Okta is warning about customized phishing kits constructed particularly for voice-based social engineering (vishing) assaults. BleepingComputer has realized that these kits are being utilized in lively assaults to steal Okta SSO credentials for knowledge theft.
In a brand new report launched right this moment by Okta, researchers clarify that the phishing kits are offered as a part of an “as a service” mannequin and are actively being utilized by a number of hacking teams to focus on identification suppliers, together with Google, Microsoft, and Okta, and cryptocurrency platforms.
Not like typical static phishing pages, these adversary-in-the-middle platforms are designed for dwell interplay by way of voice calls, permitting attackers to vary content material and show dialogs in actual time as a name progresses.
The core options of those phishing kits are real-time manipulation of targets by way of scripts that give the caller direct management over the sufferer’s authentication course of.
Because the sufferer enters credentials into the phishing web page, these credentials are forwarded to the attacker, who then makes an attempt to log in to the service whereas nonetheless on the decision.
A C2 panel permitting real-time management of authentication flows Supply: Okta
When the service responds with an MFA problem, comparable to a push notification or OTP, the attacker can choose a brand new dialog that immediately updates the phishing web page to match what the sufferer sees when making an attempt to log in. This synchronization makes fraudulent MFA requests seem authentic.
Okta says these assaults are extremely deliberate, with menace actors performing reconnaissance on a focused worker, together with which purposes they use and the cellphone numbers related to their firm’s IT help.
They then create personalized phishing pages and name the sufferer utilizing spoofed company or helpdesk numbers. When the sufferer enters their username and password on the phishing website, these credentials are relayed to the attacker’s backend, generally to Telegram channels operated by the menace actors.
This enables the attackers to instantly set off actual authentication makes an attempt that show MFA challenges. Whereas the menace actors are nonetheless on the cellphone with their goal, they’ll direct the individual to enter their MFA TOTP codes on the phishing website, that are then intercepted and used to log in to their accounts.
Okta says these platforms can bypass fashionable push-based MFA, together with quantity matching, as a result of attackers inform victims which quantity to pick. On the similar time, the phishing equipment C2 causes the web site to show an identical immediate within the browser.
Okta recommends that clients use phishing-resistant MFA comparable to Okta FastPass, FIDO2 safety keys, or passkeys.
Assaults used for knowledge theft
This advisory comes after BleepingComputer realized that Okta privately warned its clients’ CISOs earlier this week in regards to the ongoing social engineering assaults.
On Monday, BleepingComputer contacted Okta after studying that menace actors have been calling focused corporations’ workers to steal their Okta SSO credentials.
Okta is a cloud-based identification supplier that acts as a central login system for most of the most generally used enterprise internet companies and cloud platforms.
Its single sign-on (SSO) service permits workers to authenticate as soon as with Okta after which acquire entry to different platforms utilized by their firm with out having to log in once more.
Platforms that combine with Okta SSO embody Microsoft 365, Google Workspace, Dropbox, Salesforce, Slack, Zoom, Field, Atlassian Jira and Confluence, Coupa, and lots of extra.
As soon as logged in, Okta SSO customers are given entry to a dashboard that lists all of their firm’s companies and platforms, permitting them to click on and entry them. This makes Okta SSO act as a gateway to an organization’s business-wide companies.
Okta SSO dashboard offers SSO entry to an organization’s platforms Supply: Okta
On the similar time, this makes the platform extraordinarily worthwhile for menace actors, who now have entry to the corporate’s extensively used cloud storage, advertising and marketing, growth, CRM, and knowledge analytics platforms.
BleepingComputer has realized that the social engineering assaults start with menace actors calling workers and impersonating IT employees from their firm. The menace actors provide to assist the worker arrange passkeys for logging into the Okta SSO service.
The attackers trick workers into visiting a specifically crafted adversary-in-the-middle phishing website that captures their SSO credentials and TOTP codes, with among the assaults relayed in actual time by way of a Socket.IO server beforehand hosted at inclusivity-team[.]onrender.com.
The phishing web sites are named after the corporate, and generally include the phrase “inner” or “my”.
For instance, if Google have been focused, the phishing websites is likely to be named googleinternal[.] com or mygoogle[.]com.
As soon as an worker’s credentials are stolen, the attacker logs in to the Okta SSO dashboard to see which platforms they’ve entry to after which proceeds to steal knowledge from them.
“We gained unauthorized entry to your sources by utilizing a social-engineering-based phishing assault to compromise an worker’s SSO credentials,” reads a safety report despatched by the menace actors to the sufferer and seen by BleepingComputer.
“We contacted numerous workers and satisfied one to supply their SSO credentials, together with TOTPs.”
“We then seemed by way of numerous apps on the worker’s Okta dashboard that they’d entry to searching for ones that handled delicate info. We primarily exfiltrated from Salesforce as a consequence of how straightforward it’s to exfiltrate knowledge from Salesforce. We extremely recommend you to stray away from Salesforce, use one thing else.”
As soon as they’re detected, the menace actors instantly ship extortion emails to the corporate, demanding fee to stop the publication of information.
Sources inform BleepingComputer that among the extortion calls for despatched by the menace actors are signed by ShinyHunters, a widely known extortion group behind a lot of final 12 months’s knowledge breaches, together with the widespread Salesforce knowledge theft assaults.
BleepingComputer requested ShinyHunters to substantiate in the event that they have been behind these assaults however they declined to remark.
Right now, BleepingComputer has been instructed that the menace actors are nonetheless actively focusing on corporations within the Fintech, Wealth administration, monetary, and advisory sectors.
Okta shared the next assertion with BleepingComputer concerning our questions on these assaults.
“Retaining clients safe is our high precedence. Okta’s Defensive Cyber Operations group routinely identifies phishing infrastructure configured to mimic an Okta sign-in web page and proactively notifies distributors of their findings,” reads a press release despatched to BleepingComputer.
“It’s clear how subtle and insidious phishing campaigns have change into and it’s essential that corporations take all obligatory measures to safe their methods and proceed to teach their workers on vigilant safety finest practices.”
As MCP (Mannequin Context Protocol) turns into the usual for connecting LLMs to instruments and knowledge, safety groups are transferring quick to maintain these new companies protected.
This free cheat sheet outlines 7 finest practices you can begin utilizing right this moment.
As this 12 months’sOscar nominations rolled out this morning, I informed my boyfriend that Sinners, with 16 noms in complete, had made historical past. “Woke is again,” he replied.
He was joking (don’t come for him!), however his quip highlights a fairly stark dichotomy. Final 12 months, as everybody from President Donald Trump down harped on in regards to the perils of DEI, the largest cultural breakthroughs—Sinners, KPop Demon Hunters, Heated Rivalry, One Battle After One other—all showcased variety in recent methods. And it succeeded. These works weren’t simply standard amongst leftists or critics, they have been bona fide cultural phenomena.
Sinners, a horror film set within the Jim Crow South, used vampires as a metaphorical system to discover systemic racism and cultural theft—and director Ryan Coogler scored a feat in his take care of Warner Bros. that provides him the rights to the movie in 25 years. KPop Demon Hunters, a narrative by a feminine Korean-Canadian director who’d been ready over a decade for her likelihood to direct a characteristic, positioned an enormous emphasis on authenticity and introduced the already-massive subculture round Okay-pop much more into the mainstream. Heated Rivalry, a small Canadian tv manufacturing picked up by HBO, had an extraordinarily subversive tackle hockey by chronicling the horny-yet-poignant love story between two closeted professional gamers. And One Battle After One other—decried by conservative commentators who felt it lionized left-wing violence—supplied difficult views on motherhood and activism whereas skewering ICE-like agent Colonel Steven J. Lockjaw and his determined makes an attempt to slot in with different racists.
In a 12 months when the White Home issued a number of government orders removing DEI packages within the federal authorities, the successes of these initiatives felt like a type of resistance. Company media adopted Trump’s go well with, with Warner Bros. Discovery, Amazon, Paramount World, and Disney all reportedly scaling again on their variety efforts. Skydance, based by David Ellison, son of billionaire Trump supporter Larry Ellison, acquired Paramount, which briefly eliminated Jimmy Kimmel from the air resulting from his joke about Charlie Kirk supporters and gave CBS Information a seemingly conservative makeover. In the meantime, exhibits that supplied pink meat within the type of farmers, grumpy MAGA adherents, cowboys, and Christian values have been greenlit and promoted.
“There’s a feeling from … this administration that the one tales that matter are tales of straight white males, and that’s simply merely not the case,” says Jenni Werner, government creative director of the New Concord Undertaking, which develops theater, movie, and TV initiatives and says it’s dedicated to anti-oppressive and anti-racist values.
“Audiences need to really feel reworked. You need to have the ability to sit down and watch one thing, whether or not it is in your house or in a theater, that takes you into a brand new place and perhaps provides you a brand new understanding of one thing.” She provides that she has religion that artists will preserve making “boundary-pushing work,” even when it retains getting tougher.
Even earlier than Trump’s second time period, making an attempt to get out-of-the-box tales made in Hollywood has been a slog. In keeping with UCLA’s Hollywood Variety Report, launched in December, almost 80 p.c of administrators of theatrical films in 2024 have been white, together with about 75 p.c of main actors.
The report additionally suggests this discrepancy is leaving cash on the desk, noting that BIPOC moviegoers “have been overrepresented as ticket consumers for movies that had casts of greater than 20 p.c BIPOC.” Sinners grossed $368 million on the field workplace, a feat that places it within the “horror corridor of fame,” per The New York Instances.
As synthetic intelligence turns into a central a part of analysis and studying, the instruments we use to prepare and analyze info have began dealing with a few of our most delicate information. Cloud-based AI notebooks, whereas handy, typically lock customers into proprietary ecosystems and expose analysis notes, studying backlogs, and mental property to exterior servers. For college students, researchers, and impartial professionals, this creates an actual privateness danger — something from unpublished work to private insights could possibly be inadvertently saved, logged, and even used to coach exterior fashions.
The rise of AI-powered note-taking and data administration platforms has accelerated this drawback. Instruments that combine summarization, perception extraction, and contextual Q&A make studying quicker, however additionally they improve the quantity of delicate information flowing to cloud companies.
Research have proven that AI fashions can unintentionally memorize and reproduce user-provided information, elevating considerations for anybody dealing with proprietary or private analysis. On this article, we discover Open Pocket book, an open-source platform designed to supply AI-assisted note-taking whereas maintaining person information personal.
# Analyzing the Limitations of Cloud-Solely Pocket book Options
Cloud-based AI notebooks, similar to Google NotebookLM, supply comfort and seamless integration, however these advantages include trade-offs. Customers are topic to information lock-in, the place notes, annotations, and context are certain to the supplier’s ecosystem. If you wish to change companies or run a distinct AI mannequin, you face excessive prices or technical boundaries. Vendor dependency additionally limits flexibility — you can’t at all times select your most popular AI mannequin or modify the system to swimsuit particular workflows.
