

Abstract:
This weblog explains the position of p-values in statistical evaluation, highlighting their significance in testing hypotheses and understanding proof towards the null speculation. It additionally emphasizes the necessity to take into account pattern measurement and impact measurement when decoding p-values, cautioning towards arbitrary significance thresholds.
Studying Time: Roughly 7–10 minutes.
Once we take a look at one thing in science, we begin with a fundamental assumption referred to as the null speculation (H₀)—it often says “nothing is occurring” or “there is no impact.”
Then, we acquire information and calculate a quantity (referred to as a take a look at statistic) to see how uncommon our information is in comparison with what we would count on if the null speculation had been true.
The p-value tells us the possibility of getting a outcome as shocking (or much more shocking) than what we noticed, assuming the null speculation is true.
- A small p-value (like lower than 0.05) means our result’s actually shocking, so we would reject the null speculation and assume, “One thing might be occurring!”
- A massive p-value means our outcome isn’t very shocking, so we follow the null speculation.
The p-value helps scientists resolve whether or not their outcomes are significant or simply random likelihood!
Instance in Agriculture: Testing a New Fertilizer
Let’s make this clearer with an agricultural instance:
Think about a researcher desires to check whether or not a brand new fertilizer will increase wheat yield in comparison with no fertilizer. They develop wheat in ten plots of land 5 for every case:
- Group A: No fertilizer (management group)
- Group B: New fertilizer (remedy group)
After the rising season, they measure the common wheat yield.
Step-by-step:
-
Begin with the null speculation (H₀):
The brand new fertilizer has no impact on wheat yield (the yields in Group A and Group B are the identical).
-
Acquire information:
- Group A (no fertilizer) common yields 4 tons per acre.
- Group B (new fertilizer) common yields 5 tons per acre.
-
Calculate the p-value:
The p-value solutions this query:
“If the fertilizer actually has no impact, how doubtless is it to see a distinction of 1 ton (or extra) between the 2 plots simply by random likelihood?”
Utilizing statistical software program (two pattern t take a look at), the researcher calculates the p-value to be 0.02 (2%).
-
Interpret the p-value:
- A p-value of 0.02 means there’s solely a 2% likelihood of getting a distinction this huge (or bigger) if the fertilizer really doesn’t work.
- For the reason that p-value is small (lower than 0.05), the researcher rejects the null speculation and concludes that the fertilizer doubtless will increase wheat yield.
What Does a P-value Actually Imply?
The p-value is a quantity between 0 and 1 that provides us a measure of how sturdy the proof is towards the null speculation (H₀). For instance, a p-value of 0.076 means there’s a few 7.6% likelihood of observing a outcome as excessive because the one we obtained, or extra excessive, if the null speculation is true.
It’s essential to know {that a} p-value is not the chance that the choice speculation (H₁) is true. As an alternative, it tells us how doubtless it’s to see excessive outcomes underneath the belief that the null speculation is right.
Listed below are some basic pointers for decoding p-values:
- p < 0.001: Very sturdy proof towards H₀.
- p < 0.01: Sturdy proof towards H₀.
- p < 0.05: Average proof towards H₀.
- p < 0.1: Weak proof or a development.
- p ≥ 0.1: Inadequate proof to reject H₀.
Nevertheless, these cutoffs should not set in stone. Declaring outcomes as merely “vital” or “not vital” primarily based on a hard and fast threshold (like 0.05) might be deceptive. As Ronald Fisher, a pioneer in statistics, as soon as stated:
“No scientific employee has a hard and fast stage of significance at which, from 12 months to 12 months, and in all circumstances he rejects hypotheses; he somewhat offers his thoughts to every specific case within the gentle of his proof and his concepts.”
Necessary Factors About P-values
-
A p-value doesn’t present proof in help of the null speculation.
A big p-value doesn’t imply the null speculation is true; it simply means there isn’t sufficient proof to reject it. Watch out to not “settle for” the null speculation primarily based on a big p-value.
-
A small p-value doesn’t show the choice speculation is true.
It simply tells us that rejecting the null speculation is affordable primarily based on the info.
-
P-values rely upon pattern measurement.
- With a really massive pattern measurement, even very small variations can result in tiny p-values, making it straightforward to reject H₀.
- With a really small pattern measurement, even massive variations might lead to massive p-values, making it arduous to reject H₀.
-
Take into account the dimensions of the impact.
A statistically vital outcome (small p-value) doesn’t at all times imply the result’s virtually essential. Small p-values can come from:
- A small impact in a really massive pattern.
- A big impact in a really small pattern.
To get an entire image, mix the p-value with the dimensions of the impact and its confidence interval. This may provide help to perceive each the statistical and sensible significance of your outcomes.
Key Takeaway
The p-value is a useful instrument in statistical evaluation, but it surely have to be used rigorously. It’s not a magic quantity that decides every little thing, and it ought to at all times be interpreted alongside different data like pattern measurement, impact measurement, and confidence intervals. In agriculture, the place pattern sizes and variability can range vastly, understanding the total context of the info is crucial for drawing significant conclusions.
This weblog is written by Dr Raj Popat Knowledge Scientist, Syngenta Seed, Hyderabad, India




