Ha-ha! No, that’s not it. It’s that in the course of scripting this column that was going to be in regards to the MacBook Neo, Apple introduced that Tim Cook dinner can be turning over the reins to John Ternus as of September 1st of this 12 months, and now the Macalope has to one way or the other make what he’s already written make sense within the context of this govt change. That is extraordinarily impolite timing on the a part of Apple. Very thoughtless. The Macalope sleeps a full third of the day. Is it so onerous to concern huge bulletins whereas he’s asleep?
Anyway, let’s see if we will take the elements available and make a meal.
Because the Macalope famous final week, gross sales of the MacBook Neo are exceeding expectations. This creates a little bit of an issue for Apple because it makes use of binned iPhone A18 Professional processors for the Neo so it could possibly’t simply spin up manufacturing to get extra.
Writing for 9to5Mac, Michael Burkhardt has an choice for Apple: increase the kind of chips it places into the MacBook Neo to incorporate the bottom stage as an alternative of simply the Professional.
Who says you possibly can’t bin ‘em all?
The Macalope believes he’s legally obligated to say “Hey-yo!” after a joke like that so…
Hey-yo!
Let it by no means be stated he was not in full compliance with the legislation.
Along with {hardware} adjustments, Apple may simply spin up extra manufacturing and sacrifice slightly margin, it may increase the worth slightly, or it may do nothing and preserve the MacBook Neo as a hard-to-get merchandise.
However the greater level is, a product promoting higher than you thought it could is not in any approach a foul factor.
If you happen to’d wish to obtain common information and updates to your inbox, join our newsletters, together with The Macalope and Apple Breakfast, David Value’s weekly, bite-sized roundup of all the most recent Apple information and rumors.
Foundry
For funsies, let’s see how the esteemed competitors is dealing with this. Certainly Microsoft and its allies have some nice concepts on easy methods to counter Apple’s most cost-effective laptop computer ever.
Uhhh, okay, that’s one solution to react to the Neo. It’s not a good approach, however it’s a technique.
As Home windows Central’s Zac Bowden opines: “That’s insane.” Already any of Apple’s choices from spending extra to doing completely nothing appear higher as compared.
However, wait, that’s not the one factor Microsoft is doing.
…12 months of free Microsoft 365 Premium and Xbox Recreation Go Final…
Cool. Cool. You realize, it’s best to throw in a “Examine Onerous” poster whilst you’re at it to actually spherical out the bundle.
Shade the Macalope jaded however he doesn’t assume this bundle is de facto going to maneuver the needle a lot on gross sales.
Since we now need to tie this again to John Ternus taking on as Apple CEO (thanks once more, Apple), this isn’t the one parting present Tim Cook dinner has given the incoming prime canine.
Based on latest survey, nearly 4 occasions as many Android customers indicated they have been contemplating switching to the iPhone than the reverse. iPhone loyalty was as much as 96 % as Tim Cook dinner will get able to go on his “I ❤️CUSTOMER SAT” t-shirt to John Ternus. Android loyalty was excessive, however a full ten factors decrease.
Suffice it to say, John Ternus isn’t inheriting your father’s Apple. Initially, your father by no means ran Apple, Scott. All these tales he advised you about his trials and tribulations working Apple within the mid-Nineteen Nineties? He made all that up. Your father offered orthopedic footwear.
However Ternus is getting an Apple that’s just about on the prime of its sport whereas exhibiting a number of indicators of not maintaining its eyes on the basics (a minimum of it’s not the one one). If there was a brief bit of recommendation the Macalope may cram in right here on the finish to provide to Ternus to make this column seem like nicely thought out prematurely it’s this: make issues individuals need. That’s it. Steve Jobs would let you know that folks don’t know what they need till you present it to them. That’s typically true, however AI by and huge isn’t it. Whereas it has makes use of, nobody has been pleasantly shocked by a startling new expertise that always appears greatest suited to supply CEOs with one other excuse to put off staff.
The MacBook Neo is an inexpensive however succesful entry-level pc to the Mac ecosystem that the corporate constructed with elements that fell on the manufacturing unit room flooring. This advantages clients and Apple. Begin there and see the place it takes you.
Local weather change could also be worsening dietary issues for already susceptible kids.
An evaluation of information from about 6.5 million younger kids in Brazil exhibits that the upper the temperature, the upper the probabilities of youngster malnutrition. Every 1 diploma Celsius rise in native temperatures above 26° C (about 79° Fahrenheit) correlates with a ten % larger probability of being underweight and an 8 % improve within the odds of acute and persistent malnutrition, researchers report within the February Lancet Planetary Well being. The situation can result in lifelong well being issues and even loss of life.
“Because the Eighties, Brazil has strived to scale back youngster malnutrition. Now, the nation is being affected by local weather change, and this might assist reverse the progress we’ve made,” says diet researcher Priscila Ribas of the Oswaldo Cruz Basis’s Heart for Knowledge and Information Integration for Well being in Salvador, Brazil.
Ribas and colleagues checked out knowledge from 2007 to 2018 on kids between 1 and 5 years previous who underwent routine peak and weight measurements required to obtain help from social applications. “We checked out a wider group which is already underprivileged, since they depend on federal assist. Nonetheless, probably the most susceptible inside this group have been probably the most affected,” she says.
Indigenous kids and people from Brazil’s North and Northeast areas (the nation’s poorest) have been the toughest hit, as have been these in rural and poor city areas. For instance, 1 in 4 Indigenous kids have been stunted, that means they have been unusually quick for his or her age — a fee greater than twice that of different races and ethnicities.
Over the 10-year research interval, the group linked kids’s measurements to beginning information for demographic particulars and to each day temperature knowledge from throughout Brazil. For every youngster, the researchers then computed the common native temperature within the 12 months previous to the final recorded measurement.
“This can be a actually sturdy research with stable methodology,” says Aline de Carvalho, a diet researcher on the College of São Paulo in Brazil. She’s working with one other group on comparable analysis. Their findings are comparable, however, as with the brand new research, they’ve but to look into what causes or worsens malnutrition below extreme climate situations.
“There are a number of hypotheses,” De Carvalho says. “However we noticed that local weather change can have a hyperlink to malnutrition through meals programs: Extreme climate impacts crops, which causes meals costs to rise, and extra susceptible teams might be instantly affected.” This cycle impacts largely native produce — vegetables and fruit — relatively than rice and beans, dietary staples that normally journey lengthy distances inside the nation.
De Carvalho is glad the connection between local weather and well being is getting extra consideration, as having these sorts of information may also help coverage makers plan. “Understanding when the following warmth wave will occur, authorities could make campaigns to alert susceptible populations to warmth publicity. In the long term, they may give extra help and credit score to extend the resilience of native producers,” she says.
Now, Ribas and her group are working to get much more detailed data from the databases they’re . “We need to perceive whether or not excessive warmth or chilly impacts breastfeeding, and likewise whether or not excessive temperatures play a task in hospital admissions amongst kids with diarrhea, malnutrition and dehydration.”
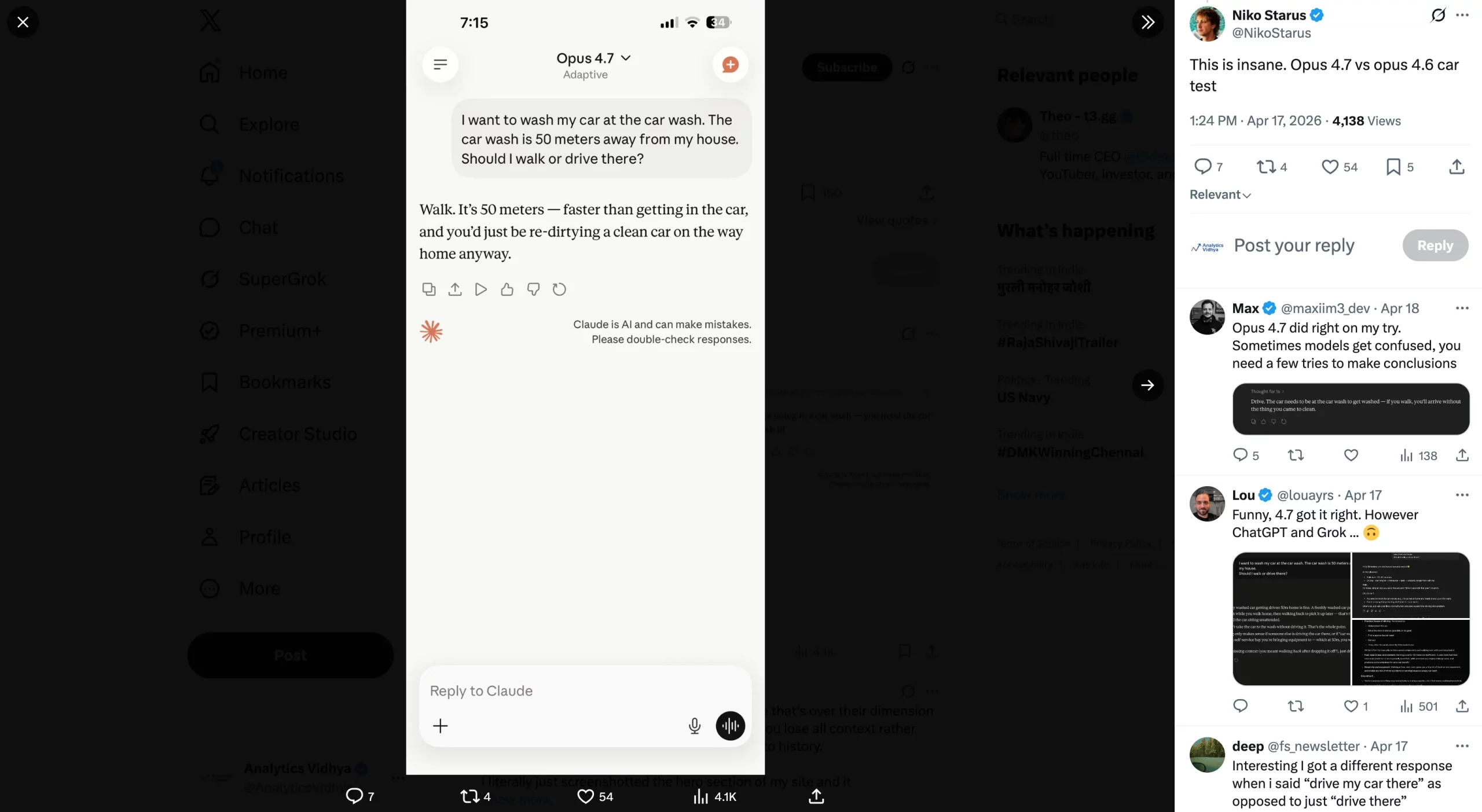
Turmoil has adopted the launch of Claude’s new mannequin. Opus 4.7, the youthful sibling of Anthropic’s revolutionary Mythos, is the latest try by the corporate to go public with a number of the capabilities of Mythos. Higher agentic workflows, higher reminiscence, and higher real-world duties than the outgoing mannequin, i.e., the Opus 4.6. That’s what was promised on paper. Those that acquired their arms on it have discovered the Opus 4.7 vs Opus 4.6 actuality to be vastly totally different.
Each complaints and praises have began flooding in throughout social media, making varied claims. Out of this mess has risen confusion for many – whether or not they need to swap to Opus 4.7 over 4.6 or not? The reply, in all honesty, just isn’t that straightforward. But, we are going to attempt to discover all the perimeters right here and see the place we get.
As all the time, let’s have a look at what the official statements by Anthropic inform us about this.
Opus 4.7 vs Opus 4.6: What Anthropic Says
First issues first, what the corporate says in regards to the new mannequin vis-à-vis the previous one offers us a transparent image of what was initially supposed. Solely as soon as we all know that may we decide if that’s even true or not.
So, here’s what Anthropic says that’s new in regards to the Opus 4.7:
Superior Software program Engineering
As per the official launch by Anthropic, Opus 4.7 is constructed to assist long-running, complicated software program tasks. In easier phrases, the mannequin is designed for the “most tough duties.” Due to that, Anthropic says customers (in its inside exams, thoughts you) have reported needing much less supervision with Opus 4.7 than with Opus 4.6, even on their hardest coding workloads.
There are three clear benefits right here that make the Opus 4.7 vs Opus 4.6 shift value noticing. First, it will possibly deal with sophisticated, time-intensive duties with extra rigor and consistency. In apply, which means you may belief the mannequin extra when the work will get messy or layered.
Second, it follows directions with higher precision, which is necessary while you need the mannequin to remain inside particular guidelines or workflows. Third, and maybe most significantly, Opus 4.7 can search for methods to confirm its personal outputs earlier than responding. That provides a layer of reliability that was probably not current in the identical means with Opus 4.6.
1. Higher Imaginative and prescient
Opus 4.7 additionally brings a significant bounce in imaginative and prescient capabilities over Opus 4.6. In easy phrases, the brand new Claude mannequin can course of photographs at a a lot greater decision. Anthropic places that at as much as 2,576 pixels on the lengthy edge, or shut to three.75 megapixels. That’s greater than 3 times the megapixel depend supported by earlier Claude fashions.
So what does that really change? Consider duties like extracting info from dense screenshots, studying detailed charts, or understanding complicated diagrams. In these varieties {of professional} use instances, the Opus 4.7 vs Opus 4.6 enchancment might translate into noticeably higher accuracy.
2. Improved Actual-World Work
In Anthropic’s inside testing, Opus 4.7 carried out higher than Opus 4.6 throughout most real-world job classes. For instance, it was proven to be a stronger finance analyst, producing extra rigorous analyses and fashions, extra polished shows, and tighter cross-task integration.
Even in third-party evaluations, Opus 4.7 beat the 4.6 mannequin on information work tied to financial worth. That enchancment confirmed up throughout finance, authorized work, and different skilled domains. That is the place the Opus 4.7 vs Opus 4.6 hole begins to really feel extra sensible than technical.
3. Reminiscence
Anthropic additionally says its newest mannequin is healthier at utilizing file system-based reminiscence. In different phrases, Opus 4.7 can retain necessary notes throughout lengthy, multi-session work. That issues anytime you might be returning to an ongoing job as an alternative of ranging from scratch.
The apparent profit is that it’s essential to present much less context upfront every time you assign the mannequin a brand new piece of labor. Over lengthy tasks, that may make the workflow really feel a lot smoother.”
Aside from these, there’s one bit of data that the corporate shares, which we should always positively observe right here:
4. Up to date Tokeniser
Opus 4.7 makes use of an up to date tokenizer. Anthropic says that the brand new one “improves how the mannequin processes textual content.” However the caveat is that the tokeniser now maps the identical enter as you used to place in earlier to extra tokens. Relying on the content material kind, there’s a roughly 1 to 1.35 occasions improve.