One other concern is the “information tax.” Every bit of delicate info you add to a cloud service carries danger, whether or not from potential breaches, misuse, or unintended mannequin coaching. Unbiased researchers, small groups, and privacy-conscious learners are notably weak, as they can not simply take in the operational or monetary prices related to these dangers.
# Defining Open Pocket book
Open Pocket book is an open-source, AI-powered platform designed to assist customers take, arrange, and work together with notes whereas maintaining full management over their information. Not like cloud-only alternate options, it permits researchers, college students, and professionals to handle their workflows with out exposing delicate info to third-party servers. At its core, Open Pocket book combines AI-assisted summarization, contextual insights, and multimodal content material administration with a privacy-first design, providing a stability between intelligence and management.
The platform targets customers who need extra than simply word storage. It’s superb for studying fans dealing with massive studying backlogs, impartial thinkers looking for a cognitive associate, and professionals who want privateness whereas leveraging synthetic intelligence. By enabling native deployment or self-hosting, Open Pocket book ensures that your notes, PDFs, movies, and analysis information stay fully underneath your management, whereas nonetheless benefiting from AI capabilities.
# Highlighting Core Options That Set Open Pocket book Aside
Open Pocket book goes past conventional note-taking by integrating superior AI instruments immediately into the analysis workflow. The concentrate on self-hosting and information possession immediately addresses considerations about vendor lock-in, privateness publicity, and adaptability limitations inherent in cloud-only options. Researchers and professionals can deploy the platform in minutes and combine it with their most popular AI fashions or utility programming interfaces (APIs), creating a really customizable data surroundings.
AI-Powered Notes: The platform can summarize massive textual content passages, extract insights, and create context-aware notes that adapt to your analysis wants. This helps customers rapidly convert studying materials into actionable data.
Privateness Controls: Each person has full management over which AI fashions work together with their content material. Native deployment ensures that delicate information by no means leaves the machine until explicitly allowed.
Multimodal Content material Integration: Open Pocket book helps PDFs, YouTube movies, TXT, PPT recordsdata, and extra, enabling customers to consolidate various kinds of analysis supplies in a single place.
Podcast Generator: Notes could be reworked into skilled podcasts with customizable voices and speaker configurations, making it straightforward to evaluate and share content material in audio format.
Clever Search & Contextual Chat: The platform performs full-text and vector searches throughout all content material and permits AI-driven Q&A periods, permitting customers to work together with their data base naturally and effectively.
Collectively, these options make Open Pocket book not only a note-taking software however a flexible analysis companion that respects privateness with out sacrificing AI-powered capabilities.
# Evaluating Open Pocket book and NotebookLM
Open Pocket book positions itself as a privacy-first, open-source various to Google NotebookLM. Whereas each platforms supply AI-assisted note-taking and contextual insights, the variations in deployment, flexibility, and information management are important. The desk beneath highlights key contrasts between the 2:
Characteristic
Google NotebookLM
Open Pocket book
Deployment
Cloud-only, proprietary
Self-hosted or native, open-source
Information Privateness
Information saved on Google servers, restricted management
Full management over information, by no means leaves the native surroundings until specified
AI Mannequin Flexibility
Fastened to Google’s fashions
Helps a number of fashions, together with native AI through Ollama
Integration Choices
Restricted to the Google ecosystem
API entry for customized workflows and exterior integrations
Content material Varieties
Textual content and primary notes
PDFs, PPTs, TXT, YouTube movies, audio, and extra
Price
Subscription-based
Free and open-source, zero-cost native deployment
Group Contribution
Closed improvement
Open-source, community-driven roadmap and contributions
Podcast Technology
Not obtainable
Multi-speaker, customizable audio podcasts from notes
# Deploying Open Pocket book
One among Open Pocket book’s greatest benefits is its capability to be deployed rapidly and simply. Not like cloud-only alternate options, it runs domestically or in your server, supplying you with full management over your information from day one. The really helpful deployment technique is Docker, which isolates the applying, simplifies setup, and ensures constant habits throughout programs.
// Docker Deployment Steps
Step 1: Create a listing for Open Pocket book This may retailer all configuration and protracted information.
mkdir open-notebook
cd open-notebook
Step 2: Run the Docker container Execute the next command to begin Open Pocket book:
--name open-notebook names the container for straightforward reference
-p 8502:8502 -p 5055:5055 maps ports for the online interface and API entry
-v ./notebook_data:/app/information and -v ./surreal_data:/mydata mount native folders to persist notes and database recordsdata. This ensures that your information is saved in your machine and stays intact even when the container is restarted
-e OPENAI_API_KEY=your_key permits integration with OpenAI fashions if desired
lfnovo/open_notebook:v1-latest-single specifies the container picture
Step 3: Entry the platform After working the container, navigate to:
// Folder Construction and Persistent Storage
After deployment, you’ll have two important folders in your native listing:
notebook_data: Shops all of your notes, summaries, and AI-processed content material
surreal_data: Comprises the underlying database recordsdata for Open Pocket book’s inner storage
By maintaining these folders in your machine, Open Pocket book ensures information persistence and full management. You possibly can again up, migrate, or examine these recordsdata at any time with out relying on a third-party service.
From creating the listing to accessing the interface, Open Pocket book could be up and working in underneath two minutes. This simplicity makes it accessible to anybody who desires a completely personal, AI-powered pocket book and not using a complicated set up course of.
# Exploring Sensible Use Circumstances
Open Pocket book is designed to assist quite a lot of analysis and studying workflows, making it a flexible software for each people and groups.
For particular person researchers, it offers a centralized platform to handle massive studying backlogs. PDFs, lecture notes, and net articles can all be imported, summarized, and arranged, permitting researchers to rapidly entry insights with out manually sifting via dozens of sources.
Groups can use Open Pocket book as a personal, collaborative data base. With native or server deployment, a number of customers can contribute notes, annotate shared assets, and construct a collective AI-assisted repository whereas maintaining information inner to the group.
For studying fans, Open Pocket book provides AI-assisted note-taking with out compromising privateness. Context-aware chat and summarization options allow learners to have interaction with materials extra successfully, turning massive volumes of content material into digestible insights.
Superior workflows embrace integrating PDFs, net content material, and even producing podcasts from notes. For instance, a researcher may feed in a number of PDFs, extract the important thing findings, and convert them right into a multi-speaker podcast for evaluate or sharing inside a research group, all whereas maintaining content material fully personal.
# Making certain Privateness and Information Possession
Open Pocket book’s structure prioritizes privateness by design. Native deployment implies that notes, databases, and AI interactions are saved on the person’s machine or the group’s server. Customers management which AI fashions work together with their information, whether or not utilizing OpenAI fashions through API, native AI fashions, or any customized integration.
API entry permits seamless workflow integration with out exposing content material to third-party cloud companies. This design ensures that context, insights, and metadata are by no means shared externally until explicitly approved to take action.
Being absolutely open-source underneath the MIT License, Open Pocket book encourages transparency and neighborhood contributions. Builders and researchers can evaluate the code, suggest enhancements, or customise the platform for particular workflows, reinforcing belief and making certain the platform aligns with the person’s privateness expectations.
# Wrapping Up
Open Pocket book represents a viable, privacy-first various to proprietary options like Google NotebookLM. By enabling native deployment, versatile AI integration, and open-source contributions, it empowers customers to keep up full management over their notes, analysis, and workflows.
For builders, researchers, and impartial learners, Open Pocket book is greater than a software; it’s a chance to reclaim management over AI-assisted studying and analysis, discover new methods to handle data, and actively contribute to a platform constructed round privateness, transparency, and neighborhood.
Shittu Olumide is a software program engineer and technical author captivated with leveraging cutting-edge applied sciences to craft compelling narratives, with a eager eye for element and a knack for simplifying complicated ideas. You too can discover Shittu on Twitter.
// The interface is gone (changed by whitespace)
//
//
//
operate transfer(creature) { // ': Animal' and ': string' are stripped
if (creature.winged) {
return `${creature.identify} takes flight.`;
}
return `${creature.identify} walks the trail.`;
}
const bat = { // ': Animal' is stripped
identify: "Bat",
winged: true
};
console.log(transfer(bat));
Node’s --experimental-strip-types flag has impressed adjustments to the TypeScript spec itself, beginning with the brand new erasableSyntaxOnly flag in TypeScript 5.8. Having the experimental flag out there at runtime is one factor, however having it constructed into the language is kind of one other. Let’s contemplate the broader results of this modification.
No extra supply maps
For debugging functions, it’s important that the categories in our instance are changed with whitespace, not simply deleted. That ensures the road numbers will naturally match-up between runtime and compile time. This preservation of whitespace is greater than only a parser trick; it’s a giant win for DX.
For years, TypeScript builders relied on supply maps to translate the JavaScript operating within the browser or server again to the TypeScript supply code of their editor. Whereas supply maps usually work, they’re infamous for being finicky. They’ll break and fail to map variables accurately, resulting in issues the place the road quantity within the stack hint doesn’t match the code in your display.
Microsoft has launched VibeVoice-ASR as a part of the VibeVoice household of open supply frontier voice AI fashions. VibeVoice-ASR is described as a unified speech-to-text mannequin that may deal with 60-minute long-form audio in a single move and output structured transcriptions that encode Who, When, and What, with assist for Custom-made Hotwords.
VibeVoice sits in a single repository that hosts Textual content-to-Speech, actual time TTS, and Computerized Speech Recognition fashions below an MIT license. VibeVoice makes use of steady speech tokenizers that run at 7.5 Hz and a next-token diffusion framework the place a Massive Language Mannequin causes over textual content and dialogue and a diffusion head generates acoustic element. This framework is principally documented for TTS, but it surely defines the general design context through which VibeVoice-ASR lives.
https://huggingface.co/microsoft/VibeVoice-ASR
Lengthy kind ASR with a single international context
Not like typical ASR (Computerized Speech Recognition) methods that first lower audio into brief segments after which run diarization and alignment as separate parts, VibeVoice-ASR is designed to just accept as much as 60 minutes of steady audio enter inside a 64K token size funds. The mannequin retains one international illustration of the total session. This implies the mannequin can keep speaker identification and subject context throughout all the hour as a substitute of resetting each few seconds.
60-minute Single-Move Processing
The first key function is that many typical ASR methods course of lengthy audio by reducing it into brief segments, which may lose international context. VibeVoice-ASR as a substitute takes as much as 60 minutes of steady audio inside a 64K token window so it may well keep constant speaker monitoring and semantic context throughout all the recording.
That is vital for duties like assembly transcription, lectures, and lengthy assist calls. A single move over the entire sequence simplifies the pipeline. There is no such thing as a have to implement customized logic to merge partial hypotheses or restore speaker labels at boundaries between audio chunks.
