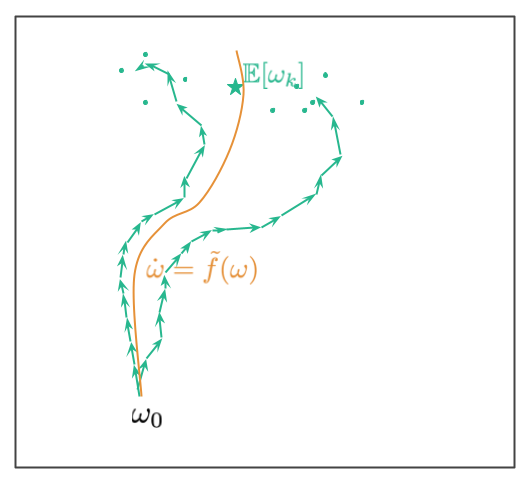Lyme illness is a fancy sickness attributable to the bacterium Borrelia burgdorferi and transmitted by ticks. It’s the most typical vector-borne sickness in North America and Europe.
The signs of Lyme illness can have an effect on a number of organs within the physique if left unaddressed. Early analysis and remedy are essential for a profitable restoration and to keep away from long-term problems.
How do you get Lyme illness?
Lyme illness is unfold by tick bites, primarily black-legged deer ticks. The ticks are vectors for Borrelia burgdorferi, the bacterium that causes Lyme illness.
Is Lyme illness contagious?
Lyme illness shouldn’t be contagious and can’t be transmitted from individual to individual.
Is Lyme illness curable?
In keeping with the US CDC, Lyme illness instances might be cured inside 2-4 weeks of antibiotics remedy. Nonetheless, some people expertise Persistent Lyme Illness (CLD) signs, together with fatigue, joint and muscle aches, cognitive points, and extra.
What’s power Lyme illness?
Persistent Lyme illness (CLD) refers to instances the place signs persist for an prolonged interval regardless of remedy. Normally, Lyme illness responds nicely to antibiotic remedy. Nonetheless, some folks proceed to expertise Persistent Lyme Illness signs, together with fatigue, joint ache, and muscle aches, even after remedy ends. This is called Publish-Therapy Lyme Illness Syndrome (PTLDS).
What ticks carry Lyme illness?
The ticks that carry Lyme illness are primarily black-legged ticks (Ixodes scapularis) within the japanese United States and western black-legged ticks (Ixodes pacificus) within the western United States.
These ticks turn into contaminated with the bacterium Borrelia burgdorferi after feeding on contaminated animals like mice and deer. When an contaminated tick bites a human, it may well transmit the micro organism, resulting in Lyme illness. Preventive measures similar to making a tick-safe zone in your yard, utilizing tick management merchandise, and sporting protecting clothes can assist cut back the danger of tick bites and Lyme illness transmission.
Is there a Lyme illness vaccine?
There is no such thing as a vaccine to assist forestall Lyme illness. Nonetheless, scientific trials for brand new Lyme illness vaccines are underway.
Is it Lyme illness, Lymes illness, or Lime illness?
The official time period is Lyme illness, though some folks might casually seek advice from it as Lyme’s illness. The tick-borne an infection is also called Lyme borreliosis.
The illness has nothing to do with limes, and it could simply be a typo when you occur to see it written this manner.
When you have ever been answerable for managing advanced enterprise logic, you know the way nested if-else statements could be a jungle: painful to navigate and simple to get misplaced. In the case of mission-critical duties, for instance formal verification or satisfiability, many builders attain for stylish instruments comparable to automated theorem provers or SMT solvers. Though highly effective, these approaches will be overkill and a headache to implement. What if all you want is a straightforward, clear guidelines engine?
The important thing thought for constructing such a light-weight engine depends on an idea that we have been taught to be insightful however impractical: fact tables. Exponential progress, their deadly flaw, makes them unfit for real-world issues. So we have been informed.
A easy statement adjustments every little thing: In virtually all sensible circumstances, the “impossibly giant” fact desk is definitely not dense with info; it’s in reality a sparse matrix in disguise.
This reframing makes the reality tables each conceptually clear and computationally tractable.
This text exhibits you flip this perception into a light-weight and highly effective guidelines engine. We’ll information you thru all the required steps to construct the engine from scratch. Alternatively, you need to use our open-source library vector-logic to begin constructing purposes on day one. This tutorial provides you with all the required particulars to grasp what’s below the hood.
Whereas all of the theoretical background and mathematical particulars will be present in our analysis paper on the State Algebra[1], right here, we give attention to the hands-on utility. Let’s roll up our sleeves and begin constructing!
A Fast Refresher on Logic 101
Fact Tables
We’ll begin with a fast refresher: logical formulation are expressions which might be constructed from Boolean variables and logical connectors like AND, OR, and NOT. In a real-world context, Boolean variables will be regarded as representing occasions (e.g. “the espresso cup is full”, which is true if the cup is definitely full and false whether it is empty). For instance, the system (f = (x_1 vee x_2)) is true if (x_1) is true, (x_2) is true, or each are. We are able to use this framework to construct a complete brute-force map of each attainable actuality — the reality desk.
Utilizing 1 for “true” and 0 for “false”, the desk for (x_1 vee x_2) appears like this:
The whole lot we have to carry out logical inference is encoded within the fact desk. Let’s see it in motion.
Logical Inference
Think about a traditional instance of the transitivity of implication. Suppose we all know that… By the best way, every little thing we are saying “we all know” is named a premise. Suppose we now have two premises:
If (x_1) is true, then (x_2) should be true ((x_1 to x_2))
If (x_2) is true, then (x_3) should be true ((x_2 to x_3))
It’s simple to guess the conclusion: “If (x_1) is true, then (x_3) should be true” ((x_1 to x_3)). Nevertheless, we may give a proper proof utilizing fact tables. Let’s first label our formulation:
[begin{align*} & f_1 = (x_1 to x_2) && text{premise 1} & f_2 = (x_2 to x_3) && text{premise 2} & f_3 = (x_1 to x_3) && text{conclusion} end{align*}]
Step one is to construct a fact desk protecting all mixtures of the three base variables (x_1), (x_2), and (x_3):
This desk accommodates eight rows, one for every task of fact values to the bottom variables. The variables (f_1), (f_2) and (f_3) are derived, as we compute their values immediately from the (x)-variables.
Discover how giant the desk is, even for this easy case!
The following step is to let our premises, represented by (f_1) and (f_2), act as a filter on actuality. We’re provided that they’re each true. Due to this fact, any row the place both (f_1) or (f_2) is fake represents an not possible situation which must be discarded.
After making use of this filter, we’re left with a a lot smaller desk:
And right here we’re: In each remaining legitimate situation, (f_3) is true. We’ve got confirmed that (f_3) logically follows from (or is entailed by) (f_1) and (f_2).
