed by the Siamese Recurrent Structure, with modifications to the similarity
measure and the embedding layers (the unique paper makes use of pre-trained phrase vectors). Utilizing this sort
of structure dates again to 2005 with Le Cun et al and is beneficial for
verification duties. The concept is to be taught a operate that maps enter patterns right into a
goal house such {that a} similarity measure within the goal house approximates
the “semantic” distance within the enter house.
After the competitors, Quora additionally described their strategy to this downside on this weblog publish.
We’re utilizing the Keras get_file() operate in order that the file obtain is cached.
Studying and preprocessing
We are going to first load information into R and do some preprocessing to make it simpler to
embody within the mannequin. After downloading the info, you’ll be able to learn it
utilizing the readr read_tsv() operate.
We are going to create a Keras tokenizer to remodel every phrase into an integer
token. We will even specify a hyperparameter of our mannequin: the vocabulary dimension.
For now let’s use the 50,000 most typical phrases (we’ll tune this parameter later).
The tokenizer might be match utilizing all distinctive questions from the dataset.
Let’s check out the variety of phrases in every query. This may helps us to
determine the padding size, one other hyperparameter of our mannequin. Padding the sequences normalizes them to the identical dimension in order that we are able to feed them to the Keras mannequin.
80% 90% 95% 99%
14 18 23 31
We will see that 99% of questions have at most size 31 so we’ll select a padding
size between 15 and 30. Let’s begin with 20 (we’ll additionally tune this parameter later).
The default padding worth is 0, however we’re already utilizing this worth for phrases that
don’t seem throughout the 50,000 most frequent, so we’ll use 50,001 as a substitute.
We’ve now completed the preprocessing steps. We are going to now run a easy benchmark
mannequin earlier than transferring on to the Keras mannequin.
Easy benchmark
Earlier than creating a sophisticated mannequin let’s take a easy strategy.
Let’s create two predictors: proportion of phrases from question1 that
seem within the question2 and vice-versa. Then we are going to use a logistic
regression to foretell if the questions are duplicate.
We obtained an accuracy of 65.7%. Not all that significantly better than random guessing.
Now let’s create our mannequin in Keras.
Mannequin definition
We are going to use a Siamese community to foretell whether or not the pairs are duplicated or not.
The concept is to create a mannequin that may embed the questions (sequence of phrases)
right into a vector. Then we are able to examine the vectors for every query utilizing a similarity
measure and inform if the questions are duplicated or not.
First let’s outline the inputs for the mannequin.
input1<-layer_input(form =c(20), title ="input_question1")input2<-layer_input(form =c(20), title ="input_question2")
Then let’s the outline the a part of the mannequin that can embed the questions in a
vector.
Now we are going to outline the connection between the enter vectors and the embeddings
layers. Word that we use the identical layers and weights on each inputs. That’s why
that is referred to as a Siamese community. It is smart, as a result of we don’t need to have totally different
outputs if question1 is switched with question2.
We then outline the similarity measure we need to optimize. We wish duplicated questions
to have greater values of similarity. On this instance we’ll use the cosine similarity,
however any similarity measure could possibly be used. Do not forget that the cosine similarity is the
normalized dot product of the vectors, however for coaching it’s not essential to
normalize the outcomes.
Now that allow’s outline the Keras mannequin by way of it’s inputs and outputs and
compile it. Within the compilation section we outline our loss operate and optimizer.
Like within the Kaggle problem, we are going to reduce the logloss (equal
to minimizing the binary crossentropy). We are going to use the Adam optimizer.
mannequin<-keras_model(checklist(input1, input2), output)mannequin%>%compile( optimizer ="adam", metrics =checklist(acc =metric_binary_accuracy), loss ="binary_crossentropy")
We will then check out out mannequin with the abstract operate.
Now that we have now an affordable mannequin, let’s tune the hyperparameters utilizing the tfruns package deal. We’ll start by including FLAGS declarations to our script for all hyperparameters we need to tune (FLAGS permit us to fluctuate hyperparmaeters with out altering our supply code):
The complete supply code of the script with FLAGS could be discovered right here.
We moreover added an early stopping callback within the coaching step with a purpose to cease coaching
if validation loss doesn’t lower for five epochs in a row. This may hopefully cut back coaching time for dangerous fashions. We additionally added a studying charge reducer to cut back the educational charge by an element of 10 when the loss doesn’t lower for 3 epochs (this system usually will increase mannequin accuracy).
We will now execute a tuning run to probe for the optimum mixture of hyperparameters. We name the tuning_run() operate, passing an inventory with
the potential values for every flag. The tuning_run() operate might be chargeable for executing the script for all combos of hyperparameters. We additionally specify
the pattern parameter to coach the mannequin for under a random pattern from all combos (decreasing coaching time considerably).
The tuning run will return a information.body with outcomes for all runs.
We discovered that the most effective run attained 84.9% accuracy utilizing the mixture of hyperparameters proven under, so we modify our coaching script to make use of these values because the defaults:
Now that we have now educated and tuned our mannequin we are able to begin making predictions.
At prediction time we are going to load each the textual content tokenizer and the mannequin we saved
to disk earlier.
Since we gained’t proceed coaching the mannequin, we specified the compile = FALSE argument.
Now let`s outline a operate to create predictions. On this operate we we preprocess the enter information in the identical approach we preprocessed the coaching information:
We will now name it with new pairs of questions, for instance:
predict_question_pairs(mannequin,tokenizer,"What's R programming?","What's R in programming?")
[1] 0.9784008
Prediction is kind of quick (~40 milliseconds).
Deploying the mannequin
To reveal deployment of the educated mannequin, we created a easy Shiny utility, the place
you’ll be able to paste 2 questions from Quora and discover the chance of them being duplicated. Attempt altering the questions under or getting into two completely totally different questions.
