The shutdown of the US authorities, about to enter its third week, is beginning to take a toll on US science. Because the shutdown started, the administration of US President Donald Trump has cancelled funding for clean-energy analysis initiatives and laid off public-health staff. The actions of some federally funded museums and laboratories have been suspended, together with the processing of grant purposes by companies such because the Nationwide Science Basis (NSF).
Funding to run the US authorities expired on 1 October after members of the US Congress did not go a spending invoice. Negotiations to finish the deadlock have made little progress. Lawmakers from the opposition Democratic celebration say that they’ll solely go the spending invoice if it extends fashionable health-care subsidies, a situation that Republicans don’t wish to negotiate. “The longer this goes on, the deeper the cuts are going to be,” Vice President JD Vance stated Sunday.
Employees reductions
On supporting science journalism
In case you’re having fun with this text, contemplate supporting our award-winning journalism by subscribing. By buying a subscription you’re serving to to make sure the way forward for impactful tales in regards to the discoveries and concepts shaping our world right this moment.
The Trump administration stated in a courtroom submitting Friday that it’ll lay off 4,100- 4,200 federal workers, an motion formally termed a discount in power (RIF). The Trump administration invoked the absence of a spending invoice as justification for the layoffs, that are an unprecedented measure throughout a shutdown. Unions representing federal staff have filed swimsuit over the layoffs.
Beginning Friday night time, some 1,300 employees members of the US Facilities for Illness Management and Prevention (CDC) obtained RIF notices, though the notices for 700 had been shortly rescinded, in keeping with Native 2883 of the American Federation of Authorities Staff, a union representing CDC workers. The layoffs would “undermine the nation’s skill to reply to public well being emergencies,” a CDC employees member affected by the layoff stated Tuesday at a information convention organized by Native 2883.
Phrase of layoffs on the CDC’s influential Nationwide Well being and Vitamin Examination Survey (NHANES) sparked explicit concern amongst epidemiologists. The programme has been amassing US well being information for the reason that early Sixties, and has helped researchers to know crucial public-health points such because the well being results of lead in petrol.
Former CDC employees member Asher Rosinger, an epidemiologist at Pennsylvania State College in College Park, says CDC staffers instructed him that the layoffs have decimated the NHANES planning department, a workforce he says is crucial to the operation of the programme. “This gold normal survey might not be capable to function sooner or later,” he says.
Double layoff
Some CDC workers have now been laid off twice within the span of half a yr, says mathematical statistician Isaac Michael. On the CDC, Michael and his colleagues ran a survey and database that monitor the expertise of recent moms in the USA — till the whole workforce was laid off in April. A number of courtroom orders have preserved their employment standing for now, although they’re nonetheless not allowed to work even when the federal government reopens. However a few of his colleagues obtained a second layoff discover inside the previous couple of days, making it unlikely they’ll ever be reinstated.
If a state experiences a future uptick in maternal or toddler deaths, “we received’t even know there’s an issue, as a result of we’re not amassing any dependable information, and we received’t be capable to do something to assist”, Michael says.
Andrew Nixon, communications director on the US Division of Well being and Human Companies (HHS), which oversees the CDC, stated that each one HHS workers receiving reduction-in-force notices had been designated as non-essential by their respective divisions, and that the division will proceed to shut “wasteful and duplicative entities”.
The administration’s courtroom submitting stated that the US Environmental Safety Company would lose 20-30 folks. Employees members at US Division of Vitality (DoE) workplaces overseeing renewable power, power effectivity and different areas have additionally obtained RIF notcies, a DoE spokesperson stated. “These workplaces are being realigned to replicate the Trump administration’s dedication to advancing reasonably priced, dependable, and safe power for the American folks,” the spokesperson stated.
Funding cuts
Coinciding with the shutdown, the administration has additionally introduced a recent spherical of cuts to analysis initiatives, including to billions of {dollars} in federal analysis grants revoked since Trump took workplace in January.
On the second day of the shutdown, the DoE introduced that it was slicing nearly US$7.6 billion in funding from 223 power initiatives, lots of them supporting renewable power. An evaluation by Nature discovered that the checklist consists of grants to 33 educational establishments, which have a mixed worth of $620 million.
Colorado State College in Fort Collins, for instance, would lose grants for seven initiatives, together with a $300 million grant to develop expertise to cut back methane emissions from small oil wells. These cuts would imply eliminating analysis positions, Cassandra Moseley, the college’s vp for analysis, stated in an announcement, and would finish analysis “to make the nation’s power infrastructure safer, extra environment friendly, and aggressive.”
An overlapping checklist that has not but been made public consists of 647 initiatives slated for termination, in keeping with the information outlet Semafor and others. The DoE didn’t reply instantly to a request for remark in regards to the grant cuts.
The Division of Protection (DOD) has stated it’s going to pay the salaries of workers furloughed because of the shutdown by tapping $8 billion in leftover funds from its analysis, improvement, check and analysis finances, a few of which is spent on science and expertise funding. It’s not clear how the shift would have an effect on analysis, or whether or not it could be authorized to reallocate the cash with out prior Congressional approval. The DOD didn’t reply to Nature’s questions in regards to the results on analysis.
Science shutdowns
The Smithsonian Establishment runs greater than a dozen museums in Washington DC and a sequence of analysis centres. It ran out of working funds on 12 October and closed lots of its amenities, together with a coastal biology analysis centre in Maryland. Laboratories throughout the analysis division of the US Nationwide Oceanic and Atmospheric Administration are additionally closed.
The NIH and NSF, amongst different companies, have stopped awarding new grants and holding critiques of grants. On the NSF, greater than 40 overview panels in disciplines comparable to astronomy, arithmetic, and chemistry had been scheduled to be held within the first two weeks of October and have been canceled.
Non-federal organizations have additionally been affected. On the Woods Gap Oceanographic Establishment in Massachusetts, actions that depend upon federal collaborations have been disrupted, says public relations director Suzanne Pelisson. In an announcement on Monday, the Georgia Institute of Expertise in Atlanta stated that the shutdown is slowing fee for the college’s federally funded analysis and that the college will halt hiring and take different cost-saving measures if the shutdown lasts past 20 October.
That situation appears more and more probably: the lead Republican within the Home of Representatives, Rep. Mike Johnson, predicted Monday that this will likely be “one of many longest shutdowns in American historical past.” The earlier report holder, in 2019, was 35 days.
This text is reproduced with permission and was first printed on October 15, 2025.
“Deloitte Australia will concern a partial refund to the federal
authorities after admitting that synthetic intelligence had been used
within the creation of a $440,000 report affected by errors together with
three nonexistent educational references and a made-up quote from a Federal
Courtroom judgement.”
One in every of— and doubtless the— central issues with LLM-based instruments is that it’s essential discover that candy spot the place the pliability provides actual worth however the outcomes are simply checked.
I’ve discovered I can get fairly good worth out of one thing like ChatGPT so long as I work in manageable chunks and maintain the method as clear as doable. With coding, that often comes right down to fairly sized macros, features, and queries that I can shortly check for errors. With proofreading, it means solely taking a look at a couple of paragraphs at a time and instructing the chatbot to make minimal corrections and checklist all adjustments.
Utilizing the instrument to provide you with precise data could be very seldom worthwhile. It nearly all the time comes right down to one in every of two excessive circumstances: both the solutions are one thing I might discover in a extra usable kind with a few minutes of looking out or by simply hitting Wikipedia; or confirming the data would take longer (and all the time be much less informative) than doing the analysis myself. Google’s AI is considerably extra helpful, however solely as a result of it supplies related hyperlinks — which I inevitably must comply with to verify the data is sweet.
For larger jobs, you nearly all the time run into the identical underlying drawback that makes autonomous driving so harmful in most conditions. Although it appears paradoxical, people typically discover it simpler to give attention to doing a activity than to give attention to ensuring a activity is being carried out correctly. There’s been a ton of analysis on this in areas like aeronautics. It seems that not solely is it tough to keep up your consideration on an autonomous system; it’s harder the higher the system works. The extra miles your “self-driving” automotive goes with out an incident, the much less possible you’re to be able to seize the wheel when it does.
LLMs additionally play to 2 nice temptations: the will to get that first draft out of the best way and the promise we make ourselves to repair one thing later. First steps might be daunting — typically practically to the purpose of paralysis — however they will very seldom be outsourced. It’s straightforward to see the enchantment of letting an AI-based instrument grind out that preliminary work, however the hassle is twofold. First, the dreary and time-consuming strategy of analysis does greater than merely compile data; it builds understanding on the a part of the researcher. Second, whereas it’s past straightforward to inform ourselves that we are going to diligently test what we’re given, that always seems to be extra dreary and time-consuming than it will have been to easily do the work ourselves within the first place. After some time, consideration wavers and our fact-checking grows extra cursory. Add to that the looming deadlines that govern the lifetime of a advisor, and also you just about assure AI-generated nonsense will make its means into vital and costly reviews.
Given the incentives, I assure you that Australian report just isn’t an remoted incident. It’s exceptional solely as a result of it was detected.