A chic and intuitive technique certainly. So, why don’t we use it for advanced methods? The reply lies in easy maths: With solely three variables, we had (2^3=8) rows. With 20 variables, we’d have over one million. Take 200, and the variety of rows would exceed the variety of atoms within the photo voltaic system. However wait, our article doesn’t finish right here. We are able to repair that.
The Sparse Illustration
The important thing thought for addressing exponentially rising fact tables lies in a compact illustration enabling lossless compression.
Past simply compressing the reality tables, we are going to want an environment friendly approach to carry out logical inference. We’ll obtain this by introducing “state vectors” — which symbolize units of states (fact desk rows) — and adopting set concept operations like union and intersection to control them.
The Compressed Fact Desk
First, we return to system (f = (x_1 to x_2)). Let’s establish the rows that make the system true. We use the image (sim) to symbolize the correspondence between the system and a desk of its “legitimate” fact assignments. In our instance of (f) for implication, we write:
Observe that we dropped the row ((1, 0)) because it invalidates (f). What would occur to this desk, if we now prolonged it to contain a 3rd variable (x_3), that (f) doesn’t depend upon? The traditional strategy would double the dimensions of the reality desk to account for (x_3) being 0 or 1, though it doesn’t add any new details about (f):
What a waste! Uninformative columns could possibly be compressed, and, for this objective, we introduce a touch (–) as a “wildcard” image. You’ll be able to consider it as a logical Schrödinger’s cat: the variable exists in a superposition of each 0 and 1 till a constraint or a measurement (within the context of studying, we name it “proof”) forces it right into a particular state, eradicating one of many prospects.
Now, we will symbolize (f) throughout a universe of (n) variables with none bloat:
We are able to generalise this by postulating that any row containing dashes is equal to the set of a number of rows obtained by all attainable substitutions of 0s and 1s within the locations of dashes. For instance (attempt it with pencil and paper!):
That is the essence of sparse illustration. Let’s introduce a couple of definitions for primary operations: We name changing dashes with 0s and 1s enlargement. The reverse course of, during which we spot patterns to introduce dashes, is named discount. The best type of discount, changing two rows with one, is named atomic discount.
An Algebra of States
Now, let’s give these concepts some construction.
A state is a single, full task of fact values to all variables — one row in a completely expanded fact desk (e.g. ((0, 1, 1))).
A state vector is a set of states (consider it as a subset of the reality desk). A logical system can now be thought of as a state vector containing all of the states that make it true. Particular circumstances are an empty state vector (0) and a vector containing all (2^n) attainable states, which we name a trivial vector and denote as (mathbf{t}). (As we’ll see, this corresponds to a t-object with all wildcards.)
A row in a state vector’s compact illustration (e.g. ((0, -, 1) )) is named a t-object. It’s our basic constructing block — a sample that may symbolize one or many states.
Conceptually, shifting the main focus from tables to units is an important step. Keep in mind how we carried out inference utilizing the reality desk technique: we used premises (f_1) and (f_2) as a filter, holding solely the rows the place each premises have been true. This operation, when it comes to the language of set concept, is an intersection.
Every premise corresponds to a state vector (the set of states that fulfill the premise). The state vector for our mixed data is the intersection of those premise vectors. This operation is on the core of the brand new mannequin.
For friendlier notation, we introduce some “syntax sugar” by mapping set operations to easy arithmetic operations:
Set Union ((cup)) (rightarrow) Addition ((+))
Set Intersection ((cap)) (rightarrow) Multiplication ((*))
The properties of those operations (associativity, commutativity, and distributivity) permit us to make use of high-school algebra notation for advanced expressions with set operations:
[ begin{align*} & (Acup B) cap (Ccup D) = (Acap C) cup (Acap D) cup (Bcap C) cup (Bcap D) & rightarrow & (A+B)cdot(C+D) = A,C + A,D + B,C + B,D end{align*} ]
Let’s take a break and see the place we’re. We’ve laid a robust basis for the brand new framework. Fact tables are actually represented sparsely, and we reinterpret them as units (state vectors). We additionally established that logical inference will be achieved by multiplying the state vectors.
We’re practically there. However earlier than we will apply this concept to develop an environment friendly inference algorithm, we want yet another ingredient. Let’s take a more in-depth have a look at operations on t-objects.
The Engine Room: Operations on T-Objects
We are actually able to go to the subsequent part — creating an algebraic engine to control state vectors effectively. The elemental constructing block of our building is the t-object — our compact, wildcard-powered illustration of a single row in a state vector.
Observe that to explain a row, we solely must know the positions of 0s and 1s. We denote a t-object as (mathbf{t}^alpha_beta), the place (alpha) is the set of indices the place the variable is 1, and (beta) is the set of indices the place it’s 0. For example:
A t-object consisting of all of the dashes (mathbf{t} = { -;; – ldots -}) represents the beforehand talked about trivial state vector that accommodates all attainable states.
From Formulation to T-Objects
A state vector is the union of its rows or, in our new notation, the sum of its t-objects. We name this row decomposition. For instance, the system (f=(x_1to x_2)) will be represented as:
Discover that this decomposition doesn’t change if we add extra variables ((x_3, x_4, dots)) to the system, which exhibits that our strategy is inherently scalable.
The Rule of Contradiction
The identical index can not seem in each the higher and decrease positions of a t-object. If this happens, the t-object is null (an empty set). For example (we highlighted the conflicting index):
That is the algebraic equal of a logical contradiction. A variable ((x_3) on this case) can’t be each true (superscript) and false (subscript) on the identical time. Any such t-object represents an not possible state and vanishes.
Simplifying Expressions: Atomic Discount
Atomic discount will be expressed cleanly utilizing the newly launched t-object notation. Two rows will be diminished if they’re similar, aside from one variable, which is 0 in a single and 1 within the different. For example:
The rule for this operation follows immediately from the definition of the t-objects: If two t-objects have index units which might be similar, aside from one index that may be a superscript in a single and a subscript within the different, they mix. The clashing index (4 on this instance) is annihilated, and the 2 t-objects merge.
By making use of atomic discount, we will simplify the decomposition of the system (f = (x_1 to x_2)). Noticing that (mathbf{t}_{12} + mathbf{t}_1^2 = mathbf{t}_1), we get:
Lastly, allow us to talk about a very powerful operation for our guidelines engine: intersection (when it comes to set concept), represented as multiplication (when it comes to algebra). How do we discover the states frequent to the 2 t-objects?
The rule governing this operation is simple: to multiply two t-objects, one varieties the union of their superscripts, in addition to the union of their subscripts (we depart the proof as a easy train for a curious reader):
[ mathbf{t}^{alpha_1}_{beta_1},mathbf{t}^{alpha_2}_{beta_2} = mathbf{t}^{alpha_1 cup alpha_2}_{beta_1cupbeta_2} ]
The rule of contradiction nonetheless applies. If the ensuing superscript and subscript units overlap, the product vanishes:
[ mathbf{t}^{alpha_1 cup alpha_2}_{beta_1cupbeta_2} = 0 quad iff quad (alpha_1 cup alpha_2) cap (beta_1cupbeta_2) not = emptyset ]
For instance:
[ begin{align*} & mathbf{t}^{12}_{34},mathbf{t}^5_6 = mathbf{t}^{125}_{346} && text{Simple combination} & mathbf{t}^{12}_{34} ,mathbf{t}^{4} = mathbf{t}^{12{color{red}4}}_{3{color{red}4}} = 0 && text{Vanishes, because 4 is in both sets} end{align*} ]
A vanishing product signifies that the 2 t-objects don’t have any states in frequent; subsequently, their intersection is empty.