Word that when deploying a Keras mannequin you solely have to load the beforehand saved mannequin file and tokenizer (no coaching information or mannequin coaching steps are required).
Wrapping up
We educated a Siamese LSTM that provides us affordable accuracy (84%). Quora’s state-of-the-art is 87%.
We will enhance our mannequin through the use of pre-trained phrase embeddings on bigger datasets. For instance, strive utilizing what’s described in this instance. Quora makes use of their very own full corpus to coach the phrase embeddings.
After coaching we deployed our mannequin as a Shiny utility which given two Quora questions calculates the chance of their being duplicates.
TL;DR: Skip the workplace scanner—iScanner enables you to scan, edit, signal, and arrange paperwork out of your telephone for $39.99.
In actuality, most workplace scanners are both gathering mud or taking over means an excessive amount of area for a way little they’re used.
The iScanner App is the trendy substitute. As a substitute of counting on {hardware}, it turns your telephone right into a full doc scanner, editor, and file supervisor—all for a one-time $39.99 (reg. $199.90).
Level your digicam at a doc, and it scans, detects edges, straightens the picture, and cleans it up routinely. You possibly can export recordsdata as PDFs, photographs, and even editable codecs like Phrase and Excel.
But it surely goes past scanning. There’s built-in OCR that acknowledges textual content in 20+ languages, so you possibly can search or edit what you’ve scanned. You too can signal paperwork, fill varieties, merge recordsdata, add annotations, or lock delicate recordsdata with a PIN.
It even consists of some additional instruments—like QR scanning, object measuring, and easy counting options—that make it greater than only a doc app.
For on a regular basis use—distant work, faculty, small enterprise duties—it’s sooner, extra versatile, and already in your pocket.
Researchers have developed organoids that may regenerate just like the endometrium, the liner of the uterus that sheds and re-forms in the course of the menstrual cycle. The crew used the miniature 3D constructions to simulate not often seen restore processes, which might inform future therapeutic methods for tissue renewal and wound therapeutic. The findings have been revealed in Cell Stem Cell on 28 April.
The endometrium has a novel potential to restore itself after menstrual shedding with out scarring, however the way it does this can be a thriller. Till this examine, it had been tough to duplicate the exercise within the laboratory and finding out it in individuals is just too invasive, says co-author Konstantina Nikolakopoulou, a molecular biologist who did the analysis whereas on the Friedrich Miescher Institute for Biomedical Analysis in Basel, Switzerland.
“It’s improbable to have a mannequin system that you are able to do experiments on,” says Deena Emera, an evolutionary biologist on the Buck Institute for Analysis on Growing old in Novato, California. Insights about endometrium restore won’t solely assist scientists to enhance understanding of gynaecological illnesses resembling endometriosis, but additionally might be related to regeneration analysis in different tissues.
On supporting science journalism
When you’re having fun with this text, contemplate supporting our award-winning journalism by subscribing. By buying a subscription you’re serving to to make sure the way forward for impactful tales in regards to the discoveries and concepts shaping our world immediately.
Lab-grown tissue
Nikolakopoulou’s organoids have been developed on the premise of fashions that her former supervisor created in 2017. For these fashions, the researchers took a biopsy from an individual’s endometrium, separated the cell sorts and combined solely the epithelial cells — the primary tissue sort within the endometrium — with a gelatinous membrane. This enabled the cells to self-organize right into a hole, spherical construction that acted just like the endometrium.
Nikolakopoulou and her crew took the mannequin to the subsequent stage by emulating the menstrual cycle in its cells. First, they handled the organoids with oestrogen and progesterone, hormones that sign the transition of menstrual phases. The crew then withdrew the hormones, which occurs naturally at this level within the cycle owing to exercise within the ovaries. In individuals, the discount of progesterone causes shedding of the endometrium, or menstruation. The kind of cells that set off shedding was not current within the organoid, which meant that the crew needed to mechanically break down the tissue with a pipette to simulate degeneration. They then watched because it regenerated, similar to in a human endometrium.
Nikolakopoulou says the organoids are easy and comprise solely epithelial cells moderately than a complete microenvironment of varied cell sorts, resembling immune, stromal and endothelial cells, and elements resembling oxygen and blood. It’s finest to first perceive the best way to “break down the puzzle, after which begin rising complexity,” she says.
Luminal helpers
Previous analysis in primates has recommended that deep-tissue stem cells are chargeable for the renewal of the endometrium.
However when Nikolakopoulou and her colleagues analysed the tissue that the organoids shed, they noticed that luminal cells, one other sort of epithelial cell, have been concerned. Situated on the floor of the endometrium, these cells assist embryos to implant within the endometrium earlier than being pregnant.
The crew additionally discovered that the luminal cells expressed a gene referred to as WNT7A, which is thought to help tissue regeneration in primates.
Intrigued by the presence of WNT7A, the researchers cloned the organoids and used gene enhancing to take away it. They discovered that the clones’ development and survival potential have been compromised in contrast with the unique organoids.
After they checked out a number of the few endometrium samples that they’ve from individuals, additionally they detected the presence of luminal cells and expression of WNT7A earlier than the endometrium reforms, supporting their function in regeneration.
Future instructions for organoid growth needs to be to extend the complexity represented within the uterine microenvironment, Nikolakopoulou says. Emera agrees that more-advanced organoid fashions with a better variety of cell sorts might imitate the tissue-breakdown course of extra precisely than the crew’s mechanical technique.
This text is reproduced with permission and was first revealed on Might 1, 2026.
It’s Time to Stand Up for Science
When you loved this text, I’d prefer to ask in your help. Scientific American has served as an advocate for science and trade for 180 years, and proper now stands out as the most crucial second in that two-century historical past.