Most buying and selling methods fail as a result of they assume the market behaves the identical on a regular basis. However actual markets shift between calm and chaotic, and methods should adapt accordingly.
This challenge builds a Python-based adaptive buying and selling technique that:
Detects present market regime utilizing a Hidden Markov Mannequin (HMM)
Trains specialist ML fashions (Random Forests) for every regime
Makes use of the most related mannequin based mostly on regime prediction
Filters weak alerts to scale back noise
Compares efficiency vs. Purchase-and-Maintain
Makes use of walk-forward backtesting to stay adaptive over time
Applies this to Bitcoin, however simply extendable to different property
It’s a modular, beginner-friendly framework that you may customise, prolong, and evolve for real-world deployment.
For the reason that weblog closely leans on probabilistic modeling, having prior publicity to Markov processes and their extension into Hidden Markov Fashions is really helpful. For that, Markov Mannequin – An Introduction and Intro to Hidden Markov Chains will present the required conceptual grounding.
A typical motive buying and selling methods fail is that they’re too inflexible.
Let me unpack that.
They apply the identical logic whether or not the market is calm and trending or unstable and chaotic. A technique that works nicely in a single atmosphere can simply collapse in one other.
So, what’s the answer? It may not be a “higher” inflexible technique, however an adaptive one to those “market regimes”.
So, what are we going to do at this time?
We will construct a Python-based buying and selling technique that first tries to determine the market’s present “temper” (or regime) after which makes use of a machine studying mannequin educated particularly for that atmosphere. We’ll stroll by the complete script, perform by perform, so you’ll be able to see the way it all suits collectively.
It is a sensible framework you’ll be able to experiment with and construct on. Let’s get into the code.
Are you prepared? Get your popcorn, eat it with the left hand, scroll down with the correct!
The Basis: Imports and Setup
First issues first, let’s get our imports out of the best way. When you’ve completed any quantitative evaluation in Python, these libraries ought to look acquainted. They’re the usual instruments for information dealing with, machine studying, and finance. For abstract of probably the most helpful libraries, QuantInsti’s Weblog on the Finest Python Libraries for Algorithmic Buying and selling is a good useful resource.
Python code:
Step 1: Getting the Knowledge
In algo buying and selling:No information, no technique!
So, our first perform, get_data, is an easy utility to obtain historic market information utilizing yfinance. We additionally calculate the every day share returns right here, as this will probably be a key enter for our regime detection mannequin later.
Python code:
Step 2: Function Engineering
Uncooked value information alone is not very helpful for a machine studying mannequin. We have to give it extra context. That is the place function engineering is available in.
The engineer_features perform does two principal issues:
Calculates Technical Indicators: It makes use of the ta library to generate dozens of indicators like RSI, MACD, and Bollinger Bands. This offers our mannequin details about momentum, volatility, and tendencies.
Ensures Stationarity: It is a essential step in time sequence evaluation. We take a look at every indicator to see if it is “stationary.” A non-stationary indicator (like a shifting common on a trending inventory) can mislead a mannequin. If an indicator is not stationary, we convert it to a share change to make it extra steady.
Lastly, we outline our goal y_signal: 1 if the worth goes up the subsequent day, and -1 if it goes down. That is what our mannequin will attempt to predict.
Python code:
Step 3: The Backtesting Engine
That is the place the core logic of the technique lives. A backtest reveals how a technique may need carried out previously. We use a “walk-forward” methodology, which is extra real looking than a easy train-test break up as a result of it repeatedly retrains the fashions on more moderen information. This helps the technique adapt to altering market habits over time. To be taught extra about this methodology, try QuantInsti’s article on Stroll-Ahead Optimization.
The run_backtest perform is doing rather a lot, so let’s break it down.
The Code: run_backtest
Python code:
Breaking Down the Backtest Logic
So, you noticed this entire code script and also you stopped consuming your popcorn, proper?
Don’t fear! We bought you lined:
On every day of the backtest, the script performs these steps:
1. Slice the Knowledge:
It creates a window_size (4 years) of the latest historic information to work with.
2. Detect the Market Regime:
It trains a Hidden Markov Mannequin (HMM) on the every day returns of the historic information. The HMM’s job is to seek out hidden “states” within the information. We have set it to seek out two states, which regularly correspond to low-volatility and high-volatility durations.
The HMM then labels every day in our historic information as belonging to both “Regime 0” or “Regime 1”.
3. Prepare Specialist Fashions:
Now, as an alternative of coaching one normal mannequin, we prepare two specialists utilizing Random Forest Classifiers.
Mannequin 0 is educated solely on information the HMM labeled as “Regime 0.” It turns into our low-volatility professional.
Mannequin 1 is educated solely on “Regime 1” information, making it our high-volatility professional.
4. Forecast and Generate a Sign:
First, the HMM predicts the chance of tomorrow being in Regime 0 vs. Regime 1.
We then feed at this time’s information to each specialist fashions. Mannequin 0 offers us its prediction, and Mannequin 1 offers us its prediction. These are chances of an upward transfer.
This is the important thing half: if the HMM is leaning in the direction of Regime 0 for tomorrow, we use the sign from Mannequin 0. If it expects Regime 1, we use the sign from Mannequin 1.
5. Filter Out Weak Alerts as a Danger Administration Software:
We do not wish to commerce on each minor sign. A 51% chance is not very convincing. We set a restrict threshold.
We solely go lengthy (1) if the chosen mannequin’s chance is excessive sufficient (e.g., > 0.53).
In any other case, we keep impartial (0). This helps filter out noise.
Step 4&5: Visualizing Outcomes and Operating the Script
In any case that work, we have to see if it paid off. The plot_results perform calculates the technique’s cumulative returns and plots them in opposition to a easy Purchase-and-Maintain technique for comparability.
Python code:
The compute_perf_stats perform prints a desk with related metrics to guage the efficiency of each methods.
Python code:
Final however not least, the principle execution block (if __name__ == ‘__main__’:) is the place you set the parameters just like the ticker and date vary, and run the entire course of.
For this train, we use Bitcoin as our most popular asset. Import information from 2008 to 2025, present backtesting outcomes from January 2024, and create the prediction function with the primary lead of the close-to-close returns.
Python code:
See the plot:
And the efficiency stats desk:
Purchase & Maintain
Technique
Annual return
50.21%
53.55%
Cumulative returns
136.83%
148.11%
Annual volatility
43.06%
26.24%
Sharpe ratio
1.16
1.76
Calmar ratio
1.78
2.67
Max drawdown
-28.14%
-20.03%
Sortino ratio
1.83
3.03
The outcomes look promising as a result of the technique returns have decrease volatility than the buy-and-hold returns. Though that is only a pattern. There are some issues you are able to do to enhance the outcomes:
Add extra enter options
Add risk-management thresholds
As an alternative of coaching your ML mannequin within the regime-specific coaching samples, you’ll be able to generate a number of paths of artificial information based mostly on every regime and optimize your ML mannequin based mostly on these artificial samples. Take a look at our weblog, TGAN for buying and selling.
You need to use extra ML fashions for every regime and create the sign based mostly on a meta learner.
Steadily Requested Questions
1. What’s a “market regime”?
A market regime is a broad characterisation of market behaviour, reminiscent of excessive volatility versus low volatility. This framework makes use of machine studying (HMM) to detect such regimes dynamically.
2. Why prepare separate fashions for various regimes?
As a result of one-size-fits-all fashions would possibly are likely to underperform in some circumstances. Fashions educated on particular market circumstances could be higher at capturing habits patterns related to that regime.
3. What sort of information does this technique use?
Worth information from Yahoo Finance through yfinance
Engineered options like RSI, MACD, Bollinger Bands
Every day returns and their regime-labeled patterns
4. What machine studying fashions are used?
Hidden Markov Fashions (HMMs) to categorise regimes
Random Forest Classifiers for predicting the subsequent transfer inside every regime
(Optionally) Meta learners or ensemble fashions will be added later
5. What’s “walk-forward” backtesting?
A practical analysis methodology the place the mannequin is retrained over increasing home windows of historic information. This simulates how a technique would possibly behave when deployed dwell.
6. Why Bitcoin?
Bitcoin provides excessive volatility, clear regime shifts, and steady market entry, making it best for showcasing adaptive methods. However the framework works for shares, foreign exchange, or futures too.
7. Can I run this with out coding?
Some coding information is required, notably in Python, pandas, and scikit-learn. However the features are modular, well-commented, and beginner-friendly.
8. How can I enhance this technique?
Add extra engineered options (quantity, macro information, sentiment, and so on.)
Use artificial information to reinforce coaching
Add stop-loss or drawdown thresholds
Experiment with completely different ML fashions (XGBoost, LSTMs, Transformers)
Add a meta learner to mix mannequin predictions
Conclusion
By figuring out the market state first after which making use of a specialist mannequin, this technique builds adaptability into its core logic. It’s much less about having a single excellent mannequin and extra about having the correct mannequin for the correct circumstances.
