Authors: Augusto Cerqua, Marco Letta, Gabriele Pinto
studying (ML) has gained a central position in economics, the social sciences, and enterprise decision-making. Within the public sector, ML is more and more used for so-called prediction coverage issues: settings the place policymakers purpose to establish items most susceptible to a adverse consequence and intervene proactively; for example, focusing on public subsidies, predicting native recessions, or anticipating migration patterns. Within the non-public sector, related predictive duties come up when companies search to forecast buyer churn, or optimize credit score danger evaluation. In each domains, higher predictions translate into extra environment friendly allocation of sources and simpler interventions.
To realize these targets, ML algorithms are more and more utilized to panel information, characterised by repeated observations of the identical items over a number of time durations. Nonetheless, ML fashions weren’t initially designed to be used with panel information, which function distinctive cross-sectional and longitudinal dimensions. When ML is utilized to panel information, there’s a excessive danger of a delicate however major problem: information leakage. This happens when info unavailable at prediction time by accident enters the mannequin coaching course of, inflating predictive efficiency. In our paper “On the Mis(Use) of Machine Studying With Panel Knowledge” (Cerqua, Letta, and Pinto, 2025), just lately revealed within the Oxford Bulletin of Economics and Statistics, we offer the primary systematic evaluation of knowledge leakage in ML with panel information, suggest clear pointers for practitioners, and illustrate the implications by way of an empirical utility with publicly accessible U.S. county information.
The Leakage Drawback
Panel information mix two constructions: a temporal dimension (items noticed throughout time) and a cross-sectional dimension (a number of items, equivalent to areas or companies). Customary ML observe, splitting the pattern randomly into coaching and testing units, implicitly assumes unbiased and identically distributed (i.i.d.) information. This assumption is violated when default ML procedures (equivalent to a random break up) are utilized to panel information, creating two primary sorts of leakage:
Temporal leakage: future info leaks into the mannequin through the coaching section, making forecasts look unrealistically correct. Moreover, previous info can find yourself within the testing set, making ‘forecasts’ retrospective.
Cross-sectional leakage: the identical or very related items seem in each coaching and testing units, that means the mannequin has already “seen” a lot of the cross-sectional dimension of the information.
Determine 1 reveals how totally different splitting methods have an effect on the chance of leakage. A random break up on the unit–time degree (Panel A) is probably the most problematic, because it introduces each temporal and cross-sectional leakage. Alternate options equivalent to splitting by items (Panel B), by teams (Panel C), or by time (Panel D), mitigate one kind of leakage however not the opposite. Because of this, no technique utterly eliminates the issue: the suitable selection depends upon the duty at hand (see beneath), since in some circumstances one type of leakage might not be an actual concern.
Determine 1 | Coaching and testing units underneath totally different splitting guidelines
Notes: On this instance, the panel information are structured with years because the time variable, counties because the unit variable, and states because the group variable. Picture made by the authors.
Two Varieties of Prediction Coverage Issues
A key perception of the examine is that researchers should clearly outline their prediction objective ex-ante. We distinguish two broad courses of prediction coverage issues:
1. Cross-sectional prediction: The duty is to map outcomes throughout items in the identical interval. For instance, imputing lacking information on GDP per capita throughout areas when just some areas have dependable measurements. The very best break up right here is on the unit degree: totally different items are assigned to coaching and testing units, whereas all time durations are saved. This eliminates cross-sectional leakage, though temporal leakage stays. However since forecasting just isn’t the objective, this isn’t an actual challenge.
2. Sequential forecasting: The objective is to foretell future outcomes primarily based on historic information—for instance, predicting county-level earnings declines one yr forward to set off early interventions. Right here, the right break up is by time: earlier durations for coaching, later durations for testing. This avoids temporal leakage however not cross-sectional leakage, which isn’t an actual concern because the similar items are being forecasted throughout time.
The improper strategy in each circumstances is the random break up by unit-time (Panel A of Determine 1), which contaminates outcomes with each sorts of leakage and produces misleadingly excessive efficiency metrics.
Sensible Tips
To assist practitioners, we summarize a set of do’s and don’ts for making use of ML to panel information:
Select the pattern break up primarily based on the analysis query: unit-based for cross-sectional issues, time-based for forecasting.
Temporal leakage can happen not solely by way of observations, but in addition by way of predictors. For forecasting, solely use lagged or time-invariant predictors. Utilizing contemporaneous variables (e.g., utilizing unemployment in 2014 to foretell earnings in 2014) is conceptually improper and creates temporal information leakage.
Adapt cross-validation to panel information. Random k-fold CV present in most ready-to-use software program packages is inappropriate, because it mixes future and previous info. As an alternative, use rolling or increasing home windows for forecasting, or stratified CV by items/teams for cross-sectional prediction.
Be certain that out-of-sample efficiency is examined on actually unseen information, not on information already encountered throughout coaching.
Empirical Software
As an instance these points, we analyze a balanced panel of three,058 U.S. counties from 2000 to 2019, focusing solely on sequential forecasting. We contemplate two duties: a regression drawback—forecasting per capita earnings—and a classification drawback—forecasting whether or not earnings will decline within the subsequent yr.
We run a whole bunch of fashions, various break up methods, use of contemporaneous predictors, inclusion of lagged outcomes, and algorithms (Random Forest, XGBoost, Logit, and OLS). This complete design permits us to quantify how leakage inflates efficiency. Determine 2 beneath stories our primary findings.
Panel A of Determine 2 reveals forecasting efficiency for classification duties. Random splits yield very excessive accuracy, however that is illusory: the mannequin has already seen related information throughout coaching.
Panel B reveals forecasting efficiency for regression duties. As soon as once more, random splits make fashions look much better than they are surely, whereas appropriate time-based splits present a lot decrease, but sensible, accuracy.
Determine 2 | Temporal leakage within the forecasting drawback
Panel A – Classification activity
Panel B – Regression activity
Within the paper, we additionally present that the overestimation of mannequin accuracy turns into considerably extra pronounced throughout years marked by distribution shifts and structural breaks, such because the Nice Recession, making the outcomes notably deceptive for coverage functions.
Why It Issues
Knowledge leakage is greater than a technical pitfall; it has real-world penalties. In coverage functions, a mannequin that appears extremely correct throughout validation could collapse as soon as deployed, resulting in misallocated sources, missed crises, or misguided focusing on. In enterprise settings, the identical challenge can translate into poor funding selections, inefficient buyer focusing on, or false confidence in danger assessments. The hazard is very acute when machine studying fashions are supposed to function early-warning programs, the place misplaced belief in inflated efficiency may end up in pricey failures.
In contrast, correctly designed fashions, even when much less correct on paper, present trustworthy and dependable predictions that may meaningfully inform decision-making.
Takeaway
ML has the potential to rework decision-making in each coverage and enterprise, however provided that utilized accurately. Panel information supply wealthy alternatives, but are particularly susceptible to information leakage. To generate dependable insights, practitioners ought to align their ML workflow with the prediction goal, account for each temporal and cross-sectional constructions, and use validation methods that forestall overoptimistic assessments and an phantasm of excessive accuracy. When these ideas are adopted, fashions keep away from the lure of inflated efficiency and as an alternative present steering that genuinely helps policymakers allocate sources and companies make sound strategic decisions. Given the speedy adoption of ML with panel information in each private and non-private domains, addressing these pitfalls is now a urgent precedence for utilized analysis.
References
A. Cerqua, M. Letta, and G. Pinto, “On the (Mis)Use of Machine Studying With Panel Knowledge”, Oxford Bulletin of Economics and Statistics (2025): 1–13, https://doi.org/10.1111/obes.70019.
This week, AWS introduced to its workers that there can be a brand new vp on the town: Chet Kapoor was becoming a member of the tech large’s cloud arm to supervise safety providers and observability in direct response to AWS’s concern that “AI is totally altering what is feasible and what’s wanted on this space.”
On the face of it, the appointment appears routine, particularly contemplating the dimensions of AWS’s operations and its reported base of roughly 143,000 workers. However, notably, the brand new function comes with an elevated diploma of seniority, reporting on to the CEO and dealing alongside CISO Amy Herzog, versus underneath her. Whereas many enterprises have been exploring a extra horizontal hierarchical construction in what’s been termed The Nice Flattening, this new job has prompted a brand new query: What does it appear like to be chargeable for AI safety? And who inside the group is finally accountable?
“AI expands the assault floor and the CISO/CIO mandate,” stated Diana Kelley, CISO at Noma Safety. “Proper now, the scope of AI safety is so specialised that anticipating CISOs to soak up it totally underneath current constructions is an enormous leap.”
Fixing a Downside vs. Getting Forward of Threats
The overall response from IT leaders to the AWS rent is optimistic, with a number of CISOs describing it as an indication that the corporate is taking AI threats critically and is dedicated to constructing operations that work inside established guardrails. Somewhat than being a transfer to repair a selected flaw in safety, executives stated it’s a part of an ongoing funding in wholesome cybersecurity apply — one which should now grapple with a completely new menace within the type of AI-supported assaults.
Dan Lohrmann, area CISO for public sector at Presidio, famous that AWS has taken “many optimistic steps” to safe its programs, knowledge, and networks, including that the explosion of AI use calls for new vigilance.
“As we transfer ahead into 2026, the breadth and depth of AI alternatives, merchandise, and threats globally current a paradigm shift in cyber protection,” Lohrmann stated. He added that he was inspired by AWS’s recognition of the necessity for extra focus and a spotlight (and staffing) on these cyberthreats.
Edward Liebig, CEO of Yoink Industries and founding father of OT SOC Choices, agreed. He described the transfer as not simply “good and overdue,” but additionally an inevitable evolution in cybersecurity administration now that AI has entered the sphere.
“AWS is not simply filling a place; they’re formalizing a brand new layer of accountability,” Liebig stated. “It is the clearest signal but that AI safety is not an experimental self-discipline however a core operational requirement.”
Certainly, the AWS rent displays a broader ripple out there: Enterprises throughout industries are acknowledging that AI — and notably agentic AI — is not solely getting used for optimistic ends. It is usually being wielded maliciously and relentlessly by menace actors.
“Agentic AI attackers can now function with a ‘reflection loop’ so they’re successfully self-learning from failed assaults and modifying their assault strategy mechanically,” stated Simon Ratcliffe, fractional CIO at Freeman Clarke. “This implies the assaults are quicker and there are extra of them … placing overwhelming stress on CISOs to reply.”
Lohrmann stated he believes present cybersecurity fashions merely aren’t satisfactory to satisfy this new species of menace, particularly now that they’re coming at unprecedented velocity. He beneficial a complete system replace, one that may proceed to pose challenges over the following few years. Kelley, however, stated she believes that whereas conventional measures stay “foundational,” in addition they should be supplemented with AI-specific approaches.
“Zero belief, least privilege, and protection in depth — they have been constructed for deterministic programs. AI breaks that paradigm,” she stated. Fashions make probabilistic selections; they be taught from knowledge which may be opaque, and their “assault floor” is not restricted to code or APIs, she defined.
“What we want now’s AI-aware safety governance: a fusion of conventional controls with discovery, stock, and steady monitoring of AI belongings,” Kelley stated.
It could solely be a number of years down the street earlier than IT leaders uncover the best strategy to fight AI assaults. What is evident is that whichever technique a corporation pursues, there’s a number of work to be performed. So who takes that duty on?
The Accountability Query
Previous to AI coming into the sphere at scale, CIOs and CISOs have been the established homeowners of enterprise know-how and safety. Executives in these roles are sometimes the primary to acknowledge that cybersecurity now requires totally new approaches — and doubtlessly new talent units.
Earlier than the AWS announcement, there have been already some high-profile new roles being created round AI administration, comparable to chief AI officer. However this particular vp function at AWS — and its place inside the broader construction — displays a shifting perspective on who needs to be proudly owning the AI ingredient of cybersecurity. Can — and will — the CIO or CISO be anticipated to take this on themselves?
Kelley stated she is assured the CISO has the essential function to play, so long as it’s reshaped with key understandings in thoughts.
“I feel the CISO’s function will evolve to satisfy the broader governance ecosystem, bringing collectively AI safety specialists, knowledge scientists, compliance officers, and ethics leads,” she stated, including cybersecurity’s mantra that AI safety is everybody’s enterprise.
“But it surely calls for devoted experience,” she stated. “Going ahead, I hope that organizations deal with AI governance and assurance as integral components of cybersecurity, not siloed add-ons.”
Lohrmann stated he sees a future that shares cybersecurity duty throughout each CISO and AI-specific roles. Some enterprises could divide the duties amongst a number of leaders, splitting the safety of services from the safety of their networks and workers.
In Liebig’s opinion, the way forward for cybersecurity management appears to be like much less hierarchical than it does now.
“As for who owns that threat, I consider the CISO stays accountable, however new roles are rising to operationalize AI integrity — mannequin threat officers, AI safety architects, and governance engineers,” he defined. “The CISO’s function ought to broaden horizontally, guaranteeing AI aligns to enterprise belief frameworks, not stand other than them.”
It is Ratcliffe who stays essentially the most satisfied of the CISO’s function and duty, inside the context of the AI menace. To him, creating new roles is the flawed observe to take altogether, he defined. As an alternative, it is about preventing AI with AI.
“Including an individual towards the machines which can be attacking isn’t actually going to make a lot distinction,” he stated. “It means the CISOs must undertake AI themselves to struggle again. The one factor that may cease AI is AI on the opposite facet.”
OpenAI hasn’t launched an open-weight language mannequin since GPT-2 again in 2019. Six years later, they shocked everybody with two: gpt-oss-120b and the smaller gpt-oss-20b.
Naturally, we wished to know — how do they really carry out?
To seek out out, we ran each fashions via our open-source workflow optimization framework, syftr. It evaluates fashions throughout totally different configurations — quick vs. low-cost, excessive vs. low accuracy — and consists of help for OpenAI’s new “considering effort” setting.
In concept, extra considering ought to imply higher solutions. In follow? Not all the time.
Our first outcomes with GPT-OSS may shock you: the most effective performer wasn’t the largest mannequin or the deepest thinker.
As an alternative, the 20b mannequin with low considering effort persistently landed on the Pareto frontier, even rivaling the 120b medium configuration on benchmarks like FinanceBench, HotpotQA, and MultihopRAG. In the meantime, excessive considering effort not often mattered in any respect.
How we arrange our experiments
We didn’t simply pit GPT-OSS in opposition to itself. As an alternative, we wished to see the way it stacked up in opposition to different sturdy open-weight fashions. So we in contrast gpt-oss-20b and gpt-oss-120b with:
qwen3-235b-a22b
glm-4.5-air
nemotron-super-49b
qwen3-30b-a3b
gemma3-27b-it
phi-4-multimodal-instruct
To check OpenAI’s new “considering effort” function, we ran every GPT-OSS mannequin in three modes: low, medium, and excessive considering effort. That gave us six configurations in complete:
gpt-oss-120b-low / -medium / -high
gpt-oss-20b-low / -medium / -high
For analysis, we solid a large web: 5 RAG and agent modes, 16 embedding fashions, and a variety of circulate configuration choices. To evaluate mannequin responses, we used GPT-4o-mini and in contrast solutions in opposition to recognized floor fact.
Lastly, we examined throughout 4 datasets:
FinanceBench (monetary reasoning)
HotpotQA (multi-hop QA)
MultihopRAG (retrieval-augmented reasoning)
PhantomWiki (artificial Q&A pairs)
We optimized workflows twice: as soon as for accuracy + latency, and as soon as for accuracy + price—capturing the tradeoffs that matter most in real-world deployments.
