The final couple of weeks have been tremendous busy in “PyTorch Land” as we’re frantically getting ready the discharge of PyTorch v1.10 and TorchVision v0.11. On this 2nd instalment of the sequence, I’ll cowl among the upcoming options which might be presently included within the launch department of TorchVision.
Disclaimer: Although the upcoming launch is full of quite a few enhancements and bug/take a look at/documentation enhancements, right here I’m highlighting new “user-facing” options on domains I’m personally . After writing the weblog put up, I additionally seen a bias in direction of options I reviewed, wrote or adopted intently their growth. Protecting (or not masking) a function says nothing about its significance. Opinions expressed are solely my very own.
New Fashions
The brand new launch is full of new fashions:
Kai Zhang has added an implementation of the RegNet structure together with pre-trained weights for 14 variants which intently reproduce the unique paper.
I’ve just lately added an implementation of the EfficientNet structure together with pre-trained weights for variants B0-B7 supplied by Luke Melas-Kyriazi and Ross Wightman.
New Information Augmentations
A couple of new Information Augmentation strategies have been added to the newest model:
Samuel Gabriel has contributed TrivialAugment, a brand new easy however extremely efficient technique that appears to offer superior outcomes to AutoAugment.
I’ve added the RandAugment methodology in auto-augmentations.
I’ve supplied an implementation of Mixup and CutMix transforms in references. These will likely be moved in transforms on the following launch as soon as their API is finalized.
New Operators and Layers
Plenty of new operators and layers have been included:
References / Coaching Recipes
Although the advance of our reference scripts is a steady effort, listed below are just a few new options included within the upcoming model:
I’ve up to date our references to help Label Smoothing, which was just lately launched by Joel Schlosser and Thomas J. Fan on PyTorch core.
I’ve included the choice to carry out Studying Charge Warmup, utilizing the newest LR schedulers developed by Ilqar Ramazanli.
Different enhancements
Listed here are another notable enhancements added within the launch:
Alexander Soare and Francisco Massa have developed an FX-based utility which permits extracting arbitrary intermediate options from mannequin architectures.
Nikita Shulga has added help of CUDA 11.3 to TorchVision.
Zhongkai Zhu has mounted the dependency points of JPEG lib (this situation has precipitated main complications to lots of our customers).
In-progress & Subsequent-up
There are many thrilling new options under-development which didn’t make it on this launch. Listed here are just a few:
Moto Hira, Parmeet Singh Bhatia and I’ve drafted an RFC, which proposes a brand new mechanism for Mannequin Versioning and for dealing with meta-data related to pre-trained weights. This can allow us to help a number of pre-trained weights for every mannequin and fix related data corresponding to labels, preprocessing transforms and so on to the fashions.
I’m presently engaged on utilizing the primitives added by the “Batteries Included” challenge in an effort to enhance the accuracy of our pre-trained fashions. The goal is to realize best-in-class outcomes for the preferred pre-trained fashions supplied by TorchVision.
Philip Meier and Francisco Massa are engaged on an thrilling prototype for TorchVision’s new Dataset and Transforms API.
Prabhat Roy is engaged on extending PyTorch Core’s AveragedModel class to help the averaging of the buffers along with parameters. The dearth of this function is usually reported as bug and can allow quite a few downstream libraries and frameworks to take away their customized EMA implementations.
Aditya Oke wrote a utility which permits plotting the outcomes of Keypoint fashions on the unique photos (the function didn’t make it to the discharge as we obtained swamped and couldn’t assessment it in time 🙁 )
I’m constructing a prototype FX-utility which goals to to detect Residual Connections in arbitrary Mannequin architectures and modify the community so as to add regularization blocks (corresponding to StochasticDepth).
Lastly there are just a few new options in our backlog (PRs coming quickly):
I hope you discovered the above abstract fascinating. Any concepts on find out how to adapt the format of the weblog sequence are very welcome. Hit me up on LinkedIn or Twitter.
Image this: your dash demo ends at 11:30 a.m. By 11:35, an AI agent has mined the assembly transcript, opened three Pull Requests, generated user-facing docs, and even drafted launch notes. Your staff didn’t skip lunch, but the backlog simply received lighter. That’s the brand new cadence of software program improvement—and the one option to hit it constantly is to make each engineer an AI-powered engineer.
How Is AI Evolving the Roles of Software program Engineers?
Writing code? That’s now not the primary occasion. The times of engineers spending most of their time typing out syntax and fixing trivial bugs? Gone. AI has modified the sport, not by changing software program engineers, however by reshaping what their job really is.
In the present day, engineers are stepping right into a extra strategic position—suppose much less “code monkeys,” extra “system orchestrators.” As a substitute of handcrafting each line, builders now collaborate with AI fashions. Copilots are prompted to scaffold apps now. Brokers are deployed to deal with edge circumstances. Automation now replaces the time-consuming ops work that used to eat hours.
Are you able to see the shift? Engineers are spending extra time designing long-lasting techniques and fewer time coding in isolation. They’re asking higher questions. Not “How do I construct this function?” however “How do I form the system so the following ten options don’t struggle it?”
It’s now not about finishing duties. It’s about enabling scale. This mindset shift—towards system considering—is what separates quick groups from future-ready groups.
Even junior builders are feeling the shift. As a substitute of being caught debugging in silence, they’re reviewing AI ideas, studying why sure approaches work, and gaining real-time mentorship by means of suggestions loops constructed into clever tooling.
Let’s name it what it’s: a promotion.
Pace Up Product Improvement With AI Into the Combine! We Guarantee Protected AI Integration In Software program Improvement with a Human-in-the-Loop Strategy
Areas The place AI Is Augmenting the Capabilities of Software program Engineers
AI isn’t simply nudging productiveness. It’s rewiring the entire toolkit. From code technology to complicated simulation, it’s filling within the tedious gaps, accelerating suggestions loops, and, frankly, pampering engineers by letting them concentrate on the enjoyable stuff.
Right here’s the place the actual magic is occurring:
1. Faster, Extra Clever Programming
AI instruments like GitHub Copilot are already writing code facet by facet with builders. Nonetheless, that’s solely the start. Sooner or later, synthetic intelligence is not going to solely assist but in addition anticipate. It acknowledges context, suggests architectural patterns, identifies design errors early, and even explains trade-offs.
