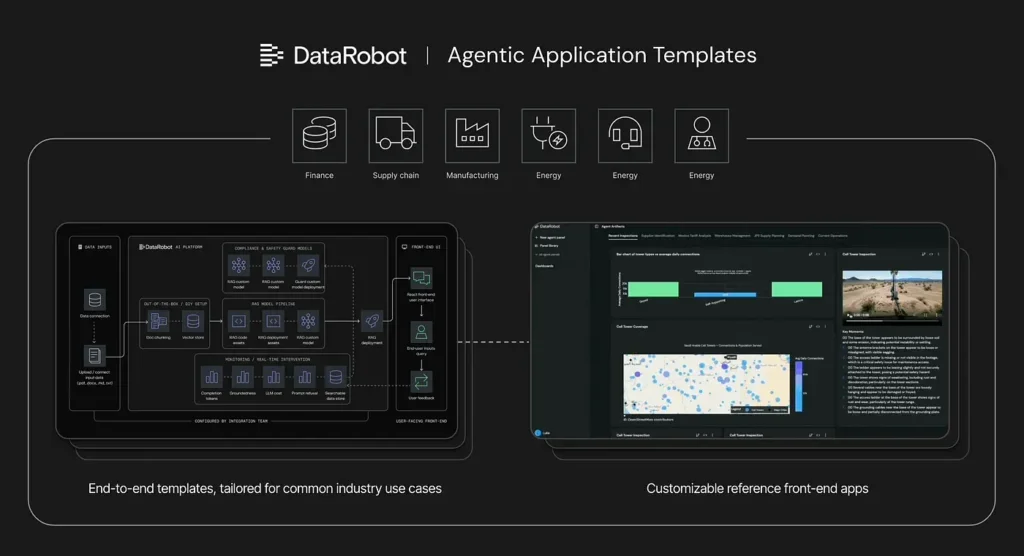
TLDR:
In case you are compute-constrained, use autoregressive fashions; if you’re data-constrained, use diffusion fashions.
Motivation
Progress in AI over the previous decade has largely been pushed by scaling compute and information. The recipe from GPT-1 to GPT-5 has appeared simple: prepare a bigger mannequin on extra information, and the result’s a extra succesful system.
But a central query stays: will this recipe proceed to carry from GPT-6 to GPT-N?
Many analysts and researchers consider the reply is not any. As an illustration, Ilya Sutskever, in his NeurIPS 2024 Take a look at-of-Time Award discuss, remarked: “Compute is rising—higher algorithms, higher {hardware}, larger clusters—however information just isn’t rising. We have now only one web, the fossil gasoline of AI.”
This concern is echoed by AI forecasters, who’ve analyzed compute and information development extra systematically and concluded that compute is outpacing information at an accelerating price.

The above Determine, illustrates this rigidity by overlaying projections from EpochAI’s evaluation. Their research extrapolates historic developments in compute, dataset utilization, and internet-scale information availability. The forecast means that by round 2028, we’ll enter a data-constrained regime: much more compute will likely be accessible than there are coaching tokens to eat.
This paper addresses the problem by asking: how can we commerce off extra compute for much less information? Our central thought is to revisit the foundations of recent generative modeling and evaluate the 2 dominant paradigms for scaling AI.
Broadly, there have been two households of algorithms that formed current progress in AI:
- Autoregressive fashions, popularized in 2019 within the textual content area with the GPT-2 paper.
- Diffusion fashions, popularized in 2020 within the imaginative and prescient area with the DDPM paper.
Each goal to maximise the joint probability, however they differ essentially in how they factorize this joint distribution.
The success of diffusion in imaginative and prescient and autoregression in language has sparked each pleasure and confusion—particularly as every neighborhood has begun experimenting with the opposite’s paradigm.
For instance, the language neighborhood has explored diffusion on textual content:
D3PM launched discrete diffusion by way of random masking, whereas Diffusion-LM utilized steady diffusion by projecting tokens to embeddings earlier than including Gaussian noise. Since then, quite a few works have prolonged this line of analysis.
Conversely, the imaginative and prescient neighborhood has experimented with doing autoregressive modeling on photos. Fashions resembling PARTI and DALLE exemplify this method with robust outcomes.
This cross-pollination has led to even better uncertainty in robotics, the place each diffusion-based and autoregressive approaches are broadly adopted. As an example this, OpenAI Deep Analysis has compiled a listing of robotics works throughout each paradigms, highlighting the shortage of consensus within the discipline.