What we have constructed here’s a framework for enthusiastic about market dynamics. One of the best ways to be taught is by doing, so I encourage you to seize the script and play with it. Strive completely different tickers, modify the conviction restrict, swap out the Random Forest for one more mannequin, or add new options. It is a strong basis for creating your individual sturdy buying and selling methods.
Subsequent Steps
When you’ve labored by the weblog and perceive how regime classification and mannequin choice work in tandem, you would possibly wish to construct on this framework utilizing extra superior instruments.
On the similar time, sturdy danger administration is essential when utilizing a number of fashions, and Place Sizing in Buying and selling provides a sensible framework for capital allocation based mostly on mannequin confidence and volatility.
For structured studying, the Technical Indicators & Methods in Python course on Quantra gives a basis in technique design utilizing rule-based indicators, serving to you distinction them together with your machine-learning strategy.
When you’re involved in diving deeper into supervised studying, mannequin analysis, and time-series forecasting, you’ll discover the Machine Studying & Deep Studying in Buying and selling studying monitor on Quantra extremely related.
Lastly, in case you are on the lookout for an end-to-end program to take your strategy-building journey additional, from idea to dwell deployment, the Government Programme in Algorithmic Buying and selling (EPAT) provides a complete curriculum, together with modules on machine studying, backtesting, and API integration with brokers.
Disclaimer: This weblog publish is for informational and academic functions solely. It doesn’t represent monetary recommendation or a suggestion to commerce any particular property or make use of any particular technique. All buying and selling and funding actions contain vital danger. At all times conduct your individual thorough analysis, consider your private danger tolerance, and think about in search of recommendation from a certified monetary skilled earlier than making any funding choices.
On this information, we’ll embark on a journey to grasp heaps from the bottom up. We’ll begin by demystifying what heaps are and their inherent properties. From there, we’ll dive into Python’s personal implementation of heaps, the heapq module, and discover its wealthy set of functionalities. So, in case you’ve ever questioned effectively handle a dynamic set of information the place the very best (or lowest) precedence component is regularly wanted, you are in for a deal with.
What’s a Heap?
The very first thing you’d wish to perceive earlier than diving into the utilization of heaps is what’s a heap. A heap stands out on the earth of information constructions as a tree-based powerhouse, notably expert at sustaining order and hierarchy. Whereas it’d resemble a binary tree to the untrained eye, the nuances in its construction and governing guidelines distinctly set it aside.
One of many defining traits of a heap is its nature as a full binary tree. Which means that each stage of the tree, besides maybe the final, is totally stuffed. Inside this final stage, nodes populate from left to proper. Such a construction ensures that heaps could be effectively represented and manipulated utilizing arrays or lists, with every component’s place within the array mirroring its placement within the tree.
The true essence of a heap, nonetheless, lies in its ordering. In a max heap, any given node’s worth surpasses or equals the values of its youngsters, positioning the biggest component proper on the root. Then again, a min heap operates on the alternative precept: any node’s worth is both lower than or equal to its youngsters’s values, making certain the smallest component sits on the root.
Recommendation: You’ll be able to visualize a heap as a pyramid of numbers. For a max heap, as you ascend from the bottom to the height, the numbers improve, culminating within the most worth on the pinnacle. In distinction, a min heap begins with the minimal worth at its peak, with numbers escalating as you progress downwards.
As we progress, we’ll dive deeper into how these inherent properties of heaps allow environment friendly operations and the way Python’s heapq module seamlessly integrates heaps into our coding endeavors.
Traits and Properties of Heaps
Heaps, with their distinctive construction and ordering ideas, carry forth a set of distinct traits and properties that make them invaluable in varied computational situations.
At the beginning, heaps are inherently environment friendly. Their tree-based construction, particularly the whole binary tree format, ensures that operations like insertion and extraction of precedence components (most or minimal) could be carried out in logarithmic time, sometimes O(log n). This effectivity is a boon for algorithms and purposes that require frequent entry to precedence components.
One other notable property of heaps is their reminiscence effectivity. Since heaps could be represented utilizing arrays or lists with out the necessity for specific tips that could baby or mother or father nodes, they’re space-saving. Every component’s place within the array corresponds to its placement within the tree, permitting for predictable and easy traversal and manipulation.
The ordering property of heaps, whether or not as a max heap or a min heap, ensures that the basis at all times holds the component of highest precedence. This constant ordering is what permits for fast entry to the top-priority component with out having to look via all the construction.
Moreover, heaps are versatile. Whereas binary heaps (the place every mother or father has at most two youngsters) are the most typical, heaps could be generalized to have greater than two youngsters, generally known as d-ary heaps. This flexibility permits for fine-tuning based mostly on particular use circumstances and efficiency necessities.
Lastly, heaps are self-adjusting. Every time components are added or eliminated, the construction rearranges itself to take care of its properties. This dynamic balancing ensures that the heap stays optimized for its core operations always.
Recommendation: These properties made heap knowledge construction an excellent match for an environment friendly sorting algorithm – heap type. To study extra about heap type in Python, learn our “Heap Kind in Python” article.
As we delve deeper into Python’s implementation and sensible purposes, the true potential of heaps will unfold earlier than us.
Varieties of Heaps
Not all heaps are created equal. Relying on their ordering and structural properties, heaps could be categorized into differing kinds, every with its personal set of purposes and benefits. The 2 essential classes are max heap and min heap.
Essentially the most distinguishing function of a max heap is that the worth of any given node is larger than or equal to the values of its youngsters. This ensures that the biggest component within the heap at all times resides on the root. Such a construction is especially helpful when there is a must regularly entry the utmost component, as in sure precedence queue implementations.
The counterpart to the max heap, a min heap ensures that the worth of any given node is lower than or equal to the values of its youngsters. This positions the smallest component of the heap on the root. Min heaps are invaluable in situations the place the least component is of prime significance, akin to in algorithms that take care of real-time knowledge processing.
Past these main classes, heaps can be distinguished based mostly on their branching issue:
Whereas binary heaps are the most typical, with every mother or father having at most two youngsters, the idea of heaps could be prolonged to nodes having greater than two youngsters. In a d-ary heap, every node has at most d youngsters. This variation could be optimized for particular situations, like lowering the peak of the tree to hurry up sure operations.
Binomial Heap is a set of binomial timber which might be outlined recursively. Binomial heaps are utilized in precedence queue implementations and supply environment friendly merge operations.
Named after the well-known Fibonacci sequence, the Fibonacci heap gives better-amortized working occasions for a lot of operations in comparison with binary or binomial heaps. They’re notably helpful in community optimization algorithms.
Python’s Heap Implementation – The heapq Module
Python gives a built-in module for heap operations – the heapq module. This module gives a set of heap-related capabilities that permit builders to remodel lists into heaps and carry out varied heap operations with out the necessity for a customized implementation. Let’s dive into the nuances of this module and the way it brings you the facility of heaps.
The heapq module does not present a definite heap knowledge kind. As a substitute, it gives capabilities that work on common Python lists, remodeling and treating them as binary heaps.
This method is each memory-efficient and integrates seamlessly with Python’s present knowledge constructions.
That implies that heaps are represented as lists in heapq. The fantastic thing about this illustration is its simplicity – the zero-based record index system serves as an implicit binary tree. For any given component at place i, its:
Left Baby is at place 2*i + 1
Proper Baby is at place 2*i + 2
Mum or dad Node is at place (i-1)//2
This implicit construction ensures that there is not any want for a separate node-based binary tree illustration, making operations easy and reminiscence utilization minimal.
House Complexity: Heaps are sometimes applied as binary timber however do not require storage of specific pointers for baby nodes. This makes them space-efficient with an area complexity of O(n) for storing n components.
It is important to notice that the heapq module creates min heaps by default. Which means that the smallest component is at all times on the root (or the primary place within the record). If you happen to want a max heap, you’d need to invert order by multiplying components by -1 or use a customized comparability operate.
Python’s heapq module gives a collection of capabilities that permit builders to carry out varied heap operations on lists.
Notice: To make use of the heapq module in your software, you will must import it utilizing easy import heapq.
Take a look at our hands-on, sensible information to studying Git, with best-practices, industry-accepted requirements, and included cheat sheet. Cease Googling Git instructions and truly study it!
Within the following sections, we’ll dive deep into every of those elementary operations, exploring their mechanics and use circumstances.
The way to Remodel a Listing right into a Heap
The heapify() operate is the place to begin for a lot of heap-related duties. It takes an iterable (sometimes a listing) and rearranges its components in-place to fulfill the properties of a min heap:
This can output a reordered record that represents a legitimate min heap:
[1, 1, 2, 3, 3, 9, 4, 6, 5, 5, 5]
Time Complexity: Changing an unordered record right into a heap utilizing the heapify operate is an O(n) operation. This might sound counterintuitive, as one would possibly count on it to be O(nlogn), however as a result of tree construction’s properties, it may be achieved in linear time.
