PLAID is a multimodal generative mannequin that concurrently generates protein 1D sequence and 3D construction, by studying the latent house of protein folding fashions.
The awarding of the 2024 Nobel Prize to AlphaFold2 marks an vital second of recognition for the of AI function in biology. What comes subsequent after protein folding?
In PLAID, we develop a technique that learns to pattern from the latent house of protein folding fashions to generate new proteins. It could actually settle for compositional perform and organism prompts, and may be skilled on sequence databases, that are 2-4 orders of magnitude bigger than construction databases. In contrast to many earlier protein construction generative fashions, PLAID addresses the multimodal co-generation drawback setting: concurrently producing each discrete sequence and steady all-atom structural coordinates.
Enterprise software program spending is increasing quickly and changing into a much bigger slice of IT budgets, difficult IT organizations to handle it extra successfully.
The development stems from a number of sources, together with a larger reliance on SaaS platforms and a proliferation of software program choices throughout classes from AI to IT operations. Higher software program adoption guardrails and governance buildings may assist management spending and get extra out of software program investments, however these measures can show difficult to deploy.
Latest stories make clear the software program spending situation:
A Boston Consulting Group (BCG) paper, citing Gartner worldwide IT spending information, pointed to a 50% improve in software program’s share of general know-how budgets between 2019 and 2025, rising from a 13% contribution to a 21% slice. The paper, printed in October, famous that “software program procurement has develop into exceedingly complicated, and corporations are struggling to cut back spending in an more and more fragmented panorama.”
A West Monroe survey of 310 procurement, IT and finance executives discovered that 93% reported rising enterprise software program prices. The consulting agency’s B2B software program spend survey, printed in September, additionally famous that 46% of the respondents reported software program value hikes above the ten% business common.
A number of Components Account for Software program Worth Hikes
Whereas inflation has ramped up the price of IT commodities in recent times, the software program spending will increase aren’t essentially tied to broader macroeconomic patterns. Enterprise software program costs have persistently risen quicker than the U.S. inflation fee, as measured by the patron value index, famous Ashwin Bhave, managing director and senior companion at BCG and a co-author on the analysis paper.
As an alternative, Bhave cites the rising enterprise dependence on SaaS platforms. Utilizing SaaS to automate core enterprise features makes it tough for purchasers to vary suppliers. This opens the way in which to vendor value hikes.
“These merchandise are getting increasingly more broadly adopted, and they’re fairly embedded within the purchasers they serve,” Bhave mentioned. “It isn’t that simple to change, and so it’s extra possible to go on value will increase.”
SaaS subscription renewal charges are additionally driving up prices. Mockingly, the rising charges are, no less than partially, a response to software program cost-cutting measures. Dhaval Moogimane, high-tech and software program observe lead at West Monroe, mentioned enterprises have adjusted the variety of seats and trimmed unused modules within the final yr. Distributors have jacked up their charges in response.
“Software program suppliers are seeing their prospects push again on the variety of seats they need to use, the variety of customers,” he mentioned. “So, pricing for renewals has gone up.”
As well as, software program distributors, recognizing greater renewal pricing, are throwing in new capabilities or modules as a negotiating tactic, Moogimane mentioned.
The arrival of extra software program, on the whole, contributes to the rising software program spend.
“There are complete classes of software program in the present day that merely did not exist 5 to 10 years in the past,” Bhave mentioned.
He cited the proliferation of cybersecurity instruments and merchandise for builders and famous the main cloud suppliers’ increasing suites, which even embrace quantum-as-a-service choices.
“There are merely extra issues to purchase and extra capabilities that firms are deploying, which can also be driving up software program prices,” Bhave mentioned.
How CIOs are Coping with Software program Software Sprawl
One step CIOs can take to maintain prices in examine is addressing software program sprawl. However containing the software unfold isn’t all about trimming bills. Organizations are discovering they’ll additionally enhance information consistency, enhance product high quality, and simplify coaching. They will additionally unencumber time to deal with innovation.
Mark Sales space, CIO at Perdue Farms, a meals and agriculture firm, has been decreasing software sprawl as a part of a broader digital transformation program. The corporate applied Dataiku’s information and AI platform, which has helped consolidate information preparation, ETL and spreadsheet instruments. Dataiku is one component in an ordinary set of data-destination instruments, the others being Snowflake, and Microsoft’s Energy BI information visualization providing.
(Supply: Perdue Farms) Mark Sales space, CIO at Perdue Farms.
Sales space described this method as having a “snowplow impact” on its transformation journey.
“We’re plowing a path, ensuring our associates perceive what instruments we use for what [purposes],” he mentioned. “Issues fall in line within the path behind it, so we’re sunsetting programs and spreadsheets.”
Purdue Farms’ information pipeline supplies one instance of the unified information technique. The information movement has been transferred to Dataiku, which extracts information from inner and exterior sources, transforms the info as wanted, and strikes it to a Snowflake repository.
The aim is to “streamline each the instruments and the method of placing information in an information lake,” Sales space mentioned.
Perdue Farms’ capability to mix information in a single location promotes consistency. Having constant information helps the corporate draw the proper conclusions in areas comparable to meals security, the place it pulls information from quite a few family-owned poultry farms, Sales space mentioned.
Knowledge software consolidation additionally simplifies coaching, since staff can deal with a core set of tech sources. It lets staff spend much less time reconciling information and extra time analyzing information and figuring out alternatives for bettering enterprise outcomes, Sales space added.
OpenText cuts software depend, boosts high quality
Shannon Bell, CIO and chief information officer at OpenText, in the meantime, says the data administration software program firm is “dramatically simplifying” its software panorama.
(Supply: OpenText) Shannon Bell, CIO and chief information officer at OpenText.
She famous that about 18 months in the past, the corporate launched an initiative to deploy extra of its personal know-how in-house. As a part of that effort, OpenText examined each enterprise area, from engineering to buyer assist. The corporate discovered that it had 1,600 instruments, which it has since lowered to about 1,200.
“The aim was to rationalize and decommission programs,” Bell mentioned.
In a single instance, OpenText’s 8,000-plus builders had been utilizing round 50 instruments. The corporate has changed these merchandise with one toolkit, OpenText Software program Supply Administration.
The associated fee financial savings proved to be a big good thing about that consolidation. Nonetheless, “it additionally helped us enhance the standard of the merchandise as a result of everybody was utilizing the identical software set,” Bell mentioned.
In one other nod to simplification, developer coaching and onboarding may revolve round one set of instruments somewhat than a mess of choices, she added.
Bell mentioned establishing goal states throughout OpenText’s enterprise domains was important for decreasing software sprawl. A goal state is likely to be a strategic software chosen for a selected area.
“If you do not have a goal state for every area, the tendency is that one other software will get acquired for that staff or that use case,” Bell mentioned.
She famous that each effort to change from a number of instruments to a strategic platform should embrace a decommissioning section. If the undertaking ends with a enterprise unit nonetheless utilizing its present instruments alongside the goal system, the group is simply rising its value base.
Bell mentioned addressing software sprawl finally unlocks time and capability for extra significant work.
“Having sunk prices in instruments that are not delivering lots of worth is a straightforward space to deal with clean-up, so you may really put your folks to work on extra progressive, high-priority initiatives,” she mentioned.
The Problem of Controlling Software program Spend
Bhave mentioned many organizations battle with software proliferation as a result of they lack a scientific software program spend administration operate. Certainly, duty for software program outlays tends to be distributed throughout totally different decision-makers in enterprise items. Nonetheless, some firms are starting to indicate curiosity in establishing oversight features that handle prices throughout the enterprise, he famous.
“You might need a physique that particularly seems at software program sprawl, units targets over a two- to three-year timeframe, and units some guardrails,” Bhave mentioned.