This ambiguity raises a elementary query: ought to we be coaching diffusion fashions or autoregressive fashions?
Fast Background:
Autoregressive language fashions:

They mannequin information distribution in a left-to-right method
Diffusion language fashions:

For a extra detailed understanding, with cool animations, please discuss with this video from Jia-Bin Huang – https://www.youtube.com/watch?v=8BTOoc0yDVA
Prior outcomes with Diffusion Language fashions
Since 2021, diffusion language fashions have sparked important curiosity, with many works specializing in bettering their design and efficiency.

Within the desk above, we spotlight consultant outcomes from a well-liked work.
The takeaways are as follows:
- Discrete diffusion performs higher than steady diffusion on textual content.
- Autoregressive fashions nonetheless obtain the strongest outcomes total.
A number of works have additionally explored the scaling habits of diffusion-based language fashions.

Nie et al report that discrete diffusion LLMs require roughly 16× extra compute than autoregressive LLMs to match the identical unfavorable log-likelihood. Comparable outcomes have been noticed in multimodal domains—for example, UniDisc finds that discrete diffusion wants about 12× extra compute than autoregression for comparable likelihoods.
Nonetheless, these outcomes conflate information and compute as a result of they’re measured in a single-epoch coaching regime. This raises an necessary ambiguity: do diffusion fashions really require 16× extra compute, or do they the truth is require 16× extra information?
On this work, we explicitly disentangle information and compute. Our objective is to review diffusion and autoregressive fashions particularly in data-constrained settings.
Our Motivation
To know why diffusion could behave in another way, let’s revisit its coaching goal.

In diffusion coaching, tokens are randomly masked and the mannequin learns to get better them. Importantly, left-to-right masking is a particular case inside this framework.

Considered this manner, diffusion could be interpreted as a type of implicit information augmentation for autoregressive coaching. As an alternative of solely studying from left-to-right sequences, the mannequin additionally advantages from many different masking methods.
And if diffusion is basically information augmentation, then its advantages needs to be most pronounced when coaching is data-bottlenecked.
This attitude explains why prior works have reported weaker outcomes for diffusion: they primarily evaluated in single-epoch settings, the place information is plentiful. In distinction, our research focuses on situations the place information is proscribed and compute could be traded off extra successfully.
Our Experiments
On this work, we prepare tons of of fashions spanning a number of orders of magnitude in mannequin dimension, information amount, and variety of coaching epochs to suit scaling legal guidelines for diffusion fashions within the data-constrained setting. We summarize a few of our key findings under.
Discovering #1:

Diffusion fashions outperform autoregressive fashions when skilled with ample compute (i.e., extra epochs & parameters). Throughout totally different distinctive information scales, we observe:
- At low compute, Autoregressive fashions win.
- After a specific amount of compute, efficiency matches—we name this the essential compute level.
- Past this, diffusion retains bettering, whereas Autoregressive plateaus or overfits.
Every level within the determine exhibits a mannequin skilled to convergence. The x-axis exhibits the whole coaching FLOPs of that time, and the y-axis exhibits one of the best validation loss achieved by that mannequin household underneath that coaching compute price range.
Discovering #2:

Autoregressive fashions start to overfit a lot shortly, whereas diffusion exhibits no indicators of overfitting even after 10x the variety of epochs. Within the above determine, we confirmed that rising compute finally favors diffusion. However compute could be scaled in two methods: (i) Growing mannequin dimension (ii) Growing the variety of epochs Within the following plot, we separate these axes.
The coloured star marks the 1-epoch level, the place Autoregressive outperforms diffusion. The star (★) denotes one of the best loss achieved by every mannequin.
- Autoregressive hits its finest across the center, then overfits.
- Diffusion retains bettering and reaches its finest loss on the far proper.
Not solely does diffusion profit from extra coaching—it additionally achieves a greater ultimate loss than Autoregressive (3.51 vs. 3.71).
Discovering #3:

Diffusion fashions are considerably extra strong to information repetition than autoregressive (AR) fashions.
We present coaching curves of fashions skilled with the identical complete compute, however totally different trade-offs between distinctive information and variety of epochs.
An “epoch” right here means reusing a smaller subset of knowledge extra occasions(e.g., 4 Ep is 4 epochs whereas utilizing 25% distinctive information, 2 Ep is 2 epochs with 50% and so forth).
- AR fashions start to overfit as repetition will increase—their validation loss worsens and considerably diverges at increased epoch counts.
- Diffusion fashions stay secure throughout all repetition ranges, exhibiting no indicators of overfitting or diverging—even at 100 epochs.
Discovering #4:

Diffusion fashions exhibit a a lot increased half-life of knowledge reuse (R_D*) —i.e., the variety of epochs after which returns from repeating information begins to considerably diminish.
We undertake the data-constrained scaling framework launched by Muennighoff et al. of their wonderful NeurIPS paper to suit scaling legal guidelines for diffusion fashions. Whereas Muennighoff et al. discovered R_D* ~ 15 for autoregressive fashions, we discover a considerably increased worth of R_D* ~ 500 for diffusion fashions—highlighting their potential to learn from much more information repetition.

The above Determine research the Decay price of knowledge worth underneath repetition: left exhibits diffusion, center AR, and proper the typical decay price for each.
Factors are empirical outcomes (darker colour = increased FLOPs, lighter colour =
decrease FLOPs; every line = mounted compute), we discover that fitted curves (represented as traces) intently match the empirical factors, indicating our scaling legal guidelines are consultant. The decay price of worth for repeated information is decrease for diffusion, reflecting its better robustness to repeating. On this experiment 100% information fraction means coaching 1 epoch with 100% distinctive information, whereas 50% means 2 epoch epoch with solely utilizing 50% distinctive information and so forth.
Discovering #5:

Muennighoff et al. confirmed that repeating the dataset as much as 4 epochs is almost as efficient as utilizing recent information for autoregressive fashions.
In distinction, we discover that diffusion fashions could be skilled on repeated information for as much as 100 epochs, whereas having repeated information virtually as efficient as recent information.
Discovering #6:
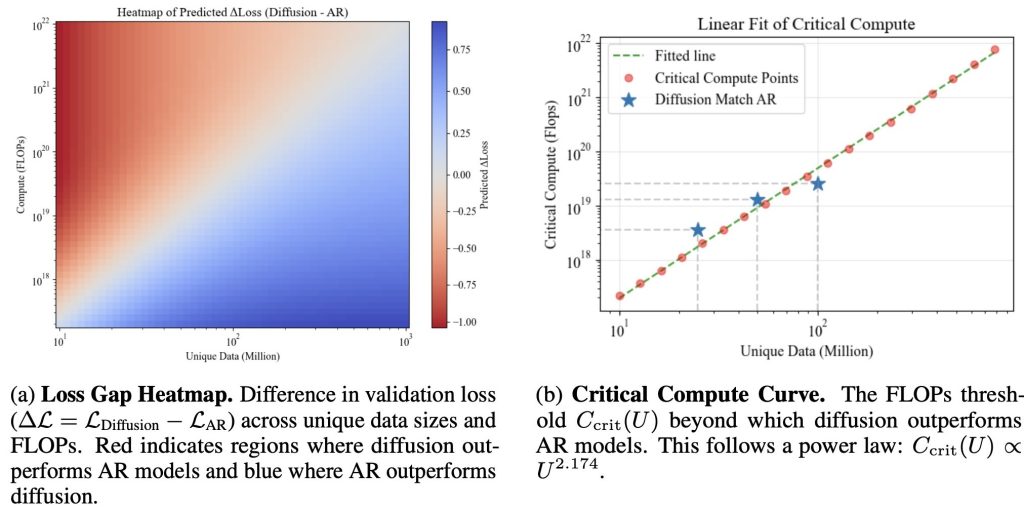
The compute required for diffusion to outperform AR follows a predictable energy legislation. Above we outlined the essential compute threshold as the quantity of FLOPs the place diffusion matches AR efficiency for a given distinctive dataset dimension.

We discover that we are able to derive a easy closed-form analytical expression for this threshold, this permits us to foretell when diffusion will surpass AR given any distinctive information dimension. Within the determine we present each the fitted curve and empirical essential threshold factors, which align intently.
Discovering #7:

The info effectivity of diffusion fashions interprets to raised downstream efficiency.
Lastly we consider the best-performing diffusion and AR fashions (skilled underneath the identical information price range) on a spread of language understanding duties.
Throughout most benchmarks, diffusion fashions outperform AR fashions, confirming that diffusion’s decrease validation loss interprets to raised downstream efficiency.
Discovering #8:
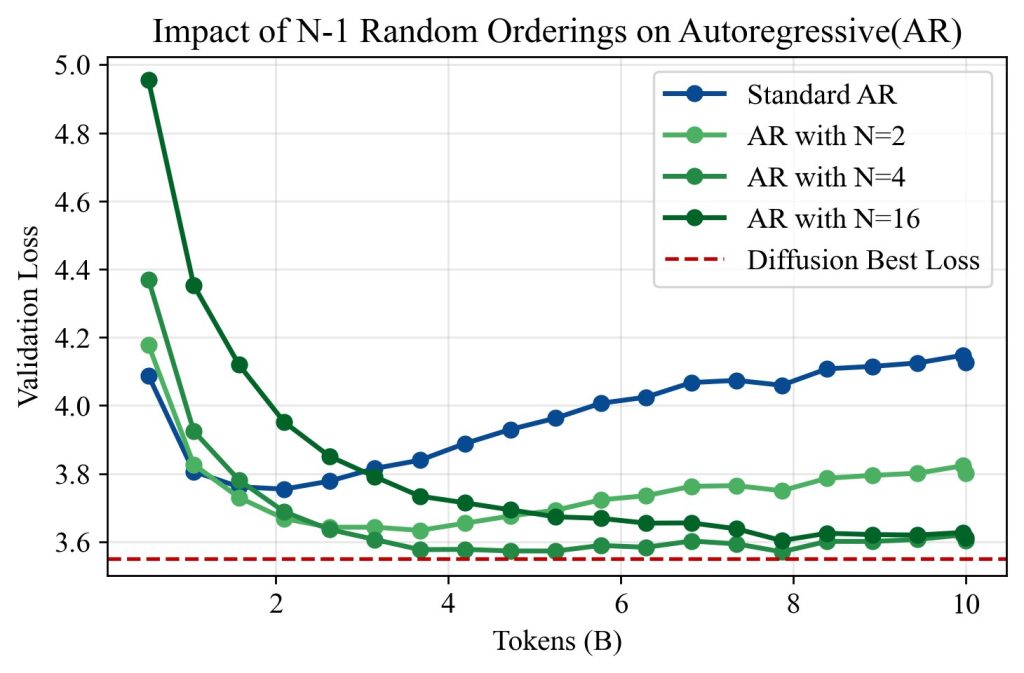
Publicity to totally different token orderings helps clarify diffusion’s information effectivity. By including express information augmentations to AR coaching, we discover that diffusion mannequin’s benefit arises from their publicity to a various set of token orderings.
As seen within the above Determine, rising N persistently lowered validation loss and delayed overfitting. At N = 16, the 100-epoch validation lack of AR fashions approached that of diffusion, suggesting that various orderings are certainly a key driver of diffusion’s information effectivity. These outcomes help our interpretation that diffusion fashions outperform AR fashions in low-data regimes as a result of they’re implicitly skilled on a richer distribution of conditional prediction duties.
Lastly, this evaluation suggests a pure continuum between the 2 paradigms: by controlling process range via masking or reordering—we might design hybrid fashions that interpolate between compute effectivity (AR-like) and information effectivity (diffusion-like).
For extra experiments and particulars please discuss with authentic paper –https://arxiv.org/abs/2507.15857
Conclusion
As the provision of high-quality information plateaus, bettering information effectivity turns into important for scaling deep studying. On this work, we present that masked diffusion fashions persistently outperform autoregressive (AR) fashions in data-constrained regimes — when coaching includes repeated passes over a restricted dataset. We set up new scaling legal guidelines for diffusion fashions, revealing their potential to extract worth from repeated information far past what AR fashions can obtain.
These outcomes problem the traditional perception that AR fashions are universally superior and spotlight diffusion fashions as a compelling different when information—not compute—is the first bottleneck. Wanting forward, environment friendly use of finite information could outline the subsequent frontier in scaling deep studying fashions. Though the research have been carried out within the context of language fashions, we consider these findings ought to apply throughout any type of sequence modeling information, resembling in robotics or healthcare. For practitioners, our takeaway is straightforward: if you’re compute-constrained, use autoregressive fashions; if you’re data-constrained, use diffusion fashions.
Bibtex:
@article{prabhudesai2025diffusion,
title={Diffusion Beats Autoregressive in Information-Constrained Settings},
creator={Prabhudesai, Mihir and Wu, Mengning and Zadeh, Amir and Fragkiadaki, Katerina and Pathak, Deepak},
journal={arXiv preprint arXiv:2507.15857},
yr={2025}
}