The Human Immunodeficiency Virus, or HIV, is a virus that assaults the immune system, making it tougher for the physique to struggle off illnesses. Based on the World Well being Group (WHO), 39 million folks had been dwelling with HIV by the top of 2022, together with adults and kids.
Most individuals dwelling with HIV have an HIV-1 an infection (HIV-2 is gradual to develop and doesn’t unfold as quick). The HIV virus is unfold by exchanging physique fluids, primarily via unprotected sexual activity, sharing needles or syringes, and from an contaminated mom to her child throughout childbirth or breastfeeding.
An HIV-1 an infection is harmful as a result of the virus assaults the immune system, the human cells that defend in opposition to an infection. It may be deadly with out well timed medical intervention and lifelong remedy.
Sadly, there’s nonetheless no remedy for HIV. One of many major causes for that is the power of the virus to mutate continuously, making it difficult to develop a single remedy that may goal all strains. Additionally, some cells contaminated with HIV can turn into dormant, solely to resurface years later. This is without doubt one of the explanation why HIV-infected people want remedy for all times.
Nevertheless, there’s hope on the horizon with CRISPR.
Utilizing CRISPR to deal with HIV
Utilizing CRISPR, scientists are enhancing out the HIV-infected immune cells within the physique, together with dormant ones. To realize this, CRISPR is getting used to chop fragments from the DNA of the HIV virus itself, rendering it unable to duplicate and unfold.
Early progress on this area has proven promising outcomes, with researchers efficiently utilizing the CRISPR-Cas system to take away HIV from contaminated cells in laboratory experiments. Nevertheless, it’s nonetheless being studied in medical trials to grasp its results on HIV-1 infections in people.
With continued developments, there’s hope that CRISPR expertise will result in a future the place HIV could be successfully handled and even cured.
margins is a robust device to acquire predictive margins, marginal predictions, and marginal results. It’s so highly effective that it may well work with any useful type of our estimated parameters by utilizing the expression() choice. I’m going to indicate you get hold of proportional modifications of an end result with respect to modifications within the covariates utilizing two totally different approaches for linear and nonlinear fashions.
Linear fashions with binary variables
After becoming a linear regression, $$E(y|x) = a + b*x$$ we are able to estimate the proportional change of the fitted values with respect to a change in (x) (also called, semielasticity) utilizing margins, eydx(x). The formulation to estimate the semielasticity differ relying on whether or not (x) is steady or discrete. If (x) is steady, start{equation} {bf eydx} = frac{d({rm ln}widehat{y})}{dx}= frac{dy}{dx}* frac{1}{widehat{y}} = frac{widehat{b}}{widehat{y}} tag{1} finish{equation} When (x) is discrete, intuitively, we expect the components can be start{equation} {bf eydx} = frac{E(widehat{y}|x = 1) – E(widehat{y} |x = 0)}{E(widehat{y}|x = 0)}tag{2} finish{equation}
Nonetheless, this isn’t precisely what margins, eydx(x) calculates. As an alternative, margins obtains the distinction of (widehat{y}) relative to the bottom within the pure logarithm kind, start{equation} {bf eydx} = E{{rm ln}(widehat{y})|x = 1} – E{{rm ln}(widehat{y})|x = 0}tag{3} finish{equation} To see an instance, let’s match our mannequin with a steady and a binary variable.
. webuse lbw, clear
(Hosmer & Lemeshow knowledge)
. quietly regress bwt age i.ui
. margins, eydx(age ui)
Common marginal results Variety of obs = 189
Mannequin VCE: OLS
Expression: Linear prediction, predict()
ey/dx wrt: age 1.ui
------------------------------------------------------------------------------
| Delta-method
| ey/dx std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
age | .003225 .003309 0.97 0.331 -.003303 .0097531
1.ui | -.2082485 .0570519 -3.65 0.000 -.3208005 -.0956964
------------------------------------------------------------------------------
Notice: ey/dx for issue ranges is the discrete change from the bottom degree.
We regressed infants’ birthweights (bwt) in opposition to moms’ age (age) and the presence of uterine irritability (ui), the place age is steady and ui is a binary variable; then we computed semielasticities. We will manually calculate the proportional modifications. The proportional change of the fitted worth of bwt with respect to a change in age needs to be calculated as _b[age]/(widehat{{bf bwt}}), the place _b[age] is the coefficient estimated for age and (widehat{{bf bwt}}) is the prediction for bwt.
The reported imply, 0.003225, matches the semielasticity that margins yielded. We calculated the prediction of bwt utilizing the generate command, however the prediction might extra simply have been obtained by utilizing the predict command. Within the output of margins, we noticed Expression: Linear prediction, predict() as a result of on this case margins operates on the linear prediction. The expression will be modified and specified utilizing the expression() choice.
Let’s transfer on to ui, the proportional change of bwt with respect to a change in ui, based mostly on (2), $$frac{widehat{{bf bwt}}|({bf ui} = 1)-widehat{{bf bwt}}|({bf ui} = 0)}{widehat{{bf bwt}}|({bf ui} = 0)}$$
This time, (-0.187989) doesn’t match the semielasticity reported by margins, (-0.2082485). As we already know, margins, eydx() doesn’t calculate the proportional change with respect to a change within the categorical variable utilizing (2). As an alternative, margins, eydx() replaces the by-product on the right-hand aspect of (1) with a change from the bottom degree of the log of (y) [see (3)]. Let’s confirm this in our instance:
margins, eydx() makes use of a technique based mostly on logs as a result of this methodology has higher numerical properties. As well as, if we’ve got a mannequin with the pure log of (y) on the left-hand aspect, then expressing the by-product with respect to the explicit variable because the distinction from a base class is a typical means of computing the proportional change. Suppose we’ve got a mannequin: $$E{{rm ln}(y)} = a + b*x$$ If variable x is categorical, then (E({rm ln}(y)|x = 1) – E({rm ln}(y)|x = 0) = b). There are instances when computing (dy/dx*(1/y)) differs from the change within the logs. That is true as we transfer away from fashions which have a logarithmic illustration however even in these instances the approximation could also be enough if the proportional change within the end result given a change within the covariate is small.