Start With a Software program Stock
Enterprises ought to deal with the necessities when making an attempt to tame software program spend. A listing of software program belongings is a spot to start out.
“Simply having hygiene and self-discipline in asset administration is tremendous vital,” Moogimane mentioned. “What do you even have and the way a lot are you really utilizing?”
Sales space additionally pointed to the “primary hygiene” of publishing an enterprise catalog. A catalog encourages enterprise groups to examine what they’ve available earlier than buying yet one more software.
“In very massive, far-flung enterprises, folks do not even know what’s already getting used,” he mentioned.
Stepped-up Administration Efforts Wanted
One other situation is the sophisticated nature of SaaS vendor pricing, which makes it tough for IT leaders to reapply cost-cutting levers they use in different facets of IT. FinOps practices, for instance, have helped enterprises trim cloud infrastructure spend. However these measures, comparable to optimizing utilization and workloads, won’t readily translate into SaaS administration.
“It is not attainable to have an ordinary playbook which you could have for the [top three to five] cloud distributors,” Bhave mentioned. “In software program, you must take into consideration 50-plus distributors if you happen to go class by class. How they handle pricing and the way [customers] purchase from them varies.”
In opposition to this backdrop, CIOs and CTOs can anticipate to spend extra of their administration efforts on software program.
“The expansion of software program has caught tech leaders unexpectedly,” Bhave mentioned. “If you concentrate on the entire tech finances, labor goes down. Infrastructure is disappearing and going into the cloud. Cloud prices, themselves, are taking place as a result of {hardware} and internet hosting are getting cheaper. The one factor that continues to be, really, is software program.”
Within the subsequent decade, software program may develop into half of the IT finances, if no more, Bhave speculated.
“During which case, the whole job goes to be about how do you handle software program,” he mentioned.
Should you’ve ever burned hours wrangling PDFs, screenshots, or Phrase information into one thing an agent can use, you understand how brittle OCR and one-off scripts could be. They break on format modifications, lose tables, and gradual launches.
This isn’t simply an occasional nuisance. Analysts estimate that ~80% of enterprise knowledge is unstructured. And as retrieval-augmented era (RAG) pipelines mature, they’re changing into “structure-aware,” as a result of flat OCR collapse underneath the load of real-world paperwork.
Unstructured knowledge is the bottleneck. Most agent workflows stall as a result of paperwork are messy and inconsistent, and parsing shortly turns right into a facet venture that expands scope.
However there’s a greater possibility:Aryn DocParse, now built-in into DataRobot, lets brokers flip messy paperwork into structured fields reliably and at scale, with out customized parsing code.
What used to take days of scripting and troubleshooting can now take minutes: join a supply — even scanned PDFs — and feed structured outputs straight into RAG or instruments. Preserving construction (headings, sections, tables, figures) reduces silent errors that trigger rework, and solutions enhance as a result of brokers retain the hierarchy and desk context wanted for correct retrieval and grounded reasoning.
Why this integration issues
For builders and practitioners, this isn’t nearly comfort. It’s about whether or not your agent workflows make it to manufacturing with out breaking underneath the chaos of real-world doc codecs.
The influence exhibits up in three key methods:
Simple doc prep What used to take days of scripting and cleanup now occurs in a single step. Groups can add a brand new supply — even scanned PDFs — and feed it into RAG pipelines the identical day, with fewer scripts to take care of and quicker time to manufacturing.
Structured, context-rich outputs DocParse preserves hierarchy and semantics, so brokers can inform the distinction between an government abstract and a physique paragraph, or a desk cell and surrounding textual content. The outcome: easier prompts, clearer citations, and extra correct solutions.
Extra dependable pipelines at scale A standardized output schema reduces breakage when doc layouts change. Constructed-in OCR and desk extraction deal with scans with out hand-tuned regex, reducing upkeep overhead and reducing down on incident noise.
What you are able to do with it
Below the hood, the mixing brings collectively 4 capabilities practitioners have been asking for:
Broad format protection From PDFs and Phrase docs to PowerPoint slides and customary picture codecs, DocParse handles the codecs that normally journey up pipelines — so that you don’t want separate parsers for each file sort.
Structure preservation for exact retrieval Doc hierarchy and tables are retained, so solutions reference the best sections and cells as an alternative of collapsing into flat textual content. Retrieval stays grounded, and citations really level to the best spot.
Seamless downstream use Outputs circulate instantly into DataRobot workflows for retrieval, prompting, or operate instruments. No glue code, no brittle handoffs — simply structured inputs prepared for brokers.
One place to construct, function, and govern AI brokers
This integration isn’t nearly cleaner doc parsing. It closes a crucial hole within the agent workflow. Most level instruments or DIY scripts stall on the handoffs, breaking when layouts shift or pipelines increase.
This integration is a part of an even bigger shift: transferring from toy demos to brokers that may motive over actual enterprise information, with governance and reliability in-built to allow them to rise up in manufacturing.
Which means you may construct, function, and govern agentic purposes in a single place, with out juggling separate parsers, glue code, or fragile pipelines. It’s a foundational step in enabling brokers that may motive over actual enterprise information with confidence.
From bottleneck to constructing block
Unstructured knowledge doesn’t must be the step that stalls your agent workflows. With Aryn now built-in into DataRobot, brokers can deal with PDFs, Phrase information, slides, and scans like clear, structured inputs — no brittle parsing required.
Join a supply, parse to structured JSON, and feed it into RAG or instruments the identical day. It’s a easy change that removes one of many greatest blockers to production-ready brokers.
One of the best ways to know the distinction is to strive it by yourself messy PDFs, slides, or scans, and see how a lot smoother your workflows run when construction is preserved finish to finish.
MacBook Professional M5 Professional & Max: In abstract
The M5 MacBook Professional launched in October 2025 however the Professional and Max fashions are but to be up to date.
Apple’s next-gen M5 Professional, and M5 Max processors promise efficiency positive factors.
Extra thrilling updates are rumored for the M6 MacBook Professional.
In October 2025, Apple launched an M5 MacBook Professional, however didn’t replace the year-old M4 Professional or M4 Max machines. There have been indications that whereas Apple was on schedule to ship the M5 MacBook Professional within the October timeframe, the wait might lengthen to spring 2026 for the M5 Professional and M5 Max fashions.
Whereas the M5 processor within the MacBook Professional boasts a brand new GPU structure with a Neural Accelerator in every core that Apple says means it may well present “over 4x the height GPU compute efficiency in comparison with M4, a forty five % enchancment in graphics efficiency in comparison with the M4, the brand new chip can be no match for the M4 Professional or and M4 Max within the extra highly effective MacBook Professional fashions nonetheless on sale.
So what modifications may very well be coming to the extra professional MacBook Professional fashions and is it going to be definitely worth the wait, or would energy customers be clever to attend a bit longer for the a lot greater modifications rumored to be simply across the nook for the M6 technology of the MacBook Professional, with the M6 mannequin probably providing a contact display screen and extra.
This text will maintain monitor of the rumors and supply a perspective based mostly on Apple’s Mac lineup. Right here’s all the things we all know to this point.
New M5 Professional/Max MacBook Professional: Design
No change to the design anticipated.
Large modifications are stated to be coming to the M6 MacBook Professional.
Apple up to date the design of the MacBook Professional in 2021. There was no change to the design of the MacBook PRo when Apple launched the M5 mannequin. So it looks like Apple will follow the present design for the M5 Professional and Max fashions.
It’s all the time doable {that a} new shade makes an look—like Area Black in 2023—however for probably the most half, the MacBook Professional design is ready for not less than one other yr.
In July 2025, Bloomberg’s Mark Gurman reported that the M5 MacBook Professional sequence is to be the final of this present design although. Apple seems to be saving the subsequent main design improve for the MacBook Professional for 2026. The M6 improve is claimed to incorporate OLED screens, a digital camera “gap” to substitute the notch, and a thinner design.