Custom-made Hotwords for area accuracy
Custom-made Hotwords are the second key function. Customers can present hotwords similar to product names, group names, technical phrases, or background context. The mannequin makes use of these hotwords to information the popularity course of.
This lets you bias decoding towards the proper spelling and pronunciation for area particular tokens with out retraining the mannequin. For instance, a dev-user can move inner undertaking names or buyer particular phrases at inference time. That is helpful when deploying the identical base mannequin throughout a number of merchandise that share comparable acoustic circumstances however very totally different vocabularies.
Microsoft additionally ships a finetuning-asrlisting with LoRA based mostly superb tuning scripts for VibeVoice-ASR. Collectively, hotwords and LoRA superb tuning give a path for each mild weight adaptation and deeper area specialization.
Wealthy Transcription, diarization, and timing
The third function is Wealthy Transcription with Who, When, and What. The mannequin collectively performs ASR, diarization, and timestamping, and returns a structured output that signifies who stated what and when.
See under the three analysis figures named DER, cpWER, and tcpWER.
https://huggingface.co/microsoft/VibeVoice-ASR
DER is Diarization Error Fee, it measures how properly the mannequin assigns speech segments to the proper speaker
cpWER and tcpWER are phrase error price metrics computed below conversational settings
These graphs summarize how properly the mannequin performs on multi speaker lengthy kind knowledge, which is the first goal setting for this ASR system.
The structured output format is properly fitted to downstream processing like speaker particular summarization, motion merchandise extraction, or analytics dashboards. Since segments, audio system, and timestamps already come from a single mannequin, downstream code can deal with the transcript as a time aligned occasion log.
Key Takeaways
VibeVoice-ASR is a unified speech to textual content mannequin that handles 60 minute lengthy kind audio in a single move inside a 64K token context.
The mannequin collectively performs ASR, diarization, and timestamping so it outputs structured transcripts that encode Who, When, and What in a single inference step.
Custom-made Hotwords let customers inject area particular phrases similar to product names or technical jargon to enhance recognition accuracy with out retraining the mannequin.
Analysis with DER, cpWER, and tcpWER focuses on multi speaker conversational eventualities which aligns the mannequin with conferences, lectures, and lengthy calls.
VibeVoice-ASR is launched within the VibeVoice open supply stack below MIT license with official weights, superb tuning scripts, and a web-based Playground for experimentation.
Macworld stories that Apple’s John Ternus has been given expanded duties, now overseeing the corporate’s whole design workforce together with each {hardware} and software program interface teams.
This vital position change positions Ternus because the main candidate to succeed Tim Cook dinner as CEO, as Cook dinner prepares for eventual retirement at age 65.
The transfer comes amid a number of key Apple govt retirements and seems to be a part of Cook dinner’s succession planning technique.
It’s been reported that CEO Tim Cook dinner’s time at Apple is nearing an finish, and Apple is grooming his alternative. Now we have one other clue to who that could be: In a brand new report, Bloomberg’s Mark Gurman mentioned that Apple Senior Vice President John Ternus now manages the corporate’s design groups. The task of latest duties was made by Cook dinner on the finish of final 12 months.
Hypothesis about Cook dinner’s tenure as CEO began to warmth up final 12 months. Cook dinner turns 65 in November, and a number of other stories have said that the gears are in movement to organize for the top of Cook dinner’s run. Gurman has reported that Ternus is the main candidate to interchange Cook dinner, however a change isn’t “imminent.” Nonetheless, his reporting makes it clear that Ternus is a rising star inside Apple Park.
Ternus’ new duties appear to present credence to him being the main CEO candidate. Gurman stories that, in his position as SVP of {hardware} engineering, Ternus had already been working with the corporate’s {hardware} design workforce. However now Ternus is main the group that develops Apple’s software program interfaces.
To additional broaden on the significance of the brand new duties, Gurman posted on X that solely “the very most outstanding figures in Apple historical past” have overseen the entire design workforce. Gurman additionally stories that Cook dinner is “attempting to show Ternus to extra elements of the corporate’s operations.”
Apple’s design workforce has solely ever been overseen by the very most outstanding figures in Apple’s historical past: Jony Ive till 2019, Cook dinner himself briefly between 2015-2017 and former COO Jeff Williams from 2019-2025. Ternus now joins that checklist. https://t.co/hW6zbLcaEH
As a part of the Chinese language spacecraft Shenzhou-15 tumbled again to Earth, its disintegration was tracked by a stunning supply: seismometers.
Seismic networks in southern California picked up floor vibrations induced by shock waves because the spacecraft entered Earth’s ambiance on April 2, 2024. Utilizing that information, scientists have been capable of monitor the trajectory of spacecraft bits extra precisely than counting on current methods to foretell it, the staff stories January 22 in Science. That implies that networks designed to detect earthquakes may also monitor falling area junk — defunct spacecraft or deserted launch {hardware} that may pose dangers to individuals and infrastructure.
As area particles plunges towards Earth, it travels quicker than the velocity of sound, producing shock waves, setting off ripple results under that have been detectable by seismometers. By analyzing the depth of these indicators, in addition to the exact timing once they attain the 127 seismometers within the community, researchers might estimate the particles’ altitude and trajectory. They might even monitor how the spacecraft broke down into a number of items, every one producing their very own cascading shock waves.
House particles is often monitored whereas in orbit utilizing ground-based radar, which may comply with objects as small as about 30 centimeters throughout. However as soon as fragments descend into the higher ambiance, interactions with the air trigger them to interrupt aside, decelerate and alter course in advanced methods. Because of this, predicted reentry paths may be off by a whole lot of kilometers. For Shenzhou-15, seismic information confirmed that it handed about 30 kilometers south of the trajectory predicted by U.S. House Command.
The work was impressed by methods used to trace meteoroids utilizing seismic and acoustic information, each on Earth and Mars. “I labored loads with NASA’s InSight mission, and for us, meteoroids have been truly a really helpful seismic supply,” says Benjamin Fernando, a seismologist and planetary scientist at Johns Hopkins College. InSight put the primary working seismometer on the floor of Mars. “A variety of what we did on this paper is actually taking methods developed for Mars and reapplying them to Earth.”
The precision of the detection is determined by the density of seismometer networks, since sonic booms propagate by way of the ambiance for less than about 100 kilometers. City areas usually have dense protection, however sparsely populated areas in seismically quiet areas don’t. This would possibly restrict the usefulness of the approach at a worldwide scale, says Daniel Stich, a seismologist on the College of Granada in Spain who was not concerned with the research.
Uncontrolled reentries have gotten extra frequent as the variety of spacecraft in orbit grows unchecked. Falling fragments can harm individuals or harm infrastructure, and particles usually incorporates poisonous fuels, flammable supplies or, in uncommon instances, radioactive energy sources. Whereas seismic monitoring is unlikely to supply advance warning, it might assist quickly assess the place particles fell and slender down areas vulnerable to contamination.
The research matches right into a latest pattern often known as environmental seismology, which makes use of seismic information to observe phenomena past earthquakes — from storms and avalanches to explosions, highway visitors throughout COVID or even Taylor Swift live shows, says Jordi Díaz Cusí, a seismologist on the Geosciences Institute of Barcelona who was not concerned with the brand new work. Monitoring the reentry of area particles, he says, “is an effective instance of how seismic information … can be utilized for issues very far faraway from their unique goal.”
I need to estimate, graph, and interpret the results of nonlinear fashions with interactions of steady and discrete variables. The outcomes I’m after will not be trivial, however acquiring what I would like utilizing margins, marginsplot, and factor-variable notation is simple.
Don’t create dummy variables, interplay phrases, or polynomials
Suppose I need to use probit to estimate the parameters of the connection
the place (y) is a binary end result, (d) is a discrete variable that takes on 4 values, (x) is a steady variable, and (P(y|x,d)) is the likelihood of my end result conditional on covariates. To suit this mannequin in Stata, I’d sort
probit y c.x##i.d c.x#c.x
I don’t must create variables for the polynomial or for the interactions between the continual variable (x) and the totally different ranges of (d). Stata understands that c.x#c.x is the sq. of (x) and that c.x##i.d corresponds to the variables (x) and (d) and their interplay. The results of what I typed would appear like this:
I didn’t must create dummy variables, interplay phrases, or polynomials. As we are going to see under, comfort isn’t the one motive to make use of factor-variable notation. Issue-variable notation permits Stata to determine interactions and to differentiate between discrete and steady variables to acquire right marginal results.
This instance used probit, however most of Stata’s estimation instructions permit using issue variables.
Utilizing margins to acquire the results I’m occupied with
I’m occupied with modeling for people the likelihood of being married (married) as a operate of years of education (training), the percentile of revenue distribution to which they belong (percentile), the variety of instances they’ve been divorced (divorce), and whether or not their mother and father are divorced (pdivorce). I estimate the next results:
The typical of the change within the likelihood of being married when every covariate adjustments. In different phrases, the typical marginal impact of every covariate.
The typical of the change within the likelihood of being married when the interplay of divorce and training adjustments. In different phrases, a mean marginal impact of an interplay between a steady and a discrete variable.
The typical of the change within the likelihood of being married when the interplay of divorce and pdivorce adjustments. In different phrases, a mean marginal impact of an interplay between two discrete variables.
The typical of the change within the likelihood of being married when the interplay of percentile and training adjustments. In different phrases, a mean marginal impact of an interplay between two steady variables.
I match the mannequin:
probit married c.training##c.percentile c.training#i.divorce ///
i.pdivorce##i.divorce
The typical of the change within the likelihood of being married when the degrees of the covariates change is given by
. margins, dydx(*)
Common marginal results Variety of obs = 5,000
Mannequin VCE : OIM
Expression : Pr(married), predict()
dy/dx w.r.t. : training percentile 1.divorce 2.divorce 1.pdivorce
----------------------------------------------------------------------------
| Delta-method
| dy/dx Std. Err. z P>|z| [95% Conf. Interval]
-------------+--------------------------------------------------------------
training | .02249 .0023495 9.57 0.000 .017885 .027095
percentile | .9873168 .062047 15.91 0.000 .8657069 1.108927
|
divorce |
1 | -.0434363 .0171552 -2.53 0.011 -.0770598 -.0098128
2 | -.1239932 .054847 -2.26 0.024 -.2314913 -.0164951
|
1.pdivorce | -.0525977 .0131892 -3.99 0.000 -.0784482 -.0267473
----------------------------------------------------------------------------
Observe: dy/dx for issue ranges is the discrete change from the bottom degree.
The primary a part of the margins output states the statistic it will compute, on this case, the typical marginal impact. Subsequent, we see the idea of an Expression. That is normally the default prediction (on this case, the conditional likelihood), however it may be every other prediction out there for the estimator or any operate of the coefficients, as we are going to see shortly.
When margins computes an impact, it distinguishes between steady and discrete variables. That is basic as a result of a marginal impact of a steady variable is a spinoff, whereas a marginal impact of a discrete variable is the change of the Expression evaluated at every worth of the discrete covariate relative to the Expression evaluated on the base or reference degree. This highlights the significance of utilizing factor-variable notation.