I’ve been a Scientific American subscriber since I used to be 12 years outdated, and it helped form the way in which I have a look at the world. SciAm at all times educates and delights me, and conjures up a way of awe for our huge, stunning universe. I hope it does that for you, too.
When you subscribe to Scientific American, you assist make sure that our protection is centered on significant analysis and discovery; that we have now the assets to report on the choices that threaten labs throughout the U.S.; and that we help each budding and dealing scientists at a time when the worth of science itself too typically goes unrecognized.
The earlier submit constructed a triangular analog of the squircle, the unit circle within the p-norm the place p is usually round 4. The case p = 2 is a Euclidean circle and the restrict as p → ∞ is a Euclidean sq..
The earlier submit launched three capabilities Li(x, y) such that the extent set of every perform
types a facet of a triangle. Then it launched a mushy penalty for every L being away 1, and the extent units of that penalty perform shaped the rounded triangles we had been searching for.
One other strategy could be to vary the L‘s barely in order that the edges are the degrees units Li(x, y) = 0. The benefit to this formulation is that the product of three numbers is 0 if and provided that one of many numbers is zero. Meaning if we outline
then the set of factors
corresponds to the three strains when c = 0 and the extent units for small c > 0 are almost triangles. The extent units will likely be clean if the gradient is non-zero, i.e. c shouldn’t be zero.
This strategy shouldn’t be distinctive to triangles. You might create clean approximations any polygon by multiplying linear capabilities that outline the edges. Or you possibly can do one thing related with curved arcs.
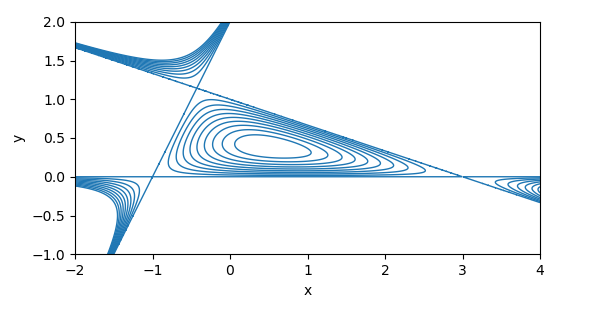
If we outline our L’s by
then our curves would be the stage units of
A number of stage units are proven beneath. The extent set for c = 0 is the straight strains.
Observe the extent units should not linked. If you happen to’re fascinated by approximate triangles, you need the elements which might be contained in the triangle.
Seismic information evaluation is an integral part of vitality exploration, however configuring complicated processing workflows has historically been a time-consuming and error-prone problem. Halliburton’s Seismic Engine, a cloud-native utility for seismic information processing, is a robust software that beforehand required handbook configuration of roughly 100 specialised instruments to create workflows. This course of was not solely time-consuming but in addition required deep experience, doubtlessly limiting the accessibility and effectivity of the software program.
To deal with this problem, Halliburton partnered with the AWS Generative AI Innovation Middle to develop an AI-powered assistant for Seismic Engine. The answer makes use of Amazon Bedrock, Amazon Bedrock Information Bases, Amazon Nova, and Amazon DynamoDB to remodel complicated workflow creation into conversations. Geoscientists and information scientists can configure processing instruments by way of pure language interplay as an alternative of handbook configuration.
On this put up, we’ll discover how we constructed a proof-of-concept that converts pure language queries into executable seismic workflows whereas offering a question-answering functionality for Seismic Engine instruments and documentation. We’ll cowl the technical particulars of the answer, share analysis outcomes exhibiting workflow acceleration of as much as 95%, and talk about key learnings that may assist different organizations improve their complicated technical workflows with generative AI.
Our collaboration with AWS has been instrumental in accelerating subsurface interpretation workflows. By integrating Amazon Bedrock providers with Halliburton Landmark’s DS365 Seismic Engine, we have been in a position to cut back historically time‑consuming workflow‑constructing duties by an order of magnitude. This generative AI–powered workflow assistant not solely improves effectivity and accuracy but in addition makes our superior geophysical instruments extra accessible to a broader vary of customers. The scalable cloud‑native structure on AWS has enabled us to ship a seamless, conversational expertise that essentially improves productiveness throughout subsurface workflows.