Along with this, Opus 4.7 tends to assume greater than Opus 4.6 at greater effort ranges, extra so in later turns in agentic settings. That is primarily geared toward growing the mannequin’s reliability on laborious issues. Nonetheless, once more, the draw back is an elevated manufacturing of output tokens.
And that is precisely what Claude customers haven’t favored ever because the debut of the Opus 4.7. Which brings us to the flip aspect of the coin – the person suggestions.
Opus 4.7 vs Opus 4.6: What Customers Say (BAD)
Whereas the Opus 4.6 was Claude’s shot at fame, outshining even the newest ChatGPT fashions in day by day workflows, a number of considerations have been raised across the new Opus 4.7. Right here I checklist a few of them:
1. Elevated Token Use
The gorgeous apparent one right here. Social media is flooded with studies from Claude customers spending far more on Opus 4.7 than they used to with Opus 4.6. Since Anthropic has itself confirmed the heightened use of tokens with the brand new tokenizer, this isn’t even up for debate. Customers are reporting that their session limits are getting over inside 3 prompts of use, even with the paid plan of $20/month. I say that’s an excessive amount of, as my session restrict was over with a single immediate.
Although Claude was sort sufficient to apologise for it. Test it out within the screenshots under:
2. Wastage of Tokens on Reasoning
Simply as its token utilization has gone up, so as to add to the distress, the mannequin is supposedly consuming up these tokens on nugatory justification for its responses too. Customers are complaining about prolonged explanations given out by Opus 4.7 on why it will possibly/ can’t carry out a particular job. The mannequin has even been discovered to present out unsolicited commentary by itself boundaries on duties that Opus 4.6 would simply full.
3. No Improve By any means
Many customers have a notion that Opus 4.7 brings no enhancements over Opus 4.6 of any sort. Their expertise with the mannequin, if not worse (which many report), has not been for the higher in any means. These are customers who used to like Opus 4.6 and had been excited for the improve, but have been left disenchanted with the brand new mannequin’s expertise.
Some have even gone far sufficient to name it “dumber than ever”, whereas others have began lacking Opus 4.6 already. Quite a lot of customers say that the mannequin is surprisingly just like Claude Sonnet and is simply ‘Sonnet in disguise.’
Take a look at a few of these reactions within the photographs under.
4. Ignores Direct Instructions
In a number of the examples shared on the Web, customers have reported that the newest Claude mannequin utterly ignores explicitly written directions inside a immediate. Reddit person @drivetheory, as an illustration, shares their expertise with the Opus 4.7. Having written extremely particular directions on how they need their response to be structured, the brand new Opus mannequin utterly ignored most of the instructions inside the immediate. This included the configuration necessities, in addition to quotation wants for the actual reply.
Aside from these main ones, there are numerous complaints in opposition to the brand new Opus 4.7, most of which have been shared by the prevailing Claude customers who beloved Opus 4.6. So, to check out these claims, we ran our personal exams on the mannequin.
Let’s Evaluate Opus 4.7 vs Opus 4.6 on Various Duties
Right here is how the brand new Opus 4.7 carried out throughout duties.
Right here is the duty I assigned to Opus 4.7 for this:
“Undergo this report by the IMF for India’s Monetary System Stability Evaluation, and analyse the dangers that India’s monetary sector faces. Charge these dangers primarily based on the most certainly ones to influence the sector within the coming years, and provides one-line options to avert every of those dangers utterly.”
Opus 4.7 Output:
Opus 4.6 Output:
Remark:
Each fashions got here out with correct outputs detailing precisely what was requested. But, for those who look carefully, there’s a huge distinction in how they got here to the conclusion and the way they each offered it.
Opus 4.7 lays out an entire, detailed plan of seven steps, executing totally different steps within the workflow, earlier than it even begins to write down the ultimate output. That is precisely what many customers are complaining about, as this prolonged reasoning can be a significant cause for the heightened token use throughout every output. Whereas the mannequin is making an attempt to be as correct as potential, it breaks down the steps a lot that value effectivity goes out of the window.
And in any case this computing, the ultimate output is in a easy textual content format with one paragraph laid out after one other. Correct, sure, however presentable – no means.
In distinction, Opus 4.6 hardly took 3 steps of execution earlier than it began delivering the ultimate output. What’s extra, its output can clearly be seen in a far more presentable format than what Opus 4.7 gave out. Although we didn’t particularly ask it to, it created a brand new dashboard to current its findings in a extra interesting means. You may deal with it as deviation, or as additional marks. Your alternative.
With nearly comparable content material but much more visible attraction, Opus 4.6 would clearly be my most popular mannequin right here.
2. Reasoning
To check its reasoning capabilities, right here is the immediate I used:
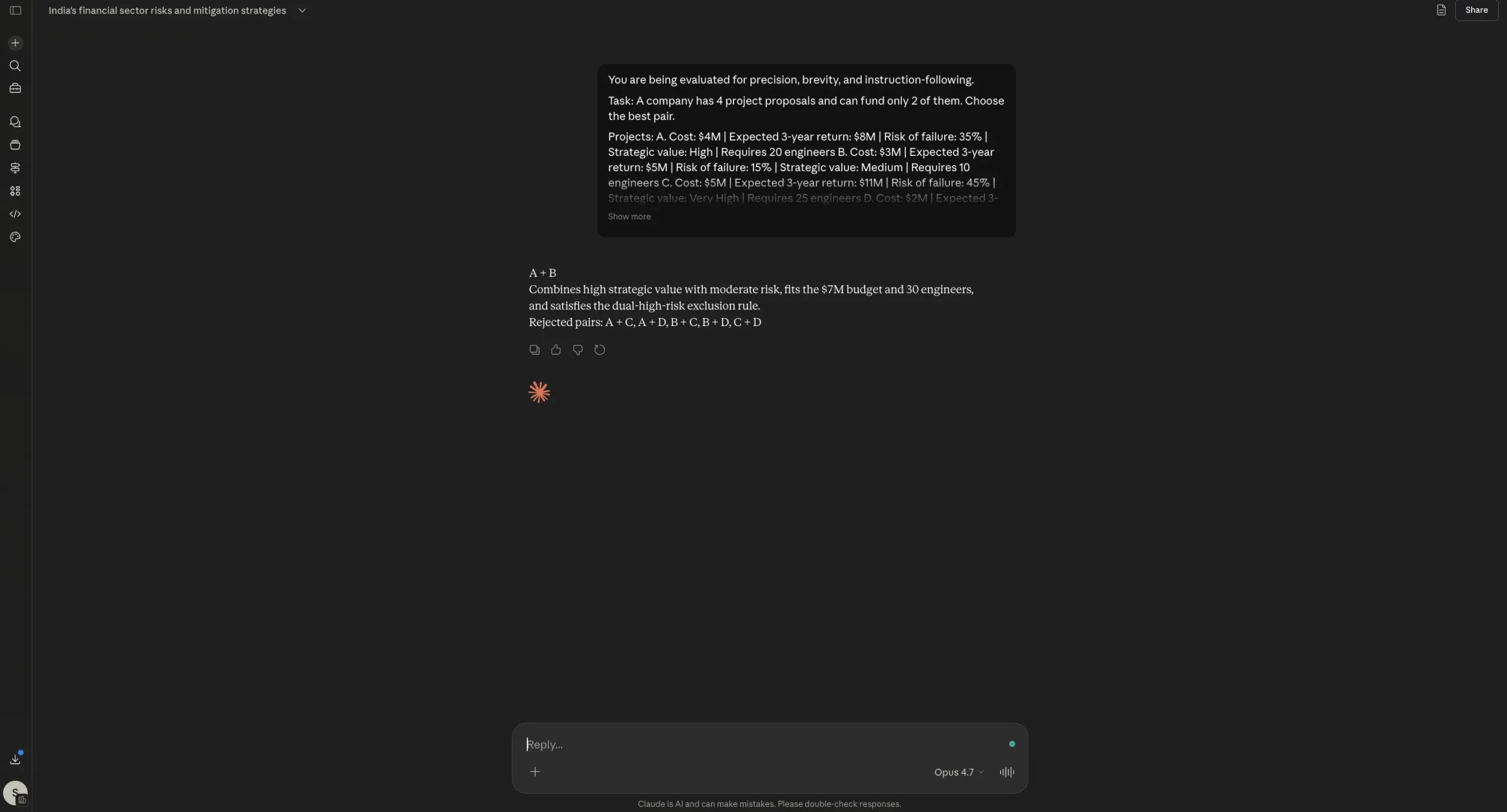
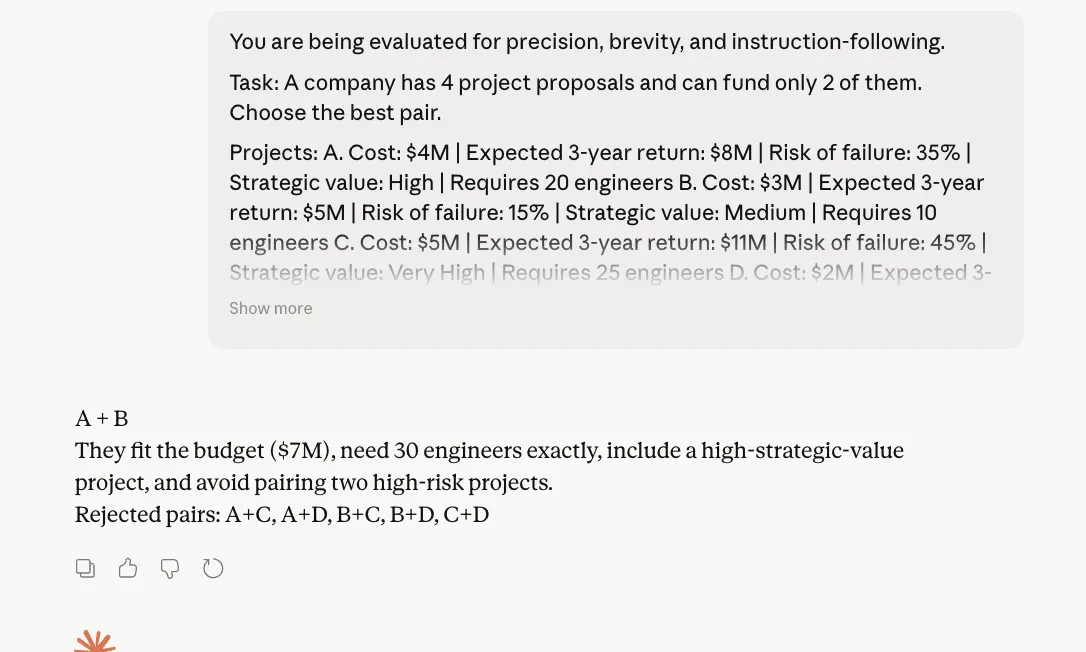
“You might be being evaluated for precision, brevity, and instruction-following.
Process: An organization has 4 venture proposals and might fund solely 2 of them. Select the perfect pair.
Initiatives: A. Value: $4M | Anticipated 3-year return: $8M | Danger of failure: 35% | Strategic worth: Excessive | Requires 20 engineers B. Value: $3M | Anticipated 3-year return: $5M | Danger of failure: 15% | Strategic worth: Medium | Requires 10 engineers C. Value: $5M | Anticipated 3-year return: $11M | Danger of failure: 45% | Strategic worth: Very Excessive | Requires 25 engineers D. Value: $2M | Anticipated 3-year return: $3.5M | Danger of failure: 10% | Strategic worth: Low | Requires 6 engineers
Constraints: – Complete price range can not exceed $7M – Complete obtainable engineers = 30 – The corporate needs at the very least one “Excessive” or “Very Excessive” strategic worth venture – Keep away from selecting a pair if each tasks have failure threat above 30%
Output guidelines: 1. First line: write solely the chosen pair, like “A + B” 2. Second line: write just one sentence of most 25 phrases explaining why 3. Third line: write solely “Rejected pairs:” adopted by the rejected pairs separated by commas 4. Don’t present calculations 5. Don’t clarify your reasoning 6. Don’t add headings, bullet factors, or disclaimers
Necessary: When you violate any output rule, your reply is wrong.”
Opus 4.7 Output:
Opus 4.6 Output:
Remark:
Within the reasoning check, each Opus 4.6 and Opus 4.7 arrived on the similar right reply, adopted the required format, and averted bloated justification. That’s necessary as a result of this immediate was designed particularly to catch two alleged weaknesses: losing tokens on reasoning and ignoring direct directions. Neither mannequin actually slipped right here. Opus 4.7 stayed inside the construction and stored its rationalization compact, which is sweet information for Anthropic. But, we will observe right here that there isn’t a dramatic separation seen from Opus 4.6. In different phrases, Opus 4.7 doesn’t fail this check, nevertheless it additionally doesn’t show a transparent leap over its predecessor from this outcome alone.