I now interpret a few the results. On common, a one-year change in training will increase the likelihood of being married by 0.022. On common, the likelihood of being married is 0.043 smaller within the case the place everybody has been divorced as soon as in contrast with the case the place nobody has ever been divorced, a mean therapy impact of (-)0.043. The typical therapy impact of being divorced two instances is (-)0.124.
Now I estimate the typical marginal impact of an interplay between a steady and a discrete variable. Interactions between steady and discrete variables are adjustments within the steady variable evaluated on the totally different values of the discrete covariate relative to the bottom degree. To acquire these results, I sort
. margins divorce, dydx(training) pwcompare
Pairwise comparisons of common marginal results
Mannequin VCE : OIM
Expression : Pr(married), predict()
dy/dx w.r.t. : training
--------------------------------------------------------------
| Distinction Delta-method Unadjusted
| dy/dx Std. Err. [95% Conf. Interval]
-------------+------------------------------------------------
training |
divorce |
1 vs 0 | .0012968 .0061667 -.0107897 .0133833
2 vs 0 | .0403631 .0195432 .0020591 .0786672
2 vs 1 | .0390664 .0201597 -.0004458 .0785786
--------------------------------------------------------------
The typical marginal impact of training is 0.039 increased when everyone seems to be divorced two instances as an alternative of everybody being divorced one time. The typical marginal impact of training is 0.040 increased when everyone seems to be divorced two instances as an alternative of everybody being divorced zero instances. The typical marginal impact of training is 0 when everyone seems to be divorced one time as an alternative of everybody being divorced zero instances. One other approach of acquiring this result’s by computing a cross or double spinoff. As I discussed earlier than, we use derivatives for steady variables and variations with respect to the bottom degree for the discrete variables. I’ll consult with them loosely as derivatives hereafter. Within the appendix, I present that taking a double spinoff is equal to what I did above.
Analyzing the interplay between two discrete variables is just like analyzing the interplay between a discrete and a steady variable. We need to see the change from the bottom degree of a discrete variable for a change within the base degree of the opposite variable. We use the pwcompare and dydx() choices once more.
. margins pdivorce, dydx(divorce) pwcompare
Pairwise comparisons of common marginal results
Mannequin VCE : OIM
Expression : Pr(married), predict()
dy/dx w.r.t. : 1.divorce 2.divorce
--------------------------------------------------------------
| Distinction Delta-method Unadjusted
| dy/dx Std. Err. [95% Conf. Interval]
-------------+------------------------------------------------
1.divorce |
pdivorce |
1 vs 0 | -.1610815 .0342655 -.2282407 -.0939223
-------------+------------------------------------------------
2.divorce |
pdivorce |
1 vs 0 | -.0201789 .1098784 -.2355367 .1951789
--------------------------------------------------------------
Observe: dy/dx for issue ranges is the discrete change from the
base degree.
The typical change within the likelihood of being married when everyone seems to be as soon as divorced and everybody’s mother and father are divorced, in contrast with the case the place nobody’s mother and father are divorced and nobody is divorced, is a lower of 0.161. The typical change within the likelihood of being married when everyone seems to be twice divorced and everybody’s mother and father are divorced, in contrast with the case the place nobody’s mother and father are divorced and nobody is divorced, is 0. We might have obtained the identical consequence by typing margins divorce, dydx(pdivorce) pwcompare, which once more emphasizes the idea of a cross or double spinoff.
Now I have a look at the typical marginal impact of an interplay between two steady variables.
The Expression is the spinoff of the conditional likelihood with respect to percentile. dydx(training) specifies that I need to estimate the spinoff of this Expression with respect to training. The typical marginal impact within the marginal impact of revenue percentile attributable to a change in training is 0.062.
As a result of margins can solely take first derivatives of expressions, I obtained a cross spinoff by making the expression a spinoff. Within the appendix, I present the equivalence between this technique and writing a cross spinoff. Additionally, I illustrate confirm that your expression for the primary spinoff is right.
Graphing
After margins, we are able to plot the leads to the output desk just by typing marginsplot. marginsplot works with the traditional graphics choices and the Graph Editor. For the primary instance above, as an illustration, I might sort
I added the choice xlabel(, angle(vertical)) to acquire vertical labels for the horizontal axis. The result’s as follows:
Conclusion
I illustrated compute, interpret, and graph marginal results for nonlinear fashions with interactions of discrete and steady variables. To interpret interplay results, I used the ideas of a cross or double spinoff and an Expression. I used simulated information and the probit mannequin for my examples. Nevertheless, what I wrote extends to different nonlinear fashions.
Appendix
To confirm that your expression for the primary spinoff is right, you evaluate it with the statistic computed by margins with the choice dydx(variable). For the instance within the textual content:
generate buyer journeys that seem easy and interesting, however evaluating whether or not these journeys are structurally sound stays difficult for present strategies.
This text introduces Continuity, Deepening, and Development (CDP) — three deterministic, content-structure-based metrics for evaluating multi-step journeys utilizing a predefined taxonomy moderately than stylistic judgment.
Historically, optimizing customer-engagement methods has concerned fine-tuning supply mechanics equivalent to timing, channel, and frequency to attain engagement and enterprise outcomes.
In apply, this meant you educated the mannequin to know guidelines and preferences, equivalent to “Don’t contact clients too usually”,“Consumer Alfa responds higher to telephone calls”, and “Consumer Beta opens emails principally within the night.”
To handle this, you constructed a cool-off matrix to stability timing, channel constraints, and enterprise guidelines to control buyer communication.
To this point, so good. The mechanics of supply are optimized.
At this level, the core problem arises when the LLM generates the journey itself. The problem is not only about channel or timing, however whether or not the sequence of messages kinds a coherent, efficient narrative that meets enterprise aims.
And all of a sudden you understand:
There isn’t a normal metric to find out if an AI-generated journey is coherent, significant, or advances enterprise targets.
What We Count on From a Profitable Buyer Journey
From a enterprise perspective, the sequence of contents per journey step can’t be random: it have to be a guided expertise that feels coherent, strikes the client ahead by significant levels, and deepens the connection over time.
Whereas this instinct is frequent, it is usually supported by customer-engagement analysis. Brodie et al. (2011) describe engagement as “a dynamic, iterative course of” that varies in depth and complexity as worth is co-created over time.
In apply, we consider journey high quality alongside three complementary dimensions:
Continuity — whether or not every message suits the context established by prior interactions.
Deepening — whether or not content material turns into extra particular, related, or personalised moderately than remaining generic.
Development — whether or not the journey advances by levels (e.g., from exploration to motion) with out pointless backtracking.
Why Current LLM Analysis Metrics Fall Quick
If we take a look at normal analysis strategies for LLMs, equivalent to accuracy metrics, similarity metrics, human-evaluation standards, and even LLM-as-a-judge, it turns into clear that none present a dependable, unambiguous strategy to consider buyer journeys generated as multi-step sequences.
Let’s look at what normal buyer journey metrics can and may’t present.
Accuracy Metrics (Perplexity, Cross-Entropy Loss)
These metrics measure confidence degree in predicting the subsequent token given the coaching knowledge. They don’t seize whether or not a generated sequence kinds a coherent or significant journey.
These metrics evaluate the generated end result to a reference textual content. Nevertheless, buyer journeys hardly ever have a single appropriate reference, as they adapt to context, personalization, and prior interactions. Structurally legitimate journeys could differ considerably whereas remaining efficient.
Undoubtedly, semantic similarity has its benefits, and we’ll use cosine similarity, however extra on that later.
Human Analysis (Fluency, Relevance, Coherence)
Human judgment usually outperforms automated metrics in assessing language high quality, however it’s poorly suited to steady journey analysis. It’s costly, suffers from cultural bias and ambiguity, and doesn’t perform as a everlasting a part of the workflow however moderately as a one-time effort to bootstrap a fine-tuning stage.
LLM-as-a-Decide (AI suggestions scoring)
Utilizing LLMs to guage outputs from different LLM methods is a formidable course of.
This strategy tends to focus extra on fashion, readability, and tone moderately than structural analysis.
LLM-as-a-Decide might be utilized in multi-stage use instances, however outcomes are sometimes much less exact as a result of elevated danger of context overload. Moreover, fine-grained analysis scores from this technique are sometimes unreliable. Like human evaluators, LAAJ additionally carries biases and ambiguities.
A Structural Method to Evaluating Buyer Journeys
Finally, the first lacking ingredient in evaluating really useful content material sequences throughout the buyer journey is construction.
Probably the most pure strategy to symbolize content material construction is as a taxonomic tree, a hierarchical mannequin consisting of levels, content material themes, and ranges of element.
As soon as buyer journeys are mapped onto this tree, CDP metrics might be outlined as structural variations:
Continuity: easy motion throughout branches
Deepening: transferring into extra particular nodes
Development: transferring ahead by buyer journey levels
The answer is to symbolize a journey as a path by a hierarchical taxonomy derived from the content material house. As soon as this illustration is established, CDP metrics might be computed deterministically from the trail. The diagram under summarizes your entire pipeline.
Picture created by the creator
Developing the Taxonomy Tree
To judge buyer journeys structurally, we first require a structured illustration of content material. We assemble this illustration as a multi-level taxonomy derived straight from customer-journey textual content utilizing semantic embeddings.
The taxonomy is anchored by a small set of high-level levels (e.g., motivation, buy, supply, possession, and loyalty). Each anchors and journey messages are embedded into the identical semantic vector house, permitting content material to be organized by semantic proximity.
Inside every anchor, messages are grouped into progressively extra particular themes, forming deeper ranges of the taxonomy. Every degree refines the earlier one, capturing growing topical specificity with out counting on handbook labeling.
The result’s a hierarchical construction that teams semantically associated journey messages and gives a steady basis for evaluating how journeys move, deepen, and progress over time.
Mapping Buyer Journeys onto the Taxonomy
As soon as the taxonomy is established, particular person buyer journeys are mapped onto it as ordered sequences of messages. Every step is embedded in the identical semantic house and matched to the closest taxonomy node utilizing cosine similarity.
This mapping converts a temporal sequence of messages right into a path by the taxonomy, enabling the structural evaluation of journey evolution moderately than treating the journey as a flat record of texts.
Defining the CDP Metrics
The CDP framework consists of three complementary metrics: Continuity, Deepening, and Development. Every captures a definite side of journey high quality. We describe these metrics conceptually earlier than defining them formally primarily based on the taxonomy-mapped journey.
Desk 1: Every CDP metric captures a distinct side of journey high quality: coherence, specificity, and development.
Setup and Computation
Earlier than analyzing actual journeys, we make clear two elements of the setup. (1) how journey content material is structurally represented, and (2) how CDP metrics are derived from that construction.