These guidelines full our building. We outlined a sparse illustration of logic and algebra for manipulating the objects. These are all of the theoretical instruments that we want. We’re able to assemble them right into a sensible algorithm.
Placing It All Collectively: Inference With State Algebra
The engine is prepared, it’s time to show it on! In its core, the thought is easy: to search out the set of legitimate states, we have to multiply all state vectors akin to premises and evidences.
If we now have two premises, represented by the state vectors ((mathbf{t}_{(1)} + mathbf{t}_{(2)})) and ((mathbf{t}_{(3)} + mathbf{t}_{(4)})), the set of states during which each are true is their product:
This instance will be simply generalised to any arbitrary variety of premises and t-objects.
The inference algorithm is simple:
Decompose: Convert every premise into its state vector illustration (a sum of t-objects).
Simplify: Use atomic discount on every state vector to make it as compact as attainable.
Multiply: Multiply the state vectors of all premises collectively. The result’s a single state vector representing all states constant together with your premises.
Cut back Once more: The ultimate product could have reducible phrases, so simplify it one final time.
Instance: Proving Transitivity, The Algebraic Method
Let’s revisit our traditional instance of implication transitivity: if (f_1 = (x_1to x_2)) and (f_2 = (x_2to x_3)) are true, show that (f_3=(x_1to x_3)) should even be true. First, we write the simplified state vectors for our premises as follows:
To show the conclusion, we will use a proof by contradiction. Let’s ask: does a situation exist the place our premises are true, however our conclusion (f_3) is fake?
The states that invalidate (f_3 = (x_1 to x_3)) are these during which (x_1) is true (1) and (x_3) is fake (0). This corresponds to a single t-object: (mathbf{t}^1_3).
Now, let’s see if this “invalidating” state vector can coexist with our premises by multiplying every little thing collectively:
[ begin{gather*} (text{Premise 1}) times (text{Premise 2}) times (text{Invalidating State Vector}) (mathbf{t}_1 + mathbf{t}^{12}),(mathbf{t}_2 + mathbf{t}^{23}), mathbf{t}^1_3 end{gather*} ]
First, we multiply by the invalidating t-object, because it’s probably the most restrictive time period:
The intersection is empty. This proves that there isn’t any attainable state the place (f_1) and (f_2) are true, however (f_3) is fake. Due to this fact, (f_3) should observe from the premises.
Proof by contradiction isn’t the one approach to resolve this downside. You will see that a extra elaborate evaluation within the “State Algebra” paper [1].
From Logic Puzzles to Fraud Detection
This isn’t nearly logic puzzles. A lot of our world is ruled by guidelines and logic! For instance, take into account a rule-based fraud-detection system.
Your data base is a algorithm like
IF card_location is abroad AND transaction_amount > $1000, THEN danger is excessive
The complete data base will be compiled right into a single giant state vector.
This proof is a single t-object, assigning 1s to noticed information which might be true and 0s to information which might be false, leaving all unobserved information as wildcards.
To decide, you merely multiply:
[ text{Knowledge Base Vector}times text{Evidence T-object} ]
The ensuing state vector immediately tells you the worth of the goal variable (comparable to danger) given the proof. No messy chain of “if-then-else” statements was wanted.
Scaling Up: Optimisation Methods
As with mechanical engines, there are a lot of methods to make our engine extra environment friendly.
Let’s face the truth: logical inference issues are computationally exhausting, that means that the worst-case runtime is non-polynomial. Put merely, regardless of how compact the illustration is, or how good the algorithm is, within the worst-case situation, the runtime can be extraordinarily lengthy. So lengthy that most definitely, you’ll have to cease the computation earlier than the result’s calculated.
The rationale SAT solvers are doing a terrific job isn’t as a result of they modify actuality. It’s as a result of the vast majority of real-life issues should not worst-case situations. The runtime on an “common” downside can be extraordinarily delicate to the heuristic optimisations that your algorithm makes use of for computation.
Thus, optimisation heuristics could possibly be one of the crucial necessary parts of the engine to realize significant scalability. Right here, we simply trace at attainable locations the place optimisation will be thought of.
Observe that when multiplying many state vectors, the variety of intermediate t-objects can develop considerably earlier than ultimately shrinking, however we will do the next to maintain the engine operating easily:
Fixed Discount: After every multiplication, run the discount algorithm on the ensuing state vector. This retains intermediate outcomes compact.
Heuristic Ordering: The order of multiplication issues. It’s typically higher to multiply smaller or extra restrictive state vectors first, as this may trigger extra t-objects to fade early, pruning the calculation.
Conclusion
We’ve got taken you on a journey to find how propositional logic will be solid into the formalism of state vectors, such that we will use primary algebra to carry out logical inference. The magnificence of this strategy lies in its simplicity and effectivity.
At no level does inference require the calculation of big fact tables. The data base is represented as a set of sparse matrices (state vector), and the logical inference is diminished to a set of algebraic manipulations that may be applied in a couple of easy steps.
Whereas this algorithm doesn’t purpose to compete with cutting-edge SAT solvers and formal verification algorithms, it presents a wonderful, intuitive method of representing logic in a extremely compact kind. It’s a strong instrument for constructing light-weight guidelines engines, and a terrific psychological mannequin for desirous about logical inference.
Strive It Your self
One of the best ways to grasp this method is to make use of it. We’ve packaged your entire algorithm into an open-source Python library known as vector-logic. It may be put in immediately from PyPI:
pip set up vector-logic
The complete supply code, together with extra examples and documentation, is offered on
We encourage you to discover the repository, attempt it by yourself logic issues, and contribute.
In case you’re all in favour of delving deeper into mathematical concept, try the unique paper [1]. The paper covers some matters which we couldn’t embrace on this sensible information, comparable to canonical discount, orthogonalisation and lots of others. It additionally establishes an summary algebraic illustration of propositional logic based mostly on t-objects formalism.
We welcome any feedback or questions.
Who We Are
References
[1] Dmitry Lesnik and Tobias Schäfer, “State Algebra for Propositional Logic,” arXiv preprint arXiv:2509.10326, 2025. Obtainable at: https://arxiv.org/abs/2509.10326
For utility builders, it’s concerning the skill to get issues accomplished with out having to create tickets and anticipate days for another person to take care of them. Self service for builders is supported via what we name golden paths or paved roads. A golden path is a pre-defined, opinionated, and supported approach of constructing, deploying, and working software program. A golden path will not be the one option to get one thing accomplished on the platform, however it actually is the advisable, curated path of least resistance.