— Phillip Norlund, Supervisor of Subsurface Applied sciences, Halliburton Landmark
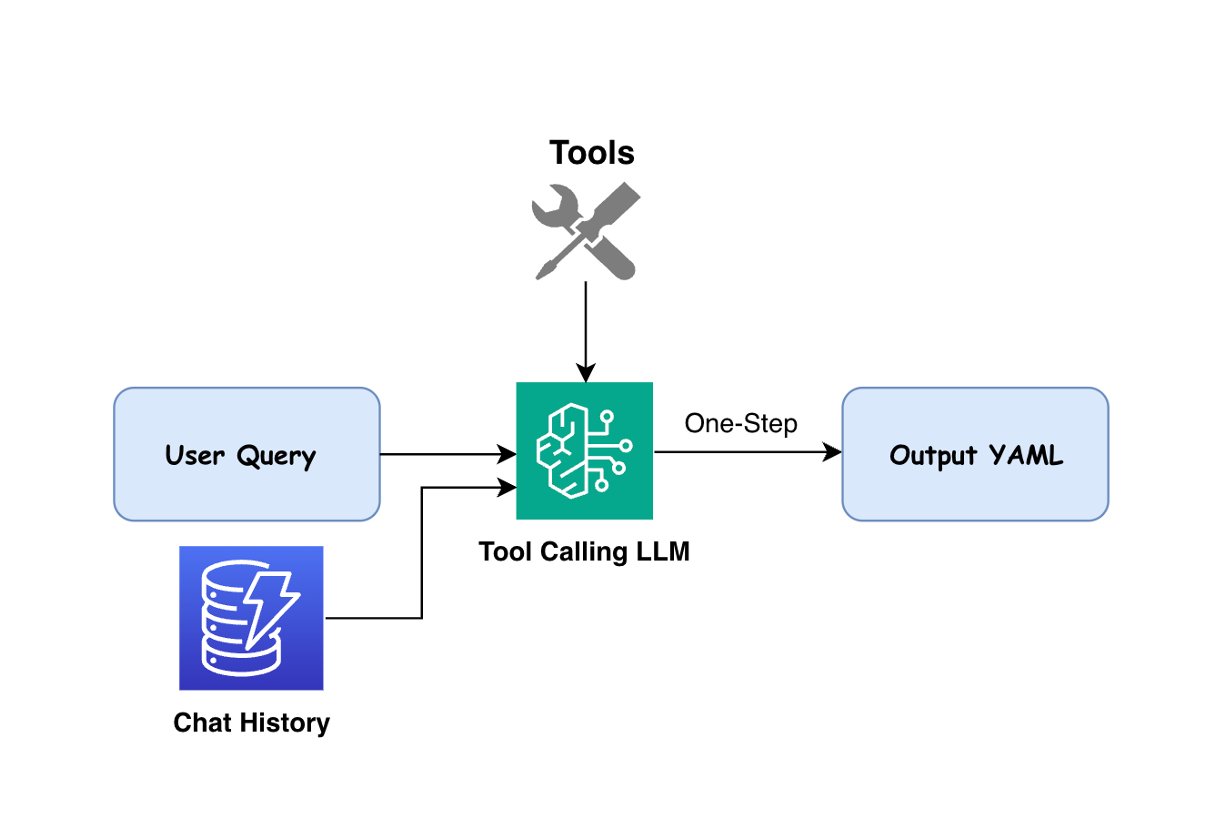
Our venture aimed to handle two key targets: remodeling pure language queries into executable seismic workflows, and offering an clever query and reply (Q&A) system for Seismic Engine documentation. To attain this, we developed an answer utilizing Amazon Bedrock that allows geoscientists to work together with complicated seismic instruments by way of pure dialog.The spine of our system is a FastAPI utility deployed on AWS App Runner, which handles consumer queries by way of a streaming interface. When a consumer submits a question, an intent router powered by Amazon Nova Lite analyzes the request to find out whether or not it’s in search of workflow era or technical data. For Q&A requests, the system makes use of Amazon Bedrock Information Bases with Amazon OpenSearch Serverless to offer related solutions from listed documentation. For workflow requests, a era agent utilizing Anthropic’s Claude on Amazon Bedrock creates YAML workflows by deciding on from 82 out there Seismic Engine instruments.
To keep up context and allow multi-turn conversations, we built-in Amazon DynamoDB for chat historical past and interplay logging. The system helps streaming responses for each Q&A and workflow era, offering fast suggestions to customers because the system processes their requests. This structure permits complicated technical workflows to be created and modified by way of pure dialog, whereas sustaining the exact management required for seismic information processing. The next diagram illustrates the answer structure.
Question routing and intent classification
After the consumer’s question is supplied to the system, the Intent Router classifies the intent label of the given question by calling Amazon Nova Lite by way of the Amazon Bedrock API. The big language mannequin (LLM) is given a immediate to provide one among three intent labels: “Workflow_Generation”, “QnA”, and “General_Question”.The “Workflow_Generation” label is used to route queries associated to workflow era, together with studying/loading datasets, information processing operations, and numerous requests involving manipulating particular datasets. The “QnA” intent label is used for questions associated to particular instruments, requests for pattern workflows, or questions on Seismic Engine documentation. The “General_Question” label is reserved for queries unrelated to Seismic Engine operations or workflows.In our implementation, Amazon Nova Lite carried out the routing process effectively, providing an excellent steadiness between accuracy and latency.
Query answering implementation
The Q&A element handles Seismic Engine-related queries by utilizing Amazon Bedrock Information Bases, a totally managed service for end-to-end Retrieval Augmented Technology (RAG) workflow. We selected Bedrock Information Bases as a result of it alleviates the operational overhead of managing vector databases, chunking methods, and embedding pipelines. As a totally managed service, it handles infrastructure scaling, safety, and upkeep routinely, in order that our group might deal with answer growth relatively than RAG infrastructure operations. The service gives native assist for a number of chunking methods together with hierarchical chunking, which maintains parent-child relationships to steadiness granular retrieval with broader doc context.The information sources embrace software documentation markdown recordsdata and Seismic Engine manuals saved in S3. We saved software documentation recordsdata unchunked since they’re comparatively quick, preserving full context for particular person instruments. For longer paperwork like Seismic Engine manuals, we used hierarchical chunking with default settings. We use Amazon Titan Textual content Embeddings V2 for embedding era and OpenSearch Serverless because the vector database. The system additionally shops metadata comparable to file names, URLs, and doc varieties for every listed merchandise for downstream use.For each retrieval and response era, we use Amazon Bedrock Information Bases’ retrieve_and_generate API with Claude 3.5 Haiku because the mannequin. The system helps multi-turn conversations by sustaining session context, and responses are formatted with inline citations for enhanced traceability.
Be aware: This answer was developed and evaluated utilizing Claude 3.5 Sonnet V2 and Claude 3.5 Haiku. Since then, these fashions have been succeeded by Claude Sonnet 4.5 and most not too long ago Claude Sonnet 4.6, in addition to Claude Haiku 4.5, all out there by way of Amazon Bedrock. The answer structure helps mannequin upgrades with out code modifications, so as to use the newest mannequin capabilities.
This method permits our system to offer context-aware, related solutions to consumer queries about Seismic Engine instruments and workflows.