New M5 Professional/Max MacBook Professional: Show
No change to show anticipated.
There isn’t a change to the show on the M5 MacBook Professional, so it’s unlikely that the M5 Max and M5 Professional fashions will get any display screen updates. Though we might see the next nits brightness score, up from the present 1,600 nits peak.
On February 11, 2025, The Elec reported that OLED shows for the MacBook Professional are going into manufacturing, however they gained’t be featured within the laptop computer till 2026.
Nevertheless, on July 28, 2025, Dealsite reported that Apple has a deal in place with Samsung Show for OLED shows for the MacBook Professional that may ship in late 2025. Which may not imply that the shows are any higher, in fact.
There may very well be one thing much more thrilling coming with the M6 technology: a touchscreen! Analyst Ming-Chi Kuo believes that Apple goes to launch a MacBook with a contact display screen, and it might arrive on a MacBook Professional as quickly as 2026. Nevertheless, this replace is just not anticipated to reach till the M6 technology and may very well be delayed till 2027.
Apple may very well be saving any drastic modifications to the MacBook Professional for 2026.
Foundry
New M5 Professional/Max MacBook Professional: Digicam
The M4 MacBook Professional added a 12MP FaceTime digital camera, an honest improve from the 1080p FaceTime digital camera. The M5 Macook Professional maintains this digital camera, so it’s unlikely the Professional and Max fashions will acquire something.
Nevertheless, we might see an analogous FaceTime digital camera replace to 18MP as seen on the iPhone 17. The sq. sensor is much less related right here because the MacBook Professional will solely ever be in a single orientation, though it might permit for extra of the world round an individual to be seen.
New M5 Professional/Max MacBook Professional: Processor
The M5 MacBook Professional that launched in October 2025 is little greater than a chip refresh and it’s possible that the M5 Professional and Max can be an analogous story. Stories had indicated to count on the standard efficiency increase from one chip technology to a different–between 15 and 25 % over the M4 chips.
On Might 8, 2025, Bloomberg’s Mark Gurman reported that Apple is engaged on M6 and M7 chips, however they gained’t be within the MacBook Professional till later. Apple can be engaged on a “extra superior Mac chip” referred to as Sotra, however no particulars have been offered.
On July 3, AppleInsider reported that Apple plans the discharge 4 customary configurations with the next code names:
J714c: M5 Max 14-inch MacBook Professional
J714s: M5 Professional 14-inch MacBook Professional
J716c: M5 Max 16-inch MacBook Professional
J716s: M5 Professional 16-inch MacBook Professional
On October 7, 2025, MaxTech’s Vadim Yuryev reported that Apple is engaged on a brand new chip design for the M5 Professional and M5 Max that may function the CPU and GPU on separate blocks. This may permit clients better choices to configure these elements. For instance, one might arrange a base CPU configuration with a maxed out GPU. Yuryev acknowledged that this new design is why the M5 Professional and M5 Max are delayed till 2026.
New M5 Professional/Max MacBook Professional: Specs
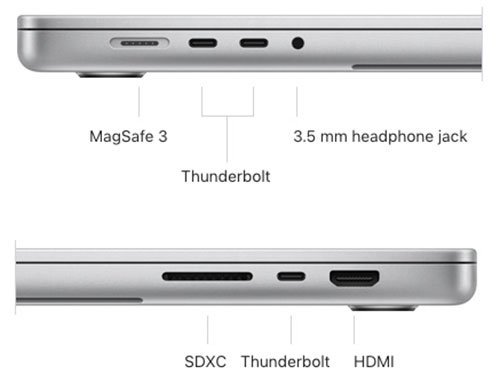
N1 chip: Wi-Fi 7 and Bluetooth 6.
Thunderbolt 5.
With the launch of the M4 MacBook Professional, Apple made a sequence of upgrades that changed outdated elements, together with upping the bottom RAM to 16GB, bringing Thunderbolt 5 to the M4 Professional and Max fashions, and providing a Nano-texture glass choice. The M5 MacBook Professional noticed no modifications to the specs apart from the processor. The Bluetooth and WiFi remained the identical. A brand new 4TB SSD choice was added, however within the U.Ok. and Europe Apple has eliminated the Energy Adapter from the field.
Nevertheless, Wi-Fi 7 is predicted to reach on the MacBook Professional M5 Professional and Max. Apple can also combine the N1 chip, as used within the iPhone 17, which can carry Wi-Fi 7 and Bluetooth 6, in addition to enhance options like Private Hotspot and AirDrop.
Apple
The entry-level mannequin nonetheless solely gives Thunderbolt 4, however the Max and Professional will proceed to supply Thunderbolt 5.
There are experiences that Apple is engaged on a 5G modem for the Mac, however it’s unlikely to reach earlier than 2026.
New M5 Professional/Max MacBook Professional: Launch date
Doable launch spring 2026.
Bloomberg’s Mark Gurman reported in March 2025 that Apple is on schedule to ship the M5 MacBook Professional “across the similar time of yr” as when the M4 and M3 MacBook Professional shipped. That implies an October/November timeframe. Gurman then reported on Might 8 that the M5 MacBook Professional might arrive “as early as the top of this yr.”
Gurman was initially assured that Apple would launch the M5 MacBook Professional by the top of 2025, and certainly it did, however his confidence was actually faltering because the launch neared, with a tweet previous to the launch declaring that M4 MacBook Professional was constrained, however not the M4 Max or M4 Professional fashions.
On the bottom stage 14-inch MacBook Professionals, customized configurations on the road retailer are constrained until the top of October. Not the case for the Professional/Max and 16-inch fashions.
Then, Vadim Yuryev, host of the Max Tech YouTube channel, predicted on October 6: “3 days of M5 chip product launches subsequent week beginning on Monday or Tuesday. M5 MacBook Professional 14-inch mannequin ONLY, M5 iPad Professional, M5 Imaginative and prescient Professional.”
So for now a spring launch for the remainder of the MacBook Professional line up appears almost certainly.
New M5 MacBook Professional: Value
Costs are unlikely to alter.
Listed below are the costs for the present customary configurations of the M4 Professional and Max MacBook Professional, for reference. Costs are unlikely to alter.
14-inch MacBook Professional
$1,999/£1,999: M4 Professional with a 12-core CPU, 16-core GPU, 24GB unified reminiscence, 512GB SSD, Thunderbolt 5
$2,399/£2,399: M4 Professional with a 14-core CPU, 20-core GPU, 24GB unified reminiscence, 512TB SSD, Thunderbolt 5
$3,199/£3,199: M4 Max with a 14-core CPU, 32-core GPU, 36GB unified reminiscence, 1TB SSD, Thunderbolt 5
16-inch MacBook Professional
$2,499/£2,499: M4 Professional with a 14-core CPU, 20-core GPU, 24GB unified reminiscence, 512GB SSD, Thunderbolt 5
$2,899/£2,899: M4 Professional with a 14-core CPU, 20-core GPU, 48GB unified reminiscence, 512TB SSD, Thunderbolt 5
$3,499/£3,499: M4 Max with a 14-core CPU, 32-core GPU, 36GB unified reminiscence, 1TB SSD, Thunderbolt 5
$3,999/£3,999: M4 Max with a 16-core CPU, 40-core GPU, 48GB unified reminiscence, 1TB SSD, Thunderbolt 5
The M5 MacBook Professional costs haven’t modified, however within the U.Ok. and Europe the Energy Adapter will price additional:
$1,599/£1,599: M5 with a 10-core CPU, 10-core GPU, 16GB unified reminiscence, 512GB SSD, Thunderbolt 4
$1,799/£1,799: M5 with a 10-core CPU, 10-core GPU, 16GB unified reminiscence, 1TB SSD, Thunderbolt 4
$1,999/£1,999: M5 with a 10-core CPU, 10-core GPU, 24GB unified reminiscence, 1GB SSD, Thunderbolt 4
The quantity of REM sleep you get might affect which particulars of your reminiscences stay in storage, a brand new mind examine suggests.