Platform engineers are sometimes ignored in the case of self service. Often, they’re simply anticipated to construct self-service capabilities for app builders however nearly by no means thought-about as engineers who have to be served by the platform themselves. However as we mentioned within the first precept of this text, an IDP ought to serve platform engineers too. Platform engineers are anticipated to offer constant infrastructures, environments, pipelines, and so forth. Similar to metropolis builders are anticipated to offer the identical voltage of electrical energy to all components of a metropolis, the identical water strain to each family, so are platform engineers anticipated to offer the identical constant foundations for builders to construct on.
This consistency can solely be achieved by way of self-service golden paths which are accessible to platform engineers. Self service for platform engineers means giving the platform staff itself a set of automated, composable constructing blocks that permits them to design, lengthen, and function the IDP effectively with out having to manually sew collectively infrastructure or re-invent patterns every time. These self-service golden paths have to have the precise guardrails built-in (for dealing with dangerous actions corresponding to eradicating environments, for instance), in addition to audit trails and correct governance at scale.
Self-service golden paths, for each builders and platform engineers are due to this fact a key precept in an IDP. Traits of such golden paths are:
Opinionated, not restrictive: They encode greatest practices (tech stack decisions, CI/CD templates, safety insurance policies) whereas leaving flexibility for edge circumstances.
Finish-to-end workflow: They cowl the complete life cycle from scaffolding an app, provisioning infrastructure, and CI/CD to observability, monitoring, and incident response.
Self-serviceable: They’re uncovered to builders via self-service instruments, UI, or CLI instructions within the IDP.
Summary away complexity: Builders and platform engineers don’t have to wire collectively Kubernetes, observability stacks, IAM, and so on. The golden path bakes these in behind straightforward interfaces.
Repeatedly maintained: Platform engineers evolve golden paths alongside organizational wants, safety necessities, and new applied sciences.
Ops-driven, declarative and automatic
Automation (clearly) is crucial for an IDP. You can not obtain the targets of an IDP with out automation. However automation with out self-discipline is only a recipe for chaos. That’s the reason ops-driven automation is the best way to go. Ops-driven automation is mainly about following GitOps workflows for adjustments made on the IDP. Each motion carried out on the IDP must be versioned, recorded, and reversible. All actions have to have audit trails.
It’s vital for an IDP’s automations to be in declarative type. That is about declaring the specified state of the system as a substitute of constantly monitoring and reacting to occasions and alerts. Consider a metropolis’s road lights. Somebody must activate the lights at nightfall and switch them off at daybreak. If one thing goes unsuitable in the course of the evening and the lights go off, somebody must attend to it and switch the lights again on. It is a cumbersome course of and requires a variety of labour. Nevertheless, think about with the ability to declare the specified state because the “lights have to be on at any time when there’s darkness.” If the system can mechanically reconcile the state of the lights to this desired state, the operation of town’s lights change into rather more environment friendly and easy. Nobody must get up in the course of the evening simply due to a glitch within the system. The system mechanically recovers by itself.
For a very hands-off expertise of working an IDP, the platform’s automations have to work in a declarative method. Declarative automations with ops-driven workflows are due to this fact a key precept to construct an IDP on.
Clever and insightful
An IDP serves many stakeholders. Whereas it might primarily cater to utility builders and platform engineers, the advantages of an IDP may be realized by many components of a company. To make this attainable, the IDP ought to expose related intelligence and insights to all events. Listed here are some examples of various stakeholders and the related knowledge and insights.
For builders and operators: Insights wanted for troubleshooting incidents. Primarly pushed by observability knowledge (i.e., logs, metrics, traces).
For enterprise stakeholders: Insights that showcase the influence of digital artifacts on the enterprise. For instance, knowledge corresponding to orders positioned, consumer development, order cancellations, and so on. This mainly includes changing technical knowledge from a company’s APIs to enterprise insights.
For engineering managers: Insights wanted for assessing the group’s velocity and stability of delivering software program. Primarily constructed on the well-known DORA metrics.
For architects: Insights that assist decide the ROI of digital artifacts, insights on the effectivity of assets, value breakdowns, and so on.
In our data-intensive period, insights with out intelligence are inadequate. For a few years, we’ve been accustomed to all types of graphs, charts, and stories. We’ve needed to endure the exhausting activity of analyzing these stories to grasp areas of enhancements. However now, many of those duties may be offloaded to AI brokers inside the IDP. Along with exhibiting graphs, charts, and stories, these brokers may also help decide the causes of failures and different areas of enhancements for our digital artifacts as properly.
Intelligence in fact applies throughout the board, not only for insights. An IDP ought to incorporate AI in every single place it is smart. Consider compliance, governance, monitoring, and so on. AI has change into a software that may help many such areas of an IDP. It’s due to this fact essential to contemplate AI and insights as a key precept of an IDP.
Product orientation
An IDP shouldn’t be a one-off mission. A mission is one thing you do as soon as and end. It has a begin date and an finish date. An IDP isn’t a completed mission. It’s one thing that continues to dwell and evolve, without end.
Supply of software program by no means ends. Moreover, the varieties of software program which are delivered and the methods by which they’re delivered inevitably change. What you ship at present is just not the identical factor that you’ll ship tomorrow. For those who deal with your IDP as a one-off mission, you’ll construct for at present’s necessities and cease, and your IDP won’t cater to the wants of tomorrow. This is the reason you want a product mindset in your IDP. Your IDP ought to evolve to satisfy future wants, holding tempo with the instruments and applied sciences of the trendy trade and offering a platform to carry up and modernize your group.
A product mindset for an IDP requires correct product administration. This contains sustaining a transparent roadmap, having common launch cadence, life-cycle administration of options, difficulty monitoring, and so forth. It additionally requires listening to non-technical components required for its success. You want to create enough consciousness across the platform, improve its adoption, collect suggestions from customers, feed these learnings into the roadmap, and proceed to iterate.
This product mindset is due to this fact a key precept of an IDP. It’s crucial for long-term success. Treating an IDP as a mission provides you with short-term advantages however finally fail in the long run. Sturdy product administration with an actual dedication to evolve the IDP like a product is what is going to assure its total success.
Closing ideas
A terrific IDP is greater than a set of instruments. It’s your “deliberate metropolis” for software program supply, offering constant abstractions, dependable guardrails, and golden paths that empower each builders and platform engineers.
Many IDPs, each home-grown and off-the-shelf options, are inclined to focus solely on lowering the cognitive load of builders and delivering software program quicker. Whereas this strategy might ship short-term wins, it creates inefficiencies and additional toil in the long term.
A profitable IDP removes limitations to effectivity and places each builders and platform engineers on self-service golden paths. It creates order, saves time, saves cash, will increase satisfaction, and considerably improves a company’s skill to innovate.
