
Picture by Editor
# Introduction
The AI business is experiencing a wave of transformation akin to the dot-com period, and entrepreneurs are speeding to stake their claims on this rising panorama. But not like earlier know-how waves, this one presents a singular attribute: the infrastructure is maturing quicker than the market can soak up it. This hole between technological functionality and sensible implementation defines the present alternative panorama.
Andrei Radulescu-Banu, founding father of DocRouter AI and SigAgent AI, brings a singular perspective to this dialog. With a PhD in arithmetic from the Massachusetts Institute of Expertise (MIT) and many years of engineering expertise, Radulescu-Banu has constructed doc processing platforms powered by giant language fashions (LLMs) and developed monitoring programs for AI brokers, all whereas serving as a fractional chief know-how officer (CTO) serving to startups implement AI options.
His journey from tutorial mathematician to hands-on engineer to AI entrepreneur was not easy. “I’ve accomplished many issues in my profession, however one factor I’ve not accomplished is definitely entrepreneurship,” he explains. “I simply want I had began this once I was, I do not know, out of faculty, really.” Now, he’s making up for misplaced time with an bold purpose of launching six startups in 12 months.
This accelerated timeline displays a broader urgency within the AI entrepreneurship house. When technological shifts create new markets, early movers usually seize disproportionate benefits. The problem lies in shifting shortly with out falling into the lure of constructing know-how searching for an issue.
# The Layering Of The AI Stack
Radulescu-Banu attracts parallels between at present’s AI increase and the web revolution. “Similar to prior to now for laptop networks, [you] had builders of infrastructure, as an instance, laptop switches and routers. And then you definately had software layer software program sitting on high, and then you definately had net purposes. So what’s attention-grabbing is that these layers are forming now for the AI stack.”
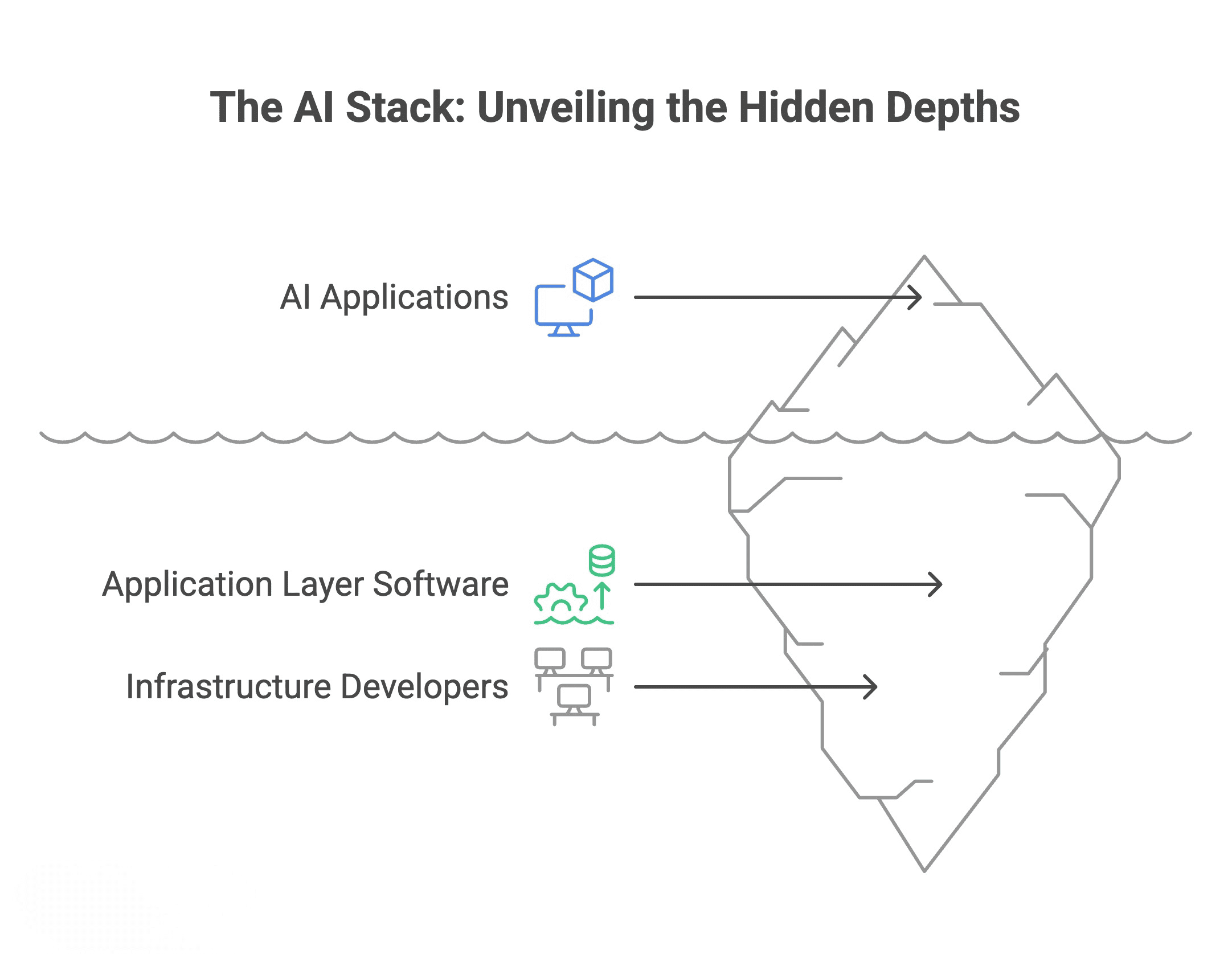
The rising AI stack | Picture by Editor
This stratification issues as a result of totally different layers observe totally different financial fashions and face totally different aggressive dynamics. Infrastructure suppliers have interaction in capital-intensive competitors, racing to construct information facilities and safe GPUs. They need to serve everybody, which implies constructing more and more generic options.
On the basis layer, firms like OpenAI, Anthropic, and Google compete intensely, driving costs down and commoditizing entry to language fashions. “Corporations like OpenAI and Anthropic, they’re virtually compelled to compete with one another and so they can’t specialize to 1 vertical,” Radulescu-Banu observes. “They must develop these generic language fashions that may remedy any drawback on the earth.”
