For years, weight problems charges within the US have gone in a single path: up. From the primary yr it was launched, Gallup’s Nationwide Well being and Nicely-Being Index has discovered that the share of US adults reporting weight problems has climbed and climbed, rising from 25.5 % in 2008 to 39.9 % in 2022. That survey caught the final leg of an epidemic that has been spreading for many years, with estimated weight problems prevalence tripling over the previous 60 years.
However perhaps not. In response to the most recent outcomes from Gallup’s survey, self-reported weight problems has began to fall, declining by practically 3 factors to 37 % in 2025. The self-reporting half is a crucial limitation — folks’s reporting of their weight tends to be imprecise — and we’ll want extra definitive proof from the Facilities for Illness Management and Prevention to make certain, but it surely’s among the earliest proof that the US could lastly be turning a nook on one of many greatest well being crises of the trendy age.
And the principle motive it seems to be occurring isn’t as a result of weight-loss consultants have stumbled upon a brand new weight loss program that at all times works (we haven’t and doubtless by no means will) or as a result of we’ve managed to ban all unhealthy junk meals (we haven’t and nearly actually by no means will). It’s probably due to the rising use of glucagon-like peptide-1 agonists, higher generally known as GLP-1 medicine like Ozempic and Wegovy.
What’s modified is we now have extremely efficient weight-loss medicines working at a scale that we’ve by no means seen earlier than.
Older weight-loss medicine tended to shave off just a few proportion factors of physique weight, they usually got here with robust trade-offs and fast weight rebound. The brand new medicine, which have been initially developed to deal with diabetes, are concentrating on the biology that makes weight so arduous to lose and maintain off: They dial down starvation within the mind, gradual gastric emptying, and enhance post-meal insulin signaling. In giant randomized trials, semaglutide 2.4 mg — the energetic ingredient utilized in medicines like Ozempic — produced about 15 % common weight reduction over 68 weeks when paired with fundamental life-style assist. Different combos have reached as a lot as 20 % on greater doses.
These impact sizes are sufficiently big that, when even a modest share of adults use them, you can begin to see motion within the inhabitants information. And as additional information from Gallup exhibits, increasingly more People try these medicine, with the survey discovering that greater than 12 % of adults reported taking them within the second and third quarters of 2025, up from lower than 6 % in early 2024.
And whereas a lot of the media protection round these medicine has targeted on weight and look, the well being advantages appear to go a lot additional. In 2024 the Meals and Drug Administration added cardiovascular threat as a motive to be prescribed the GLP-1 drug Wegovy, grounded in outcomes from a serious trial that confirmed fewer coronary heart assaults, strokes, and cardiovascular deaths in adults with weight problems or obese and established coronary heart illness. The FDA’s motion additionally opened a door for Medicare protection in sufferers with heart problems — an early signal that entry for these costly medicines might increase past the well-insured.
The upside of downsizing — and the negative effects
It’s nonetheless early days, but when the nationwide weight problems curve retains bending down, the advantages could be huge. Weight problems multiplies threat throughout practically each main explanation for dying; even small, sustained declines in prevalence translate into thousands and thousands fewer folks dwelling with diabetes, coronary heart illness, sleep apnea, and painful joint illness — and billions saved in medical prices over time. The CDC pegs direct medical spending tied to weight problems at roughly $173 billion. Turning that curve even a bit would characterize vital aid.
However we’re a great distance from fixing this downside. For one factor, as efficient as they’re, these medicine behave extra like statins than antibiotics: They work when you take them. When folks cease, weight regain is widespread.
Chances are high, although, that the present technology of GLP-1s is the worst and most costly we’ll ever have. Drug firms are already experimenting with capsule types of the drugs, which might make dosing extra exact and decrease the barrier to entry: as a lot as 20 % of the American public has some type of needle phobia (or trypanophobia, for many who need an important Scrabble phrase).
I’ll admit there’s one thing uncomfortable in regards to the thought of fixing weight problems primarily by a drug. In any case, as Well being Secretary Robert F. Kennedy Jr. is fond of claiming, can’t we repair weight problems by more healthy meals and extra train? However whereas our meals system might certainly be improved and most of us don’t get sufficient train, it’s not as if we haven’t tried, whether or not as people or as a rustic. The straightforward truth is that the modern surroundings is one that’s closely weighted towards the obesogenic. GLP-1 medicine appear to supply the most effective probability to tilt the scales again in our favor.
A model of this story initially appeared within the Good Information e-newsletter. Enroll right here!
Disrupting communication between the physique’s inside clock and the mind might assist restrict neurodegeneration in Alzheimer’s illness, in keeping with new analysis from Washington College College of Medication in St. Louis (WashU Medication). The research, revealed in Nature Growing older, explored how adjustments within the circadian system have an effect on mind well being and reminiscence in mouse fashions of Alzheimer’s illness.
Led by Erik Musiek, MD, PhD, the Charlotte & Paul Hagemann Professor of Neurology at WashU Medication, and first creator Jiyeon Lee, PhD, the analysis group investigated whether or not blocking a selected circadian clock protein would possibly gradual the development of neurodegeneration. They discovered that inhibiting the exercise of this protein lowered ranges of tau, a poisonous protein linked to Alzheimer’s pathology, and decreased harm to mind tissue.
REV-ERBα, NAD+, and Mind Growing older
The circadian protein beneath investigation, referred to as REV-ERBα, helps regulate the physique’s day by day rhythms of metabolism and irritation. Whereas its position within the mind has been much less understood, earlier research in different tissues confirmed that REV-ERBα influences ranges of nicotinamide adenine dinucleotide (NAD+), a molecule important for metabolism, vitality manufacturing, and DNA restore. Declining NAD+ ranges are intently related to mind getting older and neurodegenerative circumstances. Many over-the-counter dietary supplements goal to lift NAD+ as a technique to gradual getting older and promote mobile well being.
To check REV-ERBα’s position, the group genetically deleted the protein in two teams of mice: one by which the deletion occurred all through the physique, and one other the place it was eliminated solely in astrocytes (supportive glial cells that type a significant a part of the central nervous system). In each circumstances, NAD+ ranges rose considerably. The outcomes recommend that eliminating REV-ERBα in astrocytes instantly boosts NAD+ within the mind, pointing to a possible path for future therapies concentrating on neurodegeneration.
Drug Remedy Protects Towards Tau Pathology
In an additional experiment, the researchers blocked REV-ERBα utilizing each genetic strategies and a brand new drug that has additionally proven promise in research of amyloid-β and Parkinson’s illness. This method elevated NAD+ ranges and shielded the mice from tau-related mind harm. Tau aggregates are recognized to disrupt mind operate and drive neurodegenerative ailments comparable to Alzheimer’s.
The findings recommend that manipulating the physique’s inside clock — particularly by inhibiting REV-ERBα — might signify a brand new solution to defend the mind, stop tau buildup, and probably gradual or halt the development of Alzheimer’s illness.
Final week I posted in regards to the proportion of p values that might be ‘fragile’ below varied kinds of scientific experiments or different inferences. The proportion of p values that’s fragile had been outlined because the proportion which might be between 0.01 and 005. I used to be reacting to the query of whether or not it’s an excellent factor that the proportion fragile within the psychology literature appears to have declined over a decade or two from about 32% to about 26%. I had concluded that this didn’t actually inform us a lot about progress in response to the replication disaster.