Workflow era
For queries categorised as “Workflow_Generation”, our answer makes use of LLM brokers to transform pure language into executable YAML workflows. The agent is certain with 82 instruments out there on Seismic Engine. Based mostly on the consumer’s question and power specs that outline inputs, parameters, and outputs, the agent selects applicable instruments, determines their appropriate execution order, and generates a YAML workflow that addresses the consumer’s necessities. The next determine illustrates the workflow era course of.
We used each Claude 3.5 Sonnet V2 and Claude 3.5 Haiku in our implementation, orchestrated by way of the LangChain framework for agent administration and power binding. The fashions are supplied with detailed software descriptions and specs, in order that they will perceive every software’s capabilities and necessities. When producing workflows, the system considers not solely the express necessities within the consumer’s question but in addition contains obligatory default parameters when particular values aren’t supplied.The workflow era course of helps multi-turn conversations, in order that customers can modify beforehand generated workflows by way of pure language requests. Through the use of dialog historical past saved in Amazon DynamoDB, the LLM can both generate new workflows or modify current ones in line with the consumer’s present question.
Analysis
To judge our answer’s effectiveness, we created a complete take a look at dataset of query-workflow pairs, consisting of each low and medium complexity workflows. These have been derived from actual historic workflows and validated by material specialists to confirm they precisely signify typical consumer requests.
Workflow era outcomes
Mannequin
Complexity
Success Price
Imply Technology Time (s)
Median Technology Time (s)
Claude Haiku 3.5
easy
84%
8.3
5.9
medium
90%
12.4
9.1
Claude Sonnet 3.5 V2
easy
86%
11.2
11.5
medium
97%
15.8
16.6
Each fashions demonstrated robust efficiency, with Claude Sonnet 3.5 V2 exhibiting superior success charges, notably for medium complexity workflows. The system delivers responses by way of streaming, offering customers with fast suggestions because the workflow is generated, with full workflows delivered inside 5.9-16.6 seconds. Claude Haiku 3.5 provides quicker era instances, offering a trade-off possibility between pace and accuracy.
Comparability to baseline efficiency
Consumer Sort
% Success
% Failure
Time to Construct Easy Stream (min)
Time to Construct Complicated Stream (min)
New Consumer
70%
20%
4
20
Skilled Consumer
85%
10%
2
5
Our Resolution
84-97%
3-16%
0.13-0.26
0.21-0.28
Our generative AI answer demonstrates the next enhancements:
Success charges of 84-97% surpass each new and skilled customers.
Workflow creation time is diminished from minutes to seconds, representing over a 95% time discount.
These outcomes reveal that customers throughout expertise ranges can improve productiveness by over 95%, whereas sustaining or exceeding the accuracy of handbook workflow creation.
Conclusion
On this put up, we confirmed how we used Amazon Bedrock to remodel complicated technical processes into pure conversations. By implementing an AI-powered assistant with built-in Q&A capabilities, we achieved workflow era success charges of 84-97% whereas lowering creation time by over 95% in comparison with handbook processes. The system’s skill to deal with each low and medium complexity workflows, mixed with its contextual understanding of Seismic Engine instruments, demonstrates how generative AI can enhance industrial software program usability with out compromising accuracy.
This method additionally generalizes nicely to different domains with complicated, multi-step agentic workflows requiring specialised software information and configuration. As subsequent steps, take into account exploring multi-agent architectures utilizing frameworks like Strands Brokers SDK with Amazon Bedrock AgentCore for improved accuracy by way of specialised sub-agents.
Coaching a household of enormous language fashions (LLMs) has at all times include a painful multiplier: each mannequin variant within the household—whether or not 8B, 30B, or 70B—sometimes requires its personal full coaching run, its personal storage, and its personal deployment stack. For a dev crew operating inference at scale, this implies multiplying compute prices by the variety of mannequin sizes they wish to help. NVIDIA researchers at the moment are proposing a unique strategy referred to as Star Elastic.
Star Elastic is a post-training methodology that embeds a number of nested submodels—at completely different parameter budgets—inside a single dad or mum reasoning mannequin, utilizing a single coaching run. Utilized to Nemotron Nano v3 (a hybrid Mamba–Transformer–MoE mannequin with 30B complete parameters and three.6B lively parameters), Star Elastic produces 23B (2.8B lively) and 12B (2.0B lively) nested variants skilled with roughly 160B tokens. All three variants stay in a single checkpoint and might be extracted with none further fine-tuning.
What does “Nested” Really Imply right here
If you happen to haven’t encountered elastic or nested architectures earlier than, the concept is that this: as a substitute of coaching three separate 30B, 23B, and 12B fashions, you practice one mannequin that comprises the smaller ones as subsets of itself. The smaller submodels reuse an important weights from the dad or mum, recognized via a course of referred to as significance estimation.
Star Elastic scores every mannequin element: embedding channels, consideration heads, Mamba SSM heads, MoE consultants, and FFN channels by how a lot they contribute to mannequin accuracy. Elements are then ranked and sorted, so smaller-budget submodels at all times use the highest-ranked contiguous subset of parts from the bigger mannequin. This property known as nested weight-sharing.
The tactic helps nesting alongside a number of axes: the SSM (State House Mannequin) dimension, embedding channels, consideration heads, Mamba heads and head channels, MoE knowledgeable rely, and FFN intermediate dimension. For MoE layers particularly, Star Elastic makes use of Router-Weighted Knowledgeable Activation Pruning (REAP), which ranks consultants by each routing gate values and knowledgeable output magnitudes—a extra principled sign than naive frequency-based pruning, which ignores how a lot every knowledgeable really contributes to the layer output.