If we wish to get hold of the proportional change in (2) and its related customary error, we are able to do that with margins, expression().
Within the expression() choice, the denominator is the expected bwt when ui = 0, and the numerator is the distinction between the prediction of bwt when ui is 1 and when ui is 0. Within the output of margins, the argument of expression() is specified after Expression:. The warning message cautions about the usage of expression() with out the predict() or xb() choice. It’s secure to disregard this message right here. We are going to see examples demonstrating the usage of these choices within the Shortcuts in expression() choice part.
Linear fashions with categorical variables
ui is a binary variable with values of 0 or 1. What if we’ve got categorical variables with greater than two teams? How can we use margins, expression() to compute a proportional change on this case? We wish to get hold of the proportional change within the predicted end result when the explicit variable modifications from the bottom degree to one among the opposite ranges. Now, I’m going to introduce the racial class variable (race =1 [White] 2 [Black] 3 [Other]) within the mannequin, as an alternative of uterine irritability.
. quietly regress bwt age i.race
. generate double propblack = _b[2.race]/(_b[_cons] + _b[age]*age)
. generate double propother = _b[3.race]/(_b[_cons] + _b[age]*age)
. summarize propblack propother
Variable | Obs Imply Std. dev. Min Max
-------------+---------------------------------------------------------
propblack | 189 -.1183368 .0012359 -.1205344 -.1134239
propother | 189 -.0927893 .0009691 -.0945124 -.0889371
. margins, expression((_b[2.race]*2.race + _b[3.race]*3.race)/
> (_b[_cons]+_b[age]*age)) dydx(race)
warning: choice expression() doesn't comprise choice predict() or xb().
Common marginal results Variety of obs = 189
Mannequin VCE: OLS
Expression: (_b[2.race]*2.race + _b[3.race]*3.race)/ (_b[_cons]+_b[age]*age)
dy/dx wrt: 2.race 3.race
------------------------------------------------------------------------------
| Delta-method
| dy/dx std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
race |
Black | -.1183368 .050575 -2.34 0.019 -.2174619 -.0192117
Different | -.0927893 .0358962 -2.58 0.010 -.1631447 -.022434
------------------------------------------------------------------------------
Notice: dy/dx for issue ranges is the discrete change from the bottom degree.
The handbook calculations propblack and propother match what margins reported. Right here I specified each the expression() and dydx() choices. Within the expression() choice, the numerator consists of the coefficient for every degree of race (akin to _b[2.race]) occasions the indicator for the statement belonging to the corresponding race (akin to 2.race). The coefficient represents the distinction between this race and the bottom class for race. After taking the by-product utilizing dydx() with respect to every degree,
we find yourself with the expressions of proportional modifications with respect to Black and Different moms, $$ {bf _b[2.race]}/({bf _b[_cons]} + {bf _b[age]*age}) {bf _b[3.race]}/({bf _b[_cons]} + {bf _b[age]*age}) $$ We might have as an alternative used two separate margins, expression() instructions to compute the proportional change for every group in contrast with the bottom, much like what we did beforehand for the binary variable. Placing them in a single expression makes it doable to additional manipulate these margins. As an illustration, by estimating each proportional modifications with one margins command, we now get hold of each estimates together with the covariance of the estimates, and this enables us to check for a distinction within the proportional modifications.
Nonlinear fashions
The computations will be generalized to nonlinear fashions; the key distinction can be the hyperlink perform to compute the expected end result. Within the subsequent instance, we use probit and Poisson regressions.
. quietly probit low age i.race
. margins, expression((regular(_b[_cons] + _b[age]*age
> + _b[2.race]*2.race + _b[3.race]*3.race)
> - regular(_b[_cons] + _b[age]*age))/
> regular(_b[_cons] + _b[age]*age)) dydx(race)
warning: choice expression() doesn't comprise choice predict() or xb().
Common marginal results Variety of obs = 189
Mannequin VCE: OIM
Expression: (regular(_b[_cons] + _b[age]*age + _b[2.race]*2.race +
_b[3.race]*3.race) - regular(_b[_cons] + _b[age]*age))/
regular(_b[_cons] + _b[age]*age)
dy/dx wrt: 2.race 3.race
------------------------------------------------------------------------------
| Delta-method
| dy/dx std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
race |
Black | .662603 .5016623 1.32 0.187 -.3206371 1.645843
Different | .4874649 .3652971 1.33 0.182 -.2285042 1.203434
------------------------------------------------------------------------------
Notice: dy/dx for issue ranges is the discrete change from the bottom degree.
Within the probit regression, we modeled the likelihood of getting a low-birthweight child by utilizing moms’ age and racial classes. We obtained the proportional modifications of predicted likelihood evaluating Black with White moms and Different with White moms.
Within the Poisson regression, the variety of deaths was defined by smoking standing and age class. The proportional modifications of predicted variety of deaths have been computed by evaluating every age group with the bottom.
margins operates on marginal prediction of the end result, the place the prediction equals xb in linear regression, equals ({rm regular}(xb)) in probit regression, and equals ({rm exp}(xb) occasions {rm publicity}) in Poisson regression. Moreover, margins computes the prediction for every statement and stories the imply because the predictive margins.
Shortcuts within the expression() choice
The useful types we feed into margins, expression() will be as versatile and sophisticated as wanted. There are a number of shortcuts that I wish to spotlight right here. Let’s return to the probit regression.