It’s not about sooner coding. It’s about smarter engineering. Assume past autocomplete. Engineers at the moment are utilizing AI to spin up boilerplate in seconds, recommend logic based mostly on earlier patterns, and even catch bugs as they code. The very best groups don’t simply code sooner—they code extra deliberately, handing off the grunt work to AI to allow them to architect with readability.
2. Automated Testing and QA (That Truly Works)
No one loves writing check circumstances, however AI doesn’t complain. It generates unit, integration, and even regression assessments—at scale. And it learns out of your system’s habits over time. Altair factors out that AI-driven simulation can pre-validate how a system will reply underneath completely different masses, configurations, or situations—earlier than it even hits staging. It’s like having a QA engineer who works 24/7 and by no means skips edge circumstances.
3. Design & Simulation with Superhuman Pace
In additional technical engineering domains—product design, mechanical techniques, data-heavy platforms—AI is unlocking one thing radical: real-time simulation. These fashions use AI to foretell system habits that used to take hours (or days) of compute time. With AI within the combine, engineers can check out infinite design tweaks—with out getting caught in a simulation backlog.
4. Sensible Documentation & Data Switch
No extra “go ask Ben.” Now it’s, “Verify the AI-generated doc.” It’s not simply sooner—it’s clearer. Transparency turns into the default.
5. Enhanced Choice-Making
AI isn’t simply helping with “doing”—it’s serving to with deciding. Instruments powered by data-driven fashions can consider trade-offs in structure, infrastructure, and useful resource allocation. Do you have to use serverless or containers? Ought to that ML pipeline be batched or streaming? AI doesn’t simply guess—it runs simulations, compares previous outcomes, and offers engineers suggestions backed by precise knowledge.
6. Augmented Collaboration
AI additionally performs the mediator. It bridges the hole between product, engineering, and design by translating objectives into technical ideas and nudging groups when alignment slips. Some groups are even embedding AI into their SDLC tooling so it might floor dangers, make clear necessities, or flag PRs that want a re-examination—earlier than the human even blinks.
7. Blurred Boundaries: Cross-Useful Superpowers
AI isn’t content material to remain in a single lane—and neither ought to your groups. The rise of AI is eradicating the silos between engineers, designers, and product leaders. Now, a developer can mock up a UI prototype. Even a UX designer can recommend deployment methods. All utilizing AI-enabled instruments. The outcome? Collaboration isn’t simply cross-functional anymore—it’s co-creative. Not a handshake, however a shared, clever canvas.
8. Group Interactions & Change related
Final however not least, tradition is altering together with expertise. Implementing AI contains greater than merely plugging within the related instruments. It’s about bringing your staff alongside. It’s not sufficient to show the how. The actual shift comes when individuals get the why.
Which means candid boards the place engineers ask, “Will this change me?” and management responds with readability. It means readiness assessments, pilot packages in low-risk zones, and structured studying communities. Executed proper, AI turns into a team-builder, not a wedge. AI isn’t simply including horsepower—it’s overhauling the engine. These are the hidden gears within the transformation —excessive impression, usually neglected, however completely important.
What’s clear is that this: AI isn’t a “software” within the previous sense of the phrase. It’s a collaborator. A tireless co-pilot. A data sponge.
Uncover How Fingent Is Remodeling Software program Improvement With AI!
How Can Fingent Facilitate the Development of AI-Pushed Engineering Transformation?
It takes greater than merely plugging in a flowery software and calling it a day to embrace AI. It’s about understanding when to intervene as a human, how to belief it, and the place to make use of it. The actual ability? Placing that steadiness between automation and instinct. That’s the place Fingent is available in.
We don’t simply construct with AI—we construct for AI-native engineering.
We begin by understanding your engineering DNA.
Your tech stack, your workflows, your product lifecycle—every part. Then we search for friction. The place is time leaking? The place is human bandwidth wasted? The place is velocity throttled by legacy code, outdated processes, or siloed techniques? That’s the place we apply AI—with surgical precision.
We embed intelligence into the SDLC, not simply bolt it on.
We combine AI the place it really strikes the needle: • Immediate-based code technology wired to your repo conventions. • Autonomous check technology that learns out of your previous bugs. • Pure language to job automation that turns voice notes into ready-to-run specs. • Brokers that triage tickets, monitor system well being, and repair frequent points earlier than your staff even logs in.
We coach your staff to evolve with the instruments.
AI doesn’t work with out people who know the right way to steer it. That’s why we prepare your engineers, product managers, and ops people to talk the language of AI: higher prompts, stronger oversight, cleaner design considering. We guarantee to roll out AI along with your staff so adoption sticks, and morale climbs.
We construct responsibly—with governance, not guesswork.
Fingent units up your AI workflows with guardrails baked in: • Mannequin transparency • Audit trails • Knowledge privateness • Moral use protocols No black-box chaos. Simply accountable innovation you possibly can belief.
Backside line? Fingent helps your engineering staff go from “making an attempt AI” to thriving with it. We deliver the blueprints, the instruments, and the hands-on expertise to show AI from a buzzword right into a enterprise benefit. As a result of on this new period, you don’t simply want extra code—you want smarter groups. And we all know the right way to construct them.
Knowledge analysts must work with massive quantities of data saved in databases. Earlier than they will create reviews or discover insights, they need to first pull the proper information and put together it to be used. That is the place SQL (Structured Question Language) is available in. SQL is a software that helps analysts retrieve information, clear it up, and manage it into the specified format.
On this article, we’ll take a look at crucial SQL queries that each information analyst ought to know.
# 1. Deciding on Knowledge with SELECT
The SELECT assertion is the muse of SQL. You’ll be able to select particular columns or use * to return all accessible fields.
SELECT title, age, wage FROM staff;
This question pulls solely the title, age, and wage columns from the staff desk.
# 2. Filtering Knowledge with WHERE
WHERE narrows rows to those who match your situations. It helps comparability and logical operators to create exact filters.
SELECT * FROM staff WHERE division="Finance";
The WHERE clause returns solely staff who belong to the Finance division.
# 3. Sorting Outcomes with ORDER BY
The ORDER BY clause kinds question ends in ascending or descending order. It’s used to rank data by numeric, textual content, or date values.
SELECT title, wage FROM staff ORDER BY wage DESC;
This question kinds staff by wage in descending order, so the highest-paid staff seem first.