A Learnable Router, Not a Mounted Compression Recipe
A key distinction from prior compression strategies like Minitron is that Star Elastic makes use of an end-to-end trainable router to find out the nested submodel architectures. The router takes a goal price range (e.g., “give me a 2.8B lively parameter mannequin”) as a one-hot enter and outputs differentiable masks that choose which parts are lively at that price range degree. These masks are skilled collectively with the mannequin via Gumbel-Softmax, which permits gradient move via discrete architectural choices.
The loss operate combines data distillation (KD) the place the non-elastified dad or mum mannequin acts because the trainer with a router loss that penalizes deviation from the goal useful resource price range (parameter rely, reminiscence, or latency). This implies the router learns to make structure decisions that truly enhance accuracy beneath KD, fairly than simply minimizing a proxy metric.
Coaching makes use of a two-stage curriculum: a short-context part (sequence size 8,192 tokens) with uniform price range sampling, adopted by an extended-context part (sequence size 49,152 tokens) with non-uniform sampling that prioritizes the total 30B mannequin (p(30B)=0.5, p(23B)=0.3, p(12B)=0.2). The prolonged context part is crucial for reasoning efficiency. The analysis crew’s ablations on Nano v2—explicitly reproduced because the empirical foundation for a similar curriculum alternative on Nano v3 present positive factors of as much as 19.8% on AIME-2025 for the 6B variant and 4.0 share factors for the 12B variant from Stage 2 alone, motivating its use right here.
Elastic Finances Management: Totally different Fashions for Totally different Reasoning Phases
Current price range management in reasoning fashions together with Nemotron Nano v3’s personal default habits works by capping the variety of tokens generated throughout a part earlier than forcing a ultimate reply. This strategy makes use of the identical mannequin all through. Star Elastic unlocks a unique technique: utilizing completely different nested submodels for the pondering part versus the answering part.
The researchers evaluated 4 configurations. The optimum one, referred to as ℳS → ℳL (small mannequin for pondering, giant mannequin for answering), allocates a less expensive mannequin to generate prolonged reasoning traces and reserves the full-capacity mannequin for synthesizing the ultimate reply. The 23B → 30B configuration specifically advances the accuracy–latency Pareto frontier, attaining as much as 16% larger accuracy and 1.9× decrease latency in comparison with default Nemotron Nano v3 price range management. The instinct: reasoning tokens are high-volume however tolerant of some capability discount; the ultimate reply requires larger precision.
Quantization With out Breaking the Nested Construction
A naive strategy to deploying a quantized elastic mannequin can be to quantize every variant individually after slicing. That breaks the nested weight-sharing property and requires a separate quantization move per dimension. As a substitute, Star Elastic applies Quantization-Conscious Distillation (QAD) straight on the elastic checkpoint, preserving the nested masks hierarchy all through.
For FP8 (E4M3 format), post-training quantization (PTQ) is ample, recovering 98.69% of BF16 accuracy on the 30B variant. For NVFP4 (NVIDIA’s 4-bit floating-point format), PTQ alone causes a 4.12% common accuracy drop, so a brief nested QAD part (~5B tokens at 48K context) brings restoration again to 97.79% for the 30B variant. In each circumstances, zero-shot slicing of the 23B and 12B variants from the only quantized checkpoint is preserved.
The reminiscence implications are important. Storing separate 12B, 23B, and 30B BF16 checkpoints requires 126.1 GB; the only elastic checkpoint requires 58.9 GB. The 30B NVFP4 elastic checkpoint matches in 18.7 GB, enabling the 12B NVFP4 variant to run on an RTX 5080 the place each BF16 configuration runs out of reminiscence. On an RTX Professional 6000, the 12B NVFP4 variant reaches 7,426 tokens/s, a 3.4× throughput enchancment over the 30B BF16 baseline.
Depth vs. Width: Why Star Elastic Compresses Width
One design alternative value calling out explicitly: the analysis crew in contrast two compression methods—eradicating layers totally (depth compression) versus lowering inner dimensions like hidden dimension, knowledgeable rely, and head rely (width compression). With a 15% parameter discount and 25B tokens of data distillation, width compression recovered 98.1% of baseline efficiency whereas depth compression recovered solely 95.2%, with noticeable degradation on HumanEval and MMLU-Professional. Because of this, Star Elastic prioritizes width-based elasticity for its major outcomes, although depth compression (layer skipping) stays out there as a mechanism for excessive latency-constrained situations.
On the analysis suite—AIME-2025, GPQA, LiveCodeBench v5, MMLU-Professional, IFBench, and Tau Bench—the Elastic-30B variant matches its dad or mum Nemotron Nano v3 30B on most benchmarks, whereas the Elastic-23B and Elastic-12B variants stay aggressive towards independently skilled fashions of comparable sizes. The Elastic-23B notably scores 85.63 on AIME-2025 versus Qwen3-30B-A3B’s 80.00, regardless of having fewer lively parameters.
On coaching value, the analysis crew experiences a 360× token discount in comparison with pretraining every variant from scratch, and a 7× discount over prior state-of-the-art compression strategies that require sequential distillation runs per mannequin dimension. The 12B variant runs at 2.4× the throughput of the 30B dad or mum on an H100 GPU at bfloat16 with the identical enter/output sequence lengths.
How one can Use NVIDIA Star Elastic
Step-by-Step Information
Nemotron Nano v3 Elastic — 30B / 23B / 12B in a single checkpoint · BF16 / FP8 / NVFP4
Star Elastic fashions are distributed by way of Hugging Face and help each Transformers (for experimentation) and vLLM
(really useful for manufacturing inference). Choose the choice that matches your use case.
bash
# Choice A — vLLM (really useful for manufacturing serving)
pip set up vllm
# Choice B — Transformers (for native experimentation)
pip set up transformers torch speed up
# Elective: log in to Hugging Face if wanted
pip set up huggingface_hub
huggingface-cli login
▸ {Hardware} word: The 30B BF16 checkpoint requires ~60 GB VRAM for the total nested household.