. quietly probit low c.age##i.race
. margins, eydx(age)
Common marginal results Variety of obs = 189
Mannequin VCE: OIM
Expression: Pr(low), predict()
ey/dx wrt: age
------------------------------------------------------------------------------
| Delta-method
| ey/dx std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
age | -.0318742 .0234627 -1.36 0.174 -.0778603 .0141118
------------------------------------------------------------------------------
I launched a two-way, full-factorial time period between age and race. Right here is the useful kind spelled out to acquire margins, eydx(age):
Within the expression() choice, it isn’t mandatory to jot down out the expression for issues like linear prediction; thus, the above proportional change will be computed by
the place predict(xb) is a shortcut to discuss with the linear prediction. Additional, regular(predict(xb)) will be changed with predict(pr), the place pr stands for likelihood of the optimistic end result. The expression() choice in margins lets us assemble any capabilities of the estimated parameters and feed them again to margins. We then can use all of the computations and graphical instruments with marginsplot to visualise the consequence.
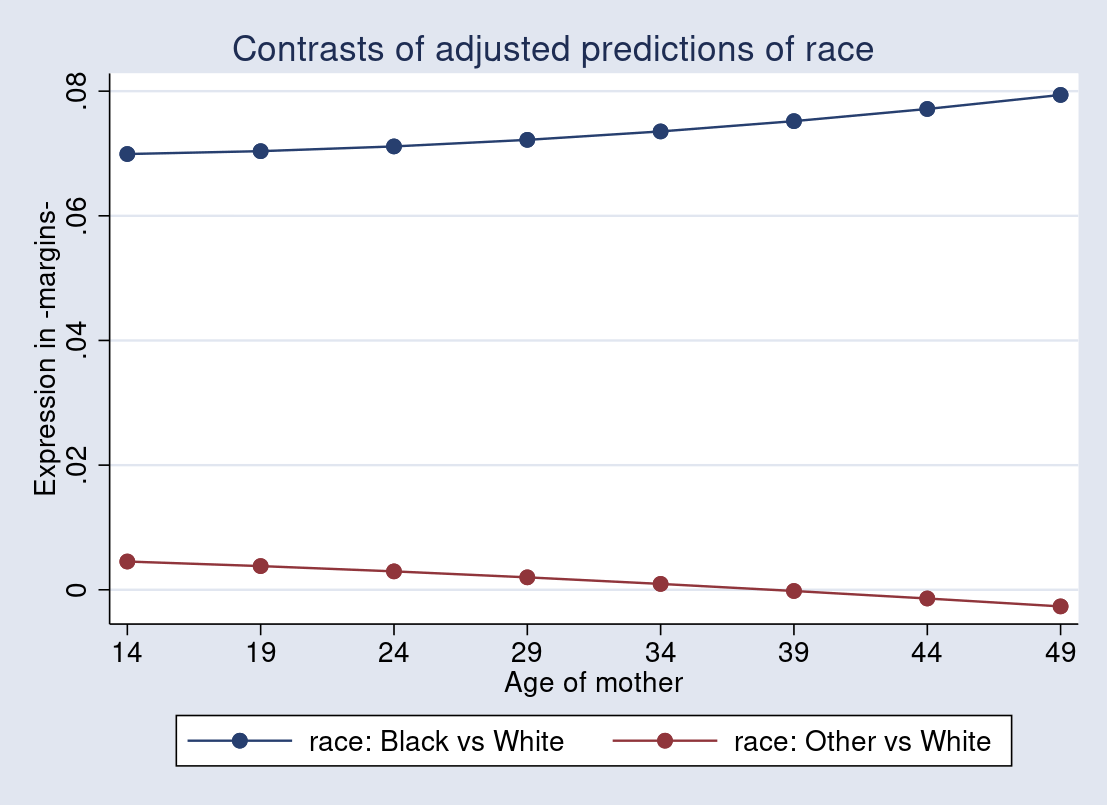
. quietly margins r.race, expression((_b[age] + _b[2.race#c.age]*2.race
> + _b[3.race#c.age]*3.race)*normalden(predict(xb))/regular(predict(xb)))
> at(age=(14(5)50))
. quietly marginsplot, noci ytitle("expression in -margins-")
I obtained the proportional modifications of predicted likelihood of getting a low-birthweight child with respect to the modifications in moms’ ages by evaluating these from Black moms and Different moms with these from White moms. The distinction can also be visualized throughout a variety of moms’ ages from 14 by way of 50. The marginally diverging sample may point out the interplay impact that racial class moderates the connection between the likelihood of getting a low-birthweight child and moms’ age.
Conclusion On this put up, we realized use the expression() choice with the margins command to acquire proportional modifications of the end result with respect to the modifications in categorical covariates in each linear and nonlinear fashions. The expression() choice is a flexible and highly effective choice that enables any useful type of estimated parameters and lets margins function on the prediction of the end result.
For Priya Donti, childhood journeys to India had been greater than a possibility to go to prolonged household. The biennial journeys activated in her a motivation that continues to form her analysis and her instructing.
Contrasting her household residence in Massachusetts, Donti — now the Silverman Household Profession Growth Professor within the MIT Division of Electrical Engineering and Laptop Science (EECS) and a principal investigator on the MIT Laboratory for Data and Resolution Techniques — was struck by the disparities in how individuals stay.
“It was very clear to me the extent to which inequity is a rampant subject all over the world,” Donti says. “From a younger age, I knew that I undoubtedly wished to handle that subject.”
That motivation was additional stoked by a highschool biology trainer, who centered his class on local weather and sustainability.
“We discovered that local weather change, this big, necessary subject, would exacerbate inequity,” Donti says. “That actually caught with me and put a hearth in my stomach.”
So, when Donti enrolled at Harvey Mudd School, she thought she would direct her vitality towards the research of chemistry or supplies science to create next-generation photo voltaic panels.
These plans, nonetheless, had been jilted. Donti “fell in love” with laptop science, after which found work by researchers in the UK who had been arguing that synthetic intelligence and machine studying can be important to assist combine renewables into energy grids.
“It was the primary time I’d seen these two pursuits introduced collectively,” she says. “I bought hooked and have been engaged on that subject ever since.”
Pursuing a PhD at Carnegie Mellon College, Donti was in a position to design her diploma to incorporate laptop science and public coverage. In her analysis, she explored the necessity for basic algorithms and instruments that might handle, at scale, energy grids relying closely on renewables.