# 4. Eradicating Duplicates with DISTINCT
The DISTINCT key phrase returns solely distinctive values from a column. It’s helpful when producing clear lists of classes or attributes.
SELECT DISTINCT division FROM staff;
DISTINCT removes duplicate entries, returning every division title solely as soon as.
# 5. Limiting Outcomes with LIMIT
The LIMIT clause restricts the variety of rows returned by a question. It’s usually paired with ORDER BY to show prime outcomes or pattern information from massive tables.
SELECT title, wage
FROM staff
ORDER BY wage DESC
LIMIT 5;
This retrieves the highest 5 staff with the very best salaries by combining ORDER BY with LIMIT.
# 6. Aggregating Knowledge with GROUP BY
The GROUP BY clause teams rows that share the identical values in specified columns. It’s used with combination features like SUM(), AVG(), or COUNT() to supply summaries.
SELECT division, AVG(wage) AS avg_salary
FROM staff
GROUP BY division;
GROUP BY organizes rows by division, and AVG(wage) calculates the typical wage for every group.
# 7. Filtering Teams with HAVING
The HAVING clause filters grouped outcomes after aggregation has been utilized. It’s used when situations depend upon combination values, comparable to totals or averages.
SELECT division, COUNT(*) AS num_employees
FROM staff
GROUP BY division
HAVING COUNT(*) > 10;
The question counts staff in every division after which filters to maintain solely departments with greater than 10 staff.
# 8. Combining Tables with JOIN
The JOIN clause combines rows from two or extra tables based mostly on a associated column. It helps retrieve linked information, comparable to staff with their departments.
SELECT e.title, d.title AS division
FROM staff e
JOIN departments d ON e.dept_id = d.id;
Right here, JOIN combines staff with their matching division names.
# 9. Combining Outcomes with UNION
UNION combines the outcomes of two or extra queries right into a single dataset. It robotically removes duplicates except you employ UNION ALL, which retains them.
SELECT title FROM staff UNION SELECT title FROM prospects;
This question combines names from each the staff and prospects tables right into a single record.
# 10. String Features
String features in SQL are used to control and rework textual content information. They assist with duties like combining names, altering case, trimming areas, or extracting elements of a string.
SELECT CONCAT(first_name, ' ', last_name) AS full_name, LENGTH(first_name) AS name_length FROM staff;
This question creates a full title by combining first and final names and calculates the size of the primary title.
# 11. Date and Time Features
Date and time features in SQL allow you to work with temporal information for evaluation and reporting. They will calculate variations, extract parts like 12 months or month, and alter dates by including or subtracting intervals. For instance, DATEDIFF() with CURRENT_DATE can measure tenure.
SELECT title, hire_date, DATEDIFF(CURRENT_DATE, hire_date) AS days_at_company FROM staff;
It calculates what number of days every worker has been with the corporate by subtracting their rent date from right this moment.
# 12. Creating New Columns with CASE
The CASE expression creates new columns with conditional logic, just like if-else statements. It allows you to categorize or rework information dynamically inside your queries.
SELECT title,
CASE
WHEN age < 30 THEN 'Junior'
WHEN age BETWEEN 30 AND 50 THEN 'Mid-level'
ELSE 'Senior'
END AS experience_level
FROM staff;
The CASE assertion creates a brand new column referred to as experience_level based mostly on age ranges.
# 13. Dealing with Lacking Values with COALESCE
COALESCE handles lacking values by returning the primary non-null worth from a listing. It’s generally used to interchange NULL fields with a default worth, comparable to “N/A.”
SELECT title, COALESCE(telephone, 'N/A') AS contact_number FROM prospects;
Right here, COALESCE replaces lacking telephone numbers with “N/A.”
# 14. Subqueries
Subqueries are queries nested inside one other question to supply intermediate outcomes. They’re utilized in WHERE, FROM, or SELECT clauses to filter, examine, or construct datasets dynamically.
SELECT title, wage FROM staff WHERE wage > (SELECT AVG(wage) FROM staff);
This question compares every worker’s wage to the corporate’s common wage by utilizing a nested subquery.
# 15. Window Features
Window features carry out calculations throughout a set of rows whereas nonetheless returning particular person row particulars. They’re generally used for rating, working totals, and evaluating values between rows.
SELECT title, wage, RANK() OVER (ORDER BY wage DESC) AS salary_rank FROM staff;
The RANK() operate assigns every worker a rating based mostly on wage, with out grouping the rows.
# Conclusion
Mastering SQL is without doubt one of the most respected expertise for any information analyst, because it offers the muse for extracting, remodeling, and decoding information. From filtering and aggregating to becoming a member of and reshaping datasets, SQL empowers analysts to transform uncooked data into significant insights that drive decision-making. By changing into proficient in important queries, analysts not solely streamline their workflows but additionally guarantee accuracy and scalability of their analyses.
Jayita Gulati is a machine studying fanatic and technical author pushed by her ardour for constructing machine studying fashions. She holds a Grasp’s diploma in Pc Science from the College of Liverpool.
We wish to hear from you! Share your ideas within the feedback and vote within the ballot under — your take could be featured in a future roundup.
The Samsung Galaxy S launch is at all times one of many 12 months’s most anticipated occasions, and the 2026 version may convey some surprises.
We’ve already seen just a few particulars in regards to the Galaxy S26 sequence, together with the Extremely’s dimensions, a doable new identify for the center mannequin, and the potential use of the Exynos 2600 chipset within the two extra reasonably priced fashions. Nevertheless, a brand new report from Korea means that Samsung may also use its homegrown chip within the Extremely mannequin, too. As a substitute of utilizing the Snapdragon 8 Gen 5 within the Galaxy S26 Extremely, as has been customary for a number of generations, Samsung may totally decide to the Exynos 2600 for all of its flagship fashions.
It’s essential to notice that the report isn’t fully convincing, so I counsel taking it with a grain of salt. Nevertheless, it does spotlight an intriguing chance for Samsung and a few potential considerations for patrons.
Don’t wish to miss one of the best from Android Authority?
If the Exynos 2600 is as pacey and punchy as Samsung hopes, it could possibly be a greater choice than the Snapdragon 8 Gen 5, which might sometimes be most well-liked for the Galaxy S26 Extremely. With its rumored 2nm manufacturing course of and NVIDIA’s Xclipse 950 GPU, it might additionally excel in battery life and gaming efficiency. It won’t be a foul transfer if Samsung decides to rely by itself expertise this time.