The dynamics on the software layer differ basically. Right here, specialization turns into a bonus slightly than a limitation. Deep understanding of particular industries, workflows, and ache factors issues greater than uncooked computational energy.
The actual alternative, he argues, lies within the software layer. “Corporations that layer on high, the wave is simply starting for that. So I am referring right here to this agentic layer, or issues like vertical purposes which are particular to authorized or to medical or to one thing another business insurance coverage or accounting.” He sees this layer as unsaturated, with room for important development over the following 5 years.
This timeline aligns with historic patterns. Through the dot-com period, infrastructure competitors consolidated shortly whereas application-layer innovation continued for years. The identical sample seems to be rising in AI, creating an extended runway for entrepreneurs targeted on fixing particular business issues.
# From Medical Data To Platform
DocRouter AI emerged from consulting work in an surprising vertical: sturdy medical gear. Radulescu-Banu spent a 12 months and a half serving to a startup course of medical information for oxygen tanks, wheelchairs, and CPAP masks. “All this course of, all this coordination may be very paper heavy. And it is a super floor for language fashions to course of,” he notes.
The sturdy medical gear sector illustrates how AI alternatives usually conceal in unglamorous corners of the economic system. These should not the enticing client purposes that dominate headlines, however they signify substantial markets with actual ache factors and prospects keen to pay for options.
The perception was recognizing that the identical drawback seems throughout industries. “The identical drawback repeats itself in lots of different industries, like for instance, the authorized. And authorized itself has many subsegments, like say you are a regulation agency and it’s essential to evaluation, I do not know, hundreds of paperwork to find one tiny element that’s vital on your case.”
This sample recognition represents an important entrepreneurial talent: seeing the summary drawback beneath particular implementations. Doc-heavy coordination challenges plague authorized discovery, patent analysis, insurance coverage claims processing, and numerous different workflows. Every vertical believes its issues are distinctive, however usually they’re variations on widespread themes.
His strategy illustrates a broader technique: construct reusable know-how. “The concept of DocRouter was to sort of take what labored for one phase of the business and develop a platform that really sits beneath and solves all the identical drawback in different verticals.”