“I wished to have a hand in growing these algorithms and power kits by creating new machine studying methods grounded in laptop science,” she says. “However I wished to guarantee that the way in which I used to be doing the work was grounded each within the precise vitality methods area and dealing with individuals in that area” to offer what was truly wanted.
Whereas Donti was engaged on her PhD, she co-founded a nonprofit known as Local weather Change AI. Her goal, she says, was to assist the group of individuals concerned in local weather and sustainability — “be they laptop scientists, lecturers, practitioners, or policymakers” — to come back collectively and entry assets, connection, and training “to assist them alongside that journey.”
“Within the local weather house,” she says, “you want consultants specifically local weather change-related sectors, consultants in several technical and social science device kits, downside homeowners, affected customers, policymakers who know the rules — all of these — to have on-the-ground scalable influence.”
When Donti got here to MIT in September 2023, it was not stunning that she was drawn by its initiatives directing the appliance of laptop science towards society’s largest issues, particularly the present risk to the well being of the planet.
“We’re actually enthusiastic about the place expertise has a a lot longer-horizon influence and the way expertise, society, and coverage all should work collectively,” Donti says. “Expertise isn’t just one-and-done and monetizable within the context of a yr.”
Her work makes use of deep studying fashions to include the physics and exhausting constraints of electrical energy methods that make use of renewables for higher forecasting, optimization, and management.
“Machine studying is already actually extensively used for issues like solar energy forecasting, which is a prerequisite to managing and balancing energy grids,” she says. “My focus is, how do you enhance the algorithms for truly balancing energy grids within the face of a spread of time-varying renewables?”
Amongst Donti’s breakthroughs is a promising resolution for energy grid operators to have the ability to optimize for price, taking into consideration the precise bodily realities of the grid, quite than counting on approximations. Whereas the answer is just not but deployed, it seems to work 10 instances sooner, and much more cheaply, than earlier applied sciences, and has attracted the eye of grid operators.
One other expertise she is growing works to offer knowledge that can be utilized in coaching machine studying methods for energy system optimization. On the whole, a lot knowledge associated to the methods is personal, both as a result of it’s proprietary or due to safety issues. Donti and her analysis group are working to create artificial knowledge and benchmarks that, Donti says, “will help to show a number of the underlying issues” in making energy methods extra environment friendly.
“The query is,” Donti says, “can we carry our datasets to some extent such that they’re simply exhausting sufficient to drive progress?”
For her efforts, Donti has been awarded the U.S. Division of Power Computational Science Graduate Fellowship and the NSF Graduate Analysis Fellowship. She was acknowledged as a part of MIT Expertise Evaluation’s 2021 listing of “35 Innovators Underneath 35” and Vox’s 2023 “Future Good 50.”
Subsequent spring, Donti will co-teach a category known as AI for Local weather Motion with Sara Beery, EECS assistant professor, whose focus is AI for biodiversity and ecosystems, and Abigail Bodner, an assistant professor in Earth, Atmospheric and Planetary Sciences, holding an MIT Schwarzman School of Computing shared place with EECS.
“We’re all super-excited about it,” Donti says.
Coming to MIT, Donti says, “I knew that there can be an ecosystem of people that actually cared, not nearly success metrics like publications and quotation counts, however in regards to the influence of our work on society.”
Textual content-to-speech (TTS) know-how has superior considerably, enabling many creators, together with myself, to provide audio for displays and demos with ease. I usually mix visuals with instruments like ElevenLabs to create natural-sounding narration that rivals studio-quality recordings. One of the best half is that open-source fashions are shortly reaching parity with proprietary choices, offering high-quality realism, emotional depth, sound results, and even the potential to generate long-form, multi-speaker audio much like podcasts.
On this article, we are going to examine the main open-source TTS fashions at the moment obtainable, discussing their technical specs, velocity, language help, and particular strengths.
# 1. VibeVoice
VibeVoice is a sophisticated text-to-speech (TTS) mannequin designed to generate expressive, long-form, multi-speaker conversational audio, comparable to podcasts, instantly from textual content. It addresses long-standing challenges in TTS, together with scalability, speaker consistency, and pure turn-taking. That is achieved by combining a big language mannequin (LLM) with ultra-efficient steady speech tokenizers that function at simply 7.5 Hz.
The mannequin makes use of two paired tokenizers, one for acoustic processing and one other for semantic processing, which assist preserve audio constancy whereas permitting for environment friendly dealing with of very lengthy sequences.
A next-token diffusion method allows the LLM (Qwen2.5 on this launch) to information the move and context of the dialogue, whereas a light-weight diffusion head produces high-quality acoustic particulars. The system is able to synthesizing as much as roughly 90 minutes of speech with as many as 4 distinct audio system, surpassing the same old limitations of 1 to 2 audio system present in earlier fashions.
# 2. Orpheus
Orpheus TTS is a cutting-edge, Llama-based speech LLM designed for high-quality and empathetic text-to-speech functions. It’s fine-tuned to ship human-like speech with distinctive readability and expressiveness, making it appropriate for real-time streaming use circumstances.
In observe, Orpheus targets low-latency, interactive functions that profit from streaming TTS whereas sustaining expressivity and naturalness in its supply. It’s open-sourced on GitHub for researchers and builders, with utilization directions and examples obtainable. Moreover, it may be accessed by means of a number of hosted demos and APIs (comparable to DeepInfra, Replicate, and fal.ai) in addition to on Hugging Face for fast experimentation.
# 3. Kokoro
Kokoro is an open-weight, 82 million-parameter text-to-speech (TTS) mannequin that delivers high quality akin to a lot bigger programs whereas remaining considerably sooner and extra cost-efficient. Its Apache-licensed weights enable for versatile deployment, making it appropriate for each industrial and hobbyist initiatives.
For builders, Kokoro gives a simple Python API (KPipeline) for fast inference and 24 kHz audio technology. Moreover, there may be an official JavaScript (npm) package deal obtainable for streaming eventualities in each browser and Node.js environments, together with curated samples and voices to judge high quality and timbre selection. In the event you favor hosted inference, Kokoro is accessible by means of suppliers like DeepInfra and Replicate, which provide easy HTTP APIs for simple integration into manufacturing programs.