In the end, the shoppers resolve, and Exynos hasn’t been extremely praised in recent times. Many customers could be hesitant in regards to the absence of a Snapdragon chipset within the flagship Samsung. Whereas it could possibly be a efficiency breakthrough, utilizing Exynos within the Extremely may negatively influence gross sales.
It’s most likely too early to foretell Samsung’s choices, however I’m inquisitive about your ideas on an Exynos-powered Galaxy S26 Extremely. Would this modification your thoughts about shopping for the flagship Samsung, or would it not not have an effect on your determination? Moreover, what are your ideas in regards to the Exynos 2600 in Samsung’s different potential S26 fashions: the S26 Professional and commonplace S26?
Listed below are some extra questions:
What can be your most well-liked chipset for the Galaxy S26 Extremely: the Snapdragon 8 Gen 5, or the Exynos 2600?
What’s your notion of the Exynos chipset line?
What would Samsung have to show so that you can belief Exynos once more?
How essential is a smartphone’s chipset to you in comparison with its different options?
Which chipset would you fairly see within the Samsung Galaxy S26 Extremely?
20 votes
Would you purchase the Galaxy S26 Extremely if it used an Exynos chip?
24 votes
👇 And you probably have a selected remark associated to your ballot alternative, or wish to reply any of the questions posed above, remember to have your say within the feedback under.
Thanks for being a part of our group. Learn our Remark Coverage earlier than posting.
That is an try at reproducing the evaluation of Part 2.7 of Bayesian Knowledge Evaluation, third version (Gelman et al.), on kidney most cancers charges within the USA within the Nineteen Eighties. I’ve achieved my finest to wash the info from the unique. Andrew wrote a weblog put up to “disillusion [us] in regards to the reproducibility of textbook evaluation”, wherein he refers to this instance. This may then be an try at reillusionment…
Within the information, the columns dc and dc.2 correspond (I believe) to the dying counts attributable to kidney most cancers in every county of the USA, respectively in 1908-84 and 1985-89. The columns pop and pop.2 are some measure of the inhabitants within the counties. It’s not clear to me what the opposite columns characterize.
Easy mannequin
Let be the inhabitants on county , and the variety of kidney most cancers deaths in that county between 1980 and 1989. A easy mannequin is the place is the unknown parameter of curiosity, representing the incidence of kidney most cancers in that county. The utmost chance estimator is .
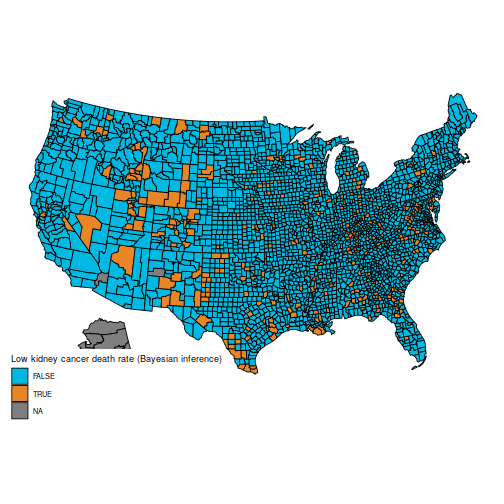
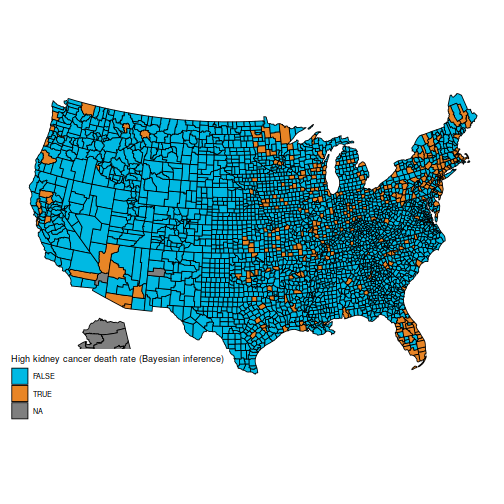
Specifically, the unique query is to grasp these two maps, which present the counties within the first and final decile for kidney most cancers deaths.
plot_usmap("counties", information=d, values="cancerlow") +
scale_fill_discrete(h.begin = 200,
identify = "Low fee of kidney most cancers deaths")
These maps are suprising, as a result of the counties with the best kidney most cancers dying fee, and people with the bottom, are considerably comparable: principally counties in the midst of the map.
(Additionally, be aware that the info for Alaska are lacking. You may conceal Alaska on the maps by including the parameter embrace = statepop$full[-2] to calls to plot_usmap.)
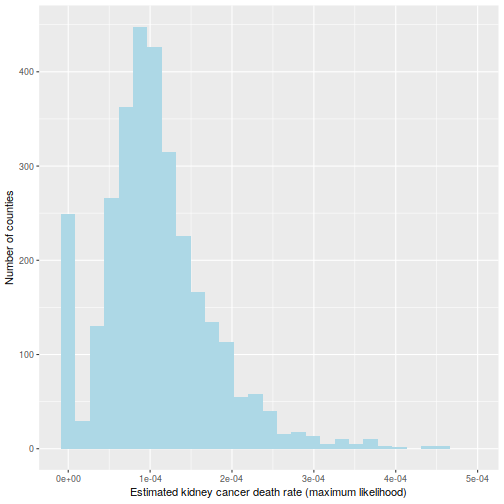
The rationale for this sample (as defined in BDA3) is that these are counties with a low inhabitants. Certainly, a typical worth for is round . Take a county with a inhabitants of 1000. It’s more likely to don’t have any kidney most cancers deaths, giving and placing it within the first decile. But when it occurs to have a single dying, the estimated fee jumps to (10 occasions the typical fee), placing it within the final decile.
That is hinted at on this histogram of the :
ggplot(information=d, aes(d$thetahat)) +
geom_histogram(bins=30, fill="lightblue") +
labs(x="Estimated kidney most cancers dying fee (most chance)",
y="Variety of counties") +
xlim(c(-1e-5, 5e-4))
Bayesian strategy
When you have ever adopted a Bayesian modelling course, you might be in all probability screaming that this requires a hierarchical mannequin. I agree (and I’m fairly certain the authors of BDA do as effectively), however here’s a extra primary Bayesian strategy. Take a standard distribution for all of the ; I’ll go for and , which is barely vaguer than the prior utilized in BDA. Clearly, it’s best to attempt numerous values of the prior parameters to examine their affect.
