mall makes use of Massive Language Fashions (LLM) to run
Pure Language Processing (NLP) operations towards your knowledge. This bundle
is accessible for each R, and Python. Model 0.2.0 has been launched to CRAN and PyPi respectively.
In R, you may set up the most recent model with:
In Python, with:
This launch expands the variety of LLM suppliers you should use with mall. Additionally,
in Python it introduces the choice to run the NLP operations over string vectors,
and in R, it permits assist for ‘parallelized’ requests.
It’s also very thrilling to announce a model new cheatsheet for this bundle. It
is accessible in print (PDF) and HTML format!
Extra LLM suppliers
The most important spotlight of this launch is the the flexibility to make use of exterior LLM
suppliers corresponding to OpenAI, Gemini
and Anthropic. As a substitute of writing integration for
every supplier one after the other, mall makes use of specialised integration packages to behave as
intermediates.
In R, mall makes use of the ellmer bundle
to combine with quite a lot of LLM suppliers.
To entry the brand new characteristic, first create a chat connection, after which move that
connection to llm_use(). Right here is an instance of connecting and utilizing OpenAI:
In Python, mall makes use of chatlas as
the combination level with the LLM. chatlas additionally integrates with a number of LLM suppliers.
To make use of, first instantiate a chatlas chat connection class, after which move that
to the Polars knowledge body by way of the .llm.use() perform:
Connecting mall to exterior LLM suppliers introduces a consideration of value.
Most suppliers cost for the usage of their API, so there’s a potential {that a}
massive desk, with lengthy texts, might be an costly operation.
Parallel requests (R solely)
A brand new characteristic launched in ellmer 0.3.0
permits the entry to submit a number of prompts in parallel, slightly than in sequence.
This makes it sooner, and probably cheaper, to course of a desk. If the supplier
helps this characteristic, ellmer is ready to leverage it by way of the parallel_chat()
perform. Gemini and OpenAI assist the characteristic.
Within the new launch of mall, the combination with ellmer has been specifically
written to benefit from parallel chat. The internals have been re-written to
submit the NLP-specific directions as a system message so as
cut back the scale of every immediate. Moreover, the cache system has additionally been
re-tooled to assist batched requests.
NLP operations and not using a desk
Since its preliminary model, mall has offered the flexibility for R customers to carry out
the NLP operations over a string vector, in different phrases, without having a desk.
Beginning with the brand new launch, mall additionally gives this similar performance
in its Python model.
mall can course of vectors contained in a record object. To make use of, initialize a
new LLMVec class object with both an Ollama mannequin, or a chatlasChat
object, after which entry the identical NLP features because the Polars extension.
# Initialize a Chat objectfrom chatlas import ChatOllamachat = ChatOllama(mannequin ="llama3.2")# Move it to a brand new LLMVecfrom mall import LLMVecllm = LLMVec(chat)
Entry the features by way of the brand new LLMVec object, and move the textual content to be processed.
llm.sentiment(["I am happy", "I am sad"])#> ['positive', 'negative']llm.translate(["Este es el mejor dia!"], "english")#> ['This is the best day!']
For extra data go to the reference web page: LLMVec
New cheatsheet
The model new official cheatsheet is now out there from Posit: Pure Language processing utilizing LLMs in R/Python.
Its imply characteristic is that one aspect of the web page is devoted to the R model,
and the opposite aspect of the web page to the Python model.
An net web page model can be availabe within the official cheatsheet website right here. It takes
benefit of the tab characteristic that lets you choose between R and Python
explanations and examples.
I wrote a weblog submit in 2023 titled A Stata command to run ChatGPT, and it stays in style. Sadly, OpenAI has modified the API code, and the chatgpt command in that submit now not runs. On this submit, I’ll present you methods to replace the API code and methods to write related Stata instructions that use Claude, Gemini, and Grok like this:
. chatgpt "Write a haiku about Stata."
Knowledge flows with ease,
Stata charts the silent truths,
Insights bloom in code.
. claude "Write a haiku about Stata."
Here's a haiku about Stata:
Stata, my previous buddy
Analyzing knowledge with ease
Insights ever discovered
. gemini "Write a haiku about Stata."
Instructions stream so quick,
Knowledge formed, fashions outlined,
Insights now seem.
. grok "Write a haiku about Stata."
Knowledge streams unfold,
Stata weaves the threads of fact,
Insights bloom in code.
The main focus of this submit, just like the earlier one, is to display how simple it’s to make the most of the PyStata options to hook up with ChatGPT and different AI instruments moderately than to provide recommendation on methods to use AI instruments to reply Stata-specific questions. Subsequently, the examples I present merely ask for a haiku about Stata. Nonetheless, you may cross any request that you’d discover useful in your Stata workflow.
Evaluate of Stata/Python integration
I’ll assume that you’re acquainted with Stata/Python integration and methods to write the unique chatgpt command. It would be best to learn the weblog posts under if these subjects are unfamiliar.
Updating the ChatGPT command
You will want an Open AI person account and your personal Open AI API key to make use of the code under. I used to be unable to make use of my previous API key from 2023, and I needed to create a brand new key.
Additionally, you will have to sort shell pip set up openai within the Stata Command window to set up the Python bundleopenai. It’s possible you’ll want to make use of a special technique to put in the openai bundle if you’re utilizing Python as a part of a platform reminiscent of Anaconda. I needed to sort shell pip uninstall openai to take away the previous model and sort shell pip set up openai to put in the newer model.
Subsequent we might want to exchange the previous Python code with newer code utilizing the trendy API syntax. I typed python operate to immediate chatgpt by way of api right into a search engine that led me to the Developer quickstart web page on the OpenAI web site. Some studying adopted by trial and error resulted within the Python code under. The Python operate query_openai() sends the immediate by way of the API, makes use of the “gpt-4.1-mini” mannequin, and receives the response. I didn’t embody any choices for different fashions, however you may change the mannequin should you like.
The remaining Python code does three issues with the response. First, it prints the response in Stata’s Outcomes window. Second, it writes the response to a file named chatgpt_output.txt. And third, it makes use of Stata’s SFI module to cross the response from Python to a neighborhood macro in Stata. The third step works effectively for easy responses, however it might result in errors for lengthy responses that embody nonstandard characters or many single or double quotations. You may place a # character at the start of the road “Macro.setLocal(…” to remark out that line and forestall the error.
It can save you the code under to a file named chatgpt.ado, place the file in your private ado-folder, and use it like another Stata command. You may sort adopath to find your private ado-folder.
seize program drop chatgpt program chatgpt, rclass model 19.5 // (or model 19 should you shouldn't have StataNow) args InputText show "" python: query_openai("`InputText'", "gpt-4.1-mini") return native OutputText = `"`OutputText'"' finish
python: import os from openai import OpenAI from sfi import Macro
def query_openai(immediate: str, mannequin: str = "gpt-4.1-mini") -> str: # Move the enter string from a Stata native macro to Python inputtext = Macro.getLocal('InputText')
# Ship the immediate by way of the API and obtain the response response = consumer.chat.completions.create( mannequin= mannequin, messages=[ {“role”: “user”, “content”: inputtext} ] )
# Print the response within the Outcomes window print(response.selections[0].message.content material)
# Write the response to a textual content file f = open(“chatgpt_output.txt”, “w”) f.write(response.selections[0].message.content material) f.shut()
# Move the response string from Python again to a Stata native macro Macro.setLocal(“OutputText”, response.selections[0].message.content material) finish
Now we will run our chatgpt command and look at the response within the Outcomes window.
. chatgpt "Write a haiku about Stata."
Knowledge flows with ease,
Stata charts the silent truths,
Insights bloom in code.
We will sort return checklist to view the response saved within the native macro r(OutputText).
. return checklist
macros:
r(OutputText) : "Knowledge flows with ease, Stata charts the silent truths, Insights bloom .."
And we will sort sort chatgpt_output.txt to view the response saved within the file chatgpt_output.txt.