Buyer-journey content material is organized right into a hierarchical taxonomy consisting of anchors (L1 journey levels), thematic heads (L2 subjects), and deeper nodes that symbolize growing specificity:
As soon as a journey is mapped onto this hierarchy, Continuity, Deepening, and Development are computed deterministically from the journey’s path by the tree.
Let a buyer journey be an ordered sequence of steps:
J = (x₁, x₂, …, xₙ)
Every step xᵢ is assigned:
aᵢ — anchor (L1 journey stage)
tᵢ — thematic head (L2 subject), the place tᵢ = 0 means “unknown”
Continuity evaluates whether or not consecutive messages stay contextually and thematically coherent.
For every transition (xᵢ →xᵢ₊₁), a step-level continuity rating cᵢ ∈ [0, 1] is assigned primarily based on taxonomy alignment, with greater weights given to transitions that keep throughout the similar subject or intently associated branches.
Transitions are ranked from strongest to weakest (e.g., similar subject, associated subject, ahead stage transfer, backward transfer), and assigned lowering weights:
1 ≥ α₁ > α₂ > α₃ > α₄ > α₅ > α₆ ≥ 0
The general continuity rating is computed as:
C(J) = (1 / (n − 1)) · Σ cᵢ for i = 1 … n−1
Deepening (D)
Deepening measures whether or not a journey accumulates worth by transferring from common content material towards extra particular or detailed interactions. It’s computed utilizing two complementary parts.
Journey-based deepening captures how depth adjustments alongside the noticed path:
Δᵢᵈᵉᵖᵗʰ = ℓᵢ₊₁ − ℓᵢ, dᵢ = max(Δᵢᵈᵉᵖᵗʰ, 0)
D_journey(J) = (1 / (n − 1)) · Σ dᵢ
Taxonomy-aware deepening measures how deeply a journey explores the precise taxonomy tree, primarily based on the heads it visits. It evaluates how most of the attainable deeper content material objects (kids, sub-children, and so on.) underneath every visited head are later seen throughout the journey.
D_taxonomy(J) = |D_seen(J)| / |D_exist(J)|
The ultimate deepening rating is a weighted mixture:
Making use of CDP Metrics to an Automotive Buyer Journey
To show how structured analysis works on lifelike journeys, we generated an artificial automotive customer-journey dataset masking the primary levels of the client lifecycle.
Picture created by the creator utilizing Excalidraw
Enter Information: Anchors and Journey Content material
The CDP framework makes use of two important inputs: anchors, which outline journey levels, and customer-journey content material, which gives the messages to guage.
Anchors symbolize significant phases within the lifecycle, equivalent to motivation, buy, supply, possession, and loyalty. Every anchor is augmented with a small set of consultant key phrases to floor it semantically. Anchors serve each as reference factors for taxonomy development and because the anticipated directional move used later within the Development metric.
Buyer-journey content material consists of quick, action-oriented CRM-style messages (emails, calls, chats, in-person interactions) with various ranges of specificity and spanning a number of levels. Though this dataset is synthetically generated, anchor data will not be used throughout taxonomy development or CDP scoring.
CJ messages:
Discover fashions that match your life-style and private targets.
Take a digital tour to find key options and trims.
Evaluate physique types to evaluate house, consolation, and utility.
E book a check drive to expertise dealing with and visibility.
Use the wants evaluation to rank must-have options.
Filter fashions by vary, mpg, or towing to slender decisions.
Taxonomy Development Outcomes
Right here, we utilized the taxonomy development course of to the automotive customer-engagement dataset. The determine under reveals the ensuing customer-journey taxonomy, constructed from message content material and anchor semantics.
Every top-level department corresponds to a journeyanchor (L1), which represents main journey levels equivalent to Motivation, Buy, Supply, Possession, and Loyalty.
Deeper ranges (L2, L3+) group messages by thematic similarity and growing specificity.
Taxonomy of Buyer-Journey Messages
What the Taxonomy Reveals
Even on this compact dataset, the taxonomy highlights a number of purposeful patterns:
Early-stage messages cluster round exploration and comparability, progressively narrowing towards concrete actions equivalent to reserving a check drive.
Buy-related content material separates naturally into monetary planning, doc dealing with, and finalization.
Possession content material reveals a transparent development from upkeep scheduling to diagnostics, price estimation, and guarantee analysis.
Loyalty content material shifts from transactional actions towards suggestions, upgrades, and advocacy.
Whereas these patterns align with how practitioners usually motive about journeys, they come up straight from the information moderately than from predefined guidelines.
Why This Issues for Analysis
This taxonomy now gives a shared structural reference:
Any buyer journey might be mapped as a path by the tree.
Motion throughout branches, depth ranges, and anchors turns into measurable.
Continuity, Deepening, and Development are not summary ideas; they now correspond to concrete structural adjustments.
Within the subsequent part, we use this taxonomy to map actual journey examples and compute CDP scores in steps.
Mapping Buyer Journeys onto the Taxonomy
As soon as the taxonomy is constructed, evaluating a buyer journey turns into a structural drawback.
Every journey is represented as an ordered sequence of customer-facing messages.
As a substitute of judging these messages in isolation, we mission them onto the taxonomy and analyze the ensuing path.
Formally, a journey J = (x₁, x₂, …, xₙ) is mapped to a sequence of taxonomy nodes: (x₁→v₁),(x₂→v₂),…,(xₙ→vₙ) the place every vᵢis the closest taxonomy node primarily based on embedding similarity.
A Step-by-Step Walkthrough: From Journey Textual content to CDP Scores
To make the CDP framework concrete, let’s stroll by a single buyer journey instance and present how it’s evaluated step-by-step.
Step 1 — The Buyer Journey Enter
We start with an ordered sequence of customer-facing messages generated by an LLM. Every message represents a touchpoint in a practical automotive buyer journey:
journey = ['Take a virtual tour to discover key features and trims.';
'We found a time slot for a test drive that fits your schedule.';
'Upload your income verification and ID to finalize the pre-approval decision.';
'Estimate costs for upcoming maintenance items.';
'Track retention offers as your lease end nears.';
'Add plates and registration info before handover.']
Step 2 — Mapping the Journey into the Taxonomy
For structural analysis, every journey step is mapped into the customer-journey taxonomy. Utilizing textual content embeddings, every message is matched to its closest taxonomy node. This produces a journey map (jmap), a structured illustration of how the journey traverses the taxonomy.
Desk 2: Every message is assigned to an anchor (stage), a thematic head, and a depth degree within the taxonomy primarily based on semantic similarity within the shared embedding house. This desk acts as the muse for all future evaluations.
Step 3 — Making use of CDP Metrics to This Journey
As soon as the journey is mapped, we compute Continuity, Deepening, and Development deterministically from step-to-step transitions.
Desk 3: Every row represents a transition between consecutive journey steps, annotated with indicators for continuity, deepening, and development.
Ultimate CDP scores (this journey):
Taken collectively, the CDP indicators point out a journey that’s largely coherent and forward-moving, with one clear second of deepening and one seen structural regression. Importantly, these insights are derived solely from construction, not from stylistic judgments in regards to the textual content.
Conclusion: From Scores to Profitable Journeys
Continuity, Deepening, and Development are decided by construction and might be utilized wherever LLMs generate multi-step content material:
to check different journeys generated by completely different prompts or fashions,
to offer automated suggestions for bettering journey era over time.
On this means, CDP scores provide structural suggestions for LLMs. They complement, moderately than change, stylistic or fluency-based analysis by offering indicators that mirror enterprise logic and buyer expertise.
Though this text focuses on automotive commerce, the idea is broadly relevant. Any system that generates ordered, goal-oriented content material requires sturdy structural foundations.
Massive language fashions are already able to producing fluent, persuasive textual content. The higher problem is making certain that textual content sequencestype coherent narratives that align with enterprise logic and consumer expertise.
CDP gives a strategy to make construction specific, measurable, and actionable.
Thanks for staying with me by this journey. Hopefully, this idea helps you assume in another way about evaluating AI-generated sequences and evokes you to deal with construction as a major sign in your personal methods. All logic introduced on this article is applied within the accompanying Python code on GitHub. You probably have any questions or feedback, please depart them within the feedback part or attain out through LinkedIn.
References
Brodie, R. J., et al. (2011). Buyer engagement: Conceptual area, elementary propositions, and implications for analysis.
The speedy progress of huge language fashions (LLMs), multi‑modal architectures and generative AI has created an insatiable demand for compute. NVIDIA’s Blackwell B200 GPU sits on the coronary heart of this new period. Introduced at GTC 2024, this twin‑die accelerator packs 208 billion transistors, 192 GB of HBM3e reminiscence and a 1 TB/s on‑bundle interconnect. It introduces fifth‑era Tensor Cores supporting FP4, FP6 and FP8 precision with two‑instances the throughput of Hopper for dense matrix operations. Mixed with NVLink 5 offering 1.8 TB/s of inter‑GPU bandwidth, the B200 delivers a step change in efficiency—as much as 4× sooner coaching and 30× sooner inference in contrast with H100 for lengthy‑context fashions. Jensen Huang described Blackwell as “the world’s strongest chip”, and early benchmarks present it affords 42 % higher vitality effectivity than its predecessor.
Fast Digest
Key query
AI overview reply
What’s the NVIDIA B200?
The B200 is NVIDIA’s flagship Blackwell GPU with twin chiplets, 208 billion transistors and 192 GB HBM3e reminiscence. It introduces FP4 tensor cores, second‑era Transformer Engine and NVLink 5 interconnect.
Why does it matter for AI?
It delivers 4× sooner coaching and 30× sooner inference vs H100, enabling LLMs with longer context home windows and combination‑of‑specialists (MoE) architectures. Its FP4 precision reduces vitality consumption and reminiscence footprint.
Who wants it?
Anybody constructing or high quality‑tuning giant language fashions, multi‑modal AI, laptop imaginative and prescient, scientific simulations or demanding inference workloads. It’s preferrred for analysis labs, AI corporations and enterprises adopting generative AI.
Tips on how to entry it?
By way of on‑prem servers, GPU clouds and compute platforms akin to Clarifai’s compute orchestration—which affords pay‑as‑you‑go entry, mannequin inference and native runners for constructing AI workflows.
The sections beneath break down the B200’s structure, actual‑world use instances, mannequin suggestions and procurement methods. Every part consists of professional insights summarizing opinions from GPU architects, researchers and trade leaders, and Clarifai ideas on how you can harness the {hardware} successfully.
B200 Structure & Improvements
How does the Blackwell B200 differ from earlier GPUs?
Reply: The B200 makes use of a twin‑chiplet design the place two reticle‑restricted dies are related by a 10 TB/s chip‑to‑chip interconnect. This successfully doubles the compute density inside the SXM5 socket. Its fifth‑era Tensor Cores add help for FP4, a low‑precision format that cuts reminiscence utilization by as much as 3.5× and improves vitality effectivity 25‑50×. Shared Reminiscence clusters supply 228 KB per streaming multiprocessor (SM) with 64 concurrent warps to extend utilization. A second‑era Transformer Engine introduces tensor reminiscence for quick micro‑scheduling, CTA pairs for environment friendly pipelining and a decompression engine to speed up I/O.