The prior is conjugate, so the posterior is . For small counties, the posterior might be extraordinarily near the prior; for bigger counties, the chance will take over.
It’s often a disgrace to make use of solely level estimates, however right here it is going to be enough: allow us to compute the posterior imply of . As a result of the prior has a robust influence on counties with low inhabitants, the histogram seems very totally different:
And the maps of counties within the first and final decile are actually a lot simpler to differentiate; as an example, Florida and New England are closely represented within the final decile. The counties represented listed here are principally populated counties: these are counties for which we’ve got cause to imagine that they’re on the decrease or increased finish for kidney most cancers dying charges.
An necessary caveat: I’m not an knowledgeable on most cancers charges (and I count on a few of the vocabulary I used is ill-chosen), nor do I declare that the info listed here are appropriate (from what I perceive, many changes should be made, however they aren’t detailed in BDA, which explains why the maps are barely totally different). I’m merely posting this as a reproducible instance the place the naïve frequentist and Bayesian estimators differ appreciably, as a result of they deal with pattern dimension in numerous methods. I’ve discovered this instance to be helpful in introductory Bayesian programs, because the distinction is straightforward to understand for college kids who’re new to Bayesian inference.
This video is a part of “Improvements In: RSV,” an editorially unbiased particular report that was produced with monetary assist from MSD, Sanofi and AstraZeneca.
Zachary Rubin: Holy cow, people. We’re getting into RSV season, and for infants, this sickness can flip critical quick. Right here’s what you must know.
On supporting science journalism
Should you’re having fun with this text, take into account supporting our award-winning journalism by subscribing. By buying a subscription you might be serving to to make sure the way forward for impactful tales in regards to the discoveries and concepts shaping our world in the present day.
I’m Dr. Zachary Rubin, double board-certified pediatrician and allergist, and each fall I see an increase in RSV circumstances in my clinic. RSV, or respiratory syncytial virus, is the main reason behind toddler hospitalization within the U.S.
At first, RSV would possibly look like only a chilly, but when your child begins respiratory quick, pulling in on the ribs or having bother feeding, it might be extra critical.
The excellent news? We now have instruments to battle again. There are new monoclonal antibody therapies that may assist infants battle off the virus, and pregnant mothers may even get vaccinated to cross antibodies to their infants earlier than beginning.
Remember to wash your arms, keep away from crowded indoor areas or masks up throughout surges, and don’t ignore wheezing or labored respiratory to maintain your self and family members protected throughout this RSV season.
It’s Time to Stand Up for Science
Should you loved this text, I’d wish to ask on your assist. Scientific American has served as an advocate for science and business for 180 years, and proper now stands out as the most crucial second in that two-century historical past.
I’ve been a Scientific American subscriber since I used to be 12 years outdated, and it helped form the way in which I take a look at the world. SciAm at all times educates and delights me, and conjures up a way of awe for our huge, stunning universe. I hope it does that for you, too.
Should you subscribe to Scientific American, you assist be certain that our protection is centered on significant analysis and discovery; that now we have the assets to report on the selections that threaten labs throughout the U.S.; and that we assist each budding and dealing scientists at a time when the worth of science itself too usually goes unrecognized.
How particular person and neighbourhood socioeconomic disadvantages collectively have an effect on health-related behaviour
Yinjie Zhu
In our research lately printed within the IJE, we discovered that socioeconomically deprived people had been extra more likely to have worse health-related way of life behaviour than their neighbours, even when they lived in neighbourhoods with little general socioeconomic drawback.
We additionally noticed a “double jeopardy” impact: an unhealthier way of life was discovered amongst folks with better particular person drawback residing in deprived neighbourhoods.
Why is way of life behaviour vital to well being?
Unfavorable way of life behaviours — equivalent to unhealthy weight loss plan, smoking, inadequate bodily exercise and alcohol misuse – may end up in persistent ailments, equivalent to weight problems and diabetes, and are related to decrease life expectancy and better mortality. Modifying these behaviours can deal with a variety of ailments. Nonetheless, neighbourhood socioeconomic standing is equally vital for well being and wellbeing.
How is socioeconomic drawback associated to way of life behaviour?
Socioeconomic drawback normally exists at two ecological ranges: particular person and neighbourhood. Particular person drawback is commonly influenced by training and earnings, whereas the neighbourhood serves as a platform for well being assets and the unfold of sure well being beliefs and social norms.
In our research, utilizing the Lifelines cohort and Biobank of 77,244 members residing within the northern Netherlands, we estimated socioeconomic drawback on the particular person and neighbourhood ranges. Neighbourhood drawback was based mostly on earnings and social safety advantages, whereas particular person drawback moreover thought of training and unemployment.
We investigated the joint impact and interrelation of those disadvantages on health-related way of life behaviours (weight loss plan high quality, smoking, alcohol consumption, hours of sleep, hours of watching TV and bodily exercise). These behaviours had been summed to create a life-style threat index, with the next index representing an unhealthier way of life.
What’s the “double jeopardy” impact?
Merely put, in our research, folks with the unhealthiest existence had the best ranges of each particular person and neighbourhood disadvantages. Nonetheless, the impression of particular person drawback was stronger in additional deprived neighbourhoods.
People who find themselves much less individually deprived will likely be extra resilient and proof against their neighbourhood drawback as a result of they’re extra more likely to entry well being assets, have the next degree of self-perceived management and have better information of the best way to keep away from unhealthy way of life behaviour.
What’s the lesson for coverage makers?
The double jeopardy impact can present sensible steering to coverage makers and public well being practitioners. It tells us that practising an unhealthy way of life will depend on each particular person and neighbourhood disadvantages. This requires built-in public insurance policies specializing in, and interesting with, folks’s environment in addition to the folks themselves.
For instance, a public coverage aiming to extend bodily exercise might contain constructing extra sports activities amenities and enlarging the neighbourhood’s playground space, in addition to organising sports activities actions and disseminating well being details about bodily exercise to folks residing within the neighbourhood.
Furthermore, future public well being initiatives ought to take into account offering extra well being assets, and enabling higher entry to them, in addition to growing social alternatives, equivalent to training and cultural actions, for socioeconomically deprived neighbourhoods, whereas additionally focusing on particular person behaviour. Solely then can we work in direction of attaining a wholesome way of life for all and mitigate society’s persistent well being inequalities.
