This put up talks about my workflow for getting began with a brand new information evaluation mission utilizing the ProjectTemplate package deal.
Replace (twenty fourth August 2016)
During the last two years, I’ve been refining this customised model of ProjectTemplate.
Overview of ProjectTemplate
ProjectTemplate is an R Bundle which facilitates information evaluation, encourages good information evaluation habits, and standardises many information analytic steps. After a few years of refining an information evaluation workflow in R, I realised that I might mainly converged on one thing just like ProjectTemplate anyway. Nonetheless, my method was not fairly as systematic, and it took extra effort than essential to get began on a brand new mission. Thus, since late 2013, I have been utilizing ProjectTemplate to organise my R information evaluation tasks.
Whereas I’ve discovered ProjectTemplate to be a wonderful instrument, I realised that once I created a brand new information evaluation mission based mostly on ProjectTemplate, I used to be repeatedly making numerous customisations to the preliminary set of information and folders. Thus, I’ve now arrange a repository to retailer these customisations in order that I can get began on a brand new information evaluation mission extra effectively. The aim of this put up is to doc these modifications.
This put up assumes an affordable information of R and ProjectTemplate. For those who’re not acquainted with ProjectTemplate, you might take a look at the ProjectTemplate web site focusing significantly on the Getting Began part. For those who’re actually eager you might additionally watch an hour lengthy video on ProjectTemplate, RStudio, and GitHub
a few directories eliminated that I do not use (e.g., diagnositics, logs, profiling)
an preliminary rmd file with the customisations talked about beneath within the studies listing
An .Rproj RStudio mission file to allow simple launching of RStudio.
A further output listing for storing tabular, textual content, and different output
Thus, at any time when I need to begin a brand new information evaluation mission I can obtain and extract the zip file of the repository on github).
Thus, after making a mission folder, the next steps could be skipped when utilizing my customised template.
Open RStudio and create RStudio Challenge in current listing
Create ProjectTemplate folder construction with library(ProjectTemplate); create.mission()
Transfer ProjectTemplate information into folder
Modify world.dcf
Setup rmd studies
I additionally doc beneath a couple of further factors about subsequent steps together with:
Organising the information listing
Updating the readme file
Setttig up git repository
Modifying world.dcf
My most well-liked beginning world.dcf settings are
data_loading: on
cache_loading: off
munging: on
logging: off
load_libraries: on
libraries: psych, lattice, Hmisc
as_factors: off
data_tables: off
A bit of clarification:
as_factors I do fairly a little bit of string processing, significantly on meta information and on output tables. I discover the automated conversion of strings into components to be a extremely annoying characteristic. Thus, setting this to off is my most well-liked setting.
load_libraries: I all the time have further libraries so it is sensible to have this on.
libraries: There are a lot of frequent packages that I exploit, however I virtually all the time make use of the above comma separate listing of packages.
Setup rmd information
Fundamentals of such information
The primary line within the first chunk is all the time:
This hundreds the whole lot required to get began with the mission.
Setup information folder
ProjectTemplate mechanically names ensuing information.frames with a reputation based mostly on the file title. That is handy. Nonetheless, it’s usually the case that the file names have to be modified from some uncooked information equipped or it could be that the unique information format shouldn’t be completely fitted to importing. In that case, I retailer the uncooked information in a separate folder referred to as raw-data after which export or create a duplicate within the desired format with the specified title within the information folder.
Overriding default information import choices
Some information information cannot be imported utilizing the default information import guidelines. After all, you may change the file to adjust to the principles. Alternatively, I believe the usual answer is so as to add a file within the lib listing (e.g., data-override.r) that imports the information information. Give the imported information file the identical title that ProjectTemplate would.
Replace readme
I modify the file to README.md to make it clear that it’s a markdown formatted file. I can then add slightly details about the mission.
Setup git repository
If utilizing github, I create a brand new repository on github.
Output folder
A typical workflow for me is to generate tables, textual content, and determine output fromthe script which is then integrated right into a manuscript doc. Whereas I actually like Sweave and RMarkdown, I usually discover it extra sensible to write down a manuscript in Microsoft Phrase. I exploit the output folder to retailer tabular output, normal textual content output, and figures.
Within the case of tabular output, there may be the duty of making certain the desk is formatted appropriately (e.g., desired variety of decimal locations, cell alignment, cell borders, font, cell merging, and so forth.). I sometimes discover this best to do in Excel. Thus, I’ve a file referred to as output-processing.xlsx. I import the tabular information into this file and apply related formatting. This may then be integrated into the manuscript. Listed here are a couple of extra notes about Desk conversion in MS Phrase.
Round 4 years in the past, now 77-year-old John Gormly went for what was speculated to be a routine blood take a look at. However the outcomes have been life-changing.
The take a look at recommended Gormly had colon most cancers, which a colonoscopy later confirmed was Stage 2, which means the most cancers had unfold by the wall of the colon however to not his lymph nodes.
“I believed [my doctor] was incorrect,” Gormly, CEO of a building firm close to Newport Seashore, California, advised Stay Science. “I am going, ‘Nah, I do not really feel something.’ However there it was. It was actual; the colonoscopy confirmed it.”
Gormly was one of many first sufferers to take a newly accepted take a look at known as Protect, which its makers say can detect colon most cancers from a blood pattern. After his analysis, Gormly had surgical procedure to take away the tumor and was again to work inside 10 days.
Science Highlight takes a deeper take a look at rising science and provides you, our readers, the attitude you want on these advances. Our tales spotlight developments in several fields, how new analysis is altering previous concepts, and the way the image of the world we stay in is being remodeled because of science.
An early model of Guardant Well being’s Protect take a look at has been commercially out there since 2022, but it surely wasn’t lined by insurance coverage. Nonetheless, after approval from the U.S. Meals and Drug Administration (FDA) in July 2024, a diagnostic model of Protect was launched commercially and is now lined by Medicare.
Protect is barely a blood drop in an ocean of rising “liquid biopsies.”
Scientists have developed blood assessments for a number of cancers, together with these of the breast, pancreas and abdomen. Some blood assessments even detect a number of varieties of most cancers. If these liquid biopsies might be rolled out broadly, they might assist detect most cancers earlier, extra simply, or with fewer invasive measures — which, in flip, might result in earlier detection and fewer most cancers deaths.
Get the world’s most fascinating discoveries delivered straight to your inbox.
However many of those assessments are nonetheless of their early phases. They usually detect a decrease fraction of most cancers instances than gold-standard screening instruments like colonoscopies do, which means they’ll doubtless complement, quite than exchange, conventional screening strategies. Others might have unacceptable charges of “false positives,” which means an individual is initially advised they’ve most cancers however diagnostic follow-ups present they don’t. This will result in useless fear or extra invasive assessments. These embrace conventional biopsies, which contain eradicating tissue samples by way of needles or surgical procedure. And for some illnesses, it is not clear that early analysis on a blood take a look at will result in higher outcomes.
Nonetheless, as these kinks are ironed out, it is doubtless that blood-based most cancers screening will grow to be a standard a part of our medical care — one which has the potential to enhance most cancers outcomes dramatically, consultants say.
John Gormly went in for a routine blood take a look at and realized he doubtless had colon most cancers. After follow-up diagnostic assessments and a comparatively easy surgical procedure to take away the most cancers, he’s now in remission. (Picture credit score: Guardant Well being)
Simplifying screening
Gormly’s physician advisable a Protect take a look at after noticing that Gormly hadn’t had a colonoscopy shortly. He is not alone. Present suggestions recommend that folks ages 45 to 75 who’re at common danger of colon most cancers get a screening, similar to a colonoscopy or a stool-based take a look at, each 5 to 10 years. But round 1 in 3 of those folks have by no means been screened.
That is an issue, as a result of colon most cancers is the fourth-most-common most cancers. Consultants have argued that early detection might eradicate 90% of colon most cancers deaths. It sometimes takes round 10 years for early, precancerous growths like polyps to morph into lethal most cancers cells, and if these cells are caught early, they’ll simply be eliminated.
Regardless of the potential for early analysis and remedy, many individuals keep away from these screenings. This can be one motive colon most cancers is the second-most-common reason for most cancers demise.
Folks keep away from screenings for a lot of causes, stated Dr. William Grady, a professor of translational science and therapeutics on the Fred Hutchinson Most cancers Middle in Seattle who helped lead the Protect trials. Some folks really feel embarrassed throughout screenings similar to colonoscopy or worry that it might be painful, he advised Stay Science. These choosing colonoscopy might wrestle to get break day work, whereas others might dislike the thought of dealing with stool for a stool-based take a look at, he stated.
“That is why there’s a possibility for blood assessments that’s actually highly effective as a result of individuals are inclined to do blood assessments; they’re handy and might be completed throughout a well being care encounter,” Grady stated.
Protect works by detecting small DNA fragments which are launched into the blood from colon most cancers cells or precancerous cells known as adenomas, a sort of polyp. The take a look at additionally picks up on delicate variations between cancerous cells and regular cells in chemical tags on DNA often known as methyl teams.