Optimizing for latency, price, and accuracy
After we optimized the GPT-OSS fashions, we checked out two tradeoffs: accuracy vs. latency and accuracy vs. price. The outcomes have been extra shocking than we anticipated:
GPT-OSS 20b (low considering effort): Quick, cheap, and persistently correct. This setup appeared on the Pareto frontier repeatedly, making it the most effective default alternative for many non-scientific duties. In follow, meaning faster responses and decrease payments in comparison with larger considering efforts.
GPT-OSS 120b (medium considering effort): Greatest suited to duties that demand deeper reasoning, like monetary benchmarks. Use this when accuracy on complicated issues issues greater than price.
GPT-OSS 120b (excessive considering effort): Costly and normally pointless. Maintain it in your again pocket for edge circumstances the place different fashions fall brief. For our benchmarks, it didn’t add worth.
Determine 1: Accuracy-latency optimization with syftrDetermine 2: Accuracy-cost optimization with syftr
Studying the outcomes extra fastidiously
At first look, the outcomes look easy. However there’s an essential nuance: an LLM’s high accuracy rating relies upon not simply on the mannequin itself, however on how the optimizer weighs it in opposition to different fashions within the combine. As an example, let’s have a look at FinanceBench.
When optimizing for latency, all GPT-OSS fashions (besides excessive considering effort) landed with comparable Pareto-frontiers. On this case, the optimizer had little cause to focus on the 20b low considering configuration—its high accuracy was solely 51%.
Determine 3: Per-LLM Pareto-frontiers for latency optimization on FinanceBench
When optimizing for price, the image shifts dramatically. The identical 20b low considering configuration jumps to 57% accuracy, whereas the 120b medium configuration really drops 22%. Why? As a result of the 20b mannequin is way cheaper, so the optimizer shifts extra weight towards it.
Determine 4: Per-LLM Pareto-frontiers for price optimization on FinanceBench
The takeaway: Efficiency will depend on context. Optimizers will favor totally different fashions relying on whether or not you’re prioritizing velocity, price, or accuracy. And given the large search area of attainable configurations, there could also be even higher setups past those we examined.
Discovering agentic workflows that work properly in your setup
The brand new GPT-OSS fashions carried out strongly in our checks — particularly the 20b with low considering effort, which frequently outpaced dearer rivals. The larger lesson? Extra mannequin and extra effort doesn’t all the time imply extra accuracy. Generally, paying extra simply will get you much less.
That is precisely why we constructed syftr and made it open-source. Each use case is totally different, and the most effective workflow for you will depend on the tradeoffs you care about most. Need decrease prices? Sooner responses? Most accuracy?
Moveable energy banks that cost your telephone are well-liked, however wi-fi battery packs utilizing Apple’s magnetic MagSafe know-how supply an easier and smarter cable-free answer for iPhone 12, 13, 14, 15, 16, 17 and Air customers.
Telephone batteries are susceptible to run dry simply once you’re heading away from an influence supply, so having a conveyable charging supply is one in all in the present day’s requirements. Annoyingly, most energy banks require you to hold round a cable, too. Wi-fi energy banks dispose of cables however include their very own main limitation—the inefficiency of wi-fi charging means you want a high-capacity energy financial institution to completely cost a drained iPhone.
MagSafe is a know-how that’s appropriate with all iPhone 12, 13, 14, 15, 16, 17 and Air fashions, from the mini to the Professional Max, however unusually lacking from the 16e mannequin. It permits equipment to attach magnetically to the again of the iPhone. For extra data learn our Full information to Apple MagSafe: What’s MagSafe?
The MagSafe connection is exact sufficient to make wi-fi charging extra environment friendly as round 20% of non-magnetic energy loss is from poor placement of a telephone and the wi-fi charging pad. Customary Qi wi-fi charging can lose as a lot as 50% of the moveable battery’s energy, however MagSafe and Qi2 wi-fi charging loses ‘simply’ 30%. Sizzling out of the gadget laboratory, the brand new Qi 2.2 (also referred to as Qi2 25W) brings even sooner 25W wi-fi charging for the iPhone 16 and 17. 15% can be loads quick sufficient for many of us however who doesn’t need the quickest doable charging when your iPhone’s battery icon is within the purple?
Whereas it’s not as environment friendly as utilizing a cable to cost a telephone, MagSafe and Qi2 are techs that brings true wi-fi charging a step nearer to removing cables altogether. Qi2 25W brings wi-fi charging near wired’s, and a few energy banks embrace a built-in USB-C cable for even sooner charging as much as 30W.
Learn on or go straight to the very best magnetic energy banks we now have examined, listed by energy, portability and performance:
Greatest measurement magnetic energy financial institution for you
It is best to contemplate measurement relating to an influence financial institution: bodily measurement and battery capability. The upper the battery capability, the extra recharging energy you’ll get from the ability financial institution—however you’ll even be carrying round a bigger, heavier merchandise. Lighter, slimmer energy banks are simpler to pocket even when clamped to your telephone. Bigger energy banks won’t slot in your trouser pocket and might slide off simpler when pocketed even when clamped magnetically.
10K energy banks (with a 10000mAh battery capability) can cost a telephone shut to 2 instances over, whereas 5K (5000mAh) battery packs normally stretch between 60-75%, which is usually sufficient to get you to the subsequent wall-socket powering alternative. In case you are counting on the ability financial institution for long-haul journey or a tenting journey, a 10K battery or greater will go well with you higher. Belkin even presents a mid-range 8K energy financial institution.
Wi-fi energy financial institution charging pace
If an influence financial institution is rated as MagSafe Licensed it would wirelessly cost at as much as 15W. Uncertified however nonetheless “Appropriate” magnetic chargers are restricted to 7.5W, so will power-up at a slower tempo. Newer Qi2 chargers and energy banks match MagSafe at 15W. See Is Qi2 as quick as MagSafe?. Apple’s new MagSafe Charger can cost the iPhone 16 and 17 fashions at 25W and new Qi2 25W energy banks now match that pace.
We’ve listed the speeds at which every moveable energy financial institution may be charged itself (Enter charger) and cost the iPhone (Output charger). Some energy banks can cost a telephone sooner when you join a cable (most have a USB-C port and a few include their very own USB-C cable built-in), and we now have highlighted these under. The upper the wattage, the sooner the charging needs to be.
After the checklist of our favorites, you’ll discover extra particulars on how MagSafe works and why you ought to be an influence financial institution’s capability in Watt Hours relatively than the principally quoted Milliamp Hours.
Greatest high-capacity 10K MagSafe energy banks
A 10000mAh (10K) battery is the candy spot for each energy and portability. 5000mAh (5K) energy banks reviewed additional down are slimmer, lighter and simpler to pocket, however usually supply a most of 70-80% recharge potential versus a 10K energy financial institution that ought to be capable of recharge an iPhone no less than one and a half instances over.
EcoFlow RAPID Magnetic Energy Financial institution 10K – Greatest wi-fi battery pack for charging choices
This iPhone magnetic energy financial institution is our total winner as it’s a champion by way of each recharging capability and pace at which it may be recharged itself. It has a big capability, refilling a iPhone 16 Professional twice over in our exams—equalling the very best we’d seen earlier than. We run the iPhone’s battery down, recharge utilizing the ability financial institution, and hold doing this till the ability financial institution is empty.
What makes this energy financial institution particular—though not distinctive—is its quick built-in 65W USB-C cable that can be utilized for fast-charging an iPhone 15, 16 or 17 or refilling the ability financial institution itself. The cable suits neatly away when not in use on the backside of the ability financial institution.
Wirelessly it would work with any MagSafe iPhone (12/13/14/15/16/17) at 15W. iPhone 15/16/17 customers can join through the built-in USB-C cable or a separate longer cable through the facet USB-C port if required, for sooner 30W charging. House owners of earlier iPhones can use a USB-C to Lightning cable as a substitute for quick 20W wired charging from the ability financial institution’s port. Be aware that the iPhone 16e doesn’t work with magnetic wi-fi charging.
The Baseus Nomos energy financial institution, reviewed under, matches it for wi-fi charging pace as each use 15W Qi2 know-how. Additionally they boast sooner wired charging through their comparable built-in USB-C cable. In our recharging exams it beat the Nomos by spreading its 10000mAh battery capability for longer: 190% vs 166%. Nevertheless, each are crushed on charging pace by the brand new era of Qi2 25W energy banks such because the Ugreen MagFlow 10K reviewed under. That stated, the 25W energy banks we now have examined didn’t match the EcoFlow or Anker on battery capability in our exams.
Whereas the 10K Anker Zolo matched the 10K EcoFlow Fast on recharging capability in our exams, however has a slower 7.5W wi-fi charging pace.
No 10K magnetic wi-fi energy financial institution can match the EcoFlow on enter pace—that’s the price at which it’s recharged itself. Its 65W enter is far sooner than the 30W boasted by the Baseus or the 20W of the Anker.
Whereas profitable on charging efficiency and capability, the EcoFlow Fast is fairly chunky in comparison with the Anker Zolo and Baseus Nomos, and notably bulkier than smaller-capacity 5K energy banks. It’s nonetheless pocketable however the barely bigger measurement is the compromise for the opposite advantages. In order for you a slimmer battery pack, search for a smaller 5000mAh choice—we’ve examined the finest slim energy banks additional on. It has a useful pull-out kickstand on the again.
This energy financial institution is clearly constructed for the iPhone 15/16/17 households—with its neat built-in USB-C cable—nevertheless it works in addition to another wi-fi energy financial institution examined right here with the opposite MagSafe iPhones, and that inbuilt cable can be utilized to cost the ability financial institution itself.
We love this iPhone magnetic energy financial institution for its massive capability, which was (albeit narrowly) the very best in our recharging exams. It refilled a light iPhone 15 Professional twice over in our exams—the very best we’ve seen. The EcoFlow Fast 10K energy financial institution was very shut in our exams, however is a bit of bigger and heavier and with a much less inexpensive price-tag.
The 10K Anker Zolo is rated at simply 7.5W for wi-fi charging as it’s only “MagSafe appropriate” relatively than utilizing licensed MagSafe or Qi2 magnetic wi-fi applied sciences. That stated, if you should recharge rapidly you should use its built-in 5.5-inch USB-C cable that can be utilized for fast-charging an iPhone 15/16/17 at 30W or refilling the ability financial institution itself at 20W. The cable may be neatly hooked right into a loop for straightforward carrying. House owners of earlier iPhones ought to use the facet USB-C port and a separate Lightning cable for 20W wired charging from the ability financial institution.
The place the Anker Zolo triumphs is its worth: it wins on capability the place it loses on charging pace, nevertheless it’s simply the very best worth when you don’t thoughts the charging pace compromise.
There are smaller-capacity 5K energy banks, however the 10K Anker Zolo continues to be very pocketable for such a high-capacity battery pack. It’s across the similar measurement as different 10000mAh MagSafe energy banks we’ve examined—apart from its sibling the Anker MagGo 10K Slim, reviewed under. Our total finest 10K magnetic energy financial institution, the EcoFlow Fast 10K, is noticeably greater, though nonetheless moveable.
Dimensions: 4.1 x 2.7 x 0.75 inches (10.4 x 6.8 x 1.9cm)
Colours: Black
This 25W wi-fi energy financial institution lived as much as its claims of wirelessly charging an iPhone 16 Professional from 0% to 50% in 32 minutes—12 to fifteen minutes sooner than a 15W energy financial institution. That may not sound lots however once you’re in a rush to cost your telephone, each minute counts. 25W wi-fi charging is restricted to the iPhone 16 and 17 households, working no less than iOS 26; older iPhones will cost at 15W utilizing this energy financial institution.
The Baseus PicoGo Magnetic 10K Energy Financial institution (AM61) is an output blazer is extra methods than one. It’s licensed Qi 2.2 so expenses wirelessly at 25W, as quick because the Ugreen MagFlow reviewed under, and just like the MagFlow additionally boasts a built-in USB-C cable. Whereas the Ugreen’s cable can wired-charge at 30W, the Baseus is rated at 45W, which is quick sufficient to maintain a MacBook going. We can be working additional exams to see how a lot recharge it may supply a MacBook; watch this area.
For those who use the wi-fi charging pad, the useful built-in USB-C cable and the spare USB-C port to concurrently cost three units—say your iPhone, Apple Watch and AirPods—complete output is restricted to 15W.
When recharging an iPhone, it refilled our take a look at 16 Professional multiple and a half instances, scoring 167% within the Macworldm Recharge Rating—going that bit additional than the Ugreen MagFlow that scored 144%. Different 10K energy banks have carried out higher: we recorded scores of 190% with the 15W EcoFlow Fast 10K and seven.5W Anker Zolo 10K, though each lag behind the Baseus by way of charging pace.
One space the place the Baseus will not be the champ is enter: the pace at which it’s recharged itself. Enter energy is 30W, which is common however nowhere close to the EcoFlow battery pack’s unmatched 65W.
The identical firm additionally sells the Baseus Nomos Magnetic 10K Energy Financial institution that, just like the PicoGo, has an built-in 45W USB-C cable, however slower 15W Qi2 wi-fi charging. Its recharge rating of 166% is remarkably near that of the 25W PicoGo. As it’s priced equally to the 25W PicoGo, the newer mannequin makes extra sense.
Ugreen MagFlow Qi2 25W Magnetic Wi-fi 10K Energy Financial institution – Tremendous-fast wi-fi energy financial institution
Execs
25W wi-fi or 30W wired charging
Giant battery capability
Constructed-in USB-C cable
Digital show
Cons
Battery capability not as nice as others examined
Worth When Reviewed:
$89.99
Greatest Costs Right this moment:
$69.99
Capability: 36Wh (10000mAh)
Enter charger: USB-C (30W)
Output charger: Wi-fi (25W) & USB-C (30W)
On take a look at charged iPhone to: 144%
Weight: 9oz (254g)
Dimensions: 4.4 x 2.8 x 0.8 inches (11.1 x 7 x 2.1cm)
Colours: Blue
This was the primary Qi2 25W wi-fi energy financial institution that we examined, and it accomplished a 50% recharge in simply over half-hour—so matching the 25W Baseus PicoGo reviewed above. It’s sooner at being recharged itself, with a 30W enter beating the PicoGo’s 20W enter.
Whole output when utilizing all three charging factors—magnetic wi-fi, USB-C cable and USB-C port—is restricted to 12.5W.
Whereas, with the Baseus PicoGo 25W, it’s the equal quickest energy financial institution at charging the iPhone, it paled a bit of in precise recharge efficiency, refilling an iPhone 16 Professional’s battery as soon as absolutely after which 44% on second recharge. That 144% recharge rating is underneath the PicoGo’s 167% and never as nice because the 190% seen with the 15W EcoFlow and seven.5W Anker Zolo wi-fi energy banks additionally reviewed above. The ability financial institution itself may be recharged at 30W, which is quicker than the PicoGo and Zolo 10K energy banks however on the 65W degree of the EcoFlow Fast.
These factors apart, the Ugreen 25W MagFlow Energy Financial institution is a super-speedy wi-fi charger for these within the greatest hurry for energy.
Dimensions: 4.1 x 2.8 x 0.58 inches (10.4 x 7.06 x 1.47cm)
Colours: Black, White, Pink, Teal
At simply 0.58 inches thick, this 10000mAh energy financial institution rivals even a number of the 5000mAh battery packs by way of slimness. It’s additionally lighter than another 10K magnetic wi-fi energy financial institution that we now have examined, and wins too on recharging energy. It’s solely the built-in USB-C cable that pushes us to advocate the Anker Zolo or Baseus energy banks for house owners of the iPhone 15/16/17. Whereas I love the built-in cables, I admit that the Anker Slim is the magnetic energy financial institution in my backpack day by day.