# 4. OpenAudio
The OpenAudio S1 is a number one multilingual Textual content-to-Speech (TTS) mannequin, educated on over 2 million hours of audio. It’s designed to provide extremely expressive and lifelike speech in a variety of languages.
OpenAudio S1 permits for fine-grained management over speech supply, incorporating quite a lot of emotional tones and particular markers (comparable to offended/excited, whispering/shouting, and laughing/sobbing). This permits an actor-like efficiency with nuanced expressiveness.
# 5. XTTS-v2
XTTS-v2 is a flexible and production-ready voice technology mannequin that allows zero-shot voice cloning utilizing a reference clip of roughly six seconds. This modern method eliminates the necessity for in depth coaching knowledge. The mannequin helps cross-language voice cloning and multilingual speech technology, permitting customers to protect a speaker’s timbre whereas producing speech in numerous languages.
XTTS-v2 is a part of the identical core mannequin household that powers Coqui Studio and the Coqui API. It builds on the Tortoise mannequin with particular enhancements that make multilingual and cross-language cloning simple.
# Wrapping Up
Selecting the best text-to-speech (TTS) resolution depends upon your particular priorities. Here’s a breakdown of some choices:
VibeVoice is good for long-form, multi-speaker conversations, using LLM-guided dialogue turns
Orpheus TTS emphasizes empathetic supply and helps real-time streaming
Kokoro provides an Apache-licensed, cost-effective resolution that allows quick deployment, delivering robust high quality for its measurement
OpenAudio S1 gives in depth multilingual help together with wealthy controls for emotion and tone
XTTS-v2 permits for fast, zero-shot cross-language voice cloning from only a 6-second pattern
Every of those options will be optimized primarily based on elements comparable to runtime, licensing, latency, language protection, or expressiveness.
Abid Ali Awan (@1abidaliawan) is an authorized knowledge scientist skilled who loves constructing machine studying fashions. Presently, he’s specializing in content material creation and writing technical blogs on machine studying and knowledge science applied sciences. Abid holds a Grasp’s diploma in know-how administration and a bachelor’s diploma in telecommunication engineering. His imaginative and prescient is to construct an AI product utilizing a graph neural community for college students battling psychological sickness.
Thanksgiving is a time to replicate upon the prior 12 months, be grateful for what we’ve got, gorge ourselves till we’re close to bursting, after which settle into our favourite chairs and watch the primary half of a TV present earlier than the tryptophan kicks in. Should you normally spend your post-meal time falling asleep to A Charlie Brown Thanksgiving, you gained’t discover it on the standard broadcast or cable channels–it’s completely on Apple TV+.
Earlier than you wave that turkey drumstick within the air and curse the state of tv and all of the darn streaming companies you want subscriptions for—sure, I’m speaking about you, Uncle Fred—you don’t want a subscription to Apple TV+ to observe A Charlie Brown Thanksgiving. Apple is making the present accessible to anybody for a restricted time. If you’re an Apple TV+ subscriber, nevertheless, you may watch it anytime.
Learn how to watch A Charlie Brown Thanksgiving totally free on Apple TV+
On November 15 and 16, anybody with an Apple ID can watch A Charlie Brown Thanksgiving. Should you personal an Apple system, you could have one, but when not, Apple IDs are free and also you don’t want a bank card to enroll. After you have signed up, you may watch in a number of methods:
By means of the TV app on an iPhone, iPad, or Mac.
As we famous when Apple did this similar cope with It’s the Nice Pumpkin, Charlie Brown, Apple has all of the traditional Peanuts specials for the vacation season that used to air over broadcast TV. Apple TV+ additionally has A Charlie Brown Christmas that can have its free airing on Dec. 13 and 14. Apple TV+ additionally has Comfortable New 12 months, Charlie Brown however it isn’t listed as free-to-view.
The Apple TV+ subscription tv streaming service is $12.99/£9.99 per 30 days and will be renewed yearly for $99/£99. Apple TV+ can be included within the Apple One subscription bundles, which embody different Apple companies, akin to Apple Music, Apple Information+, and iCloud storage. Apple One bundles are priced between $19.95/£19.95 and $37.95/£37.95 per 30 days.
Get the Widespread Science day by day publication💡
Breakthroughs, discoveries, and DIY suggestions despatched each weekday.
The Jap hellbender (Cryptobranchus a. alleganiensis) isn’t practically as fearsome as its title implies. They’re really considerably cute, if you may get previous the salamander’s slimy, mucousy pores and skin that’s earned it such nicknames, similar to “snot otter” and “lasagna lizard.”
Though hellbenders can develop as much as two ft lengthy, the amphibians are notoriously elusive and like to reside below massive, flat rocks in well-oxygenated waterways that snake by Appalachia and the Ohio River basin. They’re additionally more and more troublesome to identify, as a result of their numbers are declining attributable to ecological points. Based mostly on a current environmental examine encompassing 90 websites throughout 73 rivers, researchers on the College of Kentucky now consider that they’ve recognized one of many hellraiser’s predominant issues. They’re shedding their habitats to more and more murky, sediment-filled waters, in line with a examine revealed within the journal Freshwater Biology.
Examine co-author and biologist Steven Value mentioned that it’s fairly troublesome to nab a hellbender even should you aren’t conducting a United States Division of Pure Sources-funded survey.
“They dwell below massive rocks. Lifting these safely takes time, folks and care,” he mentioned in an accompanying assertion from the college. “If you see one within the wild in Kentucky, it’s particular.”
Reasonably than spend untold hours wading by rivers within the hopes of recognizing their hellbenders, Tomke, Value, and their colleagues as a substitute relied on hint proof from residing organisms often known as environmental DNA (eDNA). After amassing and filtering river water, the workforce examined the samples for a gene solely seen on this species. This allowed them to keep away from losing time by shifting the huge stones or snorkeling for salamanders. The biologists finally detected hellbender DNA at 22 areas throughout Kentucky, 12 of which had present historic data associated to the animals. Subsequent, they used a statistical occupancy framework to find out the place hellbenders dwell, and when their eDNA is best to pinpoint.