Earlier analysis had discovered that sleep helps fortify our reminiscences, however the query of the way it shapes the contents of those reminiscences has been more durable to pin down. Now, a examine revealed Oct. 1 within the journal Communications Biology hints that the time spent in several phases of sleep might affect this side of reminiscence storage.
The sleep cycle is break up into 4 phases: one stage of speedy eye motion (REM) and three non-REM phases, together with “deep sleep,” marked by sluggish mind waves. To check how these sleep phases affect our reminiscences, the researchers requested 32 wholesome younger adults to be taught 96 word-picture pairs — akin to an motion phrase linked to a picture of an animal or plant — whereas their mind exercise was recorded with an electroencephalogram (EEG), which screens mind waves that wash over the floor of the mind.
The volunteers have been then monitored with EEG as they slept in a single day and had their recall examined the subsequent morning. The researchers in contrast the before-and-after mind patterns utilizing a method referred to as representational similarity evaluation. These information enabled the scientists to focus each on detailed reminiscences tied to particular photographs — like a photograph of a beagle — and on broader, categorical reminiscences, masking all of the animal photographs, as an example.
“By utilizing EEG, we may monitor how mind exercise linked to reminiscences modified from earlier than to after sleep,” first examine writer Jing Liu, a analysis assistant professor at The Hong Kong Polytechnic College, advised Dwell Science in an e mail.
The workforce uncovered a sample: Brainwaves linked to the person photographs weakened after sleep, whereas the broader class indicators remained secure.
The shift was stronger when REM made up extra of a person’s complete sleep time, in comparison with deep sleep. Liu defined that this sample suggests REM sleep might assist the mind hyperlink new reminiscences with what it already is aware of, whereas slow-wave sleep helps hold these reminiscences of their authentic, more-detailed type.
Get the world’s most fascinating discoveries delivered straight to your inbox.
“Even when folks remembered the identical issues after waking, the mind patterns behind these reminiscences had shifted,” she added. This implies sleep not solely strengthens reminiscences however might reorganize how they’re represented within the mind, with REM and slow-wave sleep contributing in several methods.
Collectively, these outcomes add to proof that reminiscence consolidation — the mind’s strategy of stabilizing and reorganizing new reminiscences — entails each preservation and transformation. Somewhat than storing reminiscences of experiences precisely as they occurred, the mind could also be subtly restructuring them throughout sleep, balancing accuracy with generalization. The excellence, the researchers famous, may assist clarify how data networks within the mind evolve over time.
Nonetheless, the sample would not essentially imply that deep sleep and REM sleep work in opposition to 1 one other. Somewhat, the 2 phases help totally different sides of remembering, Dr. George Dragoi, professor of psychiatry and neuroscience at Yale College who was not concerned within the examine, advised Dwell Science in an e mail.
“The outcomes right here level to a complementary position of REM and slow-wave sleep in several types of reminiscence,” he stated, akin to normal data and details versus reminiscences of particular experiences.
He added that maintaining common sleep schedules might assist help these processes, since good sleep high quality is broadly linked to wholesome cognitive perform. “Longer REM durations might promote the sort of reminiscence transformation this examine highlights,” he prompt.
Liu, nevertheless, cautioned that the outcomes present associations, not causation.
“[EEG] prevents us from exactly figuring out the mind areas driving these adjustments,” she stated, including that combining EEG with recordings taken straight from electrodes positioned contained in the cranium may make clear the circuitry behind the impact. She additionally pointed to future research that may attempt to reactivate particular reminiscences throughout sleep — as an example, by replaying sounds or cues linked to earlier studying — or interrupt explicit sleep phases to see whether or not that adjustments how flexibly folks can use what they’ve discovered.
A photographer’s snapshot of Treasury Secretary Scott Bessent
on the United Nations Basic Meeting final week revealed a personal
message that captured the Trump administration’s deepening concern over
collapsing U.S. soybean exports to China—a disaster now entangled with a controversial financial bailout of Argentina.
“Lastly
– only a heads up, I’m getting extra intel, however that is extremely
unlucky,” learn the message, which seemed to be despatched from Agriculture
Secretary Brooke Rollins. “We bailed out Argentina yesterday (Bessent)
and in return, the Argentine’s [sic] are eradicating their export tariffs
on grains, lowering their worth, and bought a bunch of soybeans to China,
at a time once we would usually be promoting to China. Soy costs are
dropping additional due to it. This provides China extra leverage on us.”
…
The missive has additionally drawn new scrutiny to the Trump administration’s pledge to assist Argentina with a attainable $20 billion swap line
and direct U.S. purchases of presidency debt. Days after the deal,
Chinese language importers purchased greater than one million metric tons of Argentine
soybeans simply because the American harvest season started.
…
China, as soon as the most important purchaser of American soybeans, has not bought a
single cargo since Might, based on U.S. Division of Agriculture
knowledge. In 2024, China purchased $12.5 billion of the $24.5 billion value of
soybeans the U.S. exported globally—greater than 50 p.c. For months
now, the determine has been zero.
As an Arkansas good ol’ boy and a few instances press critic, I am often irritated by how little consideration the press usually provides agriculture tales, however this one seems to have legs.
Soybean farmer: Our complete value construction has elevated, however our income has decreased. It is fairly difficult. It is a massacre
As ag scientist Sarah Taber factors out, as soon as you narrow off a market,
demand for a crop doesn’t merely bounce again when the provision reopens.
Typically it by no means absolutely returns.
Completely true.
The crop that has been mainstay of (particularly) South Dakota financial system now zeroed out, in exports to their largest buyer.
These farmers know (have informed us) that they’ll by no means get these markets again. The PRC has switched to Brazil and Argentina.
Angus:
American farmers who purchased into Trump, considering tariffs would assist
them—their markets are gone. Canada’s not making noise about it; we’re
simply transferring in. Canadian corn is now being bought in Eire, Spain, and
the UK. These was once assured American markets. Not anymore.
The textbook instance is cotton.
Within the first half of the nineteenth century, America dominated the high-grade
cotton commerce whereas Egypt was a minor participant. However when the Civil Struggle
disrupted U.S. provide, British textile mills grew determined for uncooked
materials, and Egypt rushed in to fill the vacuum. By the point the conflict
ended, Egypt had turn out to be the dominant provider, with the added benefit
of being geographically nearer to Britain. It additionally constructed a fame
for high quality that persists to today.
Because of Brigham Frandsen for this weeks workshop on machine studying, AI and causal inference. Mixtape periods is indebted to him. He has taught that workshop for us 5 occasions since October 2022, not counting the thrice he’s taught his workshop on machine studying and heterogeneous therapy results (which he’ll train once more November tenth). So thanks Brigham!
The following two workshops are additionally value a lot of your time. The primary one is by Jeff Gortmaker on demand estimation and the BLP mannequin. Ariel Pakes made an look final time and I must study if that’s nonetheless the case this time. However should you’re in industrial group, or trade, or authorities, I extremely suggest you try Jeff’s workshop. Final time, it was an enormous hit — as in, it’s up to now the most well-liked workshop we’ve run on mixtape periods. And given the recognition of BLP not simply in IO, however trade extra typically, I feel at these costs, it’s value your time. This workshop will begin October twentieth and run for 3 evenings, subsequent week. Attain out should you suppose qualify for a reduction!