# The Technical Founder Paradox
One may assume technical experience gives a bonus in constructing AI startups. Radulescu-Banu’s expertise suggests in any other case. “It would even be simpler in the event you’re not overly technical,” he says. “Beginning an organization in a sure vertical, it is extra vital to know your prospects and to have an understanding of the place you wish to take the product, than understanding easy methods to construct a product. The product can virtually construct itself.”
This remark challenges assumptions many technically minded individuals maintain about entrepreneurship. The flexibility to architect elegant options or optimize algorithms doesn’t essentially translate to figuring out market alternatives or understanding buyer workflows. The truth is, deep technical data can develop into a legal responsibility when it results in over-engineering or constructing options prospects don’t worth.
He factors to the Boston robotics sector for instance. “There is a bunch of startups that come out of MIT that do robotics. And truly, lots of them wrestle fairly a bit. Why? As a result of they’re began by information scientists and by engineers.” In the meantime, Locus Robotics, began by salespeople who understood warehouse operations, “was much more profitable than the businesses that had been began by engineers.”
The Locus story reveals one thing vital about vertical markets. The salespeople who based it had spent years integrating robotics merchandise from different firms into warehouses. They understood the operational constraints, procurement processes, and precise ache factors that warehouse managers confronted. Technical excellence mattered, nevertheless it was procured slightly than developed in-house initially.
This doesn’t imply technical founders can’t succeed. “Google was began by engineers. And Google was began by PhDs, really,” he acknowledges. “There is not a tough and quick rule, however I believe from my perspective, it is virtually higher to not be an engineer once you begin an organization.”
The excellence might lie in the kind of drawback being solved. Google succeeded by fixing a technical drawback (search high quality) that was universally acknowledged. Vertical AI purposes usually require fixing enterprise course of issues the place the technical answer is only one part.
For Radulescu-Banu, this has meant a private shift. “What I am studying now could be this skill to sort of let a few of the technical issues go and never be overly targeted on the technical issues and be taught to depend on different individuals to do the technical facet.” The temptation to excellent the structure, optimize the code, or discover attention-grabbing technical tangents stays robust for a lot of technical founders, making the transition tougher. However entrepreneurship calls for focusing vitality the place it creates probably the most worth, which frequently means buyer conversations slightly than code optimization.
# Blurring The Consulting-Product Boundary
Entrepreneurs face persistent stress to categorize themselves. “Whenever you begin a dialogue about entrepreneurship, the very first thing you are advised is, are you a product or are you simply doing consulting?” Radulescu-Banu explains. Traders want merchandise as a result of consulting firms “develop linearly” whereas merchandise have “the potential to blow up.”
Nevertheless, he has found a center path. “Truly there is not sort of a straight boundary between consulting and product. You can also make it fuzzy and you may play each side.” His philosophy facilities on effectivity: “I am an advocate of by no means losing work. So every time I do one thing, I wish to ensure that I’ll use it two, thrice.”
DocRouter AI exists as each a product and a consulting device. SigAgent AI, his agent monitoring platform, shares infrastructure with DocRouter. “Sigagent is mainly 90% the identical as DocRouter, however the infrastructure is similar, the database is similar. The know-how is similar, however what’s totally different is the applying layer.” This strategy permits consulting to bootstrap product growth whereas constructing reusable platforms that serve a number of functions.
# The Maturation Of AI Reliability
The technical panorama has shifted dramatically in only one 12 months. “In the event you roll the clock again perhaps one 12 months, language fashions weren’t working that nicely. , that they had hallucinations,” Radulescu-Banu recollects. “What occurred prior to now 12 months is that the language fashions have developed to be much more exact and to hallucinate quite a bit much less.”
This fast enchancment has important implications for manufacturing AI programs. Issues that appeared intractable or dangerous twelve months in the past now have, by comparability, extra dependable options. The tempo of progress signifies that firms suspending AI adoption as a consequence of reliability considerations might discover themselves more and more behind rivals who moved earlier.
The problem has developed. “In the event you give the appropriate context to a language mannequin, you might be fairly sure that you’ll get the appropriate consequence. In order that half has been de-risked, and now it is develop into a context engineering drawback. However that does not make it any simpler as a result of it is really very difficult to provide the language mannequin precisely the piece that it wants to resolve the issue. Nothing extra, nothing much less.”