It makes use of quick Qi2 magnetic tech, so can wirelessly cost at a powerful 15W. When you’ve got a spare cable with you, it will probably cost at twice that pace through its USB-C port. This makes it as quick a wi-fi charger because the Baseus Nomos reviewed above. The Baseus charger is extra handy with its built-in USB-C cable, however house owners of iPhones 12/13/14 would possibly admire the flexibility so as to add a Lightning cable to the USB-C port and cost that manner. Wired charging through Lightning is restricted to 20W—a limitation set by Apple to make sure system security and efficiency, not by the cable or the ability financial institution. The newer Ugreen MagFlow is the excellent winner on wi-fi charging pace however is lots wider than this slim machine.
In our exams it carried out among the many better of the 10K magnetic energy banks we now have put by their paces: recharging an iPhone 15 Professional to 188% (over the course of two iPhone expenses from one energy financial institution cost).
It’s out there in as much as 4 colours relying in your nation and the place you purchase it—the pink and teal variations can be found solely direct from Anker.
There’s an excellent slimmer 5K Anker Nano mannequin, reviewed under.
Across the similar measurement because the Anker Zolo energy financial institution, reviewed above, the Anker MagGo Energy Financial institution (10K) didn’t fairly match that battery pack by way of recharging however was nonetheless spectacular—across the similar because the Baseus Nomos.
The place it beats the Zolo and matches the Nomos and EcoFlow Fast is in wi-fi charging pace. The Anker MagGo is licensed for the brand new Qi2 commonplace and so helps 15W wi-fi charging. This works with all MagSafe-supporting units: from the iPhone 12 to 17. (Be aware that the iPhone 12 doesn’t formally assist Qi2 however Macworld iPhone 12 Qi2 exams counsel that it does.)
The Zolo/Nomos/Fast have a barely extra highly effective cabled charging spec (30W vs Anker’s 27W) however the distinction is negligible. We just like the built-in USB-C cable included with these energy banks, however any first rate USB-C charging cable can be utilized with the MagGo to quick wire-charge an iPhone.
Except for sooner wi-fi charging, the Anker boasts a easy-to-read digital show that reveals you precisely how a lot cost is left within the battery pack. Seeing the precise share is way more helpful than the standard 4 LED lights seen on most energy banks. It additionally includes a stable pull-out stand on the again.
This energy financial institution stands out with its Aramid Fibre weave—a excessive energy materials that’s extra proof against warmth, cuts and abrasion than different circumstances and is usually utilized in protecting clothes and aerospace elements.
The rose gold colour additionally appears relatively good. Benks doesn’t name it that (or something) however that’s the way it appears with a delightful weave sample.
It’s Qi2 so able to 15W charging—not the quickest however what was till just lately the chopping fringe of wi-fi energy. It scored a good 165% within the Macworld recharging exams so offers you over 1.5 expenses earlier than it, too, wants filling up—which, by the best way, it takes its time doing because the 15W enter energy is lower than on different energy banks.
Benks additionally presents an equally powerful and super-slim 5K Aramid Fiber mannequin, though it’s only MagSafe Appropriate so a slower charging expertise at 7.5W. The 10K mannequin is Qi2 so sooner 15W charging energy.
A lot greater and meaner than the ability banks reviewed above, the Statik 5-in-1 Journey Charger is an influence financial institution that may cost 5 units concurrently: two by the USB-C and USB-A ports, one wirelessly by a magnetic charging pad, and two by the built-in cables (USB-C for iPhone 15/16/17 and Lightning for older iPhones).
In our exams, it was very shut in battery charging energy to the highest scorers—charging an iPhone 16 Professional practically twice over.
It claims to supply 15W of wi-fi energy however isn’t formally licensed by Apple, so we price it at 7.5W for wi-fi. There are two built-in output cables: one USB-C for iPhone 15/16/17, and one Lightning for older iPhones and Apple units. For those who don’t have any Lightning-based units this can be superfluous, though mates in want of energy might thanks if their iPhones are older. Most individuals’s AirPods are nonetheless Lightning primarily based, so chances are you’ll nicely discover a use for it.
It options built-in U.S. plug prongs so may be related straight into an influence socket relatively than requiring a separate USB-C charger. That is positive for customers primarily based within the U.S. or Canada, however not for worldwide customers, though there are U.Ok., E.U, and AU/NZ plug adapters included making it work in these nations and as a journey companion. The ability financial institution even includes a useful pull-out telephone clip that holds your telephone upright, though the position of the cables means the battery pack can’t cost your telephone whereas it’s within the mini stand.
In contrast to the extra svelte energy banks reviewed right here, the Statik SmartCharge 5-in-1 Energy Financial institution is just too large and hulking to allow you to slip the iPhone plus battery pack into your pocket. As a conveyable energy financial institution you would possibly carry in a bag in your travels, however not your pocket.
One other plug-in-the-wall energy financial institution choice is theInfinacore P3 Professional, pictured above, which prices $129 / £102, and might cost 4 units on the similar time, together with an iPhone at 15W Qi2. It lacks the built-in USB-C cable discovered on the Statik and Raycon energy financial institution chargers however because it plugs immediately right into a wall energy socket you gained’t want to hold a cable to recharge the ability financial institution itself. Just like the Statik battery pack, it comes with U.Ok., E.U, and AU/NZ journey adapter plug heads. In addition to the Qi2 charging pad, there are two USB-C ports and one USB-A. The P3 Professional additionally boasts a superb show, displaying charging pace, battery standing, temperature, and cost time remaining. We advocate this energy financial institution for MacBook customers who need a moveable 65W charger with MagSafe for wi-fi iPhone charging, plus USB choices. The Statik and Raycon aren’t as appropriate for laptop computer charging, however the P3 Professional’s 65W is sufficient to hold most MacBooks going when related.
Whereas a wi-fi charging pad saves you the trouble of carrying a cable round to cost your telephone from an influence financial institution, you continue to want a wall charger handy to recharge the ability financial institution itself… however not with the PhoneSuit Journey Magazine, which options foldable North American plug prongs so you possibly can plug the battery pack straight into an influence socket. Whereas plugged in, the ability financial institution can cost the connected iPhone wirelessly concurrently recharging the battery pack.
Two additional USB ports are additionally useful. The USB-C port can cost at 20W, a lot sooner than the 7.5W MagSafe-compatible wi-fi charging pad—however you will want a USB-C cable on this occasion: USB-C to Lightning for iPhones older than the iPhone 15, and USB-C to USB-C for the 15, 16 and 17. The USB-A port can cost one other system at as much as 18W.
The 10000mAh battery capability allowed us to cost a light iPhone to 100% after which once more one other 50%, which is about common for this measurement battery.
Greatest small moveable magnetic energy banks
For those who carry your energy financial institution round with all day, in your bag or pocket, a slimmer, lighter magnetic/MagSafe energy financial institution will go well with you higher than a bigger, heavier 10K battery pack. They’re additionally simpler to pocket when clamped to your telephone. We’ve examined lots from 3000mAh to 6000mAh to search out the very best moveable MagSafe energy financial institution that may recharge your iPhone sufficient to get you thru the remainder of the day however not sufficient to answer on throughout a weekend’s tenting.
The Anker MagGo 10K Slim Energy Financial institution, reviewed above, is simply 0.58 inches thick and weighs solely 200g however these 5K magnetic energy banks will take up even much less area in your bag or desk drawer, and are simpler to pocket with iPhone connected.
Simon Jary
1. EcoFlow RAPID Magnetic Energy Financial institution 5K – Greatest 5K magnetic battery pack for pace
Execs
Slimmer than 10K
Constructed-in USB-C cable
Constructed-in stand
15W wi-fi or 30W wired
Cons
Barely bigger than different 5K energy banks
Worth When Reviewed:
$69.99
Greatest Costs Right this moment:
Capability: 19.35Wh (5000mAh)
Enter charger: USB-C (30W)
Output charger: Wi-fi (15W) & USB-C (30W)
On take a look at charged iPhone to: 70%
Weight: 6.4oz (180g)
Dimensions: 4.3 x 2.8 x 0.6 inch (10.8 x 7 x 1.4cm)
Colours: Grey/silver
5K battery packs are slim sufficient to clamp to your iPhone and nonetheless slip into your pocket. Whereas 10000mAh energy banks boast bigger re-charging capability, in order for you a barely smaller and lighter battery pack with a stand, we advocate you select between this energy financial institution—the smaller sibling of our really useful finest 10K magnetic energy financial institution—and both the Belkin BoostCharge Professional Energy Financial institution 5K + Stand or Ugreen 5000mAh Magnetic Wi-fi Energy Financial institution, each reviewed under.
All three have a 5000mAh battery however the Belkin gained in our head-to-head recharging exams, recharging a light iPhone 16 Professional by 79% in comparison with the 5K EcoFlow Fast (70%) and Ugreen (68%). For the most important recharge, Belkin wins.
The place the 5K EcoFlow Fast will get the general nod—particularly for house owners of the iPhone 15, 16 and 17—is its built-in USB-C cable. No different 5000mAh wi-fi energy financial institution we now have examined has the useful built-in cable. A number of of our favourite 10K battery packs have built-in cables however that is the primary 5K energy financial institution to boast one. Even you probably have an earlier Lightning iPhone, the built-in cable can be utilized to prime up the ability financial institution itself.
It options 15W Qi2 wi-fi charging when clamped to the again of an iPhone, and may be charged with a cable at a prime 30W pace.
2. Belkin BoostCharge Professional Magnetic Energy Financial institution Qi2 – Greatest 5K in our exams
Execs
Spectacular in battery exams
Constructed-in stand
15W wi-fi or 12W wired
Brilliant vary of colours
Cons
USB-C port a bit of underpowered
Worth When Reviewed:
$59.99
Greatest Costs Right this moment:
$54.70
$59.95
$59.95
$59.99
Capability: 19.25Wh (5000mAh)
Enter charger: USB-C (20W)
Output charger: Wi-fi (15W) & USB-C (12W)
On take a look at charged iPhone to: 79%
Weight: 4.8oz (136g)
Dimensions: 3.9 x 2.6 x 0.6 inches (9.8 x 6.6 x 1.4cm)
This 5K battery pack was the winner in our recharging exams, recharging a light iPhone 16 Professional by 79% in comparison with 70% by the 5K EcoFlow Fast and 68% for the Ugreen energy financial institution. Solely the Kuxiu S2 Stable-State energy financial institution carried out to this degree.
The Belkin’s kickstand is simple to make use of and feels sturdy, and the battery pack itself is marginally smaller than the Ugreen. The $49.99 Torras MagStall Energy Financial institution is a bit of slimmer however wider and boasts a stand/finger-grip, though recharges to a barely lesser extent.
It options 15W Qi2 wi-fi charging when clamped to the again of an iPhone, and may be charged with a cable at 12W, which isn’t as speedy as some energy banks which have 20W and even 30W USB-C ports.
Verify right here first: Belkin and Amazon supply a alternative of colours, and the Apple Retailer now has an unique set of recent colours, together with a brighter Pink, Deep Purple with a purple stand and Teal with a yellow stand
3. Anker Nano 5K MagGo Slim Energy Financial institution – Slimmest 5K wi-fi energy financial institution
Execs
Very compact and light-weight
Spectacular in battery exams
15W wi-fi or 20W wired
Worth When Reviewed:
$54.99
Greatest Costs Right this moment:
$54.99
Capability: 19.35Wh (5000mAh)
Enter charger: USB-C (20W)
Output charger: Wi-fi (15W) & USB-C (20W)
On take a look at charged iPhone to: 77%
Weight: 4.3oz (122g)
Dimensions: 4 x 2.8 x 0.34 inches (10.2 × 7.1 x 0.86cm)
Colours: Grey, Black, and White
Most individuals carry their energy financial institution round with them, and there’s none higher in a small bag or pocket than the tremendous skinny Anker Nano MagGo 5K Slim, the slimmest magnetic energy financial institution we now have examined to this point. It’s the little sibling of the 10K Slim reviewed above.
At 0.34 inches slim, the closest rival is the Baseus PicoGo 5K, reviewed under, which is a mere 0.02 inches deeper however loses factors for charging at 7.5W relatively than the Anker’s 15W Qi2 pace.
It carried out excellently in our recharge exams, boosting an iPhone 16 Professional from 0% to 77%. Charging speeds had been impacted by the warmth, which is attributable to the good temperature management that slows issues down once they get scorching.
4. ESR Qi2 5K MagSlim Kickstand – Energy, pace and a stand
Execs
Constructed-in stand
15W wi-fi or 20W wired
Cons
Barely bigger than different 5K energy banks
Worth When Reviewed:
$43.99
Greatest Costs Right this moment:
$25.99
Capability: 18Wh (5000mAh) Enter charger: USB-C (18W) Output charger: Wi-fi (15W) & USB-C (20W) On take a look at charged iPhone to: 77% Weight: 5.3oz (151g) Dimensions: 4.1 x 2.7 x 0.6 inch (10.4 x 6.8 x 1.5cm) Colours: Black, White
This ESR magnetic energy financial institution is constructed on Qi2 tech so presents quick 15W wi-fi charging. It additionally boasts a sturdy kickstand that closes with a reassuring snap.
It carried out nicely in our iPhone battery charging exams with a rating of 77%—simply 2% lower than our highest-rated 5K energy banks (the 5K Belkin BoostCharge + Stand and Kuxiu S2, each reviewed under). The Belkin BoostCharge Professional 5K is a bit of smaller and gained in our recharge exams, however the ESR is shut sufficient within the outcomes to be value contemplating.
ESR additionally sells a 10K Qi2 Kickstand mannequin, however this fared much less nicely in our exams at 118% vs different 10K energy banks that reached 150% and extra. There are additionally 5K fashions with out the kickstand for rather less bulk and money.
5. Ugreen 5000mAh 15W MagSafe PD 3.0 Energy Financial institution – Greatest price range magnetic battery pack
You’ll discover loads of super-cheap energy banks on-line, however the best-priced magnetic energy financial institution that we now have examined from a trusted producer is the Ugreen 5000mAh Magnetic Wi-fi Energy Financial institution. For security’s sake, we advocate you keep away from the most affordable offers for merchandise from suppliers you possibly can belief—and we’ve achieved that testing for you.
It’d lack a built-in stand as seen on different comparable smaller-capacity energy banks, however the Ugreen can recharge your fading iPhone to about two-thirds full battery capability, and is tremendous slim and light-weight. It’s also blessed with the flexibility to cost at 15W through a separate cable (provided).
6. Baseus PicoGo Extremely-Slim 5K – Candy spot for measurement and recharge
Colours: Area Gray, Nebula Pink, Pure Titanium, Cosmic Black
There’s an fascinating battle for the crown of smallest, slimmest and lightest magnetic battery pack between three of the ability banks reviewed and examined right here
The Baseus PicoGo 5K is a tiny bit shorter and fewer extensive than the Vonmählen Evergreen Magazine however nearly precisely the identical slim depth and is 13g lighter. It’s exactly the identical weight (111g) because the Infinacore M3. We expect it’s the candy spot between the three, and is accessible from Amazon for lower than $23.
Recharging our iPhone 16 Professional to 71%, it carried out a lot better in our battery exams than the smallest energy financial institution (Infinacore: 56%) and really barely higher than the slimmest (Vonmählen: 70%), though that may cost sooner at 15W in comparison with the PicoGo’s 7.5W.