Learn extra:
Zhu Y, Duan M-J, Riphagen IJ, et al. Separate and mixed results of particular person and neighbourhood socio-economic drawback on health-related way of life threat components: a multilevel evaluation. Int J Epidemiol 2021; 24 April. doi: 10.1093/ije/dyab079.
Yinjie Zhu holds a Grasp’s diploma in diet and rural improvement from Ghent College and is a PhD candidate within the Division of Inner Medication (Division of Nephrology) on the College Medical Centre Groningen, The Netherlands. She is keen on how socioeconomic standing impacts way of life, dietary standing and well being outcomes in a basic inhabitants.
Duflo et al (2008) describe this in additional element:
“Because the covariates for use should be chosen upfront with the intention to keep away from specification looking out and knowledge mining, they can be utilized to stratify (or block) the pattern with the intention to enhance the precision of estimates. This system (¯rst proposed by Fisher (1926)) includes dividing the pattern into teams sharing the identical or related values of sure observable traits. The randomization ensures that therapy and management teams might be related in expectation. However stratification is used to make sure that alongside necessary observable dimensions that is additionally true in apply within the pattern….blocking is extra environment friendly than controlling ex publish for these variables, because it ensures an equal proportion of handled and untreated unit inside every block and subsequently minimizes variance.”
In addition they elaborate on blocking if you find yourself focused on subgroup evaluation:
“Other than decreasing variance, an necessary cause to undertake a stratified design is when the researchers have an interest within the impact of this system on particular subgroups. If one is within the impact of this system on a sub-group, the experiment will need to have sufficient energy for this subgroup (every sub-group constitutes in some sense a definite experiment). Stratification in accordance with these subgroups then make sure that the ratio between therapy and management items is decided by the experimenter in every sub-group, and might subsequently be chosen optimally. It’s also an assurance for the reader that the sub-group evaluation was deliberate upfront.”
Dijkman et al (2009) focus on subgroup evaluation in blocked or stratified designs in additional element:
“When stratification of randomization relies on subgroup variables, it’s extra doubtless that therapy assignments inside subgroups are balanced, making every subgroup a small trial. As a result of randomization makes it doubtless for the subgroups to be related in all facets besides therapy, legitimate inferences about therapy efficacy inside subgroups are prone to be drawn. In publish hoc subgroup analyses, the subgroups are sometimes incomparable as a result of no stratified randomization is carried out. Moreover, stratified randomization is fascinating because it forces researchers to outline subgroups earlier than the beginning of the examine.”
Each of those accounts appear very a lot in step with one another by way of serious about randomization inside subgroups making a mini trial the place causal inferences could be drawn. However I feel the important thing factor to contemplate is they’re referring to comparisons made WITHIN sub teams and never essentially BETWEEN subgroups.
Gerber and Inexperienced focus on this in one in all their chapters on evaluation of block randomized experiments :
“No matter whether or not one controls for blocks utilizing weighted regression or regression with indicators for blocks, they key precept is to match therapy and management topics inside blocks, not between blocks.”
After we begin to evaluate therapy and management items BETWEEN blocks or subgroups we’re primarily decoding covariates and this can’t be finished with a causal interpretation. Inexperienced and Gerber focus on an instance associated to variations within the efficiency of Hindu vs. Muslim colleges.
“it might simply be that faith is a marker for a bunch of unmeasured attributes which can be correlated with instructional outcomes. The set of covariates included in an experimental evaluation needn’t be an entire record of things that have an effect on outcomes: the truth that some elements are ignored or poorly measured isn’t a supply of bias when the purpose is to measure the typical therapy impact of the random intervention. Omitted variables and mismeasurement, nonetheless, can result in sever bias if the purpose is to attract causal inferences concerning the results of covariates. Causal interpretation of the covariates encounters all the threats to inference related to evaluation of observational knowledge.”
In different phrases, these sorts of comparisons face the the identical challenges associated to decoding management variables in a regression in an observational setting (see Keele, 2020).
However why would not randomization inside faith enable us to make causal statements about these comparisons? Let’s take into consideration a special instance. Suppose we wished to measure therapy results for some form of instructional intervention and we have been focused on subgroup variations within the end result between private and non-private excessive colleges. We might randomly assign therapies and controls throughout the public faculty inhabitants and do the identical throughout the non-public faculty inhabitants. We all know total therapy results could be unbiased as a result of the college sort could be completely balanced (as a substitute of balanced simply on common in a totally random design) and we’d count on all different necessary confounders to be balanced between therapies and controls on common.
We additionally know that throughout the group of personal colleges the therapy and controls ought to at the very least on common be balanced for sure confounders (median family earnings, trainer’s schooling/coaching/expertise, and maybe an unobservable confounder associated to pupil motivation).
Lets say the identical factor about comparisons WITHIN the subgroup of public colleges. However there isn’t any cause to imagine that the handled college students in non-public colleges could be similar to the handled college students in public colleges as a result of there isn’t any cause to count on that necessary confounders could be balanced when making the comparisons.
Assume we’re taking a look at variations in first semester school GPA. Possibly throughout the non-public subgroup we discover that handled handled college students on common have a primary semester school GPA that’s .25 factors greater the comparable management group. However throughout the public faculty subgroup, this variations was solely .10. We are able to say that there’s a distinction in outcomes of .15 factors between teams however can we are saying that is causal? Is the distinction actually associated to highschool sort or is faculty sort actually a proxy for earnings, trainer high quality, or motivation? If we elevated motivation or earnings within the public colleges would that make up the distinction? We would do higher if our design initially stratified on all of those necessary confounders like earnings and trainer schooling. Then we might evaluate college students in each private and non-private colleges with related household incomes and academics of comparable credentials. However…there isn’t any cause to imagine that pupil motivation could be balanced. We will not block or stratify on an unobservable confounder. Once more, as Gerber and Inexperienced state, we discover ourselves in a world that borders between experimental and non-experimental strategies. Merely, the subgroups outlined by any specific covariate that itself isn’t or can’t be randomly assigned might have totally different potential outcomes. What we are able to say from these outcomes is that faculty sort predicts the end result however doesn’t essentially trigger it.