There was some good dialogue on BlueSky after I posted on this and I might now qualify my views somewhat. The important thing factors that individuals made that I hadn’t adequately taken into consideration in my presentation have been:
When scientists decide an appropriate pattern measurement by an influence calculation, they’re most frequently basing it on the pattern measurement wanted to provide a certain quantity of energy for the “minimal distinction we need to detect”, moderately than the distinction they’re truly anticipating
One in all my key plots confirmed an obvious enhance in fragile p values even with fixed energy when the planned-for distinction between means was giant — when what was truly occurring was in all probability an artefact of the tiny pattern sizes on this very synthetic state of affairs (to be sincere, nonetheless unsure as I write this precisely what was occurring, however am fairly happy that it’s not terribly vital no matter it’s, and positively doesn’t need to be my important plot on the subject)
Extra basic fascinated by “if this lower in ‘fragile’ p values isn’t exhibiting one thing constructive, then what’s it exhibiting?” which provides me a barely extra nuanced view.
This made me resolve I ought to look extra systematically into the distinction between “deliberate for” distinction between two samples and the “precise” distinction within the inhabitants. I had completed some simulations of random variation of the particular distinction from that deliberate for, however not systematic and complete sufficient.
What I’ve completed now’s systematically examine each mixture of a sampling technique to provide 80% energy for “minimal detectable variations” from 0.05 to 0.60 (12 totally different values, spaced 0.05 aside), and precise variations of imply between 0.0 and 1.0 (11 totally different values, spaced 0.10 aside). With 10,000 simulations at every mixture we now have 12 x 11 x 10,000 = 1.32 million simulations
We are able to see that many cheap mixtures of “deliberate for” and “precise” variations between the 2 populations give fragile proportions of p values which might be fairly totally different from 26%. Specifically, within the state of affairs the place the precise distinction is greater than the “minimal detectable distinction” that the pattern measurement would have been calculated for 80% energy (which might be what most researchers are aiming for), the proportion fragile rapidly will get properly beneath 26%.
That proportion ranges from 80% when the true distinction is zero (i.e. the null speculation is true) and the p worth distribution is uniform over [0,1]; to properly beneath 10% when the pattern measurement is ample for prime (a lot higher than 80%) energy, ample to select up the true distinction between the 2 populations.
I feel that is higher at presenting the problems than my weblog final week. Right here’s how I take into consideration this challenge now:
Round 26% of p values will certainly be ‘fragile’ when the pattern measurement has been set to provide 80% energy on the idea of a detectable distinction between two populations which is certainly roughly what the precise distinction seems to be.
On the whole, a proportion of fragile p values that’s larger than this means that experiments are under-powered by design, or first rate designs with 80% energy turned out to be based mostly on minimum-detectalbe variations which might be typically not precise variations in actuality, or one thing else sinister is happening.
If in truth many or most experiments are based mostly on realities the place the precise distinction between means is greater than the minimum-detectable distinction the samples measurement was chosen for at 80% energy, we’d anticipate a proportion of p values which might be fragile to be considerably lower than 26%.
Taking these collectively, it is cheap to say that p values declining from 32% to 26% is an effective factor; however that 26% in all probability remains to be a bit too excessive and shouldn’t be appreciated to be a really synthetic benchmark; and that we will’t ensure what’s driving the decline.
Right here’s the R code to run these 1.32 million simulations, making utilizing of the foreach and doParallel R packages for parallel computing to hurry issues up a bit:
library(pwrss)library(tidyverse)library(glue)library(foreach)library(doParallel)#' Perform to run a two pattern experiment with t check on distinction of means#' @returns a single p worth#' @param d distinction in technique of the 2 populations that samples are drawn#' from. If sd1 and sd2 are each 1, then d is a proportion of that sd and#' all the things is scaleless.experiment<-perform(d,m1=0,sd1=1,sd2=1,n1=50,n2=n1,seed=NULL){if(!is.null(seed)){set.seed(seed)}x1<-rnorm(n1,m1,sd1)x2<-rnorm(n2,m1+d,sd2)t.check(x1,x2)$p.worth}#--------------varying distinction and pattern sizes---------------pd1<-tibble(planned_diff=seq(from=0.05,to=0.60,by=0.05))|># what pattern measurement do we have to have 80% energy, based mostly on that deliberate# "minimal distinction to detect"?:mutate(n_for_power=sapply(planned_diff,perform(d){as.numeric(pwrss.t.2means(mu1=d,energy=0.8,verbose=FALSE)$n[1])}))# the precise variations, which might be from zero to a lot greater than the minimal# we deliberate energy to detect:pd2<-tibble(actual_diff=seq(from=0,to=1.0,by=0.1))# Variety of simulations we do for every mixture of deliberate energy (based mostly on a# given 'minimal distinction to detect') and precise energy (based mostly on the true# distinction). when the true distinction is zero particularly, there'll solely# be 1/20 of reps that give you a 'vital' distinction, so 10000 reps in# whole provides us a pattern of 500 signficant exams to get the proportion which might be# fragile from, so nonetheless not enormous. If I might bothered I might have modified the# variety of reps to do for every mixture based mostly on some quantity that is actually# wanted, however I did not trouble.:reps_each<-10000# mix the planned-for and precise variations in an information body with a row# for every repeated sim we're going to do:information<-expand_grid(pd1,pd2)|>mutate(hyperlink=1)|>full_join(tibble(hyperlink=1,rep=1:reps_each),relationship="many-to-many",by="hyperlink")|>choose(-hyperlink)|>mutate(p=NA)print(glue("Working {nrow(information)} simulations. It will take some time."))# arrange parallel processing clustercluster<-makeCluster(7)registerDoParallel(cluster)clusterEvalQ(cluster,{library(foreach)})clusterExport(cluster,c("information","experiment"))outcomes<-foreach(i=1:nrow(information),.mix=rbind)%dopar%{set.seed(i)# the row of information for simply this simulation:d<-information[i,]# carry out the simulation and seize the p worth:d$p<-experiment(d=d$actual_diff,n1=d$n_for_power,seed=d$rep)# return the consequence as a row of information, which might be rbinded right into a single information# body of all of the parallel processes:return(d)}stopCluster(cluster)#--------------summarise and current results--------------------------# Summarise and calculate the proportions:res<-outcomes|>group_by(planned_diff,n_for_power,actual_diff)|>summarise(number_sig=sum(p<0.05),prop_fragile=sum(p>0.01&p<0.05)/number_sig)
Right here’s how I draw two plots to summarise that. I’ve the road plot proven above, and a heatmap that’s proven beneath the code. Total I feel the road plot is less complicated and clearer to learn.
# Line chart plot:res|>mutate(pd_lab=glue("80% energy deliberate for diff of {planned_diff}"))|>ggplot(aes(x=actual_diff,y=prop_fragile))+facet_wrap(~pd_lab)+geom_vline(aes(xintercept=planned_diff),color="steelblue")+geom_hline(yintercept=0.26,color="orange")+geom_point()+geom_line()+scale_y_continuous(label=p.c)+labs(y="Proportion of serious p values which might be between 0.01 and 0.05",x="Precise distinction (in normal deviations)",subtitle="Vertical blue line exhibits the place the precise distinction equals the minimal distinction to detect that the 80% energy calculation was based mostly upon.