—
New Tech Discussion board gives a venue for know-how leaders—together with distributors and different exterior contributors—to discover and talk about rising enterprise know-how in unprecedented depth and breadth. The choice is subjective, based mostly on our choose of the applied sciences we imagine to be vital and of biggest curiosity to InfoWorld readers. InfoWorld doesn’t settle for advertising collateral for publication and reserves the precise to edit all contributed content material. Ship all inquiries to doug_dineley@foundryco.com.
We’ve all been there. You’re deep in work when a colleague drops in—“Fast query, how do I export that report once more?” Or your supervisor pings you in regards to the newest PTO coverage. These micro-interruptions—let’s name them what they’re: time thieves—steal minutes that flip into hours, fragmenting focus and draining vitality.
OpenAI confirmed that it shipped an replace on October 5, which permits GPT-5 to raised deal with delicate conversations.
After the replace, GPT will robotically acknowledge when the person is just not doing properly, together with conditions like emotional or psychological misery.
Nevertheless, OpenAI says solely GPT-5 Prompt has been up to date to deal with such use circumstances.
GPT-5 Prompt is without doubt one of the quickest and low-end fashions within the lineup. It is also the default mannequin more often than not, particularly if in case you have a free account.
However what in case you’re conversing with a GPT-5-thinking mannequin and it detects emotional misery or a associated matter? It’s going to robotically route your request to GPT-5 Prompt.
“We have been utilizing our real-time router to direct delicate elements of conversations—reminiscent of these displaying indicators of acute misery—to reasoning fashions. GPT-5 Prompt now performs simply in addition to GPT-5 Considering on most of these questions,” OpenAI famous in a brand new assist doc.
In our checks, BleepingComputer beforehand discovered that GPT-5 robotically routes requests by means of totally different fashions relying on the query.
GPT-5 robotically switched mannequin to considering from prompt
Supply: BleepingComputer
In truth, in case you select GPT-5-instant particularly, GPT will nonetheless route your request by means of a considering mannequin if it thinks a unique mannequin can reply higher.
OpenAI says it labored with well being specialists on its new GPT-5 replace
OpenAI insists that these updates have been guided by psychological well being specialists and assist ChatGPT de-escalate conversations.
OpenAI will level individuals to real-world disaster sources when applicable, whereas nonetheless utilizing language that feels supportive and grounding.
GPT-5 was up to date with emotional assist earlier this month, and the up to date mannequin is now accessible for everybody.
As well as, OpenAI confirmed ChatGPT can now entry your group’s context out of your related apps.
GPT’s Firm Data assist works by means of Slack, SharePoint, Google Drive, GitHub, HubSpot, Asana, and different connectors.
That is much like how Microsoft 365 Copilot works.
Like Microsoft’s AI resolution, GPT can now present solutions tailor-made to your organization and tasks, because it has entry to all related data.
46% of environments had passwords cracked, practically doubling from 25% final 12 months.
Get the Picus Blue Report 2025 now for a complete have a look at extra findings on prevention, detection, and knowledge exfiltration developments.
Brains, spiders, (have been)wolves and slimy eyeballs would possibly sound like props from a horror film, however these eerie subjects come straight from severe scientific analysis. Research revealed in ACS journals are exploring revolutionary methods to enhance human well being, from rising mind tissue with out animal testing to creating on-demand wound care and creating edible coatings that preserve greens contemporary. Even the human eye is below investigation as scientists uncover how microplastics would possibly have an effect on our imaginative and prescient.
Rising Mini-Brains within the Lab
In a research described in ACS Sensors, scientists efficiently cultivated a small, three-dimensional “mini-brain” in a dish. Over the course of two years, cultured human nerve cells multiplied and arranged themselves right into a functioning organoid able to producing electrical exercise. This breakthrough permits researchers to discover how mind cells work together and talk with out utilizing animals in experiments. Future advances might make these organoids useful instruments for finding out mind perform — or, because the researchers jokingly be aware, a potential “lab-grown lunch choice for zombies.”
Spider-Impressed Glove Spins Wound Dressings
In ACS Utilized Supplies & Interfaces, scientists took inspiration from spiders to create a novel glove fitted with spinneret-like gadgets that launch ultra-thin polymer fibers. The invention permits medical employees to spin wound dressings immediately onto accidents in actual time. Such a system might be particularly helpful in hospitals, sports activities arenas, or battlefield environments. And in case anybody is questioning, these experiments didn’t contain any radioactive spider bites.
Wolf Apple Coating Retains Produce Brisker
Researchers reporting in ACS Meals Science & Know-how discovered that starch extracted from the wolf apple — a fruit native to Brazil and a favourite of the maned wolf — will be reworked right into a pure, edible coating that helps protect meals. When utilized to child carrots, the coating saved them vivid and contemporary for as much as 15 days at room temperature. The fabric provides a protected, cost-effective technique to lengthen the shelf lifetime of produce, whether or not or not there is a full moon.
Microplastics Present in Human Retinas
In ACS Environmental Science & Know-how Letters, scientists examined 12 autopsy human retinas (no eye of newt required) and found microplastic particles in each pattern. The plastics various in kind and focus, revealing how pervasive they’ve change into — even in such delicate tissue. The researchers say these findings lay essential groundwork for future investigations into how microplastics would possibly affect imaginative and prescient and general eye well being.
Moderation is not a kind of issues that we usually educate in Intro Stats.
However it’s a statistical software your superior undergraduates will doubtless encounter in an upper-level course.
I am not going to show you the right way to educate your college students the right way to do one. I’m, nonetheless, going to share a instance of what mediation is doing, impressed by dwelling within the metropolis within the US that has obtained essentially the most snow this season (Erie, PA, with 93.9 inches for the season as of 1.30.25).
A couple of yr in the past, CNN shared information on how a lot snow it takes to cancel faculty in varied elements of the nation.
I guarantee you, Erie and the remainder of Northwest PA (see purple define) will get hella snow however no snow days.
Nonetheless, our lack of snow days is not attributable to lack of snow. The annual quantity of snow moderates the chance to cancel faculty, such that in case you are used to plenty of snow (and have the infrastructure to deal with it) you do not cancel attributable to snow. And as a lot as individuals in snowy areas wish to dismiss considerations about snowy roads and security, the actual fact is that it’s not a mindset that results in these decisions, it’s the preparedness to take care of snow. And I wager the quantity of snow a area experiences correlates with the State and Native DOT funding for plows. That is illustrated properly under. For additional reference, I reside about an hour west of Chautauqua, NY.
To make this easy, and use the oft-imitated visible illustration of moderation:
If you happen to research sufficient econometrics, you’ll finally come throughout an asymptotic argument during which some parameter is assumed to change with pattern measurement.
This peculiar notion goes by quite a lot of names together with “Pitman drift,” a “sequence of native alternate options,” and “native mis-specification,” and crops up in a variety of issues from weak devices, to mannequin choice, to energy evaluation.
No matter you select to name it, the concept of a parameter that modifications with pattern measurement is weird, and I keep in mind spending weeks attempting to know it once I was a graduate scholar.
How may parameters, mounted portions that we’re attempting to estimate, presumably know something about our pattern measurement?