There’s a bigger capability 10K Baseus PicoGo (4 x 2.7 x 0.6 inches; 6.2oz) that’s about the identical credit-card size and width however noticeably thicker in depth than the 5K, as you’d count on from a way more highly effective battery pack. The 10K model is quicker charging at 15W Qi2, and carried out nicely in our exams with a rating of 142%.
7. Vonmählen Evergreen Magazine 5000mAh Energy Financial institution – Tremendous-slim magnetic energy financial institution
Execs
One of many slimmest examined
15W wi-fi or 20W wired
Greatest Costs Right this moment:
Capability: 19.25Wh (5000mAh) Enter charger: USB-C (20W) Output charger: Wi-fi (15W) & USB-C (20W) On take a look at charged iPhone to: 70% Weight: 4.4oz (124g) Dimensions: 3.3 x 2.4 x 0.4 inch (10.2 x 7 x 0.9cm) Colours: Black, White
Longer and wider than the smallest energy financial institution we now have examined, the well-named Infinacore M3 Mini reviewed under, the Vonmählen Evergreen Magazine 5000mAh Energy Financial institution nevertheless wins the crown for slimmest 5K energy financial institution. If you wish to shave 0.2cm off the width of the ability financial institution clamped iPhone sliding out and in of your pocket, then that is as skinny because it will get though the PhoneSuit Elite Magazine Slim 5K is about the identical depth.
It’s also sooner than the M3 Mini and Elite Magazine Slim at wirelessly charging because it helps Qi2, and in our exams it recharged an iPhone 16 Professional from 0% to 70% earlier than requiring a power-up itself, which simply beats the Infinacore and simply shades the PhoneSuit.
8. PhoneSuit Elite Magazine Slim 5K – Greatest 5K battery pack with show
Figuring out how a lot cost is left in your energy financial institution may imply the distinction between leaving the home assured that your battery pack is stuffed with juice and discovering out too late that it wants a recharge itself.
The Elite Magazine Slim from PhoneSuit has a big digital show displaying off remaining cost that’s extra accessible than the standard 4 LED dots discovered on most energy banks.
This battery pack can also be notable for its slimness, which is the same as the Vonmählen Evergreen Magazine, reviewed above. The Vonmählen energy financial institution narrowly beat it in our exams however actually not considerably so, nevertheless it does cost sooner wirelessly (15W vs 7.5W) than the PhoneSuit.
The PhoneSuit Elite Magazine Slim Professional is a 10K model, with a recharge rating of 149%, and the identical brilliant easy-to-read show for simply $10 extra however deeper (0.5in vs 0.35in).
9. Infinacore M3 Mini Wi-fi 5K Energy Financial institution – Smallest, lightest magnetic energy financial institution
Execs
Smallest, lightest we examined
7.5W wi-fi or 20W wired
Cons
Not 15W wi-fi
Decrease recharge than rivals
Worth When Reviewed:
$49.99
Greatest Costs Right this moment:
Capability: 19.25Wh (5000mAh)
Enter charger: USB-C (20W)
Output charger: Wi-fi (7.5W) & USB-C (20W)
On take a look at charged iPhone to: 56%
Weight: 3.9oz (111g)
Dimensions: 3.3 x 2.4 x 0.4 inch (8.38 x 6 x 1.1cm)
Colours: Stainless Black, Pearl Silver
In order for you a magnetic energy financial institution that’s tremendous small, the Infinacore M3 Mini Wi-fi Energy Financial institution is a slimmer, shorter and narrower and 25% lighter than most battery packs examined right here. The PhoneSuit Elite Magazine Slim and Baseus PicoGo energy banks, additionally reviewed right here, are equally mild. You’ll hardly discover any of them in your pocket or bag.
The compromise is in recharging efficiency—in our exams the M3 Mini resurrected a light iPhone 16 Professional by 56%, which may be sufficient for a number of hours service however is weaker than the opposite battery packs examined right here.
In order for you the safety of an influence financial institution in your purse or backpack, then this takes up little area and weighs subsequent to nothing, whereas providing simply sufficient juice to perk up your fading iPhone.
10. Kuxiu S2 Qi2 5000mAh – World’s first solid-state energy financial institution
Execs
Spectacular battery capability
15W wi-fi or 20W wired
Strong
Larger cost cycle than others
Worth When Reviewed:
$69.99
Greatest Costs Right this moment:
$49.99
Capability: 19Wh (5000mAh)
Enter charger: USB-C (18W)
Output charger: Wi-fi (15W) & USB-C (20W)
On take a look at charged iPhone to: 79%
Weight: 6.1oz (174g)
Dimensions: 3.3 x 2.4 x 0.4 inch (8.38 x 6 x 1.1cm)
Colours: Stainless Black, Pure Titanium
Stable-state batteries (SSB) are a brand new know-how that promise to be extra highly effective, sustainable and secure than typical Lithium-ion rivals by utilizing a stable relatively than liquid electrolyte. The Kuxiu S2 is definitely “semi solid-state” nevertheless it’s nonetheless the primary SSB energy financial institution that we’ve examined.
One of many advantages is that it’s best to get as a lot as twice as many expenses from the ability financial institution earlier than it begins to degrade: 1,000 vs a standard energy financial institution’s 500. It also needs to be extra sturdy and safer to hold and retailer.
The Kuxiu S2 carried out very nicely in our charging exams, matching the Belkin BoostCharge at 79%. With Qi2 it wirelessly expenses at 15W.
It’s not the smallest we’ve examined but additionally not the most important, though it does tip the scales greater than the tinier energy banks reviewed right here.
Greatest multi-device charging MagSafe energy banks
when you personal AirPods and an Apple Watch in addition to an iPhone, search for MagSafe energy banks that cost a number of Apple units on the similar time. As energy banks these ought to nonetheless be moveable, however typically convert into charging stands when in use. Most are two massive to slide in your pocket with the telephone connected however they’re helpful for if you end up away from base and have to energy up your favourite Apple package. Neither of the 2 we examined are rated at sooner than 7.5W.
1. OneAdaptr OneGo – Greatest 10K MagSafe energy financial institution with Watch and AirPods chargers
Dimensions: Folded: 2.8 x 0.94 x 4.7 inches (7 x 2.4 x 12cm)
Colours: White or Cool Grey
OneAdaptr has just lately up to date its OneGo 3-in-1 iPhone/Watch/AirPods charger and moveable energy financial institution, and made it much more compelling an answer. Not is the ability financial institution a separate half. Now the Watch and AirPods charging modules flip out from the again of the iPhone wi-fi charger, and the ability financial institution can recharge all of the units.
We’ve examined loads of nice moveable MagSafe wi-fi chargers however that is the smallest 3-in-1 iPhone/Apple Watch/AirPods charger that doubles up as an influence financial institution. The 10000mAh battery capability is excessive, and in our exams, we managed to get round one and three quarters recharge of an iPhone 15 Professional, which is spectacular. That’s greater than with the same iPhone/Watch charging Alogic Elevate energy financial institution (1.5 expenses).
You may get slimmer and lighter 10K energy banks however not with built-in Apple Watch and AirPods charging stands. We’ve examined and reviewed 10K battery packs that supply better charging energy: the Baseus Magnetic 10K Energy Financial institution (187%) and Anker MagGo 10K Slim (188%) each supply higher efficiency however in fact, lack the built-in Apple Watch and AirPods modules.
Sure, it’s a bit of bigger and positively heavier than a lot of the wi-fi energy banks reviewed right here, nevertheless it’s a neat answer if you’re away from an influence supply when all of your Apple units ping you that terrifying Low Energy Mode suggestion.
The Apple Watch charging module flips up from the again of the ability financial institution and feels sturdy sufficient to outlive in-bag journey. It expenses at 2W relatively than 5W so doesn’t assist Apple Watch Quick Cost however it would inject the juice that your Watch requires once you want it—no Transfer calorie counting or Train minutes want be missed.
There’s one USB-C port (the Alogic Elevate has a USB-A port for older cables) for enter or sooner wired iPhone charging (18W).
2. Alogic Elevate 4-in-1 MagSafe Wi-fi 10000mAh Energy Financial institution – Compact 10K MagSafe energy financial institution with Watch charger
The Alogic Elevate MagSafe and Apple Watch energy financial institution is a bit of fatter however shorter than the OneAdaptr OneGo, reviewed above. Whereas very comparable, it lacks the OneGo’s base with AirPods charging pad nevertheless it does boast two USB ports to the OneGo’s single enter/output port.
One USB-C port is for enter or sooner wired iPhone charging (18W); and the USB-A port is there for older charging cables. You may use both port to cost your AirPods or one other iPhone. Whereas you should use each on the similar time, simultaneous USB charging does drop energy tempo to simply 5W.
The robust-when-folded Apple Watch charging module expenses at 3W relatively than 5W so doesn’t assist Apple Watch Quick Cost however it’s a little sooner than the 2W OneGo Watch charger.
For those who don’t want the AirPods charging pad, the Alogic Elevate is as in a position and professional because the OneGo.
Greatest iPhone battery case
Whereas not a wi-fi or magnetic answer, a battery case is an influence financial institution constructed right into a protecting case to your iPhone. You’re much less more likely to depart this back-up battery at dwelling as you would possibly with a separate energy financial institution as it’s at all times along with your iPhone. The drawback of a battery case is that it’s going to doubtless be out of date once you change telephone however many people wouldn’t be with out one.
We’ve examined battery circumstances for the iPhone 15 and 16—try our roundup evaluations of the finest iPhone 15 circumstances and finest iPhone 16 circumstances. Our two favourite battery circumstances for each households of iPhone are from Mophie and Newdery. We’re actively testing the finest iPhone 17 circumstances however are but to search out an iPhone 17 battery case that we belief to advocate right here, though we’re certain Mophie or Newdery will carry one out quickly.
1. Mophie Juice Pack Battery Case for iPhone 16
Execs
Inside battery in protecting case
Extra environment friendly than a wi-fi energy financial institution
Slimmer than rival battery circumstances
Feels extra sturdy than mannequin for iPhone 15
Cons
Smaller battery than energy banks
Worth When Reviewed:
$99.95
Greatest Costs Right this moment:
$79.95
$99.95
Capability: 10.78Wh (2800mAh) for iPhone 16 and 16 Professional; 3600mAh for 16 Professional Max
Compatibility: iPhone 16, 16 Professional, 16 Professional Max
This Mophie battery case for the iPhone 16 household (omitting the 16 Plus) feels extra sturdy in its two half design than the model for the 15. It once more presents much less recharge potential than its rival however is considerably slimmer and lighter with its smaller battery capability.
Compatibility: iPhone 16, 16 Plus, 16 Professional, 16 Professional Max
This extra inexpensive battery case for all fashions of iPhone 16 is noticeably wider and fatter than the Mophie Juice Pack however that’s as a result of it hosts a bigger battery, which implies you get extra recharge potential on the worth of the majority.
The iPhone expenses wirelessly inside the case, which implies much less stress on the port however the ensuing compromise signifies that charging is notably slower. That shouldn’t matter when you are on the highway and the capability will hold your iPhone going for longer.
Compatibility: iPhone 15, 15 Professional, 15 Professional Max
No wi-fi charging right here as a result of the Juice Pack is a protecting case with an inner battery. The iPhone is charged through a wired USB-C connector, so expenses sooner and extra effectively than a wireless-only energy financial institution.
Mophie has designed this battery case to be as slim as doable whereas nonetheless providing sufficient recharge energy to get your iPhone to over a half full battery. The opposite iPhone 15 battery case we examined, the Newdery Battery Case for iPhone 15, reviewed under, is available in two a lot bigger battery capacities (5K and 10K) however the circumstances themselves are a lot heavier and hulking.
It’s a two-piece design that matches the iPhone nicely, and presents sturdy safety from knocks, bumps and drops. The highest half did slip off a few instances in testing from a good trouser pocket however ought to fare higher from a coat or bag. In order for you a one-piece iPhone battery case select one of many Newdery battery circumstances, reviewed under.
The Mophie Juice Pack is accessible for all iPhone 15 fashions besides the 15 Plus. When you’ve got an earlier iPhone mannequin, search for choices with the Newdery battery circumstances under.
The Newdery Battery Case presents full safety and practically a full battery recharge, and this twin perform makes it a less expensive different to a MagSafe case and MagSafe battery pack. Nevertheless, some might discover the cumbersome design too chunky, though the case for the iPhone 15 Professional itself weighs simply 134g.
The 5000mAh Newdery Battery Instances scored round 95% in our exams, with the 10K battery circumstances reaching an incredible 168%.
These take a look at outcomes are from the iPhone 15 Professional fashions, however Newdery has battery circumstances for all of the latest iPhones. Newdery iPhone Battery Instances on Amazon US | Amazon UK | Amazon CA.
Some fashions are wi-fi appropriate themselves so may be charged itself on most Qi charging pads.
For those who need safety in addition to longer battery life, the Newdery Battery Case presents each in an inexpensive package deal. It’s less expensive than the Mophie Juice Pack reviewed above.
For those who don’t want a conveyable energy financial institution, try the finest MagSafe chargers that we now have examined. Additionally try our exams of the finest iPhone chargers for wired charging options, and naturally to refill your iPhone energy financial institution.
How we examined
MagSafe charger testing was carried out utilizing an iPhone 13 Professional, iPhone 15 Professional and 16 Professional, subscribed to a 5G community and WiFi, with display off and all default settings.
Our take a look at is an easy battery recharge shootout. We let our test-unit iPhone Professional (3095mAh battery capability) drain to simply 10% after which set the Battery Pack to work recharging the telephone.
We then assigned the charger a rating of no matter share it managed to cost the iPhone to and subtract the ten%; we take a look at every mannequin no less than twice.
It’s not a real-world take a look at of day-to-day use the place you’ll doubtless be utilizing your telephone for numerous duties (of various battery utilization) and in several environmental situations and community configurations.
Nevertheless it does give us a standard rating format that we will use to check totally different battery-pack fashions.
Why evaluating Watt Hours is best than Milliamp Hours
Telephone batteries are usually rated in Milliamp Hours (mAh) however this can be a measure {of electrical} cost, whereas a Watt Hour is the same as one watt of power consumed for one hour of time.
When evaluating battery capacities and the way a lot an influence pack will increase a telephone’s inner battery, power is extra necessary than electrical cost.
And mAh ignores a battery voltage, which determines the wattage (energy) of a battery.
If the mAh is similar, the upper the voltage, the better the precise saved energy.
For instance, Apple’s MagSafe Battery Pack is rated at simply 1460mAh nevertheless it has a better voltage potential (7.62V) than the iPhone (3.81V) or different battery packs, which means that it will probably present extra energy to an iPhone than its mAh suggests; in reality, it’s really 2920mAh.
To enter additional depth about this learn our function iPhone battery capacities in contrast that additionally lists all iPhones battery life in mAh and Wh.
Anatomy of a magnetic energy financial institution
TORRAS
Much more than a battery goes into the making of a magnetic energy financial institution.
In fact, the battery is a very powerful part, however the wi-fi charging coils and magnetic connection are very important for environment friendly and due to this fact quick and highly effective charging.
The transmitter coil transfers energy by electromagnetic induction.
The magnets should be set as much as precisely join the transmitting coils—right here on the ability financial institution— to the receiving coils, on this case contained in the iPhone.
The instance proven above is the Torras MagStall Wi-fi Energy Financial institution, reviewed in our chart. You’ll be able to see the varied elements, together with that energy financial institution’s rotating stand/deal with.
What about non-wireless energy banks?
Wi-fi charging—particularly magnetic wi-fi charging—is tremendous handy and does away with the necessity to carry round messy cables to attach your system to the battery pack.