Gerber and Inexperienced expound on this concept:
“Subgroup evaluation needs to be considered exploratory or descriptive evaluation….if the purpose is just to foretell when therapy results might be giant, the researcher needn’t have a accurately specified causal mannequin that explains therapy results (see to elucidate or predict)….noticing that therapy results are usually giant in some teams and absent from others can present necessary clues about why therapies work. However resist the temptation to assume subgroup variations set up the causal impact of randomly various one’s subgroup attributes.”
References
Dijkman B, Kooistra B, Bhandari M; Proof-Primarily based Surgical procedure Working Group. Tips on how to work with a subgroup evaluation. Can J Surg. 2009;52(6):515-522.
Duflo, Esther, Rachel Glennerster, and Michael Kremer. 2008. “Utilizing Randomization in Improvement Economics Analysis: A Toolkit.” T. Schultz and John Strauss, eds., Handbook of Improvement Economics. Vol. 4. Amsterdam and New York: North Holland.
Gerber, Alan S., and Donald P. Inexperienced. 2012. Discipline Experiments: Design, Evaluation, and Interpretation. New York: W.W. Norton
Keele, L., Stevenson, R., & Elwert, F. (2020). The causal interpretation of estimated associations in regression fashions. Political Science Analysis and Strategies, 8(1), 1-13. doi:10.1017/psrm.2019.31
After I first began messing round with code, rounded corners required 5 background photos or an picture sprite probably created in Photoshop, so when border-radius got here onto the scene, I bear in mind everyone pondering that it was the most effective factor ever. Internet designs had been very sq. on the time, so to have border-radius was tremendous cool, and it saved us plenty of time, too.
Chris’ border-radius article from 2009, which on the time of writing is 16 years outdated (wait, how outdated am I?!), consists of vendor prefixes for older net browsers, together with “outdated Konqueror browsers” (-khtml-border-radius). What a time to be alive!
We’re a lot much less enthusiastic about rounded corners these days. In truth, sharp corners have made a comeback and are simply as standard now, as are squircles (square-ish circles or circle-y squares, take your decide), which is precisely what the corner-shape CSS property permits us to create (along with many different cool UI results that I’ll be strolling you thru in the present day).
On the time of writing, solely Chrome 139 and above helps corner-shape, which have to be used with the border-radius property or/and any of the associated particular person properties (i.e., border-top-left-radius, border-top-right-radius, border-bottom-right-radius, and border-bottom-left-radius):
Within the instance above, it’s as simple as utilizing corner-shape: bevel for the snipped corners impact after which border-bottom-right-radius: 16px for the scale.
We will do the identical factor and it actually works with a cyberpunk aesthetic:
Slanted sections utilizing corner-shape: bevel
Slanted sections is a visible impact that’s much more standard, in all probability not going wherever, and once more, helps components to look so much much less just like the containers that they’re.
Earlier than we dive in although, it’s necessary to understand that every border radii has two semi-major axes, a horizontal axis and a vertical axis, with a ‘level’ (to make use of vector terminology) on every axis. Within the instance above, each are set to 16px, so each factors transfer alongside their respective axis by that quantity, away from their nook after all, after which the beveled line is drawn between them. Within the slanted part instance under, nevertheless, we have to provide a special level worth for every axis, like this:
The primary level strikes alongside 100% of the horizontal axis whereas the second level travels 50px of the vertical axis, after which the beveled line is drawn between them, creating the slant that you simply see above.
By the way in which, having totally different values for every axis and border radius is precisely how these cool border radius blobs are made.
Sale tags utilizing corner-shape: spherical bevel bevel spherical
You’ve see these sale tags on nearly each e-commerce web site, both as photos or with rounded corners and never the sharp half (different methods simply aren’t definitely worth the bother). However now we are able to carve out the right form utilizing two various kinds of corner-shape without delay, in addition to an entire set of border radius values:
You’ll want corner-shape: spherical bevel bevel spherical to begin off. The order flows clockwise, ranging from the top-left, as follows:
top-left
top-right
bottom-right
bottom-left
Similar to with border-radius. You can omit some values, inflicting them to be inferred from different values, however each the inference logic and ensuing worth syntax lack readability, so I’d simply keep away from this, particularly since we’re about to discover a extra advanced border-radius:
Left of the ahead slash (/) we have now the horizontal-axis values of every nook within the order talked about above, and on the proper of the /, the vertical-axis values. So, to be clear, the primary and fifth values correspond to the identical nook, as do the second and sixth, and so forth. You’ll be able to unpack the shorthand if it’s simpler to learn:
Up till now, we’ve probably not wanted to totally perceive the border radius syntax. However now that we have now corner-shape, it’s undoubtedly price doing so.
As for the precise values, 16px corresponds to the spherical corners (this one’s simple to grasp) whereas the 48px 50% values are for the bevel ones, which means that the corners are ‘drawn’ from 48px horizontally to 50% vertically, which is why and the way they head into some extent.
Relating to borders — sure, the sharp components would look nicer in the event that they had been barely rounded, however utilizing borders and defines on these components yields unpredictable (however I think supposed) outcomes because of how browsers draw the corners, which sucks.
Arrow crumbs utilizing the identical methodology
Yep, identical factor.
We primarily have a grid row with adverse margins, however as a result of we are able to’t create ‘inset’ arrows or use borders/outlines, we have now to create an impact the place the pretend borders of sure arrows bleed into the following. That is performed by nesting the very same form within the arrows after which making use of one thing to the impact of padding-right: 3px, the place 3px is the worth of the would-be border. The code feedback under ought to clarify it in additional element (the whole code in the Pen is sort of fascinating, although):
ol {
/* Clip n’ spherical */
overflow: clip;
border-radius: 16px;
li {
/* Arrow colour */
background: hsl(270 100% 30%);
/* Reverses the z-indexes, making the arrows stack */
/* Outcome: 2, 1, 0, ... (sibling-x requires Chrome 138+) */
z-index: calc((sibling-index() * -1) + sibling-count());
&:not(:last-child) {
/* Arrow width */
padding-right: 3px;
/* Arrow form */
corner-shape: bevel;
border-radius: 0 32px 32px 0 / 0 50% 50% 0;
/* Pull the following one into this one */
margin-right: -32px;
}
a {
/* Similar form */
corner-shape: inherit;
border-radius: inherit;
/* Overlay background */
background: hsl(270 100% 50%);
}
}
}
Tooltips utilizing corner-shape: scoop
To create this tooltip fashion, I’ve used a popover, anchor positioning (to place the caret relative to the tooltip), and corner-shape: scoop. The caret form is identical because the arrow form used within the examples above, so be at liberty to modify scoop to bevel for those who desire the basic triangle tooltips.