Professional Insights:
NVIDIA engineers observe that FP4 triples throughput whereas retaining accuracy for LLM inference; vitality per token drops from 12 J on Hopper to 0.4 J on Blackwell.
Microbenchmark research present the B200 delivers 1.56× greater blended‑precision throughput and 42 % higher vitality effectivity than the H200.
The Subsequent Platform highlights that the B200’s 1.8 TB/s NVLink 5 ports scale practically linearly throughout a number of GPUs, enabling multi‑GPU servers like HGX B200 and GB200 NVL72.
Roadmap commentary notes that future B300 (Blackwell Extremely) GPUs will increase reminiscence to 288 GB HBM3e and ship 50 % extra FP4 efficiency—an necessary signpost for planning deployments.
Structure particulars and new options
The B200’s structure introduces a number of improvements:
Twin‑Chiplet Bundle: Two GPU dies are related by way of a 10 TB/s interconnect, successfully doubling compute density whereas staying inside reticle limits.
208 billion transistors: One of many largest chips ever manufactured.
192 GB HBM3e with 8 TB/s bandwidth: Eight stacks of HBM3e reminiscence ship eight terabytes per second of bandwidth. This bandwidth is crucial for feeding giant matrix multiplications and a focus mechanisms.
fifth‑Technology Tensor Cores: Assist FP4, FP6 and FP8 codecs. FP4 cuts reminiscence utilization by as much as 3.5× and affords 25–50× vitality effectivity enhancements.
NVLink 5: Offers 1.8 TB/s per GPU for peer‑to‑peer communication.
Second‑Technology Transformer Engine: Introduces tensor reminiscence, CTA pairs and decompression engines, enabling dynamic scheduling and decreasing reminiscence entry overhead.
L2 cache and shared reminiscence: Every SM options 228 KB of shared reminiscence and 64 concurrent warps, enhancing thread‑degree parallelism.
Optionally available ray‑tracing cores: Present {hardware} acceleration for 3D rendering when wanted.
Inventive Instance: Think about coaching a 70B‑parameter language mannequin. On Hopper, the mannequin would require a number of GPUs with 80 GB every, saturating reminiscence and incurring heavy recomputation. The B200’s 192 GB HBM3e means the mannequin suits into fewer GPUs. Mixed with FP4 precision, reminiscence footprints drop additional, enabling extra tokens per batch and sooner coaching. This illustrates how structure improvements straight translate to developer productiveness.
Use Instances for NVIDIA B200
What AI workloads profit most from the B200?
Reply: The B200 excels in coaching and high quality‑tuning giant language fashions, reinforcement studying, retrieval‑augmented era (RAG), multi‑modal fashions, and excessive‑efficiency computing (HPC).
Pre‑coaching and high quality‑tuning
Large transformer fashions: The B200 reduces pre‑coaching time by 4× in contrast with H100. Its reminiscence permits lengthy context home windows (e.g., 128k‑tokens) with out offloading.
Positive‑tuning & RLHF: FP4 precision and improved throughput speed up parameter‑environment friendly high quality‑tuning and reinforcement studying from human suggestions. In experiments, B200 delivered 2.2× sooner high quality‑tuning of LLaMA‑70B in contrast with H200.
Inference & RAG
Lengthy‑context inference: The B200’s twin‑die reminiscence allows 30× sooner inference for lengthy context home windows. This hastens chatbots and retrieval‑augmented era duties.
MoE fashions: In combination‑of‑specialists architectures, every professional can run concurrently; NVLink 5 ensures low‑latency routing. A MoE mannequin working on the GB200 NVL72 rack achieved 10× sooner inference and one‑tenth the associated fee per token.
Multi‑modal & laptop imaginative and prescient
Imaginative and prescient transformers (ViT), diffusion fashions and generative video require giant reminiscence and bandwidth. The B200’s 8 TB/s bandwidth retains pipelines saturated.
Ray tracing for 3D generative AI: B200’s optionally available RT cores speed up photorealistic rendering, enabling generative simulation and robotics.
Excessive‑Efficiency Computing (HPC)
Scientific simulation: B200 achieves 90 TFLOPS of FP64 efficiency, making it appropriate for molecular dynamics, local weather modeling and quantum chemistry.
Combined AI/HPC workloads: NVLink and NVSwitch networks create a coherent reminiscence pool throughout GPUs for unified programming.
Professional Insights:
DeepMind & OpenAI researchers have famous that scaling context size requires each reminiscence and bandwidth; the B200’s structure solves reminiscence bottlenecks.
AI cloud suppliers noticed {that a} single B200 can substitute two H100s in lots of inference situations.
Clarifai Perspective
Clarifai’s Reasoning Engine leverages B200 GPUs to run advanced multi‑mannequin pipelines. Prospects can carry out Retrieval‑Augmented Technology by pairing Clarifai’s vector search with B200‑powered LLMs. Clarifai’s compute orchestration robotically assigns B200s for coaching jobs and scales all the way down to price‑environment friendly A100s for inference, maximizing useful resource utilization.
Advisable Fashions & Frameworks for B200
Which fashions greatest exploit B200 capabilities?
Reply: Fashions with giant parameter counts, lengthy context home windows or combination‑of‑specialists architectures achieve probably the most from the B200. Common open‑supply fashions embody LLaMA 3 70B, DeepSeek‑R1, GPT‑OSS 120B, Kimi K2 and Mistral Giant 3. These fashions typically help 128k‑token contexts, require >100 GB of GPU reminiscence and profit from FP4 inference.
DeepSeek‑R1: An MoE language mannequin requiring eight specialists. On B200, DeepSeek‑R1 achieved world‑document inference speeds, delivering 30 ok tokens/s on a DGX system.
Mistral Giant 3 & Kimi K2: MoE fashions that achieved 10× pace‑ups and one‑tenth price per token when run on GB200 NVL72 racks.
LLaMA 3 70B and GPT‑OSS 120B: Dense transformer fashions requiring excessive bandwidth. B200’s FP4 help allows greater batch sizes and throughput.
Imaginative and prescient Transformers: Giant ViT and diffusion fashions (e.g., Secure Diffusion XL) profit from the B200’s reminiscence and ray‑tracing cores.
Which frameworks and libraries ought to I take advantage of?
TensorRT‑LLM & vLLM: These libraries implement speculative decoding, paged consideration and reminiscence optimization. They harness FP4 and FP8 tensor cores to maximise throughput. vLLM runs inference on B200 with low latency, whereas TensorRT‑LLM accelerates excessive‑throughput servers.
SGLang: A declarative language for constructing inference pipelines and performance calling. It integrates with vLLM and B200 for environment friendly RAG workflows.
Open supply libraries: Flash‑Consideration 2, xFormers, and Fused optimizers help B200’s compute patterns.
Clarifai Integration
Clarifai’s Mannequin Zoo consists of pre‑optimized variations of main LLMs that run out‑of‑the‑field on B200. By way of the compute orchestration API, builders can deploy vLLM or SGLang servers backed by B200 or robotically fall again to H100/A100 relying on availability. Clarifai additionally gives serverless containers for customized fashions so you’ll be able to scale inference with out worrying about GPU administration. Native Runners let you high quality‑tune fashions domestically utilizing smaller GPUs after which scale to B200 for full‑scale coaching.
Professional Insights:
Engineers at main AI labs spotlight that libraries like vLLM cut back reminiscence fragmentation and exploit asynchronous streaming, providing as much as 40 % efficiency uplift on B200 in contrast with generic PyTorch pipelines.
Clarifai’s engineers observe that hooking fashions into the Reasoning Engine robotically selects the proper tensor precision, balancing price and accuracy.
Comparability: B200 vs H100, H200 and Opponents
How does B200 evaluate with H100, H200 and competitor GPUs?
The B200 affords probably the most reminiscence, bandwidth and vitality effectivity amongst present Nvidia GPUs, with efficiency benefits even compared with competitor accelerators like AMD MI300X. The desk beneath summarizes the important thing variations.
Metric
H100
H200
B200
AMD MI300X
FP4/FP8 efficiency (dense)
NA / 4.7 PF
4.7 PF
9 PF
~7 PF
Reminiscence
80 GB HBM3
141 GB HBM3e
192 GB HBM3e
192 GB HBM3e
Bandwidth
3.35 TB/s
4.8 TB/s
8 TB/s
5.3 TB/s
NVLink bandwidth per GPU
900 GB/s
1.6 TB/s
1.8 TB/s
N/A
Thermal Design Energy (TDP)
700 W
700 W
1,000 W
700 W
Pricing (cloud price)
~$2.4/hr
~$3.1/hr
~$5.9/hr
~$5.2/hr
Availability (2025)
Widespread
mid‑2024
restricted 2025
out there 2024
Key takeaways:
Reminiscence & bandwidth: The B200’s 192 GB HBM3e and eight TB/s bandwidth dwarfs each H100 and H200. Solely AMD’s MI300X matches reminiscence capability however at decrease bandwidth.
Compute efficiency: FP4 throughput is double the H200 and H100, enabling 4× sooner coaching. Combined precision and FP16/FP8 efficiency additionally scale proportionally.
Power effectivity: FP4 reduces vitality per token by 25–50×; microbenchmark information present 42 % vitality discount vs H200.
Compatibility & software program: H200 is a drop‑in substitute for H100, whereas B200 requires up to date boards and CUDA 12.4+. Clarifai robotically manages these dependencies by means of its orchestration.
Competitor comparability: AMD’s MI300X has comparable reminiscence however decrease FP4 throughput and restricted software program help. Upcoming MI350/MI400 chips could slim the hole, however NVLink and software program ecosystem maintain B200 forward.
Professional Insights:
Analysts observe that B200 pricing is roughly 25 % greater than H200. For price‑constrained duties, H200 could suffice, particularly the place reminiscence moderately than compute is bottlenecked.
Benchmarkers spotlight that B200’s efficiency scales linearly throughout multi‑GPU clusters resulting from NVLink 5 and NVSwitch.
Inventive instance evaluating H200 and B200
Suppose you’re working a chatbot utilizing a 70 B‑parameter mannequin with a 64k‑token context. On an H200, the mannequin barely suits into 141 GB of reminiscence, requiring off‑chip reminiscence paging and leading to 2 tokens per second. On a single B200 with 192 GB reminiscence and FP4 quantization, you course of 60 ok tokens per second. With Clarifai’s compute orchestration, you’ll be able to launch a number of B200 cases and obtain interactive, low‑latency conversations.
Getting Entry to the B200
How will you procure B200 GPUs?