However wired charging is sort of at all times sooner and never a lot of an inconvenience if you’re not out and about. Over on our sister website Tech Advisor I’ve reviewed the finest energy banks that features commonplace non-wireless battery packs that may be a good answer in addition to the ability banks reviewed above.
Do magnetic energy banks work when the iPhone is in a case?
Sure, most high quality iPhone circumstances are appropriate with MagSafe having their very own magnet ring to make sure an in depth connection between the ability financial institution’s magnetic charging coils and the iPhone’s personal. You’ll find precisely that are supported in our roundups of the finest iPhone 17 circumstances, finest iPhone 16 circumstances and finest iPhone 15 circumstances.
This weblog delves into the significance of Bartlett’s take a look at for validating homogeneity of error variances in pooled/mixed experiments. It explains the take a look at’s significance, offers step-by-step calculations, and highlights its software in agricultural analysis. Sensible examples and code snippets for numerous software program are included for complete understanding.
Estimated Studying Time: ~12 minutes.
Introduction
In experimental analysis, particularly in fields like agriculture, researchers usually conduct experiments beneath various circumstances equivalent to completely different instances, places, or environments. To attract extra complete and strong conclusions, combining or pooling the info from these experiments right into a single evaluation is a typical apply.
Pooled evaluation presents a number of advantages:
Elevated Statistical Energy: Pooling knowledge will increase the whole pattern dimension () and the levels of freedom for error, thereby lowering the Imply Sq. Error (MSE). This results in a smaller crucial F-value in ANOVA, enhancing the flexibility to detect smaller therapy variations. For example, pooling knowledge from three fully randomized design (CRD) experiments, every with 10 replicates (), ends in a decrease MSE in comparison with analyzing every experiment individually ( per experiment). This enchancment permits for the detection of refined therapy results which may in any other case stay non-significant.
Interplay Evaluation: Pooled evaluation facilitates the identification of interactions between remedies and environments, places, or years by the treatment-by-environment interplay time period. This offers worthwhile insights into the consistency of therapy efficiency throughout various circumstances and broadens the applicability of the findings.
Regardless of these benefits, pooled evaluation requires the error variances of the person experiments to be homogeneous. This can be a crucial assumption to make sure the validity of the outcomes and to keep away from deceptive conclusions.
This weblog offers an in depth clarification of Bartlett’s take a look at, a statistical technique used to evaluate the homogeneity of variances. It discusses the take a look at’s software in pooled experiments and guides researchers on easy methods to carry out it successfully.
The Significance of Homogeneous Error Variances in Pooled Evaluation
For researchers conducting pooled analyses, guaranteeing homogeneity of error variances is paramount. Error variance refers back to the portion of knowledge variability that experimental components can not clarify. In ANOVA-based pooled analyses, the belief of homogeneous error variances throughout experiments underpins the validity of the F-statistic. When this assumption is violated, Imply Sq. Error (MSE) calculations could also be distorted, undermining the reliability of outcomes and rising the probability of Kind II errors—failing to detect real therapy results. Addressing heterogeneous variances might require options equivalent to Welch’s ANOVA or variance-stabilizing transformations to make sure strong conclusions.
Illustrative Situation:
Think about an experiment evaluating the effectiveness of foliar purposes of fungicides to regulate Black Sigatoka illness in bananas beneath various environmental circumstances (e.g., completely different humidity ranges). The examine includes seven fungicides (Fungicides A, B, C, D, E, F, and G) utilized to 21 banana crops (three replicates per therapy). Utilizing a Utterly Randomized Design (CRD), the remedies are randomly assigned to the crops. Under is the person ANOVA for 3 distinct environments.
Bartlett’s take a look at checks if error variances throughout environments are homogeneous. In our pooled CRD experiment, it determines if the error variability in particular person experiments is constant. Homogeneity is essential for pooling knowledge; important variations in variances imply the info can’t be pooled reliably. Let’s proceed with Bartlett’s take a look at.
Hypotheses
The null speculation is that every one the inhabitants variances (okay populations being in contrast) are equal: H₀: σ₁² = σ₂² = … = σₖ²
The choice speculation is that the inhabitants variances aren’t all equal, which means at the very least one variance differs from the others. The take a look at doesn’t explicitly determine which one is completely different, solely that at the very least one is completely different.
System for Bartlett’s Take a look at
The take a look at statistic for Bartlett’s take a look at is calculated utilizing the next system: χ² = [N−K * ln(Sₚ²) – Σᵢ(nᵢ – 1) * ln(Sᵢ²)] / C
The place:
N = Σᵢnᵢ: Whole variety of observations throughout all teams
The correction issue is calculated utilizing the system:
For our instance:
Compute the Time period
Plug within the Values to Calculate :
The take a look at statistic is computed as:
For our instance:
Examine the Computed Worth
To find out whether or not to reject the null speculation, examine the computed worth with the crucial worth from the Chi-Sq. distribution desk for on the desired significance stage (, often 0.05).
In our instance, the calculated worth (0.157) is lower than the desk worth (5.99). In Excel, the crucial worth may be calculated utilizing the system:
On the 0.05 significance stage, this consequence signifies inadequate proof to reject the null speculation. Whereas this doesn’t verify that the variances are equal, it suggests there’s not sufficient knowledge to conclude that at the very least one variance differs.
Codes with their bundle and
respective software program for performing bartletts take a look at
Code
Package deal
Software program
bartlett.take a look at(values ~group)
stats
R
bartlett.take a look at(values, grouping)
automobile
R
PROC GLM; CLASS group; MODEL
worth=group; TEST HOV;
–
SAS
Navigate to Analyze >
Descriptive Statistics > Discover.
Underneath “Plots,” choose
“Take a look at for Homogeneity of Variances (Bartlett’s).”
SPSS
scipy.stats.bartlett(data1,
data2)
scipy.stats
Python
Conclusion
Bartlett’s take a look at is an important step in validating the belief of homogeneous error variances earlier than pooling knowledge in experimental evaluation. In pooled experiments carried out throughout completely different environments or circumstances, it ensures that variances are comparable, enabling the mixed evaluation to be each dependable and significant.
When Bartlett’s take a look at signifies homogeneous variances, pooling knowledge enhances statistical energy and offers a broader understanding of therapy results and interactions. Conversely, if variances are considerably completely different, different approaches equivalent to knowledge transformations must be used to keep up the validity of conclusions. By fastidiously assessing variance homogeneity, researchers can confidently carry out pooled analyses and draw strong inferences from their knowledge.
The weblog is written with nice effort and due analysis by Jignesh Parmar
In an astonishing feat of gravitational sleuthing, astronomers have discovered a mysterious, dense blob of invisible matter embedded in a galaxy whose gentle took 7.3 billion years to succeed in us.
Precisely what this blob may be is at the moment an open query, but it surely’s completely tiny for the gap at which it was detected – simply round one million occasions the mass of the Solar. That is the smallest object to be discovered primarily based on gravity at giant cosmic distances, by an element of about 100.
“That is the lowest-mass object identified to us, by two orders of magnitude, to be detected at a cosmological distance by its gravitational impact,” explains a staff led by astrophysicist Devon Powell on the Max Planck Institute for Astrophysics in Germany.
“This work demonstrates the observational feasibility of utilizing gravitational imaging to probe the million-solar-mass regime far past our native Universe.”
Primarily based on our observations of the Universe, there’s one thing on the market that emits no gentle and solely interacts with the remainder of the Universe by way of gravity.
We name this one thing darkish matter, and there are a number of candidate explanations for what it may be. The consistency of the matter – whether or not it is easy or clumpy – might help scientists slim it down. Nonetheless, as a result of darkish matter emits no gentle, mapping its distribution is difficult.
This brings us to gravity. Every part within the Universe with mass causes spacetime to bend round it – the larger the mass, the larger the spacetime curvature. Think about placing, say, a bowling ball on a trampoline. When you roll a marble throughout the stretched trampoline mat, it should observe the curved path across the bowling ball.
Now think about the bowling ball is a galaxy and the marble is a photon. A set of photons from a distant galaxy touring by way of the spacetime warped by the gravity of a more in-depth galaxy (the bowling ball) will attain us stretched, distorted, and magnified. That is what we name a gravitational lens.
These lenses are an excellent device for learning the distant Universe, since they amplify deep house in a means that know-how can not. However astronomers also can use that stretched and distorted distant gentle to map the distribution of matter within the foreground lens.
That is what Powell and his colleagues got down to do, utilizing an in depth community of telescopes, together with the Inexperienced Financial institution Telescope, the Very Lengthy Baseline Array, and the European Very Lengthy Baseline Interferometric Community, to residence in on a well known gravitational lens system referred to as JVAS B1938+666.
This method consists of a foreground galaxy at a light-travel time of about 7.3 billion years, and a extra distant galaxy at roughly 10.5 billion years’ light-travel time whose gentle grew to become stretched and quadrupled by the foreground galaxy.
The JVAS B1938+666 lens system, with the inset revealing the place of the blob. The white pixels present the tough form of the mass. (Keck/EVN/GBT/VLBA)
One of many photos of the lensed galaxy is a brilliant, smeared arc of sunshine; in that smeared arc, the researchers discovered a pinched type of dimple. This pinch, the researchers ascertained, couldn’t have been created by the lensing galaxy alone. As an alternative, the offender needs to be a clump of mass, a willpower made with a whopping confidence degree of 26 sigma.
“From the primary high-resolution picture, we instantly noticed a narrowing within the gravitational arc, which is the tell-tale signal that we had been onto one thing,” says astronomer John McKean of the College of Groningen within the Netherlands.
“Solely one other small clump of mass between us and the distant radio galaxy might trigger this.”
The mass emits no gentle – not in optical, radio, or infrared wavelengths. It is both utterly darkish or far too dim to see. Because of this there are a number of issues it might be. The main candidates are a clump of darkish matter or a dwarf galaxy that emits too little gentle for us to detect.
Both choice is believable right now, and additional analysis efforts are wanted to find out the id of the offender.
“Given the sensitivity of our information, we had been anticipating to seek out at the very least one darkish object, so our discovery is in keeping with the so-called ‘chilly darkish matter principle’ on which a lot of our understanding of how galaxies type is predicated,” Powell says.
“Having discovered one, the query now could be whether or not we are able to discover extra and whether or not their quantity will nonetheless agree with the fashions.”
Inside the course of every week, ABC completely capitulated to threats from the FCC and right-wing station homeowners, spectacularly screwed up the optics, utterly did not foresee the plain enterprise penalties, after which unconditionally surrendered six days later. I am unable to consider a extra humiliating week for a CEO of Bob Iger’s stature, however we’ll get to that subsequent time after we speak in regards to the enterprise facet of the story.
For now, let’s speak politics.
In some methods, we’re seeing individuals make each too little
and an excessive amount of of this story. When it comes to stifling free speech, it’s most likely much less
important than the firing of Washington Submit op-ed columnist Karen Attiah. It would even be much less
important than the Vichy water that Ezra Klein has been doling out at
the New York Occasions.
With respect to different features, nevertheless, this
is each large and unprecedented. Josh Marshall, whose monitor report is unequaled in these issues, has
argued that the important thing to understanding Trump is dominance and submission. I
would add catharsis, distraction, and probably feral disinformation,
however Marshall is definitely proper about the principle driver. Marshall has
termed this the “bitch slap principle” of politics, and that’s in regards to the
finest description I’ve seen.
The strategy of wanting
overwhelmingly dominant whereas making your opponent feel and look
helpless and weak usually works very properly, however it has a few main
downsides. First off, if it fails, you’ll be able to usually discover the meant roles
reversed, with the bully wanting small and ineffectual. On a considerably
extra refined stage, a give attention to shock-and-awe politics can undermine extra
low-key and infrequently devious ways, significantly “boiling the frog.” If
you begin with boiling water and taunt the frog as you’re throwing it
in, it’s more likely to discover the temperature change.
With the
Colbert firing, CBS—in its try to appease Trump and the
Ellisons—utilized a veneer of believable deniability. It was comically
clear, instantly asserting that the number-one late night time present was
hemorrhaging money (displaying that big hits like Forrest Gump
truly misplaced cash has all the time been the muse of Hollywood
accounting). However the guidelines of the trendy institution press insisted
that the clearly disingenuous declare be given equal protection and
just about no scrutiny.
By comparability, Kimmel’s suspension was an abuse of presidency energy so
flagrant it will make Richard Nixon blush, and it struck a nerve.
Appears fairly clear to me: “the First Modification forbids the federal government from utilizing coercion backed by threats of punishment to suppress speech.” Reward hyperlink. www.nytimes.com/2025/09/19/u…
“Regardless
of the reality or falsity of Kimmel’s comment, the federal government shouldn’t
function the arbiter of fact in public debate.” It’s all to straightforward for
the federal government to make use of a truth-policing energy “as a software to threaten and
punish disfavored audio system.”
The one particular person Bob Iger least needed to talk up spoke up.
Like we stated, dominance-based methods have penalties for missed photographs and so they are typically zero-sum video games. The professional–Kimmel/anti-Trump facet clearly received this final spherical, which signifies that another person misplaced. Clearly, everybody slapped ABC round, however neither Nexstar, Sinclair, nor the administration got here out of this wanting stronger.
Elliott Morris argues that the backlash confirmed that the CEOs of firms like Disney don’t notice how unpopular Trump truly is. He is perhaps proper, however one factor’s for sure: they notice it now greater than they did a number of days in the past.
Bayesian statistics affords a versatile, adaptive framework for making buying and selling choices by updating beliefs with new market knowledge. In contrast to conventional fashions, Bayesian strategies deal with parameters as chances, making them best for unsure, fast-changing monetary markets.
They’re utilized in threat administration, mannequin tuning, classification, and incorporating knowledgeable views or different knowledge. Instruments like PyMC and Bayesian optimisation make it accessible for quants and merchants aiming to construct smarter, data-driven methods.
This weblog covers:
Need to ditch inflexible buying and selling fashions and actually harness the ability of incoming market data? Think about a system that learns and adapts, identical to you do, however with the precision of arithmetic. Welcome to the world of Bayesian statistics, a game-changing framework for algorithmic merchants. It’s all about making knowledgeable choices by logically mixing what you already know with what the market is telling you proper now.
Let’s discover how this will sharpen your buying and selling edge!
This strategy contrasts with the standard, or “frequentist,” view of likelihood, which frequently sees chances as long-run frequencies of occasions and parameters as mounted, unknown constants (Neyman, 1937).
Bayesian statistics, then again, treats parameters themselves as random variables about which we are able to have beliefs and replace them as extra knowledge is available in (Gelman et al., 2013). Truthfully, this feels tailored for buying and selling, would not it? In any case, market circumstances and relationships are infrequently set in stone. So, let’s leap in and see how you should utilize Bayesian stats to get a leg up within the fast-paced world of finance and algorithmic buying and selling.
Conditions
To completely grasp the Bayesian strategies mentioned on this weblog, it is very important first set up a foundational understanding of likelihood, statistics, and algorithmic buying and selling.
For a conceptual introduction to Bayesian statistics, Bayesian Inference Strategies and Equation Defined with Examples affords an accessible rationalization of Bayes’ Theorem and the way it applies to uncertainty and decision-making, foundational to making use of Bayesian fashions in markets.
What You may Be taught:
The core thought behind Bayesian pondering is updating beliefs with new proof.
Understanding Bayes’ Theorem: your mathematical software for perception updating.
Why Bayesian strategies are an amazing match for the uncertainties of economic markets.