Use FP8 (~31 GB) or NVFP4 (~19 GB) for H100/A100 or RTX-class deployment.
A single checkpoint comprises all three nested variants — 30B (3.6A), 23B (2.8A), and 12B (2.0A). Load as soon as; extract any variant
with out retraining. The mannequin requires trust_remote_code=True for the hybrid
Mamba–Transformer–MoE structure.
python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# The 30B BF16 elastic checkpoint — comprises all 3 nested variants
model_id = "nvidia/NVIDIA-Nemotron-Labs-3-Elastic-30B-A3B-BF16"
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
mannequin = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto" # distributes throughout out there GPUs
)
print(f"Mannequin loaded: {model_id}")
▸ Energetic vs. complete parameters: “30B complete / 3.6B lively” means the mannequin shops
30B weights however solely routes every token via 3.6B parameters per ahead move — that is how
Combination-of-Specialists (MoE) works.
The mannequin makes use of a token to generate a reasoning chain earlier than
producing its ultimate reply. Management the full token price range by way of max_new_tokens
— larger values enable longer reasoning traces on arduous issues.
python
messages = [
{
"role": "user",
"content": "What is the time complexity of QuickSort, and why?"
}
]
# Apply chat template and tokenize
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
).to(mannequin.machine)
# Generate — mannequin produces ... then the ultimate reply
outputs = mannequin.generate(
**inputs,
max_new_tokens=4096, # pondering + reply price range
temperature=0.6,
top_p=0.95,
do_sample=True
)
response = tokenizer.decode(
outputs[0][inputs["input_ids"].form[-1]:],
skip_special_tokens=True
)
print(response)
▸ Pondering price range tip: For math/coding issues, set max_new_tokens
to 8192–32768. For less complicated queries, 2048–4096 is ample and reduces latency.
For manufacturing deployments, use vLLM to serve the mannequin by way of an
OpenAI-compatible REST API. This allows batched inference, steady batching,
and better throughput — the 12B variant achieves 2.4× the throughput
of the 30B dad or mum on an H100 GPU.
bash
# Begin the vLLM server (OpenAI-compatible)
vllm serve "nvidia/NVIDIA-Nemotron-Labs-3-Elastic-30B-A3B-BF16"
# --- In a separate terminal ---
# Question the server by way of curl
curl -X POST "http://localhost:8000/v1/chat/completions"
-H "Content material-Kind: utility/json"
--data '{
"mannequin": "nvidia/NVIDIA-Nemotron-Labs-3-Elastic-30B-A3B-BF16",
"messages": [
{
"role": "user",
"content": "Explain gradient descent in 3 steps."
}
],
"max_tokens": 4096,
"temperature": 0.6
}'
# Or run by way of Docker
docker mannequin run hf.co/nvidia/NVIDIA-Nemotron-Labs-3-Elastic-30B-A3B-BF16
▸ SGLang different: SGLang can be supported —
run python3 -m sglang.launch_server --model-path "nvidia/NVIDIA-Nemotron-Labs-3-Elastic-30B-A3B-BF16" --port 30000
for a drop-in different to vLLM.
Three quantized checkpoints can be found. All protect the nested construction
— the 23B and 12B submodels might be extracted zero-shot from whichever precision checkpoint
you load. NVFP4 makes use of Quantization-Conscious Distillation (QAD) to recuperate accuracy misplaced from PTQ.
bash
# BF16 — full precision, all nested variants in 58.9 GB
vllm serve "nvidia/NVIDIA-Nemotron-Labs-3-Elastic-30B-A3B-BF16"
# FP8 (E4M3) — ~2× smaller, 30B matches in 31.4 GB
# Submit-training quantization, 98.69% accuracy restoration on 30B
vllm serve "nvidia/NVIDIA-Nemotron-Labs-3-Elastic-30B-A3B-FP8"
# NVFP4 — smallest footprint, 30B matches in 18.7 GB
# 12B NVFP4 variant runs on RTX 5080 (BF16 OOMs)
# 12B NVFP4 on RTX Professional 6000: 7,426 tokens/s (3.4× vs 30B BF16)
vllm serve "nvidia/NVIDIA-Nemotron-Labs-3-Elastic-30B-A3B-NVFP4"
Variant
30B reminiscence
23B reminiscence
12B reminiscence
Finest for
BF16 Full
58.9 GB
44.0 GB
23.2 GB
A100 / H100
FP8 PTQ
31.4 GB
23.7 GB
13.0 GB
H100 / A100 / RTX 5090
NVFP4 QAD
18.7 GB
14.1 GB
8.0 GB
RTX 5080 / 5090 / Professional 6000
Step 1 of 5
Key Takeaways
Star Elastic trains 30B, 23B, and 12B nested reasoning fashions from a single 160B-token post-training run, attaining a 360× token discount over pretraining from scratch.
Elastic price range management (23B for pondering, 30B for answering) improves the accuracy–latency Pareto frontier by as much as 16% accuracy and 1.9× latency positive factors.
A learnable router with Gumbel-Softmax permits end-to-end trainable structure choice, eliminating the necessity for separate compression runs per mannequin dimension.
Nested QAD preserves zero-shot slicing throughout FP8 and NVFP4 quantized checkpoints, lowering the 30B elastic checkpoint to 18.7 GB in NVFP4.
All three precision variants (BF16, FP8, NVFP4) are publicly out there on Hugging Face beneath nvidia/NVIDIA-Nemotron-Labs-3-Elastic-30B-A3B.