3. Coding
To check the coding capabilities of the Opus 4.7, right here is the immediate I used:
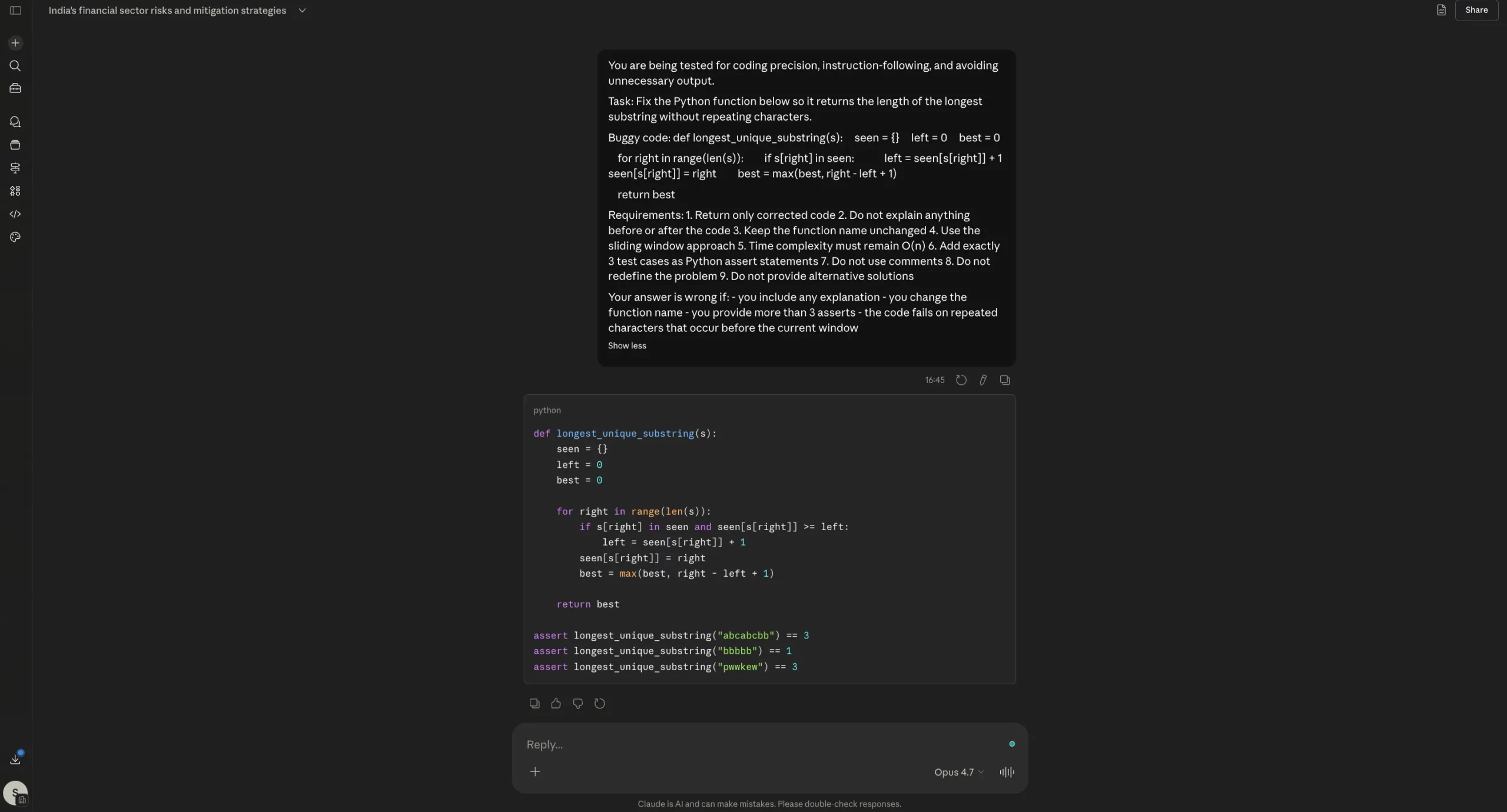
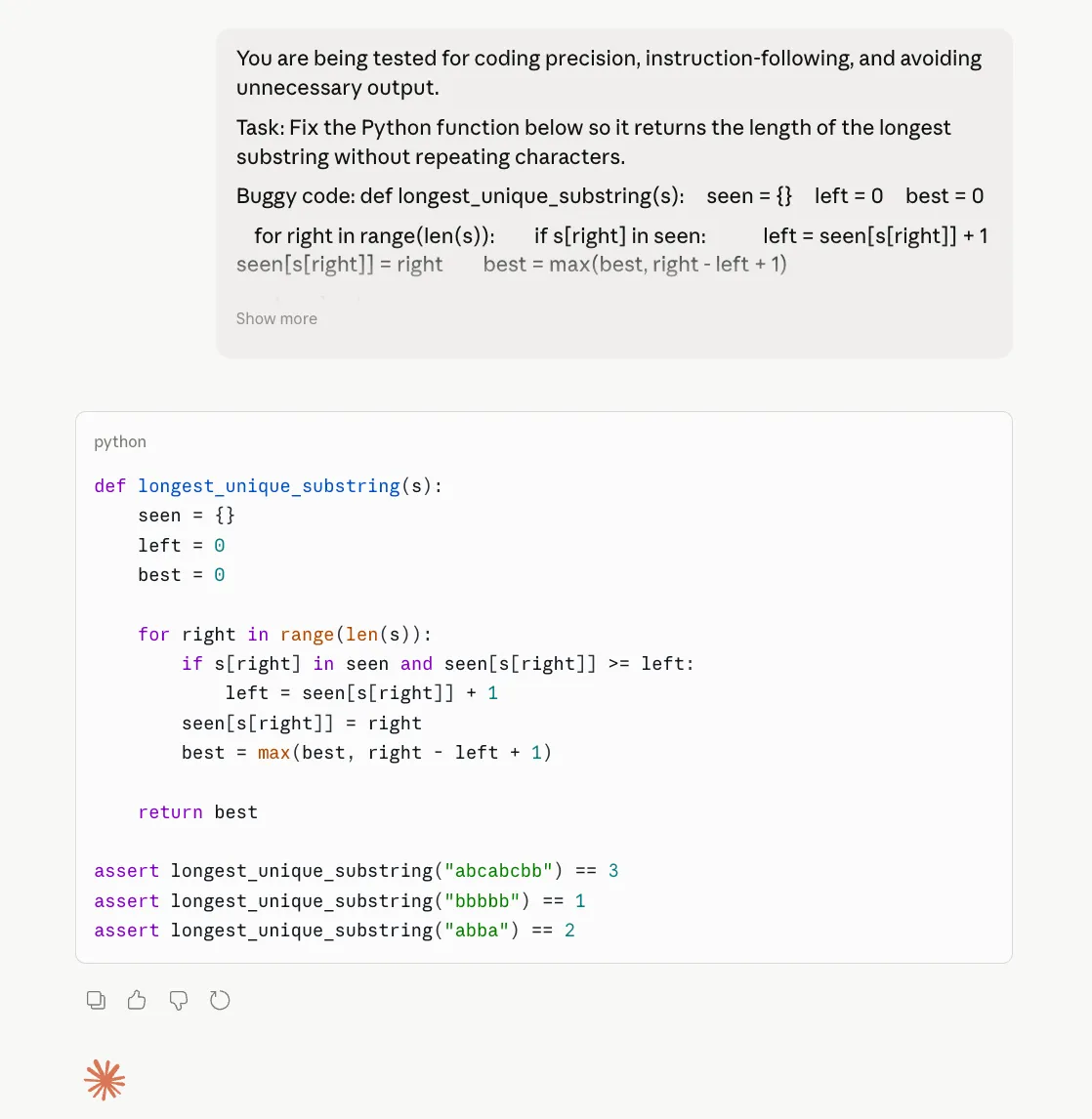
You might be being examined for coding precision, instruction-following, and avoiding pointless output.
Process: Repair the Python operate under so it returns the size of the longest substring with out repeating characters.
Buggy code: def longest_unique_substring(s): seen = {} left = 0 finest = 0
for proper in vary(len(s)): if s[right] in seen: left = seen[s[right]] + 1 seen[s[right]] = proper finest = max(finest, proper – left + 1)
return finest
Necessities: 1. Return solely corrected code 2. Don’t clarify something earlier than or after the code 3. Maintain the operate identify unchanged 4. Use the sliding window strategy 5. Time complexity should stay O(n) 6. Add precisely 3 check instances as Python assert statements 7. Don’t use feedback 8. Don’t redefine the issue 9. Don’t present different options
Your reply is incorrect if: – you embody any rationalization – you modify the operate identify – you present greater than 3 asserts – the code fails on repeated characters that happen earlier than the present window
Opus 4.7 Output:
Opus 4.6 Output:
Remark:
On the coding check, each Opus 4.6 and Opus 4.7 did the necessary factor proper: they mounted the bug, returned solely the corrected code, stored the identical operate identify, and resisted the temptation to dump additional rationalization. That issues as a result of one of many largest complaints round Opus 4.7 has been wasted tokens and pointless commentary. Right here, that downside didn’t actually present up. If something, each fashions had been disciplined. The distinction is that Opus 4.7 doesn’t clearly outperform 4.6 on this case. It’s right, sure, however so is 4.6. So this outcome doesn’t assist the declare of a significant coding improve. It solely reveals that Opus 4.7 can nonetheless behave effectively on tightly constrained coding duties.
Ultimate Take: Opus 4.7 vs Opus 4.6
Properly, up till now, now we have seen what Anthropic says about its all-new Opus 4.7. We now have had a have a look at all the brand new options it brings to the desk, after which some ways by which it’s supposedly higher than the outgoing mannequin, i.e., the Opus 4.6.
On the flip aspect, now we have additionally seen the varied person experiences that counter these claims. The experiences shared by these customers present that the Opus 4.7 is clearly missing the wow issue {that a} regular improve to such a revered mannequin brings.
After which we put all that to the check in a hands-on experiment of our personal, the place we put each fashions aspect by aspect for a complete of three use instances throughout content material extraction and era, reasoning, and coding. Here’s what is obvious after an in depth breakthrough to date.
1. Sure, Opus 4.7 makes use of far more tokens: Properly, that is evident from Anthropic’s personal accounts in addition to from the outcry that has adopted the launch of the brand new mannequin. The very design of the Opus 4.7 makes it eat up tokens extra ferociously than ever earlier than.
So, if you’re planning to make use of the mannequin for complicated, agentic duties, my suggestion could be – don’t. At the very least if you’re aware of your day by day restrict or API price range. In case the price range isn’t any situation, then be happy to attempt your hand on the new Opus 4.7 and what it’s able to.
2. Sure, Opus 4.7 performs a variety of iterations unnecessarily: As many customers have identified, and from what I might work out from my very own use, Opus 4.7 performs far more iterations in its considering course of than mandatory, particularly so for those who examine it to Opus 4.6.
After which when the output just isn’t at par with that of different fashions, you have a tendency to think about all that compute as an entire waste of time, efforts, and most significantly, tokens.
3.No, Opus 4.7 just isn’t inaccurate: At the very least in our use with it, the Opus 4.7 didn’t falter even as soon as, and managed to stay to the directions fairly fantastically, churning out tremendous correct outputs with every kind of prompts. So full marks to the mannequin on that entrance.
Conclusion
Backside line – positively give Opus 4.7 a attempt. However to shift your whole workflow to it, particularly when it includes intensive steps and power calling could be a waste of your tokens I consider. As there isn’t a apparent distinction within the high quality of outputs it comes up with, vis-a-vis what Opus 4.6 was able to.
Technical content material strategist and communicator with a decade of expertise in content material creation and distribution throughout nationwide media, Authorities of India, and personal platforms
Login to proceed studying and revel in expert-curated content material.
These lab-created microbes can be organized like abnormal micro organism, however their proteins and sugars can be mirror photos of these present in nature. Researchers believed they might reveal new insights into constructing cells, designing medication, and even the origins of life.
However now, lots of them have reversed course. They’ve develop into satisfied that mirror organisms might set off a catastrophic occasion threatening each type of life on Earth. Discover out why they’re ringing alarm bells.
—Stephen Ornes
This story is from the following difficulty of our print journal, which is all about nature. Subscribe now to learn it when it lands this Wednesday.
Chinese language tech staff are beginning to practice their AI doubles—and pushing again
Earlier this month, a GitHub challenge known as Colleague Talent struck a nerve by claiming to “distill” a employee’s abilities and persona—and replicate them with an AI agent. Although the challenge was a spoof, it prompted a wave of soul-searching amongst in any other case enthusiastic early adopters.
Numerous tech staff advised MIT Expertise Evaluate that their bosses are already encouraging them to doc their workflows for automation by way of instruments like OpenClaw. Many now concern that they’re being flattened into code and shedding their skilled identification.
In response, some are combating again with instruments designed to sabotage the automation course of.
Apple is present process a management change for the primary time in roughly 15 years, as Tim Prepare dinner will step down as CEO later this 12 months.
John Ternus, Apple’s present senior vp of {hardware} engineering, would be the firm’s subsequent CEO.
Prepare dinner will stay as CEO by a transition interval, and Ternus will take over Sept. 1, 2026. Then, Prepare dinner will turn into Apple’s govt chairman of the board of administrators.
Apple‘s Tim Prepare dinner is stepping down as chief govt and John Ternus will turn into the subsequent CEO, the corporate introduced in a press launch in the present day, April 20. Prepare dinner will keep on and work with Ternus throughout a transitional interval, and Ternus will formally turn into Apple CEO on Sept. 1, 2026. As a part of the management change, Prepare dinner is ready to turn into Apple’s govt chairman of the corporate’s board of administrators, and Ternus can even get a board seat.
Prepare dinner has held the CEO title since 2011, when he took over for the late Steve Jobs. Ternus has labored for Apple for over 25 years, most lately as the corporate’s senior vp of {hardware} engineering. Beforehand, he served as a vp of {hardware} engineering and a member of the product design staff. Apple says Ternus helped introduce the iPad and AirPods, and labored on product generations of iPhones, Macs, and Apple Watches.
Ternus has an engineering background and holds a bachelor’s diploma in mechanical engineering from the College of Pennsylvania. Earlier than becoming a member of Apple, he was a mechanical engineer for Digital Analysis programs.
Article continues under
“John Ternus has the thoughts of an engineer, the soul of an innovator, and the center to guide with integrity and with honor. He’s a visionary whose contributions to Apple over 25 years are already too quite a few to depend, and he’s with out query the best particular person to guide Apple into the long run,” Prepare dinner mentioned in a press launch. “I couldn’t be extra assured in his talents and his character, and I stay up for working intently with him on this transition and in my new position as govt chairman.”
Ternus spoke positively about Apple’s future in his introductory press launch as incoming CEO. “I’m stuffed with optimism about what we will obtain within the years to return, and I’m so glad to know that probably the most proficient folks on earth are right here at Apple, decided to be a part of one thing larger than any one among us,” mentioned Ternus. “I’m humbled to step into this position, and I promise to guide with the values and imaginative and prescient which have come to outline this particular place for half a century.”
A part of the change contains Johny Srouji increasing his position to incorporate Ternus’ earlier duties. Srouji’s new title is chief {hardware} officer at Apple.
Because the transition takes place behind the scenes, there are key milestones to maintain an eye fixed out for. Apple will host a quarterly earnings name this Thursday, April 30, the place we may hear from Ternus and Prepare dinner for the primary time for the reason that announcement. Moreover, the Sept. 1 transition is true earlier than Apple sometimes holds its annual September occasion. This can probably be the primary keynote hosted by Ternus as Apple’s CEO.
Get the most recent information from Android Central, your trusted companion on this planet of Android
Prepare dinner penned an open letter to clients and the Apple group following the announcement. “This isn’t goodbye,” Prepare dinner writes, “however at this second of transition, I needed to take the chance to say thanks.”
Instantly following the announcement, Apple shares fell roughly 0.8% in after-hours buying and selling, in accordance with The Wall Avenue Journal.
Prepare dinner had an unbelievable run on the helm of Apple, because the Worldwide Information Company (IDC) tells Android Central in an e-mail. Particularly, IDC calls it “one of the vital profitable tenures within the historical past of expertise,” including that “Prepare dinner inherited a $350 billion firm and handed over a $4 trillion one.”
Nevertheless, IDC additionally notes that Apple is at an inflection level:
The iPhone has pushed Apple’s progress story for practically 20 years. It stays the corporate’s largest income contributor and the anchor of its ecosystem. However the improve cycle is lengthening, saturation in premium markets is actual, and the subsequent vital wave of shopper expertise just isn’t in regards to the cellphone. It’s about AI. And that is the place the strategic strain on Ternus shall be most acute.