The way to Add an Aspect to the Heap
The heappush() operate lets you insert a brand new component into the heap whereas sustaining the heap’s properties:
Working the code gives you a listing of components sustaining the min heap property:
[3, 5, 7]
Time Complexity: The insertion operation in a heap, which entails putting a brand new component within the heap whereas sustaining the heap property, has a time complexity of O(logn). It is because, within the worst case, the component may need to journey from the leaf to the basis.
The way to Take away and Return the Smallest Aspect from the Heap
The heappop() operate extracts and returns the smallest component from the heap (the basis in a min heap). After elimination, it ensures the record stays a legitimate heap:
Notice: The heappop() is invaluable in algorithms that require processing components in ascending order, just like the Heap Kind algorithm, or when implementing precedence queues the place duties are executed based mostly on their urgency.
This can output the smallest component and the remaining record:
1
[3, 7, 5, 9]
Right here, 1 is the smallest component from the heap, and the remaining record has maintained the heap property, even after we eliminated 1.
Time Complexity: Eradicating the basis component (which is the smallest in a min heap or largest in a max heap) and reorganizing the heap additionally takes O(logn) time.
The way to Push a New Merchandise and Pop the Smallest Merchandise
The heappushpop() operate is a mixed operation that pushes a brand new merchandise onto the heap after which pops and returns the smallest merchandise from the heap:
This can output 3, the smallest component, and print out the brand new heap record that now contains 4 whereas sustaining the heap property:
3
[4, 5, 7, 9]
Notice: Utilizing the heappushpop() operate is extra environment friendly than performing operations of pushing a brand new component and popping the smallest one individually.
The way to Change the Smallest Merchandise and Push a New Merchandise
The heapreplace() operate pops the smallest component and pushes a brand new component onto the heap, multi function environment friendly operation:
This prints 1, the smallest component, and the record now contains 4 and maintains the heap property:
1
[4, 5, 7, 9]
Notice: heapreplace() is helpful in streaming situations the place you wish to change the present smallest component with a brand new worth, akin to in rolling window operations or real-time knowledge processing duties.
Discovering A number of Extremes in Python’s Heap
nlargest(n, iterable[, key]) and nsmallest(n, iterable[, key]) capabilities are designed to retrieve a number of largest or smallest components from an iterable. They are often extra environment friendly than sorting all the iterable once you solely want a number of excessive values. For instance, say you’ve gotten the next record and also you wish to discover three smallest and three largest values within the record:
knowledge = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
Right here, nlargest() and nsmallest() capabilities can turn out to be useful:
This gives you two lists – one accommodates the three largest values and the opposite accommodates the three smallest values from the knowledge record:
[9, 6, 5]
[1, 1, 2]
The way to Construct Your Customized Heap
Whereas Python’s heapq module gives a strong set of instruments for working with heaps, there are situations the place the default min heap habits may not suffice. Whether or not you are seeking to implement a max heap or want a heap that operates based mostly on customized comparability capabilities, constructing a customized heap could be the reply. Let’s discover tailor heaps to particular wants.
Implementing a Max Heap utilizing heapq
By default, heapq creates min heaps. Nonetheless, with a easy trick, you should utilize it to implement a max heap. The concept is to invert the order of components by multiplying them by -1 earlier than including them to the heap:
With this method, the biggest quantity (when it comes to absolute worth) turns into the smallest, permitting the heapq capabilities to take care of a max heap construction.
Heaps with Customized Comparability Features
Generally, you would possibly want a heap that does not simply evaluate based mostly on the pure order of components. As an illustration, in case you’re working with advanced objects or have particular sorting standards, a customized comparability operate turns into important.
To attain this, you may wrap components in a helper class that overrides the comparability operators:
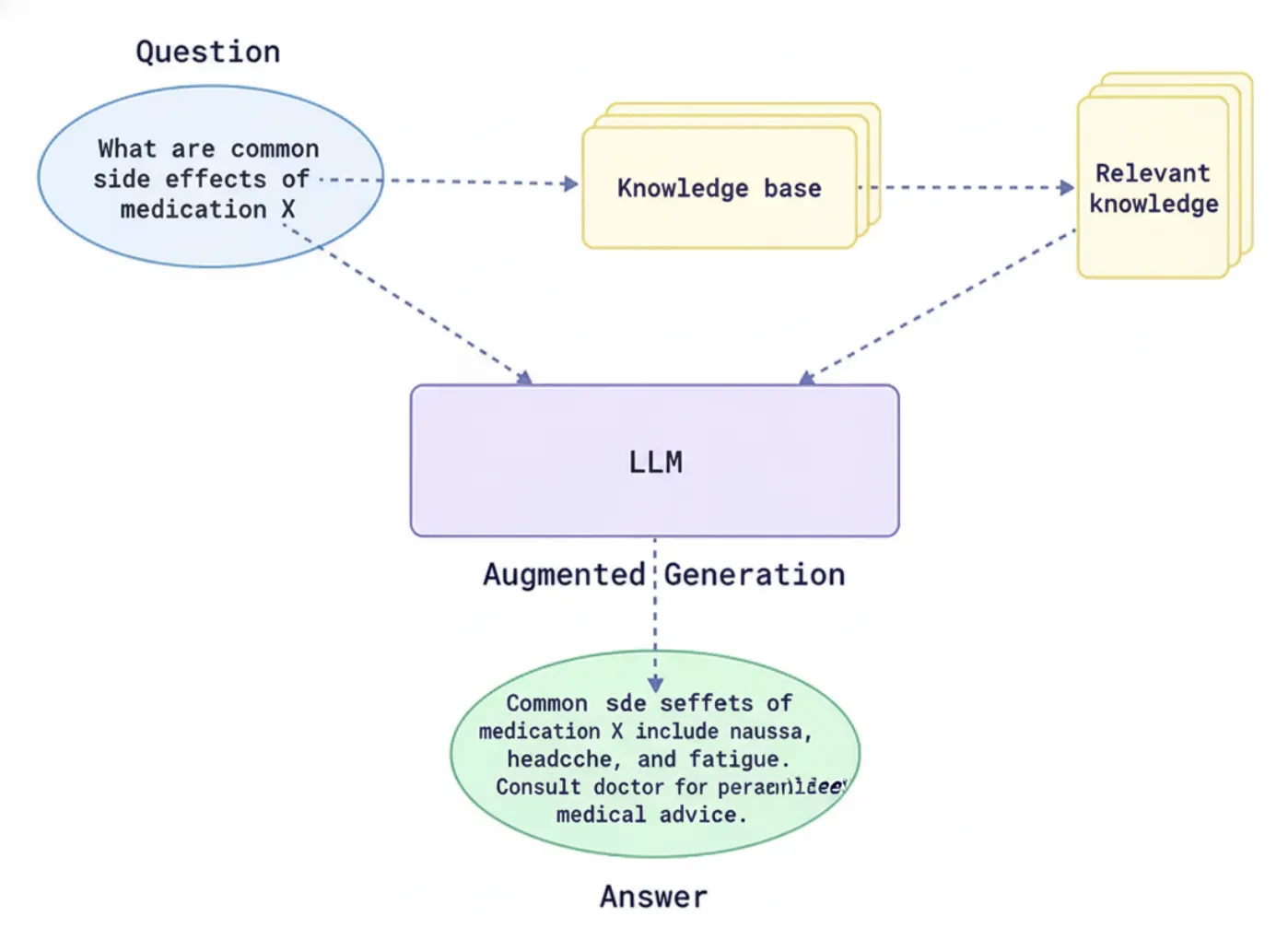
The ecosystem of retrieval-augmented technology (RAG) has taken off within the final couple of years. Increasingly open-source tasks, geared toward serving to builders construct RAG purposes, at the moment are seen throughout the web. And why not? RAG is an efficient methodology to enhance massive language fashions (LLMs) with an exterior information supply. So we thought, why not share the very best GitHub repositories for mastering RAG programs with our readers?
However earlier than we try this, here’s a little about RAG and its purposes.
RAG pipelines function within the following approach:
The system retrieves paperwork or knowledge,
Knowledge that’s informative or helpful for the context of finishing that consumer immediate, and
The system feeds that context into an LLM to supply a response that’s correct and educated for that context.
As talked about, we’ll discover completely different open-source RAG frameworks and their GitHub repositories right here that allow customers to simply construct RAG programs. The intention is to assist builders, college students, and tech fanatics select an RAG toolkit that fits their wants and make use of it.
Why You Ought to Grasp RAG Programs
Retrieval-Augmented Era has shortly emerged as some of the impactful improvements within the discipline of AI. As firms place increasingly more concentrate on implementing smarter programs with context consciousness, mastering it’s now not optionally available. Corporations are using RAG pipelines for chatbots, information assistants, and enterprise automation. That is to make sure that their AI fashions are using real-time, domain-specific knowledge, moderately than relying solely on pre-trained information.
Within the age when RAG is getting used to automate smarter chatbots, assistants, and enterprise instruments, understanding it totally can provide you an ideal aggressive edge. Realizing the right way to construct and optimize RAG pipelines can open up numerous doorways in AI growth, knowledge engineering, and automation. This shall finally make you extra marketable and future-proof your profession.