Sensible examples of Bayesian statistics in algorithmic buying and selling:
Estimating mannequin parameters that adapt to new knowledge.
Constructing easy predictive fashions (like Naive Bayes for market course).
Incorporating knowledgeable views or different knowledge into your fashions.
The Execs, Cons, and Current Tendencies of Utilizing Bayesian Approaches in Quantitative Finance.
The Bayesian Fundamentals
Prior Beliefs, New Proof, Up to date Beliefs
Okay, let’s break down the basic magic of Bayesian statistics. At its core, it is constructed on a splendidly easy but extremely highly effective thought: our understanding of the world just isn’t static; it evolves as we collect extra data.
Give it some thought like this: you have bought a brand new buying and selling technique you are mulling over.
Prior Perception (Prior Chance): Primarily based in your preliminary analysis, backtesting on historic knowledge, or perhaps a hunch, you will have some preliminary perception about how worthwhile this technique is perhaps. For example you assume there is a 60% likelihood it is going to be worthwhile. That is your prior.
New Proof (Probability): You then deploy the technique on a small scale or observe its hypothetical efficiency over just a few weeks of dwell market knowledge. This new knowledge is your proof. The chance operate tells you ways possible this new proof is, given completely different underlying states of the technique’s true profitability.
Up to date Perception (Posterior Chance): After observing the brand new proof, you replace your preliminary perception. If the technique carried out nicely, your confidence in its profitability would possibly enhance from 60% to, say, 75%. If it carried out poorly, it’d drop to 40%. This up to date perception is your posterior.
This entire strategy of tweaking your beliefs primarily based on new data is neatly wrapped up and formalised by what is known as the Bayes’ Theorem.
Bayes’ Theorem: The Engine of Bayesian Studying
So, Bayes’ Theorem is the precise formulation that ties all these items collectively. You probably have a speculation (let’s name it H) and a few proof (E), the theory seems to be like this:
Bayes’ Theorem:
( P(H mid E) = frac{P(E mid H) cdot P(H)}{P(E)} )
The place:
P(H|E) is the Posterior Chance: The likelihood of your speculation (H) being true after observing the proof (E). That is what you need to calculate; your up to date perception.
P(E|H) is the Probability: The likelihood of observing the proof (E) in case your speculation (H) have been true. For instance, in case your speculation is “this inventory is bullish,” how possible is it to see a 2% worth enhance right now?
P(H) is the Prior Chance: The likelihood of your speculation (H) being true earlier than observing the brand new proof (E). That is your preliminary perception.
P(E) is the Chance of the Proof (additionally referred to as Marginal Probability or Normalising Fixed): The general likelihood of observing the proof (E) below all attainable hypotheses. It is calculated by summing (or integrating) P(E|H) × P(H) over each attainable H. This ensures the posterior chances sum as much as 1.
Let’s attempt to make this much less summary with a fast buying and selling situation.
Instance: Is a Information Occasion Bullish for a Inventory?
Suppose an organization is about to launch an earnings report.
Speculation (H): The earnings report will probably be considerably higher than anticipated (a “constructive shock”).
Prior P(H): Primarily based on analyst chatter and up to date sector efficiency, you imagine there is a 30% likelihood of a constructive shock. So, P(H) = 0.30.
Proof (E): Within the hour earlier than the official announcement, the inventory worth jumps 1%.
Probability P(E|H): You recognize from previous expertise that if there is a genuinely constructive shock brewing, there is a 70% likelihood of seeing such a pre-announcement worth leap attributable to insider data or some sharp merchants catching on early. So, P(E|H) = 0.70.
Chance of Proof P(E): This one’s a bit of extra concerned as a result of the worth may leap for different causes, too, proper? Possibly the entire market is rallying, or it is only a false hearsay. For example:
The likelihood of the worth leap if it is a constructive shock (P(E|H)) is 0.70 (as above).
The likelihood of the worth leap if it is not a constructive shock (P(E|not H)) is, say, 0.20 (it is much less possible, however attainable).
Since P(H) = 0.30, then P(not H) = 1 – 0.30 = 0.70.
Increase! After seeing that 1% worth leap, your perception that the earnings report will probably be a constructive shock has shot up from 30% to 60%! This up to date likelihood can then inform your buying and selling determination, maybe you are now extra inclined to purchase the inventory or regulate an current place.
After all, this can be a super-simplified illustration. Actual monetary fashions are juggling a considerably larger variety of variables and far more complicated likelihood distributions. However the lovely factor is, that core logic of updating your beliefs as new data is available in? That stays precisely the identical.
Why Bayesian Statistics Shines in Algorithmic Buying and selling
Monetary markets are a wild experience, stuffed with uncertainty, continuously altering relationships (non-stationarity, if you wish to get technical), and infrequently, not a number of knowledge for these actually uncommon, out-of-the-blue occasions. Bayesian strategies supply a number of benefits on this atmosphere:
Handles Uncertainty Like a Professional: Bayesian statistics would not simply offer you a single quantity; it naturally offers with uncertainty by utilizing likelihood distributions for parameters, as a substitute of pretending they’re mounted, recognized values (Bernardo & Smith, 2000). This provides you a way more real looking image of what would possibly occur.
Updating Beliefs with New Information: Algorithmic buying and selling methods continuously course of new market knowledge. Bayesian updating permits fashions to adapt dynamically. As an illustration, the volatility of an asset is not fixed; a Bayesian mannequin can replace its volatility estimate as new worth ticks arrive.
Working with Small Information Units: Conventional frequentist strategies usually require giant pattern sizes for dependable estimates. Bayesian strategies, nevertheless, may give you fairly wise insights even with restricted knowledge, as a result of they allow you to usher in “informative priors” – mainly, your current information from specialists, comparable markets, or monetary theories (Ghosh et al., 2006). This can be a lifesaver while you’re making an attempt to mannequin uncommon occasions or new property that do not have a protracted historical past.
Mannequin Comparability and Averaging: Bayesian strategies present a extremely stable means (e.g., utilizing Bayes components or posterior predictive checks) to check completely different fashions and even common out their predictions. This usually results in extra strong and dependable outcomes (Hoeting et al., 1999).
Lets You Weave in Qualitative Insights: Acquired a robust financial motive why a sure parameter ought to in all probability fall inside a particular vary? Priors offer you a proper strategy to combine that sort of qualitative hunch or knowledgeable opinion together with your exhausting quantitative knowledge.
Clearer Interpretation of Chances: When a Bayesian mannequin tells you “there is a 70% likelihood this inventory will go up tomorrow,” it means precisely what it appears like: it’s your present diploma of perception. This is usually a lot extra easy to behave on than making an attempt to interpret p-values or confidence intervals alone (Berger & Berry, 1988).
Sensible Bayesian Purposes in Algorithmic Buying and selling
Alright, sufficient idea! Let’s get right down to brass tacks. How are you going to truly use Bayesian statistics in your buying and selling algorithms?
1. Adaptive Parameter Estimation: Conserving Your Fashions Recent
So many buying and selling fashions lean closely on parameters – just like the lookback window in your shifting common, the velocity of imply reversion in a pairs buying and selling setup, or the volatility guess in an choices pricing mannequin. However right here’s the catch: market circumstances are all the time shifting, so parameters that have been golden yesterday is perhaps suboptimal right now.
That is the place Bayesian strategies are tremendous helpful. They allow you to deal with these parameters not as mounted numbers, however as distributions that get up to date as new knowledge rolls in. Think about you are estimating the typical each day return of a inventory.
Prior: You would possibly begin with a obscure prior thought(e.g., a traditional distribution centred round 0 with a large unfold (normal deviation)) or a extra educated guess primarily based on how comparable shares within the sector have carried out traditionally.
Probability: As every new buying and selling day supplies a return, you calculate the chance of observing that return given completely different attainable values of the true common each day return.
Posterior: Bayes’ theorem combines the prior and chance to provide you an up to date distribution for the typical each day return. This posterior turns into the prior for the following day’s replace.It is a steady studying loop!
Scorching Development Alert: Strategies like Kalman Filters (that are inherently Bayesian) are extensively used for dynamically estimating unobserved variables, just like the “true” underlying worth or volatility, in noisy market knowledge (Welch & Bishop, 2006). One other space is Bayesian regression, the place the regression coefficients (e.g., the beta of a inventory) are usually not mounted factors however distributions that may evolve. For extra on regression in buying and selling, you would possibly need to try how Regression is Utilized in Buying and selling.
Simplified Python Instance: Updating Your Perception a couple of Coin’s Equity (Assume Market Ups and Downs)
For example we need to get a deal with on the likelihood of a inventory worth going up (we’ll name it ‘Heads’) on any given day. This can be a bit like making an attempt to determine if a coin is honest or biased.
Python Code:
Output:
Preliminary Prior: Alpha=1, Beta=1
Noticed Information: 6 'up' days, 4 'down' days
Posterior Perception: Alpha=7, Beta=5
Up to date Estimated Chance of an 'Up' Day: 0.58
95% Credible Interval for p_up: (0.31, 0.83)
On this code:
We begin off with a Beta(1,1) prior, which is uniform and suggests any likelihood of an ‘up’ day is equally possible.
Then, we observe 10 days of market knowledge with 6 ‘up’ days.
The posterior distribution turns into Beta(1+6, 1+4) = Beta(7, 5).
Our new level estimate for the likelihood of an ‘up’ day is 7 / (7+5) = 0.58, or 58%.
The credible interval offers us a variety of believable values.
The graph supplies a transparent visible for this belief-updating course of. The flat blue line represents our preliminary, uninformative prior, the place any likelihood for an ‘up’ day was thought-about equally possible. In distinction, the orange curve is the posterior perception, which has been sharpened and knowledgeable by the noticed market knowledge. The height of this new curve, centered round 0.58, represents our up to date, most possible estimate, whereas its extra concentrated form signifies our decreased uncertainty now that now we have proof to information us.
This can be a toy instance, but it surely exhibits the mechanics of how beliefs get up to date. In algorithmic buying and selling, this could possibly be utilized to the likelihood of a worthwhile commerce for a given sign or the likelihood of a market regime persisting.
Subsequent up, let’s speak about Naive Bayes. It is a easy probabilistic classifier that makes use of Bayes’ theorem, however with a “naive” (or to illustrate, optimistic) assumption that each one your enter options are unbiased of one another. Regardless of its simplicity, it may be surprisingly efficient for duties like classifying whether or not the following day’s market motion will probably be ‘Up’, ‘Down’, or ‘Sideways’ primarily based on present indicators. (Rish, 2001)
Right here’s the way it works (conceptually):
Outline Options: These could possibly be technical indicators (e.g., RSI < 30, MACD crossover), worth patterns (e.g., yesterday was an engulfing candle), and even sentiment scores from monetary information.
Accumulate Coaching Information: Collect historic knowledge the place you will have these options and the precise consequence (Up/Down/Sideways).
Calculate Chances from Coaching Information:
Prior Chances of Outcomes: P(Up), P(Down), P(Sideways) – merely the frequency of those outcomes in your coaching set.
Probability of Options given Outcomes: P(Feature_A | Up), P(Feature_B | Up), and many others. As an illustration, “What is the likelihood RSI < 30, given the market went Up the following day?”
Make a Prediction: For brand new knowledge (right now’s options):
Calculate the posterior likelihood for every consequence:
The end result with the best posterior likelihood is your prediction.
Python Snippet Concept (Only a idea, you’d want sklearn for this):
Python Code:
Output:
Naive Bayes Classifier Accuracy (on dummy knowledge): 0.43
This accuracy rating of 0.43 signifies the mannequin accurately predicted the market’s course 43% of the time on the unseen take a look at knowledge. Since this result’s beneath 50% (the equal of random likelihood), it means that, with the present dummy knowledge and options, the mannequin doesn’t show predictive energy. In a real-world software, such a rating would sign that the chosen options or the mannequin itself is probably not appropriate, prompting a re-evaluation of the strategy or additional function engineering.
This little snippet offers you the fundamental movement. Constructing an actual Naive Bayes classifier for buying and selling takes cautious thought of which options to make use of (that is “function engineering”) and rigorous testing (validation). That “naive” assumption that each one options are unbiased may not be completely true within the messy, interconnected world of markets, but it surely usually offers you a surprisingly good place to begin or baseline mannequin. Interested in the place to study all this? Don’t fear, pal, we’ve bought you lined! Try this course.
3. Bayesian Danger Administration (e.g., Worth at Danger – VaR)
You’ve got in all probability heard of Worth at Danger (VaR), it is a frequent strategy to estimate potential losses. However conventional VaR calculations can typically be a bit static or depend on simplistic assumptions. Bayesian VaR permits for the incorporation of prior beliefs about market volatility and tail threat, and these beliefs might be up to date as new market shocks happen. This will result in threat estimates which can be extra responsive and strong, particularly when markets get uneven.
As an illustration, if a “black swan” occasion happens, a Bayesian VaR mannequin can adapt its parameters far more rapidly to mirror this new, higher-risk actuality. A purely historic VaR, then again, would possibly take lots longer to catch up.
4. Bayesian Optimisation for Discovering Goldilocks Technique Parameters
Discovering these “good” parameters in your buying and selling technique (like the right entry/exit factors or the perfect lookback interval) can really feel like trying to find a needle in a haystack. Bayesian optimisation is a significantly highly effective method that may assist right here. It cleverly makes use of a probabilistic mannequin (usually a Gaussian Course of) to mannequin the target operate (like how worthwhile your technique is for various parameters) and selects new parameter units to check in a means that balances exploration (making an attempt new areas) and exploitation (refining recognized good areas) (Snoek et al., 2012). This may be far more environment friendly than simply making an attempt each mixture (grid search) or selecting parameters at random.
Scorching Development Alert:Bayesian optimisation is a rising star within the broader machine studying world and is extremely well-suited for fine-tuning complicated algorithmic buying and selling methods, particularly when operating every backtest takes a number of computational horsepower.
5. Weaving in Various Information and Skilled Hunches (Opinions)
Today, quants are more and more “different knowledge” sources, issues like satellite tv for pc photos, the overall temper on social media, or bank card transaction tendencies. Bayesian strategies offer you a extremely pure strategy to combine such numerous and infrequently unstructured knowledge with conventional monetary knowledge. You’ll be able to set your priors primarily based on how dependable or robust you assume the sign from another knowledge supply is.
And it is not nearly new knowledge varieties. What if a seasoned portfolio supervisor has a robust conviction a couple of explicit sector due to some geopolitical growth that is tough to quantify? That “knowledgeable opinion” can truly be formalised into a previous distribution, permitting it to affect the mannequin’s output proper alongside the purely data-driven alerts.
Current Trade Buzz in Bayesian Algorithmic Buying and selling
Whereas Bayesian strategies have been round in finance for some time, just a few areas are actually heating up and getting a number of consideration recently:
Bayesian Deep Studying (BDL): You know the way conventional deep studying fashions offer you a single prediction however do not actually let you know how “certain” they’re? BDL is right here to alter that! It combines the ability of deep neural networks with Bayesian ideas to provide predictions with related uncertainty estimates (Neal, 1995; Gal & Ghahramani, 2016). That is essential for monetary purposes the place figuring out the mannequin’s confidence is as essential because the prediction itself. For instance, think about a BDL mannequin not simply predicting a inventory worth, but in addition saying it is “80% assured the worth will land between X and Y”.
Probabilistic Programming Languages (PPLs): Languages like Stan, PyMC3 (Salvatier et al., 2016), and TensorFlow Chance are making it simpler for quants to construct and estimate complicated Bayesian fashions with out getting slowed down within the low-level mathematical particulars of inference algorithms like Markov Chain Monte Carlo (MCMC). This simpler entry is absolutely democratising using refined Bayesian strategies throughout the board (Carpenter et al., 2017).