Will we anticipate parameters to be smaller when we’ve got extra knowledge?
Will we anticipate them to be bigger when we’ve got much less knowledge?
The reply to each questions is a convincing NO.
Like all asymptotics, what I’ll name native asymptotics are nothing greater than a thought experiment that we arrange for mathematical comfort.
Ideally we might derive finite pattern outcomes for each drawback of curiosity, however that is not often doable in follow.
Because of this we flip to asymptotic outcomes, such because the central restrict theorem.
Generally this works out OK, and typically it’s a catastrophe.
The purpose of native asymptotics is to derive outcomes that extra carefully approximate the finite pattern conduct that we are able to perceive from easy examples, within the hope that this may result in higher approximations in additional sophisticated issues.
On this publish, I’ll illustrate the usefulness of native asymptotics within the easiest instance I may consider: a one-sided take a look at for the imply of a traditional distribution with identified variance.
No superior statistics or econometrics are used beneath, so even when you discovered the previous paragraph off-putting give the remaining a go: it’s possible you’ll be pleasantly shocked!
Suppose that we observe [
X_1, X_2, dots, X_{n} overset{iid}{sim}N(mu, 1)
]
and need to take a look at (H_0colon mu = 0) in opposition to the one-sided various (H_1colon mu >0).
On this admittedly quite simple instance, the Econometrics 101 take a look at statistic is [
T_{n} = sqrt{n} bar{X}_{n} sim Nleft(mu sqrt{n}, 1right)
]
the place (bar{X}_{n}) is the pattern imply.
We reject when (sqrt{n} bar{X}_{n}>z_{1-alpha}) the place (z_{1-alpha}) is the (1-alpha) quantile of a regular regular distribution.
Let’s calculate the energy of this take a look at: the likelihood of rejecting the null speculation provided that it’s false.
We discover that [
begin{eqnarray*}
mbox{Power}(T_{n}) &=& Pleft(sqrt{n} bar{X}_{n}>z_{1-alpha}right) = Pleft(Z + musqrt{n} >z_{1-alpha}right)
&=&Pleft(Z >z_{1-alpha} – musqrt{n}right) = 1 – Phileft(z_{1-alpha} – musqrt{n}right)
end{eqnarray*}
]
the place (Z) is a regular regular random variable and (Phi) is the usual regular CDF.
Now suppose we determined to do one thing utterly loopy: throw away half our pattern.
Let (bar{X}_{n/2}) denote the pattern imply based mostly on observations (1, 2, dots, lfloor N/2 rfloor)solely, the place (lfloor x rfloor) denotes the flooring perform, i.e. the best integer lower than or equal to (x).
We will nonetheless assemble a superbly legitimate take a look at with measurement (alpha) as follows.
Outline [
T_{n/2} = sqrt{lfloor n/2 rfloor } bar{X}_{n/2} sim Nleft(mu sqrt{lfloor n/2 rfloor }, 1right)
]
and reject if (sqrt{n} bar{X}_n > z_{1-alpha}).
However there’s an apparent drawback right here: there should be a value for throwing away completely good knowledge.
Certainly, if we calculate the ability for this loopy take a look at, we’ll discover that it’s strictly decrease than that of the smart take a look at based mostly on the total pattern.
Particularly, [mbox{Power}(T_{n/2}) = 1 – Phileft(z_{1-alpha} – musqrt{lfloor n/2 rfloor }right)]
utilizing the identical argument as above with (lfloor N/2 rfloor) instead of (n).
Unsurprisingly, it seems to be a foul concept to throw away half of your knowledge!
Now, for an instance this easy we’d by no means resort to asymptotics, however suppose we did.
How do these two checks evaluate because the pattern measurement goes to infinity?
The asymptotic measurement on this instance is similar because the finite-sample measurement since we all know the precise sampling distribution of the take a look at statistics below the null and neither is dependent upon pattern measurement.
However what in regards to the energy?
We’ve got, [
begin{eqnarray*}
lim_{nrightarrow infty} mbox{Power}(T_{n}) &=& lim_{nrightarrow infty}left[1 – Phileft(z_{1-alpha} – musqrt{n}right) right] = 1
lim_{nrightarrow infty} mbox{Energy}(T_{n/2}) &=& lim_{nrightarrow infty}left[1 – Phileft(z_{1-alpha} – musqrt{lfloor n/2 rfloor }right) right] = 1
finish{eqnarray*}
]
In different phrases, each of those checks are constant: because the pattern measurement goes to infinity, the ability goes to at least one.
Take into consideration this for a second: we all know that for any mounted pattern measurement a take a look at based mostly on the total pattern is strictly extra highly effective however within the restrict this distinction disappears.
This strongly means that one thing is unsuitable with evaluating two checks on the premise of their asymptotic energy.
Clearly the second take a look at is worse than the primary, however the asymptotics obscure this.
You would possibly object that I’ve cooked up a very perverse instance, nevertheless it seems that this phenomenon is sort of normal.
It’s straightforward to seek out constant checks, actually it’s tough to seek out checks that aren’t constant.
However we all know from simulation research that not all constant checks are created equal: some have a lot higher finite pattern energy than others and it’s finally finite pattern efficiency that we care about.
A method round this drawback could be to solely evaluate the finite-sample properties of various checks and by no means use asymptotics.
However we virtually by no means know the precise sampling distribution of our take a look at statistics.
That is the place native alternate options are available in.
Quite than evaluating our checks in opposition to a mounted various (mu), suppose we had been to judge it in opposition to a sequence of native alternate options that drift in direction of the null at fee (n^{-1/2}).
In different phrases, our various turns into (H_{1,n} colon mu = delta / sqrt{n}) the place, for this one-sided take a look at, (delta > 0).
If we substitute (delta/sqrt{n}) for (mu) and take the restrict as (nrightarrow infty), we discover [
begin{eqnarray*}
lim_{nrightarrow infty} mbox{Power}(T_{n}) &=& lim_{nrightarrow infty}left[1 – Phileft(z_{1-alpha} – frac{delta}{sqrt{n}}sqrt{n}right) right]
&=& 1 – Phileft(z_{1-alpha} – delta proper)
finish{eqnarray*}
]
and equally [
begin{eqnarray*}
lim_{nrightarrow infty} mbox{Power}(T_{n/2}) &=& lim_{nrightarrow infty}left[1 – Phileft(z_{1-alpha} – frac{delta}{sqrt{n}}sqrt{lfloor n/2 rfloor }right) right]
&=& 1 – Phileft(z_{1-alpha} – frac{delta}{sqrt{2}} proper)
finish{eqnarray*}
]
Wow! Our drawback has disappeared!
The asymptotic energy of the 2 checks now differs in primarily the identical means because the finite pattern energy.
Additionally notice that the ability now not converges to at least one.
Intuitively, it’s because the drifting sequence of alternate options (delta/sqrt{n}) makes it “more durable and more durable” to reject the null because the pattern measurement grows by shrinking simply quick sufficient however not so quick that the ability goes to zero.