Advantages of RAG (Picture: AnalyticsVidhya)
Within the quest for that mastery, listed below are the highest GitHub repositories for RAG programs. However earlier than that, a have a look at how these RAG frameworks truly assist.
What Does the RAG Framework Do?
The Retrieval-Augmented Era (RAG) framework is a complicated AI structure developed to enhance the capabilities of LLMs by integrating exterior data into the response technology course of. This makes the LLM responses extra knowledgeable or temporally related than the information used when initially setting up the language mannequin. The mannequin can retrieve related paperwork or knowledge from exterior databases or information repositories (APIs). It might then use it to generate responses primarily based on consumer inquiries moderately than merely counting on the information from the initially skilled mannequin.
Structure of RAG (Picture: AnalyticsVidhya)
This allows the mannequin to course of questions and develop solutions which are additionally appropriate, date-sensitive, or related to context. In the meantime, they’ll additionally mitigate points associated to information cut-off and hallucination, or incorrect responses to prompts. By connecting to each normal and domain-specific information sources, RAG permits an AI system to offer accountable, reliable responses.
Functions of this are throughout use instances, like buyer assist, search, compliance, knowledge analytics, and extra. RAG programs additionally remove the necessity to regularly retrain the mannequin or try to serve particular person consumer responses by means of the mannequin being skilled.
High Repositories to Grasp the RAG Programs
Now that we all know how RAG programs assist, allow us to discover the highest GitHub repositories with detailed tutorials, code, and sources for mastering RAG programs. These GitHub repositories will show you how to grasp the instruments, expertise, frameworks, and theories needed for working with RAG programs.
1. LangChain
LangChain is an entire LLM toolkit that permits builders to create refined purposes with options reminiscent of prompts, reminiscences, brokers, and knowledge connectors. From loading paperwork to splitting textual content, embedding and retrieval, and producing outputs, LangChain gives modules for every step of a RAG pipeline.
LangChain (know all about it right here) boasts a wealthy ecosystem of integrations with suppliers reminiscent of OpenAI, Hugging Face, Azure, and plenty of others. It additionally helps a number of languages, together with Python, JavaScript, and TypeScript. LangChain encompasses a step-by-step process design, permitting you to combine and match instruments, construct agent workflows, and use built-in chains.
LangChain’s core function set features a instrument chaining system, wealthy immediate templates, and first-class assist for brokers and reminiscence.
LangChain is open-source (MIT license) with an enormous neighborhood (70K+ GitHub stars)
Elements: Immediate templates, LLM wrappers, vectorstore connectors, brokers (instruments + reasoning), reminiscences, and many others.
Integrations: LangChain helps many LLM suppliers (OpenAI, Azure, native LLMs), embedding fashions, and vector shops (FAISS, Pinecone, Chroma, and many others.).
LangChain’s high-level APIs make easy RAG pipelines concise. For instance, right here we use LangChain to reply a query utilizing a small set of paperwork with OpenAI’s embeddings and LLM:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# Pattern paperwork to index
docs = ["RAG stands for retrieval-augmented generation.", "It combines search and LLMs for better answers."]
# 1. Create embeddings and vector retailer
vectorstore = FAISS.from_texts(docs, OpenAIEmbeddings())
# 2. Construct a QA chain (LLM + retriever)
qa = RetrievalQA.from_chain_type(
llm=OpenAI(model_name="text-davinci-003"),
retriever=vectorstore.as_retriever()
)
# 3. Run the question
outcome = qa({"question": "What does RAG imply?"})
print(outcome["result"])
This code takes the docs and masses them right into a FAISS vector retailer utilizing OpenAI embeds. It then makes use of RetrievalQA to seize the related context and generate a solution. LangChain abstracts away the retrieval and LLM name. (For added directions, please discuss with the LangChain APIs and Tutorials.)
Haystack, by deepset, is an RAG framework designed for an enterprise that’s constructed round composable pipelines. The primary thought is to have a graph-like pipeline. The one by which you wire collectively nodes (i.e, parts), reminiscent of retrievers, readers, and turbines, right into a directed graph. Haystack is designed for deployment in prod and presents many decisions of backends Elasticsearch, OpenSearch, Milvus, Qdrant, and plenty of extra, for doc storage and retrieval.
It presents each keyword-based (BM25) and dense retrieval and makes it straightforward to plug in open-source readers (Transformers QA fashions) or generative reply turbines.
It’s open-source (Apache 2.0) and really mature (10K+ stars).
Structure: Pipeline-centric and modular. Nodes could be plugged in and swapped precisely.
Elements embody: Doc shops (Elasticsearch, In-Reminiscence, and many others.), retrievers (BM25, Dense), readers (e.g., Hugging Face QA fashions), and turbines (OpenAI, native LLMs).
Ease of Scaling: Distributed setup (Elasticsearch clusters), GPU assist, REST APIs, and Docker.
Attainable Use Instances embody: RAG for search, doc QA, recap purposes, and monitoring consumer queries.
Utilization Instance
Beneath is a simplified instance utilizing Haystack’s trendy API (v2) to create a small RAG pipeline:
from haystack.document_stores import InMemoryDocumentStore
from haystack.nodes import BM25Retriever, OpenAIAnswerGenerator
from haystack.pipelines import Pipeline
# 1. Put together a doc retailer
doc_store = InMemoryDocumentStore()
paperwork = [{"content": "RAG stands for retrieval-augmented generation."}]
doc_store.write_documents(paperwork)
# 2. Arrange retriever and generator
retriever = BM25Retriever(document_store=doc_store)
generator = OpenAIAnswerGenerator(model_name="text-davinci-003")
# 3. Construct the pipeline
pipe = Pipeline()
pipe.add_node(element=retriever, identify="Retriever", inputs=[])
pipe.add_node(element=generator, identify="Generator", inputs=["Retriever"])
# 4. Run the RAG question
outcome = pipe.run(question="What does RAG imply?")
print(outcome["answers"][0].reply)
This code writes one doc into an in-memory retailer, makes use of BM25 to seek out related textual content, then asks the OpenAI mannequin to reply. Haystack’s Pipeline orchestrates the circulate. For extra, examine deepset repository right here.
LlamaIndex, previously often known as GPT Index, is a data-centric RAG framework centered on indexing and querying your knowledge for LLM use. Think about LlamaIndex as a set of instruments used to construct customized indexes over paperwork (vectors, key phrase indexes, graphs) after which question them. LlamaIndex is a robust method to join completely different knowledge sources like textual content recordsdata, APIs, and SQL to LLMs utilizing index constructions.
For instance, you possibly can create a vector index of your whole recordsdata, after which use a built-in question engine to reply any questions you might have, all utilizing LlamaIndex. LlamaIndex provides high-level APIs and low-level modules to have the ability to customise each a part of the RAG course of.
LlamaIndex is open supply (MIT License) with a rising neighborhood (45K+ stars)
Knowledge connectors: (For PDFs, docs, net content material), a number of index varieties (vector retailer, tree, graph), and a question engine that lets you navigate effectively.
Merely plug it into LangChain or different frameworks. LlamaIndex works with any LLM/embedding (OpenAI, Hugging Face, native LLMs).
LlamaIndex means that you can construct your RAG brokers extra simply by mechanically creating the index after which fetching the context from the index.
Utilization Instance
LlamaIndex makes it very straightforward to create a searchable index from paperwork. As an illustration, utilizing the core API:
from llama_index import VectorStoreIndex, SimpleDirectoryReader
# 1. Load paperwork (all recordsdata within the 'knowledge' listing)
paperwork = SimpleDirectoryReader("./knowledge").load_data()
# 2. Construct a vector retailer index from the docs
index = VectorStoreIndex.from_documents(paperwork)
# 3. Create a question engine from the index
query_engine = index.as_query_engine()
# 4. Run a question towards the index
response = query_engine.question("What does RAG imply?")
print(response)
This code will learn recordsdata within the ./knowledge listing, index them in reminiscence, after which question the index. LlamaIndex returns the reply as a string. For extra, examine the Llamindex repository right here.
RAGFlow is an RAG engine designed for enterprises from InfiniFlow to accommodate complicated and large-scale knowledge. It refers back to the aim of “deep doc understanding” in an effort to parse completely different codecs reminiscent of PDFs, scanned paperwork, photographs, or tables, and summarize them into organized chunks.
RAGFlow options an built-in retrieval mannequin with agent templates and visible tooling for debugging. Key components are the superior template-based chunking for the paperwork and the notion of grounded citations. It helps with lowering hallucinations as a result of you possibly can know which supply texts assist which reply.
RAGFlow is open-source (Apache-2.0) with a robust neighborhood (65K stars).
Highlights: parsing of deep paperwork (i.e., breaking down tables, photographs, and multi-policy paperwork), doc chunking with template guidelines (customized guidelines for managing paperwork), and citations to indicate the right way to doc provenance to reply questions.
Workflow: RAGFlow is used as a service, which suggests you begin a server (utilizing Docker), after which index your paperwork, both by means of a UI or API. RAGFlow additionally has CLI instruments and Python/REST APIs for constructing chatbots.