. sort chatgpt_output.txt
Knowledge flows with ease,
Stata charts the silent truths,
Insights bloom in code.
It labored! Let’s see whether or not we will use an analogous technique to create a Stata command for one more AI mannequin.
A Stata command to make use of Claude
Claude is a well-liked AI mannequin developed by Anthropic. Claude contains an API interface, and you will have to arrange a person account and get an API key on its web site. After buying my API key, I typed python operate to question claude api, which led me to the Get began with Claude web site. Once more, some studying and trial and error led to the Python code under. You will want to sort shell pip set up anthropic in Stata’s Command window to put in the anthropic bundle.
Discover how related the Python code under is to the Python code in our chatgpt command. The one main distinction is the code that sends the immediate by way of the API and receives the response. Every little thing else is sort of similar.
It can save you the code under to a file named claude.ado, put the file in your private ado-folder, and use it similar to another Stata command.
seize program drop claude program claude, rclass model 19.5 // (or model 19 should you shouldn't have StataNow) args InputText show "" python: query_claude() return native OutputText = `"`OutputText'"' finish
python: import os from sfi import Macro from anthropic import Anthropic
def query_claude(): # Move the enter string from a Stata native macro to Python inputtext = Macro.getLocal('InputText')
# Ship the immediate by way of the API and obtain the response response = consumer.messages.create( mannequin=”claude-3-haiku-20240307″, max_tokens=1000, messages=[ {“role”: “user”, “content”: inputtext} ] )
# Print the response to the Outcomes window print(response.content material[0].textual content)
# Write the response to a textual content file f = open(“claude_output.txt”, “w”) f.write(response.content material[0].textual content) f.shut()
# Move the response string from Python again to a Stata native macro Macro.setLocal(“OutputText”, response.content material[0].textual content)
finish
Now we will run our claude command and look at the response.
. claude "Write a haiku about Stata."
Here's a haiku about Stata:
Stata, my previous buddy
Analyzing knowledge with ease
Insights ever discovered
We will sort return checklist to view the response saved within the native macro r(OutputText).
. return checklist
macros:
r(OutputText) : "Here's a haiku about Stata: Stata, my previous buddy Analyzing knowledge with ea.."
And we will sort sort claude_output.txt to view the response saved within the file claude_output.txt.
. sort claude_output.txt
Here's a haiku about Stata:
Stata, my previous buddy
Analyzing knowledge with ease
Insights ever discovered
It’s possible you’ll typically see an error just like the one under. This doesn’t point out an issue along with your code. It’s telling you that the API service or community has timed out or has been interrupted. Merely wait and check out once more.
File "C:UsersChuckStataAppDataLocalProgramsPythonPython313Libsite-packagesanthropic
> _base_client.py", line 1065, in request
elevate APITimeoutError(request=request) from err
anthropic.APITimeoutError: Request timed out or interrupted. This may very well be as a result of a community timeout,
> dropped connection, or request cancellation. See https://docs.anthropic.com/en/api/errors#long-requests
> for extra particulars.r(7102);
A Stata command to make use of Gemini
Gemini is a well-liked AI mannequin developed by Google. Gemini additionally contains an API interface and you will have to arrange a person account and get an API key on its web site. After buying my API key, I typed python operate to question gemini api, which led me to the Gemini API quickstart web site. Once more, some studying and trial and error led to the Python code under. You will want to sort shell pip set up -q -U google-genai in Stata’s Command window to put in the google-genai bundle.
Once more, it can save you the code under to a file named gemini.ado, put the file in your private ado-folder, and use it similar to another Stata command.
seize program drop gemini program gemini, rclass model 19.5 // (or model 19 should you shouldn't have StataNow) args InputText show "" python: query_gemini() return native OutputText = `"`OutputText'"' finish
python: import os from sfi import Macro from google import genai
def query_gemini(): # Move the enter string from a Stata native macro to Python inputtext = Macro.getLocal('InputText')
# Ship immediate by way of the claude API key and get response response = consumer.fashions.generate_content( mannequin=”gemini-2.5-flash”, contents=inputtext )
# Print the response to the Outcomes window print(response.textual content)
# Write the response to a textual content file f = open(“gemini_output.txt”, “w”) f.write(response.textual content) f.shut()
# Move the response string from Python again to a Stata native macro Macro.setLocal(“OutputText”, response.textual content) finish
Now we will run our gemini command and look at the response.
. gemini "Write a haiku about Stata."
Instructions stream so quick,
Knowledge formed, fashions outlined,
Insights now seem.
We will sort return checklist to view the response saved within the native macro r(OutputText).
. return checklist
macros:
r(OutputText) : "Instructions stream so quick, Knowledge formed, fashions outlined, Insights now appea.."
And we will sort sort gemini_output.txt to view the response saved within the file gemini_output.txt.
. sort gemini_output.txt
Instructions stream so quick,
Knowledge formed, fashions outlined,
Insights now seem.
A Stata command to make use of Grok
OK, another only for enjoyable. Grok is one other in style AI mannequin developed by xAI. You will want to arrange a person account and get an API key on its web site. After buying my API key, I typed python operate to question grok api, which led me to the Hitchhiker’s Information to Grok web site. Once more, some studying and trial and error led to the Python code under. You will want to sort shell pip set up xai_sdk in Stata’s Command window to put in the xai_sdk bundle.
As soon as once more, it can save you the code under to a file named grok.ado, put the file in your private ado-folder, and use it similar to another Stata command.
seize program drop grok program grok, rclass model 19.5 // (or model 19 should you shouldn't have StataNow) args InputText show "" python: query_grok("`InputText'", "grok-4") return native OutputText = `"`OutputText'"' finish
python: import os from sfi import Macro from xai_sdk import Consumer from xai_sdk.chat import person, system
def query_grok(immediate: str, mannequin: str = "grok-4") -> str: # Move the enter string from a Stata native macro to Python inputtext = Macro.getLocal('InputText')
# Ship immediate by way of the claude API key and get response chat = consumer.chat.create(mannequin=mannequin) chat.append(person(inputtext)) response = chat.pattern()
# Print the response to the Outcomes window print(response.content material)
# Write the response to a textual content file f = open(“grok_output.txt”, “w”) f.write(response.content material) f.shut()
# Move the response string from Python again to a Stata native macro Macro.setLocal(“OutputText”, response.content material) finish
Now we will run our grok command and look at the response within the Outcomes window.
. grok "Write a haiku about Stata."
Knowledge streams unfold,
Stata weaves the threads of fact,
Insights bloom in code.
We will sort return checklist to view the reply saved within the native macro r(OutputText).
. return checklist
macros:
r(OutputText) : "Knowledge streams unfold, Stata weaves the threads of fact, Insights b.."
And we will sort sort grok_output.txt to view the leads to the file grok_output.txt.
. sort grok_output.txt
Knowledge streams unfold,
Stata weaves the threads of fact,
Insights bloom in code.
Conclusion
I hope the examples above have satisfied you that it’s comparatively simple to write down and replace your personal Stata instructions to run AI fashions. My examples have been deliberately easy and just for instructional functions. However I’m certain you possibly can think about many choices that you may add to permit the usage of different fashions for different kinds of prompts, reminiscent of sound or photos. Maybe a few of you can be impressed to write down your personal instructions and submit them on the internet.
These of you who learn this submit sooner or later could discover it irritating that the API syntax has modified once more and the code above now not works. That is the character of utilizing APIs. They modify and you’ll have to do some homework to replace your code. However there are various sources accessible on the web that can assist you replace your code or write new instructions. Good luck and have enjoyable!
There are two varieties of individuals on this planet: those that take criticism critically, positively, and act on it to make themselves a greater particular person; and those that have an allergic response to any sort of criticism and instantly hearth again a disproportionate assault in return. My private Lex Luthor was once that method. Relaxation in peace, you jerk.