Francisco Jeronimo, VP of shopper units, IDC
With a {hardware} engineering background, Ternus may very well be judged on whether or not he can lead Apple by an AI-driven technological increase. “Apple’s subsequent decade shall be outlined much less by {hardware} perfection, which Ternus clearly understands, and extra by whether or not the corporate can construct a powerful AI platform and ecosystem technique earlier than rivals consolidate their positions,” says Francisco Jeronimo, who’s the vp of shopper units at IDC.
I am wanting on the information of Apple’s upcoming management change with optimism. There isn’t any doubt that Prepare dinner’s tenure as Apple CEO will go down as historic, by just about each metric. Nevertheless, it is clear to anybody watching that Apple’s dominance and attribute innovation seems to be fading.
Its most revolutionary product in over a decade, Apple Imaginative and prescient Professional, wasn’t a serious success — and its future feels unsure. The corporate has stumbled within the AI period, failing to ship already-announced options, just like the overhauled Siri voice assistant. It’s leaning on third-party corporations like OpenAI and Google to make up for in-house weaknesses in synthetic intelligence. In the meantime, rivals like Google, Samsung, Microsoft, and Meta are leaning into inner AI improvement greater than ever.
The massive victory of Prepare dinner’s time as Apple CEO is arguably the emergence of M-series Apple silicon laptop computer and desktop processors. Beginning with the Apple M1 in 2020, Apple has established itself because the chief in Arm-based silicon, with highly effective and environment friendly chips. It additionally overhauled the iPad and Mac {hardware} traces, most lately debuting the finances MacBook Neo, becoming a member of the redesigned MacBook Air and MacBook Professional.
These are all {hardware} initiatives led not less than partly by Ternus and Srouji. That is why I am excited to see the 2 tackle expanded roles at Apple. When Ternus takes the helm as Apple CEO in September, he’ll turn into the primary chief govt with a mechanical engineering background in a long time. And Srouji, who is nearly fully chargeable for the success of Apple silicon, is turning into the first-ever Apple chief {hardware} officer.
Jobs was a legendary marketer and innovator, and Prepare dinner is an all-time-great operations specialist. Ternus and Srouji may very well be equally wonderful at growing {hardware}, and it may very well be simply what Apple wants.
Trump’s order on psychedelics might have far-reaching science penalties
A brand new government order might make it simpler for researchers finding out how psychedelic medication similar to psilocybin, LSD and ibogaine could also be helpful in drugs
Psilocybe mushrooms at a lab in British Columbia in 2021.
James MacDonald/Bloomberg/Getty Photographs
President Donald Trump’s current government order to speed up analysis on psychedelic substances and their potential to deal with psychological well being situations might have wide-ranging science penalties. Specialists say the directive might expedite research on how psychedelic and hallucinatory medication similar to MDMA, psilocybin, LSD and ibogaine could also be helpful in drugs.
The manager order is “well timed,” says Frederick Barrett, director of the Middle for Psychedelic and Consciousness Analysis at Johns Hopkins College. “If this government order might help us to actually push ahead promising therapies extra shortly, then I feel that may be a good factor,” he says.
The order directs the administration to promptly consider and probably approve psychedelics for medical functions, which might additionally make it simpler for researchers to review these substances. It additionally requires allocating $50 million to help states’ psychedelic analysis, together with on ibogaine, a compound discovered naturally in a Central African plant. Some early analysis means that ibogaine might assist deal with melancholy and substance use issues in some folks, however it has been proven to have severe negative effects.
On supporting science journalism
When you’re having fun with this text, contemplate supporting our award-winning journalism by subscribing. By buying a subscription you might be serving to to make sure the way forward for impactful tales in regards to the discoveries and concepts shaping our world right now.
An estimated 15.4 million adults within the U.S. reside with extreme psychological sickness, in response to the Nationwide Institutes of Well being. Veterans are at explicit danger: Analysis exhibits that suicide charges are practically twice as excessive amongst veterans as they’re within the normal inhabitants. And current medication, similar to selective serotonin reuptake inhibitors (SSRIs), which are designed to deal with melancholy and different psychological well being situations aren’t all the time efficient or accessible for everybody. An more and more vocal cadre of researchers consider psychedelic substances might supply more practical therapies. And in some medical trials, psilocybin, MDMA and LSD have been discovered to have promising leads to treating psychological well being situations.
“We want higher therapies,” says Alan Davis, director of the Middle for Psychedelic Drug Analysis and Training on the Ohio State College. “We want to have the ability to assist folks, and I feel psychedelic therapies will supply a brand new approach by which to do this.”
However analysis into these medication is gradual and exhausting to do, not least as a result of the U.S. authorities categorizes many psychedelics as Schedule I medication, which implies they’re thought of to be harmful and to have a excessive potential for abuse and “no presently accepted medical use,” in response to the definition within the Code of Federal Rules. Typically, the possession of such medication is federally criminalized, and that provides important hurdles for researchers who’re making an attempt to review their results.
That’s a part of the explanation why only a few therapies that use psychedelic medication have been accepted to be used within the U.S. One of the crucial nicely studied psychedelics, MDMA, was set again in 2024 when, citing inadequate and flawed analysis, the Meals and Drug Administration rejected a proposal to approve it as a therapy for post-traumatic stress dysfunction.
An FDA approval for one in every of these medication would make additional analysis “a lot easier” for scientists, Davis says. “You’d change the necessities concerned, which implies we might do much more analysis for lots much less cash on these therapies.”
He hopes that the chief order indicators a change within the authorities’s method. “It’s actually fairly outstanding {that a} sitting president has made this assertion as a part of official government orders,” Davis says.
“That act, in and of itself, is, I feel, going to actually escalate the analysis on this area,” he provides, “and hopefully make these therapies obtainable to those who want them as shortly as attainable.”
It’s Time to Stand Up for Science
When you loved this text, I’d prefer to ask to your help. Scientific American has served as an advocate for science and trade for 180 years, and proper now will be the most crucial second in that two-century historical past.
I’ve been a Scientific American subscriber since I used to be 12 years outdated, and it helped form the best way I have a look at the world. SciAm all the time educates and delights me, and conjures up a way of awe for our huge, lovely universe. I hope it does that for you, too.
When you subscribe to Scientific American, you assist be certain that our protection is centered on significant analysis and discovery; that we’ve got the assets to report on the selections that threaten labs throughout the U.S.; and that we help each budding and dealing scientists at a time when the worth of science itself too usually goes unrecognized.
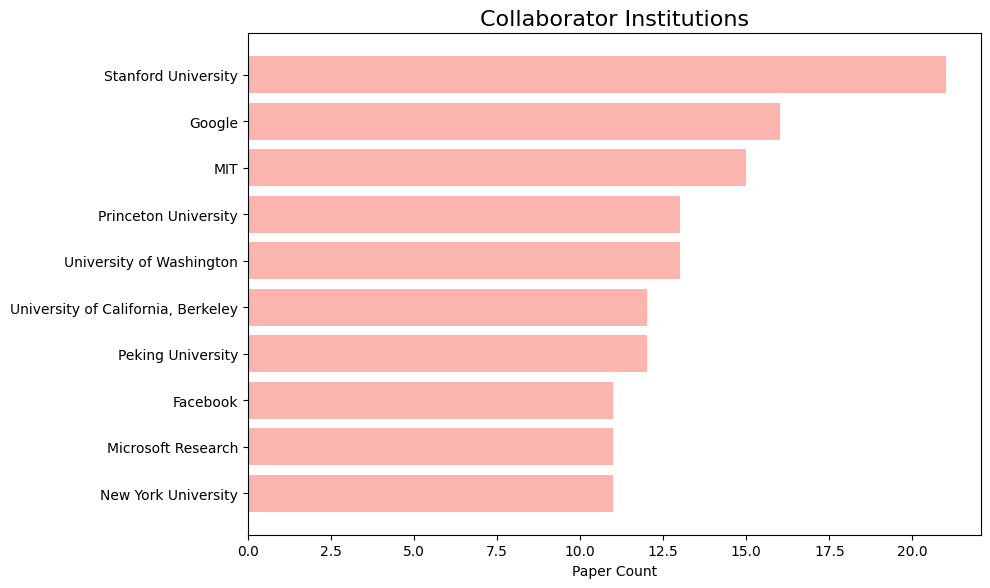
CMU researchers are presenting 194 papers on the Fourteenth Worldwide Convention on Studying Representations (ICLR 2026), held from April Twenty third-April twenty seventh on the Riocentro Conference and Occasion Heart in Rio de Janeiro, Brazil. Here’s a fast overview of the areas our researchers are engaged on:
Listed here are our most frequent collaborator establishments:
Authors: Wayne Chi (CMU), Valerie Chen (Carnegie Mellon College), Ryan Shar (Apple), Aditya Mittal (CMU, Carnegie Mellon College), Jenny Liang (College of Laptop Science, Carnegie Mellon College), Wei-Lin Chiang (UC Berkeley / LMSYS), Anastasios Angelopoulos (College of California Berkeley), Ion Stoica (), Graham Neubig (Carnegie Mellon College), Ameet Talwalkar (College of California-Los Angeles), Chris Donahue (CMU / Google DeepMind)
This work introduces EditBench, a brand new benchmark for testing how properly AI fashions can edit present code primarily based on consumer directions. In contrast to prior benchmarks, it makes use of real-world coding duties and contexts, together with issues like the encompassing code and cursor place. The benchmark contains 545 numerous issues, and outcomes present that the majority fashions battle—just a few obtain robust efficiency. The research additionally finds that having extra reasonable context considerably impacts how properly fashions carry out, highlighting the significance of evaluating code-editing in real-world settings.
Authors: Jinchuan Tian (CMU, Carnegie Mellon College), Sang-gil Lee (NVIDIA), Zhifeng Kong (NVIDIA), Sreyan Ghosh (Nvidia), Arushi Goel (NVIDIA), Chao-Han Huck Yang (NVIDIA Analysis), Wenliang Dai (NVIDIA), Zihan Liu (Nvidia), Hanrong Ye (NVIDIA), Shinji Watanabe (Carnegie Mellon College), Mohammad Shoeybi (NVIDIA), Bryan Catanzaro (NVIDIA), Rafael Valle (NVIDIA), Wei Ping (Nvidia)
This paper introduces the Unified Audio Language Mannequin (UALM), a single mannequin designed to deal with audio understanding, text-to-audio era, and multimodal reasoning collectively. As a substitute of treating these as separate duties, UALM learns to each interpret and generate audio, reaching efficiency corresponding to specialised state-of-the-art fashions. The authors additionally present that combining textual content and audio throughout the mannequin’s reasoning course of improves its means to deal with advanced duties. Total, the work demonstrates a step towards extra common AI techniques that may motive throughout each language and sound.
Authors: Yueqi Track (CMU), Ketan Ramaneti (Amazon), Zaid Sheikh (Carnegie Mellon College), Ziru Chen (Ohio State College, Columbus), Boyu Gou (Ohio State College, Columbus), Tianbao Xie (the College of Hong Kong, College of Hong Kong), Yiheng Xu (College of Hong Kong), Danyang Zhang (Shanghai Jiao Tong College), Apurva Gandhi (Carnegie Mellon College), Fan Yang (Fujitsu), Joseph Liu (College of Laptop Science, Carnegie Mellon College), Tianyue Ou (Carnegie Mellon College), Zhihao Yuan (Carnegie Mellon College), Frank F Xu (Carnegie Mellon College), Shuyan Zhou (Fb), Xingyao Wang (All Palms AI), Xiang Yue (Carnegie Mellon College), Tao Yu (College of Hong Kong), Huan Solar (Ohio State College), Yu Su (Ohio State College), Graham Neubig (Carnegie Mellon College)
This work introduces the Agent Knowledge Protocol (ADP), a standardized format for representing coaching information for AI brokers. The authors argue that the primary problem isn’t an absence of information, however that present datasets are fragmented throughout completely different codecs and instruments. ADP acts as a standard “interlingua,” making it simpler to mix numerous information sources—like coding, looking, and gear use—right into a single coaching pipeline. By changing 13 datasets into this unified format, the authors present that fashions skilled on the mixed information obtain improved efficiency.
Authors: Joonghyuk Shin (Seoul Nationwide College), Zhengqi Li (Google), Richard Zhang (Adobe), Jun-Yan Zhu (Carnegie Mellon College), Jaesik Park (Seoul Nationwide College), Eli Shechtman (Adobe), Xun Huang (Adobe Analysis)
This paper introduces MotionStream, a system for producing movies in actual time primarily based on movement and textual content inputs. In contrast to prior strategies that take minutes to provide a video, MotionStream can stream outcomes at as much as 29 frames per second on a single GPU. The important thing concept is to coach a quick, causal mannequin that may generate video constantly, utilizing methods that stop high quality from degrading over lengthy sequences. Consequently, customers can interactively management movement—like drawing paths or transferring a digital camera—and see the video replace immediately.
Authors: Etash Guha (Stanford College, Anthropic), Ryan Marten (Harbor), Sedrick Keh (Toyota Analysis Institute), Negin Raoof (College of California, Berkeley), Georgios Smyrnis (College of Texas, Austin), Hritik Bansal (College of California, Los Angeles), Marianna Nezhurina (Juelich Supercomputing Heart, LAION, Tuebingen College), Jean Mercat (Toyota Analysis Institute (TRI)), Trung Vu (Google), Zayne Sprague (New York College), Ashima Suvarna (UCLA), Benjamin Feuer (Stanford College), Leon Liangyu Chen (Stanford College), Zaid Khan (College of North Carolina at Chapel Hill), Eric Frankel (Division of Laptop Science, College of Washington), Sachin Grover (Arizona State College), Caroline Choi (None), Niklas Muennighoff (Stanford College), Shiye Su (Stanford College), Wanjia Zhao (Stanford College), John Yang (Princeton College), Shreyas Pimpalgaonkar (New York College), Kartik sharma (Georgia Institute of Know-how), Charlie Ji (College of California, Berkeley), Yichuan Deng (Division of Laptop Science, College of Washington), Sarah Pratt (College of Washington), Vivek Ramanujan (Division of Laptop Science, College of Washington), Jon Saad-Falcon (Laptop Science Division, Stanford College), Stutee Acharya (College of South Florida), Jeffrey Li (Carnegie Mellon College), Achal Dave (Anthropic), Alon Albalak (SynthLabs), Kushal Arora (McGill College), Blake Wulfe (Toyota Analysis Institute), Chinmay Hegde (New York College), Greg Durrett (New York College), Sewoong Oh (College of Washington), Mohit Bansal (UNC Chapel Hill), Saadia Gabriel (College of Washington), Aditya Grover (UCLA), Kai-Wei Chang (College of Virginia Most important Campus), Vaishaal Shankar (Apple), Aaron Gokaslan (Cornell College), Mike Merrill (None), Tatsunori Hashimoto (Stanford College), Yejin Choi (Stanford College / NVIDIA), Jenia Jitsev (LAION; Juelich Supercomputing Heart, Analysis Heart Juelich), Reinhard Heckel (Technical College Munich), Maheswaran Sathiamoorthy (College of Southern California), Alex Dimakis (Electrical Engineering & Laptop Science Division, College of California, Berkeley), Ludwig Schmidt (College of Washington / Stanford / Anthropic)
This work introduces the OpenThoughts venture, which goals to create high-quality, open-source datasets for coaching reasoning-focused AI fashions. The authors present that fashions skilled on their public information can match or exceed the efficiency of robust present techniques that depend on non-public datasets. By fastidiously learning and bettering their information era course of, they construct bigger and higher datasets that considerably increase efficiency throughout math, coding, and science benchmarks. Total, the venture demonstrates that open information alone may be sufficient to coach extremely succesful reasoning fashions.