Use Instances: Massive enterprises coping with heavy paperwork and helpful use instances the place code-based traceability and accuracy are a requisite.
This instance illustrates the chat completion API of RAGFlow, which is suitable with OpenAI. It sends a chat message to the “default” assistant, and the assistant will use the listed paperwork as a context. For extra, examine the repository.
5. txtai
txtai is an all-in-one AI framework that gives semantic search, embeddings, and RAG pipelines. It comes with an embeddable vector-searchable database, stemming from SQLite+FAISS, and utilities that can help you orchestrate LLM calls. With txtai, upon getting created an Embedding index utilizing your textual content knowledge, it is best to both be part of it to an LLM manually within the code or use the built-in RAG helper.
What I actually like about txtai is its simplicity: it could run 100% regionally (no cloud), it has a template inbuilt for a RAG pipeline, and it even gives autogenerated FastAPI companies. It’s also open supply (Apache 2.0), straightforward to prototype and deploy.
Capabilities: Semantic search index (vector DB), RAG pipeline, and FastAPI service technology.
RAG assist: txtai has a RAG class, taking in an Embeddings occasion and an LLM, which mechanically glues the retrieved context into LLM prompts for you.
LLM flexibility: Use OpenAI, Hugging Face transformers, llama.cpp, or any mannequin you need with your personal LLM interface.
Right here’s how easy it’s to run a RAG question in txtai utilizing the built-in pipeline:
from txtai import Embeddings, LLM, RAG
# 1. Initialize txtai parts
embeddings = Embeddings() # makes use of an area FAISS+SQLite by default
embeddings.index([{"id": "doc1", "text": "RAG stands for retrieval-augmented generation."}])
llm = LLM("text-davinci-003") # or any mannequin
# 2. Create a RAG pipeline
immediate = "Reply the query utilizing solely the context under.nnQuestion: {query}nContext: {context}"
rag = RAG(embeddings, llm, template=immediate)
# 3. Run the RAG question
outcome = rag("What does RAG imply?", maxlength=512)
print(outcome["answer"])
This code snippet takes a single doc and runs a RAG pipeline. The RAG helper manages the retrieval for related passages from the vector index and fill {context} within the immediate template. It’s going to can help you wrap your RAG pipeline code in an excellent layer of construction with APIs and no-code UI. Cognita does use LangChain/LlamaIndex modules beneath the hood, however organizes them with construction: knowledge loaders, parsers, embedders, retrievers, and metric modules. For extra, examine the repository right here.
6. LLMWare
LLMWare is an entire RAG framework that has a robust deviation in the direction of “smaller” specialised mannequin inference that’s safe and quicker. Most frameworks use a big cloud LLM. LLMWare runs desktop RAG pipelines with the mandatory computing energy on a desktop or native server. It limits the danger of knowledge publicity whereas nonetheless using safe LLMs for large-scale pilot research and varied purposes.
LLMWare has no-code wizards and templates for the same old RAG performance, together with the performance of doc parsing and indexing. It additionally has tooling for varied doc codecs (Workplace and PDF) which are helpful first steps for the cognitive AI performance to doc evaluation.
Open supply product (Apache-2.0, 14K+ stars) for enterprise RAG
An method that focuses on “smaller” LLMs (Ex: Llama 7B variants) and inference runs on a tool whereas providing RAG functionalities even on ARM gadgets
Tooling: providing CLI and REST APIs, interactive UIs, and pipeline templates
Distinctive Traits: preconfigured pipelines, built-in capabilities for fact-checking, and plugin options for vector search and Q&As.
Examples: enterprises pursuing RAG however can’t ship knowledge to the cloud, e.g. monetary companies, healthcare, or builders of cell/edge AI purposes.
Utilization Instance
LLMWare’s API is designed to be straightforward. Right here’s a primary instance primarily based on their docs:
from llmware.prompts import Immediate
from llmware.fashions import ModelCatalog
# 1. Load a mannequin for prompting
prompter = Immediate().load_model("llmware/bling-tiny-llama-v0")
# 2. (Optionally) index a doc to make use of as context
prompter.add_source_document("./knowledge", "doc.pdf", question="What's RAG?")
# 3. Run the question with context
response = prompter.prompt_with_source("What's RAG?")
print(response)
This code makes use of an LLMWare Immediate object. We first specify a mannequin (for instance, a small Llama mannequin from Hugging Face). We then add a folder that incorporates supply paperwork. LLMWare parses “doc.pdf” into chunks and filters primarily based on relevance to the consumer’s query. The prompt_with_source operate then makes a request, passing the related context from the supply. This returns a textual content reply and metadata response. For extra, examine the repository right here.
7. Cognita
Cognita by TrueFoundary is a production-ready RAG framework constructed for scalability and collaboration. It’s primarily about making it straightforward to go from a pocket book or experiment to deployment/service. It helps incremental indexing and has an online UI for non-developers to strive importing paperwork, choosing fashions, and querying them in actual time.
That is open supply (Apache-2.0)
Structure: Totally API-based and containerized, it could run totally regionally by means of Docker Compose (together with the UI).
Elements: Reusable libraries for parsers, loaders, embedders, retrievers, and extra. The whole lot could be custom-made and scaled.
UI – Extensibility: An online frontend is offered for experimentation and a “mannequin gateway” to handle the LLM/embedder configurations. This helps when each the developer and the analyst work collectively to construct out RAG pipeline parts.
Utilization Instance
Cognita is primarily accessed by means of its command-line interface and inner API, however this can be a conceptual pseudo snipped utilizing its Python API:
from cognita.pipeline import Pipeline
from cognita.schema import Doc
# Initialize a brand new RAG pipeline
pipeline = Pipeline.create("rag")
# Add paperwork (with textual content content material)
docs = [Document(id="1", text="RAG stands for retrieval-augmented generation.")]
pipeline.index_documents(docs)
# Question the pipeline
outcome = pipeline.question("What does RAG imply?")
print(outcome['answer'])
In an actual implementation, you’ll use YAML to configure Cognita or use its CLI as a substitute to load the information and kick off a service. The earlier snippet describes the circulate: you create a pipeline, index your knowledge, then ask questions. Cognita documentation has extra particulars. For extra, examine the whole documentation right here. This returns a textual content reply and metadata response. For extra, examine the repository right here.
Conclusion
These open-source GitHub repositories for RAG programs supply intensive toolkits for builders, researchers, and hobbyists.
LangChain and LlamaIndex supply versatile APIs for setting up custom-made pipelines and indexing options.
Haystack presents NLP pipelines which are examined in manufacturing with respect to the scalability of knowledge ingestion.
RAGFlow and LLMWare tackle enterprise wants, with LLMWare considerably restricted to on-device fashions and safety.
In distinction, txtai presents a light-weight, easy, all-in-one native RAG resolution, whereas Cognita takes care of all the pieces with a simple, modular, UI pushed platform.
The entire GitHub repositories meant for RAG programs above are maintained and include examples that will help you run simply. They collectively display that RAG is now not on the innovative of educational analysis, however is now obtainable to everybody who needs to construct an AI utility. In observe, the “most suitable choice” depends upon your wants and priorities.
Howdy! I am Vipin, a passionate knowledge science and machine studying fanatic with a robust basis in knowledge evaluation, machine studying algorithms, and programming. I’ve hands-on expertise in constructing fashions, managing messy knowledge, and fixing real-world issues. My aim is to use data-driven insights to create sensible options that drive outcomes. I am wanting to contribute my expertise in a collaborative atmosphere whereas persevering with to be taught and develop within the fields of Knowledge Science, Machine Studying, and NLP.
Login to proceed studying and revel in expert-curated content material.
For those who run firewalls, routers, or SD‑WAN NVAs in Azure and your ache is connection scale reasonably than uncooked Mbps, there’s a characteristic it’s best to take a look at: Accelerated Connections. It shifts connection processing to devoted {hardware} within the Azure fleet and allows you to dimension connection capability per NIC, which interprets into greater connections‑per‑second and extra complete energetic periods in your digital home equipment and VMs.
This text distills a current E2E chat I hosted with the Technical Product Supervisor engaged on Accelerated Connections and reveals you the best way to allow and function it safely in manufacturing. The demo and steering under are primarily based on that dialog and the present public documentation.
Accelerated Connections is configured on the NIC stage of your NVAs or VMs. You possibly can select which NICs take part. Which means you would possibly allow it solely in your excessive‑throughput ingress and egress NICs and depart the administration NIC alone.
It improves two issues that matter to infrastructure workloads:
Connections per second (CPS). New flows are established a lot sooner.
Complete energetic connections. Every NIC can maintain much more simultaneous periods earlier than you hit limits.
It does not enhance your nominal throughput quantity. The profit is stability underneath excessive connection strain, which helps scale back drops and flapping throughout surges. There’s a small latency bump since you introduce one other “bump within the wire,” however in software phrases it’s sometimes negligible in comparison with the soundness you achieve.