In fact, there are additionally two different kinds of individuals on this planet: those that give trustworthy suggestions, hoping to make the topic of the criticism a greater particular person; and those that nitpick little particulars in an try to interrupt down the topic of their contempt.
This all exists on a spectrum, by the way in which. There are very crucial folks, and individuals who barely complain when an apparent injustice or harm must be addressed. And there are individuals who will curse at you and spit in your face, whereas others are smooth spoken and meek.
Did I actually simply write that?
I was a loudmouth. Stunning for those who’ve met me within the final ten to fifteen years. Not stunning, for those who’ve recognized me since my teenage years. I used to be fairly the hothead in my time. However I at all times caught to 1 rule: I made damned certain the identical criticism couldn’t be thrown in my face. That’s, I checked for beams in my eye earlier than mentioning the motes within the eyes of others. Not solely is it good private coverage, nevertheless it simply helps keep away from pointless arguments to the tune of “I do know you might be, however what am I?”
Plus, Jesus stated it (the half concerning the mote), so it helps with the hyper-religious crowd.
I must really feel one thing
Over the previous few years, we’ve been dwelling in a world of “enragement equals engagement,” and engagement equals money. And, as a result of engagement equals money (simple money, at that), persons are fast to unfold concepts that promote anger. And nothing riles up an individual like feeling attacked for his or her views, or for one thing they don’t have any energy in altering.
It’s a variation on “if it bleeds, it leads,” proper? We take note of tragedies on the information (and even hunt down the movies of tragic occasions) as a result of it makes us really feel… one thing. We take a look at the automobile accidents on our commute, and we really feel fortunate to not be in that predicament. Or we hear a few youngster with most cancers, and we really feel blessed that our child is wholesome.
Again to criticisms
Generally you say or write one thing so spot on that it strikes on the core of who somebody is or what they do. Generally you name out an anti-vaccine activist on their logical fallacies, or level out to the creator of a paper that they did the maths all flawed. Or in my case, it’s not simply “some instances.”
Skilled and mature folks will say one thing like, “Hey, what? I tousled. Level taken.” They’ll even admit to their mistake and be clear about it. Ah, however the different kind, the emotionally immature. Whew! They get defensive. They get indignant. After which they take a look at you, discover the smallest of faults, and go nuclear.
I’ve been known as racial slurs, homophobic slurs (although I’m not homosexual, and I don’t take it as an offense to be named as such), or worse. In public well being discussions, folks typically level out my weight, as if being lean and swarthy would one way or the other validate my level. However I’m one way or the other flawed for liking tacos a bit an excessive amount of?
“Vaccines work,” I’ll say.
“You’re too fats, and I might by no means hearken to you about my well being,” they reply.
“Oh, okay… So let me go for a number of runs and eat some salad so vaccines will one way or the other work after that?”
Ridiculous.
All of it goes again to RFK Jr.
The rationale I’m writing it is because I’m having a tough time with a few of my colleagues being fast to level out that RFK Jr. has (had?) a substance use dysfunction through which he used heroin. He has been very open about this and about his street to sobriety. However a few of my colleagues are fast to level out that we shouldn’t be listening to him due to that dependancy.
It’s no totally different than disqualifying my skilled opinions due to my dependancy to tacos, and it hurts.
It’s more practical to level out the inaccuracies in his use of some proof however not others. Or to criticize his continued promotion of unproven strategies to stop, deal with, or treatment ailments and situations. Heck, I’ll take making enjoyable of his try at wooing a reporter earlier than mentioning his dependancy story. (I’ve by no means tried to woo a reporter, in order that’s why I feel it’s okay. Mote within the eye, keep in mind?)
Don’t hearken to me, although
In fact, you don’t need to hearken to me about any of this. The rationale I write that is to elucidate myself to anybody studying and to future generations on why I do the issues I do and say the issues I say. I actually need my daughter to know that, whereas I was a hothead, I did get higher with time.
And, in relation to debating or profitable arguments, it doesn’t assist to reply criticism with criticism. It’s greatest to be a grown-up and repair our errors.
When an IT staff begins to hunch, it may be a demoralizing, irritating expertise for CIOs and staff leaders. A as soon as vibrant workforce now seems to be caught in a rut as its efficiency dwindles, innovation slumps, and morale crashes.
What can a CIO do to reinvigorate a collapsing IT operation? Katherine Hosie, an government coach at Powerhouse Teaching, mentioned step one needs to be understanding the explanation for the hunch. “Is it burnout and fatigue, disappointment because of previous failures or pivots, or are present objectives too massive, unachievable?” she requested.
Root Causes
Distant work usually results in a slumping IT group, mentioned Surinder Kahai, an affiliate professor at Binghamton College’s College of Administration. “Whereas distant work affords flexibility and reduces unproductive commuting time, it additionally reduces alternatives for social interplay and reference to colleagues and the group,” he defined.
With distant work, there are fewer alternatives to collaborate on revolutionary tasks, which might carry pleasure and pleasure to a staff, Kahai mentioned. “Innovation usually occurs whenever you staff up with somebody fairly totally different from your self and get the chance to carry collectively various concepts and mix them creatively.”
Group flattening — eliminating center managers to chop prices, scale back pink tape, and/or simplify organizational charts — has accelerated lately, forcing managers to make do with much less, Kahai mentioned. The remaining managers now have extra folks of their span of management, difficult them to dedicate the identical period of time to every subordinate as earlier than. “This results in much less communication, recognition, and assist from leaders, which leads to decrease employee engagement.”
Waking up a slumping IT group requires management that invests in staff’ progress and makes them really feel extra valued, Kahai mentioned. “It suggests management that makes IT staff enthusiastic about their work — management with a imaginative and prescient that gives that means and function in what they do.”
As IT staff face uncertainty about their future, constructing a supportive setting the place others perceive their challenges and are keen to assist when wanted can be important. “No worker is immune from work-related uncertainty and stress,” Kahai mentioned. “Employees profit from position fashions who persist of their efforts and present resilience regardless of uncertainty and stress of their lives.”
Getting Again on Observe
As quickly as a hunch turns into evident, alert your staff leaders, Hosie advised. “Allow them to know you’ve got noticed a hunch of their staff and that your motive is to assist them,” she suggested. Sharing your motive will lower nervousness and confusion.
The following step needs to be conducting a radical tech audit, suggested Steve Grant, AI search strategist and founder at Figment. “You will must map the place your workflow is sagging and flag any inefficiencies within the system that gradual issues down,” he mentioned. “In case your fixes are focused and measurable, momentum will construct rapidly, as a result of your groups will see progress in areas which have doubtless lengthy pissed off them.”
The following logical step, Grant mentioned, is to incorporate the staff in setting objectives and selecting priorities. “These are the folks utilizing your system every single day, so involving them instantly builds a way of possession, turning obscure directions into widespread objectives,” he said. “This alteration will drive engagement and accountability and make workers extra invested in outcomes.”
Group leaders and members usually desire the options they develop themselves, Hosie mentioned. “Work along with your groups and assist them discover their very own solutions.” But this may increasingly take numerous restraint, she warned. “Encourage their concepts, even when they are not good after which confirm that their concepts are achievable.
Each resolution should have a single, self-selected, proprietor, Hosie mentioned. “Folks take motion once they know they’re the instantly accountable particular person,” she famous. Roll this idea into future staff conferences and one-on-ones. “It is now on you to make sure they observe by means of.”
An clever and supportive HR enterprise associate is usually a large useful resource, Hosie mentioned. “They’ve doubtless seen these challenges earlier than and might share concepts and even facilitate attainable options.” By no means waste a disaster, she suggested. “It is at all times a chance to develop and turn into stronger as a staff.”
Nonetheless, CIOs face a troublesome job — ensuring that the trains run on time whereas additionally offering course that is properly built-in with enterprise technique. “Each technical and enterprise acumen are important,” Kahai mentioned.