Horizontal orange line exhibits the noticed common proportion of 'fragile' p values within the latest psychology literature.",title="Fragility of p values in relation to precise and deliberate variations in a two pattern t check.")# Heatmap:res|>ggplot(aes(x=actual_diff,y=as.ordered(planned_diff),fill=prop_fragile))+geom_tile()+geom_tile(information=filter(res,prop_fragile>0.25&prop_fragile<0.31),fill="white",alpha=0.1,color="white",linewidth=2)+scale_fill_viridis_c(label=p.c,route=-1)+theme(panel.grid.minor=element_blank())+labs(y="Smallest detectable distinction for 80% energy",x="Precise distinction (in normal deviations)",fill="Proportion of serious p values which might be between 0.01 and 0.05:",subtitle="Pattern measurement is predicated on 80% energy for the distinction on the vertical axis. White packing containers point out the place the proportion of fragile vital p values is between 25% and 31%.",title="Fragility of p values in relation to precise and deliberate variations in a two pattern t check.")
Right here’s the heatmap we get from that. It’s prettier however I feel not truly as clear because the less complicated, faceted line plot.
That’s all for now. I don’t suppose there’s any massive implications of this. Only a higher understanding of what quantity of p values we’d anticipate to be on this fragile vary and what impacts on it.
I’m planning on some actual life information, on a very totally different subject, in my subsequent submit.
Measles is extremely contagious and spreads from individual to individual fairly quickly by way of respiratory droplets.
Like COVID-19, this makes it arduous to manage the unfold of the illness, notably in crowded locations. The illness also can result in extreme issues like pneumonia, encephalitis, and even loss of life in weak populations.
Up to now, as a result of there was no efficient therapy for measles, it was arduous to handle signs, forestall unfold, and supply care. Consequently, the illness had a excessive mortality fee, inflicting vital struggling and lack of life earlier than the vaccine was developed.
The measles mass vaccination program was profitable in decreasing deaths and hospitalizations from the measles virus.
The Measles vaccine and the MMR
Picture courtesy of GIDEON Informatics: Worldwide Measles vaccine protection in 2020
Improvement
Though measles has been round and documented for the reason that ninth century, it turned extra widespread in later centuries by way of globalization. Sadly, the virus killed hundreds of thousands earlier than a profitable vaccine was found.
The primary milestone within the historical past of the measles vaccine arrived in 1954 throughout a measles outbreak exterior Boston, MA in the US. On the time, Dr. Thomas Peebles, underneath the supervision of Dr. John Franklin Enders, remoted the measles virus for the primary time, setting the stage for a vaccine.
For his numerous achievements within the discipline of infectious ailments, Dr. Enders, the physician who led the analysis efforts, is called the ‘Father of Trendy Vaccines.’ He was later awarded the Nobel Prize in Physiology or Medication for cultivating the poliomyelitis virus.
In 1961, after small-scale testing, the measles dwell attenuated vaccine (known as the Edmonston pressure) was declared 100% efficient in opposition to measles and permitted for business use.
As mass vaccination efforts continued, in 1968, one other pioneer in vaccine expertise, Dr. Maurice Hilleman, created a weaker model of the dwell attenuated vaccine to cut back the depth of unwanted side effects. This pressure, referred to as the Edmonston-Enders pressure, was then distributed internationally.
Impression
The primary measles mass vaccination program started in Africa in 1966. In 1967, The Gambia turned the primary nation the place transmission was interrupted. Vaccination efforts continued however had been slower till there was an enormous breakthrough.
In 1971, Dr. Hilleman mixed the measles vaccine with those in opposition to mumps and rubella, creating the MMR vaccine. The MMR was a gamechanger because it accelerated mass vaccination efforts. Kids solely wanted one vaccine to guard in opposition to three ailments, and it turned simpler for healthcare employees to persuade dad and mom to offer their infants one shot as a substitute of many.
In 2005, the varicella vaccine was added to the MMR making it the MMRV vaccine. The MMR was 96% efficient in stopping measles.
Challenges
Since measles is extremely contagious, any neighborhood wants a 95% vaccination fee to think about themselves freed from the virus.
The measles vaccine was heat-sensitive, so it was arduous to take care of the vaccines on the proper temperature as they had been shipped and delivered throughout the globe, even in rural areas the place refrigeration and concrete infrastructure had been a problem.
The measles vaccination program coincided with the smallpox eradication marketing campaign, and a few public well being departments and governments prioritized smallpox eradication over measles.
In 1998, a analysis article tied the MMR vaccine to autism, spreading suspicion and misinformation. Though the examine was extremely flawed, fraudulent, and later retracted, it brought about worry and negatively impacted vaccine charges.
Future
Regardless that the measles vaccine is inexpensive and extensively out there, in 2021, there have been 128,000 measles deaths affecting largely kids underneath 5.
Measles is the main vaccine-preventable illness on the earth, and efforts to enhance vaccination efforts should proceed. Another excuse why vaccination is most necessary is as a result of there is no such thing as a particular therapy for measles; prevention is vital.
“Suppose that (Y = alpha + beta X + U).” A sentence like that is certain to come back up dozens of occasions in an introductory econometrics course, but when I had my means it will be stamped out utterly. With out additional clarification, this sentence might imply any variety of various things. Even with clarification, it’s a supply of limitless confusion for starting college students. What’s (U) precisely? What’s the which means of “(=)” on this context? We are able to do higher. Listed below are just a few options.
Inhabitants Linear Regression
Typically (Y = alpha + beta X + U) is nothing greater than the inhabitants linear regression mannequin. In different phrases ((alpha, beta)) are the options to [
min_{alpha, beta} mathbb{E}[(Y – alpha – beta X)^2].
]
The standard strategy to sign that is by including the “assumptions” that (mathbb{E}[XU] = mathbb{E}[U] = 0). It’s no surprise that college students discover this complicated. Neither of those equalities is actually an assumption; every is true by building. Relatively than “let (Y = alpha + beta X + U),” I recommend
Outline (U equiv Y – (alpha + beta X)) the place (alpha) and (beta) are the slope and intercept from a inhabitants linear regression of (Y) on (X).
This makes it clear that (U) has no lifetime of its personal; it’s outlined by the coefficients (alpha) and (beta). On this means, the equalities (mathbb{E}[XU] = mathbb{E}[U] = 0) develop into a theorem to be deduced slightly than a spurious “assumption” of linear regression. Repeat after me: the inhabitants linear regression mannequin has no assumptions. We are able to all the time select (alpha) and (beta) to make sure that (U) satisfies the equalities from above. The answer to the inhabitants least squares drawback is [
beta = text{Cov}(X,Y)/text{Var}(X),quad
alpha = mathbb{E}[Y] – beta mathbb{E}[X].
]
By the linearity of expectation, it follows that [
mathbb{E}[U] = mathbb{E}[Y – alpha – beta X] = mathbb{E}[Y] – (mathbb{E}[Y] – beta mathbb{E}[X]) – beta mathbb{E}[X] = 0
]
and equally, though with a bit extra algebra [
begin{align}
mathbb{E}[XU] &= mathbb{E}[X(Y – alpha – beta X)]
&= mathbb{E}[X(Y – left{mathbb{E}(Y) – beta mathbb{E}(X)right} – beta X)]
&= mathbb{E}[Xleft{Y – mathbb{E}(Y) right}] – beta mathbb{E}[Xleft{X – mathbb{E}(X)right} ]
&= textual content{Cov}(X,Y) – beta textual content{Var}(X) = 0.
finish{align}
]
Conditional Imply Perform
In different conditions (Y = alpha + beta X + U) is meant to signify a conditional imply operate. That is often signaled by the belief (mathbb{E}[U|X] = 0). This time round I haven’t written the phrase assumption in “scare quotes.” That’s as a result of there’s an assumption lurking right here, in contrast to within the inhabitants linear regression mannequin from above. Nonetheless, it is a hopelessly complicated means of indicating it. Right here’s a greater means:
Outline (U equiv Y – mathbb{E}(Y|X)) and assume that (mathbb{E}(Y|X) = alpha + beta X).