And the opposite one is my causal inference 2 workshop beginning Saturday, November 1st on difference-in-differences. That is the workshop that I feel will carry you to a degree of the frontier of diff-in-diff — not the bleeding edge, which continues evolving at a clip, however you’ll get this least:
the basics of diff in diff and rooted in pragmatic and utilized design rules
targeted consideration on the occasion examine and correct (and improper) specs
The function of covariates within the parallel developments assumption and correct specs strong to unrestricted heterogeneous therapy results
Extra complicated designs like estimation with repeated cross sections and differential timing
A reasonably in depth give attention to the Callaway and Sant’Anna estimator, the function of weights in aggregation, an in depth consideration to interpretation, and inference
Coding coding coding!
So come one, come all! Once more, attain out should you suppose you qualify. In case your potential to pay is beneath value, please attain out and if we will work one thing out, we are going to. Our aim is at mixtape periods to assist folks study these necessary instruments.
Replace on Boston and Harvard
Each of those entities proceed to win my coronary heart over. The scholars are sweethearts. Final night time after our assessment session for tomorrow’s examination, a pupil spent 10 minutes with me explaining the correct use of the brand new slang “low key”. Low key’s low key most likely my absolute favourite new slang, partly as a result of it’s practically inconceivable to make use of it incorrectly.
I like the scholars loads. I’ve held to daye met with 55 college students in workplace hours since I acquired right here. Every time is a brand new expertise, and I like asking them what it was like opening their acceptance letter. With out exception, they all the time share the enjoyment and gratitude and amazement they felt after they opened their acceptance letter. As a dad with children in school, I really feel so happy with all of them.
Gov 50 continues to be an thrilling journey and problem for me. I’ve managed to delay introducing regression. I targeted to this point on “easy comparisons” as the easy distinction in imply outcomes. And for unconfoundedness, I opened up as I all the time do with graphs after which backdoor criterion, however for the primary time, college students gave precisely two shits about it. And I feel I do know why.
Roughly 100-120 of my 190 college students are sophomores and freshmen. Round 120 have but to declare their main (“focus” right here is the nomenclature, not main, although). And this class is each required for the federal government focus however it’s also a basic schooling requirement. I usually meet college students removed from STEM, like historical past, artwork and philosophy.
And the rationale I feel that issues is that that is typically their first empirical challenge. It’s their first time to code and even lay palms on actual information. So ask your self — if that have been you, would you see the worth of selecting covariates? Of avoiding others? When unconfoundedness is their first non-experimental methodology?
I feel most likely the returns to graphs is far greater when the researcher has had extra expertise — that or the professor is more proficient at introducing it. Anyway, level is, it burnt every week, and I want I hadn’t completed it, however hindsight is 20/20.
So, to my level. I’ve managed to delay introducing OLS. The reason being as a result of I feel I can train OLS on the tail finish simpler than at the beginning as a result of the examination actually emphasised a number of issues:
Calculating the easy distinction in imply outcomes.
Actual matching (widespread help)
Nearest neighbor matching (widespread help considerably violated)
I feel I can initially with #1 present them the regression specification that estimates the easy distinction in imply end result with out covariates utilizing Rebecca Thorntons Malawi paper. I’ll most likely comply with it up with instructing them her new AER: Insights paper too, which illustrates I feel the worth of a really glorious designed experiment on the service of a really necessary scientific and social coverage questions. Which, as I’ve emphasised all semester to those children, is the hallmark of Rebecca’s complete profession.
So, I’ll give attention to the regression specification first with a binary therapy, after which lead into the properties of OLS. Which I’ll then transfer into multivariate regressions as a substitute for matching (versus the opposite method round) when widespread help breaks down. I simply felt that I wanted to imprint “easy comparisons” of their minds since OLS comparisons are hardly easy (eg bizarre variance weights, counter intuitive interpretation below heterogenous therapy results). So I’ll be telling them that commonplace OLS fashions with covariates would require they assume fixed therapy results as a result of I refuse to point out them regression adjustment. I’ve to save lots of one thing for Gov 51.
My PhD course for subsequent semester is coming collectively. I’ve determined it’ll be chance and statistics utilizing Bruce Hansen’s new guide, and utilized regression utilizing his different econometrics guide. I’ll even be assigning articles in order that I can sprinkle in some causal inference.
I’ll most likely cowl some fundamental stuff from Angrist, Tymon, possibly Bacon, simply to emphasise a number of issues like unconfoundedness, fixed versus heterogenous therapy results, and FWL, in addition to variance weighting in regression fashions. I feel I may cowl sensitivity evaluation by Taber, et al, Emily Oster, Carlos Cinelli.
In order that’s the newest.
Stunning Boston
On the Boston entrance, I proceed to have a stunning time. I’ve determined Boston is my favourite metropolis on this planet — anyplace. It’s such a stunning place with actually pretty folks. I actually don’t perceive it when somebody says they detest town. I feel it’s most likely due to the climate, however I’m trying ahead to the climate. I hope it’s a as soon as in a century blizzard, and I’m cuddled up below a blanket ingesting sizzling cocoa and watching NFL video games.
Talking of, I’m going to see the Eagles play the Bears in Philly over thanksgiving. I’m an enormous Eagles fan due to my love of the film Silver Linings Playbook. And I due to this fact additionally love Philly. In order that’s a visit I’m enthusiastic about. And I’m going to see the Pats play the Payments on December 14th with my buddy. Given they beat the Payments and pulled out one other win, this could possibly be turning out to be a really thrilling sport. Me and my buddy from school, who lives right here, are going. I hope I see one other struggle.
Listed below are some pics. A good friend took me to a spot on the north aspect that bought sweets. They love sweets however I like carbs. I simply assumed there was symmetry between carb lovers and candy lovers such that one to at least one we every had our personal factor. However you already know what? I used to be completely mistaken. This candy place had probably the most thoughts blowing sweets. I then realized. All I can do if I need to give a good friend a style of nice carb snacks is open a bag of kettle chips for them. I’ve really by no means seen a retailer, I noticed, devoted simply to carbs however a spot that focuses on sweets — properly these exist right here. I acquired every kind of stuff, however then I additionally couldn’t cease myself from getting some actual trash. Right here’s a fortunate charms deal with. It was implausible.
The above was a mesmerizing fountain I noticed that night time when out strolling round city with a good friend. It was choreographed and the lighting continuously modified. I simply couldn’t consider how enchanting it was. Right here’s additionally a video of these dancing, watery lights.
The climate is beginning to change already. I wore my coat the opposite day, as a result of I wakened and it was within the 30s, however the temperature rose and it was then uncomfortable. Nevertheless it’s shut, and I can’t wait.
I proceed to like my house in again bay. I like again bay. I like this metropolis. I like all the things about it. I’m grateful to the federal government dept, Harvard and town for letting me crash right here for a yr.
Right here you’ll get record of some greatest github alternate options that present non-public and public repository.
Being into software program growth we fairly often discover ourselves in the necessity to host our code to any web site. For the aim, plenty are blindly following one single medium for this, Github. It can’t be denied that Github customers have their alternative to make use of both Git or Subversion for model management. Additionally there’s a facility of limitless public code repository for all customers of Github. Another fascinating characteristic of Github is that permits to create ‘organizations’, which at its personal is a traditional account however no less than one person account is required to be listed because the proprietor of the group.
Aside from offering desktop apps for Home windows and OSX, Github additionally gives the ability to its customers and organizations to host one web site and limitless challenge pages without spending a dime on the Github’s web site. The standard area for the hosted web sites look one thing like username.github.io and tackle of the challenge pages might seem like username.github.io/project-page.
Shifting forward, we’ve got compiled a listing of few different mediums that will also be utilized in place Github with none hurt. So come let’s take a look on the record.
On opposite to the Github, the Bitbucket comes simply subsequent to it by way of utilization and international reputation. Bitbucket additionally gives a free account for the customers and organizations as nicely with restrict for 5 customers. Additionally, it gives entry to limitless non-public and public repos. One of many options which is notice worthy is its allowance for the customers to puch their information utilizing any of the Git consumer/Git command line.