The really tough half, Kahai mentioned, is that CIOs are going through an uphill battle, persuading each senior executives and different decision-makers on hiring and workforce planning in a world the place AI is more and more seen as a panacea to slumping efficiency and productiveness.
the ultimate quarter of 2025, it’s time to step again and study the developments that can form knowledge and AI in 2026.
Whereas the headlines would possibly deal with the most recent mannequin releases and benchmark wars, they’re removed from probably the most transformative developments on the bottom. The true change is taking part in out within the trenches — the place knowledge scientists, knowledge + AI engineers, and AI/ML groups are activating these complicated programs and applied sciences for manufacturing. And unsurprisingly, the push towards manufacturing AI—and its subsequent headwinds in —are steering the ship.
Listed here are the ten developments defining this evolution, and what they imply heading into the ultimate quarter of 2025.
1. “Knowledge + AI leaders” are on the rise
Should you’ve been on LinkedIn in any respect lately, you may need seen a suspicious rise within the variety of knowledge + AI titles in your newsfeed—even amongst your individual staff members.
No, there wasn’t a restructuring you didn’t find out about.
Whereas that is largely a voluntary change amongst these historically categorized as knowledge or AI/ML professionals, this shift in titles displays a actuality on the bottom that Monte Carlo has been discussing for nearly a 12 months now—knowledge and AI are not two separate disciplines.
From the assets and abilities they require to the issues they clear up, knowledge and AI are two sides of a coin. And that actuality is having a demonstrable influence on the way in which each groups and applied sciences have been evolving in 2025 (as you’ll quickly see).
2. Conversational BI is scorching—however it wants a temperature verify
Knowledge democratization has been trending in a single kind or one other for almost a decade now, and Conversational BI is the most recent chapter in that story.
The distinction between conversational BI and each different BI device is the velocity and class with which it guarantees to ship on that utopian imaginative and prescient—even probably the most non-technical area customers.
The premise is easy: if you happen to can ask for it, you may entry it. It’s a win-win for house owners and customers alike…in idea. The problem (as with all democratization efforts) isn’t the device itself—it’s the reliability of the factor you’re democratizing.
The one factor worse than dangerous insights is dangerous insights delivered shortly. Join a chat interface to an ungoverned database, and also you received’t simply speed up entry—you’ll speed up the results.
3. Context engineering is turning into a core self-discipline
Enter prices for AI fashions are roughly 300-400x bigger than the outputs. In case your context knowledge is shackled with issues like incomplete metadata, unstripped HTML, or empty vector arrays, your staff goes to face huge value overruns whereas processing at scale. What’s extra, confused or incomplete context can be a significant AI reliability situation, with ambiguous product names and poor chunking complicated retrievers whereas small adjustments to prompts or fashions can result in dramatically completely different outputs.
Which makes it no shock that context engineering has develop into the buzziest buzz phrase for knowledge + AI groups in mid-year 2025. Context engineering is the systematic strategy of getting ready, optimizing, and sustaining context knowledge for AI fashions. Groups that grasp upstream context monitoring—guaranteeing a dependable corpus and embeddings earlier than they hit costly processing jobs—will see significantly better outcomes from their AI fashions. But it surely received’t work in a silo.
The fact is that visibility into the context knowledge alone can’t handle AI high quality—and neither can AI observability options like evaluations. Groups want a complete strategy that gives visibility into the whole system in manufacturing—from the context knowledge to the mannequin and its outputs. An socio-technical strategy that mixesknowledge + AIcollectively is the one path to dependable AI at scale.
4. The AI enthusiasm hole widens
The most recent MIT report stated all of it. AI has a worth downside. And the blame rests – no less than partially – with the chief staff.
“We nonetheless have a whole lot of people who consider that AI is Magic and can do no matter you need it to do with no thought.”
That’s an actual quote, and it echoes a typical story for knowledge + AI groups
An government who doesn’t perceive the expertise units the precedence
Mission fails to offer worth
Pilot is scrapped
Rinse and repeat
Corporations are spending billions on AI pilots with no clear understanding of the place or how AI will drive influence—and it’s having a demonstrable influence on not solely pilot efficiency, however AI enthusiasm as an entire.
Attending to worth must be the primary, second, and third priorities. Which means empowering the info + AI groups who perceive each the expertise and the info that’s going to energy it with the autonomy to handle actual enterprise issues—and the assets to make these use-cases dependable.
5. Cracking the code on brokers vs. agentic workflows
Whereas agentic aspirations have been fueling the hype machine over the past 18 months, the semantic debate between “agentic AI” an “brokers” was lastly held on the hallowed floor of LinkedIn’s feedback part this summer time.
On the coronary heart of the problem is a cloth distinction between the efficiency and value of those two seemingly an identical however surprisingly divergent ways.
Single-purpose brokers are workhorses for particular, well-defined duties the place the scope is evident and outcomes are predictable. Deploy them for centered, repetitive work.
Agentic workflows deal with messy, multi-step processes by breaking them into manageable parts. The trick is breaking large issues into discrete duties that smaller fashions can deal with, then utilizing bigger fashions to validate and mixture outcomes.
For instance, Monte Carlo’s Troubleshooting Agent makes use of an agentic workflow to orchestrate lots of of sub-agents to analyze the foundation causes of knowledge + AI high quality points.
6. Embedding high quality is within the highlight—and monitoring is true behind it
In contrast to the info merchandise of previous, AI in its numerous varieties isn’t deterministic by nature. What goes in isn’t at all times what comes out. So, demystifying what beauty like on this context means measuring not simply the outputs, but additionally the programs, code, and inputs that feed them.
Embeddings are one such system.
When embeddings fail to characterize the semantic that means of the supply knowledge, AI will obtain the unsuitable context no matter vector database or mannequin efficiency. Which is exactly why embedding high quality is turning into a mission-critical precedence in 2025.
Essentially the most frequent embedding breaks are fundamental knowledge points: empty arrays, unsuitable dimensionality, corrupted vector values, and many others. The issue is that almost all groups will solely uncover these issues when a response is clearly inaccurate.
One Monte Carlo buyer captured the issue completely: “We don’t have any perception into how embeddings are being generated, what the brand new knowledge is, and the way it impacts the coaching course of. We’re frightened of switching embedding fashions as a result of we don’t understand how retraining will have an effect on it. Do we’ve to retrain our fashions that use these things? Do we’ve to utterly begin over?”
As key dimensions of high quality and efficiency come into focus, groups are starting to outline new monitoring methods that may help embeddings in manufacturing; together with components like dimensionality, consistency, and vector completeness, amongst others.
7. Vector databases want a actuality verify
Vector databases aren’t new for 2025. What IS new is that knowledge + AI groups are starting to appreciate these vector databases they’ve been counting on may not be as dependable as they thought.
During the last 24 months, vector databases (which retailer knowledge as high-dimensional vectors that seize semantic that means) have develop into the de facto infrastructure for RAG purposes.And in current months, they’ve additionally develop into a supply of consternation for knowledge + AI groups.
Embeddings drift. Chunking methods shift. Embedding fashions get up to date. All this variation creates silent efficiency degradation that’s usually misdiagnosed as hallucinations — and sending groups down costly rabbit holes to resolve them.
The problem is that, in contrast to conventional databases with built-in monitoring, most groups lack the requisite visibility into vector search, embeddings, and agent conduct to catch vector issues earlier than influence. That is more likely to result in an increase in vector database monitoring implementation, in addition to different observability options to enhance response accuracy.
8. Main mannequin architectures prioritize simplicity over efficiency
The AI mannequin internet hosting panorama is consolidating round two clear winners: Databricks and AWS Bedrock. Each platforms are succeeding by embedding AI capabilities immediately into current knowledge infrastructure reasonably than requiring groups to be taught totally new programs.
Databricks wins with tight integration between mannequin coaching, deployment, and knowledge processing. Groups can fine-tune fashions on the identical platform the place their knowledge lives, eliminating the complexity of transferring knowledge between programs. In the meantime, AWS Bedrock succeeds via breadth and enterprise-grade safety, providing entry to a number of basis fashions from Anthropic, Meta, and others whereas sustaining strict knowledge governance and compliance requirements.