Once more, this makes it clear that (U) has no lifetime of its personal. It’s constructed from (Y) and (X). The conditional imply operate (mathbb{E}(Y|X)) is solely the minimizer of (mathbb{E}[left{ Y – f(X)right}^2]) over all (well-behaved) features. By building (mathbb{E}[U|X] = 0) since [
mathbb{E}[U|X] = mathbb{E}[Y – mathbb{E}(Y|X)|X] = mathbb{E}[Y|X] – mathbb{E}[Y|X] = 0
]
by the linearity of conditional expectation and the truth that (mathbb{E}(Y|X)) is a operate of (X). However how can we ensure that the conditional imply operate is linear? This can be a bona fide assumption: it might be true or it might be false. Both means, it’s a lot clearer to emphasise that we’re making an assumption in regards to the type of the conditional imply operate, not an assumption in regards to the error time period (U equiv Y – mathbb{E}(Y|X)).
Causal Mannequin
Each interpretations of (Y = alpha + beta X + U) from above are purely predictive; they are saying nothing about whether or not (X)causes(Y). To point {that a} linear mannequin is imply to be causal, it’s conventional to write down one thing like “suppose that (Y = alpha + beta X + U) the place (X) could also be endogenous.” Typically “could also be endogenous” is changed by “the place (X) could also be correlated with (U).” What on earth is that this speculated to imply? The language is obscure, evasive, and imprecise. It additionally stretches the which means of “(=)” past all motive. Right here’s my advised enchancment:
Contemplate the causal mannequin (Y leftarrow (alpha + beta X + U)) the place (U) is unobserved and ((X,U)) could also be dependent.
Causality is intrinsically directional: cigarettes trigger lung most cancers; lung most cancers doesn’t trigger cigarettes. The notation “(leftarrow)” makes this clear. In stark distinction, the notion of mathematical equality is symmetric. If (Y = alpha + beta X + U), it’s simply as true to say that (X = (Y – alpha – U) / beta). After all that is nonsensical when utilized to cigarettes and most cancers.
In a causal mannequin, (U)does have a lifetime of its personal; it represents the causes of (Y) that we can not observe. Maybe (Y) is wage, (X) is years of education and (U) is “household background” plus “potential.” For that reason I do not write “outline (U equiv (textual content{one thing})).” We aren’t defining a residual in a prediction drawback. We’re taking a stand on how the world works by writing down a selected causal mannequin. In a randomized managed trial, any unobserved causes (U) could be impartial of (X). Right here we now have not made this assumption. We now have, nonetheless, assumed a selected type for the causal relationship: linear with fixed coefficients. Every extra yr of education causes the identical improve (or lower) in wage no matter who you’re or what number of years of education you have already got. This mannequin might be fallacious. However proper or fallacious, it’s basically distinct from the inhabitants linear regression and conditional imply fashions described above. Let’s endeavour to make this clear in our notation.
On October 20, 2025, organizations throughout industries, from banking to streaming, logistics to healthcare, skilled widespread service degradation when AWS’s US-EAST-1 area suffered a major outage. Because the ThousandEyes evaluation revealed, the disruption stemmed from failures inside AWS’s inside networking and DNS decision techniques that rippled by means of dependent companies worldwide.
The foundation trigger, a latent race situation in DynamoDB’s DNS administration system, triggered cascading failures all through interconnected cloud companies. However right here’s what separated groups that might reply successfully from these flying blind: actionable, multilayer visibility.
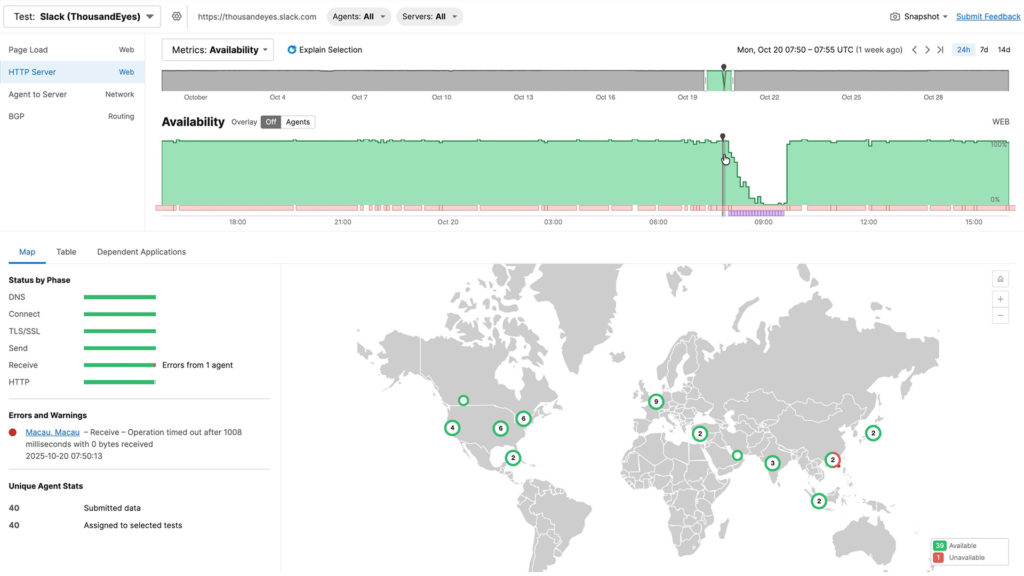
When the outage started at 6:49 a.m. UTC, refined monitoring instantly revealed 292 affected interfaces throughout Amazon’s community, pinpointing Ashburn, Virginia because the epicenter. Extra critically, as circumstances developed, from preliminary packet loss to application-layer timeouts to HTTP 503 errors, complete visibility distinguished between community points and software issues. Whereas floor metrics confirmed packet loss clearing by 7:55 a.m. UTC, deeper visibility revealed a distinct story: edge techniques had been alive however overwhelmed. ThousandEyes brokers throughout 40 vantage factors confirmed 480 Slack servers affected with timeouts and 5XX codes, but packet loss and latency remained regular, proving this was an software concern, not a community drawback.
Determine 1. Altering nature of signs impacting app.slack.com throughout the AWS outage
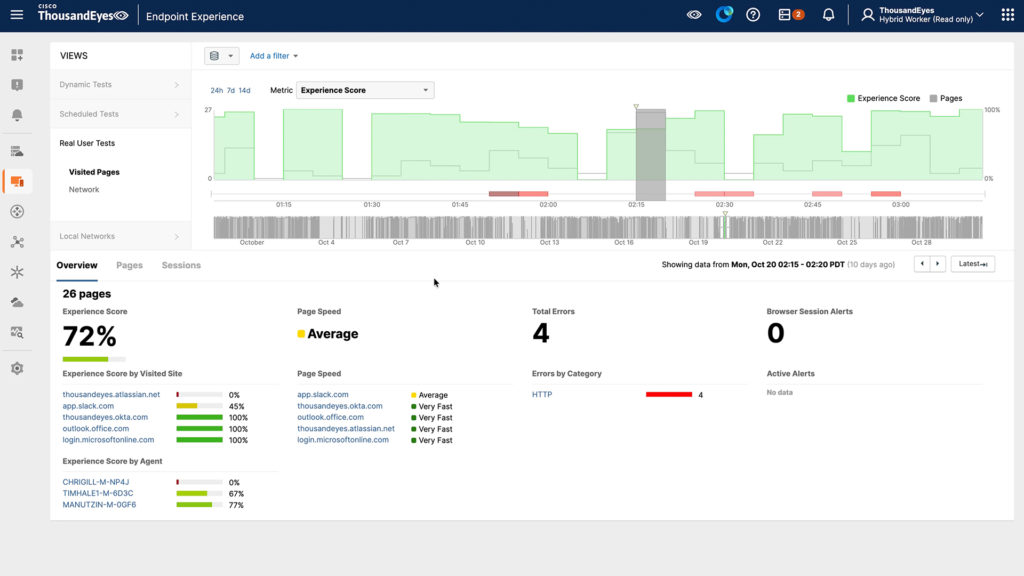
Endpoint knowledge revealed app.slack.com expertise scores of simply 45% with 13-second redirects, whereas native community high quality remained good at 100%. With out this multilayer perception, groups would waste valuable incident time investigating the improper layer of the stack.