“We may clearly tie stream habitat high quality to the place hellbender DNA turns up,” added examine co-author Sarah Tomke. “It introduced the science collectively and confirmed what managers can do on the bottom.”
The workforce decided that the amphibian’s native habitat was a bigger consider the place it lives than general water chemistry or land cowl. Bigger streams lined with higher quantities of gravel, cobble, and bedrock correlated to extra hellbenders. Nevertheless, their numbers declined the place grain and silt began blocking the crevices beneath rocks.
“High quality sediment is an enormous downside,” defined Tomke. “It fills potential nest websites and the small areas that larvae use for shelter. With out that area below rocks, animals can’t reproduce or survive for lengthy.”
Additionally they found what time of 12 months is finest to pattern for hellbenders. Early fall, particularly throughout September’s breeding interval, seems to be probably the most smart time. The creatures shed further genetic materials in early fall, making them simpler to detect.
Past their uniqueness, the examine’s authors add that hellbenders can act as glorious bellweathers for an ecosystem’s well being. When their populations diminish, it ceaselessly hurts different species who prey on the amphibians.
“Sarah’s undertaking offers us clear habitat targets,” Value mentioned. “First, hold sediment out of streams. Then defend and rebuild rocky beds and forested streambanks. That’s how we give this species an opportunity.”
Fortunately, it appears like probably the most in depth hellbender mapping effort of its type wasn’t a complete bust for its contributors.
“Seeing a hellbender is unbelievable, and holding one is subsequent stage,” Tomke mentioned.
2025 Residence of the Future Awards
Intelligent cooking instruments, distinctive home equipment, sensible dwelling methods, and every little thing else you’ll need in your house going ahead.
The Challenges of Writing a Dissertation and Methods to Handle Them
Writing a dissertation is a posh journey that exams each tutorial and private endurance. From managing huge quantities of analysis to sustaining motivation, there are a number of challenges that college students generally face. Right here’s a have a look at the highest challenges and a few methods to beat them.
1. Narrowing Down the Subject: One of many first hurdles is selecting and refining a analysis matter. Many college students begin with a broad space of curiosity however battle to give attention to a particular query that’s each unique and possible. To sort out this, start by reviewing latest literature to determine gaps or unresolved questions. Consulting with advisors or friends may provide help to refine your focus and align your matter with present discussions in your area.
2. Managing Time Successfully: Time administration is a major problem, as dissertations usually require months and even years of dedication. It’s simple to procrastinate when deadlines are far-off, resulting in a rushed course of later. To remain on monitor, break the mission into smaller, manageable duties, similar to drafting a literature assessment or analyzing information. Setting weekly or month-to-month targets and utilizing time administration instruments like Gantt charts may also help you keep a gradual tempo.
3. Dealing with Overwhelming Analysis and Knowledge: The sheer quantity of analysis wanted might be overwhelming, particularly through the literature assessment part. It’s essential to remain organized by categorizing sources and noting related factors as you go. Utilizing reference administration instruments like Zotero or Mendeley may streamline the method. For information evaluation, think about looking for assist from a statistician or utilizing information evaluation software program to scale back the effort and time required.
4. Staying Motivated and Targeted: Writing a dissertation is a protracted, solitary journey, and lots of college students expertise dips in motivation. One option to keep engaged is by organising a assist community with friends who’re additionally engaged on dissertations. Common check-ins may also help maintain you accountable and motivated. Setting small, achievable milestones and rewarding your self after reaching them may keep your focus.
5. Overcoming Author’s Block and Perfectionism: Author’s block and perfectionism usually go hand in hand, creating delays and frustration. To beat these, strive freewriting periods the place you write with out worrying about high quality. Drafting is about getting concepts down, and enhancing can come later. Accepting that your first draft gained’t be good is essential for making progress.
Writing a dissertation comes with varied challenges, from matter choice to time administration. By breaking duties into manageable steps, staying organized, and looking for assist, college students could make the method smoother and obtain their tutorial targets.
Want help along with your dissertation? Schedule a free 15-minute wants evaluation right here.
Get Your Dissertation Permitted
We work with graduate college students each day and know what it takes to get your analysis authorized.
Hace casi 30 años, estaba estudiando en casa cuando, de repente, sentí una extraña sensación. Tomé un cuaderno y una pluma y comencé a escribir y escribir. Continué escribiendo hasta muy tarde esa noche. No dormí bien y seguí escribiendo por la mañana.
Durante el siguiente día, abandoné muchas de las actividades cotidianas para seguir escribiendo. Llené un cuaderno y comencé el otro. Pero no los llené con cualquier cosa. Escribí historias cortas y largas. Tomé notas de mis libros de texto. Escribí planes para mi futuro. El punto period escribir.
Un diagnostico inesperado
Cuando noté que no podía dejar de escribir, decidí acudir a la clínica de la universidad para una consulta médica. La enfermera de turno me examinó y llamó al médico. El médico me examinó y me recomendó acudir a la sala de emergencias de un hospital cercano a la universidad.
En la sala de emergencias, el médico pensó que yo estaba bajo la influencia de algún medicamento o sustancia. Me preguntó qué había tomado y creo que no me creyó cuando le dije que estaba sobrio. Así que le llamó a un psiquiatra para que me examinara, pero estaba yo tan exhausto que me quedé dormido en la camilla.
Desperté un tiempo después y vi que el psiquiatra leía lo que yo había escrito en uno de mis cuadernos. Me pregunto cuánto tiempo me tomó escribir esa historia. Le dije que la había escrito de principio a fin la noche anterior. Después de una conversación sobre mis síntomas, me recomendó hacerme una encefalografía, un estudio de la actividad eléctrica cerebral.