What’s inflicting others to fall behind? Fragmentation and complexity. Platforms that require intensive customized integration work or drive groups to undertake totally new toolchains are shedding to options that match into current workflows.
Groups are selecting AI platforms primarily based on operational simplicity and knowledge integration capabilities reasonably than uncooked mannequin efficiency. The winners perceive that the perfect mannequin is ineffective if it’s too difficult to deploy and preserve reliably.
9. Mannequin Context Protocol (MCP) is the MVP
Mannequin Context Protocol (MCP) has emerged because the game-changing “USB-C for AI”—a common commonplace that lets AI purposes hook up with any knowledge supply with out customized integrations.
As an alternative of constructing separate connectors for each database, CRM, or API, groups can use one protocol to offer LLMs entry to the whole lot on the similar time. And when fashions can pull from a number of knowledge sources seamlessly, they ship quicker, extra correct responses.
Early adopters are already reporting main reductions in integration complexity and upkeep work by specializing in a single MCP implementation that works throughout their whole knowledge ecosystem.
As a bonus, MCP additionally standardizes governance and logging — necessities that matter for enterprise deployment.
However don’t anticipate MCP to remain static. Many knowledge and AI leaders anticipate an Agent Context Protocol (ACP) to emerge inside the subsequent 12 months, dealing with much more complicated context-sharing situations. Groups adopting MCP now might be prepared for these advances as the usual evolves.
10. Unstructured knowledge is the brand new gold (however is it idiot’s gold?)
Most AI purposes depend on unstructured knowledge — like emails, paperwork, photographs, audio information, and help tickets — to offer the wealthy context that makes AI responses helpful.
However whereas groups can monitor structured knowledge with established instruments, unstructured knowledge has lengthy operated in a blind spot. Conventional knowledge high quality monitoring can’t deal with textual content information, photographs, or paperwork in the identical means it tracks database tables.
Options like Monte Carlo’s unstructured knowledge monitoring are addressing this hole for customers by bringing automated high quality checks to textual content and picture fields throughout Snowflake, Databricks, and BigQuery.
Trying forward, unstructured knowledge monitoring will develop into as commonplace as conventional knowledge high quality checks. Organizations will implement complete high quality frameworks that deal with all knowledge — structured and unstructured — as essential belongings requiring energetic monitoring and governance.
Picture: Monte Carlo
Trying ahead to 2026
If 2025 has taught us something up to now, it’s that the groups successful with AI aren’t those with the most important budgets or the flashiest demos. The groups successful the AI race are the groups who’ve found out the way to ship dependable, scalable, and reliable AI in manufacturing.
Winners aren’t made in a testing setting. They’re made within the palms of actual customers. Ship adoptable AI options, and also you’ll ship demonstrable AI worth. It’s that straightforward.
Net scraping sometimes refers to an automated technique of gathering knowledge from web sites. On a excessive stage, you are primarily making a bot that visits a web site, detects the info you are inquisitive about, after which shops it into some acceptable knowledge construction, so you’ll be able to simply analyze and entry it later.
Nonetheless, if you happen to’re involved about your anonymity on the Web, you must in all probability take a little bit extra care when scraping the online. Since your IP deal with is public, a web site proprietor may observe it down and, doubtlessly, block it.
So, if you wish to keep as nameless as attainable, and stop being blocked from visiting a sure web site, you must think about using proxies when scraping the online.
Proxies, additionally known as proxy servers, are specialised servers that allow you to not instantly entry the web sites you are scraping. Relatively, you will be routing your scraping requests by way of a proxy server.
That manner, your IP deal with will get “hidden” behind the IP deal with of the proxy server you are utilizing. This can assist you each keep as nameless as attainable, in addition to not being blocked, so you’ll be able to maintain scraping so long as you need.
On this complete information, you will get a grasp of the fundamentals of net scraping and proxies, you will see the precise, working instance of scraping a web site utilizing proxies in Node.js. Afterward, we’ll talk about why you would possibly think about using current scraping options (like ScraperAPI) over writing your personal net scraper. On the finish, we’ll provide you with some tips about how you can overcome among the commonest points you would possibly face when scraping the online.
Net Scraping
Net scraping is the method of extracting knowledge from web sites. It automates what would in any other case be a handbook technique of gathering info, making the method much less time-consuming and vulnerable to errors.
That manner you’ll be able to acquire a considerable amount of knowledge rapidly and effectively. Later, you’ll be able to analyze, retailer, and use it.
The first motive you would possibly scrape a web site is to acquire knowledge that’s both unavailable by an current API or too huge to gather manually.
It is significantly helpful when you must extract info from a number of pages or when the info is unfold throughout totally different web sites.
There are a lot of real-world purposes that make the most of the ability of net scraping of their enterprise mannequin. Nearly all of apps serving to you observe product costs and reductions, discover least expensive flights and inns, and even acquire job posting knowledge for job seekers, use the strategy of net scraping to assemble the info that gives you the worth.
Net Proxies
Think about you are sending a request to a web site. Often, your request is shipped out of your machine (together with your IP deal with) to the server that hosts a web site you are making an attempt to entry. That implies that the server “is aware of” your IP deal with and it might block you primarily based in your geo-location, the quantity of site visitors you are sending to the web site, and lots of extra elements.
However once you ship a request by a proxy, it routes the request by one other server, hiding your authentic IP deal with behind the IP deal with of the proxy server. This not solely helps in sustaining anonymity but additionally performs an important function in avoiding IP blocking, which is a typical challenge in net scraping.
By rotating by totally different IP addresses, proxies can help you distribute your requests, making them seem as in the event that they’re coming from numerous customers. This reduces the probability of getting blocked and will increase the possibilities of efficiently scraping the specified knowledge.
Varieties of Proxies
Usually, there are 4 major sorts of proxy servers – datacenter, residential, rotating, and cell.
Every of them has its execs and cons, and primarily based on that, you will use them for various functions and at totally different prices.
Datacenter proxies are the commonest and cost-effective proxies, offered by third-party knowledge facilities. They provide excessive velocity and reliability however are extra simply detectable and could be blocked by web sites extra steadily.
Residential proxies route your requests by actual residential IP addresses. Since they seem as atypical consumer connections, they’re much less prone to be blocked however are sometimes dearer.
Rotating proxies robotically change the IP deal with after every request or after a set interval. That is significantly helpful for large-scale scraping initiatives, because it considerably reduces the possibilities of being detected and blocked.
Cellular proxies use IP addresses related to cell gadgets. They’re extremely efficient for scraping mobile-optimized web sites or apps and are much less prone to be blocked, however they sometimes come at a premium price.
ISP proxies are a more moderen sort that mixes the reliability of datacenter proxies with the legitimacy of residential IPs. They use IP addresses from Web Service Suppliers however are hosted in knowledge facilities, providing a stability between efficiency and detection avoidance.
Instance Net Scraping Venture
Let’s stroll by a sensible instance of an internet scraping venture, and show how you can arrange a fundamental scraper, combine proxies, and use a scraping service like ScraperAPI.
Organising
Earlier than you dive into the precise scraping course of, it is important to arrange your improvement setting.
For this instance, we’ll be utilizing Node.js because it’s well-suited for net scraping attributable to its asynchronous capabilities. We’ll use Axios for making HTTP requests, and Cheerio to parse and manipulate HTML (that is contained within the response of the HTTP request).
First, guarantee you could have Node.js put in in your system. If you do not have it, obtain and set up it from nodejs.org.
Then, create a brand new listing to your venture and initialize it:
$ mkdir my-web-scraping-project
$ cd my-web-scraping-project
$ npm init -y
Lastly, set up Axios and Cheerio since they’re obligatory so that you can implement your net scraping logic:
$ npm set up axios cheerio
Easy Net Scraping Script
Now that your setting is ready up, let’s create a easy net scraping script. We’ll scrape a pattern web site to assemble well-known quotes and their authors.