Determine 2. app.slack.com noticed for an finish consumer
The restoration part highlighted why complete visibility issues past preliminary detection. Even after AWS restored DNS performance round 9:05 a.m. UTC, the outage continued for hours as cascading failures rippled by means of dependent techniques, EC2 couldn’t keep state, inflicting new server launches to fail for 11 extra hours, whereas companies like Redshift waited to recuperate and clear huge backlogs.
Understanding this cascading sample prevented groups from repeatedly trying the identical fixes, as an alternative recognizing they had been in a restoration part the place every dependent system wanted time to stabilize. This outage demonstrated three important classes: single factors of failure conceal in even probably the most redundant architectures (DNS, BGP), preliminary issues create long-tail impacts that persist after the primary repair, and most significantly, multilayer visibility is nonnegotiable.
In as we speak’s warfare rooms, the query isn’t whether or not you will have monitoring, it’s whether or not your visibility is complete sufficient to rapidly reply the place the issue is happening (community, software, or endpoint), what the scope of impression is, why it’s occurring (root trigger vs. signs), and whether or not circumstances are enhancing or degrading. Floor-level monitoring tells you one thing is improper. Solely deep, actionable visibility tells you what to do about it.
The occasion was a stark reminder of how interconnected and interdependent fashionable digital ecosystems have grow to be. Functions as we speak are powered by a dense internet of microservices, APIs, databases, and management planes, lots of which run atop the identical cloud infrastructure. What seems as a single service outage usually masks a much more intricate failure of interdependent parts, revealing how invisible dependencies can rapidly flip native disruptions into international impression.
Seeing What Issues: Assurance because the New Belief Material
At Cisco, we view Assurance because the connective tissue of digital resilience, working in live performance with Observability and Safety to present organizations the perception, context, and confidence to function at machine pace. Assurance transforms knowledge into understanding, bridging what’s noticed with what’s trusted throughout each area, owned and unowned. This “belief cloth” connects networks, clouds, and functions right into a coherent image of well being, efficiency, and interdependency.
Visibility alone is now not adequate. Right this moment’s distributed architectures generate a large quantity of telemetry, community knowledge, logs, traces, and occasions, however with out correlation and context, that knowledge provides noise as an alternative of readability. Assurance is what interprets complexity into confidence by connecting each sign throughout layers right into a single operational reality.
Throughout incidents just like the October 20th outage, platforms akin to Cisco ThousandEyes play a pivotal position by offering real-time, exterior visibility into how cloud companies are behaving and the way customers are affected. As a substitute of ready for standing updates or piecing collectively logs, organizations can straight observe the place failures happen and what their real-world impression is.
Key capabilities that allow this embody:
World vantage level monitoring: Cisco ThousandEyes detects efficiency and reachability points from the surface in, revealing whether or not degradation stems out of your community, your supplier, or someplace in between.
Community path visualization: It pinpoints the place packets drop, the place latency spikes, and whether or not routing anomalies originate in transit or throughout the cloud supplier’s boundary.
Utility-layer synthetics: By testing APIs, SaaS functions, and DNS endpoints, groups can quantify consumer impression even when core techniques seem “up.”
Cloud dependency and topology mapping: Cisco ThousandEyes exposes the hidden service relationships that always go unnoticed till they fail.
Historic replay and forensics: After the occasion, groups can analyze precisely when, the place, and the way degradation unfolded, reworking chaos into actionable perception for structure and course of enhancements.
When built-in throughout networking, observability, and AI operations, Assurance turns into an orchestration layer. It permits groups to mannequin interdependencies, validate automations, and coordinate remediation throughout a number of domains, from the info middle to the cloud edge.
Collectively, these capabilities flip visibility into confidence, serving to organizations isolate root causes, talk clearly, and restore service sooner.
How one can Put together for the Subsequent “Inevitable” Outage
If the previous few years have proven something, it’s that large-scale cloud disruptions are usually not uncommon; they’re an operational certainty. The distinction between chaos and management lies in preparation, and in having the fitting visibility and administration basis earlier than disaster strikes.
Listed here are a number of sensible steps each enterprise can take now:
Map each dependency, particularly the hidden ones. Catalogue not solely your direct cloud companies but additionally the management aircraft techniques (DNS, IAM, container registries, monitoring APIs) they depend on. This helps expose “shared fates” throughout workloads that seem unbiased.
Take a look at your failover logic below stress. Tabletop and stay simulation workout routines usually reveal that failovers don’t behave as cleanly as meant. Validate synchronization, session persistence, and DNS propagation in managed circumstances earlier than actual crises hit.
Instrument from the surface in. Inner telemetry and supplier dashboards inform solely a part of the story. Exterior, internet-scale monitoring ensures you know the way your companies seem to actual customers throughout geographies and ISPs.
Design for swish degradation, not perfection. True resilience is about sustaining partial service fairly than going darkish. Construct functions that may briefly shed non-critical options whereas preserving core transactions.
Combine assurance into incident responses. Make exterior visibility platforms a part of your playbook from the primary alert to closing restoration validation. This eliminates guesswork and accelerates govt communication throughout crises.
Revisit your governance and funding assumptions. Use incidents like this one to quantify your publicity: what number of workloads depend upon a single supplier area? What’s the potential income impression of a disruption? Then use these findings to tell spending on assurance, observability, and redundancy.
The objective isn’t to get rid of complexity; it’s to simplify it. Assurance platforms assist groups repeatedly validate architectures, monitor dynamic dependencies, and make assured, data-driven choices amid uncertainty.
Resilience at Machine Velocity
The AWS outage underscored that our digital world now operates at machine pace, however belief should maintain tempo. With out the flexibility to validate what’s really occurring throughout clouds and networks, automation can act blindly, worsening the impression of an already fragile occasion.
That’s why the Cisco strategy to Assurance as a belief cloth pairs machine pace with machine belief, empowering organizations to detect, determine, and act with confidence. By making complexity observable and actionable, Assurance permits groups to automate safely, recuperate intelligently, and adapt repeatedly.
Outages will proceed to occur. However with the fitting visibility, intelligence, and assurance capabilities in place, their penalties don’t need to outline your corporation.
Let’s construct digital operations that aren’t solely quick, however trusted, clear, and prepared for no matter comes subsequent.
Expertise is quickly increasing the boundaries of human capability. We will acknowledge it in just about all walks of life once we hold our eyes open for it, however nowhere is it extra pronounced and prized than within the office.
Particularly, synthetic intelligence (AI) has catapulted the fashionable office into an period that has redefined our skilled relationship with know-how and the talents essential to navigate the dramatic modifications inside it. Simply because the web spearheaded a revolution not way back — a interval greatest described as Work 3.0 — AI is once more reshaping what is required from every of us within the workforce in the present day. With these modifications comes a mandatory reevaluation from tech leaders. Now within the midst of Work 4.0, AI is driving tech organizations to alter how they rent, develop, and collaborate throughout groups.