Basándose en ese estudio, el psiquiatra me diagnosticó con hipergrafía secundaria a una epilepsia del lóbulo temporal de mi cerebro. Es decir, el lóbulo temporal estaba activado más de lo ordinary. Y, siendo el lóbulo encargado de la creatividad, mi cerebro me ordenaba serlo. Y esa creatividad se manifestó en la escritura.
Lidiando con un cerebro diferente
Cuando estaba en la preparatoria, noté que me resultaba muy fácil escribir. Y noté que, de vez en cuando, me gustaba escribir. Es decir, me daba placer escribir. Las historias de ficción cortas o los ensayos para mis clases me hacían sentir bien. Creo que esos fueron los primeros indicios de que algo sucedía.
Con el diagnóstico, se me hizo fácil adaptarme a esos momentos en los que escribir period necesario. Tomaba mis libros de texto y escribía notas, lo cual me ayudaba a memorizar los datos para los exámenes. O escribía ensayos para clases que los requerían. Poco a poco, comencé a tomar las riendas de mi cerebro.
Claro, los médicos me recomendaron tomar ácido valproico, un antiepiléptico. Pero noté que la falta de creatividad period muy grande, hasta el punto de que me sentía ineficaz. Me daba una cierta tristeza. Así que consulté con un terapeuta de la universidad y trabajamos juntos para aprovechar al máximo mis habilidades.
Y aquí estoy
Así que aquí estoy, ya casi 30 años después, escribiéndote lo que pasó. Y te lo escribo porque he tenido tres episodios de sensación rara en los que me da vértigo y siento que el mundo se “cierra”.” Es casi como si me desmayara, pero no pierdo el conocimiento. De hecho, son más la ansiedad y el sentirme asustado que el sentirme fuera de management.
Estamos explorando nuevamente si esa actividad excesiva en mi lóbulo temporal ha regresado o si está de alguna forma asociada a lo ocurrido. Y si es así, vamos a ver qué podemos hacer al respecto. Y ya de pasada vamos a revisar el corazón porque el vértigo se viene encima con una baja en los latidos.
Y ahora conoces mi superpoder y por qué se me facilita tanto escribir. Aunque debo confesar que escribir en español sigue sin mejorar… Pero tampoco le he dado mucha práctica. Ya veremos qué pasa.
Synthetic intelligence has superior rapidly, and the world of AI has remodeled from chatbots that may write textual content to techniques that may cause, retrieve information and take motion. There are three principal constructs of intelligence behind this development: Massive Language Fashions (LLMs), Retrieval-Augmented Technology (RAG), and AI Brokers. Understanding LLMs vs RAG vs AI Brokers comparability is important to see how immediately’s AI techniques suppose, be taught, and act.
Individuals typically reference them collectively as know-how themes, however every represents a special layer of intelligence: the LLM serves because the reasoning engine, RAG connects it to real-time information, and the Agent turns that reasoning into real-world motion. To anybody architecting or utilizing AI-based techniques immediately, it’s crucial to grasp how they each differ and the way they work collectively.
The Easy Analogy: Mind, Data, and Determination
Pondering of those three as parts of a residing system could be very useful.
The LLM is the mind. It will possibly cause, create, and speak, essentially, however deliberates solely on what it is aware of.
RAG is feeding that mind, linking the thoughts to libraries, databases, and stay sources.
An AI Agent is the one making the choices, utilizing the mind and its instruments for planning, performing, and finishing objectives.
This straightforward metaphor captures the connection between the three. LLMs present intelligence, RAG updates that intelligence, and Brokers are those giving it path and function.
Massive Language Fashions: The Pondering Core
A Massive Language Mannequin (LLM) underpins virtually each up to date AI instrument. LLMs, resembling GPT-4, Claude, and Gemini, are skilled on monumental volumes of textual content from books, web sites, code, and analysis papers. They be taught the construction and which means of language and develop the power to guess what phrase ought to come subsequent in a sentence. From that single skill, a variety of talents develops summarizing, reasoning, translating, explaining, and creating.
The energy of an LLM lies in its contextual understanding. It will possibly take a query, infer what’s being requested, and produce a useful and even intelligent response. However this intelligence has a key limitation: it’s static. The mannequin solely constructed a information base from what it recorded on the time of coaching. Its reminiscence doesn’t permit it to drag in new information, lookup latest occasions, or entry non-public knowledge.
So an LLM could be very good however indifferent from its environment; it might probably make spectacular reasoning leaps however shouldn’t be related to the world past its coaching. That is the explanation it might probably typically confidently present incorrect statements, often known as “hallucinations“.
Despite these limitations, LLMs carry out exceptionally nicely for duties that contain comprehension, creativity, or specificity in language. They’re helpful for writing, summarizing, tutoring, producing code, and brainstorming. Nevertheless, when it’s essential to be correct and present, they require assist in the type of RAG.
Retrieval-Augmented Technology: Giving AI Recent Data
Retrieval-Augmented Technology (RAG) is a sample whereby a mannequin’s intelligence is augmented by its want for present, real-world information. The sample itself is moderately easy: retrieve related data from an exterior supply and supply it as context previous to having the mannequin generate a solution.
When a person asks a query, the system first searches a information base, which can be a library of paperwork, a database, or a vector search engine that indexes an embedding of the textual content. Essentially the most related passages from the information base will likely be retrieved and integrated into the immediate to generate a response from the LLM. The LLM will make its deduction based mostly on each its personal inner reasoning and the brand new data that was offered.
This permits a transition from a static mannequin to a dynamic one. Even with out re-training the LLM, it might probably leverage data that’s recent, domain-oriented, and factual. RAG primarily extends the reminiscence of the mannequin past what it’s skilled upon.
The benefits are fast.
Factual accuracy improves as a result of the mannequin is leveraging textual content that’s retrieved moderately than textual content generated by inference.
Data stays present as a result of a brand new set of paperwork might be added to the database at any given time limit.
Transparency improves as a result of builders can audit what paperwork have been used whereas having the mannequin generate a response.