Atlassian is the developer of Bitbucket offering entry to the model functionality to the customers utilizing their internet interface. A free Mac and Home windows interface can also be obtainable for utilizing Gitbucket’s personal Git and Mercurial consumer Supply Tree.
The area to your hosted web site on Bitbucket will look one thing like: accountname.bitbucket.org and area for that of challenge pages might be like: accountname.bitbucket.org/challenge. Alternatively Bitbucket additionally permits its customers to make use of their very own area title for his or her web site.
Beanstalk as one other good Github various however it isn’t free. You may get a trial of the useful resource for 2 weeks after which if you happen to want to proceed you should have a pay an quantity of minimal $15 for its least expensive Bronze package deal. Bronze package deal lets you will have most of 10 repositories with 3 Gigabytes of storage capability and most upto 5 customers.
Beanstalk helps essentially the most demanded Git and Subversion management methods for model management. It’s developed by Wildbit and likewise permits for code modifying within the browser itself in order that person want to not change to command line every so often.
GitLab is in style among the many customers because of its options like devoted challenge web site and an built-in challenge wiki. Additionally GitLab facilitates its customers by offering automated testing and code supply so {that a} person can do extra work in lesser time with out ready for the exams to cross manually. A few of the else options to be famous are pull requests, code viewer and merge battle decision.
Developed by Fog Creek, not like Github Kiln is just not a free supply to host your software program or web site. You may have an summary or expertise of their model management and code internet hosting for Git and Mercurial for 30 days trial interval, after that customers must improve to the premium model (minimal $18 a month) inorder to proceed working with Kiln. Kiln additionally fees its customers for the code overview module individually.
Should you host your web site with Kiln, your area will look one thing like this:
It’s believed by observing abundance of tasks being hosted on the SourceForge that it has existed for an extended time. When in comparison with the Github, SourceForge (developed by Slashdot Media) has a completely totally different construction of the challenge. In contrast to different web sites for model management, SourceForge permits you to host each static and dynamic pages as nicely. One of many vulnerability of this medium for model management is {that a} person is allowed to create tasks and get it hosted on the location with distinctive names solely.
Typical area to your hosted challenge will seem like proj.sourceforge.internet
Scripting languages like Python, Perl, PHP, Tcl, Ruby and Shell are being supported by the SourceForge servers. Customers are free to selecting both Git, Subversion or Mercurial for the model management system.
This Google’s Git model management got here into existence and moved to the Google Cloud platform when Google code was put out of the market by google itself. Though google gives its personal repositories to work upon, however you may even join the Cloud Supply to different model management mediums like Github, Bitbucket, and so forth. Cloud Supply gives storage for its customers codes and apps throughout the google infrastructure itself which makes it much more dependable. Customers have the freeship to go looking their code within the browser itself and likewise will get characteristic of cloud diagnostics to trace the issues whereas code retains working within the background.
Cloud Supply gives Stackdriver Debugger that helps use the debugger in parallel with the opposite purposes working.
GitKraken turned in style among the many builders day-to-day as a result of unique options it gives to it customers are simply cute. The first level of attraction in the direction of Gitkraken is its stunning interface and likewise it give attention to pace and ease of use for Git. GitKraken comes with an extremely helpful ‘undo’ button which helps its customers to shortly omit the redundancies occurred by mistake. GitKraken gives a free model which might have upto 20 customers and a premium model as nicely with a number of different good options.
We hope you guys loved studying with us. If any doubts, queries or solutions please lets us know within the remark part under. Do share in feedback if you recognize some other good github alternate options.
multiplication is undoubtedly the commonest operation carried out by GPUs. It’s the elementary constructing block of linear algebra and reveals up throughout a large spectrum of various fields resembling graphics, physics simulations and scientific computing whereas being ubiquitous in machine studying.
In immediately’s article, we’ll break down the conceptual implementation of normal matrix-matrix multiplication (GEMM) whereas introducing a number of optimisation ideas resembling tiling and reminiscence coalescing. Lastly, we’ll implement GEMM in Triton!
This text is the second of a collection on Triton and GPU kernels, In case you are not accustomed to Triton or want a refresher on GPU fundamentals, take a look at the earlier article!All of the code showcased on this article is out there on GitHub.
Disclaimer: all the next figures and animations have been made by the creator until said in any other case.
Naive GEMM
Let’s begin easy: we need to multiply two matrices X and Y with shapes (M,N) and (N,Okay) respectively. The output matrix Z=X@Y will subsequently have form (M,Okay).
This operation includes computing the dot merchandise of all pairs of rows and columns in X and Y respectively. A simple NumPy implementation would possibly look one thing like this:
Whereas straightforward to write down, learn and perceive, this implementation is extremely inefficient by way of reminiscence entry and caching. As talked about within the first article of this collection, a elementary side of GPU optimisation is minimising information transfers.
Nonetheless, our present implementation begins by loading a row from X, iteratively masses all Okay columns of Y, computes their dot product and repeats the method for each row in X. This ends in a complete of M(Okay+1) loading operations.
Naive Matrix Multiplication, purple and blue tiles characterize the vectors concerned in dot merchandise at each time step and inexperienced cells the computed output values.
As seen within the animation, the reminiscence entry sample is wasteful, as each column of Y is loaded M occasions. As an analogy: that is like operating to the grocery retailer (international reminiscence) each time you want a brand new ingredient for a dish as a substitute of getting ready all of the substances in your kitchen counter (shared reminiscence). Ideally, we wish to minimise the variety of occasions every chunk of information is loaded and maximise its reusability as soon as loaded. This leaves us with two essential axes of optimisation:
How can we enhance the entry sample to minimise redundant masses?
How a lot information can we load directly, and the place ought to or not it’s saved on the GPU?
Tiled GEMM
As talked about beforehand, the naive strategy to GEMM ends in many redundant masses, which induces pointless overhead. Ideally, we’d prefer to load every section of information solely as soon as and carry out all of the operations during which they’re used earlier than dropping them from reminiscence.
A sublime strategy to this downside is tiling, which includes dividing giant matrices in smaller “tiles” or sub-matrices. Take into account two matrices X and Y with shapes (4,6) and (6,4) respectively, X@Y ends in a matrix Z with form (4,4).
With the intention to compute the primary ingredient of Z, Z[0,0], we have to compute the dot product between the primary row of X and the primary column of Y: Z[0,0] = dot(X[0, :], Y[:, 0]). We are able to additionally break down the dot product into smaller chunks, as an example in teams of three parts: Z[0,0] = dot(X[0,0:3], Y[0:3, 0]) + dot(X[0,3:6], Y[3:6, 0]).
Alternatively, we will increase this strategy to 2 dimensions and compute a whole (2,2) block of Z at a time: Z[0:2, 0:2] = dot(X[0:2, 0:2], Y[0:2, 0:2]) + dot(X[0:2, 2:4], Y[2:4, 0:2]) + dot(X[0:2, 4:6], Y[4:6, 0:2]).
Right here’s a visible illustration of tiled matrix multiplication:
Tiled Matrix Multiplication. The computation is break up in a number of “tiles” of X and Y (highlighted in pale blue and purple), every containing a number of blocks (darkish blue and purple). In every block, we compute dot merchandise (inexperienced cells in X and Y). These dot merchandise are amassed throughout the blocks of a tile to compute the output values in Z (the buildup is represented by colours from orange to inexperienced).
The above animation illustrates how information is reused in tiled GEMM. For every 2×2 block in X and Y, we compute 4 dot merchandise, which leads to a (2,2) output matrix in Z. Since every tile comprises 3 blocks, we have to accumulate 3 of those matrices to compute the ultimate (2,2) output in Z. This accumulation is represented by coloured cells in Z.
Within the kitchen analogy, that is like fetching substances from the shop and getting ready them on the kitchen counter (i.e. small shared reminiscence), reusing them a number of occasions earlier than going again to the shop.