Work 3.0 vs. 4.0: What We Can Be taught from the Previous
The earlier wholesale office restructuring — let’s name it a mass upskilling — occurred with the introduction of the web and the rise of the digital office. Expertise was on the forefront of change then, as it’s now. So, what can we glean from our information of the inception of Work 3.0 that may assist us higher put together for the modifications in Work 4.0, particularly for hiring know-how professionals?
Whereas the markers that greatest outlined Work 3.0 have been related to expertise distribution and the alternatives offered to organizations based mostly on flexibility of location or platform, Work 4.0 is outlined by the evolution of employee ability units and the combination of human excellence with agentic AI. Put plainly, this new period of labor will develop into much less reliant on onerous expertise, expertise, and static credentials. As a substitute, excessive aptitude, emotional intelligence, and important pondering will develop into extra invaluable. Thus, it is much less restrictive from a hiring perspective.
Though Work 3.0 and 4.0 are in some ways totally different, there may be one takeaway organizations can rely on: Speedy change might be mandatory. Work 4.0 is arriving even sooner than its predecessor. In response, know-how leaders might want to rapidly adapt their methods to rent the precise individuals, upskill their groups, and function a optimistic instance to their bigger organizations.
How Work 4.0 Adjustments the Expertise Leaders Want
With the shift in office focus from onerous expertise and technical acumen to mushy expertise, know-how leaders have needed to confront the necessity to recruit and upskill their multifaceted workforce differently.
As an illustration, from my seat as a technologist, I could adapt to this shift utilizing particular methods and with sure finish objectives in thoughts for my engineering staff. I ask specific questions: What technical assets are wanted? How will we write code with AI? How will we upscale?
However as an IT chief, I even have to think about the remainder of the group — gross sales groups, advertising and marketing, buyer help. The modifications underneath Work 4.0 will not look the identical to a programmer as they do to a gross sales rep or a company accountant.
All of us must row in the identical route, however what does that appear to be? How can we upskill all staff throughout departments rapidly, whereas sustaining high quality? These issues might be shared by technical organizations and nontechnical organizations alike.
This is what is admittedly difficult: The normal upskill engine for many firms is not but outfitted to tackle Work 4.0. The event of those AI-centered expertise and the adoption of a brand new hiring mannequin are depending on a mature infrastructure. But, the chance that an organization has an outlined AI stack, with well-considered guidelines and guardrails that may assist outline and construct a curriculum, are slim to none. It is a conundrum with which many know-how leaders are already grappling.
Steps for Tech Leaders
Change is troublesome for many organizations and industries. However within the know-how sector, the place staff pleasure themselves on their technical expertise, organizational leaders face a very daunting problem of reorienting a workforce round mushy expertise — communication, adaptability, emotional intelligence. It is an infinite elevate.
Keep in mind: Upskilling is not about changing what they do greatest. It is about increasing what makes them efficient in fashionable, tech-enabled groups, and optimally integrating these groups within the age of Work 4.0. Smooth expertise in the present day are literally “energy expertise,” core differentiators in high-performance, AI-augmented groups.
Two issues have to be carried out to help this shift: First, embed soft-skill improvement into upskill methods, not as a aspect module however alongside technical studying. Each onerous and mushy expertise at the moment are mission-critical, and every augments the opposite. Second, organizations should enhance their skill to measure mushy expertise rapidly.
Investing on this kind of visibility helps tech leaders coach extra successfully, plan for expertise mobility, and make smarter hiring selections. When carried out proper, it reinforces that mushy expertise aren’t “further” — they’re important to constructing resilient, high-impact groups within the period of AI-driven, clever work.
This weblog will discover how the joint resolution from DataRobot and Deepwave — powered by NVIDIA — delivers a safe, high-performance AI stack, purpose-built for air-gapped, on-premises and high-security deployments. This resolution ensures businesses can obtain real knowledge sovereignty and operational excellence.
The necessity for autonomous intelligence
AI is evolving quickly, reworking from easy instruments into autonomous brokers that may cause, plan, and act. This shift is essential for high-stakes, mission-critical purposes comparable to RF Intelligence, the place huge RF knowledge streams demand real-time evaluation.
Deploying these superior brokers for public and authorities applications requires a brand new degree of safety, velocity, and accuracy that conventional RF evaluation options can’t present.
Program leaders usually discover themselves selecting between underperforming, advanced options that generate technical debt or a single-vendor lock-in. The stress to ship next-generation RF intelligence doesn’t subside, leaving operations leaders below stress to deploy with few choices.
The problem of radio intelligence
Radio intelligence, the real-time assortment and evaluation of radio-frequency (RF) alerts, covers each communications and emissions from digital programs. In follow, this usually means extracting the content material of RF alerts — audio, video, or knowledge streams — a course of that presents vital challenges for federal businesses.
Trendy RF alerts are extremely dynamic and require equally nimble evaluation capabilities to maintain up.
Operations usually happen on the edge in contested environments, the place handbook evaluation is simply too gradual and never scalable.
Excessive knowledge charges and sign complexity make RF knowledge terribly troublesome to make use of, and dynamically altering alerts require an evaluation platform that may adapt in real-time.
The mission-critical want is for an automatic and extremely reconfigurable resolution that may shortly extract actionable intelligence from these huge quantities of information, guaranteeing well timed, doubtlessly life-saving decision-making and reasoning.
Introducing the Radio Intelligence Agent
To fulfill this essential want, the Radio Intelligence Agent (RIA) was engineered as an autonomous, proactive intelligence system that transforms uncooked RF alerts right into a continuously evolving, context-driven useful resource. The answer is designed to function a sensible workforce member, offering new insights and proposals which can be far past search engine capabilities.
What really units the RIA aside from present know-how is its built-in reasoning functionality. Powered by NVIDIA Nemotron reasoning fashions, the system is able to synthesizing patterns, flagging anomalies, and recommending actionable responses, successfully bridging the hole between mere info retrieval and operational intelligence.
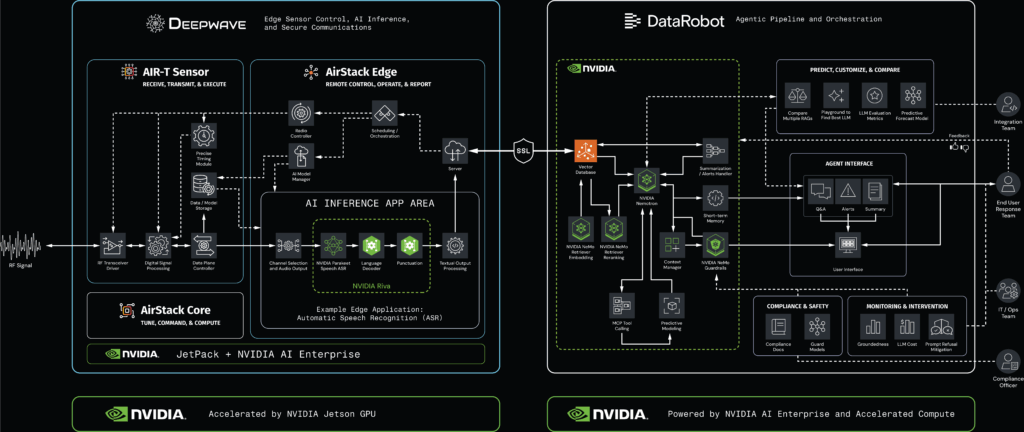
Developed collectively by DataRobot and Deepwave, and powered by NVIDIA, this AI resolution transforms uncooked RF alerts into conversational intelligence, with its total lifecycle orchestrated by the trusted, built-in management aircraft of the DataRobot Agent Workforce Platform.