In a paper revealed in March 2024 in The New England Journal of Medication, Grady’s crew confirmed that Protect detected 83% of colonoscopy-confirmed colon most cancers instances in a cohort of virtually 10,000 folks. It additionally had a false optimistic price of 10%.
As a result of Protect detects a smaller proportion of colon most cancers instances than stool-based assessments (92%) or colonoscopies (95%) do, it will not exchange these diagnostic assessments, Grady stated. Nonetheless, it might develop the variety of screening choices out there to sufferers, he added. This extra choice might enhance screening compliance, which might result in earlier illness detection and thus a discount in colon most cancers deaths.
The Protect take a look at is accepted to be used each three years, Grady stated. Nonetheless, present research are investigating whether or not it will be extra correct if it have been completed yearly or two, he added.
If Gormly’s most cancers had unfold to the remainder of his physique, it will have been a lot more durable to deal with. Folks whose colon most cancers is caught at Stage 2, like Gormly, have an 85% probability of residing not less than one other 5 years. By Stage 4, when it has unfold all through the physique, these odds go down to simply 10%.
“That might have been the tip of me, so it [Shield] positively modified my life,” Gormly stated.
A researcher working within the Protect blood testing laboratory. Guardant’s take a look at for colon most cancers was FDA-approved in 2024. (Picture credit score: Guardant Well being)
Accelerating analysis
Pancreatic most cancers is one other illness that would profit from a blood-based diagnostic take a look at. Not like colon most cancers, pancreatic most cancers is comparatively unusual, affecting 1 in 56 males and 1 in 60 girls. But pancreatic most cancers is the third-most-common reason for most cancers demise within the U.S.
That is as a result of, by the point most individuals discover signs, similar to belly ache or discomfort, the illness is already very superior, stated Ajay Goel, a professor and chair of the Division of Molecular Diagnostics and Experimental Therapeutics on the Beckman Analysis Institute of Metropolis of Hope in Duarte, California.
There is no such thing as a broad-based screening program within the U.S. for folks at common danger of pancreatic most cancers. Later phases of the illness are simply detectable by way of MRI or CT scan, Goel advised Stay Science. However by that time, the five-year survival price is extraordinarily low: round 3% as soon as the most cancers has unfold all through the physique, in contrast with 44% whether it is nonetheless restricted to the pancreas. As soon as most cancers has unfold past the pancreas, surgical elimination is normally now not doable, and coverings similar to chemotherapy and radiotherapy are minimally efficient.
A possible resolution is a brand new blood take a look at developed by Goel’s crew. It goals to detect early-stage pancreatic most cancers by figuring out small cancer-specific molecules known as microRNAs. These molecules regulate whether or not genes are switched on or off and are discovered within the blood of sufferers with early-stage illness, in addition to inside exosomes, that are tiny packages that most cancers cells launch into the blood.
In a research of practically 1,000 folks, the take a look at (which remains to be unnamed) detected between 88% and 93% of early- and late-stage pancreatic most cancers instances, utilizing blood drawn from folks within the U.S., South Korea and China. When the take a look at was modified to additionally measure the quantity of a protein often known as CA-19 within the blood, it picked up 97% of early-stage instances within the U.S. group. CA-19 is a identified biomarker of pancreatic most cancers, however by itself, it isn’t dependable sufficient for use for analysis. When mixed with CA-19 detection, the brand new take a look at had a 5% to 10% false optimistic price, Goel stated.
“If you’ll find increasingly of those cancers early on, there’s a hope that many of those sufferers might be cured,” Goel stated.
The crew envisages the take a look at being taken yearly — as an example, when sufferers see their physician for an annual bodily examination. Nonetheless, in those that have a household historical past of pancreatic most cancers, it might make sense to check extra incessantly — maybe each six months, Goel stated.
If you’ll find increasingly of those cancers early on, there’s a hope that many of those sufferers might be cured.
Ajay Goel
Multicancer detection
Scientists are additionally creating multicancer detection (MCD) assessments that display for a lot of varieties of most cancers directly. MCD assessments differ barely within the varieties of most cancers they detect and how they do it. However like most of the single-cancer detection assessments, MCD assessments search for cancer-specific molecules, similar to tumor DNA, however on a bigger scale. Some MCD assessments pattern urine or one other bodily fluid along with blood.
Even when MCD assessments do work they usually grow to be extra reasonably priced (Galleri, for instance, presently prices round $950), consultants nonetheless aren’t certain of the easiest way to make use of them. “There’s this perception that if we might solely detect all cancers early, we’d remedy the most cancers downside,” Ruth Etzioni, a professor at Fred Hutchinson who was not concerned in Grady’s work with Protect, advised Stay Science. However generally there isn’t a good therapy for early cancers, so catching them forward would not essentially result in improved outcomes.
And there is all the time a danger of false positives. After taking an MCD take a look at, sufferers might wait as much as six months to know in some way, Dr. Jennifer Croswell, a medical officer on the Nationwide Most cancers Institute, advised Stay Science. There could also be many causes for this delay, together with that it takes time to carry out a number of rounds of follow-up testing to determine which organ is affected, she stated. There are additionally presently no evidence-based medical tips that inform docs the easiest way to observe up on optimistic outcomes from MCD assessments, Croswell stated. Consequently, these assessments might create uncertainty for sufferers.
The way in which ahead
Whereas many diagnostic blood assessments for most cancers are nonetheless within the pipeline, not less than a few of these assessments will doubtless have an effect on analysis and therapy within the subsequent a number of years. As an example, Goel and colleagues at the moment are operating a medical trial to see if their take a look at can detect early-stage pancreatic most cancers in high-risk people who haven’t but been identified. If it is profitable, they intend to check it within the common inhabitants.
“I believe if issues go properly, we foresee that in all probability within the subsequent two to 4 years, this take a look at must be on {the marketplace} for use for early detection of pancreatic most cancers worldwide,” Goel stated.
In the meantime, Grady’s crew is planning to analyze whether or not Protect helps get extra folks screened for colon most cancers who are sometimes missed, similar to underrepresented minority teams or those that stay in areas with restricted well being care entry.
Protect is “the primary of, I believe, an entire sequence of assessments that we’ll be seeing developing for screening for not solely colon most cancers but in addition for breast most cancers, lung most cancers, liver most cancers,” Grady stated.
4 years later, assessments present Gormly is cancer-free. He hopes his experiences assist others who could also be tempted to skip colon most cancers screening.
“I hope that on account of this [speaking up],” he stated, “another person tries it and has the identical success I did.”
Editor’s observe: This text was first revealed March 21, 2025 and republished Oct. 17, 2025
One other day, one other anti-vaccine meme about COVID-19 vaccines “inflicting” extra deaths within the international locations that had been privileged sufficient to have them in the course of the pandemic. These anti-vaccine disinformation experts level to the deaths taking place after the COVID-19 vaccines had been accredited to be used and say, “See? The proof is correct there!” As a result of nothing else was occurring at the moment, like a pandemic or one thing.
I don’t know. I’m simply saying.
These are the identical individuals who see a rise in drowning deaths in the summertime, a rise in ice cream deaths gross sales in the identical timeframe, they usually instantly say that ice cream brought on drownings. By no means thoughts that swimming (which can result in drowning) and ice cream gross sales are each influenced by scorching climate. It’s what we within the epidemiology enterprise name a confounder.
Oooh, is ice cream related to shark bites, then?
Again in 2020, on the peak of the pandemic, I began listening to from folks a really fascinating conspiracy idea. They claimed that they had been advised by “educated folks” to keep away from being placed on a ventilator in any respect prices. “Everybody on a ventilator dies,” they stated. Properly, not everybody, after all. However, if you end up needing a ventilator, chances are high the illness may be very superior and loss of life could also be imminent. So, yeah, your possibilities of loss of life are excessive in the event you’re on the level the place you’re mechanically ventilated, but it surely wasn’t the ventilator that killed you.
It was the virus.
In epidemiology, we name being on a ventilator a mediator between the publicity (the novel coronavirus) and the end result (loss of life). If something, figuring out the loss of life fee of individuals on ventilators — together with their vaccine standing — helped us be extra assured in our suggestion to the general public concerning the vaccine. That’s, the vaccine was not stopping all illness transmission, but it surely was maintaining folks out of the hospital, off ventilators, and thus, alive.
Then there are those that check out hospitalization information and declare that as a result of they noticed X in hospitalized sufferers, then Y have to be true of the entire inhabitants. By no means thoughts that they by no means appeared on the complete inhabitants. For instance, think about you see solely head accidents within the emergency division in folks with bicycle helmets. You loudly — and proudly? — proclaim that bike helmets result in head accidents. However you by no means noticed the individuals who didn’t make it to the ER and went as an alternative to the morgue as a result of they weren’t carrying a helmet.