Within the conventional path, host CPUs consider SDN insurance policies for flows that traverse your digital community. That turns into a bottleneck for connection scale. Accelerated Connections offloads that coverage work onto specialised information processing {hardware} within the Azure fleet so your NVAs and VMs are usually not capped by host CPU and movement‑desk reminiscence constraints.
Trade companions have described this as decoupling the SDN stack from the server and shifting the quick‑path onto DPUs residing in objective‑constructed home equipment, delivered to you as a functionality you connect on the vNIC. The result’s a lot greater CPS and energetic connection scale for digital firewalls, load balancers, and switches.
You decide a efficiency tier per NIC utilizing Auxiliary SKU values. At the moment the tiers are A1, A2, A4, and A8. These map to rising capability for complete simultaneous connections and CPS, so you’ll be able to proper‑dimension price and efficiency to the NIC’s function.
As mentioned in my chat with Yusef, the mnemonic is straightforward: A1 ≈ 1 million connections, A2 ≈ 2 million, A4 ≈ 4 million, A8 ≈ 8 million per NIC, together with rising CPS ceilings. Select the smallest tier that clears your peak, then monitor and alter. Pricing is per hour for the auxiliary functionality.
Tip: Begin with A1 or A2 on ingress and egress NICs of your NVAs, observe CPS and energetic session counters throughout peak occasions, then scale up provided that wanted.
You possibly can allow Accelerated Connections by the Azure portal, CLI, PowerShell, Terraform, or templates. The setting is utilized on the community interface. Within the portal, export the NIC’s template and you will notice two properties you care about: auxiliaryMode and auxiliarySku.
Set auxiliaryMode to AcceleratedConnections and select an auxiliarySku tier (A1, A2, A4, A8).
Observe: Accelerated Connections is at present a restricted GA functionality. You could want to enroll earlier than you’ll be able to configure it in your subscription.
Standalone VMs. You possibly can allow Accelerated Connections with a cease then begin of the VM after updating the NIC properties. Plan a brief outage.
Digital Machine Scale Units. As of now, transferring current scale units onto Accelerated Connections requires re‑deployment. Parity with the standalone movement is deliberate, however don’t financial institution on it for present rollouts.
Altering SKUs later. Transferring from A1 to A2 or comparable additionally implies a downtime window. Deal with it as an in‑place upkeep occasion.
Operationally, method this iteratively. Replace a decrease‑visitors area first, validate, then roll out broadly. Use energetic‑energetic NVAs behind a load balancer so one occasion can drain when you replace the opposite.
Choose the precise NICs. Don’t allow on the administration NIC. Deal with the interfaces carrying excessive connection quantity.
Baseline and monitor. Earlier than enabling, seize CPS and energetic session metrics out of your NVAs. After enabling, confirm reductions in connection drops at peak. The purpose is stability underneath strain.
Capability planning. Begin at A1 or A2. Transfer up provided that you see sustained saturation at peak. The tiers are designed so you don’t pay for headroom you don’t want.
Anticipate a tiny latency enhance. There’s one other hop within the path. In actual software flows the profit in fewer drops and better CPS outweighs the added microseconds. Validate with your personal A/B exams.
Plan change home windows. Enabling on current VMs and resizing the Auxiliary SKU each contain downtime. Use energetic‑energetic pairs behind a load balancer and drain one aspect when you flip the opposite
Clients in regulated and excessive‑visitors industries like well being care typically discovered that connection scale compelled them to horizontally increase NVAs, which inflated each cloud spend and licensing, and sophisticated operations. Offloading the SDN coverage work to devoted {hardware} permits you to course of many extra connections on fewer situations, and to take action extra predictably.
Subsequent steps
Validate eligibility. Affirm your subscription is enabled for Accelerated Connections and that your goal areas and VM households are supported. Study article
Choose candidate workloads. Prioritize NVAs or VMs that hit CPS or movement‑desk limits at peak. Use current telemetry to select the primary area and equipment pair. 31
Pilot on one NIC per equipment. Allow on the info‑path NIC, begin with A1 or A2, then cease/begin the VM throughout a brief upkeep window. Measure earlier than and after. 32
Roll out iteratively. Broaden to extra areas and home equipment utilizing energetic‑energetic patterns behind a load balancer to reduce downtime. 33
Proper‑dimension the SKU. For those who observe sustained headroom, keep put. For those who method limits, step up a tier throughout a deliberate window. 34
“Probably the most highly effective expertise doesn’t simply clear up issues. It conjures up individuals to see what’s potential,” says Hash Bajwa.
In Episode 6 of AI Activations, Bajwa displays on a profession spanning the United Nations, Apple, and the Obama Basis. He shares how organizations can design AI experiences that transcend effectivity to create measurable impression: empowering staff, delighting clients, and reshaping operations.
If the present ceasefire in Gaza holds, it should mark the much-needed finish to an indefensibly merciless conflict. However the longer-term image, and whether or not yet one more lethal conflagration might be prevented, is one other matter. One issue — not the one one, however an enormous one — is whether or not the Israelis might be satisfied that they need to give peace negotiations a critical probability.
Ilan Goldenberg has been fascinated by how to try this for fairly a while.
Whereas serving as a high-ranking Biden administration official on the Israel-Palestine desk, Goldenberg pushed unsuccessfully for the White Home to strain the Israelis extra aggressively in pursuit of a ceasefire. Now that the Trump administration has accomplished so and secured an settlement for his or her efforts, he sees potentialities for change in Israel’s deeper strategy to the battle — both for the higher or for the more severe.
The optimistic situation appears to be like lots just like the aftermath of the 1973 Yom Kippur Struggle, wherein Israel fended off a shock invasion from Egyptian and Syrian forces. The preliminary success of the Arab assault shocked an Israeli public that had grown overconfident in its personal energy, laying the groundwork for Prime Minister Menachem Start’s determination to signal a peace treaty with Egyptian President Anwar Sadat in 1978.
The pessimistic situation resembles the aftermath of the Second Intifada within the 2000s, the bloodiest spherical of Israeli-Palestinian combating previous to the present conflict. That battle, wherein giant numbers of Israeli civilians had been killed by terrorist assaults inside its borders, led many Israelis to conclude that negotiated peace was inconceivable — producing a political shift to the best that has led to ever-deepening occupation within the West Financial institution and Israel’s shockingly brutal conduct in the course of the Gaza conflict.
So, which one is extra seemingly: an Israeli recognition of the necessity for peace, or a doubling down on the logic of perpetual conflict? Goldenberg isn’t positive. However he’s assured that there’s a wrestle shaping up proper now that would tilt the result in a single course or the opposite.
“Crucial factor goes to be elections in Israel subsequent 12 months,” he tells me. “That’s the linchpin of all of this.”
Whereas it purports to be a complete settlement, the events solely absolutely agreed to its short-term provisions — like this previous weekend’s hostage-prisoner alternate, in addition to an Israeli withdrawal from a lot of Gaza. There are not any agreed-upon particular steps for implementing its longer-term provisions, corresponding to Hamas’s disarmament or the set up of a global peacekeeping pressure in Gaza.
Turning such concepts from aspiration to actuality would require tough compromises, and there are actual causes to be skeptical of everybody concerned. President Donald Trump’s international coverage isn’t precisely recognized for its follow-through or consideration to element. In the meantime, Hamas’s post-ceasefire killing spree, wherein the group publicly executed a few of its Palestinian rivals in Gaza, means that it isn’t occupied with giving up both arms or energy.
And on the Israeli aspect, the most important drawback might be summed up in 4 phrases: Prime Minister Benjamin Netanyahu.
In energy for 15 of the final 16 years, “Bibi” has demonstrated an more and more open hostility to the very concept of significant peace negotiations. His political future relies on an alliance with extreme-right factions who suppose Israel’s greatest mistake in Gaza is that it wasn’t violent sufficient.
As long as Netanyahu is on the helm, he’ll nearly assuredly work to sabotage any try at implementing the settlement’s nineteenth and most bold provision: its hope to in the end create “a reputable pathway to Palestinian self-determination and statehood, which we recognise because the aspiration of the Palestinian individuals.” If Netanyahu’s previous conduct is any information, he’ll work doggedly to sabotage this aspect of the deal whereas making an attempt accountable Hamas for his personal obstructionism.
“He’s a person who, for 20 years, has refused to ever take a threat and transfer the inhabitants to one thing higher,” Goldenberg says. “As an alternative, he’s constantly performed to their worst instincts and to their fears.”
In follow, this appears to be like lots like Israel’s Tuesday determination, which has since been reversed, to chop the quantity of help flowing into Gaza to half of the agreed-upon ranges.
The said motive for the suspension was that Hamas hadn’t adopted by means of on its settlement handy over the our bodies of deceased Israeli hostages. Whether or not or not this was true — it’s doable, as Hamas claims, that they’re having hassle discovering the stays — there was no want for Israel to retaliate in such a Draconian manner.
Essentially the most coherent clarification for its determination is that Netanyahu and his allies need the settlement to fail however don’t need to get the blame for withdrawing from it with out trigger. In order that they’re keen to take aggressive steps to destabilize it. And at one level, these efforts are prone to succeed.