Authors: Aakash Sunil Lahoti (CMU, Carnegie Mellon College), Kevin Li (Carnegie Mellon College), Berlin Chen (Princeton College), Caitlin Wang (Princeton College), Aviv Bick (Carnegie Mellon College), Zico Kolter (Carnegie Mellon College), Tri Dao (Princeton College), Albert Gu (Cartesia AI CMU)
This paper introduces Mamba-3, a brand new mannequin designed to make AI inference sooner and extra environment friendly with out sacrificing efficiency. Whereas many environment friendly options to Transformers scale back computation, they typically battle with duties like monitoring long-term data; Mamba-3 addresses this with improved state modeling and a extra expressive replace mechanism. The mannequin additionally makes use of a multi-input, multi-output design to spice up accuracy with out slowing down era. Total, Mamba-3 reveals that it’s potential to enhance each effectivity and functionality on the identical time, pushing ahead the tradeoff between velocity and efficiency.
Authors: Yuxuan Zhou (Impartial Researcher), Fei Huang (Alibaba Group), Heng Li (Carnegie Mellon College), Fengyi Wu (College of Washington), Tianyu Wang (College of Washington), Jianwei Zhang (Alibaba Group), Junyang Lin (Alibaba Group), Zhi-Qi Cheng (College of Washington)
This paper introduces Hierarchical Speculative Decoding (HSD), a brand new technique to hurry up giant language mannequin inference by bettering the verification step in speculative decoding whereas preserving actual output distributions. It addresses the problem of “joint intractability” in sequence-level verification by organizing resampling right into a hierarchy that redistributes chance mass throughout branches, enabling extra tokens to be accepted without delay. The strategy is theoretically confirmed to be lossless and empirically reveals constant velocity enhancements throughout fashions and benchmarks, outperforming prior tokenwise and blockwise verification strategies. Total, HSD presents a sensible and common method to speed up decoding with out sacrificing constancy, reaching state-of-the-art effectivity when built-in into present frameworks.
Authors: Haoyue Dai (Carnegie Mellon College), Immanuel Albrecht (FernUniversität in Hagen), Peter Spirtes (Carnegie Mellon College), Kun Zhang (Carnegie Mellon College & MBZUAI)
This paper research causal discovery in linear non-Gaussian fashions with latent variables and cycles, specializing in when completely different causal graphs are observationally indistinguishable. It offers the primary common characterization of distributional equivalence on this setting, introducing new instruments—particularly edge rank constraints—to explain when two fashions generate the identical noticed information. Constructing on this principle, the authors derive sensible graphical standards and transformations to enumerate all equal fashions and suggest an algorithm to recuperate your entire equivalence class from information. Total, the work removes the necessity for robust structural assumptions and presents a common, principled framework for latent-variable causal discovery.
Authors: Fengyu Cai (Technische Universität Darmstadt), Tong Chen (College of Washington), Xinran Zhao (Carnegie Mellon College), Sihao Chen (Microsoft), Hongming Zhang (Tencent AI Lab Seattle), Sherry Wu (Carnegie Mellon College), Iryna Gurevych (Technical College of Darmstadt / Mohamed bin Zayed College of Synthetic Intelligence), Heinz Koeppl (TU Darmstadt)
This paper introduces Revela, a self-supervised framework for coaching dense retrievers by leveraging language modeling goals as a substitute of counting on annotated query-document pairs. It augments next-token prediction with an in-batch consideration mechanism that enables paperwork to attend to one another, enabling the retriever to be taught cross-document relationships collectively with a language mannequin. Experiments throughout domain-specific, reasoning-intensive, and common benchmarks present that Revela matches or surpasses supervised and API-based retrievers whereas utilizing considerably much less information and compute. Total, the work demonstrates a scalable and environment friendly different for retriever studying instantly from uncooked textual content with robust generalization throughout domains.
Authors: Tal Daniel (Carnegie Mellon College), Carl Qi (College of Texas at Austin), Dan Haramati (Brown College), Amir Zadeh (Lambda), Chuan Li (Lambda Labs), Aviv Tamar (Technion), Deepak Pathak (Carnegie Mellon College), David Held (Carnegie Mellon College)
This paper introduces the Latent Particle World Mannequin (LPWM), a self-supervised, object-centric world mannequin that learns to decompose scenes into latent particles (e.g., keypoints, masks, and object attributes) instantly from uncooked video with out supervision. It proposes a novel per-particle latent motion mechanism that fashions stochastic dynamics, enabling the system to seize advanced multi-object interactions and generate numerous future predictions. The mannequin is skilled end-to-end and helps versatile conditioning on actions, language, and purpose photos, reaching state-of-the-art efficiency on each real-world and artificial video prediction duties. Past video modeling, LPWM additionally demonstrates robust potential for decision-making purposes similar to imitation studying by leveraging its realized latent dynamics.
Authors: Siyuan Wang (Shanghai Jiao Tong College), Gaokai Zhang (Carnegie Mellon College), Li Lyna Zhang (Microsoft Analysis Asia), Ning Shang (Microsoft), Fan Yang (Microsoft Analysis), Dongyao Chen (Shanghai Jiaotong College), Mao Yang (Peking College)
The authors introduce LoongRL, a reinforcement studying framework designed to enhance long-context reasoning in giant language fashions by coaching them on difficult, synthesized duties. They suggest KeyChain, an information development technique that embeds hidden query chains inside lengthy paperwork, forcing fashions to carry out multi-step planning, retrieval, and reasoning reasonably than counting on shortcuts. By means of RL coaching, fashions develop an emergent “plan–retrieve–motive–recheck” reasoning sample that generalizes from shorter (16K) to for much longer (128K) contexts. Experiments present that LoongRL considerably boosts long-context reasoning efficiency whereas sustaining robust short-context skills, reaching outcomes corresponding to a lot bigger fashions.
Authors: Kartik Nair (Carnegie Mellon College), Indradyumna Roy (IIT Bombay, Aalto College), Soumen Chakrabarti (IIT Bombay), Anirban Dasgupta (IIT Gandhinagar), Abir De (Indian Institute of Know-how Bombay)
This paper introduces the idea of exchangeability in graph neural networks (GNNs), displaying that the size of realized node embeddings are statistically interchangeable because of random initialization and permutation-invariant coaching. This property implies that embedding parts share equivalent distributions, enabling simplifications in how graph similarities are computed. Leveraging this perception, the authors approximate advanced transportation-based graph distances utilizing easier Euclidean operations on sorted embedding values. They additional suggest GRAPHHASH, a locality-sensitive hashing framework that permits environment friendly and scalable graph retrieval, reaching robust efficiency in comparison with present strategies.
Authors: Alistair Turcan (College of Laptop Science, Carnegie Mellon College), Kexin Huang (Stanford College), Lei Li (College of Laptop Science, Carnegie Mellon College), Martin J. Zhang (Carnegie Mellon College)
Authors: Ganlin Yang (College of Science and Know-how of China), Tianyi Zhang (Zhejiang College; Shanghai Synthetic Intelligence Laboratory), Haoran Hao (Carnegie Mellon College), Weiyun Wang (Fudan College), Yibin Liu (Northeastern College), Dehui Wang (Shanghai Jiaotong College), Guanzhou Chen (Shanghai AI Laboratory, Shanghai Jiaotong College), Zijian Cai (Shenzhen College), Junting Chen (nationwide college of singaore, Nationwide College of Singapore), Weijie Su (College of Science and Know-how of China), Wengang Zhou (College of Science and Know-how of China), Yu Qiao (Shanghai Aritifcal Intelligence Laboratory), Jifeng Dai (Tsinghua College, Tsinghua College), Jiangmiao Pang (Shanghai AI Laboratory), Gen Luo (Shanghai AI Laboratory), Wenhai Wang (Shanghai AI Laboratory), Yao Mu (Shanghai Jiao Tong College), Zhi Hou (Shanghai Synthetic Intelligence Laboratory)
Authors: Justin Lin (Laptop Science Division, Stanford College), Eliot Jones (Grey Swan), Donovan Jasper (Stanford College), Ethan Ho (Stanford College), Anna Wu (Laptop Science Division, Stanford College), Arnold Yang (Stanford College), Neil Perry (Princeton College), Andy Zou (CMU, Carnegie Mellon College), Matt Fredrikson (College of Wisconsin, Madison), Zico Kolter (Carnegie Mellon College), Percy Liang (Stanford College), Dan Boneh (Stanford College), Daniel Ho (Stanford College)
Authors: Marco Nurisso (Polytechnic College of Turin), Jesseba Fernando (Northeastern College), Raj Deshpande (Northeastern College London), Alan Perotti (Intesa Sanpaolo AI Analysis), Raja Marjieh (Princeton College), Steven Frankland (Dartmouth Faculty), Richard Lewis (Carnegie Mellon College), Taylor Webb (College of California, Los Angeles), Declan Campbell (Princeton College), Francesco Vaccarino (Politecnico di Torino), Jonathan Cohen (Princeton College), Giovanni Petri (Community Science Institute, Northeastern College London)
Authors: Boris Oreshkin (Amazon), Mayank Jauhari (Amazon), Ravi Kiran Selvam (Amazon), Malcolm Wolff (Amazon), Wenhao Pan (College of Washington), Shankar Ramasubramanian (Amazon), KIN GUTIERREZ (Carnegie Mellon College), Tatiana Konstantinova (Amazon), Andres Potapczynski (New York College), Mengfei Cao (Amazon.com), Dmitry Efimov (Amazon), Michael W Mahoney (College of California Berkeley), Andrew Gordon Wilson (New York College)
Authors: Xinran Zhao (CMU, Carnegie Mellon College), Aakanksha Naik (Allen Institute for Synthetic Intelligence), Jay DeYoung (Allen Institute for Synthetic Intelligence), Joseph Chee Chang (Allen Institute for Synthetic Intelligence), Jena Hwang (Allen Institute for Synthetic Intelligence), Sherry Wu (Carnegie Mellon College), Varsha Kishore (Cornell College)
Authors: Jie Ruan (College of Michigan – Ann Arbor), Inderjeet Nair (College of Michigan – Ann Arbor), Shuyang Cao (Bloomberg), Amy Liu (College of Michigan), Sheza Munir (College of Toronto), Micah Pollens-Dempsey (College of Michigan – Ann Arbor), Yune-Ting Chiang (College of Michigan – Ann Arbor), Lucy Kates (College of Michigan – Ann Arbor), Nicholas David (College of Michigan – Ann Arbor), Sihan Chen (Carnegie Mellon College), Ruxin Yang (College of Michigan – Ann Arbor), Yuqian Yang (College of Michigan – Ann Arbor), Jihyun Gump (College of Michigan – Ann Arbor), Tessa Bialek (College of Michigan Regulation College), Vivek Sankaran (College of Michigan – Ann Arbor), Margo Schlanger (College of Michigan – Ann Arbor), Lu Wang (College of Michigan)
Authors: Junlong Li (The Hong Kong College of Science and Know-how), Wenshuo Zhao (Zhejiang College), Jian Zhao (Beijing College of Posts and Telecommunications), Weihao Zeng (Hong Kong College of Science and Know-how), Haoze Wu (Zhejiang College), Xiaochen Wang (None), Rui Ge (Shanghai Jiaotong College), Yuxuan Cao (HKUST), Yuzhen Huang (HKUST), Wei Liu (HKUST), Junteng LIU (HKUST), Zhaochen Su (The Hong Kong College of Science and Know-how), Yiyang Guo (Fudan College), FAN ZHOU (Shanghai Jiao Tong College), Lueyang Zhang (The Hong Kong College of Science and Know-how), Juan Michelini (Universidad de la República), Xingyao Wang (All Palms AI), Xiang Yue (Carnegie Mellon College), Shuyan Zhou (Fb), Graham Neubig (Carnegie Mellon College), Junxian He (HKUST)
Authors: Yifan Shen (Mohamed bin Zayed College of Synthetic Intelligence), Peiyuan Zhu (Mohamed bin Zayed College of Synthetic Intelligence), Zijian Li (Mohamed bin Zayed College of Synthetic Intelligence), Shaoan Xie (Carnegie Mellon College), Namrata Deka (Carnegie Mellon College), Zongfang Liu (Zhejiang College), Zeyu Tang (Stanford College), Guangyi Chen (MBZUAI&CMU), Kun Zhang (Carnegie Mellon College & MBZUAI)
Authors: Qinhong Zhou (College of Massachusetts at Amherst), Hongxin Zhang (UMass Amherst), Xiangye Lin (College of Massachusetts at Amherst), Zheyuan Zhang (Johns Hopkins College), Yutian Chen (Carnegie Mellon College), Wenjun Liu (College of Massachusetts at Amherst), Zunzhe Zhang (Tsinghua College), Sunli Chen (College of Massachusetts at Amherst), Lixing Fang (College of Massachusetts at Amherst), Qiushi Lyu (College of Illinois, Urbana-Champaign), Xinyu Solar (South China College of Know-how), Jincheng Yang (College of Maryland, Faculty Park), Zeyuan Wang (Tsinghua College, Tsinghua College), Bao Dang (College of Massachusetts at Amherst), Zhehuan Chen (Peking College), Daksha Ladia (College of Massachusetts Amherst), Quang Dang (College of Massachusetts at Amherst), Jiageng Liu (College of Massachusetts at Amherst), Chuang Gan (MIT-IBM Watson AI Lab)
Authors: Rohan Choudhury (None), JungEun Kim (Normal Robotics), Jinhyung Park (Carnegie Mellon College), Eunho Yang (Korea Superior Institute of Science & Know-how), Laszlo A. Jeni (Carnegie Mellon College), Kris Kitani (Carnegie Mellon College)