Reply: There are a number of methods to entry B200 {hardware}:
On‑premises servers: Firms can buy HGX B200 or DGX GB200 NVL72 methods. The GB200 NVL72 integrates 72 B200 GPUs with 36 Grace CPUs and affords rack‑scale liquid cooling. Nonetheless, these methods devour 70–80 kW and require specialised cooling infrastructure.
GPU Cloud suppliers: Many GPU cloud platforms supply B200 cases on a pay‑as‑you‑go foundation. Early pricing is round $5.9/hr, although provide is restricted. Anticipate waitlists and quotas resulting from excessive demand.
Compute marketplaces: GPU marketplaces enable brief‑time period leases and per‑minute billing. Think about reserved cases for lengthy coaching runs to safe capability.
Clarifai’s compute orchestration: Clarifai gives B200 entry by means of its platform. Customers join, select a mannequin or add their very own container, and Clarifai orchestrates B200 sources behind the scenes. The platform affords computerized scaling and value optimization—e.g., falling again to H100 or A100 for much less‑demanding inference. Clarifai additionally helps native runners for on‑prem inference so you’ll be able to check fashions domestically earlier than scaling up.
Professional Insights:
Knowledge middle engineers warning that B200’s 1 kW TDP calls for liquid cooling; thus colocation amenities could cost greater charges【640427914440666†L120-L134】.
Cloud suppliers emphasize the significance of GPU quotas; reserving forward and utilizing reserved capability ensures continuity for lengthy coaching jobs.
Clarifai onboarding tip
Signing up with Clarifai is easy:
Create an account and confirm your e mail.
Select Compute Orchestration > Create Job, choose B200 because the GPU kind, and add your coaching script or select a mannequin from Clarifai’s Mannequin Zoo.
Clarifai robotically units acceptable CUDA and cuDNN variations and allocates B200 nodes.
Monitor metrics within the dashboard; you’ll be able to schedule auto‑scale guidelines, e.g., downscale to H100 throughout idle durations.
GPU Choice Information
How must you resolve between B200, H200 and B100?
Reply: Use the next determination framework:
Mannequin dimension & context size: For fashions >70 B parameters or contexts >128k tokens, the B200 is important. In case your fashions slot in <141 GB and context <64k, H200 could suffice. H100 handles fashions <40 B or high quality‑tuning duties.
Latency necessities: When you want sub‑second latency or tokens/sec past 50 ok, select B200. For average latency (10–20 ok tokens/s), H200 gives a great commerce‑off.
Finances issues: Consider price per FLOP. B200 is about 25 % dearer than H200; due to this fact, price‑delicate groups could use H200 for coaching and B200 for inference time‑crucial duties.
Software program & compatibility: B200 requires CUDA 12.4+, whereas H200 runs on CUDA 12.2+. Guarantee your software program stack helps the mandatory kernels. Clarifai’s orchestration abstracts these particulars.
Energy & cooling: B200’s 1 kW TDP calls for correct cooling infrastructure. In case your facility can’t help this, take into account H200 or A100.
Future proofing: In case your roadmap consists of combination‑of‑specialists or generative simulation, B200’s NVLink 5 will ship higher scaling. For smaller workloads, H100/A100 stay price‑efficient.
Professional Insights:
AI researchers typically prototype on A100 or H100 resulting from availability, then migrate to B200 for remaining coaching. Instruments like Clarifai’s simulation let you check reminiscence utilization throughout GPU varieties earlier than committing.
Knowledge middle planners advocate measuring energy draw and including 20 % headroom for cooling when deploying B200 clusters.
Case Research & Actual‑World Examples
How have organizations used the B200 to speed up AI?
DeepSeek‑R1 world‑document inference
DeepSeek‑R1 is a mix‑of‑specialists mannequin with eight specialists. Operating on a DGX with eight B200 GPUs, it achieved 30 ok tokens per second and enabled coaching in half the time of H100. The mannequin leveraged FP4 and NVLink 5 for professional routing, decreasing price per token by 90 %. This efficiency would have been not possible on earlier architectures.
Mistral Giant 3 & Kimi K2
These fashions use dynamic sparsity and lengthy context home windows. Operating on GB200 NVL72 racks, they delivered 10× sooner inference and one‑tenth price per token in contrast with H100 clusters. The combination‑of‑specialists design allowed scaling to fifteen or extra specialists, every mapped to a GPU. The B200’s reminiscence ensured that every professional’s parameters remained native, avoiding cross‑gadget communication.
Scientific simulation
Researchers in local weather modeling used B200 GPUs to run 1 km‑decision world local weather simulations beforehand restricted by reminiscence. The 8 TB/s reminiscence bandwidth allowed them to compute 1,024 time steps per hour, greater than doubling throughput relative to H100. Equally, computational chemists reported a 1.5× discount in time‑to‑resolution for ab‑initio molecular dynamics resulting from elevated FP64 efficiency.
Clarifai buyer success
An e‑commerce firm used Clarifai’s Reasoning Engine to construct a product advice chatbot. By migrating from H100 to B200, the corporate minimize response instances from 2 seconds to 80 milliseconds and diminished GPU hours by 55 % by means of FP4 quantization. Clarifai’s compute orchestration robotically scaled B200 cases throughout visitors spikes and shifted to cheaper A100 nodes throughout off‑peak hours, saving price with out sacrificing high quality.
Inventive instance illustrating energy & cooling
Consider the B200 cluster as an AI furnace. Every GPU attracts 1 kW, equal to a toaster oven. A 72‑GPU rack due to this fact emits roughly 72 kW—like working dozens of ovens in a single room. With out liquid cooling, parts overheat shortly. Clarifai’s hosted options disguise this complexity from builders; they keep liquid‑cooled information facilities, letting you harness B200 energy with out constructing your individual furnace.
Rising Tendencies & Future Outlook
What’s subsequent after the B200?
Reply: The B200 is the primary of the Blackwell household, and NVIDIA’s roadmap consists of B300 (Blackwell Extremely) and future Vera/Rubin GPUs, promising much more reminiscence, bandwidth and compute.
B300 (Blackwell Extremely)
The upcoming B300 boosts per‑GPU reminiscence to 288 GB HBM3e—a 50 % enhance over B200—through the use of twelve‑excessive stacks of DRAM. It additionally gives 50 % extra FP4 efficiency (~15 PFLOPS). Though NVLink bandwidth stays 1.8 TB/s, the additional reminiscence and clock pace enhancements make B300 preferrred for planetary‑scale fashions. Nonetheless, it raises TDP to 1,100 W, demanding much more sturdy cooling.
Future Vera & Rubin GPUs
NVIDIA’s roadmap extends past Blackwell. The “Vera” CPU will double NVLink C2C bandwidth to 1.8 TB/s, and Rubin GPUs (possible 2026–27) will characteristic 288 GB of HBM4 with 13 TB/s bandwidth. The Rubin Extremely GPU could combine 4 chiplets in an SXM8 socket with 100 PFLOPS FP4 efficiency and 1 TB of HBM4E. Rack‑scale VR300 NVL576 methods may ship 3.6 exaflops of FP4 inference and 1.2 exaflops of FP8 coaching. These methods would require 3.6 TB/s NVLink 7 interconnects.
Software program advances
Speculative decoding & cascaded era: New decoding methods like speculative decoding and multi‑stage cascaded fashions minimize inference latency. Libraries like vLLM implement these methods for Blackwell GPUs.
Combination‑of‑Consultants scaling: MoE fashions have gotten mainstream. B200 and future GPUs will help a whole lot of specialists per rack, enabling trillion‑parameter fashions at acceptable price.
Sustainability & Inexperienced AI: Power use stays a priority. FP4 and future FP3/FP2 codecs will cut back energy consumption additional; information facilities are investing in liquid immersion cooling and renewable vitality.
Professional Insights:
The Subsequent Platform emphasizes that B300 and Rubin usually are not simply reminiscence upgrades; they ship proportional will increase in FP4 efficiency and spotlight the necessity for NVLink 6/7 to scale to exascale.
Trade analysts predict that AI chips will drive greater than half of all semiconductor income by the tip of the last decade, underscoring the significance of planning for future architectures.
Clarifai’s roadmap
Clarifai is constructing help for B300 and future GPUs. Their platform robotically adapts to new architectures; when B300 turns into out there, Clarifai customers will take pleasure in bigger context home windows and sooner coaching with out code modifications. The Reasoning Engine may even combine Vera/Rubin chips to speed up multi‑mannequin pipelines.
FAQs
Q1: Can I run my current H100/H200 workflows on a B200?
A: Sure—offered your code makes use of CUDA‑normal APIs. Nonetheless, you will need to improve to CUDA 12.4+ and cuDNN 9. Libraries like PyTorch and TensorFlow already help B200. Clarifai abstracts these necessities by means of its orchestration.
Q2: Does B200 help single‑GPU multi‑occasion GPU (MIG)?
A: No. In contrast to A100, the B200 doesn’t implement MIG partitioning resulting from its twin‑die design. Multi‑tenancy is as an alternative achieved on the rack degree by way of NVSwitch and virtualization.
Q3: What about energy consumption?
A: Every B200 has a 1 kW TDP. You will need to present liquid cooling to keep up secure working temperatures. Clarifai handles this on the information middle degree.
This autumn: The place can I hire B200 GPUs?
A: Specialised GPU clouds, compute marketplaces and Clarifai all supply B200 entry. As a consequence of demand, provide could also be restricted; Clarifai’s reserved tier ensures capability for lengthy‑time period initiatives.
Q5: How does Clarifai’s Reasoning Engine improve B200 utilization?
A: The Reasoning Engine connects LLMs, imaginative and prescient fashions and information sources. It makes use of B200 GPUs to run inference and coaching pipelines, orchestrating compute, reminiscence and duties robotically. This eliminates guide provisioning and ensures fashions run on the optimum GPU kind. It additionally integrates vector search, workflow orchestration and immediate engineering instruments.
Q6: Ought to I look ahead to the B300 earlier than deploying?
A: In case your workloads demand >192 GB of reminiscence or most FP4 efficiency, ready for B300 could also be worthwhile. Nonetheless, the B300’s elevated energy consumption and restricted early provide imply many customers will undertake B200 now and improve later. Clarifai’s platform permits you to transition seamlessly as new GPUs turn out to be out there.
Conclusion
The NVIDIA B200 marks a pivotal step within the evolution of AI {hardware}. Its twin‑chiplet structure, FP4 Tensor Cores and large reminiscence bandwidth ship unprecedented efficiency, enabling 4× sooner coaching and 30× sooner inference in contrast with prior generations. Actual‑world deployments—from DeepSeek‑R1 to Mistral Giant 3 and scientific simulations—showcase tangible productiveness beneficial properties.
Trying forward, the B300 and future Rubin GPUs promise even bigger reminiscence swimming pools and exascale efficiency. Staying present with this {hardware} requires cautious planning round energy, cooling and software program compatibility, however compute orchestration platforms like Clarifai summary a lot of this complexity. By leveraging Clarifai’s Reasoning Engine, builders can concentrate on innovating with fashions moderately than managing infrastructure. With the B200 and its successors, the horizon for generative AI and reasoning engines is increasing sooner than ever.