This kind of calculation known as a native energy evaluation.
A take a look at that has asymptotic energy higher than zero in such a setting is alleged to have “energy in opposition to native alternate options.”
This instance was a bit foolish since we already knew the reply.
However that is exactly what made it so apparent that native asymptotics make extra sense on this setting than fixed-parameter asymptotics.
Now that you simply perceive this primary instinct, I hope you’ll really feel extra assured tackling examples of native asymptotics that come up within the econometrics literature.
I wished to spotlight an intriguing paper I offered at a journal membership not too long ago:
There’s really a associated paper that got here out concurrently, learning full-batch gradient descent as a substitute of SGD:
Probably the most necessary insights in machine studying over the previous few years pertains to the significance of optimization algorithms in generalization efficiency.
Why deep studying works in any respect
To be able to perceive why deep studying works in addition to it does, it’s inadequate to cause in regards to the loss perform or the mannequin class, which is what classical generalisation concept focussed on. As a substitute, the algorithms we use to seek out minima (specifically, stochastic gradient descent) appear to play an necessary position. In lots of duties, highly effective neural networks are in a position to interpolate coaching knowledge, i.e. obtain near-0 coaching loss. There are the truth is a number of minima of the coaching loss that are just about indistinguishably good on the coaching knowledge. A few of these minima generalise properly (i.e. lead to low check error), others might be arbitrarily badly overfit.
What appears to be necessary then is just not whether or not the optimization algorithm converges rapidly to a neighborhood minimal, however which of the out there “just about world” minima it prefers to succeed in. It appears to be the case that the optimization algorithms we use to coach deep neural networks favor some minima over others, and that this choice leads to higher generalisation efficiency. The choice of optimization algorithms to converge to sure minima whereas avoiding others is described as implicit regularization.
I wrote this observe as an outline on how we/I at the moment take into consideration why deep networks generalize.
Analysing the impact of finite stepsize
One of many fascinating new theories that helped me think about what occurs in deep studying coaching is that of neural tangent kernels. On this framework we research neural community coaching within the restrict of infinitely vast layers, full-batch coaching and infinitesimally small studying charge, i.e. when gradient turns into steady gradient circulate, described by an odd differential equation. Though the speculation is beneficial and interesting, full-batch coaching with infinitesimally small studying charges could be very a lot a cartoon model of what we really do in apply. In apply, the smallest studying date does not at all times work greatest. Secondly, the stochasticity of gradient updates in minibatch-SGD appears to be of significance as properly.
What Smith et al (2021) do otherwise on this paper is that they attempt to research minibatch-SGD, for small, however not infinitesimally small, studying charges. That is a lot nearer to apply. The toolkit that permits them to review this situation is borrowed from the research of differential equations and known as backward error evaluation. The cartoon illustration under exhibits what backward error evaluation tries to realize:
For instance now we have a differential equation $dot{omega} = f(omega)$. The answer to this ODE with preliminary situation $omega_0$ is a steady trajectory $omega_t$, proven within the picture in black. We normally cannot compute this resolution in closed type, and as a substitute simulate the ODE utilizing the Euler’s methodology, $omega_{okay+1} = omega_k + epsilon f(omega_k)$. This leads to a discrete trajectory proven in teal. Because of discretization error, for finite stepsize $epsilon$, this discrete path might not lie precisely the place the continual black path lies. Errors accumulate over time, as proven on this illustration. The purpose of backward error evaluation is to discover a totally different ODE, $dot{omega} = tilde{f}(omega)$ such that the approximate discrete path we acquired from Euler’s methodology lieas close to the the continual path which solves this new ODE. Our purpose is to reverse engineer a modified $tilde{f}$ such that the discrete iteration might be well-modelled by an ODE.
Why is this convenient? As a result of the shape $tilde{f}$ takes can reveal fascinating features of the behaviour of the discrete algorithm, significantly if it has any implicit bias in the direction of shifting into totally different areas of the house. When the authors apply this system to (full-batch) gradient descent, it already suggests the form of implicit regularization bias gradient descent has.
In Gradient descent with a value perform $C$, the unique ODE is $f(omega) = -nabla C (omega)$. The modified ODE which corresponds to a finite stepsize $epsilon$ takes the shape $dot{omega} = -nablatilde{C}_{GD}(omega)$ the place
So, gradient descent with finite stepsize $epsilon$ is like operating gradient circulate, however with an added penalty that penalises the gradients of the loss perform. The second time period is what Barret and Dherin (2021) name implicit gradient regularization.
Stochastic Gradients
Analysing SGD on this framework is a little more tough as a result of the trajectory in stochastic gradient descent is, properly, stochastic. Subsequently, you do not have have a single discrete trajectory to optimize, however as a substitute you will have a distribution of various trajectories which you’d traverse for those who randomly reshuffle your knowledge. This is an image illustrating this example:
Ranging from the preliminary level $omega_0$ we now have a number of trajectories. These correspond to alternative ways we are able to shuffle knowledge (within the paper we assume now we have a hard and fast allocation of datapoints to minibatches, and the randomness comes from the order by which the minibatches are thought-about). The 2 teal trajectories illustrate two potential paths. The paths find yourself at a random location, the teal dots present further random endpoints the place trajectories might find yourself at. The teal star exhibits the imply of the distribution of random trajectory endpoints.
The purpose in (Smith et al, 2021) is to reverse-engineer an ODE in order that the continual (orange) path lies near this imply location. The corresponding ODE is of the shape $dot{omega} = -nabla C_{SGD}(omega)$, the place
the place $hat{C}_k$ is the loss perform on the $okay^{th}$ minibatch. There are $m$ minibatches in whole. Be aware that that is much like what we had for gradient descent, however as a substitute of the norm of the full-batch gradient we now have the typical norm of minibatch gradients because the implicit regularizer. One other fascinating view on that is to have a look at the distinction between the GD and SGD regularizers:
This extra regularization time period, $frac{1}{m}sum_{okay=1}^{m} |nabla hat{C}_k(omega) – C(omega)|^2$, is one thing like the overall variance of minibatch gradients (the hint of the empirical Fisher data matrix). Intuitively, this regularizer time period will keep away from elements of the parameter-space the place the variance of gradients calculated over totally different minibatches is excessive.
Importantly, whereas $C_{GD}$ has the identical minima as $C$, that is not true for $C_{SGD}$. Some minima of $C$ the place the variance of gradients is excessive, is not a minimal of $C_{SGD}$. As an implication, not solely does SGD comply with totally different trajectories than full-batch GD, it could additionally converge to fully totally different options.
As a sidenote, there are various variations of SGD, primarily based on how knowledge is sampled for the gradient updates. Right here, it’s assumed that the datapoints are assigned to minibatches, however then the minibatches are randomly sampled. That is totally different from randomly sampling datapoints with alternative from the coaching knowledge (Li et al (2015) take into account that case), and certainly an evaluation of that variant might properly result in totally different outcomes.