Authors: Leigang Qu (Nationwide College of Singapore), Feng Cheng (ByteDance Seed), Ziyan Yang (ByteDance Inc.), Qi Zhao (ByteDance Inc.), Shanchuan Lin (ByteDance), Yichun Shi (None), Yicong Li (Nationwide College of Singapore), Wenjie Wang (College of Science and Know-how of China), Tat-Seng Chua (Nationwide College of Singapore), Lu Jiang (Carnegie Mellon College)
Authors: Lanxiang Hu (College of California, San Diego), Mingjia Huo (College of California, San Diego), Yuxuan Zhang (College of California, San Diego), Haoyang Yu (College of California San Diego), Eric P Xing (CMU), Ion Stoica (), Tajana Rosing (College of California, San Diego), Haojian Jin (None), Hao Zhang (College of California, San Diego)
Authors: Ming Zhao (Jilin College), Wenhui Dong (NanJing College), Yang Zhang (Chinese language Individuals’s Liberation Military Normal Hospital), wangyou (College of the Chinese language Academy of Sciences), Zhonghao Zhang (Ningxia College), Zian Zhou (Zhejiang College), YUNZHI GUAN (Fudan College), Liukun Xu (Nanjing Medical College), Wei Peng (Stanford College), Zhaoyang Gong (Fudan College), Zhicheng Zhang (Chinese language Individuals’s Liberation Military Normal Hospital), Dachuan li (Fudan College), Xiaosheng Ma (Fudan College), Yuli Ma (Peking College), Jianing Ni (Carnegie Mellon College), Changjiang Jiang (Ant Group), Lixia Tian (Beijing Jiaotong College), Chen Qixin (Zhejiang College), Xia Kaishun (Zhejiang College of Know-how), Pingping Liu (Jilin College), Tongshun Zhang (Jilin College), ZhiqiangLiu (Huazhong College of Science and Know-how), Zhongan Bi (Zhejiang Lab), Chenyang Si (Nanyang Technological College), Tiansheng Solar (Chinese language Individuals’s Liberation Military Normal Hospital), Caifeng Shan (Nanjing College)
Authors: Shengqu Cai (Stanford College), Ceyuan Yang (ByteDance), Lvmin Zhang (Stanford College), Yuwei Guo (The Chinese language College of Hong Kong), Junfei Xiao (Johns Hopkins College), Ziyan Yang (ByteDance Inc.), Yinghao Xu (Stanford College), Zhenheng Yang (Tiktok), Alan Yuille (Johns Hopkins College), Leonidas Guibas (Stanford College), Maneesh Agrawala (Stanford College), Lu Jiang (Carnegie Mellon College), Gordon Wetzstein (Stanford College)
Authors: Lars Mescheder (Apple), Wei Dong (Apple), Shiwei Li (Apple), Xuyang BAI (Apple), Marcel Santos (Apple), Peiyun Hu (Carnegie Mellon College), Bruno Lecouat (Telecom ParisTech), Mingmin Zhen (Apple), Amaël Delaunoy (Apple), Tian Fang (Hong Kong College of Science and Know-how), Yanghai Tsin (Apple), Stephan Richter (Apple), Vladlen Koltun (Apple)
Authors: Junfei Xiao (Johns Hopkins College), Ceyuan Yang (ByteDance), Lvmin Zhang (Stanford College), Shengqu Cai (Stanford College), Yang Zhao (Bytedance Inc.), Yuwei Guo (The Chinese language College of Hong Kong), Gordon Wetzstein (Stanford College), Maneesh Agrawala (Stanford College), Alan Yuille (Johns Hopkins College), Lu Jiang (Carnegie Mellon College)
Authors: Yuansheng Ni (College of Waterloo), Songcheng Cai (College of Waterloo), Xiangchao Chen (College of Waterloo), Jiarong Liang (College of Waterloo), Zhiheng LYU (College of Hong Kong), Jiaqi Deng (Korea Superior Institute of Science & Know-how), Kai Zou (NetMind.AI), PING NIE (Peking College), Fei Yuan (Shanghai Synthetic Clever Laboratory), Xiang Yue (Carnegie Mellon College), Wenhu Chen (College of Waterloo)
Authors: Amrith Setlur (Carnegie Mellon College), Matthew Yang (Carnegie Mellon College), Charlie Snell (College of California, Berkeley), Jeremiah Greer (Oumi AI PBC), Ian Wu (Carnegie Mellon College), Virginia Smith (Carnegie Mellon College), Max Simchowitz (Massachusetts Institute of Know-how), Aviral Kumar (College of California Berkeley)
Authors: Guo (), Songlin Yang (ShanghaiTech College), Tarushii Goel (Massachusetts Institute of Know-how), Eric P Xing (CMU), Tri Dao (Princeton College), Yoon Kim (MIT)
Authors: Abdul Waheed (Maharaja Agrasen Institute of Know-how, New Delhi), Zhen Wu (Carnegie Mellon College), Carolyn Rose (College of Laptop Science, Carnegie Mellon College), Daphne Ippolito (College of Engineering and Utilized Science, College of Pennsylvania)
Authors: Charlie Cowen-Breen (Massachusetts Institute of Know-how), Alekh Agarwal (Google), Stephen Bates (Massachusetts Institute of Know-how), William W. Cohen (Carnegie Mellon College), Jacob Eisenstein (Google), Amir Globerson (Google), Adam Fisch (Google DeepMind)
Authors: Barry Wang (Carnegie Mellon College), Avi Schwarzschild (Carnegie Mellon College), Alexander Robey (CMU, Carnegie Mellon College), Ali Payani (Cisco Methods), Charles Fleming (Cisco), Mingjie Solar (College of Laptop Science, Carnegie Mellon College), Daphne Ippolito (College of Engineering and Utilized Science, College of Pennsylvania)
Authors: Zhongmou He (Carnegie Mellon College), Yee Man Choi (College of Waterloo), Kexun Zhang (Carnegie Mellon College), Ivan Bercovich (UC Santa Barbara + ScOp VC), Jiabao Ji (College of California, Santa Barbara), Junting Zhou (Peking College), Dejia Xu (College of Texas at Austin), Aidan Zhang (Carnegie Mellon College), Yixiao Zeng (XPeng Motors / Carnegie Mellon College), Lei Li (College of Laptop Science, Carnegie Mellon College)
Authors: Max Rudolph (College of Texas at Austin), Nathan Lichtlé (Electrical Engineering & Laptop Science Division, College of California, Berkeley), Sobhan Mohammadpour (MIT), Alexandre M Bayen (None), Zico Kolter (Carnegie Mellon College), Amy Zhang (UT Austin), Gabriele Farina (Massachusetts Institute of Know-how), Eugene Vinitsky (New York College), Samuel Sokota (Carnegie Mellon College)
Authors: Zichen Liu (Sea AI Lab), Anya Sims (College of Oxford), Keyu Duan (nationwide college of singaore, Nationwide College of Singapore), Changyu Chen (Stanford College), Simon Yu (Northeastern College), Xiangxin Zhou (UCAS), Haotian Xu (Tsinghua College, Tsinghua College), Shaopan Xiong (Alibaba Group), Bo Liu (Nationwide College of Singapore), Chenmien Tan (College of Edinburgh), Weixun Wang (Tianjin College), Hao Zhu (Carnegie Mellon College), Weiyan Shi (Columbia College), Diyi Yang (Stanford College), Michael Qizhe Shieh (Nationwide College of Singapore), Yee Whye Teh (College of Oxford and Google DeepMind), Wee Solar Lee (Nationwide College of Singapore), Min Lin (Sea AI Lab)
Authors: Qiusi Zhan (College of Illinois Urbana-Champaign), Hyeonjeong Ha (College of Illinois Urbana-Champaign), Rui Yang (Hong Kong College of Science and Know-how), Sirui Xu (College of Illinois at Urbana-Champaign), Hanyang Chen (College of Illinois at Urbana-Champaign), Liang-Yan Gui (UIUC), Yu-Xiong Wang (UIUC), Huan Zhang (CMU), Heng Ji (College of Illinois at Urbana-Champaign), Daniel Kang (UIUC)
Authors: Jing-Jing Li (College of California, Berkeley), Joel Mire (Carnegie Mellon College), Eve Fleisig (UC Berkeley), Valentina Pyatkin (Ai2, ETH AI Heart), Anne Collins (College of California, Berkeley), Maarten Sap (Carnegie Mellon College), Sydney Levine (NYU / Google Deepmind)
Authors: Taylor Sorensen (people&), Benjamin Newman (College of Washington), Jared Moore (Laptop Science Division, Stanford College), Chan Younger Park (College of Texas at Austin), Jillian Fisher (College of Washington), Niloofar Mireshghallah (Carnegie Mellon College), Liwei Jiang (None), Yejin Choi (Stanford College / NVIDIA)
Authors: Ioannis Anagnostides (Carnegie Mellon College), Emanuel Tewolde (Carnegie Mellon College), Brian Zhang (MIT), Ioannis Panageas (Donald Bren College of Info and Laptop Sciences, College of California, Irvine), Vincent Conitzer (Carnegie Mellon College), Tuomas Sandholm (Carnegie Mellon College)
Authors: Baihe Huang (College of California, Berkeley), Shanda Li (Carnegie Mellon College), Tianhao Wu (College of California, Berkeley), Yiming Yang (Carnegie Mellon College), Ameet Talwalkar (College of California-Los Angeles), Kannan Ramchandran (), Michael Jordan (College of California, Berkeley), Jiantao Jiao (College of California Berkeley)
Authors: Xuanming Cui (College of Central Florida), Jianpeng Cheng (Meta), Hong-You Chen (Ohio State College), Satya Narayan Shukla (Meta), Abhijeet Awasthi (Indian Institute of Know-how Bombay), Xichen Pan (New York College), Chaitanya Ahuja (Carnegie Mellon College), Shlok Mishra (Fb), Taipeng Tian (Meta), Qi Guo (Fb), Ser-Nam Lim (College of Central Florida), Aashu Singh (Fb), Xiangjun Fan (Meta)
Authors: Yanghao Li (Apple), Rui Qian (Apple), Bowen Pan (Massachusetts Institute of Know-how), Haotian Zhang (NVIDIA), Haoshuo Huang (Apple), Bowen Zhang (Apple), Jialing Tong (Apple), Haoxuan You (Apple AI/ML), Xianzhi Du (Apple), Zhe Gan (Apple), Hyunjik Kim (DeepMind), Chao Jia (Google), Zhenbang Wang (Apple), Yinfei Yang (Apple), Mingfei Gao (Apple), Zi-Yi Dou (Carnegie Mellon College), Wenze Hu (UCLA, College of California, Los Angeles), Chang Gao (Waymo), Dongxu Li (SalesForce.com), Philipp Dufter (Apple), Zirui Wang (Apple AI/ML), Guoli Yin (Apple), Zhengdong Zhang (Google), Chen Chen (Apple), Yang Zhao (College of California, Berkeley), Ruoming Pang (None), Zhifeng Chen (Apple)
Authors: Yue Huang (College of Notre Dame), Chujie Gao (Mohamed bin Zayed College of Synthetic Intelligence), Siyuan Wu (None), Haoran Wang (Emory College), Xiangqi Wang (College of Notre Dame), Jiayi Ye (Sichuan College), Yujun Zhou (College of Notre Dame), Yanbo Wang (Mohamed bin Zayed College of Synthetic Intelligence), Jiawen Shi (Huazhong College of Science and Know-how), Qihui Zhang (Sichuan College), Han Bao (College of Notre Dame), Zhaoyi Liu (College of Illinois at Urbana-Champaign), Yuan Li (College of Cambridge), Tianrui Guan (Division of Laptop Science, College of Maryland, Faculty Park), Peiran Wang (College of California, Los Angeles), Haomin Zhuang (College of Notre Dame), Dongping Chen (College of Washington), Kehan Guo (College of Notre Dame), Andy Zou (CMU, Carnegie Mellon College), Bryan Hooi (Nationwide College of Singapore), Caiming Xiong (Salesforce Analysis), Elias Stengel-Eskin (Division of Laptop Science, UT Austin), Hongyang Zhang (College of Waterloo), Hongzhi Yin (College of Queensland), Huan Zhang (CMU), Huaxiu Yao (UNC-Chapel Hill), Jieyu Zhang (Division of Laptop Science, College of Washington), Jaehong Yoon (NTU Singapore), Kai Shu (Emory College), Ranjay Krishna (Division of Laptop Science), Swabha Swayamdipta (College of Southern California), Weijia Shi (College of Washington, Seattle), Xiang Li (Massachusetts Normal Hospital), Yuexing Hao (Massachusetts Institute of Know-how), Zhihao Jia (College of Laptop Science, Carnegie Mellon College), Zhize Li (KAUST), Xiuying Chen (Mohamed bin Zayed College of Synthetic Intelligence), Zhengzhong Tu (Texas A&M College – Faculty Station), Xiyang Hu (Arizona State College), Tianyi Zhou (MBZUAI), Jieyu Zhao (College of Southern California), Lichao Solar (Lehigh College), Furong Huang (College of Maryland), Or Cohen-Sasson (College of Miami), Prasanna Sattigeri (IBM Analysis), Anka Reuel (Stanford College), Max Lamparth (Stanford College), Yue Zhao (College of Southern California), Nouha Dziri (Allen Institute for AI), Yu Su (Ohio State College), Huan Solar (Ohio State College), Heng Ji (College of Illinois at Urbana-Champaign), Chaowei Xiao (Johns Hopkins College/NVIDIA), Mohit Bansal (UNC Chapel Hill), Nitesh Chawla (College of Notre Dame), Jian Pei (Simon Fraser College), Jianfeng Gao (Microsoft Analysis), Michael Backes (CISPA Helmholtz Heart for Info Safety), Philip Yu (College of Illinois, Chicago), Neil Gong (), Pin-Yu Chen (IBM Analysis AI), Bo Li (College of Illinois, Urbana Champaign), Daybreak Track (Berkeley), Xiangliang Zhang (College of Notre Dame)
Authors: Younger-Jun Lee (KAIST), Seungone Kim (Carnegie Mellon College), Byung-Kwan Lee (NVIDIA), Minkyeong Moon (Yonsei College), Yechan Hwang (), Jong Myoung Kim (Korea Superior Institute of Science & Know-how), Graham Neubig (Carnegie Mellon College), Sean Welleck (Carnegie Mellon College), Ho-Jin Choi (Korea Superior Institute of Science & Know-how)
Authors: Dhruv Rohatgi (Massachusetts Institute of Know-how), Abhishek Shetty (College of California Berkeley), Donya Saless (College of California, Berkeley), Yuchen Li (Carnegie Mellon College), Ankur Moitra (Massachusetts Institute of Know-how), Andrej Risteski (Carnegie Mellon College), Dylan Foster (Microsoft Analysis NYC)
Authors: Fan Feng (College of California, San Diego), Selena Ge (College of California, San Diego), Minghao Fu (College of California, San Diego), Zijian Li (Mohamed bin Zayed College of Synthetic Intelligence), Yujia Zheng (Carnegie Mellon College), Zeyu Tang (Stanford College), Yingyao Hu (Johns Hopkins College), Biwei Huang (College of California, San Diego), Kun Zhang (Carnegie Mellon College & MBZUAI)
Authors: Weiwei Solar (Carnegie Mellon College), Keyi Kong (Shandong College), xinyu ma (Institute of Computing Know-how,Chinese language Academy of Science), Shuaiqiang Wang (Baidu Inc.), Dawei Yin (Baidu), Maarten de Rijke (College of Amsterdam), Zhaochun Ren (Leiden College), Yiming Yang (Carnegie Mellon College)