Federal use instances and deployment
The Radio Intelligence Agent is engineered particularly for the stringent calls for of federal operations, with each element constructed for safety, compliance, and deployment flexibility.
The ability of the RIA resolution lies in performing a major quantity of processing on the edge inside Deepwave’s AirStack Edge ecosystem. This structure ensures high-performance processing whereas sustaining important safety and regulatory compliance.
The Radio Intelligence Agent resolution strikes operations groups from easy knowledge assortment and evaluation to proactive, context-aware intelligence, enabling occasion prevention as an alternative of occasion administration. It is a step change in public security capabilities.
Occasion response optimization: The answer goes past easy alerts by appearing as a digital advisor throughout unfolding conditions. It analyzes incoming knowledge in real-time, identifies related entities and places, and recommends next-best actions to scale back response time and enhance outcomes.
Operational consciousness: The answer enhances visibility throughout a number of knowledge streams, together with audio and video feeds, in addition to sensor inputs, to create a unified view of exercise in real-time. This broad monitoring functionality reduces cognitive burden and helps groups deal with strategic decision-making quite than handbook knowledge evaluation.
Different purposes: RIA’s core capabilities are relevant for situations requiring quick, safe, and correct evaluation of large knowledge streams – together with public security, first responders, and different capabilities.
This resolution can be moveable, supporting native growth and testing, with the flexibility to transition seamlessly into non-public cloud or FedRAMP-authorized DataRobot-hosted environments for safe manufacturing in federal missions.
A deeper dive into the Radio Intelligence Agent
Think about receiving advanced RF alerts evaluation which can be trusted, high-fidelity, and actionable in seconds, just by asking a query.
DataRobot, Deepwave, and NVIDIA teamed as much as make this a actuality.
First, Deepwave’s AIR-T edge sensors obtain and digitize the RF alerts utilizing AirStack software program, powered by embedded NVIDIA GPUs.
Then, the most recent AirStack element, AirStack Edge, introduces a safe API with FIPS-grade encryption, enabling the deployment of sign processing purposes and NVIDIA Riva Speech and Translation AI fashions straight on AIR-T gadgets.
This end-to-end course of runs securely and in real-time, delivering extracted knowledge content material into the agent-based workflows orchestrated by DataRobot.
The answer’s agentic functionality is rooted in a classy, two-part system that leverages NVIDIA Llama-3_1-Nemotron-Extremely-253B-v1 to interpret context and generate subtle responses.
Question Interpreter: This element is chargeable for understanding the person’s preliminary intent, translating the pure language query into an outlined info want.
Data Retriever: This agent executes the mandatory searches, retrieves related transcript chunks, and synthesizes the ultimate, cohesive reply by connecting various knowledge factors and making use of reasoning to the retrieved textual content.
This performance is delivered by way of the NVIDIA Streaming Information to RAG resolution, which allows real-time ingestion and processing of reside RF knowledge streams utilizing GPU-accelerated pipelines.
By leveraging NVIDIA’s optimized vector search and context synthesis, the system permits for quick, safe, and context-driven retrieval and reasoning over radio-transcribed knowledge whereas guaranteeing each operational velocity and regulatory compliance.
The agent first consults a vector database, which shops semantic embeddings of transcribed audio and sensor metadata, to seek out essentially the most related info earlier than producing a coherent response. The sensor metadata is customizable and incorporates essential details about alerts, together with frequency, location, and reception time of the information.
The answer is provided with a number of specialised instruments that allow this superior workflow:
RF orchestration: The answer can make the most of Deepwave’s AirStack Edge orchestration layer to actively recollect new RF intelligence by operating new fashions, recording alerts, or broadcasting alerts.
Search instruments: It performs sub-second semantic searches throughout large volumes of transcript knowledge.
Time parsing instruments: Converts human-friendly temporal expressions (e.g., “3 weeks in the past”) into exact, searchable timestamps, leveraging the sub-10 nanosecond accuracy revealed within the metadata.
Audit path: The system maintains a whole audit path of all queries, software utilization, and knowledge sources, guaranteeing full traceability and accountability.
NVIDIA Streaming Information to RAG Blueprint instance allows the workflow to maneuver from easy knowledge lookup to autonomous, proactive intelligence. The GPU-accelerated software-defined radio (SDR) pipeline repeatedly captures, transcribes, and indexes RF alerts in real-time, unlocking steady situational consciousness.
DataRobot Agent Workforce Platform: The built-in management aircraft
The DataRobot Agent Workforce Platform, co-developed with NVIDIA, serves because the agentic pipeline and orchestration layer, the management aircraft that orchestrates all the lifecycle. This ensures businesses preserve full visibility and management over each layer of the stack and implement compliance routinely.
Key capabilities of the platform embody:
Finish-to-end management: Automates all the AI lifecycle, from growth and deployment to monitoring and governance, permitting businesses to subject new capabilities sooner and extra reliably.
Information sovereignty: DataRobot’s resolution is purpose-built for high-security environments, deploying straight into the company’s air-gapped or on-premises infrastructure. All processing happens throughout the safety perimeter, guaranteeing full knowledge sovereignty and guaranteeing the company retains sole management and possession of its knowledge and operations.
Crucially, this gives operational autonomy (or sovereignty) over all the AI stack, because it requires no exterior suppliers for the operational {hardware} or fashions. This ensures the total AI functionality stays throughout the company’s managed area, free from exterior dependencies or third-party entry.
DataRobot integrates with extremely expert, specialised companions like Deepwave, who present the essential AI edge processing to transform uncooked RF sign content material into RF intelligence and securely share it with DataRobot’s knowledge pipelines. The Deepwave platform extends this resolution’s capabilities by enabling the subsequent steps in RF intelligence gathering by way of the orchestration and automation of RF AI edge duties.
Edge AI processing: The agent makes use of Deepwave’s high-performance edge computing and AI fashions to intercept and course of RF alerts.
Diminished infrastructure: As an alternative of backhauling uncooked RF knowledge, the answer runs AI fashions on the edge to extract solely the essential info. This reduces community backhaul wants by an element of 10 million — from 4 Gbps down to simply 150 bps per channel — dramatically bettering mobility and simplifying the required edge infrastructure.
Safety: Deepwave’s AirStack Edge leverages the newest FIPS mode encryption to report this knowledge to the DataRobot Agent Workforce Platform securely.
Orchestration: Deepwave’s AirStack Edge software program orchestrates and automates networks of RF AI edge gadgets. This permits low-latency responses to RF situations, comparable to detecting and jamming undesirable alerts.
NVIDIA: Foundational belief and efficiency
NVIDIA gives the high-performance and safe basis needed for federal missions.
Safety: AI brokers are constructed with production-ready NVIDIA NIM™ microservices. These NIM are constructed from a trusted, STIG-ready base layer and help FIPS mode encryption, making them the important, pre-validated constructing blocks for reaching a FedRAMP deployment shortly and securely.
DataRobot gives an NVIDIA NIM gallery, which allows fast consumption of accelerated AI fashions throughout a number of modalities and domains, together with LLM, VLM, CV, embedding, and extra, and direct integration into agentic AI options that may be deployed wherever.