Context engineering represents a brand new class of technical problem. It combines components of knowledge structure, immediate engineering, and system design. Success requires understanding each the area (what info issues) and the mannequin’s capabilities (easy methods to construction that info for optimum outcomes). This rising self-discipline will seemingly develop into a specialised talent set as AI purposes mature.
Regulatory considerations, usually cited as obstacles to AI adoption, are primarily procedural slightly than technical. For healthcare, “you sort of cope with it with course of. You be sure you have the appropriate course of in place, you have got the appropriate auditors in place. You observe the foundations, and it may possibly all be accomplished.” These frameworks, he suggests, can really information firms towards constructing programs appropriately.
The regulatory panorama, whereas complicated, affords construction slightly than reassurance. Frameworks such because the Well being Insurance coverage Portability and Accountability Act (HIPAA), System and Group Controls (SOC) 2, Cost Card Business Information Safety Customary (PCI DSS), and monetary rules enforced by our bodies just like the Securities and Alternate Fee (SEC) and Monetary Business Regulatory Authority (FINRA) impose clear necessities, however in addition they spotlight how poorly suited many AI programs are for high-risk, regulated environments. Constructing towards these requirements from the outset is dear and constraining, and retrofitting compliance later is commonly much more troublesome, significantly as fashions evolve in opaque methods.
# The Adoption Hole
Regardless of technological readiness, industries lag in implementation. “We have all these great know-how that’s accessible, however the business shouldn’t be fast sufficient to soak up and implement every little thing that’s doable,” Radulescu-Banu observes.
The issue manifests as each a abilities scarcity and a belief deficit. “I believe what’s lacking is individuals do not belief brokers and do not belief that they will remedy issues with brokers. And the know-how has developed and it is able to do it.” He sees this repeatedly in consulting: “You be part of firms that want this work and on this firm, you see two or three engineers which are prepared to do that and so they’re studying how to do that. However the firm has 50, 100 engineers.”
This talent distribution displays how new applied sciences diffuse by way of organizations. Early adopters experiment and construct experience, however scaling requires broader organizational functionality. Corporations face a chicken-and-egg drawback: they can not absolutely decide to AI transformation with out expert groups, however constructing these abilities requires hands-on expertise with actual initiatives.
Fashionable growth instruments like Cursor, Claude Code, and GitHub Copilot can be found, however adoption faces resistance. “Some firms are anxious and they’d say, however now AI goes to see all this supply code, what are we going to do? Nicely, guess what? Now AI can rewrite all of the supply code just about in a few nights with the appropriate engineering.”
# Studying Entrepreneurship
With out co-founders or entrepreneurial colleagues, Radulescu-Banu needed to discover various studying paths. “Whenever you’re an entrepreneur, you do not have different colleagues who’re entrepreneurs who work with you. So how do you meet these individuals? Nicely, so it seems what you do is you go to those meetups and also you, once more, look over their shoulder and ask questions.”
This studying path differs basically from how most professionals develop experience. In conventional employment, studying occurs organically by way of each day interplay with colleagues. Entrepreneurship requires extra deliberate networking and knowledge-seeking. The meetup circuit turns into a substitute office for exchanging concepts and studying from others’ experiences.
The entrepreneurial neighborhood proved surprisingly supportive. “Normally entrepreneurs are very open about what they do, and so they like to assist different entrepreneurs. That is an attention-grabbing factor that they are very supportive of one another.” This allowed him to be taught entrepreneurship “on the job additionally identical to I realized engineering. It is simply that you do not be taught it doing all of your work, however you be taught it by assembly individuals and asking them how they do it.”
This openness contrasts with the aggressive dynamics one may count on. Maybe entrepreneurs acknowledge that success relies upon extra on execution than on secret data. Or maybe the act of explaining one’s strategy to others helps make clear considering and determine blind spots. Regardless of the mechanism, this knowledge-sharing tradition accelerates studying for newcomers keen to have interaction with the neighborhood.
# Regional Dynamics
Boston presents a puzzle for AI entrepreneurs. Town boasts world-class universities and distinctive expertise, but one thing doesn’t fairly click on. “Boston is peculiar in that it is obtained these nice faculties and it is obtained these individuals with nice abilities, however one way or the other, the funding equipment would not work the identical as in, as an instance, San Francisco or New York Metropolis.”