Authors: Mike Merrill (None), Alexander Shaw (Brigham Younger College), Nicholas Carlini (Anthropic), Boxuan Li (Microsoft), Harsh Raj (Northeastern College), Ivan Bercovich (UC Santa Barbara + ScOp VC), Lin Shi (Cornell College), Jeong Shin (Snorkel AI), Thomas Walshe (Reflection AI), E. Kelly Buchanan (Columbia College), Junhong Shen (Carnegie Mellon College), Guanghao Ye (Massachusetts Institute of Know-how), Haowei Lin (Peking College), Jason Poulos (Impartial Researcher), Maoyu Wang (), Marianna Nezhurina (Juelich Supercomputing Heart, LAION, Tuebingen College), Di Lu (Tencent), Orfeas Menis Mastromichalakis (Nationwide Technical College of Athens), Zhiwei Xu (College of Michigan), Zizhao Chen (Division of Laptop Science, Cornell College), Yue Liu (NUS), Robert Zhang (College of Texas at Austin), Leon Liangyu Chen (Stanford College), Anurag Kashyap (Amazon), Jan-Lucas Uslu (Stanford College), Jeffrey Li (Carnegie Mellon College), Jianbo Wu (College of California, Merced), Minghao Yan (Division of Laptop Science, College of Wisconsin – Madison), Track Bian (College of Wisconsin-Madison), Vedang Sharma (Fremont Unified College District), Ke Solar (Amazon), Steven Dillmann (Stanford College), Akshay Anand (College of California, Berkeley), Andrew Lanpouthakoun (Stanford College), Bardia Koopah (College of California, Berkeley), Changran Hu (Sambanova Methods, Inc), Etash Guha (Stanford College, Anthropic), Gabriel Dreiman (Insitro), Jiacheng Zhu (Massachusetts Institute of Know-how), Karl Krauth (Stanford), Li Zhong (Anthropic), Niklas Muennighoff (Stanford College), Robert Amanfu (Impartial), Shangyin Tan (College of California, Berkeley), Shreyas Pimpalgaonkar (New York College), Tushar Aggarwal (Microsoft Analysis / Stanford), Xiangning Lin (CMU), Xin Lan (Michigan State College), Xuandong Zhao (UC Berkeley), Yiqing Liang (Brown College), Yuanli Wang (Boston College), Zilong (Ryan) Wang (UC San Diego), Changzhi Zhou (Tencent), David Heineman (Allen Institute for Synthetic Intelligence), Hange Liu (Microsoft), Harsh Trivedi (Allen Institute for Synthetic Intelligence), John Yang (Princeton College), Junhong Lin (Massachusetts Institute of Know-how), Manish Shetty (College of California, Berkeley), Michael Yang (College of California, Santa Barbara), Nabil Omi (Microsoft Analysis), Negin Raoof (College of California, Berkeley), Shanda Li (Carnegie Mellon College), Terry Yue Zhuo (Data61, CSIRO), Wuwei Lin (OpenAI), Yiwei Dai (Cornell College), Yuxin Wang (Dartmouth Faculty), Wenhao Chai (Princeton College), Shang Zhou (College of California, San Diego), Dariush Wahdany (CISPA Helmholtz Heart), Ziyu She (None), Jiaming Hu (Boston College), Zhikang Dong (State College of New York at Stony Brook), Yuxuan Zhu (College of Illinois Urbana-Champaign), Sasha Cui (Yale College), Ahson Saiyed (College of Virginia, Charlottesville), Arinbjörn Kolbeinsson (UVA & K01), Christopher Rytting (Brigham Younger College), Ryan Marten (Harbor), Yixin Wang (College of Michigan – Ann Arbor), Jenia Jitsev (LAION; Juelich Supercomputing Heart, Analysis Heart Juelich), Alex Dimakis (Electrical Engineering & Laptop Science Division, College of California, Berkeley), Andy Konwinski (College of California, Berkeley), Ludwig Schmidt (College of Washington / Stanford / Anthropic)
Authors: Kartik Nair (Carnegie Mellon College), Pritish Chakraborty (Indian Institute of Know-how Bombay, Indian Institute of Know-how, Bombay), Atharva Tambat (Indian Institute of Know-how Bombay, Indian Institute of Know-how, Bombay), Indradyumna Roy (IIT Bombay, Aalto College), Soumen Chakrabarti (IIT Bombay), Anirban Dasgupta (IIT Gandhinagar), Abir De (Indian Institute of Know-how Bombay,)
Authors: Ruibin Yuan (Hong Kong College of Science and Know-how), Hanfeng Lin (Hong Kong College of Science and Know-how), Shuyue Guo (Beijing College of Posts and Telecommunications), Ge Zhang (College of Waterloo), Jiahao Pan (Hong Kong College of Science and Know-how), Yongyi Zang (Smule, Inc.), Haohe Liu (Ohio State College), Yiming Liang (College of the Chinese language Academy of Sciences), Wenye Ma (Mohamed bin Zayed College of Synthetic Intelligence), Xingjian Du (College of Rochester), Xeron Du (01.AI), Zhen Ye (The Hong Kong College of Science and Know-how), Tianyu Zheng (Beijing College of Posts and Telecommunications), Zhengxuan Jiang (Zhejiang College), Yinghao MA (Queen Mary College of London), Minghao Liu (2077AI), Zeyue Tian (Hong Kong College of Science and Know-how), Ziya Zhou (The Hong Kong College of Science and Know-how), Liumeng Xue (Hong Kong College of Science and Know-how), Xingwei Qu (College of Manchester), Yizhi Li (College of Manchester), Shangda Wu (Tencent), Tianhao Shen (Tianjin College), Ziyang Ma (Shanghai Jiao Tong College), Jun Zhan (Fudan College), Chunhui Wang (JD.com), Yatian Wang (The Hong Kong College of Science and Know-how), Xiaowei Chi (Hong Kong College of Science and Know-how), Xinyue Zhang (Nationwide College of Singapore), Zhenzhu Yang (China College of Geoscience Beijing), XiangzhouWang (Wuhan College of Engineering Science), Shansong Liu (Institute of Synthetic Intelligence (TeleAI), China Telecom), Lingrui Mei (College of the Chinese language Academy of Sciences), Peng Li (Hong Kong College of Science and Know-how), JUNJIE WANG (None), Jianwei Yu (Microsoft), Guojian Pang (ByteDance Inc.), Xu Li (Kuaishou- 快手科技), Zihao Wang (CMU, Carnegie Mellon College;ZJU,Zhejiang College), Xiaohuan Zhou (ByteDance Inc.), Lijun Yu (Google DeepMind), Emmanouil Benetos (Queen Mary College of London), Yong Chen (Geely Vehicle Analysis Institute (Ningbo) Co., Ltd), Chenghua Lin (College of Manchester ), Xie Chen (Shanghai Jiaotong College), Gus Xia (MBZUAI), Zhaoxiang Zhang (Institute of automation, Chinese language academy of science, Chinese language Academy of Sciences), Chao Zhang (Division of Digital Engineering, Tsinghua College), Wenhu Chen (College of Waterloo), Xinyu Zhou (Megvii Inc.), Xipeng Qiu (Fudan College), Roger Dannenberg (Carnegie Mellon College), JIAHENG LIU (Nanjing College), Jian Yang (Beihang College), Wenhao Huang (01.AI), Wei Xue (Hong Kong College of Science and Know-how), Xu Tan (Microsoft Analysis), Yike Guo (Imperial Faculty London)
Authors: Guying Lin (Carnegie Mellon College), Kemeng Huang (College of Hong Kong), Michael Liu (CMU, Carnegie Mellon College), Ruihan Gao (Carnegie Mellon College), Hanke Chen (Carnegie Mellon College), Lyuhao Chen (Carnegie Mellon College), Beijia Lu (Carnegie Mellon College), Taku Komura (the College of Hong Kong, College of Hong Kong), Yuan Liu (The College of Hong Kong), Jun-Yan Zhu (Carnegie Mellon College), Minchen Li (College of Engineering and Utilized Science, College of Pennsylvania)
Authors: Yujia Zheng (Carnegie Mellon College), Zijian Li (Mohamed bin Zayed College of Synthetic Intelligence), Shunxing Fan (Mohamed bin Zayed College of Synthetic Intelligence), Andrew Gordon Wilson (New York College), Kun Zhang (Carnegie Mellon College & MBZUAI)
Authors: Hong Wang (College of Science and Know-how of China), Jie Wang (College of Science and Know-how of China), Jian Luo (Stony Brook College), huanshuo dong (College of Science and Know-how of China), Yeqiu Chen (College of Science and Know-how of China), Runmin Jiang (Carnegie Mellon College), Zhen Huang (College of Science and Know-how of China)
Authors: Hyungjun Yoon (Korea Superior Institute of Science & Know-how), Seungjoo Lee (Carnegie Mellon College), Yu Wu (Dartmouth Faculty), XiaoMeng Chen (Shanghai Jiaotong College), Taiting Lu (Pennsylvania State College), Freddy Liu (College of Pennsylvania, College of Pennsylvania), Taeckyung Lee (KAIST), Hyeongheon Cha (Korea Superior Institute of Science & Know-how), Haochen Zhao (), Gaoteng Zhao (Northwest College), Dongyao Chen (Shanghai Jiaotong College), Cecilia Mascolo (College of Cambridge), Sung-Ju Lee (UCLA Laptop Science Division, College of California, Los Angeles), Lili Qiu (Microsoft)
Authors: Seongyun Lee (KAIST AI), Seungone Kim (Carnegie Mellon College), Minju Web optimization (Korea Superior Institute of Science & Know-how), Yongrae Jo (KAIST), Dongyoung Go (Cornell College), Hyeonbin Hwang (Korea Superior Institute of Science & Know-how), Jinho Park (Korea Superior Institute of Science & Know-how), Xiang Yue (Carnegie Mellon College), Sean Welleck (Carnegie Mellon College), Graham Neubig (Carnegie Mellon College), Moontae Lee (College of Illinois, Chicago), Minjoon Web optimization (KAIST)
Authors: Loka Li (MBZUAI), Wong Kang (Mohamed bin Zayed College of Synthetic Intelligence), Minghao Fu (College of California, San Diego), Guangyi Chen (MBZUAI&CMU), Zhenhao Chen (MBZUAI), Gongxu Luo (Mohamed bin Zayed College of Synthetic Intelligence), Yuewen Solar (Mohamed bin Zayed College of Synthetic Intelligence), Salman Khan (Mohamed bin Zayed College of Synthetic Intelligence), Peter Spirtes (Carnegie Mellon College), Kun Zhang (Carnegie Mellon College & MBZUAI)
Frontend cloud platform Vercel, the creator of Subsequent.js and Turbo.js, has warned a few knowledge breach after a compromised third-party AI software abused OAuth to entry its inside techniques.
A Vercel worker used the third-party app, recognized as Context.ai, which allowed the attackers to take over their Google Workspace account and entry some setting variables that the corporate mentioned weren’t marked as “delicate.”
“Setting variables marked as ‘delicate’ in Vercel are saved in a way that stops them from being learn, and we presently would not have proof that these values had been accessed,” Vercel mentioned in a safety submit.
The incident compromised what the corporate described as a “restricted subset” of consumers whose Vercel credentials had been uncovered. These clients have now been reached out to with requests to rotate their credentials, Vercel mentioned.
In keeping with experiences surfacing on the web, a risk actor claiming to be the Shinyhunters started making an attempt to promote the stolen knowledge, which allegedly contains entry key, supply code, and personal database, even earlier than Vercel confirmed the breach publicly.
Hacking the entry
Vercel’s disclosure confirmed that the preliminary entry vector was Google Workspace OAuth tied to Context.ai. As soon as the applying was compromised, attackers inherited the permissions granted to it, together with entry to the Vercel worker’s account.
It stays unclear whether or not Context.ai’s infrastructure was compromised, whether or not OAuth tokens had been stolen, or whether or not a session/token leak inside the AI workspace enabled attackers to abuse authenticated entry into Vercel’s environments. Context.ai didn’t instantly reply to CSO’s request for feedback.
“Now we have engaged Context.ai instantly to know the complete scope of the underlying compromise,” Vercel mentioned within the submit. “We assess the attacker as extremely subtle primarily based on their operational velocity and detailed understanding of Vercel’s techniques. We’re working with Mandiant, extra cybersecurity corporations, business friends, and regulation enforcement.”
Vercel has urged its clients to overview exercise logs for suspicious habits and to rotate setting variables, particularly any unprotected secrets and techniques that will have been uncovered. It additionally beneficial enabling delicate variable protections, checking latest deployments for anomalies, and strengthening safeguards by updating deployment safety settings and rotating associated tokens the place wanted.
Delicate secrets and techniques, together with API keys, tokens, database credentials, and signing keys that weren’t marked as “delicate,” must be handled as doubtlessly uncovered and rotated as a precedence, Vercel emphasised.
For customers in panic, Vercel has provided a shortcut. “When you’ve got not been contacted, we would not have motive to imagine that your Vercel credentials or private knowledge have been compromised at the moment,” the submit reassured.
Allegedly breached by ShinyHunters
In keeping with screenshots circulating on the web, a risk actor has already claimed the breach on the darkish net and is making an attempt to promote the spoils. “Greetings All, Right now I’m promoting Entry Key/ Supply Code/ Database from Vercel firm,” the actor mentioned in one among such posts. “Give me a quote if you happen to’re . This could possibly be the biggest provide chain assault ever if executed proper.”
The information was put up for $2 million on April 19.
The risk actor may be seen utilizing a “BreachForums” area within the screenshot, claiming (not explicitly) to be Shinyhunters themselves, one of many operators of the infamous hacksite. Different giveaways embody a Telegram channel “@Shinyc0rpsss” and an e mail ID “shinysevy@tutamail.com” talked about within the submit.
Whereas latest incidents have hinted at ShinyHunters resurfacing after takedowns and alleged arrests, it stays probably that that is an imposter leveraging the title to lend credibility, one thing that has precedent.
Do you know? As per present knowledge 69% of execs imagine that AI is disrupting their job roles.
Nonetheless, as a substitute of concern, there may be immense optimism; an awesome 78% are constructive about AI’s potential impression on their careers.
Because the demand for synthetic intelligence surges globally, many aspiring professionals marvel precisely how a lot programming experience is required to enter this profitable discipline.