 [...]
[...]
 [...]
[...]
 [...]
[...]




 [...]
[...]
 [...]
[...]









 […]
[…]


 – Statisfaction")
 evaluations of perform
evaluations of perform  . I might use plain previous Monte Carlo:
. I might use plain previous Monte Carlo:![hat{I}(f) = n^{-1}sum_{i=1}^n f(U_i),quad U_isim U([0, 1]^s).](https://s0.wp.com/latex.php?latex=%5Chat%7BI%7D%28f%29+%3D+n%5E%7B-1%7D%5Csum_%7Bi%3D1%7D%5En+f%28U_i%29%2C%5Cquad+U_i%5Csim+U%28%5B0%2C+1%5D%5Es%29.&bg=FFFFFF&fg=181818&s=0&c=20201002)
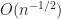 .
.![finmathcal{C}^r([0, 1]^s)](https://s0.wp.com/latex.php?latex=f%5Cin%5Cmathcal%7BC%7D%5Er%28%5B0%2C+1%5D%5Es%29&bg=FFFFFF&fg=181818&s=0&c=20201002) , Bakhvalov (1959) confirmed that the most effective fee I can hope for is
, Bakhvalov (1959) confirmed that the most effective fee I can hope for is  . That’s, there exist algorithms that obtain this fee, and algorithms attaining a greater fee merely don’t exist.
. That’s, there exist algorithms that obtain this fee, and algorithms attaining a greater fee merely don’t exist. of
of  ,
,  . Then I might compute the next estimator, based mostly on a second batch of
. Then I might compute the next estimator, based mostly on a second batch of ![hat{I}(f) := I(f_n) + n^{-1} sum_{i=1}^n (f-f_n)(U_i),quad U_isim U([0, 1]^s).](https://s0.wp.com/latex.php?latex=%5Chat%7BI%7D%28f%29+%3A%3D+I%28f_n%29+%2B+n%5E%7B-1%7D+%5Csum_%7Bi%3D1%7D%5En+%28f-f_n%29%28U_i%29%2C%5Cquad+U_i%5Csim+U%28%5B0%2C+1%5D%5Es%29.&bg=FFFFFF&fg=181818&s=0&c=20201002)
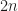 evaluations) is unbiased, that its variance is
evaluations) is unbiased, that its variance is 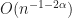 , and due to this fact its RMSE is
, and due to this fact its RMSE is 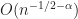 .
. , which explains why the most effective fee you may get for the previous is
, which explains why the most effective fee you may get for the previous is 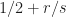 .
. , and
, and![f_n(u) = sum_{i=1}^n f(frac{2i-1}{2n}) 1_{[(i-1)/n, i/n]}(u)](https://s0.wp.com/latex.php?latex=f_n%28u%29+%3D+%5Csum_%7Bi%3D1%7D%5En+f%28%5Cfrac%7B2i-1%7D%7B2n%7D%29+1_%7B%5B%28i-1%29%2Fn%2C+i%2Fn%5D%7D%28u%29&bg=FFFFFF&fg=181818&s=0&c=20201002)
![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=FFFFFF&fg=181818&s=0&c=20201002) into
into ![[(i-1)/n, i/n]](https://s0.wp.com/latex.php?latex=%5B%28i-1%29%2Fn%2C+i%2Fn%5D&bg=FFFFFF&fg=181818&s=0&c=20201002) , and approximate
, and approximate 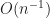 supplied
supplied 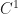 . So that you get a easy recipe to acquire the optimum fee when
. So that you get a easy recipe to acquire the optimum fee when 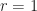 .
. and any
and any  ? The reply is in our latest paper with Mathieu Gerber, which you’ll find
? The reply is in our latest paper with Mathieu Gerber, which you’ll find {kind=link}