This remark factors to delicate however vital variations in startup ecosystems. Boston produces distinctive technical expertise and has robust tutorial establishments, however the enterprise capital tradition, threat tolerance, and community results differ from Silicon Valley. These variations have an effect on every little thing from fundraising to expertise recruitment to exit alternatives.
Understanding these regional variations issues for anybody constructing a startup exterior Silicon Valley. The challenges are actual, however so are the alternatives for many who can navigate the native ecosystem successfully. Boston’s strengths in biotech, robotics, and enterprise software program recommend that sure varieties of AI purposes might discover extra pure traction than others.
Among the hole might mirror totally different definitions of success. Silicon Valley enterprise capital optimizes for large exits and tolerates excessive failure charges. Boston’s funding neighborhood, formed partly by the area’s biotech business, might favor totally different risk-reward profiles. Neither strategy is inherently superior, however understanding these cultural variations helps entrepreneurs set acceptable expectations and techniques.
// The Mindset Shift
Maybe probably the most important transformation in Radulescu-Banu’s journey includes how he thinks about threat and alternative. Reflecting on his years as an worker, he recollects a restrictive mindset: “I used to be very loath to get facet gigs. Perhaps that was the largest mistake once I was an engineer. I used to be considering, oh, my God, I am working at this place, meaning I am virtually obligated to each second of my life, even at evening, at 8, 9, 10 p.m., to not contribute to anything.”
This mindset displays a way of loyalty or obligation to employers, mixed with concern of conflicts of curiosity, which prevents exploration of facet initiatives or entrepreneurial experiments. But many employment agreements allow facet work that doesn’t compete instantly or use firm assets.
Entrepreneurship has modified that. “I’ve began doing threat in a different way than earlier than. I’d not consider sort of pushing the envelope in a sure means, by way of product concepts, or by way of saying, why do not we simply do issues utterly totally different and go after this different factor?”
He has noticed this sample in profitable entrepreneurs. “I’ve seen different very profitable individuals who have this mentality that they are a little bit of a hustler, in an excellent sense, in a way that, , do that, strive that, , if the door is closed, get by way of the window.”
The hustler mentality intends to mirror resourcefulness, persistence, and willingness to strive unconventional approaches. When conventional paths are blocked, entrepreneurs discover alternate options slightly than accepting defeat. This high quality of adaptability might be influential in rising markets the place established playbooks don’t exist but.
# Trying Forward
The chance in AI purposes stays substantial, however timing issues. “This wave of AI coming may be very attention-grabbing. We’re at the start of the wave,” Radulescu-Banu notes. The frenzy to construct AI firms mirrors the dot-com period, full with the danger of a bubble. However not like the dot-com crash, “we’re nonetheless going to be rising” within the software layer for years to return.
Historic parallels present each encouragement and warning. The dot-com bubble produced lasting firms like Amazon, Google, and eBay alongside numerous failures. The important thing distinction lay in fixing actual issues with sustainable enterprise fashions slightly than merely driving hype. The identical sample might repeat with AI, rewarding firms that create real worth and fewer so for others.
For aspiring AI entrepreneurs, his message is evident: the know-how is prepared, the market is forming, and the adoption hole represents alternative slightly than impediment. The problem lies in balancing technical functionality with market understanding, constructing effectively by way of reusable platforms, and shifting shortly whereas industries are nonetheless studying what AI can do.
“I believe that is the place the chance is,” he concludes, talking of the agentic software layer. For these keen to navigate the complexity of consulting-product hybrids, regulatory necessities, and regional funding ecosystems, the following 5 years promise important development.
For these with the appropriate mixture of technical understanding, market perception, and willingness to be taught, the present second affords alternatives that will not persist as soon as industries absolutely soak up what’s already doable. For them, the query shouldn’t be whether or not to take part within the AI wave, however how shortly entrepreneurs can place themselves to journey it successfully.
Rachel Kuznetsov has a Grasp’s in Enterprise Analytics and thrives on tackling complicated information puzzles and looking for recent challenges to tackle. She’s dedicated to creating intricate information science ideas simpler to grasp and is exploring the assorted methods AI makes an influence on our lives. On her steady quest to be taught and develop, she paperwork her journey so others can be taught alongside her. You could find her on LinkedIn.
















00.jpg){kind=link}