Importantly, reusing loaded information over a number of steps permits this strategy to drastically scale back the variety of load operations. For (2,2) blocks, every X row and Y column is utilized in two dot merchandise. Subsequently, we’re performing twice as many operations with every block of loaded information, roughly halving the variety of load operations! Be aware that this generalises to bigger blocks as nicely, utilizing a (32,32) block would scale back the variety of masses by an element of round 32.
Now you’re most likely questioning “how giant can these blocks be”? To reply this query, let’s recall how reminiscence is managed in trendy GPUs.
GPU Reminiscence Hierarchy
We distinguish 4 essential varieties of reminiscence in Nvidia GPUs. Right here, we take the instance of an A100:
Registers: The quickest and smallest sort of reminiscence on the GPU, residing straight inside every Streaming Multiprocessor (SM). On the A100, every SM supplies 256 KB of register file area (65,536 × 32-bit registers), distributed amongst its threads. Every thread will get its personal non-public 32-bit registers for storing non permanent variables and intermediate outcomes, avoiding reminiscence site visitors altogether. Nonetheless, register utilization per thread straight impacts occupancy, as utilizing too many registers per thread limits what number of threads can run concurrently.
L1/Shared Reminiscence: On an A100, every SM has 192KB of SRAM that may be flexibly configured as both a hardware-managed L1 cache or a programmer-managed shared reminiscence. For performance-critical kernels like matrix multiplication, we explicitly use this area as shared reminiscence to stage information tiles near the compute models, bypassing the L1 cache fully. This offers us fine-grained management over information reuse.
L2 cache: This cache is slower than L1 however a lot bigger, with round 40 MB shared throughout all SMs on the A100. It serves as a world cache for each information and directions, decreasing the variety of accesses to high-latency HBM reminiscence. The L2 cache is coherent throughout SMs, which means that updates from one SM are seen to others, enabling synchronisation between thread blocks. Its bandwidth can attain a number of terabytes per second, performing as a buffer between the quick on-chip SRAM and the slower HBM.
Excessive Bandwidth Reminiscence (HBM): That is the system reminiscence, it has a capability of both 40GB or 80GB relying on the A100 mannequin. It supplies extraordinarily excessive bandwidth (as much as 2 TB/s on the 80 GB variant) however with a lotincreased latency than on-chip caches. HBM is the place giant tensors, mannequin weights, and datasets reside throughout execution. Since accessing HBM is dear, environment friendly kernels purpose to minimise information motion and maximise on-chip information reuse through registers and shared reminiscence.
As you possibly can see, the reminiscence hierarchy typically trades off capability with latency. Subsequently, maximising efficiency boils all the way down to loading information from HBM into shared reminiscence effectively and reusing it as a lot as doable.
GPU Reminiscence Hierarchy, from quickest/smallest (high) to slowest/largest (backside).
Selecting our block dimension is essential. We wish blocks to be giant sufficient to create a whole lot of parallel work, however sufficiently small that their information suits within the SM’s shared reminiscence and registers. A BLOCK_SIZE of 64 is a standard place to begin as a result of it’s a a number of of the warp dimension (32 threads), making certain full {hardware} utilisation.
Parallel Tiled GEMM
With these concerns in thoughts, a pure follow-up to our tiled GEMM is to parallelise the computation of every pairs of tiles over a number of thread blocks, as depicted on the next animation.
Parallel Tiled Matrix Multiplication. The iteration over tiles is changed by a parallel operation over a number of thread blocks.
Reminiscence Coalescing
Earlier than writing tiled GEMM in Triton, we have to think about one final element: reminiscence coalescing, a way that enables optimum use of worldwide reminiscence bandwidth. Reminiscence coalescing is achieved when subsequent threads in a warp entry subsequent reminiscence addresses. Think about a librarian needing to fetch books for a consumer, if all books are side-by-side on a shelf, they will seize them unexpectedly. In distinction, if all books are mendacity on totally different cabinets, they’ll need to seize them one after the other, which takes considerably longer.
To grasp how this is applicable to our case, be aware that matrices are saved linearly in reminiscence, in different phrases a (2,2) matrix is saved as a sequence of 4 consecutive parts. Frameworks like PyTorch undertake a row-major format, which means that parts of a matrix are per-row contiguous in reminiscence. As an illustration, parts of our (2,2) matrix can be saved as follows: [(0,0), (0,1), (1,0), (1,1)], discover that parts of the identical row are contiguous (touching) whereas parts of the identical column have a stride of 1 (separated by one ingredient).
PyTorch shops matrices in row-major format. Components of a row contiguous in reminiscence whereas parts of a column are strided.
This means that we will load rows utilizing coalesced masses, however columns do not fulfill this situation. Nonetheless, we have to entry columns of Y to compute dot merchandise. With the intention to maximise efficiency, a great apply is to transpose Y in order that we iterate on its rows moderately than its columns.
Nonetheless, transposing Y isn’t sufficient to change its format in reminiscence. As talked about beforehand, PyTorch shops matrices in a flat array. Every matrix dimension is related to a stride attribute, denoting the bounce essential to go from one ingredient to the following one alongside this dimension. As an illustration, a (10,10) matrix would have strides=(10,1). Certainly, ranging from ingredient [0,0], ingredient [1,0] is 10 reminiscence slots (i.e. one row) away, whereas ingredient [0,1] is adjoining.
When transposing a tensor, PyTorch doesn’t modify the format in reminiscence however merely recomputes the strides. With the intention to make the transpose efficient from a reminiscence standpoint we have to name Y.T.contiguous().
These are the required steps the load columns of Y effectively, nevertheless we’ll must transpose the loaded blocks throughout the kernel to carry out the dot product correctly: z_block = tl.dot(X_block, Y_block.T).
Illustration of Y, Y.T and Y.T.contiguous() of their block illustration and reminiscence format. The transpose operation modifications the behaviour of the matrix however doesn’t modify its reminiscence format. This is the reason we have to add .contiguous() to allow coalesced reads on rows.
Triton Implementation
From right here on, we first describe the kernel with out reminiscence coalescing to simplify the logic and pointer arithmetic earlier than summarising the modifications required to make the load operations coalesced on Y columns.
Let’s begin by specializing in the PyTorch wrapper across the kernel. We have to learn M, N, Okay from the enter matrices and compute their strides since these constants shall be helpful later within the kernel. Then, we outline the BLOCK_SIZE and declare the grid.
Now let’s dive into the precise kernel code. We’re going to utilize Triton’s make_block_ptr utility, which simplifies the pointer arithmetic. We create one block pointer per matrix and cross the matrix form, its strides, and the dimensions of the block as inputs. Moreover, we specify the offset, the coordinate of the top-left ingredient within the present block. For X, this corresponds to (m_idx * BLOCK_SIZE, 0) the place m_idx is the index of the present block alongside the M dimension.
From there, we outline z_acc, a zero matrix that may obtain the partial dot-products as we iterate by means of tiles. We now iterate by means of the shared dimension N, loading blocks of dimension (BLOCK_SIZE, BLOCK_SIZE), and accumulate their dot merchandise in z_acc. We then transfer the block pointers alongside the shared dimension through the use of .advance.
You might need seen that when loading information, we use boundary_check and padding_option as a substitute of masks and different as within the earlier article. These arguments are particular to using block pointers and specify which axes to examine for out-of-bound operations (right here (0,1) for x and y) and easy methods to deal with these invalid values. Right here we set them to zero to be ignored within the dot product.