Subtle MCMC and Variational Inference: As our fashions get extra formidable, the computational grunt work wanted to suit them additionally grows. Fortunately, researchers are continuously cooking up extra environment friendly MCMC algorithms (like Hamiltonian Monte Carlo) and speedier approximate strategies like Variational Inference (VI) (Blei et al., 2017), making bigger Bayesian fashions tractable for real-world buying and selling. If you wish to study extra about MCMC, QuantInsti has a wonderful weblog on Introduction to Monte Carlo Evaluation.
Dynamic Bayesian Networks for Recognizing Market Regimes: Monetary markets usually appear to flip between completely different “moods” or “regimes”, assume high-volatility vs. low-volatility durations, or bull vs. bear markets. Dynamic Bayesian Networks (DBNs) can mannequin these hidden market states and the chances of transitioning between them, permitting methods to adapt their conduct accordingly (Murphy, 2002).
The Upsides and Downsides: What to Hold in Thoughts
Like all highly effective software, Bayesian strategies include their very own set of execs and cons.
Benefits:
Intuitive framework for updating beliefs.
Quantifies uncertainty straight.
Works nicely with restricted knowledge by utilizing priors.
Permits incorporation of knowledgeable information.
Gives a coherent strategy to evaluate and mix fashions.
Limitations:
Selection of Prior: The choice of a previous might be subjective and may considerably affect the posterior, particularly with small datasets. A poorly chosen prior can result in poor outcomes. Whereas strategies for “goal” or “uninformative” priors exist, their appropriateness is commonly debated.
Computational Value: For complicated fashions, estimating the posterior distribution (particularly utilizing MCMC strategies) might be computationally intensive and time-consuming, which is perhaps a constraint for high-frequency buying and selling purposes.
Mathematical Complexity: Whereas PPLs are useful, a stable understanding of likelihood idea and Bayesian ideas remains to be wanted to use these strategies accurately and interpret outcomes.
Continuously Requested Questions
Q. What makes Bayesian statistics completely different from conventional (frequentist) strategies in buying and selling? Bayesian statistics treats mannequin parameters as random variables with a and permits beliefs to be up to date with new knowledge. In distinction, frequentist strategies assume parameters are mounted and require giant knowledge samples. Bayesian pondering is extra dynamic and well-suited to the non-stationary, unsure nature of economic markets.
Q. How does Bayes’ Theorem assist in buying and selling choices? Are you able to give an instance? Bayes’ Theorem is used to replace chances primarily based on new market data. For instance, if a inventory worth jumps 1% earlier than earnings, and previous knowledge suggests this usually precedes a constructive shock, Bayes’ Theorem helps revise your confidence in that speculation, turning a 30% perception into 60%, which may straight affect your commerce.
Q. What are priors and posteriors in Bayesian fashions, and why do they matter in finance? A prior displays your preliminary perception (from previous knowledge, idea, or knowledgeable views), whereas a posterior is the up to date perception after contemplating new proof. Priors assist enhance efficiency in low-data or high-uncertainty conditions and permit integration of different knowledge or human instinct in monetary modelling.
Q. What varieties of buying and selling issues are finest suited to Bayesian strategies? Bayesian strategies are perfect for:
Parameter estimation that adapts (instance, volatility, beta, shifting common lengths)
Classification duties with Naive Bayes fashions These approaches assist construct extra responsive and strong methods.
Q. Can Bayesian strategies work with restricted or noisy market knowledge? Sure! Bayesian strategies shine in low-data environments by incorporating informative priors. In addition they deal with uncertainty naturally, representing beliefs as distributions slightly than mounted values, essential when modelling uncommon market occasions or new property.
Q. How is Bayesian optimisation utilized in buying and selling technique design? Bayesian optimisation is used to tune technique parameters (like entry/exit thresholds) effectively. As a substitute of brute-force grid search, it balances exploration and exploitation utilizing a probabilistic mannequin (instance, Gaussian Processes), making it good for expensive backtesting environments.
Q. Are easy fashions like Naive Bayes actually helpful in buying and selling? Sure, Naive Bayes classifiers can function light-weight baseline fashions to foretell market course utilizing indicators like RSI, MACD, or sentiment scores. Whereas the belief of unbiased options is simplistic, these fashions can supply quick and surprisingly stable predictions, particularly with well-engineered options.
Q. How does Bayesian pondering improve threat administration? Bayesian fashions, like Bayesian VaR (a, replace threat estimates dynamically as new knowledge (or shocks) arrive, not like static historic fashions. This makes them extra adaptive to unstable circumstances, particularly throughout uncommon or excessive occasions.
Q. What instruments or libraries are used to construct Bayesian buying and selling fashions? Standard instruments embody:
PyMC and PyMC3 (Python)
Stan (through R or Python)
TensorFlow Chance These help strategies like MCMC and variational inference, enabling the event of every little thing from easy Bayesian regressions to Bayesian deep studying fashions.
Q. How can I get began with Bayesian strategies in buying and selling? Begin with small tasks:
Take a look at a Naive Bayes classifier on market course.
Use Bayesian updating for a method’s win price estimation.
Attempt parameter tuning with Bayesian optimisation.
Then discover extra superior purposes and think about studying assets equivalent to Quantra’s programs on machine studying in buying and selling and EPAT for a complete algo buying and selling program with Bayesian strategies.
Conclusion: Embrace the Bayesian Mindset for Smarter Buying and selling!
So, there you will have it! Bayesian statistics affords an extremely highly effective and versatile strategy to navigate the unavoidable uncertainties that include monetary markets. By providing you with a proper strategy to mix your prior information with new proof because it streams in, it helps merchants and quants construct algorithmic methods which can be extra adaptive, strong, and insightful.
Whereas it is not a magic bullet, understanding and making use of Bayesian ideas may help you progress past inflexible assumptions and make extra nuanced, probability-weighted choices. Whether or not you are tweaking parameters, classifying market circumstances, keeping track of threat, or optimising your total technique, the Bayesian strategy encourages a mindset of steady studying, and that’s completely important for long-term success within the continuously shifting panorama of algorithmic buying and selling.
Begin small, maybe by experimenting with how priors influence a easy estimation, or by making an attempt out a Naive Bayes classifier. As you develop extra snug, the wealthy world of Bayesian modeling will open up new avenues for enhancing your buying and selling edge.
For those who’re severe about taking your quantitative buying and selling expertise to the following degree, think about Quantra’s specialised programs like “Machine Studying & Deep Studying for Buying and selling” to reinforce Bayesian strategies, or EPAT for complete, industry-leading algorithmic buying and selling certification. These equip you to sort out complicated markets with a major edge.
Neyman, J. (1937). Define of a idea of statistical estimation primarily based on the classical idea of likelihood. Philosophical Transactions of the Royal Society of London. Collection A, Mathematical and Bodily Sciences, 236(767), 333-380. https://royalsocietypublishing.org/doi/10.1098/rsta.1937.0005
Gal, Y., & Ghahramani, Z. (2016). Dropout as a Bayesian approximation: Representing mannequin uncertainty in deep studying. Within the Worldwide Convention on machine studying (pp. 1050-1059). PMLR. https://proceedings.mlr.press/v48/gal16.html
Salvatier, J., Wiecki, T. V., & Fonnesbeck, C. (2016). Probabilistic programming in Python utilizing PyMC3. PeerJ Laptop Science, 2, e55. https://peerj.com/articles/cs-55/
Carpenter, B., Gelman, A., Hoffman, M. D., Lee, D., Goodrich, B., Betancourt, M., … & Riddell, A. (2017). Stan: A probabilistic programming language. Journal of Statistical Software program, 76(1), 1-32. https://www.jstatsoft.org/article/view/v076i01
Disclaimer: This weblog put up is for informational and academic functions solely. It doesn’t represent monetary recommendation or a advice to commerce any particular property or make use of any particular technique. All buying and selling and funding actions contain important threat. At all times conduct your personal thorough analysis, consider your private threat tolerance, and think about looking for recommendation from a professional monetary skilled earlier than making any funding choices.
At the moment laptop programs have gotten a brand new development in up to date instances. Such sorts of short-term programs are extremely popular for the tenth & twelfth class college students since after showing within the respective Board exams, college students can squeeze in the most effective laptop programs to enhance their odds of employability. These laptop programs are actually good for the tenth & twelfth college students since after their exams they’ve two to 3 months till the beginning of their subsequent class.
Suppose you’ve gotten accomplished your twelfth with an thrilling area ‘Computer systems’ or have any curiosity on this discipline, then there are a number of short-term programs that can lead you to a really perfect job. Right here, we’ve got searched the most effective Pc programs after the tenth or twelfth, proceed studying to search out the entire record right here, and choose the appropriate course for you.
10 Greatest Pc Programs After twelfth in India
1. Knowledge Entry Operator Course
Probably the most fundamental and short-term laptop programs that college students can select after twelfth, is designed to sharpen the scholar’s laptop typing & knowledge entry expertise that could be a course of to enter knowledge within the computerized database or spreadsheet.
This specific course is suitable for college kids who don’t search or need superior information of computer systems; it’s going to assist you to get entry-level knowledge entry or typing jobs within the firms.
The period of the course is mostly for six months however can differ from one institute to a different.
2. Programming Language Course
The programming language is called the bottom of the IT world. You are able to do nothing with out Programming. You could choose any language as per your alternative & understanding like C, C ++, PYTHON, JAVA, HACK, JAVASCRIPT, NET, ASP, RUBY, PERL, SQL, PHP, and extra. After doing the course, you’re going to get a job as a software program developer or Programmer.
However, for those who study at a sophisticated stage, then you’ll be able to create your software program or sport. Studying the programming language is the most effective laptop course that college students should contemplate after commencement for the Engineering graduates and one who will jam up with the strains of codes and create one thing actually good within the phrases of software program & internet purposes.
MS Workplace is a 3 month to a six-month program the place college students will likely be taught concerning the distinguished apps of Microsoft Workplace equivalent to MS Phrase, MS Excel, MS Powerpoint, and MS Entry. College students will study to make use of the purposes regularly.
College students after getting the certificates or diploma within the Microsoft Workplace Certificates Programme will grow to be environment friendly on the office too. Certificates or Diploma holders are properly suited to the front-end jobs the place the computer systems are used equivalent to outlets, eating places, motels, and extra.
4. Pc-Aided Design & Drawing or CADD
College students with a technical background could go for the CADD short-term course. This course helps the scholars to study completely different CAD applications & Softwares equivalent to Fusion360, Infraworks, AutoCAD, and extra. The short-term and finest laptop course, identical to CADDD will enhance the know-how of an Engineering graduate whereas ITI diploma or diploma holders could simply land on drafting associated presents after their course completion.
5. Pc {Hardware} Upkeep
There are some college students who’re very a lot excited about {hardware} than software program. Suppose you do not need to go for the above fields, then that is one wonderful possibility. The course of laptop {hardware} upkeep is finished after your twelfth Pc. This course teaches you about {hardware} upkeep and different technical particulars.
6. Animation and VFX
The a part of designing, Animation, and VFX programs are shortly changing into the preferred laptop course that college students contemplate after twelfth when on the lookout for the sector of specialization. In response to the report, the animation trade in India is predicted to develop by 15 to twenty% to the touch USD 23bn by 2021. A lot of the cities in India present diploma programs on this discipline of Animation and VFX with a period of 6 months to 2 years.
Thus, for those who like to attract and permit your creativeness to go wild on paper, then you might be properly suited to the course.
7. Digital Advertising
College students who need to make their profession within the discipline than doing the digital advertising course would be the neatest thing after the twelfth. Digital advertising at this time is probably the most rising profession. There’re over 4 lakh jobs accessible within the Advertising area. Most enterprise house owners want the assistance of the digital advertising group for selling their manufacturers and companies.
The digital advertising trade is predicted to generate over 2 million jobs by an finish of 2020. Thus, the longer term on this trade is kind of promising. Irrespective of whether or not it’s a massive participant or a small start-up, firms wish to make investments massively in digital advertising actions. They’re on the lookout for individuals who will have the ability to develop & implement the digital advertising campaigns as per their wants.
8. Tally ERP 9
It’s the most effective laptop course to contemplate after twelfth commerce, however not only for the commerce college students, however any stream college students could be part of the course.
Tally Enterprise Useful resource Planning or Tally ERP is the software program that’s used to keep up accounts within the firm & ERP 9 is the newest model. It’s the certification and diploma laptop course the place it’s possible you’ll study monetary administration, taxation, account administration, and extra.
After the course completion, it’s possible you’ll work because the tally operator or assistant the place GST and Revenue tax returns are filed, and as a brisker you must do some fundamental works just like the purchases & gross sales entries and extra.
9. Cell App Growth
Cellphones or Smartphones at this time are an indispensable a part of all people’s lives. Proper from indulging in on-line procuring to meals ordering and taking part in video games, there’s an app for the whole lot these days. It’s a development, which has made cellular app growth the quickest rising profession paths.
The cellular app developer is mostly accountable for designing & constructing impactful cellular purposes for organizations that need to higher the client engagement practices.
These short-term programs after twelfth sometimes have a period of 6 months, though this may differ from one institute to a different.
10. Graphic Designing
Becoming a member of the Graphic Designing laptop course after your twelfth will offer you a tremendous platform to show your inventive expertise. With the onset of computer systems, the stream of design can be utilized in every single place & has acquired a number of purposes in numerous fields.
After the completion of this laptop course, the scholar has an choice to pursue many profession choices favored to design that embody;
Company or Company Graphics designer
Graphics designer (Freelance or impartial)
Model and Visible Id supervisor
Graphic designer (with magazines or web sites or media or publishing corporations)
Printing specialist
Artistic director
Wrapping Up
So, these are a number of the extremely most well-liked laptop programs by the scholars after the tenth and twelfth. Hope the record of programs has helped you to know your course choice after the twelfth. Ensure you select the most effective laptop course and many of the institutes are actually providing on-line lessons as a result of present pandemic. Better of Luck!
Final week in Cambridge was Hinton bonanza. He visited the college city the place he was as soon as an undergraduate in experimental psychology, and gave a sequence of back-to-back talks, Q&A classes, interviews, dinners, and so forth. He was stopped on the road by random passers-by who recognised him from the lecture, college students and postdocs requested to take a selfie with him after his packed lectures.
Issues are very totally different from the final time I met Hinton in Cambridge: I used to be a PhD pupil, round 12 years in the past, in a Bayesian stronghold protected from deep studying affect. There was the same old electronic mail a couple of visiting tutorial, with a possibility to place your title down in the event you needed a 30 minute 1:1 dialog with him. He instructed us he discovered how the mind labored (once more)! The concept he shared again then would ultimately remodel to capsule networks. In fact everybody in our lab knew his work, however folks did not fairly go as loopy.
Whereas the craziness is partly defined by the success of deep studying, the Turing award, and so forth, it’s protected to say that his current change of coronary heart on AI existential danger performed a giant position, too. I’ve to say, given all of the press protection I already learn, I wasn’t anticipating a lot from the talks by means of content material. However I used to be fallacious there, the talks truly laid out a considerably technical argument. And it labored – some very good colleagues at the moment are contemplating a change of their analysis path in the direction of helpful AI.
I loved the talks, however did I purchase the arguments? I suppose I by no means actually do. So I assumed I will attempt my finest to put in writing it up right here, adopted by a pair factors of criticism I’ve been fascinated about since then. Although referring to many matters, together with subjective experiences and emotions LLMs might need, he very clearly stated he solely is certified to touch upon the variations between organic and digital intelligences, which he has studied for many years. Thus, I’ll deal with this argument, and whether or not this could, in itself, persuade you to alter or replace your views on AI and X-risk.