Among the many compelling choices from Samsung, Google, and OnePlus, I went with the Galaxy Watch 8 as my Put on OS smartwatch of selection. The value was an enormous motive, for the reason that Samsung Galaxy Watch 8 begins at $350, and reductions and trade-ins additional decrease the fee. One other issue was the watch’s design, which is far thinner and lower-profile than a Pixel Watch or OnePlus Watch. Greater than the rest, the Samsung Well being suite received me over.
There are a handful of Samsung Well being options that genuinely present perception into your health and long-term well being utilizing the Galaxy Watch 8’s sensors. I can look at my watch just a few occasions day by day and get prompt snapshots of how I am feeling utilizing underlying sensor information. You’ll be able to too, utilizing these 5 Galaxy Watch 8 options. They’re additionally obtainable on the Galaxy Watch 8 Traditional and the Galaxy Watch Extremely.
One of the best a part of utilizing the Galaxy Watch 8 commonly is getting an Vitality rating every day. It measures your readiness for the day forward utilizing the exercise and sleep information from the day and evening prior. It requires utilizing the Samsung Well being app with a Samsung account, however apart from that, Vitality scores are calculated routinely with no handbook setup required. Samsung makes use of the next metrics to give you your rating, out of 100 attainable factors:
Newest Movies From
Sleep time common
Sleep time consistency
Sleep regularity
Sleep timing
Earlier day exercise
Exercise consistency
Sleeping coronary heart charge
Sleeping coronary heart charge variability
As you possibly can see, sleep is a crucial a part of your Vitality rating. If you aren’t getting good sleep, your rating might be decrease, and a noon nap could or could not assist. That is as a result of Samsung accounts for the time of day of your nap, realizing that later naps disrupt your circadian rhythm and scale back vitality. There are 4 Vitality rating tiers: Wonderful (85-100), Good (75-84), Truthful (60-74), Wants consideration (0-59).
So, to get essentially the most perception from the Vitality rating in your Galaxy Watch 8, you should definitely put on it throughout sleep and all through day by day actions. Then, examine into the Samsung Well being app in your cellphone or the smartwatch tile to see your day by day rating.
For the reason that Vitality rating takes a lot of your sleep information into consideration, you may be questioning what the Sleep rating does otherwise. Just like the Vitality rating, the Sleep rating is calculated routinely when your Galaxy Watch 8 is worn to mattress. It additionally makes use of the identical scale, however components in several metrics to calculate it. Sleep rating measures your precise sleep time, deep sleep, REM sleep, restfulness, and sleep latency to calculate the ultimate rating.
Samsung additionally compares your nightly Sleep rating to the common scores to your age group. For instance, one evening I scored a 92, which was within the prime 2% of my age group. The corporate provides that getting a sleep rating of 85 or greater equals a wholesome evening’s sleep. You may as well view your blood oxygen ranges, sleep levels, loud night breathing, pores and skin temperature, coronary heart charge, and respiratory charge information within the Samsung Well being app.
Get the newest information from Android Central, your trusted companion on the earth of Android
I by no means felt like my Apple Watch supplied sufficient detailed sleep information to justify carrying it to mattress, and my Garmin is simply too cumbersome to put on the complete evening. Samsung gives the right combine with a data-rich Sleep rating expertise and slim Galaxy Watch 8 {hardware}.
Gemini is a worthy alternative for Google Assistant in your wrist, enabling faster actions and time-saving automations. I apply it to my Galaxy Watch 8 to set a handful of nightly alarms with a single command, avoiding the trouble of getting to configure alarms on the small display. You may as well use it to get instructions, begin exercises, or recommend music. It’s going to even learn out your stay well being and health stats throughout a exercise for a hands-free expertise.
To make use of it, all you must do is maintain down the aspect button or say “Hey Gemini.” You may as well allow Elevate to Speak below Settings > Gestures > Elevate To Speak to activate Gemini by lifting the Galaxy Watch 8 as much as your mouth.
Working coach
(Picture credit score: Michael Hicks / Android Central)
Samsung’s Working coach characteristic may not be changing private trainers anytime quickly, however it’s a cool Galaxy Watch 8 device for newbies. The characteristic works by having the wearer full a 12-minute lactate threshold take a look at, which tells Samsung Well being loads in regards to the wearer’s operating capabilities. Then, it’s going to construct a coaching plan that will help you attain your targets. Full a “stage take a look at” for every numbered stage, and you will advance to the subsequent one.
To attempt it for your self, open the Samsung Well being app in your watch and faucet Train. Then, discover Working coach within the checklist and faucet it. You may now full the aforementioned operating take a look at by following the on-screen prompts. After ending the take a look at, your watch will give you a personalised coaching plan primarily based in your wants.
Vascular load
(Picture credit score: Samsung)
Quite a lot of Samsung’s greatest well being options work within the background, and the identical is true of Vascular load. It tries to trace your cardiovascular wellness to stop an image of your total well being. To see it, swipe left to view the Tiles display, and faucet Add tiles. Discover the Vitals tab, and choose Vascular load. Subsequent, press Present on cellphone.
The best way to use Vascular Load | Galaxy Watch8 Sequence | Samsung – YouTube
From there, you can begin monitoring your Vascular load after establishing a baseline by carrying your watch to mattress for 3 nights.
Software program is barely a part of the story, and the Galaxy Watch 8’s skinny profile seals the deal. It is solely 8.6mm thick (excluding the protruding sensors), and which means it’s going to be snug sufficient to put on throughout powerful exercises and nightly sleep. The extra you put on a smartwatch, the higher the information it supplies. That is why the Galaxy Watch 8’s design deserves credit score for the way helpful these 5 health and well being options are.
Greatest Put on OS health watch
The Samsung Galaxy Watch 8 beats choices from Google and OnePlus to earn the title of greatest Put on OS health watch in my ebook. It is snug, correct, and loaded with options. Use the 5 on this checklist to benefit from your Samsung smartwatch.

")