We are able to now check out the efficiency of this kernel through the use of the next operate:
def bench(fn: callable, x: torch.Tensor, y: torch.Tensor, repeat: int):
flops = []
med_latency = []
for _ in tqdm(vary(repeat), desc=f"Benchmarking {fn.__name__}"):
latency_ms = triton.testing.do_bench(
lambda: fn(x, y),
quantiles=[0.5], # get the median latency
return_mode="all",
)
n_flops = 2 * M * N * Okay # matmul roughly requires 2*M*N*Okay operations
tflops = n_flops / (latency_ms / 1e3) / 1e12
med_latency.append(latency_ms)
flops.append(tflops)
flops = np.array(flops)
med_latency = np.array(med_latency)
print(f"Absolute Error: {torch.sum(torch.abs(X@Y - fn(x, y)))}")
print(f"Median Latency: {med_latency.imply():.4f} ± {med_latency.std():.3f} ms")
print(f"Throughput: {flops.imply():.4f} ± {flops.std():.3f} TeraFLOPS")
M = 8192
N = 6144
Okay = 4096
X = torch.randn((M, N), system="cuda", dtype=torch.float32)
Y = torch.randn((N, Okay), system="cuda", dtype=torch.float32)
bench(block_matmul, X, Y, repeat=10)
We get the next outputs (utilizing a T4 GPU on Colab):
Absolute Error: 0.0 # the kernel outputs the right consequence!
Median Latency: 130.7831 ± 1.794 ms
Throughput: 3.1533 ± 0.043 TeraFLOPS
Now let’s evaluation the modifications required for coalesced masses on Y: we primarily must flip the form, strides and offsets when defining the block pointer for Y. Moreover, we replace the block pointer to maneuver alongside the column dimension (beforehand row dimension). The total code for this implementation is out there on GitHub.
@triton.jit
def coalesced_block_matmul_kernel(
X_ptr, X_m_stride, X_n_stride,
Y_ptr, Y_k_stride, Y_n_stride,
Z_ptr, Z_m_stride, Z_k_stride,
M, N, Okay,
BLOCK_SIZE: tl.constexpr,
):
...
y_block_ptr = tl.make_block_ptr(
base=Y_ptr,
# flip the form, strides and offsets to match Y.T
form=(Okay, N),
strides=(Y_k_stride, Y_n_stride),
offsets=(k_idx * BLOCK_SIZE, 0),
block_shape=(BLOCK_SIZE, BLOCK_SIZE),
order=(0, 1),
)
...
for _ in vary(0, N, BLOCK_SIZE):
... # masses
z_acc += tl.dot(x, y.T) # transpose Y again for dot product
x_block_ptr = tl.advance(x_block_ptr, offsets=(0, BLOCK_SIZE))
# advance the block pointer alongside columns of Y.T (i.e rows of Y)
y_block_ptr = tl.advance(y_block_ptr, offsets=(0, BLOCK_SIZE))
tl.retailer(pointer=z_block_ptr, worth=z_acc, boundary_check=(0, 1))
def coalesced_block_matmul(X, Y):
Y = Y.T.contiguous() # Y is now (Okay,N)
M, N = X.form
Okay, _ = Y.form
Z = torch.empty((M, Okay), system="cuda")
x_stride_m, x_stride_n = X.stride()
y_stride_k, y_stride_n = Y.stride()
z_stride_m, z_stride_k = Z.stride()
... # outline BLOCK_SIZE and grid
coalesced_block_matmul_kernel[grid](
X, x_stride_m, x_stride_n,
Y, y_stride_n, y_stride_k,
Z, z_stride_m, z_stride_k,
M, N, Okay,
BLOCK_SIZE,
)
return Z
Listed here are the outcomes of our benchmark for the kernel with coalesced masses for Y:
Absolute Error: 0.0 # Once more, the kernel is appropriate!
Median Latency: 261.9420 ± 0.858 ms
Throughput: 1.5741 ± 0.005 TeraFLOPS
Surprisingly, the throughput of this second kernel is simply half of what we obtained with the primary one, regardless of bettering the effectivity of load operations 🤔
A fast inspection utilizing nsight (Nvidia’s kernel profiler, extra on that in a future article) reveals that the transpose operation throughout the kernel creates a “site visitors jam”. Particularly, the transpose creates financial institution conflicts, inflicting threads to stay idle more often than not. Notably, the warp scheduler has no eligible warp to dispatch 87.6% of the time as they’re ready for the financial institution battle to resolve. Moreover, the report reads:
———————– ———– ————– Metric Title Metric Unit Metric Worth ———————– ———– ————– … DRAM Throughput % 8.20 Compute (SM) Throughput % 21.14 …
This means that the kernel is latency certain (i.e. neither reminiscence nor compute certain, discuss with the earlier article for extra particulars). In distinction, the primary kernel is compute certain (i.e. rising compute will enhance efficiency) for the reason that compute throughput is excessive in comparison with the DRAM throughput.
———————– ———– ————– Metric Title Metric Unit Metric Worth ———————– ———– ————– … DRAM Throughput % 29.35 Compute (SM) Throughput % 74.39 …
Conclusion
This experiment highlights the significance of profiling and empirical validation. Even well-intentioned optimisations like coalescing reminiscence accesses can introduce new bottlenecks if not evaluated fastidiously. The primary kernel, although less complicated, was compute-bound and higher matched the {hardware} traits.
Within the subsequent articles of this collection, we’ll implement a softmax kernel, paying specific consideration to integrating Triton with PyTorch’s autograd and profiling kernels utilizing Nsight.
Foundry Native is an on-device AI inference resolution providing efficiency, privateness, customization, and value benefits. It integrates seamlessly into your current workflows and functions by way of an intuitive CLI, SDK, and REST API. Foundry Native has the next advantages:
On-Gadget Inference: Run fashions domestically by yourself {hardware}, lowering your prices whereas preserving all of your knowledge in your machine.
Mannequin Customization: Choose from preset fashions or use your individual to fulfill particular necessities and use instances.
Price Effectivity: Remove recurring cloud service prices by utilizing your current {hardware}, making AI extra accessible.
Seamless Integration: Join along with your functions by way of an SDK, API endpoints, or the CLI, with simple scaling to Azure AI Foundry as your wants develop.
Foundry Native is right for situations the place:
You wish to maintain delicate knowledge in your machine.
It is advisable function in environments with restricted or no web connectivity.
You wish to scale back cloud inference prices.
You want low-latency AI responses for real-time functions.
You wish to experiment with AI fashions earlier than deploying to a cloud surroundings.
You’ll be able to set up Foundry Native by operating the next command:
winget set up Microsoft.FoundryLocal
As soon as Foundry Native is put in, you obtain and work together with a mannequin from the command line by utilizing a command like:
foundry mannequin run phi-4
It will obtain the phi-4 mannequin and supply a textual content based mostly chat interface. If you wish to work together with Foundry Native by way of an online chat interface, you need to use the open supply Open WebUI mission. You’ll be able to set up Open WebUI on Home windows Server by performing the next steps:
conda.exe tos settle for --override-channels --channel https://repo.anaconda.com/pkgs/foremost conda.exe tos settle for --override-channels --channel https://repo.anaconda.com/pkgs/r conda.exe tos settle for --override-channels --channel https://repo.anaconda.com/pkgs/msys2
C:TempOpenWebUIInstaller.exe
Then from the dialog select to put in and run Open WebUI. You then must take a number of further steps to configure Open WebUI to connect with the Foundry Native endpoint.
Allow Direct Connections in Open WebUI
Choose Settings and Admin Settings within the profile menu.
Choose Connections within the navigation menu.
Allow Direct Connections by turning on the toggle. This permits customers to connect with their very own OpenAI suitable API endpoints.
Join Open WebUI to Foundry Native:
Choose Settings within the profile menu.
Choose Connections within the navigation menu.
Choose + by Handle Direct Connections.
For the URL, enter http://localhost:PORT/v1 the place PORT is the Foundry Native endpoint port (use the CLI command foundry service standing to search out it). Observe that Foundry Native dynamically assigns a port, so it is not all the time the identical.