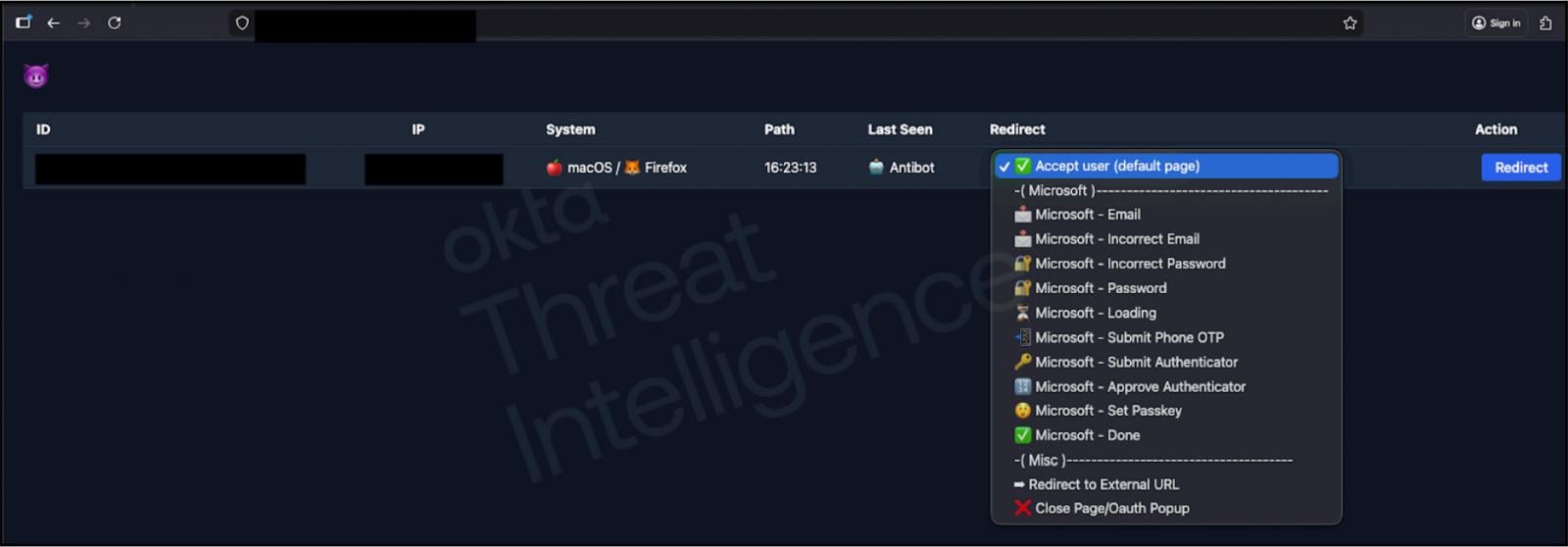


.jpg "Sorry MAGA, Turns Out Folks Nonetheless Like ‘Woke’ Artwork")




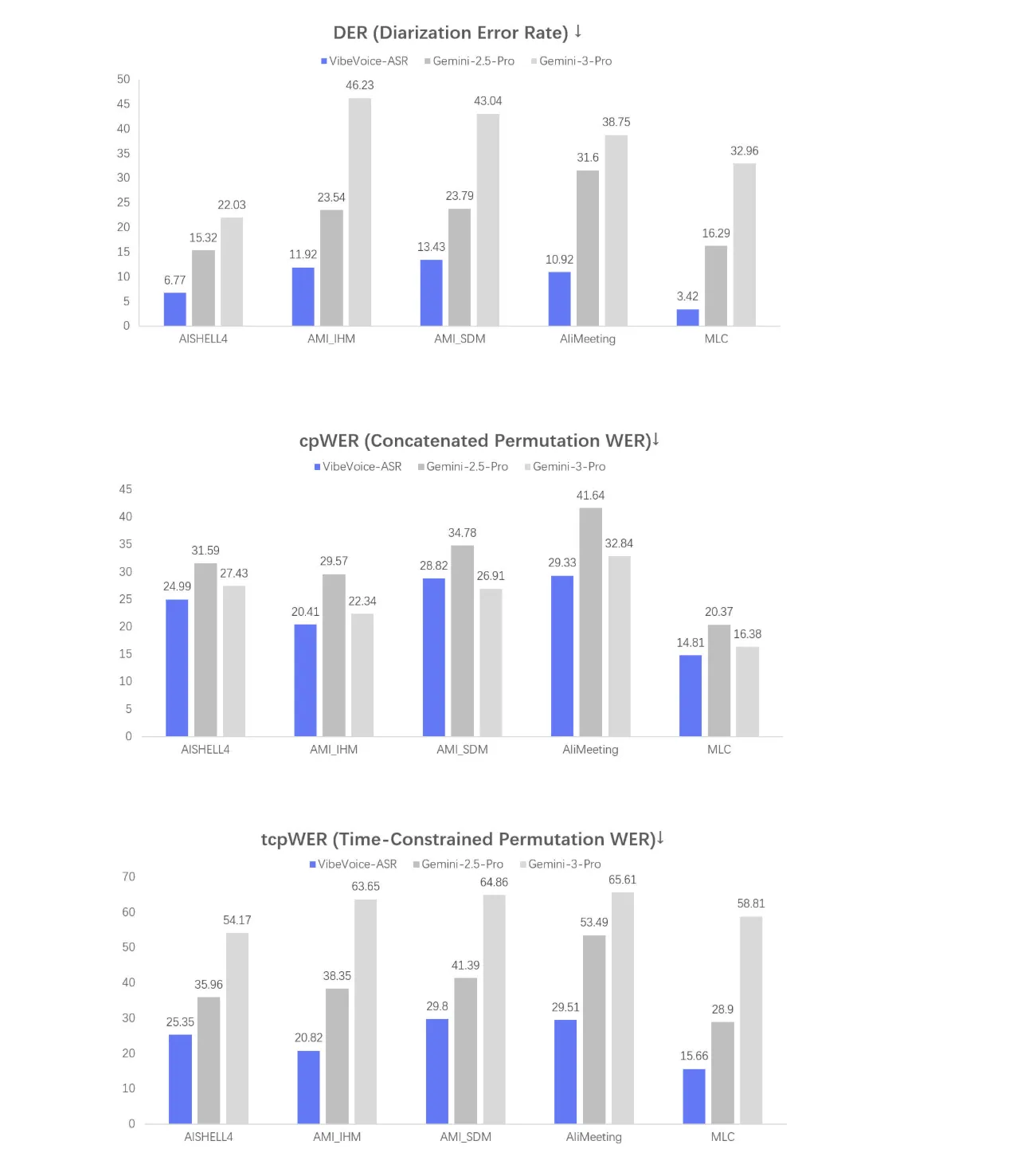








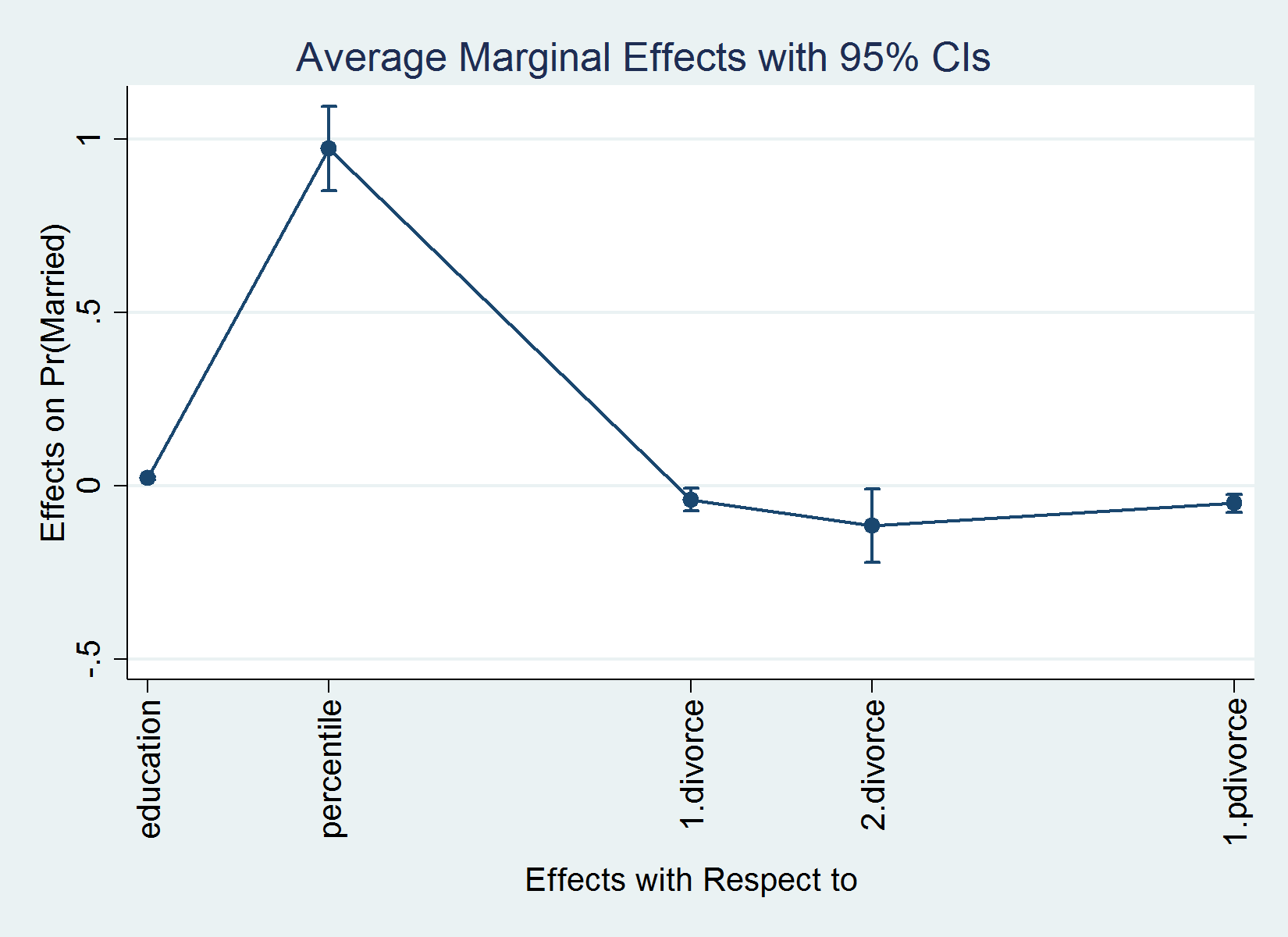{kind=link}