That’s Berkson’s Bias, my very younger epidemiologist. The publicity (carrying a motorcycle helmet) and the end result (a head damage) are extra seemingly in emergency division sufferers than the overall inhabitants. I imply, sadly, we’re not all out on bicycles. And those that are out on bicycles usually tend to find yourself within the ER in the event that they get a head damage, as an alternative of the morgue.
Roughly more likely to go to the ER?
After which, final however not least, when you’ve got information that exhibits a pattern within the mixture, however the pattern reverses if you analyze it by subgroups… Sure! You bought it. It’s Simpson’s Paradox at play. It’s one other type of bias (like Berkson’s) the place the way you analyzed your information tells you a special story than what’s actual. And Simpson’s wraps again to confounding.
What actually confounds me is that, even when all of that is defined to some folks, they nonetheless maintain on to their preconceived notions. Ironic… Their biases forestall them from seeing the bias of their evaluation.
This leads me to the principle level of this little rant: What’s the purpose?
What’s the purpose of mentioning epidemiological and statistical information to people who find themselves obsessive about making boogeymen out of issues which can be useful to them? What’s the purpose of main those that’ve gone astray?
After which I keep in mind that it’s not about me or my frustrations. It’s concerning the folks on the sidelines, and the youngsters of the anti-vaccine crew. These youngsters had no selection within the matter, and they’re the almost definitely to bear the brunt of epidemics of vaccine-preventable ailments.
It could sound cliché however, if I can cease one individual from turning into anti-vaccine, then I’ve completed my job. All it takes is one individual to alter earlier than others do, and “the voyage of a thousand miles begins with a single step” type of factor…
If you wish to be taught extra about these biases and the way they affect public well being selections, please think about signing up for my Public Well being Evening College. Or not less than test it out and share some stuff from it.
At the moment I’m going to share a simulation I’ve been engaged on as an instance one thing I wrote about yesterday. The brief model of what I stated was nearly like a collection of easy deductions, one after one other, which began as soon as I noticed what inhabitants weighting does and doesn’t do. At the moment I’m going to assessment that perception that I had written about, however I’m additionally going to introduce code in order that you can also mess around with this outcome and see for your self that relying on the choice mechanism, parallel traits could not maintain for each the weighted and unweighted case, and as a consequence it might not be potential to establish each the weighted and unweighted ATT goal parameters utilizing the identical diff-in-diff design. It’s not in all probability correct to name it an impossibility outcome, as a result of it’s certainly potential, however the situations do place restrictions on the kind of choice into therapy.
However first, let’s seek the advice of the magic 8-ball to see if I might be paywalling this put up. As you recall, I randomize the paywall as I battle as a rule with paywalling extra typically — evidenced by round 6 months now of posting all my content material with out any paywall. So we go to my python script, we flip a coin thrice, and if it’s heads 2+ occasions, I paywall, and if it isn’t, I don’t. And at the moment it was, like yesterday, heads two out of three which implies paywall!
Thanks all for supporting the substack. It’s reader supported, I’m making an attempt to get again to extra common posts about econometrics, and might be randomly paywalling once more as earlier than. I admire all of your help (each subscribers and never), and hope that this put up is insightful and attention-grabbing. Although Alfred Adler would say that your emotions and ideas are your life process, and never mine, so possibly I simply provide this up as a present and you are able to do with it what you need.
We people could also be a little bit crafty and mischievous (nervous chuckle!) however we absolutely are centered on numerous issues. And once we are centered on one thing, we give it full precedence to we matter it fully. Proper? Certainly one of such issues on which we’re totally centered is studying. Our mind is a powerhouse which is all the time prepared to soak up info.
And this functionality of the mind makes us succesful to studying complete new issues each second. Human mind is all the time wanting to study something new which appears proper! And the invention of know-how has vibrant with it a number of mysteries and unsolved puzzles which, to be trustworthy, can take tens of millions of years to be revealed fully.
So, it won’t be improper to say that we now have lots to study. And with know-how got here numerous technical devices, our of which the should vital are computer systems and laptops. In easy phrases, we are able to describe a pc as a mix of 1000’s of transistors. Now, we all know communication is an enormous factor.
We people talk with one another lots. And we are able to talk with our machine mates as nicely! Yeah, it’s executed by a way referred to as coding. Coding is principally a language via which we talk with numerous machines and provides them directions on their actions.
And coding is hard man! So are you going through issues in studying and utilizing the coding language like me? Here’s a record of high 5 apps which may make coding simple.
Prime 5 Finest Coding Apps
SoloLearn
SoloLearn is a superb Android app to study coding from the start. At present it’s the Editor’s Selection so on the Play Retailer!
SoloLearn presents quite a lot of coding classes ranging from freshmen to professionals. It presents 1000’s of coding matters to study coding, brush up your abilities or stay are of the most recent tendencies within the coding market. It offers in virtually all kinds of laptop languages ranging from Java, Python, C, C++, Kotlin, Ruby, Swift and plenty of extra. It had three largest coder base who’re all the time prepared that will help you in your issues. You may also create classes of your personal space of experience and turn out to be s group influencer on the platform!
Programming Hero
Programming Hero is the subsequent finest app on which you’ll be able to rely for studying coding language. It has a number of constructive critiques from customers everywhere in the world.
What makes Programming Hero completely different from different coding apps is the way in which it teaches coding. By this app, you may study coding in a enjoyable approach via numerous video games! They use enjoyable teen conversations and game-like challenges to make coding enjoyable. Numerous areas of experience embrace HTML, Python, C55, C++, JavaScript and so forth. You may study rapidly by understanding the coffins and supplying them immediately. Listed here are some finest app creating firms which rent the very best coders. So you’re getting positioned as nicely!
Programming Hub
Programming Hub is a coding platform which takes studying coding language to a complete new degree via its options. Loads of constructive reviewers make it probably the greatest apps delivering coding information.
The app experience in numerous technical languages resembling HTML5, C55, C, C++, Python, Swift and so forth. And it is among the chosen apps offering classes on Synthetic Intelligence. There are numerous chew sized interactive programs which is able to assist you a large number in studying coding. The professional panel and different coders from all world wide are all the time prepared to resolve your doubts in minutes. It had one of many largest pre-compiled applications with outputs for studying and practising. And it is usually the quickest compiler on Android with compilations to run over 20+ coding languages altogether!
Mimo
Don’t go on the lovable identify bro! The Mimo software for coding has been nominated as the very best self-improvement app of 2018 by Google Play Retailer and it has a motive!
Mimo make coding enjoyable and fascinating with its enigmatic classes. It offers within the number of coding languages like Java, JavaScript, C#, C++, Python, Swift and plenty of extra. By the assistance of Mimo, you may study programming and construct web sites by spending solely 5 minutes per day. Hundreds of thousands of coders from world wide are all the time energetic and cab aid you remedy your doubts at anytime. The chew sized interactive programs aid you in studying coding from the start and go on to the skilled degree.
Different options embrace the coding challenges which allow you to enhance your information and expertise by competing with the coders and aid you in realizing your flaws.
Grasshopper
It’s an superior platform which has full details about coding and programming and may make you a professional in coding inside no time.
The app has a Simone and intuitive person interface and experience in languages like Java, JavaScript, Python, C, C#, C++, Kotlin, Swift and plenty of extra. It has one of many largest collections of Java tutorials and there are millions of classes current on Java which additionally include detailed feedback for higher understanding. Classes have been made for the freshmen and professionals. You may construct your personal programme and publish on the web site! General it’s a nice app!
These had been a couple of superior apps to make coding simple. Remark down under if you understand another good programming app.
Giant language fashions excel at processing in depth contexts, enabling them to generate coherent essays, perform multi-step reasoning, and preserve conversational threads over 1000’s of tokens. Nonetheless, as sequence lengths develop, so do the computational and reminiscence calls for throughout autoregressive decoding. Engineers should steadiness maximizing context window dimension and staying inside {hardware} limits.
On the coronary heart of this problem lies the key-value (KV) cache, which shops each previous key and worth tensor for every consideration head, thereby avoiding redundant computations. Whereas caching accelerates per-token technology, its reminiscence footprint scales linearly with the variety of consideration heads, sequence size, and mannequin depth. Left unchecked, KV cache necessities can balloon to tens of gigabytes, forcing trade-offs in batch dimension or context size.
Grouped Question Consideration (GQA) provides a center floor by reassigning a number of question heads to share a smaller set of KV heads. This easy but highly effective adjustment reduces KV cache dimension and not using a substantial impression on mannequin accuracy.
On this submit, we’ll discover the basics of KV cache, examine consideration variants, derive memory-savings math, stroll via code implementations, and share best-practice suggestions for tuning and deploying GQA-optimized fashions.
This lesson is the first of a 3-part sequence on LLM Inference Optimization — KV Cache:
Transformers compute, for every token in a sequence, three projections: queries , keys , and values . Throughout autoregressive technology, at step , the mannequin should attend to all earlier tokens .
With out caching, one would recompute
for each layer and each previous token — an value per token that rapidly turns into prohibitive.