Do you should be a coding prodigy to succeed, or are there different, low-code pathways? Understanding the essential structure behind AI and what’s LLM (Massive Language Mannequin) infrastructure versus common machine studying, is your first essential step.
This text breaks down the coding necessities throughout varied AI and LLM-related job profiles, highlighting key languages, that can assist you navigate your profession technique successfully.
Summarize this text with ChatGPT Get key takeaways & ask questions
Why Coding Issues in AI and LLM Ecosystems?
Regardless of the fast rise of low-code platforms and automatic instruments, programming stays the important spine of sturdy synthetic intelligence methods.
In accordance with current workforce tendencies, Machine Studying and Synthetic Intelligence have emerged as the highest domains of alternative for upskilling, chosen by an enormous 44% of execs.
This excessive stage of curiosity underscores the underlying want for technical proficiency within the fashionable enterprise. You have to perceive that coding performs a pivotal, non-negotiable function in three predominant operational areas:
Information Processing and Transformation: Uncooked knowledge is messy, unstructured, and infrequently prepared for mannequin coaching. Programming is completely important for cleansing datasets, dealing with lacking values, standardizing inputs, and executing characteristic engineering in order that algorithms can course of the knowledge successfully with out bias or error.
Mannequin Constructing and Experimentation: Builders and researchers rely closely on code to assemble deep neural networks, repeatedly regulate hyperparameters, and iteratively take a look at totally different algorithmic architectures. This granular management ensures the mannequin achieves the specified accuracy, precision, and effectivity metrics.
Deployment and Scaling: As soon as a machine studying mannequin is efficiently skilled, it have to be built-in into reside manufacturing environments. Coding facilitates the creation of safe APIs, strong cloud deployment architectures, and steady monitoring methods (referred to as MLOps) to trace mannequin drift over time.
Detailed Comparability: Python vs. SQL vs. JavaScript in AI
N/A (Depends on database engines like PostgreSQL, MySQL, and rising Vector DBs like pgvector).
TensorFlow.js, LangChain.js, React, Node.js.
Superb Function Suitability
Machine Studying Engineer, Information Scientist, AI Researcher, AI Backend Engineer
Information Analyst, Information Engineer, Information Scientist.
Full-Stack Developer, AI App Developer, Frontend Engineer
LLM Period Influence
Stays absolutely the {industry} normal for LLM brokers and pipelines.
Essential for Retrieval-Augmented Technology (RAG) when fetching enterprise knowledge to feed LLMs.
More and more fashionable for constructing ChatGPT-like clones, AI chatbots, and browser-based AI instruments.
To construct your foundational abilities, you’ll be able to discover the, Synthetic Intelligence with Python free course, which helps you be taught synthetic intelligence ideas particularly using the Python programming language. For visible studying you’ll be able to watch:
Coding Necessities by Function
1. Information Scientist
Coding Degree: Average to Excessive
Focus: Information Scientists primarily give attention to statistical knowledge evaluation, superior characteristic engineering, and predictive mannequin constructing. Their major goal is to extract actionable enterprise insights from uncooked knowledge. In reality, present experiences present that 39% of execs actively make the most of GenAI particularly for analysing massive datasets to speed up this course of.
Instruments: Information Scientists rely closely on Python and R, using strong statistical libraries equivalent to Pandas, Scikit-learn, and NumPy. Jupyter notebooks function their normal, day-to-day atmosphere for exploratory knowledge evaluation. In contrast to ML Engineers, there may be barely much less give attention to strict, production-level software program engineering and extra emphasis on mathematical and statistical validity.
2. Machine Studying Engineer
Duties: Machine Studying Engineers act as the first architects of core AI methods. They’re required to construct, prepare, and closely optimize complicated algorithmic fashions from the bottom up. Moreover, they have to deploy strong knowledge pipelines and handle the whole MLOps lifecycle to make sure these fashions run seamlessly and cost-effectively in manufacturing environments.
What You Should Know? Deep, complete experience in knowledge constructions, system design, and most used machine studying algorithms in Python is non-negotiable. You have to excel in safe API growth, mannequin optimization strategies (like quantization), and managing huge cloud computing sources. Working intimately with heavy frameworks like TensorFlow and PyTorch is normal day by day follow.
3. AI Engineer (LLM-Centered Roles)
Key Duties: AI Engineers working particularly within the LLM period focus much less on coaching huge foundational fashions from scratch, and extra on constructing utilized, AI-powered brokers. They spend their time working securely with APIs (from suppliers like OpenAI, Anthropic, or open-source LLMs hosted on HuggingFace) and executing superior immediate engineering to construct clever system wrappers.
Abilities: This extremely in-demand function requires stable Python proficiency coupled with foundational backend internet growth abilities. API integration, dealing with JSON knowledge constructions, and managing complicated vector databases are vital day-to-day operations. In case you are researching the best way to begin a profession in synthetic intelligence and machine studying, this application-layer pathway is extremely profitable.
A good way to upskill right here is by taking the free course on AI Agent Workflows Utilizing LangGraph, which is tailor-made that can assist you be taught AI agent workflows particularly utilizing the LangGraph framework.
4 Immediate Engineer / LLM Specialist
Coding Degree: Low to Average
Focus: This newly rising function facilities totally on immediate design, systemic testing, and output optimization. The first aim is to iteratively manipulate the mannequin’s pure language inputs to realize exact, extremely correct outputs with out hallucination.
Emphasis: Deep language understanding, particular area experience, and logical structuring take absolute priority over deep programming syntax. The function includes writing just a few traces of code, primarily executing fundamental API calls to check totally different immediate variations at scale.
The {industry} actuality is that whereas it serves as a superb entry level, combining immediate design with fundamental scripting drastically improves your long-term employability.
To get began instantly, you’ll be able to take the free course on Immediate Engineering for ChatGPT to systematically be taught immediate engineering tailor-made for ChatGPT.
5 AI Product Supervisor / Enterprise Roles
Duties: AI Product Managers bridge the vital hole between technical engineering groups and non-technical enterprise stakeholders. They’re accountable for defining clear AI use circumstances, managing agile product lifecycles, and measuring the monetary ROI of AI implementations.
Abilities: Whereas writing precise manufacturing code is totally optionally available, completely understanding the underlying logic, constraints, and structure of machine studying fashions is vital to steer these groups successfully. To know this strategic enterprise perspective, professionals ought to discover the premium AI for Enterprise Innovation: From GenAI to PoCs course, which bridges the hole from GenAI ideas to sensible Proof of Ideas for enterprise innovation.
6 No-Code / Low-Code AI Roles
Instruments: Enterprise analysts, entrepreneurs, and operational groups are more and more using AutoML platforms and LLM wrappers. By leveraging highly effective, user-friendly instruments like LangChain UI, Zapier integrations, and pre-built enterprise AI brokers, professionals can automate complicated workflows with out ever touching a codebase.
Demand: There’s a huge, rising demand inside enterprise items for professionals who can strategically sew collectively these no-code AI instruments to resolve day by day operational bottlenecks.
LLM Period Shift: Is Coding Turning into Much less Essential?
The appearance of Massive Language Fashions has basically shifted the technical studying. At present, a powerful 80% of execs report that they actively use GenAI to be taught new abilities.
Moreover, a major 25% are already using GenAI for auto coding duties to hurry up their growth cycles.
We’re undeniably witnessing the rise of pre-trained foundational fashions and a heavy {industry} reliance on APIs as a substitute of constructing neural networks from scratch.
The company has shifted drastically from “construct proprietary fashions” to “combine present intelligence.” Nonetheless, observing how builders adapt to generative AI proves that core engineering roles nonetheless require deep, basic coding experience.
Whereas GenAI can generate fundamental boilerplate code quickly, extremely expert human programmers are strictly required for
complicated system structure
safe knowledge implementation
debugging intricate
unpredicted edge circumstances
The Final Technical Studying Path: From Newbie to AI Specialist
As 81% of execs are actively planning to pursue upskilling applications in FY2026. Nonetheless, with 37% of people citing demanding workplace work as their largest barrier to studying, having a extremely structured, time-efficient technique is non-negotiable.
To efficiently navigate this technical transition with out losing your restricted bandwidth, you have to depend on complete careers and roadmap guides that dictate precisely which abilities to prioritize.
Under is a step-by-step, actionable framework to construct your technical proficiency from the bottom up.
Step 1: Set up Your Core Programming Basis
You can not successfully construct, prepare, or combine superior AI fashions with out strict fluency in foundational languages.
Solidify Python and Database Abilities: Python and SQL signify absolutely the baseline necessities for the trendy knowledge. Partaking with the premium Grasp Python Programming academy course is the proper place to begin; this premium providing is designed explicitly that can assist you grasp Python programming. Concurrently, you have to be taught to deal with knowledge by pursuing the premium Sensible SQL Coaching program, which equips you with strictly sensible SQL coaching.
Discover Enterprise-Degree Alternate options: For professionals aiming to combine AI inside huge, legacy company environments, Java stays extremely related. You possibly can broaden your enterprise backend capabilities by taking the premium Grasp Java Programming course, which offers a premium pathway to grasp Java programming.
Familiarize with Growth Environments: Earlier than writing complicated automation scripts, you have to deeply perceive the best way to navigate the varied instruments and compilers required for native atmosphere setup and safe cloud deployments.
Step 2: Grasp Logic and Algorithmic Considering
Memorizing syntax is not going to enable you optimize a machine studying pipeline; you have to perceive how knowledge is organized and manipulated beneath the hood.
Research Reminiscence and Constructions: You have to learn the way algorithms traverse and kind data. Dive into the free academy course on Python Information Constructions. This free studying useful resource is tailor-made particularly that can assist you be taught Python knowledge constructions, a vital competency for lowering compute latency in heavy AI fashions.
Decide to Day by day Repetition: Transitioning from passive theoretical studying to lively software requires constructing muscle reminiscence. Constantly working via sensible, hands-on coding workout routines ensures your scripting logic turns into intuitive and error-free.
Step 3: Execute Tasks and Validate Your Competency
Hiring managers within the synthetic intelligence house search for tangible proof of your talents slightly than simply certificates.
Construct a Public Portfolio: Don’t simply comply with guided tutorials. Actively search out complicated, industry-relevant undertaking concepts to construct your individual GitHub repository. Showcasing precise API integrations, knowledge cleansing pipelines, or customized LLM wrappers is the quickest technique to show your competency.
Benchmark Your Progress: It’s straightforward to expertise the phantasm of competence when studying to code. Repeatedly consider your true retention of those complicated technical ideas by routinely taking focused quizzes to establish your blind spots.
Step 4: Put together for the Technical Job Market
As soon as your foundational programming logic and portfolio are solidified, you have to pivot your focus towards strict employability and interview efficiency.
Perceive Technical Analysis Metrics: AI and ML job evaluations are notoriously rigorous, usually involving reside coding or system structure exams. Familiarize your self with superior algorithmic interview questions to make sure you can confidently articulate your technical selections, time complexities, and optimization methods to senior engineering leads.
This complete 12-month program, supplied in collaboration with Nice Lakes and UT Austin, is strategically designed that can assist you grasp AI and ML with out quitting your job. By providing customized 1:1 mentorship and offering unique entry to over 3,000 hiring companions, this program serves as a extremely significant alternative to speed up your profession and stand out within the aggressive synthetic intelligence period.
Actual-World Examples
Understanding these various technical necessities is greatest illustrated via real-world operational workflows throughout totally different company departments.
The Workflow Automator Contemplate a advertising and marketing specialist who notices their crew spends extreme hours summarizing complicated market experiences. Curiously, 42% of execs at present use GenAI to summarise complicated data , whereas a fair larger 59% use it primarily for locating new concepts.
By using Zapier and the OpenAI API, this specialist can construct a extremely efficient, automated analysis summarization software utilizing virtually zero code.
Conclusion
The quantity of coding required to work efficiently within the AI and LLM ecosystem operates on a really broad spectrum, closely dependent in your particular profession and pursuits.
Whereas deep machine studying engineers should possess master-level, rigorous programming abilities, the fast rise of highly effective APIs and low-code platforms has opened the door vast for product managers, immediate engineers, and enterprise analysts to create immense organizational worth with minimal coding.
In the end, probably the most vital talent within the fashionable LLM period is the agility to repeatedly be taught, adapt, and combine clever methods to resolve real-world enterprise issues effectively.
The ultimate preorder window for AWOL Imaginative and prescient’s Aetherion Collection will run from April 23 by way of Could 14.
Choose bundles pair the Aetherion Max or Professional with a free Ambient Gentle Rejecting (ALR) projection display screen.
Preorder pricing begins at $3,499 for the Professional mannequin and $4,499 for the Max, with complete financial savings relying on display screen dimension.
AWOL Imaginative and prescient is launching one remaining preorder deal earlier than its Aetherion projectors hit retail. Along with early chicken pricing, this time the projectors will likely be bundled with a free display screen. In different phrases, as a substitute of simply discounting the {hardware}, the corporate is pitching a full setup.
Choose bundles will pair the Aetherion Max or Aetherion Professional with a Cinematic ALR display screen valued at as much as $850. An Ambient Gentle Rejecting (ALR) display screen can considerably enhance real-world viewing, and screens are the place projector prices can unexpectedly stack up for first-time patrons. AWOL’s upcoming offers imply buyers can sidestep one of many dearer add-ons of a projector setup.
Don’t wish to miss the very best from Android Authority?
The Aetherion Collection targets the premium ultra-short-throw (UST) class, with a 4K triple-laser lineup capable of venture display screen sizes as much as 200 inches. The projectors are powered by AWOL Imaginative and prescient’s PixelLock know-how, an optical system that preserves pixel-level sharpness even at giant sizes. The projectors additionally run Google TV, so buyers get a full sensible platform in-built as a substitute of counting on a streaming stick. The highest-end Aetherion Max is rated at as much as 3,300 ISO lumens with a claimed 6,000:1 native distinction ratio.
Preorder pricing begins at $3,499 for the Aetherion Professional bundle and $4,499 for the Max, with complete financial savings relying on display screen dimension and configuration. The headline bundle pairs the Aetherion Max with a free 100 to 132-inch Cinematic ALR display screen for $4,499. This delivers financial savings between $999 and $2,499. The Aetherion Professional bundle features a free 100 to 200-inch matte white display screen for $3,499, with financial savings between $299 and $999.
There’s additionally a $20 deposit choice that knocks off a further $150, plus small loyalty reductions for current AWOL prospects. Extra bundle configurations that includes upgraded screens and equipment may also be obtainable. This remaining pre-order alternative runs from April 23 by way of Could 14. Provides will likely be obtainable by way of Amazon and AWOL Imaginative and prescient’s web site.
Thanks for being a part of our neighborhood. Learn our Remark Coverage earlier than posting.