RAG is a serious step in AI structure improvement. RAG successfully hyperlinks the reasoning energy of LLMs and the reconciled anchoring of information to actual life. It’s this mixture that approaches remodeling a wise textual content generator right into a dependable assistant in complement and in collaboration.
Whereas LLMs can suppose and RAG can inform, neither can accomplish that, which is the place the AI Brokers are available.
An Agent wraps round a language mannequin a management loop, which supplies it company. As a substitute of solely answering questions, it might probably make decisions, name instruments, and full duties. In different phrases, it not solely talks; it does.
Brokers function by the loop of notion, planning, motion, and reflection. They first interpret a purpose, resolve the steps to finish it, execute the steps utilizing accessible instruments or APIs, observe the end result, and revise if wanted. This permits an Agent to handle advanced, multi-step duties with out human involvement, together with looking out, analyzing, summarizing, and reporting.
For instance, an AI Agent may analysis a subject round which to create a presentation, pull supporting knowledge, synthesize that right into a abstract for a slide deck, after which ship that abstract slide deck by way of e-mail. One other Company may handle repeat workflows, monitor techniques, or deal with scheduling. The LLM gives the reasoning and decision-making, and the encompassing agent scaffolding gives construction and management.
Establishing techniques like these takes considerate design. Brokers have many extra complexities in comparison with chatbots, together with error dealing with, entry rights, and monitoring. They want security mechanisms to keep away from unintended actions, significantly when utilizing exterior instruments. Nevertheless, well-designed brokers can convey lots of of hours of human pondering to life and operationalize language fashions into digital staff.
How the Three Work Collectively
The suitable combine is determined by the use case.
If you wish to use an LLM for pure language duties: writing, summarizing, translating, or explaining one thing.
Use RAG if you’re involved about accuracy, freshness, or area specificity, like answering questions from inner paperwork or technical manuals.
Use an Agent when actual autonomy is required: while you want techniques to cause, implement, and handle workflows;
In all of those instances, for advanced purposes, the layers are sometimes used collectively: the LLM reasoning, the RAG layer for factual correctness, and the Agent defining what the subsequent actions ought to be.
Selecting the Proper Strategy
The right mix relies upon upon the duty.
Use an LLM by itself for purely language-based duties (for instance: writing, summarizing, translating, or explaining).
Use RAG when accuracy, time-sensitivity, or domain-specific information issues, resembling answering questions based mostly on inner paperwork (e.g., insurance policies, inner memos, and many others) or a technical guide.
Use an Agent while you additionally want actual autonomy: techniques that may resolve, act, and handle workflows.
There are a lot of situations when these layers are assembled for advanced purposes. The LLM does the reasoning, the RAG layer assures factual accuracy, and the Agent decides what the system truly does subsequent.
Challenges and Concerns
Whereas the mix of LLMs, RAG, and Brokers is robust, it additionally comes with new obligations.
When working with RAG pipelines, builders have to contemplate and handle context size and context which means, guaranteeing the mannequin has simply sufficient data to stay grounded. Safety and privateness issues are paramount, significantly when utilizing delicate or proprietary knowledge. Brokers have to be constructed with strict security mechanisms since they’ll act autonomously.
Analysis is one more problem. Conventional metrics like accuracy can not consider reasoning high quality, retrieved relevance, or success charge for a accomplished motion. As AI techniques turn out to be extra agentic, we’ll want different technique of evaluating efficiency that additionally incorporate transparency, reliability, and moral habits.
The development from LLMs to RAG to AI Brokers is a logical evolution in synthetic intelligence: from pondering techniques, to studying techniques, to performing techniques.
LLMs present reasoning and language comprehension, RAG places that intelligence into right, up to date data, and Brokers convert each into intentional, autonomous motion. Collectively, these present the premise for precise clever techniques, ones that won’t solely course of data, however perceive context, make selections, and take purposeful motion.
In abstract, the way forward for AI is within the fingers of LLMs for pondering, RAG for realizing, and Brokers for doing.
Regularly Requested Questions
Q1. What’s the principal distinction between LLMs, RAG, and AI Brokers?
A. LLMs cause, RAG gives real-time information, and Brokers use each to plan and act autonomously.
Q2. When ought to RAG be used as a substitute of a plain LLM?
A. Use RAG when accuracy, up-to-date information, or domain-specific context is important.
Q3. What permits AI Brokers to take real-world actions?
A. Brokers mix LLM reasoning with management loops that permit them plan, execute, and modify duties utilizing instruments or APIs.
Hello, I’m Janvi, a passionate knowledge science fanatic presently working at Analytics Vidhya. My journey into the world of information started with a deep curiosity about how we will extract significant insights from advanced datasets.
Login to proceed studying and revel in expert-curated content material.
Simply as a proposal to return JavaFX to the Java Improvement Package has drawn curiosity within the OpenJDK group, Oracle too says it desires to make the Java-based wealthy shopper utility extra approachable inside the JDK. JavaFX was faraway from the JDK with Java 11 greater than seven years in the past.
An October 29 publish by Bruce Haddon on an OpenJDK dialogue listing argues that the explanations for the separation of JavaFX from the JDK—particularly, that JavaFX contributed tremendously to the bloat of the JDK, that the separation allowed the JDK and JavaFX to evolve individually, and that the event and upkeep of JavaFX had moved from Oracle to Gluon—are a lot much less relevant in the present day. Haddon notes that JDK bloat has been addressed by modularization, that the JDK and the JavaFX releases have stored in lockstep, and that each Java and JavaFX developments can be found in open supply (OpenJDK and OpenJFX), so integrating the releases would nonetheless allow group involvement and innovation.
“Additional, it will be of nice comfort to builders to not must make two installations after which configure their IDEs to entry each libraries (probably not straightforward in nearly all IDEs, requiring understanding of many in any other case ignorable choices of every IDE),” Haddon wrote. “It’s each my perception and my advice that the time has come for the re-integration of JavaFX (as the popular GUI characteristic) with the remainder of the JDK.”












{kind=link}