KV caching sidesteps this by storing the previous keys and values in reminiscence as they’re first computed, in order that at step , the mannequin solely must compute
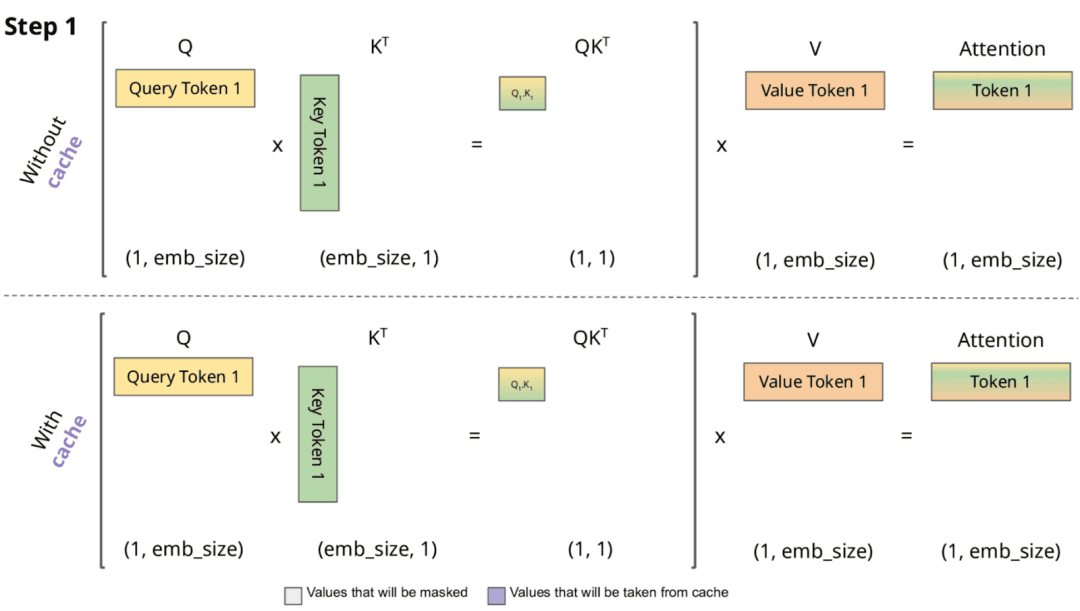
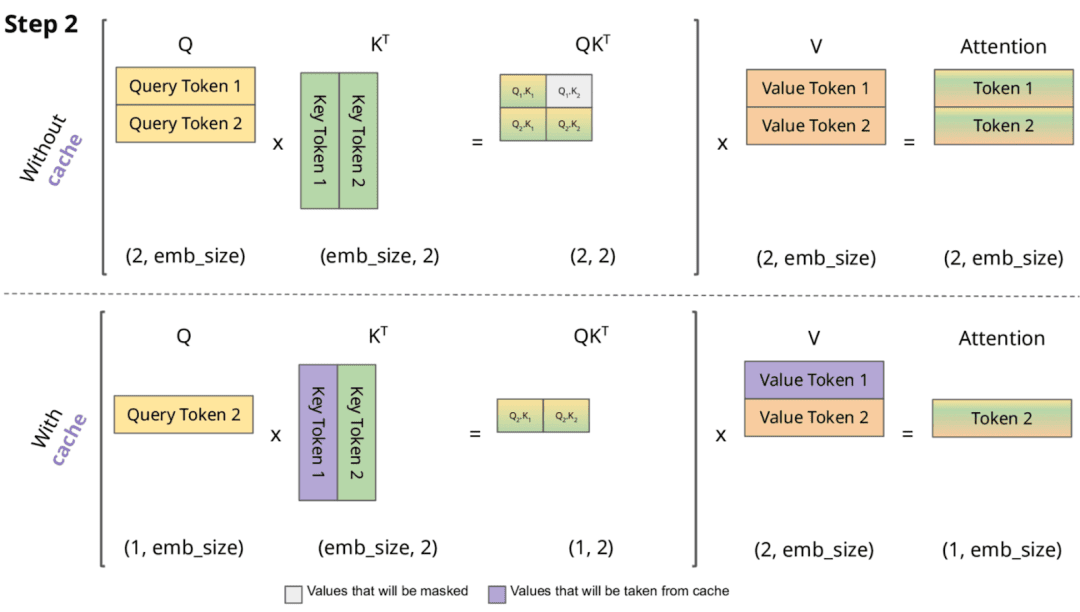
after which carry out consideration towards the cached (Figures 1 and a pair of).
As a result of every consideration head at layer maintains its personal key and worth sequences of dimension , the cache for that head and layer grows linearly within the context size .
Determine 1: No Distinction with and with out KV Cache for first token (supply: Chan, 2023).
Concretely, if there are consideration heads, and we retailer each keys and values in 2 bytes (FP16) per component, the per-layer KV cache dimension is
Over layers and a batch of dimension , the entire KV cache requirement turns into
Past uncooked storage, every new token’s consideration computation should scan via the complete cached sequence, yielding a compute value proportional to
Thus, each reminiscence bandwidth (studying , ) and computation (dot-product of towards all cached keys) scale linearly with the rising context.
KV caching dramatically reduces the work of recomputing () and (), but it surely additionally makes the cache’s dimension and structure a first-class concern when pushing context home windows into the 1000’s of tokens.
Determine 2: From the second token onward, KV Caching makes use of already cached key and worth sequences for computing consideration scores (supply: Chan, 2023).
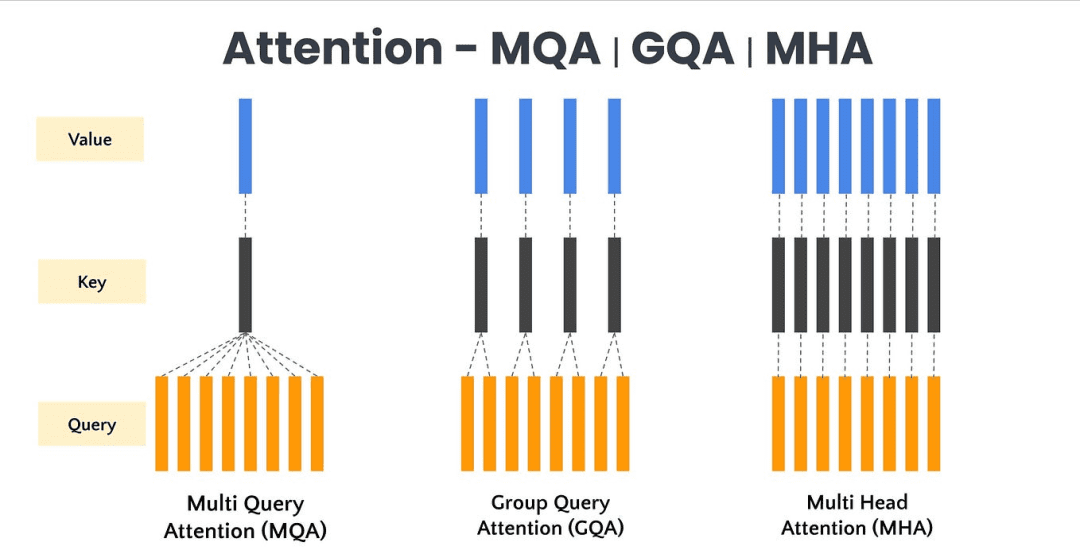
Grouped Question Consideration (GQA) modifies the usual multi-head consideration (MHA) by having a number of question heads share a lowered set of key and worth heads (Determine 3).
In vanilla MHA, the variety of key heads and worth heads equals the variety of question heads :
GQA introduces a grouping issue in order that
which means every group of question heads attends to a single shared key and worth head.
Regardless of this sharing, the question projections stay one per head:
Keys and values are computed solely per group: for group index , we now have
Throughout consideration, every question head makes use of the shared pair :
By chopping the variety of key and worth projections from to , GQA reduces each the parameter depend in and and the reminiscence wanted to retailer their outputs, whereas leaving the general mannequin dimension and ultimate output projection unchanged.
Primarily based on totally different values of , we are able to categorize consideration into the next sorts (Desk 1):
Desk 1: Comparability of consideration variants based mostly on group dimension G, KV cache utilization, and typical functions (supply: by the writer).
Determine 3: Comparability of Groped Question Consideration with Multihead Consideration and Multi-Question Consideration (supply: Shap, 2024).
The KV cache shops previous key and worth tensors of form for every head, the place is the present context size, and is the bytes per component (e.g., 2 for FP16).
In customary MHA, the per-layer cache reminiscence is
Below GQA, solely key and worth heads are saved, giving
Thus, the cache dimension shrinks by an element of ():
Importantly, the compute value of the dot-product consideration — proportional to — stays the identical.
This decouples reminiscence bandwidth from FLOPs, so decreasing the cache immediately interprets to quicker long-context inference with out altering per-token computational load.