A fast walkthrough:
Don’t eat yellow snow
#tooltip {
/* Outline anchor */
anchor-name: --tooltip;
/* Vital reset */
margin: 0;
/* Heart vertically */
align-self: anchor-center;
/* Pin to proper aspect + 15 */
left: calc(anchor(proper) + 15px);
&::after {
/* Create caret */
content material: "";
width: 5px;
peak: 10px;
corner-shape: scoop;
border-top-left-radius: 100% 50%;
border-bottom-left-radius: 100% 50%;
/* Anchor to tooltip */
position-anchor: --tooltip;
/* Heart vertically */
align-self: anchor-center;
/* Pin to left aspect */
proper: anchor(left);
/* Popovers have this already (required in any other case) */
place: mounted;
}
}
Should you’d reasonably these had been hover-triggered, the upcoming Curiosity Invoker API is what you’re searching for.
Life like highlighting utilizing corner-shape: squircle bevel
The component, used for semantic highlighting, defaults with a yellow background, but it surely doesn’t precisely create a highlighter impact. By including the next two strains of CSS, which admittedly I found by experimenting with fully random values, we are able to make it look extra like a hand-waved spotlight:
We will additionally use squircle by itself to create these fancy-rounded app icons, or use them on buttons/playing cards/kind controls/and so on. for those who assume the ‘outdated’ border radius is beginning to look a bit stale:
Hand-drawn containers utilizing the identical methodology
Similar factor, solely bigger. Type of appears like a hand-drawn field?
Notched border radii are ugly and I gained’t hear in any other case. I don’t assume you’ll need to use them to create a visible impact, however I’ve discovered that they’re helpful for background clipping for those who set the irrelevant axis to 50% and the axis of the aspect that you simply need to clip by the quantity that you simply need to clip it by. So for those who needed to clip 30px off the background from the left for instance, you’d select 30px for the horizontal axes and 50% for the vertical axes (for the -left-radius properties solely, after all).
So, corner-shape is definitely a helluva lot of enjoyable. It definitely has extra makes use of than I anticipated, and little question with some experimentation you’ll provide you with some extra. With that in thoughts, I’ll go away it to you CSS-Tricksters to fiddle with (bear in mind although, you’ll have to be utilizing Chrome 139 or greater).
As a parting present, I go away you with this very cool however fully ineffective CSS Tie Fighter, made with corner-shape and anchor positioning:
Entry the code to this tutorial and all different 500+ tutorials on PyImageSearch
Enter your electronic mail handle beneath to study extra about PyImageSearch College (together with how one can obtain the supply code to this submit):
What’s included in PyImageSearch College?
Quick access to the code, datasets, and pre-trained fashions for all 500+ tutorials on the PyImageSearch weblog
Excessive-quality, properly documented supply code with line-by-line explanations (guaranteeing you recognize precisely what the code is doing)
Jupyter Notebooks which can be pre-configured to run in Google Colab with a single click on
Run all code examples in your net browser — no dev setting configuration required!
Help for all main working techniques (Home windows, macOS, Linux, and Raspbian)
Full entry to PyImageSearch College programs
Detailed video tutorials for each lesson
Certificates of Completion for all programs
New programs added each month! — keep on prime of state-of-the-art tendencies in laptop imaginative and prescient and deep studying
PyImageSearch College is de facto one of the best Laptop Visions “Masters” Diploma that I want I had when beginning out. With the ability to entry all of Adrian’s tutorials in a single listed web page and with the ability to begin enjoying round with the code with out going by way of the nightmare of organising every part is simply superb. 10/10 would advocate.
Sanyam BhutaniMachine Studying Engineer and 2x Kaggle Grasp






 , and
, and  the variety of kidney most cancers deaths in that county between 1980 and 1989. A easy mannequin is
the variety of kidney most cancers deaths in that county between 1980 and 1989. A easy mannequin is 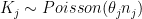 the place
the place 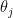 is the unknown parameter of curiosity, representing the incidence of kidney most cancers in that county. The utmost chance estimator is
is the unknown parameter of curiosity, representing the incidence of kidney most cancers in that county. The utmost chance estimator is 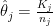 .
.
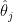 is round
is round 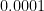 . Take a county with a inhabitants of 1000. It’s more likely to don’t have any kidney most cancers deaths, giving
. Take a county with a inhabitants of 1000. It’s more likely to don’t have any kidney most cancers deaths, giving 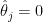 and placing it within the first decile. But when it occurs to have a single dying, the estimated fee jumps to
and placing it within the first decile. But when it occurs to have a single dying, the estimated fee jumps to  (10 occasions the typical fee), placing it within the final decile.
(10 occasions the typical fee), placing it within the final decile. :
:
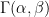 distribution for all of the
distribution for all of the 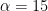 and
and  , which is barely vaguer than the prior utilized in BDA. Clearly, it’s best to attempt numerous values of the prior parameters to examine their affect.
, which is barely vaguer than the prior utilized in BDA. Clearly, it’s best to attempt numerous values of the prior parameters to examine their affect.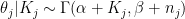 . For small counties, the posterior might be extraordinarily near the prior; for bigger counties, the chance will take over.
. For small counties, the posterior might be extraordinarily near the prior; for bigger counties, the chance will take over.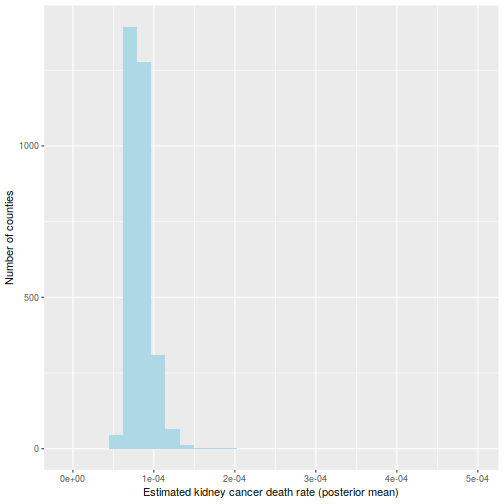



















{kind=link}