Abstract
Hinton compares intelligence on digital and analogue {hardware}.
Analogue {hardware} permits for decrease power price however at the price of mortality: algorithm and {hardware} are inseparable – the argument goes.
Digital intelligence has two benefits: aggregating studying from parallel experiences, and backpropagation which is implausible on analogue {hardware}
Hinton concludes these benefits can/will result in superhuman digital intelligence.
I critically consider the claims about each parallelism and the prevalence of backprop over biologically believable algorithms
Mortal Computation
For a very long time Hinton, and others, thought of our present neural network-based “synthetic brains”, which run on digital computer systems, to be inferior to organic brains. Digital neural networks fall quick on energy-efficiency: organic brains devour a lot much less power regardless that by some measures they’re orders of magnitude larger and extra advanced than at the moment’s digital neural networks.
Hinton subsequently got down to construct extra energy-efficient “brains” primarily based on analogue {hardware}. Digital computer systems, he argues, obtain good separation of software program and {hardware} by working on the stage of abstraction of discrete bits. This allows computation that runs on one pc to be precisely reproduced on another digital pc. On this sense, the software program is immortal: if the {hardware} dies, the algorithm can stay on on one other pc. This immortality comes at a excessive power value: guaranteeing digital computer systems work precisely, they devour numerous power.
That is in distinction with analogue {hardware}, which can comprise flaws and slight variations in conductances. Thus each analogue pc is barely totally different, and studying algorithms operating in them should adapt to the imperfections of analogue {hardware}. Whereas they might devour rather a lot much less power, this additionally implies that a “mannequin” educated on one analogue machine can’t be simply ported to a different piece of {hardware} because it has tailored to the precise flaws and imprecisions of the chip it was educated on. Brains operating on analogue {hardware} are mortal: as soon as the {hardware} dies, the algorithm dies with it.
tldr: anaogue intelligence is power environment friendly however mortal, digital intelligence is immortal however energy-hungry
Benefits of digital brains
Hinton then realised that studying algorithms operating on digital units have benefits in comparison with “mortal” algorithms operating on analogue {hardware}.
Parallelism: Since computation is transportable, parallel copies of the identical mannequin could be run, and data/data could be exchanged between these copies utilizing high-bandwidth sharing of weights or gradient updates. Consequently, a digital “thoughts” may be performing tens of 1000’s of duties in parallel, then mixture the learnings from every of those parallel actions right into a single mind. In contrast, analogue brains can’t be parallelised this manner, as a result of the imprecision of {hardware} makes speaking details about the contents of the mannequin unimaginable. One of the best they will do is to “inform one another” what they discovered, and alternate info utilizing an inefficient type of data distillation.
Backpropagation: As well as, an additional benefit is that digital {hardware} permits for the implementation of algorithms like back-propagation. Hinton argued for a very long time that backpropagation appears biologically implausible, and can’t be carried out on analogue {hardware}. One of the best studying algorithms Hinton might provide you with for mortal computation is the forward-forward algorithm, which is resembles evolution methods. Its updates are rather a lot noisier in comparison with backpropagated gradients, and it actually would not scale to any first rate sized studying drawback.
These two observations: that digital computation could be parallelised, and permits a superior studying algorithm, backpropagation, which analogue brains can not implement, lead Hinton to conclude that digital brains will ultimately change into smarter than organic brains, and primarily based on current progress he believes this may occasionally occur a lot sooner he had beforehand thought, inside the subsequent 5-20 years.
Does the argument maintain water?
I can see quite a lot of methods wherein the brand new arguments laid out for why digital ‘brains’ shall be superior to organic ones might be attacked. Listed here are the 2 details of counterarguments:
How people be taught vs how Hinton’s brains be taught
Hinton’s argument truly critically hinges on synthetic neural networks being as environment friendly at studying from any single interplay as organic brains are. In spite of everything, it would not matter what number of parallel copies of an ML algorithm you run if the quantity of “studying” you get from every of these interactions is orders of magnitude smaller than what a human would be taught. So let’s take a look at this extra intently.
Hinton truly thought of a really restricted type of studying: imitation studying or distillation. He argues that when Alice teaches one thing to Bob, Bob will change the weights of his mind in order that he turns into extra more likely to say what Alice simply instructed her sooner or later. This can be how an LLM may be taught, nevertheless it’s not how people be taught from interplay. Let’s contemplate an instance.
As a non-native English speaker, I keep in mind once I first encountered the idea of irreversible binomials in English. I watched a language studying video whose content material was quite simple, one thing like: “We at all times say apples and oranges, by no means oranges and apples. We at all times say black and white, by no means white and black. and so forth…” Now, upon listening to this, I understood what this meant. I learnt the rule. Subsequent time I stated one thing about apples and oranges, I remembered that I should not say “oranges and apples”. Maybe I made a mistake, I remembered the rule exists, felt embarrassed, and doubtless generated some adverse reinforcement from which additional studying occurred. Listening to this one sentence modified how I apply this rule in plenty of particular circumstances, it did not make me extra more likely to go round and inform folks “We at all times say apples and oranges, by no means oranges and apples”, I understood tips on how to apply the rule to alter my behaviour in related circumstances.
Suppose you needed to show an LLM a brand new irreversible binomial, for instance that it ought to by no means say “LLMs and people”, it ought to at all times say “people and LLMs” as an alternative. With at the moment’s mannequin you might both
fine-tune on plenty of examples of sentences containing “people and LLMs”, or
present it RLHF situations the place a sentence containing “people and LLMs” was most well-liked by a human over the same sentence containing “LLMs and people”
or prepend the above rule to the immediate sooner or later, storing the rule in-context. (this one would not appear to be it might essentially work nicely)
In distinction, you’ll be able to merely inform this rule to a human, they may keep in mind it, recognise if the rule is related in a brand new scenario, and use it immediately, maybe even with out apply. This type of ‘metacognition’ – realizing what to be taught from content material, recognising if a mistake was made and studying from it – is at the moment is totally lacking from LLMs, though as I wrote above, maybe not for a really very long time.
Because of this, even when an LLM sat down with 10,000 physics lecturers concurrently, it would not essentially get 10,000 extra worth out of these interactions than a single organic mind spending time with a single physics trainer. That is as a result of LLMs be taught from examples, or from human preferences between numerous generated sentences, fairly than by understanding guidelines and later recalling them in related conditions. In fact, this may occasionally change very quick, this type of studying from instruction could also be attainable in LLMs, however the primary level is:
there’s a restrict to how a lot studying digital brains can extract from interacting with the world at the moment
The “it’ll by no means work” sort arguments
In one in every of his shows, Hinton reminded everybody that for a very long time, neural networks have been utterly dismissed: optimisation will get caught in a neighborhood minimal, we stated, they may by no means work. That turned out to be utterly false and deceptive, native minima will not be a limitation of deep studying in spite of everything.
But his present argument entails saying that “analogue brains” cannot have a studying algorithm nearly as good as backpropagation. That is largely primarily based on the proof that though he tried exhausting, he didn’t discover a biologically believable studying algorithm that’s as environment friendly as backpropagation in statistical studying. However what if that is simply what we at the moment suppose? In spite of everything the entire ML group might persuade ourselves that assist vector machines have been superior to neural networks? What if we prematurely conclude digital brains are superior to analogue brains simply because we’ve not but managed to make analogue computation work higher.
Abstract and Conclusion
To summarise, Hinton’s argument has two pillars:
that digital intelligence can create efficiencies over analogue intelligence by parallelism, aggregating studying from a number of interactions right into a single mannequin
and that digital intelligence permits basically extra environment friendly studying algorithms (backprop-based) which analogue intelligence can not match
As we’ve got seen, neither of those arguments are watertight, and each could be questioned. So how a lot credence ought to we placed on this?
I say it passes my bar for an attention-grabbing narrative. Nonetheless, as a story, I do not contemplate it a lot stronger than those we developed once we argued “strategies primarily based on non-convex optimisation will not work”, or “nonparametric ML strategies are finally superior to parametric ones”, or “very giant fashions will overfit”.
Whether or not LLMs, maybe LLMs with a small variety of bells and whistles used creatively will cross the ‘human stage’ bar (remedy most duties a human might accomplish by a text-based interface with the world)? I’m at the moment equally skeptical of the theoretically motivated arguments both means. I personally do not anticipate anybody to have the ability to produce a convincing sufficient argument that it is not attainable. I’m rather a lot much less skeptical about the entire premise than again in 2016 once I wrote about DeepMind’s pursuit of intelligence.






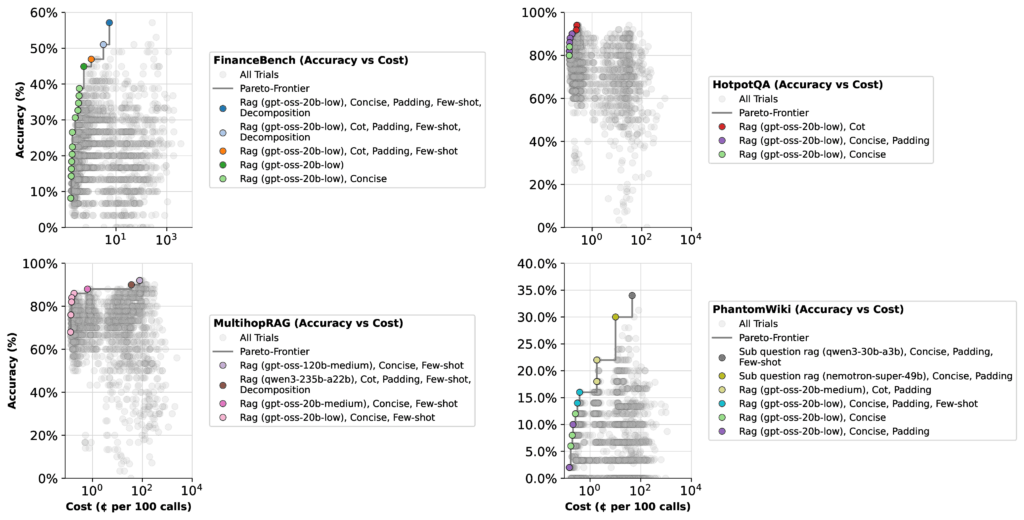
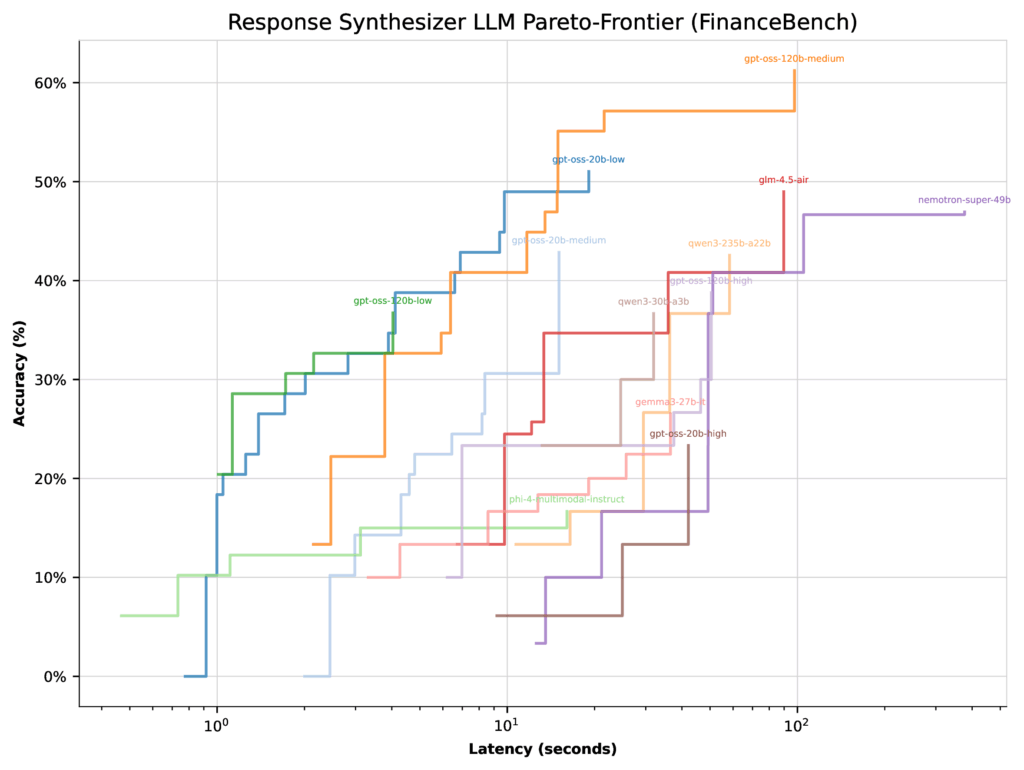
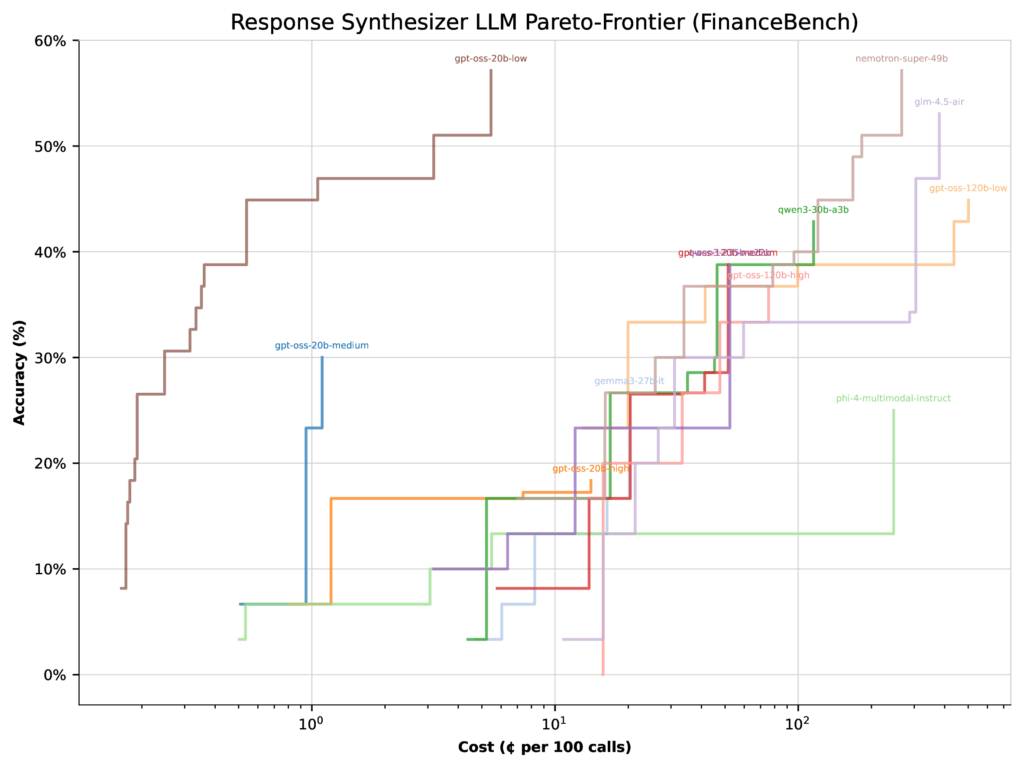





































{kind=link}