On this part, we’ll see how utilizing Grouped Question Consideration improves the inference time and KV Cache dimension. For simplicity, we’ll implement a toy transformer mannequin with 1 layer of a Grouped Question Consideration layer.
We outline a grouped question consideration module on Traces 6-13. Right here, we inherit from nn.Module and seize the primary dimensions: hidden_dim, num_heads, and group_size. We compute kv_heads = num_heads // group_size to find out what number of key and worth heads we’ll truly challenge, and head_dim = hidden_dim // num_heads because the dimension per question head.
On Traces 15-18, we instantiate 4 linear layers: one every for projecting queries (q_proj), keys (k_proj), and values (v_proj), and a ultimate out_proj to recombine the attended outputs again into the mannequin’s hidden house.
On Traces 20-27, the ahead methodology begins by unpacking batch_size and seq_len from the enter tensor x. We then challenge x into queries, keys, and values. Queries are formed into (batch, num_heads, seq_len, head_dim) on Line 24, whereas keys and values use (batch, kv_heads, seq_len, head_dim) on Traces 25 and 26.
On Traces 29 and 30, we append these newly computed key and worth tensors alongside the time dimension into kv_cache, preserving all previous context for autoregressive decoding.
Subsequent, we align the cached key and worth heads to match the variety of question heads. On Traces 33 and 34, we use repeat_interleave to broaden every group’s cached (, ) from kv_heads to num_heads so each question head can attend.
On Traces 37-39, we implement scaled dot-product consideration: we compute uncooked scores through q @ k_expᵀ divided by √head_dim, apply softmax to acquire consideration weights, after which multiply by v_exp to provide the attended outputs.
Lastly, on Traces 41-43, we merge the per‐head outputs again to (batch, seq_len, hidden_dim) and go them via out_proj, returning each the up to date consideration output and the expanded kv_cache.
Now that we now have carried out the grouped question consideration module, we’ll implement a 1-layer toy Transformer block that takes a sequence of enter tokens, together with KV Cache, and performs one feedforward go.
We outline a TransformerBlock class on Traces 1-11, the place the constructor wires collectively a grouped MultiHeadAttention layer (self.attn), two LayerNorms (self.norm1 and self.norm2), and a two-layer feed-forward community (self.ff) that expands the hidden dimension by 4× after which tasks it again.
On Traces 13-18, the ahead methodology takes enter x and the kv_cache, runs x via the eye module to get attn_out and an up to date cache, then applies a residual connection plus layer norm (x = norm1(x + attn_out)).
Subsequent, we feed this via the FFN, add one other residual connection, normalize once more (x = norm2(x + ff_out)), and at last return the reworked hidden states alongside the refreshed kv_cache.
The code under runs an inference to generate a sequence of tokens in an autoregressive method.
On Traces 1-6, we outline run_inference, pull out hidden_dim and num_heads, and construct a listing of goal seq_lengths (1 to 101 in steps of 10), together with empty lists for kv_cache_sizes and inference_times.
On Traces 8-11, we initialize kv_cache with empty tensors for 'okay' and 'v' of form [1, num_heads//group_size, 0, head_dim] so it could possibly develop as we generate tokens.
Then, within the loop over every seq_len on Traces 13-17, we simulate feeding one random token x at a time into the transformer block, timing the ahead go, and updating kv_cache.
Lastly, on Traces 19-23, we measure the entire variety of components within the cached keys and values, append that to kv_cache_sizes, file the elapsed time to inference_times, after which return all three lists for plotting or evaluation.
On Traces 1 and a pair of, we arrange a 12×5-inch determine and declare the primary subplot for KV cache development.
Between Traces 4-7, we loop over numerous group_size values, instantiate a TransformerBlock for every, name run_inference to assemble sequence lengths and cache sizes, and plot the KV cache dimension versus the variety of generated tokens.
On Traces 14-18, we change to the second subplot, repeat the loop to gather and plot inference instances towards token counts, and at last, on Traces 21-28, we set axis labels, add a title and legend, tighten the structure, and name plt.present() to render each charts (Determine 4).
Determine 4: Discount in KV cache dimension and inference time through the use of Group Question Consideration (supply: picture by the writer).
As proven in Determine 4, utilizing grouped question consideration considerably reduces the KV cache dimension and inference time in comparison with vanilla multihead self-attention (group dimension 1).
Course data:
86+ whole courses • 115+ hours hours of on-demand code walkthrough movies • Final up to date: October 2025 ★★★★★ 4.84 (128 Scores) • 16,000+ College students Enrolled
I strongly imagine that when you had the fitting trainer you could possibly grasp pc imaginative and prescient and deep studying.
Do you suppose studying pc imaginative and prescient and deep studying needs to be time-consuming, overwhelming, and sophisticated? Or has to contain advanced arithmetic and equations? Or requires a level in pc science?
That’s not the case.
All you must grasp pc imaginative and prescient and deep studying is for somebody to elucidate issues to you in easy, intuitive phrases. And that’s precisely what I do. My mission is to alter training and the way advanced Synthetic Intelligence subjects are taught.
Should you’re critical about studying pc imaginative and prescient, your subsequent cease must be PyImageSearch College, probably the most complete pc imaginative and prescient, deep studying, and OpenCV course on-line immediately. Right here you’ll discover ways to efficiently and confidently apply pc imaginative and prescient to your work, analysis, and tasks. Be a part of me in pc imaginative and prescient mastery.
Inside PyImageSearch College you will discover:
&examine; 86+ programs on important pc imaginative and prescient, deep studying, and OpenCV subjects
&examine; 86 Certificates of Completion
&examine; 115+ hours hours of on-demand video
&examine; Model new programs launched repeatedly, guaranteeing you’ll be able to sustain with state-of-the-art strategies
&examine; Pre-configured Jupyter Notebooks in Google Colab
&examine; Run all code examples in your net browser — works on Home windows, macOS, and Linux (no dev surroundings configuration required!)
&examine; Entry to centralized code repos for all 540+ tutorials on PyImageSearch
&examine; Simple one-click downloads for code, datasets, pre-trained fashions, and so forth.
&examine; Entry on cell, laptop computer, desktop, and so forth.
We start by framing the problem of lengthy‐context inference in transformer fashions. As sequence lengths develop, storing previous key and worth tensors within the KV cache turns into a significant reminiscence and bandwidth bottleneck. To deal with this, we introduce Grouped Question Consideration (GQA), an architectural modification that permits a number of question heads to share a smaller set of key-value heads, thereby decreasing the cache footprint with minimal impression on accuracy.
Subsequent, we unpack the mechanics of KV caching — why transformers retailer per‐head key and worth sequences, how cache dimension scales with head depend , context size , and mannequin depth , and the ensuing latency strain from studying giant caches every token. We then formally outline GQA, displaying how the grouping issue reduces the variety of KV projections from to and yields a discount in cache reminiscence. We illustrate this with equations and intuitive diagrams, contrasting vanilla multi‐head consideration, multi‐question consideration, and the GQA center floor.
Lastly, we stroll via a hands-on implementation: constructing a toy TransformerBlock in PyTorch that helps arbitrary GQA groupings, wiring up KV cache development, and operating inference experiments throughout group sizes. We plot how cache dimension and per-token inference time evolve for , analyze the memory-latency trade-off, and distill sensible tips for selecting and integrating GQA into real-world LLM deployments.
Mangla, P. “Introduction to KV Cache Optimization Utilizing Grouped Question Consideration,” PyImageSearch, P. Chugh, S. Huot, A. Sharma, and P. Thakur, eds., 2025, https://pyimg.co/b241m
@incollection{Mangla_2025_intro-to-kv-cache-optimization-using-grouped-query-attention,
writer = {Puneet Mangla},
title = {{Introduction to KV Cache Optimization Utilizing Grouped Question Consideration}},
booktitle = {PyImageSearch},
editor = {Puneet Chugh and Susan Huot and Aditya Sharma and Piyush Thakur},
12 months = {2025},
url = {https://pyimg.co/b241m},
}
To obtain the supply code to this submit (and be notified when future tutorials are printed right here on PyImageSearch), merely enter your e mail tackle within the type under!
Obtain the Supply Code and FREE 17-page Useful resource Information
Enter your e mail tackle under to get a .zip of the code and a FREE 17-page Useful resource Information on Laptop Imaginative and prescient, OpenCV, and Deep Studying. Inside you will discover my hand-picked tutorials, books, programs, and libraries that can assist you grasp CV and DL!
Among the many prime gadgets holding CIOs up at evening is knowing who ought to lead the AI technique at their organizations.
SAS CIO Jay Upchurch instructed InformationWeek that CIOs world wide are grappling with figuring out the place the duty lies for organizational AI methods and who ought to take the lead on company-wide AI mandates. The CIO will, after all, implement AI applied sciences, Upchurch defined, however selecting who leads the cost on AI technique is a separate problem.
“Is it pushed from the highest down, as a board or CEO mandate? Is it a groundswell of curiosity from staff?” Upchurch mentioned.