So, create a JavaScript file named sample-scraper.js and write all of the code within it. Import the packages you will have to ship HTTP requests and manipulate the HTML:
Subsequent, create a wrapper perform that can include all of the logic you must scrape knowledge from an internet web page. It accepts the URL of a web site you need to scrape as an argument and returns all of the quotes discovered on the web page:
Word: All of the quotes are saved in a separate div ingredient with a category of quote. Every quote has its textual content and creator – textual content is saved below the span ingredient with the category of textual content, and the creator is throughout the small ingredient with the category of creator.
Lastly, specify the URL of the web site you need to scrape – on this case, https://quotes.toscrape.com, and name the scrapeWebsite() perform:
All that is left so that you can do is to run the script from the terminal:
$ node sample-scraper.js
Integrating Proxies
To make use of a proxy with axios, you specify the proxy settings within the request configuration. The axios.get() technique can embody the proxy configuration, permitting the request to route by the desired proxy server. The proxy object comprises the host, port, and non-obligatory authentication particulars for the proxy:
Word: You’ll want to exchange these placeholders together with your precise proxy particulars.
Apart from this transformation, the complete script stays the identical:
Take a look at our hands-on, sensible information to studying Git, with best-practices, industry-accepted requirements, and included cheat sheet. Cease Googling Git instructions and truly study it!
For web sites with advanced JavaScript interactions, you would possibly want to make use of a headless browser as a substitute of easy HTTP requests. Instruments like Puppeteer or Playwright can help you automate an actual browser, execute JavaScript, and work together with dynamic content material.
Headless browsers can be configured to make use of proxies, making them highly effective instruments for scraping advanced web sites whereas sustaining anonymity.
Integrating a Scraping Service
Utilizing a scraping service like ScraperAPI affords a number of benefits over handbook net scraping because it’s designed to deal with all the main issues you would possibly face when scraping web sites:
Mechanically handles frequent net scraping obstacles resembling CAPTCHAs, JavaScript rendering, and IP blocks.
Mechanically handles proxies – proxy configuration, rotation, and rather more.
As an alternative of constructing your personal scraping infrastructure, you’ll be able to leverage ScraperAPI’s pre-built options. This saves vital improvement time and sources that may be higher spent on analyzing the scraped knowledge.
ScraperAPI affords numerous customization choices resembling geo-location focusing on, customized headers, and asynchronous scraping. You’ll be able to personalize the service to fit your particular scraping wants.
Utilizing a scraping API like ScraperAPI is usually more cost effective than constructing and sustaining your personal scraping infrastructure. The pricing is predicated on utilization, permitting you to scale up or down as wanted.
ScraperAPI permits you to scale your scraping efforts by dealing with tens of millions of requests concurrently.
To implement the ScraperAPI proxy into the scraping script you have created to date, there are only a few tweaks you must make within the axios configuration.
To start with, guarantee you could have created a free ScraperAPI account. That manner, you will have entry to your API key, which might be obligatory within the following steps.
When you get the API key, use it as a password within the axios proxy configuration from the earlier part:
And, that is it, all your requests might be routed by the ScraperAPI proxy servers.
However to make use of the total potential of a scraping service you will must configure it utilizing the service’s dashboard – ScraperAPI is not any totally different right here.
It has a user-friendly dashboard the place you’ll be able to arrange the online scraping course of to greatest suit your wants. You’ll be able to allow proxy or async mode, JavaScript rendering, set a area from the place the requests might be despatched, set your personal HTTP headers, timeouts, and rather more.
And the very best factor is that ScraperAPI robotically generates a script containing all the scraper settings, so you’ll be able to simply combine the scraper into your codebase.
Greatest Practices for Utilizing Proxies in Net Scraping
Not each proxy supplier and its configuration are the identical. So, it is necessary to know what proxy service to decide on and how you can configure it correctly.
Let’s check out some suggestions and methods that will help you with that!
Rotate Proxies Usually
Implement a proxy rotation technique that modifications the IP deal with after a sure variety of requests or at common intervals. This strategy can mimic human shopping habits, making it much less probably for web sites to flag your actions as suspicious.
Deal with Price Limits
Many web sites implement price limits to stop extreme scraping. To keep away from hitting these limits, you’ll be able to:
Introduce Delays: Add random delays between requests to simulate human habits.
Monitor Response Codes: Monitor HTTP response codes to detect when you find yourself being rate-limited. Should you obtain a 429 (Too Many Requests) response, pause your scraping for some time earlier than making an attempt once more.
Implement Exponential Backoff: Relatively than utilizing mounted delays, implement exponential backoff that will increase wait time after every failed request, which is more practical at dealing with price limits.
Use High quality Proxies
Selecting high-quality proxies is essential for profitable net scraping. High quality proxies, particularly residential ones, are much less prone to be detected and banned by goal web sites. That is why it is essential to know how you can use residential proxies for your online business, enabling you to seek out useful leads whereas avoiding web site bans. Utilizing a mixture of high-quality proxies can considerably improve your possibilities of profitable scraping with out interruptions.
High quality proxy providers usually present a variety of IP addresses from totally different areas, enabling you to bypass geo-restrictions and entry localized content material. A proxy extension for Chrome additionally helps handle these IPs simply by your browser, providing a seamless method to swap places on the fly.
Dependable proxy providers can supply sooner response instances and better uptime, which is important when scraping massive quantities of information.
Nonetheless, keep away from utilizing a proxy that’s publicly accessible with out authentication, generally known as an open proxy. These are sometimes gradual, simply detected, banned, and will pose safety threats. They’ll originate from hacked gadgets or misconfigured servers, making them unreliable and doubtlessly harmful.
As your scraping wants develop, gaining access to a sturdy proxy service permits you to scale your operations with out the effort of managing your personal infrastructure.
Utilizing a good proxy service usually comes with buyer help and upkeep, which might prevent effort and time in troubleshooting points associated to proxies.
Dealing with CAPTCHAs and Different Challenges
CAPTCHAs and anti-bot mechanisms are among the commonest obstacles you will encounter whereas scraping an internet.
Web sites use CAPTCHAs to stop automated entry by making an attempt to distinguish actual people and automatic bots. They’re attaining that by prompting the customers to unravel numerous sorts of puzzles, establish distorted objects, and so forth. That may make it actually tough so that you can robotically scrape knowledge.
Though there are a lot of each handbook and automatic CAPTCHA solvers obtainable on-line, the very best technique for dealing with CAPTCHAs is to keep away from triggering them within the first place. Usually, they’re triggered when non-human habits is detected. For instance, a considerable amount of site visitors, despatched from a single IP deal with, utilizing the identical HTTP configuration is certainly a pink flag!
So, when scraping a web site, strive mimicking human habits as a lot as attainable:
Add delays between requests and unfold them out as a lot as you’ll be able to.
Usually rotate between a number of IP addresses utilizing a proxy service.
Randomize HTTP headers and consumer brokers.
Keep and use cookies appropriately, as many web sites observe consumer classes.
Contemplate implementing browser fingerprint randomization to keep away from monitoring.
Past CAPTCHAs, web sites usually use subtle anti-bot measures to detect and block scraping.
Some web sites use JavaScript to detect bots. Instruments like Puppeteer can simulate an actual browser setting, permitting your scraper to execute JavaScript and bypass these challenges.
Web sites generally add hidden type fields or hyperlinks that solely bots will work together with. So, strive avoiding clicking on hidden parts or filling out kinds with invisible fields.
Superior anti-bot methods go so far as monitoring consumer habits, resembling mouse actions or time spent on a web page. Mimicking these behaviors utilizing browser automation instruments can assist bypass these checks.
However the easiest and most effective method to deal with CAPTCHAs and anti-bot measures will certainly be to make use of a service like ScraperAPI.