Connection to generalization
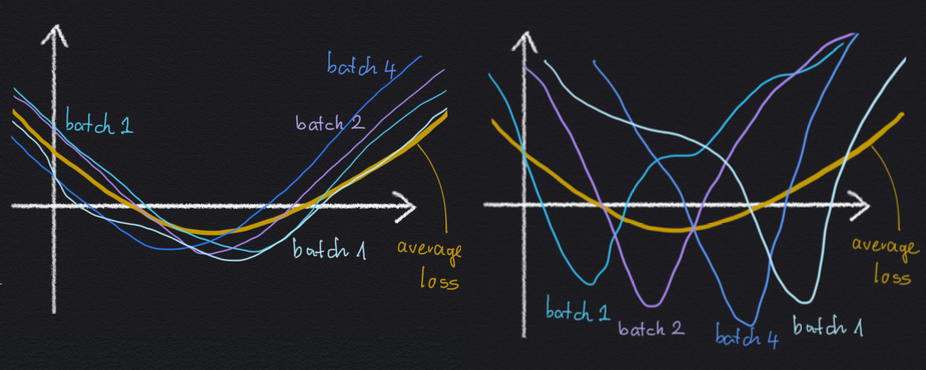
Why would an implicit regularization impact avoiding excessive minibatch gradient variance be helpful for generalisation? Nicely, let’s take into account a cartoon illustration of two native minima under:
Each minima are the identical as a lot as the typical loss $C$ is anxious: the worth of the minimal is similar, and the width of the 2 minima are the identical. But, within the left-hand scenario, the vast minimal arises as the typical of a number of minibatch losses, which all look the identical, and which all are comparatively vast themselves. Within the right-hand minimal, the vast common loss minimal arises as the typical of quite a lot of sharp minibatch losses, which all disagree on the place precisely the situation of the minimal is.
If now we have these two choices, it’s cheap to count on the left-hand minimal to generalise higher, as a result of the loss perform appears to be much less delicate to whichever particular minibatch we’re evaluating it on. As a consequence, the loss perform additionally could also be much less delicate as to whether a datapoint is within the coaching set or within the check set.
Abstract
In abstract, this paper is a really fascinating evaluation of stochastic gradient descent. Whereas it has its limitations (which the authors do not attempt to disguise and focus on transparently within the paper), it nonetheless contributes a really fascinating new method for analysing optimization algorithms with finite stepsize. I discovered the paper to be well-written, with the reason of considerably tedious particulars of the evaluation clearly laid out. However maybe I favored this paper most as a result of it confirmed my intuitions about why SGD works, and what kind of minima it tends to favor.
New-to-the-role CIOs face the daunting activity of shortly coming on top of things on the enterprise priorities of their group and potential safety threats, all whereas constructing relationships with different members of the C-suite.
With so many competing calls for, how ought to new CIOs focus their time and budgets to ascertain themselves as indispensable strategic leaders?
A current Gartner survey of CIOs and IT executives presents clear steering, stated Srinath Sampath, a vice chairman analyst on the analysis and advisory agency.
“Greater than every other a part of their jobs, cybersecurity and threat administration had been deemed to be essentially the most important actions that they completely wanted to get proper, in any other case their jobs can be at stake,” Sampath stated, talking at this month’s Gartner IT Symposium/Xpo occasion in Orlando, Fla.
Sampath stated that as their corporations’ “de facto chief expertise threat officers,” new CIOs should promptly implement a course of for mitigating the highest expertise dangers for the enterprise, whereas offering assurance to stakeholders.
As a result of few CIOs have an infinite price range for threat administration, they need to first achieve an understanding of their group’s enterprise targets so as to strategically stability threat administration towards monetary constraints.
“[CIOs] should ship a sure stage of desired worth for a price that the group is keen to afford, and at a suitable stage of threat to the enterprise,” stated Sampath, acknowledging the issue of the duty.
“Clearly, you do not have a number of time to show your jobs, as you get pulled into completely different instructions by completely different stakeholders, and everybody desires you to ship outcomes yesterday,” he stated.
He supplied the next steps to take:
Begin with a Danger Administration Plan
In response to the stress to shortly display their worth to the group, new CIOs ought to begin by growing a stable threat administration plan, Sampath stated. One of many first steps is to research the reliability and credibility of organizational knowledge, he stated.
CIOs ought to supply knowledge from completely different divisions of their group and determine the largest threats and vulnerabilities, along with rising safety points. This knowledge can embody previous incident experiences and audit findings, however CIOs also needs to study trade boards and experiences to “perceive and eradicate blind spots out of your view,” Sampath defined.
New CIOs might want to set up a cadence for conducting and reporting on threat assessments, similar to month-to-month or quarterly, “so that you’re re-evaluating and validating your understanding, and your group’s understanding, of what the largest threat exposures are, and that you are looking at it from numerous lenses like impression and probability,” he stated. “Some dangers would possibly come actually quick and others may be slow-moving.”
Srinath Sampath, an analyst at Gartner, speaks on the firm’s current IT Symposium/Xpo in Orlando. Sampath stated a Gartner survey discovered that CIOs and IT leaders contemplate cybersecurity and threat administration actions they need to get proper. (Supply: Kelsey Ziser/InformationWeek)
Set up Relationships inside the C-suite
Relationship constructing will even be key to the danger administration improvement course of, Sampath stated.
“One of many first belongings you wish to do is to collect and achieve fast situational consciousness about what are the expectations that your stakeholders have from you,” Sampath stated. “When do they anticipate to see sure varieties of outcomes and adjustments?”
To determine stakeholder expectations, Sampath suggests establishing a “listening tour” with different C-suite executives. Throughout this train, it is necessary for the CIO to construct a “good working relationship” with the CISO and decide the right way to “collaborate and coordinate threat administration actions” so there is a plan in place ought to a cybersecurity menace come up.
The listening tour course of also needs to reveal the board and government staff’s “threat urge for food,” Sampath added. CIOs might want to perceive the right way to stability executives’ tolerance all through an operational or technological disruption with the monetary value of mitigation.
Balancing response time to a menace with budgetary constraints means touchdown “at a spot the place the group feels snug with the degrees of threat that they are accepting, and it is one thing that you would be able to ship as a corporation.”
Danger Administration Is a Group Effort
CIOs also needs to create a committee or governing physique as a part of their threat administration technique, together with illustration throughout enterprise divisions that is not restricted to contributors representing IT and safety roles, Sampath stated.
“Make certain there may be some enterprise illustration in there, as a result of this isn’t purely about expertise,” he stated. “That is about technology-driven enterprise impacts and enterprise dangers to the general enterprise.”
With a stable threat administration plan in place, assist all through the group and from the C-suite, new-to-the-role CIOs can set themselves up for fulfillment within the close to time period. Making the hyperlink between expertise dangers and monetary and operational failures (or outcomes) is essential.
“Attempt to create a connection between the underlying expertise threat exposures and the last word enterprise penalties that your C-suite and stakeholders finally care about,” Sampath suggested.