SAS, for its half, has taken a multi-pronged strategy to implementing its AI technique throughout the group, guaranteeing buy-in from each the chief group and the worker base.
Having help from management throughout the group has been important to realizing this broad-based strategy to AI implementation. Every division throughout the group has a tech chief who can advocate for his or her division and assist the IT group higher perceive their expertise necessities, Upchurch mentioned.
At a latest SAS occasion, CTO Bryan Harris additionally emphasised the significance of company-wide buy-in for AI when deploying the expertise. Step one in AI deployments, he mentioned, is “constructing belief between you and your workforce.”
(Supply: Shane Snider/Knowledge Heart Information) Bryan Harris, CTO of SAS, mentioned the corporate’s strategy to AI at a SAS Championship 2025 occasion.
“Firms want daring and inspirational leaders who spend money on their workforce by way of this continued change,” Harris mentioned. “As you spend money on individuals and their abilities, you construct belief. And constructing belief will increase AI adoption, which in flip will increase your aggressive benefit. It is all related.”
Among the many leaders in control of AI technique at SAS is an AI working council that features eight individuals from the chief group and different ranges of administration. The council meets frequently to “evaluate requests for brand new AI which may come into the enterprise,” Upchurch mentioned.
One subject the council has mentioned is how regional laws may have an effect on the deployment of recent AI applied sciences within the varied international locations the place SAS does enterprise.
“So it is not IT or authorized saying ‘sure or no.’ It is a group of people which have an curiosity within the security and safety of our staff, our knowledge, our firm’s knowledge, and our clients’ knowledge,” Upchurch mentioned.
A Productiveness-First Strategy to AI
With out enterprise-wide help, IT groups run the danger of rolling out an costly AI that sits on a shelf amassing mud, he added. That is partly why SAS selected to first roll out AI to help worker productiveness.
Instruments that automate and help with mundane duties, like Microsoft Copilot or Anthropic’s Claude, could be tailor-made to staff’ particular roles, serving to them really feel valued and giving them the “present of time” to give attention to higher-impact work, Upchurch mentioned.
Harris mentioned the AI give attention to productiveness has already proved a boon for the corporate. “When [employees] offload this tedious work, they’ve extra time to assume, consider and make higher choices,” he mentioned. “Nobody is debating the ROI of this primary section.”
Advantages of an AI-Prepared Workforce
Certainly, SAS staff are pretty educated about AI and have been fast to use it, Upchurch mentioned. In September, SAS carried out a Microsoft Copilot license for SAS staff to construct their very own AI brokers to help their productiveness targets. By early October, staff had created 760 AI brokers.
Having an AI-literate worker base has been useful “when it comes to velocity and effectivity” for deploying AI throughout the group, Upchurch added.
SAS’ 12,000 staff are “extremely knowledgeable about what AI is and learn how to do it the best approach,” Upchurch mentioned. “After I’ve talked to numerous my CIO friends, they battle with that, in order that they’re out chasing knowledge literacy or AI literacy or one thing else with their very own worker base.”
Nonetheless, change administration is just not a straightforward process for any group, Upchurch mentioned.
“You possibly can clear knowledge up, and with sufficient time and money you are able to do a venture and ship a functionality, however getting individuals to embrace and alter their mindset is tough work,” he mentioned. “The best expertise, the best tasks, can land flat if the corporate or the group is just not able to obtain it, and that is very true in AI.”
What’s Subsequent for SAS’ AI Technique: Reimagining Workflows
After worker productiveness — the primary space of focus within the firm’s inside AI technique — SAS will give attention to infusing AI into work processes to “reimagine workflows,” and utilizing AI for autonomous operations, Upchurch mentioned. The intention is to rethink how work will get executed with AI, as a substitute of merely automating present processes.
In the long run, Upchurch mentioned SAS is concentrated on utilizing AI for autonomous operations resembling computerized software program anomaly detection and remediation. In the meantime, it is the “superb innovation and curiosity tradition,” not the expertise, that accounts for the corporate’s progress.
“After we see these two issues come collectively, it fuels each other, and it simply continues to breed success for us,” he mentioned.
Are you involved concerning the affect of AI in your career? You’re not alone.
With Synthetic Intelligence altering the world, and nonetheless altering it at a staggering tempo, folks all all over the world are asking themselves how they are often related -or even ahead- of the occasions of clever automation.
Organizations are making use of AI to automate processes, optimize decision-making, and supply a better buyer expertise. This wave of adoption has generated an enormous demand for skilled personnel with the potential to slender the hole between AI applied sciences and precise enterprise necessities.
On this article, we’ll talk about the 8 high-demand AI jobs in 2025 and what they entail, the abilities required to work, and how one can put together to work in these positions. These positions not solely have excessive progress prospects and aggressive pay but additionally the chance to safe probably the most profitable careers in 2025 and past.
Why AI Careers Are Booming in 2025
With the adoption of AI expertise in enterprise processes has led to a 25% productiveness increase within the manufacturing enterprise, by which over 35 p.c of e-commerce revenues come by AI-based methods. The AI job market represents a big selection of future-proof employment alternatives to those that are keen to be part of AI-powered job roles that deliver the following wave of automation & data-driven decision-making throughout industries.
8 Excessive-Demand AI Jobs in 2025
1. AI Engineer
The AI Engineers are essential contributors to the event of AI as they’re engaged of their actions, which embody creating AI options & growing their purposes in real-world problem-solving wants.
The on a regular basis duties of AI Engineers encompass mannequin growth exercise & enterprise management involvement.
They align AI options & integrative exercise amongst AI instruments, merchandise, & providers, incomes an annual median wage of $145,080
To develop into profitable within the space, one must grasp Python programming, possess the information of such frameworks as TensorFlow or PyTorch, & know discover the answer to difficult issues.
Moreover, should you’re simply beginning with Synthetic Intelligence, Grasp Synthetic Intelligence by Nice Studying is right to discover the basics of AI, machine studying, deep neural networks, GenAI, & to construct key expertise within the newest applied sciences.
2. Machine Studying Engineer
A Machine Studying Engineer develops computerized studying algorithms that may allow computer systems to be taught by the datasets & mechanically enhance their efficiency in a minimal quantity of human code.
Machine studying engineers perform their roles by creating, testing, & implementing machine studying fashions & automating actions.
The common annual wage of a machine studying engineer within the US is $109,143.
Their position is essential as a result of they design and implement clever methods, resembling advice engines and fraud detection fashions, that assist organizations make smarter choices, optimize operations, and ship customized person experiences.
These trying to construct experience on this area typically pursue specialised applications, resembling an on-line MS in Synthetic Intelligence and Machine Studying, which give a complete basis in programming, statistics, and operations of ML frameworks.
3. Information Scientist
Information Scientists research in depth databases to generate sensible info that guides enterprise planning. The position of Information Scientists stays important all through the e-commerce, finance, and healthcare sectors, as they make the most of knowledge insights to boost operational effectivity and sample prediction.
The scope of their duties consists of growing knowledge fashions, performing predictive analytics, and supporting key firm choices.
Skilled success for knowledge analysts requires experience in each knowledge evaluation strategies and programming expertise, in addition to machine studying practices and statistical strategies.
To attain success within the discipline, you will need to choose an appropriate instructional path. Formal levels, together with Bachelor’s and Grasp’s applications, set up the essential theoretical and sensible foundations, whereas specialised choices, such because the MS in Information Science program, additional sharpen the skilled expertise that companies urgently want and permit you to earn the common annual wage of $65,674.
Carefully associated to knowledge science roles, Information Architects play a significant half in designing the infrastructure that helps large-scale analytics and AI methods. Be taught extra about what a Information Architect does, required expertise, and profession pathways on this information: Find out how to develop into a Information Architect.
4. AI Analysis Scientist
AI Analysis Scientists advance AI expertise by growing novel algorithms and conducting analysis experiments that propel the sector ahead.
The analysis staff conducts deliberate experiments and publishes their outcomes by collaboration with tutorial establishments and industrial companions.
To excel on this place, one requires professional-level mathematical expertise, mixed with in depth studying expertise and a stable understanding of analysis strategies.
AI Analysis Scientists are essential in growing technological advances, which decide how AI purposes evolve all through time.
Understanding the key duties and instruments of a Information Analyst may assist construct a powerful base for progress in AI-focused roles, as many professionals start their careers as Information Analysts earlier than advancing into knowledge science or AI specializations, incomes a median annual wage of $115,443 as an AI analysis scientist within the US.
5. Robotics Engineer
Throughout the discipline of robotics engineering, professionals design and develop clever robotic methods to automate varied industrial operations, starting from manufacturing actions to logistics and healthcare purposes, and earn ancommon annual wage of $120,997 per 12 months.
The duties of those professionals embody robotic creation, coding actions, check runs, and system upkeep.
They develop clever machines by an ideal mix of robotics engineering and Synthetic Intelligence integration capabilities to execute autonomous advanced duties.
The implementation of automation by industries drives continuous growth within the want for Robotics Engineers and exhibits no signal of slowing down.