Sending your scraping requests by ScraperAPI’s API will guarantee you could have the very best likelihood of not being blocked. When the API receives the request, it makes use of superior machine studying strategies to find out the very best request configuration to stop triggering CAPTCHAs and different anti-bot measures.
Conclusion
As web sites grew to become extra subtle of their anti-scraping measures, using proxies has change into more and more necessary in sustaining your scraping venture profitable.
Proxies show you how to preserve anonymity, stop IP blocking, and allow you to scale your scraping efforts with out getting obstructed by price limits or geo-restrictions.
On this information, we have explored the basics of net scraping and the essential function that proxies play on this course of. We have mentioned how proxies can assist preserve anonymity, keep away from IP blocks, and distribute requests to imitate pure consumer habits. We have additionally lined the various kinds of proxies obtainable, every with its personal strengths and excellent use instances.
We demonstrated how you can arrange a fundamental net scraper and combine proxies into your scraping script. We additionally explored the advantages of utilizing a devoted scraping service like ScraperAPI, which might simplify lots of the challenges related to net scraping at scale.
In the long run, we lined the significance of rigorously selecting the best sort of proxy, rotating them recurrently, dealing with price limits, and leveraging scraping providers when obligatory. That manner, you’ll be able to make sure that your net scraping initiatives might be environment friendly, dependable, and sustainable.
Do not forget that whereas net scraping could be a highly effective knowledge assortment method, it ought to at all times be accomplished responsibly and ethically, with respect for web site phrases of service and authorized concerns.
If you happen to ever end up in Battery Park Metropolis in Decrease Manhattan, flip down Vesey Avenue towards North Finish Avenue. You’ll arrive at one thing uncommon: a set of stones, soil and moss, artfully organized to look over the Hudson River.
It’s the Irish Starvation Memorial, a bit of public art work that commemorates the devastating Irish famine of the mid-Nineteenth century, which led to the deaths of a minimum of 1 million folks and completely altered Eire’s historical past, forcing the emigration of thousands and thousands extra Irish to cities like New York.
The Irish famine is uncommon in how closely commemorated it’s, with greater than 100 memorials in Eire itself and world wide. Different famines, together with ones that killed much more folks just like the 1943 Bengal famine in India or China’s 1959–’61 famine, largely go with out main public memorials.
It shouldn’t be this manner. Researchers estimate that since 1870 alone, roughly 140 million folks have died of famine. Return additional in historical past, and famines change into ever extra frequent and ever extra lethal. One horrible famine in northern Europe within the early 14th century killed as a lot as 12 p.c of the whole area’s inhabitants in a handful of years. Even outdoors famine years, the supply of meals was a relentless stress on the human inhabitants.
So, whereas starvation continues to be far too frequent at present, famines themselves are far, far rarer — and are more likely to be the results of human failures than of crop failures. It’s one of many nice human achievements of the fashionable age, one we too typically fail to acknowledge.
The information will get even higher: By the newest tallies, the world is on observe to develop extra grain this 12 months than ever earlier than. The UN’s Meals and Agriculture Group (FAO) initiatives document ranges of manufacturing of worldwide cereal crops like wheat, corn and rice within the 2025–’26 farming season. Hidden inside that knowledge is one other quantity that’s simply as essential: a world stocks-to-use ratio round 30.6 p.c — that means the world is producing almost a 3rd extra of those foundational crops than it’s at present utilizing.
The US Division of Agriculture’s August outlook factors the identical manner: a document US corn crop, and much more importantly, a document yield, or the quantity of crop grown per acre of land. That final quantity is very essential: the extra we are able to develop on one acre, the much less land we have to farm to satisfy world demand for meals. The FAO Meals Worth Index, which tracks the price of a world basket of meals commodities, is up a bit this 12 months, however is almost 20 p.c under the height in the course of the early months of the conflict in Ukraine.
Zoom out, and the lengthy arc of enchancment is starker. Common energy out there per individual worldwide have been climbing for many years, from roughly 2,100 to 2,200 kcal/day within the early Sixties to only underneath 3,000 kcal/day by 2022. In the meantime, cereal yields have roughly tripled since 1961. These two strains — extra meals per individual, extra grain per hectare — have helped carry us out of the outdated Malthusian shadow.
As with farming, begin on the seed. The short-straw wheat and rice of the Inexperienced Revolution made essentially the most of fertilizer, hybrid seeds added a yield bonus, genetically modified crops arrived within the ’90s, and now CRISPR lets breeders make surgical edits to a plant’s personal genes.
When you’ve received the seeds, you want fertilizer. The world was as soon as depending on pure sources of nitrogen that there was a mad sprint to harvest nitrogen-rich dried hen poop or guano within the Nineteenth century, however in 1912, Fritz Haber and Carl Bosch developed their course of for creating artificial nitrogen for fertilizer. The Haber-Bosch course of is so essential that half of at present’s meals possible depends upon it.
Now add water. The place as soon as most farmers needed to rely upon the climate to water their crops, irrigated farmland has greater than doubled since 1961, with that land offering some 60 p.c of the world’s cereal crops, and in flip half the world’s energy. Extremely productive farmland like California’s Central Valley could be unimaginable with out intensive irrigation.
And at last, get the meals to folks. Higher logistics and world commerce has created a system that may shuffle energy from surplus to deficit when one thing goes flawed regionally.
However this doesn’t imply the system is ideal — or perpetual.
Why will we nonetheless have starvation?
Whereas the world routinely grows greater than sufficient energy, wholesome diets stay out of attain for billions. The World Financial institution estimates round 2.6 billion folks can’t afford a nutritious diet. That quantity has fallen barely from previous years, however the state of affairs is getting worse in sub-Saharan Africa.
When famines do happen at present, the causes are typically much more political than they’re agronomical. The horrible famines in Gaza and Sudan, the place greater than 25 million persons are vulnerable to going hungry, are so terrible exactly as a result of they present the results of man-made entry failures amid a world of abundance. (Although in Gaza, a minimum of, the obvious peace deal is lastly offering hope for reduction.)
One other risk to progress in opposition to famine additionally has a political dimension: local weather change. Although fundamental crop harvests and yields have up to now confirmed largely resilient in opposition to the results of warming, local weather scientists warn that dangers to meals safety will rise with temperatures, particularly by way of warmth, drought, and compound disasters that may hit a number of breadbaskets without delay. The excellent news is that adaptation — smarter agronomy, stress-tolerant varieties, irrigation effectivity — can cushion losses as much as round 2 levels Celsius. However our choices could slender past that.
A extra self-inflicted wound may come by way of commerce restrictions. One of many worst current meals worth crises, in 2007 and 2008, occurred much less due to manufacturing failures than political ones, as governments restricted exports, main to cost spikes that hit the poor hardest. That’s a worrying precedent given the Trump administration’s renewed push for tariffs and commerce boundaries.
The Irish Starvation Memorial is a reminder of how horrible shortage could be — and the way far we’ve come. After hundreds of years when starvation was a given, humanity has constructed a meals system that, for all its flaws, feeds eight billion and retains setting harvest information. For all of the challenges we face at present and which will come tomorrow, that’s a narrative value commemorating.
A model of this story initially appeared within the Good Information e-newsletter. Enroll right here!
The STAR detector on the Relativistic Heavy Ion Collider
BROOKHAVEN NATIONAL LABORATORY
We’re getting nearer to understanding when the robust nuclear drive loosens its grip on essentially the most primary constituents of matter, letting quarks and gluons inside particles abruptly flip right into a sizzling particle soup.
There’s a particular mixture of temperature and strain at which all three phases of water – liquid, ice and vapour – exist concurrently. For many years, researchers have been in search of an analogous “important level” for matter ruled by the robust nuclear drive, which binds quarks and gluons into protons and neutrons.