This doesn’t imply that they need to return to combating tomorrow. Resuming the conflict can be a brazen insult to Trump, who’s more and more staking his status on bringing “peace” to the Center East. There’s a excellent probability that, as Goldenberg places it, “the foremost combating is over,” it doesn’t matter what.
However the query isn’t just whether or not bombs will begin dropping within the quick future. It’s whether or not one thing is being accomplished to stop one other conflagration a number of years down the road. That requires tackling the underlying situation of battle between the 2 sides: the shortage of a totally negotiated settlement that addresses the respectable fears and aspirations of each peoples. With out that, one other spherical of vicious combating is inevitable.
Israel’s “most consequential” election
If this logic holds, then Netanyahu should depart workplace for this ceasefire to ultimately set the stage for a real peace. Because of this, Israel’s upcoming elections — at the moment scheduled for October 2026, although they could possibly be known as sooner — are shaping as much as be enormously consequential. Michael Koplow, an knowledgeable on the Israel Coverage Discussion board suppose tank, has written that “the approaching elections would be the most consequential in Israel’s historical past.”
The excellent news, not less than for individuals who want an enduring peace, is that Netanyahu is prone to lose.
“Hardly something within the final 12 months and a half has essentially modified Netanyahu’s polling energy.”
— Dahlia Scheindlin, Israeli pollster
Early post-ceasefire polls have Netanyahu and his radical proper coalition companions profitable 48 seats out of a complete of 120 within the Knesset (Israel’s parliament). That’s really a slight enchancment over their prior numbers, however it’s nonetheless properly wanting the 61 seats essential to type a governing coalition — a shortfall that’s been remarkably constant over time.
“Hardly something within the final 12 months and a half has essentially modified Netanyahu’s polling energy,” says Dahlia Scheindlin, a number one Israeli pollster.
Possibly the widespread pleasure inside Israel on the return of the hostages modifications issues; we haven’t but seen strong polling knowledge since their launch. However the long-run consistency within the numbers is so placing that it suggests there is perhaps deeper, harder-to-fix issues for the prime minister.
Netanyahu’s continued refusal to take any accountability for the October 7 assault — and even convene an actual fee to research accountability — has infuriated Israelis who nonetheless stay with the trauma of that day’s occasions. Moreover, most Israelis consider Netanyahu has been prolonging the conflict for political causes, which might counsel the ceasefire was not an accomplishment however one thing compelled on him. It’s additionally value remembering that Netanyahu is an indicted prison who launched an assault on the independence of Israel’s judiciary previous to the conflict, one which prompted the biggest protest motion within the nation’s historical past.
Regardless of Netanyahu’s vaunted survival expertise, in different phrases, the percentages this time round are very a lot towards him.
However Netanyahu’s defeat doesn’t assure that Israel will get on a path to peace. It’s a vital situation — as long as he’s in workplace, a sturdy peace is probably going inconceivable — however it isn’t a adequate one. To unravel the Israeli a part of the peace equation, you have to tackle the general public’s post-October 7 souring on the prospects for any sort of actual settlement. And that requires management keen to make the case to them.
“Throughout violent escalations, I’ve not often seen the Israeli public go forward of its leaders in getting extra reasonable,” Scheindlin says. The 1978 Camp David settlement, she notes, was initially met with skepticism from the Israeli public. However when you had “a legitimately elected chief making the case…then individuals modified their minds, and inside just a few months they supported the settlement with very excessive majorities.”
No one is aware of whether or not such management exists at present.
The opposition to Netanyahu is made up of a gaggle of events that span the ideological gamut. Their leaders embody far-right settlers like Naftali Bennett, center-right hawks like Benny Gantz, Zionist liberals like Yair Golan, and even Arab Islamists like Mansour Abbas.
These events share little aside from a deep distaste for Netanyahu, and that makes any coalition they type liable to break down. Such a grand opposition took energy in 2021, with Bennett as its first prime minister, solely to fall below the burden of its personal contradictions — and set the stage for Netanyahu’s return to energy.
At current, we don’t know what subgroupings of those events will do higher and which is able to do worse. Lots will rely not simply on Netanyahu’s defeat, however which of the varied out-of-government events do higher and what kind of governing coalition the election yields. A authorities led by Bennett is, for instance, much less prone to interact in critical negotiations than one led by the centrist Yair Lapid.
It’s, briefly, eminently doable that this fragile ceasefire may collapse ultimately, even when Netanyahu goes all the way down to defeat. But when he stays in energy, these odds approximate certainty. If Trump, or anybody else, needs this deal to really lay the groundwork for peace, they should start with eradicating Netanyahu from the equation.
“There’s plenty of hinge factors,” Goldenberg says. “However the first one must be him.”
My curiosity in cryptocurrency is primarily technical, and privateness cash are essentially the most technically attention-grabbing. The maths behind cash like Monero and Zcash is way extra refined than the mathematics behind Bitcoin.
I’m additionally within the privateness angle since I work in knowledge privateness. The zero-knowledge proof (ZKP) expertise developed for and examined in privateness cash is relevant exterior of cryptocurrency.
I don’t observe the worth of privateness cash, however I heard concerning the worth of Zcash doubling just lately.
I’d like to know why that occurred, particularly why it occurred so all of a sudden, although I’m very skeptical of publish hoc explanations of worth adjustments. I roll my eyes after I hear reporters say the inventory market moved up or down by some p.c due to this or that occasion. Any clarification for the combination conduct of a fancy system that matches into sound byte is unlikely to include greater than a kernel of reality.
Replace: The worth has gone up one other 65% within the two days since I wrote this publish.
Bitcoin is insurance coverage towards fiat. ZCash is insurance coverage towards Bitcoin.
This was after Zcash had began rising, so Naval’s assertion wasn’t the reason for the rise. However the thought behind his assertion was within the air earlier than he crystalized it. Perhaps the latest enhance within the worth of Bitcoin led to the rise of Zcash as a hedge towards Bitcoin falling. It’s inconceivable to know. Merchants don’t fill out questionnaires explaining their motivations.
It has been prompt that extra individuals are keen on utilizing Zcash as a privacy-preserving foreign money, not simply shopping for it for monetary hypothesis. It’s believable that this might be a contributing issue within the rise of Zcash, although curiosity in monetary privateness is unlikely to spike over the course of 1 week, barring one thing dramatic like FDR’s confiscation of personal gold in 1933.
The worth of Monero elevated together with Zcash, although not as by practically as a lot.
This means there could also be elevated curiosity in privateness cash extra usually and never simply in Zcash.
It will be attention-grabbing to see how individuals are utilizing Zcash and Monero—how a lot is being spent on items and providers and the way a lot is simply being traded as an funding—however this could be troublesome since privateness cash obscure the main points of transactions by design.
A brand new vaccine can successfully stop a number of varieties of most cancers, with as much as 88 % efficacy for some types of tumor in mouse exams.
Like a vaccine designed to stop or scale back sickness from viral infections, this most cancers vaccine works by coaching the immune system to assault tumors after they subsequent seem.
Nanoparticles within the vaccine current a recognizable part of most cancers cells as an antigen – a label that alerts our immune cells to a menace. A second materials, described as a ‘tremendous’ adjuvant, additional stimulates the immune system to go on the offensive.
Within the first exams, scientists on the College of Massachusetts Amherst vaccinated a gaggle of mice with nanoparticles containing melanoma peptides, earlier than exposing the check animals to melanoma cells just a few weeks later.
Of the mice that obtained the nanoparticle vaccine, 80 % survived and stayed tumor-free for the 250-day length of the examine. In contrast, all the mice that weren’t vaccinated or got completely different formulations succumbed inside seven weeks.
Within the second check, the crew used a extra common antigen – a substance referred to as tumor lysate, made from broken-up most cancers cells. It was hypothesized that the lysate could alert the immune system to a variety of most cancers varieties, which might be useful in preventative circumstances.
Mice got this model of the vaccine earlier than being uncovered to both melanoma, pancreatic, or triple-negative breast most cancers. And once more, the bulk remained tumor-free: 88 % of these uncovered to pancreatic most cancers, 75 % for breast most cancers, and 69 % for melanoma.
A graphical summary of how the most cancers vaccine works. (Kane et al., Cell Rep. Med. 2025)
The researchers unsuccessfully tried to simulate the unfold of most cancers within the surviving mice, discovering one hundred pc of them remained tumor-free.
“By engineering these nanoparticles to activate the immune system through multi-pathway activation that mixes with cancer-specific antigens, we will stop tumor progress with exceptional survival charges,” says Prabhani Atukorale, biomedical engineer at UMass Amherst.
The crew says the bottom line is the so-called tremendous adjuvant, which consists of lipid nanoparticles that encapsulate two immune adjuvants and ship them collectively to spice up the immune response. In fact, at this stage, the work has solely been carried out in mice, so there is not any assure that outcomes will translate to people.
However this method may probably be adaptable to a variety of various most cancers varieties, serving to to each deal with sufferers after analysis and forestall most cancers from taking maintain in high-risk sufferers.