Automation additionally extends past robotics into software program high quality and efficiency testing. Professionals aiming to make sure the reliability of AI methods can discover a profession as an Automation Check Engineer, answerable for designing check frameworks and enhancing AI mannequin effectivity. Be taught extra on this detailed Automation Check Engineer Profession Information.
6. Pc Imaginative and prescient Engineer
Via the event of methods, Pc Imaginative and prescient Engineers allow computer systems to grasp visible info from photos and video content material.
Their programming empowers purposes to acknowledge faces, drive autonomous autos, and ship augmented actuality capabilities.
Incomes the common annual wage of $168,803, these specialists are answerable for creating and fine-tuning algorithms that allow machines to interpret visible knowledge, thereby bridging the hole between uncooked pictures and actionable insights for real-world purposes, resembling medical diagnostics and robotics.
The required skills for this discipline embody deep studying strategies, picture processing, and superior laptop imaginative and prescient strategies, expertise which might be more and more valued as knowledge turns into central for enterprise options and innovation.
7. AI Chatbot Developer / NLP Engineer
The mixture of AI Chatbot Builders and NLP Engineers is reworking how companies work together with clients by growing methods and conversational brokers that may perceive and generate human language.
These professionals design multi-tiered chatbots and construct refined NLP fashions to strengthen dialogue and person engagement. They collaborate intently with different engineers to create methods that may comprehend human voice and textual content and react accordingly, with the common annual wage of an NLP engineer $86,193.
Their work requires competency in NLP, Python, and mastery of chatbot frameworks, in addition to an understanding of combine AI fashions for responsive, context-aware conversations.
A powerful basis, resembling one constructed by a complete Pure Language Processing tutorial, is essential for excelling on this discipline.
As LLM and NLP AI fashions proceed to be into demand with AI chatbot developer, a associated and fast-emerging position is that of the Immediate Engineer who designs and optimizes the inputs that information AI fashions to supply related outputsis additionally on the increase.
You possibly can discover extra about develop into a immediate engineer and construct the precise ability set for this GenAI-driven position.
8. AI Product Supervisor
The position of the AI Product Supervisor exists to merge technical operations with enterprise priorities, making certain that AI venture effectivity aligns with organizational ideas. For an in depth understanding of what the position entails, discover this complete information on AI Product Supervisor expertise, duties, and profession progress.
Incomes the common annual wage of $128,091, these professionals steer product path and oversee growth duties, sustaining efficient staff relationships all through the method.
Data of product administration, AI proficiency, communication expertise, and enterprise understanding are important competencies.
The central significance of AI Product Managers in enterprise technique growth is rising, as they’re essential for attaining profitable AI implementation and maximizing the worth of AI investments.
CONCLUSION
Within the 12 months 2025, AI may have quite a few alternatives with many rewarding roles that shall be supplied to people with applicable competencies.
Amongst these professions, AI Engineers, Information Scientists, NLP consultants, and AI Product managers are the careers that enhance the technological and enterprise functioning of recent society.Those that wish to develop into leaders within the space of educational innovation and superior expertise analysis can apply to get a Doctorate in AI and Machine Studying to discover new technological frontiers.
Pierre Jacob, John O’Leary and Yves Atchadé’s wonderful paper on Unbiased MCMC with couplings will likely be learn on the Royal Statistical Society tomorrow; Pierre has already introduced the paper on the Statisfaction weblog. Though we received’t be current tomorrow, we’ve got learn it at size in our native studying group with Xian Robert and PhD college students Grégoire Clarté, Adrien Hairault and Caroline Lawless, and have submitted the next dialogue.
We congratulate the authors for this wonderful paper.
In “conventional” MCMC, it’s customary to verify that stationarity has been attained by operating a small variety of parallel chains, initiated at completely different beginning factors, to confirm that the ultimate distribution is unbiased of the initialization — although the one versus a number of chain(s) debate errupted from the beginning with Gelman and Rubin (1992) versus Geyer (1992).
As famous by the authors, a nasty selection of the preliminary distribution can result in poor properties. In essence, this happens and stays undetected for the present proposal as a result of the coupling of the chains happens lengthy earlier than the chain reaches stationarity. We wish to make two ideas to alleviate this situation, and therefore add a stationarity verify as a byproduct of the run.
The chains and have to have the identical preliminary distribution, however completely different pairs of chains on completely different parallel cores can afford completely different preliminary distributions. The ensuing estimator stays unbiased. We’d subsequently recommend that parallel chains be initiated from distributions which put weight on completely different elements of the parameter area. Concepts from the Quasi-Monte Carlo literature (see Gerber & Chopin 2015) may very well be used right here.
We additionally word that though the marginal distributions of and have to be similar, any joint distribution on produces an unbiased algorithm. We’d recommend that it’s preferable that and meet (shortly) after the chains have reached stationarity. Right here is one attainable technique to this finish: let and be two distributions which put weight on completely different elements of the area, and . If , take and , else take and . The marginal distribution of each and is , however the two chains will begin in several elements of the parameter area and are more likely to meet after they’ve each reached stationarity.
The best algorithm is one which provides an accurate reply when it has converged, and a warning or error when it hasn’t. MCMC chains which haven’t but reached stationarity (for instance as a result of they haven’t discovered all modes of a multimodal distribution) might be arduous to detect. Right here, this situation is extra more likely to be detected since it will result in the coupling not occuring: is giant, and it is a function, because it warns the practitioner that their kernel is ill-fitted to the goal density.
In the event you occur to glimpse a “taking pictures star” earlier than daybreak throughout the subsequent a number of days, there is a good probability that what you noticed was a fraction left behind in area by the well-known Halley’s Comet. For it’s throughout the third week of October {that a} meteor show spawned by the particles shed by Halley reaches its peak: the Orionid meteor bathe.
The Orionids aren’t one of many 12 months’s richest meteor shows. If the August Perseids and December Geminids might be thought-about the “first string” among the many annual meteor showers by way of brightness and reliability, then the Orionids are on the junior varsity crew.
And this will probably be a superb 12 months to search for them, because the moon will arrive at new part on Tuesday morning, Oct. 21 at the exact same time that the Orionids are reaching their most and therefore won’t pose any hindrance in any respect for these waiting for these fiery streaks throughout their prime predawn viewing hours. Good!
The meteor moniker “Orionid” comes from the truth that the radiant — that spot on the sky from the place the meteors seem to fan out from — is simply above Orion‘s second brightest star, ruddy Betelgeuse.
Orion, in fact, is a winter constellation. At this second, in early autumn, he seems forward of us in our path across the solar, and as such has not fully risen above the japanese horizon till after 11:00 p.m. native daylight time. A number of hours later, between 4 and 5:00 a.m. — Orion will probably be excessive within the sky towards the south-southeast. The upper within the sky Orion is, the extra meteors will seem everywhere in the sky. The Orionids are considered one of only a handful of recognized meteor showers that may be noticed equally effectively from each the Northern and Southern Hemispheres.
However to see the best variety of meteors, do not look within the path of the radiant, however relatively about 30 levels from it, within the path of the purpose instantly overhead (the zenith). Your clenched fist held at arm’s size is roughly equal to 10 levels, so trying “three fists” up from Betelgeuse will probably be the place to pay attention your view.
An evening sky map displaying the Orionids meteor bathe. (Picture credit score: Starry Evening/Chris Vaughan)
Halley’s legacy
As famous on the onset of this dialogue, the Orionids have an illustrious lineage: Just like the Eta Aquariid meteors of early Could, they’re bits of particles shed way back by Halley’s Comet. The 2 showers are basically one and the identical; Earth intersects a single, broad stream of meteoroids at two locations in its orbit on reverse sides of the solar. Usually, just like the Eta Aquarids, Orionid meteors are usually dim and never effectively seen from city areas, so it is instructed that you simply discover a darkish (and protected) rural location to see the perfect Orionid exercise.
Breaking area information, the newest updates on rocket launches, skywatching occasions and extra!
“They’re simply recognized … from their pace,” write David Levy and Stephen Edberg in Observe: Meteors, an Astronomical League guide. “At 66 kilometers (41 miles) per second, they seem as quick streaks, quicker by a hair than their sisters, the Eta Aquarids of Could. And just like the Eta Aquarids, the brightest have a tendency to go away long-lasting trains. Fireballs are attainable three days after most.” This side is undoubtedly linked in a roundabout way to the make-up of Halley’s Comet.
The Orionids are a delight for any skywatcher. (Picture credit score: Mountain Gentle Images Inc/Getty Pictures)
The bathe is definitely a fancy of a number of sub-showers with totally different maxima unfold over a number of days. Halley’s Comet’s final go to by means of the internal photo voltaic system was within the late winter of 1986 and it’s due again within the midsummer of 2061. However every time it has swept previous the solar — and it has carried out so in all probability numerous lots of, if not 1000’s of occasions — it has launched tiny particles, largely ranging in dimension from mud to sand grains, which journey close to and alongside the comet’s orbit, creating a unclean path of particles that has been distributed kind of uniformly all alongside its total orbit.