Smashing ions in particle colliders can create a state the place the robust drive breaks down and permits quarks and gluons to type a soupy “quark-gluon plasma”. Nevertheless it stays murky whether or not this transition is preceded by a important level. Xin Dong at Lawrence Berkeley Nationwide Laboratory in California and his colleagues have now gotten nearer to clearing it up.
They analysed the quantity and distribution of particles created within the aftermath of a smash-up of two very energetic gold ions on the Relativistic Heavy Ion Collider at Brookhaven Nationwide Laboratory in New York state. Dong says they have been successfully attempting to create a section diagram for quarks and gluons – a map exhibiting what varieties of matter the robust drive permits to type below totally different circumstances. The brand new experiment didn’t pin down the important level on this map with nice certainty, nevertheless it considerably narrowed the area the place it may very well be.
There is part of the section diagram the place matter “melts” into plasma step by step, like butter softening on the counter, however the important level would align with a extra abrupt transition, like chunks of ice instantly showing in liquid water, says Agnieszka Sorensen on the Facility for Uncommon Isotope Beams in Michigan, who wasn’t concerned within the work. The brand new experiment will serve not solely as a information for the place to search for this level, nevertheless it has additionally revealed which particle properties might provide the most effective clues that it exists, she says.
Claudia Ratti on the College of Houston in Texas says that many researchers have been excitedly anticipating this new evaluation as a result of it yielded a precision that earlier measurements couldn’t obtain, and did so for part of the section diagram the place theoretical calculations are notoriously tough. Just lately, a number of predictions for the important level location have converged, and the problem for experimentalists might be to analyse the information for the even decrease collision energies corresponding to those predictions, she says.
An unambiguous detection of the important level could be a generational breakthrough, says Dong. That is partly as a result of the robust drive is the one basic drive that physicists suspect has a important level. Moreover, this drive has performed a big position in shaping our universe: it ruled the properties of sizzling and dense matter created proper after the massive bang, and it’s nonetheless dictating the construction of neutron stars. Dong says collider experiments like the brand new one may assist us perceive what goes on inside of those unique cosmic objects as soon as we full the robust drive section diagram.
In today’s fast-paced digital world, terms like Artificial Intelligence (AI) and Machine Learning (ML) are often used interchangeably, but they are not the same. Understanding the distinction is essential, especially for students, professionals, and anyone curious about the technological forces shaping our future.
What is Artificial Intelligence (AI)?
Artificial Intelligence is the broad field of creating machines or systems that can simulate human intelligence. The goal is to enable machines to think, reason, learn, and make decisions — just like humans.
Key Characteristics of AI:
* Problem-solving and decision-making
* Natural language understanding (e.g., chatbots)
* Image recognition and interpretation
* Predictive analytics
* Planning and optimization
Everyday Examples of AI:
* Voice assistants (Siri, Alexa, Google Assistant)
* Self-driving cars
* Smart recommendation systems (Netflix, YouTube)
What is Machine Learning (ML)?
Machine Learning is a subset of AI. It refers to the ability of systems to learn from data and improve over time without being explicitly programmed. Instead of hardcoding instructions, ML models are trained with examples.
Key Characteristics of ML:
* Data-driven learning
* Improves with more data
* Finds patterns and relationships in datasets
* Requires training and testing phases
Everyday Examples of ML:
* Spam email filters
* Personalized online shopping recommendations
* Predictive text suggestions
How AI and ML Relate to Each Other
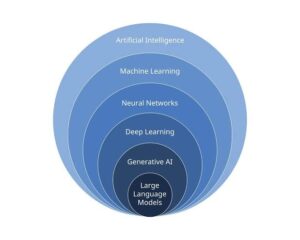
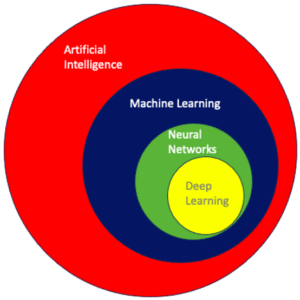
Think of AI as the **goal** — creating intelligent machines — and ML as one **method** to achieve that goal.
🔍 Analogy:
* **AI** is the concept of building an intelligent brain.
* **ML** is like teaching that brain by feeding it experiences (data) so it learns over time.
Where Deep Learning Fits In
Deep Learning (DL) is a **subset of Machine Learning** that uses artificial neural networks inspired by the human brain. It’s particularly powerful for processing unstructured data such as images, audio, and text.
Why the Distinction Matters**
Understanding the difference helps:
Students & Researchers: – Choose the right learning path.
Businesses:– Pick the right tech solutions.
Consumers:– Make informed decisions about AI-powered products.
Conclusion:
While AI is the grand vision of machines that can think and act like humans, ML is one of the most promising ways to achieve that vision — by enabling machines to learn from data and improve on their own. Knowing the difference empowers you to understand, appreciate, and leverage these technologies in everyday life.
Data visualization is the graphical representation of information and data. By using visual elements like charts, graphs, and maps, data visualization tools provide an accessible way to see and understand trends, outliers, and patterns in data.
In today’s data-driven world, effective visualization is crucial for making informed decisions, whether in business, science, healthcare, or everyday life.
This article explores:
– The importance of data visualization
– Common types of data visualizations
– Best practices for effective visualization
– Tools and technologies used in data visualization
Why is Data Visualization Important?
Humans process visual information much faster than text or numbers. Studies show that the brain interprets visuals **60,000 times faster** than text. Here’s why data visualization matters:
1. Simplifies Complex Data: – Large datasets become easier to digest when represented visually.
2. Reveals Patterns & Trends: – Helps identify correlations and anomalies that may go unnoticed in raw data.
3. Enhances Decision-Making: Businesses and researchers rely on visuals for strategic insights.
4. Improves Communication: Visuals make data storytelling more compelling and persuasive.
Example:
A sales team can use a **line chart** to track monthly revenue growth instead of analyzing spreadsheets.
A comparative image between raw data table vs. a visualized line chart showing sales trends
Common Types of Data Visualizations:
Different data types require different visualization techniques. Below are some widely used formats:
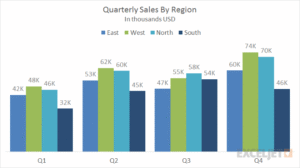
1. Bar Charts:
– Best for comparing quantities across categories.
– Example: Comparing sales performance across regions.
a bar chart showing sales by region:
2. Line Graphs:
– Ideal for tracking changes over time.
– Example: Stock market trends over a year.
A line graph depicting stock price fluctuations:
3. Pie Charts
– Shows parts of a whole (percentage distribution).
– Example: Market share of different smartphone brands.
4. Scatter Plots:
– Displays relationships between two variables.
– Example: Correlation between study hours and exam scores.
5. Heatmaps
– Represents data density using color gradients.
– Example: Website click-through rates across different pages.
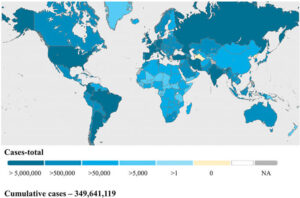
6. Geographic Maps
– Visualizes location-based data.
– Example: COVID-19 cases by country.
Best Practices for Effective Data Visualization
Not all visuals are equally effective. Follow these principles for clarity and impact:
✅ **Choose the Right Chart** – Match the visualization to your data type.
✅ **Keep It Simple** – Avoid clutter; focus on key insights.
✅ **Use Color Wisely** – Highlight important data points without overwhelming the viewer.
✅ **Label Clearly** – Ensure axes, legends, and titles are descriptive.
✅ **Tell a Story** – Guide the viewer through the data narrative.
## **Popular Data Visualization Tools**
Several tools help create stunning visuals:
| **Tool** | **Best For** | **Example Use Case** |
|——————|———————————-|——————————-|
| **Tableau** | Interactive dashboards | Business analytics |
Data visualization transforms raw data into meaningful insights, enabling better understanding and decision-making. Whether you’re a data scientist, business analyst, or student, mastering visualization techniques is essential in today’s information-rich world.