Reasoning: The agent’s core intelligence is powered by NVIDIA Nemotron fashions. These AI fashions with open weights, datasets, and recipes, mixed with main effectivity and accuracy, present the high-level reasoning and planning capabilities for the agent, enabling it to excel at advanced reasoning and instruction-following. It goes past easy lookups to attach advanced knowledge factors, delivering true intelligence, not simply knowledge retrieval.
Speech & Translation: NVIDIA Riva Speech and Translation, allows real-time speech recognition, translation, and synthesis straight on the edge. By deploying Riva alongside AIR-T and AirStack Edge, audio content material extracted from RF alerts will be transcribed and translated on-device with low latency. This functionality permits radio frequency intelligence brokers to show intercepted voice site visitors into actionable, multilingual knowledge streams that seamlessly circulation into DataRobot’s agentic AI workflows.
A collaborative method to mission-critical AI
The mixed strengths of DataRobot, NVIDIA, and Deepwave create a complete, safe, production-ready resolution:
DataRobot: Finish-to-end AI lifecycle orchestration and management.
NVIDIA: Aaccelerated GPU infrastructure, optimized software program frameworks, validated designs, safe and performant basis fashions and microservices.
Deepwave: RF sensors with embedded GPU edge processing, safe datalinks, and streamlined orchestration software program.
Collectively, these capabilities energy the Radio Intelligence Agent resolution, demonstrating how agentic AI, constructed on the DataRobot Agent Workforce Platform, can carry real-time intelligence to the sting. The result’s a trusted, production-ready path to knowledge sovereignty and autonomous, proactive intelligence for the federal mission.
For extra info on utilizing RIA to show RF knowledge into actual time insights, go to deepwave.ai/ria.
To be taught extra about how we might help advance your company’s AI ambitions, join with DataRobot federal specialists.
Google is ending help for first- and second-generation Nest Thermostats, that means they are going to be unpaired and faraway from Google’s Nest and Residence functions. They will not be bricked, simply relegated to non-networked performance. These fashions are almost 15 years outdated, too, although it appears many are nonetheless working completely.
Beginning October 25, 2025, your machine will likely be unpaired and eliminated out of your Nest app or Residence app. This additionally removes third-party assistants and different related or cloud-based options like Residence/Away Help and multi-device Eco mode management. Nest Protects may even disconnect from the thermostat and emergency shut off will not run. As well as, you will not have the ability to:
Google purchased Nest in January 2014 for $3.2 billion, then Google’s second-largest acquisition after Motorola. However it’s stored the glowy model alive, not least resulting from its loyal customers. This is Shawn Knight on the twilight of the pre-Google gadgets.
To be clear, early adopters can nonetheless use their thermostats – they’re simply dropping the distant connectivity that made them interesting to start with. … Some are miffed, and rightfully so. Having to interchange expensive {hardware} resulting from core performance being stripped out is irritating, particularly when stated {hardware} labored completely fantastic for years on finish. Alternatively, one can perceive why Google would not wish to proceed to pour assets into an historical platform simply to maintain it on life help.
After Christmas dinner in 2021, our household was glued to the tv, watching the nail-biting launch of NASA‘s $10 billion James Webb Area Telescope. There had not been such a leap ahead in telescope expertise since Hubble was launched in 1990.
Six months later, Webb’s first pictures have been revealed, of probably the most distant galaxies but seen. Nonetheless, for our workforce in Australia, the work was solely starting.
We’d be utilizing Webb’s highest-resolution mode, known as the aperture masking interferometer or AMI for brief. It is a tiny piece of exactly machined metallic that slots into one of many telescope’s cameras, enhancing its decision.
Our outcomes on painstakingly testing and enhancing AMI are actually launched on the open-access archive arXiv in a pairof papers. We will lastly current its first profitable observations of stars, planets, moons and even black gap jets.
Working with an instrument 1,000,000 miles away
Hubble began its life seeing out of focus — its mirror had been floor exactly, however incorrectly. By taking a look at recognized stars and evaluating the best and measured pictures (precisely like what optometrists do), it was doable to determine a “prescription” for this optical error and design a lens to compensate.
Get the world’s most fascinating discoveries delivered straight to your inbox.
The first mirror of the Webb telescope consists of 18 exactly floor hexagonal segments. (Picture credit score: NASA/Chris Gunn)
Against this, Webb is roughly 1 million miles (1.5 million km) away — we won’t go to and repair it, and want to have the ability to repair points with out altering any {hardware}.
That is the place AMI is available in. That is the one Australian {hardware} on board, designed by astronomer Peter Tuthill.
It was placed on Webb to diagnose and measure any blur in its pictures. Even nanometers of distortion in Webb’s 18 hexagonal main mirrors and plenty of inside surfaces will blur the pictures sufficient to hinder the research of planets or black holes, the place sensitivity and determination are key.
AMI filters the sunshine with a fastidiously structured sample of holes in a easy metallic plate, to make it a lot simpler to inform if there are any optical misalignments.
AMI permits for a exact check sample that may assist right any points with JWST’s focus. (Picture credit score: Anand Sivaramakrishnan/STScI)
Searching blurry pixels
We needed to make use of this mode to watch the start locations of planets, in addition to materials being sucked into black holes. However earlier than any of this, AMI confirmed Webb wasn’t working fully as hoped.
At very advantageous decision — on the degree of particular person pixels — all the pictures have been barely blurry as a consequence of an digital impact: brighter pixels leaking into their darker neighbors.
This isn’t a mistake or flaw, however a elementary characteristic of infrared cameras that turned out to be unexpectedly critical for Webb.
In a brand new paper led by College of Sydney PhD pupil Louis Desdoigts, we checked out stars with AMI to be taught and proper the optical and digital distortions concurrently.
We constructed a pc mannequin to simulate AMI’s optical physics, with flexibility in regards to the shapes of the mirrors and apertures and in regards to the colors of the celebs.
We related this to a machine studying mannequin to characterize the electronics with an “efficient detector mannequin” — the place we solely care about how nicely it may well reproduce the info, not about why.
After coaching and validation on some check stars, this setup allowed us to calculate and undo the blur in different information, restoring AMI to full perform. It does not change what Webb does in house, however relatively corrects the info throughout processing.
It labored superbly — the star HD 206893 hosts a faint planet and the reddest-known brown dwarf (an object between a star and a planet). They have been recognized however out of attain with Webb earlier than making use of this correction. Now, each little dots popped out clearly in our new maps of the system.
This correction has opened the door to utilizing AMI to prospect for unknown planets at beforehand unimaginable resolutions and sensitivities.
It really works not simply on dots
In a companion paper by College of Sydney PhD pupil Max Charles, we utilized this to trying not simply at dots — even when these dots are planets — however forming complicated pictures on the highest decision made with Webb. We revisited well-studied targets that push the boundaries of the telescope, testing its efficiency.
With the brand new correction, we introduced Jupiter’s moon Io into focus, clearly monitoring its volcanoes because it rotates over an hour-long timelapse.
As seen by AMI, the jet launched from the black gap on the centre of the galaxy NGC 1068 carefully matched pictures from much-larger telescopes.
Lastly, AMI can sharply resolve a ribbon of mud round a pair of stars known as WR 137, a faint cousin of the spectacular Apep system, lining up with principle.
The code constructed for AMI is a demo for way more complicated cameras on Webb and its follow-up, Roman house telescope. These instruments demand an optical calibration so advantageous, it is only a fraction of a nanometre — past the capability of any recognized supplies.
Our work exhibits that if we are able to measure, management, and proper the supplies we do should work with, we are able to nonetheless hope to search out Earth-like planets within the far reaches of our galaxy.
This edited article is republished from The Dialog beneath a Artistic Commons license. Learn the authentic article.