The comet bits have additionally unfold a good distance from it sideways, which is why among the particles now intersect the Earth despite the fact that the comet’s orbit doesn’t. Concerning the 12 months 530 A.D. Halley’s orbit intersected that of the Earth. Presently, the least distance between the 2 orbits is 6,042,000 miles (9,710,000 km).
Observing ideas
Orionid visibility extends from Oct. 16 to 26, with peak exercise of maybe 15 to 30 meteors per hour approaching the morning of Oct. 21. Step outdoors earlier than dawn on any of those mornings and for those who catch sight of a meteor, there’s a couple of 75 % probability that it possible is a by-product of Halley’s Comet. The final Orionid stragglers often seem someday in early to mid-November.
Remember to bundle up very warmly; maybe convey a sleeping bag. Discover a darkish spot with an open view of the sky. The much less mild air pollution, the higher; a bathe like this one which’s wealthy in faint meteors is very onerous hit by synthetic skyglow. The path to observe is wherever your sky is darkest. Lie again, let your eyes adapt to the evening, and be affected person.







: half 2")






 , keys
, keys  , and values
, and values  . Throughout autoregressive technology, at step
. Throughout autoregressive technology, at step  , the mannequin should attend to all earlier tokens
, the mannequin should attend to all earlier tokens  .
. } = X^{(ell)} W_K,quad V^{(ell)} = X^{(ell)} W_V")
 and each previous token — an
and each previous token — an ") value per token that rapidly turns into prohibitive.
value per token that rapidly turns into prohibitive. }_t = x_t W_Q")
}_{1:t-1},V^{(ell)}_{1:t-1}}") (Figures 1 and a pair of).
(Figures 1 and a pair of). at layer
at layer  , the cache for that head and layer grows linearly within the context size
, the cache for that head and layer grows linearly within the context size  .
. 
 consideration heads, and we retailer each keys and values in 2 bytes (FP16) per component, the per-layer KV cache dimension is
consideration heads, and we retailer each keys and values in 2 bytes (FP16) per component, the per-layer KV cache dimension is.")
 layers and a batch of dimension
layers and a batch of dimension  , the entire KV cache requirement turns into
, the entire KV cache requirement turns into

 and worth heads
and worth heads  equals the variety of question heads
equals the variety of question heads  :
:
 in order that
in order that
},quad i=1,dots,H_q.")
/Gbigrrfloor+1") , we now have
, we now have},quad V_j = X W_V^{(j)}.")
 makes use of the shared pair
makes use of the shared pair ") :
: =text{softmax} left(dfrac{Q_i K_j^top}{sqrt{d_{text{head}}}}right) V_j.")
 to
to  , GQA reduces each the parameter depend in
, GQA reduces each the parameter depend in  and
and  and the reminiscence wanted to retailer their outputs, whereas leaving the general mannequin dimension and ultimate output projection unchanged.
and the reminiscence wanted to retailer their outputs, whereas leaving the general mannequin dimension and ultimate output projection unchanged.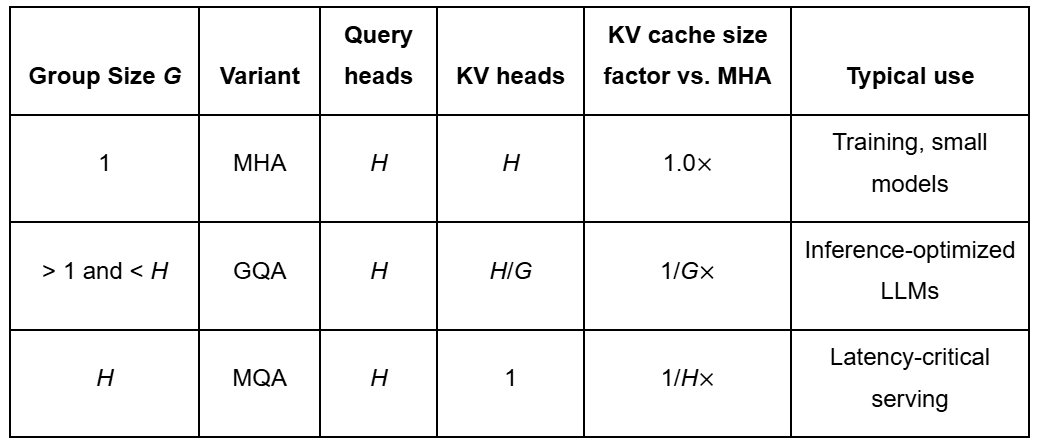
![[Ttimes d_{text{head}}]](https://b2633864.smushcdn.com/2633864/wp-content/latex/341/34197615c404759fe8a2a01c44b308ce-ffffff-000000-0.png?lossy=2&strip=1&webp=1 "[Ttimes d_{text{head}}]") for every head, the place
for every head, the place  is the bytes per component (e.g., 2 for FP16).
is the bytes per component (e.g., 2 for FP16). 
 key and worth heads are saved, giving
key and worth heads are saved, giving

 — stays the identical.
— stays the identical.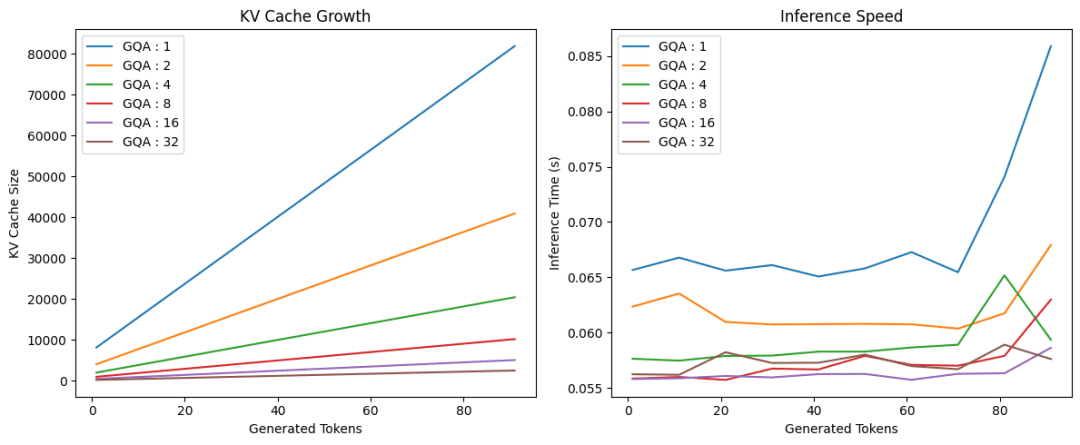
 and yields a
and yields a  discount in cache reminiscence. We illustrate this with equations and intuitive diagrams, contrasting vanilla multi‐head consideration, multi‐question consideration, and the GQA center floor.
discount in cache reminiscence. We illustrate this with equations and intuitive diagrams, contrasting vanilla multi‐head consideration, multi‐question consideration, and the GQA center floor. , analyze the memory-latency trade-off, and distill sensible tips for selecting
, analyze the memory-latency trade-off, and distill sensible tips for selecting 




 and
and  have to have the identical preliminary distribution, however completely different pairs of chains on completely different parallel cores can afford completely different preliminary distributions. The ensuing estimator stays unbiased. We’d subsequently recommend that parallel chains be initiated from distributions which put weight on completely different elements of the parameter area. Concepts from the Quasi-Monte Carlo literature (see Gerber & Chopin 2015) may very well be used right here.
have to have the identical preliminary distribution, however completely different pairs of chains on completely different parallel cores can afford completely different preliminary distributions. The ensuing estimator stays unbiased. We’d subsequently recommend that parallel chains be initiated from distributions which put weight on completely different elements of the parameter area. Concepts from the Quasi-Monte Carlo literature (see Gerber & Chopin 2015) may very well be used right here.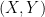 produces an unbiased algorithm. We’d recommend that it’s preferable that
produces an unbiased algorithm. We’d recommend that it’s preferable that  and
and  be two distributions which put weight on completely different elements of the area, and
be two distributions which put weight on completely different elements of the area, and  . If
. If  , take
, take 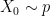 and
and  , else take
, else take 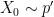 and
and 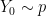 . The marginal distribution of each
. The marginal distribution of each 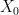 and
and  is
is 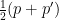 , however the two chains will begin in several elements of the parameter area and are more likely to meet after they’ve each reached stationarity.
, however the two chains will begin in several elements of the parameter area and are more likely to meet after they’ve each reached stationarity.![mathbb E[tau]](https://s0.wp.com/latex.php?latex=%5Cmathbb+E%5B%5Ctau%5D&bg=ffffff&fg=000000&s=0&c=20201002) is giant, and it is a function, because it warns the practitioner that their kernel is ill-fitted to the goal density.
is giant, and it is a function, because it warns the practitioner that their kernel is ill-fitted to the goal density.
